Embed Size (px)
Citation preview

1
Yahoo’s Next Generation User Profile Platform
Kai Liu, Lu Niu
Yahoo Inc.

2
Agenda
- What is User Profile - Architecture Evolution - Schema Design- Optimization- Future Work

3
Agenda
- What is User Profile - Definition- Use Cases- Logical View- User ID Type
- Architecture Evolution - Schema Design- Optimization- Future Work
4
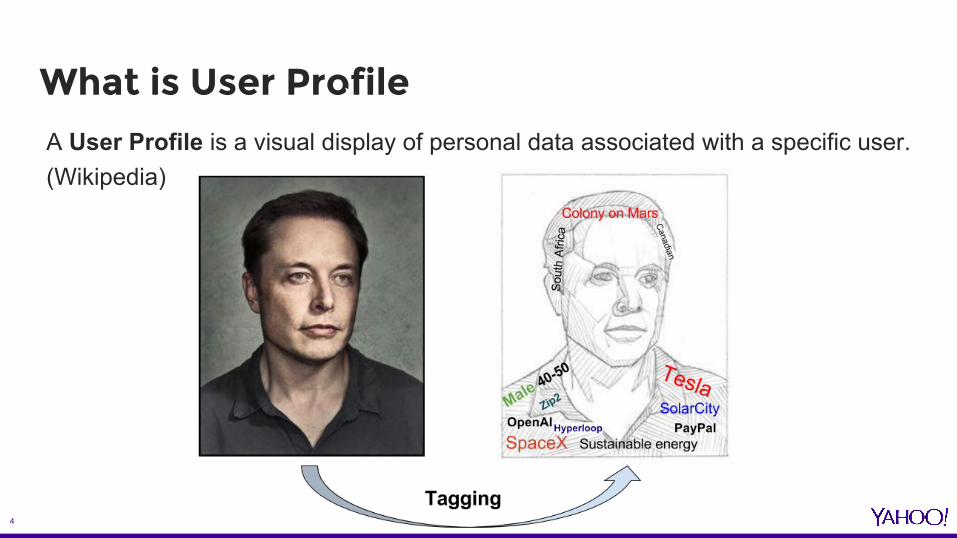
What is User ProfileA User Profile is a visual display of personal data associated with a specific user.(Wikipedia)
5
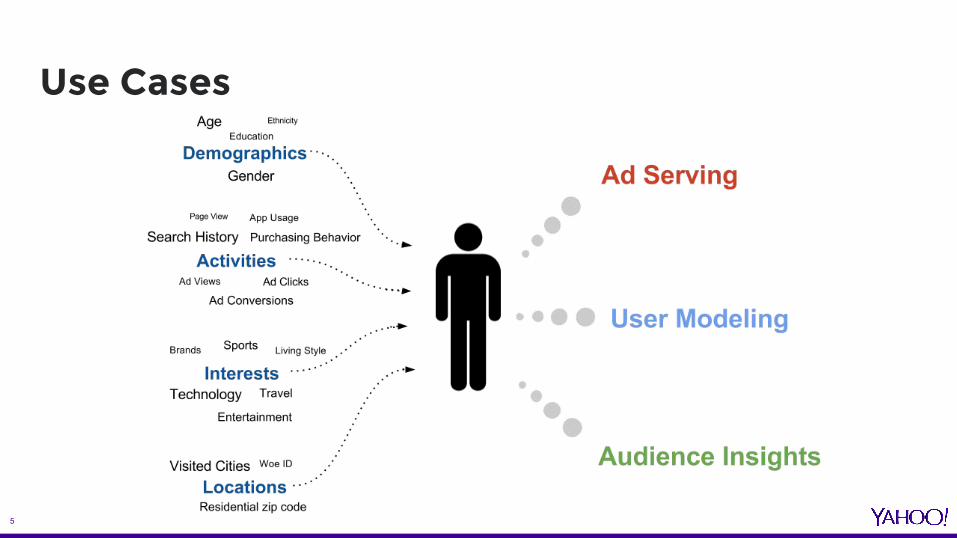
Use Cases
6
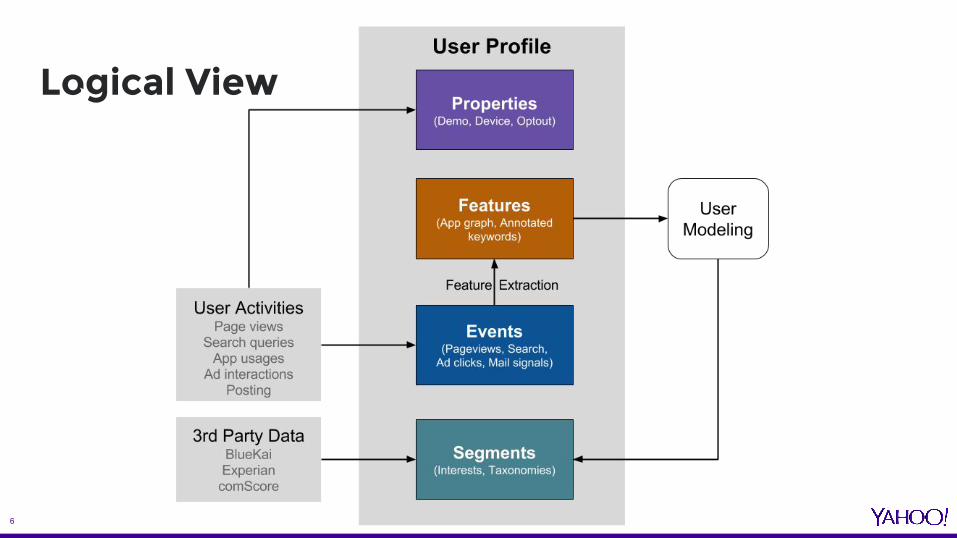
Logical View

7
User ID Type
- Desktop- BID: for anonymous users- SID: for registered users
- Mobile- IDFA: for iOS devices- GPSAID: for Android devices
8
Agenda
- What is User Profile - Architecture Evolution
- Old architecture- Problems- New architecture
- Schema Design- Optimization- Future Work
9
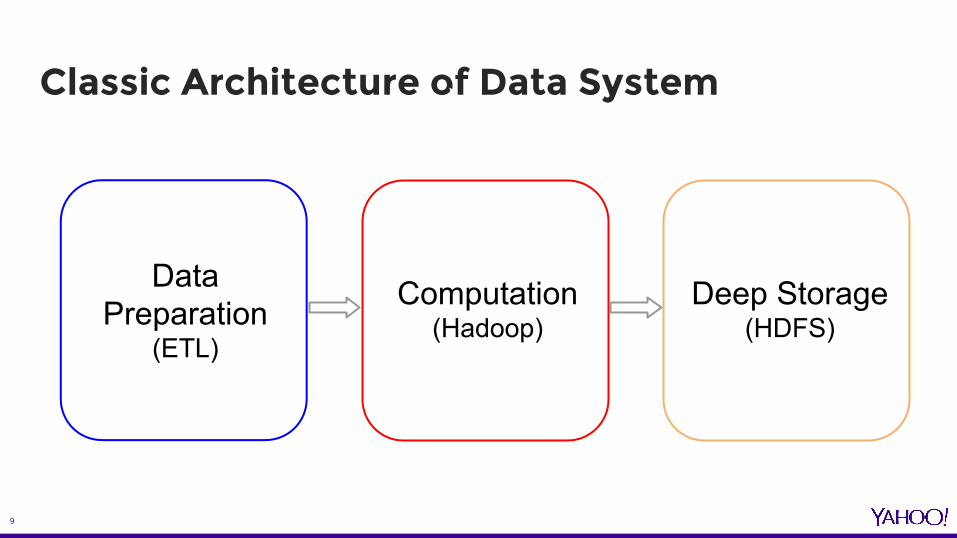
Classic Architecture of Data System
Data Preparation
(ETL)
Computation(Hadoop)
Deep Storage(HDFS)
10
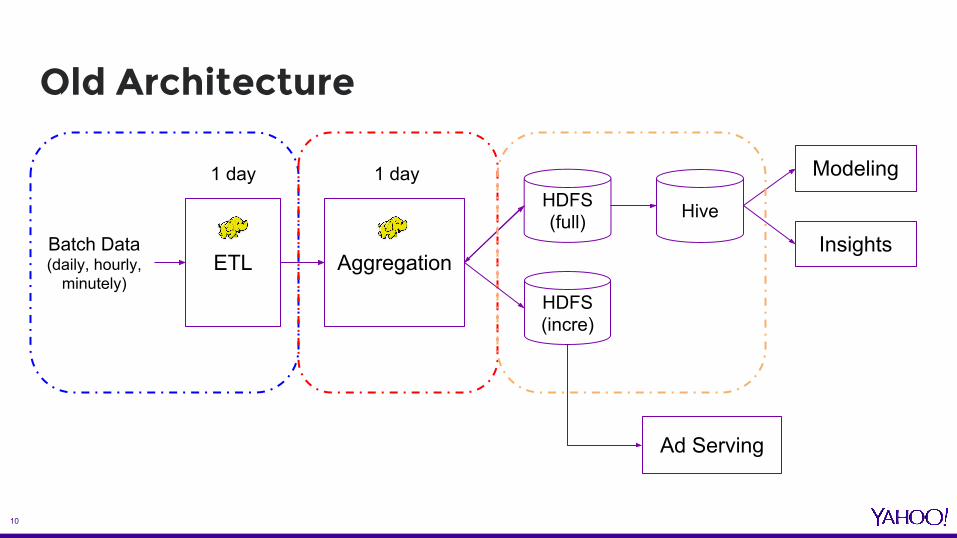
Old Architecture
HDFS(full) Hive
AggregationETLBatch Data(daily, hourly,
minutely)
Ad Serving
HDFS(incre)
1 day 1 day Modeling
Insights

11
Problems
- Aggregation is very expensive- HDFS follows Write Once Read Many approach. - Actually only ~30% of users get updates every day.
- Impossible to support multiple update frequencies- Lack of capability to process event stream

12
- Spark- Fast- Consistent stack (batch/streaming)
- HBase- Random read/write capabilities- Flexible schema
- Hive- Large scale ad-hoc query engine- SQL like interface
New Architecture Components
13
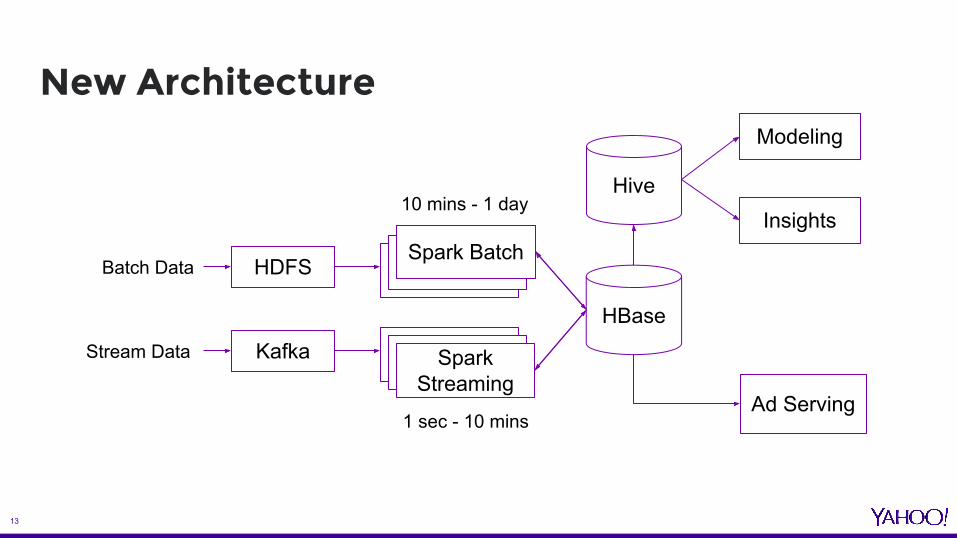
New Architecture
HBase
Hive
HDFS
Kafka
Batch Data
Stream Data
10 mins - 1 day
1 sec - 10 minsAd Serving
Spark Batch
Spark Streaming
Modeling
Insights

14
How problems get solved
- Incremental updates avoid full data load. - Multiple Spark jobs with different frequencies running
concurrently.- Spark streaming for event stream processing.

15
Agenda
- What is User Profile - Architecture Evolution - Schema Design
- Understand the data- Table design
- Optimization- Future Work
16
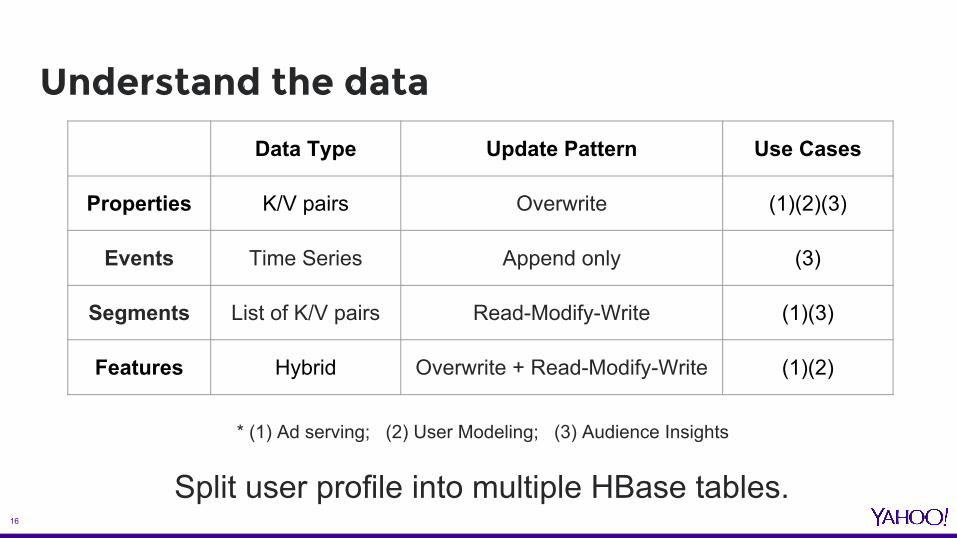
Understand the data
* (1) Ad serving; (2) User Modeling; (3) Audience Insights
Split user profile into multiple HBase tables.
Data Type Update Pattern Use Cases
Properties K/V pairs Overwrite (1)(2)(3)
Events Time Series Append only (3)
Segments List of K/V pairs Read-Modify-Write (1)(3)
Features Hybrid Overwrite + Read-Modify-Write (1)(2)
17
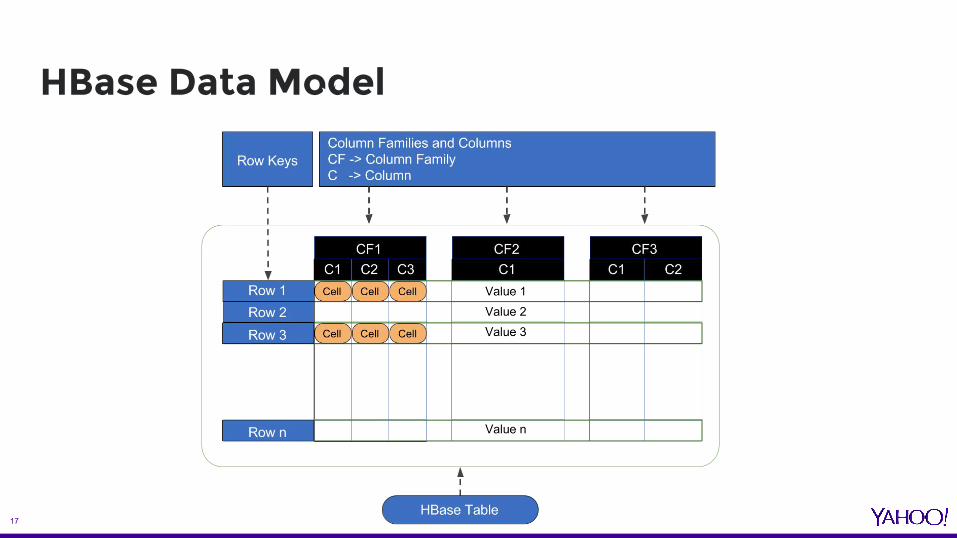
HBase Data Model
18
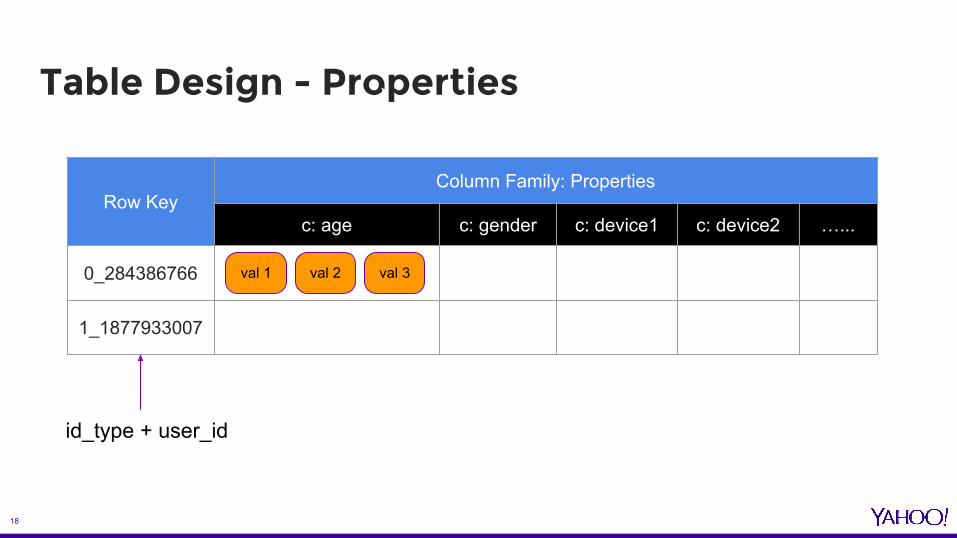
Table Design - Properties
Row KeyColumn Family: Properties
c: age c: gender c: device1 c: device2 …...
0_284386766
1_1877933007
id_type + user_id
val 1 val 2 val 3
19
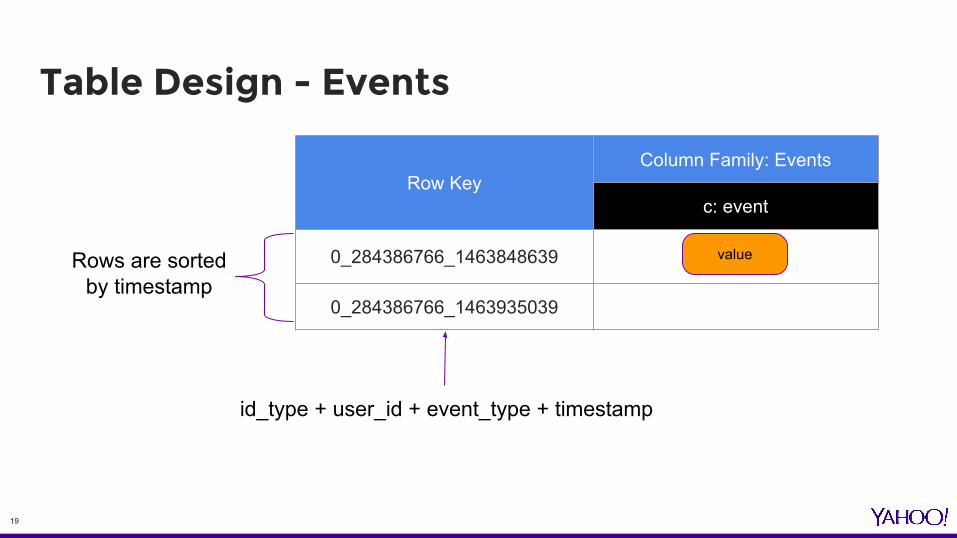
Table Design - Events
Row KeyColumn Family: Events
c: event
0_284386766_1463848639
0_284386766_1463935039
id_type + user_id + event_type + timestamp
valueRows are sorted by timestamp
20
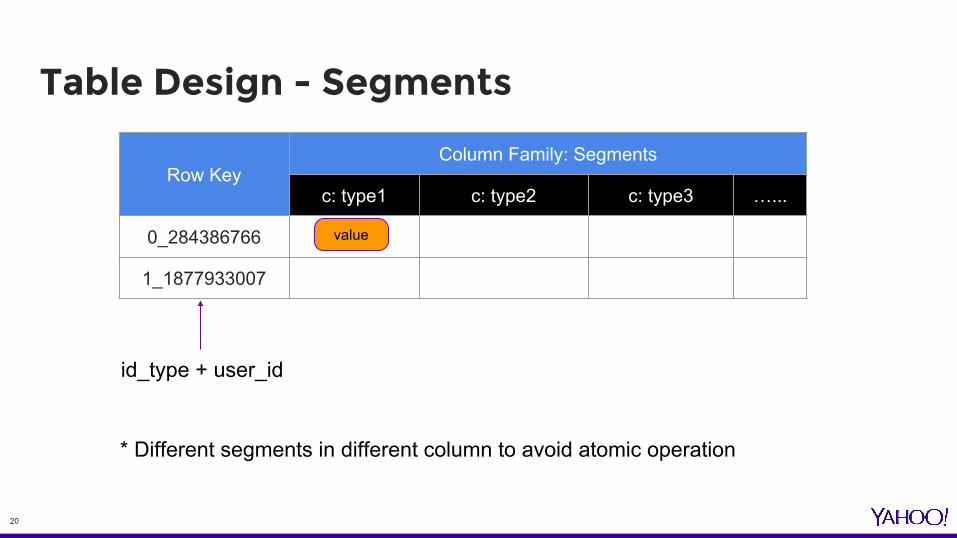
Table Design - Segments
Row KeyColumn Family: Segments
c: type1 c: type2 c: type3 …...
0_284386766
1_1877933007
id_type + user_id
* Different segments in different column to avoid atomic operation
value
21
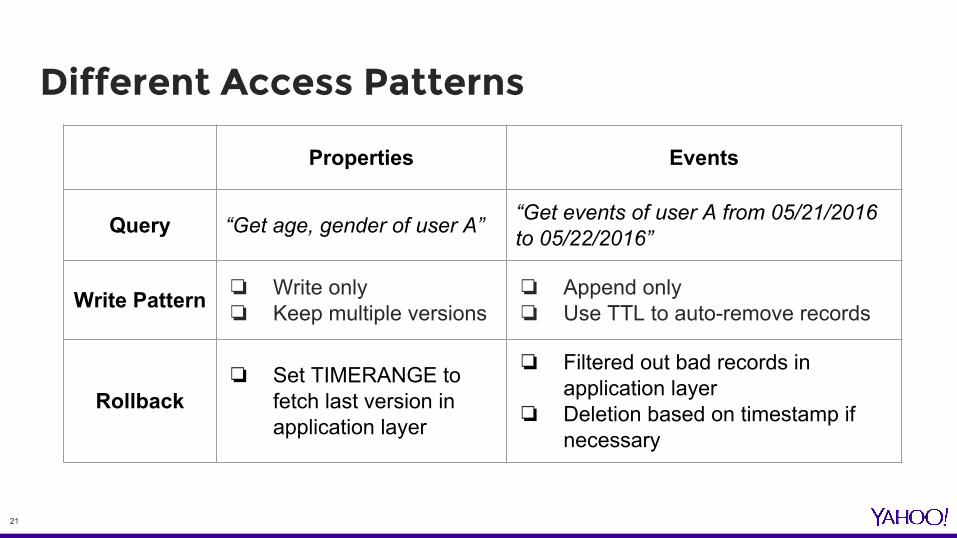
Properties Events
Query “Get age, gender of user A” “Get events of user A from 05/21/2016 to 05/22/2016”
Write Pattern ❏ Write only❏ Keep multiple versions
❏ Append only❏ Use TTL to auto-remove records
Rollback❏ Set TIMERANGE to
fetch last version in application layer
❏ Filtered out bad records in application layer
❏ Deletion based on timestamp if necessary
Different Access Patterns

22
Agenda
- What is User Profile - Architecture Evolution - Schema Design- Optimization
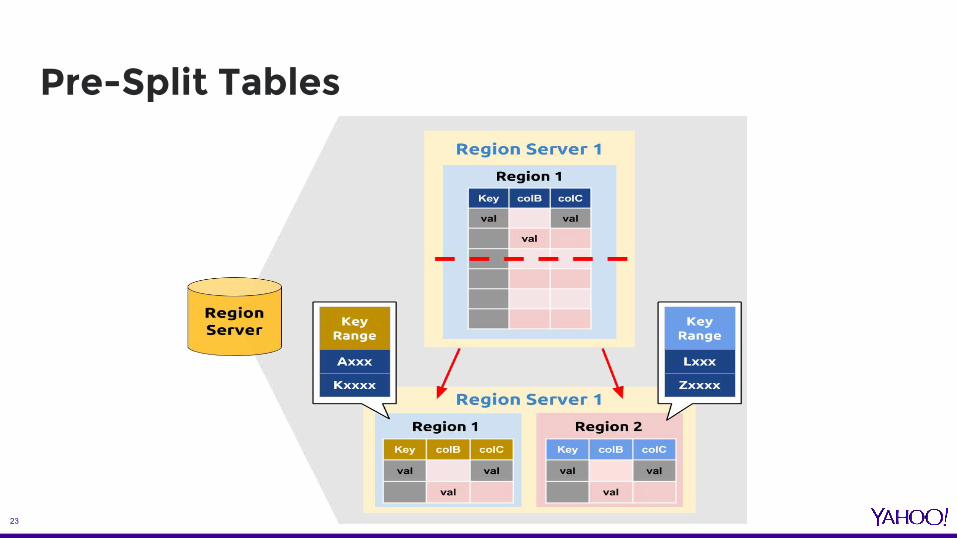
- Pre-split tables- Pre-aggregation in Spark- Lazy aggregation for inactive users- Sequential read on Hive
- Future Work
23
Pre-Split Tables
24
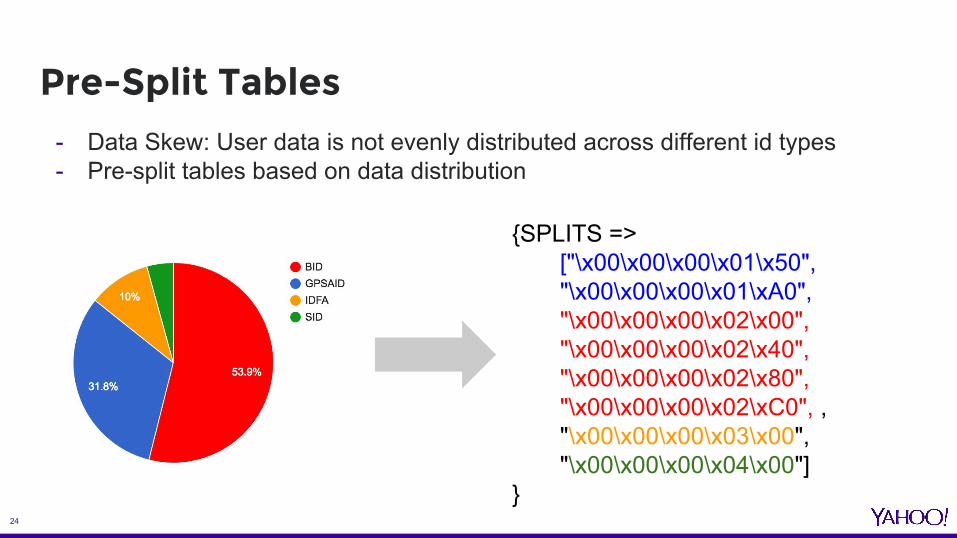
Pre-Split Tables- Data Skew: User data is not evenly distributed across different id types - Pre-split tables based on data distribution
{SPLITS =>["\x00\x00\x00\x01\x50", "\x00\x00\x00\x01\xA0", "\x00\x00\x00\x02\x00", "\x00\x00\x00\x02\x40", "\x00\x00\x00\x02\x80", "\x00\x00\x00\x02\xC0", , "\x00\x00\x00\x03\x00", "\x00\x00\x00\x04\x00"]
}
25
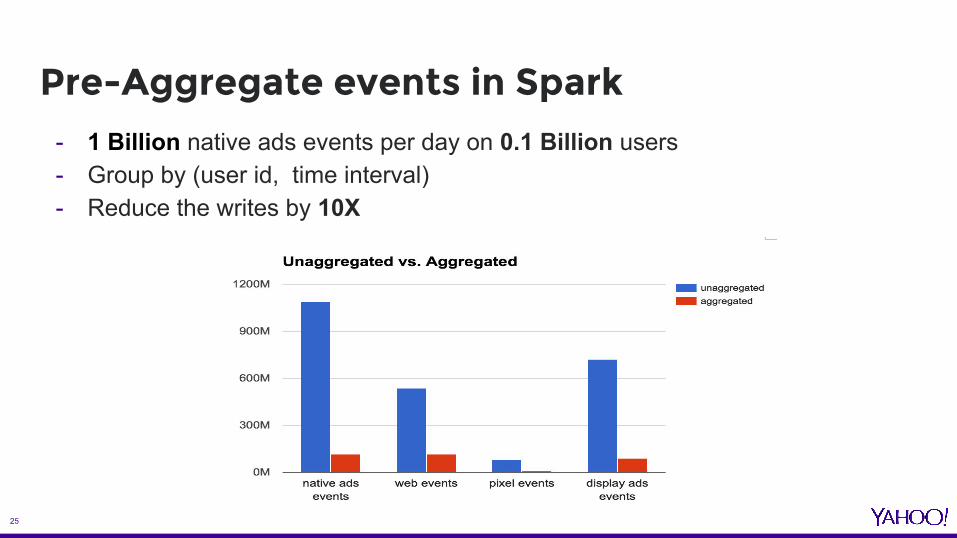
- 1 Billion native ads events per day on 0.1 Billion users - Group by (user id, time interval)- Reduce the writes by 10X
Pre-Aggregate events in Spark
26
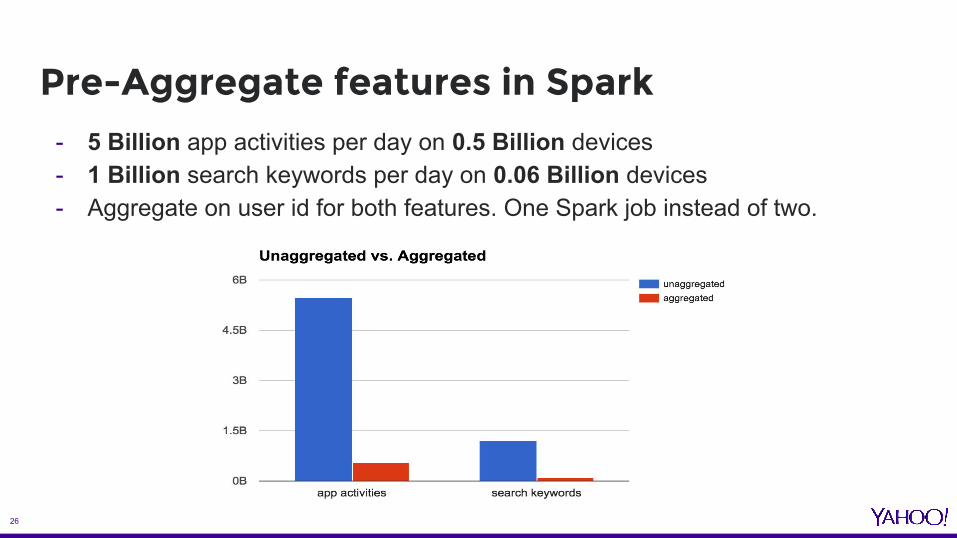
Pre-Aggregate features in Spark- 5 Billion app activities per day on 0.5 Billion devices- 1 Billion search keywords per day on 0.06 Billion devices- Aggregate on user id for both features. One Spark job instead of two.

27
Lazy aggregation for inactive users
- Problem: read-modify-write is expensive- Facts:
- A large portion of the users might not be accessed frequently- Update jobs are not evenly distributed over time
- Solution: Lazy aggregation for inactive users
28
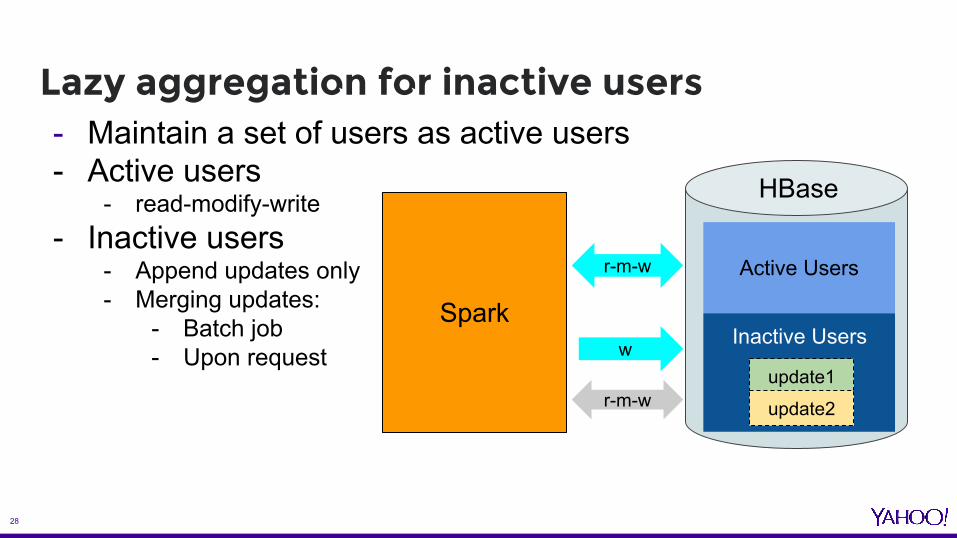
- Maintain a set of users as active users- Active users
- read-modify-write- Inactive users
- Append updates only- Merging updates:
- Batch job- Upon request
Lazy aggregation for inactive users
Spark
r-m-w
w
HBase
r-m-w
Active Users
Inactive Users
update1
update2

29
Sequential read on Hive
- HBase to Hive- Sync data to Hive using HBase snapshots without
impact Region Servers. - Hive access the data using HBaseStorageHandler.
- Move sequential reads to Hive- User modeling- Audience insights

30
Agenda
- What is User Profile - Architecture Evolution - Schema Design- Optimization- Future Work

31
Future Work
- Explore Impala/Presto for better query performance; - Expose API for incremental modeling capability.

32
Questions?

33
Appendix

34
More optimization- Less column family as possible- Turn off autoflush- Throttling writes if necessary- Compress data before sending to Hbase- Kryo for serialization



![NEXT-GENERATION SSD VERIFICATION PLATFORM WITH …dcslab.hanyang.ac.kr/nvramos/nvramos12/presentation/[NVRAM]Yoon.pdf · NEXT-GENERATION SSD VERIFICATION PLATFORM WITH TERA-SCALE](https://img.pdfslide.us/doc/110x75/5a8529bd7f8b9a882e8c1097/next-generation-ssd-verification-platform-with-nvramyoonpdfnext-generation.jpg)