Embed Size (px)
Citation preview

Russian Paraphrase Identification using simple lexical overlap with
SVMs
AINL FRUCT, 2016, Russia
Asli Eyecioglu Ozmutlu [email protected]
University of Sussex

Introduction
• What is paraphrase identification?
• Available paraphrase corpora
• Paraphrase Identification with Knowledge-Lean Techniques o Character and word level features o SVMs (Linear and RBF Kernels) o Binary and three-class classification o Languages :English, Turkish and Russian

Paraphrases of Definition of Paraphrasing
Definition Author
Para
phra
sing
is generally considered to be meaning-preserving relation (Culicover, 1968)
alternative way to convey the same information (Barzilay &
McKeown, 2001)
represents (possibly partial) equivalencies between different expressions
that correspond to the same meaning
(Glickman & Dagan,
2003)
is talking about same situation in different words and different syntax (Hirst, 2003)
is the restatement (or reuse) of text giving the meaning in other form (Fernando &
Stevenson, 2008)
is text-to-text relation between two non-identical text fragments that
express the same idea in different ways
(Lintean & Rus, 2010)
is semantic equivalence (Madnani & Dorr,
2010)
is the act of replacing linguistic uVerances (typically text) with other
linguistic uVerances, bearing similar meaning but different form.
(Marton, 2010)

PARAPHRASING
• DEGREE OF PARAPHRASING o Lexical o Phrasal
o Sentential
• PARAPHRASING APPLICATIONS o Paraphrase Identification o Paraphrase Generation o Paraphrase Extraction

Paraphrase Corpora• Paraphrase Corpora in English
o Microsoft Research Paraphrase Corpus (MSRPC) (gold standard data) o Plagiarism Detection Corpus (PAN) o Twitter Paraphrase Corpus (TPC) o Others (On Paraphrase Identification Corpora by Rus et al.,2014)
• Paraphrase Corpora in other languages
o TICC Headline Paraphrase Corpus (English and Dutch) o The Hebrew Paraphrase Corpus (Hebrew) o WiCoPaCo (French) o Microsoft Video Description Corpus (Multilingual) o Turkish Paraphrase Corpus (TuPC) o Russian Paraphrase Corpus

Paraphrase Identification using Knowledge-Lean Techniques
• What does knowledge-lean mean? • Pre-processing • Overlap Features
o Size of union o Size of intersection o Sentence length
• SVM Classifiers o Linear Kernel o RBF Kernel

Knowledge Poor aka Knowledge-Lean
• The term “knowledge-poor” is first introduced (as far as we are aware) by Hearst and Hearst and Grefenstette (1992) . Their motivation is the usage of knowledge-poor corpus-based approaches for the automatic discovery of lexical relations. They believe that knowledge-poor corpus-based approaches result in stronger results without the need of complex knowledge-based approaches.
• The term “knowledge-lean” is used in the same way by Pedersen and Bruce (1998) in order to draw attention to the significance of corpus-based measures compared to knowledge-based measures for word sense disambiguation task.

Knowledge-Lean• A knowledge-lean approach
o requires less alteration of experimental data, o less usage of time-consuming resources, o and less complex methods
• Knowledge-lean approaches o have better potential applicability to less resourced languages, o reduction in manual annotation effort, o and potential to learn from current samples of the actual data to be processed
rather that a possibly unrepresentative approximation.
• Methods are considered knowledge-lean if they make use only of the text at hand, and avoid the use of external processing tools and other resources.
• Knowledge-lean PI methods may thus employ shallow overlap measures based on lexical items or n-grams, but they might also make use of distributional techniques based on simple text statistics.

Knowledge-Lean
• Rus, Banjade and Lintean (2014) argue that the best methods for the paraphrase identification task can be obtained from lexical overlap measures, optimized with the combinations of several pre-processing steps.

Knowledge-lean vs. Knowledge-rich
Knowledge-Lean Knowledge-rich
• Lexical Overlap • Character n-grams • Word n-grams • Distributional Similarity
• Constructed thesaurus (ex: WordNet)
• Hand-crafted semantic and syntactic tools

Pre-processing and Extracting Features
• Only tokenization and lowercasing
Size of union (U): the size of the union of the tokens in the two texts of a candidate paraphrase pair. Size of intersection(N): the number of tokens common to the texts of a candidate paraphrase pair. Text Size : the size of the set of tokens representing a given text.

Pre-processing and Extracting Features
A pair of sentences is represented with a set of four features denoted with U, N, L1, and L2. U is the size of union, N is the size of intersection. The features L1 and L2 are the length of sentence 1 and length of sentence 2, respectively, of a candidate paraphrase pair. These four features are computed for word and character n-grams (up to three) features. C2 ( U,N,L1,L2)
4 features
C2 ( U,N,L1,L2), C3 ( U,N,L1,L2)
8 features

SVM Classifiers• Adapted from scikit-learn (
http://scikit-learn.org/stable/)
• Feature Scaling
• Feature Ablation
• Linear Kernel and RBF Kernel with Default Parameters

Paraphrase Identification on the MSRPC, TPC
and TuPC• ASOBEK: Twitter Paraphrase Identification with
simple overlap features and SVMs (NAACL, 2015) o Our results obtained from TPC are ranked 1st among 19 participating teams and
36 submitted runs. o MSRPC results are competitive as compared to most sophisticated methods.
• Constructing a Turkish Corpus for Paraphrase Identification and Semantic Similarity (CICling, 2016) o High performance and competitive baseline

Russian Paraphrase Identification
• Task 1-standard (three-class classification)
o Submitted 10 runs
• Task 2- standard (binary classification)
o Submitted 8 runs
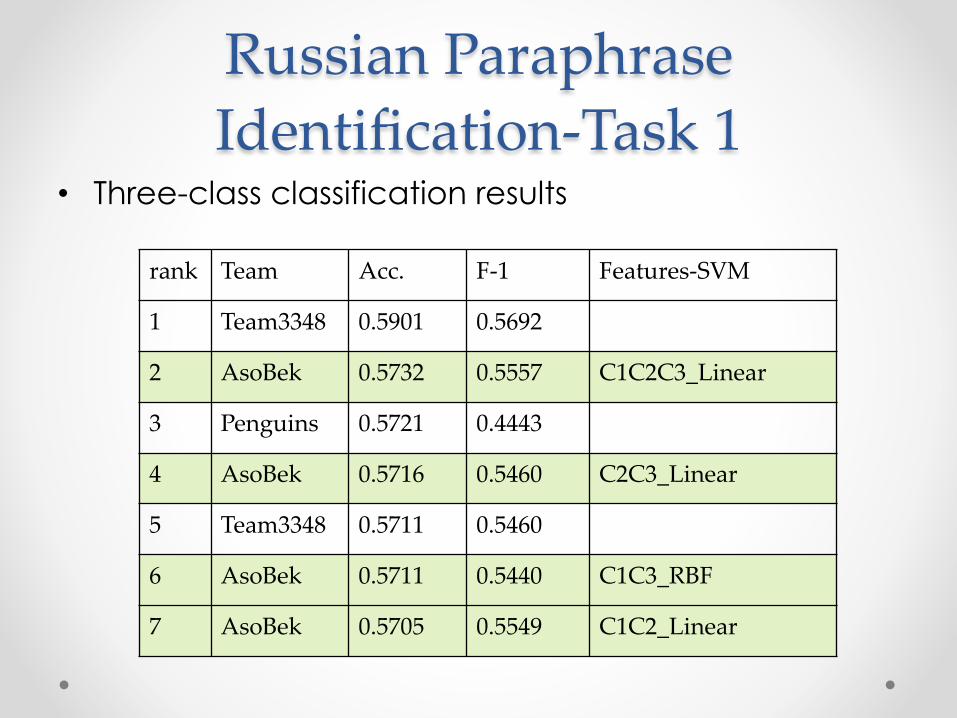
Russian Paraphrase Identification-Task 1
• Three-class classification results
rank Team Acc. F-1 Features-SVM
1 Team3348 0.5901 0.5692
2 AsoBek 0.5732 0.5557 C1C2C3_Linear
3 Penguins 0.5721 0.4443
4 AsoBek 0.5716 0.5460 C2C3_Linear
5 Team3348 0.5711 0.5460
6 AsoBek 0.5711 0.5440 C1C3_RBF
7 AsoBek 0.5705 0.5549 C1C2_Linear
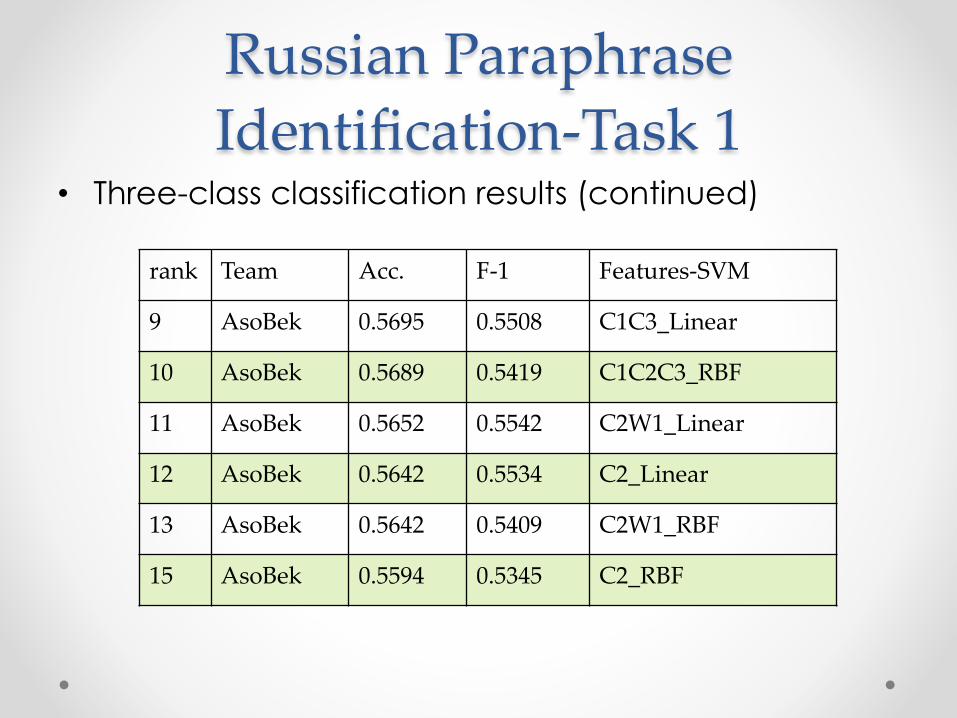
Russian Paraphrase Identification-Task 1
• Three-class classification results (continued)
rank Team Acc. F-1 Features-SVM
9 AsoBek 0.5695 0.5508 C1C3_Linear
10 AsoBek 0.5689 0.5419 C1C2C3_RBF
11 AsoBek 0.5652 0.5542 C2W1_Linear
12 AsoBek 0.5642 0.5534 C2_Linear
13 AsoBek 0.5642 0.5409 C2W1_RBF
15 AsoBek 0.5594 0.5345 C2_RBF
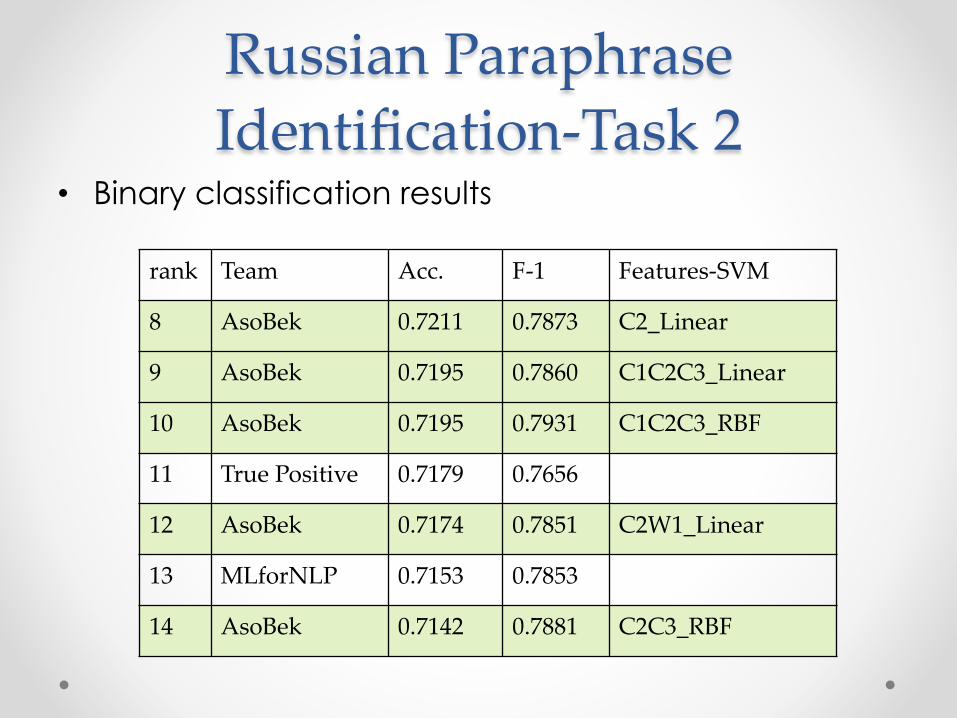
Russian Paraphrase Identification-Task 2
• Binary classification results
rank Team Acc. F-1 Features-SVM
8 AsoBek 0.7211 0.7873 C2_Linear
9 AsoBek 0.7195 0.7860 C1C2C3_Linear
10 AsoBek 0.7195 0.7931 C1C2C3_RBF
11 True Positive 0.7179 0.7656
12 AsoBek 0.7174 0.7851 C2W1_Linear
13 MLforNLP 0.7153 0.7853
14 AsoBek 0.7142 0.7881 C2C3_RBF

Conclusion• Knowledge-lean methods perform better than
knowledge-rich methods.
• Knowledge-lean methods can be applied to different languages: English, Turkish and Russian.
• SVMs works well with simple overlap features (character and word level)
• Three-class classification results are better than binary classification results for Russian Paraphrase Identification task

References• Hearst, M. A., & Grefenstette, G. (1992). Refining Automatically-Discovered Lexical Relations: Combining
Weak Techniques for Stronger Results. In Statistically-Based Natural Language Programming Techniques, Papers from the 1992 AAAI Workshop (pp. 64–72). Menlo Park, CA.
• Pedersen, T., & Bruce, R. (1998). Knowledge lean word-sense disambiguation. In Proceedings of the Fifteenth National Conference on Artificial Intelligence (pp. 800–805). AAAI Press.
• Rus, V., Banjade, R., & Lintean, M. (2014). On Paraphrase Identification Corpora. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14). Reykjavik, Iceland: European Language Resources Association (ELRA).
• Eyecioglu, A., & Keller, B. (2015). ASOBEK : Twitter Paraphrase Identification with Simple Overlap Features and SVMs. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015) (pp. 64–69). Denver, Colorado.
• Eyecioglu, A., & Keller, B. (2016). Constructing A Turkish Corpus for Paraphrase Identification and Semantic Similarity. In Proceedings of the 17th International Conference on Intelligent Text Processing and Computational Linguistics. Lecture Notes in Computer Science (Vol. 9623, pp. 562–574).

![[XLS] · Web view11/1/2016 1/25/2016 1/22/2016 1/22/2016 1/21/2016 1/21/2016 1/21/2016 1/21/2016 1/21/2016 1/21/2016 1/21/2016 1/21/2016 1/20/2016 1/20/2016 1/19/2016 1/18/2016 1/18/2016](https://img.pdfslide.us/doc/110x75/5c8e2bb809d3f216698ba81b/xls-web-view1112016-1252016-1222016-1222016-1212016-1212016-1212016.jpg)




























