Embed Size (px)
Citation preview

Linking digitized collections across metadata silos
Jeff Mixter and Titia van der Werf
OCLC Research
July 2, 2014
LIBER 2014
Connecting the Dots

Introduction
• Projects such as Europeana and the Digital Public Library of America have highlighted the importance of sharing metadata across silos
• While both of these projects have been successful in harvesting collections data, they have had problems with rationalizing the data and forming a coherent understanding of the aggregation
• In order to properly share data across silos and to better share data on the Web, for both human as well as machine consumption, there needs to be a concerted effort to apply best practices and standards that are universally understood and consumed

Current Situation
• Organizations create digital collections and generate metadata in repository silos. This metadata is generally:
•Not connecting the digitized items to their analogue sources•Not connecting names to authority records (persons, organizations, places, etc.) nor subject descriptions to controlled vocabularies•Not connecting to related online items accessible elsewhere
• Aggregators harvest this metadata that, in the process, generally gets “dumbeddown”:
•The University of Illinois OAI-PMH Data provider registry notes that 2964 repositories use dc. The next highest is MARC21 at 545 repositories•Even if dc.extensions are used, they are often lost in the OAI-PMH harvesting process•Aggregators usually ignore idiosyncratic use of metadata schemas and enforce the use of designated metadata fields
•Digital collection items are not very visible to search engines• A recent JISC project determined “Only about 50% of items appeared on the first page of Google results using the item name or title”

a case study: “a good example”
Search string: exposition organisée pour le centenaire des
"Fleurs du Mal"
& search on full-text string from document: "Eugène Crépet"
Search in:1. BnF Catalogue (Library Catalogue)
2. Gallica (Repository)
3. WorldCat (Aggregator via DCG harvester)
4. TEL (Aggregator)
5. Europeana (Aggregator)
6. Google (Search Engine)
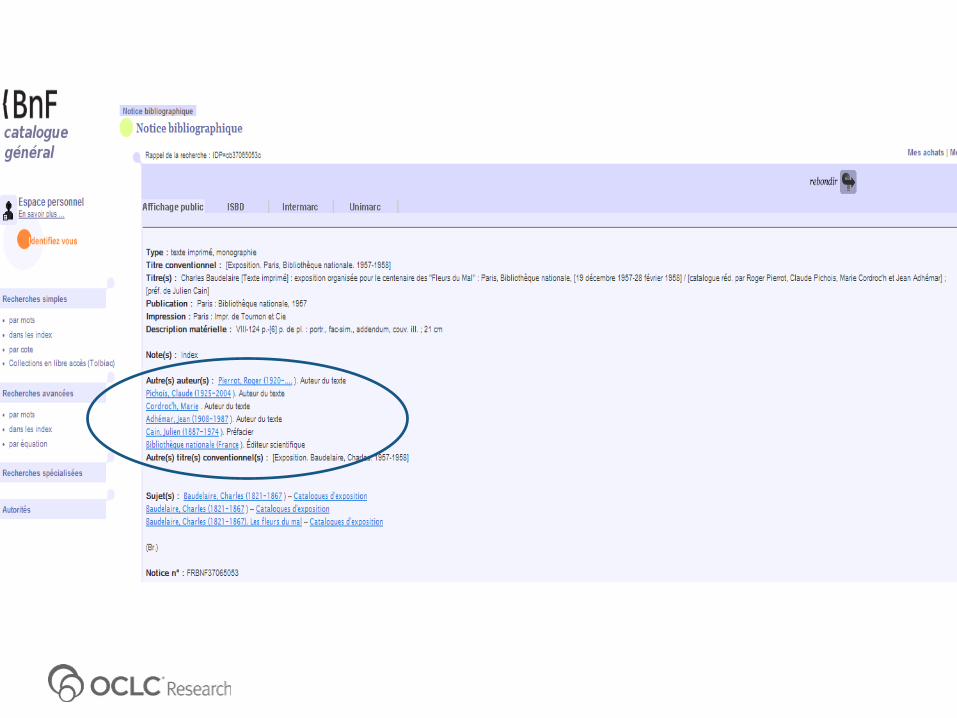
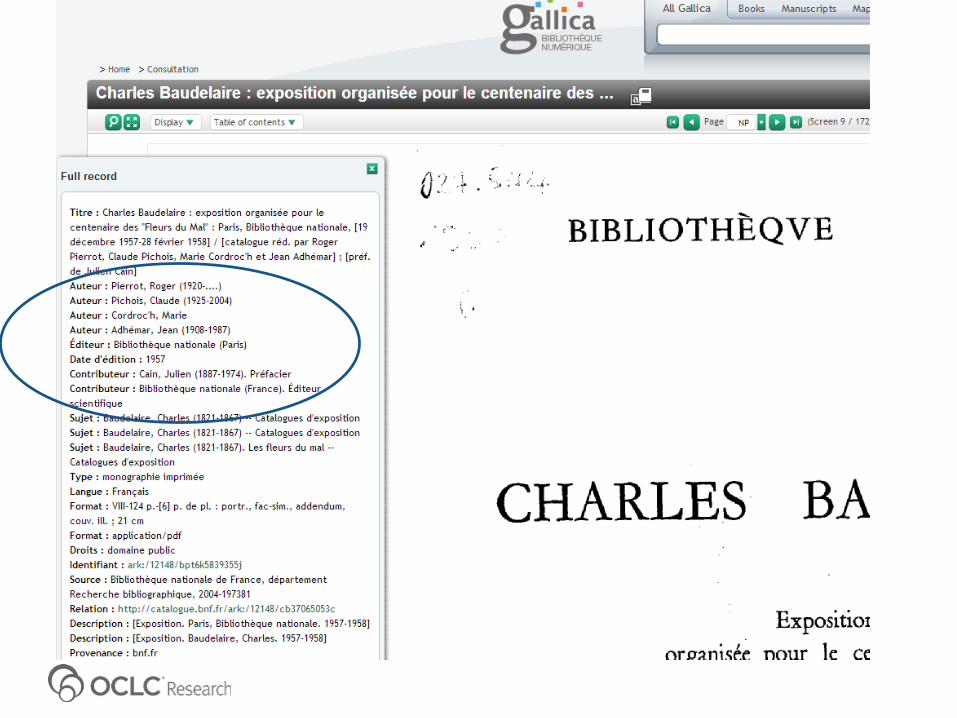

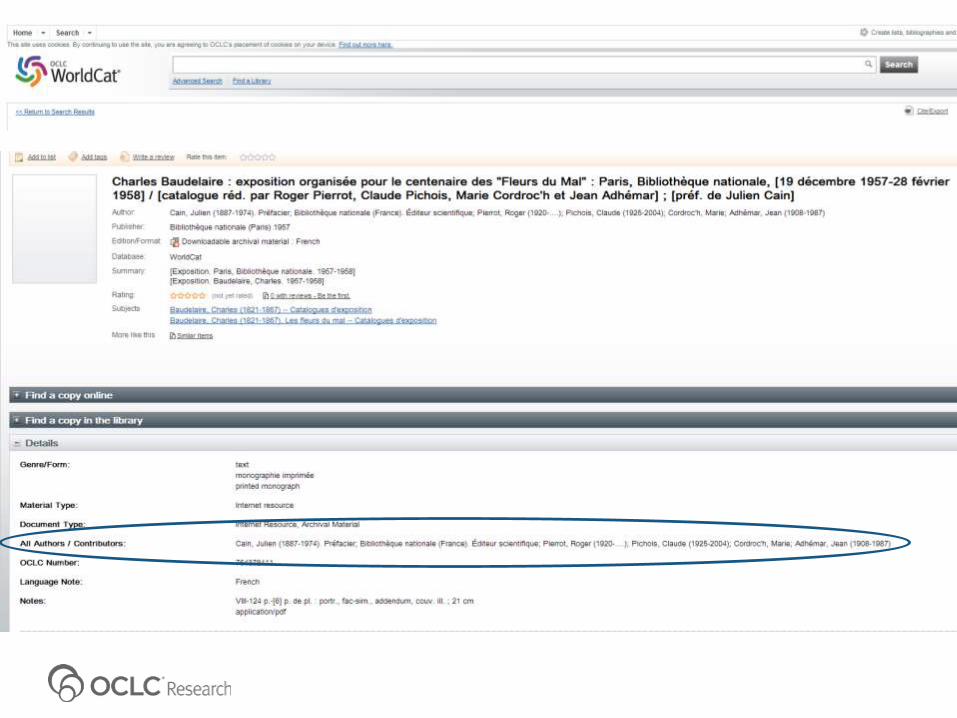
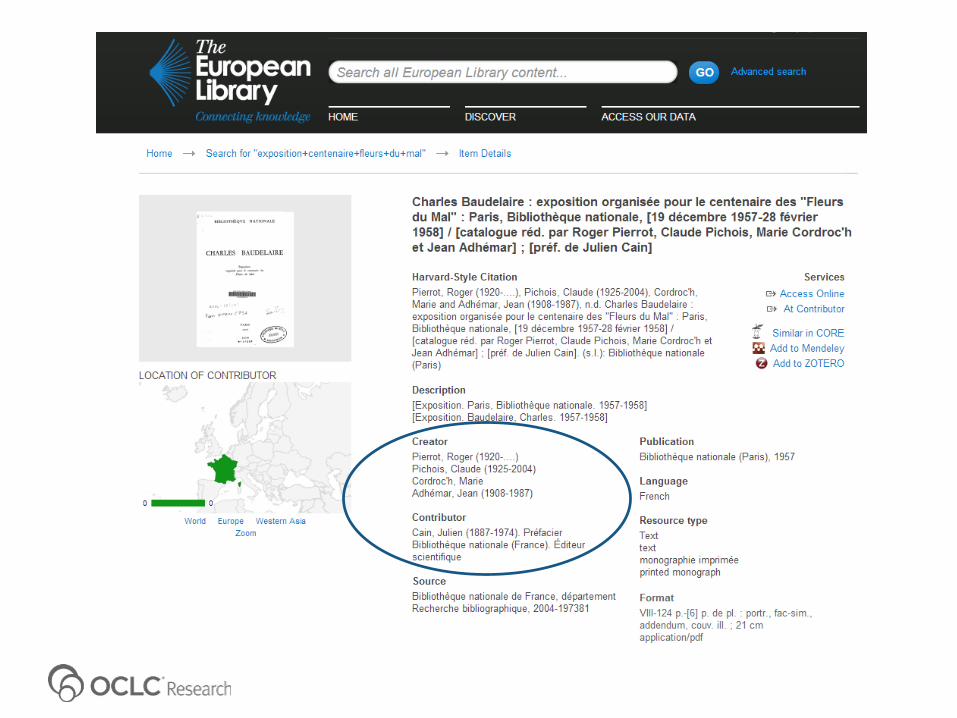



Observations
1. A lot of duplication of effort and waste of resources in developing aggregator services within the same domain
2. A lot of missed opportunities to connect to related data inside&outside the own silo (both repository and aggregation levels)
3. Visibility/discoverability via SEO is a sign of digital maturity
4. Aggregators generally do not use the FT-indexes available from repositories to enrich their search functionality

Problem Statements
1. How to share metadata and reduce costs?2. How to make digital collections more interoperable
across data silos?3. How to make digital collections more visible to search
engines?

Data sharing
• ‘Data sharing’ is a rather simple term and does not do justice to what it means in today’s knowledge society
• What we want to do is:1. Publish data on the Web in a format that can be consumed and indexed by
aggregators/web applications2. Share data with other organizations with the goal of ‘connecting the dots’3. This entails connecting points in your data to points in other organization’s
data. This could be People, Places, Events, Organizations, Topics etc.4. Connecting data across silos will help improve the ability for patrons to
browse and navigate related data/items without having to do multiple searches in multiple portals

Data sharing
BNFFrance
DNBGermany
BLUK
BNESpain KB
Netherlands
Europeana
TEL
APEnet
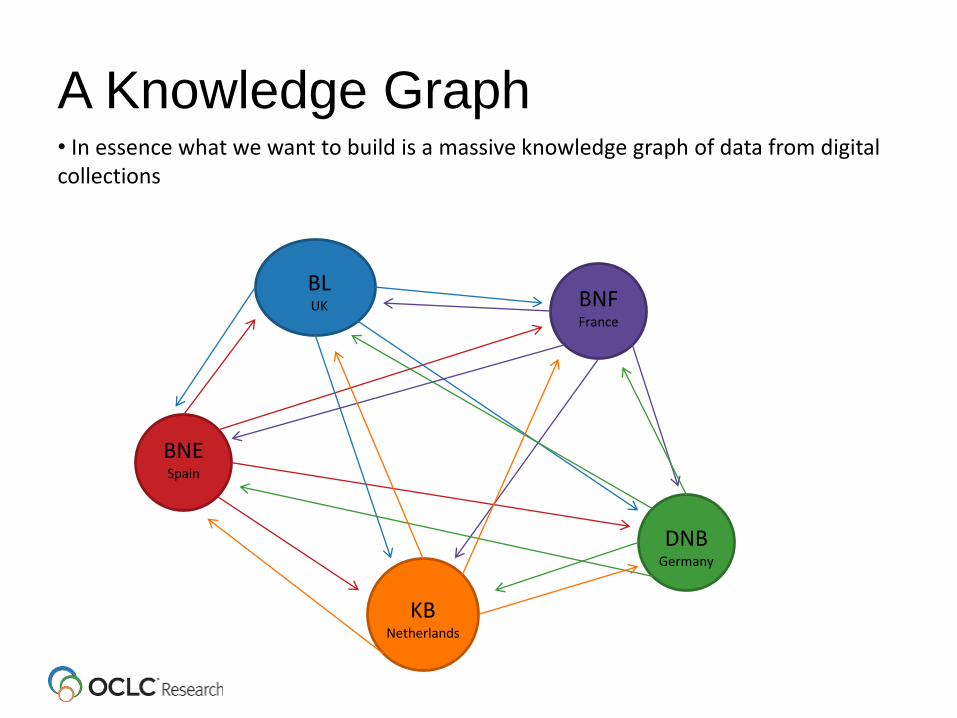
A Knowledge Graph• In essence what we want to build is a massive knowledge graph of data from digital collections
BNFFrance
DNBGermany
KBNetherlands
BNESpain
BLUK

A Knowledge Graph• Better yet, we actually want to connect individual dots within and across data silos. This is the essence of Linked Data•This requires changes in how repository data is published
Vincent van Gogh
Vincent van Gogh
Vincent van Gogh
Vincent van Gogh
Vincent van Gogh
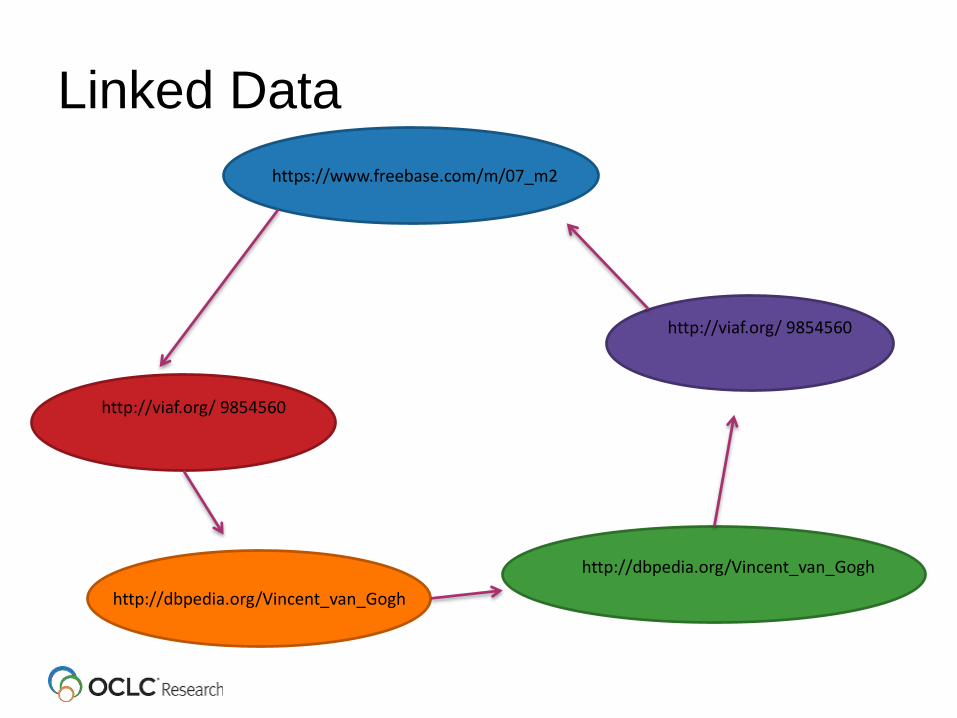
Linked Data
https://www.freebase.com/m/07_m2
http://viaf.org/ 9854560
http://viaf.org/ 9854560
http://dbpedia.org/Vincent_van_Gogh
http://dbpedia.org/Vincent_van_Gogh

Linked Data
•Linked Data is a way of publishing data on the Web in a format that can be easily consumed and understood by both humans and machines. It relies on linking data points together to form a complex graph of information
• Linked Data relies on identifiers called URIs
• Things NOT Strings!
• Linked Data can also be used to help connect data across silos and across domains of practice

Schema.org• Schema.org is a Linked Data vocabulary that is understood and indexed by search engines
• It is widely used:• It is used on 15% of web pages harvested by Google• over 5 million web sites• over 25 billion referenced entities
• Google Web Master tools can tell users how much structured data Google is seeing and indexing
• WorldCat.org has unique 4.63 million structured data entities over 1.48 million pages
• So why Schema.org?• Discoverability on the web• Interoperability with data outside of the library domain

OCLC Projects• In 2012, OCLC added Schema.org tags to WorldCat.org records, improving the way in which library information is represented to search engines.

http://www.worldcat.org/oclc/808127130

OCLC Projects
•In 2012, OCLC published VIAF data as Linked Open Data
•In 2013, OCLC developed a VIAF bot for Wikipedia
http://inkdroid.org/journal/2012/05/15/diving-into-viaf/comment-page-1/

OCLC Projects• In April of this year (2014), OCLC released a beta version of its Works data as Linked Data, marked up in Schema.org (197M work descriptions)
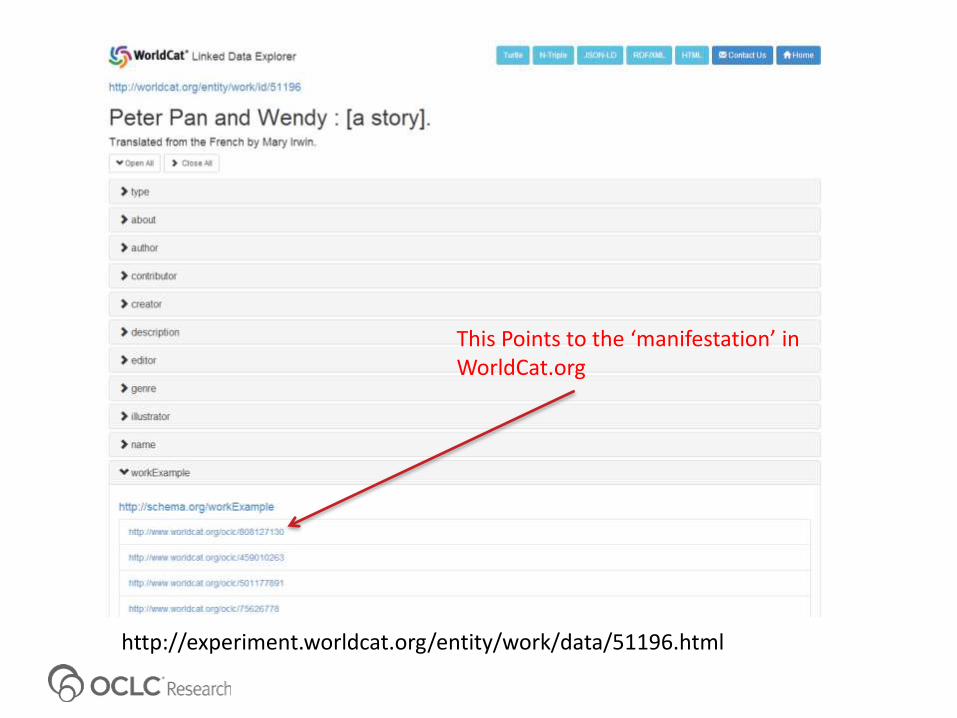
This Points to the ‘manifestation’ in WorldCat.org
http://experiment.worldcat.org/entity/work/data/51196.html

Other OCLC Projects
• There is an exploratory project underway to take the Digital Collections Gateway metadata create more granular Linked Data descriptions
• A USC collection was used as a test case• Using original metadata rich descriptions of people, places, events and items were created
•As OCLC continues to use the Schema.org vocabulary to items found in libraries archives and museums, we have begun to create extension terms to supplement shortcomings in Schema.org
• There is also a W3C Community Group Schema Bib Extend that proposes additional terms to Schema.org for review and consideration

Becoming a player in the web of data

Questions?

Thank You!
©2014 OCLC. This work is licensed under a Creative Commons Attribution 3.0 Unported License. Suggested attribution: “This
work uses content from [presentation title] © OCLC, used under a Creative Commons Attribution license:
http://creativecommons.org/licenses/by/3.0/”
Jeff Mixter – [email protected]
Titia van der Werf – [email protected]





























