Embed Size (px)
Citation preview

Jump Start into Apache SparkSeattle Spark Meetup – 1/12/2016
Denny Lee, Technology Evangelist

Seattle Meetup

Join us at Spark Summit East February 16-18, 2016 | New York City
Code: SeattleMeetupEast for 20% Discount

Apply to the Academic Partners Programdatabricks.com/academic

Thanks!
March 28th – 31st Code: UGSEASPRK to save 20%
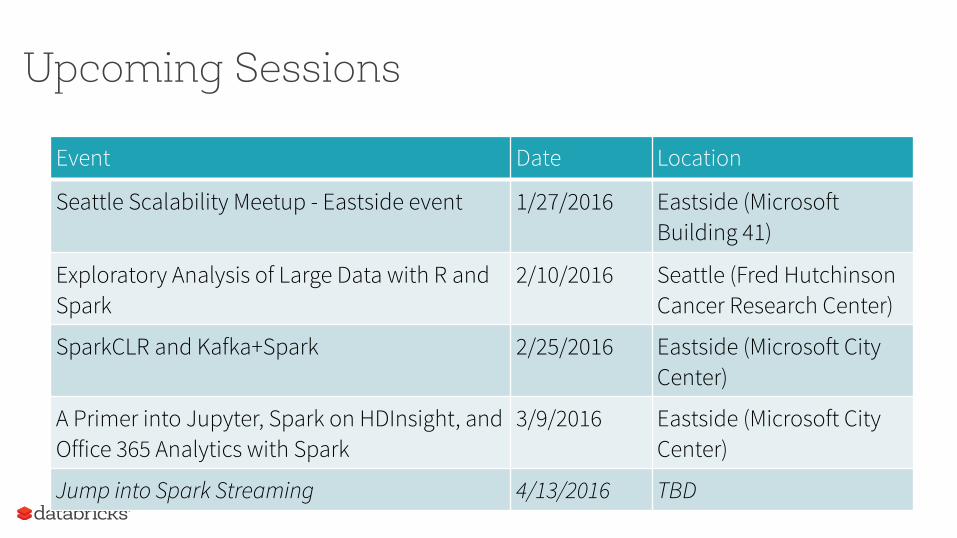
Upcoming Sessions
Event Date Location
Seattle Scalability Meetup - Eastside event 1/27/2016 Eastside (Microsoft Building 41)
Exploratory Analysis of Large Data with R and Spark
2/10/2016 Seattle (Fred Hutchinson Cancer Research Center)
SparkCLR and Kafka+Spark 2/25/2016 Eastside (Microsoft City Center)
A Primer into Jupyter, Spark on HDInsight, and Office 365 Analytics with Spark
3/9/2016 Eastside (Microsoft City Center)
Jump into Spark Streaming 4/13/2016 TBD

About Me: Denny LeeTechnology Evangelist, Databricks (Working with Spark since v0.5)
Former: • Senior Director of Data Sciences Engineering at Concur (now
part of SAP) • Principal Program Manager at Microsoft
Hands-on Data Engineer, Architect more than 15y developer internet-scale infrastructure for both on-premises and cloud including Bing’s Audience Insights, Yahoo’s 24TB SSAS cube, and Isotope Incubation Team (HDInsight)
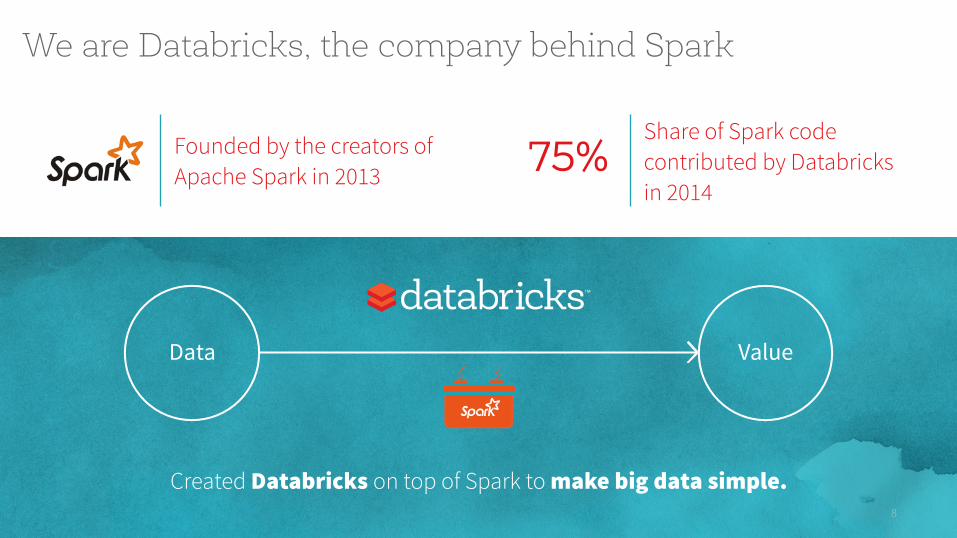
We are Databricks, the company behind Spark
Founded by the creators of Apache Spark in 2013
Share of Spark code contributed by Databricks in 2014
75%
8
Data Value
Created Databricks on top of Spark to make big data simple.

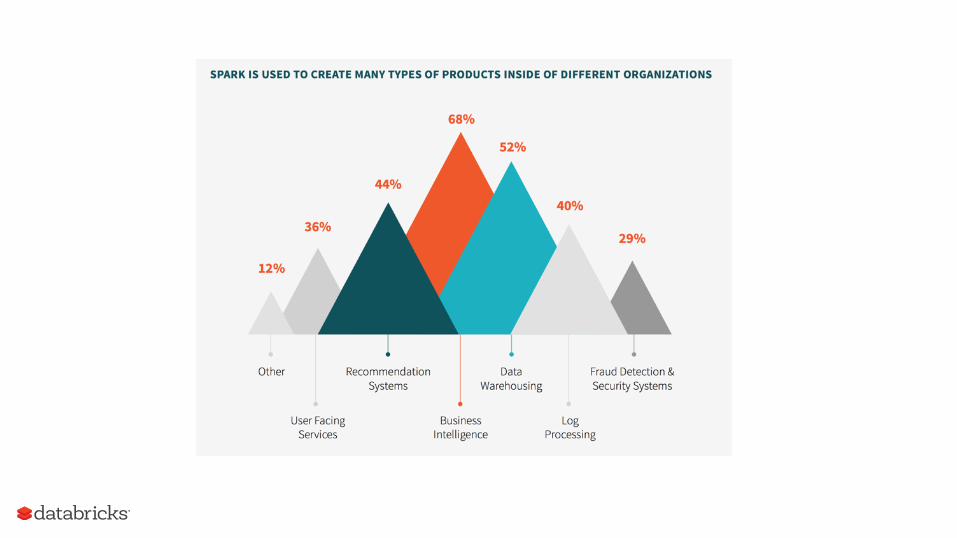
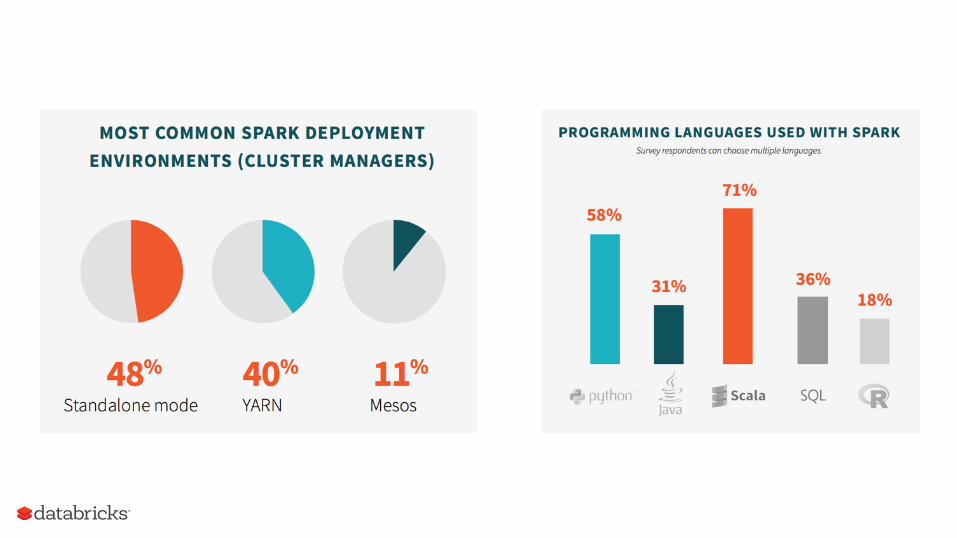
Spark Survey 2015 Highlights

Spark adoption is growing rapidly
Spark use is growing beyond Hadoop
Spark is increasing access to big data
Spark Survey Report 2015 Highlights
TOP 3 APACHE SPARK TAKEAWAYS



Quick StartQuick Start Using Python | Quick Start Using Scala
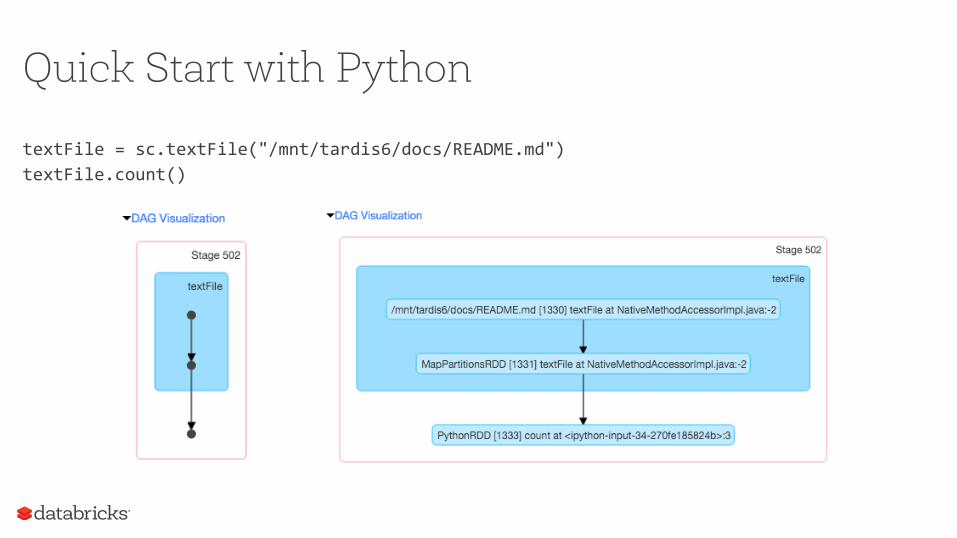
Quick Start with Python
textFile=sc.textFile("/mnt/tardis6/docs/README.md")textFile.count()
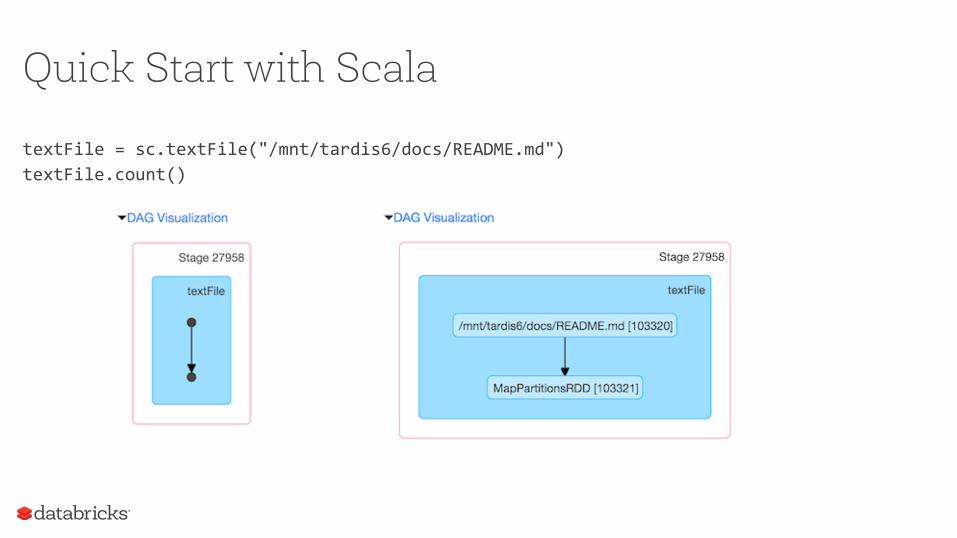
Quick Start with Scala
textFile=sc.textFile("/mnt/tardis6/docs/README.md")textFile.count()

RDDs
• RDDs have actions, which return values, and transformations, which return pointers to new RDDs.
• Transformations are lazy and executed when an action is run • Transformations: map(),flatMap(),filter(),mapPartitions(),mapPartitionsWithIndex(),sample(),union(),distinct(),groupByKey(),reduceByKey(),sortByKey(),join(),cogroup(),pipe(),coalesce(),repartition(),partitionBy(),...
• Actions: reduce(),collect(),count(),first(),take(),takeSample(),takeOrdered(),saveAsTextFile(),saveAsSequenceFile(),saveAsObjectFile(),countByKey(),foreach(),...
• Persist (cache) distributed data in memory or disk

Ad Tech ExampleAdTech Sample Notebook (Part 1)

…
Apache Spark Engine
Spark Core
Spark Streaming
Spark SQL MLlib GraphX
Unified engine across diverse workloads & environments
Scale out, fault tolerant
Python, Java, Scala, and R APIs
Standard libraries

Create External Table with RegEx
CREATEEXTERNALTABLEaccesslog(ipaddressSTRING,...)ROWFORMATSERDE'org.apache.hadoop.hive.serde2.RegexSerDe'WITHSERDEPROPERTIES("input.regex"='^(\\S+)(\\S+)(\\S+)\\[([\\w:/]+\\s[+\\-]\\d{4})\\]\\"(\\S+)(\\S+)(\\S+)\\"(\\d{3})(\\d+)\\"(.*)\\"\\"(.*)\\"(\\S+)\\"(\\S+),(\\S+),(\\S+),(\\S+)\\"’)LOCATION"/mnt/mdl/accesslogs/"

External Web Service Call via Mapper
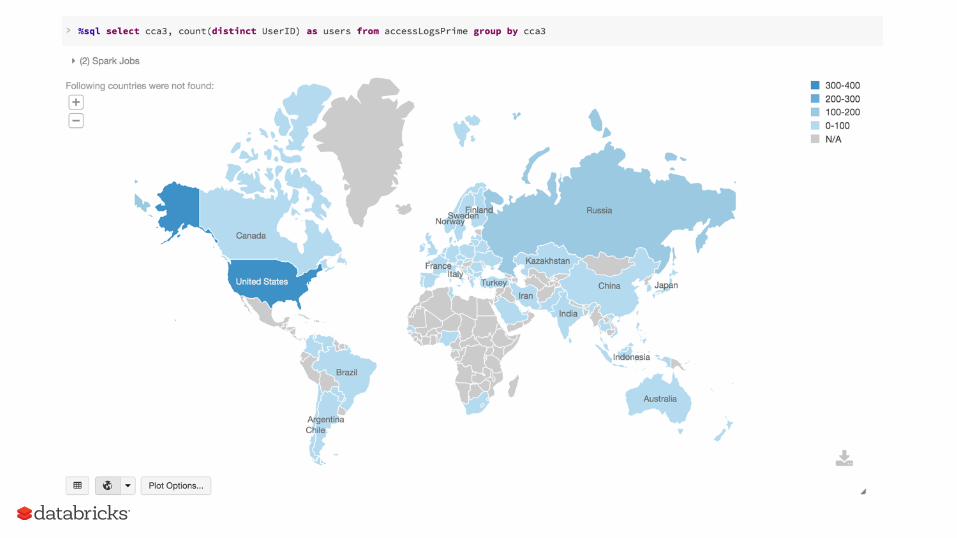
#Obtaintheuniqueagentsfromtheaccesslogtableipaddresses=sqlContext.sql("selectdistinctip1from\accesslogwhereip1isnotnull").rdd
#getCCA2:ObtainstwolettercountrycodebasedonIPaddressdefgetCCA2(ip):url='http://freegeoip.net/csv/'+ipstr=urllib2.urlopen(url).read()returnstr.split(",")[1]
#LoopthroughdistinctIPaddressesandobtaintwo-lettercountrycodesmappedIPs=ipaddresses.map(lambdax:(x[0],getCCA2(x[0])))

Join DataFrames and Register Temp Table
#JoincountrycodeswithmappedIPsDFsowecanhaveIPaddressand#three-letterISOcountrycodesmappedIP3=mappedIP2\.join(countryCodesDF,mappedIP2.cca2==countryCodesDF.cca2,"left_outer")\.select(mappedIP2.ip,mappedIP2.cca2,countryCodesDF.cca3,countryCodesDF.cn)
#RegisterthemappingtablemappedIP3.registerTempTable("mappedIP3")

Add Columns to DataFrames with UDFsfromuser_agentsimportparsefrompyspark.sql.typesimportStringTypefrompyspark.sql.functionsimportudf
#CreateUDFstoextractoutBrowserFamilyinformationdefbrowserFamily(ua_string):returnxstr(parse(xstr(ua_string)).browser.family)udfBrowserFamily=udf(browserFamily,StringType())
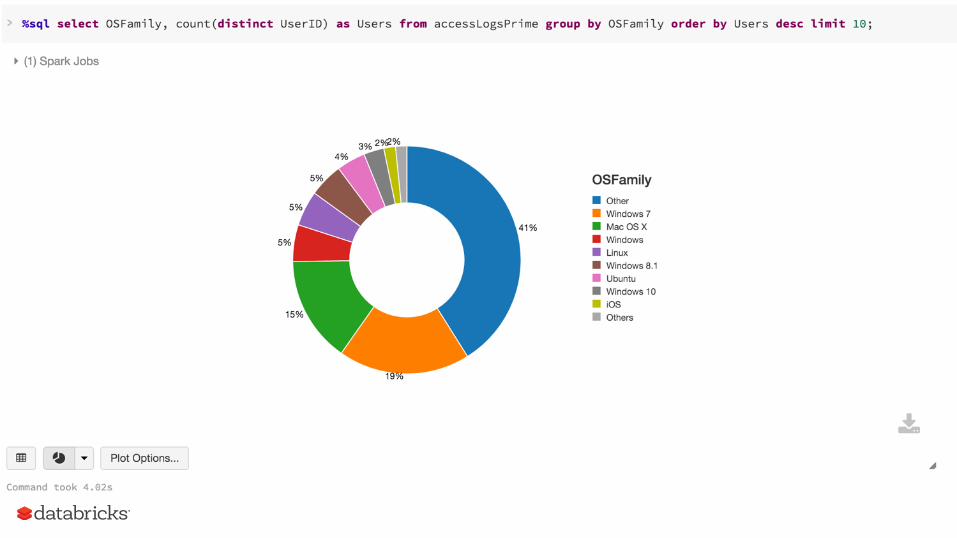
#ObtaintheuniqueagentsfromtheaccesslogtableuserAgentTbl=sqlContext.sql("selectdistinctagentfromaccesslog")
#AddnewcolumnstotheUserAgentInfoDataFramecontainingbrowserinformationuserAgentInfo=userAgentTbl.withColumn('browserFamily',\udfBrowserFamily(userAgentTbl.agent))

Use Python UDFs with Spark SQL
#Definefunction(convertsApacheweblogtime)defweblog2Time(weblog_timestr):...
#DefineandRegisterUDFudfWeblog2Time=udf(weblog2Time,DateType())sqlContext.registerFunction("udfWeblog2Time",lambdax:weblog2Time(x))
#CreateDataFrameaccessLogsPrime=sqlContext.sql("selecthash(a.ip1,a.agent)asUserId,
m.cca3,udfWeblog2Time(a.datetime),...")udfWeblog2Time(a.datetime)
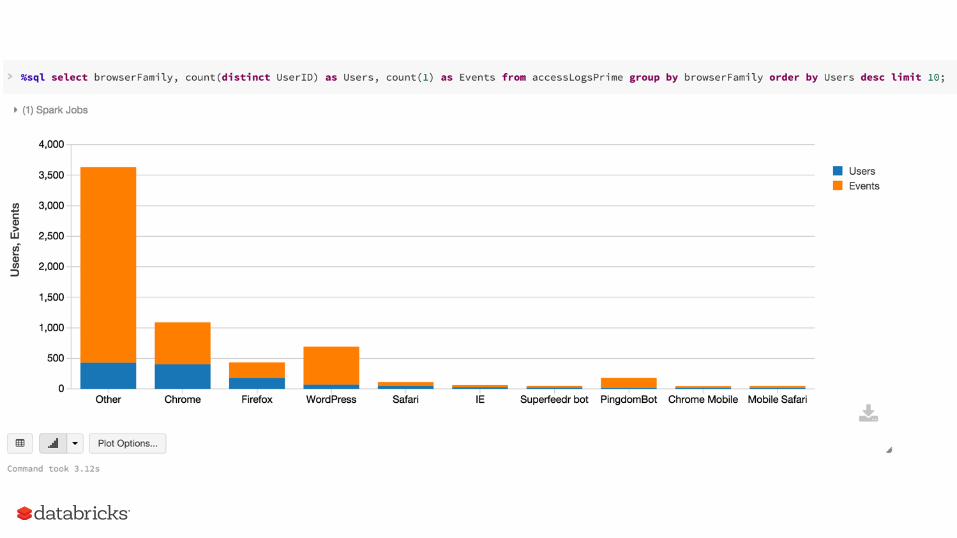
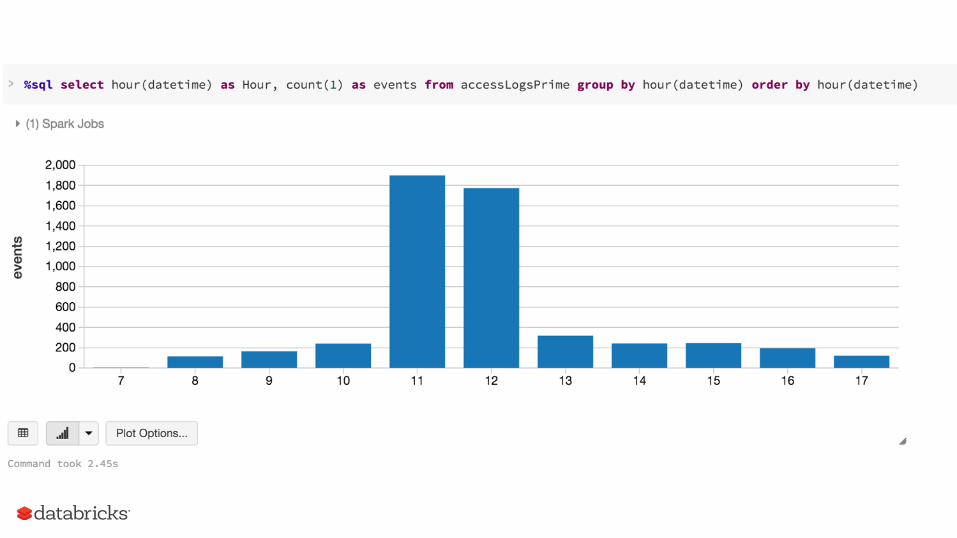

Spark API Performance
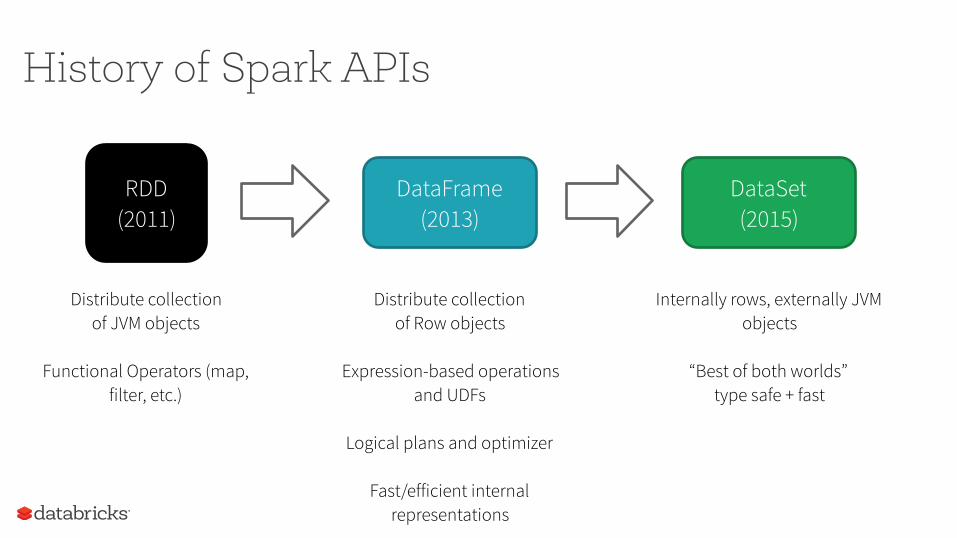
History of Spark APIs
RDD (2011)
DataFrame (2013)
Distribute collection of JVM objects
Functional Operators (map, filter, etc.)
Distribute collection of Row objects
Expression-based operations and UDFs
Logical plans and optimizer
Fast/efficient internal representations
DataSet (2015)
Internally rows, externally JVM objects
“Best of both worlds” type safe + fast

Benefit of Logical Plan:Performance Parity Across Languages
SQL
R
Python
Java/Scala
Python
Java/Scala
Runtime for an example aggregation workload (secs)
0 2.5 5 7.5 10
DataFrame
RDD
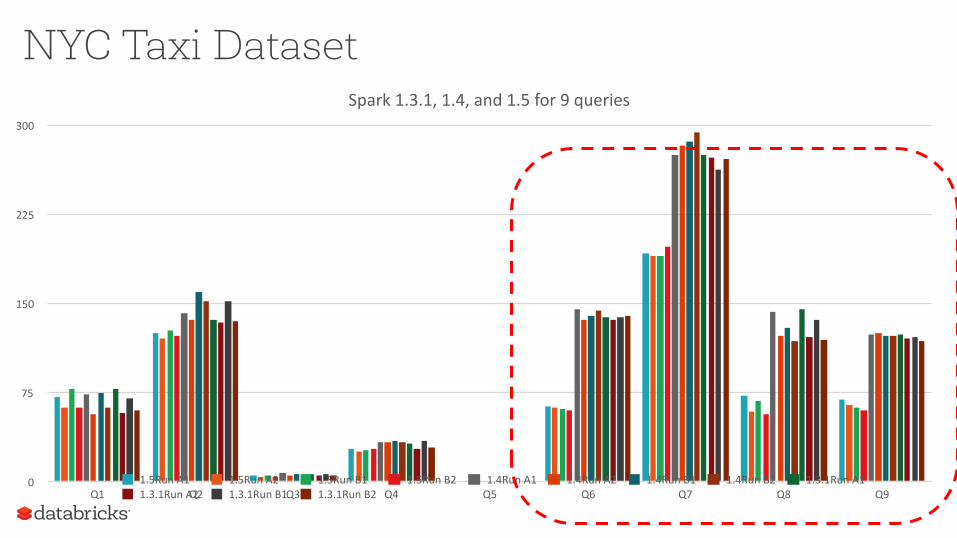
NYC Taxi DatasetSpark1.3.1,1.4,and1.5for9queries
0
75
150
225
300
Q1 Q2 Q3 Q4 Q5 Q6 Q7 Q8 Q91.5RunA1 1.5RunA2 1.5RunB1 1.5RunB2 1.4RunA1 1.4RunA2 1.4RunB1 1.4RunB2 1.3.1RunA11.3.1RunA2 1.3.1RunB1 1.3.1RunB2

Dataset API in Spark 1.6
Typed interface over DataFrames / Tungsten
caseclassPerson(name:String,age:Long)
valdataframe=read.json(“people.json”)valds:Dataset[Person]=dataframe.as[Person]
ds.filter(p=>p.name.startsWith(“M”)).toDF().groupBy($“name”).avg(“age”)
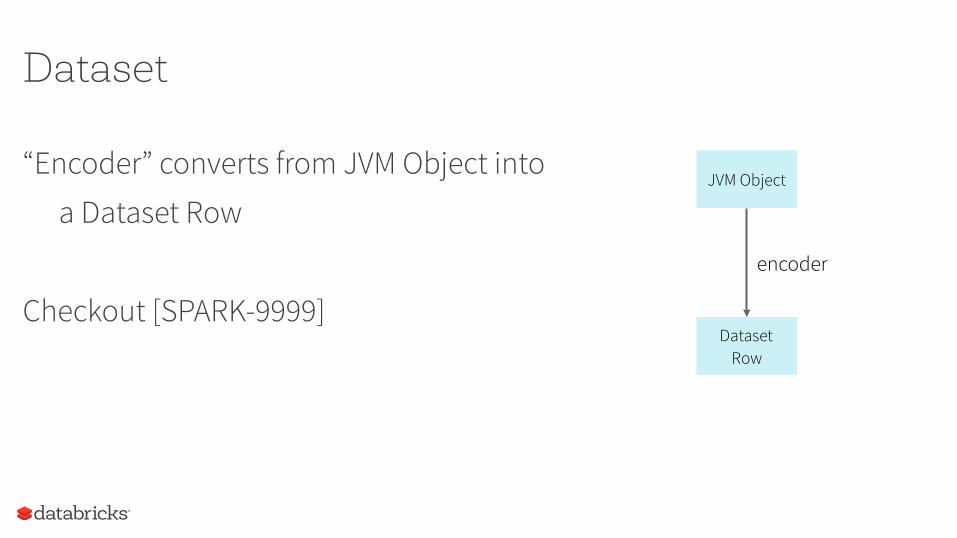
Dataset
“Encoder” converts from JVM Object into
a Dataset Row
Checkout [SPARK-9999]
JVM Object
Dataset Row
encoder

Tungsten Execution
PythonSQL R Streaming
DataFrame (& Dataset)
Advanced Analytics

References
• Spark DataFrames: Simple and Fast Analysis on Structured Data [Michael Armbrust]
• Apache Spark 1.6 presented by Databricks co-founder Patrick Wendell
• Announcing Spark 1.6 • Introducing Spark Datasets • Spark SQL Data Sources API: Unified Data Access for the Spark
Platform

Join us at Spark Summit East February 16-18, 2016 | New York City

Apply to the Academic Partners Programdatabricks.com/academic

Thanks!





























