Embed Size (px)
Citation preview

Use Cases For Cassandra in Federal
and State Government
Chris Bradford and Matt Overstreet

Matt Overstreet● Software Architect● Search relevancy engineer● Has worked on systems ranging
from Tractor Trailer weigh stations to celebrity websites
● Likes Cassandra
GitHub: omnifroodle

● DataStax Cassandra Architect● Contributor to CQLEngine -
Python C* ORM● Developed Trireme -
a C* migration engine● Created the world’s smallest C*
cluster
Chris Bradford
Twitter: @bradfordcp
GitHub: bradfordcp

Who we are● Consulting firm based in
Charlottesville Virginia● Founded in 2005● 30 consultants delivering projects● Focused on Search in 2010, specifically
Solr and Lucene● Delivering Cassandra Consulting since
2012● Datastax Gold partner● Great with Search, Analytics and
Discovery

Blog & Publications● Blog: http://o19s.com/blog/● Twitter: @o19s● Books
o Relevant Search (Manning)
o Building a Search Server with Elasticsearch (Packt)
o Apache Solr Enterprise Search Server (Packt)

How we got hereOpenSource Connections started with a deep expertise in full text search.
As the size and velocity of the data we interact with grew, so did our toolset for storing, presenting and processing that data.

OSC Toolkit

Some Use Cases- Analytics Workloads
- Welfare Fraud Detection- Intrusion Detection
- Distributed Data Warehousing- Data Warehouse/Sink- Replication & Recovery

Analytics WorkloadsLook for patterns of user error, fraud and abuse in forms submitted to an agency.
Requires the ability to compare submissions to look for similar identifiers such like name, street address, etc

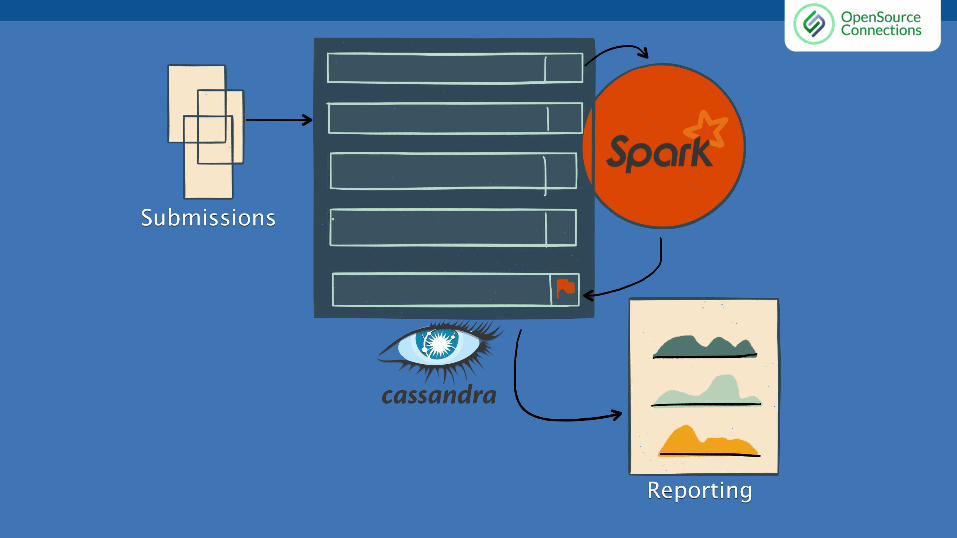
Welfare Fraud Detection● Massive amounts of data● Hard to compare and find patterns● Difficult to incorporate human analysis

Welfare Fraud Detection● Ingest data into the system or work on
data in place● Fraud Score Generation
o Automated ruleso Manually
● Employees can now focus on reviewing the flagged records

Intrusion Detection● Stream log data in to C* from
applications● Surface metrics through a security
dashboard● Perform analysis on records looking for
anomalies (Optional)CREATE TABLE ids ( window TIMESTAMP, route VARCHAR, status_code VARCHAR, request_id TIMEUUID, PRIMARY KEY ((window, route, status_code), request_id));
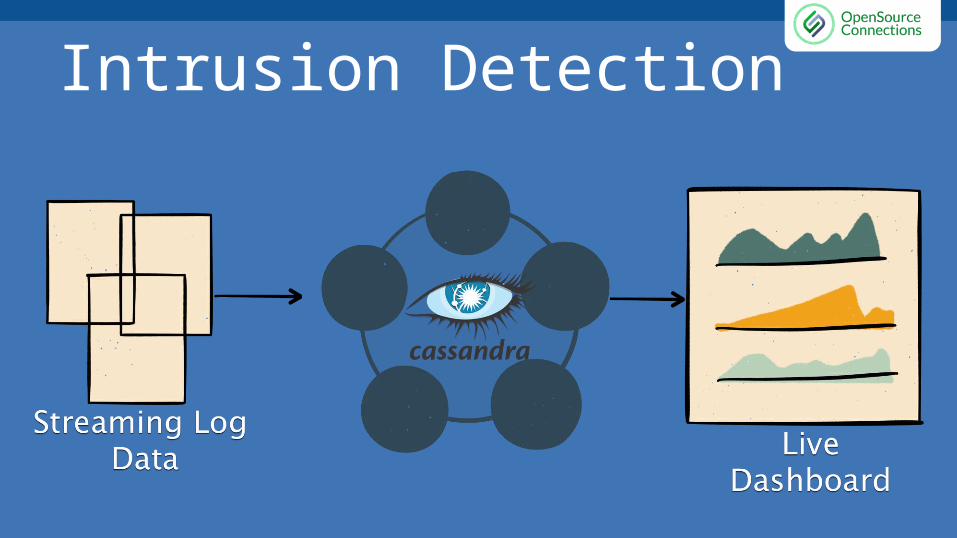
Intrusion Detection

Distributed Data Warehouse● Cassandra is designed in a peer
to peer architecture. There are no “masters” or “slaves”.
● True distributed load, write anywhere, read anywhere.
● Built-in replication between data centers.
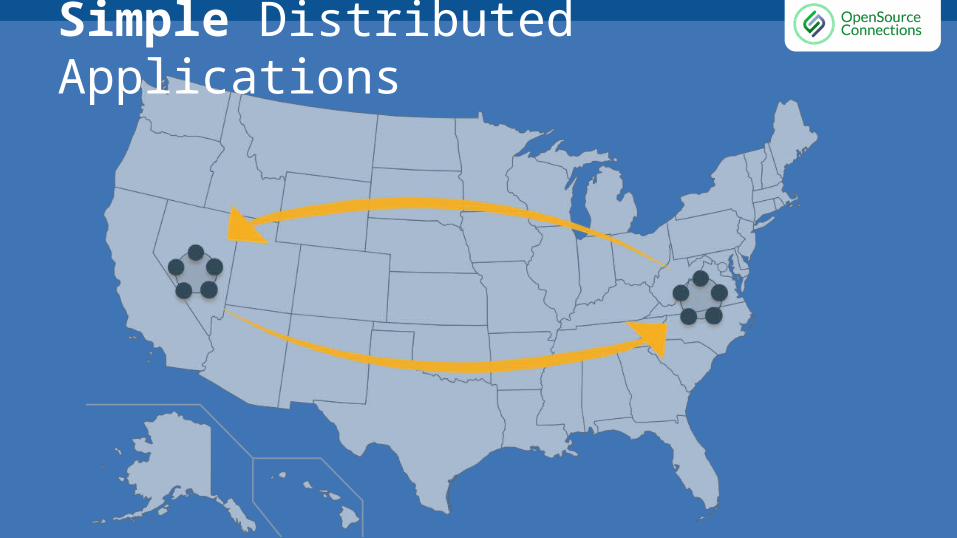
Simple Distributed Applications
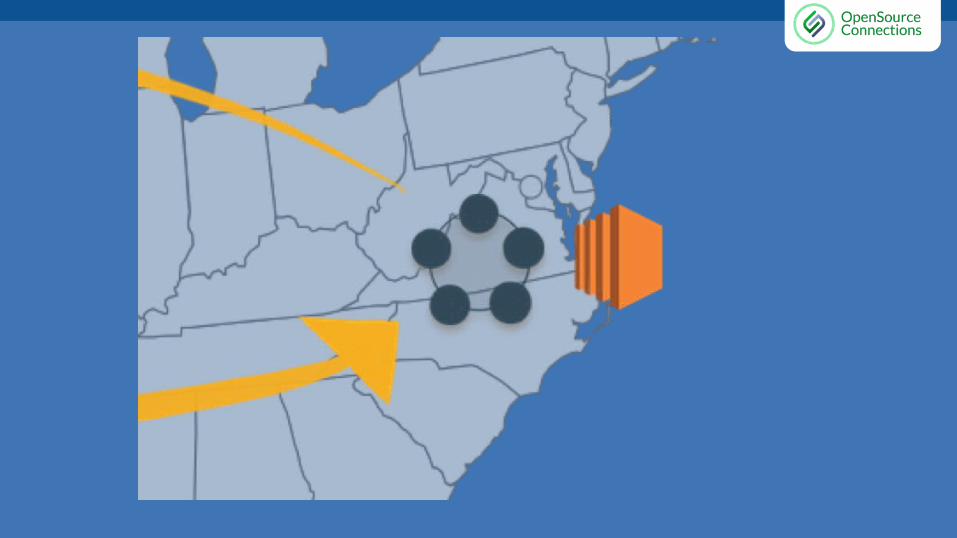

Data Warehouse● Cassandra is used to house case data
from disparate systems● Data is then pushed into a full text
search index● Cases may now be searched through
an intuitive web interface


Operations
● Widely compatible with programming
languages used in enterprise
development
● OpsCenter monitoring tool
● Cassandra scales predictably
● Fault-tolerant

Use Case Review● Analytics Workloads
○ Welfare Fraud Detection○ Intrusion Detection
● Distributed Data Warehousing○ Data Warehouse/Sink○ Replication & Recovery

Q & A





























