Embed Size (px)
Citation preview

Understanding Music Playlists
10 July 2015 ICML 2015 Workshop - Machine Learning and Music Discovery
Keunwoo ChoiGeorge FazekasMark Sandler
@c4dm @Queen Mary University of London

Content
• Music Playlist
• Finding 1
• Finding 2
• Finding 3
• Conclusion

Playlist and Recommendation
• Music recommendation == playlist generation in many cases; especially for common music listener.
• Because recommending a song doesn’t make sense.
• Because simply picking top-N songs might fail.
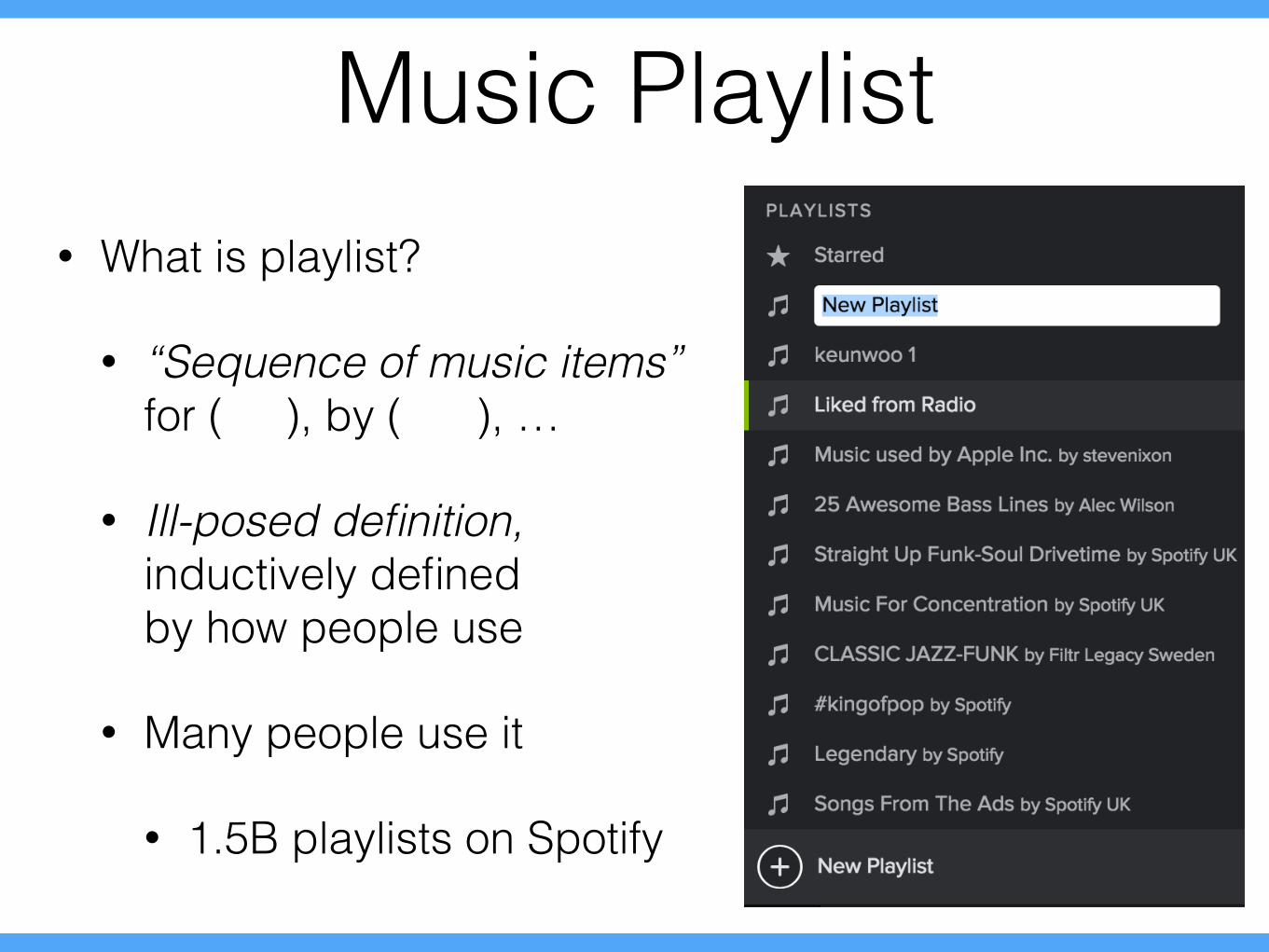
Music Playlist• What is playlist?
• “Sequence of music items”for ( ), by ( ), …
• Ill-posed definition, inductively defined by how people use
• Many people use it
• 1.5B playlists on Spotify

Different Assumptions• What is a good playlist?
Sequence of similar songs
Smooth transitions
Fixed start/end song
Given duration
?

Datasets
Deezer-2015
144,726 songs 50,000 playlists
during 2007-2015
EchoNest track features (high-level
features such as speechness,
dancability, …)
AoTM-2011
97,411 songs 86,310 playlists
during 1998-2011
EchoNest Timbre Features, energy/
key/loudness/mode…
+ playlist category

Datasets• Hierarchy of playlist categories
Genre
Rock Jazz Hiphop R&B Electronic Folk Rock/Pop
Mixed Genre Blues Raggae Country
Punk Hardcore Dance/House
Activity
Sleep Road trip
Emotion
Break up
Depression
Others
Indie Alternating DJ Theme Single
artist Cover Narrative

Three Findings

F1. User clusters in audio-based feature domain
Jennings, 2007
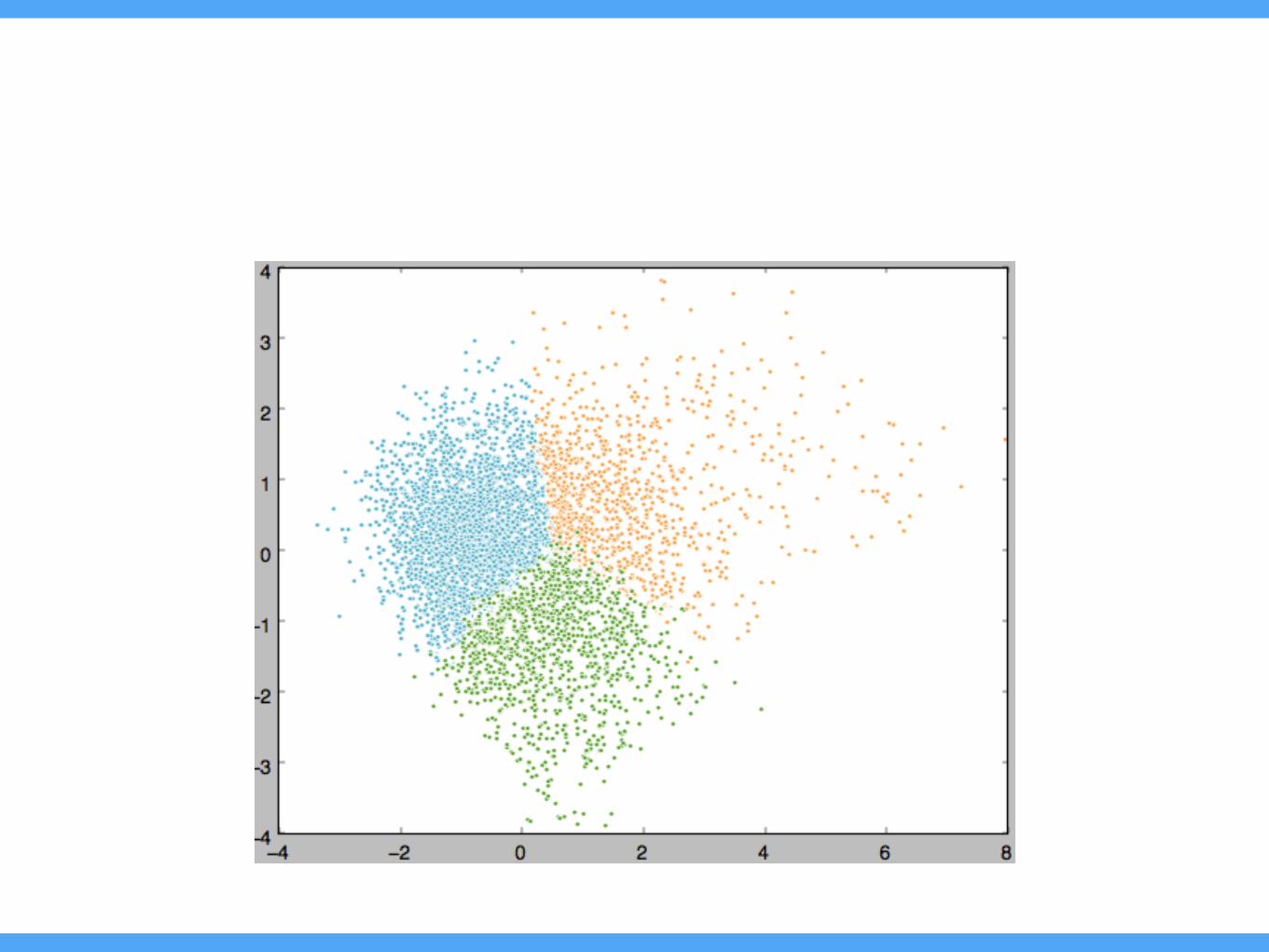
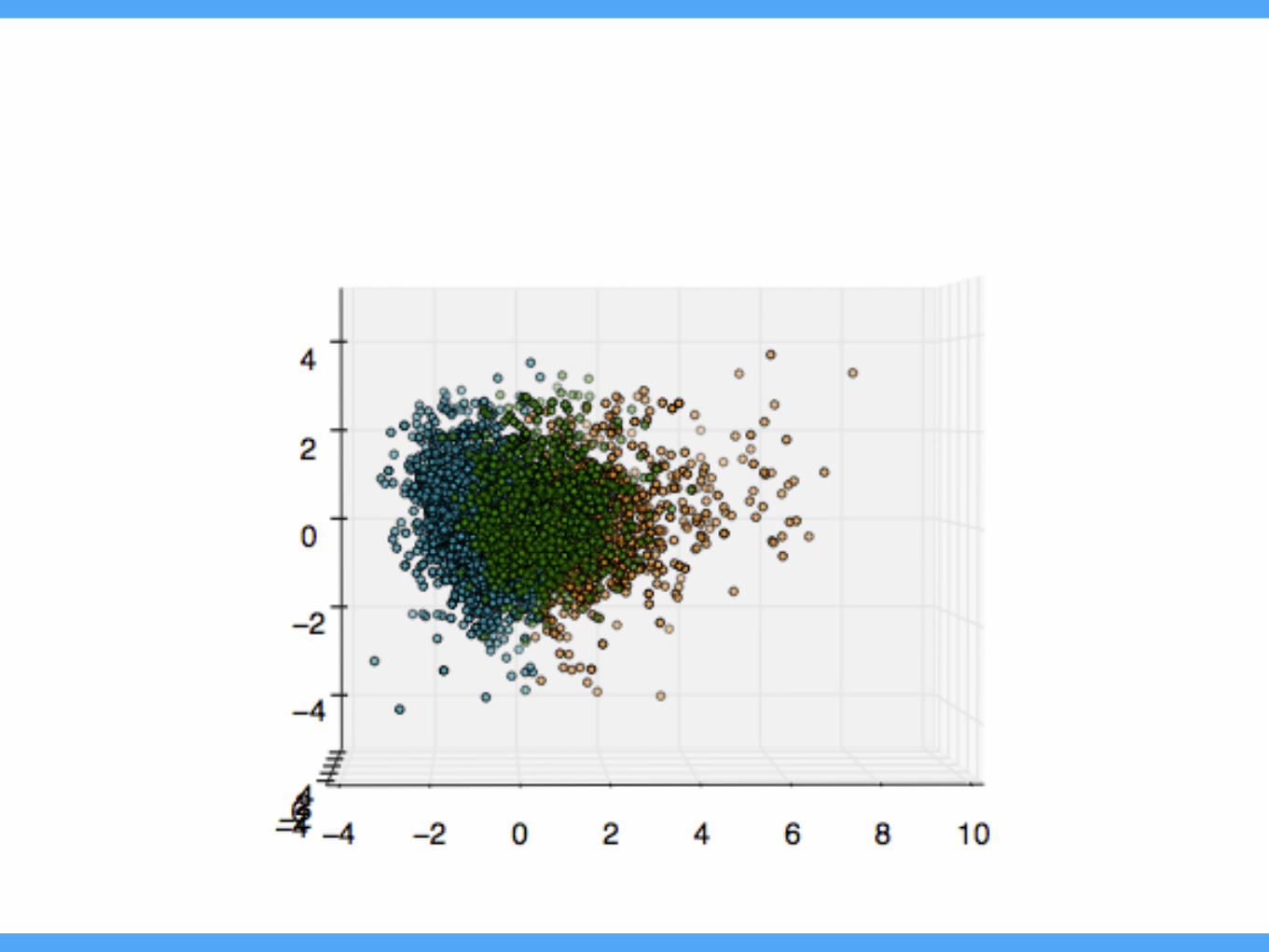

• No structural difference
• Playlist itself doesn’t represent the user that much. (Or is not easily observed.)
• Usage data may be required
• Usage hours, number of songs/artists, diversity of preferences, price tier, social activities, …

F2. Similarity vs. Diversity
“Songs in a playlist should be similar”
“Songs in a playlist shouldn’t be too similar”
Similar Familiar Unified
vs.Interesting Not boring
Diverse

• Audio feature similarity between songs
• within-playlistvs.arbitrary pairs
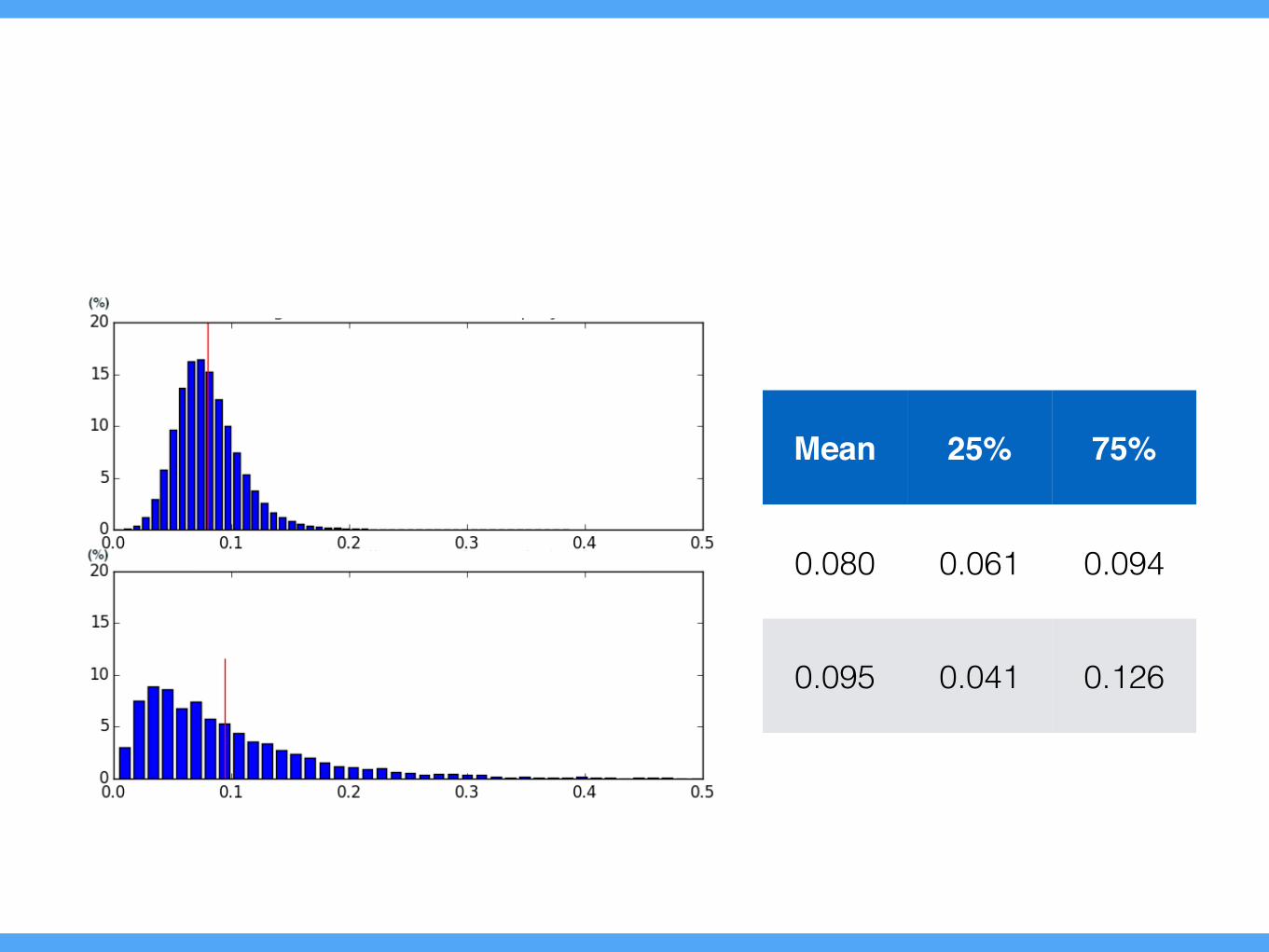
Mean 25% 75%
0.080 0.061 0.094
0.095 0.041 0.126

3. Different similarity given category
• Compute the similarity of songs in the playlists for each category (for each feature)
• Get rankings of categories (for each feature)
• Get average of the rankings
• Plot it (with nice colours)
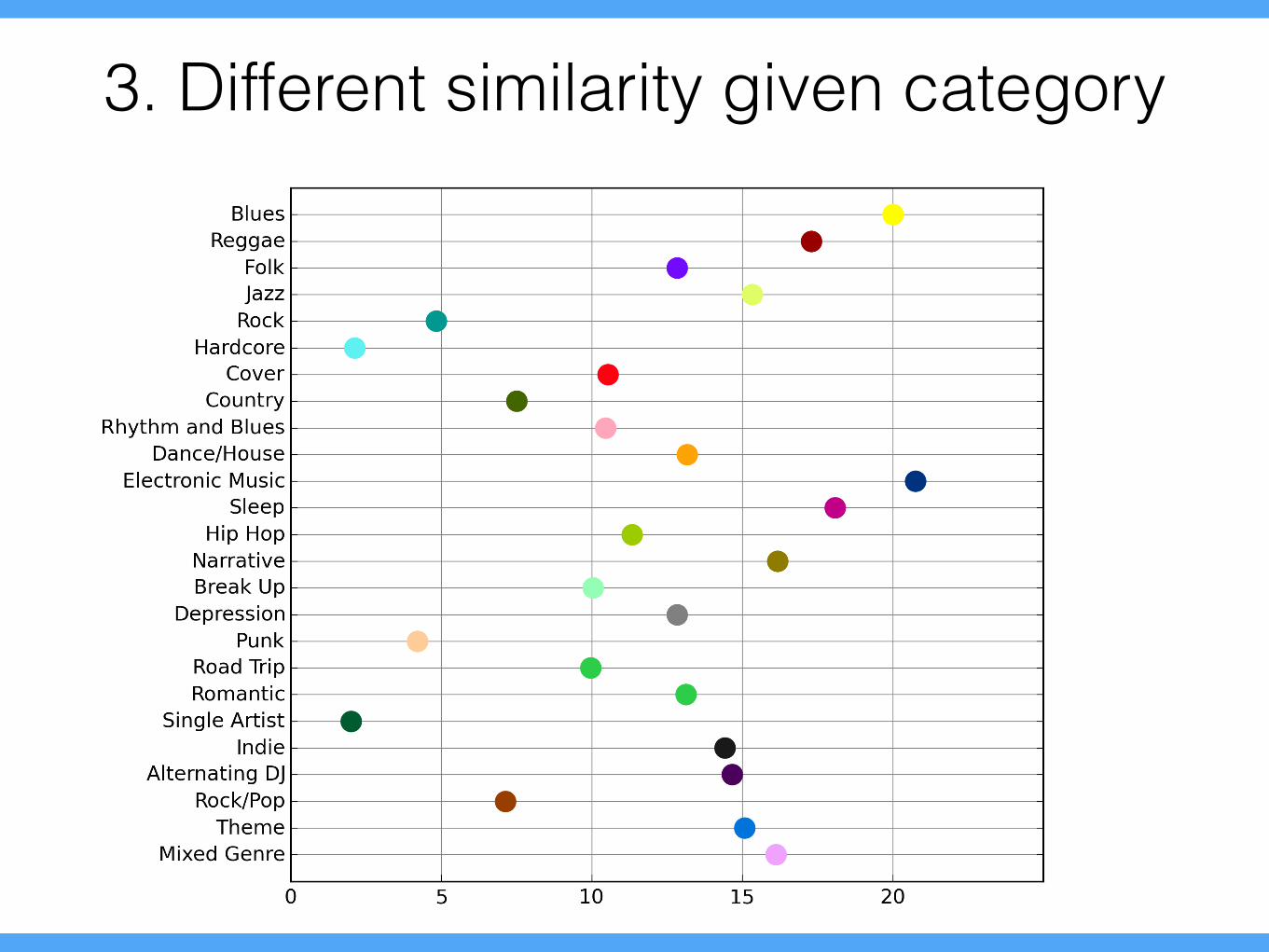
3. Different similarity given category

Summary• User (behaviour) information is required to build user
model based on clustering
• Should find an appropriate range of similarity for better playlist generation
• which varies given dataset, features, and similarity measure.
• Desired song similarity may be different for each category
• Different parameters/prior should be set.

Future work , or just curious about…
• How much do people care about playlist? How much do people put efforts on it?
• Mix Tape/CD was important for us (music researchers), so as (modern) playlist for people?
• Looks like they are just containers for a set of songs rather than a sequence songs.