Embed Size (px)
Citation preview

Universidad Central de Venezuela Facultad de Ciencias Económicas y Sociales
Área de Postgrado en Estadística y Actuariado Programa Integrado de Postgrado en Estadística
GENERALIZACION DE ALGUNAS PRUEBAS CLASICAS DE COMPARACION DE CURVAS DE SUPERVIVENCIA AL CASO
DE EVENTOS DE NATURALEZA RECURRENTE
TRABAJO PRESENTADO ANTE LA ILUSTRE UNIVERSIDAD CENTRAL DE VENEZUELA PARA OPTAR AL GRADO DE DOCTOR
EN ESTADISTICA Y ACTUARIADO
Autor: M. Sc. Carlos M. Martínez M.
C.I. 8.917.031 [email protected]
Tutor:
Dr. Guillermo Ramírez C.I. 3.609.750
Caracas, Febrero 2009

Copyright, 2009 © Carlos M. Martínez M. © Facultad de Ciencias Sociales, Universidad Central de Venezuela Febrero, 2009 ISBN: 978-980-12-3605-4 Lft: 487200962043




DEDICATORIA
A mis PADRES
Quienes me han dado todo incluyendo la vida.
A mis hijos y a mis nietos
A quienes amo intensamente.
A mi esposa
Con la que he compartido lo poco que tengo.
A mis familiares
Con quienes deseo compartir mucho.
A mis amigos.
Carlos M. Martínez M.
Caracas, Diciembre 2009.

AGRADECIMIENTOS
Agradecimiento al todopoderoso quien me ha dado la fuerza de voluntad y la sabiduría
necesaria para desarrollar este trabajo. Agradecimiento a las autoridades de la
Universidad de Carabobo, institución donde realice mis estudios de pregrado y
postgrado en Ingeniería Industrial y donde actualmente me desempeño como profesor
universitario. Agradecido de sus autoridades quienen me han dado la oportunidad y el
apoyo necesario para realizar estos estudios doctorales.
Agradecimiento a las autoridades de la Universidad Central de Venezuela, institución
que me ha acogido en su seno y me ha abrigado en su manto de enseñanza y sabiduría y
donde se me ha permitido desarrollar esta investigación. Institución donde se han
formado excelentes profesionales y que siempre será reconocida como “la casa que
vence la sombra”. Agradecimiento inmenso a las autoridades de la Oficina de
Planificación del Sector Universitario, institución que con su programa ALMA MATER
para la formación de doctores, me seleccionaron y creyeron en mí para realizar esta
investigación, institución quien suministró parte de los recursos financieros para que
este doctorado se llevara a cabo.
Agradecimiento inmenso al Dr. Guillermo Ramírez y la Dra. Maura Vásquez quienes
aceptaron la tutoría y dirección de esta investigación, quienes con su valioso tiempo y
consejos lograron guiarme a desarrollar la misma. Agradecimiento inmenso al Dr. Luis
Salas profesor de la Escuela de Estadística y Actuariado de FACES de la UCV y
profesor del Postgrado de esa misma escuela, quien con sus consejos, voluntarias,
entusiastas e invalorables consultas, logró un cambio positivo en el rumbo inicial de mi
proyecto de tesis doctoral y me encaminó a realizar este bellísimo tema de
investigación. Agradecimiento al jurado de esta tesis quienes con su profesionalismo,
valoraron, corrigieron y dieron sugerencias para mejorar este trabajo. Agradecimiento a
todos los que creyeron en mí y me apoyaron moralmente, a quienes colaboraron con el
desarrollo de esta investigación. Agradecimiento inmenso a todo el personal docente,
administrativo y obrero del Área de postgrado de la UCV, agradecimiento inmenso a
quienes contribuyeron con mi preparación profesional y me dieron la fuerza moral para
dar este paso importante en mi vida. Agradecimiento inmenso a todos.
Carlos M. Martínez M.
Caracas, Diciembre 2009.

RESUMEN
Los eventos recurrentes son fenómenos que ocurren en muchas áreas. En nuestro entorno suelen suceder infinidades de eventos de este tipo, cabe mencionar: enfermedades virales, aparición de tumores cancerigenos, fiebres, fallas en maquinarias y equipos, nacimientos, homicidios, terremotos, lluvias, erupciones de volcanes, accidentes laborales, accidentes automovilísticos, entre otros. En el análisis de supervivencia (AS) la variable de estudio es el tiempo que transcurre desde un momento inicial conocido hasta que se produce un evento predeterminado. El AS con eventos recurrentes (dos o más ocurrencia por unidad bajo estudio) difiere del análisis clásico (una ocurrencia por unidad). La naturaleza de estos eventos obliga al uso de otras técnicas diferentes a las que se utilizan en el AS tradicional. Recientemente, se han desarrollo novedosas técnicas y modelos dirigidas a estudio de fenómenos recurrentes. En esta investigación se tratan algunos de estos modelos y nuestro objetivo es la comparación de curvas de supervivencia entre grupos que experimentan estos fenómenos. La idea consiste en generar estadísticos de comparación que permitan diferenciar estadísticamente las curvas de supervivencia estimadas a través de uno de los modelos existentes. Los estadísticos propuestos en esta investigación son generalizaciones de los estadísticos ponderados del análisis clásico. Estadísticos que hemos desarrollados y extendidos para comparar las curvas de supervivencia en fenómenos con eventos recurrentes para los casos de dos o más grupos. En la investigación se evalúan algunas propiedades de los estadísticos de comparación propuestos utilizando técnicas de simulación y programas diseñados en lenguaje R. En dichas simulaciones se analizan y evalúan los comportamientos de dichos estadísticos, se estiman las probabilidades de cometer errores tipo I y las potencias de las pruebas correspondientes. Cada simulación se ejecuta aumentando sistemáticamente los tamaños de las muestras, considerando tiempos de interocurrencias simulados bajo diferentes escenarios distribucionales con tiempos de censuras aleatorias. En cuanto a las aplicaciones, se utilizan bases de datos de problemas que han sido tratados por otros investigadores, bases de datos que están publicadas y disponibles en la bibliografía, obteniendo resultados fabulosos. Entre las bases de datos utilizadas, se encuentran: los datos de provenientes del experimento de Byar, que corresponden a los tiempos (meses) de reapariciones de tumores de ciento dieciséis (116) pacientes enfermos con cáncer superficial de vejiga tratado con: placebo, thiotepa y piridoxina. Nuestro objetivo es comparar las funciones de supervivencia de los tres grupos y determinar si existen diferencias significativas en los tratamientos. La segunda aplicación se hizo a los datos del experimento de Aalen-Husebye que corresponde al estudio de la motilidad del intestino delgado (actividad muscular) de diecinueve (19) pacientes. Nuestro objetivo consiste en determinar si existen diferencias significativas entre las curvas de supervivencia obtenidas de los períodos del Complejo Motor Migratorio de estos pacientes. Otra aplicación se hizo a los datos del estudio hecho por González-Peña, correspondiente a los tiempos de rehospitalizaciones de cuatrocientos tres (403) pacientes diagnosticados e intervenidos quirúrgicamente con cáncer colorectal. Nuestro objetivo consiste en determinar si existen diferencias significativas entre las curvas de supervivencia de los tiempos de rehospitalización de grupos de pacientes estratificados a través de un conjunto de variables socio-demográficas o clínicas, como son: las variables quimioterapia, estado tumoral y distancia. Otros datos tratados son los estudiados por Gail et al., quien presentó un experimento cancerigeno realizado a cuarenta y ocho (48) ratas con dos tratamientos, a quienes se les midieron los tiempos de detección de tumores mamarios provenientes de un cáncer inoculado. El objetivo en este trabajo consiste en determinar si existen diferencias significativas entre las curvas de supervivencia de los tiempos de detecciones de los tumores entre el grupo control y el grupo tratado. Palabras clave: Análisis de supervivencia, eventos recurrentes, procesos contadores, pruebas de
comparación ponderadas.

CONTENIDO
Pag.
INDICE DE TABLAS i INDICE DE FIGURAS iv INTRODUCCIÓN vi Capitulo I. EL PROBLEMA 1 1.1 Planteamiento del problema 1 1.2 Objetivos de la investigación 4
1.2.1 Objetivo General 4 1.2.2 Objetivos Específicos 4
1.3 Justificación del estudio 5 1.4 Alcance y limitaciones del estudio 6 Capitulo II. MARCO TEÓRICO 7 2.1 Bases teóricas 7
2.1.1 ¿En que consiste el análisis de supervivencia? 7 2.1.2 Áreas de aplicación del análisis de supervivencia 8 2.1.3 Datos censurados del análisis de supervivencia 9 2.1.4 Funciones del análisis de supervivencia 11
2.1.4.1 Función de supervivencia 11 2.1.4.2 Función de riesgo instantáneo 12 2.1.4.3 Función de riesgo acumulado 14 2.1.4.4 Relaciones entre las funciones del análisis de funciones 15 2.1.4.5 Medidas descriptivas del análisis de supervivencia 16
2.1.5 Métodos de estimación del análisis de supervivencia 18 Capitulo III. MODELOS CLÁSICOS DEL ANÁLISIS DE SUPERVIVENCIA 20 3.1 Orígenes del análisis de supervivencia 20 3.2 Modelos Actuariales 21
3.2.1 Modelo actuarial de Bhomer 21 3.2.2 Formula de Greenwood 25
3.2.3 Modelo actuarial de Berkson-Gage 26 3.2.4 Modelo de Cutler-Ederer 27
3.3 Modelo de Kaplan-Meier 30 3.4 Otros modelos noparametricos del análisis de supervivencia 31
3.4.1 Modelo de supervivencia de Altshuler 32 3.4.2 Modelo de supervivencia de Peterson 32 3.4.3 Modelo de supervivencia de Prentice 32 3.4.4 Modelo de supervivencia de Prentice-Marek 33 3.4.5 Modelo de supervivencia de Andersen et al. 33 3.4.6 Modelo de supervivencia de Harris-Albert 33 3.4.7 Modelo de supervivencia de Moreau et al. 33 3.4.8 Modelo de supervivencia de Hosmer-Lemeshow 33

3.5 Modelo de riesgos proporcionales de Cox 34 3.6 Modelo de riesgos proporcionales de Cox estratificados 38
3.6.1 Modelo general estratificado 38 3.6.2 Modelo de no-interacción con coeficientes estratificados 39 3.6.3 Modelo de interacción con coeficientes estratificados 39
3.7 Extensiones del modelo de riesgos proporcionales de Cox para variables dependientes del tiempo 39
Capitulo IV. PROCESOS DE CONTEO, MARTINGALAS Y SU RELACIÓN CON EL ANÁLISIS DE SUPERVIVENCIA 41 4.1 Introducción 41 4.2 Procesos estocásticos 42
4.2.1 Características de los procesos estocásticos 42 4.3 Tiempos de interocurrencia de los eventos 45 4.4 Martingalas 45 4.5 Procesos de conteo y análisis de supervivencia 46
4.5.1 Preliminares 46 4.5.2 Notación de los procesos de conteo aplicados en la estimación de las distribuciones del análisis de supervivencia 47 4.5.3 Procesos de conteo en estimaciones no paramétrica del análisis de supervivencia 48
4.5.3.1 Estimador Nelson-Aalen 49 4.5.3.2 Estimador Kaplan-Meier 51 4.5.3.3 Estimador del modelo de riesgos proporcionales de Cox 52
Capitulo V. MODELOS DE SUPERVIVENCIA CON EVENTOS
RECURRENTES 53 5.1 Introducción 53 5.2 Modelos semiparamétricos 54
5.2.1 Modelos de Prentice-Williams-Peterson 54 5.2.1.1 Primer modelo de PWP (modelo PWP01) 55 5.2.1.2 Segundo modelo de PWP (modelo PWP02) 56
5.2.2 Modelo de Andersen-Gill ( modelo AG ) 57 5.2.3 Modelo Wei-Lin-Weissfeld ( modelo WLW ) 58
5.3 Modelos no paramétricos 59 5.3.1 Modelos de Fragilidad 59 5.3.2 Modelo Wang-Chang ( modelo WC ) 60 5.3.3 Modelos de Peña-Strawderman-Hollander 62
5.3.3.1 Modelo de Kaplan-Meier generalizado (modelo GPLE) 62 5.3.3.2 Modelo de fragilidad multiplicativa (modelo FRMLE) 65
Capitulo VI. PRUEBAS DE COMPARACIÓN EN EL ANÁLISIS DE
SUPERVIVENCIA 67 6.1 Introducción 67 6.2 Pruebas de contraste no paramétricas para comparar muestras con datos no
censurados 69 6.2.1 Prueba de los signos 69

6.2.2 Prueba de Wilcoxon 70 6.2.3 Prueba de Mann-Whitney 71 6.2.4 Prueba de Kruskal-Wallis 72 6.2.5 Prueba de Cochran 73
6.3 Pruebas de contraste no paramétricas para comparar curvas del análisis de supervivencia clásico 74
6.3.1 Prueba de Mantel-Haenszel 74 6.3.2 Prueba generalizada de Wilcoxon, prueba de Gehan (primera
propuesta) 75 6.3.3 Prueba de Gehan (segunda propuesta) 78 6.3.4 Prueba de Mantel 81
6.3.4.1 Procedimiento alternativo a Gehan 81 6.3.4.2 Aplicación directa del procedimiento de Wilcoxon para
datos en presencia de censuras arbitrarias 82 6.3.5 Prueba generalizada Kruskal-Wallis de Breslow 84 6.3.6 Prueba de Peto-Peto 86 6.3.7 Prueba de Cox 87 6.3.8 Prueba de Tarone-Ware 88 6.3.9 Prueba de Prentice 90 6.3.10 Prueba Prentice-Marek 91 6.3.11 Prueba de Gill 92 6.3.12 Prueba Harrington-Fleming 92 6.3.13 Prueba de Fleming-Harrington 93
6.4 Pruebas de contraste para comparar fenómenos con eventos recurrentes 94 6.4.1 Propuesta de Pepe-Cai 94 6.4.2 Propuesta de Glyn-Buring 95 6.4.3 Propuesta de Daganaksoy-Nelson 95
Capitulo VII. PRUEBAS DE COMPARACIÓN DE CURVAS DE
SUPERVIVENCIA CON EVENTOS DE CARÁCTER RECURRENTES. PROPUESTAS 97
7.1 Introducción 97 7.2 Estadísticos de contraste para comparar las curvas de supervivencia
con eventos recurrentes, para el caso de dos grupos. Una propuesta 97 7.2.1 Planteamiento del problema 97 7.2.2 Notación básica 98 7.2.3 Propuestas para el caso de dos muestras 102
7.3 Estadísticos de contraste para comparar las curvas de supervivencia con eventos recurrentes, para el caso de k grupos. Propuestas 105 7.3.1 Planteamiento del problema 105 7.3.2 Notación básica 106 7.3.3 Propuestas para el caso de k muestras 107
7.3.3.1 Primera propuesta 107 7.3.3.2 Segunda propuesta 110

Capitulo VIII. VALIDACIÓN DE LOS ESTADÍSTICOS DE CONTRASTE PARA COMPARAR CURVAS DE SUPERVIVENCIA CON EVENTOS RECURRENTES 113
8.1 Introducción 113 8.2 Estudio de simulaciones 113
8.2.1 Estudio de simulaciones para el caso de dos grupos 118 8.2.2 Estudio de simulaciones para el caso de tres grupos 120
Capitulo IX. APLICACIONES DE LOS ESTADÍSTICOS DE COMPARACIÓN PARA EVENTOS RECURRENTES 122 9.1 Introducción 122 9.2 Datos del experimento de Byar (1980) 122
9.2.1 Comparación curvas de supervivencia grupo placebo vs. grupo Thiotepa 125
9.2.2 Comparación curvas de supervivencia grupo placebo vs. grupo Piridoxina 129
9.2.3 Comparación curvas de supervivencia grupo thiotepa vs. grupo Piridoxina 133
9.2.4 Comparación de las curvas de supervivencia de los tres grupos 136 9.3 Datos del experimento de Aalen-Husebye (1991) 137 9.4 Datos del cáncer colorectal de González -Peña (2003, 2004) 141
9.4.1 Comparación de curvas de supervivencia para tiempos de rehospitalizaciones en pacientes sin y con quimioterapia. 143
9.4.2 Comparación de curvas de supervivencia para tiempos de rehospitalizaciones en pacientes estratificado por la variable distancia. 144
9.4.3 Comparación de curvas de supervivencia para tiempos de rehospitalizaciones en pacientes estratificado el estado tumoral. 145
9.4.4 Comparación de curvas de supervivencia para tiempos de rehospitalizaciones en pacientes estratificado el estado tumoral (comparación dos a dos). 146 9.4.3.1 Comparación curvas de supervivencia
grupo Dukes A-B vs. grupo Dukes C 146 9.4.3.2 Comparación curvas de supervivencia grupo
Dukes A-B vs. grupo Dukes D 147 9.4.3.3 Comparación curvas de supervivencia grupo
Dukes C vs. grupo Dukes D 148 9.5 Datos del experimento de Gial (1980) 149 CONCLUSIONES 152 BIBLIOGRAFÍA 156 APÉNDICES 163

i
INDICE DE TABLAS
Pag.
Tabla 2.1 Áreas de aplicación del análisis de supervivencia 8 y 9
Tabla 3.1 Formato normalizado de tablas actuariales para el análisis
de supervivencia de Cutler-Ederer 29
Tabla 5.1 Tiempos de interocurrencia del evento en las unidades bajo estudio 61
Tabla 6.1 Número de ocurrencias del evento en el tiempo tz para ambos grupos
poblacionales I y II. 74
Tabla 6.2 Número de ocurrencias del evento y censuras en el intervalo i-ésimo
de tiempo en el 1er grupo. 77
Tabla 6.3 Número de ocurrencias del evento en el tiempo tz para el k-ésimo grupo
Poblacional 84
Tabla 6.4 Número de ocurrencias del evento en el tiempo tz para los grupos
poblacionales. 88
Tabla 7.1 Resumen del número de ocurrencias del evento en el tiempo de
interocurrencia z para los grupos 1 y 2. 102
Tabla 7.2. Propuestas de pesos en pruebas de contraste para modelos de
supervivencia con recurrencia. 104
Tabla 7.3 Resumen del número de ocurrencias del evento en el tiempo de
interocurrencia z en todo los grupos. 105
Tabla 7.4 Resumen de los números de ocurrencias del evento en el instante z
para los grupos r y r’. 107
Tabla 9.1 Datos de reaparición de tumores en pacientes enfermos con
cáncer de vejiga 123
Tabla 9.2 Estimaciones de la curvas de supervivencia de los grupos:
combinado placebo-thiotepa, placebo y thiotepa 126.
Tabla 9.3 Resultados de las pruebas de comparación de las curvas de
supervivencia de los grupos placebo y thiotepa utilizando propuestas. 127
Tabla 9.4 Resultados de las estimaciones las MCF de los grupos placebo y
thiotepa y sus diferencias, utilizando propuesta de
Dognaksoy-Nelson (1998). 128
Tabla 9.5 Estimaciones de la curva de supervivencia del grupo combinado
y los grupos placebo y piridoxina 130

ii
Tabla 9.6 Resultados de las pruebas de comparación de las curvas de
supervivencia de los grupos placebo y piridoxina. 130
Tabla 9.7 Resultados de las estimaciones las MCF de los grupos placebo
y piridoxina y sus diferencias, utilizando propuesta de
Dognaksoy-Nelson (1998) 132
Tabla 9.8 Estimaciones de la curva de supervivencia del grupo combinado
piridoxina-thiotepa 133
Tabla 9.9 Resultados de las pruebas de comparación de las curvas de
supervivencia de los grupos piridoxina y thiotepa 134
Tabla 9.10 Resultados de las estimaciones las MCF de los grupos piridoxina
y thiotepa y sus diferencias, utilizando propuesta de
Dognaksoy-Nelson (1998) 135
Tabla 9.11 Estimaciones de la curva de supervivencia del grupo combinado
placebo-thiotepa-piridoxina 136
Tabla 9.12 Resultados de las pruebas de comparación de las curvas de
supervivencia de los tres grupos 137
Tabla 9.13 Datos del período del complejo migratorio motor (CMM) 138
Tabla 9.14 Estimaciones de la curva de supervivencia del período
CMM del grupo combinado hombres- mujeres 139
Tabla 9.15 Estimaciones de la curva de supervivencia del grupo
del período CMM en hombres y mujeres 140
Tabla 9.16 Resultados de las pruebas de comparación de las curvas
de supervivencia del período CMM 141
Tabla 9.17 Datos de rehospitalización de los primeros veinticinco (25) pacientes
enfermos con cáncer de colon de un total de cuatrocientos tres (403) 142
Tabla 9.18 Resultados de las pruebas de comparación de las curvas de
supervivencia en los tiempos de rehospitalizaciones de pacientes enfermos
con cáncer de colon, con y sin quimioteratía 143
Tabla 9.19 Resultados de las pruebas de comparación de las curvas de
supervivencia e los tiempos de rehospitalizaciones de pacientes enfermos
con cáncer de colon estratificados por la variable distancia 144
Tabla 9.20 Resultados de las pruebas de comparación de las curvas de supervivencia
de los tiempos de rehospitalizaciones de pacientes enfermos con
cáncer de colon estratificados a través de la variable estado tumoral 145
Tabla 9.21 Resultados de las pruebas de comparación de las curvas de supervivencia

iii
de los tiempos de rehospitalizaciones de pacientes enfermos con cáncer de colon
estratificados a través de la variable estado tumoral,grupos: grupo Dukes A-B
vs. grupo Dukes C. 146
Tabla 9.22 Resultados de las pruebas de comparación de las curvas de supervivencia
de los tiempos de rehospitalizaciones de pacientes enfermos con cáncer
de colon estratificados a través de la variable estado tumoral,
grupos: grupo Dukes A-B vs. grupo Dukes D 147
Tabla 9.23 Resultados de las pruebas de comparación de las curvas de supervivencia
de los tiempos de rehospitalizaciones de pacientes enfermos con cáncer
de colon estratificados a través de la variable estado tumoral,
grupos: grupo Dukes C vs. grupo Dukes D 148
Tabla 9.24 Tiempo de reaparición de tumores en ratas de sexo femenino
con cáncer mamarios 149
Tabla 9.25 Resultados de las pruebas de comparación de las curvas de supervivencia
de los tiempos de detecciones de tumores en los grupos:
grupo tratado vs. grupo control 150

iv
INDICE DE FIGURAS
Pag.
Figura 2.1 Representación gráfica de datos censurados y no censurados
del análisis de supervivencia 10
Figura 2.2 Representación gráfica de algunas funciones de densidad de
probabilidades 11
Figura 2.3 Representación gráfica de algunas funciones de supervivencia 12
Figura 2.4 Representación gráfica de funciones de riesgo instantáneo 14
Figura 2.5 Representación gráfica de las funciones de riesgos acumulados 15
Figura 3.1 Representación gráfica de los p subintervalos del período de observación 22
Figura 5.1 Representación gráfica de la recurrencia de eventos en la i-ésima
unidad de investigación 61
Figura 9.1 Representación gráfica de tiempos de reaparición de tumores en los grupos
placebo, piridoxina y thiotepa 125
Figura 9.2 Representación gráfica de la comparación del grupo placebo vs. grupo
thiotepa 126
Figura 9.3 Representación gráfica de las MCF del grupo placebo vs. grupo thiotepa 127
Figura 9.4 Representación gráfica de la diferencia de las MCF del grupo placebo vs.
grupo thiotepa 128
Figura 9.5 Representación gráfica de la comparación del grupo placebo vs. grupo
piridoxina 129
Figura 9.6 Representación gráfica de las MCF del grupo placebo vs. grupo piridoxina 131
Figura 9.7 Representación gráfica de la diferencia de las MCF del grupo placebo vs.
grupo piridoxina para todo los grupos 131
Figura 9.8 Representación gráfica de la comparación del grupo piridoxina vs
thiotepa 133
Figura 9.9 Representación gráfica de las MCF del grupo piridoxina vs. grupo thiotepa 134.
Figura 9.10 Representación gráfica de la diferencia de las MCF del grupo piridoxina
vs. grupo thiotepas. 135
Figura 9.11 Representación gráfica de la comparación de los tres grupos 136
Figura 9.12 Representación gráfica de los períodos CMM en hombres y mujeres 138
Figura 9.13 Representación gráfica de la supervivencia de los períodos CMM en
hombres y mujeres 139

v
Figura 9.14 Representación gráfica de la supervivencia de los tiempos de
rehospitalizaciones de pacientes enfermos con cáncer de colon
con y sin quimioteratía 143
Figura 9.14 Representación gráfica de la supervivencia de los tiempos de
rehospitalizaciones de pacientes enfermos con cáncer de colon
estratificados por la variable distancia 144
Figura 9.15 Representación gráfica de la supervivencia de los tiempos de
rehospitalizaciones de pacientes enfermos con cáncer de colon
estratificados a través de la variable estado tumoral 145
Figura 9.16 Representación gráfica de la supervivencia de los tiempos de
rehospitalizaciones de pacientes enfermos con cáncer de colon
estratificados a través de la variable estado tumoral, grupo
Dukes A-B vs. grupo Dukes 146
Figura 9.17 Representación gráfica de la supervivencia de los tiempos de
rehospitalizaciones de pacientes enfermos con cáncer de colon
estratificados a través de la variable estado tumoral, grupo
Dukes A-B vs. grupo Dukes D 147
Figura 9.18 Representación gráfica de la supervivencia de los tiempos de
rehospitalizaciones de pacientes enfermos con cáncer de colon
estratificados a través de la variable estado tumoral, grupo
Dukes C vs. grupo Dukes D supervivencia de los tres grupos 148
Figura 9.19 Representación gráfica de la supervivencia de los tiempos
de detecciones de tumores en los grupos: grupo tratado vs. grupo control 150

vi
INTRODUCCIÓN
El análisis de supervivencia consta de un conjunto de herramientas estadísticas que
permiten estudiar la aparición de eventos en el tiempo, conocidos como “tiempos de
supervivencia”, “tiempos de vida” o “tiempos de falla”. Este tiempo corresponde al
lapso comprendido entre un momento inicial, (inicio de un tratamiento, diagnóstico,
operación) y un momento final de ocurrencia de un evento terminal conocido o
predefinido (que puede representar muerte, cura, falla, aparición de tumores, entre
otras). La estructura de datos del análisis de supervivencia la conforma una serie de
observaciones provenientes de las unidades bajo estudio, incluyendo datos de
supervivencia completos (con unidades con eventos terminales ocurridos en el tiempo
de observación) y datos de supervivencia censurados (con eventos terminales no
ocurridos en el tiempo de observación).
Cuando el análisis es aplicado al estudio de eventos de tipo biológico asociados con la
ocurrencia de eventos que provienen de plantas, animales o seres humanos, usualmente
es llamado análisis de supervivencia y cuando el análisis es dirigido a las industrias o
seres inanimados, se conoce como análisis de confiabilidad. Las aplicaciones de las
técnicas en ambas áreas dependen de las restricciones en el problema. El uso de estas
técnicas se ha extendido a otras áreas de investigación como la sicología, bioingeniería,
medicina, física, astronomía y eventos de vida. Tradicionalmente los estudios de
supervivencia se orientaron al análisis de una única ocurrencia de un evento por unidad
bajo estudio (análisis de supervivencia clásico). Sin embargo, desde hace cuatro
décadas los estudios se han extendido a la aparición de eventos recurrentes (análisis de
supervivencia recurrente). Los eventos recurrentes son sucesos que pueden presentarse
en muchas áreas: fallas en automóviles, fallas en computadoras, fallas en un sistema de
trasmisión de energía, reaparición de tumores en personas enfermas con cáncer, ataques
de epilepsia, fiebre provocada por enfermedades infecciosas, accidentes
automovilísticos, accidentes laborales, delitos, matrimonios, divorcios, nacimientos,
entre otros. El análisis de este tipo muy particular de información debe tomar en cuenta
tanto el problema de la censura como el de la recurrencia.
El surgimiento y el desarrollo de nuevos procedimientos y nuevas herramientas del
análisis de supervivencia recurrente son recientes y no son del todo conocidas. Los

vii
primeros aportes datan desde los años ochenta, con los trabajos de Prentice-Willians-
Perterson (1981), Andersen-Gill (1982) y Wei-Lin-Weissfeld (1989). La literatura
sobre el tema es escasa y muy especializada. La mayor parte de la información sobre el
tema y sobre los aportes actuales en el área se consiguen en revistas científicas, entre las
que se encuentran: Biometrics, Biometrika, Biometria, JRSS, JASA, Annal of Statistics,
Statistics in Medicine y Technometrics. Los aportes más recientes sobre el tema
incluyen los trabajos de: Wang-Chang (1999), Peña et al. (2001), Nelson (2003),
Hollander-Setruraman (2004), González-Peña (2003), González-Peña (2004),
González-Peña-Straderman (2005), Peña-Slate (2005) y Peña E. (2006). En esta
investigación se trata el tema de la modelación de eventos recurrentes en grupos
poblacionales y el objetivo principal es la comparación de curvas de supervivencia en
esos grupos. El propósito fundamental consiste en generar estadísticos de comparación
que permitan diferenciar estadísticamente las curvas de supervivencia estimadas a través
de cualquiera de estos métodos.
En el trabajo se ilustran y describen los modelos de supervivencia con eventos
recurrentes. Se incluyen las propuestas desde que Prentice y colaboradores propusieron
sus dos modelos de regresión condicionales, estratificados tipo Cox, adaptados al caso
recurrente a principio de los años ochenta. En este capítulo se describen dos conjuntos
de modelos bien definidos: En primer lugar, los modelos de regresión
semiparamétricos, que fueron diseñados en los años ochenta para estudiar los
fenómenos recurrentes considerando los efectos de covariables. Estos modelos son
extensiones del modelo de Cox que incorporan una o más variables en el análisis. Se
asume que los tiempos entre ocurrencias del evento son independientes e idénticamente
distribuidos donde la probabilidad de supervivencia en las unidades bajo estudio está
afectada por los efectos de estas covariables. El segundo conjunto de modelos no
considera los efectos de covariables, y son conocidos como modelos no paramétricos,
libres de cualquier distribución de probabilidad y consideran los casos de dependencia
y no dependencia entre los tiempos de interocurrencias. En el capitulo VI se detallan
una serie de estadísticos de pruebas de contraste que se han sido propuestos para
comparar curvas del análisis de supervivencia tradicional incluidos los casos de
comparación de dos o más subgrupos poblacionales. También se incluyen algunas
propuestas para la comparación de grupos en el caso de recurrencia como las de Pepe-
Cai (1993), Glyn-Buring (1996) y Daganaksoy-Nelson (1998).

viii
En este trabajo se presentan nuestras propuestas, que son estadísticos de contraste
diseñados para comparar curvas de supervivencia de grupos poblacionales que
experimentan eventos recurrentes. Se trata de estadísticos ponderados y generalizados,
desarrollados para comparar dichas curvas los casos de dos o más grupos. La idea de
nuestras propuestas están centrada en la generalización de los estadísticos de
comparación ponderados del análisis de supervivencia clásico al caso recurrente. Las
estimaciones de las funciones del análisis de supervivencia son realizadas a través del
modelo GLPE propuesto por Peña et al. (2001).

Capitulo I. El problema ______________________________________________________________________
1
Capitulo I. EL PROBLEMA
1.1 PLANTEAMIENTO DEL PROBLEMA
El análisis de supervivencia esta formado por un conjunto de procedimientos
estadísticos que permiten analizar datos en los cuales la variable de estudio es el tiempo
que transcurre desde un momento inicial hasta que se produce un evento determinado en
ciertas unidades de estudio. El suceso puede describir muertes, nacimientos,
enfermedades, descubrimientos, empleos, fallas, ataques terroristas, matrimonios,
divorcios, delitos o cualquier otro acontecimiento de interés. Hasta la década de los
ochenta, los estudios de supervivencia se habían realizado considerando la ocurrencia de
un solo evento por unidad de estudio. Este tipo análisis, actualmente se conoce como
análisis supervivencia clásico. En estas últimas cuatro décadas investigadores como:
Prentice et al. (1981), Andersen-Gill (1982) y Wei et al. (1989), diseñaron un
conjunto de estimadores donde la ocurrencia del evento podría presentarse según un
esquema recurrente. Los modelos de supervivencia propuestos por estos autores entran,
dentro de la clasificación de modelo tipo Cox (1972), adaptados al ámbito recurrente.
Recientemente, autores como Wang-Chang (1999), Peña et al. (2001), Peña-Slate
(2005) y Peña E. (2006), han diseñado un conjunto de modelos para resolver algunos
problemas en el manejo de datos de supervivencia de carácter recurrente. En los dos
primeros, se abordan aspectos como la dependencia entre tiempos de ocurrencia del
evento, heterogeneidad en datos muestrales y el manejo de la variable tiempo de
ocurrencia del primer evento. Los modelos mencionados entran en la clasificación de
modelos no paramétricos y/o modelos de fragilidad. Los modelos dinámicos que son
otros tipos de modelos del análisis de supervivencia no son considerados en este trabajo.
Cuando se realizan estudios del análisis de supervivencia los investigadores;
generalmente se centran en dos objetivos primordiales: las estimaciones de las
funciones de supervivencia y riegos y la comparación de estas funciones en subgrupos
poblacionales. El análisis clásico dispone de herramientas estadísticas suficientemente
potentes para realizar estos análisis, cada una de las cuales apunta hacia la resolución de
problemas como la estimación de la función de supervivencia (S), la estimación de la
función de riesgo instantáneo (h ó λ), la estimación de la función de riesgo acumulado
(H ó Λ) y la comparación de grupos poblacionales. Entre los modelos más conocidos y

Capitulo I. El problema ______________________________________________________________________
2
utilizados en las estimaciones de las funciones del análisis, se encuentran los modelos
actuariales, el modelo de Kaplan-Meier (1958) y el modelo de Cox (1972). En
relación al problema de comparación de subgrupos poblacionales se han diseñado varias
pruebas entre las que destacan las de Mantel-Haenszel (1959), Gehan (1965), Mantel
(1966), prueba de Kruskal-Wallis propuesta por Breslow (1970), Peto-Peto (1972),
Cox (1972), Tarone-Ware (1977), Prentice (1978), Fleming et al. (1987) y Fleming-
Harrington (1991).
La naturaleza y estructura de los datos en los estudios de supervivencia con eventos
recurrentes difiere de la estructura de los datos del análisis clásico. Utilizar técnicas que
han sido diseñadas bajo otros esquemas, sin considerar el ámbito de esas nuevas
estructuras, tienden a conducir a decisiones erróneas, sesgadas e ineficientes. Fleming-
Lin (2000), presentaron una investigación donde señalan una variedad de trabajos que
se han desarrollado en la disciplina a lo largo de la historia, en los que se describen los
avances y el rumbo que han tomado estas nuevas investigaciones. Manifiestan el interés
y la necesidad que existe de masificar el conocimiento, uso y aplicación de estas nuevas
herramientas, y resaltan los problemas que se han presentado en cuanto al uso de
notaciones no estandarizadas.
Recientemente se han diseñado modelos para tratar el problema de estimación de las
funciones del análisis de supervivencia en el campo recurrente. Sin embargo, existe una
serie de problemas y situaciones particulares a las que aún no se les ha dado respuestas
satisfactorias y en esa dirección muchos investigadores han dirigido sus esfuerzos. Uno
de ellos es la comparación de subgrupos poblaciones con eventos recurrentes analizados
con técnicas del análisis de supervivencia. La necesidad de comparar grupos con
eventos recurrentes existe y aunque no se ha manifestado ese interés en forma explicita
es una realidad a la que hay buscarle soluciones. Estas necesidades se incrementarán en
la medida que surjan nuevos modelos para este tipo de análisis y se tenga mayor
conocimiento de su uso. En una extensa revisión bibliográfica sobre el manejo de
comparaciones de grupos con datos recurrentes sólo se logró encontrar tres tipos de
propuestas: Pepe-Cai (1993), Glynn-Buring (1996) y Daganaksoy-Nelson (1998).
Pepe-Cai proponen una prueba de comparación para las funciones de las razones
de recurrencia del evento o razones de riesgo en dos muestras basada en la prueba
de comparación logrank de Mantel-Haenszel. Glynn-Buring (1996) manifestaron la

Capitulo I. El problema ______________________________________________________________________
3
necesidad que existía de disponer de técnicas estadísticas correctas para comparar
grupos poblacionales o grupos tratados con eventos de carácter recurrente y proponen
un índice de medición para realizar esa comparación. La última de estas propuestas fue
hecha por Doganaksoy-Nelson (1998) y se refiere a un método de comparación basado
en las estimaciones de las funciones de la razón acumulada de ocurrencia del evento.
Esta propuesta fue publicada en línea en la red de Internet a mediados del año 2006.
Creemos sin embargo, que el problema de comparación con datos recurrentes no se ha
tratado a fondo y falta mucho por desarrollar al respecto. Existe un vacío con relación al
tema que es necesario llenar y dar una solución en concreto. El problema de
comparación de grupos en el campo recurrente es una necesidad y aunque no se ha
manifestado abiertamente de manera explícita, quizás por lo reciente de los estudios en
fenómenos con patrones de recurrencia y por el desconocimiento de estas nuevas
técnicas la necesidad existe. Cualquier aporte que se haga en este campo, contribuirá a
mejorar y a enriquecer esta área de investigación y será de gran provecho para el
avance y el desarrollo de esta disciplina.
En este trabajo se plantea la problemática de comparación de curvas de supervivencia
en grupos que experimentan eventos recurrentes y se diseñan estadísticos que se ajustan
a estas nuevas estructuras de datos. El objetivo principal consiste en proponer
estadísticos de contraste para realizar la comparación. En la investigación se estudiará el
comportamiento de dichos estadísticos bajo diferentes esquemas distribucionales. Se
diseñaran programas computacionales para realizar las estimaciones de los estadísticos
propuestos, la comparación de subgrupos poblacionales, el cálculo de la potencia de las
pruebas y las estimaciones de los errores.

Capitulo I. El problema ______________________________________________________________________
4
1.2 OBJETIVOS DE LA INVESTIGACIÓN
1.2.1 OBJETIVO GENERAL
Proponer y evaluar procedimientos estadísticos de comparación de curvas de
supervivencia de grupos poblacionales que experimentan fenómenos con eventos de
naturaleza recurrente.
1.2.2 OBJETIVOS ESPECIFICOS
1.2.2.1 Proponer estadísticos de contraste para comparar curvas de supervivencia en
fenómenos con datos de naturaleza recurrente, para el caso de dos grupos.
1.2.2.2 Evaluar algunas propiedades de los estadísticos de contraste propuestos para el
caso de dos grupos a través de datos simulados bajo diferentes esquemas
distribucionales.
1.2.2.3 Proponer estadísticos de contraste para comparar curvas de supervivencia con
datos de naturaleza recurrente para el caso de k grupos.
1.2.2.4 Evaluar algunas propiedades estadísticas de los estimadores de contraste
propuestos para el caso de k grupos haciendo uso datos simulados bajo
diferentes escenarios distribucionales.
1.2.2.5 Diseñar herramientas automatizadas bajo el lenguaje de programación R que
permitan calcular los estadísticos de contraste propuestos.
1.2.2.6 Evaluar la sensibilidad de los estadísticos propuestos bajo diferentes supuestos
distribucionales.

Capitulo I. El problema ______________________________________________________________________
5
1.3 JUSTIFICACIÓN DEL ESTUDIO
La teoría de supervivencia aplicada a fenómenos con eventos recurrentes es reciente y
comparada con la teoría clásica es muy poco lo que se conoce al respecto. Estudios
reciente sobre el tema, como el realizado por Fleming-Lin (2000), reflejan que la
demanda de conocimiento en esta área de investigación se ha incrementando, hasta el
punto de que la curiosidad de conocer sobre el tema se ha convertido en una necesidad.
Algunos autores como Prentice, Andersen-Gill, Wei, Peña y Wang-Chang, han
propuesto estimadores de curvas de supervivencia con eventos recurrentes. Sin
embargo, en el área de comparación es poco lo que se ha avanzado. Con este trabajo
pretendemos poner a disposición de los investigadores, herramientas útiles y valiosas
que puedan contribuir en campos tan diversos como la Biomedicina (enfermedades), la
Ingeniería (tiempo de fallas o confiabilidad) y las Ciencias Sociales (Eventos de vida).
Creemos que los resultados de esta investigación representan un modesto pero
importante aporte en el análisis de supervivencia.
Queremos insistir en que la particularidad de la estructura de datos en los estudios de
supervivencia con eventos recurrentes demanda la aplicación de técnicas de análisis que
introduzcan explícitamente esa condición. Este hecho permitiría obtener modelos más
adecuados, que a su vez redundarían en una toma decisiones de mayor validez y
pertinencia.

Capitulo I. El problema ______________________________________________________________________
6
1.4 ALCANCE Y LIMITACIONES DEL ESTUDIO
En este trabajo se pretende generalizar específicamente los procedimientos clásicos de
comparación basados en las pruebas de Mantel-Haenszel, Gehan, Breslow, Tarone-
Ware, Peto-Peto, Prentice, Fleming et al. y Fleming-Harrington, a problemas con
eventos recurrentes tanto para el caso de comparación de dos grupos como para el caso
de k-grupos. En la investigación se estudiarán modelos de supervivencia no
paramétricos y los semiparamétricos. No se considerarán los modelos paramétricos
aunque se tendrán como referencia general. Los modelos de supervivencia con eventos
recurrentes a considerar en la investigación serán los modelos propuestos por Prentice
et al. (1981), Andersen-Gill (1982), Wei et al. (1989), Wang-Chang (1999) y Peña et
al. (2001). La notación utilizada para el desarrollo de los estadísticos de comparación de
las curvas de supervivencia será la propuesta por Peña et al. (2001). Las limitaciones
más importantes para este estudio son lo reciente de las investigaciones sobre el área, el
grado de especialización del tema, la escasez de literatura y la poca disponibilidad de
datos con la estructura adecuada. En cuanto al manejo de los datos, se incluirán los
datos completos de supervivencia y los datos censurados por la derecha.
En los estudios realizados en esta área se han utilizado diferentes programas
computacionales como STATA, NCSS, SAS, Minitab, SPSS, S-Plus y R, entre otros.
En la revisión de estos programas se logró determinar que ninguno de ellos abarca en su
totalidad los modelos del análisis de supervivencia con eventos recurrentes. Por este
motivo nos hemos visto en la necesidad de diseñar rutinas propias en lenguaje R, que
permitan realizar los diferentes análisis, considerando los modelos de trabajo e
incluyendo las pruebas de comparación propuestas en el trabajo. Se diseñarán además
programas que permitan generar bases de datos con diferentes esquemas
distribucionales que simulen situaciones reales y que permitan realizar los análisis
correspondientes.

Capitulo II. Marco Teórico
______________________________________________________________________
7
Capitulo II. MARCO TEÓRICO 2.1 Bases teóricas 2.1.1 ¿En que consiste el análisis de supervivencia? El término supervivencia proviene del hecho que en sus inicios este tipo de análisis era
aplicado en el área médica y el evento de estudio era el evento “muerte”. Con el
transcurrir del tiempo, los investigadores en el área médica comenzaron a aplicarlo en
otro tipo de fenómenos, como la aparición de enfermedades no letales en seres vivos.
Posteriormente su uso se hizo extensivo a otras áreas de aplicación, como la Sociología,
Sicología, Ingeniería, Biología, Bioingeniería, Física y Astronomía. Cuando el análisis
es aplicado en el contexto de la Ingeniería, se ha convenido en denominarlo análisis de
confiabilidad y se utiliza básicamente para modelar el tiempo entre “fallas” en
maquinarias y equipos. En términos generales podría decirse que el análisis de
supervivencia forma parte de los estudios longitudinales, siendo el tiempo que
transcurre hasta la aparición de eventos la variable que se modela. En los análisis de
supervivencia hay que definir un período de observación para cada unidad bajo estudio.
Este período de observación consta de un momento de inicio que se conoce como
origen y un momento final que culmina con la ocurrencia del evento o con una censura.
Debido a que el tiempo es una variable aleatoria continua, en principio se podría pensar
que el análisis de supervivencia podría ser estudiado mediante técnicas de regresión
clásica. Sin embargo, existen dos dificultades de peso que no lo permiten. La primera
razón, es que el tiempo es una variable aleatoria positiva que no se distribuye
normalmente. La segunda es el fenómeno de la censura, que impide la realización de
transformaciones para normalizar la variable. Las censuras son fenómenos que impiden
observar el tiempo total de ocurrencia del evento en la unidad de investigación durante
el período de observación establecido. Los objetivos del análisis de supervivencia se pueden resumir de la siguiente manera:
1. Estimar e interpretar la función de supervivencia y las funciones de riesgo. 2. Determinar los efectos de las variables explicativas sobre el tiempo de
ocurrencia. 3. Predecir la probabilidad de ocurrencia en ciertas unidades bajo estudio, dados
ciertos valores de las variables explicativas. 4. Comparar funciones del análisis de supervivencia de subgrupos poblacionales.
Capitulo II. Marco Teórico
______________________________________________________________________
8
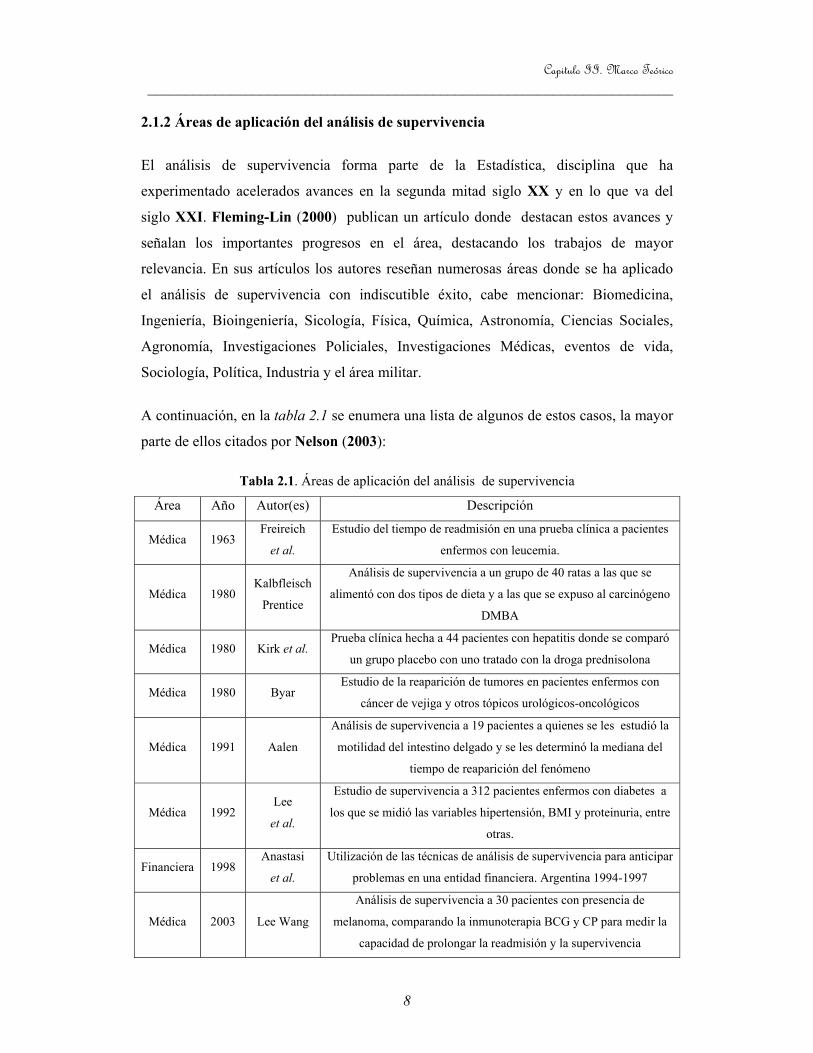
2.1.2 Áreas de aplicación del análisis de supervivencia
El análisis de supervivencia forma parte de la Estadística, disciplina que ha
experimentado acelerados avances en la segunda mitad siglo XX y en lo que va del
siglo XXI. Fleming-Lin (2000) publican un artículo donde destacan estos avances y
señalan los importantes progresos en el área, destacando los trabajos de mayor
relevancia. En sus artículos los autores reseñan numerosas áreas donde se ha aplicado
el análisis de supervivencia con indiscutible éxito, cabe mencionar: Biomedicina,
Ingeniería, Bioingeniería, Sicología, Física, Química, Astronomía, Ciencias Sociales,
Agronomía, Investigaciones Policiales, Investigaciones Médicas, eventos de vida,
Sociología, Política, Industria y el área militar.
A continuación, en la tabla 2.1 se enumera una lista de algunos de estos casos, la mayor
parte de ellos citados por Nelson (2003):
Tabla 2.1. Áreas de aplicación del análisis de supervivencia
Área Año Autor(es) Descripción
Médica 1963 Freireich
et al.
Estudio del tiempo de readmisión en una prueba clínica a pacientes
enfermos con leucemia.
Médica 1980 Kalbfleisch
Prentice
Análisis de supervivencia a un grupo de 40 ratas a las que se
alimentó con dos tipos de dieta y a las que se expuso al carcinógeno
DMBA
Médica 1980 Kirk et al. Prueba clínica hecha a 44 pacientes con hepatitis donde se comparó
un grupo placebo con uno tratado con la droga prednisolona
Médica 1980 Byar Estudio de la reaparición de tumores en pacientes enfermos con
cáncer de vejiga y otros tópicos urológicos-oncológicos
Médica 1991 Aalen
Análisis de supervivencia a 19 pacientes a quienes se les estudió la
motilidad del intestino delgado y se les determinó la mediana del
tiempo de reaparición del fenómeno
Médica 1992 Lee
et al.
Estudio de supervivencia a 312 pacientes enfermos con diabetes a
los que se midió las variables hipertensión, BMI y proteinuria, entre
otras.
Financiera 1998 Anastasi
et al.
Utilización de las técnicas de análisis de supervivencia para anticipar
problemas en una entidad financiera. Argentina 1994-1997
Médica 2003 Lee Wang
Análisis de supervivencia a 30 pacientes con presencia de
melanoma, comparando la inmunoterapia BCG y CP para medir la
capacidad de prolongar la readmisión y la supervivencia

Capitulo II. Marco Teórico
______________________________________________________________________
9
Continuación tabla 2.1
Social 2003 García
et al.
Análisis de supervivencia para modelar el tiempo transcurrido hasta que un egresado obtiene el primer empleo
significativo. Los datos utilizados corresponden a la cohorte de
egresados, 1997-2000, de la titulación “Diplomatura en Enfermería
de la Universidad Católica San Antonio de Murcia”.
Social 2005 Bucheli
Vigna Un estudio de los determinantes del divorcio en Uruguay
Industria 2006 Borges
Luzardo
Modelos de eventos recurrentes aplicados a la industria de
producción de aluminio.
Economía 2007 Ayala
et al.
Verificación de los Supuestos del Modelo de Cox. Caso de Estudio:
Banca Comercial venezolana 1996 – 2004.
2.1.3 Datos censurados del análisis de supervivencia Una característica muy común en los estudios de supervivencia es que algunos
individuos no experimentan el evento de interés durante el período de estudio. Los datos
de supervivencia provenientes de estos individuos se conocen como datos censurados.
Las censuras son fenómenos que impiden observar el tiempo exacto de supervivencia
en la unidad de investigación durante el período de observación y serán denotadas con
la letra “C”, de modo que “ci” representará el tiempo censurado en la i-ésima unidad.
Entre los diferentes motivos por los que los datos pueden estar censurados se pueden
mencionar: los abandono o retiro, pérdida parcial de información y la no ocurrencia del
evento durante el período de observación. Un ejemplo es el caso de un individuo a
quien se le esta haciendo un seguimiento de una enfermedad en un experimento y éste
deja de acudir a las revisiones médicas por cambio de localidad. La no ocurrencia del
evento durante el período de observación es la causa de censura más común en este tipo
de estudio. En esta unidad se desconoce el verdadero tiempo de supervivencia y sólo se
sabe que es mayor que su tiempo de observación.
Las censuras se pueden clasificar en tres tipos: censura por la derecha, censura por la
izquierda y censura por intervalo. Cuando culmina el período de estudio y no se puede
observar la ocurrencia del evento en la unidad, se dice que el dato está censurado por la
derecha. La figura 2.1 muestra los datos de supervivencia de cinco unidades
experimentales.

Capitulo II. Marco Teórico
______________________________________________________________________
10
Figura 2.1. Representación gráfica de datos censurados y no censurados.
La ocurrencia del evento se describe con “x” y la censura con “o”. Se puede apreciar
que las unidades 1, 3 y 5 experimentaron el evento, mientras que las unidades 2 y 4 no
lo experimentaron. La unidad 2 corresponde al típico dato censurado por la derecha y
las unidades 1 y 3 corresponden a datos no censurados. Observe que aún cuando la
unidad 5 experimentó el evento, este dato esta censurado por la izquierda. Por su parte,
la unidad 4 está doblemente censurada, tanto por la izquierda como por la derecha. Este
tipo de censura, conocida como censura por intervalo, no es muy frecuente aunque no es
nula la probabilidad de encontrarlo.
En los estudios de supervivencia se asume que las unidades censuradas se comportan
del mismo modo que las que experimentan el evento durante el período de observación.
Se supone además que las censuras ocurren en forma aleatoria y no de manera
intencional. Si una unidad fuese retirada antes de tiempo por voluntad de alguien,
indirectamente se estaría afectando la información acerca del pronóstico de
supervivencia de la unidad, produciéndose sesgos en el modelo. Si esto ocurre, se dice
que la censura es de tipo informativo; el resto de las censuras son censuras de tipo no
informativo. Por lo general no importa la cantidad de datos censurados que intervienen,
lo relevante es que las censuras sean no informativas.
Capitulo II. Marco Teórico
______________________________________________________________________
11
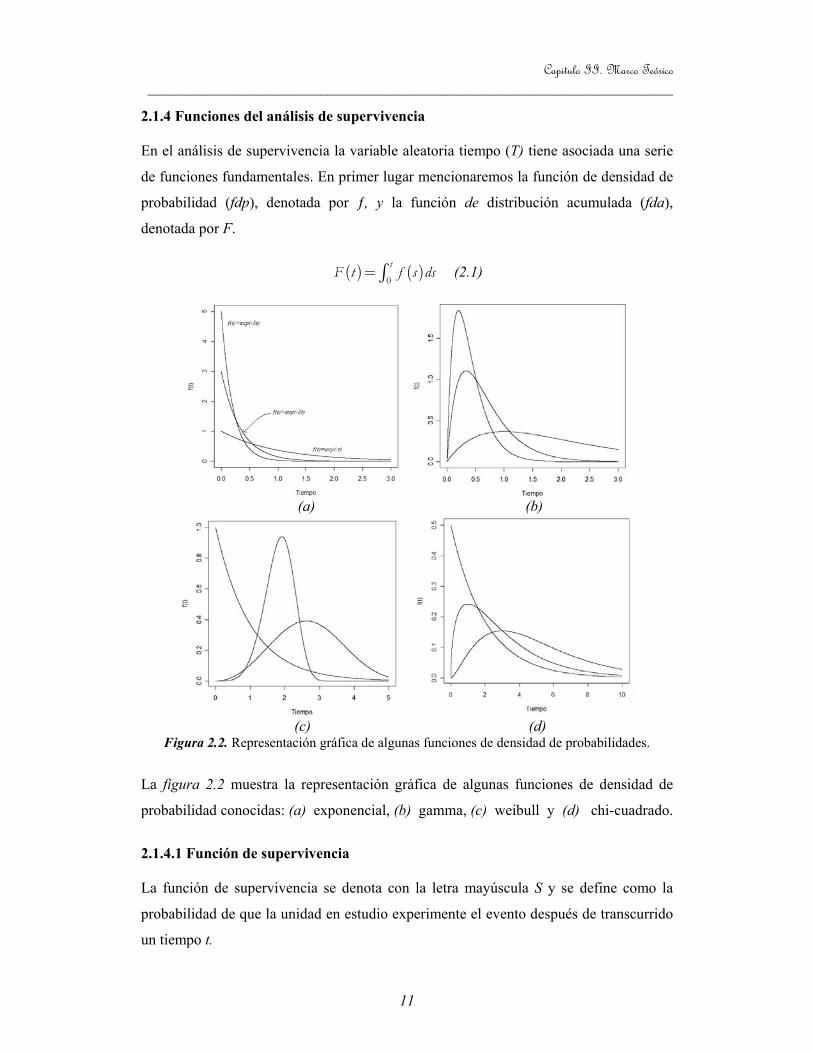
2.1.4 Funciones del análisis de supervivencia En el análisis de supervivencia la variable aleatoria tiempo (T) tiene asociada una serie
de funciones fundamentales. En primer lugar mencionaremos la función de densidad de
probabilidad (fdp), denotada por ƒ, y la función de distribución acumulada (fda),
denotada por F.
( ) ( )0
tF t f s ds= ∫ (2.1)
(a) (b)
(c) (d)
Figura 2.2. Representación gráfica de algunas funciones de densidad de probabilidades.
La figura 2.2 muestra la representación gráfica de algunas funciones de densidad de
probabilidad conocidas: (a) exponencial, (b) gamma, (c) weibull y (d) chi-cuadrado.
2.1.4.1 Función de supervivencia La función de supervivencia se denota con la letra mayúscula S y se define como la
probabilidad de que la unidad en estudio experimente el evento después de transcurrido
un tiempo t.

Capitulo II. Marco Teórico
______________________________________________________________________
12
Esta función se puede expresar como:
( ) [ ]S t P T t= > (2.2)
A partir de las expresiones (2.1) y (2.2), se deduce que:
( ) ( )1S t F t= − (2.3)
y en consecuencia, S es una función positiva, decreciente y tal que cuando t → 0,
entones S(t) → 1, y cuando t → ∞, entonces S(t) → 0.
Figura 2.3. Representación gráfica de algunas funciones de supervivencia.
La figura 2.3 muestra las curvas correspondientes a tres funciones de supervivencia de
S1(t), S2(t) y S3(t). Observe que las tres curvas son decrecientes, unas más acentuadas
que otras.
2.1.4.2 Función de riesgo instantáneo
En términos intuitivos, la función de riesgo instantáneo viene siendo la razón de
ocurrencia del evento por unidad de tiempo. Algunos autores la denotan con la letra
griega λ y otros con la letra h, que será la notación que utilizaremos en este trabajo.
Esta función se define como la probabilidad instantánea de ocurrencia del evento en un

Capitulo II. Marco Teórico
______________________________________________________________________
13
intervalo de tiempo de longitud infinitesimal ∆t, asumiendo que la unidad no ha
experimentado el evento o ha sobrevivido hasta el momento t (ver expresión 2.4).
( ) ( )/, 00
P t T t t T tlimh t tt t≤ < +∆ >
= ∀ ≥∆ → ∆ (2.4)
Utilizando el concepto de probabilidad condicional, se tiene que:
( ) ( )( )
/P t T t t
P t T t t T tP T t< < +∆
≤ < +∆ > =>
que es equivalente a:
( ) ( ) ( )( )
/F t t F t
P t T t t T tS t+∆ −
≤ < +∆ > =
Si se sustituye esta relación en la expresión (2.4) y se toma el límite cuando ∆t → 0, se
demuestra que la función de riesgo instantáneo se puede expresar en términos de la
función de densidad f y la función de supervivencia S, tal y como se aprecia a
continuación en la expresión (2.5):
( ) ( )( )
f th t
S t= (2.5)
A esta función se le ha denominado de diversas maneras: razón instantánea de falla,
fuerza de mortalidad, razón condicional de falla y razón de falla en edad específica,
entre otras. La función de riesgo juega un papel importantísimo en el análisis de
supervivencia y es una de las funciones de mayor utilidad. De la expresión (2.4) se
puede decir que la cantidad h(t)∆t representa la proporción de individuos con edad t,
que pueden experimentar el evento en el intervalo de tiempo [t, t+∆t).
La figura 2.4 muestra tres curvas de riesgo instantáneo, h1(t), h2(t) y h3(t). La función de
riesgo h1(t) representa el caso de unidades con riesgo instantáneo monótonamente
creciente en el tiempo, la función de riesgo h3(t) muestra un riesgo instantáneo
monótonamente decreciente y la función de riesgo h2(t) muestra un riesgo instantáneo
constante en el tiempo.

Capitulo II. Marco Teórico
______________________________________________________________________
14
Figura 2.4. Representación gráfica de funciones de riesgo instantáneo.
2.1.4.3 Función de riesgo acumulado La función de riesgo acumulado como su nombre lo indica, representa el acumulado
del riesgo instantáneo en el intervalo [0,t]. Algunos autores lo denotan con la letra
griega Λ y otros con la letra mayúscula H, que es la que utilizaremos en esta tesis H.
Así, si se consideran escalas continuas de tiempo:
( ) ( )
0
tH t h s ds= ∫ (2.6)
y para escalas discretas de tiempo:
( ) ( )z zT tz
H t h T T∀ ≤
⎡ ⎤= ∆⎢ ⎥⎣ ⎦
∑ (2.7)
En la figura (2.5) se pueden observar algunas de las gráficas de funciones de riesgo
acumulado más comunes en problemas del análisis de supervivencia:

Capitulo II. Marco Teórico
______________________________________________________________________
15
Figura 2.5. Representación gráfica de las funciones de riesgos acumulados.
Las tres curvas son monótonamente crecientes, pero las tasas de crecimiento en las tres
curvas son diferentes. En la primera, la curva de riesgo acumulado H1(t), representa el
caso de unidades con riesgo instantáneo o razón de riesgo que crece con mayor rapidez
al transcurrir el tiempo. Lo contrario sucede en la curva H3(t), que representa el caso de
unidades con riesgo instantáneo o razón de riesgo instantáneo que decrece con el
tiempo y la curva H2(t), que representa el caso de unidades con riesgo instantáneo o
razón de riesgo instantáneo constante en el tiempo.
2.1.4.4 Relaciones entre las funciones del análisis de funciones
En los estudios de supervivencia es muy frecuente utilizar las relaciones entre el
conjunto de funciones básicas. Es muy común conseguir en la bibliografía relaciones
entre f(t), F(t), S(t), h(t) y H(t). Por ejemplo, a partir de la expresión 2.1, se puede decir
que:
( ) ( )df t F tdt
= (2.8)
Como: F(t) =1 - S(t), entonces : F´(t)= - S´(t), por lo tanto,
( ) ( )df t S tdt
=− (2.9)
Si se sustituye f(t) de la expresión (2.9), en la expresión (2.5), se obtiene que:

Capitulo II. Marco Teórico
______________________________________________________________________
16
( ) ( )( )'S t
h tS t
=− (2.10)
En consecuencia,
( ) ( )dh t Ln S tdt
⎡ ⎤=− ⎣ ⎦ (2.11)
Por otro lado, como el riesgo acumulado es la integral del riesgo instantáneo (ver
expresión (2.6)), entonces se puede decir que:
( ) ( )dh t H tdt
= (2.12)
Igualando las expresiones 2.11 y 2.12 y desarrollando, se tendrá que,
( ) ( )H t Ln S t⎡ ⎤=− ⎣ ⎦ (2.13)
Así, se si despeja S(t) de la expresión 2.13, se tendrá que:
( )( )-
eH t
S t = (2.14)
que es equivalente a:
( )( )0e
t h s dsS t
−∫= (2.15)
Esto nos indica que todas las expresiones anteriores guardan estrechas relaciones entre
sí. Conociendo alguna de las funciones (f(t), F(t), S(t), h(t) o H(t))se puede obtener el
resto de ellas.
2.1.4.5 Medidas descriptivas del análisis de supervivencia
La mediana es una de las medidas descriptivas de tendencia central más utilizadas para
caracterizar las distribuciones de los tiempos de supervivencia poblacionales o
muestrales. Cuando se estima una función de supervivencia de grupos o subgrupos
poblacionales es prácticamente obligatorio estimar la mediana de los tiempos de
supervivencia. Esta medida indica el tiempo en el cual el 50% de unidades en estudio no
ha experimentado la ocurrencia del evento, o dicho de otra manera, indica el momento tz
en el cual la supervivencia S(tz) es igual a 0.5. Como la función de supervivencia es

Capitulo II. Marco Teórico
______________________________________________________________________
17
estimada en momentos puntuales de tiempo, digamos tz para z=1,2,…,p, no siempre es
posible determinar el momento exacto cuando la supervivencia es igual a 0.5. En este
caso, la mediana se define como el tiempo de supervivencia más pequeño en el cual el
valor estimado de la función de supervivencia es al menos 0.5. En términos
matemáticos:
( ) ˆ / 0.5z z z
t min t S t= ≤ (2.16)
Un procedimiento similar se describe cuando se desea estimar cualquier percentil de la
distribución de los tiempos de supervivencia. El p-ésimo percentil de la distribución de
los tiempos de supervivencia se define como:
( ) ˆˆ / 1 /100z z z
t min t S t p= ≤ − (2.17)
Otras medidas descriptivas útiles para la interpretación en el análisis de supervivencia
son el tiempo promedio de supervivencia y la tasa promedio de riesgo.
El tiempo promedio de supervivencia (T ) se determina como:
1
n
jjT
Tn==∑
(2.18)
donde, j
T es el tiempo de supervivencia de la j-ésima unidad y n es el número de
unidades que experimentan el evento.
El riesgo instantáneo promedio (h ) se determina como:
1
n
jj
Número total de ocurrenciashT
=
=
∑ (2.19)
Para mayores detalles sobre medidas descriptivas de la distribución de los tiempos de
supervivencia y sus intervalos de confianza, ver Collet (2003) o Kleinbaum-Klein
(2005).

Capitulo II. Marco Teórico
______________________________________________________________________
18
2.1.5 Métodos de estimación del análisis de supervivencia
Cuando el análisis de supervivencia se realiza considerando sólo una única ocurrencia
del evento por unidad bajo estudio se le conoce como análisis de supervivencia clásico. En este tipo de análisis, generalmente se intenta alcanzar tres tipos de objetivos: la
estimación de la función de supervivencia, las estimaciones de las funciones de riesgo y
la comparación de las curvas de supervivencia en grupos poblacionales. Entre los
autores que han hecho aportes importantes en la modelación y estimaciones de las
funciones de supervivencia clásica, se encuentran Bhomer (1912), Cutler-Ederer
(1958), Berkson-Gage (1950), Kaplan-Meier (1958), Altshuler (1970), Cox (1972),
Prentice (1978), Prentice-Marek (1979), Aalen (1978), Nelson (1970), Fleming et al.
(1980), Andersen et al. (1982), Harris-Albert (1991), Moreau (1992), Hosmer-
Lemeshow (1999). En el ámbito de comparación de curvas de supervivencia, los
autores que sobresalen son Mantel-Haenszel (1959), Gehan (1965), Mantel (1967),
Breslow (1970), Cox (1972), Peto-Peto (1972), Tarone-Ware (1977), Prentice
(1978), Tarone (1981), Fleming et al. (1980), Fleming-Harrington (1991) y más
recientemente, Moreau et al. (1992). Los trabajos de estos autores son la base del
desarrollo de esta disciplina y han sido de gran utilidad en muy diversos campos de la
actividad científica.
En las últimas cuatro décadas, investigadores como Prentice et al. (1981), Andersen-
Gill (1982) y Wei et al. (1987), estudiaron casos de ocurrencias de evento que se
presentan según un esquema recurrente y propusieron nuevos modelos para describir
estas nuevas situaciones no consideradas en los modelos clásicos. Recientemente,
Wang-Chang (1999) y Peña (2001) han propuesto modelos no paramétricos para
resolver algunos problemas en el manejo de datos en la supervivencia en el campo
recurrente. En sus modelos los autores tratan los problemas de la dependencia entre
tiempos de ocurrencia del evento, la heterogeneidad de datos muestrales y el manejo de
la primera ocurrencia del evento.
Las técnicas y métodos diseñados para el análisis de supervivencia se pueden clasificar
en dos grandes grupos: los métodos de estimación del análisis clásico y los métodos de
estimación en el ámbito recurrente. Los métodos clásicos, a su vez, están enmarcados

Capitulo II. Marco Teórico
______________________________________________________________________
19
en tres subclases: los no paramétricos, los paramétricos y los semiparamétricos. Por su
parte, los métodos de estimación en el ámbito recurrente pueden clasificarse en cuatro
grandes subgrupos: los semiparamétricos, los no paramétricos, los métodos de
fragilidad y los dinámicos. En esta tesis nos centraremos en la descripción y análisis de
los métodos no paramétricos y semiparamétricos, haciendo más énfasis en los no
paramétricos.

Capitulo III. Modelos Clásicos del Análisis de Supervivencia ______________________________________________________________________________
20
Capitulo III. MODELOS CLÁSICOS DEL ANÁLISIS DE SUPERVIVENCIA
3.1 Orígenes del análisis de supervivencia
Los estudios científicos formales del análisis de la supervivencia surgieron en el siglo XX,
experimentaron avances importantes durante la segunda mitad del mismo siglo y actualmente su
desarrollo sigue en crecimiento. Son muchos los investigadores que se han dedicado a desarrollar
la teoría del análisis de supervivencia a lo largo de su relativa y corta historia. Entre los métodos
de análisis de mayor relevancia e impacto podemos citar: el método actuarial de supervivencia
de Cutler-Ederer (1958), la propuesta de la estimación de la función de supervivencia de
Kaplan-Meier (1958), los modelos de supervivencia de riesgos proporcionales de Cox (1972) y
mucho más recientemente los modelos de supervivencia con eventos recurrentes.
El desarrollo del método actuarial, cuyos orígenes remontan al siglo XV, no puede atribuirse a
un único autor. Entre sus precursores debe destacarse en primer lugar a John Graunt, quien en
su época, (1662) publicó reportes semanales de nacimientos y muertes observados en la ciudad
de Londres, identificando patrones en las causas de muerte en diferentes zonas rurales y urbanas
de la población. Graunt fue quien propuso las primeras Tablas de Vida, y construyó y publicó
las primeras Tablas de Mortalidad de la ciudad de Londres (1662), a las que denominó “Natural
and Political Observations Mentioned in a following Index, and made upon the Bills of
Mortality”. John Graunt fue un hombre extraordinariamente audaz e inteligente. Disponiendo
de información mínima logró inferir, entre otras cosas, que regularmente nacían más hombres
que mujeres, que había una clara variación estacional en la ocurrencia de las muertes y que 36%
de los nacidos vivos morirían antes de cumplir los seis años. Con ello, Graunt dio los primeros
pasos para el desarrollo de las actuales tablas de vida.
Otro gran precursor de los estudios de sobrevivencia fue el economista británico William Petty.
Músico, médico y amigo de Graunt, publicó también trabajos relacionados con los patrones de
mortalidad, natalidad y enfermedad entre la población inglesa y propuso, por primera vez, la
creación de una agencia gubernamental encargada de la recolección e interpretación sistemática
de la información sobre nacimientos, casamientos y muertes, y de su distribución según sexo,
edad, ocupación, nivel educativo y otras condiciones de vida. También sugirió la construcción de

Capitulo III. Modelos Clásicos del Análisis de Supervivencia ______________________________________________________________________________
21
tablas de mortalidad por edad de ocurrencia, anticipándose al desarrollo de las actuales tablas
usadas para comparar poblaciones. Esta manera de tratar la información poblacional fue
denominada por Petty "Aritmética Política". También debe mencionarse entre los pioneros del
estudio de la sobrevivencia a Halley (1693).
Las tablas de vida son un procedimiento clásico para describir la mortalidad que
experimenta una población. Hoy en día estas tablas siguen siendo una herramienta muy utilizada
en campos como la demografía o los seguros de vida. El objetivo de una tabla de vida es
expresar el patrón de mortalidad que experimenta un colectivo de individuos en unas condiciones
dadas. Se distinguen dos tipos de tablas: las poblacionales, que son una herramienta de carácter
fundamentalmente descriptivo, y las actuariales, que generalmente se utilizan para estimar la
curva de supervivencia a partir de muestras.
3.2 Modelos Actuariales
Los modelos actuariales de supervivencia son modelos clásicos, no paramétricos, cuyo origen no
está claramente precisado. Algunos investigadores se lo atribuyen a Bhomer (1912), otros a
Berkson-Gage (1950) y otros a Cutler-Ederer (1958). Las tablas de vida actuariales han sido
ampliamente utilizadas en datos clínicos por muchas décadas. Gehan (1969) provee métodos
para estimar las tres funciones de supervivencia (supervivencia, densidad y riesgo). Los métodos
de tablas de vida requieren que el número de observaciones sea lo suficientemente grande para
poder agruparlos en intervalos, con la finalidad de mejorar las estimaciones. También son útiles
en aquellos casos en los que no se dispone de los tiempos exactos de ocurrencia del evento y la
información se encuentra agrupada en intervalos de tiempo. Los datos de mortalidad para un país
determinado son un ejemplo de ello ya que la información de varios años se suele agrupar en
intervalos. Para realizar un análisis de supervivencia con estos datos, las estimaciones se suelen
obtener mediante el método actuarial.
3.2.1 Modelo actuarial de Bhomer
Bohmer (1912) publica un trabajo en el que propone utilizar subintervalos de tiempo para
estimar la función de supervivencia. Actualmente, este método entra en la clasificación de los

Capitulo III. Modelos Clásicos del Análisis de Supervivencia ______________________________________________________________________________
22
“métodos actuariales de supervivencia” y es adecuado cuando el número de observaciones es
muy grande o cuando no se conocen los tiempos de ocurrencia exactos. La metodología de
estimación mediante tablas actuariales son antiguas, pero los estudios teóricos de las propiedades
de los estimadores correspondientes son bastante recientes. En la actualidad, nuevos estudios y
nuevos aportes sobre este tema aún están por realizarse. En el método actuarial, el tiempo de observación esta definido por el intervalo [t1,tp+1). Donde, t1
es el momento inicial del período de observación, que es igual a cero, y tp+1 es el mayor de los
tiempos de supervivencia de las unidades bajo estudio. En teoría se puede suponer que tp+1 tiende
a infinito. En los estudios actuariales es necesario definir un período de estudio adecuado al
fenómeno observado. No es conveniente, por ejemplo, fijar un tiempo de observación de 300
años para el estudio del tiempo de vida de una persona. El tiempo de observación se divide
convenientemente en p subintervalos, independientes entre sí y no solapados, tal y como se
muestra a continuación:
t1=0 t2 t3 t4 …. tp-1 tp ∞
Figura 3.1. Representación gráfica de los p subintervalos del período de observación.
De esta manera cada subintervalo tendrá una longitud igual a bz = tz+1 – tz. Al inicio de cada
subintervalo existen nz individuos a riesgo y durante el transcurso del mismo se producen dz
eventos. Si L es la longitud total del mayor de los periodos de observación en las n unidades
bajo estudio y p el número total de subintervalos a considerar, entonces la longitud del z-ésimo
intervalo, Iz = [tz,tz+1), será igual a L/p. En total serán p subintervalos:
[t1 , t2), [t2, t3), [t3, t4),…, [tp, tp+1)
Si T es la variable aleatoria referida al tiempo de ocurrencia del evento y se quiere definir la
probabilidad de sobrevivir al subintervalo [tz,tz+1), que denotamos por pz, entonces:
pz = P( T ≥ tz+1 / T ≥ tz ) (3.1)
Utilizando el concepto de probabilidad condicional:

Capitulo III. Modelos Clásicos del Análisis de Supervivencia ______________________________________________________________________________
23
pz = )()( 1
z
z
tTPtTP≥≥ + (3.2)
de modo que:
P( T ≥ tz+1 ) = pz x P(T ≥ tz ) (3.3)
En forma análoga:
P( T ≥ tz ) = pz-1 x P( T ≥ tz-1 ) (3.4)
Sustituyendo la ecuación (3.4) en la ecuación (3.3):
P( T ≥ tz+1 ) = pz x pz-1 x P( T ≥ tz-1 ) (3.5)
Si hacemos z =2 en la expresión 3.5 se obtiene:
P( T ≥ t3 ) = p2 x p1 x P( T ≥ t1 ) (3.6)
Si además se asume que P(T ≥ t1 ) = 1, entonces:
P( T ≥ t3 ) = p2 x p1 (3.7)
y como P(T ≥ t3) = P(T > t2), generalizando la expresión 3.6 se obtiene:
P( T ≥ tz+1 ) = pz x pz-1 x ... x p2 x p1 (3.8)
En consecuencia, la función de sobrevivencia:
S( tz ) = ∏=
z
jjp
1
(3.9)
expresión que permite estimar la probabilidad de sobrevivencia a partir de las estimaciones de
los pj. Bohmer propuso estimar esas probabilidades utilizando la siguiente información:

Capitulo III. Modelos Clásicos del Análisis de Supervivencia ______________________________________________________________________________
24
nj = número de unidades experimentales en riesgo al inicio del j-ésimo intervalo.
dj = número de eventos ocurridos en el j-ésimo intervalo.
pj = probabilidad de sobrevivir al intervalo j-ésimo dado que la unidad experimental estaba
en riesgo al comienzo de dicho intervalo.
El estimador de pj se define como:
jp = j
jj
ndn −
(3.10)
Si sustituimos la expresión 3.10 en la expresión 3.9, se obtiene que:
)(ˆztS = ∏
=⎟⎟⎠
⎞⎜⎜⎝
⎛ −z
j j
jj
ndn
1
(3.11)
En este método se asume que:
1.- Existe independencia entre dos intervalos cualesquiera.
2.- No existe pérdida de información.
3.- El número de eventos ocurridos en el j-ésimo intervalo, denotado por dj, se distribuye de
manera uniforme.
4.- Los subintervalos no están solapados
El objetivo principal en el método actuarial de Bhomer consiste en estimar las funciones de
supervivencia y riesgo a partir de los valores de nj y dj. Las estimaciones se realizan con datos
agrupados en subintervalos con un procedimiento muy similar a las tablas de frecuencias. Los
resultados del método actuarial de Bhomer suelen presentarse en tablas normalizadas que
incluyen la siguiente información:
[tj,tj+1) = j-ésimo intervalo
bj = Longitud del j-ésimo intervalo
tmj = punto medio del j-ésimo intervalo
nj = número de unidades experimentales a riesgo al inicio del j-ésimo intervalo.

Capitulo III. Modelos Clásicos del Análisis de Supervivencia ______________________________________________________________________________
25
qj = proporción de unidades que experimentan el evento de interés en el j-ésimo
intervalo (qj = dj/nj)
pj = proporción de unidades sobrevivientes al j-ésimo intervalo ( pj = 1 – qj)
f(tmj) = proporción de eventos en el j-ésimo intervalo por unidad de tiempo.
)(ˆmjtf =
j
jj
btStS )(ˆ)(ˆ
1+− (3.12)
h(tmj) = tasa instantánea condicional del evento, estimada en el punto medio del j-ésimo
subintervalo.
)(ˆ mjth = )(ˆ)(ˆ
mj
mj
tS
tf (3.13)
Como las estimaciones se calculan en los puntos medios de los subintervalos, se tiene que:
)(ˆ mjth = ( )2/jjj
j
dnxbd−
(3.14)
Como puede observarse, todas estas estimaciones son sensibles a la longitud de los intervalos, al
número de unidades a riesgo en cada subintervalo y al número de unidades que experimentan el
evento.
3.2.2 Formula de Greenwood
Greenwood (1926) publica un trabajo donde sugiere una metodología que hoy en día permite
determinar la varianza de cualquier estimador de la función de supervivencia, incluyendo el
propuesto por Bhomer (1912). Este método es uno de los más populares y mayormente
utilizados en los programas de computación especializados en el área. El estimador de la
varianza de la función de supervivencia utilizando el método de Greenwood viene dado por:

Capitulo III. Modelos Clásicos del Análisis de Supervivencia ______________________________________________________________________________
26
Var[ )(ˆztS ] = [ )(ˆ
ztS ]2 ∑= −
z
j jjj
j
dnxnd
1 )( (3.15)
y se obtiene a través de un procedimiento denominado método delta. La deducción del
estimador se puede apreciar en el apéndice A de este trabajo. Aplicando un procedimiento
similar se obtienen los estimadores de varianza de los las funciones f(tmz) y h(tmz),los cuales se
muestran a continuación:
Var[ )(ˆmjtf ] =
2ˆ ˆ( )
z z
z
S t xq
b
⎡ ⎤⎢ ⎥⎣ ⎦ ∑
−
= ⎥⎥⎦
⎤
⎢⎢⎣
⎡+
1
1 ˆˆ
ˆˆz
j zz
z
jj
j
qxnp
pxnq
(3.16)
Var[ )(ˆ mjth ] = [ ]
zz
mz
qxnth
ˆ)( 2
⎥⎥⎦
⎤
⎢⎢⎣
⎡⎥⎦⎤
⎢⎣⎡−
2
)(ˆ211 zmz xbthx (3.17)
3.2.3 Modelo actuarial de Berkson-Gage
Berkson-Gage (1950) sugirió una metodología para construir tablas actuariales similar a la de
Bhomer (1912). Estos autores consideraron aspectos que no fueron tomados en cuenta en el
modelo de Bhomer, como las pérdidas y abandonos de las unidades en estudio, que denotaron
por lj y wj respectivamente. Las tablas actuariales de Berkson-Gage se construyen a partir de la
siguiente información:
Muertes número de individuos que fallecen en el j-ésimo subintervalo (dj)
Abandonos número de abandonos o pérdidas en el j-ésimo subintervalo (wj)
A riesgo número de individuos a riesgo al inicio del j-ésimo subintervalo (nj)
Ajuste a riesgo ajuste del número de individuos a riesgo (n’j = nj – wj/2)
P(muerte) probabilidad de muerte de un individuo que ha sobrevivido hasta el inicio
del subintervalo (qj=dj/n’j)
P(sobreviva) probabilidad de que un individuo sobreviva al j-ésimo subintervalo
(pj=1- qj)

Capitulo III. Modelos Clásicos del Análisis de Supervivencia ______________________________________________________________________________
27
)(ˆztS = ∏
=
z
jjp
1
ˆ (3.18)
Para hallar intervalos de confianza para S(tz) se utiliza el procedimiento de máxima
verosimilitud y la distribución asintótica de S(tz).
3.2.4 Modelo de Cutler-Ederer
Cutler-Ederer (1958) sugirieron un método relativamente simple y muy práctico para realizar el
cálculo de las estimaciones de las funciones de supervivencia en las tablas de vida. Hoy en día
esta metodología es ampliamente utilizada y se le conoce como método actuarial de
supervivencia de Cutler-Ederer. Se trata de una generalización de las tablas actuariales
propuestas por Bhomer y Berkson-Gage, con la diferencia de que introduce el concepto de
censura. Las tablas actuariales de Cutler-Ederer son utilizadas, con ciertas variantes, en los
programas Minitab, SPSS y NCSS, entre otros. En esta metodología la longitud de los
subintervalos no necesariamente tiene que ser constante y, al igual que los métodos actuariales
anteriores, utiliza tablas normalizadas que facilitan las estimaciones (ver tabla 3.1). A
continuación se detalla la información de dichas tablas:
Columna 1. Descripción del extremo izquierdo del j-ésimo subintervalo (tj). Se considera que
la longitud de los intervalos es finita, con excepción del último.
Columna 2. Número de individuos al comienzo de cada intervalo(n’j)
Columna 3. Número de pérdidas (lj) y/o abandonos (wj ) en el j-ésimo subintervalo
Columna 4. Número de individuos expuestos a riesgo en el intervalo j-ésimo, denotado por: nj = n’j –(1/2)cj y cj = lj + wj, donde cj son los datos censurados.
Columna 5. Número de individuos que experimentan el evento de interés en el j-ésimo intervalo (dj)
Columna 6. Proporción de individuos que experimentaron el evento en el j-ésimo intervalo, (qj = dj / n’j)
Columna 7. Proporción de supervivencia al j-ésimo intervalo (pj = 1 - qj)
Columna 8. Estimación de la función de supervivencia ( S(tj)= pj x S(tj-1) )
Columna 9. Estimación de la función de densidad ( f(tmz) )
Columna 10. Estimación de la función de riesgo ( h(tmz) )

Capitulo III. Modelos Clásicos del Análisis de Supervivencia ______________________________________________________________________________
28
Columna 11. Estimación del error de la función de supervivencia
Columna 12. Estimación del error de la función de densidad
Columna 13. Estimación del error de la función de riesgo Se asume que las pérdidas y/o los abandonos ocurren de manera aleatoria e independiente,
independencia entre los subintervalos y que la ocurrencia de los eventos y las censuras en cada
intervalo se distribuyen uniformemente. De esta manera se tiene que:
)(ˆztS =
⎪⎪⎪
⎩
⎪⎪⎪
⎨
⎧
≥⎟⎟⎠
⎞⎜⎜⎝
⎛
−−
<
∏=
02/
1
00
1z
z
j jj
j
z
tsicn
d
tsi (3.18)
Una vez estimada la función de supervivencia a través de la expresión 3.18, con las expresiones
(3.12) y (3.13) se pueden estimar f(tmz) y h(tmz). Como la estimación de la función de
supervivencia está afectada por las censuras, las estimaciones de f(tmz) y h(tmz) también lo
estarán.

Capitulo III. Modelos Clásicos del Análisis de Supervivencia ______________________________________________________________________________
29
Tabla 3.1 Formato normalizado de tablas actuariales para el análisis de supervivencia de Cutler-Ederer
Interval tmj bj lj wj dj n’j nj qj pj S(tj) f(tmj) h(tjm)
[t1, t2) tm1 b1 l1 w1 d1 n’1 n1 q1 p1 S(t1)=1 f(tm1) h(tm1)
[t2, t3) tm2 b2 l2 w2 d2 n’2 n2 q2 p2 S(t2) f(tm2) h(tm2)
…… …… …… …… …… …… …… …… …… …… …… …… ……
…… …… …… …… …… …… …… …… …… …… …… …… ……
[tj, tj+1) tmj bj lj wj dj n’j nj qj pj S(tj) f(tmj) h(tmj)
…... …… …… …… …… …… …… …… …… …… …… …… ……
…... …… …… …… …… …… …… …… …… …… …… …… ……
[tz-1, tz) tm,z-1 bz-1 lz-1 wz-1 dz-1 n’z-1 nz-1 qz-1 pz-1 S(tz-1) f(tm,z-1) h(tm,z-1)
[tz, ∞) tmz bz lz wz dz n’z nz qz pz S(tz) f(tmz) h(mz) Fuente: Tomado de Cutler-Ederer, J. Chroc. Dis.,1958.

Capitulo III. Modelos Clásicos del Análisis de Supervivencia
______________________________________________________________________
30
3.3 Modelo de Kaplan-Meier
Kaplan-Meier (1958) proponen un estimador de la función de supervivencia en
presencia de datos censurados, conocido hoy en día como estimador del “Límite-
Producto” de Kaplan-Meier. Este modelo está enmarcado dentro de los modelos
clásicos no paramétricos y puede afirmarse que constituye un hito histórico en los
estudios de la supervivencia, hasta el punto de convertirse en uno de los artículos
científicos más consultados y referenciados en la bibliografía del área. La diferencia
metodológica entre este método y el actuarial es que los tiempos de ocurrencia del
evento en esta metodología no se agrupan en subintervalos sino que la función de
supervivencia es estimada para cada momento de ocurrencia. El estimador de Kaplan-
Meier se basa en el mismo principio actuarial: se calcula la supervivencia mediante un
producto de probabilidades condicionales. En el modelo se supone independencia en
los momentos de ocurrencia del evento, se asume una muestra representativa de tamaño
n y tiempos de supervivencia no repetidos. En ese caso el estimador de Kaplan-Meier,
en función de los rangos de los datos, viene dado por la siguiente expresión:
)(ˆztS = ∏
=⎟⎟⎠
⎞⎜⎜⎝
⎛
+−
−z
j j
j
rnrn
1 1 (3.19)
donde rj representa el valor de posición o rango correspondiente a la j-ésima ocurrencia
del evento, una vez ordenados los tiempos. Se puede demostrar que la expresión (3.19)
es equivalente a la expresión (3.11), en aquellos casos donde no hay tiempos de
supervivencia repetidos, o sea que dj=1. Kaplan y Meier también propusieron un
estimador de la función de supervivencia en función del número de eventos ocurridos en
el momento t y del número de unidades a riesgo justo antes de ese momento. La
expresión del estimador es equivalente al estimador de la expresión (3.19). El estimador
es conocido, hoy en día, como estimador limite-producto de Kaplan-Meier y es útil para
aquellos casos en los que d j ≥ 1 :
)(ˆztS = ∏
=⎟⎟⎠
⎞⎜⎜⎝
⎛ −z
j j
jj
ndn
1
(3.20)
donde nj es el número de individuos que han sobrevivido hasta el momento tj y dj el
número de muertes y pérdidas entre los momento j-1 y j-ésimo.

Capitulo III. Modelos Clásicos del Análisis de Supervivencia
______________________________________________________________________
31
Procedimiento para calcular la función de supervivencia de Kaplan-Meier a través
de la expresión (3.19)
1. Ordene en forma ascendente los tiempos de ocurrencia de los eventos
incluyendo los tiempos censurados.
2. Asigne los rangos correspondientes a los tiempos ordenados en el paso anterior.
3. Tabule y calcule la probabilidad de supervivencia en cada uno de los tiempos de
ocurrencia del evento de estudio, a través de la expresión (3.19).
4. Grafique la curva de supervivencia.
Es importante notar que estimador de Kaplan-Meier, según expresión (3.19), también
puede ser expresado como:
)(ˆztS = )(ˆ
1−ztS x 1+−
−
z
z
rnrn (3.21)
Kaplan y Meier también obtuvieron un estimador de la varianza del estimador Límite-
Producto, definido como:
Var[ )(ˆztS ] = [ )(ˆ
ztS ]2 ∑= +−−
z
j jj rnrn1 )1)((1 (3.22)
3.4 Otros modelos no paramétricos del análisis de supervivencia
Existen otros modelos o propuestas de estimadores no paramétricos tipo estimador
limite-producto de Kaplan-Meier que forman parte de los estimadores clásicos de
la función de supervivencia. A continuación se enumeran algunos de ellos:
Altshuler (1970), Aalen (1978), Prentice (1978), Prentice-Marek (1979), Fleming
et al. (1980), Andersen et al. (1982), Harris-Albert (1991), Moreau et al. (1992) y
Hosmer-Lemeshow (1999).
3.4.1 Modelo de supervivencia de Altshuler
Altshuler (1970) propuso un estimador de la función supervivencia equivalente al
estimador de Kaplan-Meier (1958), basado en el hecho que, e-x ~1-x, expresión cierta,
cuando x 0. Este estimador también fue considerado por Nelson (1969, 1972) y por
Aalen (1978), por lo que algunos autores lo denominan estimador de Nelson-Aalen:

Capitulo III. Modelos Clásicos del Análisis de Supervivencia
______________________________________________________________________
32
)(ˆztS = ∏
=
−z
j
nd
j
j
e1
(3.23)
Es uno estimadores más utilizados en la teoría moderna del análisis de supervivencia y
ha sido desarrollado por varios autores haciendo uso de la teoría de procesos de conteo.
Autores como: Andersen et al. (1993), Fleming-Harrintong (1991) y Therneau-
Grambsch (2000) presentan varios aplicaciones de esta metodología, que son
referencias obligadas para entender el uso de esta metodología en este tipo de estudios.
3.4.2 Modelo de supervivencia de Peterson
Peterson (1979) sugirió un método de estimación para la función de riesgos
acumulados del análisis de supervivencia no paramétrico, basado en el estimador de
Kaplan-Meier y cuya expresión se muestra a continuación:
)(ˆztH = − ∑
=⎟⎟⎠
⎞⎜⎜⎝
⎛ −z
j j
jj
ndn
Ln1
(3.24)
3.4.3 Modelo de supervivencia de Prentice
Prentice (1978) propuso un estimador consistente de la función de supervivencia, dado
por la siguiente expresión:
)(ˆztS = ∏
= +
z
j j
j
nn
1 1 (3.25)
que resulta útil en aquellos casos en los que no existen datos de supervivencia repetidos.
3.4.4 Modelo de supervivencia de Prentice-Marek
Prentice-Marek (1979) propusieron un estimador que modifica el estimador
consistente de la función de supervivencia propuesto por Prentice (1978) y lo
generalizan al caso de tiempos de supervivencia repetidos:
)(ˆztS = ∏
= +
+−z
j j
jj
ndn
1 11
(3.26)

Capitulo III. Modelos Clásicos del Análisis de Supervivencia
______________________________________________________________________
33
3.4.5 Modelo de supervivencia de Andersen et al.
Andersen et al. (1982) sugirieron un estimador similar al propuesto por Prentice-
Marek con la diferencia de que incorporan un factor de corrección en el modelo igual a
nz/(nz+1):
)(ˆztS =
⎥⎥⎦
⎤
⎢⎢⎣
⎡
+
+−∏=
z
j j
jj
ndn
1 11
1+z
z
nn (3.27)
3.4.6 Modelo de supervivencia de Harris-Albert (1991)
Harris-Albert (1991) propusieron la siguiente modificación del estimador propuesto
por Prentice-Marek:
)(ˆztS = ∏
= +
−+z
j jj
jj
dndn
1
1 (3.28)
3.4.7 Modelo de supervivencia de Moreau et al.
Moreau et al. (1992) propusieron en su trabajo un estimador que verifica la condición
de regularidad de Prentice-Marek (1978) pero generalizado al caso de tiempos de
supervivencia repetidos:
)(ˆztS = ∏
= +
z
j jj
j
dnn
1
(3.29)
3.4.8 Modelo de supervivencia de Hosmer-Lemeshow
Hosmer-Lemeshow (1999) plantearon la siguiente modificación del estimador de
Andersen, aplicable a los casos de empate:
)(ˆztS =
⎥⎥⎦
⎤
⎢⎢⎣
⎡
+
−+∏−
=
1
1 11z
j j
jj
ndn
1+z
z
nn
(3.30)

Capitulo III. Modelos Clásicos del Análisis de Supervivencia
______________________________________________________________________
34
3.5 Modelo de riesgos proporcionales de Cox
Cox (1972) sugirió un modelo de riesgos proporcionales tipo regresión no lineal para
realizar el análisis de supervivencia. El modelo permite determinar los efectos de
covariables en el riesgo instantáneo de ocurrencia del evento y en la supervivencia de
las unidades bajo estudio. Estas covariables son medidas al inicio del período de
observación y se denotan aquí mediante X1, X2, ..., Xq. El modelo postula que:
h( t / X ) = ho(t) ∑β=
q
1jjjX
e (3.31)
donde h(t / X) es la función de riesgo instantáneo, dadas las variables: X1, X2, ... , Xq,
ho(t ) es la función de riesgo base, dependiente del tiempo e independiente de las
variables y βj es el coeficiente correspondiente a la variable Xj. Si se denota como β el
vector de coeficientes, con componentes (β1, β2,..., βq)’ y como X como el vector de
covariables, digamos (X1, X2 , ..., Xq)’, entonces:
h( t / X ) = ho(t) eβ'X (3.32)
Si β es nulo, las covariables no afectan al riesgo instantáneo de ocurrencia y en
consecuencia, la función de riesgo instantáneo coincide con la función de riesgo
instantáneo base, convirtiéndose así en un modelo no paramétrico. El modelo propuesto
por Cox es no lineal, multivariante y semiparamético. No lineal debido a su estructura
matemática, multivariante porque considera varias covariables y semiparamétrico
porque tiene una parte que depende de parámetros y otra que no. La parte paramétrica es
llamada puntaje de riesgo (risk score) y la parte no paramétrica contiene la función de
riesgo instantáneo base, la cual no está especificada y debe estimarse a través de otros
métodos.
El modelos de riesgos proporcionales propuesto por Cox es ampliamente utilizado en
el área médica y en ingeniería. El artículo publicado por Cox ha sido por muchos años
uno de los artículos más citados y utilizados en el área científica. Para mayores detalles
sobre el tema puede consultarse a Hosmer-Lemeshov (1999), Collet (2003), Lee-
Wang (2003), Kleinbaum-Klein (2005) y Klein-Moeschberger (2005).
El modelo de Cox asume que los riesgos de dos sujetos cualesquiera i y j son
proporcionales. Si dividimos:

Capitulo III. Modelos Clásicos del Análisis de Supervivencia
______________________________________________________________________
35
)X/t(h)X/t(h
j
i = Xj'
o
X'o
e)t(he)t(h i
β
β
(3.33)
o sea:
)X/t(h)X/t(h
j
i = eβ' (Xi −Xj) (3.34)
Si asumimos que esta expresión es constante y la denotamos con la letra griega γ:
γ = eβ' (Xi −Xj) (3.35)
tenemos que:
h(t/Xi) = γ h(t/Xj) (3.36)
de ahi el nombre de riesgos proporcionales. Una expresión análoga a la 2.15 para el caso del modelo de Cox viene dada por:
S( t / X ) = ∫−
t0 ds)X/s(he (3.37)
y de igual manera para la expresión 2.14:
S( t / X ) = e −H(t/X) (3.38)
donde H(t/X) es la función de riesgo acumulado dado el vector de covariables. Si se
sustituye el riesgo instantáneo tipo Cox en la definición de la función de riesgo
acumulado se obtiene:
H( t / X ) = ∫ βt
0X' dse)s(ho (3.39)
o sea:
H( t / X ) = eβ'X Ho(t) (3.40)
Si se sustituye ahora la expresión (3.40) en la expresión (3.38), se obtiene que:
S( t / X ) = [e – Ho(t) ]θ (3.41)
con θ = eβ'X , y en consecuencia:
S( t / X ) = [ So(t) ]θ (3.42)
ya que:
So(t) = e – Ho(t) (3.43)

Capitulo III. Modelos Clásicos del Análisis de Supervivencia
______________________________________________________________________
36
Desarrolladas las relaciones existentes entre las funciones de supervivencia del modelo
de Cox, el siguiente paso consiste en resolver el problema de estimación de los
parámetros del modelo. En principio se podría pensar en el procedimiento de los
mínimos cuadrados. Sin embargo, su aplicación no es adecuada debido a la estructura
matemática del modelo. Este problema fue resuelto por el propio Cox quien propuso
para ello la función de verosimilitud parcial (LP). La idea se fundamenta en el aporte
parcial al riesgo de cada una de las unidades bajo estudio en la construcción del riesgo
total. La función de verosimilitud parcial de Cox (1975) se define como:
Lp(β) = ∏ ∑=
δ
∈
β
β
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡n
1i)t(Rj
X
X
i
i
'j
'i
ee (3.44)
Donde, n es el total de observaciones o tiempos de supervivencia ordenados en forma
creciente, incluyendo datos censurados y no censurados. La sumatoria del denominador
corresponde al conjunto de unidades a riesgo en el momento ti, denotado por R(ti). La
variable δi es la indicatriz que denota presencia o ausencia del evento, vale uno si se
está en presencia del evento y cero si el dato es censurado. Esta expresión esta diseñada
de forma que la variable δi solo considere los casos donde δi=1. Las unidades a riesgo
son todas aquéllas con tiempo de supervivencia o censura mayor o igual a ti. Se asume
que la expresión (3.44) esutilizada si no existen empates en los tiempos de
supervivencia. Si p es el total de observaciones o tiempos de supervivencia diferentes,
ordenados en forma creciente y considerando sólo los casos donde δi=1. El logaritmo de
la función de verosimilitud parcial viene dado por:
lp(β) = ∑ ∑= ∈
β
⎥⎥⎦
⎤
⎢⎢⎣
⎡⎟⎟⎠
⎞⎜⎜⎝
⎛−β
p
1z )t(Rj
X'z
z
'jeLnX (3.45)
Para determinar el máximo de función parcial de verosimilitud se deriva la expresión
(3.45) respecto del vector de parámetros β y se iguala al vector nulo. Así:
β∂
β∂ )(lp = ( )
∑ ∑∑
=∈
β
∈
β
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−p
1z)t(Rl
X)t(Rj
'j
X
'z
z
'l
z
'j
e
XeX (3.46)

Capitulo III. Modelos Clásicos del Análisis de Supervivencia
______________________________________________________________________
37
Ahora bien, si se denotamos:
wzj(β) = ∑
∈
β
β
)t(Rl
X
X
z
'l
'j
ee (3.47)
entonces:
β∂
β∂ )(lp = [ ]∑=
β−p
1z
'w
'z )(XX
z (3.48)
siendo:
)(X 'w z
β = 'j
)t(Rjzj X)(w
z
β∑∈
(3.49)
Si ahora se iguala la expresión 3.48 al vector nulo:
[ ]∑=
β−p
1z
'w
'z )(XX
z = θ (3.50)
se obtiene un sistema de ecuaciones no lineales que contiene tantas incógnitas como
covariables involucradas en el modelo. Para encontrar la solución se aplica el
procedimiento de Newton-Raphson, el cual se detalla en el apéndice B. Actualmente
existen muchos programas computarizados comerciales que ya incluyen este
procedimiento, como por ejemplo SPSS, BMDP, SAS, S-Plus, STATA, MINITAB,
NCSS y R.
El estimador de varianza de los estimadores de los coeficientes β se obtiene de la misma
manera como el obtenido a partir de la función de máxima verosimilitud y se calcula
como la inversa negativa de la segunda derivada del logaritmo de la función de
verosimilitud parcial. Esta derivada es igual a:
2
2 )(ββ
∂
∂ pl = −
[ ] ∑
∑
∑∑∑=
∈
β
∈
β
∈
β
∈
β
⎪⎪
⎭
⎪⎪
⎬
⎫
⎪⎪
⎩
⎪⎪
⎨
⎧
⎥⎦
⎤⎢⎣
⎡
⎥⎦
⎤⎢⎣
⎡−⎥
⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡p
1z2
)t(Rj
X
2
)t(Rjj
X2'j
)t(Rj
X
)t(Rj
X
z
'j
z
'j
z
'j
z
'j
e
Xe)X(diagdiagee (3.51)
donde diag(X’j) es la matriz diagonal correspondiente al vector X’j. La matriz de
varianzas y covarianzas de los estimadores de coeficientes β, llamada matriz de
información de Fisher viene dada por:

Capitulo III. Modelos Clásicos del Análisis de Supervivencia
______________________________________________________________________
38
Var β = ( I (β) ) −1 (3.52)
donde:
I (β) = − 2
2 )(ββ
∂
∂ pl (3.53)
El método de estimación del vector de coeficientes β a partir de la función de
verosimilitud parcial está basado en el supuesto que no existen empates en los tiempos
de supervivencia de las unidades bajo estudio y supone escala de tiempo continua. Para
los casos de empate existen tres metodologías: las propuestas por Breslow (1974) y
Efron (1977) que son métodos aproximados y la de Kalbfleisch-Prentice (1980)
quienes propusieron un método exacto. Todas estas metodologías de estimación de
parámetros del modelo del Cox están incorporadas y disponibles en la mayoría de los
programas comerciales mencionados anteriormente.
3.6 Modelo de riesgos proporcionales de Cox estratificados
El modelo estratificado de Cox es una modificación del modelo de riesgos
proporcionales que incorpora un nuevo subíndice g referido al estrato. Los estratos
definen las diferentes categorías de una nueva variable denotada por Z*. Se consideran
diversos casos según se considere o no la interacción entre las variables de
estratificación y las covariables.
3.6.1 Modelo general estratificado Este modelo no incluye explícitamente la variable de estratificación Z*, pero si
considera una estratificación a través de la categorización de la línea base del modelo,
dando como resultado una curva de supervivencia por estrato. Este modelo se expresa
como.
hg( t / X ) = hog eX'β (3.54)
donde g es la variable que incluye la estratificación y hog define la función de riesgo
base instantáneo por estrato. Obsérvese que los coeficientes de las covariables son
comunes para todos los estratos. En este modelo la estimación de los coeficientes se
obtiene a partir de la maximización de la función general de verosimilitud parcial, la
cual es a su vez obtenida como el producto de las funciones parciales de verosimilitud
de todos los estratos.

Capitulo III. Modelos Clásicos del Análisis de Supervivencia
______________________________________________________________________
39
3.6.2 Modelo de no-interacción con coeficientes estratificados
Este modelo tampoco incluye explícitamente la variable de estratificación Z*, pero
considera tanto la estratificación a través de la categorización de la línea base del
modelo como la estratificación a través de los coeficientes de las covariables. Se obtiene
como resultado una curva de supervivencia por estrato. El modelo se expresa como.
hg ( t / X ) = hog(t) eX'βg (3.55)
donde g es la variable de estratificación, hog define la función de riesgo base instantáneo
por estrato y βg es el vector de coeficientes del estrato correspondiente.
3.6.3 Modelo de interacción con coeficientes estratificados
El modelo estratificado de Cox con interacción es un modelo que incluye explícitamente
la variable de estratificación Z*, mediante la incorporación de k*-1 variables tipo
dummy. El modelo se expresa en la forma:
hg( t / X) = hog(t) x exp[β1X1 + ... + βqXq + β11
*1Z X1 + ... + βq1
*1Z Xq + (3.56)
β12
*2Z X1 + ... + βq2
*2Z Xq + ...
β1,k-1
*1kZ − X1 + ... + βq,k-1
*1kZ − Xq ]
donde g es la variable de estratificación y hog define la función de riego base
instantáneo por estrato.
3.7 Extensiones del modelo de riesgos proporcionales de Cox para variables
dependientes del tiempo.
En este caso se considera un conjunto de variables predictoras independientes del
tiempo y otro conjunto de variables dependientes del tiempo. El modelo se plantea
como una extensión del modelo de riesgos proporcionales de Cox, tal y como se
muestra a continuación:
h[t / X, Xl(t)] = ho(t) x exp Xj'β + Xl'γ (3.57)

Capitulo III. Modelos Clásicos del Análisis de Supervivencia
______________________________________________________________________
40
donde X’j es el vector de variables predictoras o covariables no dependientes del
tiempo, con q1 componentes y X’l(t) es el vector de variables predictoras o
covariables dependientes del tiempo, con q2 componentes, β es el vector de
coeficientes de las covariables no dependientes del tiempo, digamos (β1, β2,..., βq1)’
y γ es el vector de coeficientes de las covariables dependientes del tiempo,
digamos (γ1, γ2,..., γq2)’.

Capítulo IV. Procesos de Conteo, Martingalas y su Relación el Análisis de Supervivencia ______________________________________________________________________
41
Capitulo IV: PROCESOS DE CONTEO, MARTINGALAS Y SU RELACIÓN CON EL ANÁLISIS DE SUPERVIVENCIA
4.1 Introducción
El estudio y desarrollo de las técnicas del análisis de supervivencia mediante procesos
de conteo tiene sus orígenes a finales de los años setenta. Aalen (1975) desarrolló las
primeras ideas y posteriormente, Andersen-Gill (1982) lograron avances importantes
en el uso de los procesos contadores en la modelación de datos de vida. Con esta nueva
perspectiva, integraron y generalizaron el modelo de riesgos proporcionales de Cox a
los casos de eventos recurrentes. Posteriormente, otros autores lograron trasladar los
conceptos fundamentales de los procesos de conteo a otros modelos del análisis de
supervivencia con eventos recurrentes. Con la incorporación de este enfoque se ha
enriquecido este campo de investigación y se han desarrollado excelentes trabajos en el
área. Ejemplo de ello son los trabajos recientemente publicados por Peña et. al (2001) y
Wang-Chang (1999). Autores como, Fleming-Harrintong (1991), Andersen et. al
(1993) y Therneau-Grambsch (2000), presentan bibliografías interesantes sobre el
tema.
Un proceso de conteo Ntt≥0 es un proceso estocástico donde, Nt es una variable
aleatoria que indica el número de sucesos ocurridos de un cierto fenómeno hasta el
momento t. Esta variable tiene asociada una función de distribución de probabilidades
conocida o no, que permite describir dicho fenómeno. Lo importante aquí es que los
procesos estocásticos se pueden utilizar para modelar problemas del análisis de
supervivencia y su uso ha facilitado el estudio de las propiedades de diferentes
estimadores. Uno de los objetivos principales de esta investigación es utilizar los
modelos no paramétricos para realizar el estudio de supervivencia en fenómenos
recurrentes a través de los procesos de conteo. En este capítulo se describen estos
procesos, se discuten algunos conceptos básicos relacionados con la función de
supervivencia, la función de riesgo y la función de riesgo acumulada, y se desarrollan
algunos modelos de supervivencia definidos a través de estos procesos. Se presentan
algunos conceptos relacionados con la teoría de procesos estocásticos, procesos
estocásticos independientes y estacionarios, procesos de conteo, procesos de conteo
homogéneos y no homogéneos, martingalas, propiedades locales de procesos
estocásticos, entre otros. Se definen los procesos de renovación y se describen algunas

Capítulo IV. Procesos de Conteo, Martingalas y su Relación el Análisis de Supervivencia ______________________________________________________________________
42
de sus propiedades estadísticas. Se introduce además el teorema de descomposición
de Doob-Meyer para submartingalas y para submartingalas locales.
4.2 Procesos estocásticos Definición 4.2.1: Un proceso estocástico es una colección de variables aleatorias X(t)t∈T, con T ⊆ R, definida en un espacio de probabilidades (Ω, F, P), donde t es el parámetro que se asocia al tiempo y X(t) representa el estado en el instante t. El conjunto de parámetros T se llama dominio de definición del proceso. 4.2.1 Características de los procesos estocásticos Del mismo modo que en una variable unidimensional X, en un proceso estocástico
podemos obtener algunas características que describen su comportamiento: medias,
varianzas y covarianzas. Puesto que las características del proceso pueden variar a lo
largo de t estas características no serán parámetros sino funciones de t. Así:
La función de medias del proceso:
µt = m(t) = E [X(t) ] (4.1)
La función de las varianzas del proceso: 2
tσ = Var [X(t)] = E[X2(t)] − E2[X(t)] (4.2) La función de autocovarianzas del proceso: Cov[Xs, Xh] = E[Xs Xh] − E[Xs] E[Xh] Cov(t, t+h) = Cov(t+h, t) = Cov[X(t), X(t+h)] = γ(h) (4.3)
La función de autocorrelación (función de autocovarianza estandarizada)
ρ(h) = )0()(
γγ h (4.4)
Definición 4.2.2: Sea X(t)t∈T un proceso estocástico i) Si, T es un conjunto numerable, entonces el proceso estocástico se dice que es en
tiempo discreto. ii) Si, T es un intervalo de una recta real, entonces el proceso estocástico se dice que
en tiempo continuo. iii) Si, T ⊆ Rn con n > 1 entonces el proceso se denomina campo aleatorio

Capítulo IV. Procesos de Conteo, Martingalas y su Relación el Análisis de Supervivencia ______________________________________________________________________
43
Definición 4.2.3: Sea X(t)t∈T un proceso estocástico real y t1,t2,...,tn⊂ T, con t1<t2< …<tn, entonces: Ft1...tn (x1, ... xn) = P( Xt1 ≤ x1,..., Xtn ≤ xn ) (4.5)
es la función de distribución conjunta finita dimensional del proceso. Definición 4.2.4: Sea la pareja (Ω, F) un espacio medible. Una filtración en (Ω, F) es una familia no-decreciente Ft, t ≥0 de sub-σ-álgebras de F. De tal forma que una filtración puede ser escrita como: Fi = σ(Xi(s); i = 1,2, …, n; 0 ≤ s ≤ t). (4.6)
Fs ≤ Ft, lo que refleja el incremento de la información con el paso del tiempo.
Definición 4.2.5: Se dice que un proceso real en tiempo continuo X(t)t∈T es de incrementos independientes o de renovación si para los valores t1,t2,...,tn⊂ T, con t1<t2< …<tn, se tiene que:
X(t1)−X(to), X(t2)−X(t1),... X(tn)−X(tn-1) (4.7)
son variables aleatorias independientes. Se tiene por lo tanto que en un proceso de
renovación los cambios en intervalos de tiempo que no se solapan son independientes.
Definición 4.2.6: Se dice que un proceso estocástico real en tiempo continuo X(t) t∈T es de incrementos estacionarios, si la distribución de X(s+t)-X(s), fijo t, es la misma para cualquier valor de s, siempre y cuando s+t pertenezca a T. Definición 4.2.7: Sea εnn∈N una sucesión de variables aleatorias incorrelacionadas de media cero y varianza 2
εσ . Su función de autocovarianza es: γ(h) = 0 si h ≠ 0 ∧ γ(h) = 2
εσ si h = 0 (4.8)
Se trata pues de un proceso estacionario en covarianza cuya función de autocorrelación:
1 0
( ) 0 0si h
h si h=⎧
γ = ⎨ ≠⎩ (4.9)
Definición 4.2.8: Se dice que un proceso estocástico real en tiempo continuo, N(t)t≥0 es puntual o de conteo, si N(t) representa el número de veces que ocurre un suceso hasta el instante de tiempo t. Por lo que:
i) N(t)∈ N ∀t ii) N(s) ≤ N(t) si s < t. Los incrementos son no negativos.

Capítulo IV. Procesos de Conteo, Martingalas y su Relación el Análisis de Supervivencia ______________________________________________________________________
44
Un proceso de conteo es entonces de incrementos independientes si el número de
sucesos que tiene lugar en intervalos de tiempos que no se solapan, son variables
aleatorias independientes, y será de incrementos estacionarios si la distribución del
número de sucesos que tiene lugar en un intervalo de tiempo es la misma en el caso de
intervalos de igual longitud. Un proceso de conteo es independiente cuando lo que ha
ocurrido en un intervalo de tiempo, no influye en el número de sucesos que ocurrirán en
otro intervalo diferente de tiempo.
Definición 4.2.9: Se dice que un proceso de conteo, N(t)t≥ es homogéneo de Poisson de tasa λ>0, si:
i) N(0)=0. ii) Es de incrementos independientes iii) P[N(t+s) - N(s ) = n] = [(λt)n/n!] e-λt ∀n∈N, ∀s,t >0.
El proceso es de incrementos estacionarios y los incrementos siguen una distribución de
Poisson de parámetro λt para intervalos de tiempo de longitud t.
De esta forma, el número de sucesos esperado hasta un instante t, es: E[N(t)] = E[N(t+0)-N(0)] = λt (4.10) Teorema 4.2.1: Un proceso de conteo, N(t)t≥0, es homogéneo de Poisson de tasa λ>0, si y sólo si se verifica que:
i) N(0) = 0 ii) Es de incrementos independientes y estacionarios iii) P[N(h)=1] = λh+ σ(h) iv) P[N(h)≥ 2] = σ(h)
donde σ(h) se es una función que cumple:
0
lim→h
hh)(σ = 0 (4.11)
o sea, que la función σ(h) converge a 0 más rápidamente que h. Definición 4.2.10: Se dice que un proceso de conteo, N(t)t≥0, es no homogéneo de Poisson de tasa λ(t)>0, si:
i) N(0)=0 ii) Es de incrementos independientes iii) P[N(t+h) - N(h) = n] = [(λ(t)t)n/n!] e-λ(t)t ∀n∈N, ∀ h,t >0.

Capítulo IV. Procesos de Conteo, Martingalas y su Relación el Análisis de Supervivencia ______________________________________________________________________
45
El proceso es de incrementos independientes y no estacionarios, y los incrementos
siguen una distribución de Poisson de parámetro λ que depende de t.
Teorema 4.2.2: Un proceso de conteo, N(t)t≥0 es no homogéneo de Poisson de tasa λ(t)>0, si y sólo si se verifica que:
i) N(0)=0 ii) Es de incrementos independientes iii) P[N(t+h)-N(t)=1] = λ(t)h+ σ(h) iv) P[N(t+h)-N(t)≥ 2]= σ(h)
4.3 Tiempos de interocurrencia de los eventos En un proceso de Poisson de tasa λ, los tiempos entre dos eventos consecutivos, T1,T2,…,Tk, son variables aleatorias independientes e idénticamente distribuidas con distribución exponencial de parámetro λ. Si:
Sk = ∑=
k
jjT
1
(4.12)
entonces Sk sigue una distribución gamma de parámetros k y λ. 4.4 Martingalas Definición 4.4.1: Sea (Ω, F, P) un espacio de probabilidades, sea Ft = σ(Ni(s),Yi(s+), Xi(s); i = 1,2, …, n; 0 ≤ s ≤ t) una filtración. La sucesión de variables aleatorias M(t)t∈T, definida sobre el espacio de probabilidades dado se llama martingala con respecto a Ft t≥0, si: i) Para todo t ∈ T, Mt es medible con respecto a Ft,
ii) E [ Mt ] <∞ para todo t iii) E[X t / Fs] = Xs para todo s < t
El proceso es una submartingala si iii) es reemplazado por la desigualdad: E[M(t)/ Fs] ≥ M(s) para todo s<t (4.13) Cuando la desigualdad “≥” es reemplazada por “<”, el proceso es llamado supermartingala. En un proceso de conteo N = (N1,N2,…,Nk), donde Nj(t) es el número de sucesos
registrados en [0,t], para t≥0, con Nj(0)=0 y para todo j=0,1,2…k, las variables Nj(t) son
trayectorias constantes a trozos, con discontinuidades de salto de magnitud +1, sin
saltos simultáneos.

Capítulo IV. Procesos de Conteo, Martingalas y su Relación el Análisis de Supervivencia ______________________________________________________________________
46
N(t) también es un proceso de conteo, conocido como proceso agregado, e igual a:
N(t) = ∑=
k
jjN
1
(4.14)
En este proceso la intensidad, denotada por λj(t), esta dada por:
λj(t) = 0
lim→∆t t∆
1 E∆Nj(t)/Ft (4.15)
λj(t) = 0
lim→∆t t∆
1 P∆N(t) ≥ 1/Ft (4.16)
λj(t) = 0
lim→∆t t∆
1 P∆N(t) =1/Ft (4.17)
donde ∆Nj(t)=Nj(t+∆t)-Nj(t). La intensidad acumulada, denotada por Λj(t), esta dada por: Λj(t) = ∫
t
j dss0
)(λ (4.18)
De esta manera Mj(t) = Nj(t) - Λj(t) es una martingala, conocida como ruido estocástico. Se cumple entonces que: ∆Mj(t) = ∆Nj(t)− ∆Λj(t) (4.19)
∆Mj(t) ≈ ∆Nj(t)− ∆tλj(t)
∆Mj(t) ≈ ∆Nj(t)− E∆Nj(t)/ Ft
Lo que implica que un proceso de conteo esta formado por un proceso predecible
Λj(t) más un ruido estocástico Mj(t), conocido como martingala. La expresión
(4.19) es conocida como la descomposición Doob-Meyer. Así, en un proceso de conteo
de Poisson de tasa λ se tiene que λ(t)=λ, Λ(t)=λt, N(t)-λt es la martingala y λt es el
compensador.
4.5 Procesos de conteo y análisis de supervivencia 4.5.1 Preliminares El análisis de supervivencia se ha visto fortalecido significativamente desde que se le
integraron los conceptos de los procesos de conteo y la teoría de martingalas. Son
muchos los avances que se han logrado, y con este trabajo esperamos contribuir con un
modesto aporte al conocimiento en esta área de investigación.

Capítulo IV. Procesos de Conteo, Martingalas y su Relación el Análisis de Supervivencia ______________________________________________________________________
47
En esta sección ilustraremos el uso de la metodología de los procesos de conteo y la
teoría de martingalas en el análisis clásico de la teoría de supervivencia, como paso
previo al desarrollo de los capítulos posteriores dedicados al caso recurrente.
4.5.2 Notación de los procesos de conteo aplicados en la estimación de las
distribuciones del análisis de supervivencia.
Adaptaremos la notación de la sección 2.1.4 a este nuevo contexto, denotando la
función de riesgo por λ(t) (en lugar de h(t)) y la función de riesgo acumulado por Λ(t)
(en lugar de H(t)). Para considerar el caso de las observaciones censuradas asumiremos
que para las n unidades experimentales se asocian las variables no negativas Y1, Y2, …,
Yn independientes e idénticamente distribuidas con distribución continua común igual
a F, y las variables no negativas C1, C2, … , Cn independientes e idénticamente
distribuidas con distribución común igual a G. Se supone además que ambos conjuntos
de variables Yi y Ci son independientes. De esta manera, el conjunto de datos para las n
unidades estará dado por (T1, δ1), (T2, δ2),… , (Tn, δn), donde:
Ti = min ( Yi, Ci )
(4.36)
δi = I Yi ≤ Ci
Definimos como indicador de riesgo a una variable dummy que indica si una
unidad bajo estudio está en riesgo o no en un momento determinado:
Yi(t) = I Ti > t (4.21)
Si denotamos como antes por Ft a la filtración de un proceso de conteo, que contiene
información del proceso en el intervalo [0,t], entonces Ft- será la filtración que contiene
información del proceso en el intervalo [0,t). La probabilidad de que dN(t)=1 dado Ft-
en cualquier instante de tiempo, puede escribirse como:
PdN(t)=1/ Ft- = ∫t
oduuh )( (4.22)
que es equivalente a:
PN(t+dt)-N(t)=1/ Ft- = PdN(t)=1/ Ft- (4.23)

Capítulo IV. Procesos de Conteo, Martingalas y su Relación el Análisis de Supervivencia ______________________________________________________________________
48
ya que:
PN(t+dt)-N(t)=1/ Ft- ≈ h(t)dt (4.24)
siendo además:
A(t) = ∫t
duu0
)(α (4.25)
la intensidad acumulada. A continuación se muestran algunos conceptos de la teoría
martingala de los procesos de conteo. En este caso una martingala toma la forma:
M(t) = N(t) - A(t) (4.26)
Por lo tanto, se espera que:
EdM(t)/Ft- = 0 (4.27)
y en consecuencia:
EdM(t)/ Fs = M(s) para todo 0 ≤ s <t (4.28)
Una martingala puede considerarse entonces como una descomposición Doob-Meyer,
es decir como la diferencia de un proceso de conteo menos un proceso regular y
predecible, llamado compensador. El compensador en una martingala es la intensidad
acumulada:
N(t) = A(t) + M(t) (4.29)
expresión análoga a la descomposición de cualquier proceso estadístico:
Datos = Modelo + ruido (4.30)
En este caso:
Conteo observado = Conteo esperado + error (4.31)
4.5.3 Procesos de conteo en estimaciones no paramétrica del análisis de
supervivencia. Para realizar las estimaciones no paramétricas del análisis de supervivencia a través de
los procesos de conteo es necesario conocer tanto las variables (Ti , δi) como las
variables del proceso de conteo (Ni(t), Yi(t)), donde Ni(t) representa el número de

Capítulo IV. Procesos de Conteo, Martingalas y su Relación el Análisis de Supervivencia ______________________________________________________________________
49
unidades que experimentan el evento en el momento t y Yi(t) el número de unidades en
riesgo justo antes del momento t:
Ni(t) = ITi ≤ t, δi=1 (4.32)
Yi(t) = Ti ≥ t (4.33)
En el análisis de supervivencia, la intensidad α(t) es igual a la función de riesgo λ(t)
cuando la unidad está en riesgo e igual a cero cuando el evento ya ha sido
experimentado. De modo que la intensidad del proceso puede expresarse como:
α(t) = Y(t) λ(t) (4.34)
Para especificar el modelo en términos de su historia denotamos por dNi(t) al
incremento de Ni sobre el intervalo de tiempo infinitesimal [t,t+dt], así que:
EdNi(t)/ Ft- = Yi(t) λ(t)dt (4.35)
donde dNi(t) sólo puede ser 1 ó 0. Entonces:
EdNi(t)/ Ft- = P dNi(t)=1/ Ft- (4.36)
que es equivalente a P dNi(t)=1/Yi(t). Lo que significa que si Yi(t)=0, la unidad i-
ésima ya ha experimentado en evento y la probabilidad dada es cero, y si Yi(t)=1 la
unidad estará en riesgo, y:
P dNi(t)=1/Yi(t)=1= Yi(t) λ(t)dt (4.37)
4.5.3.1 Estimador Nelson-Aalen
Uno de los estimadores más utilizados en el análisis de supervivencia es el estimador
Nelson-Aalen, que parte de la base de que es más fácil estimar la función de riesgo
acumulado que las otras funciones del análisis. Para estimar la función de riesgo
instantáneo, es necesario definir dos procesos agregados, )(tN y )(tY . Donde )(tN es
el número de unidades que experimentaron el evento en el intervalo [0,t] y )(tY es el
número de unidades experimentales en riesgo en el momento t:

Capítulo IV. Procesos de Conteo, Martingalas y su Relación el Análisis de Supervivencia ______________________________________________________________________
50
)(tN = ∑=
n
ii tN
1
)( y )(tY = ∑=
n
ii tY
1
)( (4.38)
Por otra parte, de acuerdo con la definición de riesgo acumulado se tiene que para un
intervalo de tiempo de longitud infinitesimal:
Λ(t + ∆t) − Λ(t) ≈ λ(t)∆t (4.39) Λ(t + ∆t) − Λ(t) ≈ P(t ≤ T < t+∆t / T ≥t) Esta diferencia puede ser estimada mediante:
Λ(t + ∆t) − Λ(t) ≈ [ )( ttN ∆+ − )(tN ] / )(tY (4.40)
Si se considera una cantidad suficientemente grande de subintervalos de longitud ∆ti, se
obtiene el estimador Nelson-Aalen de la función de riesgo acumulado mediante:
( )( )( ):
ˆ i
i t ti i
N tt
Y t≤
∆Λ = ∑ (4.41)
Al tomar límite cuando ∆ti tiende a cero:
( )( )
( )0ˆ t dN st
Y sΛ = ∫ (4.42)
Basándose en la relación (2.1.4) Breslow (1972) sugirió siguiente estimador no
paramétrico de la función de supervivencia para el caso de distribuciones continuas:
( )ˆ
:
ˆ e d tiB i t ti
S − Λ
≤= ∏ (4.43)
siendo:
( ) ( )( )
ˆ ii
i
dN td t
Y tΛ = (4.44)
donde los dΛ(ti) son los incrementos del estimador Nelson-Aalen de las ocurrencias
de los eventos. Para estimar la varianza de este estimador se puede recurrir al hecho de

Capítulo IV. Procesos de Conteo, Martingalas y su Relación el Análisis de Supervivencia ______________________________________________________________________
51
los procesos de conteo puede ser modelado como un proceso de Poisson, al menos
localmente para periodos de tiempo relativamente pequeños.
En vista, de que en un proceso de Poisson la media es igual a la varianza, condicionada
a su pasado, entonces:
( )2
:
( )ˆ( ) i
i t ti i
N tVar t
Y t≤
∆Λ = ∑ (4.45)
y al tomar límite:
( ) ( )
( )20
ˆ t dN tVar tY t
Λ = ∫ (4.46)
Greenwood (1926) propuso otro estimador de la varianza del riesgo acumulado
definido por:
( ) ( )
( ) ( ) ( )0ˆ t
G
dN uVar tY u Y u dN u
Λ =⎡ ⎤−⎣ ⎦
∫ (4.47)
( ) ( )( ) ( ) ( ):
ˆ i
i t ti i i i
N tVar t
Y t Y t N t≤
∆Λ =
⎡ ⎤− ∆⎣ ⎦∑ (4.48)
que como puede apreciarse es mayor que el estimador de Nelson-Aalen. Ambos
estimadores son útiles en aquellos casos donde no existen empates en los tiempos de
ocurrencia del evento. Si este es el caso, Therneau-Grambsch (2000) proponen los
siguientes estimadores del riesgo acumulado y su varianza:
( )
( ) 1
00
1ˆ( )dN u
t
jt
Y u j
−
=
⎡ ⎤Λ = ⎢ ⎥
−⎢ ⎥⎣ ⎦∑∫ (4.49)
( ) ( ) 1
200
1ˆ( )
dN ut
jVar t
Y u j
−
=Λ =
⎡ ⎤−⎣ ⎦∑∫ (4.50)
4.5.3.2 Estimador Kaplan-Meier
Fleming-Harrrington (1984) demostraron la relación entre el estimador de la función
de supervivencia de Breslow (1972) y el estimador de Kaplan-Meier (1958),

Capítulo IV. Procesos de Conteo, Martingalas y su Relación el Análisis de Supervivencia ______________________________________________________________________
52
comparando numéricamente varias tamaños muestras y porcentaje de censura. La
expresión para el estimador de Kaplan-Meier es la siguiente:
:
ˆ ˆ( ) 1 ( )KM ii t ti
S t d t≤
⎡ ⎤= − Λ⎣ ⎦∏ (4.51)
que para casos discretos, y escrito en notación de los procesos considerados, se expresa
como:
( )( ):
ˆ 1 iKM i t ti i
N tS
Y t≤
⎡ ⎤∆⎢ ⎥= −⎢ ⎥⎣ ⎦
∑ (4.52)
Los estimadores de Breslow y Kaplan-Meier son muy similares cuando los incrementos
( )ˆd tΛ son pequeños, que es lo que ocurre cuando muchas unidades están en riesgo.
Esta relación es debida a que: e-x ≈ 1 – x, para valores pequeños de x. En efecto, los dos
estimadores son asintóticamente equivalentes, cuando x tiende a cero. Se puede
demostrar que ( ) ( )ˆ ˆB KMS t S t≥ para muestras finitas. Cuando existen datos con
tiempos de ocurrencia iguales o repetidos (empates), las diferencias entre estos dos
estimadores, pueden ser significativamente grandes. En ese caso se sugiere utilizar el
estimador de Breslow. Fleming y Harrrington propusieron un estimador de la función de
supervivencia para el caso de empates, muy cercano al estimador Kaplan-Meier pero
más pequeño que el estimador de Breslow.
4.5.3.3 Estimador del modelo de riesgos proporcionales de Cox
Como una derivación del estimador Nelson-Aalen y reemplazando el vector β por su
estimación, se obtiene el estimador de Aalen-Breslow:
( )ˆ '
1
( )ˆ( )( ) e
to n X ti
ii
dN ttY u
β
=
Λ =⎡ ⎤
×⎢ ⎥⎢ ⎥⎣ ⎦
∫∑
(4.53)

Capítulo V. Modelos de Supervivencia con Eventos Recurrentes ______________________________________________________________________
53
Capitulo V. MODELOS DE SUPERVIVENCIA CON EVENTOS RECURRENTES
5.1 Introducción El objetivo principal de este capítulo consiste en presentar algunos modelos del análisis
de supervivencia con eventos recurrentes. En primer lugar nos referiremos a los
modelos semiparamétricos y en segundo lugar a los no paramétricos.
En el primer conjunto de modelos se incluyen los dos modelos de Prentice-Willlian-
Peterson (1981), el modelo de Andersen-Gill (1982) y el modelo de Wei-Lin-
Weissfeld (1989). Autores como: Therneau et al. (1990), Allison (1995), Therneau-
Hamilton (1997), Therneau-Grambsch (2000), Barceló (2002), Kalbfleisch-
Prentice (2002), Prentice-Kalbfleisch (2003), Lee-Wang (2003), Keinbaum-Klein
(2005), entre otros, presentan una bibliografía bastante completa sobre el tema. Entre
los programas computarizados especializados y adaptados al tópico, que contienen
rutinas automatizadas para el estudio de estos modelos, se encuentran STATA, SPSS,
NCSS, SAS, S-Plus y R.
En el segundo conjunto de modelos se incluyen el modelo de Wang-Chang (1999) y
los dos modelos de Peña et al. (2001). Estos autores tratan el problema de eventos
recurrentes desde la óptica no paramétrica. Estudian aquellos casos donde las unidades
bajo estudio provienen de una misma población con tiempos de interocurrencias
independientes e idénticamente distribuidos, como aquellos casos donde las unidades
provienen de la misma población con tiempos de interocurrencias correlacionados
(individuos “gemelos”). Si por ejemplo, a un grupo de individuos de este tipo se les
quiere estudiar los tiempos de aparición de tumores, ataques de epilepsia u otra
enfermedad, resulta natural suponer que las ocurrencias del evento en estos individuos
están correlacionadas y por lo tanto resulta inadecuada la aplicación de un modelo que
no considere explícitamente esta condición. Otra situación similar es aquélla en la que
los tiempos de interocurrencias del evento están asociados a una variable latente no
observable y donde existe una clara diferenciación en la ocurrencia del evento:
individuos que tienen alta probabilidad de ocurrencia del evento (fragilidad alta) e
individuos con baja probabilidad de ocurrencia del evento (fragilidad baja).

Capítulo V. Modelos de Supervivencia con Eventos Recurrentes ______________________________________________________________________
54
Wang-Chang (1999) proponen un modelo no paramétrico aplicable al caso de
fenómenos recurrentes con tiempos correlacionados. El diseño de este modelo permite
que también pueda utilizarse en aquellos casos donde los tiempos no están
correlacionados a sea son independientes. Peña et al. (2001) proponen dos modelos
para resolver ciertos aspectos del análisis de supervivencia con eventos recurrentes.
Primero, proponen un modelo no paramétrico que considera independencia entre los
tiempos de interocurrencias, como generalización del modelo clásico de Kaplan-Meier
(1958). El segundo modelo incorpora en el modelo una variable de fragilidad no
medible en forma multiplicativa; pero, también considera la independencia en los
tiempos de interocurrencias del evento. Esta variable latente (la fragilidad) representa la
probabilidad que tienen los individuos de experimentar la ocurrencia del evento. Estos
últimos trabajos son recientes y la bibliografía sobre este tema específico es escasa. Sin
embargo, existen investigaciones que recogen algunos aspectos relacionados con ellos:
los de Hollander-Setruraman (2002), González-Peña (2004), González-Peña-
Straderman (2005) y Cook-Lawless (2007).
5.2 Modelos semiparamétricos 5.2.1 Modelos de Prentice-Williams-Peterson Prentice et al. (PWP) en su trabajo de 1981, propusieron dos modelos para eventos
recurrentes. Ambos modelos (PWP01 y PWP02), son extensiones del modelo de
riesgos proporcionales de Cox (1972). Los autores introducen en sus modelos el
concepto de estrato, en un sentido diferente al que usualmente se le da. Definen los
estratos por la cantidad de veces que la unidad experimenta el evento de estudio. Así,
una unidad que experimente una ocurrencia pertenecerá al primer estrato, si
experimenta el evento dos veces pertenecerá tanto al primer y como al segundo
estrato y así sucesivamente. O sea que el estrato s-ésimo está formado por las
unidades que experimentan s o más veces el evento de estudio. Los modelos de
recurrencia tipo Cox se pueden clasificar como condicionales o marginales según la
ocurrencia del evento en el estrato s-ésimo esté afectada o no por la ocurrencia del
evento en el estrato anterior.
Para estimar los parámetros de los modelos PWP, los autores recurrieron a la función de
verosimilitud parcial, propuesta por Cox (1975) para estimar los parámetros de su
modelo y discutida en la sección 3.5, expresión (3.44) de este trabajo. Hay que destacar

Capítulo V. Modelos de Supervivencia con Eventos Recurrentes ______________________________________________________________________
55
que la construcción de la función de verosimilitud parcial para los modelos PWP
difieren de la construcción de la función de verosimilitud parcial del modelo original de
Cox debido a que las estructuras de los datos en estos modelos difieren. Una
característica común en todos ellos es que se asume independencia en los tiempos de
interocurrencia.
Cuando los eventos son de tipo recurrente, los modelos de regresión de riesgos
proporcionales tienen una estructura matemática mucho más complicada que los
modelos de regresiones clásicos. En ambos casos las estimaciones se realizan aplicando
métodos numéricos e iterativos como el de Newton-Raphson, ideados para resolver
ecuaciones no lineales ver apéndice B.
Otro problema común que se resuelve a través de estos procedimientos iterativos en los
modelos tipo Cox es el de la estimación de la función base (supervivencia o riesgo),
problema que se complica aún más cuando aparecen tiempos de supervivencia repetidos
en las unidades de investigación. Estas dificultades (tiempos de supervivencia repetidos)
han sido abordadas por Breslow (1972), Efron (1977) y Kalbfleisch-Prentice (1980).
5.2.1.1 Primer modelo de PWP (modelo PWP01)
En el primer modelo PWP, el riesgo instantáneo en cada estrato está en función del
vector de coeficientes del estrato s-ésimo, denotado por bs, del riesgo instantáneo base
del estrato s-ésimo, denotado por h0s y del vector de covariables, xi. El vector de
covariables xi es medido en la unidad experimental al comienzo de su período de
observación y esta formado por todas las covariables del estudio. Por otro lado, como la
función de riesgo instantáneo esta afectada por la función de riesgo instantáneo base de
los estratos, se produce una función de riesgo instantáneo para cada uno de ellos. De
esta manera habrá tantas funciones de riesgos instantáneo como estratos existan en
el estudio. Este modelo entra en la clasificación de modelos condicionales, debido a
que, para que una unidad esté en riesgo en un estrato s-ésimo, mínimo debe haber
experimentado s-1 eventos. En este modelo se habrá que estimar un riesgo base para
cada estrato y la función de riesgo instantáneo queda definida como:
( ) ( )'
0/ , e
b xs i
s i sh t b x h t= × (5.1)

Capítulo V. Modelos de Supervivencia con Eventos Recurrentes ______________________________________________________________________
56
donde s es el estrato definido por la frecuencia de ocurrencia del evento, h(t/ bs ,xi ) es
el riesgo instantáneo de la i-ésima unidad de investigación en el tiempo t en el estrato
s-ésimo. h0s(t) es el riesgo instantáneo base en el estrato s-ésimo en el tiempo t, bs es el
vector de coeficientes del estrato s-ésimo y xi es el vector de covariables de la i-ésima
unidad de investigación en el tiempo t. Si ds es el máximo tiempo de ocurrencia del
evento en el estrato s-ésimo, tsi es el tiempo de ocurrencia de la i-ésima unidad de
investigación del estrato s-ésimo, xsi es el vector de covariables de la i-ésima unidad
de investigación del estrato s-ésimo, xsl es el vector de covariables de la l-ésima
unidad de investigación del estrato s-ésimo y R(tsi,s) es el conjunto de unidades a
riesgo en el tiempo tsi del estrato s-ésimo la función de verosimilitud parcial de este
modelo esta dada por:
( )
'
'1 1
,
( )d s s si
s il R t s s slsl
exp b xL b
exp b x≥ =∈
⎛ ⎞⎟⎜ ⎟⎜ ⎟⎜⎝ ⎠= ⎛ ⎞⎟⎜ ⎟⎜ ⎟⎜⎝ ⎠
∏∏∑
(5.2)
5.2.1.2 Segundo modelo de PWP (modelo PWP02)
En el segundo modelo de PWP, al igual que el primer modelo de PWP, los riesgos
instantáneos en cada estrato están en función de los coeficientes de las covariables del
estrato s-ésimo (bs), de los riesgos instantáneos base (hos) del estrato y del vector de
covariables xi. La diferencia fundamental con el modelo PWP01 es que se utilizan los
tiempos de interocurrencia (brecha de tiempo o gap time en lengua inglesa), que son los
tiempos medidos entre ocurrencias. Los tiempos de interocurrencia se miden desde el
momento de culminación del evento inmediatamente anterior hasta el momento de la
nueva ocurrencia. Este modelo también entra en la clasificación de los modelos
condicionales. La función de riesgo para la i-ésima unidad de investigación, esta dada por:
( ) ( )'
0 1/ ,
b xs i
s i s sh t b x h t t e
−= − × (5.3)
donde h0s(t-ts-1) es el riesgo instantáneo base en el estrato s-ésimo en el momento t-ts-1.

Capítulo V. Modelos de Supervivencia con Eventos Recurrentes ______________________________________________________________________
57
El segundo modelo PWP considera una función de riesgo instantáneo base por cada
estrato, que al igual que el primer modelo, produce una función de riesgo instantáneo
para cada estrato. La función de verosimilitud parcial de este modelo, se define como:
( )
'
'1 1
,
( )d s s si
s il R u s s slsl
exp b xL b
exp b x≥ =∈
⎛ ⎞⎟⎜ ⎟⎜ ⎟⎜⎝ ⎠= ⎛ ⎞⎟⎜ ⎟⎜ ⎟⎜⎝ ⎠
∏∏∑
(5.4)
donde ds es el máximo tiempo de ocurrencia del evento en el estrato s-ésimo, tsi es el
tiempo de ocurrencia de la i-ésima unidad de investigación del estrato s-ésimo, xsi(tsi) es
el vector de covariables de la i-ésima unidad de investigación del estrato s-ésimo en
el tiempo tsi, xsl(tsi) es el vector de covariables de la l-ésima unidad de investigación
del estrato s-ésimo en el tiempo tsi y R(usl,s) es el conjunto de unidades a riesgo en el
tiempo usl=tsl-t(s-1)l del estrato s-ésimo y quienes han experimentado s-1 eventos.
5.2.2 Modelo de Andersen-Gill (modelo AG) Andersen-Gill (1982) propusieron un modelo semiparamétrico de riesgos
proporcionales para eventos recurrentes, asumiendo que los eventos son del mismo tipo
y que la función de supervivencia y la funciones de riesgo instantáneo y acumulados se
estiman en los momentos calendarios de ocurrencia del evento, medidos desde el inicio
del estudio de la unidad experimental hasta los momentos de ocurrencia. La estructura
de datos para el modelo de Andersen-Gill es similar a la estructura de datos utilizada en
el primer modelo PWP con la diferencia que en este modelo la función de riesgo base
no se estratifica. El resultado será una única función de riesgo para todas las unidades
experimentales. En este modelo una unidad siempre estará en riesgo al menos que sea
censurada. Esto ocasiona que sucesos previos en la unidad experimental puedan influir
en la ocurrencia de eventos posteriores. Por esta razón este modelo es considerado
como un modelo condicional. La función de riesgo instantáneo h(t,xi) para la i-ésima
unidad de investigación en este modelo, esta dada por:
( ) ( ) ( )
0h , h '
i i it x Y t t exp b x⎡ ⎤= ⎣ ⎦ (5.5)
donde h(t ,xi) es el riesgo instantáneo de la i-ésima unidad de investigación en el tiempo
t. Yi(t) es un indicador igual a uno cuando la i-ésima unidad de investigación esta en

Capítulo V. Modelos de Supervivencia con Eventos Recurrentes ______________________________________________________________________
58
riesgo en el tiempo t y cero en otros casos, h0(t) es el riesgo base en el tiempo t, b es el
vector de coeficientes del modelo y xi es el vector de covariables de la i-ésima unidad
medido al inicio de su período de observación.
La función de verosimilitud parcial de este modelo esta dada por:
( )( )
( )
( )
1 0
1
'
'
ti
ni i
ni t
j ji
Y t exp b xL b
Y t exp b x
δ
= >
=
⎡ ⎤⎢ ⎥⎡ ⎤
⎣ ⎦⎢ ⎥=⎢ ⎥
⎡ ⎤⎢ ⎥⎢ ⎥⎣ ⎦⎢ ⎥⎣ ⎦
∏∏∑
(5.6)
donde δi(t) es igual a uno si la i-ésima unidad de investigación experimenta el evento en
el tiempo t y cero en otros casos. Más detalles sobre las estimaciones de los
coeficientes de este modelo pueden verse en Threneau-Grambsch (2000), Lee-Wang
et al. (2003) y Keinbaum-Klein (2005).
5.2.3 Modelo Wei-Lin-Weissfeld ( modelo WLW )
Wei et al. (1989) propusieron un modelo marginal para el análisis de supervivencia con
eventos recurrentes. Este modelo es también una extensión del modelo de riesgos
proporcionales de Cox y consiste en un modelo estratificado definido por las
recurrencias de los eventos considerados. Los eventos pueden ser del mismo tipo o de
diferentes naturaleza. En este modelo todas las unidades experimentales aparecen en
todos los estratos. Los estimadores finales son una media ponderada de los estimadores
en cada estrato. Cada unidad de investigación está en riesgo desde el inicio del estudio y
la ocurrencia de cada de evento no depende de ninguna ocurrencia previa, el tiempo de
ocurrencia del evento en cada unidad experimental se mide desde el inicio de su periodo
de observación. La función de riesgo para la i-ésima unidad de investigación en el s-
ésimo estrato, esta dada por:
( ) ( ) ( )
0h h '
si si s s sit Y t t exp b x⎡ ⎤= ⎢ ⎥⎣ ⎦ (5.7)
donde hsi (t) es el riesgo instantáneo de la i-ésima unidad de investigación en el
s-ésimo estrato, en el momento, Ysi(t) es una variable indicatriz, que es igual a uno
cuando la i-ésima unidad de investigación está en riesgo en el s-ésimo estrato e igual a

Capítulo V. Modelos de Supervivencia con Eventos Recurrentes ______________________________________________________________________
59
cero en otros casos, hs0(t) es la función riesgo instantáneo base en el s-ésimo estrato en
el momento t, a la que hay que estimar ya que esta función no está especificada, bs es el
vector de coeficientes del modelo en el s-ésimo estrato y xsi es el vector de covariables
de la i-ésima unidad de investigación en el s-ésimo estrato. La función de verosimilitud
parcial para el s-ésimo estrato, esta dada por:
( ) ( )( )1
exp( ' )
exp '
in
s sis s
i l R t s sls si
b xL b
b x
δ
= ∈
⎡ ⎤⎢ ⎥⎢ ⎥= ⎢ ⎥⎢ ⎥⎣ ⎦
∏∑
(5.8)
5.3 Modelos no paramétricos
5.3.1 Modelos de Fragilidad
Los modelos de fragilidad asumen que existe una variable aleatoria no medible en la
función de riesgo que afecta la ocurrencia de los eventos de estudio. Esta variable es la
causante de la variabilidad o heterogeneidad de los individuos en los grupos. La
fragilidad se asume independiente de la censura. Generalmente, la variación puede
surgir de variables comunes en las unidades experimentales, no observables, que se
omiten y que generan la dependencia, o bien puede provenir de covariables
individuales, no observadas, no incluidas en el estudio. Esa variable de fragilidad,
generalmente denotada como Zi, se introduce en los modelos en forma multiplicativa y
usualmente se asume que su distribución de probabilidades es la gamma. Si se utiliza el
modelo AG, el nuevo modelo queda planteado como:
( ) ( ) ( )h / , Y h '
i i i i o it x z z t t exp b x⎡ ⎤= ⎢ ⎥⎣ ⎦ (5.9)
Si la variabilidad (medida por su varianza) de la fragilidad es igual a cero, este modelo
se reduce al modelo AG. En otros casos, la estimación de los parámetros utilizando
directamente la función verosimilitud parcial no es posible, por lo que debe acudirse a
otros procedimientos iterativos como el algoritmo EM. Los modelos frágiles son
modelos de regresión de efectos aleatorios, ampliamente utilizados en análisis de
sobrevivencia. Estos modelos fueron introducidos por Vaupel et al. (1990). Una breve
introducción es presentada por Hougaard (1995). Una excelente presentación es dada
por Andersen et al. (1993). La extensión para el caso multivariado es desarrollada por
Hougaard (2000).

Capítulo V. Modelos de Supervivencia con Eventos Recurrentes ______________________________________________________________________
60
Generalmente, cuando se estudian fenómenos de carácter recurrente, los investigadores
pueden estar interesados en determinar el efecto marginal de las covariables sobre la
función de riesgo de los tiempos de ocurrencia de las unidades experimentales. En ese
caso lo recomendable es recurrir a los modelos marginales de supervivencia, como el
WLW. En algunas ocasiones, se puede estar interesado en la influencia de ocurrencias
pasadas de un evento en la ocurrencia de eventos futuros. Si éste es el caso, lo
recomendable es recurrir a modelos como los PWP y el AG. En ambos casos se asume
la independencia en los tiempos de interocurrencia del evento y que los riesgos entre
individuos son proporcionales. Pero, ¿qué pasa si esta presente la hetocedasticidad en la
muestra?, ¿qué sucede cuando existen problemas de correlación en los tiempos de
interocurrencia?, ¿qué sucede cuando en la muestra hay una mezcla de individuos de
poblaciones diferentes?, ¿es posible utilizar los modelos expuestos hasta ahora?. La
respuesta es no. Hay que recurrir a otros modelos que consideren estas situaciones
especiales particulares. Es bien conocido que en situaciones de la vida real los tiempos
de ocurrencia de un evento recurrente en las unidades experimentales pueden estar
correlacionados, debido a que existen individuos en la muestra que pueden estar
vinculados por una característica común. Como el caso por ejemplo, del estudios de
pacientes con enfermedades del corazón, donde algunos individuos tienen relaciones de
parentesco. A estos grupos de “familias”, se les suele llamar cluster. En estos casos, los
modelos anteriormente discutidos diferentes al modelo de fragilidad no son adecuados.
Hay que recurrir entonces a otros modelos. Entre la bibliografía que trata estas
situaciones particulares, podemos citar a Andersen et al. (1993) y Klein-
Moeschberger (2005), quienes además incluyen modelos tipo paramétrico no
discutidos en este trabajo.
5.3.2. Modelo Wang-Chang ( modelo WC ) Wang-Chang (1999) propusieron un modelo marginal de la función de supervivencia
que considera tanto el caso donde existe independencia entre los tiempos de
interocurrencia del evento como aquellos en los que existe correlación entre ellos. El
estimador propuesto por Wang-Chang (WC) se define mediante dos procesos de
conteo, d*(t) y R*(t). El primero representa el número de individuos con tiempos de
interocurrencia iguales a t cuando ocurre al menos un evento, y el segundo representa
el promedio de individuos que están en riesgo en el tiempo t. El estimador de la función

Capítulo V. Modelos de Supervivencia con Eventos Recurrentes ______________________________________________________________________
61
de supervivencia propuesto por este autor tiene la misma forma que el estimador del
limite-producto de Kaplan-Meier:
( )( )( )
*
*1 :
ˆ 1n
ij
i j T tij ij
d TS t
R T= ≤
⎡ ⎤⎢ ⎥⎢ ⎥= −⎢ ⎥⎢ ⎥⎢ ⎥⎣ ⎦
∏ ∏ (5.10)
donde Tij es el j-ésimo tiempo de interocurrencia del evento de la i-ésima unidad
bajo estudio.
Figura 5.1 Representación gráfica de la recurrencia de eventos en la i-ésima unidad.
Sij es el j-ésimo tiempo calendario de ocurrencia del evento de la i-ésima unidad de
investigación, con Si0 = 0 y Sij = Ti1+ Ti2+…+ Tiki.. Ki es el número de eventos
que experimenta la i-ésima unidad, Ki = max j:j=1,2,… y Sij ≤ τi, τi es el tiempo
total de observación de la i-ésima unidad de investigación y n es el número total de
tiempos de interocurrencias del evento. (Ver figura 5.1 y tabla 5.1)
Tabla 5.1 Tiempos de interocurrencias del evento en las unidades bajo estudio.
Unidad
i Ki
Tiempos de interocurrencia
Tij
Tiempo de estudio
τi 1 K1 T11,T12,…,T1ki τ1
2 K2 T21,T22,…,T2ki τ2
. . …... .
. . …... .
n Kn Tn1,Tn2,…,Tnki τn
Evento no observado
Si0 = 0 Si1
Fin del estudio
Si2 Si3
Ti1 Ti2 Ti3 τi -Ti3
τi
Tiempos calendarios
Tiempos de interocurrencias
Tiempo de estudio

Capítulo V. Modelos de Supervivencia con Eventos Recurrentes ______________________________________________________________________
62
Además, se tiene que:
( ) ∑ ∑= = ⎭
⎬⎫
⎩⎨⎧
=>
=n
i
K
jij
i
ii
tTIK
KItd
1 1*
* 0 (5.11)
donde:
⎩⎨⎧
>=
=0
01*
ii
ii KsiK
KsiK (5.12)
y,
( ) ∑ ∑= =
⎥⎦
⎤⎢⎣
⎡=≥−+≥=
n
i
K
jiiKiij
i
i
iKItSItTI
KtR
1 1*
* 01 τ (5.13)
5.3.3 Modelos de Peña-Strawderman-Hollander (PSH) 5.3.3.1 Modelo de Kaplan-Meier generalizado (modelo GPLE) Peña et al. (2001) propusieron dos modelos para analizar fenómenos con eventos
recurrentes utilizando análisis de supervivencia. En su trabajo, estos autores resuelven
tres aspectos de interés inherentes a esta problemática, como son: i) La distribución de
la primera ocurrencia del evento. Generalmente, el tiempo hasta la primera ocurrencia
en este tipo de fenómenos, se comporta de manera diferente a los tiempos de
interocurrencias posteriores. ii) Correlación entre los tiempos de interocurrencias y iii)
El efecto de covariables sobre los tiempos de interocurrencias. En el primer modelo
estos autores proponen un estimador no paramétrico, bajo el supuesto de individuos
idénticamente distribuidos, que generaliza el estimador clásico de supervivencia de
Kaplan-Meier al caso de eventos recurrentes y resuelven el problema mediante el uso de
procesos de conteo, utilizando las ideas de Gill (1980) y Selke (1988).
Los procesos contadores propuestos, denotados mediante N e Y, están doblemente
indexados, debido a que se miden en dos escalas de tiempo: un tiempo calendario (S)
que describe el tiempo que transcurre desde el inicio del estudio hasta un momento
determinado, y otra escala de tiempo T que mide la longitud de los tiempos entre
ocurrencias. Los procesos contadores son N[s,t] que mide la cantidad de eventos con
tiempos de interocurrencia menor o igual a t en el intervalo de tiempo calendario [0,s],

Capítulo V. Modelos de Supervivencia con Eventos Recurrentes ______________________________________________________________________
63
e Y[s,t] que mide el número de eventos con tiempo de interocurrencia mayor o igual a t
en el tiempo calendario [0,s].
Supóngase que se dispone de n unidades bajo estudio, independientes entre sí, y sea Tij
el tiempo transcurrido entre la (j-1)-ésima ocurrencia y la j-ésima en la i-ésima
unidad, para todo i = 1,2, …, n y j = 1,2, …,Ki, con:
: 0,1,2,... :i iK iiK max j j S= ∈ ≤ τ (5.14)
Ki representa el máximo número de ocurrencias del evento que experimenta la i-ésima
unidad en el intervalo [0, τi], siendo τi el período de observación correspondiente a la i-
ésima unidad. Se asume que estos los períodos de observación son variables aleatorias
independientes e idénticamente distribuidas (iid) con una distribución de
probabilidades G(w) = Pτi ≤w, y que los Tij son variables aleatorias iid con una
función de distribución acumulada continua igual a F(t )= PTij ≤ t. Si se asume que
Si0=0, entonces:
'' 0
1,2,..., 1,2,...,j
ij ij ijS T i n j K
== ∀ = ∧ =∑ (5.15)
El vector de variables aleatorias observables para la i-ésima unidad experimental, está
dado por:
1 2, , , ,..., ,i i i i iK i iKi iK T T T T⎛ ⎞τ τ −⎜ ⎟⎝ ⎠
Es obvio que la observación de la última variable en ese vector es redundante, ya que
puede obtenerse a partir de las observaciones restantes del vector. Los procesos
contadores agregados para las n unidades se denotan mediante las siguientes
expresiones:
1
( , ) ( , )n
iiN s t N s t
== ∑ (5.16)
( ) ( )1
, ,n
iiY s t Y s t
== ∑ (5.17)
donde:
( ) ( )
1, 1,2,...,
K si
i ijjN s t I T t i n
−
== ≤ ∀ =∑ (5.18)

Capítulo V. Modelos de Supervivencia con Eventos Recurrentes ______________________________________________________________________
64
siendo Ki(s-) el máximo número de eventos que experimenta la i-ésima unidad en el
intervalo [0,s) y:
( ) ( )
( )1, ( , ) 1,2,...,
K si
i ij i iK sijY s t I T t I min s S t i n
−
−== ≥ + τ − ≥ ∀ =∑ (5.19)
Peña y colaboradores definen el estimador de la función de supervivencia en eventos
recurrentes, como una generalización del estimador clásico de límite producto de
Kaplan-Meier. Para ello establecen una analogía entre la información requerida por este
último estimador y la correspondiente al caso de fenómenos con recurrencia. En
consideración a lo anterior y utilizando los procesos contadores, se definen dos
conceptos fundamentales:
N(s,∆w) =N(s,t+∆w)-N(s,w) número de eventos en el intervalo [0,s] cuyos tiempos
de interocurrencia son exactamente iguales a w. Este concepto se corresponde con el término dj que mide el numero de ocurrencias en el momento tj del análisis clásico.
Y(s,w) número de eventos en el intervalo [0,s] cuyos tiempos
de interocurrencia son iguales o mayores a w. Este concepto esta en concordancia con el término nj que describe el numero de unidades que han sobrevivido al momento tj.
El estimador de la función de supervivencia para el caso de recurrencia de los eventos
propuesto por Peña et al. (2001) generaliza el estimador límite del producto de Kaplan-
Meier (modelo GPLE),
( )( )
,ˆ( ) 1,w t
N s wS t
Y s w≤
⎡ ⎤∆= −⎢ ⎥
⎣ ⎦∏ (5.20)
Los autores demuestran que la varianza de este estimador está dada por:
( )ˆVar σ2 2
PSHS(t) = S t × (t) (5.21)
Estos autores, señalan que:
( )( ) ( )
2
0
( , )ˆ( , ) , ,
t
PSH
N s dwtY s w Y s w N s w
σ =− ∆⎡ ⎤⎣ ⎦
∫ (5.22)
así que:

Capítulo V. Modelos de Supervivencia con Eventos Recurrentes ______________________________________________________________________
65
( )ˆ ˆˆ ˆVar σ2 2
PSHS(t) = S t × (t) (5.23)
El estimador de varianza de este modelo es similar al estimador clásico de la función de
supervivencia de Kaplan-Meier para datos censurado por la derecha, tal y como se
ilustró en la expresión 3.22. En caso de no existir empates en los tiempos de
interocurrencia, la varianza del estimador se puede determinar a través de la siguiente
expresión:
( ) ( )2
1 1ˆ ( )
, , 1
n K i ij
PSHi j
ij ij
I T tt
Y s T Y s T= =
≤σ =
⎡ ⎤−⎢ ⎥⎣ ⎦
∑∑ (5.24)
donde:
( ) 1 1
,n K i
ij ik ij i iK ijii kY s T I T T I S T
= =
⎧ ⎫⎪ ⎪= ≥ + τ − ≥⎨ ⎬⎪ ⎪⎩ ⎭
∑ ∑ (5.25)
5.3.3.2 Modelo de fragilidad multiplicativa (modelo FRMLE)
Peña et al. (2001) propusieron otro modelo de supervivencia para eventos recurrentes
que considera la fragilidad que presentan las unidades experimentales en la ocurrencia
de un evento en particular. Los autores lo llamaron Estimador de Fragilidad Máximo
Verosímil denotado como (FRMLE), por sus siglas en inglés de “FRagilty Maximun
Likelihood Estimator”. En este trabajo los autores consideran la correlación entre los
tiempos de interocurrencia de eventos y proponen un modelo para estimar la función
marginal de supervivencia, que considera que la correlación esta inducida por una
variable con distribución gamma de parámetro de escala y forma iguales a α,
respectivamente.
El problema de individuos con comportamiento correlacionado no es considerado en los
modelos anteriores, por lo que los autores introducen en su modelo una variable de
fragilidad que recoge la heterogeneidad de los individuos. Entendiéndose por
heterogeneidad la existencia de subgrupos de individuos más susceptibles a
experimentar la ocurrencia del evento que otros.
Para describir esta correlación en el modelo, se define una variable positiva, no
observable, digamos Zi, con Z1,Z2, ….,Zn como variables aleatorias independientes e

Capítulo V. Modelos de Supervivencia con Eventos Recurrentes ______________________________________________________________________
66
idénticamente distribuidas con una distribución HZ. La función de supervivencia la
condicionada viene dada por:
( ) ( )[ ] ( ) ( )duuzZtSotSzZtS i
zi
∫====t0 0
0
z-// e λ (5.26)
donde λ0(t) es la función de riesgo base, S0(t) es la función de supervivencia base y
Z1, Z2,…, Zn son las fragilidades, que se asumen independientes de la censura e
idénticamente distribuidas, con una cierta distribución H. En el modelo Peña et al.
(2001), H es una distribución gamma, con parámetros de forma y escala iguales a α.
Como consecuencia de esto, la función de supervivencia conjunta de (Ti1,Ti2,…,Tik) para
un determinado k, está dada por:
( ) ( ) ( )1
0 01
zk z
jjdzS t S t z e
αα− −α∞
=∏∫⎡ ⎤ α⎢ ⎥= ⎢ ⎥ Γ α⎣ ⎦
( )01
( ) k
jj
S tt
α
=∑
⎡ ⎤⎢ ⎥
α⎢ ⎥= ⎢ ⎥⎢ ⎥α+ Λ⎢ ⎥⎢ ⎥⎣ ⎦
(5.27)
Como los tiempos de interocurrencias son independientes, la función de supervivencia
conjunta,
( ) ( )
α
αα
⎥⎦
⎤⎢⎣
⎡Λ+
=t
tS0
(5.28)
siendo Λ0(t) la función marginal de riesgo acumulada.
Las estimaciones semiparamétricas de las funciones de supervivencia fueron discutidas
por Nielsen et al. (1992) y Dempster et al. (1977) entre otros. Peña et al. (2001),
demostraron que α y Λ0(t) pueden ser obtenidas vía maximización de la función
marginal de verosimilitud y con una implementación del algoritmo EM (Expectation-
Maximization). De esta forma el estimador de (5.28), estaría dada por:
( ) ( )
α
αα
⎥⎦
⎤⎢⎣
⎡Λ+
=ts
tS,ˆˆ
ˆˆ0
(5.29)
donde ( )ts,ˆ
0Λ es un estimador de la función marginal de riesgo acumulado Λ0(t).

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
67
Capitulo VI PRUEBAS DE COMPARACIÓN EN EL ANÁLISIS DE SUPERVIVENCIA
6.1 Introducción El objetivo de este capítulo es dar a conocer una serie de estadísticos de prueba que se
utilizan para comparar curvas del análisis de supervivencia tradicional, provenientes de
dos o más subgrupos poblacionales, definidos a través de la estratificación de una
variable de interés. Esta variable puede representar una medida importante que permite
formar dichos subgrupos y de los cuales se sospecha que existan diferencias
significativas en sus curvas de supervivencia. El objetivo de la comparación en el
análisis de supervivencia es parecido a aquellos procedimientos diseñados para
comparar estadísticos provenientes de muestras independientes, como la prueba t, la
prueba de los signos, la prueba no paramétrica de los rangos signados de Wilcoxon
(1945), la prueba U de Mann-Whitney (1947), la prueba de Kruskal-Wallis
(1952), la prueba ponderada de Cochran (1954) y la prueba de análisis de varianza de
dos o más vías. Todas estas pruebas de comparación se utilizan para evaluar diferencias
entre estadísticos que han sido estimados con base en la información que se obtiene de
estos subgrupos, y la mayoría tiene la limitante de que se sólo pueden ser utilizados en
casos sin datos censurados. Esta es la razón que imposibilita su aplicación directa en la
comparación de subgrupos en el análisis de supervivencia. Por ello, muchos
investigadores se han dedicado a diseñar pruebas de comparación específicas para este
tipo de análisis.
Cuando se realizan estudios de supervivencia, generalmente los investigadores se
plantean dos objetivos. El primer consiste en la estimación e interpretación de la función
de supervivencia y funciones afines, y el segundo corresponde a la comparación de
estas funciones en los subgrupos considerados. Para alcanzar este último objetivo
muchos autores han planteado y desarrollado una diversidad de pruebas estadísticas. La
mayor parte de ellas han sido diseñadas para el caso de no recurrencia (debido a que la
unidad bajo estudio solo experimenta una ocurrencia del evento). Entre las más
utilizadas para comparar curvas de supervivencia en el análisis tradicional podemos
mencionar la prueba del logaritmo del rango (logrank) propuesta por Mantel-Haenszel
(1959), la prueba generalizada de Wilcoxon propuesta por Gehan (1965), la prueba de
Mantel (1967), la prueba generalizada de Kruskal-Wallis propuesta por Breslow
(1970), la prueba de Cox (1972), la prueba de Peto-Peto (1972), la prueba de Tarone-

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
68
Ware (1977), la prueba de rangos lineales con datos censurados por la derecha
propuesta por Prentice (1978), la prueba de Tarone (1981), la prueba de Harrington-
Fleming (1982) que generaliza parte de las pruebas anteriores y una versión más
general propuesta por Fleming et al. (1987). Todas ellas han sido diseñadas para
comparar dos o más subgrupos poblacionales en el análisis de supervivencia tradicional
donde se considera una única ocurrencia del evento en la unidad bajo estudio. Detalles
sobre estas pruebas se pueden consultar en: Therneau et al. (1990), Fleming-
Harrington (1991), Andersen-Borgan-Gill-Keiding (1991), Allison (1995),
Therneau-Hamilton (1997), Hosmer-Lemeshow (1999), Therneau-Grambsch
(2000), Kalbfleisch-Prentice (2002), Barceló (2002), Collet (2003), Prentice-
Kalbfleisch (2003), Lee-Wang (2003) o Keinbaum-Klein (2005).
Desde la década de los 90 han surgidos nuevos modelos que permiten realizar este tipo
de análisis para el caso recurrente. En una revisión exhaustiva de la bibliografía
especializada sólo se logró detectar tres trabajos que consideran pruebas de
comparación en fenómenos de este tipo: Pepe-Cai (1993), Glyn-Buring (1996) y
Doganaksoy-Nelson (1998). En este capítulo se describen estas tres pruebas, lo que
nos permite disponer de un marco teórico sólido que las fundamenta y nos da una
oportunidad para cotejarlas con las propuestas que plantearemos en los últimos tres
capítulos de este trabajo.

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
69
6.2 Pruebas de contraste no paramétricas para comparar muestras con datos no censurados.
La mayor parte de los contraste de hipótesis requieren varios supuestos acerca de la
distribución de la población cuyas muestras se analizan. El más común de ellos es que
se asume que las muestras provienen de poblaciones con distribución normal. En
aquellos casos en que estos supuestos no se cumplen, se utilizan métodos de
comparación independientes de las distribuciones poblacionales y de los parámetros
asociados a éstas. En esta sección se presentarán algunas de estas pruebas no
paramétricas.
6.2.1 Prueba de los signos
La prueba de los signos es un método no paramétrico que permite contrastar la igualdad
de dos medianas poblacionales. Sea Di la variable definida como el valor absoluto de la
diferencia entre dos observaciones:
1, 2, ...,
i i iD X Y i n= − ∀ = (6.1)
Las variables aleatorias Di se asumen independientes. Se consideran únicamente las r
Di no nulas (r ≤ n). Si se asume que los datos provienen de poblaciones con la misma
mediana, debe verificarse que P(Xi<Yi) = P(Xi>Yi) = 0.5. De modo que para que la
Hipótesis de igualdad de las medianas poblacionales H0: Mx=My, sea cierta debería
haber tantos valores Xi<Yi, como valores Xi>Yi , salvo las fluctuaciones atribuibles al
azar propio del proceso de muestreo. Bajo estas condiciones se definen las variables:
n+ = Número de observaciones donde Xi<Yi
n− = Número de observaciones donde Xi>Yi
Estas variables se distribuyen según el modelo binomial con parámetros (n=r;p=0.5). Si
se toma el valor z = min(n+,n-) y utilizando una prueba bilateral se puede contrastar la
hipótesis de igualdad de las medianas. Si el tamaño de la muestra es suficientemente
grande y r suficientemente pequeño, el modelo binomial se puede aproximar a través de
un modelo normal, utilizando la siguiente aproximación:

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
70
0.5
20.5
rzZ
r
+ −= (6.2)
6.2.2 Prueba de Wilcoxon
La prueba propuesta por Wilcoxon (1945), conocida hoy en día como prueba de los
rangos signados, es un método no paramétrico que permite comparar si las medias de
dos muestras difieren. Supóngase que se dispone de dos muestras con n observaciones
cada una. Sea xi la observación que proviene de la primera muestra e yi la observación
que proviene de la segunda muestra. Sea Di la variable definida como el valor absoluto
de la diferencia entre las variables Xi e Yi , entonces:
1, 2, ...,
i i iD X Y i n= − ∀ = (6.3)
Las variables aleatorias Di se asumen independientes. Se consideran únicamente las r
Di no nulas (r ≤ n). Se ordenan las Di en forma creciente y se les asigna el rango Ri. En
caso de empates, se resuelve asignando el promedio de los rangos de las Di
correspondientes.
Sea θi = Ixi > yi la variable indicatriz que vale uno cuando xi > yi y cero en otro caso,
y sea:
1
r
i iiW R+
== θ∑ (6.4)
Sea δi = Ixi < yi la variable indicatriz que vale uno cuando xi < yi y cero en otro caso,
y sea:
1
r
i iiW R
−
== δ∑ (6.5)
Si la distribución de las diferencias Di es simétrica, W+ y W-, tomaran valores parecidos.
Fuerte discrepancia hará dudar de la veracidad de la hipótesis de igualdad de las
medianas. Si W se toma como el menor entre W+ y W- y se tipifica, obtenemos:

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
71
3
1
( 1)4
( 1)(2 1)24 48
k
i
n nWZ
n n n t t=
+−=
+ + −−∑
(6.6)
donde k se refiere al número de rangos distintos en los que existen empates y ti es el
número de observaciones empatadas en el rango i.
6.2.3 Prueba de Mann-Whitney
La prueba de Mann-Whitney (1947) es un método no paramétrico que se utiliza para
contrastar dos muestras independientes cuyos datos han sido obtenidos, al menos en una
escala ordinal. Esta prueba también se conoce como estadístico U y es una excelente
alternativa a la prueba t sobre diferencias de medias cuando no se cumplen los supuestos
de normalidad y homocedasticidad. Considérense dos muestras independientes de
tamaños n1 y n2, respectivamente, que se supone provienen de la misma población. Sea,
xi la observación de proveniente de la primera muestra e yi la observación proveniente
de la segunda muestra. Al combinarse las dos muestras, se dispone de n = n1+n2
observaciones. Se considera la muestra combinada, se ordenan las n observaciones y se
le asigna el rango Ri correspondiente. En caso de empates, se resuelve asignando el
promedio de los rangos de las observaciones con esa condición.
Sea θi = Ixi ∈ X la variable indicatriz que vale uno cuando xi ∈ X y cero en otro caso
y sea:
1 1
n
i iiS R
== θ∑ (6.7)
Sea δi = Ixi ∈ Y la variable indicatriz que vale uno cuando xi ∈ Yi y cero en otro caso
y sea:
2 1
n
i iiS R
== δ∑ (6.8)
Se definen los estadísticos:
( )1 1
1 1 2 1
1
2
n nU n n S
+= − − (6.9)

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
72
( )2 2
2 1 2 2
1
2
n nU n n S
+= − − (6.10)
El estadístico de contraste U:
1 2
1 1
1 22 2
2
2
n nU si U
U n nU si U
⎧⎪⎪ <⎪⎪⎪=⎨⎪⎪ >⎪⎪⎪⎩
(6.11)
Para valores de n1 y n2 suficientemente grandes, se puede tipificar la variable U y
trabajar con la variable Z:
( )
3 3
1 2
1
( 1)2
1 12 12
k
i
n nUZ
n n n n t tn n =
+−=
⎡ ⎤− −⎢ ⎥−⎢ ⎥− ⎢ ⎥⎣ ⎦∑
(6.12)
donde k se refiere al número de rangos distintos en los que existen empates y ti es el
número de observaciones empatadas en el rango i.
6.2.4 Prueba de Kruskal-Wallis
Kruskal-Wallis (1952) generalizó la prueba de Mann-Whitney y propuso un estadístico
de contraste para comparar dos o más muestras independientes. Supóngase que existe
un lote de k muestras aleatorias independientes provenientes de una o varias
poblaciones, de tamaños: n1, n2,…, nk. Se considera al conjunto de observaciones como
una muestra combinada, se ordenan y se les asignan los rangos Ri correspondientes y en
caso de empates se resuelve asignando el promedio de los rangos de observaciones con
esa condición.
Sea Xj es la variable de interés en la j-ésima muestra, xij la i-ésima observación en la j-
ésima muestra y θij = Ixij ∈ Xj la variable indicatriz que vale uno cuando xij ∈ Xj y
cero en otro caso.
Sean además:
1
1, ...,n
j i j iiS R j k
== θ ∀ =∑ (6.13)

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
73
1, 2, ...,jj
j
SS j k
n= ∀ = (6.14)
Se define el estadístico de prueba de igualdad de la hipótesis de igualdad de las
medianas como:
( )
( )
2
1
12 3 11
kj
j j
SH n
n n n== − +
+ ∑ (6.15)
Bajo la hipótesis nula de que los k grupos poblacionales son iguales, el estadístico H
tiene una distribución chi-cuadrado con k-1 grados de libertad.
6.2.5 Prueba de Cochran
Cochran (1954) sugirió un estadístico de contraste para comparar las diferencias
ponderadas correspondientes a dos tratamientos, que han sido cruzados con r variables
dicotómicas asociadas. Utilizando la notación de Cochran, para la z-ésima tabla se
tendrá que nz1 y nz2 son los tamaños de las muestras para los dos tratamientos, pz1 y pz2
proporciones observadas de respuestas favorables para los dos tratamientos y:
Pz = (nz1pz1+nz2pz2)/(nz1+nz2)
Qz = 1-Pz
dz = pz1 - pz2
wz = nz1nz2/(nz1+nz2)
La prueba propuesta por Cochran se define mediante:
11
22
1
p
z zz
p
z z zz
w dY
w P Q
=
=
=⎡ ⎤⎢ ⎥⎢ ⎥⎢ ⎥⎣ ⎦
∑
∑
(6.16)
Bajo la hipótesis nula Y se distribuye normal de media cero y varianza uno, así que su
cuadrado tiene una distribución chi-cuadrado con un grado de libertad. Radhakrishna
(1965) investigó la eficiencia de la selección de los pesos en la combinación de tablas
de contingencias 2x2 para varias alternativas de la forma f(pz1) - f(pz2) = ∆; donde f(p)
es una función monótona conocida para 0<p<1 y ∆ constante. Para diferencias
constantes mostró la eficiencia relativa para varias escalas como la logit, la probit, la

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
74
arcsen, la aritmética, la constante, la logarítmica y la raíz cuadrada. El método de
comparación mayormente utilizado que permite medir independencia o asociación entre
datos provenientes de grupos poblacionales es el referido a la combinación de varias
tablas de contingencias de tamaño 2x2.
6.3 Pruebas de contraste no paramétricas para comparar curvas del análisis de supervivencia clásico
6.3.1 Prueba de Mantel-Haenszel Mantel-Haenszel (1959) propusieron un estadístico que permite relacionar las pruebas
de asociación de las tablas de contingencia con los contrastes de igualdad de curvas de
supervivencia entre subgrupos poblacionales. Supóngase que se quiere contrastar las
curvas de supervivencia de dos grupos poblacionales. Supóngase además que hay p
tiempos diferentes de ocurrencia del evento en el grupo combinado, digamos: t(1), t(2),…t(p) y que en el momento tz ocurren d1z eventos en el primer grupo y d2z eventos en
el segundo, para todo z = 1,2,…p. En cada momento tz, hay n1z unidades a riesgo en el
primer grupo y n2z unidades en el segundo. En consecuencia, en el momento tz
habrá nz = n1z + n2z unidades a riesgo en el grupo combinado y ocurrirán dz = d1z + d2z
eventos (ver tabla 6.1).
Tabla 6.1 Número de ocurrencias del evento en el momento tz para los grupos I y II.
Grupos
Número de ocurrencia
del evento
Número de unidades
sobrevivientes
Número de unidades en
riesgo justo antes t(z)
G1 d1z n1z – d1z n1z
G2 d2z n2z – d2z n2z
Combinados dz nz - dz nz
Si se considera que en el momento z-ésimo se tiene una población formada por dos
grupos, digamos G1 y G2 y se define la variable aleatoria d1z como el número de
eventos que ocurren en el grupo G1 en el momento tz. En ese momento se tiene un
población de tamaño nz definida por el total de individuos a riesgo, clasificada en dos
subpoblaciones de tamaños n1z para el grupo G1 y n2z para el grupo G2. Si se pudiera
considerar que el número de ocurrencias dz para los dos grupos combinados es una
muestra aleatoria sin reemplazamiento de la población anterior, entonces la variable

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
75
aleatoria d1z sigue una distribución hipergeométrica H(nz, n1z, dz) cuya media es igual a
dzn1z /nz y varianza:
Var d1z = dz z
z1
nn
z
z1z
nnn −
1ndn
z
zz
−− (6.21)
La hipótesis nula (Ho) que se desea contrastar es que no hay diferencia entre las curvas
de supervivencia de ambos grupos, lo que se logra evaluando la diferencia entre el
número de eventos observados y el número de eventos esperados en cada uno de los
momentos de ocurrencia, bajo los supuestos de Ho. Esto es equivalente a comparar el
número de eventos ocurridos en cualquiera de los grupos con respecto al número de
eventos esperados en el grupo combinado (Cochran, op. cit.). El estadístico de
contraste se basa en una función de la variable aleatoria definida por el número de
eventos en cada momento y se construye como una suma de variables aleatorias
independientes estandarizadas, bajo el supuesto de que las ocurrencias en un momento
determinado son independientes de las que ocurren en cualquier otro momento.
( )( )
1 11
11
p
z zz
p
zz
d E dZ
Var d
=
=
⎡ ⎤−⎢ ⎥⎣ ⎦=
∑
∑ (6.22)
Cochran (1954) demuestra que esta variable aleatoria se comporta como una
distribución normal tipificada y en consecuencia su cuadrado sigue una distribución χ2
con un grado de libertad. La prueba de Mantel-Haenszel (también conocida como
prueba logrank o test de riesgos proporcionales) es muy potente para detectar
diferencias cuando los logaritmos de las curvas de supervivencia son proporcionales.
Sin embargo, si las curvas de supervivencia se entrecruzan la prueba logrank presenta
problemas para detectar las diferencias.
6.3.2 Prueba generalizada de Wilcoxon, prueba de Gehan (primera propuesta) Gehan (1965a) propuso un estadístico que permite comparar curvas de supervivencia
en presencia de censuras arbitrarias por la derecha. Este estadístico generaliza el
estadístico de Wilcoxon (1945) y esta relacionado con el estadístico de Mann-Whitney
(1947) y el de Kendall (1955). Supóngase que se dispone de dos conjuntos de

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
76
observaciones de supervivencia de dos subgrupos poblacionales de tamaños n1 y n2,
respectivamente. Si r1 y r2 son los números de censuras por la derecha en ambos
grupos, entonces n1-r1 y n2-r2 son los números totales de ocurrencias del evento en los
grupos. Sean xi, yj son los tiempos de ocurrencias del evento en ambos grupos y xi’ e
yj’ los tiempos de censuras. Esquemáticamente:
' ' '
1 2 11
1 2 1 11 1 1
, , ....,1
, , ...,r
r r n
x x x r censurasGrupo
x x x n r tiempos de supervivencia+ +
⎫⎪⎪⎪⎪⎬⎪− ⎪⎪⎪⎭
' ' '
1 2 22
1 2 2 22 2 2
, , ....,2
, , ...,r
r r n
y y y r censurasGrupo
y y y n r tiempos de supervivencia+ +
⎫⎪⎪⎪⎪⎬⎪− ⎪⎪⎪⎭
Si F1 y F2 son las funciones de distribuciones acumuladas, las hipótesis que se desean
contrastar son:
H0: F1 = F2
H1: F1 ≠ F2
El estadístico de prueba de Gehan:
1 2
1 1
n n
i ji jW U
= ==∑∑ (6.23)
con:
'
' '
'
1
0
1
i j i j
i j i j i j j i
i j i j
si x y o x y
U si x y o x y o y x
si x y o x y
⎧⎪⎪ − < ≤⎪⎪⎪⎪⎪= = < <⎨⎪⎪⎪⎪ + > ≥⎪⎪⎪⎩
(6.24)
donde W se distribuye, para muestras grandes, aproximadamente con una ley normal de
media cero y varianza:
( )
1 2 21 2
1 11
n n
i ji j
n nVar W U
n n = ==
− ∑∑ (6.25)

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
77
Cuando los tamaños de las muestras son los suficientemente grandes (Gehan indica que
para tamaños de muestras mayores a veinticinco simultáneamente), el recomienda un
procedimiento equivalente, donde se agrupan la ocurrencia de los eventos y las censuras
en intervalos de tiempos no solapados, como se procede en las tablas de vida:
Tabla 6.2 Número de ocurrencias del evento y censuras en el intervalo i-ésimo de tiempo en el
1er grupo.
1er Grupo
Subintervalo Nº de eventosAcumulado del
Nº de eventos
Nº de eventos
Censurados
1 f11 F11 c11
. . . .
. . . .
i fi1 Fi1 ci1
. . . .
. . . .
s fs1 Fs1 cs1
donde fir representa el número de eventos en el i-ésimo subintervalo en el 1er grupo y
Fi1 el número acumulado de eventos que han ocurrido hasta el i-ésimo subintervalo en el
1er grupo:
1 11
i
i ijF f
==∑ (6.26)
La longitud de los subintervalos no necesariamente debe ser la misma. Gehan desarrolló
el estadístico que se muestra a continuación:
1 1 1,2 2 2 1,11
s
i i i i i iiW f c F f c F
− −=
⎡ ⎤ ⎡ ⎤= + − +⎢ ⎥ ⎢ ⎥⎣ ⎦ ⎣ ⎦∑ (6.27)
Para simplificar los cálculos en la estimación de la varianza de dicho estimador, Gehan
desarrolló, las siguientes expresiones:
1 2i i im f f= +
1,1 1,2i i i
l c c+ +
= +

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
78
1 21
i
i j jjM f f
=
⎡ ⎤= +⎢ ⎥⎣ ⎦∑
( ) 01 , 0
i i id M M d= + =
1
s
i jjL l
==∑
1 2 1i i i
e n n M L−
= + − −
1 2 1 1
3 1i i i i
f n n M m L− −
= + − − − −
donde la varianza se puede estimar a través de:
( )1 2
0 11 1 1/ ,
1
s s s
i i i i i i ii i i
n nVar W P H m d l d m e f
n n −= = =
⎡ ⎤⎢ ⎥= + +⎢ ⎥− ⎢ ⎥⎣ ⎦∑ ∑ ∑ (6.28)
La variable:
0/ ,
WZVar W P H
= (6.29)
se distribuye asintóticamente normal con media cero y varianza uno, donde P es el
patrón de observaciones. Para mayores detalles sobre la normalidad asintótica,
consistencia, y desarrollo del estimador de varianza puede consultarse el trabajo de
Gehan (1965).
6.3.3 Prueba de Gehan (segunda propuesta) Gehan (1965b) propone un estadístico que permite comparar curvas de supervivencia
para contrastar aquellos casos que no pueden ser estudiados por el método anterior. Esta
metodología permite la comparación de datos de supervivencia en presencia de censuras
arbitrarias tanto por la derecha, como por la izquierda. Supóngase ahora que se dispone
de dos conjuntos de observaciones de estudios de supervivencia, de tamaños n1 y n2,
respectivamente. Se define a r1 y r2 como los números de censuras por la derecha en
ambos grupos, s1 y s2 como los números de censuras por la izquierda en ambos grupos,
n1-r1 y n2-r2 como los números totales de ocurrencias del evento en ambos grupos, xi e
yj como los tiempos de ocurrencias del evento en ambos grupos, xi’ e yj’ como los

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
79
tiempos de censuras por la derecha y xi” e yj
” como los tiempos de censuras por la
izquierda. Esquemáticamente:
' ' '
1 2 11
" " "
1 2 11 1 1 1
1 2 1 1 11 1 1 1 1
, , ....,
1, , ....,
, , ...,
r
r r r s
r s r s n
x x x r censuras por la derecha
Grupox x x s censuras por la izquierda
x x x n r s tiempos de supervivencia+ + +
+ + + +
⎫⎪⎪⎪⎪⎪⎪⎪⎬⎪⎪⎪⎪− − ⎪⎪⎪⎭
' ' '
1 2 22
" " "
1 2 22 2 2 2
1 2 2 2 22 2 2 2 2
, , ....,
2, , ....,
, , ...,
r
r r r s
r s r s n
y y y r censuras por la derecha
Grupoy y y s censuras por la izquierda
y y y n r s tiempos de supervivencia+ + +
+ + + +
⎫⎪⎪⎪⎪⎪⎪⎪⎬⎪⎪⎪⎪− − ⎪⎪⎪⎭
Si F1 y F2 son las funciones de distribuciones acumuladas, las hipótesis que se desean
contrastar son:
H0: F1 = F2
H1: F1 ≠ F2
El estadístico de prueba de Gehan para este caso esta dado por:
1 2
1 1
n n
i ji jW U
= ==∑∑ (6.30)
donde W es la suma de todas las n1n2 comparaciones de las dos muestras, con:
' " '
' '
' ' "
1 ,
0
1 ,
i j i j i i j
i j i j i j j i
i j i j i i j
si x y o x y o x y y
U si x y o x y o y x
si x y o x y o x x y
⎧⎪⎪− < ≤ ≤⎪⎪⎪⎪⎪= = < <⎨⎪⎪⎪⎪+ > ≥ ≥⎪⎪⎪⎩
(6.31)
Gehan demostró que para muestras grandes W se distribuye según la ley normal de
media nula y varianza:
( )
1 2 21 2
1 11
n n
i ji j
n nVar W U
n n = ==
− ∑∑ (6.32)

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
80
Para muestras lo suficientemente grandes, Gehan propuso un método que agrupa las
observaciones censuradas y no censuradas, tal y como se discutió en la sesión 6.3.2.
mi = número de observaciones no censuradas con rango i correspondiente a los
distintos tiempos de ocurrencias una vez ordenados. li
- = número de observaciones censuradas por la izquierda con valores menores al rango i pero mayor al rango i-1.
li
+ = número de observaciones censuradas por la derecha con valores mayores al rango i pero menores al rango i-1.
La media y la varianza condicional de W bajo la hipótesis nula H0:
0/ , 0E W P H = (6.33)
( ) ( )( )
( )
( )( )
1 20 1
11 1
1
/ , 11
1 2 2 1
1
s
i i i i ii
s s
i i i i i i i ii i
s
i i i i ii
n nVar W P H m a m a m
n n
l a a m b b M L
l b m b m
=
−
−= =
=
⎡⎢= − − + +⎢− ⎢⎣
⎛ ⎞⎟⎜+ + − − − +⎟⎜ ⎟⎜⎝ ⎠
⎤⎥+ + − ⎥⎥⎦
∑
∑ ∑
∑
(6.34)
con:
01
, 0j
j iiM m con M
== =∑
0 01 1
, 0, , 0j j
j i j ii iL l con L L l con L+ + + − − −
= == = = =∑ ∑
1
,i i i i s s i i
a M L b M L M L− + −
−= + = + − −
El estadístico de contraste propuesta por Gehan para este caso viene dado por:
( )0/ ,
WZVar W P H
= (6.35)
que se distribuye normal con media cero y varianza uno. Estas demostraciones pueden
consultarse en el Apendice B del trabajo de Gehan (1965).

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
81
6.3.4 Prueba de Mantel
Mantel (1967) propuso dos métodos de comparación de dos grupos poblacionales con
datos de supervivencia con censuras arbitrarias (censuras por la izquierda, censuras por
la derecha y/o censuras mixtas). Estos métodos consisten en pruebas de puntuaciones,
que son modificaciones de la prueba de la suma de los rangos de Wilcoxon. El primero
es un procedimiento alternativo a Gehan que consiste en una rutina simple que permite
realizar los cálculos de los Ui, en torno al estadístico W y su varianza. El segundo
procedimiento, que en esencia es una aplicación directa del procedimiento de Wilcoxon,
es útil para datos con censura arbitrarias por la derecha o por la izquierda.
6.3.4.1 Procedimiento alternativo a Gehan
Supóngase que se dispone de los datos de supervivencia provenientes de dos subgrupos
poblacionales de tamaño n1 y n2. Suponga que estos datos se combinan y se ordenan en
forma creciente, como si se tratase de una sola muestra (considerándose tanto los datos
censurados como los no censurados). El método propuesto por Mantel (1967) se puede
considerar como un método alternativo al estadístico de Gehan (1965), que algunos
autores califican como método directo, y cuyo procedimiento se define a continuación.
Sea:
Ui = R1i − R2i ∀i = 1,2,…,n1+n2 (6.36)
11
n
GM i iiW U
== θ∑ (6.37)
donde θ1i = Ila i-ésima observación pertenece al 1er grupo es la variable indicatriz
que vale uno si la observación pertenece al 1er grupo y cero en otro caso, los valores de
R1i y R2i dependerán de si el dato es o no censurado. Si el dato es no censurado, R1i se
define como el número de observaciones menores a ti. Si el dato es censurado R1i se
define como el número de observaciones censuradas y no censuradas menores o
iguales a ti, siendo, ti el i-ésimo tiempo de ocurrencia en la muestra combinada una
vez ordenados los datos. Si el dato es no censurado, R2i se define como el número de
observaciones censuradas y no censuradas mayores a ti y si el dato es censurado R2i es
igual cero. Una vez determinados los valores de R1i y R2i se puede determinar el valor
de WGM como:

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
82
( )1 1 21
n
GM i i iiW R R
=
⎡ ⎤= θ −⎢ ⎥⎣ ⎦∑ (6.38)
cuya media y varianza viene dada por:
E WGM / P,Ho = 0 (6.39)
( )2
1 20 1
/ ,1
n
GM ii
n nVar W P H U
n n ==
− ∑ (6.40)
El estadístico de contraste propuesto por Mantel se define como:
( )0/ ,
GM
GM
WZ
Var W P H= (6.41)
que se distribuye normal con media cero y varianza uno.
6.3.4.2 Aplicación directa del procedimiento de Wilcoxon para datos en presencia
de censuras arbitrarias Este procedimiento propuesto por Mantel (1967) está basado en el uso directo de la
prueba de la suma de los rangos de Wilcoxon, reorganizado de tal manera que se pueda
aplicar a casos en presencia de empates y datos con censuras arbitrarias por la derecha
y/o por la izquierda. Es una prueba alternativa a la de Gehan (1965) y entra en el grupo
que utilizan las puntuaciones Ui. A continuación describimos el procedimiento para el
cálculos de las puntuaciones Ui:
Supóngase que se dispone los datos de supervivencia provenientes de dos subgrupos
poblacionales de tamaño n1 y n2. Supóngase además que estos datos se combinan y se
ordenan en forma creciente, como si se tratase de una sola muestra (considerándose
tanto los datos censurados como los no censurados).
Sea:
1 2
1, 2, ...,i 1i 2i
U R - R i n n= ∀ = + (6.42)
11
n
M i iiW U
=
⎡ ⎤= θ ×⎢ ⎥⎣ ⎦∑ (6.43)
donde θ1i = Ila i-ésima observación pertenece al 1er grupo es la variable indicatriz
referida al 1er grupo y R1i y R2i se calculan de la siguiente forma:

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
83
Cálculo de los valores de R1i
1. Asigne los rangos de las observaciones, de la menor a la mayor, en orden
creciente, omitiendo los datos censurados por la derecha.
2. Asigne a los datos omitidos (datos censurados por la derecha) el rango de la
observación inmediatamente superior.
3. Reducir el rango de las observaciones repetidas al menor valor entre ellos.
4. Reducir el rango de las observaciones censuradas por la izquierda a la unidad.
Cálculo de los valores de R2i
1. Asigne los rangos de las observaciones, de la mayor a la menor, en orden
creciente y omitiendo los datos censurados por la izquierda.
2. Asigne a los datos omitidos (datos censurados por la izquierda) el rango de la
observación inmediatamente inferior.
3. Reducir el rango de las observaciones repetidas al menor valor entre ellos.
4. Reducir el rango de las observaciones censuradas por la derecha a la unidad.
así:
( )1 1 21
n
M i i iiW R R
=
⎡ ⎤= θ −⎢ ⎥⎣ ⎦∑ (6.44)
cuya media y varianza viene dada por:
0/ 0
ME W H = (6.45)
( )2
1 20 1
/1
n
M ii
n nVar W H U
n n ==
− ∑ (6.46)
El estadístico de contraste propuesto por Mantel:
( )0/ ,
GM
GM
WZ
Var W P H= (6.47)
que se distribuye normalmente con media cero y varianza uno.

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
84
6.3.5 Prueba generalizada Kruskal-Wallis de Breslow Breslow (1970) sugirió una generalización de la prueba de Kruskal-Wallis, con la cual
extendió la prueba generalizada de Wilcoxon propuesta por Gehan (1965a), para
comparar datos de supervivencia, al caso de k muestras (con k≥2). Esta prueba también
es aplicable a aquellos casos donde en las observaciones están presentes los datos
censurados por la derecha. La prueba fue diseñada para distribuciones de censura que no
necesariamente son iguales en los grupos. La propuesta diseñada por Breslow permite
comparar funciones de supervivencia o funciones de riesgo de dos o más grupos. Estos
estadísticos propuestos por este autor tienen distribución asintóticamente chi-cuadrado
bajo sus respectivas hipótesis nulas. Breslow en su trabajo determinó la eficiencia y la
potencia asintótica de estos estadísticos, y presentó varias aplicaciones y ejemplos
numéricos. Este autor extendió la prueba logrank de Mantel-Haenszel y la prueba
generalizada de Wilcoxon propuesta por Gehan, utilizado estadísticos tipo U para
comparar el número de observaciones en los grupos con los valores esperados.
Supóngase que se dispone de un total de n observaciones de datos de supervivencia
provenientes de k muestras poblacionales. Denotamos por nr el número de unidades en
el r-ésimo grupo, para todo r = 1,2,…,k. Si S1(t), S2(t), …, Sk(t) son las funciones de
supervivencia teórica de los k grupos, enunciaremos la hipótesis a contrastar como: H0: S1(t) = S2(t) = … = Sk(t) H1: Otros casos En el tiempo t(z, ocurren dz eventos en el grupo combinado, con, dz = d1z + d2z + … + drz y habrá nz unidades en riesgo, con nz = n1z + n2z + … + nrz . Tabla 6.3 Número de ocurrencias del evento en el tiempo tz para el k-ésimo grupo poblacional.
Grupos
Número de ocurrencia
del evento
Número de unidades
sobrevivientes
Número de unidades en
riesgo justo antes t(z)
1 d1z n1z – d1z n1z
2 d2z n2z – d2z n2z
. …. ….. …
r drz nrz – drz nrz
r´ dr´z nr´z – dr´z nr´z
. …. ….. …
k dkz nkz – dkz nkz
Combinados dz nz - dz nz

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
85
Los estadísticos propuestos por Breslow:
1
1, 2, ...,p
zL r rk rzz z
dU d n r k
n=
⎡ ⎤⎢ ⎥= − ∀ =⎢ ⎥⎢ ⎥⎣ ⎦
∑ (6.48)
1
1, 2, ...,p
zWr z rz rzz z
dU n d n r k
n=
⎡ ⎤⎛ ⎞⎟⎜⎢ ⎥⎟⎜ ⎟= − ∀ =⎢ ⎥⎜ ⎟⎜ ⎟⎢ ⎥⎜ ⎟⎜⎝ ⎠⎢ ⎥⎣ ⎦∑ (6.49)
Se toman k-1 de estas cantidades y se expresan en forma de vector con k-1
componentes y los denotamos como: UL = (UL1, UL2, …, ULk-1) y UW = (UW1, UW2,
…, UWk-1). Denotaremos las matrices de varianzas y covarianzas de las variables UL y
UW, por Σ[UL] y Σ[UW] respectivamente.
Los elementos componentes de la matriz Σ[UL] son de la forma:
( )( )
´´ ´1
1, 2, ..., 1, ´ 1, 2, ..., 11
prz z z z r z
r r rrz zz z
n d n d n r kCov U U r knn n=
⎡ ⎤⎛ ⎞−⎢ ⎥⎟⎜ ⎧ = −⎪⎟ ⎪⎜⎢ ⎥⎟= δ − ∀⎜ ⎨⎟⎢ ⎥⎜ = −⎟ ⎪⎜ ⎪⎩⎟⎜−⎢ ⎥⎝ ⎠⎢ ⎥⎣ ⎦
∑ (6.50)
donde δr r´ es tal que:
´
1 ´0 ´rr
si r rsi r r
⎧ =⎪⎪δ =⎨ ≠⎪⎪⎩
Los elementos componentes de la matriz Σ[UW] son de la forma:
( )( )
2 ´´ ´1
1, 2, ..., 1, ´ 1, 2, ..., 11
prz z z z r z
r r z rrz zz z
n d n d n r kCov U U n r knn n=
⎡ ⎤⎛ ⎞−⎢ ⎥⎟⎜ ⎧ = −⎪⎟ ⎪⎜⎢ ⎥⎟= δ − ∀⎜ ⎨⎟⎢ ⎥⎜ = −⎟ ⎪⎜ ⎪⎩⎟⎜−⎢ ⎥⎝ ⎠⎢ ⎥⎣ ⎦
∑ (6.51)
donde δr r´ es tal que:
´
1 ´0 ´rr
si r rsi r r
⎧ =⎪⎪δ =⎨ ≠⎪⎪⎩
Finalmente, los estadísticos de contraste para comparar las funciones del análisis de
supervivencia bajo la hipótesis nula vienen dados por:

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
86
2 ' 1
1gl k L L LU U U
−
= −⎡ ⎤χ = Σ ⎢ ⎥⎣ ⎦ (6.52)
ó
2 ' 1
2gl k W W WU U U
−
= −⎡ ⎤χ = Σ ⎢ ⎥⎣ ⎦ (6.53)
cuya distribución es chi-cuadrado con k-2 grados de libertad, cuando la hipótesis nula es
cierta. Diversos programas comerciales especializados incorporan estas metodologías en
el análisis de supervivencia.
6.3.6 Prueba de Peto-Peto
Las pruebas de comparación de curvas de supervivencia que utilizan la estimación de la
varianza a partir de la distribución hipergeométrica son conocidas como pruebas
ponderadas. Las pruebas que utilizan estimación permutada de la varianza suelen recibir
el nombre de pruebas de puntuaciones. Peto-Peto (1972) detalló los métodos de
construcción de la prueba logrank, la prueba de los rangos probit y la prueba de la suma
de los rangos de Wilcoxon. Para ello utilizó una función c(y,ψ), a la que denominó
función conversora, que proporciona pruebas asintóticamente eficientes. Estos métodos
permiten generar estadísticos de rangos con datos censurados. Peto-Peto generalizó el
estadístico de Wilcoxon a partir de la diferencia de las puntuaciones dadas a las
observaciones de la muestra combinada una vez ordenada, de forma que:
z z z
w c C= − (6.54)
donde cz = 2 SPP (tz) - 1 y Cz = SPP(tz) – 1. cz son las puntuaciones dadas a las
observaciones no censuradas y Cz las puntuaciones dadas a las observaciones
censuradas. SPP(tz) es el estimador de la función de supervivencia de la muestra
combinada en el tiempo z-ésimo. Como la función de supervivencia varía en el tiempo,
estos autores consideraron incluirlas en la familia de curvas de supervivencia tipo Gρ
(alternativa tipo Lehmann). SPP(tz) está definido como:
( )ˆ1
zPP t tz z
nS t
n≤
⎡ ⎤⎢ ⎥= ⎢ ⎥+⎢ ⎥⎣ ⎦
∏ (6.55)

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
87
El estadístico propuesto por Peto-Peto pertenece al conjunto de estadísticos ponderados
que permiten comparar curvas de supervivencia, de la forma:
( ) ( )( ) ( )
1 11
2
11
ˆ
ˆ
p
PP z z zzPP p
PP z zz
S t d E dZ
S t Var d
=
=
⎡ ⎤⎡ ⎤−⎢ ⎥⎢ ⎥⎢ ⎥⎣ ⎦⎣ ⎦=⎡ ⎤⎢ ⎥⎢ ⎥⎣ ⎦
∑
∑ (6.56)
que se corresponde con los estadísticos descritos en las expresiones (6.16) y (6.17). Este
estadístico también tiene una distribución normal con media cero y varianza uno, así
que su cuadrado se distribuye como una chi-cuadrado con un grado de libertad.
6.3.7 Prueba de Cox
Cox (1972) propuso una prueba para comparar dos grupos de supervivencia cuyos
riesgos son proporcionales. La prueba de Cox, aunque expresada con notación de
supervivencia diferente a la utilizada hasta la fecha de la propuesta, es exactamente
igual a la propuesta por Mantel-Haenszel (1959) y discutida en este trabajo en la
sección 6.3.1. El estadístico de Cox se denota como UC y se define como:
1 11
p
C z zzU r m A
=
⎡ ⎤= − ⎢ ⎥⎣ ⎦∑ (6.57)
( ) ( )1 11
11
pz z z
z zz z
m r mI A A
r=
⎡ ⎤−⎢ ⎥⎢ ⎥= −⎢ ⎥−⎢ ⎥⎢ ⎥⎣ ⎦
∑ (6.58)
donde z es el número total de tiempos de ocurrencias del evento en la muestra
combinada una vez ordenados, r1 es el número de eventos observados en la muestra
del primer grupo, mz es el número de eventos observados en el tiempo z-ésimo y A1z
es la proporción de unidades a riesgo en el tiempo z-ésimo del primer grupo. Así, el
estadístico:
UCI
= (6.59)
se distribuye normal con media cero y varianza uno, bajo la hipótesis de igualdad de
ambos grupos. Obsérvese que si se utiliza la notación empleada en Mantel-Haenszel,
entonces:

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
88
111 1
p pz
z z zz z z
nm A d
n= =
⎡ ⎤⎢ ⎥⎡ ⎤= ⎢ ⎥⎢ ⎥⎣ ⎦ ⎢ ⎥⎣ ⎦
∑ ∑ (6.60)
1 11
p
zzr d
==∑ (6.61)
( )( )
1 1
11
1
pz z z z z
z zz z
n d n d nI
nn n=
⎡ ⎤⎛ ⎞−⎢ ⎥⎟⎜ ⎟⎜⎢ ⎥⎟= −⎜ ⎟⎢ ⎥⎜ ⎟⎜ ⎟⎜−⎢ ⎥⎝ ⎠⎢ ⎥⎣ ⎦
∑ (6.62)
que se corresponde con el estadístico de prueba logrank propuesto por
Mantel_Haenszel (1959).
6.3.8 Prueba de Tarone-Ware
Tarone-Ware (1977) propuso una prueba de contraste diseñada para comparar curvas
de supervivencia, provenientes de k grupos poblacionales, estimadas a través de los
métodos tradicionales. La prueba de Tarone-Ware está basada en la metodología de
Radhakrishna (1965) que maximiza la eficiencia asintótica de Stuart (1954). Las
pruebas ponderadas asignan pesos wz a cada tabla de contingencia de dimensión 2x2 en
cada tiempo de ocurrencia del evento. Supóngase, por ejemplo, un experimento en el
cual se dispone de n unidades dispuestas en k+1 grupos y de los cuales existe un grupo
al que se le considera como placebo. Supóngase que a los grupos distintos del placebo
se le asigna una ponderación igual a dr y que al grupo placebo se le da una ponderación
igual a cero (d0 = 0). Esto se hace porque a los grupo se le suministra una dosis que se
presume hace que el resto de los grupos difiera del placebo. Sin embargo, nuestra
hipótesis nula sigue siendo que estas dosis no tienen efectos significativos en los grupos
y que las curvas de supervivencia son iguales. La idea consiste en construir en cada
tiempo de ocurrencia una tabla de contingencia, como la que se ilustra a continuación:
Tabla 6.4 Número de ocurrencias del evento en el tiempo tz para los grupos poblacionales.
Nivel de dosis d0 d1 …… dk Total
Número de eventos M0z M1z …… Mk z Mz
Unidades en riesgo N0z N1z …... Nk z Rz
donde Nrz es el número de unidades en riesgo en el r-ésimo grupo y en el tiempo
z-ésimo, Mrz es el número de eventos ocurridos en el tiempo z-ésimo en el r-ésimo

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
89
grupo, Rz es el número total de unidades a riesgo en el tiempo z-ésimo y
Arz = Nrz / Rz es la contribución proporcional del r-ésimo grupo del riesgo total en el
tiempo z-ésimo. Tarone-Ware usó la estandarización indirecta del número de eventos
esperados en el r-ésimo grupo en el tiempo tz:
( )1
1, 2, ...,p
r z r z r zzU w M E r k
=
⎡ ⎤= − ∀ =⎢ ⎥⎣ ⎦
∑ (6.63)
Los eventos esperados están dados por Erz = Mz Arz, p es el número total de tiempos
diferentes de ocurrencia del evento y Ur representa la suma ponderada de la
diferencia entre los eventos observados menos los eventos esperados del r-ésimo
grupo. Si U´ = (U1, U2, … , Uk) es el vector cuyos componentes son las sumas de
diferencias ponderadas de los valores observados y valores esperados y si Σ[U] es la
matriz de varianzas y covarianzas de orden es k x k, cuyos elementos:
( )( )2
1, 1, 2, ...,
t n
r z z z r z z r zzV w A i r A r k
=
⎡ ⎤= α δ − ∀ =⎢ ⎥⎢ ⎥⎣ ⎦
∑ (6.64)
y donde αz = (Rz – Mz)/(Rz-1) y δz(i,r) es uno si i=r y cero en otros casos, para todo
i = 1,2,..,k y r = 1,2,…,k en cada momento z-ésimo. El estadístico propuesto por
Tarone-Ware para k grupos es una modificación del estadístico Wilcoxon:
[ ]2 1
1´
gl kU U U
−
= −χ = Σ (6.65)
que tiene una distribución chi-cuadrado con k-1 grados de libertad bajo la hipótesis nula.
Una prueba para medir los diferentes efectos de las dosis esta basada en el estadístico T
definido como:
( )[ ]( )
2''d U
Td U d
=Σ
(6.66)
donde d es el vector de las diferentes dosis suministrados a los k grupos, tal que:
d’=(d1,d2,…,dk). Tarone-Ware determinan que el estadístico T se distribuye
asintóticamente chi-cuadrado con un grado de libertad. Estos autores consideran tres
escalas de pesos, la escala logit que considera wz=1, la escala aritmética donde wz=nz y
la escala arcsin donde wz=√nz. La prueba logrank propuesta por Mantel-Haenszel
(1959) y la de Wilcoxon generalizada propuesta por Gehan (1965a) son capaces de
detectar diferencias entre datos de supervivencia provenientes de grupos poblacionales.

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
90
Gehan tiene mayor capacidad de detectar diferencias tempranas en los tiempos de
supervivencia que la prueba logrank y tiene mayor potencia en aquellos casos donde la
razón de riesgo no es constante. La prueba propuesta por Tarone-Ware tiene una
potencia intermedia entre la logrank y la de Gehan. La prueba logrank tiene mejor
efectividad en aquellos casos cuando la distribución de supervivencia tiene razón de
riesgo constante y pierde potencia cuando estas se alejan de esta condición.
6.3.9 Prueba de Prentice
Prentice (1978) sugirió pruebas de rangos lineales para datos censurados por la
derecha, que se corresponden con las pruebas de contraste ponderadas, cuyos pesos
dependen de la función de supervivencia de la muestra combinada. Esta función de
supervivencia puede ser estimada a través del estimador de Kaplan-Meier (1958),
mediante la expresión:
( )ˆ z zKM t tz z
n dS t
n≤
⎡ ⎤−⎢ ⎥= ⎢ ⎥⎢ ⎥⎣ ⎦
∏ (6.67)
o mediante el estimador de la curva de supervivencia de Altshuler (1970):
( )ˆ zAlt t tz z
dS t exp
n≤
⎡ ⎤⎢ ⎥= −⎢ ⎥⎢ ⎥⎣ ⎦
∑ (6.68)
De esta forma los pesos usados en el estadístico de prueba de Prentice, quedan
denotados como:
( )ˆ 1, 2, ...,z KM z
w S t z p= ∀ = (6.69)
ó
( )ˆ 1, 2, ...,z Alt z
w S t z p= ∀ = (6.70)
Nótese que cuando la función de supervivencia S(t) es estimada a través del estimador
Kaplan-Meier o a través del estimador de Altshuler los pesos son parecidos a los pesos
sugeridos por Peto-Peto (1972). El estadístico propuesto por Prentice también pertenece
al conjunto de estadísticos ponderados que permiten comparar curvas de supervivencia
que se distribuyen normalmente con media cero y varianza uno. El estadístico se define
de la siguiente manera:

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
91
( ) ( ) ( ) ( )
1 11
2
11
ˆ
ˆ
p
KM z z zzP p
KM z zz
S t d E dZ
S t Var d
=
=
⎡ ⎤−⎢ ⎥⎣ ⎦=
⎧ ⎫⎪ ⎪⎡ ⎤⎪ ⎪⎨ ⎬⎢ ⎥⎪ ⎪⎣ ⎦⎪ ⎪⎩ ⎭
∑
∑ (6.71)
6.3.10 Prueba Prentice-Marek
Prentice-Makek (1979) sugirieron una prueba ponderada, cuyos pesos dependen de la
función de supervivencia, estimada por un método considerado como una modificación
del estimador de Kaplan-Meier:
( )1
ˆ1
z zP t tz z
n dS t
n≤
⎡ ⎤+ −⎢ ⎥= ⎢ ⎥+⎢ ⎥⎣ ⎦
∏ (6.72)
Los pesos usados aquí vienen dados por:
( )1ˆ 1, 2, ...,1
zz P z
z
nw S t z p
n−= × ∀ =
+ (6.73)
Cuando dz = 1 los pesos coinciden con los sugeridos por Peto-Peto (1972). El
estadístico propuesto por Prentice-Marek pertenece al conjunto de estadísticos
ponderados a través de las estimaciones de las curvas supervivencia que da mayor peso
a las primeras diferencias entre los valores observados y los valores esperados. Esta
prueba es también conocida como la prueba de Peto modificada y su estadístico de
prueba esta dado por:
( ) ( )
( ) ( )
1 1 11
2
1 11
ˆ1
ˆ1
pz
P z z zz z
PMp
zP z zz z
nS t d E d
nZ
nS t Var d
n
−=
−=
⎧ ⎫⎪ ⎪⎪ ⎪⎡ ⎤⎪ ⎪× −⎨ ⎬⎢ ⎥⎪ ⎪+ ⎣ ⎦⎪ ⎪⎪ ⎪⎩ ⎭=⎧ ⎫⎪ ⎪⎡ ⎤⎪ ⎪⎢ ⎥⎪ ⎪⎪ ⎪×⎨ ⎬⎢ ⎥⎪ ⎪+⎢ ⎥⎪ ⎪⎣ ⎦⎪ ⎪⎪ ⎪⎩ ⎭
∑
∑
(6.74)
cuya distribución es asintóticamente normal con media cero y varianza uno.

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
92
6.3.11 Prueba de Gill
El estadístico propuesto por Gill (1980) pertenece a la familia de pruebas ponderadas
tipo Gρ, en la cual los pesos en cada momento z-ésimo (tiempo de ocurrencia del
evento), vienen dados por:
wz = Sρ(tz-1)[(n1+n2)/(n1n2)]1/2 (6.75)
6.3.12 Prueba Harrington-Fleming
Harrington-Fleming (1982) propusieron una clase de estadísticos de rangos lineales
para contrastar muestras con datos de supervivencia con censura por la derecha. Esta
clase contiene a casos especiales, tales como la prueba logrank de Mantel-Haenszel
(1959), la de Prentice (1978) que generaliza a Wilcoxon y que es similar a la
generalización de Peto-Peto (1972). Harrington y Fleming utilizan la teoría de
martingalas para establecer la eficiencia relativa y la normalidad asintótica de los
estadísticos de prueba bajo la hipótesis de igualdad de las curvas de supervivencia de
los grupos. El estadístico propuesto por estos autores también pertenece a la familia de
pruebas ponderadas tipo Gρ, en la cual los pesos en cada momento z-ésimo (tiempo de
ocurrencia del evento), están dados por:
wz = [S(tz-1)]ρ (6.76)
donde ρ ≥ 0 y S(tz-1) = SKM(tz-1). De esta manera, el estadístico propuesto por
Harrington-Fleming pasa a formar parte de la familia de pruebas ponderadas utilizadas
para comparar datos de supervivencia para dos grupos poblacionales, discutido en
sesiones anteriores:
( ) ( )( ) ( )
1 1 11
2
1 11
ˆ
ˆ
p
KM z z zzHF p
KM z zz
S t d E dZ
S t Var d
ρ
−=
ρ
−=
⎧ ⎫⎪ ⎪⎡ ⎤ ⎡ ⎤⎪ ⎪−⎨ ⎬⎢ ⎥ ⎢ ⎥⎪ ⎪⎣ ⎦ ⎣ ⎦⎪ ⎪⎩ ⎭=⎧ ⎫⎪ ⎪⎡ ⎤⎪ ⎪×⎨ ⎬⎢ ⎥⎪ ⎪⎣ ⎦⎪ ⎪⎩ ⎭
∑
∑ (6.77)
Obsérvese que si ρ = 0 la ponderación se corresponde con los pesos de la prueba
logrank, en la cual wz = 1. Mientras que si ρ = 1, el estadístico suministra una prueba
cercana a la prueba de Wilcoxon tipo Peto-Peto (1972), similar a la prueba de Prentice
(1978), cuando la función de supervivencia es estimada por el método de Kaplan-Meier.

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
93
La principal ventaja de los estadísticos de Peto-Peto, Prentice, Prentice-Marek y
Harrington-Fleming sobre los estadísticos que generalizan la prueba de Wilcoxon es que
todos ellos utilizan como pesos relativos la curva de supervivencia combinada de los
grupos. El estadístico tipo Gρ es un subconjunto de estadísticos generales tipo K
propuesto por Gill (1980).
6.3.13 Prueba de Fleming-Harrington
Fleming-Harrington (1991) sugirieron una familia de estadísticos al que denotaron
por Gρ,γ. Esta familia forma parte del conjunto de estadísticos que permite ponderar las
diferencias entre los valores observados y los valores esperados, y en las cuales los
pesos están dados por:
wz=[S(tz-1)]ρ[1- S(tz-1)]γ (6.78)
con ρ ≥ 0, γ ≥ 0 y donde S(tz-1) = SKM(tz-1). Esta metodología no ha sido implementada
en la mayoría de los programas comerciales a excepción del software NCSS del 2007,
que trata problema de comparación de datos del análisis de supervivencia para datos
censurados y no censurados e incluyen las pruebas de la familia de Fleming-
Harrington (1981), Harrington-Fleming (1982) y Fleming-Harrington (1991).
Como ya se ha dicho, entre los objetivos de este trabajo está el de proponer una rutina
computarizada en lenguaje R que permitirá realizar las estimaciones correspondientes
de estas pruebas. Estas rutinas se discutirán en los capítulos XVIII y IX.
Los estadísticos propuestos por Fleming-Harrington conforman una familia de pruebas
que generalizan la mayoría de los estadísticos de este tipo. Obsérvese que cuando γ = 0,
la familia de estadísticos del tipo Gρ,γ se reduce a la clase del tipo Gρ, que pertenece a la
familia de pruebas introducida por Harrington-Fleming (1982); cuando ρ = 1 y γ = 0,
el estadístico suministra una prueba cercana a la prueba de Wilcoxon tipo Peto-Peto
(1972); cuando ρ = 0 y γ =0 la familia de pruebas tipo Gρ,γ se reduce a la prueba
logrank de Mantel-Haenszel (1959). La estimación de los estadísticos tipo Gρ,γ tiene la
siguiente forma:

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
94
( ) ( ) ( )( ) ( ) ( )
1 1 1 11
2 2
1 1 11
ˆ ˆ1
ˆ ˆ1
p
KM z KM z z zzFH p
KM z KM z zz
S t S t d E dZ
S t S t Var d
ρ γ
− −=
ρ γ
− −=
⎧ ⎫⎪ ⎪⎡ ⎤ ⎡ ⎤ ⎡ ⎤⎪ ⎪− −⎨ ⎬⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎪ ⎪⎣ ⎦ ⎣ ⎦ ⎣ ⎦⎪ ⎪⎩ ⎭=⎧ ⎫⎪ ⎪⎡ ⎤ ⎡ ⎤⎪ ⎪− ×⎨ ⎬⎢ ⎥ ⎢ ⎥⎪ ⎪⎣ ⎦ ⎣ ⎦⎪ ⎪⎩ ⎭
∑
∑ (6.79)
6.4 Pruebas de contraste para comparar fenómenos con eventos recurrentes Entre los trabajos científicos publicados en revistas especializadas donde se aborda el
uso de estadísticos de contraste para la comparación fenómenos con eventos recurrentes,
podemos destacar a Pepe-Cai (1993), Glynn-Buring (1996) y Doganaksoy-Nelson
(1998).
6.4.1 Propuesta de Pepe-Cai
En su propuesta, Pepe-Cai (1993) muestra los métodos y analiza los datos de tiempos
de ocurrencia de múltiples eventos. En su artículo los autores consideran dos problemas
específicos: el primero es el análisis de tiempos de fallas recurrentes, para el caso en el
que existen múltiples fallas del mismo tipo en cada individuo. El segundo problema es
el análisis del efecto de una covariable categórica dependiente del tiempo en los tiempos
de fallas simples. Pepe-Cai proponen una prueba de comparación para las funciones
de las razones de recurrencia del evento o razones de riesgo en dos muestras,
basada en la prueba de comparación logrank de Mantel-Haenszel (Op. cit.). El
estadístico de rangos lineales generalizados LR puede ser escrito como la suma de las
diferencias entre los valores observados y los valores esperados en todos los tiempos de
ocurrencias de los eventos Ti:
( ) ( )1 11
zR R R
j jjO T E TL
=
⎡ ⎤= −⎢ ⎥⎢ ⎥⎣ ⎦
∑ (6.80)
donde O1R(T) son los valores observados en la primera muestra en el momento T y
E1R(T) es el valor esperado en la primera muestra en el momento T bajo la hipótesis
nula, obtienido a partir de:
( ) ( ) ( )( )
1
1 1
1 2( )
R
R R jR Rj j
j j
dN TE T Y T
Y T Y T
⎡ ⎤⎢ ⎥⎢ ⎥= ⎢ ⎥⎢ ⎥+⎢ ⎥⎣ ⎦
(6.81)

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
95
La idea de los autores fue generalizar el estadístico logrank de comparación del análisis
clásico a funciones de razones de recurrencias.
6.4.2 Propuesta de Glyn-Buring
Glynn-Buring (1996) fueron de los autores que mencionaron la necesidad que existía
de disponer de técnicas estadísticas correctas para comparar grupos poblacionales o
grupos tratados con eventos de carácter recurrente, y propusieron un índice de medición
para esa comparación. Para resolver el problema los autores definieron una medida de la
razón de ocurrencia del evento estimada como el número de eventos ocurridos
(incluyendo la múltiple ocurrencia del evento por persona) dividido entre el número
total de personas tratadas en el experimento. Los autores expresan que desde el punto de
vista clínico esta medida es más relevante e interpretable en la aparición de ciertos tipos
de enfermedades poblacionales como los ataques de asma, el cáncer, los infartos del
miocardio y los ataques epilépticos entre otras.
6.4.3 Propuesta de Doganaksoy-Nelson
Doganaksoy-Nelson (1998) presentaron un método no paramétrico para comparar dos
muestras con datos recurrentes. El método provee estimaciones para dos funciones
denominadas función acumulada media (MCF por sus siglas en inglés Mean Cumulative
Function) del “número” y del “costo” de recurrencia para ambos grupos. La
metodología de la función acumulada media incluye conceptos básicos de las funciones
históricas acumuladas de la MCF para una unidad y/o para la población basada en el
número o en el costo de recurrencia. La distribución poblacional del número de
ocurrencias acumuladas en tiempo t tiene una media M(t). Esta función se incrementa
suavemente con el tiempo t. Cuando se gráfica, se puede apreciar una curva similar a
cualquiera de las que se muestran en la figura 6.1. En esta figura se observan tres tipos
de curvas MCF, todas crecientes. Lo que diferencia una de otras es la razón de
crecimiento. En la primera, la razón de crecimiento va de menos a más, lo que significa
que la razón de aparición de los eventos crece con el tiempo; en la segunda, la razón de
ocurrencia de los eventos es constante en el tiempo, mientras que en la tercera ocurre lo
contrario que en la primera; aunque M3(t) crece con el tiempo su razón decrece cuando
aumenta t.

Capitulo VI. Pruebas de Comparación en el Análisis de Supervivencia ______________________________________________________________________
96
Figura 6.1 Representación gráfica de las funciones acumuladas medias.
Se asume que la función M(t) es una función continua y derivable, de modo que:
( )m t M(t)t∂=∂
(6.82)
es la razón media a la cual se incrementa el número o costo de recurrencias acumulada.
Esta función se conoce como “razón de recurrencia”, “función de la razón instantánea
de reparación” o “función de intensidad”.
El método de comparación de dos muestras con datos recurrentes propuesto por
Doganaksoy y Nelson está centrado en el contraste de las funciones acumuladas
medias. Bajo el supuesto distribucional correspondiente y denotando por M1*(t) y
M2*(t), a las funciones acumuladas medias de los grupos 1 y 2 respectivamente, el
estadístico M1*(t) - M2
*(t) sigue una distribución normal con media igual a M1(t) -
M2(t) y varianza V[M1*(t)] + V[M2
*(t)], por cuanto las muestras se asumen
independientes. Nelson (1995) propuso los estimadores v[M1(t) ] y v[M2(t) ] para
V[M1*(t)] y V[M2
*(t)], respectivamente.

Capítulo VII. Pruebas de Comparación de Curvas de Supervivencia con eventos de carácter recurrente ______________________________________________________________________
97
Capitulo VII. PRUEBAS DE COMPARACIÓN DE CURVAS DE SUPERVIVENCIA CON EVENTOS DE CARÁCTER RECURRENTE. PROPUESTAS
7.1 Introducción El objetivo del presente capítulo consiste en proponer estadísticos de contraste para
comparar curvas de supervivencia de dos o más grupos que experimentan un evento
recurrente y cuyas estimaciones son realizadas a través del modelo de Kaplan-Meier
generalizado GPLE, modelo propuesto por Peña et al. (2001) y discutido en la sección
5.3.3.1 de este trabajo. La idea surge de los modelos de comparación del análisis clásico
y constituyen generalizaciones de los estadísticos de comparación ponderados del
análisis de supervivencia tradicional al caso recurrente.
Es de destacar, que aún cuando las estimaciones de las funciones de supervivencia se
harán con el modelo GPLE, su uso puede hacerse extensivo al resto de la familia de
modelos recurrentes. Para ello, habría que realizar los ajustes correspondientes y
adaptarlos al modelo deseado.
7.2 Estadísticos de contraste para comparar las curvas de supervivencia con
eventos recurrentes, para el caso de dos grupos. Una propuesta. 7.2.1 Planteamiento del problema Supóngase que estamos interesados en comparar las curvas de supervivencia con
eventos recurrentes de dos grupos de unidades poblacionales, cuyas curvas han sido
estimadas usando el modelo GPLE y cuyos grupos han sido definidos a través de la
estratificación de una variable de interés, por ejemplo sexo, edad o estrato social.
Nuestro problema consiste en comparar las curvas de supervivencia de ambos grupos y
determinar si las curvas de supervivencia difieren significativamente desde el punto de
vista estadístico.
Para realizar la comparación de las curvas es necesario plantear el siguiente contraste de
hipótesis:
H0: S1(t) = S2(t) H1: S1(t) ≠ S2(t)
Para efectuar dicha prueba es necesario evaluar la diferencia que existe entre el número
observado de eventos en cualquiera de los grupos y el número esperado de eventos en el

Capítulo VII. Pruebas de Comparación de Curvas de Supervivencia con eventos de carácter recurrente ______________________________________________________________________
98
grupo combinado, bajo el supuesto que la hipótesis nula es cierta. Si ambas curvas son
iguales, el número observado de eventos en el grupo seleccionado (en todos los
momentos de ocurrencia) es igual al número esperado de eventos del grupo combinado.
Como consecuencia de ello, comparar las curvas de ambos grupos es equivalente a
comparar la curva de cualquiera de los grupos con la curva de supervivencia esperada
de la muestra combinada, ver Cochran (Op. cit.), Mantel-Haenszel (1959).
Si introducimos ciertas modificaciones en los conceptos y en los modelos del análisis de
sobrevivencia clásico, podemos extender el uso de los estadísticos de comparación al
caso recurrente. En este trabajo se utilizaran los conceptos y notaciones propuestas por
Peña et al. (2001).
7.2.2 Notación básica
Utilizaremos la letra r para denotar los grupos (r = 1,2). nr representará el total de
unidades bajo estudio en el r-ésimo grupo, con n = n1+n2. Ki denota el total de
ocurrencias del evento en la i-ésima unidad bajo estudio en el grupo combinado y Kri
el total de eventos experimentados por la i-ésima unidad en el r-ésimo grupo. K es
el total de eventos en todas las unidades en el grupo combinado y Kr el total de
eventos en las unidades pertenecientes al r-ésimo grupo.
Entonces:
K = K1+K2+…+Kn o K = K1 + K2 (7.1)
o también:
K = 2
1 1
nr
rir i
K= =∑∑ (7.2)
Estas últimas notaciones están escritas en negrillas, para diferenciar los Ki de los Kr. El
subíndice i se utiliza para identificar a la i-ésima unidad en los grupos. El subíndice
j se utiliza para indicar a la j-ésima ocurrencia del evento en cualesquiera de las n
unidades bajo estudio, con j = 1,2,…Ki o j =1,2,…Kri dependiendo de si se está
considerando el grupo combinado o el r-ésimo grupo. Tij describe el j-ésimo tiempo de
interocurrencia del evento en la i-ésima unidad bajo estudio en el grupo combinado y
Trij el j-ésimo tiempo de interocurrencia de la i-ésima unidad en el r-ésimo grupo.
Los tiempos Tij se asumen independientes e idénticamente distribuidos. La función de
distribución de los Tij viene dada por:

Capítulo VII. Pruebas de Comparación de Curvas de Supervivencia con eventos de carácter recurrente ______________________________________________________________________
99
F(t) = P(Tij ≤ t).
Sij se define como el tiempo transcurrido desde el momento inicial hasta que se produce
la j-ésima repetición del evento en el individuo i del grupo combinado (tiempo
calendario). Se conviene en establecer que Si0 = 0 y Ti0 = 0 para todo i=1,2,…n. Se
tiene entonces que:
'' 0
1,2,..., 1,2,...,j
ij i j ijS T i n j K
== ∀ = ∧ =∑ (7.3)
Srij se define como el j-ésimo tiempo calendario de la i-ésima unidad en el r-ésimo
grupo, y se asume que Sri0=0 y T ri0=0, para todo i=1,2,…,nr y para todo r=1,2. Se
tiene entonces que:
'' 0
1,2; 1,2,..., 1,2,..., .j
rij rij rijS T r i n j K
== ∀ = = ∧ =∑ (7.4)
τi y τri denotan el tiempo de observación de la i-ésima unidad bajo estudio en el grupo
combinado y en el r-ésimo grupo respectivamente. Para cada unidad se dispone de
un tiempo de observación igual a [0, τi] o [0, τri], dependiendo de si se está
considerando el grupo combinado o el grupo r. El tiempo de observación τ es una
variable aleatoria con función de probabilidades desconocida igual a:
G(t) = P(τ≤ t)
Si denotamos el tiempo de censura de la i-ésima unidad como Ci, tenemos:
1, 2, ..., .
i i iK iC S i n= τ − ∀ = (7.4)
Para referirnos a los grupos se utiliza la notación Cri que es el tiempo de censura de la
i-ésima unidad en el grupo r:
1, 2, ..., 1, 2.
ri ri riK riC S i n r= τ − ∀ = ∧ = (7.5)
Asumiremos independencia entre las censuras y los tiempos de interocurrencias, y sólo
consideraremos censuras por la derecha.

Capítulo VII. Pruebas de Comparación de Curvas de Supervivencia con eventos de carácter recurrente ______________________________________________________________________
100
Al igual que Peña et al. (2001), definiremos procesos contadores en cada uno de los
grupos. En el modelo GPLE, Ni(s,t) representa el número de eventos observados en la
i-ésima unidad en el tiempo calendario [0,s] con tiempos de interocurrencias menores o
iguales a t e Yi(s,t) representa el número de eventos observados en la i-ésima unidad en
el tiempo calendario [0,s] con tiempos de interocurrencias mayores o iguales a t.
Definiremos aquí:
( ) ( )'' 1
, 1,2,..., 1,2,..., .j
i j ij j ijN s t I T t i n j K s
== ≤ ∀ = ∧ = −∑ (7.6)
( ) ' ( )' 1
1,2,...,, min( , )
1,2,..., ( )
j
i j ij j i iK s jiji
i nY s t I T t I s S t
j K s−=
=⎧⎪ ∧= ≥ + τ − ≥ ∀ ⎨⎪ = −⎩
∑ (7.7)
Estos autores también definieron dos procesos agregados: N(s,t) que representa el
número de eventos observados en todas las unidades en el tiempo calendario [0,s] con
tiempos de interocurrencias menores o iguales a t e Y(s,t) que representa el número de
eventos observados en todas la unidades en el tiempo calendario [0,s] con tiempos de
interocurrencias mayores o iguales a t:
1
( , ) ( , )n
iiN s t N s t
== ∑ (7.8)
( ) ( )1
, ,n
iiY s t Y s t
== ∑ (7.9)
Utilizando estos conceptos, plantearon y desarrollaron el estimador de la función del
análisis de supervivencia limite-producto de Kaplan-Meier:
( )( )
,ˆ( ) 1,z t
N s zS t
Y s z≤
⎡ ⎤∆= −⎢ ⎥
⎣ ⎦∏ (7.10)
definiendo la variable N(s,∆z) como el número de eventos observados en las unidades
bajo estudio en el tiempo calendario [0,s] con tiempos de interocurrencias iguales
a z, donde, el índice z representa los tiempos de interocurrencias de los eventos
ordenados.
z = Tij: con Tij ordenados en forma creciente, i =1,…,n y j =1,…,ki
En forma análoga, definiremos en este trabajo los siguientes procesos contadores:

Capítulo VII. Pruebas de Comparación de Curvas de Supervivencia con eventos de carácter recurrente ______________________________________________________________________
101
Nri(s,t) que representa el número de eventos observados en la i-ésima unidad del
r-ésimo grupo en el tiempo calendario [0,s] con tiempos de interocurrencias menores o
iguales a t:
( ) ( )
'' 1
1,2, 1,2,...
1,2,...,
j
ri j rij j rjri
rN s t I T t i n
j K s=
⎧ =⎪
= ≤ ∀ =⎨⎪ = −⎩
∑ (7.11)
e Yri(s,t) que representa el número de eventos observados en la i-ésima unidad en el
r-ésimo grupo en el tiempo calendario [0,s] con tiempos de interocurrencias mayores o
iguales a t:
( ) ( ) ( )
'' 1
1,2, min( , ) 1,2,...,
1,2,...,
j
ri j rij j ri riK s j rrijri
rY s t I T t I s S t i n
j K s−=
⎧ =⎪
= ≥ + τ − ≥ ∀ =⎨⎪ = −⎩
∑ (7.12)
De modo que los procesos agregados en los grupos quedan definidos, como: N(s,t;r)
que es el número de eventos observados en las unidades del r-ésimo grupo en el
tiempo calendario [0,s] con tiempos de interocurrencias menores o iguales a t:
=
= ∀ =∑1
( , ; ) ( , ) 1,2.nr
riiN s t r N s t r (7.13)
e Y(s,t;r) que es el número de eventos observados en las unidades del r-ésimo grupo en
el tiempo calendario [0,s] con tiempos de interocurrencias mayores o iguales a t:
( ) ( )=
= ∀ =∑1
, ; , 1,2.nr
riiY s t r Y s t r (7.14)
Los procesos agregados generales quedan definidos como:
( ) ( )= = =
= =∑ ∑ ∑2 2
1 1 1( , ) ( , ) , , ;
nr
rir i rN s t N s t o N s t N s t r (7.15)
( ) ( ) ( ) ( )= = =
= =∑ ∑ ∑2 2
1 1 1, , , , ;
nr
rir i rY s t Y s t o Y s t Y s t r (7.16)
y los estimadores de las funciones de supervivencia para cada grupo, viene dado por:
( )( )
, ;ˆ ( ) 1 1, 2., ;r
z t
N s z rS t r
Y s z r≤
⎡ ⎤∆= − ∀ =⎢ ⎥
⎣ ⎦∏ (7.17)
El estimador de la función del análisis de supervivencia para el grupo combinado, SC(t),
queda definido como:
( )( )
,ˆ ( ) 1,C
z t
N s zS t
Y s z≤
⎡ ⎤∆= −⎢ ⎥
⎣ ⎦∏ (7.18)

Capítulo VII. Pruebas de Comparación de Curvas de Supervivencia con eventos de carácter recurrente ______________________________________________________________________
102
7.2.3 Propuestas para el caso de dos muestras Sea N(s,∆z;1) el número de eventos observados en las unidades del 1er grupo en el
tiempo calendario [0,s] y con tiempos de interocurrencias iguales z en un total de
eventos observados igual a N(s, ∆z). Donde, N(s, ∆z) es el número de eventos
observados en las unidades del grupo combinado en el tiempo calendario [0,s] con
tiempos de interocurrencias iguales a z. De la definición de la variable N(s,∆z;1) se
desprende que se trata de una variable aleatoria con distribución hipergeométrica
H(Y(s,z), Y(s,z,1), N(s,∆z)), cuyas media y varianza son iguales a:
( ) ( ) ( )( ), ;1
, ;1 ,,
Y s zE N s z N s z
Y s z∆ = ∆ (7.19)
( ) ( ) ( )( ) ( ) ( )
( ), , , ;1 ( , ;1), ;1 , 1
, ( , ), 1Y s z N s z Y s z Y s zVar N s z N s z
Y s z Y s zY s z− ∆⎡ ⎤ ⎡ ⎤⎣ ⎦∆ = ∆ −⎢ ⎥−⎡ ⎤ ⎣ ⎦⎣ ⎦
(7.20)
Tabla 7.1 Resumen del número de ocurrencias del evento en el tiempo de interocurrencia
z-ésimo para los grupos 1 y 2.
Grupos
Número de eventos
observados en [0,s] con
tiempos de interocurrencia
o censura mayor o igual a
Número de eventos
observados en [0,s] con
tiempos de interocurrencia
iguales a z
Número de eventos
observados en [0,s] con
tiempos de interocurrencia
o censuras mayores a z
1 Y(s,z;1) N(s,∆z;1) Y(s,z;1) - N(s,∆z;1)
2 Y(s,z;2) N(s,∆z;2) Y(s,z;2) - N(s,∆z;2)
Combinados Y(s,z) N(s ∆z) Y(s,z) - N(s ∆z)
La tabla 7.1 muestra la variable que representa el número de eventos observados en
[0,s] con tiempos de interocurrencias iguales a z, tanto en el grupo combinado como
para los grupos, así como la variable del número de eventos experimentados por todas
las unidades con tiempos de interocurrencias mayores o iguales a z. El estadístico de
prueba se define como:
( ) ( )
( ) ( )
2
, ;1 , ;10,1
, ;1
zz t
zz t
w N s z E N s zZ N
w Var N s z
=
=
⎡ ⎤∆ − ∆⎣ ⎦=
∆
∑
∑∼ (7.21)

Capítulo VII. Pruebas de Comparación de Curvas de Supervivencia con eventos de carácter recurrente ______________________________________________________________________
103
El anterior es en esencia el estadístico de contraste ponderado propuesto por Cochran
(1954) para comparar muestras independientes, pero modificado y adaptado al caso del
análisis de supervivencia con eventos recurrentes, ver apéndice C sección C.3. Se
define como una combinación lineal de las diferencias que existen entre el número de
eventos experimentados por las unidades en un grupo determinado en todos los
momentos de ocurrencias del evento y su valor esperado. Esta combinación lineal es
una suma ponderada de variables aleatorias estandarizadas que se asumen
independientes. El estadístico Z tiene un comportamiento asintótico normal, ver Childs-
Balakrishan (2000). Su cuadrado tendrá un comportamiento aproximado chi-cuadrado
(χ2) con un grado de libertad:
( ) ( )
( )
2
2 2
12
, ;1 , ;1
, ;1
zz
gl
zz
w N s z E N s z
Zw Var N s z
∀
=
∀
⎡ ⎤⎡ ⎤∆ − ∆⎢ ⎥⎣ ⎦
⎢ ⎥⎣ ⎦= χ
∆
∑
∑∼ (7.22)
En el capítulo anterior se mencionaron diferentes pruebas de contraste para comparar
curvas de supervivencia en el análisis de supervivencia clásico. Se hizo referencia
además a que algunas de ellas tienden a ser más sensibles que otras, en el sentido de que
tienden a aceptar o a rechazar la hipótesis nula con mayor frecuencia que otras. Esto nos
da la posibilidad de seleccionar entre una amplia gama de alternativas, dependiendo del
comportamiento de la curvas de supervivencia de ambos grupos y del escenario de
trabajo en el análisis.
Las pruebas de comparación del análisis de supervivencia clásico son modificaciones o
adaptaciones del estadístico de Cochran y lo que fundamentalmente las hace diferentes
es el uso de los pesos wz. Si wz = 1 se obtiene la prueba de Mantel-Haenszel (log-
rank). Si wz = nz se obtiene la prueba generalizada de Wilcoxon (Gehan). Esta prueba
da mayor peso a las diferencias de los primeros tiempos de supervivencia del
evento. Tarone-Ware propusieron una modificación de la prueba de Wilcoxon,
con wz =(nz)1/2. Peto-Peto (1972) propusieron una prueba con una ponderación wz =
SPM(tz), que también da mayor peso a las primeras diferencias entre los eventos
observados y los eventos esperados de los primeros tiempos de supervivencia. SPM(tz)
representa la estimación de la función de supervivencia a través del método de
Prentice-Marek, la cual disminuye desde uno a cero en la medida que aumentan los
tiempos de supervivencia. El resto de las pruebas son modificaciones de las pruebas

Capítulo VII. Pruebas de Comparación de Curvas de Supervivencia con eventos de carácter recurrente ______________________________________________________________________
104
anteriores o generalizaciones de las anteriores, como la de Fleming et al. y la de
Harrington-Fleming.
Como ya se ha dicho, todas las pruebas clásicas de comparación fueron diseñadas para
los casos donde los fenómenos de estudio son no recurrentes. Resulta razonable pensar
que es posible extender el uso de estas ponderaciones a problemas de comparación de
curvas de supervivencia con eventos recurrentes, generalizando su uso hacia ese campo.
De los estadísticos de prueba discutidos en la sección 6.4, sólo Pepe-Cai (1993) han
estado cerca de realizar una propuesta similar a las de este trabajo. En la siguiente tabla
presentamos una serie de ponderaciones que dan lugar a generalizaciones de las pruebas
clásicas al ámbito recurrente, denotadas con el subíndice rec para indicar su adaptación
al caso recurrente. Tabla 7.2. Propuestas de pesos en pruebas de contraste para modelos de supervivencia
con recurrencia.
Prueba clásica Prueba Peso (wz) Peso Relativo
Mantel-Haenzsel LRrec 1 Constante
Gehan Grec Y(s,z) -
Peto-Peto PPrec SC(t) Decreciente
Tarone-Ware TWrec ( , )Y s z -
Peto-Prentice PPrrec SC(tz-1) Decreciente
Prentice-Marek PMrec SC(t) × Y(s,z) / [Y(s,z) +1] Decreciente
Fleming-Harrington-
O’sullivan
FHOrec
[SC(t)]ρ ρ ≥ 1: Decreciente
ρ=0: Constante
0<ρ<1: Creciente Fleming et al. FHrec [SC(t)]ρ[1- SC(t)] r -
Martínez Mrec [SC(t)]ρ[1- SC(t)] r Y(s,z)α / [Y(s,z) +1]β -
Cmartínez CMrec [Y(s,z)-N(s,∆z)]/Y(s,z) Decreciente SC(tz) = Supervivencia de la muestra combinada estimada por el modelo GPLE

Capítulo VII. Pruebas de Comparación de Curvas de Supervivencia con eventos de carácter recurrente ______________________________________________________________________
105
7.3 Estadísticos de contraste para comparar las curvas de supervivencia con eventos recurrentes, para el caso de k grupos. Propuestas.
7.3.1 Planteamiento del problema En la sección anterior se propusieron pruebas de contraste para comparar curvas de
supervivencia en dos grupos en fenómenos con eventos recurrentes. En esta sección se
propone un conjunto de estadísticos de contraste ponderados para comparar curvas de
supervivencia con eventos recurrentes para el caso de k grupos. Comparar las curvas de
supervivencia consiste en determinar si los k grupos difieren entre sí o al menos existe
un grupo que difiere del resto.
Se trata de utilizar pruebas que permita realizar el siguiente contraste de hipótesis:
H0: S1(t) = S2(t) = … = Sk(t) H1: No todas las Sj(t) son iguales donde S1(t), S2(t), …, Sk(t) son las funciones de supervivencia teórica de los k subgrupos.
La hipótesis nula que se desea contrastar es que no hay diferencias significativas en las
curvas de supervivencia de los subgrupos poblacionales. Esta prueba puede hacerse
mediante todas las comparaciones dos a dos, o bien comparando cada curva con la del
grupo combinado.
La tabla 7.3 muestra las ocurrencias del evento en todos los grupos en el instante z.
Tabla 7.3 Resumen del número de ocurrencias del evento en el instante z para todo los grupos.
Grupo
Número de eventos
observados en [0,s] con
tiempos de interocurrencia o
censura mayor o igual a z
Número de eventos
observados en [0,s] con
tiempos de interocurrencia
iguales a z
Número de eventos
observados en [0,s] con
tiempos de interocurrencia
o censuras mayores a z
1 Y(s,z;1) N(s,∆z;1) Y(s,z;1) - N(s,∆z;1)
2 Y(s,z;2) N(s,∆z;2) Y(s,z;2) - N(s,∆z;2)
….. ….. ….. …..
k Y(s,z;k) N(s,∆z;k) Y(s,z;k) - N(s,∆z;k)
Combinados Y(s,z) N(s, ∆z) Y(s,z) - N(s ∆z)

Capítulo VII. Pruebas de Comparación de Curvas de Supervivencia con eventos de carácter recurrente ______________________________________________________________________
106
7.3.2 Notación básica
La notación que se emplea en estas propuestas es análoga a la usada en la sección 7.2.1.
con la diferencia de que ahora disponemos de k grupos. Uno de los supuestos
fundamentales que se consideran en esta metodología, es que los grupos están
ordenados adecuadamente según la variable de estratificación. Todas las definiciones,
dadas para el caso de dos grupos se hacen extensivas para k grupos:
' 0
1,2,..., ; 1,2,..., 1,2,...,j
rij rij rijS T r k i n j K
== ∀ = = ∧ =∑ (7.23)
1, 2, ..., 1, 2, ..., .ri ri riK ri
C S i n r k= τ − ∀ = ∧ = (7.24)
( ) '' 1, 1,2,..., 1,2,...,
j
i j ij j ijN s t I T t i n j K
== ≤ ∀ = ∧ =∑ (7.25)
( ) '' 1, 1,2,..., 1,2,...,
j
i j ij j i iK j iijY s t I T t I S t i n j K
== ≥ + τ − ≥ ∀ = ∧ =∑ (7.26)
1
( , ) ( , )n
iiN s t N s t
== ∑ (7.27)
( ) ( )1
, ,n
iiY s t Y s t
== ∑ (7.28)
( ) '' 1
1,2,..., 1,2,...,
1,2,...,
j r
ri j rij jjri
i nN s t I T t r k
j K=
⎧ =⎪
= ≤ ∀ =⎨⎪ =⎩
∑ (7.29)
( ) ' 1
1,2,...,, 1,2,...,
1,2,...,
j r
ri j rij j ri riK j ririj
i nY s t I T t I S t j K
r k=
⎧ =⎪
= ≥ + τ − ≥ ∀ =⎨⎪ =⎩
∑ (7.30)
=
= ∀ =∑1
( , ; ) ( , ) 1,2,..., .nr
riiN s t r N s t r k (7.31)
( ) ( )=
= ∀ =∑1
, ; , 1,2,..., .nr
riiY s t r Y s t r k (7.32)
El proceso agregado general:
( ) ( )= = =
= =∑ ∑ ∑1 1 1
( , ) ( , ) , , ;k n kr
rir i rN s t N s t o N s t N s t r (7.33)

Capítulo VII. Pruebas de Comparación de Curvas de Supervivencia con eventos de carácter recurrente ______________________________________________________________________
107
( ) ( ) ( ) ( )= = =
= =∑ ∑ ∑1 1 1
, , , , ;k n kr
rir i rY s t Y s t o Y s t Y s t r (7.34)
El estimador de la función de supervivencia para el grupo r queda definido como:
( )( )
, ;ˆ ( ) 1 1, 2, ..., ., ;r
z t
N s z rS t r k
Y s z r≤
⎡ ⎤∆= − ∀ =⎢ ⎥
⎣ ⎦∏ (7.35)
El estimadores de la función del análisis de supervivencia de la muestra combinada,
queda definido como:
( )( )
,ˆ ( ) 1,C
z t
N s zS t
Y s z≤
⎡ ⎤∆= −⎢ ⎥
⎣ ⎦∏ (7.36)
7.3.3 Propuestas para el caso de k muestras
7.3.3.1 Primera propuesta
La primera propuesta consiste en comparar los grupos dos a dos. Esta metodología es
quizás la más laboriosa, por cuanto hay que realizar un máximo de k(k-1)/2 pruebas.
Para mantener un orden de comparación, podría seguirse una secuencia como la que se
indica a continuación: (1,2),(1,3),…,(1,k),(2,3),(2,4),…,(2,k),(3,4),…,(3,k),…,(k-1,k). El
par (r,r’) indica que se contrasta el grupo r con el grupo r’ con r ≠ r’. La idea
consiste en utilizar para cada comparación el estadístico para dos grupos propuesto en la
sesión 7.2.3. En la tabla 7.4 presentamos el resumen de las observaciones en el tiempo
de ocurrencia z en los grupos r y r’.
Tabla 7.4 Resumen del número de ocurrencias del evento en el tiempo de interocurrencia z
para los grupos r y r’.
Grupos
Número de eventos
observados en [0,s] con
tiempos de interocurrencia
o censura mayor o igual a z
Número de eventos
observados en [0,s] con
tiempos de interocurrencia
iguales a z
Número de eventos
observados en [0,s] con
tiempos de interocurrencia
o censuras mayores a z
r Y(s,z;r) N(s,∆z;r) Y(s,z;r) - N(s,∆z;r)
r’ Y(s,z;r’) N(s,∆z;r’) Y(s,z;r’) - N(s,∆z;r’)
Combinados Y(s,z) N(s ∆z) Y(s,z) - N(s ∆z)

Capítulo VII. Pruebas de Comparación de Curvas de Supervivencia con eventos de carácter recurrente ______________________________________________________________________
108
El estadístico de contraste, será:
( ) ( )
( ) '
2
w , ; , ;'
w , ;
zz t
rr
zz t
N s z r E N s z rZ r r
Var N s z r
=
=
⎡ ⎤∆ − ∆⎣ ⎦= ∀ ≠
∆
∑
∑ (7.37)
con N(s, ∆z)= N(s, ∆z;r)+ N(s, ∆z;r’) y Y(s, z)= Y(s, z;r)+ Y(s, z;r’). Como se indicó
en la sesión 7.2.3, el cuadrado de este estadístico sigue una distribución chi-cuadrado
con un grado de libertad. Las pruebas se realizan hasta encontrar significación o en su
defecto hasta realizar el total de las pruebas.
En vista de que el número de total de pruebas aumenta en la medida en que aumenta el
número total de grupos. Proponemos aplicar un procedimiento secuencial que permita
controlar adecuadamente el error tipo I en los múltiples contrastes que se efectúan al
considerar la hipótesis nula: Ho = ∩ Hi. donde cada Hi establece la igualdad en una de
las q = k(k-1)/2 comparaciones de las curvas de sobrevivencia dos a dos. La hipótesis
Ho es cierta si todos las Hi son ciertas, es decir cuando las k curvas de sobrevivencia son
iguales.
La hipótesis alternativa: Ho = ∪ Hi
c, es cierta (es decir Ho es rechazada) si al menos
una de las Hi es falsa. Cada hipótesis Hi es de la forma: Sr(t) = Sr'(t) y su p-valor
correspondiente: Pi=Prob(χ2(1) > oi). Donde oi es el valor observado del estadístico de
contraste para esa comparación. Resulta claro que si oi es mayor que el valor crítico
(χ21,1-α) es porque el p-valor correspondiente pi es menor que α, y en consecuencia se
rechaza la hipótesis particular Hi. Proponemos la utilización de procedimientos
mejorados de Bonferroni del tipo paso a paso, que comienzan ordenando los p-valores
obtenidos:
p(1) ≥ p(2) … ≥ p(q)
por lo que denotamos las hipótesis correspondientes como H(1), H(2),… H(q). La idea es
comenzar contrastando la hipótesis más significativa (la que tiene menor p-valor) y
continuar mientras se produzcan rechazos. En cada paso se compara el p-valor
correspondiente pi con el valor crítico vi (que puede ser igual a α o una función de éste).

Capítulo VII. Pruebas de Comparación de Curvas de Supervivencia con eventos de carácter recurrente ______________________________________________________________________
109
El procedimiento algorítmico es el siguiente:
Se comienza con el p-valor más pequeño p(q). Si p(q) es mayor que v1, se aceptan todas
las hipótesis y se concluye que todas las funciones de sobrevivencia son iguales. En
caso contrario se rechaza H(q) y se pasa a la siguiente etapa. Si p(q-1) es mayor que v2, se
aceptan las hipótesis desde la 2 en adelante y termina el proceso. En caso contrario se
rechaza H(q-1) y se pasa a la siguiente etapa. El procedimiento finaliza cuando se
encuentra una hipótesis a partir de la cual se aceptan todas, o bien, cuando se hayan
rechazado todas. En el diagrama siguiente representamos algorítmicamente este
procedimiento descendente (Véase a este respecto Ramírez y Vásquez. (1999))
INICIO
Ordenar los p-valores p(1) ≥ p(2 )≥ … ≥ p(q)
¿es p(q) > v1?
Rechazar H(q)
¿es p(q-1) > v2?
Rechazar H(q-1)
¿es p(1) > vq?
Rechazar H(q)
FIN
Aceptar H(q)… H(1)
Aceptar H(q-1)… H(1)
Aceptar H(1)

Capítulo VII. Pruebas de Comparación de Curvas de Supervivencia con eventos de carácter recurrente ______________________________________________________________________
110
Holm (1979) propone como valores críticos: α/q, α/(q-1), … α/(q-i+1), … ,α. Este
autor demostró además que el nivel de significación global se mantiene en α y que la
potencia es mayor a la del procedimiento clásico de Bonferroni..
7.3.3.2 Segunda propuesta
Esta propuesta esta basada en la prueba de Tarone-Ware (1977), que fue diseñada para
comparar k curvas de supervivencia estimadas a través de los métodos tradicionales.
Se trata de proponer una prueba que permita realizar el contraste de hipótesis:
H0: S1(t) = S2(t) = … = Sk(t)
H1: No todas las Sj(t) son iguales
donde Si(t) es las función de supervivencia teórica del i-ésimo grupo. Para plantear el
procedimiento de contraste utilizaremos las variables aleatorias definidas en la sección
7.2.3. La idea básica es comparar la proporción de ocurrencias en cada grupo,
N(s,∆z;r)/Y(s,z;r), con la misma proporción pero en el grupo combinado, N(s,∆z)/Y(s,z).
Si Ho es cierta, la proporción en el grupo será similar a la proporción en el grupo
combinado. Para hacer esta comparación en todos los momentos de ocurrencia se
propone la siguiente combinación lineal ponderada de las diferencias:
( ) ( )( )
( )( )z
z
, ; ,, ; 1, 2, ...,
, ; ,r rt
N s z r N s zU Y s z r w r k
Y s z r Y s z≤
⎧ ⎫⎡ ⎤∆ ∆⎪ ⎪= − ∀ =⎨ ⎬⎢ ⎥⎪ ⎪⎣ ⎦⎩ ⎭
∑ (7.38)
donde los wrz son las ponderaciones para cada momento de ocurrencia z en el r-ésimo
grupo. Por otra parte, tomando en cuenta 7.18 y 7.19, tenemos que el estadístico Ur se
puede reescribir como una combinación lineal ponderada de diferencias entre variables
aleatorias hipergeométricas y sus correspondientes valores esperados:
( ) ( ) ( )( )z
z
, ;, ; , 1, 2, ...,
,r rt
Y s z rU w N s z r N s z r k
Y s z≤
⎡ ⎤= ∆ − ∆ ∀ =⎢ ⎥
⎣ ⎦∑ (7.39)
Bajo esta perspectiva, y haciendo uso del Teorema Central de Limite, la variable
Ur puede aproximarse bajo Ho mediante una distribución normal con media cero y
varianza Var(Ur). Como se trata de k grupos, podemos definir el vector U, con

Capítulo VII. Pruebas de Comparación de Curvas de Supervivencia con eventos de carácter recurrente ______________________________________________________________________
111
Ut = (U1, U2,…Uk) y con matriz de varianzas y covarianzas igual a ΣU =[CovUr,Ur’],
cuyo elemento genérico en la posición (r, r´) es de la forma:
CovUr,Ur’ = ∑ 2rzw αz Arz [δrr’ − Ar′z] ∀r, r’=1,2... k (7.40)
donde:
α z = N(s, ∆z)[Y(s,z)- N(s, ∆z)]/[ Y(s,z)-1]
Arz = N(s,∆z;r)/ Y(s,z) y Ar’z = N(s,∆z;r’)/ Y(s,z)
δrr’=1 sí r = r’ y δrr’ = 0, sí r ≠ r’
o equivalentemente:
( ) ( )( )
( ) ( )( )
2 , , , ; ( , ; ), 1 1, 2, ..., 1, ( , ), 1r rz
z
Y s z N s z Y s z r Y s z rVar U w N s z r kY s z Y s zY s z∀
⎧ ⎫− ∆⎡ ⎤ ⎡ ⎤⎪ ⎪⎣ ⎦= ∆ − ∀ = −⎨ ⎬⎢ ⎥−⎡ ⎤ ⎣ ⎦⎪ ⎪⎣ ⎦⎩ ⎭∑ (7.41)
y
( ) ( )( )
( ) ( )( )
2
´
, , , ; ( , ; ´), , ´, ( , ), 1r r rz
z
Y s z N s z Y s z r Y s z rCov U U w N s z r rY s z Y s zY s z∀
⎧ ⎫− ∆⎡ ⎤ ⎡ ⎤⎪ ⎪⎣ ⎦= ∆ − ∀ ≠⎨ ⎬⎢ ⎥−⎡ ⎤ ⎣ ⎦⎪ ⎪⎣ ⎦⎩ ⎭∑ (7.42)
El hecho de que las variables Ur sean tales que U1+U2+…+Uk = 0, para todo w1z=
w2z=…= wkz= wz (ver demostración en apéndice C), implica que una de ellas es
combinación lineal de las restantes, y en consecuencia, la matriz de varianzas y
covarianzas no es invertible. Si se suprime alguna variable, por ejemplo la primera, no
hay pérdida sustantiva de información, y la matriz de varianzas y covarianzas del nuevo
vector U con k-1 componentes será invertible, condición que se requiere para proponer
el siguiente estadístico: 2 1
1
t
gl k UU U
−
= −χ = Σ (7.43)
Que se corresponde con una forma cuadrática que sigue una distribución chicuadrado
con k-1 grados de libertad, estructura propuesta por Tarone-Ware (1977) e inicialmente
tratada por Breslow (1970) para el caso de comparación del análisis de supervivencia
tradicional. Para nuestra propuesta mantendremos las ponderaciones señaladas en la
tabla 7.2 de este trabajo. De esta forma, podemos disponer de un conjunto de pruebas
estadísticas ponderadas que me permiten capturar las diferencias existentes entre las

Capítulo VII. Pruebas de Comparación de Curvas de Supervivencia con eventos de carácter recurrente ______________________________________________________________________
112
curvas de supervivencia con eventos recurrentes en los k grupos poblacionales que
deseamos comparar.
O en otro caso y bajo el supuesto de que las variables que componen el nuevo vector U
siguen distribuciones normales, otro estadístico de contraste a proponer es:
G = dΣd'
U)(d'
U
2
(7.44)
que sigue una distribución chi-cuadrado con un grado de libertad, siendo d el vector de
coeficientes de contraste.

Capitulo VIII. Validación de los Estadísticos de Contraste para Comparar Curvas de Supervivencia con Eventos Recurrentes
______________________________________________________________________
113
Capitulo VIII. VALIDACIÓN DE LOS ESTADÍSTICOS DE CONTRASTE PARA COMPARAR CURVAS DE SUPERVIVENCIA CON EVENTOS RECURRENTES
8.1 Introducción Los métodos estadísticos son herramientas de apoyo fundamental para evaluar
objetivamente los resultados de una investigación. Como ya se ha dicho, en esta
investigación utilizaremos métodos no paramétricos, que aunque tienen menor potencia
que los paramétricos, constituyen valiosas alternativas de solución a una gran cantidad
de problemas prácticos, por no ser tan exigentes con los supuestos distribucionales.
La estrategia de validación que vamos a utilizar consistirá en realizar múltiples
simulaciones de datos de sobrevivencia con eventos recurrentes bajo diferentes
esquemas distribucionales, aplicar el modelo GLPE para estimar las curvas y calcular
los estadísticos de comparación para contrastar la hipótesis de igualdad de 2 y de 3
grupos.
8.2 Escenarios de las simulaciones
Se consideraron tres niveles de significación (1%, 5% y 10%), los tiempos de
interocurrencia estuvieron distribuidos bajo diferentes esquemas (exponenciales,
weibull, gamma, etc), las censuras tuvieron distribuciones desconocidas y se utilizaron
distintos tamaños muestrales (5, 10, 15, 20, 25, 50 y 100).
Las simulaciones se hicieron para el caso de comparación de dos y tres muestras de
tamaños iguales, basadas en un total de 1000 simulaciones por caso. En cada simulación
se generaron muestras aleatorias con tiempos de interocurrencia distribuidos bajo las
distribuciones especificadas y se obtuvo el porcentaje de rechazo de la hipótesis de
igualdad de curvas de supervivencia grupales. Para realizar tales simulaciones se
utilizaron dos programas computacionales diseñados bajo lenguaje R, que se presentan
en el apéndice E de este trabajo, los resultados tabulados y gráficos de estas
simulaciones se ilustran en el apéndice D de este trabajo.
En el caso en que las curvas sean efectivamente iguales, la mejor prueba será aquella
con menor porcentaje de rechazo de la hipótesis nula y la menos favorable la que tiene

Capitulo VIII. Validación de los Estadísticos de Contraste para Comparar Curvas de Supervivencia con Eventos Recurrentes
______________________________________________________________________
114
mayor porcentaje de rechazo. Por el contrario, en el caso en que las curvas sean
diferentes, la mejor prueba será la que produzca un mayor porcentaje de rechazos.
A continuación se enumeran los escenarios de las simulaciones para el caso de dos
muestras.
Escenario I: Muestras aleatorias con tiempos de interocurrencia exponenciales
iguales con λ1 = 0.02 y λ2 = 0.02, tiempos de censura con
distribuciones desconocidas, niveles de significación de 1%, 5% y
10%, tamaños muestrales iguales a 5, 10, 15, 20, 25, 50 y 100.
Escenario II: Muestras aleatorias con tiempos de interocurrencia exponenciales
diferentes con λ1 = 0.02 y λ2 = 0.04, tiempos de censura con
distribuciones desconocidas, niveles de significación de 1%, 5% y
10%, tamaños muestrales iguales a 5, 10, 15, 20, 25, 50 y 100.
Escenario III: Muestras aleatorias con tiempos de interocurrencia chi-cuadrado
iguales con gl1 = 10 y gl2 = 10, tiempos de censura con distribuciones
desconocidas, niveles de significación de 1%, 5% y 10%, tamaños
muestrales de 5, 10, 15, 20, 25, 50 y 100.
Escenario IV: Muestras aleatorias con tiempos de interocurrencia chi-cuadrado
diferentes con gl1 = 10 y gl2 = 15, tiempos de censura con
distribuciones desconocidas, niveles de significación de 1%, 5% y
10%, tamaños muestrales de 5, 10, 15, 20, 25, 50 y 100.
Escenario V: Muestras aleatorias con tiempos de interocurrencia gamma iguales con
α1 = 50, β1 = 2, α2 = 50 y β2 = 2, tiempos de censura con
distribuciones desconocidas, niveles de significación de 1%, 5% y
10%, tamaños muestrales de 5, 10, 15, 20, 25, 50 y 100.
Escenario VI: Muestras aleatorias con tiempos de interocurrencia gamma diferentes
con α1 = 50, β1 = 2, α2 = 60 y β2 = 2, tiempos de censura con
distribuciones desconocidas, niveles de significación de 1%, 5% y
10%, tamaños muestrales de 5, 10, 15, 20, 25, 50 y 100.

Capitulo VIII. Validación de los Estadísticos de Contraste para Comparar Curvas de Supervivencia con Eventos Recurrentes
______________________________________________________________________
115
Escenario VII: Muestras aleatorias con tiempos de interocurrencia uniformes iguales
con Li1 = 10, Ls1 = 20, Li2 = 10 y Ls2 = 20, tiempos de censura con
distribuciones desconocidas, niveles de significación de 1%, 5% y
10%, tamaños muestrales de 5, 10, 15, 20, 25, 50 y 100.
Escenario VIII: Muestras aleatorias con tiempos de interocurrencia uniformes
diferentes con Li1 = 10, Ls1 = 20, Li2 = 15 y Ls2 = 25, tiempos de
censura con distribuciones desconocidas, niveles de significación de
1%, 5% y 10%, tamaños muestrales de 5, 10, 15, 20, 25, 50 y 100.
Escenario IX: Muestras aleatorias con tiempos de interocurrencia weibull iguales con
α1 = 0.9, β1 = 30, α2 = 0.9 y β2 = 30, tiempos de censura con
distribuciones desconocidas, niveles de significación de 1%, 5% y
10%, tamaños muestrales de 5, 10, 15, 20, 25, 50 y 100.
Escenario X: Muestras aleatorias con tiempos de interocurrencia weibull diferentes
con α1 = 0.9, β1 = 30, α2 = 0.9 y β2 = 40, tiempos de censura con
distribuciones desconocidas, niveles de significación de 1%, 5% y
10%, tamaños muestrales de 5, 10, 15, 20, 25, 50 y 100.
Escenario XI: Muestras aleatorias con tiempos de interocurrencia decrecientes
iguales, tiempos de censura con distribuciones desconocidas, niveles
de significación de 1%, 5% y 10%, tamaños muestrales de 5, 10, 15,
20, 25, 50 y 100.
Escenario XII: Muestras aleatorias con tiempos de interocurrencia decrecientes,
tiempos de censura con distribuciones desconocidas, niveles de
significación de 1%, 5% y 10%, tamaños muestrales de 5, 10, 15, 20,
25, 50 y 100.
Escenario XIII: Muestras con tiempos de interocurrencia crecientes aleatorios iguales,
tiempos de censura con distribuciones desconocidas, niveles de
significación de 1%, 5% y 10%, tamaños muestrales de 5, 10, 15, 20,
25, 50 y 100.

Capitulo VIII. Validación de los Estadísticos de Contraste para Comparar Curvas de Supervivencia con Eventos Recurrentes
______________________________________________________________________
116
Escenario XIV: Muestras con tiempos de interocurrencia crecientes no aleatorios
diferentes, tiempos de censura con distribuciones desconocidas,
niveles de significación de 1%, 5% y 10%, tamaños muestrales de 5,
10, 15, 20, 25, 50 y 100.
A continuación se enumeran los escenarios de las simulaciones para el caso de tres
muestras asumiendo tiempos de interocurrencia con distribuciones conocidas:
Escenario A: Muestras aleatorias con tiempos de interocurrencia exponenciales
iguales con λ1 = 0.02, λ2 = 0.02 y λ3 = 0.02, tiempos de censura con
distribuciones desconocidas, niveles de significación de 1%, 5% y
10%, tamaños muestrales de 5, 10, 15, 20, 25, 50 y 100.
Escenario B: Muestras aleatorias con tiempos de interocurrencia exponenciales
diferentes con λ1 = 0.02, λ2 = 0.02 y λ3 = 0.04, tiempos de censura con
distribuciones desconocidas, niveles de significación de 1%, 5% y
10%, tamaños muestrales de 5, 10, 15, 20, 25, 50 y 100.
Escenario C: Muestras aleatorias con tiempos de interocurrencia chi-cuadrado
iguales con gl1 = 10, gl2 = 10 y gl3 = 10, tiempos de censura con
distribuciones desconocidas, niveles de significación de 1%, 5% y
10%, tamaños muestrales de 5, 10, 15, 20, 25, 50 y 100.
Escenario D: Muestras aleatorias con tiempos de interocurrencia chi-cuadrado
diferentes con gl1 = 10, gl2 = 10 y gl3 = 15, tiempos de censura con
distribuciones desconocidas, niveles de significación de 1%, 5% y
10%, tamaños muestrales de 5, 10, 15, 20, 25, 50 y 100.
Escenario E: Muestras aleatorias con tiempos de interocurrencia gamma iguales con
α1 = 50, β1 = 2, α2 = 50, β2 = 2, α3 = 50 y β3 = 2, tiempos de censura
con distribuciones desconocidas, niveles de significación de 1%, 5% y
10%, tamaños muestrales de 5, 10, 15, 20, 25, 50 y 100.
Escenario F: Muestras aleatorias con tiempos de interocurrencia gamma diferentes
con α1 = 50, β1 = 2, , α2 = 50 y β2 = 2, α3 = 60 y β3 = 2, tiempos de

Capitulo VIII. Validación de los Estadísticos de Contraste para Comparar Curvas de Supervivencia con Eventos Recurrentes
______________________________________________________________________
117
censura con distribuciones desconocidas, niveles de significación de
1%, 5% y 10%, tamaños muestrales de 5, 10, 15, 20, 25, 50 y 100.
Escenario G: Muestras aleatorias con tiempos de interocurrencia uniformes iguales
con Li1 = 10, Ls1 = 20, Li2 = 10, Ls2 = 20, Li3 = 10 y Ls3 = 20,
tiempos de censura con distribuciones desconocidas, niveles de
significación de 1%, 5% y 10%, tamaños muestrales de 5, 10, 15, 20,
25, 50 y 100.
Escenario H: Muestras aleatorias con tiempos de interocurrencia uniformes
diferentes con Li1 = 10, Ls1 = 20, Li2 = 10, Ls2 = 20, Li3 = 15 y Ls3 =
25, tiempos de censura con distribuciones desconocidas, niveles de
significación de 1%, 5% y 10%, tamaños muestrales de 5, 10, 15, 20,
25, 50 y 100.
Escenario I: Muestras aleatorias con tiempos de interocurrencia weibull iguales con
α1 = 0.9, β1 = 30, α2 = 0.9, β2 = 30, α3 = 0.9 y β3 = 30, tiempos de
censura con distribuciones desconocidas, niveles de significación de
1%, 5% y 10%, tamaños muestrales de 5, 10, 15, 20, 25, 50 y 100.
Escenario J: Muestras aleatorias con tiempos de interocurrencia weibull diferentes
con α1 = 0.9, β1 = 30, α2 = 0.9, β2 = 30, α3 = 0.9 y β3 = 40, tiempos de
censura con distribuciones desconocidas, niveles de significación de
1%, 5% y 10%, tamaños muestrales de 5, 10, 15, 20, 25, 50 y 100.
Escenario K: Muestras aleatorias con tiempos de interocurrencia decrecientes,
diferentes, aritméticos, con tiempos de censura con distribuciones
desconocidas, niveles de significación de 1%, 5% y 10%, tamaños
muestrales de 5, 10, 15, 20, 25, 50 y 100.
Escenario L: Muestras con tiempos de interocurrencia crecientes, diferentes,
aritméticos, con tiempos de censura con distribuciones desconocidas,
niveles de significación de 1%, 5% y 10%, tamaños muestrales de 5,
10, 15, 20, 25, 50 y 100.

Capitulo VIII. Validación de los Estadísticos de Contraste para Comparar Curvas de Supervivencia con Eventos Recurrentes
______________________________________________________________________
118
8.2.1 Resultados de las simulaciones para el caso de dos grupos
En esta sección se dan los resultados de las simulaciones para la comparación de dos
grupos poblacionales bajo los escenarios especificados en el apartado anterior. Las
tablas resumen de todas las simulaciones se presentan en el apéndice D.
Escenario I: En este escenario, muestras aleatorias con tiempos de interocurrencia
exponenciales iguales, se puede apreciar que los estadísticos más
favorables para las pruebas de comparación fueron CMrec y Grec,
seguidos de las pruebas PPrec, PMrec y FHOrec. Las pruebas con
peores resultados fueron LRrec, FHrec y Mrec.
Escenario III: En este escenario, muestras aleatorias con tiempos de interocurrencia
chi-cuadrado iguales, se puede apreciar que los estadísticos más
favorables para las pruebas de comparación fueron FHOrec, PPrec, y
PMrec seguidos de las pruebas Grec y CMrec. Las pruebas con
resultados menos favorables fueron LRrec, PPrrec, FHWrec y Mrec.
Escenario V: En este escenario, muestras aleatorias con tiempos de interocurrencia
gamma iguales, se puede apreciar que los estadísticos más favorables
para las pruebas de comparación fueron TWrec, PPrec, FHOrec y
PMrec, seguidos de las pruebas Grec y CMrec. Las pruebas con
resultados menos favorables fueron PPrrec y LRrec.
Escenario VII: En este escenario, muestras aleatorias con tiempos de interocurrencia
uniformes iguales, se puede apreciar que los estadísticos más
favorables para las pruebas de comparación fueron PPrec, FHOrec y
PMrec, seguidos de las pruebas CMrec y Grec. Las pruebas con
resultados menos favorables, fueron FHrec, Mrec, LRrec y PPrrec.
Escenario IX: En este escenario, muestras aleatorias con tiempos de interocurrencia
Weibull iguales, se puede apreciar que el estadístico más favorable
para realizar las pruebas de comparación fue CMrec, seguido de las
pruebas Grec, PPrec, FHOre y PMrec. Las pruebas con resultados
menos favorables fueron FHrec, PPrrec, Mrec y LRrec.

Capitulo VIII. Validación de los Estadísticos de Contraste para Comparar Curvas de Supervivencia con Eventos Recurrentes
______________________________________________________________________
119
Escenario II: En este escenario, muestras aleatorias con tiempos de interocurrencia
exponenciales diferentes, se puede apreciar que el estadístico más
favorable para realizar las pruebas de comparación fue LRrec, seguido
de las pruebas FHrec, Mrec y TWrec. Las pruebas con peores
resultados fueron Grec y CMrec.
Escenario IV: En este escenario, muestras aleatorias con tiempos de interocurrencia
uniformes diferentes, se puede apreciar que el estadístico más
favorable para las pruebas de comparación fue PPrrec, seguido de las
pruebas Grec y CMrec. Las pruebas con peores resultados fueron
FHrec y Mrec. El resto de las pruebas presentan resultados
intermedios.
Escenario VI: En este escenario, muestras aleatorias con tiempos de interocurrencia
gamma diferentes, se puede apreciar que los estadísticos más
favorables para las pruebas de comparación son PMrec y FHrec
seguidos de las pruebas TWrec y CMrec. Las pruebas con peores
resultados son FHrec y Mrec. El resto de las pruebas presentan
resultados intermedios.
Escenario VIII: En este escenario, muestras aleatorias con tiempos de interocurrencia
chi-cuadrado diferentes se puede apreciar que el estadístico más
favorable para las pruebas de comparación es LRrec, seguido de las
pruebas PPrrec y TWrec. Las pruebas con peores resultados son
Mrec y FHrec. El resto de las pruebas presentan resultados
intermedios.
Escenario X: En este escenario, muestras aleatorias con tiempos de interocurrencia
weibull diferentes se puede apreciar que el estadístico más favorable
para las pruebas de comparación es LRrec, seguido de las pruebas
PPrrec, FHrec y Mrec. Las pruebas con peores resultados fueron
CMrec y Grec. El resto de las pruebas presentan resultados
intermedios.

Capitulo VIII. Validación de los Estadísticos de Contraste para Comparar Curvas de Supervivencia con Eventos Recurrentes
______________________________________________________________________
120
Escenario XII: En este escenario, muestras con tiempos de interocurrencia
decrecientes diferentes, se puede apreciar que los estadísticos más
favorables para las pruebas de comparación fueron Grec y CMrec
seguidos de las pruebas PMrec, PPrrec y PPrec. Las pruebas con
peores resultados fueron Mrec y FHrec. El resto de las pruebas
presentan resultados intermedios. En este escenario ocurre que a
excepción de las pruebas mencionadas, se necesitan tamaños de
muestras mayores que 15 para comenzar a detectar las diferencias.
Escenario XIV: En este escenario, muestras con tiempos de interocurrencia diferentes,
se puede apreciar que el estadístico más favorable para las pruebas de
comparación es LRrec, seguido de las pruebas FHrec y Mrec. Las
pruebas con peores resultados fueron CMrec y Grec. El resto de las
pruebas presentan resultados intermedios. En este escenario ocurre
que a excepción de las pruebas mencionadas, se necesitan tamaños de
muestras mayores que 25 para comenzar a detectar las diferencias.
8.2.2 Resultados de las simulaciones para el caso de tres grupos
En esta sección se dan los resultados de las simulaciones para la comparación de tres
grupos poblacionales bajo diferentes escenarios. Las tablas resumen de todas las
simulaciones y sus representaciones gráficas se presentan en el apéndice D.
Escenario A: En este escenario, muestras aleatorias con tiempos de interocurrencia
exponenciales iguales se puede apreciar que el estadístico más
favorable para las pruebas de comparación es Grec. Las pruebas con
peores resultados en la comparación fueron LRrec, FHrec, FHrec y
Mrec.
Escenario C: En este escenario, muestras aleatorias con tiempos de interocurrencia
chi-cuadrado iguales, se puede apreciar que los estadísticos más
favorables para las pruebas de comparación fueron FHOrec, PPrec y
PMrec, seguidos de las pruebas Grec y CMrec. Las pruebas con
resultados menos favorables fueron LRrec, PPrrec, FHWrec y Mrec.

Capitulo VIII. Validación de los Estadísticos de Contraste para Comparar Curvas de Supervivencia con Eventos Recurrentes
______________________________________________________________________
121
Escenario E: En este escenario, muestras aleatorias con tiempos de interocurrencia
gamma iguales, se puede apreciar que los estadísticos más favorables
para las pruebas de comparación fueron TWrec, PPrec, FHOrec y
PMrec, seguidos de las pruebas Grec y CMrec. Las pruebas con
resultados menos favorables fueron PPrrec y LRrec.
Escenario G: En este escenario, muestras aleatorias con tiempos de interocurrencia
uniformes iguales, se puede apreciar que los estadísticos más
favorables para las pruebas de comparación fueron PPrec, FHOrec y
PMrec, seguidos de las pruebas CMrec y Grec. Las pruebas con
resultados menos favorables fueron FHrec, Mrec, LRrec y PPrrec.
Escenario I: En este escenario, muestras aleatorias con tiempos de interocurrencia
Weibull iguales, se puede decir que el estadístico más favorable para
realizar las pruebas de comparación es CMrec, seguido de las pruebas
Grec, PPrec, FHOre y PMrec. Las pruebas con resultados menos
favorables, fueron FHrec, PPrrec, Mrec y LRrec.

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
122
Capitulo IX. APLICACIONES DE LOS ESTADÍSTICOS DE COMPARACIÓN A FENÓMENOS CON EVENTOS RECURRENTES.
9.1 Introducción En este capítulo presentaremos la aplicación de las pruebas propuestas en la resolución
de problemas de la vida real. Utilizaremos datos ya trabajados por otros autores, que
están disponibles en la bibliografía consultada y a través de internet. Algunas de ellas
son http://www.siam.org/books/sa10/, http://www.ats.ucla.edu/stat/R/examples/asa/,
http://lib.stat.cmu.edu/datasets/ y http://www.sph.emory.edu/~dkleinb/surv2.htm. La
naturaleza de los fenómenos en estudio, orígenes y estructuras de las bases de datos
analizadas por estos investigadores, son adecuadas y oportunas para utilizarlas como
ejemplos ilustrativos.
9.2 Datos del experimento de Byar (1980)
La tabla 9.1 ilustra los datos del experimento de Byar (1980) correspondiente a los
tiempos de reapariciones de tumores medidos en meses para ciento dieciséis (116)
pacientes enfermos con cáncer superficial de vejiga. Estos pacientes fueron sometidos a
un proceso de aleatorización en la asignación de los siguientes tratamientos placebo (47
pacientes), piridoxina (31 pacientes) y thiotepa (38 pacientes).
Al inicio del estudio los tumores presentes en los pacientes fueron removidos. En
algunos casos se presentaron recurrencia múltiples de tumores, los cuales también
fueron extirpados al ser encontrados en los chequeos médicos. Al inicio del estudio, a
cada paciente se le midieron dos variables de interés: el número inicial de tumores
(num) y el tamaño (size) o diámetro del mayor de ellos, medido en centímetros. Estos
datos están publicados y disponibles en el trabajo de Andrews-Herzberg (1985).
El objetivo inicial de la investigación de Byar consistía en determinar si las variables
num y/o size tenían efectos significativos en la reaparición de los tumores de los
pacientes, y luego comparar los tres tratamientos. Muchos investigadores del área de
supervivencia recurrentes han trabajado con esta base de datos, entre ellos: Nelson
(2005), Gónzalez-Peña (2003), Peña et al. (2001) y Doganaksoy-Nelson (1998)
quienes han modelado las funciones de supervivencia y han comparado los grupos
tratados.

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
123
Tabla 9.1 Datos de reaparición de tumores en pacientes enfermos con cáncer de vejiga. Grupo Placebo
Tumores iniciales Tumores iniciales
j Id Numero Tamaño
Tiempo
censura
Tiempos
reapariciones j id Numero Tamaño
Tiempo
censura
Tiempos
Reapariciones
1 1 1 3 1 - 25 25 2 1 30 3,6,8,12,26 2 2 2 1 4 - 26 26 1 3 31 12,15,24 3 3 1 1 7 - 27 27 1 2 32 - 4 4 5 1 10 - 28 28 2 1 34 - 5 5 4 1 6 - 29 29 2 1 36 - 6 6 4 1 10 4 30 30 3 1 36 29 7 7 1 1 14 - 31 31 1 2 37 - 8 8 1 3 18 5 32 32 4 1 40 9,17,23,24 9 9 1 1 18 12,16 33 33 5 1 40 16,19,23,29,34,4010 10 3 3 23 34 34 1 2 41 - 11 11 1 3 23 10,15 35 35 1 1 43 3 12 12 1 1 23 3,16,23 36 36 2 6 43 6 13 13 3 1 23 3,9,21 37 37 2 1 44 3,6,9 14 14 2 3 24 7,10,16,24 38 38 1 1 45 9,11,20,26,3015 15 1 1 25 3,15,25 39 39 1 1 48 18 16 16 1 2 26 - 40 40 1 3 49 17 17 8 1 26 1 41 41 3 1 51 35 18 18 1 4 26 2,26 42 42 1 7 53 17 19 19 1 2 28 25 43 43 3 1 53 3,15,46,51,5320 20 1 4 29 - 44 44 1 1 59 21 21 1 2 29 - 45 45 3 2 61 2,15,24,30,34,39,43,49,5222 22 4 1 29 - 46 46 1 3 64 5,14,19,27,4123 23 1 6 30 28,30 47 47 2 3 64 2,8,12,13,17,21,33,4924 24 1 5 30 2,17,22 - - - - - -
Grupo Pyridoxina Tumores iniciales Tumores iniciales
j Id Numero Tamaño Tiempo
censura
Tiempos
reaparicionesj id Numero Tamaño
Tiempo
censura
Tiempos
Reapariciones48 48 1 2 2 - 64 64 1 1 38 - 49 49 4 6 4 3,4 65 65 1 2 39 3,7,12,16,19,28,34,36,3950 50 1 1 4 - 66 66 1 1 40 - 51 51 1 1 5 2,3 67 67 1 1 40 - 52 52 2 3 7 - 68 68 3 1 42 2,6,10,16,23,27,36, 39,4253 53 1 1 8 - 69 69 1 1 45 - 54 54 4 3 8 4 70 70 2 1 45 10 55 55 1 1 11 3 71 71 1 4 46 6,20 56 56 1 1 14 - 72 72 1 1 46 8,15,18,20, 22,25, 38, 4057 57 1 2 26 - 73 73 1 1 48 42 58 58 1 2 29 - 74 74 2 1 54 - 59 59 8 1 30 5 75 75 1 1 54 44,47 60 60 1 3 32 - 76 76 4 1 55 8,14,20,25,29,33, 48, 4961 61 1 1 33 - 77 77 1 1 57 - 62 62 1 4 34 3,10,22,26,34 78 78 3 8 60 - 63 63 3 7 37 15,19,25 - - - - - -
Grupo Thiotepa Tumores iniciales Tumores iniciales
J Id Numero Tamaño Tiempo
Tiempos
reaparicionesj id Numero Tamaño
Tiempo
censura
Tiempos
Reapariciones79 79 1 3 1 - 98 98 8 3 36 26,35 80 80 1 1 1 - 99 99 1 1 38 - 81 81 8 1 5 5 100 100 1 1 39 22,23,27,3282 82 1 2 9 - 101 101 6 1 39 4,16,23,27,33,36,3783 83 1 1 10 - 102 102 3 1 40 24,26,29,4084 84 1 1 13 - 103 103 3 2 41 - 85 85 2 6 14 3 104 104 1 1 41 - 86 86 5 3 17 1,3,5,7,10 105 105 1 1 43 1,27 87 87 5 1 18 106 106 1 1 44 - 88 88 1 3 18 17 107 107 6 1 44 2,20,23,27,3889 89 5 1 19 2 108 108 1 2 45 - 90 90 1 1 21 17,19 109 109 1 4 46 2 91 91 1 1 22 - 110 110 1 4 46 - 92 92 1 3 25 - 111 111 3 3 49 - 93 93 1 5 25 - 112 112 1 1 50 - 94 94 1 1 25 113 113 4 1 50 4,24,47 95 95 1 1 26 6,12,13 114 114 3 4 54 - 96 96 1 1 27 6 115 115 2 1 54 38 97 97 2 1 29 2 116 116 1 3 59 -
Fuente: Andrews-Herzberg (1985) pp. 254-259

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
124
Autores como Doganaksoy-Nelson (1998) determinaron que para un nivel del 5% no
existen diferencias significativas entre los grupos placebo y thiotepa. La técnica de
comparación utilizada fue detallada en la sección 6.4. Sun-Wei (2000) analizaron y
demostraron que la thiotepa reduce la tasa de reaparición de los tumores en los
pacientes y que el número inicial de tumores tiene efectos significativos como factor de
pronóstico en la reaparición de los mismos. Wei et. al (1989) utilizaron esta base de
datos para ejemplificar una aplicación de la propuesta de su modelo.
El objetivo planteado en esta investigación es determinar si existen diferencias
significativas entre las curvas de supervivencia de los tiempos de reaparición de los
tumores entre los tres grupos: placebo, thiotepa y piridoxina. Como una de las
restricciones del modelo GPLE es que el último tiempo de interocurrencia esté
censurado por la derecha, nos hemos visto en la necesidad de realizar algunos cambios
en la base de datos de aquellos experimentos donde esto no suceda. El cambio consiste
en que aquellas unidades experimentales que culminen el período de observación con
una ocurrencia deben ser censuradas con un tiempo ligeramente superior al último
tiempo de ocurrencia.
En esta investigación se realizarán las pruebas de comparación en cuatro (4) fases:
Fase I: Comparación de curvas de supervivencia en pacientes tratados con thiotepa y
el grupo placebo. Fase II: Comparación de curvas de supervivencia en pacientes tratados con
piridoxina y el grupo placebo. Fase III: Comparación de curvas de supervivencia en pacientes tratados con thiotepa
y con piridoxina. Fase IV: Comparación simultanea de curvas de supervivencia para los tres grupos en
pacientes tratados con placebo, thiotepa y piridoxina. La figura 9.1 ilustra los tiempos de reaparición de los tumores en los ciento dieciséis
(116) pacientes. La gráfica muestra los tres grupos involucrados en el estudio. Se
utilizarán los estadísticos propuestos y se compararán los resultados con los obtenidos
mediante la técnica de Doganaksoy-Nelson (1998).

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
125
0 10 20 30 40 50 60
020
4060
8010
012
0
TIEMPO
Obs
erva
cion
es
REPRESENTACIÓN GRÁFICA DE LOS TIEMPOS DE SUPERVIVENCIASoftware realizado por: Carlos Martínez
Modelo GPLE
inicio evento censura
Figura 9.1 Representación gráfica de tiempos de reaparición de tumores en los grupos placebo,
piridoxina y thiotepa. 9.2.1 Comparación curvas de supervivencia grupo placebo vs. grupo thiotepa 9.2.1.1 Utilizando estadísticos ponderados La figura 9.1, las tablas 9.2 y 9.3 muestran las salidas de la rutina diseñada para estimar
y graficar las funciones de supervivencia de dos grupos, con eventos recurrentes y para
estimar los estadísticos de comparación de las curvas de supervivencia para ambos
grupos y sus valores p-valores correspondientes.

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
126
0 10 20 30
0.0
0.2
0.4
0.6
0.8
1.0
tiempo
Pro
babi
lidad
de
supe
rviv
enci
a es
timad
a
ESTIMACIÓN DE LA FUNCIÓN DE SUPERVIVENCIASoftware realizado por: Carlos Martínez
Muestra combinadaGrupo placeboGrupo thiotepa
Figura 9.2. Representación gráfica de la comparación del grupo placebo vs. grupo thiotepa
Tabla 9.2 Estimaciones de la curvas de supervivencia de los grupos: combinado
placebo-thiotepa, placebo y thiotepa. Grupo combinado Grupo placebo Grupo thiotepa
time n.event n.risk surv n.event surv n.event Surv 1 8 209 0.9617 2 0.9840 6 0.927 2 18 196 0.8734 9 0.9130 9 0.811
3 19 174 0.7780 14 0.8000 5 0.745
4 14 153 0.7068 9 0.7260 5 0.677
5 10 135 0.6545 9 0.6500 1 0.663
6 14 125 0.5812 10 0.5660 4 0.608
7 3 110 0.5653 2 0.5490 1 0.594
8 3 102 0.5487 3 0.5220 0 0.594
9 7 97 0.5091 6 0.4670 1 0.579
10 2 88 0.4975 2 0.4490 0 0.579
11 2 84 0.4857 0 0.4490 2 0.547
12 7 81 0.4437 6 0.3910 1 0.531
13 2 74 0.4317 2 0.3720 0 0.531
14 2 69 0.4192 2 0.3530 0 0.531
15 1 66 0.4129 1 0.3430 0 0.531
16 2 63 0.3997 2 0.3210 0 0.531
17 3 57 0.3787 2 0.3100 1 0.495
18 2 53 0.3644 1 0.2980 1 0.476
20 1 49 0.3570 0 0.2980 1 0.456
22 1 47 0.3494 0 0.2980 1 0.435
23 1 45 0.3416 0 0.2980 1 0.413
24 2 42 0.3254 1 0.2850 1 0.392
25 1 40 0.3172 1 0.2720 0 0.392
26 2 35 0.2991 0 0.2720 2 0.339
28 1 31 0.2894 1 0.2580 0 0.339
29 1 30 0.2798 1 0.2440 0 0.339
31 1 25 0.2686 1 0.2250 0 0.339
35 1 21 0.2558 1 0.2000 0 0.339
38 1 16 0.2398 0 0.2000 1 0.311

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
127
Tabla 9.3 Resultados de las pruebas de comparación de las curvas de supervivencia de los grupos placebo y thiotepa utilizando propuestas.
Prueba Chi-cuadrado p-valor LRrec 1.8160 0.1778 Grec 0.2162 0.6420 TWrec 0.8589 0.3540 PPec 0.4025 0.5258 PMrec 0.3934 0.5305 PPrrec 0.5038 0.4778 FHrec1=0, p2=0 1.8160 0.1778 CMrec p1=0, p2=0, p3=0, p4= 0 1.8160 0.1778 CMrec p1=0, p2=0, p3=1, p4= 0 0.2162 0.6420 CMrec p1=0, p2=0, p3=1/2, p4= 0 0.8589 0.3540 CMrec p1=1, p2=0, p3=0 , p4= 0 0.4025 0.5258 CMrec p1=1, p2=0, p3=1, p4= -1 0.3934 0.5305 Mrec 1.7971 0.1801
La figura 9.2 muestra las curvas de supervivencia de los grupos placebo, thiotepa y el
grupo combinado. Se aprecian diferencias importantes entre las curvas de supervivencia
de placebo y thiotepa. Los resultados presentados en la Tabla 9.3 correspondientes a las
diferentes pruebas propuestas, indican que no se rechaza la hipótesis de igualdad de las
curvas de supervivencia en ninguno de los casos. Ello permite concluir que el
tratamiento con thiotepa en pacientes enfermos con cáncer de vejiga no tiene efectos
significativos en los tiempos de reaparición de los tumores.
9.2.1.2 Utilizando propuesta de Doganaksoy-Nelson (1998)
0 10 20 30 40 50
0.0
0.5
1.0
1.5
2.0
2.5
3.0
tiempo calendarios (meses)
MC
F
ESTIMACIÓN DE LA MCFSoftware realizado por: Carlos Martínez (2008)
++
++
+ + ++ + +
+ + +
++
+ ++ +
++
+
++
+ + ++
++
++
++
++
+
+
+
+
+
++
++ +
+ + + + + ++ + + +
++
+
+ + + + + ++
++
+
++
Grupo placeboGrupo Thiotepa
Figura 9.3 Representación gráfica de las MCF del grupo placebo vs grupo thiotepa

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
128
0 10 20 30 40 50
-10
12
3
tiempo calendarios (meses)
Dife
renc
ias
de la
s M
CF
DIFERENCIAS DE LAS MCFSoftware realizado por: Carlos Martínez (2008)
+ ++ + + + + +
+ + ++ + +
++ + + + + + + + +
+ ++ + +
+ + ++ + + +
+ + ++
++ +
++
+
+
-
-
- - - - - -- - -
- - -
--
- - - -- - -
-- - - - -
- - -- - - -
-- -
--
- -
-
-
-
-
-
- -- - - - - - - - - - -
- - - - - - - -- - - -
- - -- - -
- - - -- - - -
-- -
--
--
Figura 9.4. Representación gráfica de la diferencia de las MCF del grupo placebo vs grupo
thiotepa
Tabla 9.4 Resultados de las estimaciones las MCF de los grupos placebo y thiotepa y sus diferencias, utilizando propuesta de Doganaksoy-Nelson (1998).
Tiempo Eventos MCF
placebo MCF
thiotepa MCF1-MCF2 Tiempo Eventos MCF
Placebo MCF
thiotepa MCF1-MCF2 1 4 0.02128 0.07895 -0.05767 25 2 1.52101 0.85386 0.66715 2 8 0.10823 0.19006 -0.08183 26 5 1.61476 0.92529 0.68947 3 9 0.26041 0.24561 0.01479 27 5 1.64924 1.07343 0.57580 4 2 0.26041 0.30117 -0.04076 28 1 1.68372 1.07343 0.61029 5 4 0.32707 0.32974 -0.00267 29 3 1.75515 1.11047 0.64468 6 5 0.39374 0.38688 0.00686 30 3 1.87515 1.11047 0.76468 7 2 0.41596 0.41546 0.00051 32 1 1.87515 1.14893 0.72622 8 2 0.46142 0.41546 0.04596 33 2 1.92515 1.18893 0.73622 9 4 0.55233 0.41546 0.13687 34 2 2.02515 1.18893 0.83622 10 3 0.59778 0.44403 0.15375 35 2 2.07778 1.22893 0.84885 11 1 0.62159 0.44403 0.17756 36 1 2.07778 1.26893 0.80885 12 5 0.71683 0.47344 0.24339 37 1 2.07778 1.31439 0.76339 13 2 0.74064 0.50374 0.23690 38 2 2.07778 1.40963 0.66816 14 1 0.76445 0.50374 0.26071 39 1 2.14028 1.40963 0.73066 15 5 0.88640 0.50374 0.38266 40 2 2.20278 1.45963 0.74316 16 5 0.98396 0.53404 0.44992 41 1 2.27421 1.45963 0.81458 17 6 1.08152 0.59465 0.48687 43 1 2.35113 1.45963 0.89151 18 1 1.10591 0.59465 0.51126 46 1 2.46224 1.45963 1.00262 19 3 1.15854 0.62590 0.53264 47 1 2.46224 1.50963 0.95262 20 2 1.18486 0.65816 0.52670 49 2 2.71224 1.50963 1.20262 21 2 1.23749 0.65816 0.57933 51 1 2.85510 1.50963 1.34548 22 3 1.29012 0.69042 0.59970 52 1 3.02177 1.50963 1.51214 23 5 1.34275 0.78719 0.55556 53 1 3.18843 1.50963 1.67881 24 6 1.46040 0.85386 0.60654 - - - - -

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
129
La tabla 9.4 muestra las estimaciones de las MCF para los grupos placebo y thiotepa,
así como la diferencia entre ellas. Las figuras 9.3 y 9.4 ilustran las gráficas de esas
estimaciones. La figura 9.3 muestra las estimaciones de las MCF para ambos grupos y
la figura 9.4 ilustra la diferencia entre ellas. La figura 9.4. muestra la diferencia de las
estimaciones entre ambas curvas y las bandas de confianzas para un nivel de
significación del 95%. Se aprecia que las bandas de confianza incluyen la línea del cero,
por lo que se puede concluir que esa diferencia no es significativa. Esto corrobora la
decisión en la sección 9.2.1.1, donde se utilizaron los estadísticos ponderados.
9.2.2 Comparación curvas de supervivencia del grupo placebo vs. grupo piridoxina La figura 9.5 ilustra las curvas de supervivencia de los dos grupos estimadas a través
del modelo GPLE. Utilizaremos los estadísticos propuestos y se comparará con los
resultados que se obtienen utilizando la técnica de Doganaksoy.
9.2.2.1 Utilizando estadísticos ponderados En la figura 9.5 se muestran las curvas de supervivencia de los grupos placebo,
piridoxina y el grupo combinado, observándose leves diferencias entre placebo y
piridoxina.
0 10 20 30 40
0.0
0.2
0.4
0.6
0.8
1.0
tiempo
Pro
babi
lidad
de
supe
rviv
enci
a es
timad
a
ESTIMACIÓN DE LA FUNCIÓN DE SUPERVIVENCIASoftware realizado por: Carlos Martínez
Muestra combinadaGrupo placeboGrupo pyridoxine
Figura 9.5 Representación gráfica de la comparación del grupo placebo vs. grupo piridoxina.

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
130
Tabla 9.5 Estimaciones de la curva de supervivencia del grupo combinado y los grupos placebo y piridoxina.
Grupo combinado Grupo placebo Grupo piridoxina time n.event n.risk surv n.event surv n.event surv
1 5 211 0.976 2 0.9840 3 0.964 2 15 205 0.905 9 0.9130 6 0.893 3 26 186 0.778 14 0.8000 12 0.746 4 19 159 0.685 9 0.7260 10 0.624 5 12 135 0.624 9 0.6500 3 0.586 6 18 123 0.533 10 0.5660 8 0.484 7 5 102 0.507 2 0.5490 3 0.442 8 6 92 0.474 3 0.5220 3 0.398 9 8 82 0.428 6 0.4670 2 0.366 10 3 73 0.410 2 0.4490 1 0.350 12 7 69 0.368 6 0.3910 1 0.334 13 3 61 0.350 2 0.3720 1 0.318 14 3 57 0.332 2 0.3530 1 0.301 15 2 52 0.319 1 0.3430 1 0.283 16 2 48 0.306 2 0.3210 0 0.283 17 1 44 0.299 2 0.3100 0 0.283 18 1 43 0.292 1 0.2980 0 0.283 24 1 39 0.284 1 0.2850 0 0.283 25 1 38 0.277 1 0.2720 0 0.283 28 1 32 0.268 1 0.2580 0 0.283 29 1 31 0.260 1 0.2440 0 0.283 31 1 25 0.249 1 0.2250 0 0.283 35 1 19 0.236 1 0.2000 0 0.283 42 1 8 0.207 0 0.2000 1 0.236 44 1 7 0.177 0 0.2000 1 0.189
Tabla 9.6 Resultados de las pruebas de comparación de las curvas de supervivencia de los grupos placebo y piridoxina.
Nombre del estadístico Chi.cuadrado p.valor LRrec 0.3052411 0.5806152 Grec 1.4448446 0.2293570 TWrec 0.9551746 0.3284056 PPec 1.1322772 0.2872901 PMrec 1.1430319 0.2850126 PPrrec 1.4669461 0.2258281 FHrec1=0, p2=0 0.3052411 0.5806152 CMrec p1=0, p2=0, p3=0, p4= 0 0.3052411 0.5806152 CMrec p1=0, p2=0, p3=1, p4= 0 1.4448446 0.2293570 CMrec p1=0, p2=0, p3=1/2, p4= 0 0.9551746 0.3284056 CMrec p1=1, p2=0, p3=0 , p4= 0 1.1322772 0.2872901 CMrec p1=1, p2=0, p3=1, p4= -1 1.1430319 0.2850126 Mrec 0.2440728 0.6212799
Los resultados de la tabla 9.6 indican que no se puede rechazar la hipótesis de igualdad
de las curvas de supervivencia de ambos grupos. Así que el tratamiento con piridoxina
en pacientes enfermos con cáncer de vejiga no tiene efectos significativos en los
tiempos de reaparición de los tumores.

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
131
9.2.2.2 Utilizando propuesta de Doganaksoy-Nelson (1998).
0 10 20 30 40 50
0.0
0.5
1.0
1.5
2.0
2.5
3.0
tiempo calendarios (meses)
MC
F
ESTIMACIÓN DE LA MCFSoftware realizado por: Carlos Martínez (2008)
++
++
+ + ++ + +
+ + +
++
+ ++ +
++
+
++
+ + ++
++
++
++
++
+
+
+
+
+
+
++ +
+ ++ +
++ +
++
++
++
+
+ ++ +
+ ++
++
++
++
++
+
++
Grupo placeboGrupo Pyridoxina
Figura 9.6 Representación gráfica de las MCF del grupo placebo vs. grupo piridoxina
La tabla 9.7 muestra las estimaciones de las MCF para los grupos placebo y piridoxina
así como la diferencia entre ellas. La figura 9.7 muestra la diferencia de las
estimaciones entre ambas curvas y las bandas de confianzas para un nivel de
significación del 95%. Puede apreciarse que las bandas de confianza incluyen la línea
del cero, resultando así que esa diferencia no es significativa.
0 10 20 30 40 50
-1.0
-0.5
0.0
0.5
1.0
tiempo calendarios (meses)
Dife
renc
ias
de la
s M
CF
DIFERENCIAS DE LAS MCFSoftware realizado por: Carlos Martínez (2008)
+ ++
+ + + + ++
+ ++ + +
+ +
+ ++
++
+ +
++
+ + + +
+ + ++
++ + +
+
++
+
++
+
+
+
+
+
-
-
--
- - - -- - -
- - -
--
- - --
- - -
- -- - -
-
- --
--
- - --
-
--
--
-
-
-
-- -
- -- -
- - - - - - -- -
-
--
- -
-
- - - - -
- - --
-- - -
-
-
Figura 9.7. Representación gráfica de la diferencia de las MCF del grupo placebo vs. grupo
piridoxina
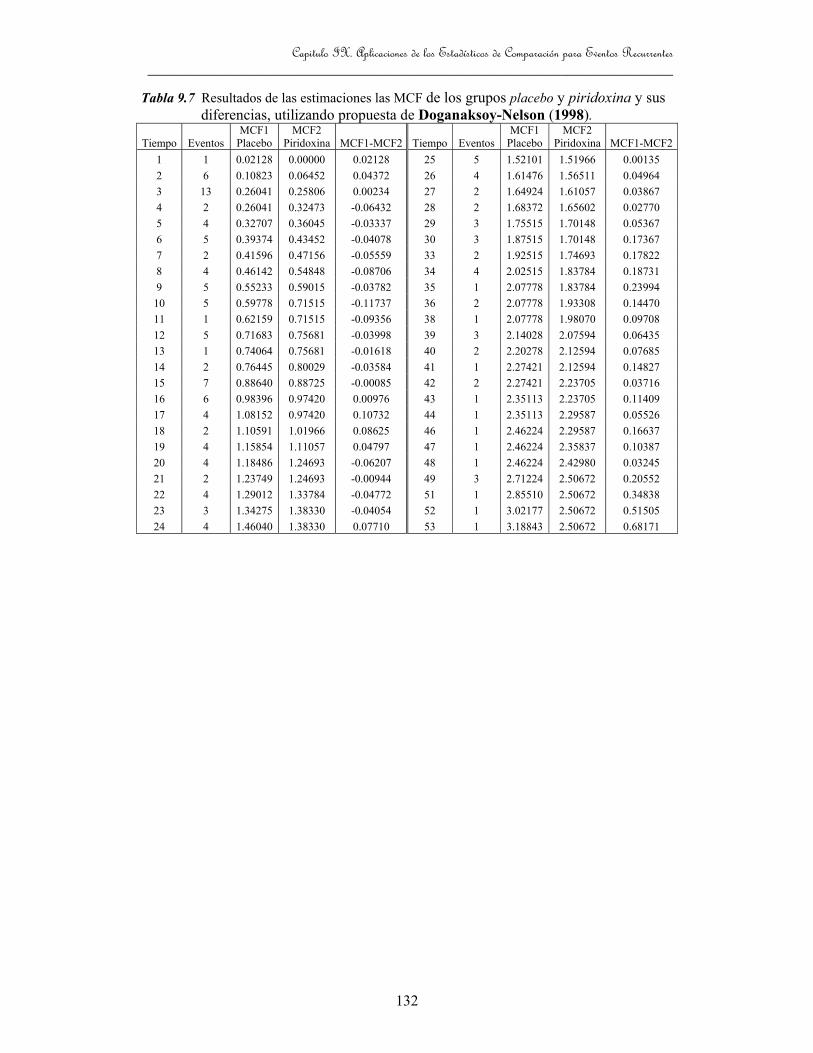
Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
132
Tabla 9.7 Resultados de las estimaciones las MCF de los grupos placebo y piridoxina y sus diferencias, utilizando propuesta de Doganaksoy-Nelson (1998).
Tiempo Eventos MCF1
Placebo MCF2
Piridoxina MCF1-MCF2 Tiempo Eventos MCF1
Placebo MCF2
Piridoxina MCF1-MCF21 1 0.02128 0.00000 0.02128 25 5 1.52101 1.51966 0.00135 2 6 0.10823 0.06452 0.04372 26 4 1.61476 1.56511 0.04964 3 13 0.26041 0.25806 0.00234 27 2 1.64924 1.61057 0.03867 4 2 0.26041 0.32473 -0.06432 28 2 1.68372 1.65602 0.02770 5 4 0.32707 0.36045 -0.03337 29 3 1.75515 1.70148 0.05367 6 5 0.39374 0.43452 -0.04078 30 3 1.87515 1.70148 0.17367 7 2 0.41596 0.47156 -0.05559 33 2 1.92515 1.74693 0.17822 8 4 0.46142 0.54848 -0.08706 34 4 2.02515 1.83784 0.18731 9 5 0.55233 0.59015 -0.03782 35 1 2.07778 1.83784 0.23994 10 5 0.59778 0.71515 -0.11737 36 2 2.07778 1.93308 0.14470 11 1 0.62159 0.71515 -0.09356 38 1 2.07778 1.98070 0.09708 12 5 0.71683 0.75681 -0.03998 39 3 2.14028 2.07594 0.06435 13 1 0.74064 0.75681 -0.01618 40 2 2.20278 2.12594 0.07685 14 2 0.76445 0.80029 -0.03584 41 1 2.27421 2.12594 0.14827 15 7 0.88640 0.88725 -0.00085 42 2 2.27421 2.23705 0.03716 16 6 0.98396 0.97420 0.00976 43 1 2.35113 2.23705 0.11409 17 4 1.08152 0.97420 0.10732 44 1 2.35113 2.29587 0.05526 18 2 1.10591 1.01966 0.08625 46 1 2.46224 2.29587 0.16637 19 4 1.15854 1.11057 0.04797 47 1 2.46224 2.35837 0.10387 20 4 1.18486 1.24693 -0.06207 48 1 2.46224 2.42980 0.03245 21 2 1.23749 1.24693 -0.00944 49 3 2.71224 2.50672 0.20552 22 4 1.29012 1.33784 -0.04772 51 1 2.85510 2.50672 0.34838 23 3 1.34275 1.38330 -0.04054 52 1 3.02177 2.50672 0.51505 24 4 1.46040 1.38330 0.07710 53 1 3.18843 2.50672 0.68171

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
133
9.2.3 Comparación curvas de supervivencia grupo piridoxina vs. thiotepa
La figura 9.8 ilustra las curvas de supervivencia de piridoxina y thiotepa, estimadas a
través del modelo GPLE. 9.2.3.1 Utilizando estadísticos ponderados
0 10 20 30 40
0.0
0.2
0.4
0.6
0.8
1.0
tiempo
Pro
babi
lidad
de
supe
rviv
enci
a es
timad
a
ESTIMACIÓN DE LA FUNCIÓN DE SUPERVIVENCIASoftware realizado por: Carlos Martínez
Muestra combinadaGrupo piridoxinaGrupo thiotepa
Figura 9.8 Representación gráfica de la comparación del grupo piridoxina vs thiotepa.
Tabla 9.8 Estimaciones de la curva de supervivencia del grupo combinado
piridoxina-thiotepa Time n.event n.risk surv time n.event n.risk Surv
1 9 166 0.9458 14 1 50 0.4141 2 15 153 0.8531 15 1 48 0.4055 3 17 134 0.7448 17 2 45 0.3875 4 15 116 0.6485 18 1 42 0.3782 5 4 98 0.6221 20 1 40 0.3688 6 12 94 0.5426 22 1 38 0.3591 7 4 78 0.5148 23 1 36 0.3491 8 3 70 0.4927 24 1 35 0.3391 9 3 65 0.4700 26 2 30 0.3165
10 1 61 0.4623 38 1 21 0.3014 11 2 59 0.4466 42 1 14 0.2799 12 2 56 0.4307 44 1 13 0.2584 13 1 53 0.4226 - - - -
La figura 9.8 muestra las curvas de supervivencia de los grupos piridoxina, thiotepa y
grupo combinado. En la gráfica se observa que existe una leve diferencia entre las
curvas de supervivencia de ambos grupos. No se puede rechazar la hipótesis de
igualdad de las curvas de supervivencia de los grupos piridoxina y thiotepa.
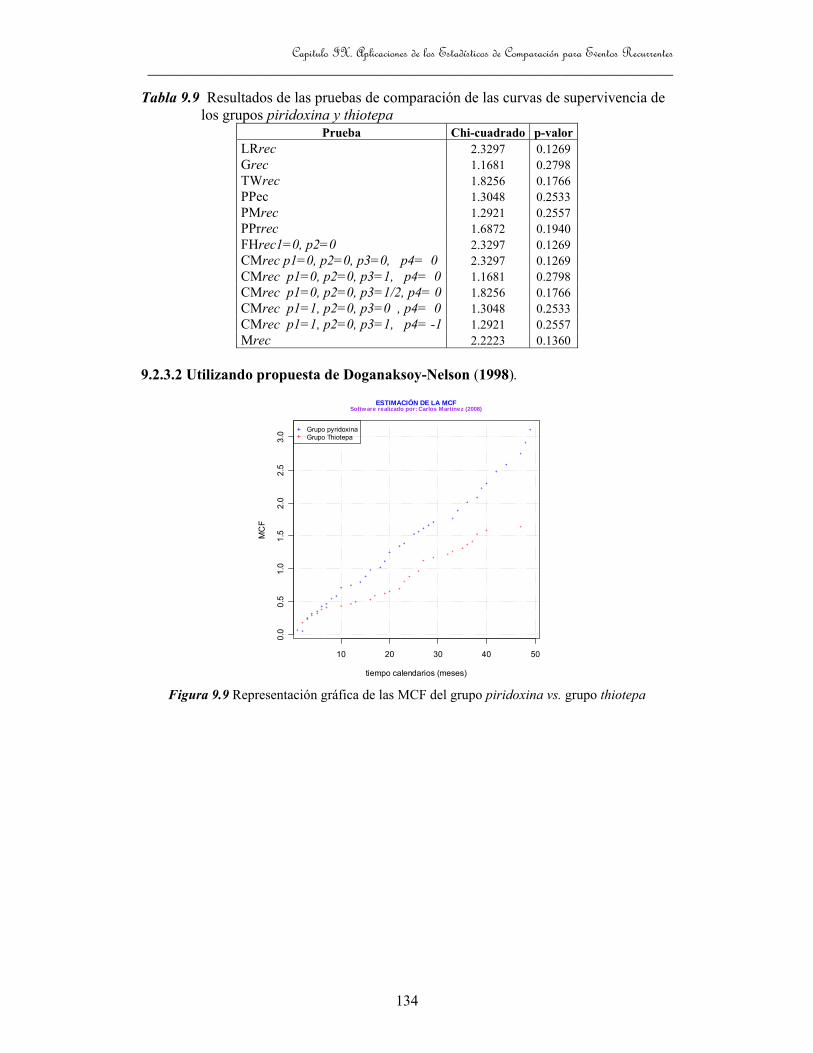
Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
134
Tabla 9.9 Resultados de las pruebas de comparación de las curvas de supervivencia de los grupos piridoxina y thiotepa
Prueba Chi-cuadrado p-valor LRrec 2.3297 0.1269 Grec 1.1681 0.2798 TWrec 1.8256 0.1766 PPec 1.3048 0.2533 PMrec 1.2921 0.2557 PPrrec 1.6872 0.1940 FHrec1=0, p2=0 2.3297 0.1269 CMrec p1=0, p2=0, p3=0, p4= 0 2.3297 0.1269 CMrec p1=0, p2=0, p3=1, p4= 0 1.1681 0.2798 CMrec p1=0, p2=0, p3=1/2, p4= 0 1.8256 0.1766 CMrec p1=1, p2=0, p3=0 , p4= 0 1.3048 0.2533 CMrec p1=1, p2=0, p3=1, p4= -1 1.2921 0.2557 Mrec 2.2223 0.1360
9.2.3.2 Utilizando propuesta de Doganaksoy-Nelson (1998).
10 20 30 40 50
0.0
0.5
1.0
1.5
2.0
2.5
3.0
tiempo calendarios (meses)
MC
F
ESTIMACIÓN DE LA MCFSoftw are realizado por: Carlos Martínez (2008)
+
++ +
+ ++ +
+ ++
++ +
+
++ +
+ ++
++
+
+
++
++
++
+
+
+
+
++
+ ++ + + + + +
+ + + +
++
+
++
++
++
+
++
+
++
Grupo pyridoxinaGrupo Thiotepa
Figura 9.9 Representación gráfica de las MCF del grupo piridoxina vs. grupo thiotepa

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
135
0 10 20 30 40 50
-10
12
3
tiempo calendarios (meses)
Dife
renc
ias
de la
s M
CF
DIFERENCIAS DE LAS MCFSoftw are realizado por: Carlos Martínez (2008)
+ +
+ + + + ++ +
+ + + ++
++ +
++ +
++
+ ++ + + + +
+ ++ + +
+ +
++
+
+
+
-
-
- - - - -- -
- - - --
- - --
-- -
-
- -- - - - -
- -- - -
- -
--
-
-
-
-
-- - - - - - - - - - -
- -- - -
- --
-- -
- - - - -- - -
--
- --
--
-
-
Figura 9.10 Representación gráfica de la diferencia de las MCF del grupo piridoxina vs. grupo
thiotepa Tabla 9.10 Resultados de las estimaciones las MCF de los grupos piridoxina y thiotepa y
sus diferencias, utilizando propuesta de Doganaksoy-Nelson (1998).
Tiempo Eventos MCF1
piridoxina MCF2
thiotepa MCF1-MCF2 Tiempo EventosMCF1
piridoxinaMCF2
thiotepa MCF1-MCF21 3 0.00000 0.08333 -0.08333 24 2 1.39946 0.89323 0.50623 2 6 0.06452 0.19444 -0.12993 25 3 1.53583 0.89323 0.64259 3 8 0.26452 0.25000 0.01452 26 3 1.58128 0.97323 0.60805 4 4 0.33118 0.30556 0.02563 27 5 1.62890 1.13323 0.49567 5 2 0.36690 0.33413 0.03277 28 1 1.67652 1.13323 0.54329 6 4 0.44097 0.39127 0.04970 29 2 1.72414 1.17869 0.54545 7 2 0.47801 0.41984 0.05817 32 1 1.72414 1.22631 0.49783 8 2 0.55493 0.41984 0.13509 33 2 1.77969 1.27631 0.50339 9 1 0.59660 0.41984 0.17676 34 2 1.89734 1.27631 0.62103
10 4 0.72160 0.44841 0.27319 35 1 1.89734 1.32631 0.57103 12 2 0.76508 0.47782 0.28725 36 3 2.02234 1.37894 0.64340 13 1 0.76508 0.50813 0.25695 37 1 2.02234 1.43157 0.59077 14 1 0.80855 0.50813 0.30043 38 3 2.08901 1.53683 0.55217 15 2 0.89946 0.50813 0.39134 39 2 2.23187 1.53683 0.69503 16 3 0.99037 0.53938 0.45100 40 2 2.30879 1.59239 0.71640 17 2 0.99037 0.60389 0.38648 42 2 2.49061 1.59239 0.89822 18 1 1.03583 0.60389 0.43193 44 1 2.59061 1.59239 0.99822 19 3 1.12674 0.63615 0.49058 47 2 2.75727 1.65121 1.10606 20 4 1.26310 0.66949 0.59361 48 1 2.92394 1.65121 1.27273 22 3 1.35401 0.70520 0.64881 49 1 3.12394 1.65121 1.47273 23 4 1.39946 0.81631 0.58315 - - - - -
La tabla 9.10 muestra las estimaciones de las MCF para los grupos placebo y thiotepa,
así como la diferencia entre ellas. Las figuras 9.9 y 9.10 ilustran las gráficas de esas
estimaciones. No hay diferencias significativas entre ellas.

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
136
9.2.4 Comparación de las curvas de supervivencia de los tres grupos
En esta sección se compararán en forma simultánea las curvas de supervivencia de los
tres grupos. A través de las comparaciones dos a dos realizadas en las secciones
anteriores, se encontró que no existen diferencias significativas entre ellos. Utilizaremos
ahora la técnica propuesta para la comparación de k grupos. No se utiliza la técnica de
Doganaksoy debido a que esta técnica fue diseñada para comparar grupos dos a dos.
0 10 20 30 40
0.0
0.2
0.4
0.6
0.8
1.0
tiempo
Pro
babi
lidad
de
supe
rviv
enci
a es
timad
a
ESTIMACIÓN DE LA FUNCIÓN DE SUPERVIVENCIASoftware realizado por: Carlos Martínez
Muestra combinadaGrupo placeboGrupo pyridoxineGrupo thiotepa
Figura 9.11 Representación gráfica de la comparación de los tres grupos.
Tabla 9.11 Estimaciones de la curva de supervivencia del grupo combinado
placebo-thiotepa-piridoxina. time n.event n.risk surv time n.event n.risk surv
1 11 293 0.9625 17 3 73 0.3518 2 24 277 0.8791 18 2 69 0.3416 3 31 247 0.7687 20 1 65 0.3363 4 24 214 0.6825 22 1 63 0.3310 5 13 184 0.6343 23 1 61 0.3256 6 22 171 0.5527 24 2 58 0.3143 7 6 145 0.5298 25 1 56 0.3087 8 6 132 0.5057 26 2 50 0.2964 9 9 122 0.4684 28 1 44 0.2896
10 3 111 0.4558 29 1 43 0.2829 11 2 106 0.4472 31 1 37 0.2753 12 8 103 0.4124 35 1 31 0.2664 13 3 94 0.3993 38 1 25 0.2557 14 3 88 0.3857 42 1 16 0.2397 15 2 83 0.3764 44 1 15 0.2238 16 2 79 0.3668 - - - -

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
137
Tabla 9.12 Resultados de las pruebas de comparación de las curvas de supervivencia de los tres grupos
Prueba Chi-cuadrado p-valor LRrec 2.98493 0.22482 Grec 0.21711 0.48307 TWrec 0.00126 0.97173 PPec 0.06956 0.79198 PMrec 0.07285 0.78724 PPrrec 0.08550 0.76998 FHrec1=0, p2=0 0.06956 0.79198 CMrec p1=0, p2=0, p3=0, p4= 0 1.39251 0.23798 CMrec p1=0, p2=0, p3=1, p4= 0 0.21711 0.64125 CMrec p1=0, p2=0, p3=1/2, p4= 0 0.00126 0.97173 CMrec p1=1, p2=0, p3=0 , p4= 0 0.06956 0.79198 CMrec p1=1, p2=0, p3=1, p4= -1 1.37843 0.24037 Mrec 0.31468 0.57482
Los resultados de la tabla 9.12, indican que efectivamente no se puede rechazar la
hipótesis de igualdad de las curvas de supervivencia de los tres grupos.
9.3 Datos del experimento de Aalen-Husebye (1991) La tabla 9.13 ilustra los datos del experimento de Aalen-Husebye (1991)
correspondientes al estudio de la motilidad del intestino delgado (actividad muscular) de
diecinueve (19) pacientes estudiados en un área de gastroenterología. Los individuos
fueron examinados continuamente desde las 5:45 p.m. hasta las 7:25 a.m., durante un
tiempo total de 13 horas y 40 minutos de observación. A los pacientes se les
suministraba una comida estandarizada con 405 Kcal a las 6:00 p.m., para inducir la
contracción del intestino delgado. Después de períodos irregulares de tiempos de
contracciones, ocurre un estado de reposo y el proceso repite hasta culminada la
digestión o finaliza el tiempo de observación. Se midieron en minutos los tiempos de
ciclo denominado Complejo Migratorio Motor (CMM). El objetivo inicial y principal
del estudio consistía en determinar el tiempo medio en minutos del período del CMM
en dichos pacientes.
En el estudio se consideraron dos aproximaciones: Una que consistió en utilizar un
modelo Weibull con una componente gamma de fragilidad y otra basada en
componentes de varianza. Los autores asumieron independencia entre los tiempos de
interocurrencias, argumentando que los procesos de los períodos del CMM
individuales se comportan como un proceso de renovación. Peña sugiere utilizar un
método gráfico para comparar las medias de supervivencia de dichos modelos. En su

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
138
trabajo los autores determinan en forma gráfica que los tres modelos de estimación de
curvas de supervivencia se comportan de forma similar. González-Peña (2004)
proponen una herramienta computacional diseñada en lenguaje R, que permite graficar
simultáneamente los datos para los tres estimadores señalados (GPLE, FRMLE y
WC).
Tabla 9.13 Datos del período del complejo migratorio motor (CMM).
J id Numero de ocurrencias, Ki Tiempo censura Tiempos de interocurrencias
Sexo
1 1 8 54 112,145,39,52,21,34,33,51 Males 2 2 2 30 206,147 Males 3 3 3 4 284, 59, 186 Males 4 4 3 87 94, 98, 84 Males 5 5 1 131 67 Males 6 6 9 23 124,34, 87, 75, 43, 38,58, 142, 75 Males 7 7 5 111 116, 71, 83, 68, 125 Males 8 8 4 110 111, 59, 47, 95 Females 9 9 4 44 98, 161, 154, 55 Females 10 10 2 122 166, 56 Females 11 11 5 85 63, 90, 63, 103, 51 Females 12 12 4 72 47, 86, 68, 144 Females 13 13 3 6 120, 106, 176 Females 14 14 4 85 112, 25, 57, 166 Females 15 15 3 86 132, 267, 89 Females 16 16 5 12 120, 47, 165, 64, 113 Females 17 17 4 39 162, 141, 107, 69 Females 18 18 6 13 106, 56, 158, 41, 41, 168 Females 19 19 5 4 147, 134, 78, 66, 100 Females
Fuente: González-Peña (2004) El objetivo aquí consiste en determinar si existen diferencias significativas entre las
curvas de supervivencia de los pacientes de sexo masculino y los de sexo femenino.
0 100 200 300 400 500 600 700
05
1015
TIEMPO
Obs
erva
cion
es
REPRESENTACIÓN GRÁFICA DE LOS TIEMPOS DE SUPERVIVENCIASoftware realizado por: Carlos Martínez
Modelo GPLE
inicio evento censura
Figura 9.12 Representación gráfica de los períodos CMM en hombres y mujeres.

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
139
50 100 150 200 250
0.0
0.2
0.4
0.6
0.8
1.0
tiempo
Pro
babi
lidad
de
supe
rviv
enci
a es
timad
a
ESTIMACIÓN DE LA FUNCIÓN DE SUPERVIVENCIASoftw are realizado por: Carlos Martínez
Muestra combinadaHombresMujeres
Figura 9.13 Representación gráfica de la supervivencia de los períodos CMM en hombres y
mujeres. Tabla 9.14 Estimaciones de la curva de supervivencia del período CMM del grupo
combinado hombres- mujeres. time n.event n.risk Surv time n.event n.risk surv time n.event n.risk surv 21 1 94 0.98936 71 1 58 0.64370 125 1 23 0.30441 25 1 92 0.97861 75 2 56 0.62071 132 1 21 0.28992 33 1 90 0.96773 78 1 54 0.60922 134 1 20 0.27542 34 2 89 0.94599 83 1 53 0.59772 141 1 19 0.26093 38 1 87 0.93511 84 1 52 0.58623 142 1 18 0.24643 39 1 86 0.92424 86 1 49 0.57426 144 1 17 0.23193 41 2 84 0.90223 87 1 47 0.56205 145 1 16 0.21744 43 1 82 0.89123 89 1 45 0.54956 147 2 15 0.18845 47 3 80 0.85781 90 1 44 0.53707 154 1 13 0.17395 51 2 77 0.83553 94 1 43 0.52458 158 1 12 0.15945 52 1 75 0.82439 95 1 42 0.51209 161 1 11 0.14496 55 1 73 0.81310 98 2 41 0.48711 162 1 10 0.13046 56 2 72 0.79051 100 1 39 0.47462 165 1 9 0.11597 57 1 70 0.77922 103 1 38 0.46213 166 2 8 0.08698 58 1 69 0.76792 106 2 37 0.43715 168 1 6 0.07248 59 2 68 0.74534 107 1 35 0.42466 176 1 5 0.05798 63 2 66 0.72275 111 1 33 0.41179 186 1 4 0.04349 64 1 64 0.71146 112 2 31 0.38522 206 1 3 0.02899 66 1 63 0.70017 113 1 29 0.37194 267 1 2 0.01450 67 1 62 0.68887 116 1 28 0.35865 284 1 1 0.00000 68 2 61 0.66629 120 2 27 0.33209 - - - - 69 1 59 0.65499 124 1 24 0.31825 - - - -

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
140
Tabla 9.15 Estimaciones de la curva de supervivencia del grupo del período CMM en hombres y mujeres.
Hombres Mujeres time n.event n.risk surv std.error time n.event n.risk surv std.error 21 1 37 0.9730 0.0263 25 1 57 0.9825 0.0172 33 1 34 0.9444 0.0377 41 2 55 0.9467 0.0295 34 2 33 0.8871 0.0520 47 3 52 0.8921 0.0407 38 1 31 0.8585 0.0574 51 1 49 0.8739 0.0437 39 1 30 0.8299 0.0620 55 1 48 0.8557 0.0463 43 1 29 0.8013 0.0659 56 2 47 0.8193 0.0507 51 1 28 0.7727 0.0693 57 1 45 0.8011 0.0527 52 1 27 0.7440 0.0722 59 1 44 0.7829 0.0545 58 1 25 0.7143 0.0750 63 2 43 0.7465 0.0575 59 1 24 0.6845 0.0773 64 1 41 0.7283 0.0588 67 1 23 0.6548 0.0792 66 1 40 0.7100 0.0600 68 1 22 0.6250 0.0808 68 1 39 0.6918 0.0611 71 1 21 0.5952 0.0820 69 1 38 0.6736 0.0621 75 2 20 0.5357 0.0830 78 1 36 0.6549 0.0630 83 1 18 0.5059 0.0832 86 1 33 0.6351 0.0641 84 1 17 0.4762 0.0832 89 1 31 0.6146 0.0651 87 1 16 0.4464 0.0828 90 1 30 0.5941 0.0660 94 1 14 0.4145 0.0824 95 1 29 0.5736 0.0667 98 1 13 0.3826 0.0816 98 1 28 0.5531 0.0673 112 1 11 0.3479 0.0806 100 1 27 0.5326 0.0677 116 1 10 0.3131 0.0790 103 1 26 0.5122 0.0680 124 1 9 0.2783 0.0768 106 2 25 0.4712 0.0680 125 1 8 0.2435 0.0737 107 1 23 0.4507 0.0680 142 1 6 0.2029 0.0701 111 1 21 0.4292 0.0679 145 1 5 0.1623 0.0648 112 1 20 0.4078 0.0676 147 1 4 0.1218 0.0574 113 1 19 0.3863 0.0672 186 1 3 0.0812 0.0468 120 2 18 0.3434 0.0656 206 1 2 0.0406 0.0310 132 1 15 0.3205 0.0648 284 1 1 0.0000 0.0000 134 1 14 0.2976 0.0638
- - - - - 141 1 13 0.2747 0.0626 - - - - - 144 1 12 0.2518 0.0611 - - - - - 147 1 11 0.2289 0.0593 - - - - - 154 1 10 0.2060 0.0572 - - - - - 158 1 9 0.1831 0.0548 - - - - - 161 1 8 0.1602 0.0520 - - - - - 162 1 7 0.1374 0.0487 - - - - - 165 1 6 0.1145 0.0448 - - - - - 166 2 5 0.0687 0.0332 - - - - - 168 1 3 0.0458 0.0269 - - - - - 176 1 2 0.0229 0.0176 - - - - - 267 1 1 0.0000 0.0000

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
141
Tabla 9.16 Resultados de las pruebas de comparación de las curvas de supervivencia del período CMM.
Prueba Chi-cuadrado p-valor LRrec 0.21229 0.64498 Grec 1.77883 0.18229 TWrec 1.12913 0.28796 PPec 1.68459 0.19432 PMrec 1.71560 0.19026 PPrrec 1.67673 0.19536 FHrec1=0, p2=0 0.21229 0.64498 CMrec p1=0, p2=0, p3=0, p4= 0 0.21229 0.64498 CMrec p1=0, p2=0, p3=1, p4= 0 1.77883 0.18229 CMrec p1=0, p2=0, p3=1/2, p4= 0 1.12913 0.28796 CMrec p1=1, p2=0, p3=0 , p4= 0 1.68459 0.19432 CMrec p1=1, p2=0, p3=1, p4= -1 1.71560 0.19026 Mrec 0.36851 0.54382
Los resultados de la tabla 9.16, indican que no se puede rechazar la hipótesis de
igualdad de las curvas de supervivencia de los grupos hombres y mujeres. Esto quiere
decir que la variable sexo no tiene efectos significativos en los períodos CMM. 9.4 Datos del cáncer colorectal de González -Peña (2003, 2004) La tabla 9.17 ilustra los datos del estudio hecho por González-Peña (2003, 2004),
correspondientes a los tiempos de rehospitalización de cuatrocientos tres (403)
pacientes diagnosticados e intervenidos quirúrgicamente con cáncer colorectal. Uno de
los objetivos principales del estudio consistió en determinar el tiempo mediano de
supervivencia de rehospitalización de pacientes enfermos con el cáncer. Otro objetivo
del estudio consistió en determinar si existían diferencias significativas en los tiempos
medianos de rehospitalizaciones debido a ciertas variables socio-demográficas y
clínicas, como sexo, edad y estado tumoral. Variables que estratificaron de la siguiente
manera: el sexo (male = 1, female = 2), la edad en tres grupos (Menores de 60 años = 1,
entre 60 y 74 años = 2 y mayores o iguales a 75 = 3) y el estado tumoral en tres grupos
usando la clasificación de Dukes (A-B = 1, C = 2 y D = 3). Todos los pacientes
incluidos en el estudio se operaron entre enero de 1996 y diciembre de 1998. El
momento de la operación fue considerado como el momento inicial de observación.
Todos los pacientes fueron seguidos y observados hasta Junio del 2002. Esto indica que
cada paciente tiene su propio período de observación, que puede ser igual o diferente al
del resto de los pacientes. Para el estudio los autores utilizaron un software desarrollado
por ellos denominado survrec. El procedimiento estadístico se basó en una
comparación de medianas por grupos y por estimadores de PHS y WC.

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
142
Se desea determinar si existen diferencias significativas entre las curvas de
supervivencia de los tiempos de rehospitalización de grupos de pacientes estratificados
debido a las variables quimioterapia, estado tumoral y distancia. La variable
quimioterapia se estratifico en dos clases (el paciente no recibió quimioterapia = 1, el
paciente recibió quimioterapia = 2), el estado tumoral se clasificó en tres grupos usando
la clasificación de Dukes (A-B=1, C=2 y D=3) y la distancia entre el hospital y la
residencia del paciente se estratificó en dos grupos (menor o igual a 30 Km = 1 y mayor
a 30 Km = 2). El Estudio se realizó en cuatro fases: Fase I: Comparación de curvas de supervivencia para tiempos de rehospitalizaciones
en pacientes sin y con quimioterapia. Fase II: Comparación de curvas de supervivencia para tiempos de rehospitalizaciones
en pacientes que viven como máximo a 30 km. del hospital y pacientes que viven a más de 30 km. del hospital.
Fase III: Comparación simultanea de curvas de supervivencia para tiempos de rehospitalizaciones en pacientes clasificados con estados tumorales Dukes. A-B, C y D.
Fase IV: Comparación dos a dos de curvas de supervivencia para tiempos de rehospitalizaciones en pacientes clasificados con estados tumorales Dukes. A-B, C y D.
Tabla 9.17 Datos de rehospitalización de los primeros veinticinco (25) pacientes enfermos con
cáncer de colon de un total de cuatrocientos tres (403).
j Id
Numero de
rehostalizaciones chemoter
Clasificación
Dukes
distancia Tiempo censura
Tiempos de
rehospitalizaciones
1 5634 2 2 3 1 580 24,433 2 10767 1 2 3 1 693 489 3 15843 1 1 2 1 768 15 4 19655 4 2 1 1 1362 163, 125, 350, 48 5 25109 1 2 1 1 10 1134 6 34713 3 2 1 1 0 627, 563, 216 7 34975 2 2 1 1 986 38, 4, 21 8 35290 0 1 2 1 1466 - 9 41330 1 1 2 1 1326 148 10 43886 0 2 1 1 1113 - 11 43373 2 2 1 1 1357 267, 9 12 49110 0 2 1 1 1189 - 13 53187 1 1 2 1 179 1028 14 54964 0 2 1 1 1125 - 15 57524 2 1 3 1 0 734, 158 16 58244 1 1 1 1 0 389 17 58344 0 1 3 1 1255 - 18 59712 0 2 1 2 932 - 19 59720 0 2 3 1 304 - 20 62263 1 2 3 1 0 99 21 64982 1 2 1 1 872 686 22 74381 0 2 2 1 1374 - 23 74425 1 2 3 1 0 540 24 76442 1 2 2 1 42 226 25 78472 0 2 2 1 1255 -
Fuente: Package: survrec versión 1.1-5(2002)

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
143
9.4.1 Comparación de curvas de supervivencia para tiempos de rehospitalizaciones en pacientes sin y con quimioterapia.
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
1.0
tiempo
Pro
babi
lidad
de
supe
rviv
enci
a es
timad
a
ESTIMACIÓN DE LA FUNCIÓN DE SUPERVIVENCIASoftware realizado por: Carlos Martínez
Muestra combinadaSin quimioterapiaCon quimioterapia
Figura 9.14 Representación gráfica de la supervivencia de los tiempos de rehospitalizaciones de
pacientes enfermos con cáncer de colon con y sin quimioterapia.
Tabla 9.18 Resultados de las pruebas de comparación de las curvas de supervivencia en los tiempos de rehospitalizaciones de pacientes enfermos con cáncer de colon, con y sin quimioteratía.
Prueba Chi-cuadrado p-valor
LRrec 15.958230 0.000065 Grec 15.863010 0.000068 TWrec 16.614240 0.000046 PPec 16.097500 0.000060 PMrec 16.101130 0.000060 PPrrec 16.389230 0.000052 FHrec p1=0, p2=0 15.958230 0.000065 CMrec p1=0, p2=0, p3=0, p4= 0 15.958230 0.000065 CMrec p1=0, p2=0, p3=1, p4= 0 15.863010 0.000068 CMrec p1=0, p2=0, p3=1/2, p4= 0 16.614240 0.000046 CMrec p1=1, p2=0, p3=0 , p4= 0 16.097500 0.000060 CMrec p1=1, p2=0, p3=1, p4= -1 16.101130 0.000060 Mrec 15.929830 0.000066
Los resultados de la tabla 9.18 indican que se rechaza la hipótesis de igualdad de las
curvas de supervivencia de los grupos de pacientes con y sin quimioterapia. Esto quiere
decir que los tiempos de rehospitalización en pacientes enfermos con cáncer de colon
difieren significativamente entre pacientes que reciben quimioterapia y aquéllos que no
la reciben.

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
144
9.4.2 Comparación de curvas de supervivencia para tiempos de rehospitalizaciones en pacientes estratificado por la variable distancia.
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
1.0
tiempo
Pro
babi
lidad
de
supe
rviv
enci
a es
timad
a
ESTIMACIÓN DE LA FUNCIÓN DE SUPERVIVENCIASoftware realizado por: Carlos Martínez
Muestra combinadaMenor o igual a 30 kmMayor a 30 Km.
Figura 9.14 Representación gráfica de la supervivencia de los tiempos de rehospitalizaciones de
pacientes enfermos con cáncer de colon estratificados por la variable distancia. Tabla 9.19 Resultados de las pruebas de comparación de las curvas de supervivencia e
los tiempos de rehospitalizaciones de pacientes enfermos con cáncer de colon estratificados por la variable distancia.
Prueba Chi-cuadrado p-valor LRrec 0.00123 0.97197 Grec 0.00000 0.99828 TWrec 0.00001 0.99819 PPec 0.00004 0.99473 PMrec 0.00004 0.99492 PPrrec 0.00031 0.98590 FHrec p1=0, p2=0 0.00123 0.97197 CMrec p1=0, p2=0, p3=0, p4= 0 0.00123 0.97197 CMrec p1=0, p2=0, p3=1, p4= 0 0.00000 0.99828 CMrec p1=0, p2=0, p3=1/2, p4= 0 0.00001 0.99819 CMrec p1=1, p2=0, p3=0 , p4= 0 0.00004 0.99473 CMrec p1=1, p2=0, p3=1, p4= -1 0.00004 0.99492 Mrec 0.00070 0.97893
Según la tabla 9.19 no se puede rechazar la hipótesis de igualdad de las curvas de
supervivencia de los grupos estratificados a través de la variable distancia. Los
pacientes que viven a más de 30 Km del hospital se comportan en cuanto al tiempo de
rehospitalización de misma manera de los pacientes que viven a menos de 30 Km., del
hospital, como era de esperarse.
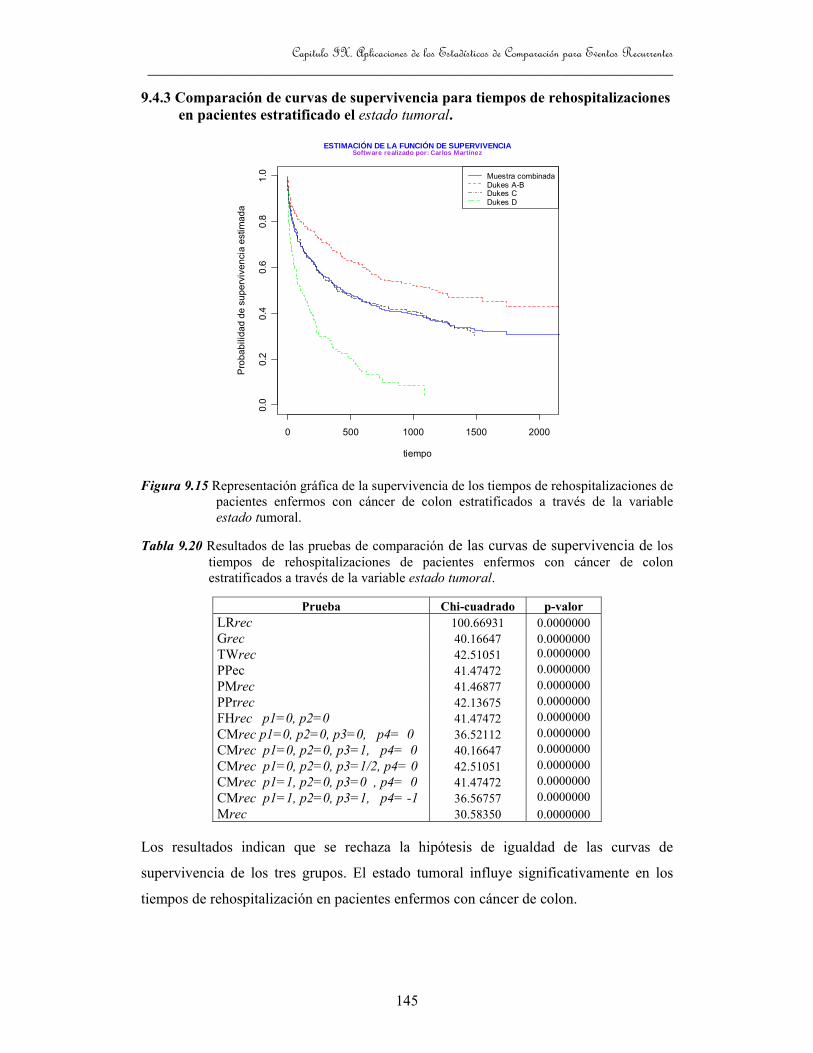
Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
145
9.4.3 Comparación de curvas de supervivencia para tiempos de rehospitalizaciones en pacientes estratificado el estado tumoral.
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
1.0
tiempo
Pro
babi
lidad
de
supe
rviv
enci
a es
timad
a
ESTIMACIÓN DE LA FUNCIÓN DE SUPERVIVENCIASoftware realizado por: Carlos Martínez
Muestra combinadaDukes A-BDukes CDukes D
Figura 9.15 Representación gráfica de la supervivencia de los tiempos de rehospitalizaciones de
pacientes enfermos con cáncer de colon estratificados a través de la variable estado tumoral.
Tabla 9.20 Resultados de las pruebas de comparación de las curvas de supervivencia de los
tiempos de rehospitalizaciones de pacientes enfermos con cáncer de colon estratificados a través de la variable estado tumoral.
Prueba Chi-cuadrado p-valor
LRrec 100.66931 0.0000000 Grec 40.16647 0.0000000 TWrec 42.51051 0.0000000 PPec 41.47472 0.0000000 PMrec 41.46877 0.0000000 PPrrec 42.13675 0.0000000 FHrec p1=0, p2=0 41.47472 0.0000000 CMrec p1=0, p2=0, p3=0, p4= 0 36.52112 0.0000000 CMrec p1=0, p2=0, p3=1, p4= 0 40.16647 0.0000000 CMrec p1=0, p2=0, p3=1/2, p4= 0 42.51051 0.0000000 CMrec p1=1, p2=0, p3=0 , p4= 0 41.47472 0.0000000 CMrec p1=1, p2=0, p3=1, p4= -1 36.56757 0.0000000 Mrec 30.58350 0.0000000
Los resultados indican que se rechaza la hipótesis de igualdad de las curvas de
supervivencia de los tres grupos. El estado tumoral influye significativamente en los
tiempos de rehospitalización en pacientes enfermos con cáncer de colon.

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
146
9.4.3 Comparación de curvas de supervivencia para tiempos de rehospitalizaciones en pacientes estratificado el estado tumoral (comparación dos a dos).
9.4.3.1 Comparación curvas de supervivencia grupo Dukes A-B vs. grupo Dukes C
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
1.0
tiempo
Pro
babi
lidad
de
supe
rviv
enci
a es
timad
a
ESTIMACIÓN DE LA FUNCIÓN DE SUPERVIVENCIASoftware realizado por: Carlos Martínez
Muestra combinadaDukes A-BDukes C
Figura 9.16 Representación gráfica de la supervivencia de los tiempos de rehospitalizaciones de
pacientes enfermos con cáncer de colon estratificados a través de la variable estado tumoral, grupo Dukes A-B vs grupo Dukes C.
Tabla 9.21 Resultados de las pruebas de comparación de las curvas de supervivencia e los
tiempos de rehospitalizaciones de pacientes enfermos con cáncer de colon estratificados a través de la variable estado tumoral, grupos: grupo Dukes A-B vs grupo Dukes C.
Prueba Chi-cuadrado p-valor LRrec 12.99447 0.0003124 Grec 13.19901 0.0002801 TWrec 13.42073 0.0002489 PPec 13.44673 0.0002454 PMrec 13.44732 0.0002454 PPrrec 13.62523 0.0002232 FHrec p1=0, p2=0 12.99447 0.0003124 CMrec p1=0, p2=0, p3=0, p4= 0 12.99447 0.0003124 CMrec p1=0, p2=0, p3=1, p4= 0 13.19901 0.0002801 CMrec p1=0, p2=0, p3=1/2, p4= 0 13.42073 0.0002489 CMrec p1=1, p2=0, p3=0 , p4= 0 13.44673 0.0002454 CMrec p1=1, p2=0, p3=1, p4= -1 13.44732 0.0002454 Mrec 12.99180 0.0003129
Se rechaza la hipótesis de igualdad de las curvas de supervivencia de los grupos de
pacientes estratificado por la clasificación Dukes A-B y la clasificación Dukes C. Los
tiempos de rehospitalización en pacientes enfermos con cáncer de colon clasificados
Dukes A-B difieren significativamente de los pacientes pertenecientes al grupo Dukes C.

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
147
9.4.3.2 Comparación curvas de supervivencia grupo Dukes A-B vs. grupo Dukes D
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
1.0
tiempo
Pro
babi
lidad
de
supe
rviv
enci
a es
timad
a
ESTIMACIÓN DE LA FUNCIÓN DE SUPERVIVENCIASoftw are realizado por: Carlos Martínez
Muestra combinadaDukes A-BDukes D
Figura 9.17 Representación gráfica de la supervivencia de los tiempos de rehospitalizaciones de
pacientes enfermos con cáncer de colon estratificados a través de la variable estado tumoral, grupo Dukes A-B vs. grupo Dukes D.
Se rechaza la hipótesis de igualdad de las curvas de supervivencia de los grupos de
pacientes estratificado por la clasificación Dukes A-B y la clasificación Dukes D. Los
tiempos de rehospitalización en pacientes enfermos con cáncer de colon clasificados
como Dukes A-B difieren significativamente de los tiempos de rehospitalización de los
pacientes pertenecientes al grupo Dukes D.
Tabla 9.22 Resultados de las pruebas de comparación de las curvas de supervivencia e los
tiempos de rehospitalizaciones de pacientes enfermos con cáncer de colon estratificados a través de la variable estado tumoral, grupos: grupo Dukes A-B vs. grupo Dukes D.
Prueba Chi-cuadrado p-valor
LRrec 99.36419 0.00000 Grec 77.39723 0.00000 TWrec 88.45493 0.00000 PPec 82.69036 0.00000 PMrec 82.61607 0.00000 PPrrec 84.58509 0.00000 FHrec p1=0, p2=0 99.36419 0.00000 CMrec p1=0, p2=0, p3=0, p4= 0 99.36419 0.00000 CMrec p1=0, p2=0, p3=1, p4= 0 77.39723 0.00000 CMrec p1=0, p2=0, p3=1/2, p4= 0 88.45493 0.00000 CMrec p1=1, p2=0, p3=0 , p4= 0 82.69036 0.00000 CMrec p1=1, p2=0, p3=1, p4= -1 82.61607 0.00000 Mrec 99.26651 0.00000

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
148
9.4.3.3 Comparación curvas de supervivencia grupo Dukes C vs. grupo Dukes D
0 200 400 600 800 1000 1200 1400
0.0
0.2
0.4
0.6
0.8
1.0
tiempo
Pro
babi
lidad
de
supe
rviv
enci
a es
timad
a
ESTIMACIÓN DE LA FUNCIÓN DE SUPERVIVENCIASoftware realizado por: Carlos Martínez
Muestra combinadaDukes CDukes D
Figura 9.18 Representación gráfica de la supervivencia de los tiempos de rehospitalizaciones de
pacientes enfermos con cáncer de colon estratificados a través de la variable estado tumoral, grupo Dukes C vs. grupo Dukes D.
Tabla 9.23 Resultados de las pruebas de comparación de las curvas de supervivencia e los
tiempos de rehospitalizaciones de pacientes enfermos con cáncer de colon estratificados a través de la variable estado tumoral, grupos: grupo Dukes C vs. grupo Dukes D.
Prueba Chi-cuadrado p-valor LRrec 45.29624 0.00000 Grec 31.95584 0.00000 TWrec 38.25675 0.00000 PPec 34.66676 0.00000 PMrec 34.61546 0.00000 PPrrec 35.63474 0.00000 FHrec p1=0, p2=0 45.29624 0.00000 CMrec p1=0, p2=0, p3=0, p4= 0 45.29624 0.00000 CMrec p1=0, p2=0, p3=1, p4= 0 31.95584 0.00000 CMrec p1=0, p2=0, p3=1/2, p4= 0 38.25675 0.00000 CMrec p1=1, p2=0, p3=0 , p4= 0 34.66676 0.00000 CMrec p1=1, p2=0, p3=1, p4= -1 34.61546 0.00000 Mrec 45.18530 0.00000
Los resultados muestran que debe rechazarse la hipótesis de igualdad de las curvas de
supervivencia de los grupos de pacientes estratificado por la clasificación Dukes C y la
clasificación Dukes D. Los tiempos de rehospitalización en pacientes enfermos con
cáncer de colon clasificados como Dukes C difieren significativamente de los tiempos
de rehospitalización de los pacientes pertenecientes al grupo Dukes D.

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
149
9.5 Datos del experimento de Gail (1980)
Gail et al. (1980) presentó los datos de un experimento cancerígeno realizado a
cuarenta y ocho (48) ratas del sexo femenino a quienes se les midieron los tiempos de
detección de tumores mamarios provenientes de un cáncer. Las ratas fueron expuestas
al cáncer durante sesenta (60) días y a través de un proceso de aleatorización fueron
asignadas a un cierto tipo de tratamiento o a un grupo control. Veintitrés (23) de las
ratas fueron sometidas a dicho tratamiento y veinticinco (25) de ellas fueron
consideradas como grupo control. Los períodos de seguimiento para las ratas fueron de
ciento veintidós (122) días, iniciando la observación desde el momento de la
aleatorización. El seguimiento se hizo día a día y cada vez que detectaban tumores en
las ratas se anotaban los días calendarios de detección de nuevos tumores. En la tabla
9.13 se ilustran los tiempos entre detecciones de tumores en cada una de las ratas. Estos
datos están publicados en el trabajo de Cook-Lawless (2007). Se desea determinar si
existen diferencias significativas entre las curvas de supervivencia de los tiempos de
detecciones de los tumores entre el grupo control y el grupo tratado.
Tabla 9.24 Tiempo de reaparición de tumores en ratas de sexo femenino con cáncer mamarios.
id
Numero de
detecciones,
Ki
Tiempo censura después
de la última detección
(días)
Tiempos entre
detección del tumor
(días)
Grupo
1 1 0 122 Tratado2 0 122 - Tratado3 2 37 3, 85 Tratado4 1 30 92 Tratado5 4 30 70, 4, 11, 7 Tratado6 3 0 38, 54, 30 Tratado7 6 45 28, 7, 10, 25, 7, 30 Tratado8 1 30 92 Tratado9 1 101 21 Tratado10 5 30 11, 13, 42, 8, 18 Tratado11 2 52 56, 14 Tratado12 1 91 31 Tratado13 5 30 3, 5, 16, 11, 57 Tratado14 2 52 56, 14 Tratado15 3 91 31 Tratado16 4 42 3, 14, 35, 28 Tratado17 5 15 17, 42, 33, 9, 6 Tratado18 5 0 45, 7, 33, 16, 21 Tratado19 1 30 92 Tratado20 2 87 21, 14 Tratado21 6 38 24, 7, 11, 6, 22, 4 Tratado22 0 122 - Tratado23 1 91 31 Tratado24 7 3 3, 39, 17, 2, 51, 7 Control25 11 10 28, 3, 4, 10, 7, 18, 8, 22,5 Control26 9 3 31, 7, 10, 4, 22, 3, 24, 18 Control27 2 8 11, 103 Control28 9 32 35, 10, 29, 5, 3, 5, 5 Control29 4 45 8, 62, 7 Control30 6 8 17, 18, 17, 25, 34, 13 Control

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
150
Continuación tabla 9.2431 7 8 21, 3, 42, 8, 27, 13 Control32 6 80 8, 9, 21, 4 Control33 1 70 52 Control34 13 30 28, 3, 7, 14, 22, 3, 3, 12 Control35 2 3 17, 102 Control36 1 70 52 Control37 10 15 11, 3, 3, 35, 4, 24, 27 Control38 4 32 17, 18, 31, 24 Control39 5 48 28, 38, 4, 4 Control40 11 3 3, 11, 10,º4,º3, 4, 13, 26, 3, 42 Control41 11 3 21, 7, 17, 11, 7, 17, 5, 7, 9, 18 Control42 9 3 28, 7, 17, 7, 7, 24, 7, 22 Control43 12 0 8, 16, 18, 3, 14, 4, 14, 24, 18, 3 Control44 1 42 80 Control45 3 0 92, 30 Control46 1 101 21 Control47 3 48 3, 25, 46 Control48 3 0 24, 50, 48 Control Fuente: Cook-Lawless (2007) pp. 3
0 20 40 60 80 100 120
0.0
0.2
0.4
0.6
0.8
1.0
tiempo
Pro
babi
lidad
de
supe
rviv
enci
a es
timad
a
ESTIMACIÓN DE LA FUNCIÓN DE SUPERVIVENCIASoftware realizado por: Carlos Martínez
Muestra combinadaGrupo tratadoGrupo control
Figura 9.19 Representación gráfica de la supervivencia de los tiempos de detecciones de
tumores en los grupos: grupo tratado vs grupo control. Tabla 9.25 Resultados de las pruebas de comparación de las curvas de supervivencia e los
tiempos de detecciones de tumores en los grupos: grupo tratado vs. grupo control. Prueba Chi-cuadrado p-valor
LRrec 14.9565300 0.0001100 Grec 13.2889900 0.0002670 TWrec 14.6945200 0.0001264 Porec 13.4059000 0.0002508 PMrec 13.3669200 0.0002561 PPrrec 15.4924800 0.0000828 FHrec p1=0,p2=0 14.9565300 0.0001100 CMrec p1=0,p2=0,p3=0,p4=0 14.9565300 0.0001100 CMrec p1=0,p2=0,p3=1,p4=0 13.2889900 0.0002670 CMrec p1=0,p2=0,p3=1/2,p4=0 14.6945200 0.0001264 CMrec p1=1,p2=0,p3=0,p4=0 13.4059000 0.0002508 CMrec p1=1,p2=0,p3=1,p4=-1 13.3669200 0.0002561 Mrec 14.7818700 0.0001207

Capitulo IX. Aplicaciones de los Estadísticos de Comparación para Eventos Recurrentes ______________________________________________________________________
151
Los p-valores indican claramente que la hipótesis de igualdad de las curvas de
supervivencia de los dos grupos debe rechazarse. Los tiempos de detección de los
tumores en las ratas enfermas con cáncer del grupo tratado difieren significativamente
de los tiempos de rehospitalización de las ratas pertenecientes al grupo control.

Conclusiones ______________________________________________________________________
152
CONCLUSIONES
Una vez culminada esta investigación podemos indicar que se cumplieron con todos los
objetivos planteados en la misma. En esta investigación se logró ilustrar; tanto, las
metodologías clásicas del análisis de supervivencia; así como, la mayoría de las
metodologías del análisis de supervivencia con eventos recurrentes. El logro más
importante de la investigación, según nuestra óptica, es que se logró proponer y evaluar
procedimientos estadísticos de comparación que permiten diferenciar curvas de
supervivencia de grupos poblacionales que experimentan fenómenos con eventos de
naturaleza recurrente. Este trabajo representa un aporte de importancia invalorable para
diversas áreas de la ciencia. En especial; por ejemplo, para analizar la aparición de
enfermedades recurrentes en seres vivos o para estudiar la aceleración o retardo en el
sanamiento que produce el uso de un medicamente específico en tratamiento de
enfermedades recurrentes.
En este trabajo se logra plasmar y analizar los métodos de estimación utilizados para el
análisis de supervivencia clásico que son estudios donde los fenómenos consideran sólo
una única ocurrencia del evento por unidad de estudio. Entre los métodos considerados,
se encuentran: Los métodos actuariales: Bhomer (1912), Berkson-Gage (1950) y
Cutler-Ederer (1958). Los modelos no paramétrticos: Kaplan-Meier (1958), Nelson-
Aalen (1979), Altshuler (1970), Harris-Albert (1970), Prentice (1978), Peterson
(1979), Prentice-Marek (1979), Andersen et al. (1982), Andersen et al. (1982),
Moreau et al.(1992) y Hosmer-Lemeshow (1999). Y los modelos semiparamétricos:
Cox (1972) y extensiones del modelo de Cox. En la investigación se estudiaron los
métodos de comparación de dos o más grupo del análisis de supervivencia tradicional,
entre ellas: La prueba logrank propuesta por Mantel-Haenszel (1959), la prueba
generalizada de Wilcoxon propuesta por Gehan (1965), la prueba de Mantel (1967), la
prueba generalizada de Kruskal-Wallis propuesta por Breslow (1970), la prueba de
Cox (1972), la prueba de Peto-Peto (1972), la prueba de Tarone-Ware (1977), la
prueba de rangos lineales con datos censurados por la derecha propuesta por Prentice
(1978), la prueba de Tarone (1981), la prueba de Harrington-Fleming (1982) que
generaliza parte de las pruebas anteriores y una versión más general propuesta por
Fleming et al. (1987). Otro conjunto de modelos que fueron estudiados en esta
investigación fueron los modelos para el análisis de supervivencia con eventos
recurrentes. Entre ellos: Los modelos tipo Cox para eventos recurrentes: Modelo de

Conclusiones ______________________________________________________________________
153
Prentice et al. (1981), modelo de Andersen-Gill (1982) y modelo de Wei et al. (1989),
Los modelos no paramétricos: modelo de Wang-Chang (1999), modelo de GPLE de
Peña et al. (2001) y el modelo de fragilidad multiplicativa: modelo de FRMLE de
Peña et al. (2001).
En este trabajo se logró proponer estadísticos de contrastes ponderados para comparar
curvas de supervivencia que son estimadas a través del modelo GPLE de Peña et al.
(2001). Los estadísticos propuestos fueron diseñados para comparar dos o más grupos
que experimentan eventos recurrentes. En la investigación se logró generalizar los
estadísticos de comparación ponderados del análisis de supervivencia tradicional al caso
recurrente, equivalentes a las pruebas del análisis tradicional. Aún cuando los
estadísticos de comparación fueron diseñados para comparar curvas de supervivencia
estimadas para modelo GPLE, su uso puede hacerse extensivo al resto de la familia de
modelos recurrentes. Queda abierta la posibilidad de extender el uso de estos
estadísticos de comparación, al resto de los modelos recurrentes.
En cuanto al aspecto computacional se lograron contribuciones importantes. En este
trabajo de investigación se desarrollaron un total de cinco programas o conjunto de
rutinas computarizadas en lenguaje R aplicables a las estimaciones en el campo
recurrente. Estos programas hacen uso de paquetes como: tcltk, stats, suvival y survrec.
Entre los programas desarrollaros en esta investigación, incluyen:
a.- Un programa que permiten realizar las estimaciones de los estadísticos de
comparación para el caso de comparación de dos grupos para estimar las pruebas
propuestas en esta investigación.
b.- Un programa que permite realizar las estimaciones de los estadísticos de
comparación para los casos de tres grupos para pruebas propuestas en este
trabajo.
c.- Dos programas para realizar las simulaciones de las estimaciones de potencia
y error tipo I de las pruebas de hipótesis correspondientes a la comparación de
curvas de supervivencia tipo GPLE, una para el caso de la comparación de dos
grupos y el otro para la comparación tres grupos, respectivamente. Este
programa permite seleccionar al usuario: Número de simulación (máximo 1000),
tamaños de los grupos a comparar, tipo de distribución de los tiempos de

Conclusiones ______________________________________________________________________
154
interocurrencias (iguales o diferentes) y el tipo de distribución del tiempo de
censura.
d.- Un programa que permite realizar las estimaciones del estadístico de
comparación de grupos que experimentan eventos recurrentes, estadístico
propuestos por Doganaksoy-Nelson (1998) para el caso de dos grupos.
En el trabajo se realizaron una serie de simulaciones que permitieron comparar los
estimadores de pruebas propuestos y cuyos resultados están plasmado en capítulo VIII y
el apéndice D de esta investigación. Las simulaciones fueron oportunas para evaluar en
forma empírica aspectos de interés en las pruebas de comparación a través de sus
estimaciones, como son: potencia y error tipo I. Las simulaciones se hicieron bajo
diversos escenarios donde se consideraron: tiempos de interocurrencias independientes
distribuidos exponenciales, weibull, gamma, chicuadrado, uniforme, aritméticos
crecientes o aritméticos decrecientes. Se modificaron sistemáticamente los tamaños de
muestras desde tamaños 5, 10, 15, 20, 25, 50 y 500 y se escogieron tres niveles de
significación (1%, 5% y 10%) y donde se consideraron un máximo de 1000
simulaciones por caso. Las simulaciones arrojaron que la prueba de mayor potencia en
el caso donde los tiempos de interocurrencia estan distribuidos exponenciales con
parámetros diferentes (escenario II) es la prueba LRrec, seguido de las pruebas FHrec,
Mrec y TWrec y las pruebas con potencias más pobres fueron las pruebas Grec y
CMrec. Sin embargo, los resultados son diferentes en el escenario XII, los resultados
arrojaron que las pruebas con mayor potencia fueron las pruebas Grec y CMrec y las
pruebas de menor potencia fueron Mrec y FHrec. Esto, nos permite concluir que
dependiendo de la distribución de los tiempos de interocurrencia algunas pruebas
tendrán mayor potencia que otras. Otro resultados de interés que es necesario destacar
es que cuando se mide la potencia para diferenciar grupos con tiempos de
interocurrencia distribuidos con parámetro(s) igual(es) los resultados de pruebas más
favorables para detectar tal situación se invierten con relación a las pruebas favorables
del escenario II y XII descritos anteriormente, igualmente sucede para el resto de los
escenarios.
En relación a la aplicación de las herramientas propuesta en el trabajo, fue necesario
aplicarlas a una serie de problemas tratados por expertos del área. La primera aplicación
de los estadísticos de comparación se hizo en los datos de provenientes del experimento

Conclusiones ______________________________________________________________________
155
de Byar (1980), correspondiente a los tiempos de reapariciones de tumores medidos en
meses de ciento dieciséis (116) pacientes enfermos con cáncer superficial de vejiga
tratado con: placebo, thiotepa y piridoxina. La idea consistió en comparar las funciones
de supervivencia de los tres grupos y determinar si existen diferencias significativas en
los tres tratamientos. La segunda aplicación se hizo a los datos del experimento de
Aalen-Husebye (1991) correspondientes al estudio de la motilidad del intestino delgado
(actividad muscular) de diecinueve (19) pacientes. El objetivo en nuestro estudio
consiste en determinar si existen diferencias significativas entre las curvas de
supervivencia obtenidas de los períodos del Complejo Motor Migratorio de los
pacientes hombres y pacientes mujeres. La tercera aplicación se hizo en los datos del
estudio hecho por González-Peña (2003, 2004), correspondientes a los tiempos de
rehospitalizaciones de cuatrocientos tres (403) pacientes diagnosticados e intervenidos
quirúrgicamente con cáncer colorectal. Los objetivos en este presente trabajo consisten
en determinar si existen diferencias significativas entre las curvas de supervivencia de
los tiempos de rehospitalización de grupos de pacientes estratificados debido a un
conjunto de variables socio-demográficas o clínicas, como son: las variables
quimioterapia, estado tumoral y distancia de la habitación del paciente al hospital . La
cuarta y última aplicación se hizo en los datos de Gail et al. (1980), quien presentó un
experimento cancerigeno realizado a cuarenta y ocho (48) ratas del sexo femenino a
quienes se les midieron los tiempos de detección de tumores mamarios provenientes de
un cáncer inoculado. Los resultados de estas pruebas están plasmado en el capítulo IX
de esta investigación.

Bibliografía ______________________________________________________________________
156
BIBLIOGRAFIA
[1] Aalen O., (1978), “Nonparametric inference for a family of counting process,”
Annal of Statistics, 6,701–726.
[2] Aalen O., Husebye E., (1991), “Statistical Analysis of Repeated Events
Forming Renewal Processes,” Statistics in Medicine, 10,1227–1240.
[3] Allison P., (1995), “Survival Analysis using the SAS system a practical guide”,
SAS Institute Inc. Cary, NC, USA.
[4] Altshuler B., (1970), “Theory for the measurement of competing risks in animal
experiments”. Math. Biosciences, 6, 1-11.
[5] Andersen P., Borgan φ., Gill R., Keiding, (1982), “N. Linear nonparametric
tests for comparison of counting processes, with application to censored survival
data (with discussion)”. Internat. Statis. Review, 50, 219-258.
[6] Andersen P., Gill R., (1982). “Cox’s regression model for counting processes:
A large sample study”. Annals of Statistics 10, 1100–1120.
[7] Andersen P., Borgan O., Gill R., Keiding N., (1993), “Statistical Models
Based on Counting Processes”, New York: Springer-Verlag.
[8] Andrews D., Herzberg A., (1985), “Data. A collections of problems from many
Fields for the student and research worker”. Springer series in Statistics,
Springer-Verlag, USA.
[9] Barceló M., (2002), “Modelos marginales y condicionales en el análisis de
supervivencia multivariante”. Gac Sanit 2003; 16(Supl 2): 59-68.
[10] Berkson J., Gage R., (1950), “Calculation of survival rates for cancer”.
Proceedings of the staff meetings of the Mayo Clinic, 25, 270-286.
[11] Berkson J., Gage R., (1952), “Survival curve cancer patients following
treatment”. American Statistical Association Journal, 501-515.
[12] Bhomer P., (1912), “Theorie der unabhängigen Wahrscheinlichkeiten” en
Rapports, Mémoires et Procès-verbaux de Septième Congrès International
d´Áctuaries, Ámsterdam volumen 2 p.p. 327-343.
[13] Breslow N., (1970): “A generalized Kruskal- Wallis test for comparing K
sample subject to unequal patterns ofstudy of the life table and product limit
estimates under random censorship . Biometrika, 57, 579-594.
[14] Breslow N., (1972): “Discussion of the paper by D.R. Cox. J.R.R.S, B34, 216-
217.

Bibliografía ______________________________________________________________________
157
[15] Breslow N., (1974): “Covariance analysis of censored survival data”.
Biometrics, 30, 89-100.
[16] Byar D., (1980): “The veterans administrations study of chemoprophylaxis for
recurrent stage I bladder tumors: Comparisons of placebo, pyridoxine, and
topical thiotepa. In Bladder tumor and other Topics in Urological Oncology.
New York: Plenum, 363-370.
[17] Childs A., Balakrishnan N., (2000), “Some approximations to the multivariate
hypergeometric distribution with applications to hypothesis testing”,
Computational oStatistics & Data Analysis, 35, 137-154.
[18] Cochran W., (1954), “Some methods of strengthening the common χ2 tests”,
Biometrics, 10, 417-451.
[19] Collet D., (2003), “Modelling Survival Data in Medical Research”, Chapman-
Hall/CRC, 2da Edición.
[20] Cox D., (1972), “Regression models and life-tables”, Journal of the Royal
Statistical Society-Series B, 34, 187-220.
[21] Cox D., (1975), “Likelihood parcial”, Journal of the Royal Statistical Society-
Series B, 34, 187-220.
[22] Cook R., Lawless J., (2007), “The Statistical Analysis of recurrente Events”,
Springer, Statistics for Biology and Healt. USA.
[23] Cutler S., Ederer F., (1958), “Maximun utililization on the life table method in
analysing survival”, Journal of Choronic Diseases, 8, 699-712.
[24] Dempster A., Laird N., Rubin D., (1977), “Maximun Likelihood from
incomplete data via the EM algorithm”, RSS, 1-38.
[25] Doganaksoy N., Nelson W., (1998), “A method to Compare Two Samples of
Recurrence Data”, Lifetime Data Analysis, 48, 51-63.
[26] Dorado C., Hollander M., Setruraman J., (1997), “Nonparametric estimation
for a general repair model”, Annals of Statistic, 25, 1140-1160.
[27] Efron, B. (1977), “The efficiency of Cox’s likelihood function for censored
datavanalysis”. Journal of American Statistical Association, 72, 557-565.
[28] Fleming T., O’Fallon J., O’Brien P., Harrington D., (1980), “Modified
Kolmogorov-Smirnov test procedures with application to arbitrarily right-
censored data”. Biometrics, 36, 607-625.

Bibliografía ______________________________________________________________________
158
[29] Fleming T., Harrington D., (1984), “Nonparametric estimation of the survival
distribution incensored data”. Commun. Statist.-Theory and Methods, 13 (20),
2469-2486.
[30] Fleming T., Harrington D., O’Sullivan M., (1987), “Supremum versions of
the log-rank and generalized Wilcoxon statistics”. J.A.S.A., 82 (397), 312-320.
[31] Fleming T., Harrington D., (1991), “Counting Processes and Survival
Analysis”, Weley series in probability and statistics, New York.
[32] Fleming, T. R. y Lin, D.Y., (2000), “Survival Analysis in Clinical Trials: Past
Developments and Future Directions”, Biometrics, 56, 971-983.
[33] Gehan E., (1965), “A generalized Wilcoxon test for comparing arbitrarily
singly-censored samples”. Biometrika, 52, 203-223.
[34] Gehan E., (1965), “A generalized two-sample Wilcoxon test for doubly
censored data”. Biometrika, 52, 650-653.
[35] Gehan E., (1969), “Estimate survival functions from the life table”. J. chron.
Dis., 21, 229-644.
[36] Gail M., Santner T., Brown C., (1980), “An analysis of comparative
cancinogenesis experiments based on multiple times to tumor”. Biometrics, 36,
255-266.
[37] Gill R., (1980), “Nonparametric Estimation Based on Censored Observations of
a Markov Renewal Process”. Zeitschrift für Wahrscheinlichkeitstheorie und
Verwandte Gebiete, 53, 97–116.
[38] Glynn R., Buring J., (1996), “Ways of measuring rates of recurrent events”.
Division of Preventive Medicine, Deparment of Medicine, Brighan and Wome´s
Hospital and Harvard Medical School, Boston, MA 02215, USA. BMJ, 312,
364-367.
[39] González J., Peña E., (2003). “Bootstrapinping median survival with recurrent
event data”. IX conferencia Española de Biometría, Mayo 2003.
[40] González J., Peña E., (2004). “Estimación noparamétrica de la función de
supervivencia para datos con eventos recurrentes”. Revista Española de salud
pública, 78, 189-199.
[41] González J., Peña E., Strawderman R., (2005). “The survrec Package”, The
Comprensive R Archive Network:, http://cran.r-project.org.

Bibliografía ______________________________________________________________________
159
[42] Grennwood, M. (1926). “Reports on public Health and medical subjects”, N°
33. Appendix I, The errors of sampling of Survivorship tables, London, H.M.
Stationery office.
[43] Harris E., Albert A., (1991), “Survivolship analysis for clinical study”, Marcel
Dekker, New york, USA.
[44] Harrington D., Fleming T., (1982), “A class of rank test procedure for
censored survival data”, Biometrika, 60 (3), 553-566.
[45] Hollander M ., Sethuraman, J., (2004), “Nonparametric inference for repair
models”, The Indian Journal of Statistics. Special issue in memory of D. Basu,
64, Serie A, Pt. 3, 693-706.
[46] Hosmer D., Lemeshow S., (1999), Applied survival analysis regression
modeling of time to event data, Wiley series in probability . A Wliley-
Intercience publication, New York.
[47] Hougaard, P., (1995), “Frailty models for survival data”. New York: Springer-
Verlag.
[48] Hougaard P., (2000), “Analysis of Multivariate Survival Data”, Lifetime Data
Anal., 1, 255-273.
[49] Johnson N., Kotz S., Balakrishnan N., (1997), “Discrete Multivariate
Distributions”. John Wiley, New York.
[50] Kalbeisch J., Prentice R., (1980), “The Statistical Analysis of the Failure Time
Data”. John Wiley & Sons, Inc. New York.
[51] Kalbeisch J., Prentice R., (2002), “The Statistical Analysis of the Failure Time
Data”. John Wiley & Sons, Inc. 2da edition, New York.
[52] Kaplan E., Meier P., (1958), “Nonparametric estimation from incomplete
observations”, Journal of the American Statistical Association, 53, 457-481.
[53] Kleinbaum D., Klein M. (2005), “Survival Analysis: a self-learning text”,
Springer, New York, 2da. Edition, ISBN: 0-387-23918-9.
[54] Klein J., Moeschberger M. (2005), “Survival Analysis”, Springer, 2da. Edition,
ISBN: 978-0-387-95399-1.
[55] Kruskal W., Wallis W., (1952), “Use of ranks in one-criterion variance
analysis”. Journal of the American Statistical Association, 47, 583-621.
[56] Lee-Wang, (2003), “Statistical methods for survival data análysis”. Wiley series
in probability and statistics. 3ra edition. New Jersey.

Bibliografía ______________________________________________________________________
160
[57] Letón E., (1998), “Comparación de curvas de supervivencia mediante tests no
paramétricos”. Trabajo de investigación, UCM.
[58] Letón E., Zuluaga P., (2001), “Equivalence between score and weighted tests
for survival curves”. Communications in Statistics: Theory and Methods, 30 (4),
591-608.
[59] Letón E., Zuluaga P., (2002), “Survival tests for r groups”. Biometrical Journal,
44 (1), 15-27.
[60] Mann H., Whitney D., (1947), “On a test of whether one of two random
variables is stochasticalll larger than the other”. Ann. Math. Statist. 18, 50-60.
[61] Mantel N., (1966), “Evaluation of survival data and two new rank order
statistics arising in its consideration”. Cancer Chemotherapy Rep., 50 (3), 163-
170.
[62] Mantel N., (1967), “Ranking procedures for arbitrarily restricted observation.”
Biometrics, 23, 65-78.
[63] Mantel N., Haenszel W., (1959), “Statistical aspects of the analysis of data
from retrospective studies of disease”. Journal of the National Cancer
Institute, 22 (4), 719-748.
[64] Moreau T., Maccario J., Lellouch J., Huber C., (1992), “Weighted log rank
statistics for comparing two distributions”. Biometrika, 79 (1), 195-198.
[65] Nelson W., (1969), “Harzard plotting for incomplete failure data”, J. Qual.
Technol. 1, 27-52.
[66] Nelson W., (1972), “Theory and applications of harzard plotting for censored
failure data. Technometrics. 14, 945-965.
[67] Nelson W., (1995), “Confidence limits for recurrent data-aplied to cost or
number of product repairs”. Technometrics. 37, 147-157.
[68] Nelson W., (2003), “Recurrent Events Data Analysis for Product Repairs,
Disease Recurrences, and other Applications”, ASA-SIAM, Series on Statistics
and Aplied Probability #10, Philadelphia.
[69] Nielsen G., Gill R., Andersen P., Sorensen T., (1992), “A Counting Process
Approach to Maximum Likelihood Estimation in Frailty Models”, Scandinavian
Journal of Statistics, 19, 25–43.
[70] Peña E., Strawderman R., Hollander M., (2001). “Nonparametric estimation
with recurrent event data”. Journal of the American Statistical Association
96, 1299–1315.

Bibliografía ______________________________________________________________________
161
[71] Peña E., Slate E., (2005). “Dynamic Modeling in reliability and survival
analysis”. Modern Statistical and Mathematical Methods in Reliability. (A.
Wilson, N. Limnios, Keller-McNulty and Y. Armijo, eds) 55-71. World
Scientific, Singapore.
[72] Peña, E., (2006). “Dynamic Modeling and Statistical Analysis of Events
Times”. Statistical Science, 21(4), 487–500.
[73] Peña E., Slate E., González J., (2007). “Semiparametric inference for a general
class of models for recurrent events”. ScienceDirect. Journal of statistical
planinnig and inference.137, 1727-1747.
[74] Peto R., Peto J.,(1972), “Asymptotically efficient rank invariant test procedures
(with discussion)”. J.R.S.S., A, 135, 185-207.
[75] Peterson, R., (1977),”Expressing the Kaplan-Meier estimations as a function of
empirical subsurvival functions. Journal of the Amarican Statistical
Associations, 72, 854-858.
[76] Pepe M., Cai J., (1993), “Some graphical display and marginal regression
analyses for recurrent failure times and time dependent covariates”. J.A.S.A, 88,
811-820.
[77] Prentice R., (1978), “Linear rank tests with right censored data”. Biometrika, 8,
65 (1), 167-179.
[78] Prentice R., Marek P., (1979), A qualitative discrepancy between censored
data rank tests. Biometrics, 35, 861-867.
[79] Prentice R., Kalfleisch D., (2003). “Aspects of the analysis of multivariate
failure time data”. SORT, 27(1), 65-78.
[80] Prentice R., Williams B., Peterson A., (1981). “On the regression analysis of
multivariate failure time data”. Biometrika, 68, 373–379.
[81] R Development Core Team (2006). R: A language and environment for
statistical computing. R Foundation for Statistical Computing, Vienna, Austria.
ISBN 3-900051-07-0, URL http://www.R-project.org.
[82] Radhakrishna S., (1965), “Combination of results from several 2x2
contingency tables”. Biometrics, 21, 86-98.
[83] Sellke, T. (1988), “Weak Convergence of the Aalen Estimator for a Censored
Renewal Process,” in Statistical Decision Theory and Related Topics IV, (eds. S.
Gupta and J. Berger), New York: Springer-Verlag, Vol. 2, 183–194.

Bibliografía ______________________________________________________________________
162
[84] Stuart A., (1954), “Asymptotic relative efficiencies of distributions-free test of
randomness against normal alternatives”. American Statistic Association
Journal. 147-157.
[85] Sun J., Wei L., (2000), “Regression analysis of panel count data with covariate-
dependent observation and censoring times”. JRSS. B 62, 293-302.
[86] Tarone, R.E., (1975), “Tests for trend in life table analysis”. Biometrika, 62 (3),
679-682.
[87] Tarone R., (1981), “On the distribution of the maximum of the logrank statistic
and the modified Wilcoxon statistic”. Biometrics, 37, 79-85.
[88] Tarone R., Ware J., (1977), “On distribution-free tests for equality of survival
distributions”. Biometrika, 64 (1), 156-160.
[89] Therneau T., Grambsch P., Fleming T., (1990), “Martingale-based residuals
for survival models”. Biometrika, 77(1), 147-160.
[90] Therneau T., Hamilton S., (1997), “rhDNase as an example of recurrent event
analysis”. Statistics in Medicine, 16, 2029-2047.
[91] Therneau T., Grambsch P., (2000), “Modeling survival data: extending the
Cox model”. New York: Springer-Verlag.
[92] Vaupel, J., (1990), “Kindred Lifetimes: Frailty Models in population Genetics”,
in convergent issues in Genetics and Demography, eds. J. Adams, D. Lam, A.
Herman P. Smouse, London: Oxford University Press, pp 156-170.
[93] Wang M., Chang S., (1999). “Nonparametric estimation of a recurrent survival
function”. Journal of the American Statistical Association 94, 146–153.
[94] Wei L., Lin D., Weissfeld L., (1989). “Regression analysis of multivariate
incompletge failure time data by modeling marginal distributions”. Journal of
the American Statistical Association 84, 1065–1073.
[95] Wilcoxon F., (1945), “Individual comparisons by ranking methods”. Biometrics,
1, 80-83.

Apéndices ______________________________________________________________________
163
APÉNDICE A
VARIANZA DE GREENWOOD METODO DELTA
Un problema muy común que se le presenta a los estadísticos cuando diseñan
estimadores de algún parámetro, es la derivación de su estimador de la varianza. Un
procedimiento comúnmente utilizado es el llamado método delta, método que ha sido
utilizado para obtener las varianzas de los estimadores cuando este no se deriva de la
simple suma de sus observaciones. La idea básica del método consiste en utilizar del
cálculo la llamada serie de Taylor para derivar una función lineal aproximada de una
función mucho más complicada. Para aplicar el método delta se aproxima la función
original a una función aproximada utilizando la serie de Taylor evaluada en su media.
A.1 Caso univariante
Supóngase que se dispone de una función de una variable aleatoria X, denotada por
f(X). Para aplicar el método delta se utiliza los dos primeros términos de la serie de
Taylor evaluada en la media de la variable aleatoria X, así:
( ) ( ) ( )( ) 'f X f X f= µ + −µ µ (A.1)
Donde,
( ) ( )'X
f f XX =µ
∂µ =∂
(A.2)
De modo que:
( ) ( ) ( ) 2'Var f X Var X f⎡ ⎤ ⎡ ⎤= −µ µ⎣ ⎦ ⎣ ⎦
( ) ( )2 2'Var f X f⎡ ⎤ ⎡ ⎤= σ µ⎣ ⎦ ⎣ ⎦ (A.3)
Donde, σ2 es la varianza de la variable aleatoria X.

Apéndices ______________________________________________________________________
164
A.2 Caso multivariante
Supóngase que la función f(X) en una función no lineal que depende de varias variables
aleatorias, digamos: X1,X2, … , Xp. Si se desea estimar la varianza de la función f(X) a
través del método delta, la forma general de la varianza de f(X) esta dada por:
( ) ( ) ( ) ( )
( )
( )
( )
1
2
1 2
ˆ, , ..., ...
p
p
f XX
f XX
Var f X f X f X f XX X X
f XX
⎡ ⎤∂⎢ ⎥⎢ ⎥∂⎢ ⎥⎢ ⎥∂⎢ ⎥⎢ ⎥∂⎡ ⎤ ⎢ ⎥∂ ∂ ∂⎢ ⎥⎡ ⎤ ⎢ ⎥= ×∑×⎢ ⎥⎣ ⎦ ⎢ ⎥∂ ∂ ∂⎢ ⎥ ⎢ ⎥⎣ ⎦ ⎢ ⎥⎢ ⎥⎢ ⎥∂⎢ ⎥⎢ ⎥∂⎢ ⎥⎣ ⎦
(A.4)
Donde: ∑ es la matriz de varianzas y covarianzas de las variables. X1,X2, … , Xp.
A.3 Varianza de Greenwood
Supóngase que se desea estimar la varianza del estimador de la función de
supervivencia de Bhomer (expresión 3.9), cuyo estimador esta dado por:
1 2( ) ...
z zS t p p p= × × × (A.5)
De modo que al aplicar la expresión A.4 al estimador S(tz), se obtiene que:
( )( )
( )
12 3
1 32
2 3 1
...
...
..
..
.....
z
z
z z
z
zz
S tp p p p
S t p p pp
p p pS t
p−
⎡ ⎤∂⎢ ⎥⎢ ⎥∂ ⎡ ⎤⎢ ⎥ ⎢ ⎥⎢ ⎥∂ ⎢ ⎥⎢ ⎥ ⎢ ⎥⎢ ⎥∂ ⎢ ⎥⎢ ⎥ ⎢ ⎥⎢ ⎥= ⎢ ⎥⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥⎢ ⎥∂ ⎢ ⎥⎣ ⎦⎢ ⎥⎢ ⎥∂⎢ ⎥⎣ ⎦

Apéndices ______________________________________________________________________
165
( ) ( ) ( )( ) ( ) ( )
( ) ( ) ( )
1 1 2 1
2 1 2 2
1 2
ar , . . . ,
, ar . . . ,ˆ . . .
. . .
. . .
, , . . . ar
z
z
z z z
V p Cvar p p Cvar p p
Cvar p p V p Cvar p p
Cvar p p Cvar p p V p
⎡ ⎤⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥∑= ⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎣ ⎦
Desarrollando la expresión A.4, se obtiene que:
( ) ( ) ( ) ( )1 1
,z z
z z z i ji j i j
Var S t S t S t Cvar p pp p= =
⎡ ⎤∂ ∂⎡ ⎤ ⎢ ⎥= × ×⎢ ⎥ ⎢ ⎥∂ ∂⎣ ⎦ ⎢ ⎥⎣ ⎦
∑∑ (A.6)
Así:
( ) ( ) ( ) ( ) ( ) ( )2
2
ar2 ,i
z z z z i ji j z i j z i ji
V pVar S t S t S t S t Cvar p p
p pp∀ = ≤ ≠ ≤
⎡ ⎤∂ ∂⎡ ⎤ ⎡ ⎤ ⎢ ⎥= + × ×⎢ ⎥ ⎢ ⎥ ⎢ ⎥∂ ∂⎣ ⎦ ⎣ ⎦ ⎢ ⎥⎣ ⎦
∑ ∑ (A.7)
Si se asume unidades independientes y subintervalos independientes no solapados y
sucesos tipo Bernoulli con varianza piqi/ni. El segundo término de la expresión A.7 se
hace igual a cero, de modo que:
( ) ( ) ( )2
21
zi
z z ii
Var pVar S t S t
p=
⎡ ⎤ ⎡ ⎤=⎢ ⎥ ⎢ ⎥⎣ ⎦ ⎣ ⎦
∑
Entonces:
( ) ( ) 2
21
1zi i
z z ii i
p pVar S t S t
n p=
⎡ ⎤−⎢ ⎥⎡ ⎤ ⎡ ⎤ ⎣ ⎦=⎢ ⎥ ⎢ ⎥⎣ ⎦ ⎣ ⎦
∑
( ) ( ) 2
1
1zi
z z i i i
pVar S t S t
n p=
⎡ ⎤−⎢ ⎥⎡ ⎤ ⎡ ⎤ ⎣ ⎦=⎢ ⎥ ⎢ ⎥⎣ ⎦ ⎣ ⎦
∑

Apéndices ______________________________________________________________________
166
Como: pi=1-di/ni entonces:
( ) ( ) 2
11
iz
iz z i
ii
i
dn
Var S t S td
nn
=
⎡ ⎤⎢ ⎥⎢ ⎥⎢ ⎥⎡ ⎤ ⎡ ⎤ ⎣ ⎦=⎢ ⎥ ⎢ ⎥ ⎡ ⎤⎣ ⎦ ⎣ ⎦ ⎢ ⎥−⎢ ⎥⎢ ⎥⎣ ⎦
∑
( ) ( ) 2
1
zi
z z ii i i
dVar S t S t
n n d=
⎡ ⎤ ⎡ ⎤=⎢ ⎥ ⎢ ⎥ ⎡ ⎤⎣ ⎦ ⎣ ⎦ −⎢ ⎥⎣ ⎦∑ (l.q.q.d)
Que representa el estimador de varianza tipo Greenwood (1926) del estimador de la
función de supervivencia clásica.

Apéndices ______________________________________________________________________
167
APÉNDICE B
MÉTODO DE NEWTON-RAPHSON
El método de Newton-Raphson es un procedimiento numérico iterativo que se utiliza
para resolver ecuaciones no lineales. Un procedimiento de aproximaciones sucesivas
donde cada aproximación se conoce como iteración. Si las aproximaciones sucesivas
son cada vez más cercanas podemos decir que las iteraciones convergen.
B.1 Caso univariado
Supóngase que se quiere determinar los valores de x tal que f(x)=0. El método de
Newton-Raphson requiere de una solución inicial en x, digamos 0
x tal que f(0
x ) es
cercano a cero preferiblemente. La primera aproximación de la iteración esta dada por:
( )( )
01 0
0
ˆˆ ˆ
ˆ'
f xx x
f x= − (B.1)
Donde, f’(0
x ) es la primera derivada de f(x) evaluada en x = 0
x . Si se generaliza la
expresión B.1, la iteración k+1 esta dada por:
( )( )1 0
ˆˆ ˆ
ˆ'k
kk
f xx x
f x+= − (B.2)
La iteración termina en la k-ésima iteración si f(xk) es cercano a cero o si d = xk+1 – xk es
menor que una cierta apreciación cercana a cero.
B.1 Caso multivariado
El método de de Newton-Raphson se puede generalizar para resolver sistemas de
ecuaciones con una o más incógnitas. Supóngase que se quiere determinar los valores de
x1,x2,…,xp tales que:

Apéndices ______________________________________________________________________
168
f1 (x1,x2,…,xp)=0
f2 (x1,x2,…,xp)=0
.
.
. fp (x1,x2,…,xp)=0
Sea aij la derivada parcial de fi con respecto a xj, así: aij=∂fi/∂xj. La matriz,
11 12 1
21 22 2
1 2
. . .
. . .
. . .
. . .
. . .
p
p
p p pp
a a a
a a a
J
a a a
⎡ ⎤⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥= ⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎣ ⎦
Se conoce como matriz Jacobiana y su inversa esta dada por J-1, con:
11 12 1
21 22 21
1 2
. . .
. . .
. . .
. . .
. . .
p
p
p p pp
b b b
b b b
J
b b b
−
⎡ ⎤⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥= ⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎣ ⎦
Sea xk
1,xk2,…,xk
p la raíz aproximada de la k-ésima iteración y f k1, f k
2, …, f kp los
valores correspondientes a cada una de las funciones, tal que:
f k1=f1 (xk1,xk
2,…,xkp)
f k2=f2 (xk1,xk
2,…,xkp)
.
.
. f kp= fp (xk
1,xk2,…,xk
p)
Si bkij es el ij-ésimo elemento Jacobiano de J -1 evaluado en xk
1,xk2,…,xk
p entonces la
k+1 aproximación esta dada por:

Apéndices ______________________________________________________________________
169
1
1 1 111 12 11
21 22 22 2 2
11 2
. . .
. . .
. . .. . .
. . .. . .
. . .. . .. . .
k k k
pk k k
p
k k kp p pp
p p p
x x fb b b
b b bx x f
b b bx x f
+
+
+
⎡ ⎤ ⎡ ⎤ ⎡ ⎤⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎡ ⎤⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎢ ⎥⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎢ ⎥⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎢ ⎥⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎢ ⎥⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎢ ⎥= −⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎢ ⎥⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎢ ⎥⎢ ⎥ ⎢ ⎥ ⎢⎢ ⎥⎢ ⎥ ⎢ ⎥ ⎢⎢ ⎥⎢ ⎥ ⎢ ⎥ ⎢⎢ ⎥⎢ ⎥⎢ ⎥ ⎢ ⎥ ⎢⎣ ⎦⎢ ⎥ ⎢ ⎥ ⎢⎣ ⎦ ⎣ ⎦ ⎣ ⎦
⎥⎥⎥⎥⎥
El procedimiento termina cuando el vector xk+1 ≈ xk. O cuando las diferencia de las
componentes del vector d = xk+1 - xk son menores que una apreciación prefijada.

Apéndices ______________________________________________________________________
170
APÉNDICE C
C.1 DEMOSTRACIÓN
Defina a Ur como:
( ) ( ) ( )( )z
z
, ;, ; , 1, 2, ...,
,r r
Y s z rU w N s z r N s z r k
Y s z∀
⎡ ⎤= ∆ − ∆ ∀ =⎢ ⎥
⎣ ⎦∑ (C1)
Sea: U=(U1,U2,…,Uk)´ un vector de variables aleatorias cuyos elementos son iguales a
la suma ponderada de la diferencia entre la variable N(s,∆z;r), que representa el
número de eventos observados en las unidades del r-ésimo grupo en el tiempo
calendario [0,s] con tiempo de interocurrencia igual a ∆z, y su valor esperado
EN(s,∆z;r)=N(s,∆z)Y(s,z;r)/Y(s,z) en todos los momentos de ocurrencias de los
eventos. Se cumple que:
10
k
rrU
==∑ (C2)
Demostración: Sustituya la expresión (C1) en la expresión (C2):
( ) ( ) ( )( )z
1 1 z
, ;, ; ,
,
k k
r rr r
Y s z rU w N s z r N s z
Y s z= = ∀
⎡ ⎤= ∆ − ∆⎢ ⎥
⎣ ⎦∑ ∑∑
Desarrolle la sumatoria en r,
( ) ( ) ( )( )
( ) ( ) ( )( )1z z1 z z
, ;1 , ;, ;1 , ... , ; ,
, ,
k
r kr t
Y s z Y s z kU w N s z N s z w N s z k N s z
Y s z Y s z= ∀ ≤
⎡ ⎤ ⎡ ⎤⎢ ⎥ ⎢ ⎥= ∆ − ∆ + + ∆ − ∆⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥⎣ ⎦ ⎣ ⎦
∑ ∑ ∑
( ) ( ) ( )( ) ( )
( )1
11 z z
, ;1 ... , ;, ;1 ... , ; ,
,
kz kz
r z kzr
w Y s z w Y s z kU w N s z w N s z k N s z
Y s z= ∀ ∀
⎡ ⎤+ +⎢ ⎥⎡ ⎤= ∆ + + ∆ − ∆⎢ ⎥⎢ ⎥⎣ ⎦ ⎢ ⎥⎣ ⎦∑ ∑ ∑
Si: w1z = w2z =… = wkz = wz , entonces:
( ) ( ) ( ) ( ) ( )( )1 z z
, ;1 ... , ;, ;1 ... , ; ,
,
k
r z zr
Y s z Y s z kU w N s z N s z k w N s z
Y s z= ∀ ∀
⎡ ⎤+ +⎢ ⎥⎡ ⎤= ∆ + + ∆ − ∆⎣ ⎦ ⎢ ⎥⎢ ⎥⎣ ⎦∑ ∑ ∑
y como:
( ) ( ) ( )( , ) , ;1 ... , ; e , ( , ;1) ... ( , ; )N s z N s z N s z k Y s z Y s z Y s z k∆ = ∆ + + ∆ = + +
( ) ( ) ( )( )1
,, , 0
,
k
r z zr z z
Y s zU w N s z w N s z
Y s z= ∀ ∀= ∆ − ∆ =∑ ∑ ∑ L.q.q.d.

Apéndices ______________________________________________________________________
171
C.2 DISTRIBUCIÓN HIPERGEOMÉTRICA MULTIVARIADA
Tomado de Johnson-Kotz-Balakrishnan (1997) y Childs-Balakrishnan (2000)
Considere una población de m individuos, de los cuales hay m1 de la clase C1, m2 de la
clase C2, …. y mk de la clase Ck, con m=m1+m2+…+mk. Suponga que, se toma una
muestra de tamaño n y que la muestra se toma una a una sin reemplazamiento del total
de los m individuos disponibles. Existen mn
⎛ ⎞⎟⎜ ⎟⎜ ⎟⎜⎝ ⎠ conjunto de individuos posibles en la
selección de los cuales: 1
kr
r r
mn=
⎛ ⎞⎟⎜ ⎟⎜ ⎟⎜ ⎟⎟⎜⎝ ⎠∏ conjuntos contienen n1 individuos del tipo M1, n2 del
tipo M2, …, y nk del tipo Mk. La distribución conjunta de N=(N1,N2,…,Nk)´ que
representa al número de individuos tipos C1,C2,…,y Ck, respectivamente, tienen una
función de probabilidades, dada por:
( ) 1
1 2, , ...,
kr
r rk
mn
Pr n n nmn
=
⎛ ⎞⎟⎜ ⎟⎜ ⎟⎜ ⎟⎟⎜⎝ ⎠= ⎛ ⎞⎟⎜ ⎟⎜ ⎟⎜⎝ ⎠
∏ (C3)
Con, 1
, 0 , 1, 2, ...,k
r r rrn n n m r k
== ≤ ≤ ∀ =∑ . La distribución con la expresión C3 se
conoce como distribución hipergeométrica multivariada con parámetros
(n;m1,m2,…,mk). La cual se denota por símbolo como:
( )
( )
1 2. . ; , , ...,
. . ;
kMult Hypg n m m m
o
Mult Hypg n m
donde, si k=2 la distribución se reduce a la distribución hipergeométrica univariada
ordinaria. Observe que, existen solamente existen k-1 variables, ya que:
1
1
k
k rrn n n
−
== −∑
Existen algunas relaciones entre esta distribución y la distribución multinomial
multivariada. Cuando m tiende a infinito con, mr/m=pr para todo r = 1,2,..,k, la

Apéndices ______________________________________________________________________
172
distribución hipergeométrica multivariada tiende a comportarse como la distribución
multinomial con parámetros (n;p1,p2,…,pk).
De la expresión C3, se puede deducir la distribución marginal de las variables Nr, que
corresponde a la distribución hipergeométrica univariante (n;mr,m) de modo que:
( ) 1, 2, ..., e 0,1, ...,
r r
i ir i i r
m m mn n n
Pr N n r k n m nmn
⎛ ⎞⎛ ⎞−⎟ ⎟⎜ ⎜⎟ ⎟⎜ ⎜⎟ ⎟⎜ ⎜⎟ − ⎟⎟ ⎟⎜ ⎜⎝ ⎠⎝ ⎠= = ∀ = = ≤⎛ ⎞⎟⎜ ⎟⎜ ⎟⎜⎝ ⎠
Propiedades:
1, 2, ...,rr
mE N n r k
m⎡ ⎤= ∀ =⎢ ⎥⎣ ⎦ (C4)
( )1
1r r
r
m mm nVar N n
m m m
⎡ ⎤−⎡ ⎤ ⎢ ⎥= −⎢ ⎥ ⎢ ⎥⎣ ⎦ − ⎢ ⎥⎣ ⎦ (C5)
( ) ( ) ''
,1
r rr r
m mm nCov N N n
m m m−
=−−
(C6)
( )( )
12
''
'
, r rr r
r r
m mCorr N N
m m m m
⎡ ⎤⎢ ⎥⎡ ⎤=−⎢ ⎥⎢ ⎥⎣ ⎦ ⎢ ⎥− −⎢ ⎥⎣ ⎦
(C7)
Note que tanto la covarianza y como la correlación son negativos. Cuando m→∞, las
expresiones C4, C5, C6 y C7, se reducen a:
1, 2, ...,r r r
E N m p r k⎡ ⎤= ∀ =⎢ ⎥⎣ ⎦ (C8)
r r rVar N np q⎡ ⎤=⎢ ⎥⎣ ⎦ (C9)
( )' ',
r r r rCov N N np p=− (C10)
( )( )
12
''
'
,1 1
r rr r
r r
p pCorr N N
p p
⎡ ⎤⎢ ⎥⎡ ⎤=−⎢ ⎥⎢ ⎥⎣ ⎦ ⎢ ⎥− −⎢ ⎥⎣ ⎦
(C11)
Que se corresponde con la definición de la distribución multinomial.

Apéndices ______________________________________________________________________
173
C.3 ESTANDARIZACIÓN DE LA DISTRIBUCIÓN HIPERGEOMÉTRICA
Childs-Balakrishan (2000) estudiaron la estandarización de la variable aleatoria
hipergeométrica multivariada y su aproximación a la distribución normal. De forma
que:
( )0,1 1, 2, ...,
11
rr
rr r
mN n
mW N r km mm n n
m m m
−= ∀ =
⎛ ⎞⎛ ⎞− ⎟⎜⎟⎜ ⎟−⎜⎟ ⎟⎜ ⎜⎟⎜ ⎟⎝ ⎠ ⎜− ⎝ ⎠
∼ (C12)
Consecuentemente, si se tiene un conjunto k de variables aleatorias independientes y
normales estandarizadas, digamos: Z1, Z2,… ,Zk. Entonces, el conjunto de variables
aleatorias que se ilustran a continuación:
( ) ( ) ( )1/ 2 1/2 1/2
1 2, , ...,
1 1 1 k
k k kZ Z Z Z Z Zk k k⎛ ⎞ ⎛ ⎞ ⎛ ⎞⎟ ⎟ ⎟⎜ ⎜ ⎜− − −⎟ ⎟ ⎟⎜ ⎜ ⎜⎟ ⎟ ⎟⎜ ⎜ ⎜⎝ ⎠ ⎝ ⎠ ⎝ ⎠+ + +
Bajo la hipótesis de igualdad de las mr, la distribución conjunta de Z1,Z2,… ,Zk puede
aproximarse una distribución normal multivariante con medias ceros, varianzas iguales
a uno y covarianzas iguales a -1/(k-1).
C.4 USO DE LA DISTRIBUCIÓN HIPERGEOMÉTRICA MULTIVARIADA
EN LAS GENERALIZACIONES DE LOS ESTADÍSTICOS DE
COMPARACIONES CLÁSICAS.
Considere un tiempo de ocurrencia calendario [0,s], en el cual existen Y(s,z) eventos
observados con tiempos de interocurrencia mayores iguales a z, de los cuales hay
Y(s,z;1) eventos pertenecientes al grupo uno, Y(s,z;2) eventos pertenecientes al grupo
dos y así sucesivamente hasta el grupo k-ésimo. De modo que: ( ) ( )1
, , ;k
rY s z Y s z r
==∑ .
Si se toma una muestra sin reemplazamiento de tamaño n e igual a N(s,∆z) que
representa el número de eventos en el tiempo calendario [0,s] con tiempos de
interocurrencias iguales a ∆z. De modo que: ( ) ( )1
, , ;k
rN s z N s z r
=∆ = ∆∑ . Entonces,

Apéndices ______________________________________________________________________
174
existen ( )( )
,,
Y s zN s z⎛ ⎞⎟⎜ ⎟⎜ ⎟⎜ ⎟⎜ ∆⎝ ⎠
formas posibles de obtener los n eventos de los Y(s,z) eventos
observados. De los cuales, ( )( )1
, ;, ;
k
r
Y s z rN s z r=
⎛ ⎞⎟⎜ ⎟⎜ ⎟⎜ ⎟⎜ ∆⎝ ⎠∏ conjuntos de unidades posibles que pueden
contener N(s,∆z;r) del tipo Y(s,z;r) para todo r=1,2,…,k. La distribución conjunta del
vector N = [N(s,∆z;1) N(s,∆z;2) …… N(s,∆z;k)]´ que es un vector de variables
aleatorias multivariado tiene como función de probabilidades :
( ) ( ) ( )
( )( )
( )( )
( )( )
( )( )
, ;1 , ; 2 , ;...
, ;1 , ; 2 , ;, ;1 , , ; 2 , ..., , ;
,,
Y s z Y s z Y s z kN s z N s z N s z k
f N s z N s z N s z kY s z
N s z
⎛ ⎞⎛ ⎞ ⎛ ⎞⎟ ⎟ ⎟⎜ ⎜ ⎜⎟ ⎟ ⎟⎜ ⎜ ⎜⎟ ⎟ ⎟⎜ ⎜ ⎜⎟ ⎟ ⎟⎜ ⎜ ⎜∆ ∆ ∆⎝ ⎠⎝ ⎠ ⎝ ⎠⎡ ⎤∆ ∆ ∆ =⎣ ⎦ ⎛ ⎞⎟⎜ ⎟⎜ ⎟⎜ ⎟⎜ ∆⎝ ⎠
Que se corresponde con la distribución de probabilidades definida en la sección C.2
de este apéndice. Las distribuciones marginales de las variables N(s,∆z;r), para todo
r = 1,2,…,k se distribuyen hipergeométrica, de modo que se cumple que:
( ) ( , ; ), ; ( , ) 1, 2, ...,( , )
Y s z rE N s z r N s z r kY s z
⎡ ⎤∆ = ∆ ∀ =⎣ ⎦
( ) ( ) ( )( )
( ) ( )( )
( )( )
[ , , ] , ; , ;, ; , 1 1, 2, ...,
, 1 , ,Y s z N s z Y s z r Y s z r
Var N s z r N s z r kY s z Y s z Y s z
⎡ ⎤− ∆ ⎢ ⎥⎡ ⎤∆ = ∆ − ∀ =⎣ ⎦ ⎢ ⎥− ⎢ ⎥⎣ ⎦
( ) ( )( ) ( )( ) ( )
( )( )
', , , ; '( , ; ), ; , , ; ' ( , ) 1, ...,, 1 , , ' 1, ...,
r rY s z N s z Y s z rY s z rCov N s z r N s z r N s z r kY s z Y s z Y s z r k
⎧ ≠⎪⎡ ⎤− ∆ ⎪⎣ ⎦ ⎪⎡ ⎤∆ ∆ =− ∆ ∀ =⎨⎣ ⎦ ⎪− ⎪ =⎪⎩
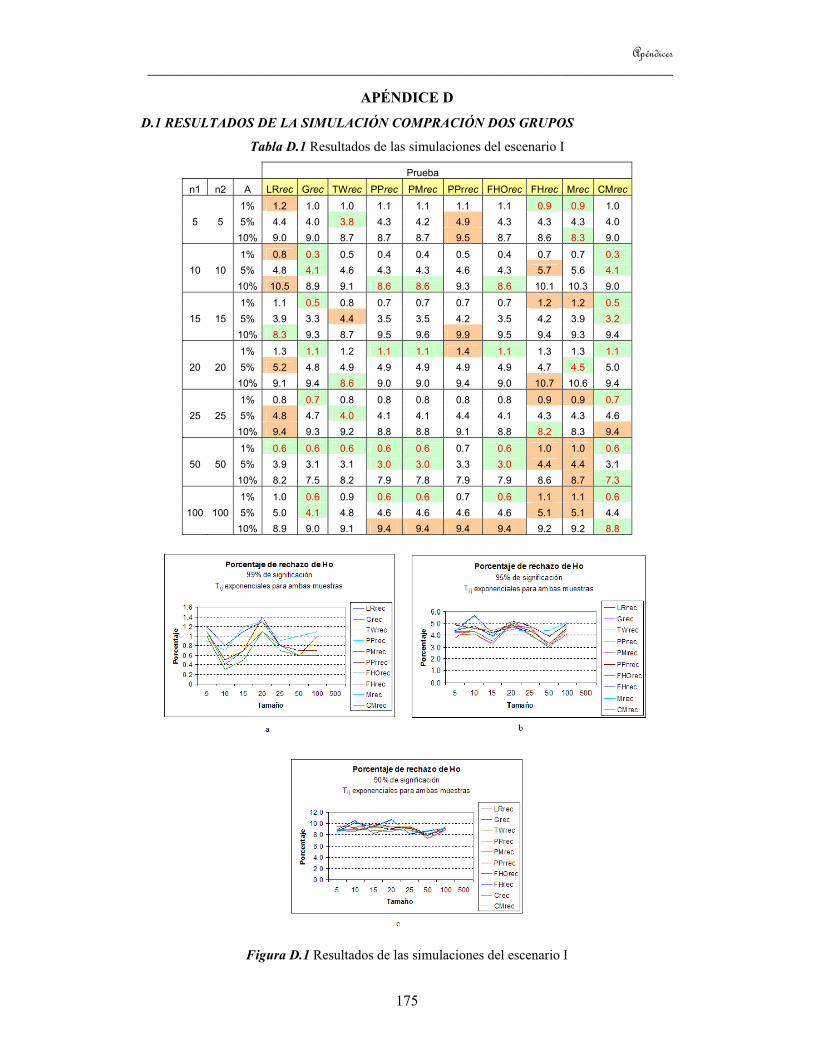
Apéndices ______________________________________________________________________
175
APÉNDICE D
D.1 RESULTADOS DE LA SIMULACIÓN COMPRACIÓN DOS GRUPOS
Tabla D.1 Resultados de las simulaciones del escenario I
Prueba n1 n2 Α LRrec Grec TWrec PPrec PMrec PPrrec FHOrec FHrec Mrec CMrec
1% 1.2 1.0 1.0 1.1 1.1 1.1 1.1 0.9 0.9 1.0 5 5 5% 4.4 4.0 3.8 4.3 4.2 4.9 4.3 4.3 4.3 4.0 10% 9.0 9.0 8.7 8.7 8.7 9.5 8.7 8.6 8.3 9.0
1% 0.8 0.3 0.5 0.4 0.4 0.5 0.4 0.7 0.7 0.3 10 10 5% 4.8 4.1 4.6 4.3 4.3 4.6 4.3 5.7 5.6 4.1
10% 10.5 8.9 9.1 8.6 8.6 9.3 8.6 10.1 10.3 9.0 1% 1.1 0.5 0.8 0.7 0.7 0.7 0.7 1.2 1.2 0.5
15 15 5% 3.9 3.3 4.4 3.5 3.5 4.2 3.5 4.2 3.9 3.2 10% 8.3 9.3 8.7 9.5 9.6 9.9 9.5 9.4 9.3 9.4 1% 1.3 1.1 1.2 1.1 1.1 1.4 1.1 1.3 1.3 1.1
20 20 5% 5.2 4.8 4.9 4.9 4.9 4.9 4.9 4.7 4.5 5.0 10% 9.1 9.4 8.6 9.0 9.0 9.4 9.0 10.7 10.6 9.4 1% 0.8 0.7 0.8 0.8 0.8 0.8 0.8 0.9 0.9 0.7
25 25 5% 4.8 4.7 4.0 4.1 4.1 4.4 4.1 4.3 4.3 4.6 10% 9.4 9.3 9.2 8.8 8.8 9.1 8.8 8.2 8.3 9.4
1% 0.6 0.6 0.6 0.6 0.6 0.7 0.6 1.0 1.0 0.6 50 50 5% 3.9 3.1 3.1 3.0 3.0 3.3 3.0 4.4 4.4 3.1
10% 8.2 7.5 8.2 7.9 7.8 7.9 7.9 8.6 8.7 7.3
1% 1.0 0.6 0.9 0.6 0.6 0.7 0.6 1.1 1.1 0.6 100 100 5% 5.0 4.1 4.8 4.6 4.6 4.6 4.6 5.1 5.1 4.4
10% 8.9 9.0 9.1 9.4 9.4 9.4 9.4 9.2 9.2 8.8
Figura D.1 Resultados de las simulaciones del escenario I

Apéndices ______________________________________________________________________
176
Tabla D.2 Resultados de las simulaciones del escenario II
Prueba n1 n2 Α LRrec Grec TWrec PPrec PMrec PPrrec FHOrec FHrec Mrec CMrec
1% 25.1 14.6 19.3 16.8 16.0 20.7 16.8 21.7 21.5 14.7 5 5 5% 47.3 37.0 42.3 38.8 37.9 42.8 38.8 43.6 42.7 37.0 10% 60.7 50.3 57.0 51.9 51.5 55.6 51.9 56.4 55.7 50.3 1% 50.8 40.7 51.1 43.9 43.7 47.6 43.9 52.9 52.9 40.8
10 10 5% 80.0 65.7 75.3 68.6 68.2 71.6 68.6 74.6 74.6 65.7 10% 89.2 77.3 85.0 80.4 80.2 82.2 80.4 83.4 83.2 77.2 1% 80.8 62.5 73.9 67.8 67.8 70.1 67.8 75.8 75.6 62.5
15 15 5% 94.1 84.3 90.1 87.0 86.8 87.7 87.0 89.6 89.6 84.3 10% 97.8 91.0 95.4 93.1 92.7 93.5 93.1 95.0 94.7 91.0 1% 92.1 77.9 87.9 83.3 83.0 84.8 83.3 88.0 88.0 77.9
20 20 5% 98.6 92.4 96.5 94.5 94.5 95.1 94.5 96.7 96.6 92.4 10% 99.7 96.2 99.0 97.4 97.2 97.7 97.4 98.4 98.4 96.1
1% 97.8 88.0 94.4 91.4 91.2 92.0 91.4 94.8 94.6 88.2 25 25 5% 99.5 96.5 98.6 97.8 97.7 97.8 97.8 98.8 98.7 96.5
10% 99.9 98.4 99.4 98.8 98.8 98.8 98.8 99.5 99.5 98.4
1% 100.0 100.0 100.0 100.0 100.0 100.0 99.9 100.0 100.0 99.7 50 50 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
10% 100.0 99.7 99.9 99.9 99.9 99.9 100.0 100.0 100.0 100.0
1% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100 100 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
Figura D.2 Resultados de las simulaciones del escenario II

Apéndices ______________________________________________________________________
177
Tabla D.3 Resultados de las simulaciones del escenario III
Prueba n1 n2 Α LRrec Grec TWrec PPrec PMrec PPrrec FHOrec FHrec Mrec CMrec
1% 0.7 0.6 0.7 0.7 0.7 0.9 0.7 1.1 1.1 0.6 5 5 5% 5.0 3.4 3.4 3.2 3.2 4.3 3.2 4.4 4.2 3.4 10% 9.6 9.6 9.4 8.9 8.8 11.3 8.9 8.7 8.6 9.0 1% 1.1 0.6 0.9 0.7 0.7 0.8 0.7 1.0 0.9 0.6
10 10 5% 5.3 4.0 4.6 4.2 4.1 4.8 4.2 4.5 4.6 4.0 10% 10.0 9.1 9.3 8.8 8.9 9.5 8.8 10.4 10.4 9.2 1% 0.9 1.2 1.3 1.3 1.3 1.4 1.3 1.2 1.2 1.2
15 15 5% 6.2 5.0 5.5 5.1 5.1 5.6 5.1 4.9 4.9 5.1 10% 11.3 10.8 10.7 10.6 10.7 11.0 10.6 9.0 8.9 11.0 1% 1.1 0.8 1.0 0.7 0.7 0.7 0.7 1.3 1.3 0.8
20 20 5% 4.6 2.9 3.5 3.5 3.3 3.8 3.5 5.1 5.0 2.7 10% 9.9 8.1 8.2 7.6 7.6 7.9 7.6 9.9 9.8 8.1
1% 0.8 0.9 0.9 0.8 0.8 0.9 0.8 0.8 0.8 0.9 25 25 5% 4.3 3.9 3.8 4.1 4.1 4.5 4.1 4.1 4.2 4.2
10% 9.6 9.5 8.8 9.2 9.2 9.7 9.2 9.2 9.4 9.4
1% 1.0 1.0 1.0 1.0 1.0 1.1 1.0 0.8 0.8 1.1 50 50 5% 5.0 4.6 5.3 4.8 4.8 5.0 4.8 4.6 4.5 4.4
10% 11.0 9.6 10.3 9.7 9.7 9.9 9.9 9.7 9.8 9.8
1% 0.9 0.5 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.5 100 100 5% 4.8 5.4 4.4 5.2 5.2 5.2 5.2 4.7 4.6 5.3
10% 9.9 10.2 11.2 10.5 10.5 10.7 10.5 9.8 9.8 10.5
Figura D.3 Resultados de las simulaciones del escenario III

Apéndices ______________________________________________________________________
178
Tabla D.4 Resultados de las simulaciones del escenario IV
Prueba n1 n2 Α LRrec Grec TWrec PPrec PMrec PPrrec FHOrec FHrec Mrec CMrec
1% 49.8 58.3 57.3 57.9 58.1 61.7 57.9 34.5 35.1 58.3 5 5 5% 72.7 80.5 79.1 79.7 79.6 82.1 79.7 59.2 59.6 80.4 10% 81.6 88.6 87.7 88.3 88.2 89.8 88.3 69.8 70.2 88.6 1% 87.3 94.2 93.6 94.2 94.2 95.0 94.2 69.5 70.0 94.2
10 10 5% 96.3 98.7 98.3 98.5 98.5 98.7 98.5 87.3 88.0 98.7 10% 98.0 99.3 99.3 99.3 99.3 99.3 99.3 93.8 94.0 99.3 1% 96.0 99.0 98.7 98.8 98.8 98.8 98.8 87.0 87.4 99.0
15 15 5% 99.1 99.6 99.6 99.6 99.6 99.6 99.6 95.3 95.4 99.5 10% 99.4 99.9 99.6 99.8 99.8 99.8 99.8 97.8 97.9 99.9 1% 98.7 100.0 100.0 100.0 100.0 100.0 100.0 93.4 93.4 100.0
20 20 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 98.3 98.5 100.0 10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 99.1 99.1 100.0
1% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 98.9 98.9 100.0 25 25 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 99.7 99.7 100.0
10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 99.8 99.8 100.0
1% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 50 50 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
1% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100 100 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
Figura D.4 Resultados de las simulaciones del escenario IV

Apéndices ______________________________________________________________________
179
Tabla D.5 Resultados de las simulaciones del escenario V
Prueba n1 n2 Α LRrec Grec TWrec PPrec PMrec PPrrec FHOrec FHrec Mrec CMrec
1% 0.8 0.8 0.5 0.8 0.8 1.1 0.8 0.7 0.7 0.8 5 5 5% 6.5 4.3 5.0 4.3 4.3 5.7 4.3 6.3 6.2 4.3 10% 11.9 9.6 10.0 9.2 9.4 11.0 9.2 11.2 10.8 9.5 1% 0.7 0.9 1.1 0.9 0.9 1.1 0.9 0.8 0.8 0.9
10 10 5% 5.3 4.5 4.3 4.6 4.4 5.2 4.6 5.3 5.2 4.5 10% 9.4 9.1 8.9 9.0 9.0 10.0 9.0 10.0 10.2 9.1 1% 1.2 0.5 0.8 0.5 0.5 0.8 0.5 1.1 1.2 0.5
15 15 5% 4.0 3.7 4.2 3.8 4.0 4.3 3.8 4.8 4.9 3.8 10% 8.7 10.0 8.7 9.9 10.1 10.8 9.9 10.1 10.1 10.0 1% 1.0 1.1 1.0 1.1 1.1 1.1 1.1 0.5 0.5 1.1
20 20 5% 5.1 5.1 5.6 5.1 5.2 5.3 5.1 5.6 5.3 5.1 10% 10.6 11.0 10.7 10.9 10.8 11.5 10.9 10.8 10.7 11.1
1% 0.9 1.0 0.8 1.0 1.0 1.0 1.0 1.0 1.0 1.0 25 25 5% 5.1 5.3 5.0 5.1 5.1 5.6 5.1 5.2 5.3 5.3
10% 10.6 10.5 10.6 10.5 10.5 10.8 10.5 10.5 10.6 10.4
1% 0.8 0.7 0.7 0.7 0.7 0.7 0.7 0.8 0.8 0.7 50 50 5% 4.3 4.1 4.3 4.1 4.1 4.3 4.1 3.9 3.9 4.2
10% 8.7 9.6 9.5 9.6 9.6 9.7 9.6 8.3 8.3 9.7
1% 1.0 1.0 0.8 1.0 1.0 1.0 1.0 1.2 1.2 0.9 100 100 5% 5.5 5.2 5.5 5.2 5.2 5.3 5.2 5.5 5.5 5.3
10% 10.0 9.7 10.2 9.8 9.7 9.9 9.8 10.0 10.0 9.7
Figura D.5 Resultados de las simulaciones del escenario V
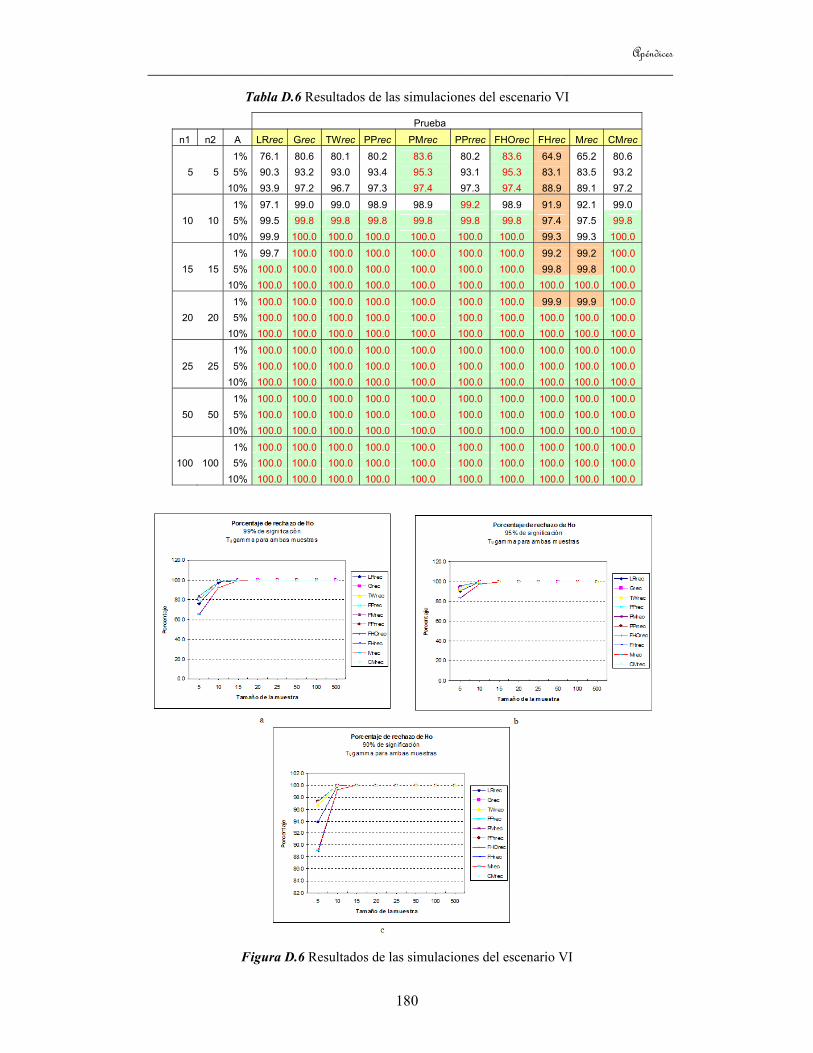
Apéndices ______________________________________________________________________
180
Tabla D.6 Resultados de las simulaciones del escenario VI
Prueba n1 n2 Α LRrec Grec TWrec PPrec PMrec PPrrec FHOrec FHrec Mrec CMrec
1% 76.1 80.6 80.1 80.2 83.6 80.2 83.6 64.9 65.2 80.6 5 5 5% 90.3 93.2 93.0 93.4 95.3 93.1 95.3 83.1 83.5 93.2 10% 93.9 97.2 96.7 97.3 97.4 97.3 97.4 88.9 89.1 97.2 1% 97.1 99.0 99.0 98.9 98.9 99.2 98.9 91.9 92.1 99.0
10 10 5% 99.5 99.8 99.8 99.8 99.8 99.8 99.8 97.4 97.5 99.8 10% 99.9 100.0 100.0 100.0 100.0 100.0 100.0 99.3 99.3 100.0 1% 99.7 100.0 100.0 100.0 100.0 100.0 100.0 99.2 99.2 100.0
15 15 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 99.8 99.8 100.0 10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 1% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 99.9 99.9 100.0
20 20 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
1% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 25 25 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
1% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 50 50 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
1% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100 100 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
Figura D.6 Resultados de las simulaciones del escenario VI

Apéndices ______________________________________________________________________
181
Tabla D.7 Resultados de las simulaciones del escenario VII
Prueba n1 n2 Α LRrec Grec TWrec PPrec PMrec PPrrec FHOrec FHrec Mrec CMrec
1% 1.7 0.8 1.0 0.8 0.8 1.2 0.8 1.9 1.9 0.8 5 5 5% 6.8 6.0 6.3 6.0 6.0 7.2 6.0 6.5 6.2 6.0 10% 12.1 11.7 11.7 11.6 11.6 12.8 11.6 12.1 12.5 11.6 1% 1.7 1.8 1.7 1.8 1.8 1.9 1.8 1.0 0.9 1.9
10 10 5% 7.0 5.6 5.9 5.4 5.4 5.8 5.4 6.0 6.0 5.7 10% 12.7 10.7 11.4 10.6 10.6 11.6 10.6 11.6 11.3 10.6 1% 1.3 0.6 0.9 0.6 0.6 0.6 0.6 1.3 1.3 0.6
15 15 5% 5.6 5.1 5.0 5.1 5.0 5.2 5.1 6.0 6.0 5.0 10% 11.7 10.9 10.4 10.7 10.7 11.1 10.7 12.5 12.6 10.8 1% 2.0 1.3 1.4 1.2 1.2 1.5 1.2 2.2 2.2 1.3
20 20 5% 7.1 6.1 7.2 6.1 6.2 6.8 6.1 7.0 6.9 6.2 10% 12.3 13.5 12.4 13.5 13.2 13.5 13.5 12.8 12.8 13.6
1% 0.4 0.8 0.8 0.7 0.7 0.8 0.7 1.2 1.2 0.6 25 25 5% 4.3 4.1 4.5 4.1 4.1 4.3 4.1 5.5 5.5 4.1
10% 11.6 9.9 10.5 9.9 9.9 10.4 9.9 11.4 11.3 9.9
1% 1.2 1.5 1.1 1.5 1.5 1.5 1.5 1.4 1.4 1.5 50 50 5% 5.0 6.1 6.5 5.9 5.8 6.2 5.9 5.9 6.0 5.9
10% 11.0 11.0 10.8 10.9 10.8 11.1 10.9 10.3 10.3 10.9
1% 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.4 0.4 0.5 100 100 5% 4.6 3.3 4.0 3.3 3.3 3.3 3.3 4.0 4.0 3.4
10% 8.5 8.6 8.1 8.6 8.5 8.6 8.6 8.5 8.4 7.9
Figura D.7 Resultados de las simulaciones del escenario VII

Apéndices ______________________________________________________________________
182
Tabla D.8 Resultados de las simulaciones del escenario VIII
Prueba n1 n2 Α LRrec Grec TWrec PPrec PMrec PPrrec FHOrec FHrec Mrec CMrec
1% 23.7 17.5 20.3 17.4 17.0 21.5 17.4 12.5 12.0 17.5 5 5 5% 48.8 40.3 45.2 40.2 39.9 46.0 40.2 30.8 30.3 40.1 10% 61.3 55.6 57.2 54.7 54.5 57.2 54.7 42.4 41.5 55.5 1% 55.3 43.3 47.3 42.8 42.8 45.6 43.0 28.5 28.1 43.7
10 10 5% 80.0 70.0 73.8 68.9 68.2 71.4 68.9 49.3 48.1 69.8 10% 88.3 80.3 82.5 79.4 79.1 80.9 79.4 62.8 61.1 80.2 1% 82.4 66.5 72.6 66.1 65.6 67.9 66.1 43.4 42.5 66.5
15 15 5% 95.3 87.0 89.6 86.5 86.4 87.8 86.5 69.1 68.7 86.6 10% 97.5 93.0 95.3 93.0 92.9 93.3 93.0 79.0 78.2 93.0 1% 93.3 82.5 87.4 82.3 82.1 83.2 82.3 60.5 59.5 82.3
20 20 5% 98.1 93.4 96.1 93.2 93.1 93.8 93.2 81.4 80.9 93.5 10% 99.1 97.1 97.9 97.0 96.7 97.2 97.0 89.0 88.3 97.0
1% 97.5 90.5 93.7 90.2 89.9 90.8 90.2 71.2 70.2 90.1 25 25 5% 99.6 97.8 98.4 97.7 97.6 97.8 97.7 97.6 87.1 97.8
10% 99.9 99.0 99.6 99.0 99.0 99.0 99.0 93.0 92.6 99.1
1% 100.0 99.9 100.0 99.9 99.9 99.9 99.9 97.1 96.9 99.9 50 50 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 99.4 99.3 100.0
10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 99.9 99.9 100.0
1% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100 100 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
Figura D.8 Resultados de las simulaciones del escenario VIII

Apéndices ______________________________________________________________________
183
Tabla D.9 Resultados de las simulaciones del escenario IX
Prueba n1 n2 Α LRrec Grec TWrec PPrec PMrec PPrrec FHOrec FHrec Mrec CMrec
1% 0.7 0.2 0.5 0.3 0.3 0.6 0.3 1.1 1.0 0.2 5 5 5% 5.3 3.3 3.6 3.3 3.4 4.3 3.3 4.8 4.5 3.3 10% 9.2 7.1 7.6 7.4 7.1 9.1 7.4 11.1 11.0 7.1 1% 0.9 0.6 0.8 0.8 0.8 0.8 0.8 0.7 0.7 0.6
10 10 5% 3.0 3.7 3.8 4.0 4.0 4.3 4.0 3.7 3.4 3.8 10% 9.0 9.1 8.2 8.9 8.5 9.3 8.9 8.4 8.3 9.1 1% 0.7 0.5 0.7 0.6 0.6 0.7 0.6 0.9 0.9 0.5
15 15 5% 4.0 4.7 4.7 4.6 4.6 5.0 4.6 4.2 4.1 4.9 10% 9.7 10.3 9.3 10.1 10.0 10.4 10.1 7.9 7.8 10.2 1% 0.7 1.1 0.8 0.8 0.8 0.9 0.8 0.9 0.9 1.1
20 20 5% 3.8 4.8 4.3 4.5 4.6 4.7 4.5 4.1 4.4 4.7 10% 9.1 8.6 8.0 7.9 7.8 8.5 7.9 10.0 9.8 8.5
1% 0.8 0.4 0.5 0.5 0.5 0.6 0.5 0.9 0.9 0.4 25 25 5% 4.0 4.1 4.0 4.1 4.0 4.1 4.1 3.9 3.8 4.1
10% 8.1 7.6 8.4 7.4 7.5 7.9 7.4 7.5 7.7 7.7
1% 0.6 0.6 0.6 0.5 0.5 0.5 0.5 0.7 0.7 0.6 50 50 5% 4.3 4.5 4.3 4.7 4.7 4.8 4.7 3.4 3.4 4.5
10% 9.1 8.7 8.9 8.6 8.6 8.8 8.6 8.5 8.4 8.9
1% 1.0 0.6 0.7 0.5 0.5 0.5 0.5 1.2 1.2 0.5 100 100 5% 4.1 3.6 3.8 3.4 3.4 3.4 3.4 4.0 4.0 3.6
10% 9.3 7.4 7.9 7.5 7.5 7.6 7.5 9.0 9.1 7.3
Figura D.9 Resultados de las simulaciones del escenario IX
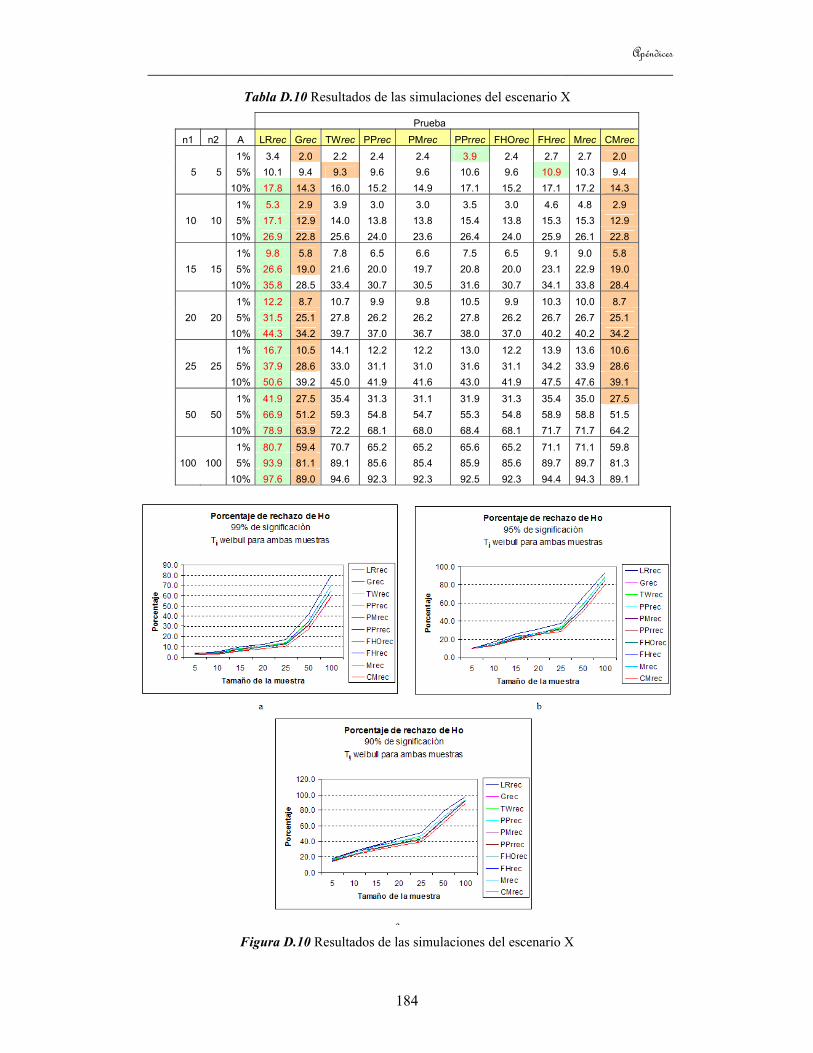
Apéndices ______________________________________________________________________
184
Tabla D.10 Resultados de las simulaciones del escenario X
Prueba n1 n2 Α LRrec Grec TWrec PPrec PMrec PPrrec FHOrec FHrec Mrec CMrec
1% 3.4 2.0 2.2 2.4 2.4 3.9 2.4 2.7 2.7 2.0 5 5 5% 10.1 9.4 9.3 9.6 9.6 10.6 9.6 10.9 10.3 9.4 10% 17.8 14.3 16.0 15.2 14.9 17.1 15.2 17.1 17.2 14.3 1% 5.3 2.9 3.9 3.0 3.0 3.5 3.0 4.6 4.8 2.9
10 10 5% 17.1 12.9 14.0 13.8 13.8 15.4 13.8 15.3 15.3 12.9 10% 26.9 22.8 25.6 24.0 23.6 26.4 24.0 25.9 26.1 22.8 1% 9.8 5.8 7.8 6.5 6.6 7.5 6.5 9.1 9.0 5.8
15 15 5% 26.6 19.0 21.6 20.0 19.7 20.8 20.0 23.1 22.9 19.0 10% 35.8 28.5 33.4 30.7 30.5 31.6 30.7 34.1 33.8 28.4 1% 12.2 8.7 10.7 9.9 9.8 10.5 9.9 10.3 10.0 8.7
20 20 5% 31.5 25.1 27.8 26.2 26.2 27.8 26.2 26.7 26.7 25.1 10% 44.3 34.2 39.7 37.0 36.7 38.0 37.0 40.2 40.2 34.2
1% 16.7 10.5 14.1 12.2 12.2 13.0 12.2 13.9 13.6 10.6 25 25 5% 37.9 28.6 33.0 31.1 31.0 31.6 31.1 34.2 33.9 28.6
10% 50.6 39.2 45.0 41.9 41.6 43.0 41.9 47.5 47.6 39.1
1% 41.9 27.5 35.4 31.3 31.1 31.9 31.3 35.4 35.0 27.5 50 50 5% 66.9 51.2 59.3 54.8 54.7 55.3 54.8 58.9 58.8 51.5
10% 78.9 63.9 72.2 68.1 68.0 68.4 68.1 71.7 71.7 64.2
1% 80.7 59.4 70.7 65.2 65.2 65.6 65.2 71.1 71.1 59.8 100 100 5% 93.9 81.1 89.1 85.6 85.4 85.9 85.6 89.7 89.7 81.3
10% 97.6 89.0 94.6 92.3 92.3 92.5 92.3 94.4 94.3 89.1
Figura D.10 Resultados de las simulaciones del escenario X

Apéndices ______________________________________________________________________
185
Tabla D.11 Resultados de las simulaciones del escenario XII
Prueba n1 n2 Α LRrec Grec TWrec PPrec PMrec PPrrec FHOrec FHrec Mrec CMrec
1% 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 5 5 5% 0.0 0.4 0.0 0.0 0.1 0.0 0.0 0.0 0.0 0.4 10% 3.2 11.3 4.5 7.5 7.6 4.5 7.5 0.0 0.0 11.6 1% 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
10 10 5% 0.0 11.8 0.8 5.3 5.5 5.5 5.3 0.0 0.0 12.0 10% 12.3 71.1 40.1 59.8 60.1 68.4 59.8 0.0 0.0 70.6 1% 0.0 0.2 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.3
15 15 5% 0.7 68.6 17.5 50.6 51.0 57.0 50.6 0.0 0.0 68.0 10% 47.7 98.7 88.7 96.4 96.5 97.5 96.4 0.0 0.0 98.1 1% 0.0 6.1 0.0 1.7 1.8 2.1 1.7 0.0 0.0 7.2
20 20 5% 3.2 98.4 71.2 96.6 96.7 97.5 96.6 0.0 0.0 98.2 10% 86.7 100.0 99.8 100.0 100.0 100.0 100.0 0.0 0.0 100.0
1% 0.0 46.1 0.7 20.6 21.7 24.6 20.6 0.0 0.0 45.1 25 25 5% 23.2 100.0 98.7 99.8 99.9 99.9 99.8 0.0 0.0 99.8
10% 97.9 100.0 100.0 100.0 100.0 100.0 100.0 0.0 0.0 100.0
1% 6.2 100.0 100.0 100.0 100.0 100.0 100.0 0.0 0.0 100.0 50 50 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 0.0 0.0 100.0
10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 0.0 0.0 100.0
1% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 0.0 0.0 100.0 100 100 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 0.0 0.0 100.0
10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 0.0 0.0 100.0
Figura D.11 Resultados de las simulaciones del escenario XII

Apéndices ______________________________________________________________________
186
Tabla D.12 Resultados de las simulaciones del escenario XIV
Prueba n1 n2 α LRrec Grec TWrec PPrec PMrec PPrrec FHOrec FHrec Mrec CMrec
1% 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 5 5 5% 0.3 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 10% 5.2 0.0 0.0 0.0 0.0 0.0 0.0 0.4 0.1 0.0 1% 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
10 10 5% 22.4 0.0 0.0 0.0 0.0 0.0 0.0 1.3 0.6 0.0 10% 89.3 0.0 3.5 0.0 0.0 0.0 0.0 30.3 25.2 0.0 1% 0.6 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
15 15 5% 94.9 0.0 0.9 0.0 0.0 0.0 0.0 48.1 41.5 0.0 10% 100.0 0.0 70.7 2.0 1.0 6.7 2.0 95.1 94.0 0.0 1% 42.5 0.0 0.0 0.0 0.0 0.0 0.0 5.0 3.6 0.0
20 20 5% 100.0 0.0 43.0 0.0 0.0 0.2 0.0 95.8 94.8 0.0 10% 100.0 4.5 99.8 48.9 44.1 63.4 48.9 100.0 100.0 4.5
1% 94.8 0.0 0.0 0.0 0.0 0.0 0.0 44.5 39.8 0.0 25 25 5% 100.0 0.0 95.9 7.4 4.9 14.0 7.4 99.9 99.9 0.0
10% 100.0 59.2 100.0 97.6 96.3 98.9 97.6 100.0 100.0 59.2
1% 100.0 0.0 100.0 30.5 26.0 39.4 30.5 100.0 100.0 0.0 50 50 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
1% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100 100 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
Figura D.12 Resultados de las simulaciones del escenario XIV
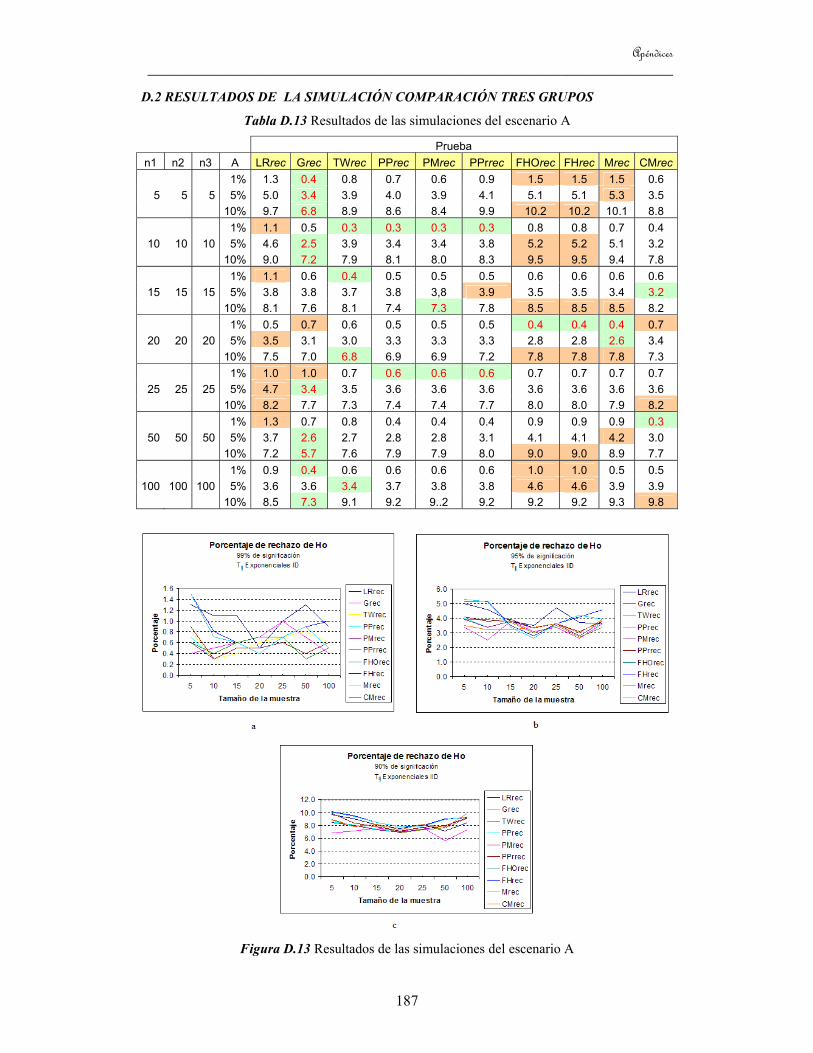
Apéndices ______________________________________________________________________
187
D.2 RESULTADOS DE LA SIMULACIÓN COMPARACIÓN TRES GRUPOS
Tabla D.13 Resultados de las simulaciones del escenario A
Prueba n1 n2 n3 Α LRrec Grec TWrec PPrec PMrec PPrrec FHOrec FHrec Mrec CMrec
1% 1.3 0.4 0.8 0.7 0.6 0.9 1.5 1.5 1.5 0.6 5 5 5 5% 5.0 3.4 3.9 4.0 3.9 4.1 5.1 5.1 5.3 3.5 10% 9.7 6.8 8.9 8.6 8.4 9.9 10.2 10.2 10.1 8.8 1% 1.1 0.5 0.3 0.3 0.3 0.3 0.8 0.8 0.7 0.4
10 10 10 5% 4.6 2.5 3.9 3.4 3.4 3.8 5.2 5.2 5.1 3.2 10% 9.0 7.2 7.9 8.1 8.0 8.3 9.5 9.5 9.4 7.8 1% 1.1 0.6 0.4 0.5 0.5 0.5 0.6 0.6 0.6 0.6
15 15 15 5% 3.8 3.8 3.7 3.8 3,8 3.9 3.5 3.5 3.4 3.2 10% 8.1 7.6 8.1 7.4 7.3 7.8 8.5 8.5 8.5 8.2 1% 0.5 0.7 0.6 0.5 0.5 0.5 0.4 0.4 0.4 0.7
20 20 20 5% 3.5 3.1 3.0 3.3 3.3 3.3 2.8 2.8 2.6 3.4 10% 7.5 7.0 6.8 6.9 6.9 7.2 7.8 7.8 7.8 7.3 1% 1.0 1.0 0.7 0.6 0.6 0.6 0.7 0.7 0.7 0.7
25 25 25 5% 4.7 3.4 3.5 3.6 3.6 3.6 3.6 3.6 3.6 3.6 10% 8.2 7.7 7.3 7.4 7.4 7.7 8.0 8.0 7.9 8.2 1% 1.3 0.7 0.8 0.4 0.4 0.4 0.9 0.9 0.9 0.3
50 50 50 5% 3.7 2.6 2.7 2.8 2.8 3.1 4.1 4.1 4.2 3.0 10% 7.2 5.7 7.6 7.9 7.9 8.0 9.0 9.0 8.9 7.7 1% 0.9 0.4 0.6 0.6 0.6 0.6 1.0 1.0 0.5 0.5
100 100 100 5% 3.6 3.6 3.4 3.7 3.8 3.8 4.6 4.6 3.9 3.9 10% 8.5 7.3 9.1 9.2 9..2 9.2 9.2 9.2 9.3 9.8
Figura D.13 Resultados de las simulaciones del escenario A

Apéndices ______________________________________________________________________
188
Tabla D.14 Resultados de las simulaciones del escenario B
Prueba n1 n2 n3 α LRrec Grec TWrec PPrec PMrec PPrrec FHOrec FHrec Mrec CMrec
1% 26.0 17.9 31.9 30.0 29.7 32.8 36.4 35.9 35.9 26.8 5 5 5 5% 50.7 38.7 58.7 54.4 53.7 56.8 59.0 59.0 59.0 51.1 10% 64.8 52.5 71.4 67.2 66.7 69.7 70.9 70.9 71.0 64.5 1% 64.7 48.7 70.5 65.6 65.5 67.1 68.5 68.5 68.4 61.2
10 10 10 5% 84.9 72.1 88.1 85.5 85.0 86.7 87.2 87.2 87.1 83.0 10% 91.1 82.2 93.2 91.1 91.1 91.5 93.2 93.2 93.1 90.0 1% 87.4 73.2 88.6 85.4 85.0 86.1 88.1 88.1 87.8 81.9
15 15 15 5% 96.8 89.4 97.1 95.6 95.6 95.7 96.2 96.2 96.2 93.9 10% 97.8 93.9 98.8 98.0 98.0 98.0 98.4 98.4 98.4 96.9 1% 96.4 87.3 96.4 94.3 94.3 94.7 97.1 97.1 97.1 92.3
20 20 20 5% 98.9 95.3 99.5 99.2 99.2 99.2 99.4 99.4 99.4 98.0 10% 99.9 97.6 99.9 99.8 99.7 99.8 99.8 99.8 99.8 99.3 1% 99.2 94.4 99.4 98.8 98.8 98.8 99.1 99.1 99.1 97.6
25 25 25 5% 99.9 98.6 100.0 99.9 99.9 99.9 100.0 100.0 100.0 99.4 10% 100.0 99.3 100.0 100.0 100.0 100.0 100.0 100.0 100.0 99.9 1% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
50 50 50 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 1% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
100 100 100 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
Figura D.14 Resultados de las simulaciones del escenario B

Apéndices ______________________________________________________________________
189
Tabla D.15 Resultados de las simulaciones del escenario C
Prueba n1 n2 n3 Α LRrec Grec TWrec PPrec PMrec PPrrec FHOrec FHrec Mrec CMrec
1% 2.3 1.3 0.6 0.8 0.9 1.0 1.0 1.0 1.0 0.8 5 5 5 5% 5.3 3.8 4.3 3.9 3.9 5.2 6.0 6.0 5.9 3.8 10% 10.3 7.6 10.7 9.5 9.6 10.6 11.4 11.4 11.3 9.5 1% 1.3 1.1 0.8 0.6 0.6 0.6 0.3 0.3 0.3 0.6
10 10 10 5% 5.9 4.4 3.2 3.0 3.1 3.1 4.4 4.4 4.5 3.2 10% 10.7 9.0 8.2 7.8 7.8 7.8 9.9 9.9 9.7 7.4 1% 1.1 0.7 0.6 0.5 0.5 0.6 0.7 0.7 0.7 0.4
15 15 15 5% 5.7 5.3 5.0 4.6 4.6 5.0 5.1 5.1 4.9 4.4 10% 10.3 10.0 10.6 10.1 10.1 10.7 10.3 10.3 10.2 10.2 1% 0.9 0.7 0.4 0.9 0.9 1.0 0.7 0.7 0.7 1.1
20 20 20 5% 4.5 5.2 4.7 4.5 4.5 4.6 4.8 4.8 4.9 4.6 10% 10.0 9.6 10.2 10.3 10.3 10.5 9.8 9.8 9.5 10.5 1% 1.9 1.7 1.5 1.5 1.5 1.5 1.5 1.5 1.5 1.3
25 25 25 5% 5.8 5.6 4.9 4.6 4.6 4.6 4.5 4.5 4.5 4.8 10% 9.6 10.8 10.8 10.4 10.3 10.7 10.1 10.1 10.0 10.2 1% 0.7 0.8 1.4 1.4 1.4 1.4 0.6 0.5 0.5 1.6
50 50 50 5% 5.4 5.7 5.4 5.5 5.4 5.6 5.2 5.2 5.2 5.8 10% 10.9 10.5 10.7 11.6 11.6 11.6 10.1 10.1 10.2 11.5 1% 1.4 1.0 1.2 1.2 1.2 1.2 1.1 1.1 1.1 1.0
100 100 100 5% 5.0 4.5 3.5 3.7 3.7 3.7 4.0 4.0 4.0 4.2 10% 9.9 8.8 8.1 8.5 8.5 8.6 9.3 9.3 9.3 8.8
Figura D.15 Resultados de las simulaciones del escenario C

Apéndices ______________________________________________________________________
190
Tabla D.16 Resultados de las simulaciones del escenario D
Prueba n1 n2 n3 Α LRrec Grec TWrec PPrec PMrec PPrrec FHOrec FHrec Mrec CMrec
1% 60.9 71.6 78.9 81.3 81.4 83.1 48.6 48.6 48.8 82.7 5 5 5 5% 78.7 89.0 92.6 94.0 94.0 94.3 70.0 70.0 70.9 94.3 10% 86.1 93.7 95.4 96.0 96.0 96.4 79.2 79.2 79.5 96.2 1% 90.6 97.2 98.6 99.1 99.1 99.2 77.4 77.4 77.8 99.2
10 10 10 5% 96.6 99.7 99.8 99.8 99.8 99.8 90.0 90.0 90.5 99.8 10% 98.2 99.9 99.9 99.9 99.9 99.9 94.3 94.3 94.4 99.9 1% 98.6 99.7 99.9 100.0 100.0 100.0 91.5 91.5 91.7 100.0
15 15 15 5% 99.7 100.0 100.0 100.0 100.0 100.0 97.9 97.9 97.9 100.0 10% 99.8 100.0 100.0 100.0 100.0 100.0 98.8 98.8 98.8 100.0 1% 99.7 99.9 100.0 100.0 100.0 100.0 97.4 97.4 97.4 100.0
20 20 20 5% 100.0 100.0 100.0 100.0 100.0 100.0 99.5 99.5 99.5 100.0 10% 100.0 100.0 100.0 100.0 100.0 100.0 99.8 99.8 99.9 100.0 1% 100.0 100.0 100.0 100.0 100.0 100.0 99.5 99.5 99.5 100.0
25 25 25 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 1% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
50 50 50 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 1% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
100 100 100 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
Figura D.16 Resultados de las simulaciones del escenario D
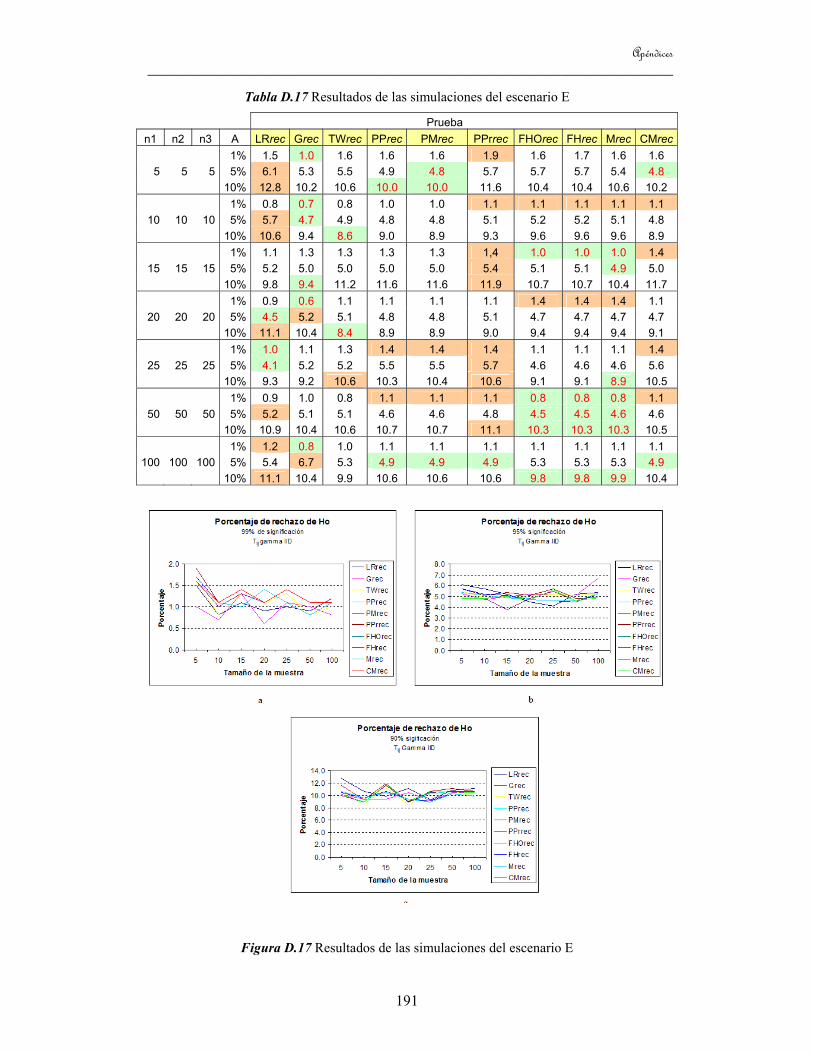
Apéndices ______________________________________________________________________
191
Tabla D.17 Resultados de las simulaciones del escenario E
Prueba n1 n2 n3 Α LRrec Grec TWrec PPrec PMrec PPrrec FHOrec FHrec Mrec CMrec
1% 1.5 1.0 1.6 1.6 1.6 1.9 1.6 1.7 1.6 1.6 5 5 5 5% 6.1 5.3 5.5 4.9 4.8 5.7 5.7 5.7 5.4 4.8 10% 12.8 10.2 10.6 10.0 10.0 11.6 10.4 10.4 10.6 10.2 1% 0.8 0.7 0.8 1.0 1.0 1.1 1.1 1.1 1.1 1.1
10 10 10 5% 5.7 4.7 4.9 4.8 4.8 5.1 5.2 5.2 5.1 4.8 10% 10.6 9.4 8.6 9.0 8.9 9.3 9.6 9.6 9.6 8.9 1% 1.1 1.3 1.3 1.3 1.3 1,4 1.0 1.0 1.0 1.4
15 15 15 5% 5.2 5.0 5.0 5.0 5.0 5.4 5.1 5.1 4.9 5.0 10% 9.8 9.4 11.2 11.6 11.6 11.9 10.7 10.7 10.4 11.7 1% 0.9 0.6 1.1 1.1 1.1 1.1 1.4 1.4 1.4 1.1
20 20 20 5% 4.5 5.2 5.1 4.8 4.8 5.1 4.7 4.7 4.7 4.7 10% 11.1 10.4 8.4 8.9 8.9 9.0 9.4 9.4 9.4 9.1 1% 1.0 1.1 1.3 1.4 1.4 1.4 1.1 1.1 1.1 1.4
25 25 25 5% 4.1 5.2 5.2 5.5 5.5 5.7 4.6 4.6 4.6 5.6 10% 9.3 9.2 10.6 10.3 10.4 10.6 9.1 9.1 8.9 10.5 1% 0.9 1.0 0.8 1.1 1.1 1.1 0.8 0.8 0.8 1.1
50 50 50 5% 5.2 5.1 5.1 4.6 4.6 4.8 4.5 4.5 4.6 4.6 10% 10.9 10.4 10.6 10.7 10.7 11.1 10.3 10.3 10.3 10.5 1% 1.2 0.8 1.0 1.1 1.1 1.1 1.1 1.1 1.1 1.1
100 100 100 5% 5.4 6.7 5.3 4.9 4.9 4.9 5.3 5.3 5.3 4.9 10% 11.1 10.4 9.9 10.6 10.6 10.6 9.8 9.8 9.9 10.4
Figura D.17 Resultados de las simulaciones del escenario E

Apéndices ______________________________________________________________________
192
Tabla D.18 Resultados de las simulaciones del escenario F
Prueba n1 n2 n3 Α LRrec Grec TWrec PPrec PMrec PPrrec FHOrec FHrec Mrec CMrec
1% 83.4 89.7 94.5 94.9 94.9 96.0 75.9 75.9 76.0 95.4 5 5 5 5% 94.3 97.1 98.7 98.9 98.9 99.1 88.9 88.9 89.3 98.9 10% 96.7 98.9 99.3 99.2 99.2 99.3 93.9 93.9 93.9 99.2 1% 99.4 100.0 100.0 100.0 100.0 100.0 97.2 97.2 97.4 100.0
10 10 10 5% 99.9 100.0 100.0 100.0 100.0 100.0 99.4 99.4 99.4 100.0 10% 99.9 100.0 100.0 100.0 100.0 100.0 99.6 99.6 99.6 100.0 1% 100.0 100.0 100.0 100.0 100.0 100.0 99.7 99.7 99.7 100.0
15 15 15 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 1% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
20 20 20 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 1% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
25 25 25 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 1% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
50 50 50 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 1% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
100 100 100 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
Figura D.18 Resultados de las simulaciones del escenario F

Apéndices ______________________________________________________________________
193
Tabla D.19 Resultados de las simulaciones del escenario G
Prueba n1 n2 n3 Α LRrec Grec TWrec PPrec PMrec PPrrec FHOrec FHrec Mrec CMrec
1% 2.3 1.8 1.2 1.1 1.1 1.5 1.7 1.7 1.8 1.1 5 5 5 5% 6.9 6.2 6.5 5.5 5.5 6.4 6.0 6.0 5.6 5.4 10% 12.3 10.4 9.8 9.8 9.8 11.0 11.2 11.2 10.9 9.7 1% 1.5 1.0 0.7 0.6 0.5 0.7 0.7 0.7 0.7 0.6
10 10 10 5% 5.6 4.8 5.0 5.3 5.4 5.9 4.8 4.8 4.8 5.3 10% 11.1 9.7 11.2 11.3 11.2 12.0 10.2 10.2 10.3 11.4 1% 0.9 0.8 1.0 1.1 1.2 1.3 0.6 0.6 0.6 1.1
15 15 15 5% 5.1 4.9 4.4 4.7 4.7 5.2 4.8 4.8 5.0 4.8 10% 10.4 10.1 10.3 10.1 10.0 10.4 9.3 9.3 9.5 10.0 1% 1.1 0.9 0.8 0.8 0.8 0.9 1.0 1.0 1.0 0.8
20 20 20 5% 4.2 4.8 5.1 4.7 4.8 4.9 4.5 4.5 4.6 5.0 10% 10.6 9.2 10.0 10.0 10.1 10.2 9.7 9.7 9.7 9.8 1% 1.0 1.5 1.6 1.3 1.4 1.5 1.4 1.4 1.4 1.5
25 25 25 5% 7.4 6.7 5.2 5.2 5.2 5.3 5.1 5.1 4.9 5.1 10% 13.3 12.4 10.8 10.7 10.8 11.1 10.1 10.1 10.3 10.7 1% 1.0 1.0 1.2 1.2 1.2 1.2 1.1 1.1 1.1 1.2
50 50 50 5% 5.5 4.4 4.9 5.1 5.1 5.1 5.0 5.0 5.0 5.0 10% 9.4 8.0 10.2 10.4 10.4 10.6 9.1 9.1 9.1 10.8 1% 1.5 0.7 1.8 1.7 1.7 1.7 1.5 1.5 1.5 1.4
100 100 100 5% 4.7 4.9 5.7 5.6 5.6 5.6 6.0 6.0 6.1 5.3 10% 9.7 9.5 10.8 10.5 10.5 10.5 11.5 11.5 11.5 9.8
Figura D.19 Resultados de las simulaciones del escenario G

Apéndices ______________________________________________________________________
194
Tabla D.20 Resultados de las simulaciones del escenario H
Prueba n1 n2 n3 Α LRrec Grec TWrec PPrec PMrec PPrrec FHOrec FHrec Mrec CMrec
1% 27.5 24.3 35.1 34.0 33.7 36.8 19.1 19.1 19.0 34.5 5 5 5 5% 53.3 45.9 60.1 56.9 56.3 59.9 37.7 37.7 37.0 75.2 10% 67.1 58.9 71.0 68.1 68.1 69.8 502.0 50.2 49.5 68.2 1% 66.4 55.2 68.5 64.3 64.2 66.5 40.7 40.1 40.1 64.7
10 10 10 5% 85.0 75.2 85.7 82.1 82.0 83.1 64.3 63.4 63.4 82.2 10% 92.0 83.1 92.9 89.8 89.4 90.3 75.8 75.8 75.3 90.0 1% 88.6 75.4 88.4 83.9 83.7 84.9 61.2 60.9 60.9 84.1
15 15 15 5% 97.5 90.5 96.7 95.1 95.0 95.4 82.5 81.1 81.8 95.2 10% 99.0 94.5 99.0 97.4 97.2 97.6 90.1 89.9 89.9 97.3 1% 96.4 89.0 96.0 96.0 92.5 92.8 75.7 75.7 75.4 93.2
20 20 20 5% 99.4 95.9 98.7 98.7 97.6 97.7 90.5 90.5 90.3 97.7 10% 99.6 97.8 99.6 99.0 99.0 99.1 94.3 94.3 94.2 99.1 1% 99.1 94.8 98.8 96.9 96.9 97.3 84.2 84.2 93.8 97.1
25 25 25 5% 100.0 98.9 99.8 99.4 99.4 99.4 95.8 95.8 95.6 99.4 10% 100.0 99.3 100.0 99.7 99.7 99.7 98.3 98.3 98.3 99.7 1% 100.0 100.0 100.0 100.0 100.0 100.0 99.8 99.8 99.8 100.0
50 50 50 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 1% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
100 100 100 5% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
Figura D.20 Resultados de las simulaciones del escenario H

Apéndices ______________________________________________________________________
195
Tabla D.21 Resultados de las simulaciones del escenario I
Prueba n1 n2 n3 Α LRrec Grec TWrec PPrec PMrec PPrrec FHOrec FHrec Mrec CMrec
1% 1.2 0.6 0.9 1.0 1.0 1.0 1.4 1.4 1.3 1.0 5 5 5 5% 5.1 3.8 4.3 3.4 3.3 4.3 6.1 6.1 6.3 3.7 10% 10.5 8.4 8.6 8.1 8.2 9.4 10.4 10.4 10.3 8.2 1% 1.2 0.8 0.7 0.6 0.6 0.7 1.2 1.2 1.2 0.7
10 10 10 5% 4.7 3.6 3.5 3.4 3.3 3.8 4.4 4.4 4.3 3.1 10% 9.5 8.1 8.3 8.0 7.8 8.3 9.0 9.0 8.7 8.5 1% 0.9 0.5 1.0 1.4 1.4 1.4 1.0 1.0 1.0 1.4
15 15 15 5% 4.3 3.6 4.8 4.8 4.8 4.9 4.9 4.9 4.9 4.7 10% 10.3 8.2 8.9 9.9 10.0 10.1 10.1 10.1 10.1 9.4 1% 0.6 0.5 0.6 0.7 0.7 0.7 0.7 0.7 0.7 0.8
20 20 20 5% 3.5 4.0 3.0 3.5 3.5 3.6 3.9 3.9 3.8 3.3 10% 7.7 7.6 7.6 7.2 7.2 7.6 9.6 9.6 9.5 7.5 1% 0.7 0.7 0.8 0.8 0.8 0.8 0.8 0.8 0.8 0.9
25 25 25 5% 4.1 4.9 4.3 4.5 4.5 4.5 3.8 3.8 3.8 4.9 10% 9.3 9.1 8.7 9.0 9.0 9.0 9.1 9.1 9.3 9.1 1% 0.7 0.8 1.0 0.9 0.9 1.0 0.5 0.5 0.5 1.0
50 50 50 5% 4.5 3.5 3.6 4.2 4.2 4.2 3.6 3.6 3.6 3.9 10% 8.2 8.0 8.3 7.8 7.8 7.9 9.2 9.2 9.2 8.3 1% 0.5 0.5 0.8 0.7 0.7 0.7 0.7 0.7 0.7 0.7
100 100 100 5% 3.8 3.2 4.2 4.0 4.0 4.0 3.7 3.7 3.7 4.5 10% 7.9 7.0 7.8 8.8 8.8 9.0 7.8 7.8 7.8 8.6
Figura D.21 Resultados de las simulaciones del escenario I

Apéndices ______________________________________________________________________
196
Tabla D.22 Resultados de las simulaciones del escenario J
Prueba n1 n2 n3 Α LRrec Grec TWrec PPrec PMrec PPrrec FHOrec FHrec Mrec CMrec
1% 3.0 2.1 3.5 3.3 3.3 3.7 4.2 4.2 4.2 3.0 5 5 5 5% 9.6 7.6 10.6 10.3 10.4 11.6 12.6 12.6 12.1 10.4 10% 16.4 14.8 18.6 17.8 17.7 18.9 20.8 20.8 20.9 17.5 1% 6.1 4.0 7.6 6.7 6.5 7.2 8.1 8.1 7.9 6.3
10 10 10 5% 16.9 13.7 21.3 19.7 19.7 20.2 20.5 20.5 20.5 19.2 10% 26.3 23.6 31.5 29.5 29.3 30.5 28.7 28.7 28.8 28.3 1% 8.5 5.9 10.6 9.2 9.1 9.5 12.4 12.4 12.2 8.9
15 15 15 5% 24.5 17.4 27.8 25.9 25.8 26.9 29.7 29.7 29.4 23.9 10% 35.0 27.8 41.5 38.5 38.4 39.3 41.7 41.7 41.9 36.4 1% 11.8 7.9 17.2 15.0 15.0 15.8 17.6 17.6 17.6 14.4
20 20 20 5% 33.7 23.6 38.4 34.8 34.5 35.3 39.6 39.6 39.7 32.6 10% 46.7 35.5 52.3 47.7 47.6 48.4 51.6 51.6 51.5 44.6 1% 17.3 10.9 21.6 19.2 19.2 19.4 21.0 21.0 20.9 17.6
25 25 25 5% 37.3 28.2 43.5 41.3 41.1 42.0 43.6 43.6 43.6 37.4 10% 50.3 39.2 56.8 53.4 53.4 53.6 56.5 56.5 56.4 50.6 1% 45.8 30.4 49.1 44.1 44.2 44.4 50.2 50.2 49.9 39.5
50 50 50 5% 70.6 54.9 75.1 70.1 70.0 70.5 73.5 73.5 73.5 65.2 10% 80.9 67.5 82.9 80.1 80.1 80.2 83.9 83.9 84.0 76.8 1% 83.4 67.4 86.1 82.9 82.9 83.2 84.1 84.1 84.1 77.6
100 100 100 5% 94.4 85.2 96.1 93.3 93.3 93.4 95.0 95.0 95.0 90.1 10% 97.5 89.9 98.2 97.3 97.2 97.3 97.5 97.5 97.4 95.5
Figura D.22 Resultados de las simulaciones del escenario J

Apéndices ______________________________________________________________________
197
Tabla D.23 Resultados de las simulaciones del escenario K Prueba n1 n2 n3 α LRrec Grec TWrec PPrec PMrec PPrrec FHOrec FHrec Mrec CMrec
1% 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 5 5 5 5% 0.0 0.0 4.5 8.3 8.4 12.8 0.0 0.0 0.0 12.9 10% 0.0 3.1 51.3 53.7 53.5 65.8 0.0 0.0 0.0 64.4 1% 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.7
10 10 10 5% 0.0 3.5 37.8 63.9 64.4 70.6 0.0 0.0 0.0 77.5 10% 0.3 44.2 95.9 98.6 98.6 98.9 0.0 0.0 0.0 98.9 1% 0.0 0.2 0.5 12.9 13.3 16.2 0.0 0.0 0.0 29.8
15 15 15 5% 0.0 55.6 92.1 98.7 98.8 99.0 0.0 0.0 0.0 99.7 10% 2.7 95.4 100.0 100.0 100.0 100.0 0.0 0.0 0.0 100.0 1% 0.0 8.9 15.0 66.6 67.1 69.9 0.0 0.0 0.0 82.8
20 20 20 5% 0.0 95.9 99.9 100.0 100.0 100.0 0.0 0.0 0.0 100.0 10% 23.9 99.9 100.0 100.0 100.0 100.0 0.0 0.0 0.0 100.0 1% 0.0 59.8 70.0 97.0 97.0 97.7 0.0 0.0 0.0 98.6
25 25 25 5% 2.0 100.0 100.0 100.0 100.0 100.0 0.0 0.0 0.0 100.0 10% 73.6 100.0 100.0 100.0 100.0 100.0 0.0 0.0 0.0 100.0 1% 3.4 100.0 100.0 100.0 100.0 100.0 0.0 0.0 0.0 100.0
50 50 50 5% 100.0 100.0 100.0 100.0 100.0 100.0 0.0 0.0 0.0 100.0 10% 100.0 100.0 100.0 100.0 100.0 100.0 0.0 0.0 0.0 100.0 1% 100.0 100.0 100.0 100.0 100.0 100.0 0.0 0.0 0.0 100.0
100 100 100 5% 100.0 100.0 100.0 100.0 100.0 100.0 0.0 0.0 0.0 100.0 10% 100.0 100.0 100.0 100.0 100.0 100.0 0.0 0.0 0.0 100.0
Figura D.23 Resultados de las simulaciones del escenario K

Apéndices ______________________________________________________________________
198
Tabla D.24 Resultados de las simulaciones del escenario L
Prueba n1 n2 n3 Α LRrec Grec TWrec PPrec PMrec PPrrec FHOrec FHrec Mrec CMrec
1% 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 5 5 5 5% 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 10% 0.5 0.0 1.8 0.0 0.0 0.0 0.0 2.0 1.4 0.0 1% 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.1 0.1 0.0
10 10 10 5% 2.0 0.0 0.8 0.0 0.0 0.0 0.0 29.7 26.7 0.0 10% 45.1 0.0 61.4 4.4 3.7 10.0 4.4 86.9 84.5 0.3 1% 0.0 0.0 0.0 1.0 0.0 0.0 0.0 7.9 7.9 0.0
15 15 15 5% 70.6 0.0 56.1 1.1 1.0 1.8 1.1 96.6 96.4 0.0 10% 98.6 0.0 99.9 76.4 73.2 85.0 76.4 99.9 99.9 22.9 1% 19.0 0.0 0.0 0.0 0.0 0.0 0.0 70.3 67.2 0.0
20 20 20 5% 99.8 0.0 99.5 42.7 42.7 51.4 42.7 100.0 100.0 1.5 10% 100.0 0.0 100.0 99.9 99.8 100.0 99.9 100.0 100.0 94.1 1% 86.6 0.0 19.7 0.0 0.0 0.0 0.0 99.0 98.8 0.0
25 25 25 5% 100.0 0.0 100.0 98.4 97.4 98.9 98.4 100.0 100.0 45.4 10% 100.0 1.2 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 1% 100.0 0.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 91.6
50 50 50 5% 100.0 99.5 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 1% 100.0 100 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100
100 100 100 5% 100.0 100 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 10% 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
Figura D.24 Resultados de las simulaciones del escenario L

Apéndices ______________________________________________________________________
199
APÉNDICE E
Programa para generar dos muestras aleatorias, estimar potencias y error tipo I require(tcltk) || stop("tcltk support is absent") require(stats) #_____________________________________________________________________ selecciontl.y1<-function() seleccion6<<- variable6[as.numeric(tkcurselection(tl.y1))+1] tkconfigure(frase06,text=seleccion6,background = "lightgreen") #_____________________________________________________________________ selecciontl.yB<-function() seleccionB<<- variableB[as.numeric(tkcurselection(tl.yB))+1] tkconfigure(fraseB,text=seleccionB,background = "lightgreen") #_____________________________________________________________________ selecciontl.pruebas<-function() seleccionpruebas<<- variablepruebas[as.numeric(tkcurselection(tl.pruebas))+1] tkconfigure(frasepruebas,text=seleccionpruebas,background = "lightgreen") #_____________________________________________________________________ tomavalores<-function() kDis <<- as.character(tclObj(kernelDis)) kCen <<- as.character(tclObj(kernelCen)) kcompara<<-as.character(tclObj(kernelCompara)) To<<-seleccionpruebas print(kDis) print(kcompara) print(kCen) print(seleccion6) print(seleccionB) print(seleccionpruebas) print("") #_____________________________________________________________________ KiA<<-1 KiB<<-1 seleccion6<<-1 seleccionB<<-1 seleccionpruebas<-1 kDis<-"Iguales" #_____________________________________________________________________ size1 <- 1 kernelDis<- tclVar("Chicuadrado") kernelCen<- tclVar("Chicuadrado") kernelCompara<- tclVar("Iguales") sz1 <- as.numeric((size1)) #_____________________________________________________________________ sizeB <- 1 szB <- as.numeric((sizeB)) sizepruebas <- 1 #_____________________________________________________________________ base <- tktoplevel(width=700,height=25) tkwm.title(base, "POTENCIA DE LAS PRUEBAS DE COMPARACIÓN") spec.frm <- tkframe(base,borderwidth=20) left.frm <- tkframe(spec.frm) right.frm <- tkframe(spec.frm)

Apéndices ______________________________________________________________________
200
#_____________________________________________________________________ frame.y1 <- tkwidget(spec.frm, "labelframe", text = "Total de individuos muestra A") tl.y1<- tklistbox(frame.y1, height = 7, yscrollcommand=function(...)tkset(scr.y11,...), width = 10, selectmode = "single", background = "white") scr.y11 <- tkscrollbar(frame.y1, repeatinterval = 1, command = function(...) tkyview(tl.y1, ...)) variable6 <- c(1:500) for (p in (1:500)) tkinsert(tl.y1,"end",variable6[p]) tkselection.set(tl.y1, 0) tkgrid(tl.y1, scr.y11, sticky="news") #_____________________________________________________________________ tkgrid(frase06<-tklabel(frame.y1, text= size1,background = "red")) tkgrid(botomtl.y1<- tkbutton(frame.y1,text="Selecciona",command=selecciontl.y1)) #_____________________________________________________________________ frame.yB <- tkwidget(spec.frm, "labelframe", text = "Total de individuos muestra B") tl.yB<- tklistbox(frame.yB, height = 7, yscrollcommand=function(...)tkset(scr.y1B,...), width = 10, selectmode = "single", background = "white") scr.y1B <- tkscrollbar(frame.yB, repeatinterval = 1, command = function(...) tkyview(tl.yB, ...)) variableB <- c(1:500) for (p in (1:500)) tkinsert(tl.yB,"end",variableB[p]) tkselection.set(tl.yB, 0) tkgrid(tl.yB, scr.y1B, sticky="news") #_____________________________________________________________________ tkgrid(fraseB<-tklabel(frame.yB, text= sizeB,background = "red")) tkgrid(botomtl.yB<- tkbutton(frame.yB,text="Selecciona", command=selecciontl.yB)) #_____________________________________________________________________ frame.pruebas <- tkwidget(right.frm, "labelframe", text = "Total de pruebas") tl.pruebas<- tklistbox(frame.pruebas, height = 1, yscrollcommand=function(...)tkset(scr.pruebas,...), width = 10, selectmode = "single", background = "white") scr.pruebas <- tkscrollbar(frame.pruebas, repeatinterval = 1, command = function(...) tkyview(tl.pruebas, ...)) variablepruebas <- c(1:1000) for (p in (1:1000)) tkinsert(tl.pruebas,"end",variablepruebas[p]) tkselection.set(tl.pruebas, 0) tkgrid(tl.pruebas, scr.pruebas, sticky="news") #_____________________________________________________________________ tkgrid(frasepruebas<-tklabel(frame.pruebas, text= sizepruebas, background = "red")) tkgrid(botomtl.pruebas<- tkbutton(frame.pruebas,text="Selecciona", command=selecciontl.pruebas)) #_____________________________________________________________________ frameDis <- tkframe(left.frm, relief="groove", borderwidth=2) tkpack(tklabel(frameDis, text="Distribución de los Tij")) for ( i in c("Chicuadrado", "Uniforme", "Gamma",

Apéndices ______________________________________________________________________
201
"Exponencial", "Weibull","Decreciente","Creciente") ) tmpDis <- tkradiobutton(frameDis, command=tomavalores, text=i, value=i, variable=kernelDis) tkpack(tmpDis, anchor="w") #_____________________________________________________________________ frameCen <- tkframe(right.frm, relief="groove", borderwidth=2) tkpack(tklabel(frameCen, text="Distribución Censuras")) for ( i in c("Chicuadrado", "Uniforme", "Gamma", "Exponencial", "Weibull","Desconocida") ) tmpCen <- tkradiobutton(frameCen, command=tomavalores, text=i, value=i, variable=kernelCen) tkpack(tmpCen, anchor="w") #_____________________________________________________________________ frameCompara <- tkframe(left.frm, relief="groove", borderwidth=2) tkpack(tklabel(frameCompara, text="Parámetros de Tij")) for ( i in c("Iguales", "Diferentes") ) tmpCompara <- tkradiobutton(frameCompara, command=tomavalores, text=i, value=i, variable=kernelCompara) tkpack(tmpCompara, anchor="w") #_____________________________________________________________________ tkpack(left.frm, right.frm,frame.y1,frame.yB,side="left", anchor="n") tkpack(left.frm,frameDis,fill="x",side="left") tkpack(right.frm,frame.pruebas,frameCen, fill="x",side="right") tkpack(frameCompara) #_____________________________________________________________________ Cancelar<-tkbutton(base,text="Cancelar",command=function()tkdestroy(base)) q.but <- tkbutton(base,text="OK",command=function()#tkdestroy(base); source("geParaSimularselecmod.R")) tkpack(spec.frm) tkpack(q.but) tkpack(Cancelar)
Programa auxiliar que permite generar dos muestras aleatorias require(survrec) tomavalores() contadorW1p<-0;contadorW5p<-0;contadorW10p<-0 contadorG1p<-0;contadorG5p<-0;contadorG10p<-0 contadorTW1p<-0;contadorTW5p<-0;contadorTW10p<-0 contadorPP1p<-0;contadorPP5p<-0;contadorPP10p<-0 contadorPM1p<-0;contadorPM5p<-0;contadorPM10p<-0 contadorPPr1p<-0;contadorPPr5p<-0;contadorPPr10p<-0 contadorHF10p<-0;contadorHF5p<-0;contadorHF1p<-0 contadorFH10p<-0;contadorFH5p<-0;contadorFH1p<-0 contadorCM10p<-0;contadorCM5p<-0;contadorCM1p<-0 contadorCarlos10p<-0;contadorCarlos5p<-0;contadorCarlos1p<-0 conta<<-0 #To<-1000 To<-seleccionpruebas KiA<<-matrix(3,seleccion6,1) KiB<<-matrix(3,seleccionB,1) TijA<<-matrix(NA,seleccion6,max(KiA)) TijB<<-matrix(NA,seleccionB,max(KiB)) CiA<<-matrix(NA,seleccion6,1) CiB<<-matrix(NA,seleccionB,1)

Apéndices ______________________________________________________________________
202
selc<-"normal" distribution<-function(type) if (kcompara=="Iguales") switch (type, "Chicuadrado" = for(i in 1:seleccion6)for (j in 1:3) TijA[i,j]<<-round(rchisq(1,10,ncp=0),3) for (i in 1:seleccion6) CiA[i,1]<<-round(rchisq(1,10/2,ncp=0),3) for(i in 1:seleccionB)for (j in 1:3) TijB[i,j]<<-round(rchisq(1,10,ncp=0),3) for (i in 1:seleccionB) CiB[i,1]<<-round(rchisq(1,10/2,ncp=0),3) , "Uniforme" = for(i in 1:seleccion6)for (j in 1:3) TijA[i,j]<<-round(runif(1,25,35),3) for (i in 1:seleccion6) CiA[i,1]<<-round(runif(1,0,15),3) for(i in 1:seleccionB)for (j in 1:3) TijB[i,j]<<-round(runif(1,25,35),3) for (i in 1:seleccionB) CiB[i,1]<<-round(runif(1,0,15),3) , "Gamma" = for(i in 1:seleccion6)for (j in 1:3) TijA[i,j]<<-round(rgamma(1,50,2,2),3) for (i in 1:seleccion6) CiA[i,1]<<-round(rgamma(1,25,2,2),3) for(i in 1:seleccionB)for (j in 1:3) TijB[i,j]<<-round(rgamma(1,50,2,2),3) for (i in 1:seleccionB) CiB[i,1]<<-round(rgamma(1,25,2,2),3) , "Exponencial" = for(i in 1:seleccion6)for (j in 1:3) TijA[i,j]<<-round(rexp(1,1/50),3) for (i in 1:seleccion6) CiA[i,1]<<-round(rexp(1,1/25),3) for(i in 1:seleccionB)for (j in 1:3) TijB[i,j]<<-round(rexp(1,1/50),3) for (i in 1:seleccionB) CiB[i,1]<<-round(rexp(1,1/25),3) , "Decreciente" = for(i in 1:seleccion6)for (j in 1:3) limi<-runif(1,100,120); TijA[i,j]<<-round(limi/(2*i),3) for (i in 1:seleccion6) CiA[i,1]<<-round(runif(1,50,60)/(2*i),3) for(i in 1:seleccionB)for (j in 1:3) limi<-runif(1,100,120); TijB[i,j]<<-round(limi/(2*i),3) for (i in 1:seleccionB) CiB[i,1]<<-round(runif(1,50,60)/(2*i),3) , "Creciente" = for(i in 1:seleccion6)for (j in 1:3) limi<-runif(1,100,120); TijA[i,j]<<-round(limi*i,3) for (i in 1:seleccion6) CiA[i,1]<<-round(runif(1,50,60)*i,3) for(i in 1:seleccionB)for (j in 1:3) limi<-runif(1,100,120); TijB[i,j]<<-round(limi*i,3) for (i in 1:seleccionB) CiB[i,1]<<-round(runif(1,50,60)*i,3) , "Weibull" = for(i in 1:seleccion6)for (j in 1:3) TijA[i,j]<<-round(rweibull(1,0.9,30),3) for (i in 1:seleccion6) CiA[i,1]<<-round(rweibull(1,0.9,15),3) for(i in 1:seleccionB)for (j in 1:3) TijB[i,j]<<-round(rweibull(1,0.9,30),3)

Apéndices ______________________________________________________________________
203
for (i in 1:seleccionB) CiB[i,1]<<-round(rweibull(1,0.9,15),3) ) if (kcompara=="Diferentes") switch (type, "Chicuadrado" = for(i in 1:seleccion6)for (j in 1:3) TijA[i,j]<<-round(rchisq(1,10,ncp=0),3) for (i in 1:seleccion6) CiA[i,1]<<-round(rchisq(1,10/2,ncp=0),3) for(i in 1:seleccionB)for (j in 1:3) TijB[i,j]<<-round(rchisq(1,15,ncp=0),3) for (i in 1:seleccionB) CiB[i,1]<<-round(rchisq(1,15/2,ncp=0),3) , "Uniforme" = for(i in 1:seleccion6)for (j in 1:3) TijA[i,j]<<-round(runif(1,25,35),3) for (i in 1:seleccion6) CiA[i,1]<<-round(runif(1,0,20),3) for(i in 1:seleccionB)for (j in 1:3) TijB[i,j]<<-round(runif(1,27,37),3) for (i in 1:seleccionB) CiB[i,1]<<-round(runif(1,0,25),3) , "Gamma" = for(i in 1:seleccion6)for (j in 1:3) TijA[i,j]<<-round(rgamma(1,50,2,2),3) for (i in 1:seleccion6) CiA[i,1]<<-round(rgamma(1,25,2,2),3) for(i in 1:seleccionB)for (j in 1:3) TijB[i,j]<<-round(rgamma(1,60,2,2),3) for (i in 1:seleccionB) CiB[i,1]<<-round(rgamma(1,30,2,2),3) , "Exponencial" = for(i in 1:seleccion6)for (j in 1:3) TijA[i,j]<<-round(rexp(1,1/50),3) for (i in 1:seleccion6) CiA[i,1]<<-round(rexp(1,1/25),3) for(i in 1:seleccionB)for (j in 1:3) TijB[i,j]<<-round(rexp(1,1/100),3) for (i in 1:seleccionB) CiB[i,1]<<-round(rexp(1,1/50),3) , "Decreciente" = for(i in 1:seleccion6)for (j in 1:3) TijA[i,j]<<-round(runif(1,80,120)/(2*i),3) for (i in 1:seleccion6) CiA[i,1]<<-round(runif(1,40,60)/(2*i),3) for(i in 1:seleccionB)for (j in 1:3) TijB[i,j]<<-round(runif(1,110,150)/(2*i),3) for (i in 1:seleccionB) CiB[i,1]<<-round(runif(1,55,75)/(2*i),3) , "Creciente" = for(i in 1:seleccion6)for (j in 1:3) limi<-runif(1,100,120); TijA[i,j]<<-round(limi*i,3) for (i in 1:seleccion6) CiA[i,1]<<-round(runif(1,50,60)*i,3) for(i in 1:seleccionB)for (j in 1:3) limi<-runif(1,120,140); TijB[i,j]<<-round(limi*i,3) for (i in 1:seleccionB) CiB[i,1]<<-round(runif(1,60,70)*i,3) , "Weibull" = for(i in 1:seleccion6)for (j in 1:3) TijA[i,j]<<-round(rweibull(1,0.9,30),3) for (i in 1:seleccion6) CiA[i,1]<<-round(rweibull(1,0.9,15),3) for(i in 1:seleccionB)for (j in 1:3) TijB[i,j]<<-round(rweibull(1,0.9,40),3) for (i in 1:seleccionB) CiB[i,1]<<-round(rweibull(1,0.9,20),3)

Apéndices ______________________________________________________________________
204
) #===================================================================== while (conta<=To-1) conta<-conta+1 distribution(kDis) IndividuoA<-matrix(1:seleccion6) IndividuoB<-matrix(1:seleccionB) tiemposiniciales<<-matrix(0,seleccion6+seleccionB,1) I<-matrix(1:(totalindividuos<-max(IndividuoA)+max(IndividuoB))) Ki<-matrix(c(KiA,KiB)) Tij<-cbind(Ti1=c(TijA[,1],TijB[,1]),Ti2=c(TijA[,2],TijB[,2]), Ti3=c(TijA[,3],TijB[,3])) Ci<-c(CiA,CiB) tabla<-data.frame(I,Ki,Tij,Ci) J<-matrix(1:(totalindividuos*4)) Tijs<-matrix(NA,max(I),3+1) Tijs[,1]<-Tij[,1] Tijs[,2]<-Tij[,2] Tijs[,3]<-Tij[,3] Tijs[,4]<-Ci Tiempo<-cbind(c(t(Tijs))) Censura<-matrix(NA,max(I),3+1) Censura[,1]<-1 Censura[,2]<-1 Censura[,3]<-1 Censura[,4]<-0 Evento<-cbind(c(t(Censura))) Unidades<-matrix(c(I,I,I,I),max(I),4) Unidad<-cbind(c(t(Unidades))) Muestra01<-matrix(1,4*max(IndividuoA),1) Muestra02<-matrix(2,4*max(IndividuoB),1) Muestra<-cbind(muestra=c(Muestra01,Muestra02)) Sij<-matrix(NA,max(I),3+1) Sij[,1]<-0 Sij[,1]<-Tij[,1] Sij[,2]<-Tij[,1]+Tij[,2] Sij[,3]<-Tij[,1]+Tij[,2]+Tij[,3] Sij[,4]<-Sij[,3]+Ci Tiempocalendario<-cbind(c(t(Sij))) Tiempoinicial<-Tiempocalendario-Tiempo XL<-data.frame(J=J,id=Unidad,Time1=Tiempoinicial,time=Tiempo, Sij=Tiempocalendario,event=Evento,muestra=Muestra) #===================================================================== fit1<-survfitr(Survr(id,time,event)~as.factor(muestra),data=XL,type="pe") fit2<-survfitr(Survr(id,time,event)~1,data=XL,type="pe") MedianaGPLECombinada<-q.search(fit2,q=0.50) MedianaGPLGrupo01<-q.search(fit1$"1",q=0.50) MedianaGPLGrupo02<-q.search(fit1$"2",q=0.50) failed<-matrix(fit2$failed) censored<-matrix(fit2$censored)

Apéndices ______________________________________________________________________
205
time<-matrix(fit2$time) n.event<-matrix(fit2$n.event) AtRisk<-matrix(fit2$AtRisk) m<-fit2$m k<-matrix(m) #================================================================= n<-ncol(matrix(fit2$time)) m<-nrow(matrix(fit2$time)) n1<-ncol(matrix(fit1$"1"$time)) m1<-nrow(matrix(fit1$"1"$time)) I<-matrix(1,m,1) X<-matrix(fit2$time) Y<-matrix(fit1$"1"$time) Z<-matrix(fit1$"1"$censored) Tiempo1<-matrix(0,m,1) n.eventG1<-matrix(0,m,1) NEG1<-matrix(fit1$"1"$n.event) Ariesgo<-matrix(0,m,1) cuenta<-matrix(0,m,1) Ncensura<-matrix(0,m,1) AriesgoG1<-matrix(0,m,1) mm<-nrow(X) tiempocensura<-matrix(fit1$"1"$censored) for (z in 1:m) for (zz in 1:m1)if (X[z,1]== Y[zz,1])Tiempo1[z,1]<-Y[zz,1]; n.eventG1[z,1]<-NEG1[zz,1];zz<-m1 else Tiempo1[z,1]<-X[z,1] data.frame(Tiempo=Tiempo1,n.eventosG1=n.eventG1) AriesgoG1tiempo1<-t(fit1$"1"$AtRisk)%*% matrix(1,nrow(fit1$"1"$AtRisk),1) N<-fit1$"1"$n+t(fit1$"1"$m)%*% matrix(1,nrow(fit1$"1"$m),1) data.frame(Tiempo=Y,AriesgoG1tiempo1=AriesgoG1tiempo1) for (z in 1:m) cuenta[z,1]<-0 for (zz in 1:nrow(tiempocensura) )if (tiempocensura[zz,1]<=Tiempo1[z,1]) cuenta[z,1]<-cuenta[z,1]+1 data.frame(Tiempo=Tiempo1,cuenta=cuenta) for (z in 1:m-1) Ncensura[z,1]<--cuenta[z,1]+cuenta[z+1,1] data.frame(Tiempo=Tiempo1,Ncensuras=Ncensura) Ariesgot0<-N Ariesgo[1,1]<-N-cuenta[1,1] AriesgoG1tiempoG1<-t(fit1$"1"$AtRisk)%*% matrix(1,nrow(fit1$"1"$AtRisk),1) for (z in 1:m) for (zz in 1:m1) if (X[z,1]== Y[zz,1]) Ariesgo[z,1]<-AriesgoG1tiempoG1[zz,1] data.frame(Tiempo=Tiempo1,Ariesgo=Ariesgo) for (z in 2:m) if (Ariesgo[z,1]==0) Ariesgo[z,1]<-Ariesgo[z-1,1]-Ncensura[z-1,1]-n.eventG1[z-1,1] data.frame(Tiempo=Tiempo1,Ariesgo=Ariesgo,n.eventG1=n.eventG1,Ncensura=Ncensura) for (z in 1:m) AriesgoG1[z,1]<-Ariesgo[z,1] AriesgoTotal<-t(fit2$AtRisk)%*% matrix(1,nrow(fit2$AtRisk),1) NTotal<-fit2$n+t(fit2$m)%*% matrix(1,nrow(fit2$m),1) G1<-AriesgoG1*(AriesgoTotal-AriesgoG1)*n.event*(AriesgoTotal-n.event) Varianzan.eventG1<-G1/((AriesgoTotal*AriesgoTotal)*(AriesgoTotal-matrix(1,nrow(n.event),1))) for (jj in 1:nrow(Varianzan.eventG1)) if (Varianzan.eventG1[jj,1]=="NaN") Varianzan.eventG1[jj,1]<-0 ValoresesperadoG1<-AriesgoG1*n.event*(1/AriesgoTotal) #____________________________________________________________________

Apéndices ______________________________________________________________________
206
Pesos<-matrix(1,nrow(n.event),1) Diferencias<-n.eventG1-ValoresesperadoG1 Numerador<-t(Pesos*Diferencias)%*%matrix(1,nrow(n.event),1) Denominador<-t((Pesos*Pesos)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadísticoWilcoxonChi.cuadrado<-Numerador*Numerador/Denominador GruporeferenciaGT <-cbind(Tiempo1,AriesgoTotal,n.event) GruporeferenciaG1 <-cbind(Tiempo1,AriesgoG1,n.eventG1) Gruporeferencia <-cbind(Tiempo1,ValoresesperadoG1,Varianzan.eventG1) GruporeferenciaGG<-cbind(GruporeferenciaGT,AriesgoG1,n.eventG1) GruporeferenciaGG data.frame(Tiempo=Tiempo1,Valor.esp=ValoresesperadoG1,Varianza=Varianzan.eventG1) EstadísticoWilcoxonChi.cuadrado p.valorW<-1-pchisq(EstadísticoWilcoxonChi.cuadrado,df=1) p.valorW #____________________________________________________________________ PesosGehan<-GruporeferenciaGG[,2] NumeradorGehan<-t(PesosGehan)%*%Diferencias DenominadorGehan<-t((PesosGehan*PesosGehan)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoGehan<-NumeradorGehan*NumeradorGehan/DenominadorGehan EstadisticoGehan p.valorGehan<-1-pchisq(EstadisticoGehan,df=1) p.valorGehan #____________________________________________________________________ PesosTaroneWare<-sqrt(GruporeferenciaGG[,2]) NumeradorTaroneWare<-t(PesosTaroneWare)%*%Diferencias DenominadorTaroneWare<-t((PesosTaroneWare*PesosTaroneWare)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoTaroneWare<-NumeradorTaroneWare*NumeradorTaroneWare/DenominadorTaroneWare EstadisticoTaroneWare p.valorTaroneWare<-1-pchisq(EstadisticoTaroneWare,df=1) p.valorTaroneWare #____________________________________________________________________ supervivencia<-matrix(summary(fit2)) nnn<-nrow(supervivencia)/4 Supervivencia<-supervivencia[(3*nnn+1):(4*nnn),1] PesosPetoPeto<-Supervivencia NumeradorPetoPeto<-t(PesosPetoPeto)%*%Diferencias DenominadorPetoPeto<-t((PesosPetoPeto*PesosPetoPeto)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoPetoPeto<-NumeradorPetoPeto*NumeradorPetoPeto/DenominadorPetoPeto EstadisticoPetoPeto p.valorPetoPeto<-1-pchisq(EstadisticoPetoPeto,df=1) p.valorPetoPeto #____________________________________________________________________ supervivencia<-matrix(summary(fit2)) nnn<-nrow(supervivencia)/4 factor<-(GruporeferenciaGG[,2]/(GruporeferenciaGG[,2]+matrix(1,nnn,1))) Supervivencia<-factor*supervivencia[(3*nnn+1):(4*nnn),1] PesosPetoMod<-Supervivencia NumeradorPetoMod<-t(PesosPetoMod)%*%Diferencias

Apéndices ______________________________________________________________________
207
DenominadorPetoMod<-t((PesosPetoMod*PesosPetoMod)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoPetoMod<-NumeradorPetoMod*NumeradorPetoMod/DenominadorPetoMod EstadisticoPetoMod p.valorPetoMod<-1-pchisq(EstadisticoPetoMod,df=1) p.valorPetoMod #____________________________________________________________________ supervivencia<-matrix(summary(fit2)) nnn<-nrow(supervivencia)/4 Supervivencia<-supervivencia[(3*nnn+1):(4*nnn),1] supe<-supervivencia[(3*nnn+1):(4*nnn-1),1] PesosPetoPrentice<-matrix(c(1,supe),nnn,1) NumeradorPetoPrentice<-t(PesosPetoPrentice)%*%Diferencias DenominadorPetoPrentice<-t((PesosPetoPrentice*PesosPetoPrentice)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoPetoPrentice<-NumeradorPetoPrentice*NumeradorPetoPrentice/DenominadorPetoPeto EstadisticoPetoPrentice p.valorPetoPrentice<-1-pchisq(EstadisticoPetoPrentice,df=1) p.valorPetoPrentice #____________________________________________________________________ PesosHF<-(PesosPetoPeto)^(1)*(matrix(1,nrow(n.event))-PesosPetoPeto)^(0) NumeradorHF<-t(PesosHF)%*%Diferencias DenominadorHF<-t((PesosHF*PesosHF)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoHF<-NumeradorHF*NumeradorHF/DenominadorHF EstadisticoHF p.valorHF<-1-pchisq(EstadisticoHF,df=1) p.valorHF #____________________________________________________________________ PesosCM<-(PesosPetoPeto)^(1)*(matrix(1,nrow(n.event))-PesosPetoPeto)^(1)* (PesosGehan)^(0)*(PesosGehan+matrix(1,nrow(n.event),1))^(0) NumeradorCM<-t(PesosCM)%*%Diferencias DenominadorCM<-t((PesosCM*PesosCM)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoCM1100<-NumeradorCM*NumeradorCM/DenominadorCM EstadisticoCM1100 p.valorCM1100<-1-pchisq(EstadisticoCM1100,df=1) p.valorCM1100 #____________________________________________________________________ PesosCM<-(PesosPetoPeto)^(0)*(matrix(1,nrow(n.event))-PesosPetoPeto)^(0)* (PesosGehan)^(1)*(PesosGehan+matrix(1,nrow(n.event),1))^(0) NumeradorCM<-t(PesosCM)%*%Diferencias DenominadorCM<-t((PesosCM*PesosCM)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoCM0010<-NumeradorCM*NumeradorCM/DenominadorCM EstadisticoCM0010 p.valorCM0010<-1-pchisq(EstadisticoCM0010,df=1) p.valorCM0010 #____________________________________________________________________ PesosCM<-(PesosPetoPeto)^(0)*(matrix(1,nrow(n.event))-PesosPetoPeto)^(0)* (PesosGehan)^(1/2)*(PesosGehan+matrix(1,nrow(n.event),1))^(0)

Apéndices ______________________________________________________________________
208
NumeradorCM<-t(PesosCM)%*%Diferencias DenominadorCM<-t((PesosCM*PesosCM)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoCM00.50<-NumeradorCM*NumeradorCM/DenominadorCM EstadisticoCM00.50 p.valorCM00.50<-1-pchisq(EstadisticoCM00.50,df=1) p.valorCM00.50 #____________________________________________________________________ PesosCM<-(PesosPetoPeto)^(1)*(matrix(1,nrow(n.event))-PesosPetoPeto)^(0)* (PesosGehan)^(0)*(PesosGehan+matrix(1,nrow(n.event),1))^(0) NumeradorCM<-t(PesosCM)%*%Diferencias DenominadorCM<-t((PesosCM*PesosCM)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoCM1000<-NumeradorCM*NumeradorCM/DenominadorCM EstadisticoCM1000 p.valorCM1000<-1-pchisq(EstadisticoCM1000,df=1) p.valorCM1000 #____________________________________________________________________ PesosCM<-(PesosPetoPeto)^(1)*(matrix(1,nrow(n.event))-PesosPetoPeto)^(1)* (PesosGehan)^(1)*(PesosGehan+matrix(1,nrow(n.event),1))^(-1) NumeradorCM<-t(PesosCM)%*%Diferencias DenominadorCM<-t((PesosCM*PesosCM)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoCM111N1<-NumeradorCM*NumeradorCM/DenominadorCM EstadisticoCM111N1 p.valorCM111N1<-1-pchisq(EstadisticoCM111N1,df=1) p.valorCM111N1 #____________________________________________________________________ Wc<-matrix(NA,nrow(time),1) Wctime<-matrix(NA,nrow(time),1) Wj<-matrix(NA,nrow(time),1) Wtime<-matrix(NA,nrow(time),1) Wj<- -log(fit2$surv) Wc[1,1]<-Wj[1] for (i in 2:nrow(time)) Wc[i,1]<- Wj[i]-Wj[i-1] for (i in 1:nrow(time)) if (time[i,1]==0) Wtime[i,1]<-0.0001 else Wtime[i,1]<-time[i,1] Wctime[1,1]<-Wtime[1,1] for (i in 2:nrow(time)) Wctime[i,1]<-Wtime[i,1]-Wtime[i-1,1] peso<-Wc/Wctime PesosCarlos<-round((PesosGehan)/n.event,3) #PesosCarlos<-round((PesosGehan/Wc),3) #Sp<- PesosPetoPrentice #Sp1<-matrix(NA,nrow(time),1) #Sp1[1,1]<-1-Sp[1,1] #for (i in 2:nrow(time)) Sp1[i,1]<-Sp[i-1,1]-Sp[i,1] #Wj[1,1]<-Sp1[1,1]/(Wc[1,1]) #for (i in 2:nrow(time)) Wj[i,1]<- Sp1[i,1]/((Wc[i,1])) #PesosCarlos<-round(PesosGehan/(n.event),3) #PesosCarlos<-round(matrix(1/n.event),3) NumeradorCarlos<-t(PesosCarlos)%*%Diferencias DenominadorCarlos<-t((PesosCarlos*PesosCarlos)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoCarlos<-NumeradorCarlos*NumeradorCarlos/DenominadorCarlos EstadisticoCarlos p.valorCarlos<-1-pchisq(EstadisticoCarlos,df=1)

Apéndices ______________________________________________________________________
209
p.valorCarlos #____________________________________________________________________ Nomb.Est<-matrix(c("Wilcoxon", "Gehan", "Tarone Ware", "Peto Peto", "Peto Mod.", "Peto Prentice", "H-F p1=0, p2=0", "CM p1=1, p2=1, p3=0, p4= 0", "CM p1=0, p2=0, p3=1, p4= 0", "CM p1=0, p2=0, p3=1/2, p4= 0", "CM p1=1, p2=0, p3=0 , p4= 0", "CM p1=1, p2=0, p3=1, p4=-1", "Martinez")) Estadisticos<-matrix(c(EstadísticoWilcoxonChi.cuadrado, EstadisticoGehan, EstadisticoTaroneWare, EstadisticoPetoPeto, EstadisticoPetoMod, EstadisticoPetoPrentice, EstadisticoHF, EstadisticoCM1100, EstadisticoCM0010, EstadisticoCM00.50, EstadisticoCM1000, EstadisticoCM111N1, EstadisticoCarlos)) p.valores <-round(matrix(c(p.valorW, p.valorGehan, p.valorTaroneWare, p.valorPetoPeto, p.valorPetoMod, p.valorPetoPrentice, p.valorHF, p.valorCM1100, p.valorCM0010, p.valorCM00.50, p.valorCM1000, p.valorCM111N1,p.valorCarlos)),7) tabla<-data.frame(Nomb.Est,Chi.cuadrado=Estadisticos,p.valor=p.valores) if (p.valorW<0.10) contadorW10p<-contadorW10p+1 if (p.valorW<0.05) contadorW5p<-contadorW5p+1 if (p.valorW<0.01) contadorW1p<-contadorW1p+1 if (p.valorGehan<0.10) contadorG10p<-contadorG10p+1 if (p.valorGehan<0.05) contadorG5p<-contadorG5p+1 if (p.valorGehan<0.01) contadorG1p<-contadorG1p+1 if (p.valorTaroneWare<0.10) contadorTW10p<-contadorTW10p+1 if (p.valorTaroneWare<0.05) contadorTW5p<-contadorTW5p+1 if (p.valorTaroneWare<0.01) contadorTW1p<-contadorTW1p+1 if (p.valorPetoPeto<0.10) contadorPP10p<-contadorPP10p+1 if (p.valorPetoPeto<0.05) contadorPP5p<-contadorPP5p+1 if (p.valorPetoPeto<0.01) contadorPP1p<-contadorPP1p+1 if (p.valorPetoMod<0.10) contadorPM10p<-contadorPM10p+1 if (p.valorPetoMod<0.05) contadorPM5p<-contadorPM5p+1 if (p.valorPetoMod<0.01) contadorPM1p<-contadorPM1p+1 if (p.valorPetoPrentice<0.10) contadorPPr10p<-contadorPPr10p+1

Apéndices ______________________________________________________________________
210
if (p.valorPetoPrentice<0.05) contadorPPr5p<-contadorPPr5p+1 if (p.valorPetoPrentice<0.01) contadorPPr1p<-contadorPPr1p+1 if (p.valorHF<0.10) contadorHF10p<-contadorHF10p+1 if (p.valorHF<0.05) contadorHF5p<-contadorHF5p+1 if (p.valorHF<0.01) contadorHF1p<-contadorHF1p+1 if (p.valorCM1100<0.10) contadorFH10p<-contadorFH10p+1 if (p.valorCM1100<0.05) contadorFH5p<-contadorFH5p+1 if (p.valorCM1100<0.01) contadorFH1p<-contadorFH1p+1 if (p.valorCM111N1<0.10) contadorCM10p<-contadorCM10p+1 if (p.valorCM111N1<0.05) contadorCM5p<-contadorCM5p+1 if (p.valorCM111N1<0.01) contadorCM1p<-contadorCM1p+1 if (p.valorCarlos<0.10) contadorCarlos10p<-contadorCarlos10p+1 if (p.valorCarlos<0.05) contadorCarlos5p<-contadorCarlos5p+1 if (p.valorCarlos<0.01) contadorCarlos1p<-contadorCarlos1p+1 print(conta) #===================================================================== fit1<-survfitr(Survr(id,time,event)~as.factor(muestra),data=XL,type="pe") fit2<-survfitr(Survr(id,time,event)~1,data=XL,type="pe") print(summary(fit1)) print(summary(fit2)) MedianaGPLECombinada<-q.search(fit2,q=0.50) MedianaGPLGrupo01<-q.search(fit1$"1",q=0.50) MedianaGPLGrupo02<-q.search(fit1$"2",q=0.50) MedianaGPLECombinada MedianaGPLGrupo01 MedianaGPLGrupo02 X11() plot(fit2$time,fit2$survfunc,xlab="tiempo", ylab="Probabilidad de supervivencia", ylim=c(0,1.05),type="l",col = "blue", lwd=1) title(main=list("COMPARACIÓN DE FUNCIONES DE SUPERVIVENCIA", cex = 0.8, font = 2.3,col = "blue")) mtext("Software realizado por: Carlos Martínez", cex = 0.7, font = 2,col = "purple",line=1) mtext(kDis,cex = 0.7, font = 2,col = "black",line=3) lines(fit1$"1"$time,fit1$"1"$survfunc, type = "l",lty=2, col = "red") lines(fit1$"2"$time,fit1$"2"$survfunc, type = "l",lty=3, col = "black") legend("right",c("Muestra combinada","Grupo 01","Grupo 02"), col =c("blue","red","black"),lty=c(1,2,3),cex=0.8) X11() plot(fit2$time,-log(fit2$surv),xlab="tiempo", ylab="Riesgos acumulados", type="s",col = "blue", lwd=1) title(main=list("ESTIMACIÓN DE LA FUNCIÓN DE RIESGO", cex = 0.8, font = 2.3,col = "blue")) mtext("Software realizado por: Carlos Martínez", cex = 0.7, font = 2,col = "purple",line=1) legend("right",c("Modelo GPLE"), col =c("blue"),lty=c(1),cex=0.8) X11() plot(1:nrow(time),PesosCarlos) print("--------") print("Mantel-Haenszel") print(contadorW10p*100/To) print(contadorW5p*100/To) print(contadorW1p*100/To) print("--------")

Apéndices ______________________________________________________________________
211
print("Gehan") print(contadorG10p*100/To) print(contadorG5p*100/To) print(contadorG1p*100/To) print("--------") print("Tarone-Ware") print(contadorTW10p*100/To) print(contadorTW5p*100/To) print(contadorTW1p*100/To) print("--------") print("Peto-Peto") print(contadorPP10p*100/To) print(contadorPP5p*100/To) print(contadorPP1p*100/To) print("Peto-Modificado") print(contadorPM10p*100/To) print(contadorPM5p*100/To) print(contadorPM1p*100/To) print("--------") print("Peto-Prentice") print(contadorPPr10p*100/To) print(contadorPPr5p*100/To) print(contadorPPr1p*100/To) print("--------") print("Fleming-Harrington-O'sullivan") print(contadorHF10p*100/To) print(contadorHF5p*100/To) print(contadorHF1p*100/To) print("--------") print("Fleming-Harrington") print(contadorFH10p*100/To) print(contadorFH5p*100/To) print(contadorFH1p*100/To) print("--------") print("Mrec") print(contadorCM10p*100/To) print(contadorCM5p*100/To) print(contadorCM1p*100/To) print("--------") print("CMrec") print(contadorCarlos10p*100/To) print(contadorCarlos5p*100/To) print(contadorCarlos1p*100/To) tomavalores()
Programa para generar tres muestras aleatorias
require(tcltk) || stop("tcltk support is absent") require(stats) #_____________________________________________________________________ selecciontl.y1<-function() seleccion6<<- variable6[as.numeric(tkcurselection(tl.y1))+1] tkconfigure(frase06,text=seleccion6,background = "lightgreen") #_____________________________________________________________________ selecciontl.yB<-function() seleccionB<<- variableB[as.numeric(tkcurselection(tl.yB))+1] tkconfigure(fraseB,text=seleccionB,background = "lightgreen")

Apéndices ______________________________________________________________________
212
#_____________________________________________________________________ selecciontl.yC<-function() seleccionC<<- variableC[as.numeric(tkcurselection(tl.yC))+1] tkconfigure(fraseC,text=seleccionC,background = "lightgreen") #_____________________________________________________________________ selecciontl.pruebas<-function() seleccionpruebas<<- variablepruebas[as.numeric(tkcurselection(tl.pruebas))+1] tkconfigure(frasepruebas,text=seleccionpruebas,background = "lightgreen") #_____________________________________________________________________ tomavalores<-function() kDis <<- as.character(tclObj(kernelDis)) kCen <<- as.character(tclObj(kernelCen)) kcompara<<-as.character(tclObj(kernelCompara)) To<<-seleccionpruebas print(kDis) print(kcompara) print(kCen) print(seleccion6) print(seleccionB) print(seleccionC) print(seleccionpruebas) print("") #_____________________________________________________________________ KiA<<-1 KiB<<-1 KiC<<-1 seleccion6<<-1 seleccionB<<-1 seleccionC<<-1 seleccionpruebas<-1 kDis<-"Iguales" #_____________________________________________________________________ size1 <- 1 kernelDis<- tclVar("Chicuadrado") kernelCen<- tclVar("Chicuadrado") kernelCompara<- tclVar("Iguales") sz1 <- as.numeric((size1)) #_____________________________________________________________________ sizeB <- 1 szB <- as.numeric((sizeB)) sizeC <- 1 szC <- as.numeric((sizeC)) sizepruebas <- 1 #_____________________________________________________________________ base <- tktoplevel(width=700,height=25) tkwm.title(base, "POTENCIA DE LAS PRUEBAS DE COMPARACIÓN PARA TRES MUESTRAS") spec.frm <- tkframe(base,borderwidth=20) left.frm <- tkframe(spec.frm) right.frm <- tkframe(spec.frm) #_____________________________________________________________________ frame.y1 <- tkwidget(spec.frm, "labelframe", text = "Total de individuos muestra A") tl.y1<- tklistbox(frame.y1, height = 7, yscrollcommand=function(...)tkset(scr.y11,...),

Apéndices ______________________________________________________________________
213
width = 10, selectmode = "single", background = "white") scr.y11 <- tkscrollbar(frame.y1, repeatinterval = 1, command = function(...) tkyview(tl.y1, ...)) variable6 <- c(1:500) for (p in (1:500)) tkinsert(tl.y1,"end",variable6[p]) tkselection.set(tl.y1, 0) tkgrid(tl.y1, scr.y11, sticky="news") #_____________________________________________________________________ tkgrid(frase06<-tklabel(frame.y1, text= size1,background = "red")) tkgrid(botomtl.y1<- tkbutton(frame.y1,text="Selecciona",command=selecciontl.y1)) #_____________________________________________________________________ frame.yB <- tkwidget(spec.frm, "labelframe", text = "Total de individuos muestra B") tl.yB<- tklistbox(frame.yB, height = 7, yscrollcommand=function(...)tkset(scr.y1B,...), width = 10, selectmode = "single", background = "white") scr.y1B <- tkscrollbar(frame.yB, repeatinterval = 1, command = function(...) tkyview(tl.yB, ...)) variableB <- c(1:500) for (p in (1:500)) tkinsert(tl.yB,"end",variableB[p]) tkselection.set(tl.yB, 0) tkgrid(tl.yB, scr.y1B, sticky="news") #_____________________________________________________________________ tkgrid(fraseB<-tklabel(frame.yB, text= sizeB,background = "red")) tkgrid(botomtl.yB<- tkbutton(frame.yB,text="Selecciona", command=selecciontl.yB)) #_____________________________________________________________________ frame.yC <- tkwidget(spec.frm, "labelframe", text = "Total de individuos muestra C") tl.yC<- tklistbox(frame.yC, height = 7, yscrollcommand=function(...)tkset(scr.y1C,...), width = 10, selectmode = "single", background = "white") scr.y1C <- tkscrollbar(frame.yC, repeatinterval = 1, command = function(...) tkyview(tl.yC, ...)) variableC <- c(1:500) for (p in (1:500)) tkinsert(tl.yC,"end",variableC[p]) tkselection.set(tl.yC, 0) tkgrid(tl.yC, scr.y1C, sticky="news") #_____________________________________________________________________ tkgrid(fraseC<-tklabel(frame.yC, text= sizeC,background = "red")) tkgrid(botomtl.yC<- tkbutton(frame.yC,text="Selecciona", command=selecciontl.yC)) #_____________________________________________________________________ frame.pruebas <- tkwidget(right.frm, "labelframe", text = "Total de pruebas") tl.pruebas<- tklistbox(frame.pruebas, height = 1, yscrollcommand=function(...)tkset(scr.pruebas,...), width = 10, selectmode = "single", background = "white") scr.pruebas <- tkscrollbar(frame.pruebas, repeatinterval = 1, command = function(...) tkyview(tl.pruebas, ...)) variablepruebas <- c(1:1000)

Apéndices ______________________________________________________________________
214
for (p in (1:1000)) tkinsert(tl.pruebas,"end",variablepruebas[p]) tkselection.set(tl.pruebas, 0) tkgrid(tl.pruebas, scr.pruebas, sticky="news") #_____________________________________________________________________ tkgrid(frasepruebas<-tklabel(frame.pruebas, text= sizepruebas, background = "red")) tkgrid(botomtl.pruebas<- tkbutton(frame.pruebas,text="Selecciona", command=selecciontl.pruebas)) #_____________________________________________________________________ frameDis <- tkframe(left.frm, relief="groove", borderwidth=2) tkpack(tklabel(frameDis, text="Distribución de los Tij")) for ( i in c("Chicuadrado", "Uniforme", "Gamma", "Exponencial", "Weibull","Decreciente","Creciente") ) tmpDis <- tkradiobutton(frameDis, command=tomavalores, text=i, value=i, variable=kernelDis) tkpack(tmpDis, anchor="w") #_____________________________________________________________________ frameCen <- tkframe(right.frm, relief="groove", borderwidth=2) tkpack(tklabel(frameCen, text="Distribución Censuras")) for ( i in c("Chicuadrado", "Uniforme", "Gamma", "Exponencial", "Weibull","Desconocida") ) tmpCen <- tkradiobutton(frameCen, command=tomavalores, text=i, value=i, variable=kernelCen) tkpack(tmpCen, anchor="w") #_____________________________________________________________________ frameCompara <- tkframe(left.frm, relief="groove", borderwidth=2) tkpack(tklabel(frameCompara, text="Parámetros de Tij")) for ( i in c("Iguales", "Diferentes") ) tmpCompara <- tkradiobutton(frameCompara, command=tomavalores, text=i, value=i, variable=kernelCompara) tkpack(tmpCompara, anchor="w") #_____________________________________________________________________ tkpack(left.frm, right.frm,frame.y1,frame.yB,frame.yC,side="left", anchor="n") tkpack(left.frm,frameDis,fill="x",side="left") tkpack(right.frm,frame.pruebas,frameCen, fill="x",side="right") tkpack(frameCompara) #_____________________________________________________________________ Cancelar<-tkbutton(base,text="Cancelar",command=function()tkdestroy(base)) q.but <- tkbutton(base,text="OK",command=function()#tkdestroy(base); source("geParaSimularseleTRESMUESTRAS.R") ) tkpack(spec.frm) tkpack(q.but) tkpack(Cancelar)

Apéndices ______________________________________________________________________
215
Programa auxiliar que permite generar tres muestras aleatorias require(survrec) tomavalores() contadorW1p<-0;contadorW5p<-0;contadorW10p<-0 contadorG1p<-0;contadorG5p<-0;contadorG10p<-0 contadorTW1p<-0;contadorTW5p<-0;contadorTW10p<-0 contadorPP1p<-0;contadorPP5p<-0;contadorPP10p<-0 contadorPM1p<-0;contadorPM5p<-0;contadorPM10p<-0 contadorPPr1p<-0;contadorPPr5p<-0;contadorPPr10p<-0 contadorHF10p<-0;contadorHF5p<-0;contadorHF1p<-0 contadorFH10p<-0;contadorFH5p<-0;contadorFH1p<-0 contadorCM10p<-0;contadorCM5p<-0;contadorCM1p<-0 contadorCarlos10p<-0;contadorCarlos5p<-0;contadorCarlos1p<-0 conta<<-0 #To<-1000 To<-seleccionpruebas KiA<<-matrix(3,seleccion6,1) KiB<<-matrix(3,seleccionB,1) KiC<<-matrix(3,seleccionC,1) TijA<<-matrix(NA,seleccion6,max(KiA)) TijB<<-matrix(NA,seleccionB,max(KiB)) TijC<<-matrix(NA,seleccionC,max(KiC)) CiA<<-matrix(NA,seleccion6,1) CiB<<-matrix(NA,seleccionB,1) CiC<<-matrix(NA,seleccionC,1) selc<-"normal" distribution<-function(type) if (kcompara=="Iguales") switch (type, "Chicuadrado" = for(i in 1:seleccion6)for (j in 1:3) TijA[i,j]<<-round(rchisq(1,10,ncp=0),3) for (i in 1:seleccion6) CiA[i,1]<<-round(rchisq(1,10/2,ncp=0),3) for(i in 1:seleccionB)for (j in 1:3) TijB[i,j]<<-round(rchisq(1,10,ncp=0),3) for (i in 1:seleccionB) CiB[i,1]<<-round(rchisq(1,10/2,ncp=0),3) for(i in 1:seleccionC)for (j in 1:3) TijC[i,j]<<-round(rchisq(1,10,ncp=0),3) for (i in 1:seleccionC) CiC[i,1]<<-round(rchisq(1,10/2,ncp=0),3) , "Uniforme" = for(i in 1:seleccion6)for (j in 1:3) TijA[i,j]<<-round(runif(1,25,35),3) for (i in 1:seleccion6) CiA[i,1]<<-round(runif(1,0,15),3) for(i in 1:seleccionB)for (j in 1:3) TijB[i,j]<<-round(runif(1,25,35),3) for (i in 1:seleccionB) CiB[i,1]<<-round(runif(1,0,15),3) for(i in 1:seleccionC)for (j in 1:3) TijC[i,j]<<-round(runif(1,25,35),3) for (i in 1:seleccionC) CiC[i,1]<<-round(runif(1,0,15),3) , "Gamma" = for(i in 1:seleccion6)for (j in 1:3) TijA[i,j]<<-round(rgamma(1,50,2,2),3) for (i in 1:seleccion6) CiA[i,1]<<-round(rgamma(1,25,2,2),3)

Apéndices ______________________________________________________________________
216
for(i in 1:seleccionB)for (j in 1:3) TijB[i,j]<<-round(rgamma(1,50,2,2),3) for (i in 1:seleccionB) CiB[i,1]<<-round(rgamma(1,25,2,2),3) for(i in 1:seleccionC)for (j in 1:3) TijC[i,j]<<-round(rgamma(1,50,2,2),3) for (i in 1:seleccionC) CiC[i,1]<<-round(rgamma(1,25,2,2),3) , "Exponencial" = for(i in 1:seleccion6)for (j in 1:3) TijA[i,j]<<-round(rexp(1,1/50),3) for (i in 1:seleccion6) CiA[i,1]<<-round(rexp(1,1/25),3) for(i in 1:seleccionB)for (j in 1:3) TijB[i,j]<<-round(rexp(1,1/50),3) for (i in 1:seleccionB) CiB[i,1]<<-round(rexp(1,1/25),3) for(i in 1:seleccionC)for (j in 1:3) TijC[i,j]<<-round(rexp(1,1/50),3) for (i in 1:seleccionC) CiC[i,1]<<-round(rexp(1,1/25),3) , "Decreciente" = for(i in 1:seleccion6)for (j in 1:3) limi<-runif(1,100,120); TijA[i,j]<<-round(limi/(2*i),3) for (i in 1:seleccion6) CiA[i,1]<<-round(runif(1,50,60)/(2*i),3) for(i in 1:seleccionB)for (j in 1:3) limi<-runif(1,100,120); TijB[i,j]<<-round(limi/(2*i),3) for (i in 1:seleccionB) CiB[i,1]<<-round(runif(1,50,60)/(2*i),3) for(i in 1:seleccionC)for (j in 1:3) limi<-runif(1,100,120); TijC[i,j]<<-round(limi/(2*i),3) for (i in 1:seleccionC) CiC[i,1]<<-round(runif(1,50,60)/(2*i),3) , "Creciente" = for(i in 1:seleccion6)for (j in 1:3) limi<-runif(1,100,120); TijA[i,j]<<-round(limi*i,3) for (i in 1:seleccion6) CiA[i,1]<<-round(runif(1,50,60)*i,3) for(i in 1:seleccionB)for (j in 1:3) limi<-runif(1,100,120); TijB[i,j]<<-round(limi*i,3) for (i in 1:seleccionB) CiB[i,1]<<-round(runif(1,50,60)*i,3) for(i in 1:seleccionC)for (j in 1:3) limi<-runif(1,100,120); TijC[i,j]<<-round(limi*i,3) for (i in 1:seleccionC) CiC[i,1]<<-round(runif(1,50,60)*i,3) , "Weibull" = for(i in 1:seleccion6)for (j in 1:3) TijA[i,j]<<-round(rweibull(1,0.9,30),3) for (i in 1:seleccion6) CiA[i,1]<<-round(rweibull(1,0.9,15),3) for(i in 1:seleccionB)for (j in 1:3) TijB[i,j]<<-round(rweibull(1,0.9,30),3) for (i in 1:seleccionB) CiB[i,1]<<-round(rweibull(1,0.9,15),3) for(i in 1:seleccionC)for (j in 1:3) TijC[i,j]<<-round(rweibull(1,0.9,30),3) for (i in 1:seleccionC) CiC[i,1]<<-round(rweibull(1,0.9,15),3) ) if (kcompara=="Diferentes") switch (type, "Chicuadrado" = for(i in 1:seleccion6)for (j in 1:3) TijA[i,j]<<-round(rchisq(1,10,ncp=0),3) for (i in 1:seleccion6) CiA[i,1]<<-round(rchisq(1,10/2,ncp=0),3)

Apéndices ______________________________________________________________________
217
for(i in 1:seleccionB)for (j in 1:3) TijB[i,j]<<-round(rchisq(1,15,ncp=0),3) for (i in 1:seleccionB) CiB[i,1]<<-round(rchisq(1,15/2,ncp=0),3) for(i in 1:seleccionC)for (j in 1:3) TijC[i,j]<<-round(rchisq(1,15,ncp=0),3) for (i in 1:seleccionC) CiC[i,1]<<-round(rchisq(1,15/2,ncp=0),3) , "Uniforme" = for(i in 1:seleccion6)for (j in 1:3) TijA[i,j]<<-round(runif(1,25,35),3) for (i in 1:seleccion6) CiA[i,1]<<-round(runif(1,0,20),3) for(i in 1:seleccionB)for (j in 1:3) TijB[i,j]<<-round(runif(1,27,37),3) for (i in 1:seleccionB) CiB[i,1]<<-round(runif(1,0,25),3) for(i in 1:seleccionC)for (j in 1:3) TijC[i,j]<<-round(runif(1,27,37),3) for (i in 1:seleccionC) CiC[i,1]<<-round(runif(1,0,25),3) , "Gamma" = for(i in 1:seleccion6)for (j in 1:3) TijA[i,j]<<-round(rgamma(1,50,2,2),3) for (i in 1:seleccion6) CiA[i,1]<<-round(rgamma(1,25,2,2),3) for(i in 1:seleccionB)for (j in 1:3) TijB[i,j]<<-round(rgamma(1,60,2,2),3) for (i in 1:seleccionB) CiB[i,1]<<-round(rgamma(1,30,2,2),3) for(i in 1:seleccionC)for (j in 1:3) TijC[i,j]<<-round(rgamma(1,60,2,2),3) for (i in 1:seleccionC) CiC[i,1]<<-round(rgamma(1,30,2,2),3) , "Exponencial" = for(i in 1:seleccion6)for (j in 1:3) TijA[i,j]<<-round(rexp(1,1/50),3) for (i in 1:seleccion6) CiA[i,1]<<-round(rexp(1,1/25),3) for(i in 1:seleccionB)for (j in 1:3) TijB[i,j]<<-round(rexp(1,1/100),3) for (i in 1:seleccionB) CiB[i,1]<<-round(rexp(1,1/50),3) for(i in 1:seleccionC)for (j in 1:3) TijC[i,j]<<-round(rexp(1,1/100),3) for (i in 1:seleccionC) CiC[i,1]<<-round(rexp(1,1/50),3) , "Decreciente" = for(i in 1:seleccion6)for (j in 1:3) TijA[i,j]<<-round(runif(1,80,120)/(2*i),3) for (i in 1:seleccion6) CiA[i,1]<<-round(runif(1,40,60)/(2*i),3) for(i in 1:seleccionB)for (j in 1:3) TijB[i,j]<<-round(runif(1,110,150)/(2*i),3) for (i in 1:seleccionB) CiB[i,1]<<-round(runif(1,55,75)/(2*i),3) for(i in 1:seleccionC)for (j in 1:3) TijC[i,j]<<-round(runif(1,110,150)/(2*i),3) for (i in 1:seleccionC) CiC[i,1]<<-round(runif(1,55,75)/(2*i),3) , "Creciente" = for(i in 1:seleccion6)for (j in 1:3) limi<-runif(1,100,120); TijA[i,j]<<-round(limi*i,3) for (i in 1:seleccion6) CiA[i,1]<<-round(runif(1,50,60)*i,3) for(i in 1:seleccionB)for (j in 1:3) limi<-runif(1,120,140); TijB[i,j]<<-round(limi*i,3) for (i in 1:seleccionB) CiB[i,1]<<-round(runif(1,60,70)*i,3) for(i in 1:seleccionC)for (j in 1:3) limi<-runif(1,120,140); TijC[i,j]<<-round(limi*i,3) for (i in 1:seleccionC) CiC[i,1]<<-round(runif(1,60,70)*i,3)

Apéndices ______________________________________________________________________
218
, "Weibull" = for(i in 1:seleccion6)for (j in 1:3) TijA[i,j]<<-round(rweibull(1,0.9,30),3) for (i in 1:seleccion6) CiA[i,1]<<-round(rweibull(1,0.9,15),3) for(i in 1:seleccionB)for (j in 1:3) TijB[i,j]<<-round(rweibull(1,0.9,40),3) for (i in 1:seleccionB) CiB[i,1]<<-round(rweibull(1,0.9,20),3) for(i in 1:seleccionC)for (j in 1:3) TijC[i,j]<<-round(rweibull(1,0.9,40),3) for (i in 1:seleccionC) CiC[i,1]<<-round(rweibull(1,0.9,20),3) ) #=========================================================================== while (conta<=To-1) conta<-conta+1 distribution(kDis) IndividuoA<-matrix(1:seleccion6) IndividuoB<-matrix(1:seleccionB) IndividuoC<-matrix(1:seleccionC) tiemposiniciales<<-matrix(0,seleccion6+seleccionB+seleccionC,1) I<-matrix(1:(totalindividuos<-max(IndividuoA)+max(IndividuoB)+max(IndividuoC))) Ki<-matrix(c(KiA,KiB,KiC)) Tij<-cbind(Ti1=c(TijA[,1],TijB[,1],TijC[,1]),Ti2=c(TijA[,2],TijB[,2],TijC[,2]), Ti3=c(TijA[,3],TijB[,3],TijC[,3])) Ci<-c(CiA,CiB,CiC) tabla<-data.frame(I,Ki,Tij,Ci) J<-matrix(1:(totalindividuos*4)) Tijs<-matrix(NA,max(I),3+1) Tijs[,1]<-Tij[,1] Tijs[,2]<-Tij[,2] Tijs[,3]<-Tij[,3] Tijs[,4]<-Ci Tiempo<-cbind(c(t(Tijs))) Censura<-matrix(NA,max(I),3+1) Censura[,1]<-1 Censura[,2]<-1 Censura[,3]<-1 Censura[,4]<-0 Evento<-cbind(c(t(Censura))) Unidades<-matrix(c(I,I,I,I),max(I),4) Unidad<-cbind(c(t(Unidades))) Muestra01<-matrix(1,4*max(IndividuoA),1) Muestra02<-matrix(2,4*max(IndividuoB),1) Muestra03<-matrix(3,4*max(IndividuoC),1) Muestra<-cbind(muestra=c(Muestra01,Muestra02,Muestra03)) Sij<-matrix(NA,max(I),3+1) Sij[,1]<-0 Sij[,1]<-Tij[,1] Sij[,2]<-Tij[,1]+Tij[,2] Sij[,3]<-Tij[,1]+Tij[,2]+Tij[,3] Sij[,4]<-Sij[,3]+Ci

Apéndices ______________________________________________________________________
219
Tiempocalendario<-cbind(c(t(Sij))) Tiempoinicial<-Tiempocalendario-Tiempo XL<-data.frame(J=J,id=Unidad,Time1=Tiempoinicial,time=Tiempo, Sij=Tiempocalendario,event=Evento,muestra=Muestra) #===================================================================== fit1<-survfitr(Survr(id,time,event)~as.factor(muestra),data=XL,type="pe") fit2<-survfitr(Survr(id,time,event)~1,data=XL,type="pe") MedianaGPLECombinada<-q.search(fit2,q=0.50) MedianaGPLGrupo01<-q.search(fit1$"1",q=0.50) MedianaGPLGrupo02<-q.search(fit1$"2",q=0.50) MedianaGPLGrupo03<-q.search(fit1$"3",q=0.50) failed<-matrix(fit2$failed) censored<-matrix(fit2$censored) time<-matrix(fit2$time) n.event<-matrix(fit2$n.event) AtRisk<-matrix(fit2$AtRisk) m<-fit2$m k<-matrix(m) #================================================================= n<-ncol(matrix(fit2$time)) m<-nrow(matrix(fit2$time)) n1<-ncol(matrix(fit1$"1"$time)) m1<-nrow(matrix(fit1$"1"$time)) n2<-ncol(matrix(fit1$"2"$time)) m2<-nrow(matrix(fit1$"2"$time)) n3<-ncol(matrix(fit1$"3"$time)) m3<-nrow(matrix(fit1$"3"$time)) I<-matrix(1,m,1) X<-matrix(fit2$time) Y1<-matrix(fit1$"1"$time) Z1<-matrix(fit1$"1"$censored) Y2<-matrix(fit1$"2"$time) Z2<-matrix(fit1$"2"$censored) Y3<-matrix(fit1$"3"$time) Z3<-matrix(fit1$"3"$censored) Tiempo1<-matrix(0,m,1) Tiempo2<-matrix(0,m,1) Tiempo3<-matrix(0,m,1) n.eventG1<-matrix(0,m,1) n.eventG2<-matrix(0,m,1) n.eventG3<-matrix(0,m,1) NEG1<-matrix(fit1$"1"$n.event) NEG2<-matrix(fit1$"2"$n.event) NEG3<-matrix(fit1$"3"$n.event) Ariesgo<-matrix(0,m,1) cuenta<-matrix(0,m,1) Ncensura<-matrix(0,m,1) AriesgoG1<-matrix(0,m,1) AriesgoG2<-matrix(0,m,1) AriesgoG3<-matrix(0,m,1) mm<-nrow(X) #================================================================= tiempocensura<-matrix(fit1$"1"$censored) for (z in 1:m) for (zz in 1:m1)if (X[z,1]== Y1[zz,1])Tiempo1[z,1]<-Y1[zz,1]; n.eventG1[z,1]<-NEG1[zz,1];zz<-m1

Apéndices ______________________________________________________________________
220
else Tiempo1[z,1]<-X[z,1] data.frame(Tiempo=Tiempo1,n.eventosG1=n.eventG1) AriesgoG1tiempo1<-t(fit1$"1"$AtRisk)%*% matrix(1,nrow(fit1$"1"$AtRisk),1) N<-fit1$"1"$n+t(fit1$"1"$m)%*% matrix(1,nrow(fit1$"1"$m),1) data.frame(Tiempo=Y1,AriesgoG1tiempo1=AriesgoG1tiempo1) for (z in 1:m) cuenta[z,1]<-0 for (zz in 1:nrow(tiempocensura) )if (tiempocensura[zz,1]<=Tiempo1[z,1]) cuenta[z,1]<-cuenta[z,1]+1 data.frame(Tiempo=Tiempo1,cuenta=cuenta) for (z in 1:m-1) Ncensura[z,1]<--cuenta[z,1]+cuenta[z+1,1] data.frame(Tiempo=Tiempo1,Ncensuras=Ncensura) Ariesgot0<-N Ariesgo[1,1]<-N-cuenta[1,1] AriesgoG1tiempoG1<-t(fit1$"1"$AtRisk)%*% matrix(1,nrow(fit1$"1"$AtRisk),1) for (z in 1:m) for (zz in 1:m1) if (X[z,1]== Y1[zz,1]) Ariesgo[z,1]<-AriesgoG1tiempoG1[zz,1] data.frame(Tiempo=Tiempo1,Ariesgo=Ariesgo) for (z in 2:m) if (Ariesgo[z,1]==0) Ariesgo[z,1]<-Ariesgo[z-1,1]-Ncensura[z-1,1]-n.eventG1[z-1,1] data.frame(Tiempo=Tiempo1,Ariesgo=Ariesgo,n.eventG1=n.eventG1,Ncensura=Ncensura) for (z in 1:m) AriesgoG1[z,1]<-Ariesgo[z,1] AriesgoTotal<-t(fit2$AtRisk)%*% matrix(1,nrow(fit2$AtRisk),1) NTotal<-fit2$n+t(fit2$m)%*% matrix(1,nrow(fit2$m),1) G1<-AriesgoG1*(AriesgoTotal-AriesgoG1)*n.event*(AriesgoTotal-n.event) Varianzan.eventG1<-G1/((AriesgoTotal*AriesgoTotal)*(AriesgoTotal-matrix(1,nrow(n.event),1))) for (jj in 1:nrow(Varianzan.eventG1)) if (Varianzan.eventG1[jj,1]=="NaN") Varianzan.eventG1[jj,1]<-0 ValoresesperadoG1<-AriesgoG1*n.event*(1/AriesgoTotal) #================================================================= tiempocensura2<-matrix(fit1$"2"$censored) for (z in 1:m) for (zz in 1:m2)if (X[z,1]== Y2[zz,1])Tiempo2[z,1]<-Y2[zz,1]; n.eventG2[z,1]<-NEG2[zz,1];zz<-m2 else Tiempo2[z,1]<-X[z,1] data.frame(Tiempo=Tiempo2,n.eventosG2=n.eventG2) AriesgoG2tiempo2<-t(fit1$"2"$AtRisk)%*% matrix(1,nrow(fit1$"2"$AtRisk),1) N<-fit1$"2"$n+t(fit1$"2"$m)%*% matrix(1,nrow(fit1$"2"$m),1) data.frame(Tiempo=Y2,AriesgoG2tiempo2=AriesgoG2tiempo2) for (z in 1:m) cuenta[z,1]<-0 for (zz in 1:nrow(tiempocensura2) )if (tiempocensura2[zz,1]<=Tiempo2[z,1]) cuenta[z,1]<-cuenta[z,1]+1 data.frame(Tiempo=Tiempo2,cuenta=cuenta) for (z in 1:m-1) Ncensura[z,1]<--cuenta[z,1]+cuenta[z+1,1] data.frame(Tiempo=Tiempo2,Ncensuras=Ncensura) Ariesgot0<-N AriesgoG2[1,1]<-N-cuenta[1,1]

Apéndices ______________________________________________________________________
221
AriesgoG2tiempoG2<-t(fit1$"2"$AtRisk)%*% matrix(1,nrow(fit1$"2"$AtRisk),1) for (z in 1:m) for (zz in 1:m2) if (X[z,1]== Y2[zz,1]) AriesgoG2[z,1]<-AriesgoG2tiempoG2[zz,1] data.frame(Tiempo=Tiempo2,Ariesgo=AriesgoG2) for (z in 2:m) if (AriesgoG2[z,1]==0) AriesgoG2[z,1]<-AriesgoG2[z-1,1]-Ncensura[z-1,1]-n.eventG2[z-1,1] data.frame(Tiempo=Tiempo2,Ariesgo=AriesgoG2,n.eventG2=n.eventG2,Ncensura=Ncensura) for (z in 1:m) AriesgoG2[z,1]<-AriesgoG2[z,1] AriesgoTotal<-t(fit2$AtRisk)%*% matrix(1,nrow(fit2$AtRisk),1) NTotal<-fit2$n+t(fit2$m)%*% matrix(1,nrow(fit2$m),1) G2<-AriesgoG2*(AriesgoTotal-AriesgoG2)*n.event*(AriesgoTotal-n.event) Varianzan.eventG2<-G2/((AriesgoTotal*AriesgoTotal)*(AriesgoTotal-matrix(1,nrow(n.event),1))) for (jj in 1:nrow(Varianzan.eventG2)) if (Varianzan.eventG2[jj,1]=="NaN") Varianzan.eventG2[jj,1]<-0 ValoresesperadoG2<-AriesgoG2*n.event*(1/AriesgoTotal) #================================================================= tiempocensura3<-matrix(fit1$"3"$censored) for (z in 1:m) for (zz in 1:m3)if (X[z,1]== Y3[zz,1])Tiempo3[z,1]<-Y3[zz,1]; n.eventG3[z,1]<-NEG3[zz,1];zz<-m3 else Tiempo3[z,1]<-X[z,1] data.frame(Tiempo=Tiempo3,n.eventosG3=n.eventG3) AriesgoG3tiempo3<-t(fit1$"3"$AtRisk)%*% matrix(1,nrow(fit1$"3"$AtRisk),1) N<-fit1$"3"$n+t(fit1$"3"$m)%*% matrix(1,nrow(fit1$"3"$m),1) data.frame(Tiempo=Y3,AriesgoG3tiempo3=AriesgoG3tiempo3) for (z in 1:m) cuenta[z,1]<-0 for (zz in 1:nrow(tiempocensura3) )if (tiempocensura3[zz,1]<=Tiempo3[z,1]) cuenta[z,1]<-cuenta[z,1]+1 data.frame(Tiempo=Tiempo3,cuenta=cuenta) for (z in 1:m-1) Ncensura[z,1]<--cuenta[z,1]+cuenta[z+1,1] data.frame(Tiempo=Tiempo3,Ncensuras=Ncensura) Ariesgot0<-N AriesgoG3[1,1]<-N-cuenta[1,1] AriesgoG3tiempoG3<-t(fit1$"3"$AtRisk)%*% matrix(1,nrow(fit1$"3"$AtRisk),1) for (z in 1:m) for (zz in 1:m3) if (X[z,1]== Y3[zz,1]) AriesgoG3[z,1]<-AriesgoG3tiempoG3[zz,1] data.frame(Tiempo=Tiempo3,Ariesgo=AriesgoG3) for (z in 2:m) if (AriesgoG3[z,1]==0) AriesgoG3[z,1]<-AriesgoG3[z-1,1]-Ncensura[z-1,1]-n.eventG3[z-1,1] data.frame(Tiempo=Tiempo3,Ariesgo=AriesgoG3,n.eventG3=n.eventG3,Ncensura=Ncensura) for (z in 1:m) AriesgoG3[z,1]<-AriesgoG3[z,1] AriesgoTotal<-t(fit2$AtRisk)%*% matrix(1,nrow(fit2$AtRisk),1) NTotal<-fit2$n+t(fit2$m)%*% matrix(1,nrow(fit2$m),1) G3<-AriesgoG3*(AriesgoTotal-AriesgoG3)*n.event*(AriesgoTotal-n.event)

Apéndices ______________________________________________________________________
222
Varianzan.eventG3<-G3/((AriesgoTotal*AriesgoTotal)*(AriesgoTotal-matrix(1,nrow(n.event),1))) for (jj in 1:nrow(Varianzan.eventG3)) if (Varianzan.eventG3[jj,1]=="NaN") Varianzan.eventG3[jj,1]<-0 ValoresesperadoG3<-AriesgoG3*n.event*(1/AriesgoTotal) #================================================================= CovaG1G2<-AriesgoG1*(-AriesgoG2)*n.event*(AriesgoTotal-n.event) CoVarianzan.eventG1G2<-CovaG1G2/((AriesgoTotal*AriesgoTotal)*(AriesgoTotal-matrix(1,nrow(n.event),1))) for (jj in 1:nrow(CoVarianzan.eventG1G2)) if (CoVarianzan.eventG1G2[jj,1]=="NaN") CoVarianzan.eventG1G2[jj,1]<-0 CovaG1G3<-AriesgoG1*(-AriesgoG3)*n.event*(AriesgoTotal-n.event) CoVarianzan.eventG1G3<-CovaG1G3/((AriesgoTotal*AriesgoTotal)*(AriesgoTotal-matrix(1,nrow(n.event),1))) for (jj in 1:nrow(CoVarianzan.eventG1G3)) if (CoVarianzan.eventG1G3[jj,1]=="NaN") CoVarianzan.eventG1G3[jj,1]<-0 CovaG2G3<-AriesgoG2*(-AriesgoG3)*n.event*(AriesgoTotal-n.event) CoVarianzan.eventG2G3<-CovaG2G3/((AriesgoTotal*AriesgoTotal)*(AriesgoTotal-matrix(1,nrow(n.event),1))) for (jj in 1:nrow(CoVarianzan.eventG2G3)) if (CoVarianzan.eventG2G3[jj,1]=="NaN") CoVarianzan.eventG2G3[jj,1]<-0 #____________________________________________________________________ Pesos<-matrix(1,nrow(n.event),1) DiferenciasG1<-n.eventG1-ValoresesperadoG1 DiferenciasG2<-n.eventG2-ValoresesperadoG2 DiferenciasG3<-n.eventG3-ValoresesperadoG3 NumeradorG1<-t(Pesos*DiferenciasG1)%*%matrix(1,nrow(n.event),1) NumeradorG2<-t(Pesos*DiferenciasG2)%*%matrix(1,nrow(n.event),1) NumeradorG3<-t(Pesos*DiferenciasG3)%*%matrix(1,nrow(n.event),1) Numerador<-NumeradorG1+NumeradorG2+NumeradorG3 DenominadorG1<-t((Pesos*Pesos)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) DenominadorG2<-t((Pesos*Pesos)*Varianzan.eventG2)%*%matrix(1,nrow(n.event),1) DenominadorG3<-t((Pesos*Pesos)*Varianzan.eventG3)%*%matrix(1,nrow(n.event),1) Denominador<-DenominadorG1+DenominadorG2+DenominadorG3 EstadísticoLogRankChi.cuadradoestra<-Numerador*Numerador/Denominador EstadísticoLogRankChi.cuadradoestra p.valorLRestra<-1-pchisq(EstadísticoLogRankChi.cuadradoestra,df=1) p.valorLRestra DenominadorG1G2<-t((Pesos*Pesos)*CoVarianzan.eventG1G2)%*%matrix(1,nrow(n.event),1) MatrizVarianza<-matrix(c(DenominadorG1,DenominadorG1G2, DenominadorG1G2,DenominadorG2),nrow=2,ncol=2) MatrizVarianzainversa<-solve(matrix(c(DenominadorG1,DenominadorG1G2, DenominadorG1G2,DenominadorG2),nrow=2,ncol=2)) Vectordediferencias<-matrix(c(NumeradorG1,NumeradorG2),nrow=2,ncol=1) EstadísticoLogRankChi.cuadrado<-t(Vectordediferencias)%*%MatrizVarianzainversa%*%Vectordediferencias p.valorLR<-1-pchisq(EstadísticoLogRankChi.cuadrado,df=2) p.valorLR GruporeferenciaGT <-cbind(Tiempo1,AriesgoTotal,n.event) GruporeferenciaG1 <-cbind(Tiempo1,AriesgoG1,n.eventG1)

Apéndices ______________________________________________________________________
223
Gruporeferencia <-cbind(Tiempo1,ValoresesperadoG1,Varianzan.eventG1) GruporeferenciaGG<-cbind(GruporeferenciaGT,AriesgoG1,n.eventG1) GruporeferenciaGG data.frame(Tiempo=Tiempo1,Valor.esp=ValoresesperadoG1,Varianza=Varianzan.eventG1) #____________________________________________________________________ PesosGehan<-GruporeferenciaGG[,2] NumeradorGehan<-t(PesosGehan)%*%DiferenciasG1 NumeradorG1Gehan<-t(PesosGehan)%*%DiferenciasG1 NumeradorG2Gehan<-t(PesosGehan)%*%DiferenciasG2 DenominadorGehan<-t((PesosGehan*PesosGehan)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoGehan<-NumeradorGehan*NumeradorGehan/DenominadorGehan EstadisticoGehan p.valorGehan<-1-pchisq(EstadisticoGehan,df=1) p.valorGehan DenominadorG1Gehan<-t((PesosGehan*PesosGehan)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) DenominadorG1G2Gehan<-t((PesosGehan*PesosGehan)*CoVarianzan.eventG1G2)%*%matrix(1,nrow(n.event),1) MatrizVarianza<-matrix(c(DenominadorG1Gehan,DenominadorG1G2Gehan, DenominadorG1G2Gehan,DenominadorG1Gehan), nrow=2,ncol=2) MatrizVarianzainversa<-solve(MatrizVarianza) VectordediferenciasGehan<-matrix(c(NumeradorG1Gehan,NumeradorG2Gehan),nrow=2,ncol=1) EstadísticoGehanChi.cuadrado<-t(VectordediferenciasGehan)%*%MatrizVarianzainversa%*%VectordediferenciasGehan p.valorGehan<-1-pchisq(EstadísticoGehanChi.cuadrado,df=2) p.valorGehan #____________________________________________________________________ PesosTaroneWare<-sqrt(GruporeferenciaGG[,2]) NumeradorTaroneWare<-t(PesosTaroneWare)%*%DiferenciasG1 DenominadorTaroneWare<-t((PesosTaroneWare*PesosTaroneWare)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoTaroneWare<-NumeradorTaroneWare*NumeradorTaroneWare/DenominadorTaroneWare EstadisticoTaroneWare p.valorTaroneWare<-1-pchisq(EstadisticoTaroneWare,df=1) p.valorTaroneWare #____________________________________________________________________ supervivencia<-matrix(summary(fit2)) nnn<-nrow(supervivencia)/4 Supervivencia<-supervivencia[(3*nnn+1):(4*nnn),1] PesosPetoPeto<-Supervivencia NumeradorPetoPeto<-t(PesosPetoPeto)%*%DiferenciasG1 DenominadorPetoPeto<-t((PesosPetoPeto*PesosPetoPeto)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoPetoPeto<-NumeradorPetoPeto*NumeradorPetoPeto/DenominadorPetoPeto EstadisticoPetoPeto p.valorPetoPeto<-1-pchisq(EstadisticoPetoPeto,df=1) p.valorPetoPeto

Apéndices ______________________________________________________________________
224
#____________________________________________________________________ supervivencia<-matrix(summary(fit2)) nnn<-nrow(supervivencia)/4 factor<-(GruporeferenciaGG[,2]/(GruporeferenciaGG[,2]+matrix(1,nnn,1))) Supervivencia<-factor*supervivencia[(3*nnn+1):(4*nnn),1] PesosPetoMod<-Supervivencia NumeradorPetoMod<-t(PesosPetoMod)%*%DiferenciasG1 DenominadorPetoMod<-t((PesosPetoMod*PesosPetoMod)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoPetoMod<-NumeradorPetoMod*NumeradorPetoMod/DenominadorPetoMod EstadisticoPetoMod p.valorPetoMod<-1-pchisq(EstadisticoPetoMod,df=1) p.valorPetoMod #____________________________________________________________________ supervivencia<-matrix(summary(fit2)) nnn<-nrow(supervivencia)/4 Supervivencia<-supervivencia[(3*nnn+1):(4*nnn),1] supe<-supervivencia[(3*nnn+1):(4*nnn-1),1] PesosPetoPrentice<-matrix(c(1,supe),nnn,1) NumeradorPetoPrentice<-t(PesosPetoPrentice)%*%DiferenciasG1 DenominadorPetoPrentice<-t((PesosPetoPrentice*PesosPetoPrentice)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoPetoPrentice<-NumeradorPetoPrentice*NumeradorPetoPrentice/DenominadorPetoPeto EstadisticoPetoPrentice p.valorPetoPrentice<-1-pchisq(EstadisticoPetoPrentice,df=1) p.valorPetoPrentice #____________________________________________________________________ PesosHF<-(PesosPetoPeto)^(1)*(matrix(1,nrow(n.event))-PesosPetoPeto)^(1) NumeradorHF<-t(PesosHF)%*%DiferenciasG1 DenominadorHF<-t((PesosHF*PesosHF)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoHF<-NumeradorHF*NumeradorHF/DenominadorHF EstadisticoHF p.valorHF<-1-pchisq(EstadisticoHF,df=1) p.valorHF #____________________________________________________________________ PesosCM<-(PesosPetoPeto)^(1)*(matrix(1,nrow(n.event))-PesosPetoPeto)^(1)* (PesosGehan)^(0)*(PesosGehan+matrix(1,nrow(n.event),1))^(0) NumeradorCM<-t(PesosCM)%*%DiferenciasG1 DenominadorCM<-t((PesosCM*PesosCM)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoCM1100<-NumeradorCM*NumeradorCM/DenominadorCM EstadisticoCM1100 p.valorCM1100<-1-pchisq(EstadisticoCM1100,df=1) p.valorCM1100 #____________________________________________________________________ PesosCM<-(PesosPetoPeto)^(0)*(matrix(1,nrow(n.event))-PesosPetoPeto)^(0)* (PesosGehan)^(0)*(PesosGehan+matrix(1,nrow(n.event),1))^(0) NumeradorCM<-t(PesosCM)%*%DiferenciasG1

Apéndices ______________________________________________________________________
225
DenominadorCM<-t((PesosCM*PesosCM)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoCM0000<-NumeradorCM*NumeradorCM/DenominadorCM EstadisticoCM0000 p.valorCM0000<-1-pchisq(EstadisticoCM0000,df=1) p.valorCM0000 #____________________________________________________________________ PesosCM<-(PesosPetoPeto)^(0)*(matrix(1,nrow(n.event))-PesosPetoPeto)^(0)* (PesosGehan)^(1)*(PesosGehan+matrix(1,nrow(n.event),1))^(0) NumeradorCM<-t(PesosCM)%*%DiferenciasG1 DenominadorCM<-t((PesosCM*PesosCM)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoCM0010<-NumeradorCM*NumeradorCM/DenominadorCM EstadisticoCM0010 p.valorCM0010<-1-pchisq(EstadisticoCM0010,df=1) p.valorCM0010 #____________________________________________________________________ PesosCM<-(PesosPetoPeto)^(0)*(matrix(1,nrow(n.event))-PesosPetoPeto)^(0)* (PesosGehan)^(1/2)*(PesosGehan+matrix(1,nrow(n.event),1))^(0) NumeradorCM<-t(PesosCM)%*%DiferenciasG1 DenominadorCM<-t((PesosCM*PesosCM)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoCM00.50<-NumeradorCM*NumeradorCM/DenominadorCM EstadisticoCM00.50 p.valorCM00.50<-1-pchisq(EstadisticoCM00.50,df=1) p.valorCM00.50 #____________________________________________________________________ PesosCM<-(PesosPetoPeto)^(1)*(matrix(1,nrow(n.event))-PesosPetoPeto)^(0)* (PesosGehan)^(0)*(PesosGehan+matrix(1,nrow(n.event),1))^(0) NumeradorCM<-t(PesosCM)%*%DiferenciasG1 DenominadorCM<-t((PesosCM*PesosCM)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoCM1000<-NumeradorCM*NumeradorCM/DenominadorCM EstadisticoCM1000 p.valorCM1000<-1-pchisq(EstadisticoCM1000,df=1) p.valorCM1000 #____________________________________________________________________ PesosCM<-(PesosPetoPeto)^(1)*(matrix(1,nrow(n.event))-PesosPetoPeto)^(1)* (PesosGehan)^(1)*(PesosGehan+matrix(1,nrow(n.event),1))^(-1) NumeradorCM<-t(PesosCM)%*%DiferenciasG1 DenominadorCM<-t((PesosCM*PesosCM)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoCM111N1<-NumeradorCM*NumeradorCM/DenominadorCM EstadisticoCM111N1 p.valorCM111N1<-1-pchisq(EstadisticoCM111N1,df=1) p.valorCM111N1 #____________________________________________________________________ Wc<-matrix(NA,nrow(time),1) Wctime<-matrix(NA,nrow(time),1) Wj<-matrix(NA,nrow(time),1)

Apéndices ______________________________________________________________________
226
Wtime<-matrix(NA,nrow(time),1) Wj<- -log(fit2$surv) Wc[1,1]<-Wj[1] for (i in 2:nrow(time)) Wc[i,1]<- Wj[i]-Wj[i-1] for (i in 1:nrow(time)) if (time[i,1]==0) Wtime[i,1]<-0.0001 else Wtime[i,1]<-time[i,1] Wctime[1,1]<-Wtime[1,1] for (i in 2:nrow(time)) Wctime[i,1]<-Wtime[i,1]-Wtime[i-1,1] peso<-Wc/Wctime PesosCarlos<-round((PesosGehan)/n.event,3) #PesosCarlos<-round((PesosGehan-n.event)/(PesosGehan),3) #if (PesosGehan[m] == n.event[m,1]) #PesosCarlos[1:m-1]<-(PesosGehan[1:m-1]/(PesosGehan[1:m-1]-n.event[1:m-1,1])) #PesosCarlos[m]<-1 #PesosCarlos<-round((PesosGehan/Wc),3) #Sp<- PesosPetoPrentice #Sp1<-matrix(NA,nrow(time),1) #Sp1[1,1]<-1-Sp[1,1] #for (i in 2:nrow(time)) Sp1[i,1]<-Sp[i-1,1]-Sp[i,1] #Wj[1,1]<-Sp1[1,1]/(Wc[1,1]) #for (i in 2:nrow(time)) Wj[i,1]<- Sp1[i,1]/((Wc[i,1])) #PesosCarlos<-round(PesosGehan/(n.event),3) #PesosCarlos<-round(matrix(1/n.event),3) NumeradorCarlos<-t(PesosCarlos)%*%DiferenciasG1 DenominadorCarlos<-t((PesosCarlos*PesosCarlos)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoCarlos<-NumeradorCarlos*NumeradorCarlos/DenominadorCarlos EstadisticoCarlos p.valorCarlos<-1-pchisq(EstadisticoCarlos,df=1) p.valorCarlos #____________________________________________________________________ Nomb.Est<-matrix(c("Logrank", "Gehan", "Tarone Ware", "Peto Peto", "Peto Mod.", "Peto Prentice", "H-F p1=0, p2=0", "CM p1=0, p2=0, p3=0, p4= 0", "CM p1=0, p2=0, p3=1, p4= 0", "CM p1=0, p2=0, p3=1/2, p4= 0", "CM p1=1, p2=0, p3=0 , p4= 0", "CM p1=1, p2=0, p3=1, p4=-1", "Martinez")) Estadisticos<-matrix(c(EstadísticoLogRankChi.cuadrado, EstadisticoGehan, EstadisticoTaroneWare, EstadisticoPetoPeto, EstadisticoPetoMod, EstadisticoPetoPrentice, EstadisticoHF, EstadisticoCM1100, EstadisticoCM0010, EstadisticoCM00.50, EstadisticoCM1000, EstadisticoCM111N1,EstadisticoCarlos))

Apéndices ______________________________________________________________________
227
p.valores <-round(matrix(c(p.valorLR, p.valorGehan, p.valorTaroneWare, p.valorPetoPeto, p.valorPetoMod, p.valorPetoPrentice, p.valorHF, p.valorCM1100, p.valorCM0010, p.valorCM00.50, p.valorCM1000, p.valorCM111N1,p.valorCarlos)),7) tabla<-data.frame(Nomb.Est,Chi.cuadrado=Estadisticos,p.valor=p.valores) if (p.valorLR<0.10) contadorW10p<-contadorW10p+1 if (p.valorLR<0.05) contadorW5p<-contadorW5p+1 if (p.valorLR<0.01) contadorW1p<-contadorW1p+1 if (p.valorGehan<0.10) contadorG10p<-contadorG10p+1 if (p.valorGehan<0.05) contadorG5p<-contadorG5p+1 if (p.valorGehan<0.01) contadorG1p<-contadorG1p+1 if (p.valorTaroneWare<0.10) contadorTW10p<-contadorTW10p+1 if (p.valorTaroneWare<0.05) contadorTW5p<-contadorTW5p+1 if (p.valorTaroneWare<0.01) contadorTW1p<-contadorTW1p+1 if (p.valorPetoPeto<0.10) contadorPP10p<-contadorPP10p+1 if (p.valorPetoPeto<0.05) contadorPP5p<-contadorPP5p+1 if (p.valorPetoPeto<0.01) contadorPP1p<-contadorPP1p+1 if (p.valorPetoMod<0.10) contadorPM10p<-contadorPM10p+1 if (p.valorPetoMod<0.05) contadorPM5p<-contadorPM5p+1 if (p.valorPetoMod<0.01) contadorPM1p<-contadorPM1p+1 if (p.valorPetoPrentice<0.10) contadorPPr10p<-contadorPPr10p+1 if (p.valorPetoPrentice<0.05) contadorPPr5p<-contadorPPr5p+1 if (p.valorPetoPrentice<0.01) contadorPPr1p<-contadorPPr1p+1 if (p.valorHF<0.10) contadorHF10p<-contadorHF10p+1 if (p.valorHF<0.05) contadorHF5p<-contadorHF5p+1 if (p.valorHF<0.01) contadorHF1p<-contadorHF1p+1 if (p.valorCM1100<0.10) contadorFH10p<-contadorFH10p+1 if (p.valorCM1100<0.05) contadorFH5p<-contadorFH5p+1 if (p.valorCM1100<0.01) contadorFH1p<-contadorFH1p+1 if (p.valorCM111N1<0.10) contadorCM10p<-contadorCM10p+1 if (p.valorCM111N1<0.05) contadorCM5p<-contadorCM5p+1 if (p.valorCM111N1<0.01) contadorCM1p<-contadorCM1p+1 if (p.valorCarlos<0.10) contadorCarlos10p<-contadorCarlos10p+1 if (p.valorCarlos<0.05) contadorCarlos5p<-contadorCarlos5p+1 if (p.valorCarlos<0.01) contadorCarlos1p<-contadorCarlos1p+1 print(conta) #=====================================================================fit1<-survfitr(Survr(id,time,event)~as.factor(muestra),data=XL,type="pe") fit2<-survfitr(Survr(id,time,event)~1,data=XL,type="pe") print(summary(fit1)) print(summary(fit2)) MedianaGPLECombinada<-q.search(fit2,q=0.50) MedianaGPLGrupo01<-q.search(fit1$"1",q=0.50) MedianaGPLGrupo02<-q.search(fit1$"2",q=0.50) MedianaGPLGrupo03<-q.search(fit1$"3",q=0.50) MedianaGPLECombinada MedianaGPLGrupo01 MedianaGPLGrupo02

Apéndices ______________________________________________________________________
228
MedianaGPLGrupo03 X11() plot(fit2$time,fit2$survfunc,xlab="tiempo", ylab="Probabilidad de supervivencia", ylim=c(0,1.05),type="l",col = "blue", lwd=1) title(main=list("COMPARACIÓN DE FUNCIONES DE SUPERVIVENCIA", cex = 0.8, font = 2.3,col = "blue")) mtext("Software realizado por: Carlos Martínez", cex = 0.7, font = 2,col = "purple",line=1) mtext(kDis,cex = 0.7, font = 2,col = "black",line=3) lines(fit1$"1"$time,fit1$"1"$survfunc, type = "l",lty=2, col = "red") lines(fit1$"2"$time,fit1$"2"$survfunc, type = "l",lty=3, col = "black") lines(fit1$"3"$time,fit1$"3"$survfunc, type = "l",lty=4, col = "green") legend("right",c("Muestra combinada","Grupo 01","Grupo 02","Grupo 03"), col =c("blue","red","black","green"),lty=c(1,2,3,4),cex=0.8) X11() plot(fit2$time,-log(fit2$surv),xlab="tiempo", ylab="Riesgos acumulados", type="s",col = "blue", lwd=1) title(main=list("ESTIMACIÓN DE LA FUNCIÓN DE RIESGO", cex = 0.8, font = 2.3,col = "blue")) mtext("Software realizado por: Carlos Martínez", cex = 0.7, font = 2,col = "purple",line=1) legend("right",c("Modelo GPLE"), col =c("blue"),lty=c(1),cex=0.8) X11() plot(1:nrow(time),PesosCarlos) print("Logrank") print(contadorW10p*100/To) print(contadorW5p*100/To) print(contadorW1p*100/To) print("--------") print("Gehan") print(contadorG10p*100/To) print(contadorG5p*100/To) print(contadorG1p*100/To) print("--------") print("Tarone-Ware") print(contadorTW10p*100/To) print(contadorTW5p*100/To) print(contadorTW1p*100/To) print("--------") print("Peto-Peto") print(contadorPP10p*100/To) print(contadorPP5p*100/To) print(contadorPP1p*100/To) print("--------") print("Peto Modificado") print(contadorPM10p*100/To) print(contadorPM5p*100/To) print(contadorPM1p*100/To) print("--------") print("Peto-Prentice") print(contadorPPr10p*100/To) print(contadorPPr5p*100/To) print(contadorPPr1p*100/To) print("--------")

Apéndices ______________________________________________________________________
229
print("Fleming-Harrington-Osullivan") print(contadorHF10p*100/To) print(contadorHF5p*100/To) print(contadorHF1p*100/To) print("--------") print("Fleming-Harrington") print(contadorFH10p*100/To) print(contadorFH5p*100/To) print(contadorFH1p*100/To) print("--------") print("Martinez") print(contadorCM10p*100/To) print(contadorCM5p*100/To) print(contadorCM1p*100/To) print("--------") print("Carlos") print(contadorCarlos10p*100/To) print(contadorCarlos5p*100/To) print(contadorCarlos1p*100/To) tomavalores()

Apéndices ______________________________________________________________________
230
APÉNDICE F
Programa para comparar las curvas de supervivencia GPLE de dos subgrupos
require(survrec) fn<-choose.files(filters=Filters[c('txt'),],index=4) nombre<-as.character(fn) XL<-read.table(nombre, header = TRUE,fill = TRUE) XL<-fix(XL) XL x<-factor(XL$group) Factores<-x x<-c(levels(x)) Nivelesdefactores<-matrix(x) #====================================================================== fit1<-survfitr(Survr(id,time,event)~as.factor(group),data=XL,type="pe") fit2<-survfitr(Survr(id,time,event)~1,data=XL,type="pe") print(summary(fit1)) print(summary(fit2)) fit1[[Nivelesdefactores[1,1]]] fit1[[Nivelesdefactores[2,1]]] MedianaGPLECombinada<-q.search(fit2,q=0.50) MedianaGPLGrupo01<-q.search(fit1[[Nivelesdefactores[1,1]]],q=0.50) MedianaGPLGrupo02<-q.search(fit1[[Nivelesdefactores[2,1]]],q=0.50) MedianaGPLECombinada MedianaGPLGrupo01 MedianaGPLGrupo02 #====================================================================== plot(fit2$time,fit2$survfunc,xlab="tiempo", ylab="Probabilidad de supervivencia estimada",xlim=c(0,0.95*max(fit2$time)), ylim=c(0,1.05),type="s",col = "blue", lwd=1) title(main=list("ESTIMACIÓN DE LA FUNCIÓN DE SUPERVIVENCIA", cex = 0.8, font = 2.3,col = "blue")) mtext("Software realizado por: Carlos Martínez", cex = 0.7, font = 2,col = "purple",line=1) lines(fit1[[Nivelesdefactores[1,1]]]$time, fit1[[Nivelesdefactores[1,1]]]$survfunc, type = "s",lty=2, col = "red") lines(fit1[[Nivelesdefactores[2,1]]]$time, fit1[[Nivelesdefactores[2,1]]]$survfunc, type = "s",lty=3, col = "black") legend("topright",c("Muestra combinada","Grupo tratado","Grupo control"), col =c("blue","red","black"),lty=c(1,2,3),cex=0.8) #====================================================================== failed<-matrix(fit2$failed) censored<-matrix(fit2$censored) time<-matrix(fit2$time) n.event<-matrix(fit2$n.event) AtRisk<-matrix(fit2$AtRisk) m<-fit2$m k<-matrix(m)

Apéndices ______________________________________________________________________
231
#================================================================= mm<-0 m<-0 nn<-0 for (z in 1:10) nom<-as.character(paste("Unidad = ",z,"\n")) m<-k[z,1] nn<-mm+1 timebase<-0 tiempocalendario1=matrix(0,nrow=m+2,ncol=1) x1<-matrix(0,nrow=m+2,ncol=1) x2<-matrix(0,nrow=m+2,ncol=1) y1<-matrix(0,nrow=m+2,ncol=1) y2<-matrix(0,nrow=m+2,ncol=1) tiempocalendario1[1,1]<-0 x1[1,1]<-0 x2[1,1]<-0 y1[1,1]<-0 y2[1,1]<-0 for (i in 2:(m+2)) if (i<m+2) timebase<-timebase+failed[i-1+mm,1]; tiempocalendario1[i,1]<-timebase if (i==(m+2)) timebase<-timebase+censored[z,1]; tiempocalendario1[i,1]<-timebase rx <<- max(tiempocalendario1[1:(m+2),1]) ry <<-max(failed[nn:(nn+m-1),1],censored[z,1]) X11() plot(0:1.01*rx,0:1.01*ry, xlab = "Tiempo calendario", ylab = "Tiempo interocurrencia") title(main=nom) mtext("Software realizado por: Carlos Martínez", cex = 0.7, font = 2,col = "purple",line=1) mtext("Doctorado en estadística: UCV 2006", cex = 0.6, font = 2,col = "blue",line=1.5) abline(h = 0, col = gray(.90)) abline(v = tiempocalendario1[(m+2),1], col = gray(.90)) r<-1 for (r in (1:(m+2))) if (r<(m+2-1)) x1[r,1]<-tiempocalendario1[r,1] y1[r,1]<-tiempocalendario1[1,1] x2[r,1]<-tiempocalendario1[(r+1),1] y2[r,1]<-failed[(r+mm),1] if (r<(m+2-1)) segments(x1[r,1],y1[r,1],x2[r,1],y2[r,1],lty=1,col = "red") abline(h = y2[r,1], col = gray(.90)) abline(v = x2[r,1], col = gray(.90)) text(x2[r,1],y2[r,1],labels=y2[r,1],adj=c(0,1),cex=0.7,pos="2")

Apéndices ______________________________________________________________________
232
if (r==(m+2)) x1[r,1]<-tiempocalendario1[(r-1),1] y1[r,1]<-tiempocalendario1[1,1] x2[r,1]<-tiempocalendario1[(m+2),1] y2[r,1]<-censored[z,1] segments(x1[r,1],y1[r,1],x2[r,1],y2[r,1],lty=1,col = "red") abline(h = y2[r,1], col = gray(.90)) abline(v = x2[r,1], col = gray(.90)) text(x2[r,1],y2[r,1],labels=y2[r,1],adj=c(0,1),cex=0.7,pos="2") mm<-mm+m #================================================================= x.anterior<-0 y.anterior<-0 mousedown <- function(buttons, x, y) if (x > 0.2019003 && y > 0.2452379 && x < 0.909739 && y < 0.8261904) abline(h = ry*(y.anterior-0.2428570)/(0.8023809-0.2428570)+0.2428570, col = gray(.90)); abline(v = rx*(x.anterior-0.2019003)/(0.87886-0.2019003)+0.2019003, col = gray(.90)); abline(h = ry*(y-0.2428570)/(0.8023809-0.2428570)+0.2428570, col = "blue"); abline(v = rx*(x-0.2019003)/(0.87886-0.2019003)+0.2019003, col = "blue") x.anterior<<-x y.anterior<<-y box() #NULL #================================================================= n<-ncol(matrix(fit2$time)) m<-nrow(matrix(fit2$time)) n1<-ncol(matrix(fit1[[Nivelesdefactores[1,1]]]$time)) m1<-nrow(matrix(fit1[[Nivelesdefactores[1,1]]]$time)) I<-matrix(1,m,1) X<-matrix(fit2$time) Y<-matrix(fit1[[Nivelesdefactores[1,1]]]$time) Z<-matrix(fit1[[Nivelesdefactores[1,1]]]$censored) Tiempo1<-matrix(0,m,1) n.eventG1<-matrix(0,m,1) NEG1<-matrix(fit1[[Nivelesdefactores[1,1]]]$n.event) Ariesgo<-matrix(0,m,1) cuenta<-matrix(0,m,1) Ncensura<-matrix(0,m,1) AriesgoG1<-matrix(0,m,1) mm<-nrow(X) #================================================================= tiempocensura<-matrix(fit1[[Nivelesdefactores[1,1]]]$censored) for (z in 1:m) for (zz in 1:m1)if (X[z,1]== Y[zz,1])Tiempo1[z,1]<-Y[zz,1]; n.eventG1[z,1]<-NEG1[zz,1];zz<-m1 else Tiempo1[z,1]<-X[z,1] data.frame(Tiempo=Tiempo1,n.eventosG1=n.eventG1) AriesgoG1tiempo1<-t(fit1[[Nivelesdefactores[1,1]]]$AtRisk)%*% matrix(1,nrow(fit1[[Nivelesdefactores[1,1]]]$AtRisk),1)

Apéndices ______________________________________________________________________
233
N<-fit1[[Nivelesdefactores[1,1]]]$n+t(fit1[[Nivelesdefactores[1,1]]]$m)%*% matrix(1,nrow(fit1[[Nivelesdefactores[1,1]]]$m),1) data.frame(Tiempo=Y,AriesgoG1tiempo1=AriesgoG1tiempo1) for (z in 1:m) cuenta[z,1]<-0 for (zz in 1:nrow(tiempocensura) )if (tiempocensura[zz,1]<=Tiempo1[z,1]) cuenta[z,1]<-cuenta[z,1]+1 data.frame(Tiempo=Tiempo1,cuenta=cuenta) for (z in 1:m-1) Ncensura[z,1]<--cuenta[z,1]+cuenta[z+1,1] data.frame(Tiempo=Tiempo1,Ncensuras=Ncensura) Ariesgot0<-N Ariesgo[1,1]<-N-cuenta[1,1] AriesgoG1tiempoG1<-t(fit1[[Nivelesdefactores[1,1]]]$AtRisk)%*% matrix(1,nrow(fit1[[Nivelesdefactores[1,1]]]$AtRisk),1) for (z in 1:m) for (zz in 1:m1) if (X[z,1]== Y[zz,1]) Ariesgo[z,1]<-AriesgoG1tiempoG1[zz,1] data.frame(Tiempo=Tiempo1,Ariesgo=Ariesgo) for (z in 2:m) if (Ariesgo[z,1]==0) Ariesgo[z,1]<-Ariesgo[z-1,1]-Ncensura[z-1,1]-n.eventG1[z-1,1] data.frame(Tiempo=Tiempo1,Ariesgo=Ariesgo,n.eventG1=n.eventG1,Ncensura=Ncensura) for (z in 1:m) AriesgoG1[z,1]<-Ariesgo[z,1] AriesgoTotal<-t(fit2$AtRisk)%*% matrix(1,nrow(fit2$AtRisk),1) NTotal<-fit2$n+t(fit2$m)%*% matrix(1,nrow(fit2$m),1) G1<-AriesgoG1*(AriesgoTotal-AriesgoG1)*n.event*(AriesgoTotal-n.event) Varianzan.eventG1<-G1/((AriesgoTotal*AriesgoTotal)*(AriesgoTotal-matrix(1,nrow(n.event),1))) for (jj in 1:nrow(Varianzan.eventG1)) if (Varianzan.eventG1[jj,1]=="NaN") Varianzan.eventG1[jj,1]<-0 ValoresesperadoG1<-AriesgoG1*n.event*(1/AriesgoTotal) #____________________________________________________________________ Pesos<-matrix(1,nrow(n.event),1) Diferencias<-n.eventG1-ValoresesperadoG1 Numerador<-t(Pesos*Diferencias)%*%matrix(1,nrow(n.event),1) Denominador<-t((Pesos*Pesos)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadísticoWilcoxonChi.cuadrado<-Numerador*Numerador/Denominador GruporeferenciaGT <-cbind(Tiempo1,AriesgoTotal,n.event) GruporeferenciaG1 <-cbind(Tiempo1,AriesgoG1,n.eventG1) Gruporeferencia <-cbind(Tiempo1,ValoresesperadoG1,Varianzan.eventG1) GruporeferenciaGG<-cbind(GruporeferenciaGT,AriesgoG1,n.eventG1) GruporeferenciaGG data.frame(Tiempo=Tiempo1,Valor.esp=ValoresesperadoG1,Varianza=Varianzan.eventG1) EstadísticoWilcoxonChi.cuadrado p.valorW<-1-pchisq(EstadísticoWilcoxonChi.cuadrado,df=1) p.valorW #____________________________________________________________________ PesosGehan<-GruporeferenciaGG[,2] NumeradorGehan<-t(PesosGehan)%*%Diferencias DenominadorGehan<-t((PesosGehan*PesosGehan)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoGehan<-NumeradorGehan*NumeradorGehan/DenominadorGehan EstadisticoGehan p.valorGehan<-1-pchisq(EstadisticoGehan,df=1) p.valorGehan #____________________________________________________________________

Apéndices ______________________________________________________________________
234
#____________________________________________________________________ PesosTaroneWare<-sqrt(GruporeferenciaGG[,2]) NumeradorTaroneWare<-t(PesosTaroneWare)%*%Diferencias DenominadorTaroneWare<-t((PesosTaroneWare*PesosTaroneWare)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoTaroneWare<-NumeradorTaroneWare*NumeradorTaroneWare/DenominadorTaroneWare EstadisticoTaroneWare p.valorTaroneWare<-1-pchisq(EstadisticoTaroneWare,df=1) p.valorTaroneWare #____________________________________________________________________ supervivencia<-matrix(summary(fit2)) nnn<-nrow(supervivencia)/4 Supervivencia<-supervivencia[(3*nnn+1):(4*nnn),1] PesosPetoPeto<-Supervivencia NumeradorPetoPeto<-t(PesosPetoPeto)%*%Diferencias DenominadorPetoPeto<-t((PesosPetoPeto*PesosPetoPeto)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoPetoPeto<-NumeradorPetoPeto*NumeradorPetoPeto/DenominadorPetoPeto EstadisticoPetoPeto p.valorPetoPeto<-1-pchisq(EstadisticoPetoPeto,df=1) p.valorPetoPeto #____________________________________________________________________ supervivencia<-matrix(summary(fit2)) nnn<-nrow(supervivencia)/4 factor<-(GruporeferenciaGG[,2]/(GruporeferenciaGG[,2]+matrix(1,nnn,1))) Supervivencia<-factor*supervivencia[(3*nnn+1):(4*nnn),1] PesosPetoMod<-Supervivencia NumeradorPetoMod<-t(PesosPetoMod)%*%Diferencias DenominadorPetoMod<-t((PesosPetoMod*PesosPetoMod)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoPetoMod<-NumeradorPetoMod*NumeradorPetoMod/DenominadorPetoMod EstadisticoPetoMod p.valorPetoMod<-1-pchisq(EstadisticoPetoMod,df=1) p.valorPetoMod #____________________________________________________________________ supervivencia<-matrix(summary(fit2)) nnn<-nrow(supervivencia)/4 Supervivencia<-supervivencia[(3*nnn+1):(4*nnn),1] supe<-supervivencia[(3*nnn+1):(4*nnn-1),1] PesosPetoPrentice<-matrix(c(1,supe),nnn,1) NumeradorPetoPrentice<-t(PesosPetoPrentice)%*%Diferencias DenominadorPetoPrentice<-t((PesosPetoPrentice*PesosPetoPrentice)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoPetoPrentice<-NumeradorPetoPrentice*NumeradorPetoPrentice/DenominadorPetoPeto EstadisticoPetoPrentice p.valorPetoPrentice<-1-pchisq(EstadisticoPetoPrentice,df=1) p.valorPetoPrentice #____________________________________________________________________

Apéndices ______________________________________________________________________
235
PesosHF<-(PesosPetoPeto)^(0)*(matrix(1,nrow(n.event))-PesosPetoPeto)^(0) NumeradorHF<-t(PesosHF)%*%Diferencias DenominadorHF<-t((PesosHF*PesosHF)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoHF<-NumeradorHF*NumeradorHF/DenominadorHF EstadisticoHF p.valorHF<-1-pchisq(EstadisticoHF,df=1) p.valorHF #____________________________________________________________________ PesosCM<-(PesosPetoPeto)^(0)*(matrix(1,nrow(n.event))-PesosPetoPeto)^(0)* (PesosGehan)^(0)*(PesosGehan+matrix(1,nrow(n.event),1))^(0) NumeradorCM<-t(PesosCM)%*%Diferencias DenominadorCM<-t((PesosCM*PesosCM)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoCM0000<-NumeradorCM*NumeradorCM/DenominadorCM EstadisticoCM0000 p.valorCM0000<-1-pchisq(EstadisticoCM0000,df=1) p.valorCM0000 #____________________________________________________________________ PesosCM<-(PesosPetoPeto)^(0)*(matrix(1,nrow(n.event))-PesosPetoPeto)^(0)* (PesosGehan)^(1)*(PesosGehan+matrix(1,nrow(n.event),1))^(0) NumeradorCM<-t(PesosCM)%*%Diferencias DenominadorCM<-t((PesosCM*PesosCM)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoCM0010<-NumeradorCM*NumeradorCM/DenominadorCM EstadisticoCM0010 p.valorCM0010<-1-pchisq(EstadisticoCM0010,df=1) p.valorCM0010 #____________________________________________________________________ PesosCM<-(PesosPetoPeto)^(0)*(matrix(1,nrow(n.event))-PesosPetoPeto)^(0)* (PesosGehan)^(1/2)*(PesosGehan+matrix(1,nrow(n.event),1))^(0) NumeradorCM<-t(PesosCM)%*%Diferencias DenominadorCM<-t((PesosCM*PesosCM)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoCM00.50<-NumeradorCM*NumeradorCM/DenominadorCM EstadisticoCM00.50 p.valorCM00.50<-1-pchisq(EstadisticoCM00.50,df=1) p.valorCM00.50 #____________________________________________________________________ PesosCM<-(PesosPetoPeto)^(1)*(matrix(1,nrow(n.event))-PesosPetoPeto)^(0)* (PesosGehan)^(0)*(PesosGehan+matrix(1,nrow(n.event),1))^(0) NumeradorCM<-t(PesosCM)%*%Diferencias DenominadorCM<-t((PesosCM*PesosCM)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoCM1000<-NumeradorCM*NumeradorCM/DenominadorCM EstadisticoCM1000 p.valorCM1000<-1-pchisq(EstadisticoCM1000,df=1) p.valorCM1000 #____________________________________________________________________

Apéndices ______________________________________________________________________
236
PesosCM<-(PesosPetoPeto)^(1)*(matrix(1,nrow(n.event))-PesosPetoPeto)^(0)* (PesosGehan)^(1)*(PesosGehan+matrix(1,nrow(n.event),1))^(-1) NumeradorCM<-t(PesosCM)%*%Diferencias DenominadorCM<-t((PesosCM*PesosCM)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoCM101N1<-NumeradorCM*NumeradorCM/DenominadorCM EstadisticoCM101N1 p.valorCM101N1<-1-pchisq(EstadisticoCM101N1,df=1) p.valorCM101N1 #____________________________________________________________________ PesosCarlos<-((PesosGehan-n.event)/(PesosGehan)) #if (PesosGehan[m] == n.event[m,1]) #PesosCarlos[1:m-1]<-(PesosGehan[1:m-1]/(PesosGehan[1:m-1]-n.event[1:m-1,1])) #PesosCarlos[m]<-1 NumeradorCarlos<-t(PesosCarlos)%*%Diferencias DenominadorCarlos<-t((PesosCarlos*PesosCarlos)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoCarlos<-NumeradorCarlos*NumeradorCarlos/DenominadorCarlos EstadisticoCarlos p.valorCarlos<-1-pchisq(EstadisticoCarlos,df=1) p.valorCarlos #____________________________________________________________________ Nomb.Est<-matrix(c("LRrec", "Grec", "TWrec", "PPrec", "PMrec", "PPrrec", "FHrec p1=0, p2=0", "CMrec p1=0, p2=0, p3=0, p4= 0", "CMrec p1=0, p2=0, p3=1, p4= 0", "CMrec p1=0, p2=0, p3=1/2, p4= 0", "CMrec p1=1, p2=0, p3=0 , p4= 0", "CMrec p1=1, p2=0, p3=1, p4=-1", "Mrec")) Estadisticos<-matrix(c(EstadísticoWilcoxonChi.cuadrado, EstadisticoGehan, EstadisticoTaroneWare, EstadisticoPetoPeto, EstadisticoPetoMod, EstadisticoPetoPrentice, EstadisticoHF, EstadisticoCM0000, EstadisticoCM0010, EstadisticoCM00.50, EstadisticoCM1000, EstadisticoCM101N1, EstadisticoCarlos)) p.valores <-round(matrix(c(p.valorW, p.valorGehan, p.valorTaroneWare, p.valorPetoPeto, p.valorPetoMod, p.valorPetoPrentice, p.valorHF,

Apéndices ______________________________________________________________________
237
p.valorCM0000, p.valorCM0010, p.valorCM00.50, p.valorCM1000, p.valorCM101N1,p.valorCarlos)),7) tabla<-data.frame(Nomb.Est,Chi.cuadrado=Estadisticos,p.valor=p.valores) print(tabla) MM<-max(Estadisticos) Estadisticos/MM
Programa para compara las curvas de supervivencia GPLE de tres subgrupos require(survrec) fn<-choose.files(filters=Filters[c('txt'),],index=4) nombre<-as.character(fn) XL<-read.table(nombre, header = TRUE,fill = TRUE) XL<-fix(XL) XL x<-factor(XL$group) Factores<-x x<-c(levels(x)) Nivelesdefactores<-matrix(x) #======================================================================== fit1<-survfitr(Survr(id,time,event)~as.factor(group),data=XL,type="pe") fit2<-survfitr(Survr(id,time,event)~1,data=XL,type="pe") print(summary(fit1)) print(summary(fit2)) fit1[[Nivelesdefactores[1,1]]] fit1[[Nivelesdefactores[2,1]]] fit1[[Nivelesdefactores[3,1]]] MedianaGPLECombinada<-q.search(fit2,q=0.50) MedianaGPLGrupo00<-q.search(fit1[[Nivelesdefactores[1,1]]],q=0.50) MedianaGPLGrupo01<-q.search(fit1[[Nivelesdefactores[2,1]]],q=0.50) MedianaGPLGrupo02<-q.search(fit1[[Nivelesdefactores[3,1]]],q=0.50) MedianaGPLECombinada MedianaGPLGrupo00 MedianaGPLGrupo01 MedianaGPLGrupo02 #======================================================================== plot(fit2$time,fit2$survfunc,xlab="tiempo", ylab="Probabilidad de supervivencia estimada", type="s",col = "blue", lwd=1, xlim =c(0,0.95*max(fit2$time)),ylim=c(0,1)) title(main=list("ESTIMACIÓN DE LA FUNCIÓN DE SUPERVIVENCIA", cex = 0.8, font = 2.3,col = "blue")) mtext("Software realizado por: Carlos Martínez", cex = 0.7, font = 2,col = "purple",line=1) lines(fit1[[Nivelesdefactores[1,1]]]$time, fit1[[Nivelesdefactores[1,1]]]$survfunc, type = "s",lty=2, col = "red") lines(fit1[[Nivelesdefactores[2,1]]]$time, fit1[[Nivelesdefactores[2,1]]]$survfunc, type = "s",lty=2, col = "black")

Apéndices ______________________________________________________________________
238
lines(fit1[[Nivelesdefactores[3,1]]]$time, fit1[[Nivelesdefactores[3,1]]]$survfunc, type = "s",lty=2, col = "green") legend("topright",c("Muestra combinada","Dukes A-B","Dukes C", "Dukes D"),col =c("blue","red","black","green"),lty=c(1,2,3,4),cex=0.8) #======================================================================== failed<-matrix(fit2$failed) censored<-matrix(fit2$censored) time<-matrix(fit2$time) n.event<-matrix(fit2$n.event) AtRisk<-matrix(fit2$AtRisk) m<-fit2$m k<-matrix(m) #================================================================= mm<-0 m<-0 nn<-0 for (z in 1:5) nom<-as.character(paste("Unidad = ",z,"\n")) m<-k[z,1] nn<-mm+1 timebase<-0 tiempocalendario1=matrix(0,nrow=m+2,ncol=1) x1<-matrix(0,nrow=m+2,ncol=1) x2<-matrix(0,nrow=m+2,ncol=1) y1<-matrix(0,nrow=m+2,ncol=1) y2<-matrix(0,nrow=m+2,ncol=1) tiempocalendario1[1,1]<-0 x1[1,1]<-0 x2[1,1]<-0 y1[1,1]<-0 y2[1,1]<-0 for (i in 2:(m+2)) if (i<m+2) timebase<-timebase+failed[i-1+mm,1]; tiempocalendario1[i,1]<-timebase if (i==(m+2)) timebase<-timebase+censored[z,1]; tiempocalendario1[i,1]<-timebase rx <<- max(tiempocalendario1[1:(m+2),1]) ry <<-max(failed[nn:(nn+m-1),1],censored[z,1]) X11() plot(0:1.01*rx,0:1.01*ry, xlab = "Tiempo calendario", ylab = "Tiempo interocurrencia") title(main=nom) mtext("Software realizado por: Carlos Martínez", cex = 0.7, font = 2,col = "purple",line=1) mtext("Doctorado en estadística: UCV 2006", cex = 0.6, font = 2,col = "blue",line=1.5)

Apéndices ______________________________________________________________________
239
abline(h = 0, col = gray(.90)) abline(v = tiempocalendario1[(m+2),1], col = gray(.90)) r<-1 for (r in (1:(m+2))) if (r<(m+2-1)) x1[r,1]<-tiempocalendario1[r,1] y1[r,1]<-tiempocalendario1[1,1] x2[r,1]<-tiempocalendario1[(r+1),1] y2[r,1]<-failed[(r+mm),1] if (r<(m+2-1)) segments(x1[r,1],y1[r,1],x2[r,1],y2[r,1],lty=1,col = "red") abline(h = y2[r,1], col = gray(.90)) abline(v = x2[r,1], col = gray(.90)) text(x2[r,1],y2[r,1],labels=y2[r,1],adj=c(0,1),cex=0.7,pos="2") if (r==(m+2)) x1[r,1]<-tiempocalendario1[(r-1),1] y1[r,1]<-tiempocalendario1[1,1] x2[r,1]<-tiempocalendario1[(m+2),1] y2[r,1]<-censored[z,1] segments(x1[r,1],y1[r,1],x2[r,1],y2[r,1],lty=1,col = "red") abline(h = y2[r,1], col = gray(.90)) abline(v = x2[r,1], col = gray(.90)) text(x2[r,1],y2[r,1],labels=y2[r,1],adj=c(0,1),cex=0.7,pos="2") mm<-mm+m x.anterior<-0 y.anterior<-0 mousedown <- function(buttons, x, y) if (x > 0.2019003 && y > 0.2452379 && x < 0.909739 && y < 0.8261904) abline(h = ry*(y.anterior-0.2428570)/(0.8023809-0.2428570)+0.2428570, col = gray(.90)); abline(v = rx*(x.anterior-0.2019003)/(0.87886-0.2019003)+0.2019003, col = gray(.90)); abline(h = ry*(y-0.2428570)/(0.8023809-0.2428570)+0.2428570, col = "blue"); abline(v = rx*(x-0.2019003)/(0.87886-0.2019003)+0.2019003, col = "blue") x.anterior<<-x y.anterior<<-y box() NULL #================================================================= n<-ncol(matrix(fit2$time)) m<-nrow(matrix(fit2$time)) n1<-ncol(matrix(fit1[[Nivelesdefactores[1,1]]]$time)) m1<-nrow(matrix(fit1[[Nivelesdefactores[1,1]]]$time)) n2<-ncol(matrix(fit1[[Nivelesdefactores[2,1]]]$time)) m2<-nrow(matrix(fit1[[Nivelesdefactores[2,1]]]$time)) n3<-ncol(matrix(fit1[[Nivelesdefactores[3,1]]]$time)) m3<-nrow(matrix(fit1[[Nivelesdefactores[3,1]]]$time))

Apéndices ______________________________________________________________________
240
I<-matrix(1,m,1) X<-matrix(fit2$time) Y1<-matrix(fit1[[Nivelesdefactores[1,1]]]$time) Z1<-matrix(fit1[[Nivelesdefactores[1,1]]]$censored) Y2<-matrix(fit1[[Nivelesdefactores[2,1]]]$time) Z2<-matrix(fit1[[Nivelesdefactores[2,1]]]$censored) Y3<-matrix(fit1[[Nivelesdefactores[3,1]]]$time) Z3<-matrix(fit1[[Nivelesdefactores[3,1]]]$censored) Tiempo1<-matrix(0,m,1) Tiempo2<-matrix(0,m,1) Tiempo3<-matrix(0,m,1) n.eventG1<-matrix(0,m,1) n.eventG2<-matrix(0,m,1) n.eventG3<-matrix(0,m,1) NEG1<-matrix(fit1[[Nivelesdefactores[1,1]]]$n.event) NEG2<-matrix(fit1[[Nivelesdefactores[2,1]]]$n.event) NEG3<-matrix(fit1[[Nivelesdefactores[3,1]]]$n.event) Ariesgo<-matrix(0,m,1) cuenta<-matrix(0,m,1) Ncensura<-matrix(0,m,1) AriesgoG1<-matrix(0,m,1) AriesgoG2<-matrix(0,m,1) AriesgoG3<-matrix(0,m,1) mm<-nrow(X) #================================================================= tiempocensura<-matrix(fit1[[Nivelesdefactores[1,1]]]$censored) for (z in 1:m) for (zz in 1:m1)if (X[z,1]== Y1[zz,1])Tiempo1[z,1]<-Y1[zz,1]; n.eventG1[z,1]<-NEG1[zz,1];zz<-m1 else Tiempo1[z,1]<-X[z,1] data.frame(Tiempo=Tiempo1,n.eventosG1=n.eventG1) AriesgoG1tiempo1<-t(fit1[[Nivelesdefactores[1,1]]]$AtRisk)%*% matrix(1,nrow(fit1[[Nivelesdefactores[1,1]]]$AtRisk),1) N<-fit1[[Nivelesdefactores[1,1]]]$n+t(fit1[[Nivelesdefactores[1,1]]]$m)%*% matrix(1,nrow(fit1[[Nivelesdefactores[1,1]]]$m),1) data.frame(Tiempo=Y1,AriesgoG1tiempo1=AriesgoG1tiempo1) for (z in 1:m) cuenta[z,1]<-0 for (zz in 1:nrow(tiempocensura) )if (tiempocensura[zz,1]<=Tiempo1[z,1]) cuenta[z,1]<-cuenta[z,1]+1 data.frame(Tiempo=Tiempo1,cuenta=cuenta) for (z in 1:m-1) Ncensura[z,1]<--cuenta[z,1]+cuenta[z+1,1] data.frame(Tiempo=Tiempo1,Ncensuras=Ncensura) Ariesgot0<-N Ariesgo[1,1]<-N-cuenta[1,1] AriesgoG1tiempoG1<-t(fit1[[Nivelesdefactores[1,1]]]$AtRisk)%*% matrix(1,nrow(fit1[[Nivelesdefactores[1,1]]]$AtRisk),1) for (z in 1:m) for (zz in 1:m1) if (X[z,1]== Y1[zz,1]) Ariesgo[z,1]<-AriesgoG1tiempoG1[zz,1] data.frame(Tiempo=Tiempo1,Ariesgo=Ariesgo) for (z in 2:m) if (Ariesgo[z,1]==0) Ariesgo[z,1]<-Ariesgo[z-1,1]-Ncensura[z-1,1]-n.eventG1[z-1,1] data.frame(Tiempo=Tiempo1,Ariesgo=Ariesgo,n.eventG1=n.eventG1,Ncensura=Ncensura) for (z in 1:m) AriesgoG1[z,1]<-Ariesgo[z,1] AriesgoTotal<-t(fit2$AtRisk)%*% matrix(1,nrow(fit2$AtRisk),1) NTotal<-fit2$n+t(fit2$m)%*% matrix(1,nrow(fit2$m),1) G1<-AriesgoG1*(AriesgoTotal-AriesgoG1)*n.event*(AriesgoTotal-n.event)

Apéndices ______________________________________________________________________
241
Varianzan.eventG1<-G1/((AriesgoTotal*AriesgoTotal)*(AriesgoTotal-matrix(1,nrow(n.event),1))) for (jj in 1:nrow(Varianzan.eventG1)) if (Varianzan.eventG1[jj,1]=="NaN") Varianzan.eventG1[jj,1]<-0 ValoresesperadoG1<-AriesgoG1*n.event*(1/AriesgoTotal) #================================================================= tiempocensura2<-matrix(fit1[[Nivelesdefactores[2,1]]]$censored) for (z in 1:m) for (zz in 1:m2)if (X[z,1]== Y2[zz,1])Tiempo2[z,1]<-Y2[zz,1]; n.eventG2[z,1]<-NEG2[zz,1];zz<-m2 else Tiempo2[z,1]<-X[z,1] data.frame(Tiempo=Tiempo2,n.eventosG2=n.eventG2) AriesgoG2tiempo2<-t(fit1[[Nivelesdefactores[2,1]]]$AtRisk)%*% matrix(1,nrow(fit1[[Nivelesdefactores[2,1]]]$AtRisk),1) N<-fit1[[Nivelesdefactores[2,1]]]$n+t(fit1[[Nivelesdefactores[2,1]]]$m)%*% matrix(1,nrow(fit1[[Nivelesdefactores[2,1]]]$m),1) data.frame(Tiempo=Y2,AriesgoG2tiempo2=AriesgoG2tiempo2) for (z in 1:m) cuenta[z,1]<-0 for (zz in 1:nrow(tiempocensura2) )if (tiempocensura2[zz,1]<=Tiempo2[z,1]) cuenta[z,1]<-cuenta[z,1]+1 data.frame(Tiempo=Tiempo2,cuenta=cuenta) for (z in 1:m-1) Ncensura[z,1]<--cuenta[z,1]+cuenta[z+1,1] data.frame(Tiempo=Tiempo2,Ncensuras=Ncensura) Ariesgot0<-N AriesgoG2[1,1]<-N-cuenta[1,1] AriesgoG2tiempoG2<-t(fit1[[Nivelesdefactores[2,1]]]$AtRisk)%*% matrix(1,nrow(fit1[[Nivelesdefactores[2,1]]]$AtRisk),1) for (z in 1:m) for (zz in 1:m2) if (X[z,1]== Y2[zz,1]) AriesgoG2[z,1]<-AriesgoG2tiempoG2[zz,1] data.frame(Tiempo=Tiempo2,Ariesgo=AriesgoG2) for (z in 2:m) if (AriesgoG2[z,1]==0) AriesgoG2[z,1]<-AriesgoG2[z-1,1]-Ncensura[z-1,1]-n.eventG2[z-1,1] data.frame(Tiempo=Tiempo2,Ariesgo=AriesgoG2,n.eventG2=n.eventG2,Ncensura=Ncensura) for (z in 1:m) AriesgoG2[z,1]<-AriesgoG2[z,1] AriesgoTotal<-t(fit2$AtRisk)%*% matrix(1,nrow(fit2$AtRisk),1) NTotal<-fit2$n+t(fit2$m)%*% matrix(1,nrow(fit2$m),1) G2<-AriesgoG2*(AriesgoTotal-AriesgoG2)*n.event*(AriesgoTotal-n.event) Varianzan.eventG2<-G2/((AriesgoTotal*AriesgoTotal)*(AriesgoTotal-matrix(1,nrow(n.event),1))) for (jj in 1:nrow(Varianzan.eventG2)) if (Varianzan.eventG2[jj,1]=="NaN") Varianzan.eventG2[jj,1]<-0 ValoresesperadoG2<-AriesgoG2*n.event*(1/AriesgoTotal) #================================================================= tiempocensura3<-matrix(fit1[[Nivelesdefactores[3,1]]]$censored) for (z in 1:m) for (zz in 1:m3)if (X[z,1]== Y3[zz,1])Tiempo3[z,1]<-Y3[zz,1]; n.eventG3[z,1]<-NEG3[zz,1];zz<-m3 else Tiempo3[z,1]<-X[z,1]

Apéndices ______________________________________________________________________
242
data.frame(Tiempo=Tiempo3,n.eventosG3=n.eventG3) AriesgoG3tiempo3<-t(fit1[[Nivelesdefactores[3,1]]]$AtRisk)%*% matrix(1,nrow(fit1[[Nivelesdefactores[3,1]]]$AtRisk),1) N<-fit1[[Nivelesdefactores[3,1]]]$n+t(fit1[[Nivelesdefactores[3,1]]]$m)%*% matrix(1,nrow(fit1[[Nivelesdefactores[3,1]]]$m),1) data.frame(Tiempo=Y3,AriesgoG3tiempo3=AriesgoG3tiempo3) for (z in 1:m) cuenta[z,1]<-0 for (zz in 1:nrow(tiempocensura3) )if (tiempocensura3[zz,1]<=Tiempo3[z,1]) cuenta[z,1]<-cuenta[z,1]+1 data.frame(Tiempo=Tiempo3,cuenta=cuenta) for (z in 1:m-1) Ncensura[z,1]<--cuenta[z,1]+cuenta[z+1,1] data.frame(Tiempo=Tiempo3,Ncensuras=Ncensura) Ariesgot0<-N AriesgoG3[1,1]<-N-cuenta[1,1] AriesgoG3tiempoG3<-t(fit1[[Nivelesdefactores[3,1]]]$AtRisk)%*% matrix(1,nrow(fit1[[Nivelesdefactores[3,1]]]$AtRisk),1) for (z in 1:m) for (zz in 1:m3) if (X[z,1]== Y3[zz,1]) AriesgoG3[z,1]<-AriesgoG3tiempoG3[zz,1] data.frame(Tiempo=Tiempo3,Ariesgo=AriesgoG3) for (z in 2:m) if (AriesgoG3[z,1]==0) AriesgoG3[z,1]<-AriesgoG3[z-1,1]-Ncensura[z-1,1]-n.eventG3[z-1,1] data.frame(Tiempo=Tiempo3,Ariesgo=AriesgoG3,n.eventG3=n.eventG3,Ncensura=Ncensura) for (z in 1:m) AriesgoG3[z,1]<-AriesgoG3[z,1] AriesgoTotal<-t(fit2$AtRisk)%*% matrix(1,nrow(fit2$AtRisk),1) NTotal<-fit2$n+t(fit2$m)%*% matrix(1,nrow(fit2$m),1) G3<-AriesgoG3*(AriesgoTotal-AriesgoG3)*n.event*(AriesgoTotal-n.event) Varianzan.eventG3<-G3/((AriesgoTotal*AriesgoTotal)*(AriesgoTotal-matrix(1,nrow(n.event),1))) for (jj in 1:nrow(Varianzan.eventG3)) if (Varianzan.eventG3[jj,1]=="NaN") Varianzan.eventG3[jj,1]<-0 ValoresesperadoG3<-AriesgoG3*n.event*(1/AriesgoTotal) #================================================================= CovaG1G2<-AriesgoG1*(-AriesgoG2)*n.event*(AriesgoTotal-n.event) CoVarianzan.eventG1G2<-CovaG1G2/((AriesgoTotal*AriesgoTotal)*(AriesgoTotal-matrix(1,nrow(n.event),1))) for (jj in 1:nrow(CoVarianzan.eventG1G2)) if (CoVarianzan.eventG1G2[jj,1]=="NaN") CoVarianzan.eventG1G2[jj,1]<-0 CovaG1G3<-AriesgoG1*(-AriesgoG3)*n.event*(AriesgoTotal-n.event) CoVarianzan.eventG1G3<-CovaG1G3/((AriesgoTotal*AriesgoTotal)*(AriesgoTotal-matrix(1,nrow(n.event),1))) for (jj in 1:nrow(CoVarianzan.eventG1G3)) if (CoVarianzan.eventG1G3[jj,1]=="NaN") CoVarianzan.eventG1G3[jj,1]<-0.0000001 CovaG2G3<-AriesgoG2*(-AriesgoG3)*n.event*(AriesgoTotal-n.event) CoVarianzan.eventG2G3<-CovaG2G3/((AriesgoTotal*AriesgoTotal)*(AriesgoTotal-matrix(1,nrow(n.event),1)))

Apéndices ______________________________________________________________________
243
for (jj in 1:nrow(CoVarianzan.eventG2G3)) if (CoVarianzan.eventG2G3[jj,1]=="NaN") CoVarianzan.eventG2G3[jj,1]<-0.0000001 #____________________________________________________________________ Pesos<-matrix(1,nrow(n.event),1) DiferenciasG1<-n.eventG1-ValoresesperadoG1 DiferenciasG2<-n.eventG2-ValoresesperadoG2 DiferenciasG3<-n.eventG3-ValoresesperadoG3 NumeradorG1<-t(Pesos*DiferenciasG1)%*%matrix(1,nrow(n.event),1) NumeradorG2<-t(Pesos*DiferenciasG2)%*%matrix(1,nrow(n.event),1) NumeradorG3<-t(Pesos*DiferenciasG3)%*%matrix(1,nrow(n.event),1) Numerador<-NumeradorG1+NumeradorG2+NumeradorG3 DenominadorG1<-t((Pesos*Pesos)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) DenominadorG2<-t((Pesos*Pesos)*Varianzan.eventG2)%*%matrix(1,nrow(n.event),1) DenominadorG3<-t((Pesos*Pesos)*Varianzan.eventG3)%*%matrix(1,nrow(n.event),1) Denominador<-DenominadorG1+DenominadorG2+DenominadorG3 EstadísticoLogRankChi.cuadradoestra<-Numerador*Numerador/Denominador EstadísticoLogRankChi.cuadradoestra p.valorLRestra<-1-pchisq(EstadísticoLogRankChi.cuadradoestra,df=1) p.valorLRestra DenominadorG1G2<-t((Pesos*Pesos)*CoVarianzan.eventG1G2)%*%matrix(1,nrow(n.event),1) MatrizVarianza<-matrix(c(DenominadorG1,DenominadorG1G2, DenominadorG1G2,DenominadorG2),nrow=2,ncol=2) MatrizVarianzainversa<-solve(matrix(c(DenominadorG1,DenominadorG1G2, DenominadorG1G2,DenominadorG2),nrow=2,ncol=2)) Vectordediferencias<-matrix(c(NumeradorG1,NumeradorG2),nrow=2,ncol=1) EstadísticoLogRankChi.cuadrado<-t(Vectordediferencias)%*%MatrizVarianzainversa%*%Vectordediferencias p.valorLR<-1-pchisq(EstadísticoLogRankChi.cuadrado,df=2) p.valorLR GruporeferenciaGT <-cbind(Tiempo1,AriesgoTotal,n.event) GruporeferenciaG1 <-cbind(Tiempo1,AriesgoG1,n.eventG1) Gruporeferencia <-cbind(Tiempo1,ValoresesperadoG1,Varianzan.eventG1) GruporeferenciaGG<-cbind(GruporeferenciaGT,AriesgoG1,n.eventG1) GruporeferenciaGG data.frame(Tiempo=Tiempo1,Valor.esp=ValoresesperadoG1,Varianza=Varianzan.eventG1) #____________________________________________________________________ PesosGehan<-GruporeferenciaGG[,2] NumeradorGehan<-t(PesosGehan)%*%DiferenciasG1 NumeradorG1Gehan<-t(PesosGehan)%*%DiferenciasG1 NumeradorG2Gehan<-t(PesosGehan)%*%DiferenciasG2 DenominadorGehan<-t((PesosGehan*PesosGehan)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoGehan<-NumeradorGehan*NumeradorGehan/DenominadorGehan EstadisticoGehan p.valorGehan<-1-pchisq(EstadisticoGehan,df=1) p.valorGehan DenominadorG1Gehan<-t((PesosGehan*PesosGehan)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1)

Apéndices ______________________________________________________________________
244
DenominadorG1G2Gehan<-t((PesosGehan*PesosGehan)*CoVarianzan.eventG1G2)%*%matrix(1,nrow(n.event),1) MatrizVarianza<-matrix(c(DenominadorG1Gehan,DenominadorG1G2Gehan, DenominadorG1G2Gehan,DenominadorG1Gehan), nrow=2,ncol=2) MatrizVarianzainversa<-solve(MatrizVarianza) VectordediferenciasGehan<-matrix(c(NumeradorG1Gehan,NumeradorG2Gehan),nrow=2,ncol=1) EstadísticoGehanChi.cuadrado<-t(VectordediferenciasGehan)%*%MatrizVarianzainversa%*%VectordediferenciasGehan p.valorGehan<-1-pchisq(EstadísticoGehanChi.cuadrado,df=2) p.valorGehan #____________________________________________________________________ #____________________________________________________________________ PesosTaroneWare<-sqrt(GruporeferenciaGG[,2]) NumeradorTaroneWare<-t(PesosTaroneWare)%*%DiferenciasG1 DenominadorTaroneWare<-t((PesosTaroneWare*PesosTaroneWare)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoTaroneWare<-NumeradorTaroneWare*NumeradorTaroneWare/DenominadorTaroneWare EstadisticoTaroneWare p.valorTaroneWare<-1-pchisq(EstadisticoTaroneWare,df=1) p.valorTaroneWare #____________________________________________________________________ supervivencia<-matrix(summary(fit2)) nnn<-nrow(supervivencia)/4 Supervivencia<-supervivencia[(3*nnn+1):(4*nnn),1] PesosPetoPeto<-Supervivencia NumeradorPetoPeto<-t(PesosPetoPeto)%*%DiferenciasG1 DenominadorPetoPeto<-t((PesosPetoPeto*PesosPetoPeto)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoPetoPeto<-NumeradorPetoPeto*NumeradorPetoPeto/DenominadorPetoPeto EstadisticoPetoPeto p.valorPetoPeto<-1-pchisq(EstadisticoPetoPeto,df=1) p.valorPetoPeto #____________________________________________________________________ supervivencia<-matrix(summary(fit2)) nnn<-nrow(supervivencia)/4 factor<-(GruporeferenciaGG[,2]/(GruporeferenciaGG[,2]+matrix(1,nnn,1))) Supervivencia<-factor*supervivencia[(3*nnn+1):(4*nnn),1] PesosPetoMod<-Supervivencia NumeradorPetoMod<-t(PesosPetoMod)%*%DiferenciasG1 DenominadorPetoMod<-t((PesosPetoMod*PesosPetoMod)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoPetoMod<-NumeradorPetoMod*NumeradorPetoMod/DenominadorPetoMod EstadisticoPetoMod p.valorPetoMod<-1-pchisq(EstadisticoPetoMod,df=1) p.valorPetoMod

Apéndices ______________________________________________________________________
245
#____________________________________________________________________ supervivencia<-matrix(summary(fit2)) nnn<-nrow(supervivencia)/4 Supervivencia<-supervivencia[(3*nnn+1):(4*nnn),1] supe<-supervivencia[(3*nnn+1):(4*nnn-1),1] PesosPetoPrentice<-matrix(c(1,supe),nnn,1) NumeradorPetoPrentice<-t(PesosPetoPrentice)%*%DiferenciasG1 DenominadorPetoPrentice<-t((PesosPetoPrentice*PesosPetoPrentice)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoPetoPrentice<-NumeradorPetoPrentice*NumeradorPetoPrentice/DenominadorPetoPeto EstadisticoPetoPrentice p.valorPetoPrentice<-1-pchisq(EstadisticoPetoPrentice,df=1) p.valorPetoPrentice #____________________________________________________________________ PesosHF<-(PesosPetoPeto)^(1)*(matrix(1,nrow(n.event))-PesosPetoPeto)^(0) NumeradorHF<-t(PesosHF)%*%DiferenciasG1 DenominadorHF<-t((PesosHF*PesosHF)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoHF<-NumeradorHF*NumeradorHF/DenominadorHF EstadisticoHF p.valorHF<-1-pchisq(EstadisticoHF,df=1) p.valorHF #____________________________________________________________________ PesosCM<-(PesosPetoPeto)^(1)*(matrix(1,nrow(n.event))-PesosPetoPeto)^(1)* (PesosGehan)^(0)*(PesosGehan+matrix(1,nrow(n.event),1))^(0) NumeradorCM<-t(PesosCM)%*%DiferenciasG1 DenominadorCM<-t((PesosCM*PesosCM)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoCM1100<-NumeradorCM*NumeradorCM/DenominadorCM EstadisticoCM1100 p.valorCM1100<-1-pchisq(EstadisticoCM1100,df=1) p.valorCM1100 #____________________________________________________________________ PesosCM<-(PesosPetoPeto)^(0)*(matrix(1,nrow(n.event))-PesosPetoPeto)^(0)* (PesosGehan)^(0)*(PesosGehan+matrix(1,nrow(n.event),1))^(0) NumeradorCM<-t(PesosCM)%*%DiferenciasG1 DenominadorCM<-t((PesosCM*PesosCM)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoCM0000<-NumeradorCM*NumeradorCM/DenominadorCM EstadisticoCM0000 p.valorCM0000<-1-pchisq(EstadisticoCM0000,df=1) p.valorCM0000 #____________________________________________________________________ PesosCM<-(PesosPetoPeto)^(0)*(matrix(1,nrow(n.event))-PesosPetoPeto)^(0)* (PesosGehan)^(1)*(PesosGehan+matrix(1,nrow(n.event),1))^(0) NumeradorCM<-t(PesosCM)%*%DiferenciasG1 DenominadorCM<-t((PesosCM*PesosCM)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoCM0010<-NumeradorCM*NumeradorCM/DenominadorCM EstadisticoCM0010 p.valorCM0010<-1-pchisq(EstadisticoCM0010,df=1) p.valorCM0010

Apéndices ______________________________________________________________________
246
#____________________________________________________________________ PesosCM<-(PesosPetoPeto)^(0)*(matrix(1,nrow(n.event))-PesosPetoPeto)^(0)* (PesosGehan)^(1/2)*(PesosGehan+matrix(1,nrow(n.event),1))^(0) NumeradorCM<-t(PesosCM)%*%DiferenciasG1 DenominadorCM<-t((PesosCM*PesosCM)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoCM00.50<-NumeradorCM*NumeradorCM/DenominadorCM EstadisticoCM00.50 p.valorCM00.50<-1-pchisq(EstadisticoCM00.50,df=1) p.valorCM00.50 #____________________________________________________________________ PesosCM<-(PesosPetoPeto)^(1)*(matrix(1,nrow(n.event))-PesosPetoPeto)^(0)* (PesosGehan)^(0)*(PesosGehan+matrix(1,nrow(n.event),1))^(0) NumeradorCM<-t(PesosCM)%*%DiferenciasG1 DenominadorCM<-t((PesosCM*PesosCM)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoCM1000<-NumeradorCM*NumeradorCM/DenominadorCM EstadisticoCM1000 p.valorCM1000<-1-pchisq(EstadisticoCM1000,df=1) p.valorCM1000 #____________________________________________________________________ PesosCM<-(PesosPetoPeto)^(1)*(matrix(1,nrow(n.event))-PesosPetoPeto)^(1)* (PesosGehan)^(1)*(PesosGehan+matrix(1,nrow(n.event),1))^(-1) NumeradorCM<-t(PesosCM)%*%DiferenciasG1 DenominadorCM<-t((PesosCM*PesosCM)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoCM111N1<-NumeradorCM*NumeradorCM/DenominadorCM EstadisticoCM111N1 p.valorCM111N1<-1-pchisq(EstadisticoCM111N1,df=1) p.valorCM111N1 #____________________________________________________________________ #____________________________________________________________________ Wc<-matrix(NA,nrow(time),1) Wctime<-matrix(NA,nrow(time),1) Wj<-matrix(NA,nrow(time),1) Wtime<-matrix(NA,nrow(time),1) Wj<- -log(fit2$surv) Wc[1,1]<-Wj[1] for (i in 2:nrow(time)) Wc[i,1]<- Wj[i]-Wj[i-1] for (i in 1:nrow(time)) if (time[i,1]==0) Wtime[i,1]<-0.0001 else Wtime[i,1]<-time[i,1] Wctime[1,1]<-Wtime[1,1] for (i in 2:nrow(time)) Wctime[i,1]<-Wtime[i,1]-Wtime[i-1,1] peso<-Wc/Wctime PesosCarlos<-round((PesosGehan)/n.event,3) #PesosCarlos<-round((PesosGehan-n.event)/(PesosGehan),3) #if (PesosGehan[m] == n.event[m,1]) #PesosCarlos[1:m-1]<-(PesosGehan[1:m-1]/(PesosGehan[1:m-1]-n.event[1:m-1,1])) #PesosCarlos[m]<-1 #PesosCarlos<-round((PesosGehan/Wc),3)

Apéndices ______________________________________________________________________
247
#Sp<- PesosPetoPrentice #Sp1<-matrix(NA,nrow(time),1) #Sp1[1,1]<-1-Sp[1,1] #for (i in 2:nrow(time)) Sp1[i,1]<-Sp[i-1,1]-Sp[i,1] #Wj[1,1]<-Sp1[1,1]/(Wc[1,1]) #for (i in 2:nrow(time)) Wj[i,1]<- Sp1[i,1]/((Wc[i,1])) #PesosCarlos<-round(PesosGehan/(n.event),3) #PesosCarlos<-round(matrix(1/n.event),3) NumeradorCarlos<-t(PesosCarlos)%*%DiferenciasG1 DenominadorCarlos<-t((PesosCarlos*PesosCarlos)*Varianzan.eventG1)%*%matrix(1,nrow(n.event),1) EstadisticoCarlos<-NumeradorCarlos*NumeradorCarlos/DenominadorCarlos EstadisticoCarlos p.valorCarlos<-1-pchisq(EstadisticoCarlos,df=1) p.valorCarlos #____________________________________________________________________ Nomb.Est<-matrix(c("Logrank", "Gehan", "Tarone Ware", "Peto Peto", "Peto Mod.", "Peto Prentice", "H-F p1=0, p2=0", "CM p1=0, p2=0, p3=0, p4= 0", "CM p1=0, p2=0, p3=1, p4= 0", "CM p1=0, p2=0, p3=1/2, p4= 0", "CM p1=1, p2=0, p3=0 , p4= 0", "CM p1=1, p2=0, p3=1, p4=-1", "Martinez")) Estadisticos<-matrix(c(EstadísticoLogRankChi.cuadrado, EstadisticoGehan, EstadisticoTaroneWare, EstadisticoPetoPeto, EstadisticoPetoMod, EstadisticoPetoPrentice, EstadisticoHF, EstadisticoCM1100, EstadisticoCM0010, EstadisticoCM00.50, EstadisticoCM1000, EstadisticoCM111N1,EstadisticoCarlos)) p.valores <-round(matrix(c(p.valorLR, p.valorGehan, p.valorTaroneWare, p.valorPetoPeto, p.valorPetoMod, p.valorPetoPrentice, p.valorHF, p.valorCM1100, p.valorCM0010, p.valorCM00.50, p.valorCM1000, p.valorCM111N1,p.valorCarlos)),7) tabla<-data.frame(Nomb.Est,Chi.cuadrado=Estadisticos,p.valor=p.valores) print(tabla) MM<-max(Estadisticos) Estadisticos/MM










![Analysis of recurrent gap time data using the weighted ...resampling method has been applied to clustered survival data [27, 28], it cannot be naively applied to recurrent gap time](https://img.pdfslide.us/doc/110x75/5f32b79d9a2f1a48ed188b85/analysis-of-recurrent-gap-time-data-using-the-weighted-resampling-method-has.jpg)


















