Embed Size (px)
Citation preview

COPO: Collaborative Open Plant Omics
Rob DaveyData Infrastructure and Algorithms Group Leader
[email protected]@froggleston


Acknowledgements
Oxford eResearch Centre
Susanna Sansone
Alejandra Gonzalez-Beltran
Philippe Rocca-Serra
Warwick
Jim Beynon
Katherine Denby
Ruth Bastow
EMBL-EBI
Paul Kersey
TGAC
Vicky Schneider
Tanya Dickie
Emily Angiolini
Matt Drew
Toni Etuk Felix Shaw

COPO
• Recently awarded BBSRC grant
• TGAC, Univ. Oxford, Univ. Warwick, EMBL-EBI
• Supported by GARNet, iPlant, Eagle Genomics
• Empower bioscience plant researchers to:
1. Enable standards-compliant data collection, curation and
integration
2. Enhance access to data analysis and visualisation pipelines
3. Facilitate data sharing and publication to promote reuse
• Train plant researchers in best practice for data sharing and
producing citable Research Objects

COPO
• (Good) Science is founded on reproducibility
• Reproducibility depends on:
• reducing reinvention (“friction”)*
• describing methods and data
• maximising benefit to the researcher
• Papers are seen as the typical way of distributing information
• Data description sorely under-represented and used
• Benefits are often opaque
• Fear of being scooped, loss of control, reputation, etc* http://cameronneylon.net/blog/network-enabled-research/

COPO
• What prevents plant scientists from openly depositing their data
and metadata?
• Lack of interoperability between:
• metadata annotation services
• data repository services
• data analysis services
• data publishing services
• Researchers might not:
• be aware that the services exist
• have the expertise to use them
• see the value in properly describing their data

COPO
• What prevents plant scientists from openly depositing their data
and metadata?
• Lack of interoperability between:
• metadata annotation services
• data repository services
• data analysis services
• data publishing services
• Researchers might not:
• be aware that the services exist
• have the expertise to use them
• see the value in properly describing their data
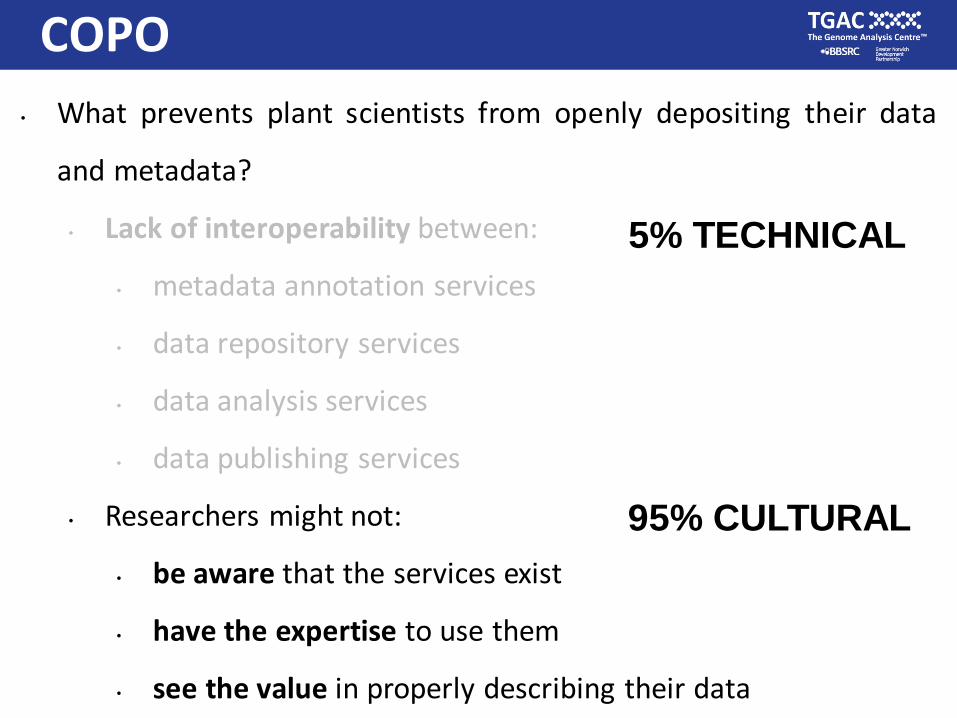
5% TECHNICAL
COPO
• What prevents plant scientists from openly depositing their data
and metadata?
• Lack of interoperability between:
• metadata annotation services
• data repository services
• data analysis services
• data publishing services
• Researchers might not:
• be aware that the services exist
• have the expertise to use them
• see the value in properly describing their data
5% TECHNICAL
95% CULTURAL

COPO
• Data:
• Sample, Sequence, Genome, Proteome, Metabolome, Phenotyping
• Code:
• GitHub, BitBucket, Zenodo
• Analysis:
• Galaxy, iPlant, Bioconductor, Taverna, local code/services
• Publication:
• figshare, Scientific Data, Dryad, F1000, PeerJ, Gigascience
• Beyond the PDF:
• Utopia, GitHub
• Training:
• Materials, examples, workshops, bootcamps

COPO
• It's not because these services don't exist!
• Clearly, barriers exist between the scientist and the service
• Infrastructure can help by:
• wiring existing services together
• improving access to services
• making consistent metadata attribution easier
• facilitating collaboration
• raising profile of the benefits of open science
• How do we collaborate successfully to make this happen?
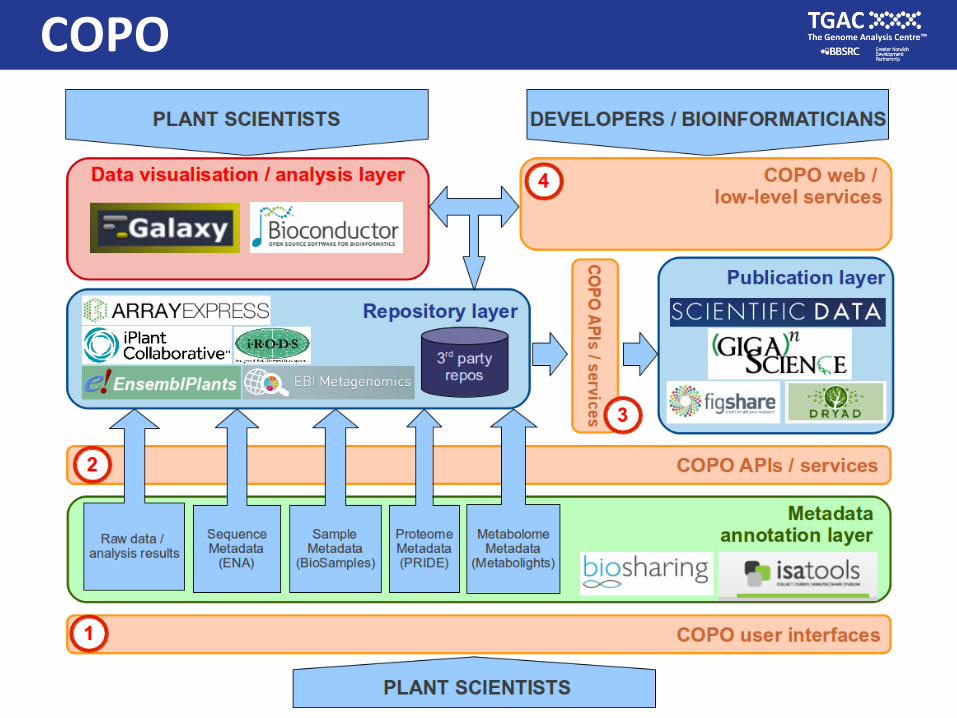
• Mapping services with Application Programming Interfaces
COPO

COPO
• Single-sign on (SSO), e.g. ORCID
• Deposit multi-omics data in one go
• Genomics, metabolomics, proteomics, and so on
• No context-switching between services
• Brokering of research data
• Wizard systems guide users based on selected semantic terms
• Selecting options at given points informs the path
• Intuitive and less time intensive
• Mix of required repository metadata and extra descriptors
• Building knowledge graphs of linked data
INTEROPERABILITY

COPO• Run and deposit analytical workflows
• Describe software used, versions
• Data IO between platforms, e.g. Galaxy, iPlant
• Support virtualisation, e.g. iPlant Atmosphere, Docker, Amazon AWS
• Data is well-described, open, and DOIs will be minted
• Finding and integrating data improved greatly
• Make suggestions to users based on their metadata/data/workflows
• Users get recognition for sharing well-described data
• Data citation
• Programmatic access to all layers
REPRODUCIBILITY
COPO
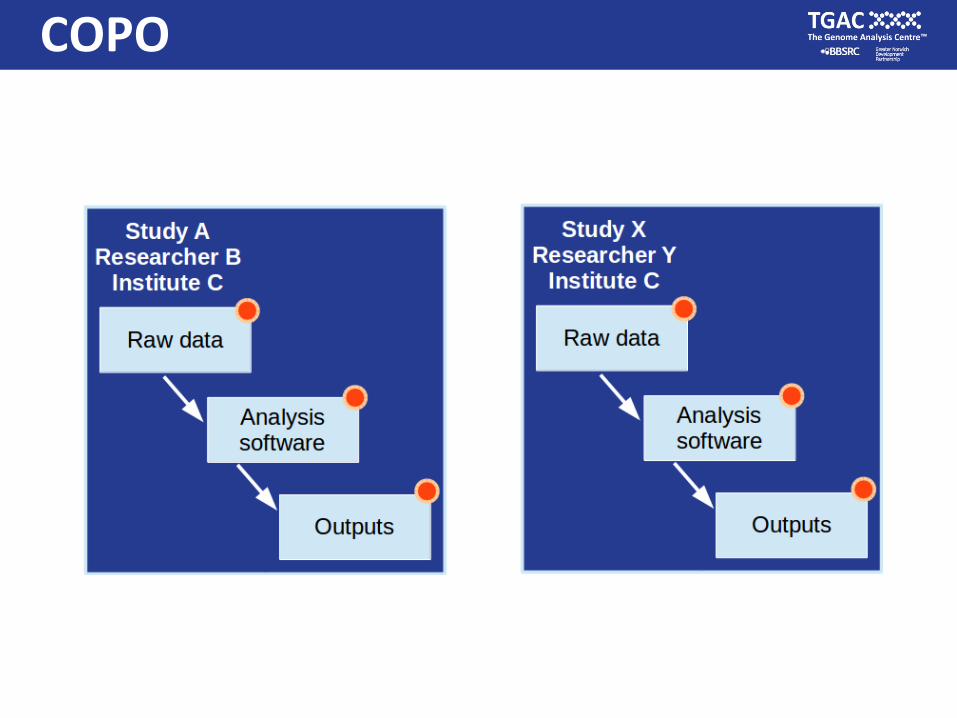
COPO
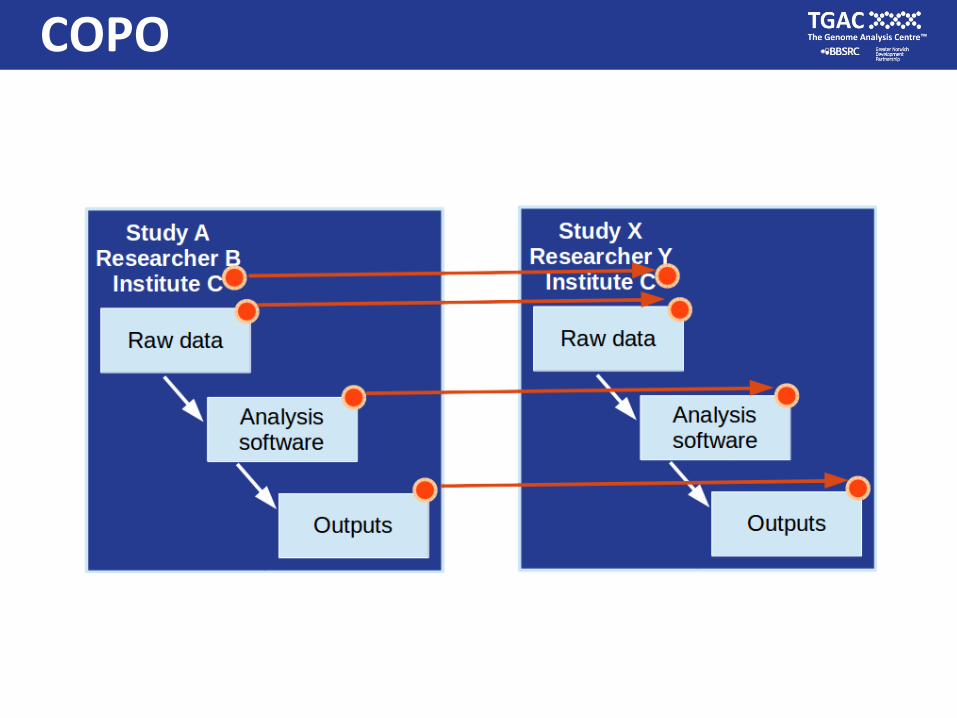
COPO
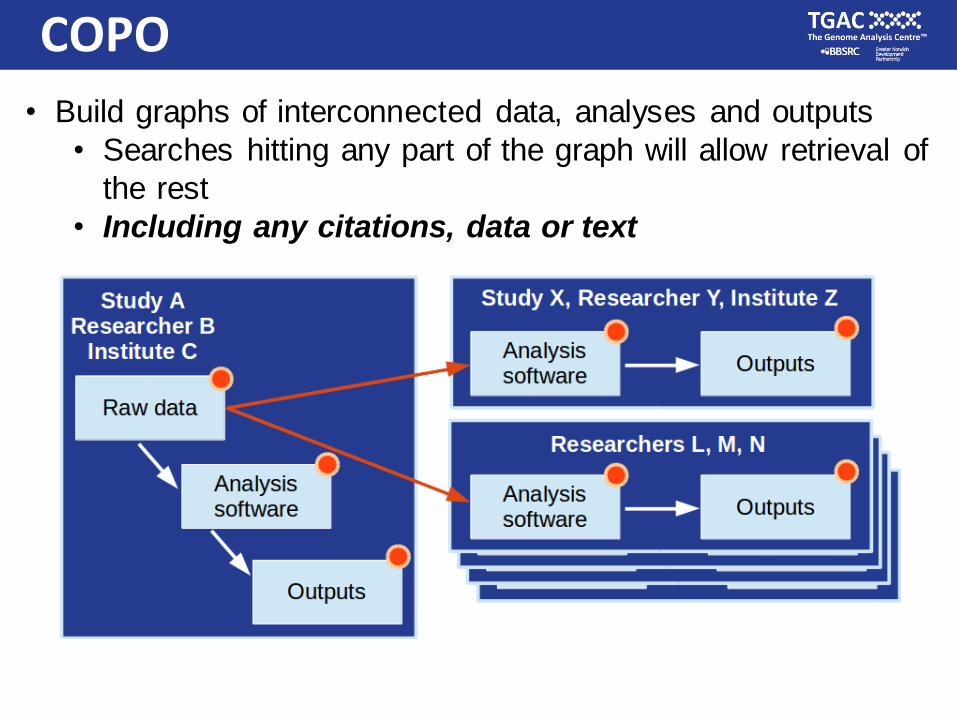
COPO
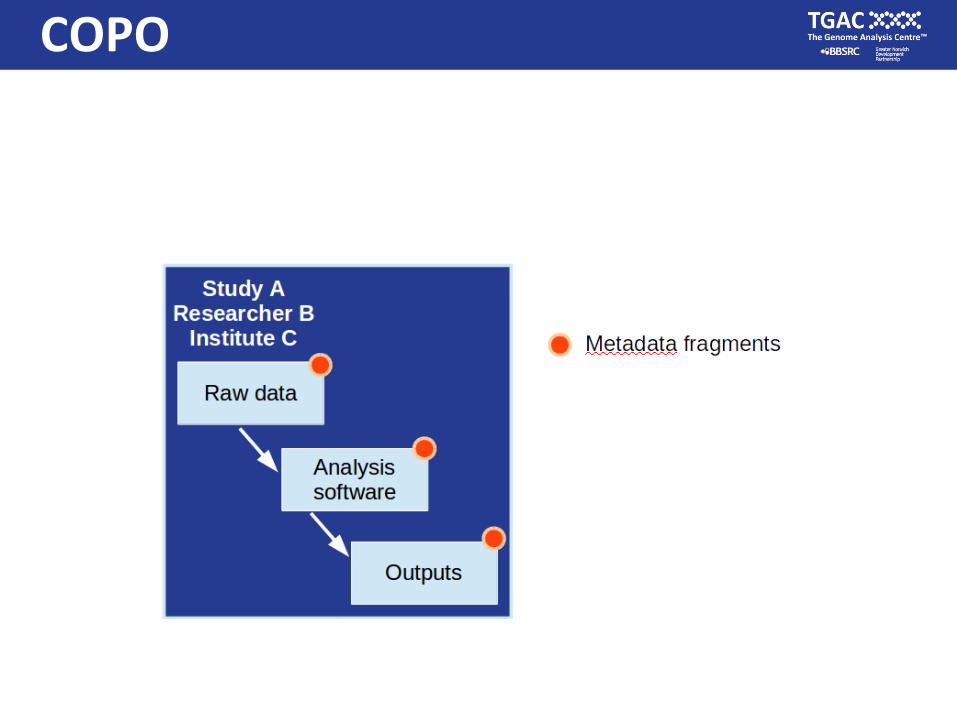
• Build graphs of interconnected data, analyses and outputs
• Searches hitting any part of the graph will allow retrieval of
the rest
• Including any citations, data or text

COPO
• Not just raw/processed data is valuable
• COPO supports submission of supplementary data to Figshare
• PDFs (posters, papers)
• CSV/Excel
• movies/images (size permitting)
• Zenodo/Github releases for code DOIs
• e.g. ENCODE Digital Curation Center’s software metadata
descriptors
• EDAM/Software ontology

COPO
• What have we achieved so far?
• TGAC infrastructure to support brokering of data
• iRODS and web server virtual machines
• High speed transfer Aspera links to EBI
• Prototype user interface for multi-omics data submissions
• Oauth2 support (“sign in with” ORCiD, Google, Twitter)
• Moving to OpenID Connect?
• Profiles and collections for managing metadata
• Metadata for sequencing
• Tracking data uploads and accession status

COPO
• What have we achieved so far?
• Developing JSON specification for COPO objects
• Easily stored in document-based databases, e.g. MongoDB
• Interconversion between ISA formats
• ISATab (TSV based) to JSON, and vice versa
• Linked Data specifications
• Community interactions
• First user requirements workshop at TGAC
• F1000, GigaScience
• This meeting!

COPO• COPO will:
• Facilitate easy relevant data description
• Intuitively submit data and metadata to multiple public repositories
• Integrate with other research data management platforms
• Wheat Information System, iPlant, …
What are the barriers for plant research data?
5% technical, 95% cultural
• Work with other infrastructure builders to provide truly open connected
ecosystems for data?
• How can we help researchers realise the benefits of sharing data?