Embed Size (px)
Citation preview

TAUS Executive Forum 2015April 9-10, Tokyo

TM-Town's mission is to create a better translation world through technology and specialization.

Job matching based on natural language processing of prior work
Incoming translation
job
matching algorithm
1. work is loaded
2. loaded work can be leveraged3. the system "learns" each translators' areas of experience4. better matching

A bank for your linguistic assets
1. Safekeeping
2. Access anywhere
3. Earn interest

For translators• a place to store and manage your TM's and glossaries, and do cool and useful things with them
• a place to potentially connect with “spot on” clients simply by allowing your prior work to speak for itself - without a word of it being disclosed
For translation buyers
For translation companies
• a place to connect with “spot on” translators based on the material you need translated -- without needing to disclose the work before selection
• as the work is done by specialists, and the matching process is more automated and more accurate, benefits may be obtained in the areas of quality, price and turnaround
• a tool to enable your project managers or vendor managers to more quickly, more easily and more accurately select the best people for new translation jobs

A translation enablement platform - what’s that?
• Unlimited private storage of TMs & glossaries • TM & glossary analytics • Term extraction • Automatic alignment • Easy file conversion (TMX, XLIFF, XLS, CSV) • Ability to share term glossaries • A powerful API • Integration with CAT / TEnT tools • Job matching on the basis of your prior work

Dropbox for translatorswith added benefits

Automatic term extraction and glossary creation
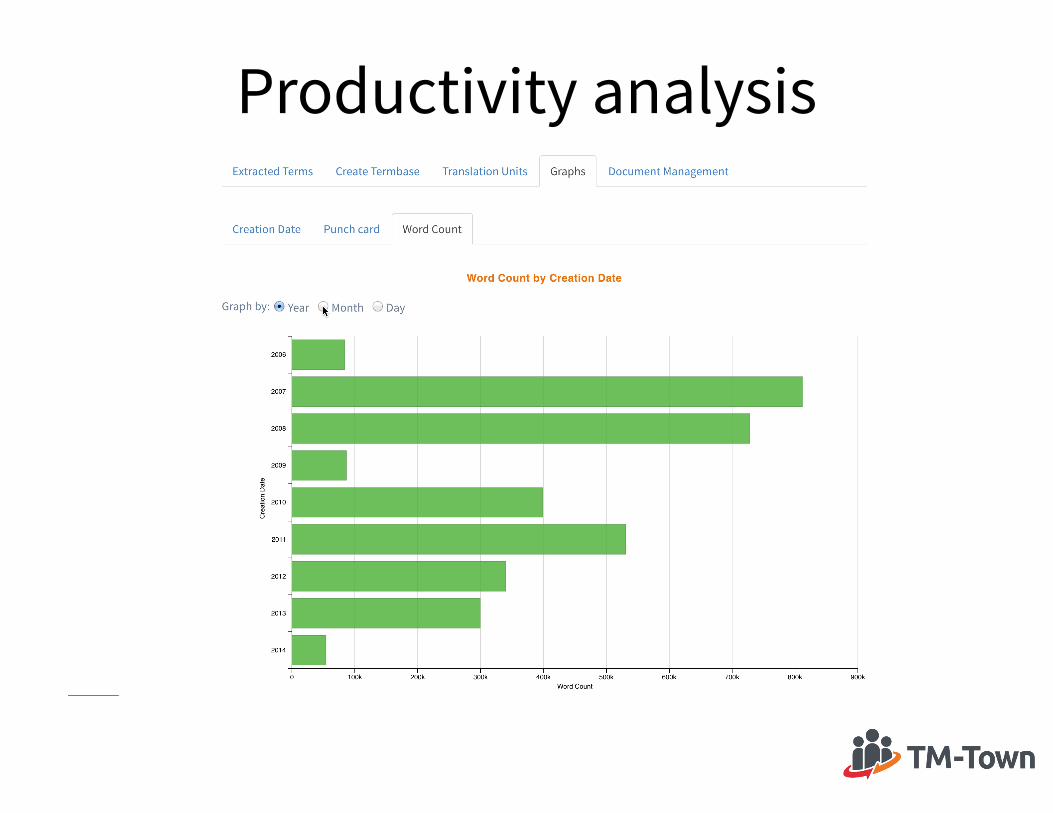
Productivity analysis

A powerful API
• Easy integration with other CAT tools • Well-documented • Public and private endpoints

API integration in CAT tools
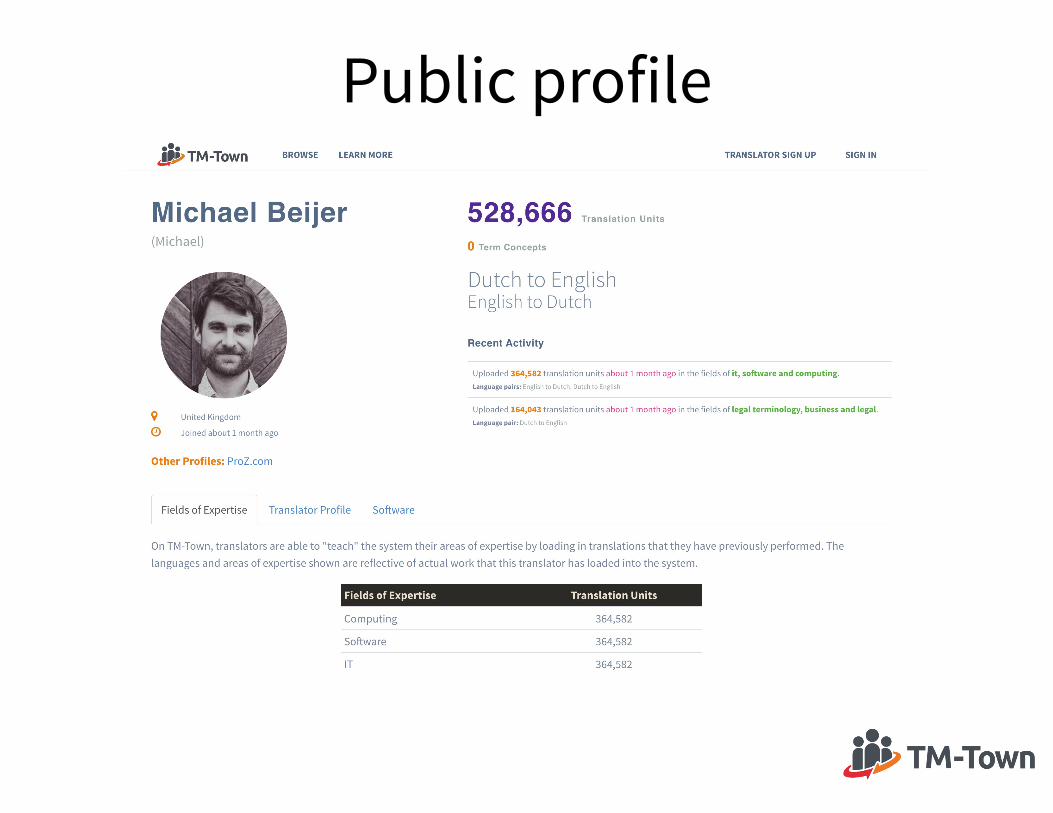
Public profile

Privacy
• 3 pieces of metadata are public 1. Language pair(s) 2. Field(s) of expertise you select 3. Number of translation units or term concepts
• The content of any document you upload is automatically private and secure

Segmentation - why reinvent the wheel?
• Most segmentation libraries are built to support only English (or English plus a few other languages)
• Current solutions do not handle ill-formatted content well
• Some libraries perform really well when trained with data in a specific language and a specific domain, but what happens when your data could come from any language and/or domain
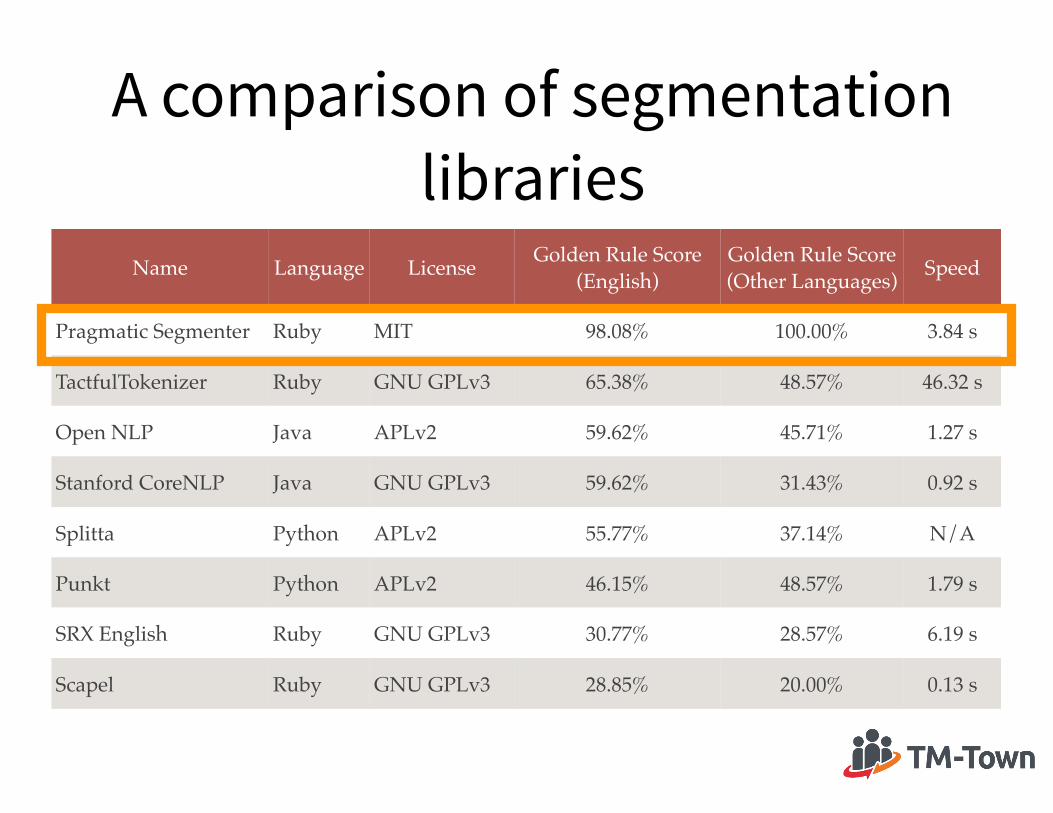
A comparison of segmentation libraries
Name Language License Golden Rule Score !(English)
Golden Rule Score (Other Languages) Speed
Pragmatic Segmenter Ruby MIT 98.08% 100.00% 3.84 s
TactfulTokenizer Ruby GNU GPLv3 65.38% 48.57% 46.32 s
Open NLP Java APLv2 59.62% 45.71% 1.27 s
Stanford CoreNLP Java GNU GPLv3 59.62% 31.43% 0.92 s
Splitta Python APLv2 55.77% 37.14% N/A
Punkt Python APLv2 46.15% 48.57% 1.79 s
SRX English Ruby GNU GPLv3 30.77% 28.57% 6.19 s
Scapel Ruby GNU GPLv3 28.85% 20.00% 0.13 s

Bitext alignment - areas for improvement
• Early misalignment compounds into errors throughout
• Accuracy may suffer for non-Roman languages unless the algorithm is properly tuned
• Does not handle cross alignments nor uneven alignments

A method for higher accuracy• Machine translate A - B and B - A • Relative sentence length • Order or position in the document
0 1 2 3 4 5
0
1 X
2 X
3
4 X
5 X
X






























