Embed Size (px)
Citation preview

How to add a language to the linguistic resources map
Corina Forăscu
Alexandru Ioan Cuza University of Iasi - Faculty of Computer Science & Romanian Academy Research Institute for Artificial Intelligence “Mihai Drăgănescu”
Distinguished Speakers Departmental Seminars
10th of February, 2015

How to efficiently use time in research and… personal life?
Why are languages and language technologies (LT) important in our societies?
How to deal with a less-studied language?
How to build and exploit new language resources?
How much time is needed?
How to represent and use time (temporal information in NLP applications)?

Agenda
Languages
Language technologies
for Romanian
Language resources
for Romanian
Research projects / competitions &
scientific / personal events
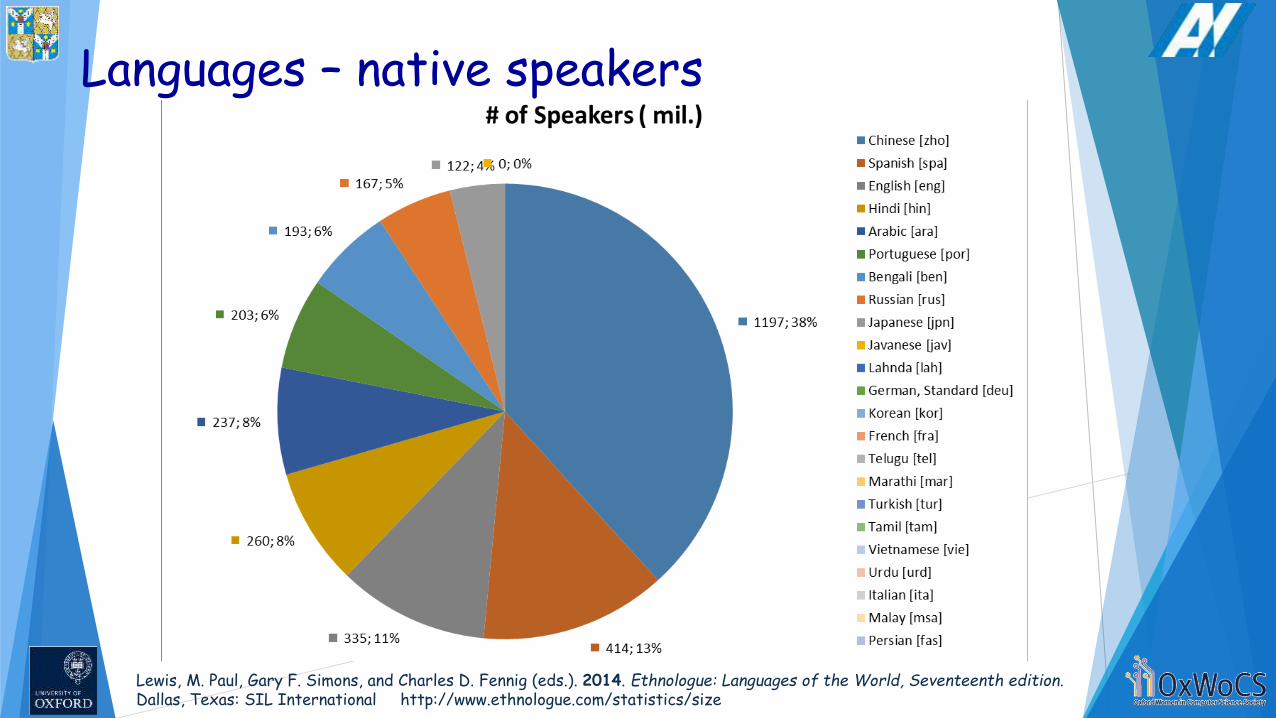
Languages – native speakers
Lewis, M. Paul, Gary F. Simons, and Charles D. Fennig (eds.). 2014. Ethnologue: Languages of the World, Seventeenth edition.Dallas, Texas: SIL International http://www.ethnologue.com/statistics/size
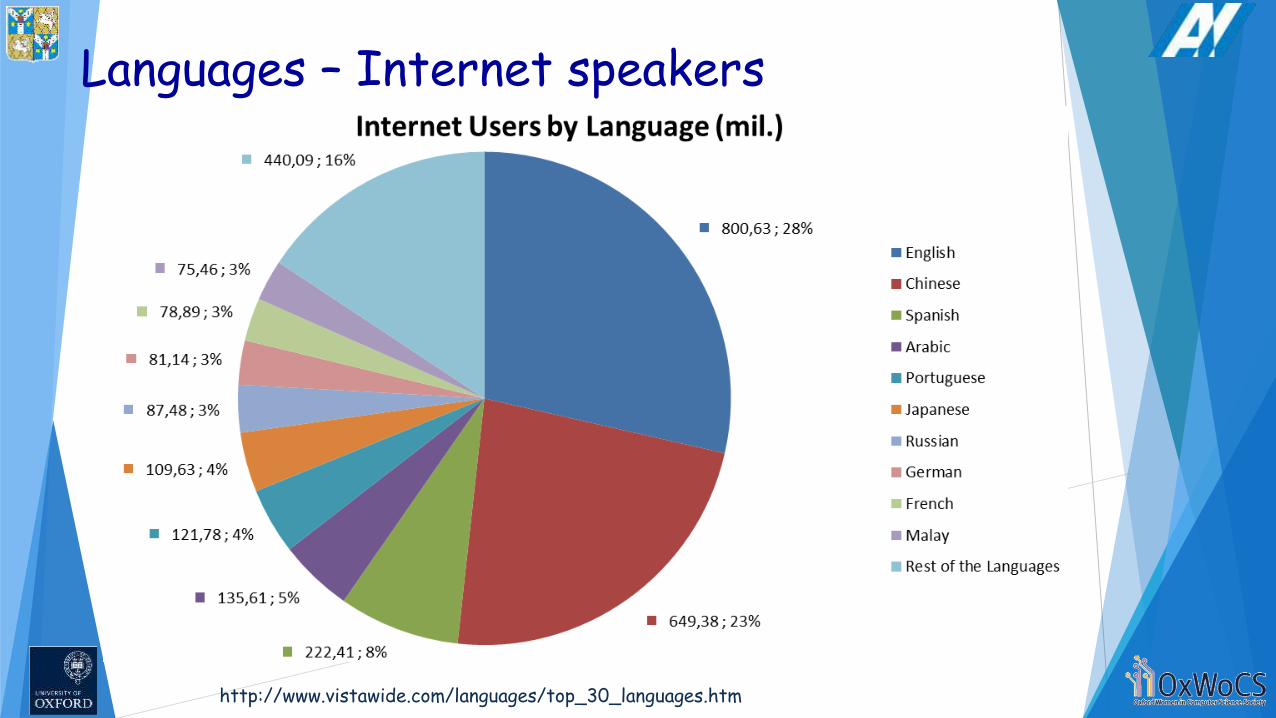
Languages – Internet speakers
http://www.vistawide.com/languages/top_30_languages.htm
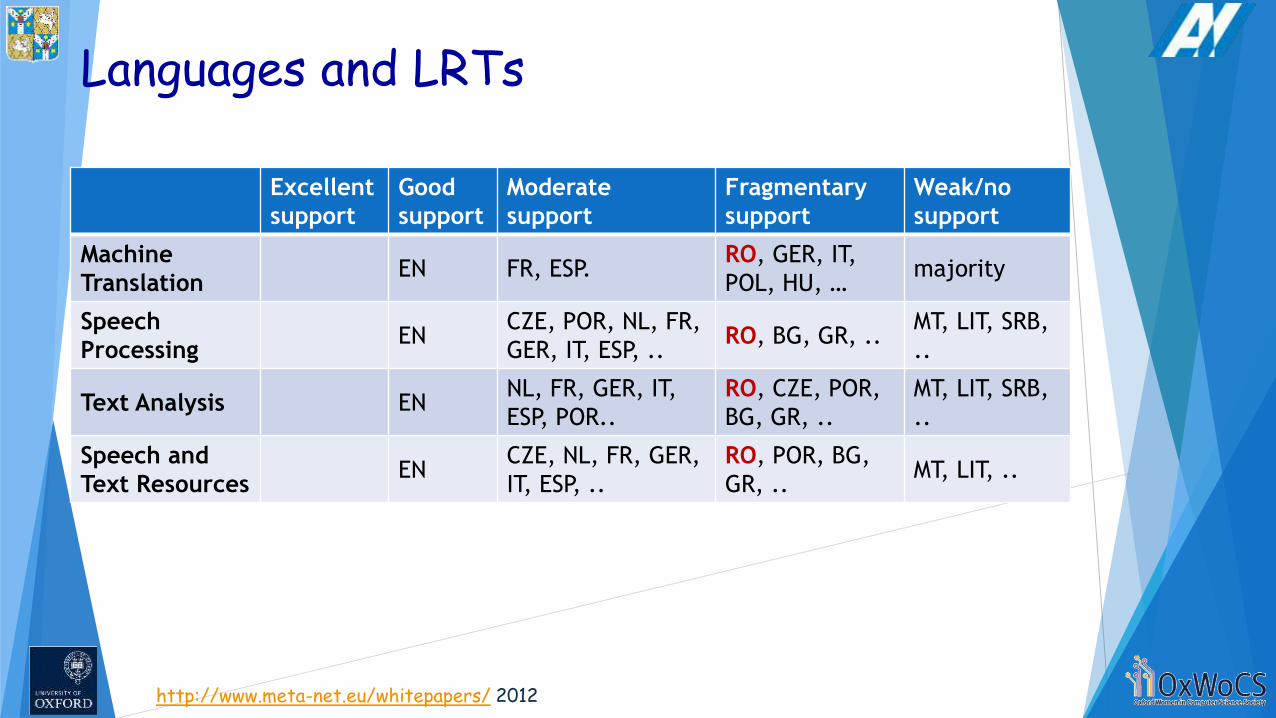
Languages and LRTs
Excellent
support
Good
support
Moderate
support
Fragmentary
support
Weak/no
support
Machine
TranslationEN FR, ESP.
RO, GER, IT,
POL, HU, … majority
Speech
ProcessingEN
CZE, POR, NL, FR,
GER, IT, ESP, ..RO, BG, GR, ..
MT, LIT, SRB,
..
Text Analysis ENNL, FR, GER, IT,
ESP, POR..
RO, CZE, POR,
BG, GR, ..
MT, LIT, SRB,
..
Speech and
Text ResourcesEN
CZE, NL, FR, GER,
IT, ESP, ..
RO, POR, BG,
GR, ..MT, LIT, ..
http://www.meta-net.eu/whitepapers/ 2012
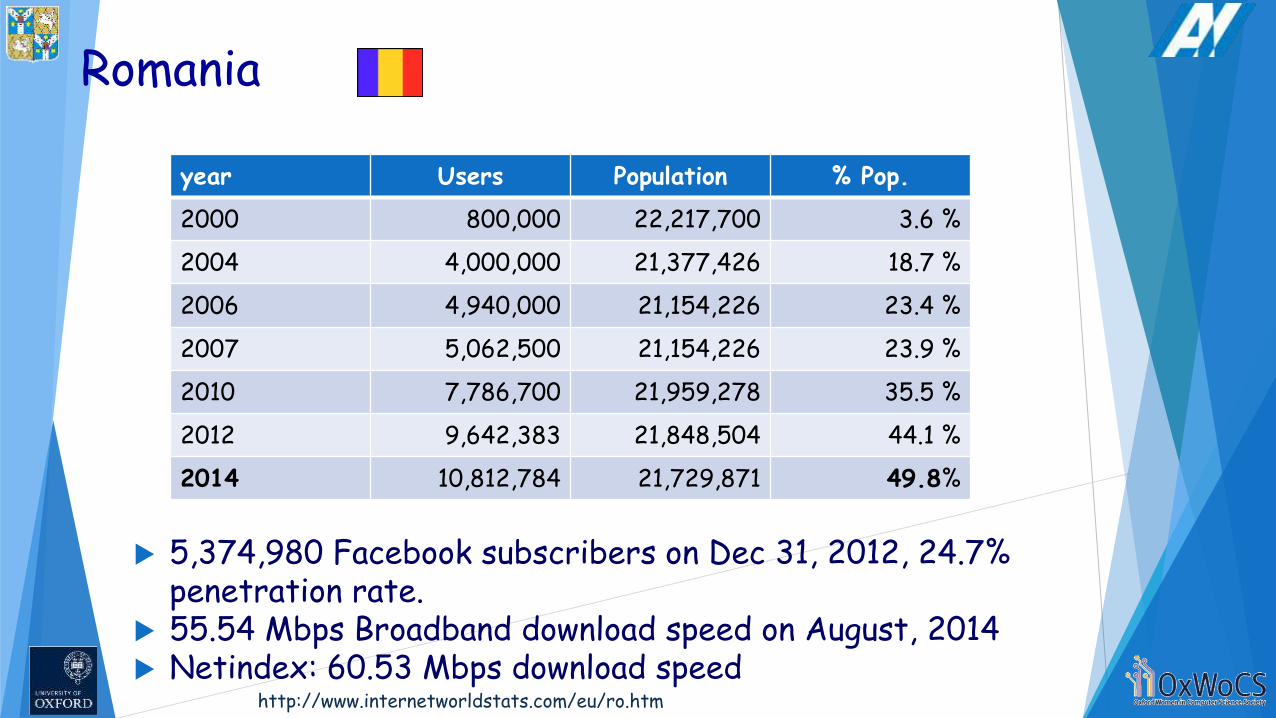
Romania
http://www.internetworldstats.com/eu/ro.htm
year Users Population % Pop.
2000 800,000 22,217,700 3.6 %
2004 4,000,000 21,377,426 18.7 %
2006 4,940,000 21,154,226 23.4 %
2007 5,062,500 21,154,226 23.9 %
2010 7,786,700 21,959,278 35.5 %
2012 9,642,383 21,848,504 44.1 %
2014 10,812,784 21,729,871 49.8%
5,374,980 Facebook subscribers on Dec 31, 2012, 24.7% penetration rate.
55.54 Mbps Broadband download speed on August, 2014 Netindex: 60.53 Mbps download speed

Romanian
Romance language, with influences from old Slavic, Turkish, Greek, German, Hungarian, Bulgarian, Russian
spoken by about 29 mil. people, with 4 official dialects
highly inflected language
pro-drop language ([en] It rains. / [ro] Plouă)
with clitic doubling ([en] I see her. [ro] O văd pe ea.)
with negative concord
with double negation
Mihai Eminescu
Emil Cioran
Mircea Eliade
Mircea Cărtărescu

BLARK - Basic LAnguage Resource Kit
(a) the minimal general text corpus to be able to do anyprecompetitive research for the language at all,annotated according to some generally accepted standards
(a’) something similar for a spoken text corpus
(b) a collection of basic tools to manipulate and analyze the corpora LT systems
(c) a collection of skills that constitute the minimal starting point for the development of a competitive NL/Speech technology industry
http://www.elsnet.org/dox/blark.html
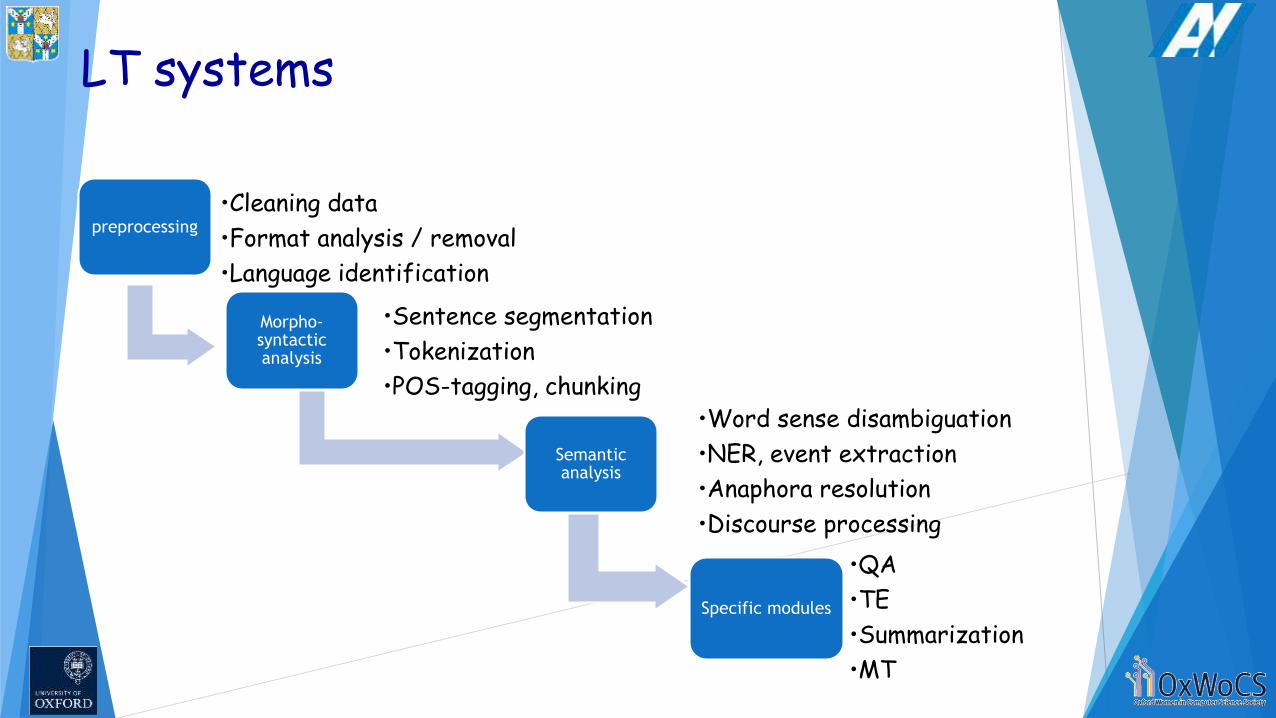
LT systems
preprocessing
•Cleaning data
•Format analysis / removal
•Language identification
Morpho-syntacticanalysis
•Sentence segmentation
•Tokenization
•POS-tagging, chunking
Semantic analysis
•Word sense disambiguation
•NER, event extraction
•Anaphora resolution
•Discourse processing
Specific modules
•QA
•TE
•Summarization
•MT

Language Identification
web service derived from a stand alone application that was initially aimed at autonomously collecting web data for English and Romanian
distinguishes among the 22 languages of the European Union., present in the JRC-Acquis parallel corpus

Romanian LTs: morpho-syntactic analysis
UAIC Romanian POS tagger
http://nlptools.infoiasi.ro/WebPosRo/ (webservice)
Sentence-splitting, tokenizing, POS-tagging (406 MSD tags, based on a 1.25 mil. words morphologic dictionary and a statistical model) and lemmatizing,
TTL (Tokenizing, Tagging and Lemmatizing free running texts )
http://www.racai.ro/tools/text/ (webservice & standalone application)
sentence splitting, tokenization, POS tagging (cca 600 CTAGs), lemmatization and chunking on Romanian, English and French texts.
Precision Without rules With rules
For unknown words 88.88% 93.31%
For all words 95.12% 97.03%

Romanian diacritics recovery – DIAC +
fata / fată / fată / făta / fâță
the girl / girl / (she) calves / (to) calve / a fussy girl
Diacritics have a high frequency (every third word might contain at least one diacritical character)
Diacritics have a significant contribution to the morpho-lexical and semantic disambiguation of the words
Plugin for Office 2003/2007/2010/2013
http://www.racai.ro/downloads/diac/diac+.zip
Based on tokenization, sentence splitting, lemmatization, and especially POS tagging (MSD tags) DIAC disambiguates between several possible word forms that may or may not contain diacritics

Romanian LTs: NP-chunker
The Romanian NP Chunker uses the UAIC POS tagger and GGS(Graphical Grammar Studio http://sourceforge.net/projects/ggs/), a visual tool for describing grammars.
A Romanian grammar has been developed allowing fully recursive NP chunks.
http://nlptools.infoiasi.ro/WebNpChunkerRo/ (webservice)
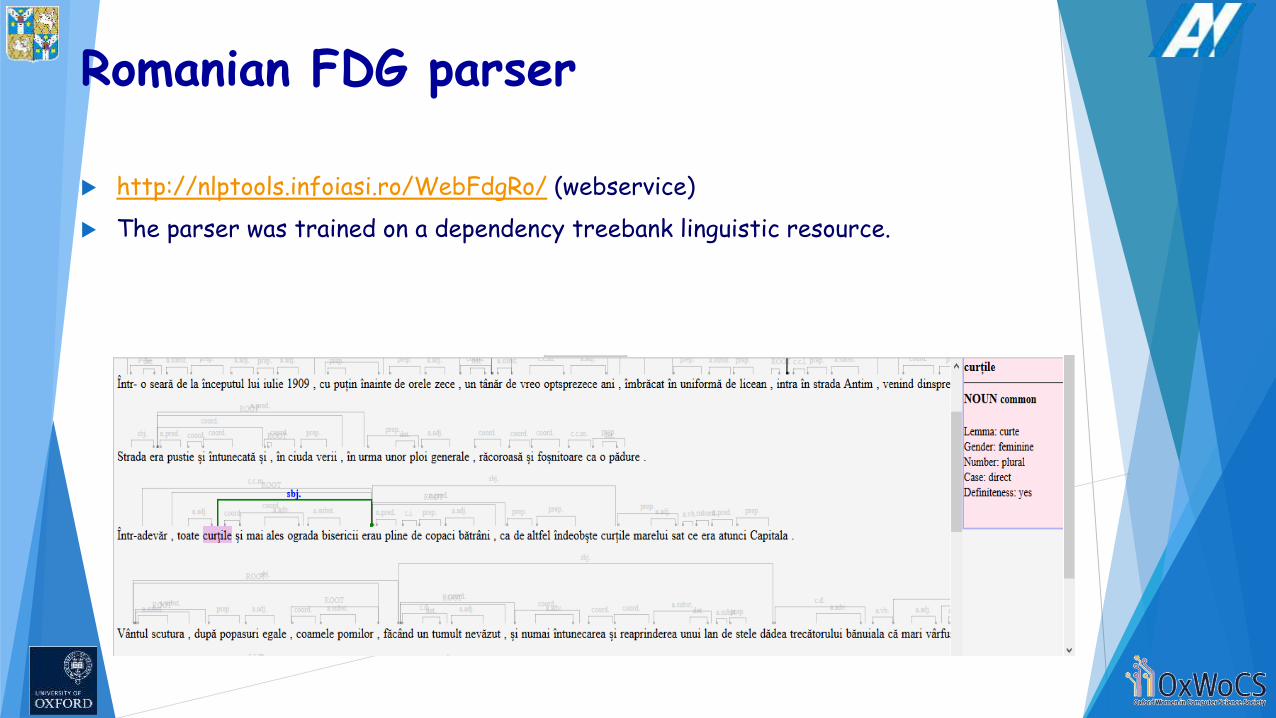
Romanian FDG parser
http://nlptools.infoiasi.ro/WebFdgRo/ (webservice)
The parser was trained on a dependency treebank linguistic resource.

Romanian Word Linker - LexPar
A link between two syntactico-semantic related words in a sentence is an approximation of a dependency relation, with no orientation and no labeling.
A link structure of a sentence is constructed with a Lexical Attraction Model
Dan Tufiș, Radu Ion, Alexandru Ceaușu, and Dan Ștefănescu. RACAI's Linguistic Web Services. In Proceedings of the 6th Language Resources and Evaluation Conference - LREC 2008, Marrakech, Morocco, May 2008. ELRA - European LanguageResources Association.‘
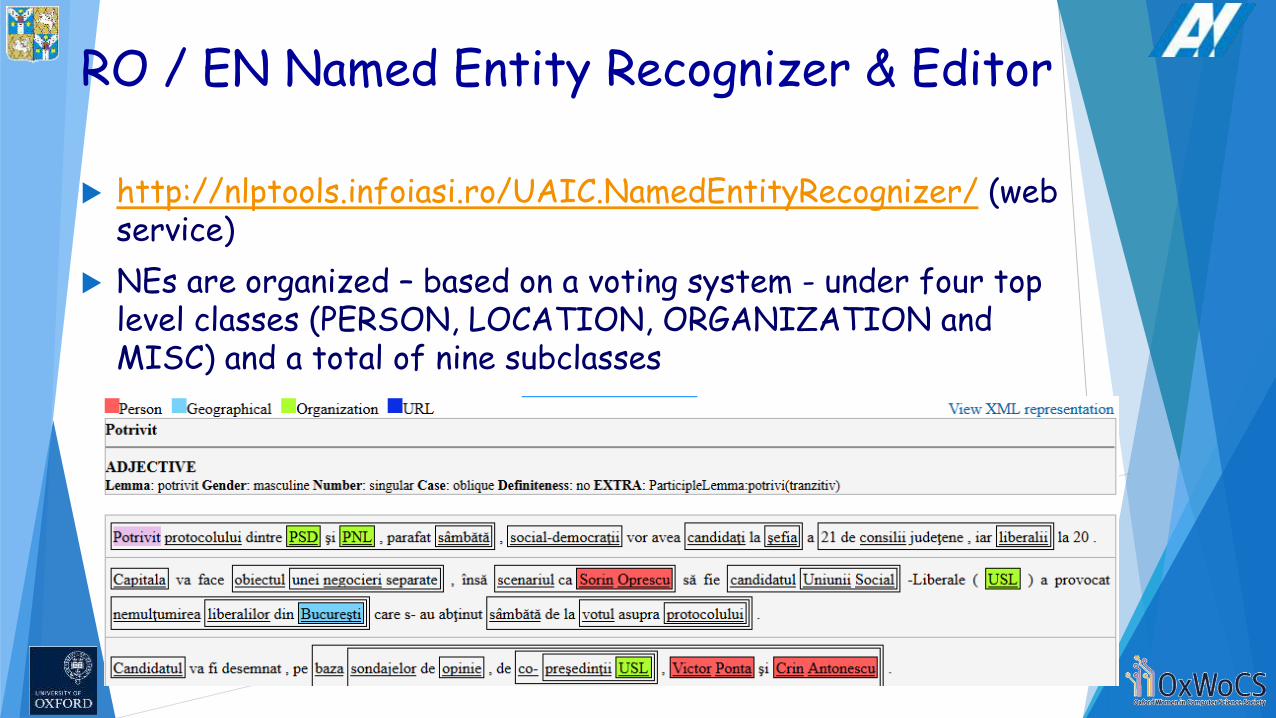
RO / EN Named Entity Recognizer & Editor
http://nlptools.infoiasi.ro/UAIC.NamedEntityRecognizer/ (web service)
NEs are organized – based on a voting system - under four top level classes (PERSON, LOCATION, ORGANIZATION and MISC) and a total of nine subclasses

RO / EN Anaphora Recognizer & Editor
http://nlptools.infoiasi.ro/UAIC.AnaphoraResolution/
http://nlptools.infoiasi.ro/UAIC.AnaphoraEditor/
Features used to decide if there is a co-referential chain between two NPs:
number agreement, gender agreement, and morphological description, implementing on the head noun;
similarity between the two noun phrases, both at lemma level and text level implemented on the head noun and also on the entire noun phrase;
condition if the two noun phrases belong to the same phrase or not.

RO / EN Clause Splitter & Editor
http://nlptools.infoiasi.ro/UAIC.ClauseSplitter/http://nlptools.infoiasi.ro/UAIC.ClauseEditor/
Features used to features used to build the model of compound verbs:
Distance between the verbs
the existence of punctuation or markers between them
the lemma and the morphological description of the verbs

RO / EN Discourse Parser
http://nlptools.infoiasi.ro/UAIC.DiscourseParser/
The generated discourse trees put in evidence only the nuclearity of the nodes, while the name of relations is ignored.
The discourse parser adopts an incremental policy in developing the trees and it is constrained by two general principles in discourse parsing: sequentiality of the terminal nodes (Marcu, 2000) and attachment restricted to the right frontier.

EBMT system
http://www.racai.ro/tools/translation/racai-translation-system/
Available for EN RO, EN GER, EN ESP, RO SLO

Language resources
Dictionaries monolingual / bilingual… eDTLR
(60) Wordnets RoWordnet
Lexical / morphological resources
Corpora
Mono / multi-lingual translation / language models CoRoLa
comparable
parallel RoTimeBank, JRC-Acquis, Ro-Semcor
treebanks
Text collections

Romanian Wordnet
Balkanet, 2004: lexical semantic network of Romanian
Hierarchy Preservation Principle and Conceptual Density Principle
aligned at the conceptual level with the English WordNet with Princeton WordNet 3.0, SUMO&MILO ontologies, the IRST DOMAINS taxonomy
PWN 2.0-3.0 mappings http://dev.racai.ro/dw/PWNMappings20-30/PWN_3.0-2.0_Concept_Mapping.zip
It includes the SentiWordNet subjectivity mark-up.
words belonging both to the general vocabulary and to various domains of activity
Cca 60.000 synsets
Used in word sense disambiguation, machine translation and question answering systems

Romanian Wordnet (2)
http://www.racai.ro/en/tools/text/rowordnet-visualizer/
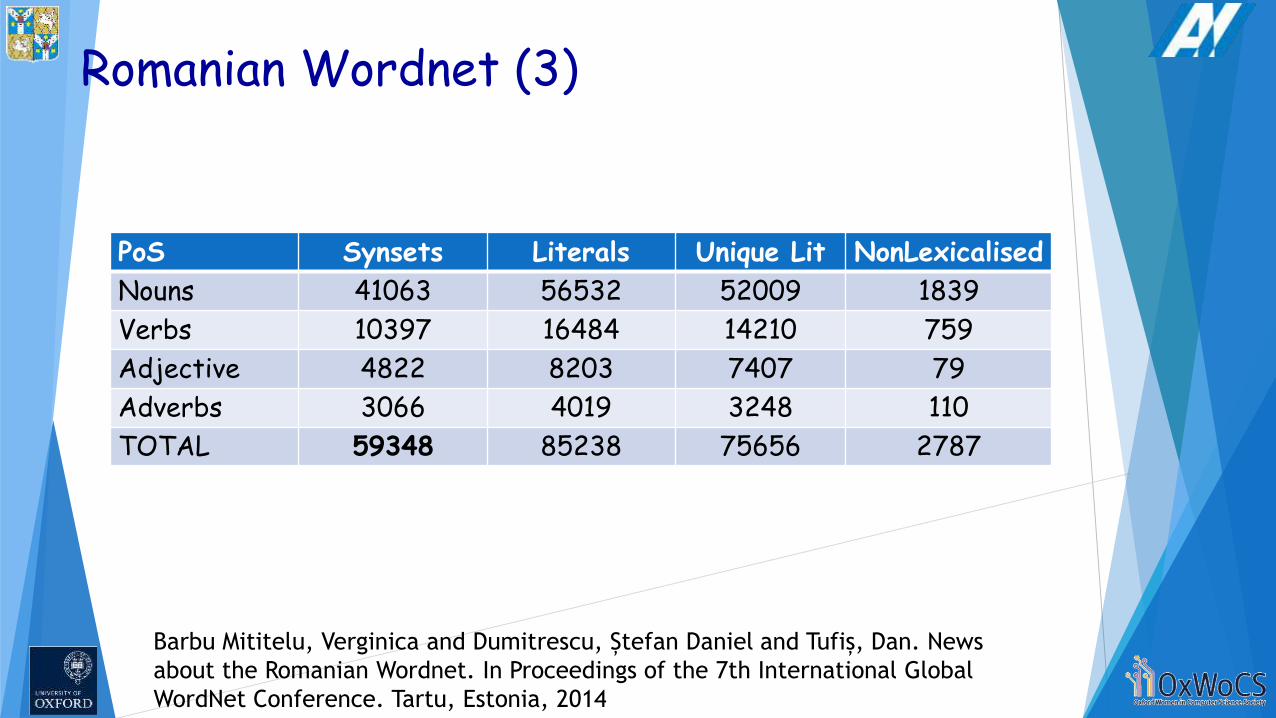
Romanian Wordnet (3)
PoS Synsets Literals Unique Lit NonLexicalised
Nouns 41063 56532 52009 1839
Verbs 10397 16484 14210 759
Adjective 4822 8203 7407 79
Adverbs 3066 4019 3248 110
TOTAL 59348 85238 75656 2787
Barbu Mititelu, Verginica and Dumitrescu, Ștefan Daniel and Tufiș, Dan. News
about the Romanian Wordnet. In Proceedings of the 7th International Global
WordNet Conference. Tartu, Estonia, 2014

DTLR Romanian Academy, since 1913
33 volumes, more than 15,000 pages and about 175,000 entries, with citations collected from more than 2,500 volumes of the written Romanian literature

eDTLR
The digital form of DTLR, including its sources in digital formand the software to access them
National project, 2007 - 2010
Steps in Building eDTLR:
Preliminary processing of the paper version
Scanning
Image Processing
Automatic recognition of symbols - OCR
Correction phases – volunteers + specialists
Parsing the entries
Correcting the structure - specialists
Linking the dictionary entries to sources

CoRoLa – the reference electronic corpus of contemporary Romanian language
http://www.racai.ro/en/research-activities/corola-program-prioritar-al-academiei-romane/
a big corpus (more than 500 million word forms)
all functional styles will be represented
written texts: from books, newspaper articles, booklets, theses and technical reports
oral texts: 300 hours of recordings accompanied by their transcripts
pre-processed and annotated texts (at least at the morphological level, but maybe also at a syntactic and even semantic and discourse level).

CoRoLa - partners
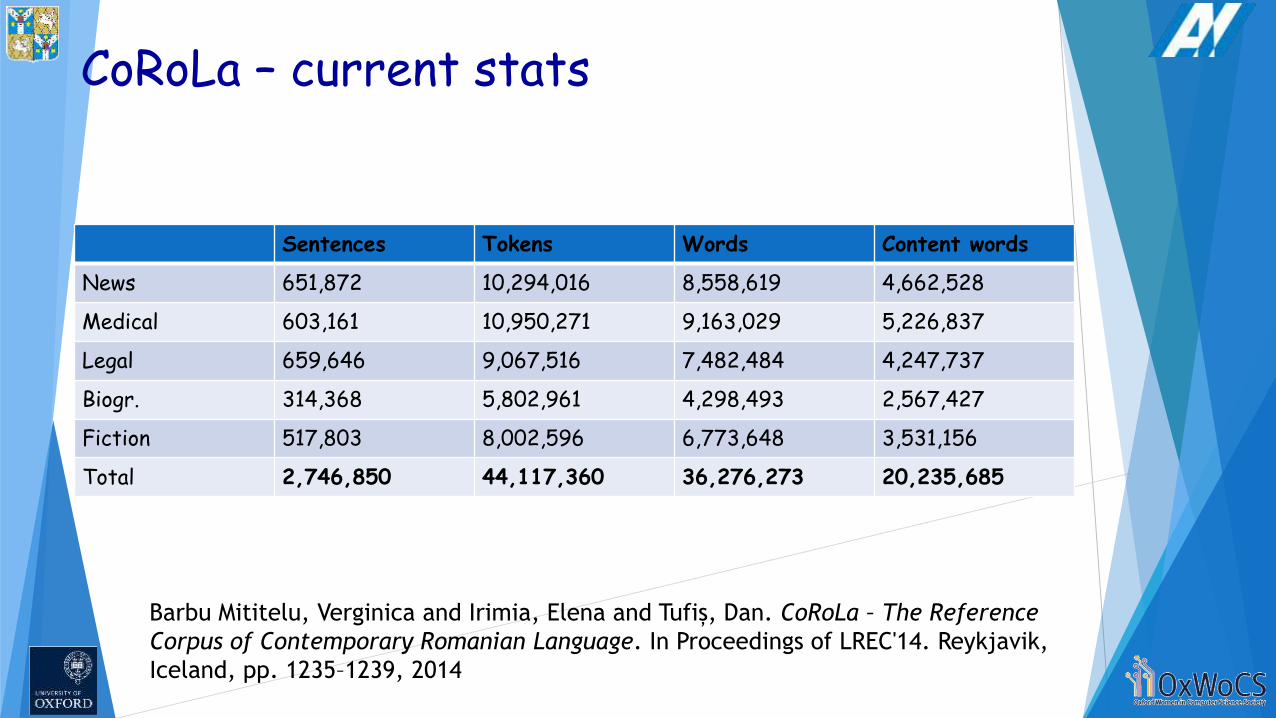
CoRoLa – current stats
Sentences Tokens Words Content words
News 651,872 10,294,016 8,558,619 4,662,528
Medical 603,161 10,950,271 9,163,029 5,226,837
Legal 659,646 9,067,516 7,482,484 4,247,737
Biogr. 314,368 5,802,961 4,298,493 2,567,427
Fiction 517,803 8,002,596 6,773,648 3,531,156
Total 2,746,850 44,117,360 36,276,273 20,235,685
Barbu Mititelu, Verginica and Irimia, Elena and Tufiș, Dan. CoRoLa – The Reference
Corpus of Contemporary Romanian Language. In Proceedings of LREC'14. Reykjavik,
Iceland, pp. 1235–1239, 2014

RoTimeBank - motivations1. QA:
• when?, how often? or how long?
• Temporally-anchored questions
2. IE & IR
• Tracks in evaluation campaigns (SemEval, ACE, TAC)
3. MT:
• translated and normalized temporal references
• mappings between different behavior of tenses fromlanguage to language
4. DP:
• temporal structure of discourse
• Summarization (biographic summaries)

RoTimeBank – motivations (2)• Time-consuming, error-prone annotation for
Romanian• “fuzzy” situations
• all sentences express an EVENT • acum câteva zile, (în) următoarele luni• long-distance relations (dependencies)
• Extensions to other domains (literature, legislation)
• ISO standard

TimeML standard
A metadata standard developed especially for (English) news articles, for marking events: EVENT, MAKEINSTANCE temporal anchoring of events: TIMEX3,
SIGNAL
links between events and/or timexes: TLINK, ALINK, SLINK
ISO proposal including Italian, Chinese, Korean

TimeBank corpus
183 English news report documents TimeMLannotated, freely distributed through LDC
4715 sentences with 10586 unique lexical units, from a total of 61042 lexical units
•
Non-TimeML Markup in Time Bank 1.1: structure information: header
named entity recognition: <ENAMEX>, <NUMEX>,<CARDINAL>
sentence boundary information: <s>

TimeBank - Parallel corpus creation & processing
1. Translation (guidelines)2. Pre-processing (tokenizing, POS-tagging)3. Alignment (word-level, manual
correction)4. Annotation import (automatic, with
manual evaluation)5. ISO-TimeML adapted to Romanian
(annotation guideline)

Analysis of the annotation import
1. Types of temporal annotation import 1. Perfect transfer
2. Transfer with some amendments due to TimeMLspecifications
3. Transfer with amendments imposed by with language specific phenomena
4. Impossible transfer
2. Temporal elements not (yet) marked in the Romanian & English corpus
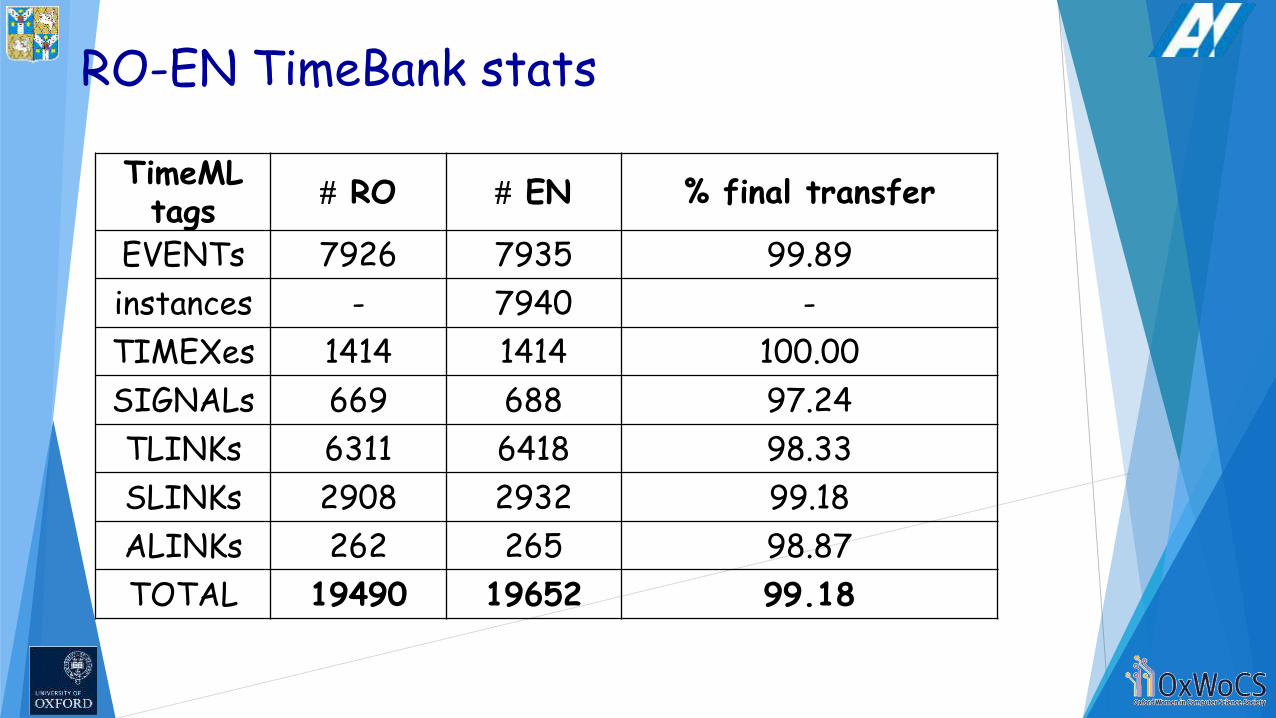
RO-EN TimeBank stats
TimeMLtags
RO EN % final transfer
EVENTs 7926 7935 99.89
instances - 7940 -
TIMEXes 1414 1414 100.00
SIGNALs 669 688 97.24
TLINKs 6311 6418 98.33
SLINKs 2908 2932 99.18
ALINKs 262 265 98.87
TOTAL 19490 19652 99.18

Final thoughts
Time is the only critic without ambition.
(John Steinbeck)
Time is a great teacher. Unfortunately, it killsall its pupils.
(Hector Berlioz)

Evaluation competitions for LRT development
CLEF: Cross-Language Evaluation Forum
Conference and Labs of the Evaluation Forum
QA@CLEF 2007-2008
ResPublQA 2009 – 2010
QA4MRE 2011-2013
QALD 2015-2015
GikiCLEF 2009
MultiLing @ ACL 2013

Scientific & raising awareness events
EUROLAN summer schools2015, 12th edition, Sibiu, Romania:
Linguistic Linked Open Datahttp://eurolan.info.uaic.ro/2015/
ConsILR workshops (Conference on Linguistic Resources and Tools for Processing the Romanian Language)http://consilr.info.uaic.ro/2014/index.php?list=eng
CICLing 2010, GWC 2016 LT4RD 2012 – Language Technologies in Romanian
Diaspora Following Anita Borg @ Iasi, through WITchIS


References
METANET whitepapers - http://www.meta-net.eu/whitepapers/overview
Steven Krauwer (2003), “The Basic Language Resource Kit (BLARK) as the First Milestone for the Language Resources Roadmap”, in Proceedings of the InternationalWorkshop “Speech and Computer”, Moscow, Russia.






























