Embed Size (px)
Citation preview

AN IN-DEPTH ANALYSIS OF TAGS AND CONTROLLED METADATA FOR BOOK SEARCH
T OINE BOGERSVIV IEN P ET RAS
MARCH 23, 2017iCONFERENCE 2017

OUTLINE
▸ Introduction
▸ Methodology & Experimental Setup
▸ Analysis
– Tags vs. Controlled Vocabularies
– Book Search Requests
– Failure Analysis
▸ Conclusions & Future Work
2

INTRODUCTION

MOTIVATION
▸ Readers often struggle with existing systems (i.e., library catalogs, Amazon, eBook sellers) to discover new books
– Information needs are contextual, personal & complex
– Book metadata does not contain the necessary information
4

EARLIER WORK
▸ iConference 2015
– Tags outperform controlled vocabularies for search, but sometimes controlled vocabularies are better.
– Controlled vocabularies contains more unique terms, tags more repetition of terms.
▸ Why?
– Terminology
– Popularity / frequency
– Type of request
5

STUDY OBJECTIVES
▸ Why are tags better than controlled vocabularies for book search?
– Which types of book search requests are better addressed using tags and which using CV?
– Which book search requests fail completely and what characterizes such requests?
6

METHODOLOGY & EXPERIMENTAL SETUP

EXPERIMENTAL SETUP
▸ Controlled Vocabulary content (CV)
– DDC class labels
– Subjects
– Geographic names
– Category labels
– LCSH terms
▸ Tags
– Each tag occurs as many times as it has been assigned bythe users
▸ Unique tags
– Each tag occurs only once
8

AMAZON/LIBRARYTHING COLLECTION 9
TagsTags
Controlled Vocabulary Content (CV)
DDC class labelssubjectsgeographic namescategory labels
LCSH terms
Unique TagsUnique Tags per record

ANNOTATED LT TOPIC
10
Recommended books
Topic title
Narrative

EXPERIMENTAL SETUP
▸ Amazon / LibraryThing collection of book records
– 2 million records
▸ LibraryThing forum topics for search requests
– 334 search requests for testing
▸ Relevance judgements
– Recommendations from LT members with graded relevance scoring(highest relevance if book is added by searcher)
▸ Evaluation metric
– Normalized Discounted Cumulated Gain (NDCG@10)
▸ IR system
– Indri 5.4 toolkit
10

ANALYSIS

TAGS vs. CONTROLLED VOCABULARIES
▸ Question 1: Is there a difference in performance between CV and Tags in retrieval?
▸ Answer
– Tags perform significantlybetter than CV
– The combination of both results in even better performance than just fortags, but not significantly so
– Losing tag frequencyinformation helps rather thanhurts performance (also notsignificantly)
12

TAGS vs. CONTROLLED VOCABULARIES
▸ Question 2: Do tags outperform CV because of the so-called popularity effect?
▸ Answer
– No, there does not seem to be a popularity effect
– Types = unique words in a record
– Tokens = all instances of words in a record
13

TAGS vs. CONTROLLED VOCABULARIES
▸ Question 3: Do Tags and CV complement or cancel each other out?
▸ Answer
– Tags and CV complement each other: they are successful on different sets of requests
– But most zero-difference requests (74.0%) actually fail completely!When and why?
14

REQUESTS – RELEVANCE ASPECTS
▸ What makes a suggested book relevant to the user?
– Distinguish between eight relevance aspects (Reuter, 2007; Koolen et al., 2015)
16
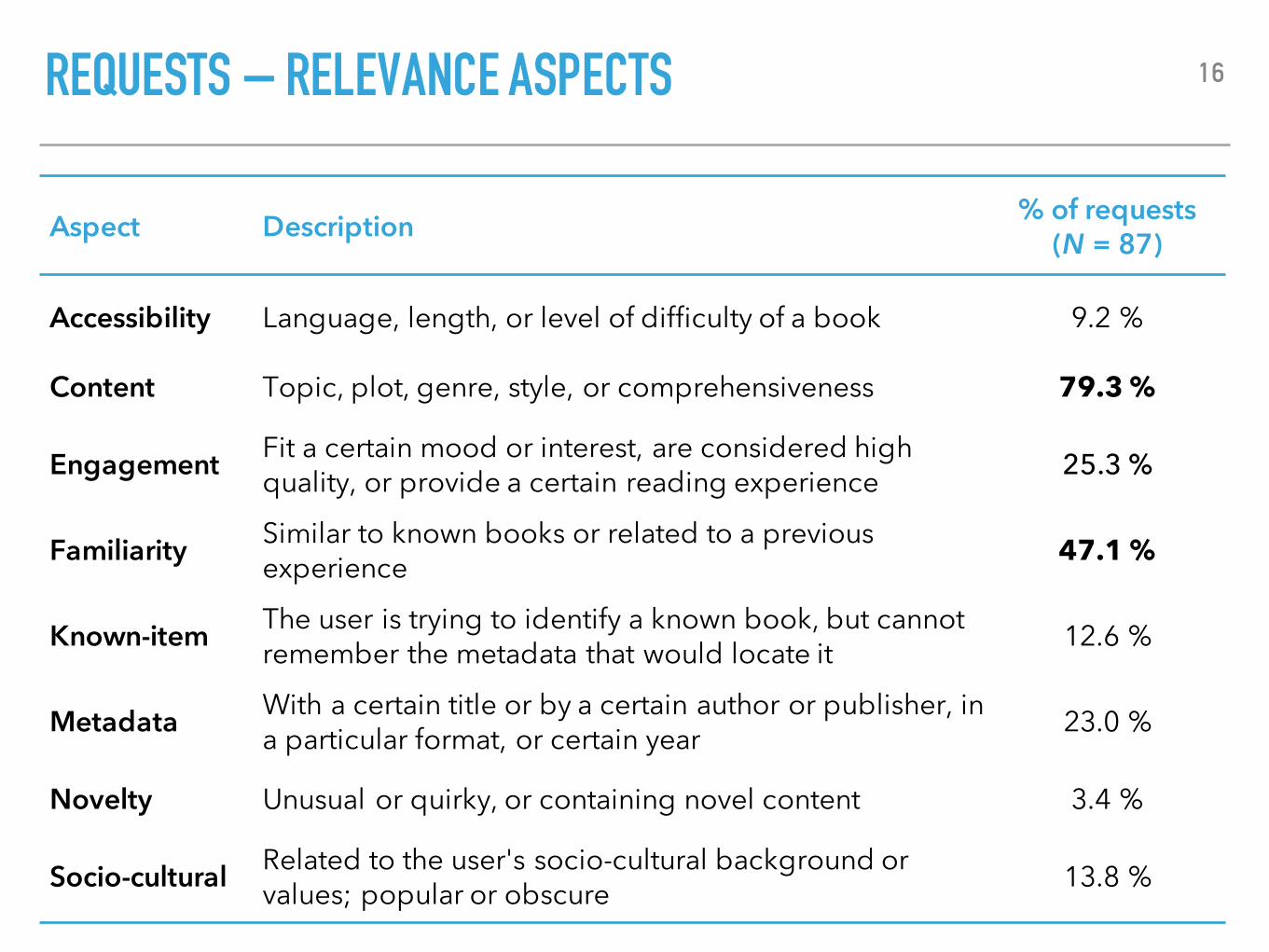
REQUESTS – RELEVANCE ASPECTS
Aspect Description % of requests(N = 87)
Accessibility Language, length, or level of difficulty of a book 9.2 %
Content Topic, plot, genre, style, or comprehensiveness 79.3 %
Engagement Fit a certain mood or interest, are considered high quality, or provide a certain reading experience 25.3 %
Familiarity Similar to known books or related to a previous experience 47.1 %
Known-item The user is trying to identify a known book, but cannot remember the metadata that would locate it 12.6 %
Metadata With a certain title or by a certain author or publisher, in a particular format, or certain year 23.0 %
Novelty Unusual or quirky, or containing novel content 3.4 %
Socio-cultural Related to the user's socio-cultural background or values; popular or obscure 13.8 %
16

REQUESTS – RELEVANCE ASPECTS
▸ Question 4: What types of book requests are best served by the Unique tags and CV collections?
▸ Answer
– CV terms show a tendency to work best for requests that touch upon aspects of engagement
– Other requests are best served by Unique tags
17

REQUESTS – RELEVANCE ASPECTS
iConference ���� [Petras & Bogers]
Relevanceaspect
Description Requestsoverall
UniqueTags> CV
CV > Uni-queTags
(N = ��) (N = ��) (N = ��)
Accessibility Language, length, or level of di�culty of a book �.�% �.�% ��.�%Content Topic, plot, genre, style, or comprehensiveness ��.�% ��.�% ��.�%Engagement Fit a certain mood or interest, are considered high
quality, or provide a certain reading experience��.�% ��.�% ��.�%
Familiarity Similar to known books or related to a previousexperience
��.�% ��.�% ��.�%
Known-item
The user is trying to identify a known book, butcannot remember the metadata that would locate it
��.�% ��.�% �.�%
Metadata With a certain title or by a certain author or pub-lisher, in a particular format, or certain year
��.�% ��.�% ��.�%
Novelty Unusual or quirky, or containing novel content �.�% �.�% �%Socio-cultural
Related to the user’s socio-cultural background orvalues; popular or obscure
��.�% ��.�% �.�%
Table �: Distribution of the relevance aspects over all �� successful book requests (column �), the requests where Unique
tags outperform CV terms by ���% or more (column �), and the requests where CV terms outperform Unique tags by ���%or more (column �). More than one aspect can apply to a single book request, so numbers to not add up to ���%.
0,00 0,10 0,20 0,30 0,40 0,50 0,60 0,70 0,80 0,90 1,00
Socio-cultural (N = 10)
Novelty (N = 2)
Metadata (N = 17)
Known-item (N = 11)
Familiarity (N = 36)
Engagement (N = 21)
Content (N = 63)
Accessibility (N = 7)
Unique tagsCV
0.0 0.20.1 0.40.3 0.60.5 0.80.7 1.00.9
Socio-cultural(N = 10)
0.11270.0428
Novelty(N = 2)
0.53040.0000
Metadata(N = 17)
0.24540.1259
Known-item(N = 11)
0.35930.1818
Familiarity(N = 36)
0.18330.0701
Engagement(N = 21)
0.11210.1425
Content(N = 63)
0.19650.0821
Accessibility(N = 7)
0.12350.0749
Performance grouped by relevance aspect
NDCG@10
Figure �: Results for the Unique tags and CV test collections, grouped by the eight relevance aspects expressed in the ��successful book search requests. Average NDCG@�� scores over all requests expressing a particular relevance aspect areshown in grey and as horizontal bars, with error bars in black.
�
18

REQUESTS – TYPE OF BOOK
▸ Question 5: What types of book requests (fiction or non-fiction) are best served by Unique tags or CV?
▸ Answer
– Unique tags work significantly better for fiction
– CV work better for non-fiction (but not significantly so)
19

FAILURE ANALYSIS
▸ Question 6: Do failed book search requests fail because of data sparsity, a lower recall base, or a lack of examples?
▸ Answer
– Neither sparsity nor the size of the recall base are the reason for retrieval failure
– The number of examples provided by the requester has significant positive influence on performance
(N = 247)(N = 87)
(N = 334)
20

FAILURE ANALYSIS
▸ Question 7: Do book search requests fail because of their relevance aspects?
▸ Answer
– No, relevance aspects are distributed equally for successful & failed requests
– Only Accessibility-and Metadata-related search requests seem to fail more often
21

FAILURE ANALYSIS
▸ Question 8: Does the type of book that is being requested (fiction vs. non-fiction) have an influence on whether requests succeed or fail?
▸ Answer
– Requests for works of fiction fail significantly more often
22

CONCLUSIONS &FUTURE WORK

FINDINGS
▸ Tags outperform CV...
– ...probably because their terminology is closer to the user‘slanguage (not because of the popularity effect)
▸ Sometimes CV are better, for example, for non-fiction books...
– ...whereas tags are better for fiction and for content-related, familiarity or known-item searches
▸ We believe that tags are simply better able to match the user‘slanguage when looking for books
– Although they are still not that great at it!
– Book search is still hard, especially for fiction books
25

OPEN QUESTIONS
▸ How can book metadata be adapted to be closer to thevocabulary used in real-world book search requests?
▸ What other aspects (besides type of requested book orrelevance aspect of search request) contribute to requestdifficulty?
▸ Our question to you:
– What other questions can we ask of this data?
26

QUESTIONS?
Paper URL: http://bit.ly/iconf2017





























