Embed Size (px)
Citation preview

BIG DATA & HADOOP
- V I N O T H K U M A R

WHAT WE ARE GOING TO LEARN?
• What is Bigdata?
• What is HADOOP?
• Distributed Computing.
• 4V’s of Big data.
• HADOOP Daemons.
• Writing files to HDFS.
• Reading files from HDFS.
• Replication factor
• Rack Awareness
• Map/Reduce

WHAT IS BIG DATA?
• Big data are collection of data sets so large and complex that it becomes difficult to process using on-
hand database management tools or traditional data processing applications (SOURCE : White Tom,
Definitive Guide).
• Why do we need to manage this Big data?
The data is growing enormously. In earlier days, employees and customers were generating data.(Eg,
Feedback form, Survey results).But in today's world, even the machines has started generating data (
Eg, Sensor, RFID, Satelllite). In fact, 90% of the world data is generated in last 3 years.
Company realized that it needs to manage this huge amount of data. Imagine the data flow that
happens in search engines like Google. Google came up with the idea of distributed computing and
parallel processing which is very well explained in their research papers : “Google File system and
MAP Reduce”. It showed the world how they were able to process this huge data.
http://static.googleusercontent.com/media/research.google.com/en//archive/gfs-sosp2003.pdf
http://research.google.com/archive/mapreduce.html
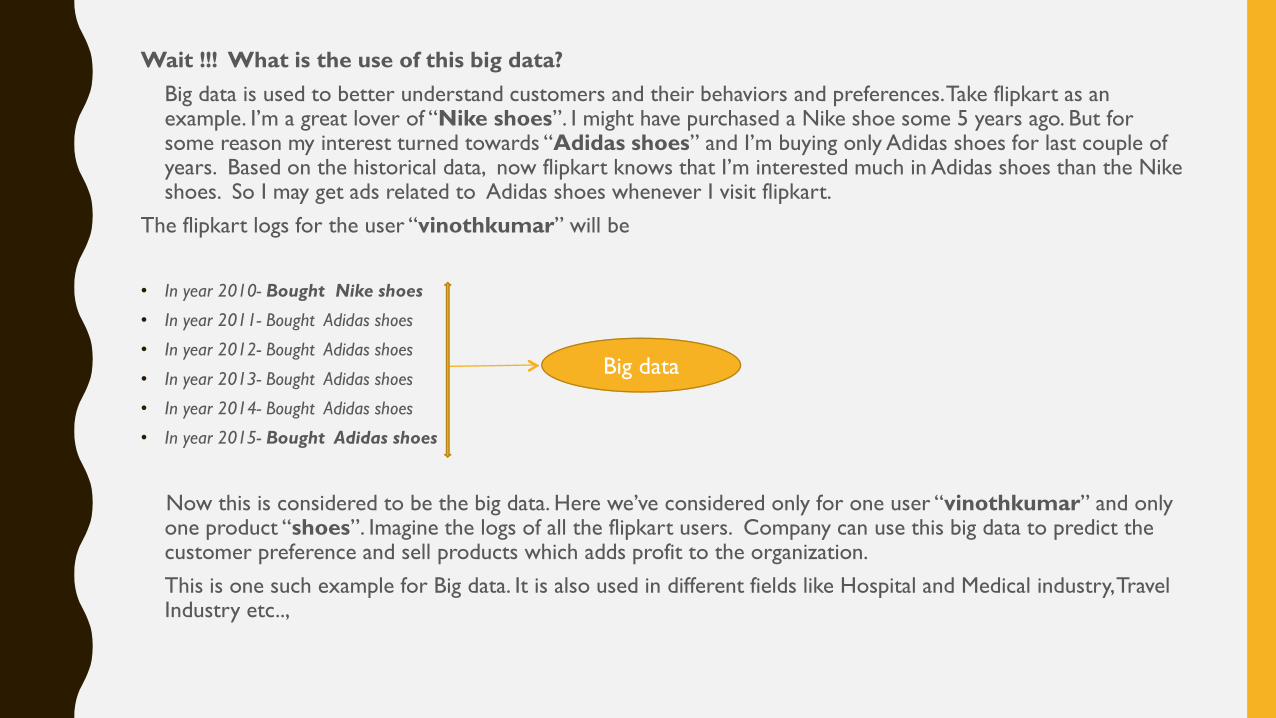
Wait !!! What is the use of this big data?
Big data is used to better understand customers and their behaviors and preferences. Take flipkart as an example. I’m a great lover of “Nike shoes”. I might have purchased a Nike shoe some 5 years ago. But for some reason my interest turned towards “Adidas shoes” and I’m buying only Adidas shoes for last couple of years. Based on the historical data, now flipkart knows that I’m interested much in Adidas shoes than the Nike shoes. So I may get ads related to Adidas shoes whenever I visit flipkart.
The flipkart logs for the user “vinothkumar” will be
• In year 2010- Bought Nike shoes
• In year 2011- Bought Adidas shoes
• In year 2012- Bought Adidas shoes
• In year 2013- Bought Adidas shoes
• In year 2014- Bought Adidas shoes
• In year 2015- Bought Adidas shoes
Now this is considered to be the big data. Here we’ve considered only for one user “vinothkumar” and only one product “shoes”. Imagine the logs of all the flipkart users. Company can use this big data to predict the customer preference and sell products which adds profit to the organization.
This is one such example for Big data. It is also used in different fields like Hospital and Medical industry, Travel Industry etc..,
Big data

WHAT IS HADOOP • What is HADOOP ?
In simple words, HADOOP is a framework for managing/processing this big data.
The data is divided into smaller piece of chunks and the data is distributed across “n” number
of systems.We then process the data in parallel approach to obtain the final result.
NETWORK IDS – Real time application.(This is my graduate project .Source code on request )
Imagine a scenario, the company has realized that data breach has occurred and it wants to
track the malicious activity from a particular IP. The company had a wire shark running 24/7 to
capture the data packets and the file is stored in .pcap format. Imagine the size of the file to
be 1000 TB. Using traditional computing, it takes huge amount of time to process this data
where as in HADOOP framework, the data is split and stored in 1000 systems. Now each
system has to process just 1 TB of data and it is processed in parallel to obtain the result more
quickly .i.e the malicious activities observed from a particular IP.

DISTRIBUTED COMPUTING
• Let’s understand the concept of Distributed computing with a simple scenario.
• Consider “Ox and the Load” example. Ox are used to carry the load.
• When the load size increases, we didn’t decide to grow up the ox.

DISTRIBUTED COMPUTING
Instead, we decided to increase the number of the Ox.
The same concept is applied in the the process of distributed computing.
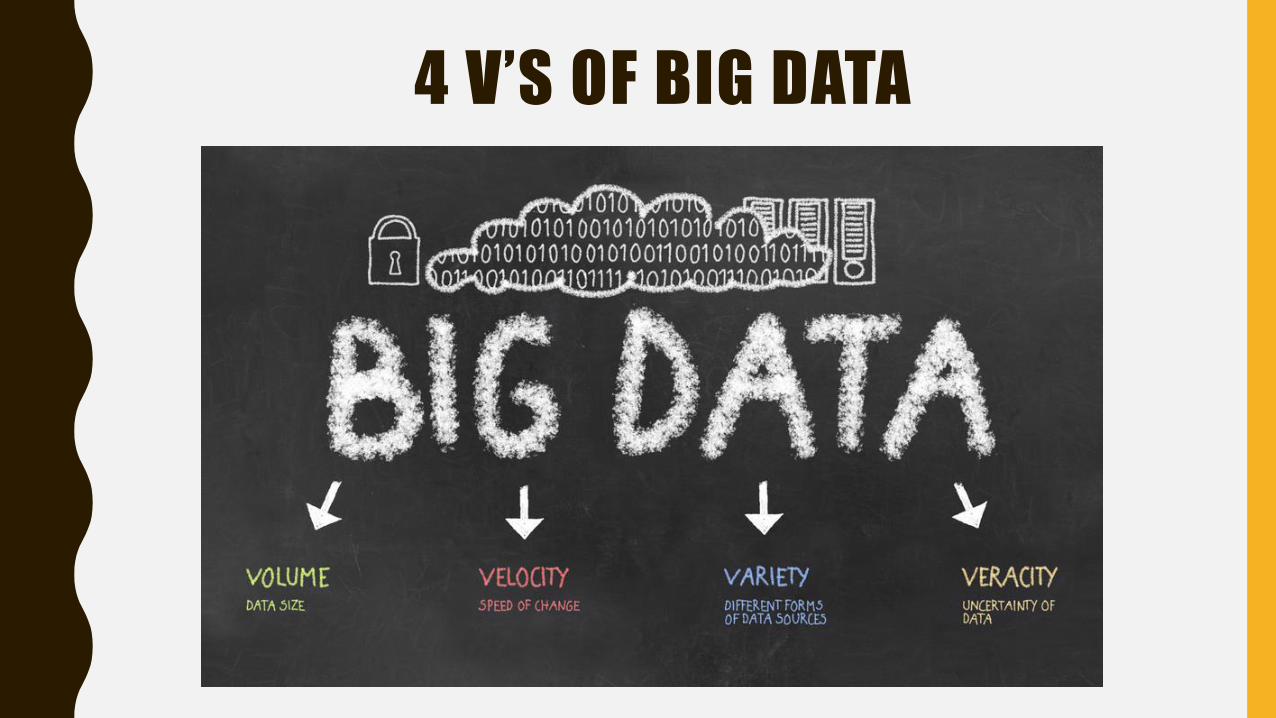
4 V’S OF BIG DATA
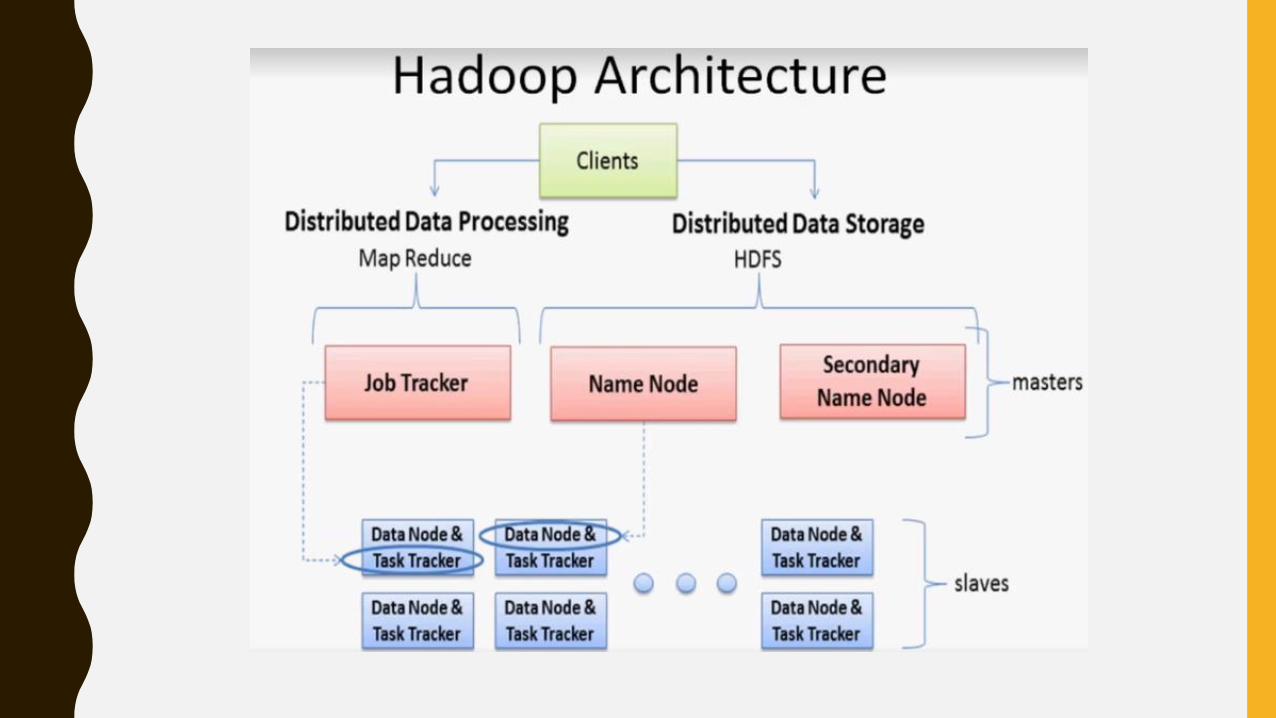

HADOOP DAEMONSDaemon is a service provided by the operating system which runs in the background. It exits
as soon as the server exits/Shutdown. There are 5 daemons in the HADOOP Architecture
which are categorized into two types Masters and Slaves.
MASTERS
1. Name node
2. Task Tracker
3. Secondary Name node
SLAVES
4. Data node
5. Job Tracker

• As the name says, SLAVES always acts as per the command /order received from the MASTER.
• Think this scenario like a typical job in IT Industry. Employees always report their work to
their corresponding reporting manager. Similarly, data node and job tracker are the SLAVES
which reports to the MASTER Name node and Job Tracker correspondingly
• Name Node (NN):
– Heart of the Hadoop architecture.
– Contains metadata information like where the data is stored.
• Secondary Name Node (SNN):
– Nope, you’ve guessed it wrong. SNN is not exactly a back up for NN. Instead it will store the
“Checkpoints”. It means at that particular instance or checkpoint, it will take a back up of NN.
SNN is also known as checkpoint servers.
– Checkpoints (CP) :
If you are a gamer, you might have heard about the term called checkpoint. When your mission is
failed, you will resume from that checkpoint and not from the start of the game. Same thing goes
with SNN. When NN is failed, SNN will act as a temporary NN from that particular CP.
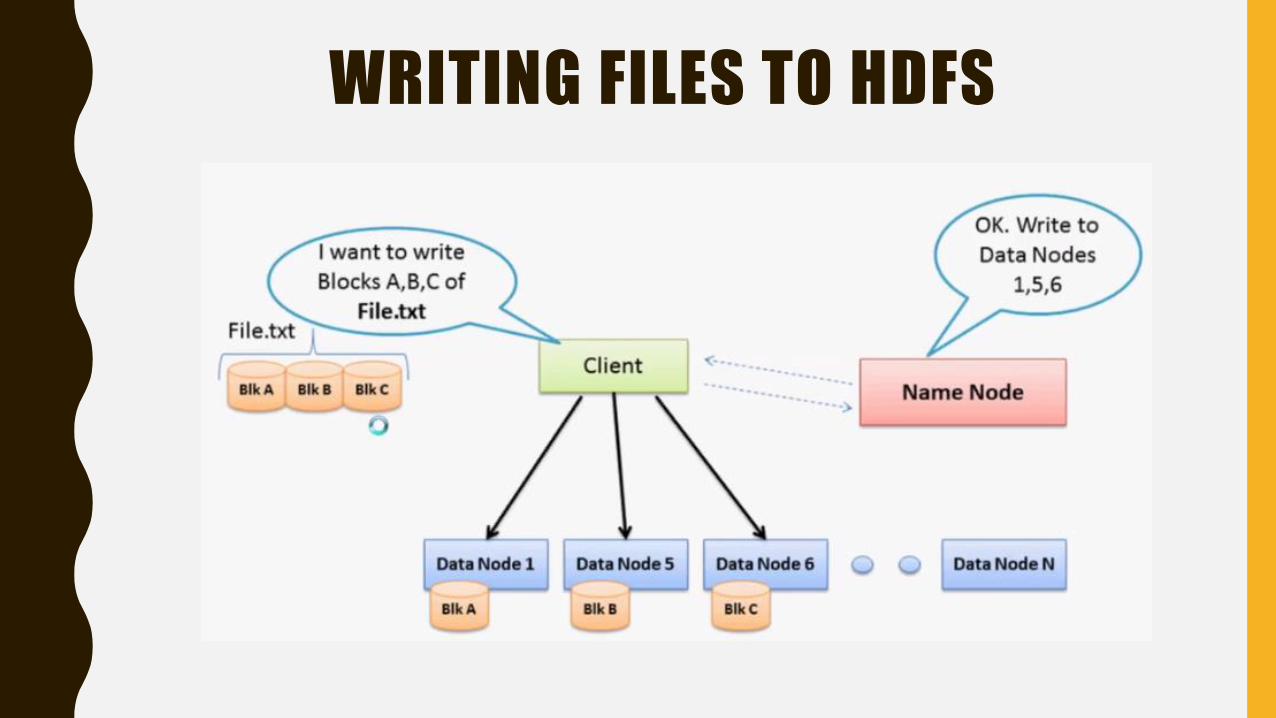
WRITING FILES TO HDFS
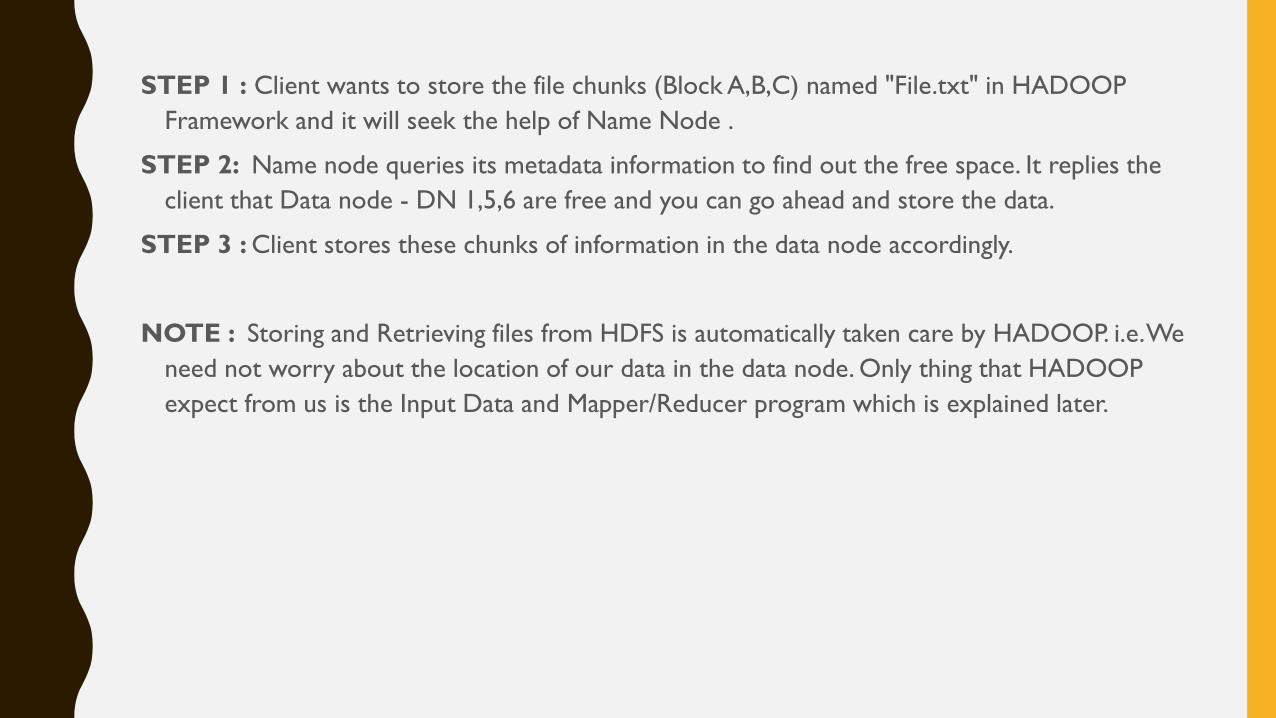
STEP 1 : Client wants to store the file chunks (Block A,B,C) named "File.txt" in HADOOP
Framework and it will seek the help of Name Node .
STEP 2: Name node queries its metadata information to find out the free space. It replies the
client that Data node - DN 1,5,6 are free and you can go ahead and store the data.
STEP 3 : Client stores these chunks of information in the data node accordingly.
NOTE : Storing and Retrieving files from HDFS is automatically taken care by HADOOP. i.e. We
need not worry about the location of our data in the data node. Only thing that HADOOP
expect from us is the Input Data and Mapper/Reducer program which is explained later.
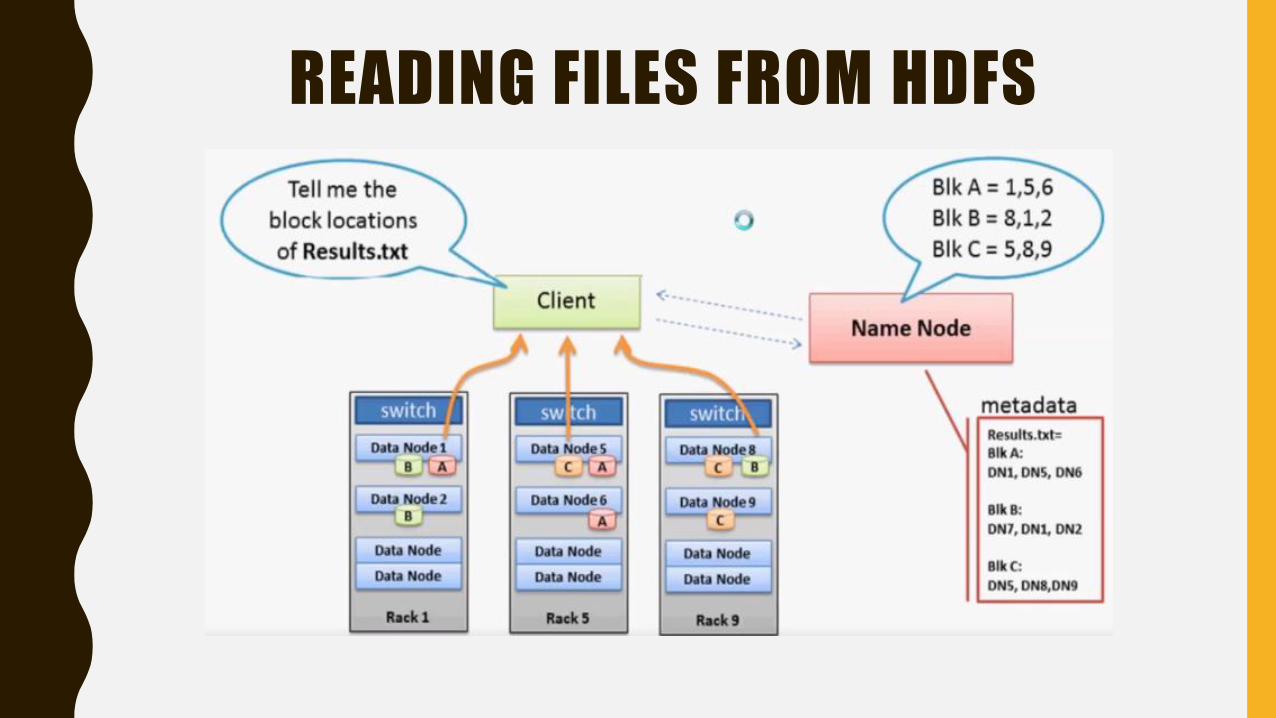
READING FILES FROM HDFS

STEP 1: Client wants to retrieve the information of "Result.txt (Blk A,B,C) ". So it will seek
the help of Name node
STEP 2: Name Node queries its metadata information to find out where result.txt is stored.
It replies the client that
Blk A is stored in DN1,5,6
Blk B is stored in DN 8,1,2
Blk C is stored in DN 5,8,9
You may be wondering why HADOOP is storing the same block in 3 different location in the
data node, (Eg: Blk A is stored in DN 1, 5 and 6) that is where Replication Factor ( RF)
comes into picture.

REPLICATION FACTORHADOOP Architecture is designed in such a way that data loss shouldn’t occur. But still failure
may occur for whatsoever . In such cases, we need to ensure the availability of data. So each
block of data is replicated thrice and stored in the data node. So the replication factor for
Hadoop is defined as 3.
But If you notice carefully, you can see Blk A is stored twice in Rack-5 and once in Rack-1. This
is the specialty in HADOOP Architecture.

RACK AWARENESS• If Block A (Blk A) has to be retrieved from the data node, hadoop will normally prefer the
RACK space which has stored two copies of the same Blk A. In the previous slide RACK-5.
• RACK-5 has two copies of Blk A stored in DN-5 and 6.
• Imagine a scenario, the file pointer (FP) is in RACK-5, and for some reasons DN-5 got failed.
So the Hadoop will have to fetch Blk A from either DN-6 present in RACK-5 or from DN-1
present in RACK-1.
• Search time to locate the block will be increased if hadoop has to go to DN-1 in RACK-1.
Instead it can quickly retrieve another copy of Blk A from DN-6 which is present in the same
RACK-5. So by default HADOOP stores two copies of block in the same RACK and another
copy in a different RACK.
• This concept is known as RACK AWARENESS that makes HADOOP more effective while
retrieving data.
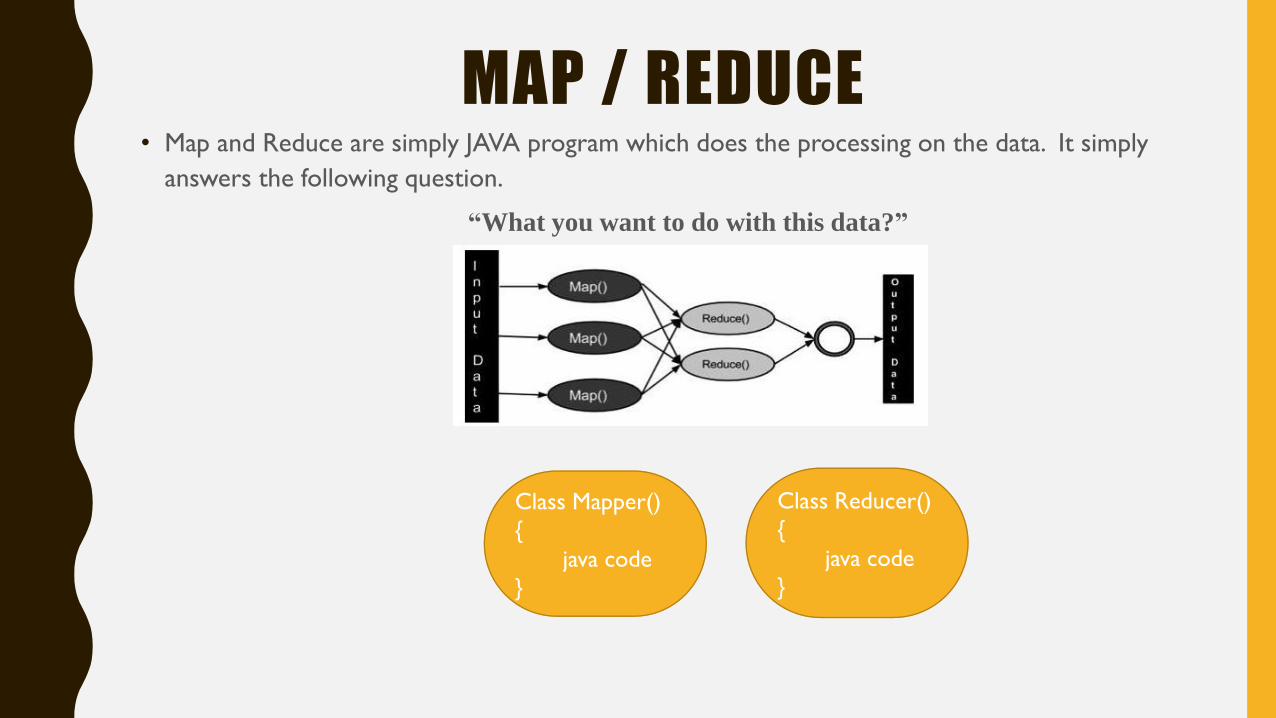
MAP / REDUCE• Map and Reduce are simply JAVA program which does the processing on the data. It simply
answers the following question.
“What you want to do with this data?”
Class Reducer()
{
java code
}
Class Mapper()
{
java code
}

Writing your first hadoop program
Word Count is a simple application that counts the number of occurrences of each word
in a given input set. This example is generally considered to be the “Hello Word”
program of the programming languages
Visit the following link to learn how to install Hadoop and to write the mapper and
reducer code to find out the number of occurrence of the word
http://javabeginnerstutorial.com/hadoop/your-first-hadoop-map-reduce-job
• Mapper :
The mapper simply process the input data based on the java code written on the
mapper class (In the example above : To count the occurrence of word in input file) and
creates several small chunks of data.
• Reducer :
The reducer phase simply process the chunks of data created after mapper phase and
gives the output in the reduced or user required format after applying shuffle and sorting.
This can be better understood with the diagram which explained in the next slide.
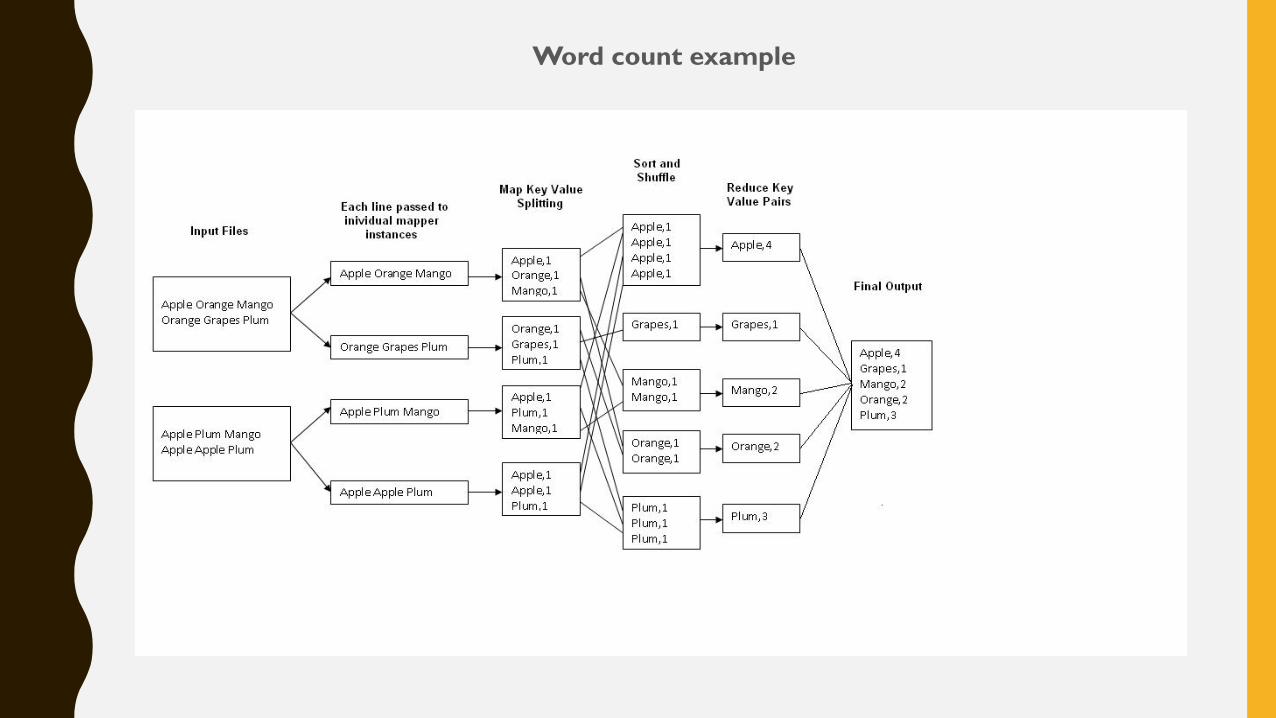
Word count example

CONCLUSION
• Big data and Hadoop is considered to be the hottest topic in the IT industry. Everyone wants
to learn this technology . But we don’t have much professionals who has in depth knowledge in
these frameworks. So there is always a demand for big data engineers
• Concept of HADOOP and BIG DATA is very vast. It’s very difficult to explain the whole
HADOOP ecosystem in slides. This presentation mainly focus on the beginners to kick start
their brain.exe in the field of Big data and HADOOP.
• I’ve tried my best to explain the concept in a simple way that can be understood even by a
beginner.
• Feedbacks are always appreciated.
• Thanks for taking time to read my slides.

REFERENCES
• https://www.udemy.com/big-data-and-hadoop-essentials-free-tutorial
• www.Hadoop-skills.net
• https://www.udemy.com/overview-of-big-data-hadoop/
• http://www.tutorialspoint.com/hadoop/

THANK YOU





























