Embed Size (px)
Citation preview

Applications of Markov Decision Processes (MDPs)in the Internet of Things (IoT) and Sensor Networks
Mohammad Abu Alsheikhhttps://sites.google.com/site/mohabualsheikh
School of Computer EngineeringNanyang Technological University
April 2016
1 / 26

Survey and summary of the field
See our comprehensive survey article:Abu Alsheikh, M.; Hoang, D.T.; Niyato, D.; Tan, H.; Lin, S., "Markov Decision ProcessesWith Applications in Wireless Sensor Networks: A Survey," IEEE CommunicationsSurveys & Tutorials, vol.17, no.3, pp.1239,1267, thirdquarter 2015
2 / 26

Outline
Outline
1 Introduction and Motivation
2 Markov Decision Processes (MDPs): Overview
3 Applications of MDPs in the IoT and Sensor Networks
4 Future Trends and Open Issues
5 Summary and Conclusions
3 / 26

Introduction and Motivation
Introduction and Motivation
4 / 26

Introduction and Motivation Motivation
Motivation
QuestionWhy are Markov Decision Processes (MDPs) required in the Internet of Things (IoT) andsensor networks?
Wireless sensor networks (WSNs)Consist of autonomous and resource-limited devices, e.g., the bandwidth and energylimitationsOperate in stochastic (random) environments under uncertaintyScale and generate massive data, e.g., the Internet of Things (IoT)
WSN dynamics can be modeled using a mathematical framework called Markov decisionprocesses (MDPs)
MDPs entail that the system possesses the Markov property (i.e., future states of a WSNdepend only upon the present state)
5 / 26
Introduction and Motivation Motivation
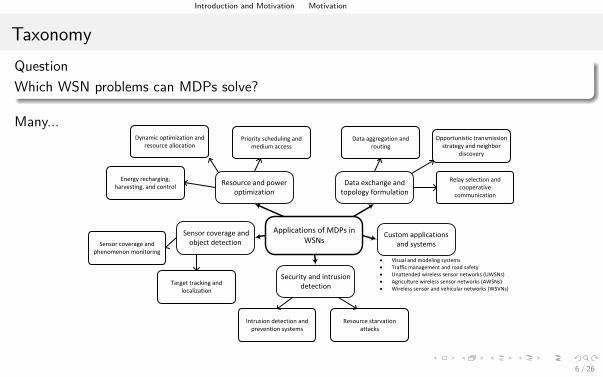
TaxonomyQuestionWhich WSN problems can MDPs solve?
Many...
Applications of MDPs in WSNs
Data exchange and topology formulation
Resource and power optimization
Security and intrusion detection
Sensor coverage and object detection
Custom applications and systems
Data aggregation and routing
Opportunistic transmission strategy and neighbor
discovery
Relay selection and cooperative
communication
Energy recharging, harvesting, and control
Dynamic optimization and resource allocation
Priority scheduling and medium access
Sensor coverage and phenomenon monitoring
Target tracking and localization
· Visual and modeling systems· Traffic management and road safety· Unattended wireless sensor networks (UWSNs)· Agriculture wireless sensor networks (AWSNs)· Wireless sensor and vehicular networks (WSVNs)
Intrusion detection and prevention systems
Resource starvation attacks
6 / 26

Introduction and Motivation Motivation
Summary of Benefits
MDP modeling provides the following general benefits to WSNs’ operations:
Using MDPs for dynamically optimizing the network operations to fit the physicalconditions results in significantly improved resource utilizationThe MDP model allows a balanced design of different objectives (optimization problemswith multiple objectives)The solution of an MDP model, referred to as a policy, can be implemented based on alook-up table with low computation requirementsMDPs are flexible with many variants that can fit the distinct conditions in WSNapplications
7 / 26

Markov Decision Processes (MDPs): Overview
Markov Decision Processes (MDPs): Overview
8 / 26

Markov Decision Processes (MDPs): Overview The Markov Decision Process Framework
Definition
An MDP is defined as a tuple 〈S,A,P,R, T 〉 where,
S is a finite set of states,A is a finite set of actions,P is a transition probability function from state s to state s ′ after action a is taken,R is the immediate reward obtained after action a is made, andT is the set of decision epoch, which can be finite or infinite.
π denotes a “policy” which is a mapping from a state to an action. The goal of an MDP is tofind an optimal policy to maximize or minimize a certain objective function
9 / 26

Markov Decision Processes (MDPs): Overview The Markov Decision Process Framework
MDP Types (Time Horizon)
For the finite time horizon MDP, an optimal policy π∗ to maximize the expected totalreward is defined as follows:
max Vπ(s) = Eπ,s[ T∑
t=1R(s ′t |st , π(at)
)](1)
where st and at are the state and action at time t, respectively.For the infinite time horizon MDP, the objective can be to maximize the expecteddiscounted total reward or to maximize the average reward. The former is defined asfollows:
max Vπ(s) = Eπ,s[ T∑
t=1γtR
(s ′t |st , π(at)
)], (2)
while the latter is expressed as follows:
max Vπ(s) = lim infT→∞
1T Eπ,s
[ T∑t=1R(s ′t |st , π(at)
)]. (3)
Here, γ is the discounting factor and E[·] is the expectation function.10 / 26

Markov Decision Processes (MDPs): Overview Solutions of MDPs
Solutions for Finite Time Horizon MDPs
If we denote v∗(s) as the maximum achievable reward at state s, then we can find v∗(s) atevery state recursively by solving the following Bellman’s optimal equations:
v∗t (s) = maxa∈A
[Rt(s, a) +
∑s′∈SPt(s ′|s, a)v∗t+1(s ′)
]. (4)
Based on the optimal Bellman equations, two typical approaches for finite time horizon MDPsexist.
Backwards induction (also known as the dynamic programming approach)Forward induction (also known as the value iteration approach)
Backward induction is especially useful when we know the state of MDPs in the last period.By contrast, forward induction is applied when we only know the initial state.
11 / 26

Markov Decision Processes (MDPs): Overview Solutions of MDPs
Solutions for Finite Time Horizon MDPs: Forward Induction
The idea is to divide the optimization problem based on the number of steps to goGiven an optimal policy for t − 1 time steps to go, we calculate the Q-values for k stepsto go. After that, we can obtain the optimal policy based on the following equations:
Qt(s, a) = R(s, a, s ′) +∑s′
P(s, a, s ′)v∗t−1(s ′),
v∗t (s) = maxa∈A
Q∗t (s, a) and π∗t (s) = argmaxa∈A
Q∗t (s, a),
where vt(s) is the value of state s and Qt(s, a) is the value of taking action a at state s.This process will be performed until the last period is reached.
12 / 26

Markov Decision Processes (MDPs): Overview Solutions of MDPs
Solutions for Infinite Time Horizon MDPs
Solving an infinite time horizon MDPs is more complex than finite time horizon MDPsInfinite time horizon MDPs are more widely: In practice the operation time of systems isoften unknown and assumed to be infinite
Solution methods
1 Value iteration (VI)2 Policy iteration (PI)3 Linear programming (LP)4 Approximation method5 Online learning
MDP Toolbox for Python https://github.com/sawcordwell/pymdptoolbox
13 / 26
Markov Decision Processes (MDPs): Overview Extensions of MDPs and Complexity
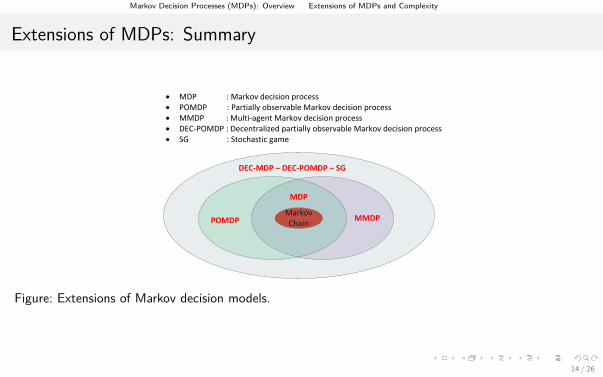
Extensions of MDPs: Summary
· MDP : Markov decision process· POMDP : Partially observable Markov decision process· MMDP : Multi-agent Markov decision process· DEC-POMDP : Decentralized partially observable Markov decision process· SG : Stochastic game
Markov Chain
MDP
MMDPPOMDP
DEC-MDP – DEC-POMDP – SG
Figure: Extensions of Markov decision models.
14 / 26

Applications of MDPs in the IoT and Sensor Networks
Applications of MDPs in the IoT and Sensor Networks
15 / 26
Applications of MDPs in the IoT and Sensor Networks Summary
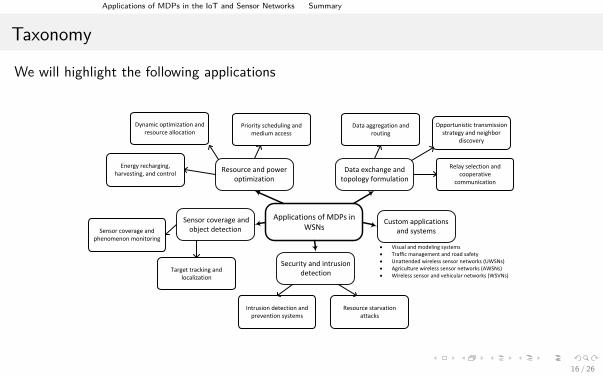
Taxonomy
We will highlight the following applications
Applications of MDPs in WSNs
Data exchange and topology formulation
Resource and power optimization
Security and intrusion detection
Sensor coverage and object detection
Custom applications and systems
Data aggregation and routing
Opportunistic transmission strategy and neighbor
discovery
Relay selection and cooperative
communication
Energy recharging, harvesting, and control
Dynamic optimization and resource allocation
Priority scheduling and medium access
Sensor coverage and phenomenon monitoring
Target tracking and localization
· Visual and modeling systems· Traffic management and road safety· Unattended wireless sensor networks (UWSNs)· Agriculture wireless sensor networks (AWSNs)· Wireless sensor and vehicular networks (WSVNs)
Intrusion detection and prevention systems
Resource starvation attacks
16 / 26

Applications of MDPs in the IoT and Sensor Networks Highlights
Data Exchange and Topology Formulation
A WSN can experience continual changes in its topology and transmission routes (e.g., nodeaddition and failure). The use of MDPs in these applications can be summarized as follows:
Data aggregation and routing: MDP models are used to obtain the most energy efficientsensor alternative for data exchange and gathering in cooperative multi-hopcommunications in WSNs. Different metrics can be included in the decision making suchas transmission delay, energy consumption, and expected network congestion.Opportunistic transmission strategy: Assuming sensors with adjustable transmission level,the MDP models adaptively select the minimum transmit power for the sensors to reachthe destination.Relay selection: When the location and distance information is available at the sourcenode, a relay selection decision can be optimized by using simple MDP-based techniquesto reduce the energy consumption of the relay and source nodes.
17 / 26

Applications of MDPs in the IoT and Sensor Networks Highlights
Resource and Power Optimization
A major issue of WSN design is the resource usage (e.g., energy, bandwidth, andcomputational power) at the node and network levels.
Energy control: For the energy charging of sensors, an MDP is used to decide on theoptimal time and order of sensor charging. These energy recharging methods considereach node’s battery charging/discharging time and available energy. Moreover, some ofthem deal with the stochastic nature of energy harvesting in WSNs.Dynamic optimization: A sensor node should optimize its operation at all protocol stacks,e.g., data link and physical layers. This is to match the physical conditions of theenvironment, e.g., weather.Duty cycling and channel access scheduling: The MDP-based methods predict theoptimal wake up and sleep patterns of the sensors.
18 / 26

Applications of MDPs in the IoT and Sensor Networks Highlights
Sensing Coverage and Object Detection
Sensor nodes can be deployed manually or randomly. Moreover, some nodes can be mobile,and thus the deployed locations can change dynamically. In all deployment scenarios, MDPsare used to achieve the following benefits:
Sensing coverage: The MDP models are used to predict the minimum number of activenodes to achieve the required coverage performance over time. Moreover, some workassumes that mobile nodes can change their location. In the latter, the MDP can predictoptimal movement strategies (e.g., movement steps and directions) of the nodes to coverthe monitored area.Target tracking: To increase the probability of object detection, WSNs use MDPs topredict the future locations of the targeted object, and to activate sensors at the expectedlocations and switch off sensors in other locations. Additionally, the MDP models canpredict optimal movement directions of nodes to increase the probability of targetdetection.
19 / 26

Applications of MDPs in the IoT and Sensor Networks Highlights
Security and Intrusion Detection
The few MDP-based security methods in the literature discuss the following issues:
Intrusion detection: One method for the detection of intrusion vulnerable node is basedon an MDP. This is done by analyzing the correlation among samples collected from thenodes. Thus, the intrusion and intrusion-free samples are traced by an intrusion detectionsystem (IDS).Resource starvation attacks: Resource starvation attacks aim at denying nodes fromaccessing the network resources such as wireless bandwidth. This is similar to thedenial-of-service (DoS) attack. MDP-based security methods are developed to analyzethe attacking entity behavior to select the optimal security configuration.
20 / 26

Future Trends and Open Issues
Future Trends and Open Issues
21 / 26

Future Trends and Open Issues
Challenges of Applying MDPs to WSNs
There are still some limitations of MDPs in WSNs that need further research study:
Time Synchronization: Most existing studies assume perfect time synchronization amongnodesThe Curse of Dimensionality: This is an inherent problem of MDPs when the state spaceand/or the action space become largeStationarity and Time-Varying Models: It is assumed that the MDP’s transitionprobabilities and reward function are time invariable. Nevertheless, in some systems, thisassumption may be infeasibleReal System Measurements: The existing literature lacks insight into long-runningexperiments using real world testbeds and deployments to assess system-wideperformance under changing conditions
22 / 26

Future Trends and Open Issues
Emerging MDP Models
State Abstraction Using Self-Organizing Maps: This can reduce the complexity of solvingproblems with continuous and discrete state values which is a promising benefit forpractical applications of MDPs in WSNsLearning Unknown Parameters: The uncertainty in modeling parameters, e.g., transitionprobabilities.Near-Optimal Solutions: Sensor nodes are independent controllers located in anenvironment and their decisions have mutual effects on each other
23 / 26

Future Trends and Open Issues
Emerging Topics in WSNs
WSNs find new applications and serves as a key platform in many smart technologies andInternet of Things (IoT)
Cross-Layer Optimized Sensor NetworksCognitive Radio Sensor NetworksPrivacy ModelsInternet-of-Things (IoT)
24 / 26

Summary and Conclusions
Summary and Conclusions
25 / 26

Summary and Conclusions
Conclusions
WSNs operate as stochastic systems because of randomness in the monitoredenvironmentsWSNs require adaptive and robust methods to address data exchange, topologyformulation, resource and power optimization, sensing coverage and object detection, andsecurity challengesThe MDP framework is a powerful decision-making tool to develop adaptive algorithmsand protocols for WSNs and IoT
26 / 26





























