Embed Size (px)
Citation preview

ADO.NET XML Data Serialization

XML is the key element responsible for the greatly improved interoperability of the
Microsoft ADO.NET object model when compared to Microsoft ActiveX Data Objects
(ADO). In ADO, XML was merely an I/O format (nondefault) used to persist the
contents of a disconnected recordset. The participation of XML in the building and in
the interworkings of ADO.NET is much deeper. The aspects of ADO.NET in which the
interaction and integration with XML is stronger can be summarized in two categories:
object serialization and remoting and a dual programming interface.

In ADO.NET, you have several options for saving objects to, and restoring objects
from, XML documents. In effect, this capability belongs to one object only—the
DataSet object—but it can be extended to other container objects with minimal
coding. Saving objects like DataTable and DataView to XML is essentially a special case
of the DataSet object serialization.

Serializing DataSet ObjectsLike any other .NET Framework object, a DataSet object is stored in memory in a
binary format. Unlike other objects, however, the DataSet object is always remoted
and serialized in a special XML format, called a DiffGram
When the DataSet object trespasses across the boundaries of the application
domains (AppDomains), or the physical borders of the machine, it is automatically
rendered as a DiffGram. At its destination, the DataSet object is silently rebuilt as a
binary and immediately usable object.

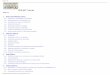
In ADO.NET, serialization of an object is performed either through the public
ISerializable interface or through public methods that expose the object's internal
serialization mechanism
As .NET Framework objects, ADO.NET objects can plug into the standard .NET
Framework serialization mechanism and output their contents to
standard and user-defined formatters

The .NET Framework provides a couple of builtin formatters: the binary formatter and
the Simple Object Access Protocol (SOAP) formatter. A .NET Framework object makes
itself serializable by implementing the methods of the ISerializable interface—
specifically, the GetObjectData method, plus a particular flavor of the constructor.
According to this definition, both the DataSet and the DataTable objects are
serializable.

All the methods that the DataSet object uses internally to support the .NET
Framework serialization process are publicly exposed to applications through a group
of methods, one pair of which clearly stands out—ReadXml and WriteXml.
Note that GetXml returns a string that contains XML data. As such, it requires more
overhead than simply using WriteXml to write XML to a file. You should not use GetXml
and GetXmlSchema unless you really need to obtain the DataSet representation or
schema as distinct strings for in-memory manipulation. The GetXmlSchema method
returns the DataSet object's XML Schema Definition (XSD) schema; there is no way to
obtain the DataSet object's XML-Data Reduced (XDR) schema.

Writing Data as XMLThe contents of a DataSet object can be serialized as XML in two ways that I'll call
stateless and stateful. Although these expressions are not common throughout the
ADO.NET documentation, I believe that they capture the gist of the two XML schemas
that can be used to persist a DataSet object's contents

Preserving Schema and Type InformationThe stateless XML format is a flat format. Unless you explicitly add schema information,
the XML output is weakly typed. There is no information about tables and columns, and
the original content of each column is normalized to a string. If you need a higher level
of type and schema fidelity, start by adding an in-line XSD schema.
In general, a few factors can influence the final structure of the XML document that
WriteXml creates for you. In addition to the overall XML format—DiffGram or a plain
hierarchical representation of the current contents—important factors include the
presence of schema information, nested relations, and how table columns are mapped
to XML elements.

Writing Schema InformationWhen you serialize a DataSet object, schema information is important for two reasons.
First, it adds structured information about the layout of the constituent tables and their
relations and constraints. Second, extra table properties are persisted only within the
schema. Note, however, that schema information describes the structure of the XML
document being created and is not a transcript of the database metadata.
The schema contains information about the constituent columns of each DataTable
object. (Column information includes name, type, any expression, and all the contents
of the ExtendedProperties collection.)

The schema is always written as an in-line XSD. As mentioned, there is no way for you
to write the schema as XDR, as a document type definition (DTD), or even as an
added reference to an external file. The following listing shows the schema source for
a DataSet object named NorthwindInfo that consists of two tables: Employees and
Territories. The Employees table has three columns—employeeid, lastname, and
firstname. The Territories table includes employeeid and territoryid columns. (These
elements appear in boldface in this listing.)

<xs:schema id="NorthwindInfo" xmlns=""
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:msdata="urn:schemas-microsoft-com:xml-msdata">
<xs:element name="NorthwindInfo" msdata:IsDataSet="true">
<xs:complexType>
<xs:choice maxOccurs="unbounded">
<xs:element name="Employees">
<xs:complexType>
<xs:sequence>

<xs:element name="employeeid" type="xs:int" />
<xs:element name="lastname" type="xs:string" />
<xs:element name="firstname" type="xs:string" />
</xs:sequence>
</xs:complexType>
</xs:element>

<xs:element name="Territories">
<xs:complexType>
<xs:sequence>
<xs:element name="employeeid" type="xs:int" />
<xs:element name="territoryid" type="xs:string" />
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:choice>
</xs:complexType>
</xs:element>
</xs:schema>

The <xs:choice> element describes the body of the root node <NorthwindInfo> as an
unbounded sequence of <Employees> and <Territories> nodes. These first-level
nodes indicate the tables in the DataSet object. The children of each table denote the
schema of the DataTable object.

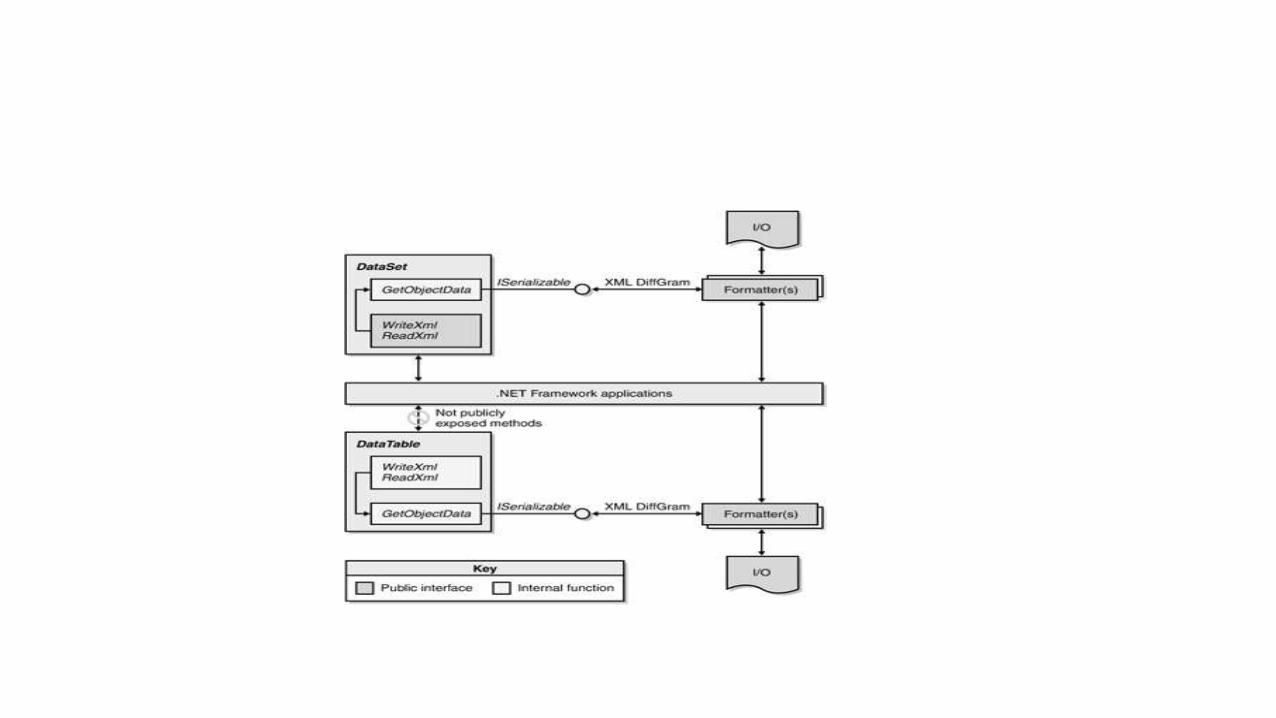
In-Line Schemas and Validation<DataSetName>
<schema>...</schema>
<Table1>...</Table1>
<Table2>...</Table2>
<DataSetName>
How the .NET Framework validating reader parses a serialized DataSet objectwith an in-line schema.

Serializing to Valid XMLThis fact, in addition to the forward only nature of the parser, irreversibly alters the
parser's perception of what the real document schema is. The solution is simple:
move the schema out of the DataSet XML serialization output, and group both nodes
under a new common root, as shown here:

<Wrapper>
<xs:schema> ... </xs:schema>
<DataSet>
.
</DataSet>
</Wrapper>

Customizing the XML RepresentationThe schema of the DataSet object's XML representation is not set in stone and can be
modified to some extent. In particular, each column in each DataTable object can
specify how the internal serializer should render its content. By default, each column
is rendered as an element, but this feature can be changed to any of the values in the
MappingType enumeration. The DataColumn property that specifies the mapping
type is ColumnMapping.

Rendering Data RelationsA DataSet object can contain one or more relations gathered under the Relations
collection property. A DataRelation object represents a parent/child relationship set
between two DataTable objects. The connection takes place on the value of a matching
column and is similar to a primary key/foreign key relationship. In ADO.NET, the
relation is entirely implemented in memory and can have any cardinality: one-to-one,
one-to-many, and even many-to-one.

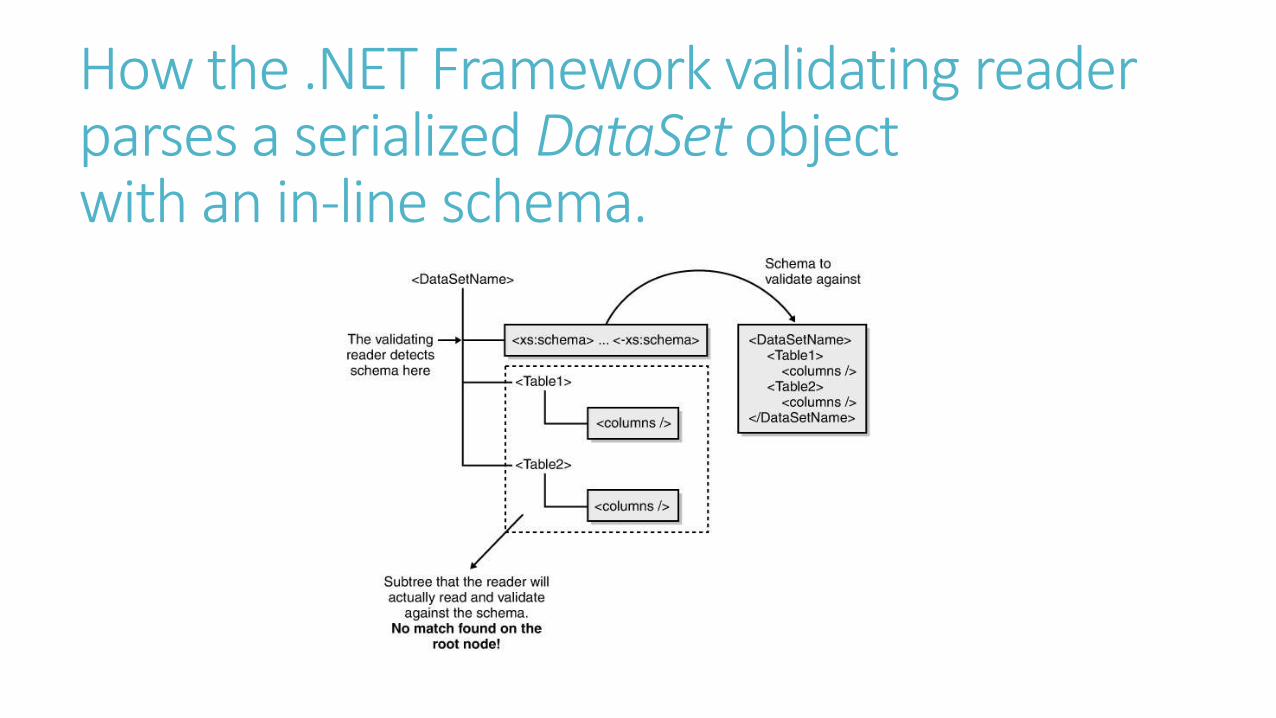
Inside the DataView ObjectThe DataView class represents a customized view of a DataTable object. The
relationship between DataTable and DataView objects is governed by the rules of a
well-known design pattern: the document/view model. According to this model, the
DataTable object acts as the document, and the DataView object acts as the view. At
any moment, you can have multiple, different views of the same underlying data. More
important, you can manage each view as an independent object with its own set of
properties, methods, and events.
A DataView object maintains an index of the table rows that match the criteria.

Binary Data SerializationThere are basically two ways to serialize ADO.NET objects: using the object's own XML
interface, and using .NET Framework data formatters. So far, we have reviewed the
DataSet object's methods for serializing data to XML, and you've learned how to persist
other objects like DataTable and DataView to XML. Let's look now at what's needed to
serialize ADO.NET objects using the standard .NET Framework data formatters.
The big difference between methods like WriteXml and .NET Framework data
formatters is that in the former case, the object itself controls its own serialization
process. When .NET Framework data formatters are involved, any object can behave in
one of two ways. The object can declare itself as serializable (using the Serializable
attribute) and passively let the formatter extrapolate any significant information that
needs to be serialized. This type of object serialization uses .NET Framework reflection
to list all the properties that make up the state of an object.

The second behavior entails the object implementing the ISerializable interface, thus
passing the formatters the data to be serialized. After this step, however, the object no
longer controls the process. A class that neither is marked with the Serializable attribute
nor implements the ISerializable interface can't be serialized. No ADO.NET class
declares itself as serializable, and only DataSet and DataTable implement the
ISerializable interface. For example, you can't serialize to any .NET Framework
formatters a DataColumn or a DataRow object.

Loading DataSet Objects from XMLThe contents of an ADO.NET DataSet object can be loaded from an XML stream or
document—for example, from an XML stream previously created using the WriteXml
method. To fill a DataSet object with XML data, you use the ReadXml method of the
class.
The ReadXml method fills a DataSet object by reading from a variety of sources,
including disk files, .NET Framework streams, or instances of XmlReader objects. In
general, the ReadXml method can process any type of XML file, but of course the
nontabular and rather irregularly shaped structure of XML files might create some
problems and originate unexpected results when the files are rendered in terms of rows
and columns.
In addition, the ReadXml method is extremely flexible and lets you load data according
to a particular schema or even infer the schema from the data.
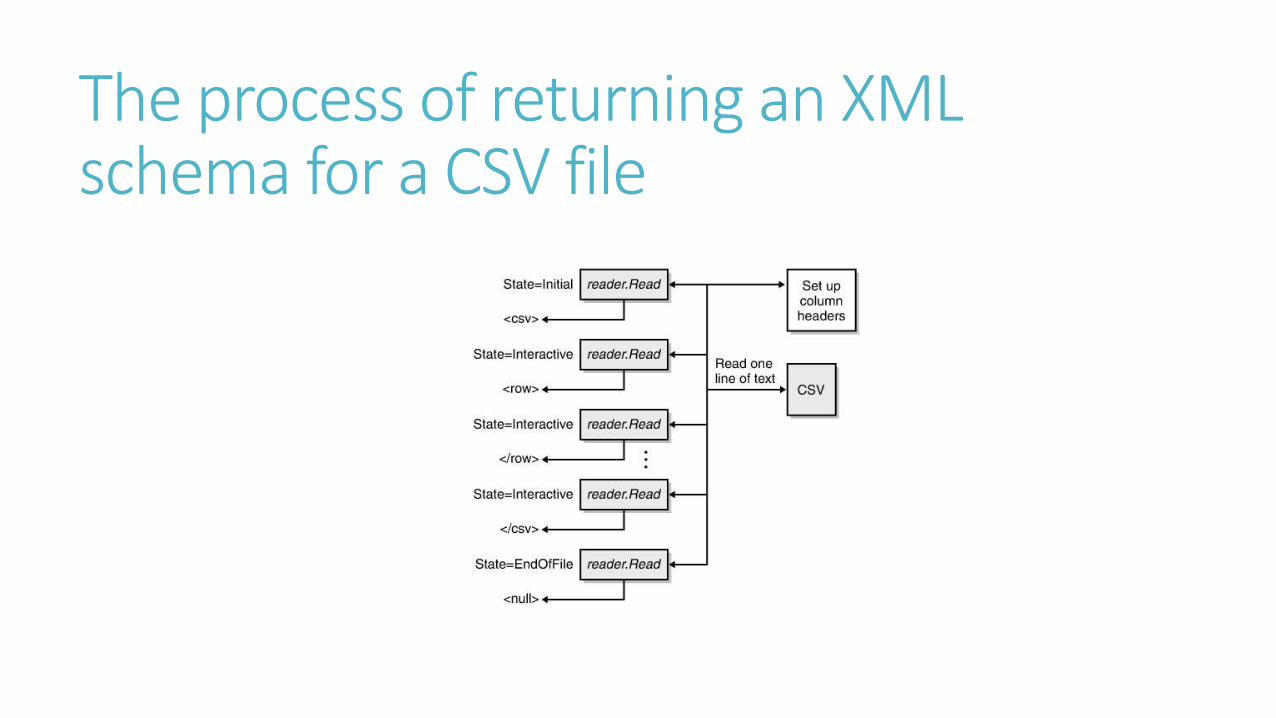
The process of returning an XML schema for a CSV file

The Read MethodWhen a new node is returned, the reader updates the node's depth and state. In
addition, the reader stores fresh information in node-specific properties such as
Name, NodeType, and Value, as shown here:
public override bool Read()
{
if (m_readState == ReadState.Initial)
{
if (m_hasColumnHeaders)
{

string m_headerLine = m_fileStream.ReadLine();
m_headerValues = m_headerLine.Split(',');
}
SetupRootNode();
m_readState = ReadState.Interactive;
return true;
}

if (m_readState != ReadState.Interactive)
return false;
// Return an end tag if there's one opened
if (m_mustCloseRow)
{
SetupEndElement();
return true;
}
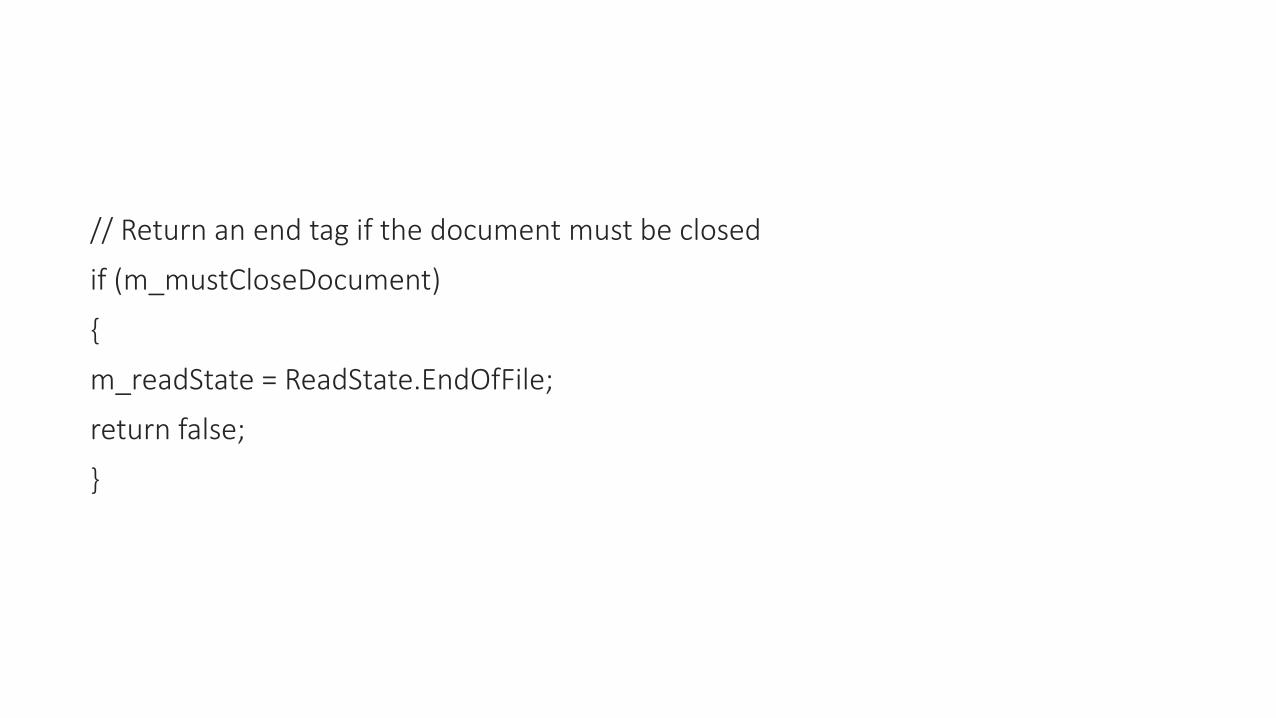
// Return an end tag if the document must be closed
if (m_mustCloseDocument)
{
m_readState = ReadState.EndOfFile;
return false;
}

// Open a new tag
m_currentLine = m_fileStream.ReadLine();
if (m_currentLine != null)
m_readState = ReadState.Interactive;
else
{
SetupEndRootNode();
return true;
}

element
m_tokenValues.Clear();
string[] tokens = m_currentLine.Split(',');
for (int i=0; i<tokens.Length; i++)
{
string key = "";
if (m_hasColumnHeaders)
key = m_headerValues[i].ToString();
else
key = CsvColumnPrefix + i.ToString();
m_tokenValues.Add(key, tokens[i]);
}

SetupElement();
return true;
}
For example, when the start tag of a new element is returned,
the following code runs:

private void SetupElement()
{
m_isRoot = false;
m_mustCloseRow = true;
m_mustCloseDocument = false;

m_name = CsvRowName;
m_nodeType = XmlNodeType.Element;
m_depth = 1;
m_value = null;
// Reset the attribute index

In ADO.NET, XML is much more than a simple output format for serializing data. You
can use XML to streamline the entire contents of a DataSet object, but you can also
choose the actual XML schema and control the structure of the resulting XML
document.

There are several ways to persist a DataSet object's contents. You can create a
snapshot of the currently stored data using a standard layout referred to here as the
ADO.NET normal form. This data format can include schema information or not.
Saving to the ADO.NET normal form does not preserve the state of the DataSet object
And discards any information about the previous state of each row. If you want
stateful