Embed Size (px)
Citation preview

Presto @ Netflix: Interactive Queries
at Petabyte Scale
Nezih Yigitbasi and Zhenxiao Luo
Big Data Platform

Outline
» Big data platform @ Netflix
» Why we love Presto?
» Our contributions
» What are we working on?
» What else we need?
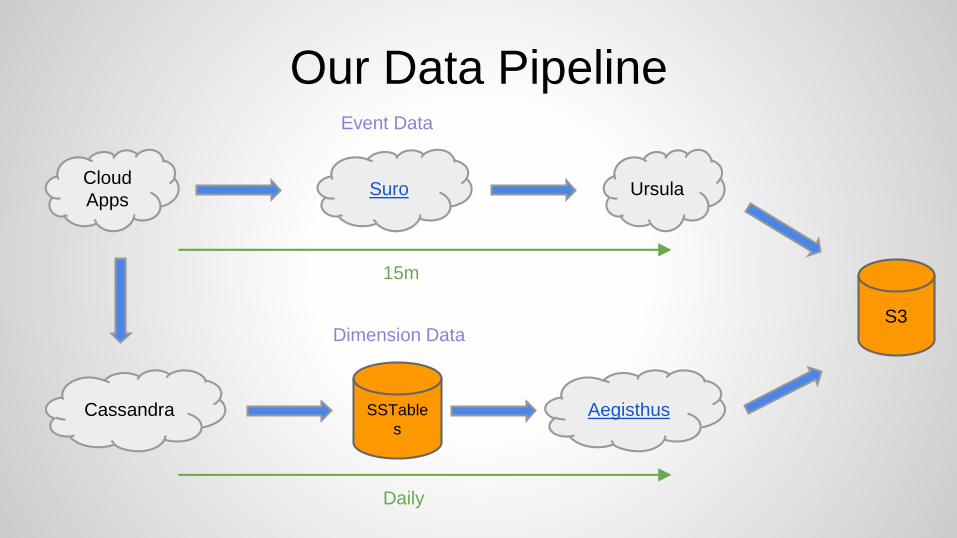
Cloud
Apps
S3
Suro Ursula
SSTable
sCassandra Aegisthus
Event Data
15m
Daily
Dimension Data
Our Data Pipeline
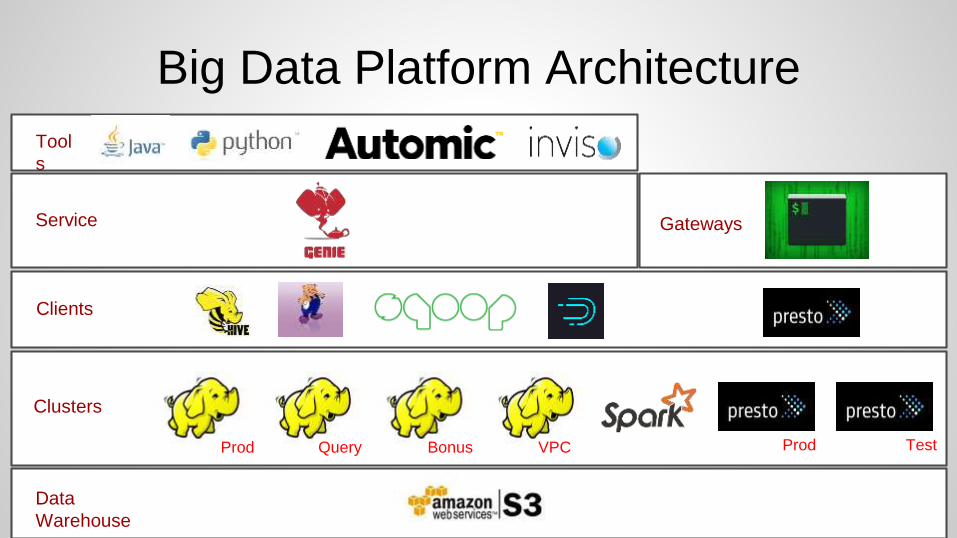
Data
Warehouse
Service
Tool
s
Gateways
Big Data Platform Architecture
Prod
Clients
Clusters
VPCQuery Prod TestBonusProd

» Batch jobs (Pig, Hive)» ETL jobs
» reporting and other analysis
» Ad-hoc queries» interactive data exploration
» Looked at Impala, Redshift, Spark, and Presto
Our Use Cases

Deployment
» v 0.86
» 1 coordinator (r3.4xlarge)
» 250 workers (m2.4xlarge)
Tooling
Numbers
» ~2.5K queries/day against our 10PB Hive DW on S3
» 230+ Presto users out of 300+ platform users
» presto-cli, Python, R,
BI tools (ODBC/JDBC), etc.
» Atlas/Suro for monitoring/logging
Presto @ Netflix

Why we love Presto?
» Open source
» Fast
» Scalable
» Works well on AWS
» Good integration with the Hadoop stack
» ANSI SQL

Our Contributions
24 open PRs, 60+ commits
» S3 file system
» multipart upload, IAM roles, retries, monitoring, etc.
» Functions for complex types
» Parquet
» name/index-based access, type coercion, etc.
» Query optimization
» Various other bug fixes

» Vectorized reader* Read based on column vectors
» Predicate pushdown Use statistics to skip data
» Lazy load Postpone loading the data until needed
» Lazy materialization Postpone decoding the data until needed
What are we Working on?Parquet Optimizations
* PARQUET-
131

Netflix Integration
» BI tools integration» ODBC driver, Tableau web connector, etc.
» Better monitoring » Ganglia ⟶ Atlas
» Data lineage» Presto ⟶ Suro⟶ Charlotte

» Graceful cluster shrink
» Better resource management
» Dynamic type coercion for all file formats
» Support for more Hive types (e.g., decimal)
» Predictable metastore cache behavior
» Big table joins similar to Hive
What else we need?

THANK YOU