Embed Size (px)
Citation preview

A Presenta*on from The NewMR “Advances in Quan*ta*ve Research” Event
19 September, 2012
Event sponsored by Affinnova All copyright owned by The Future Place and the presenters of the material
For more informa=on about Affinnova visit www.affinnova.com For more informa=on about NewMR events visit newmr.org
Taking Nothing Seriously: A Review of Approaches to Modeling the ‘None’ Op=on Kevin D. Karty PhD, Affinnova

www.affinnova.com Kevin Karty, Affinnova, USA NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
Taking Nothing Seriously:
Much Ado About Nothing
Kevin Karty Vice President, Analytics
Bin Yu Director, Analytics

3 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
The Problem
• In a conventional choice base conjoint study, we typically show something like the example below
• In actual implementation, the expression of “None” may be conducted in different ways… – A choice option with equal size and consistent location (as below) – A bottom bar below the other options (in a different color)
• We’ve tried lots of different visual treatments, always with the same result – people just don’t pick “None” enough
Nothing Usually Doesn’t Mean Very Much

4 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
The Problem
• Here is an example of the usage of “None” from a standard interface for a complex (and lengthy) study on new retail store layouts
• Over 60% of all respondents use “None” on fewer than 20% of all choice tasks – and nearly 40% of respondents NEVER used “None”
• This study offered strong insights, but the variation in simulated store usage across many formats was small even when major changes were made to inputs
Num
ber o
f Use
rs W
ho S
elec
ted
“Non
e”
Cum
ulat
ive
Perc
enta
ge o
f Use
rs W
ho
Sele
cted
Non
e N
or F
ewer
Tim
es
Nothing Usually Doesn’t Mean Very Much
Number of Times NONE Selected
60% of respondents selected ‘None’ on fewer than 5 out of 25 choice sets
40% of respondents never selected ‘None’ on any of 25 choice sets

5 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
The Problem
This study proved useful for a few reasons… • There was no “true” answer,
since the store layout was hypothetical – a directional simulator was sufficient
• “None” usage INCREASED throughout the duration of the respondent experience
• Respondents became more discriminating as they saw things they liked in previous choice tasks – Actually had negative aggregate
utility for some features due to this displacement effect
Freq
uenc
y of
“N
one”
Sel
ectio
ns
Acr
oss
Res
pond
ents
Nothing Usually Doesn’t Mean Very Much

6 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
Initial Exploration of Alternatives
• Overstatement is a recognized problem in behavioral economics, where “None” is interpreted as the “external good” – We know from experimental behavioral economics that when
consumers compare a thing to an unspecified external good, they are more likely to buy the thing
• This can be improved by having consumers compare a thing to specific goods – they are usually less likely to buy the thing – However, this can be twisted around by offering a comparison
to an asymmetrically inferior good (e.g. asymmetric dominance)
• So we tried to solve the “None” problem by offering multiple “None” options…
• Our question: If we offer multiple “None” options, each describing a different class of external goods from a related category, would this help?
Using Multiple “None’s”
None
None
None
None

7 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
Initial Exploration of Alternatives
• Goal in this study was to optimize a new line for a snacking product in a niche subcategory – Current line had low
market penetration…
• To increase the sensitivity to the “external good”, we created five “None” buttons – One generic, and four
specifying other types of items in adjacent categories
– Compared to similar studies we saw increased “None” usage, but not enough to solve the problem…
Num
ber o
f Use
rs W
ho S
elec
ted
“Non
e”
Cum
ulat
ive
Perc
enta
ge o
f Use
rs W
ho S
elec
ted
“Non
e”N
or F
ewer
Tim
es
Example: Using Multiple “None’s”
Number of Times NONE Selected
70% of respondents selected ‘None’ on fewer than 5 out of 20 choice sets

8 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
Initial Exploration of Alternatives
• Interestingly, “None” usages (for all “None” buttons as an aggregate) did NOT increase as respondents progressed through the exercise…
• However, “None” usage was still unrealistically low
Freq
uenc
y of
“N
one”
Sel
ectio
ns A
cros
s R
espo
nden
ts
Using Multiple “None’s”

9 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
Initial Exploration of Alternatives
• Actual product penetration among targeted grocery shoppers was <20% even with substantial price promotion and awareness, and decent product placement
• However, when we simulated the line of products (without any competitors present), our projected purchase rate is 84% even when we include all five “None’s” in the simulation – When we only include the generic “None”, our projected purchase rate is 90%, which is close
to our result from a similar study in an adjacent category for the same client where we did not include multiple “None” buttons
• We can of course “calibrate” the data in any number of ways, but these calibrations always create problems… – For example, if we increase the utility of None by a fixed amount for each respondent until
our simulations match HH penetration, we end up arbitrarily assigning some number of people who NEVER said “None” to “None” (we need simulated Penetration <20%, but >40% of people never used any of the “None” buttons ever)
– Other calibration methods incur different problems
• All of this is because we fundamentally have BAD DATA: When consumers tell us they would buy something (rather than nothing) they don’t really mean it!
Using Multiple “None’s”

10 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
Initial Exploration of Alternatives
• One possible explanation for the under-usage of “None” was lack of visibility or focus
• We know that Dual Response (yes / no) can increase “None” usage…but generally not enough
• If we expand the standard Dual Response (yes / no) to a 5 point scale sequential response, can we increase “None” usage further?
• To answer this question, we fielded two separate legs in a fairly standard conjoint study – Category: online payment processing product – 6 attributes: 8 x 7 x 6 x 6 x 4 x 3
• (The attribute with 3 levels was sub-branding)
Dual Response Dual Response è Ordinal Scale Sequential Response
11 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
Initial Exploration of Alternatives
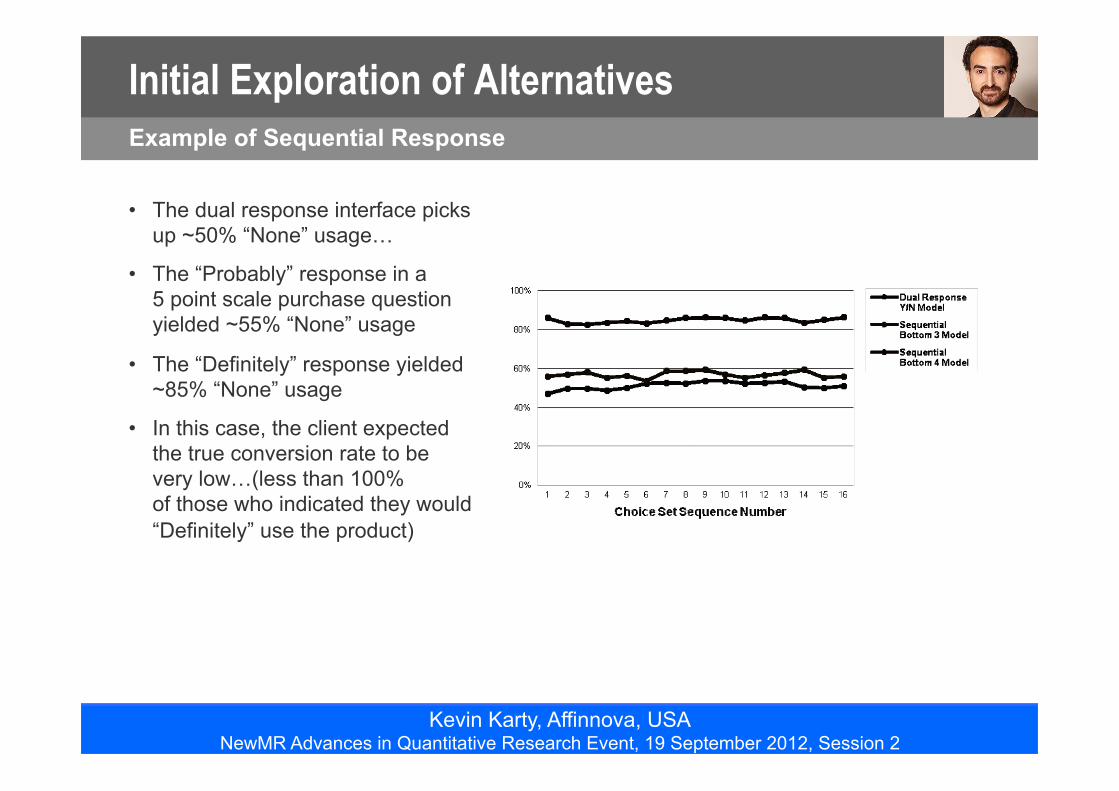
• The dual response interface picks up ~50% “None” usage…
• The “Probably” response in a 5 point scale purchase question yielded ~55% “None” usage
• The “Definitely” response yielded ~85% “None” usage
• In this case, the client expected the true conversion rate to be very low…(less than 100% of those who indicated they would “Definitely” use the product)
Example of Sequential Response

12 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
“None” Problem: Really Two Separate Problems
Overstatement Consumers are far more likely to give us a thumbs up on a product than they are to actually buy it

13 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
These Two Problems Have Solutions…
Overstatement Separate choice task from confirmation task
Use a scale that can create separation in responses based on commitment

14 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
“None” Problem: Really Two Separate Problems
Lack of a Valid Reference Point to Anchor the External Good
When consumers are considering the alternative to a purchase, they are rarely cognizant of the real alternatives

15 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
These Two Problems Have Solutions…
Lack of a Valid Reference Point to Anchor the External Good Give consumers a valid anchor point to compare against when assessing purchase intent for a new product or service

16 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
Our Experimental Setup
• Get a real apples-to-apples comparison… – Initially we had hoped to conduct
5 parallel studies – No [research] plan survives first
contact with the enemy
• Five Parallel Studies – Traditional “None” as extra option – Dual Response “None” (yes / no) – Sequential Response 5 Point Scale – Multiple “None” Buttons – Sequential Response 5 Point Scale
With Dynamic Anchoring
– No [research] plan survives first contact with the enemy CFO
Three

17 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
Choosing the Category…
Selected a category that we were already studying for other internal research… • We already owned scanner data • Growing category due to
increased usage • Familiar to everyone who is a
potential user • High rate of product innovation
in last decade • We had developed a set of new
product concepts in-house with clear functional benefits in a growing segment of the market
Our Category…

18 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
Our Cat Litter Study
“Client” Objective: Assess potential of a set of new product concepts targeting the natural / green segment among cat litter purchasers
– We have already optimized these concept propositions for different market sub-segments
Challenge • We would prefer NOT to represent the entire category, since the total
number of products is quite large and this becomes costly
• Our goal is to predict which concept will perform best in market, and ideally by how much – We want to represent real packaging, BUT we don’t have real pack-level
creative for our new concept yet – We do not want the complexity of doing a full brand / pricing study – need
to keep it simple
• This places heavy demands on our “None” option

19 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
Our New Cat Litter Concepts
• One starting point (manager’s best guess)
• Four concepts developed from an earlier optimization phase with dozens of names, benefits, reasons to believe, etc. that we “borrowed” from existing products
Starting Point
Five New Concepts

20 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
Six Included Competitors…
• Three main brands, three natural brands • Less than 50% of the market by sales

21 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
Interface I
Standard “NONE” represented as the fourth item in a choice set in the fixed location with equal size stimulus
Standard “None” Button

22 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
Interface II
After making a choice, indicate whether you would actually purchase the product (yes or no response)
Dual Response Yes / No Follow-Up

23 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
Interface III
• After making a choice, indicate how likely you would buy the product instead of the brand you buy most often (5-point scale response)
• Brand-Most-Often is piped from a screener question
Sequential 5-Point Scale Follow-Up with Dynamic BMO Piping

24 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
Model Definitions
Model Interface Definition of NONE
Standard NONE Model NONE button NOTA button
Dual Response Yes / No Model Yes / No follow-up No in the Yes / No
follow-up question
Sequential Bottom 3 Model
Sequential 5-point scale follow-up with
dynamic BMO piping
Bottom 3 choices in the 5-point scale follow-up question
Sequential Bottom 4 Model
Sequential 5-point scale follow-up with
dynamic BMO piping
Bottom 4 choices in the 5-point scale follow-up question
n = 300 for all models
25 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
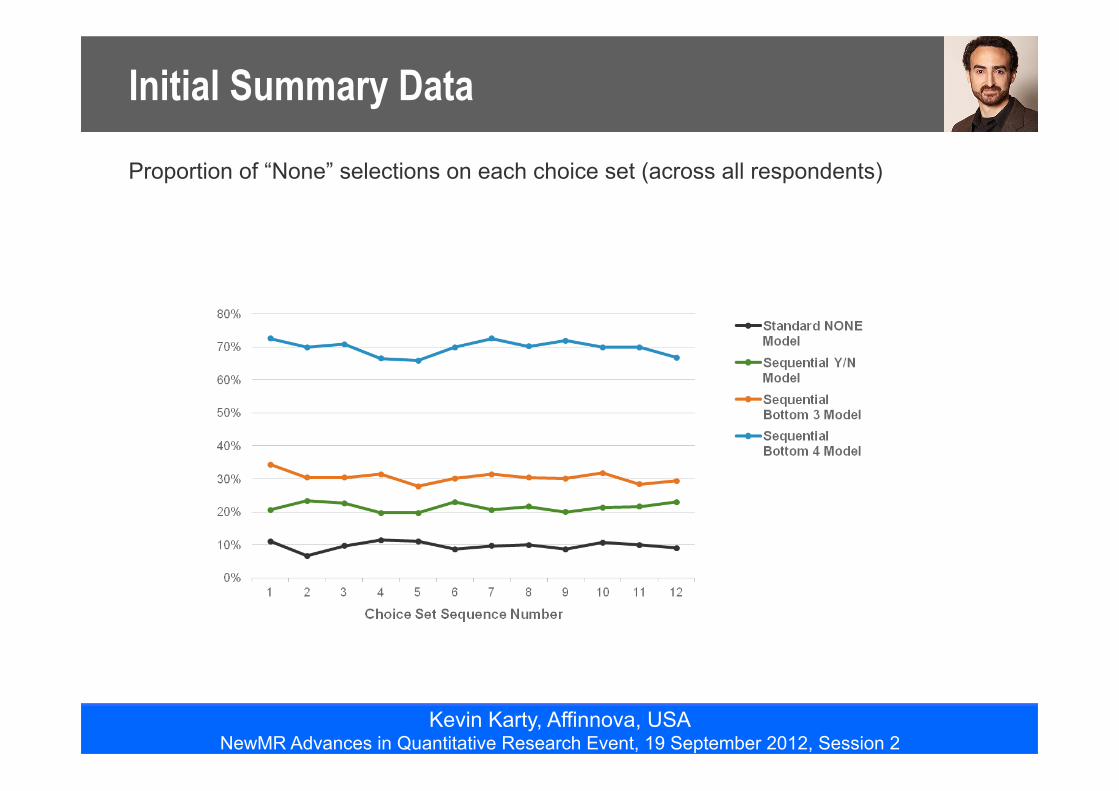
Initial Summary Data
Proportion of “None” selections on each choice set (across all respondents)

26 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
But Does It Matter?
• We can begin by comparing share projections for the products that are already in market to actual market sales
• We adjust for distribution by multiplying projected share by ACV, and renormalizing – “None” is given the benefit of the doubt, and assumed to have 100% distribution
Brands
Current Market Share
(by Volume) Distribution
Arm & Hammer Scoopable 15.2% 74.9%
Fresh Step Scoopable 11.8% 78.1%
Tidy Cats Scoopable 17.6% 77.9%
Arm & Hammer Essentials 0.6% 43.4%
Feline Pine 1.1% 47.0%
World’s Best Cat Litter 0.5% 44.8%
NONE (including Other Brands) 53.3% 100.0%

27 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
Projections vs. Actual
• Unadjusted for distribution, Sequential Bottom 4 Model comes closest to matching reality
• All of the models over-predict the niche products substantially, with Standard NONE Model being the worst
28 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
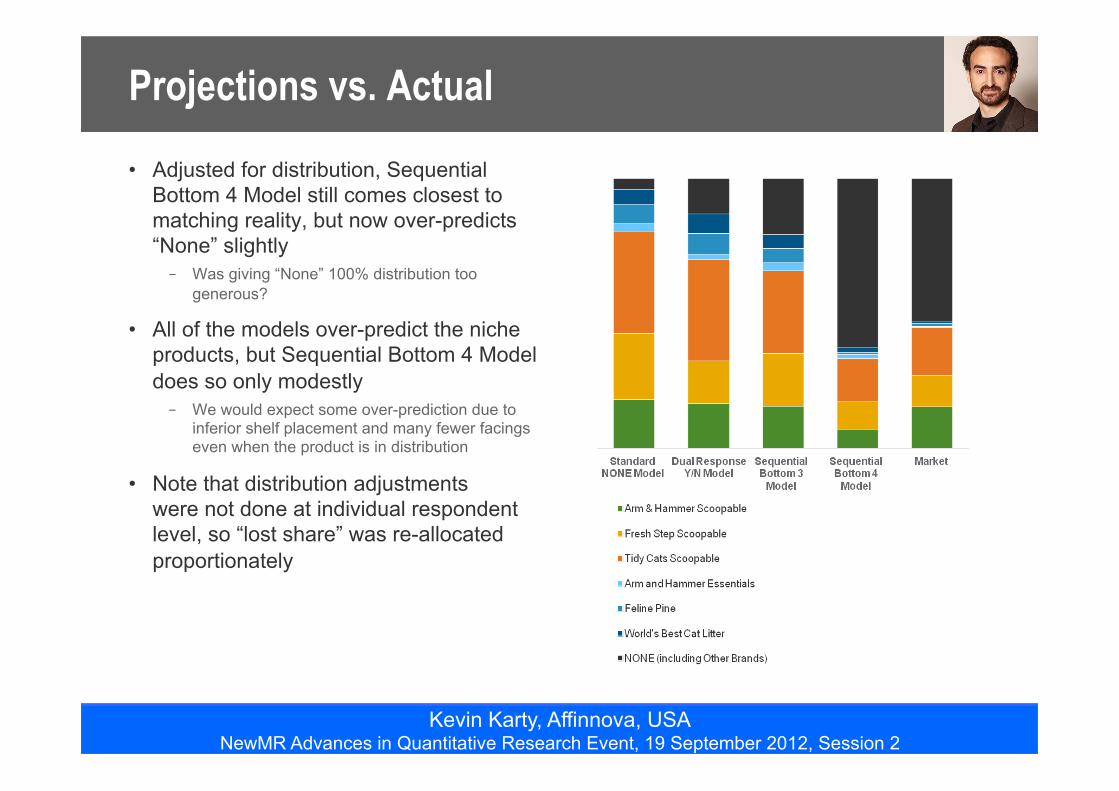
Projections vs. Actual
• Adjusted for distribution, Sequential Bottom 4 Model still comes closest to matching reality, but now over-predicts “None” slightly – Was giving “None” 100% distribution too
generous?
• All of the models over-predict the niche products, but Sequential Bottom 4 Model does so only modestly – We would expect some over-prediction due to
inferior shelf placement and many fewer facings even when the product is in distribution
• Note that distribution adjustments were not done at individual respondent level, so “lost share” was re-allocated proportionately

29 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
What If We Use Specific Effect Adjustments?
• Applied specific effect adjustments to match the predicted “None” share to the share of “Other Brands” in the market
• Identified respondents with highest individual utility for “None” è Assigned them to None
Most Often Brand NOT Assigned to “None”
Assigned to “None”
Arm & Hammer Scoopable 8% 14%
Fresh Step Scoopable 20% 20%
Tidy Cats Scoopable 25% 11%
Arm & Hammer Essentials 3% 2%
Feline Pine 3% 1%
World’s Best Cat Litter 0% 3%
Other Brands (“None”) 42% 49%
Sample Size 154 146
Among respondents assigned to an included brand instead of “None”, 42% used an “Other Brand” most often…
Among respondents assigned to “None”, only 49% used an “Other Brand” most often…
Cur
rent
Bra
nd U
sed
Mos
t Ofte
n
Assigned to “None” by Standard Model (with Specific Effects Adjustments)?

30 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
What If We Use Specific Effect Adjustments?
• Repeating this analysis for the other models, we see very weak linkage between allocation to “None” in the first two models and stated brand most often usage
• Slight improvement in Model 3
• Substantial improvement in Model 4
Standard NONE Model
Dual Response Y / N Model
Sequential Bottom 3 Model
Sequential Bottom 4 Model
Most Often Brand A B A B A B A B
Arm & Hammer Scoopable 8% 14% 13% 10% 12% 11% 14% 9%
Fresh Step Scoopable 20% 20% 11% 14% 26% 17% 28% 15%
Tidy Cats Scoopable 25% 11% 21% 20% 21% 22% 28% 15%
Arm & Hammer Essentials 3% 2% 9% 3% 4% 5% 7% 1%
Feline Pine 3% 1% 0% 1% 1% 0% 0% 1%
World’s Best Cat Litter 0% 3% 1% 4% 1% 0% 1% 1%
Other Brands (“None”) 42% 49% 45% 49% 35% 46% 23% 58% Sample Size 154 146 159 141 144 156 149 151
Segment A: Respondents for whom the highest utility is on one of the products included in the study Segment B: Respondents for whom the highest utility is on “None” C
urre
nt B
rand
Use
d M
ost O
ften
31 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
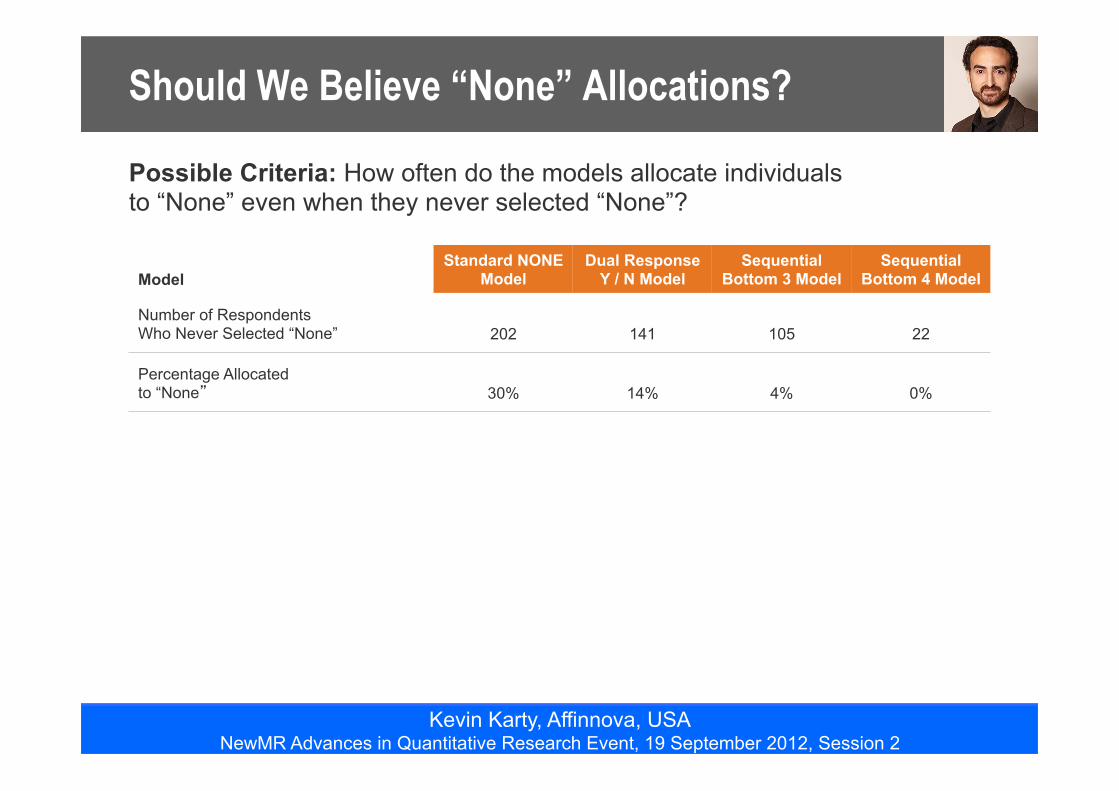
Should We Believe “None” Allocations?
Possible Criteria: How often do the models allocate individuals to “None” even when they never selected “None”?
Model Standard NONE
Model Dual Response
Y / N Model Sequential
Bottom 3 Model Sequential
Bottom 4 Model
Number of Respondents Who Never Selected “None” 202 141 105 22
Percentage Allocated to “None” 30% 14% 4% 0%

32 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
Should We Believe “None” Allocations?
Possible Criteria: What impact does it have on our new product projections? • Here we simulate adding the new concepts (without adjusting for
distribution) to the mix of existing products and “None” • The first three models yield similar answers • All models yield the same ordering • The Sequential Bottom 4 Model yields lower overall projections, and
a substantially lower gap between Concept 1 and the Starting Point
Model Standard
NONE Model Dual Response
Y / N Model Sequential Bottom 3
Model Sequential Bottom 4
Model Concept 1 vs. Comp. 17% 17% 18% 8% Concept 2 vs. Comp. 17% 16% 17% 8% Concept 3 vs. Comp. 17% 14% 14% 7% Concept 4 vs. Comp. 15% 13% 16% 8% Starting Point vs. Comp. 11% 13% 12% 6%

33 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
Some Theoretical Concerns
• While Sequential Bottom 4 Model predicts well, the “None” share is a bit too high
• Also, if respondents select “None” 4 of every 5 choice tasks, we lose a lot of relative preference information on second-best products…
• On the other hand, who cares? Why should the relative preference between Product A and Product B matter if the consumer would never purchase either of them?
ALTERNATIVE: Formal Sequential Response Model

34 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
Formal Sequential Response Model
• Assume that both data types (choice data and sequential response scale data) are consistent manifestations of the same underlying dynamic… – That is, if we had an infinite amount of data of either type, we would arrive at the
same parameter estimates for part worth utilities
• Net result – Uses more information – Allows us to apply “normative weights” to Top Box and Second Box
Purchase Interest
Unified Latent Preference Model: Choice Likelihood x Scale Response Likelihood
Likert Scale Scores Discrete Choice Data
35 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
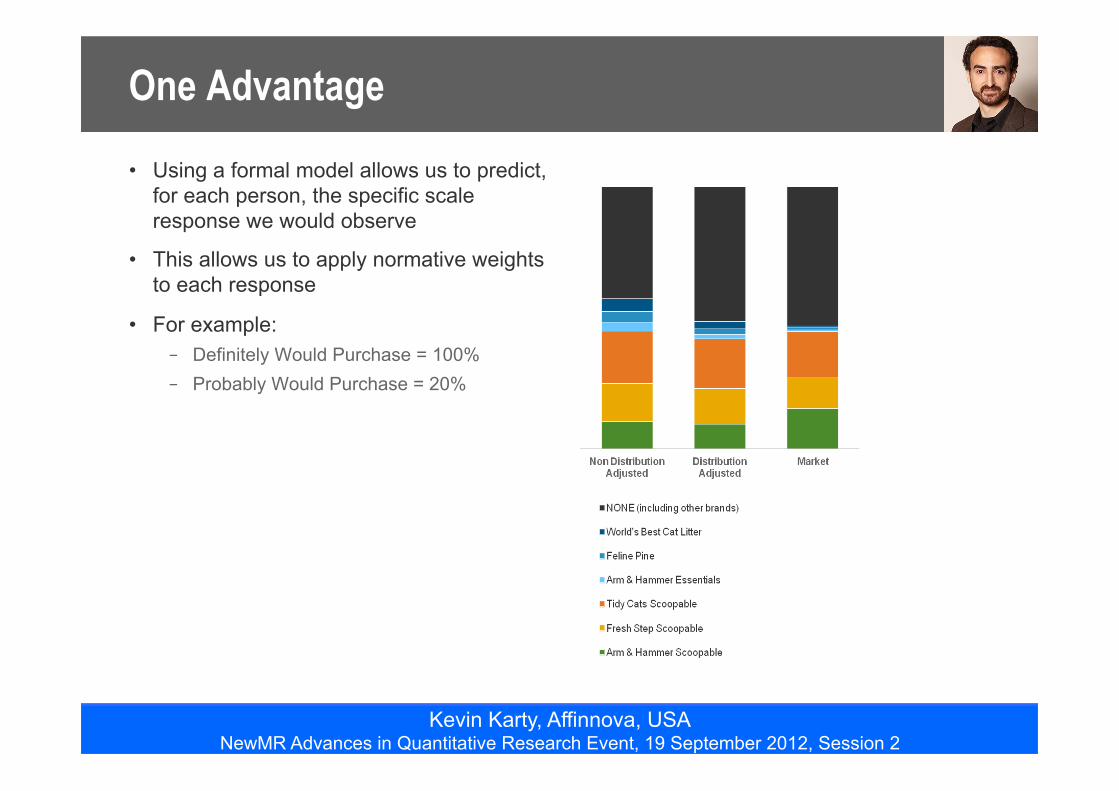
One Advantage
• Using a formal model allows us to predict, for each person, the specific scale response we would observe
• This allows us to apply normative weights to each response
• For example: – Definitely Would Purchase = 100% – Probably Would Purchase = 20%

36 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
Remaining Questions
• Does sequential response work as well if we do NOT pipe in individual-specific information? – In our parallel testing we included conventional approaches and the most
customized sequential response we could imagine
• What normative weights are appropriate to apply to the top box and second box in a formal sequential response model? – Do weights differ by category? – What about the level of refinement of the stimulus?
• How well does this approach apply to main effects models? – For example, new product projections for bundled
telecommunications or finance products?

37
Thank You

38 Kevin Karty, Affinnova, USA
NewMR Advances in Quantitative Research Event, 19 September 2012, Session 2
Q & A
Ray Poynter VCU, Vision Critical
Kevin Karty Affinnova
Q & A

A Presenta*on from The NewMR “Advances in Quan*ta*ve Research” Event
19 September, 2012
Event sponsored by Affinnova All copyright owned by The Future Place and the presenters of the material
For more informa=on about Affinnova visit www.affinnova.com For more informa=on about NewMR events visit newmr.org
Taking Nothing Seriously: A Review of Approaches to Modeling the ‘None’ Op=on Kevin D. Karty PhD, Affinnova





























