Embed Size (px)
Citation preview

Monitoring- driven эксплуатацияНиколай Сивко

План• Взгляд на службу эксплуатации с точки зрения
бизнеса
• Договариваемся про KPI
• Как жить с KPI
• Мониторинг: требования
• Мониторинг: метрики
• Мониторинг: триггеры
• Мониторинг: инцидент

План• Взгляд на службу эксплуатации с точки
зрения бизнеса
• Договариваемся про KPI
• Как жить с KPI
• Мониторинг: требования
• Мониторинг: метрики
• Мониторинг: триггеры
• Мониторинг: инцидент

Требования бизнеса• Сайт должен работать
• Есть ответственный за работоспособность сайта
• Сайт должен работать быстро (говорят, это влияет на разные важные коверсии :)
• Минимальные операционные и капитальные затраты

Сайт работает (было)
• Раз в минуту проходят основные пользовательские сценарии
• Время ответа укладывается в нужные рамки

Сайт работает (сейчас)• количество ошибок < 20/s
• 95-я персентить времени ответа < 4s (на самом деле обычно ~500ms)
• внешние чеки на случай проблем с каналами

Сайт работает (хотим)
• количество ошибок < 20/s
• 95-я персентить времени ответа < 4s
• количество запросов не упало
• пользовательская активность на нужном уровне (в нашем случае: активность по резюме, вакансиям, откликам)

Кто отвечает за аптайм• На практике: админы И разработчики
• На инциденты всегда реагируют админы

План• Взгляд на службу эксплуатации с точки зрения
бизнеса
• Договариваемся про KPI
• Как жить с KPI
• Мониторинг: требования
• Мониторинг: метрики
• Мониторинг: триггеры
• Мониторинг: инцидент

Попытка #1
• Нужно, чтобы админы просыпались по SMS, чинили сайт, если не могут починить, будили кого-то из девелоперов и чинили вместе
• Выходит, что KPI админов - это время реакции на инцидент!

Попытка #1
“Время простоя за квартал 5 часов, максимальные время реакции 2 минуты, мы молодцы, сделали всё, что можем, хотим премию!”

Попытка #2
• Админы должны отвечать за аптайм
• Но приложение сайта для админов black box
• Мы вложимся в QA, все проблемы включая производительность будем ловить на стендах (утопия)
• Человек должен отвечать только за то, на что может влиять!

Попытка #3
• Давайте поделим аптайм на зоны ответственности
• Админы будут отвечать только за свое
• Что делать со всем остальным решим потом

Формализуем
• любой выход за пределы SLA - считаем , что сайт лежит (даже если что-то работает)
• на любой инцидент реагируют админы (дежурные или все сразу)
• по каждому инциденту обязательный разбор, поиск причины, классификация
• считаем суммарный downtime
• делим по зонам ответственности

Классы проблем• Проблема с релизом (взорвалось или были ошибки
при деплое)
• Ошибка в приложении (утекло, тяжелый запрос убил базу, не отработал таймаут до удаленного сервиса, итд)
• Железо + сеть + каналы + ДЦ
• Ошибка админа
• Проблемы с БД
• Плановый downtime (иногда нужно)• Ошибка мониторинга (чтобы не удалять инциденты
никогда)

Зона ответственности СЭ• Проблема с релизом
• Ошибка в приложении
• Железо + сеть + каналы + ДЦ
• Ошибка админа
• Проблемы с БД
• Плановый downtime
• Ошибка мониторинга

Премия = f(аптайм)Простой за квартал Аптайм, % % оклада в премию
<= 12 минут >= 99.99 120
<= 40 минут >= 99.97 100
<= 1 часа >= 99.95 80
<= 2 часов >= 99.90 60
<= 3 часов >= 99.85 50
> 3 часов < 99.85 0

План• Взгляд на службу эксплуатации с точки зрения
бизнеса
• Договариваемся про KPI
• Как жить с KPI
• Мониторинг: требования
• Мониторинг: метрики
• Мониторинг: триггеры
• Мониторинг: инцидент

Первый квартал c KPI• Оказывается, нужно работать :)
• Надо привыкать думать над каждым действием
• Многие операции перевели в разряд “рискованных”, их выполнять стали в часы минимальной нагрузки, объявляя плановый downtime
• Начали проводить учения, тестировать сценарии деградации системы (выключать rabbitmq, memcached, свои сервисы, без которых все должно жить)

Первый квартал c KPI
• Мониторинг начал ловить очень много всего нового
• Logrotate, разные cron’ы давали 500ки, на которые раньше не реагировали
• Начали вдумчиво настраивать таймауты, ретраи итд
• Где-то пересмотрели архитектуру и запланировали переделку
• Самое сложное: выяснять причины ВСЕХ инцидентов
• Перестал устраивать существующий мониторинг

План• Взгляд на службу эксплуатации с точки зрения
бизнеса
• Договариваемся про KPI
• Как жить с KPI
• Мониторинг: требования
• Мониторинг: метрики
• Мониторинг: триггеры
• Мониторинг: инцидент

Требования• Узнать, что есть проблема
• Видеть, что происходит: насколько проблема масштабна, какие компоненты затронуты
• Иметь достаточно метрик, чтобы копаться “задним числом”
• Ускорять выявление проблем, все важное из логов вынести на графики
• Простота расширения

Что у нас было• Nagios + centreon (+ патчи)
• Nagios + своя штука для графиков + свой poller SNMP
• У разработчиков всегда были свои cacti, graphite итд
• Свое решение - monik (был выделенный разработчик мониторинга)

Проблемы• У нас нет цели разрабатывать мониторинг
• Зато есть много другой работы
• Всё, что мы разрабатывали устаревает, появляются новые требования
• Взять и попробовать что-то новое – тоже время
• В opensource практически нет full-stack решений, есть отдельно хранилища, собиралки, алертилки, дашбордилки
• Практически всё нужно доделывать под себя

SaaS мониторинг• Не нужно писать код
• У нас нет супер-секретных метрик
• Специализированная компания: они могут себе позволить тесты, мониторинг мониторинга, отказоустойчивость (у нас всегда мониторинг жил на 1 сервере)
• Мы “большой” клиент, можем договориться о доработках под нас
• Ценник сравним с выделенным разработчиком у нас
• Мы работаем с okmeter.io

План• Взгляд на службу эксплуатации с точки зрения
бизнеса
• Договариваемся про KPI
• Как жить с KPI
• Мониторинг: требования
• Мониторинг: метрики
• Мониторинг: триггеры
• Мониторинг: инцидент

Проблемы• Как правило мониторингом покрывают только
самые критичные подсистемы
• Мы пробовали включать покрытие мониторингом в процедуру выпуска новых сервисов – не работает
• Часто снимают не всё (где-то забыли включить jmx, где-то пустить мониторинг в postgresql)
• Инфраструктура меняется: запускаются новые jvm, pg, nginx, haproxy итд
• Метрики сильно обобщены, видно, что есть проблема, но не видно, где конкретно

Подход• Все что можно снять без конфига, снимаем всегда
и со всех машин
• Если агенту нужны права или донастройка, это алерт в мониторинге
• Метрики максимально детальные в пределах разумного, агрегаты можно сделать на лету
• Ждем: алерт, если поймали TCP соединения с хостов, на котором не стоит агент

Общие метрики• cpu, memory, swap, swap i/o
• net: bandwidth, pps, errors
• disk: usage, inodes usage, i/o read/write ops/bytes/time(%)
• time offset относительно эталона (+хотим проверять таймзону)
• состояния raid (array/BBU)

Про каждый процесс• CPU time (user/system)
• Memory (RSS)
• Disk I/O (read/write bytes, ops)
• Swap Usage -> Swap Rate
• Thread count
• Open FDs count
• Open files limit

Про каждый TCP LISTEN• Если remote IP из той же сети – все метрики для
каждого IP отдельно
• Количество соединений в разных состояниях (ESTABLISHED, TIME_WAIT, …)
• 95я персентиль TCP RTT (с учетом SACK не является реальным RTT в сети, но для сравнения было-стало работает хорошо)
• Количество соединений в backlog и лимит
• Похожие метрики для исходящих TCP соединений

Nginx• Если есть работающий процесс nginx, находится и
парсится конфиг
• Парсится log_format и access_log
• Если лог нельзя распарсить – алерт
• Если в логе нет $request_time, $upstream_response_time - алерт
• RPS в разрезе status, top urls, cache_status, method
• Персентили и гистограммы для таймингов в тех же разрезах

Jvm• Если есть работающий процесс jvm, парсятся
аргументы запуска
• Определяем параметры JMX, если выключено – алерт
• Снимаем heap, GC, memory pools, threads
• Если есть mbeans cassandra – снимаем детальные метрики
• Так же планируем снимать метрики jetty, grizzly, c3p0, hibernate,…

Postgresql• Пробуем с predefined паролем
• Если не пускает - алерт с просьбой настроить пароль или загрантить
• Если не настроено pg_stat_statements - алерт с просьбой включить
• Если не хватает прав – алерт
• Снимаем всё про top запросов/таблиц/индексов, bgwriter, текущие соединения, локи итд (pg_stat_*)

Метрики из логовplugin: logparser
config:
file: /var/log/hhapi/hhapi.log
#2015-02-17 00:07:44,604 INFO User-Agent: HH-
Live/41 (iPhone; iOS 8.1.3; Scale/2.00)
regex: '(?P<dt>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\
d{2}),\d+ [^:]+ User-Agent: HH-Live/(?
P<build>\d+) \((?P<device>[A-Za-z]+); (?
P<os>[^;]+)'
time_field: dt
time_field_format: 2006-01-02 15:04:05

Метрики из логов
metrics:
- type: rate
name: api.nativeapps.rate
labels:
build: =build
device: =device
os: =os
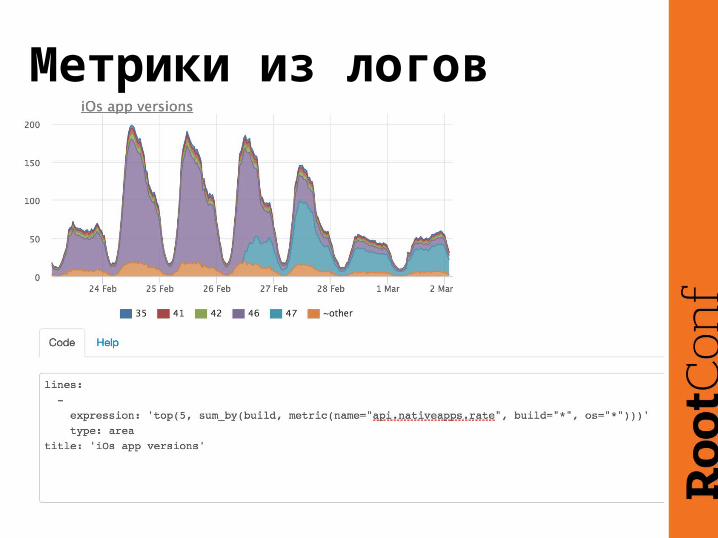
Метрики из логов

Метрики из SQL plugin: postgresql_query
config:
…
query: SELECT count(*) as value,
COALESCE(old_value, 'NULL') as old_status,
new_value new_status from
resume_field_change_history where change_date
>= now() - INTERVAL '60 seconds' and
change_date < now() and field_name='status'
group by old_value, new_value
metric_name: resume.changes.count

Метрики из SQL

План• Взгляд на службу эксплуатации с точки зрения
бизнеса
• Договариваемся про KPI
• Как жить с KPI
• Мониторинг: требования
• Мониторинг: метрики
• Мониторинг: триггеры
• Мониторинг: инцидент

Принципы• Проактивного мониторинга не существует (disk
usage если только)
• В нагруженной системе всё меняется за доли секунды, понять последовательность событий нереально даже при секундном разрешении (как правило достаточно минутного)
• зависимости между алертами хорошо сделать невозможно
• в нормальном состоянии не должно быть активных алертов

Принципы• Critical событие – это то, на что нужно срочно
среагировать и починить (CPU usage > 90% не нужно срочно чинить)
• У нас 3 critical триггера (HTTP-5xx, Q95, ext http check)
• Все остальные Warning, Info – всего лишь подсказки, у большинства нет нотификаций вообще
• Лучше зажечь много warning-ов и выбрать глазами причину проблемы, чем пытаться автоматически определить, где причина, а где следствие

Принципы• Чтобы после SMS не ждать recovery, а сразу чинить
- есть отложенная нотификация (notify after 2 min)
• Идеально - увидеть проблему в списке алертов
• Если нет, нужно смотреть на дашборды, где нужно глазами исключать возможные причины
• В следующий раз такая же проблема должна быть в списке алертов

Принципы• Если есть алерт, который вы не собираетесь чинить
- выключайте
• Если есть постоянный поток писем от мониторинга, он заруливается в отдельную папку в почте и не читается, проще выключить
• Если вас не интересует CPU usage на hadoop машине – настройте исключение

Наши триггеры• Про все внутренние сервисы – warning по http-
5xx+499, q95
• Про все процессы: open files usage > 90%
• Про все LISTEN сокеты: TCP ack backlog usage > 90%
• Про диски: usage > 95%, IO usage > 99% в течении 10 минут
• Про raid: status, bbu, operations (если идет проверка mdraid может просесть i/o, если на железке идет профилактика батарейки – может отключиться write cache)

Наши триггеры• Живы все nginx, haproxy, … – там где они были хоть
раз запущены (если загорается лишний – закрываем руками)
• Давно нет данных от агента на каком-то сервере
• Нет данных от JVM/pg/….
• Jvm heap usage > 99% на протяжении 2 минут (ловим OOM, не везде настроена автоперезапускалка)
• Time offset > 10 seconds
• В важных очередях > N сообщений

План• Взгляд на службу эксплуатации с точки зрения
бизнеса
• Договариваемся про KPI
• Как жить с KPI
• Мониторинг: требования
• Мониторинг: метрики
• Мониторинг: триггеры
• Мониторинг: инцидент

Сайт лёг - инцидент
• SMS/еmail уведомление
• Мониторинг создает задачу в JIRA (начало инцидента)
• Админ реагирует, подтверждает это переводом задачи в статус “Проблемой занимаются” (любой сотрудник в компании это видит)

Чиним• Смотрим текущие алерты
• Синхронизируемся в чате
• Основной график – “Светофор” + рядом ~10 графиков

Конкретный сервис

Или база

После восстановления• Починили, мониторинг меняет статус задачи на
“Инцидент исчерпан”
• Поиск причины, общение в JIRA
• Заполняем класс проблемы в задаче, перевод в статус “Закрыто”
• Если по результатам нужна разработка, есть продолжение workflow
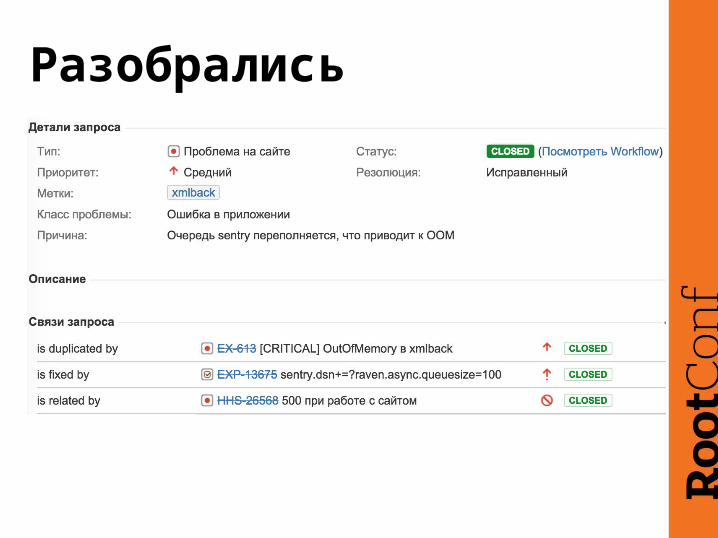
Разобрались

По результатам• Человеческая ошибка: обсудить, почему
произошло, как избежать (может автоматизировать что-то)
• Проблемы с релизом: доработка автотестов, процедуры выкладки
• Проблема в приложении: задача в разработку
• Железо/сеть/каналы/ДЦ: задача для админов (починить/уменьшить вероятность/обеспечить самовосстановление/уменьшить downtime в будущем)

По результатам• Добавить метрик в мониторинг?
• Детализировать метрики ?
• Новый триггер ?
• Новый “говорящий” график на дашборд?






























