Embed Size (px)
Citation preview

Sadayuki FuruhashiFounder & Software Architect
Treasure Data, inc.
PlazmaTreasure Data’s distributed analytical database growing 40,000,000,000 records/day.
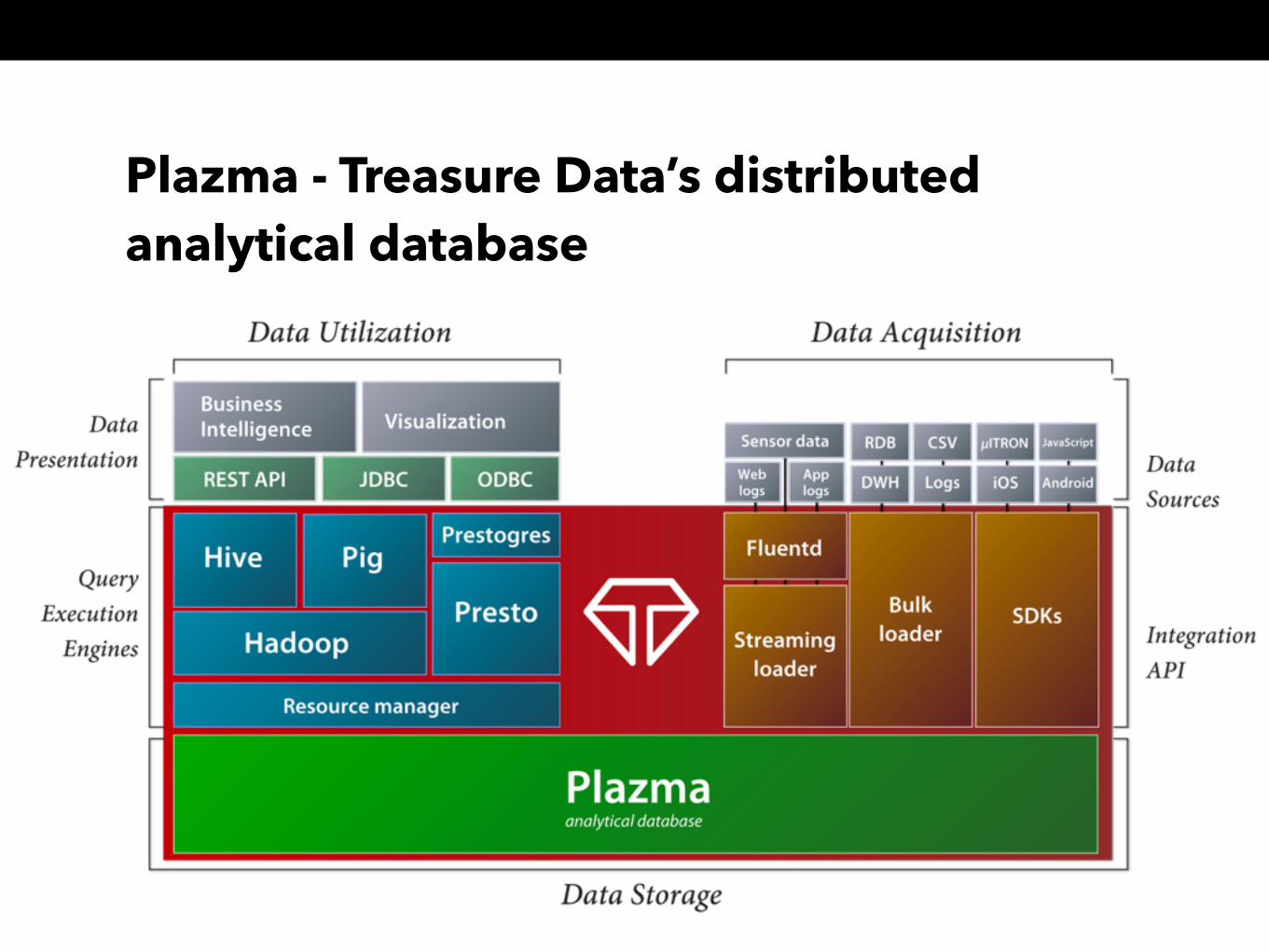
Plazma - Treasure Data’s distributed analytical database

Plazma by the numbers
> Data importing > 450,000 records/sec
≒ 40 billion records/day
> Query processing using Hive > 2 trillion records/day > 2,828 TB/day

Today’s talk1. Data importing
> Realtime Storage & Archive Storage > Deduplication
2. Data processing > Column-oriented IO > Schmema-on-read > Schema auto detection
3. Transaction & Metadata > Schema auto detection > INSERT INTO

1. Data Importing

Import Queue
td-agent / fluentd
Import Worker
✓ Buffering for1 minute
✓ Retrying(at-least once)
✓ On-disk buffering on failure
✓ Unique ID for each chunk
API Server
It’s like JSON.
but fast and small.
unique_id=375828ce5510cadb {“time”:1426047906,”uid”:1,…} {“time”:1426047912,”uid”:9,…} {“time”:1426047939,”uid”:3,…} {“time”:1426047951,”uid”:2,…} …
MySQL (PerfectQueue)
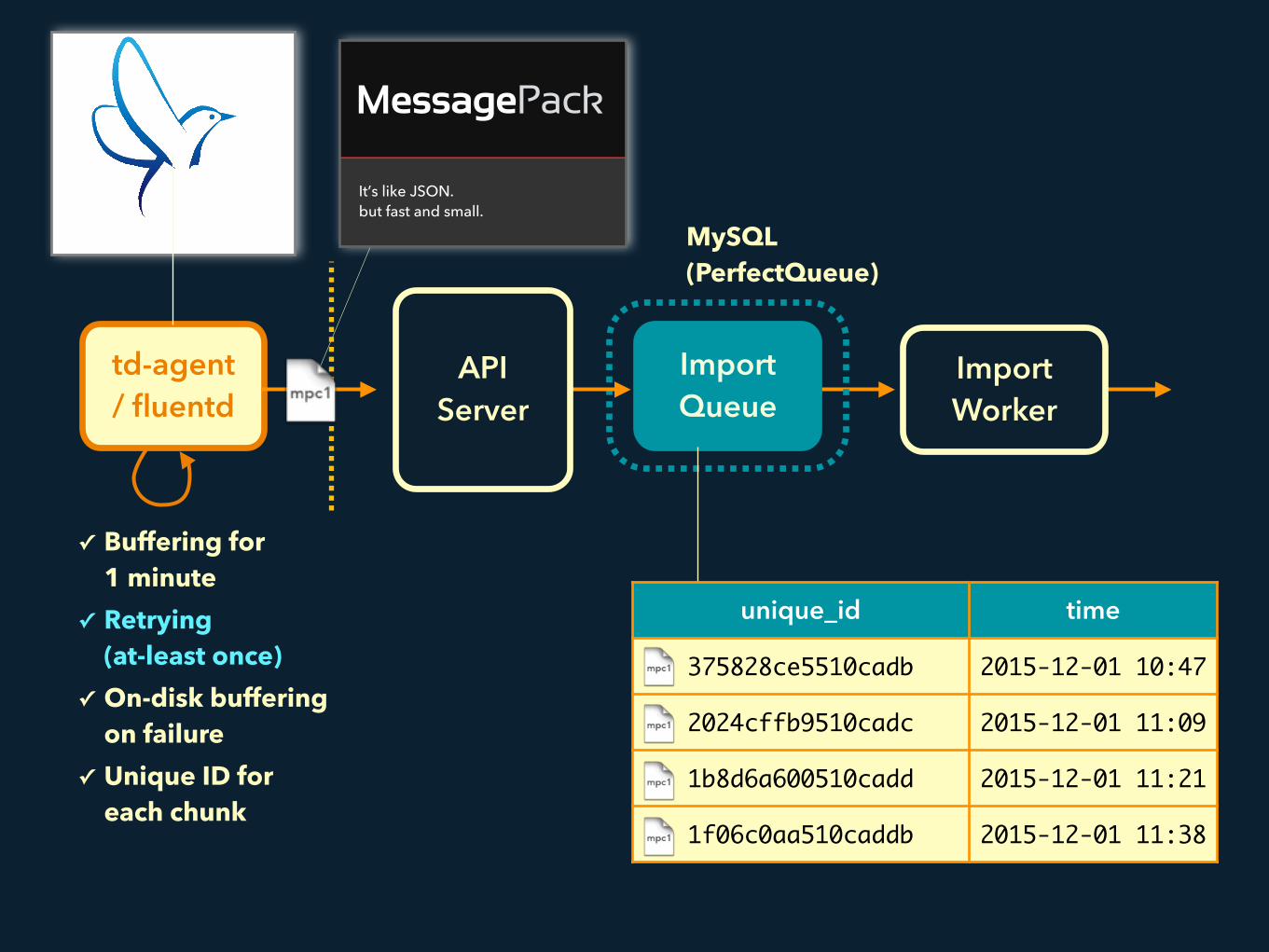
Import Queue
td-agent / fluentd
Import Worker
✓ Buffering for1 minute
✓ Retrying(at-least once)
✓ On-disk buffering on failure
✓ Unique ID for each chunk
API Server
It’s like JSON.
but fast and small.
MySQL (PerfectQueue)
unique_id time
375828ce5510cadb 2015-12-01 10:47
2024cffb9510cadc 2015-12-01 11:09
1b8d6a600510cadd 2015-12-01 11:21
1f06c0aa510caddb 2015-12-01 11:38

Import Queue
td-agent / fluentd
Import Worker
✓ Buffering for1 minute
✓ Retrying(at-least once)
✓ On-disk buffering on failure
✓ Unique ID for each chunk
API Server
It’s like JSON.
but fast and small.
MySQL (PerfectQueue)
unique_id time
375828ce5510cadb 2015-12-01 10:47
2024cffb9510cadc 2015-12-01 11:09
1b8d6a600510cadd 2015-12-01 11:21
1f06c0aa510caddb 2015-12-01 11:38UNIQUE (at-most once)
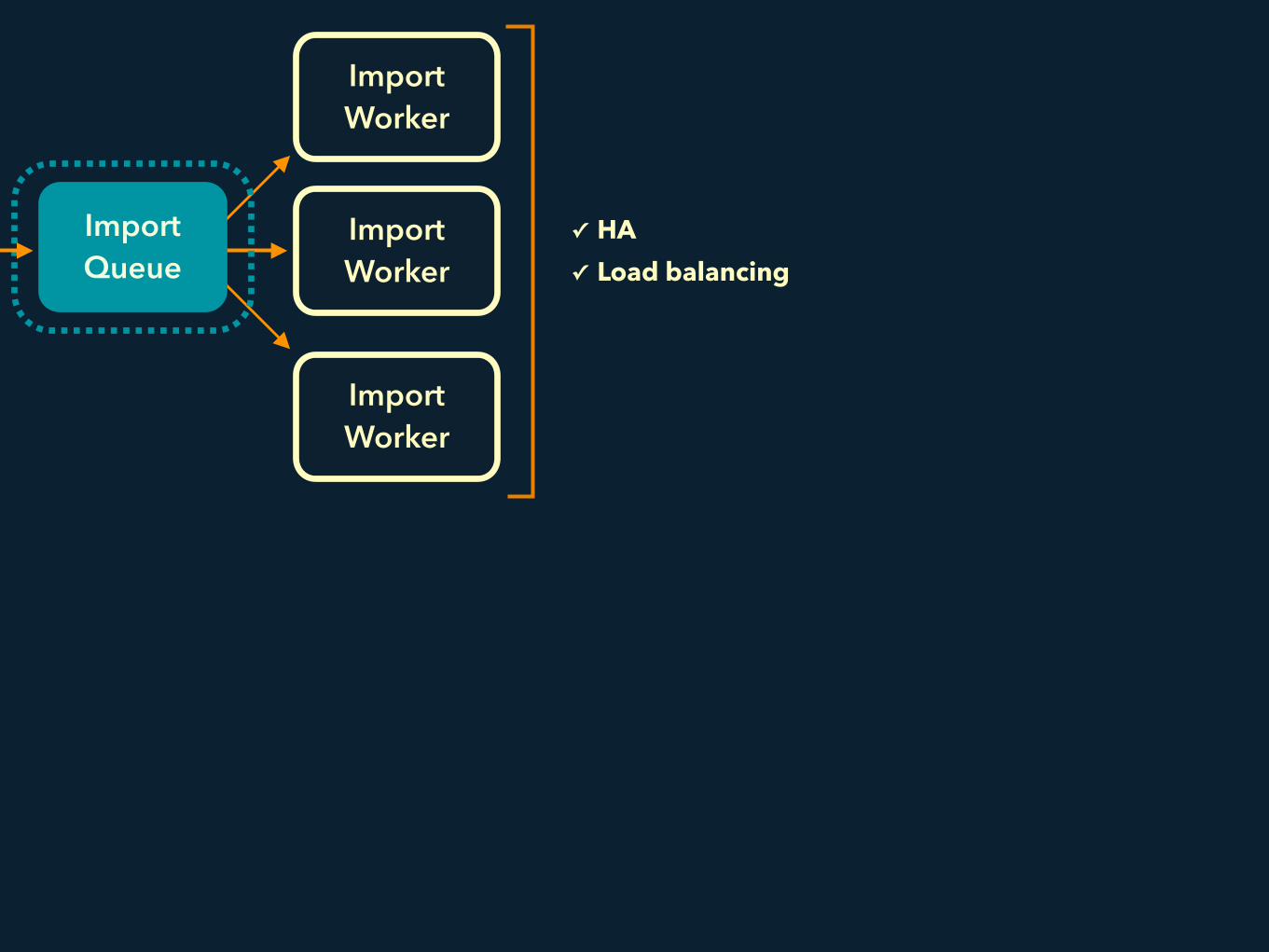
Import Queue
Import Worker
Import Worker
Import Worker
✓ HA ✓ Load balancing

Realtime Storage
PostgreSQL
Amazon S3 / Basho Riak CS
Metadata
Import Queue
Import Worker
Import Worker
Import Worker
Archive Storage

Realtime Storage
PostgreSQL
Amazon S3 / Basho Riak CS
Metadata
Import Queue
Import Worker
Import Worker
Import Worker
uploaded time file index range records
2015-03-08 10:47 [2015-12-01 10:47:11, 2015-12-01 10:48:13] 3
2015-03-08 11:09 [2015-12-01 11:09:32, 2015-12-01 11:10:35] 25
2015-03-08 11:38 [2015-12-01 11:38:43, 2015-12-01 11:40:49] 14
… … … …
Archive Storage
Metadata of the records in a file (stored on PostgreSQL)

Amazon S3 / Basho Riak CS
Metadata
Merge Worker(MapReduce)
uploaded time file index range records
2015-03-08 10:47 [2015-12-01 10:47:11, 2015-12-01 10:48:13] 3
2015-03-08 11:09 [2015-12-01 11:09:32, 2015-12-01 11:10:35] 25
2015-03-08 11:38 [2015-12-01 11:38:43, 2015-12-01 11:40:49] 14
… … … …
file index range records
[2015-12-01 10:00:00, 2015-12-01 11:00:00] 3,312
[2015-12-01 11:00:00, 2015-12-01 12:00:00] 2,143
… … …
Realtime Storage
Archive Storage
PostgreSQL
Merge every 1 hourRetrying + Unique (at-least-once + at-most-once)

Amazon S3 / Basho Riak CS
Metadata
uploaded time file index range records
2015-03-08 10:47 [2015-12-01 10:47:11, 2015-12-01 10:48:13] 3
2015-03-08 11:09 [2015-12-01 11:09:32, 2015-12-01 11:10:35] 25
2015-03-08 11:38 [2015-12-01 11:38:43, 2015-12-01 11:40:49] 14
… … … …
file index range records
[2015-12-01 10:00:00, 2015-12-01 11:00:00] 3,312
[2015-12-01 11:00:00, 2015-12-01 12:00:00] 2,143
… … …
Realtime Storage
Archive Storage
PostgreSQL
GiST (R-tree) Index on“time” column on the files
Read from Archive Storage if merged. Otherwise, from Realtime Storage

Data Importing> Scalable & Reliable importing
> Fluentd buffers data on a disk > Import queue deduplicates uploaded chunks > Workers take the chunks and put to Realtime Storage
> Instant visibility > Imported data is immediately visible by query engines. > Background workers merges the files every 1 hour.
> Metadata > Index is built on PostgreSQL using RANGE type and
GiST index

2. Data processing

time code method
2015-12-01 10:02:36 200 GET
2015-12-01 10:22:09 404 GET
2015-12-01 10:36:45 200 GET
2015-12-01 10:49:21 200 POST
… … …
time code method
2015-12-01 11:10:09 200 GET
2015-12-01 11:21:45 200 GET
2015-12-01 11:38:59 200 GET
2015-12-01 11:43:37 200 GET
2015-12-01 11:54:52 “200” GET
… … …
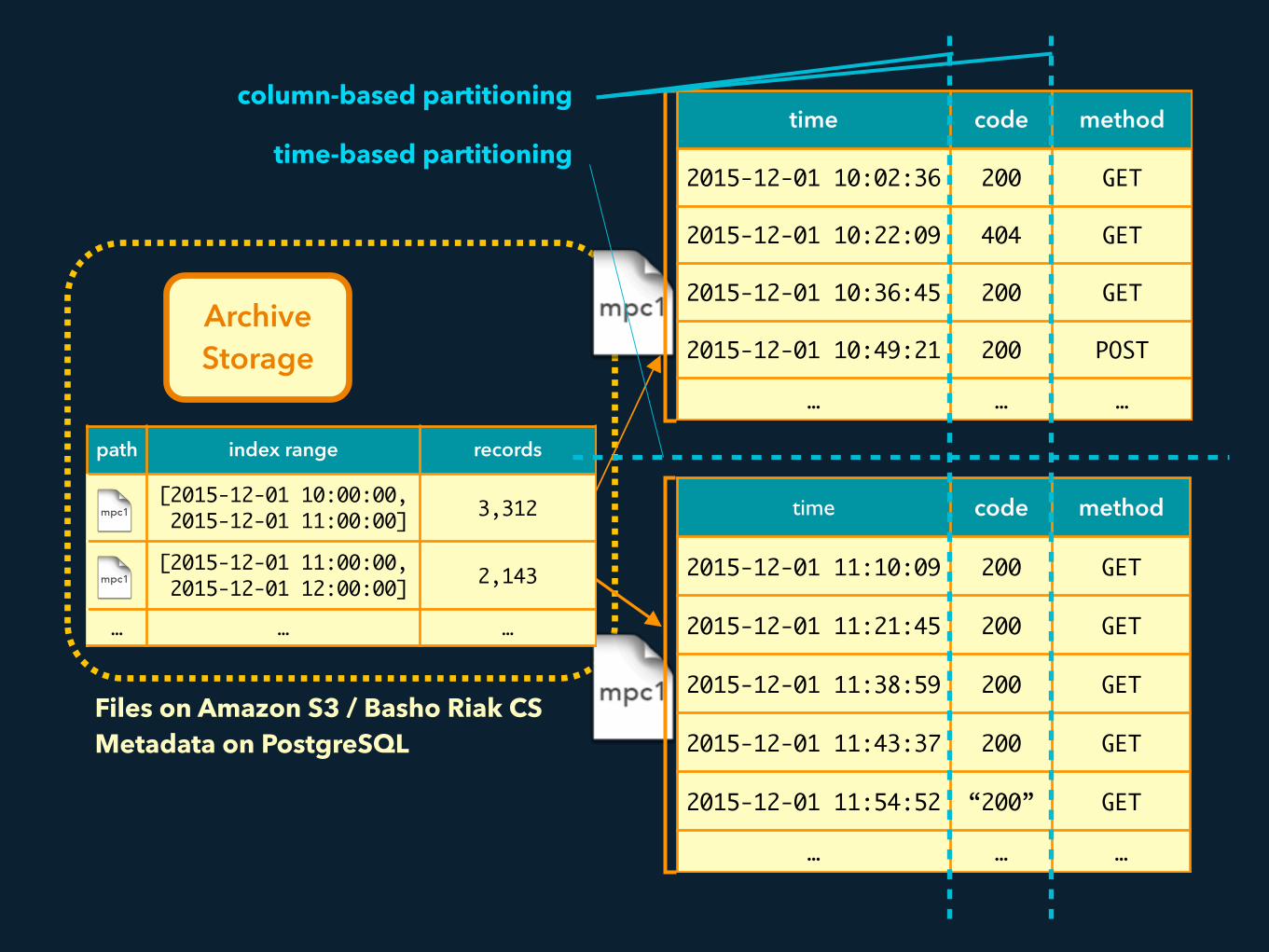
Archive Storage
Files on Amazon S3 / Basho Riak CS Metadata on PostgreSQL
path index range records
[2015-12-01 10:00:00, 2015-12-01 11:00:00] 3,312
[2015-12-01 11:00:00, 2015-12-01 12:00:00] 2,143
… … …
MessagePack ColumnarFile Format
time code method
2015-12-01 10:02:36 200 GET
2015-12-01 10:22:09 404 GET
2015-12-01 10:36:45 200 GET
2015-12-01 10:49:21 200 POST
… … …
time code method
2015-12-01 11:10:09 200 GET
2015-12-01 11:21:45 200 GET
2015-12-01 11:38:59 200 GET
2015-12-01 11:43:37 200 GET
2015-12-01 11:54:52 “200” GET
… … …
Archive Storage
path index range records
[2015-12-01 10:00:00, 2015-12-01 11:00:00] 3,312
[2015-12-01 11:00:00, 2015-12-01 12:00:00] 2,143
… … …
column-based partitioning
time-based partitioning
Files on Amazon S3 / Basho Riak CS Metadata on PostgreSQL

time code method
2015-12-01 10:02:36 200 GET
2015-12-01 10:22:09 404 GET
2015-12-01 10:36:45 200 GET
2015-12-01 10:49:21 200 POST
… … …
time code method
2015-12-01 11:10:09 200 GET
2015-12-01 11:21:45 200 GET
2015-12-01 11:38:59 200 GET
2015-12-01 11:43:37 200 GET
2015-12-01 11:54:52 “200” GET
… … …
Archive Storage
path index range records
[2015-12-01 10:00:00, 2015-12-01 11:00:00] 3,312
[2015-12-01 11:00:00, 2015-12-01 12:00:00] 2,143
… … …
column-based partitioning
time-based partitioning
Files on Amazon S3 / Basho Riak CS Metadata on PostgreSQL
SELECT code, COUNT(1) FROM logs WHERE time >= 2015-12-01 11:00:00 GROUP BY code

time code method
2015-12-01 10:02:36 200 GET
2015-12-01 10:22:09 404 GET
2015-12-01 10:36:45 200 GET
2015-12-01 10:49:21 200 POST
… … …
user time code method
391 2015-12-01 11:10:09 200 GET
482 2015-12-01 11:21:45 200 GET
573 2015-12-01 11:38:59 200 GET
664 2015-12-01 11:43:37 200 GET
755 2015-12-01 11:54:52 “200” GET
… … …
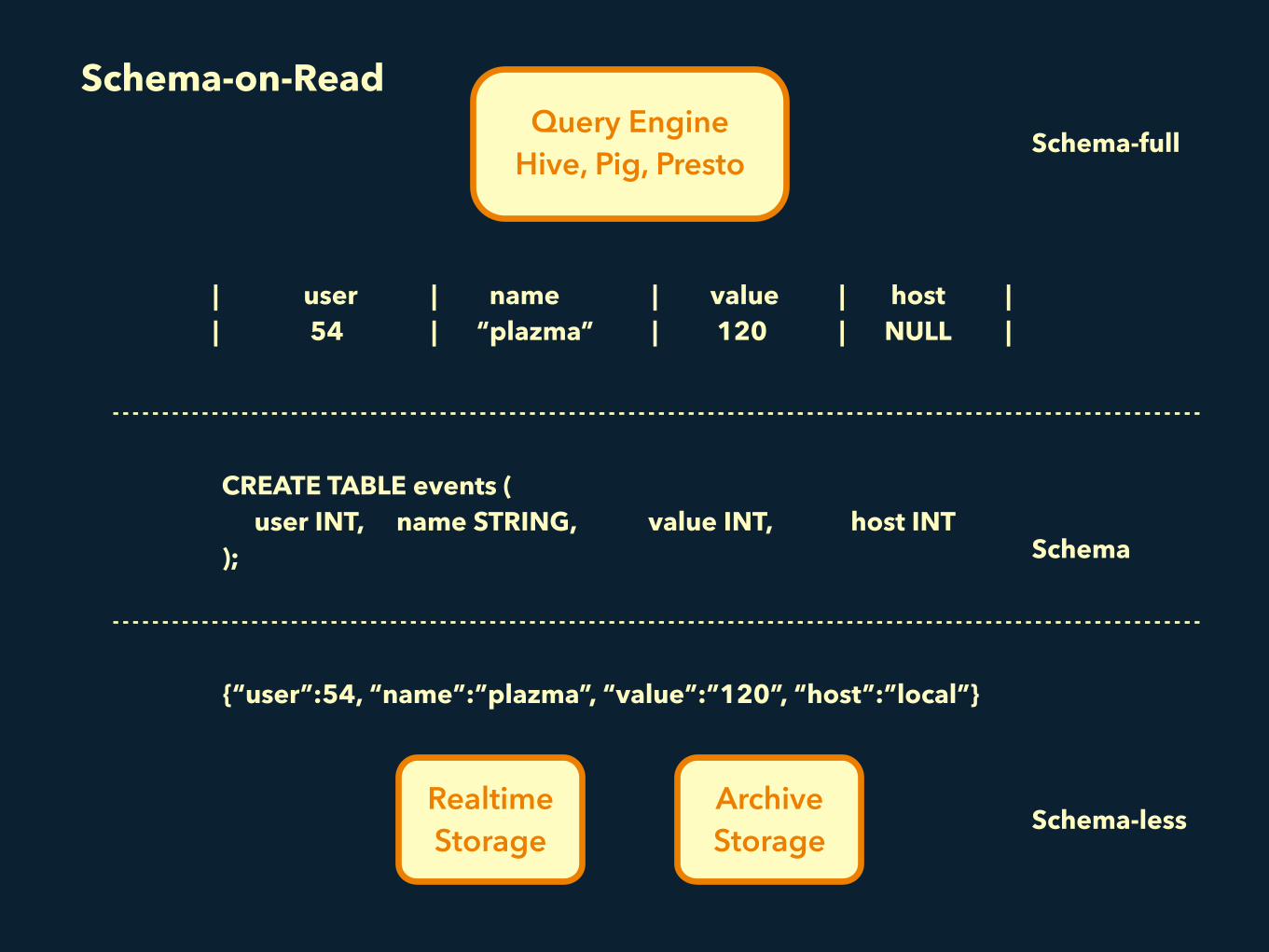
MessagePack ColumnarFile Format is schema-less✓ Instant schema change
SQL is schema-full✓ SQL doesn’t work
without schema
Schema-on-Read
Realtime Storage
Query EngineHive, Pig, Presto
Archive Storage
Schema-full
Schema-less
Schema
{“user”:54, “name”:”plazma”, “value”:”120”, “host”:”local”}
CREATE TABLE events ( user INT, name STRING, value INT, host INT );
| user | 54
| name | “plazma”
| value | 120
| host | NULL
| |
Schema-on-Read

Realtime Storage
Query EngineHive, Pig, Presto
Archive Storage
Schema-full
Schema-less
Schema
{“user”:54, “name”:”plazma”, “value”:”120”, “host”:”local”}
CREATE TABLE events ( user INT, name STRING, value INT, host INT );
| user | 54
| name | “plazma”
| value | 120
| host | NULL
| |
Schema-on-Read

2. Transaction & Metadata

Plazma’s Transaction API
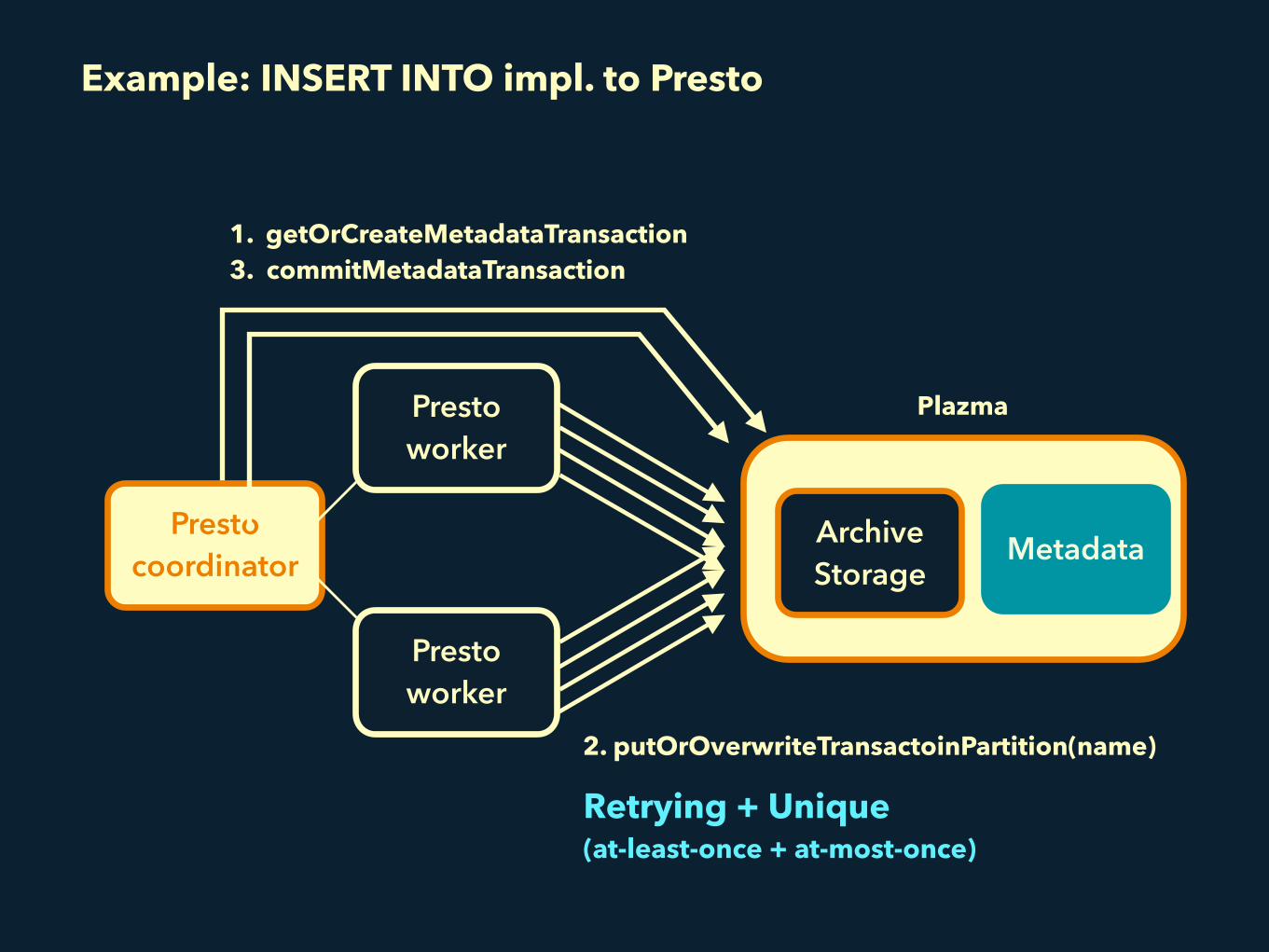
> getOrCreateMetadataTransaction(uniqueName) > start a named transaction. > if already started, abort the previous one and restart.
> putOrOverwriteTransactoinPartition(name) > insert a file to the transaction. > if the file already exists, overwrite it.
> commitMetadataTransaction(uniqueName) > make the inserted files visible. > If the transaction is already committed before, do nothing.
Prestoworker
Prestocoordinator
Prestoworker
Example: INSERT INTO impl. to Presto
MetadataArchive Storage
Plazma
1. getOrCreateMetadataTransaction 3. commitMetadataTransaction
2. putOrOverwriteTransactoinPartition(name)
Retrying + Unique (at-least-once + at-most-once)

Reducer
HiveQueryRunner
Reducer
Example: INSERT INTO impl. to Hive
MetadataArchive Storage
Plazma
1. getOrCreateMetadataTransaction 3. commitMetadataTransaction
2. putOrOverwriteTransactoinPartition(name)
Retrying + Unique (at-least-once + at-most-once)

HiveQueryRunner
Example: INSERT INTO impl. to Hive, rewriting query plan
HiveQueryRunner
Reducer
Reducer
Mapper
Mapper
Reducer
Reducer
Mapper
Mapper
Reducer
Reducer
Mapper
Mapper
Rewrite query plan Partitioning by time
Files are not partitioned by time

Why not MySQL? - benchmark
0
45
90
135
180
INSERT 50,000 rows SELECT sum(id) SELECT sum(file_size) WHERE index range
0.656.578.79
168
3.6617.2
MySQL PostgreSQL
(seconds)
Index-only scan
GiST index + range type

Metadata optimization
> Partitioning & TRUNCATE > DELETE produces many garbage rows and large WAL > TRUNCATE doesn’t
> PostgreSQL parameters > random_page_cost == seq_page_cost > statement_timeout = 60 sec > hot_standby_feedback = 1

1. Backend Engineer
2. Support Engineer
3. OSS Engineer
(日本,東京,丸の内)
We’re hiring!































