Augmenting GPU Hardware through Software Innovations ---A Reflection on a Dozen Years of Efforts
ComputerScience,NorthCarolinaStateUniversity
XipengShen

�2
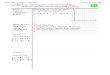
EvolutionofNVIDIAGPU
900
750
600
450
300
150
GB/s2008 2010 2012 2014 2016 2018
228GFlops
1050
Pascal
14.8TFlops
Volta
MemBandwidth
AdaptedfromNVIDIA’sPresentation
DynamicParallelism
CudaFP64
Tensorcores3DMemoryNVLinkUnifiedMemoryMixedPrecision

�3Credit:NVIDIA
Tremendous Successes

4
Three “Dark Clouds” Persist
IrregularMem&Control
Non-DataParallelism
PreemptiveScheduling
GPU

Thread block
Massive Parallelism
Streaming multiprocessor (SM)
A_kernel_function (…) { … [thread_ID] … … …}
�5
GPU
Each thread: a little work, a few data accesses.But hundreds of thousands of them.
Great for Regular Data-Parallel Computing.

Thread block
Massive Parallelism
Streaming multiprocessor (SM)
A_kernel_function (…) { … [thread_ID] … … …}
�6
GPU
• “Cloud”1:SPMTmodelisnotdesignedforothertypesofparallelism• E.g.,pipelineparallelism,taskparallelism
• “Cloud”2:GPUremainssensitivetodivergenceincontrols&accesses
• Memorycoalescing,threaddivergence
• “Cloud”3:Massivestatestostoreandrecoverforpreemption
• Despiteaddedhardwaresupport

7
Our Explorations on GPU PerformanceCompiler-based software solutions
11/069/07
5/096/10
3/1110/11
6/122/13
9/1312/14
5/156/15
12/156/16
2/17
CUDArelease
NVIDIALCPCtalk
IPDPScrossinputadap.opt.
ICSremovethreaddiverg.dyn.
ASPLOSGStreamline
PACTtreatsynch.correct.GPU2CPU
ICSsyn.relax.&opt.GPU2CPU
PPOPPmemcoalesc.
PACTNVMforGPU
MicroPORPLE
ICSSMcentric
HotOSCo-runonFused
MicroFreeLaunch
ICSMultiview
PPOPPEffiSha
10/17
MicroVersaPipe
5/17
IPDPSCo-sched.
ASPLOSHiWayLib
4/19

8
Three Persistent “Dark Clouds”
IrregularMem&Control
Non-DataParallelism
PreemptiveScheduling
GPU

�9
Pipeline Applications
Networkpacketprocessing
Imagerendering Facedetection
imagecredit:Whippletree,cs.adelaide.edu.au
Highthroughput&lowlatencybothdesired
DeepNeuralNetworks

�10
Kernel-by-Kernel
if(accumulatedEnoughJob){stage1_kernel(ManyJobs);stage2_kernel(ManyJobs);stage3_kernel(ManyJobs);
}
Run-to-Completion
if(accumulatedEnoughJob){gpuKernel{
stage1(oneJob);stage2(oneJob);stage3(oneJob);
}}
NeitherbuildsanactualpipelineonGPU.

�11
IsactualpipelinepossibleonGPU?
Requiresbothspatialandtemporalcontrolsofthreadsexecutions.
SM-centric Kernel + SW-based Scheduling

SM-Centric Kernel
12
Thread-centric task model ⇒ SM-centric task model
original_kernel: taskID = f (workerID); processTask (taskID);
ith worker
ith task
↕
new_kernel: smID = getSMID(); taskID = JobQ [smID].next(); if (taskID!=NULL) processTask (taskID);
ith task queue
↕ith SM
⇒
⇒…
Simplified
[ICS’15]

�13
Kernel-by-Kernel
if(accumulateEnoughJob){stage1_kernel(ManyJobs);stage2_kernel(ManyJobs);stage3_kernel(ManyJobs);
}
Run-to-Completion
gpuKernel{stage1(oneJob);stage2(oneJob);stage3(oneJob);
}
New Exec. Models Enabled

14
KbK
responsiveness

VersaPipe
�15
Realizeefficientpipelineexecutions
Automaticallyconfigureexecutionmodels
Screencomplexityfromprogrammers
A Versatile Programming Framework for Pipelined Computing on GPU[Micro17]
https://github.com/JamesTheZ/VersaPipe

16
Speedups
Megakernel
Megakernel:Whippletree[TOG2014]
Default

PipelineBeyondGPU
�17
[Monday11:30amDataMovementIISession]
“HiWayLib:ASoftwareFrameworkforEnablingHighPerformanceCommunicationsforHeterogeneousPipelineComputations”
• Communicationspeed.
• Terminationchecks.
• Taskqueuecontention.

Dynamic Parallelism• The amount of parallelism is dynamic.
• Example: Breadth-First Search(BFS).
!18
0
11 1
?? ? ??
Graph
Level 0
Level 1
Level 2
1
?? ?
In parallel
1
??
In parallel
Parallelism is determined by the # of neighbors!
Many other applications: Graph Coloring,
Survey Propagation,
Shortest Path,
Minimal Spanning Tree,
Connected Components Labeling,
…

Current Support on GPU• Sub-kernel Launch (SKL)
!19
Main (…) { …
A_GPU_Kernel <<< … >>> (…); }
A_GPU_kernel ( … ){
… subkernel <<< … >>> ( … ); }
0
11 1
22 2 22

Large overhead of SKL
• Practices: Careful programming to use task lists etc.
• Programming productivity lost
• HW extensions (e.g.,[Kim+:Micro2014 [Wang+:ISCA2015])
• Add HW complexities
!20
Slow
dow
n (X
)
0
5.5
11
16.5
22
GC BFS MST_dfind2 AverageSP SSSP MSTv

Solution: Free Launch
• A compiler-based program transformation.
!21
Free Launch: Source-to-Source
Compiler
Program: Worklist style
Productivity & EfficiencyProgram: SKL style
Remove SKLRedistribute subtasks to
parent threads
[Micro’15]
Get the best of both worlds:
• Intuitive coding • Low overhead • Superb load balance
37X Speedup

22
Three Persistent “Dark Clouds”
IrregularMem&Control
Non-DataParallelism
PreemptiveScheduling
GPU

Xipeng Shen [email protected]
Dynamic Irregularities
23
A[ ]:
P[ ] = { 0, 5, 1, 7, 4, 3, 6, 2}
... = A[P[tid]];
tid: 0 1 2 3 4 5 6 7
Degrade throughput by up to (warp size) times. (warp size = 32 in modern GPUs)
memory
2 4 10 0 6 0 0A[ ]:
tid: 0 1 2 3 4 5 6 7 if (A[tid]) {...}
control flow (thread divergence)
for (i=0;i<A[tid]; i++) {...}
{a mem seg.
P[ ] = { 0, 1, 2, 3, 4, 5, 6, 7}
AproblemexistsonallGPUs.

Solution 1: Thread-Data Remapping
24
{a mem seg.
4 trans/warp
{
a mem seg.
1 trans/warp
Irregularity in a warp: problematic; across warps: okey!
Principle of solution:Turn intra-warp irreg. into reg. or inter-warp irreg.

G-Streamline[ASPLOS’2011, PPOPP’13]
25
1.08—2.5Xspeedups
First framework enabling runtime thread-data remapping.
CPU-GPU pipeline to hide transformation overhead.
Kernel splitting to resolve dependences.

Xipeng Shen [email protected]
Solution 2: Data Placement
!26
Global memory
Texture memory
Shared memory
Constant memory
(L1/L2 cache)(Read-only cache)
(Texture cache)
A
B
C
D
…
Data in a program
?????
3X performance difference
GPU

Xipeng Shen [email protected]
PORPLE: Portable Data Placement Engine
!27
[Micro’2014]
Offerportability
Offerinputadaptivity
Createplacement-agnosticcode

Observations
• DecentspeedupsonK20c,M2075,C1060.• frombetteruseoftexturemem,constantmem&cache.
• StillmatteronnewGPUs?
�28[PMBS’2018 by Bari et al.]
VariationsofDataPlacementsinMemory
SPMVGlobalmemisbaseline.

ProblemShiftsbeyondoneGPU
�29
NVIDIADGX2

UnifiedMemory
�30
LogicalView PhysicalView
Tuning-2[read-only]
Tuning-1[preferred]Default
credit:NVIDIA

31
Three Persistent “Dark Clouds”
IrregularMem&Control
Non-DataParallelism
PreemptiveScheduling
GPU

�32
GPU
Kernel A (long running, low priority)
Kernel B (high priority)
Application 1
Application 2
A major issue for responsiveness, priority, and fairness.
Wait, wait, wait …
BeforePascal:Nopreemptionsupport.

�33
EffiSha[PPOPP’2017]
Firstsoftware-controlledpreemptiveschedulingofGPUkernels.

Execution Time
34
transformedGPU program-1
. . .
CPU GPU
transformedGPU program-2
transformedGPU program-mSched.
policies
EffiSha runtime daemon
launching requests/
notificationskernel
(re)launch
eviction flag
evictable kernel-1
readwrite
evictable kernel-2
evictable kernel-1

�35
Still a Problem?SincePascal:Instruction-levelpreemptionbecomessupported.
• Contextsize:7MBSharedMem&20MBRegistersonV100.
• Memorycapacitylimitation/performanceinterference.
• Unsafeisolation(e.g.,leftoveronsharedmemory).

36
IrregularMem&Control
Non-DataParallelism
PreemptiveScheduling
Reliability Security
GPU
Two More Clouds

Conclusion
• GPU changes fast; some challenges persist • SW support is essential
• Focusing on principled barriers gives lasting value
• Call for continuous innovations • Versatile support of parallelism • Portable support of memory opt. (intra- & inter-dev) • Efficient support of safe sharing • Reliable support of critical uses
�37
Recommended