
Web Archiving at the National Library of Australia
National Library of Indonesia Staff5 October 2010
Paul KoerbinManager, Web Archiving
National Library of Australia

Web Archiving at the NLA Background
History Organisation Participants
Approaches to web archiving PANDORA selective archiving Whole domain harvesting
Skills and operational tasks Workflows and systems
PANDAS

History: web archiving at the NLA
April 1996: ‘Electronic Unit’ established Part of Acquisitions Branch 3 staff, 6 months to develop selection (scope)
guidelines and identify resources September 1996: ‘Australian Serials and
Electronic Unit’ established Technical services restructure, multi-tasking, matrix
management October 1996 first titles harvested
November 1996: PANDORA born as ‘proof of concept project’ As at June 1997, 30 titles harvested

History: web archiving at the NLA May 1998: public access to PANDORA titles July 1998: first PANDORA ‘partner’ began
participation 11th participant joined in 2010
October 1998: first ‘Certified Agreement’ commenced in the Library Change to staffing classifications; professional
librarian streams abolished June 2001: PANDAS v.1 released
Web archiving workflow system developed by NLA 2002: Digital Archiving Branch
Our own identity at last! Began first trial of ‘mainstreaming’ web archiving in
Serials and Govt Deposit sections

History: web archiving at the NLA August 2002: PANDAS v.2 released July 2003: joined IIPC 2004: PANDORA added to UNESCO Australian
Memory of the World Register July 2005: first .au domain harvest
Subsequent harvests in 2006, 2007, 2008 & 2009 December 2006: ‘Web Archiving and Digital
Preservation Branch’ July 2007: PANDAS v.3 released 2010: PANDORA search moved to Trove May 2010: Whole-of-govt ‘opt-out’
arrangements endorsed by SIGB

ManagerWeb Archiving
(base level executive)
Team Leader(senior librarian)
Web Archiving Section
Team Member(APS5)
Web Archiving Section
Team Member(APS4)
Web Archiving Section
Team Member(APS4)
Web Archiving Section
Web Archiving Section

Digitisatio
n
DIVISION 1 – COLLECTIONS MANAGEMENT
Australian Collection Develop’t
Special Materials
Cataloguing, Standards &
Training
WEB ARCHIVING AND
DIGITAL PRESERVATION
BRANCH
WebArchiving
Imaging Services
Jakarta Office
SERIALS BRANCH
DIVISION SUPPORT
UNIT
Overseas Collection
Development Section
MONOGRAPH
S BRANCH
DIGITAL COLLECTIONS MANAGEMENT
BRANCH
ASIAN COLLECTIONS BRANCH
ILMS Section
Serials Section
Preservatio
n Standards
Collections Preservatio
n
PRESERVATION BRANCH
ASSISTANT DIRECTOR-GENERAL
BIBLIOGRAPHIC STANDARDS
AND STRATEGIES
BRANCH
Digital Preservatio
n
Newspaper Digitisation
Project
Australian Newspaper Plan
Acquisition & Access
RDA

PANDORA Participants 11 participants including the NLA All state and territory libraries (except
Tasmania and ACT) Major heritage institutions
National Film and Sound Archive Australian War Memorial Australian Institute of Aboriginal and Torres
Strait Islander Studies National Gallery of Australia

PANDORA Participants Memorandum of Understanding
Respective obligations (NLA and Agencies) Adherence to policy and procedures
Curatorial and collection management (operational staff) Selection – participant guidelines Permissions Harvesting – scoping and quality checking Cataloguing Publishing – access through PANDORA

What is web archiving? A web archive is not the same as the
live web Brings a different value to web content
Creating artefacts from the web Preserved snapshots, slices, gobbets of
time Challenge of timeliness
At certain times some things are more interesting and valuable
Focus on the future and long term access (preservation objective)

Approaches to web archiving? Selective (specific targets)
websites single publications
Domain Country domains (e.g. .au or .id) Sub-domains(e.g. .gov.au)
Thematic Scoped around topics, events, forms of
publishing Seed lists

12
PANDORA - Australia’s Web Archive Selective approach – Australian content Collaboration with participating
agencies No legal deposit Permissions based collecting Timely and scheduled collecting Quality checked Described and indexed (searchable) Accessible to the public Modest in size

13
Australian web domain harvests
Annual domain harvests 2005-2009 Working with the Internet Archive Covers .au top level domain and a bit more … No legal deposit Permissions not sought No public access (yet) Quantity over quality (not QA action) Full text indexed (searchable) not catalogued Opportunistic rather than timely

14
Comparative statisticsPANDORA
Files: 94 million
Size: 4.23 TB
Domain Harvest
2005 2006 2007 2008 2009
Unique files
185 million 596 million 516 million 1 billion 765 million
Hosts crawled
811,523 1,046,038 1,247,614 3,038,658 1,074,645
Size TBs 6.69 19.04 18.47 34.55 24.29
Domain Harvests
Files: 3 billion
Size: 103 TB

Skills and tasks
Operational, Library’s ‘core business’ staff: Librarians, web curators, web archivists,
cataloguers … by any other name
Perform all associated tasks: Selection, permissions, acquisition
(harvesting) processes, quality checking, cataloguing, publishing (resource discovery)

Operational skills and tasks Collection development
Selection expertise in ‘new media’ Corporate objectives, priorities, resources
Collection management Cataloguing: MARC, LCSH, Dewey PANDORA subjects
Technical skills Scoping gather filters and settings Harvesting and code problem analysis and resolution
(HTML, JavaScript, stylesheets) Understanding web technologies
Experience and self-learning New technologies, Web 2.0, timely collecting, always
new challenges

IT commitment and support All infrastructure maintained at NLA
Systems and applications Storage of archival content
Continuous development of systems from 1997-2007 3 version releases of PANDAS
Technical support for applications and systems
Expertise to assist with harvesting problems
Support for domain harvests

Overview of PANDORA procedures
PANDAS (PANDORA Digital Archiving System) Workflow management system Httrack harvesting software
Agencies (PANDORA participants) Users
Administrators (PANDAS and Agency) Standard user Informational user
‘Worktrays’ manage individual and agency workflow

Overview of PANDORA workflows Some concepts:
Titles The target entity: a single document, a website,
and everything in-between
Publishers Permissions
Instances Each instance of an archived title
Users (‘owners’) Belong to Agencies and own titles Manage workflow among different agencies/people


Worktrays - Selection
Nominating titles Shared agency worktray Before selection decision is made
Selection statuses: Selected Rejected Monitored


Worktrays - Permission
Requesting publisher permission Licence under Copyright Act
Copy, preserve and make accessible
Manage and record publisher contact
Record permission status Title level permission Publisher level permission (‘blanket’)


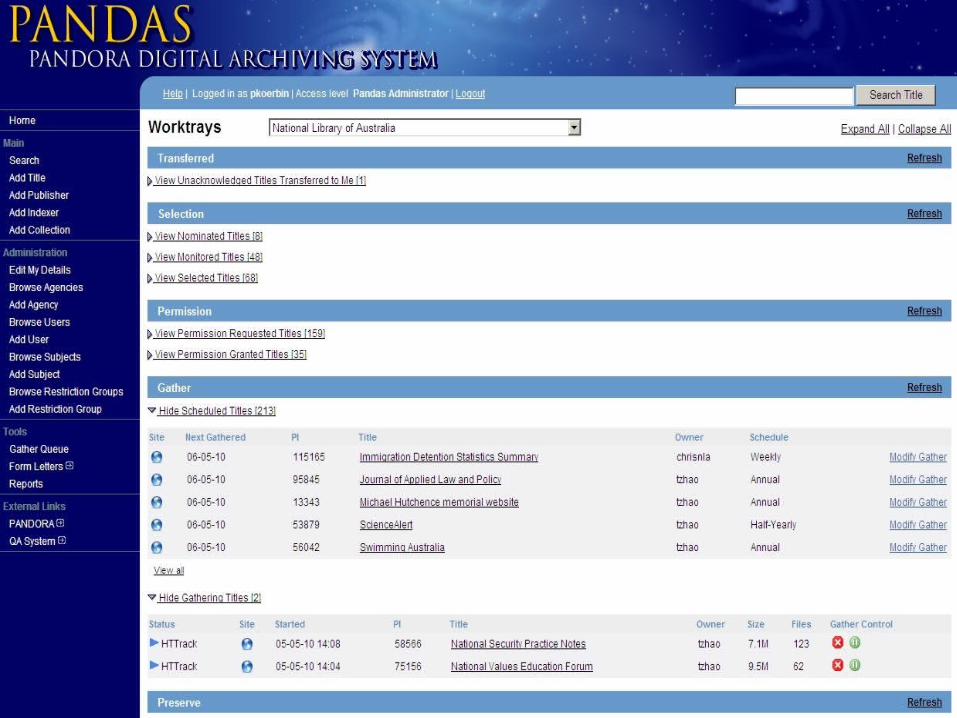
Worktrays – Gather (Harvest)
Set harvesting schedules Regular, specific days, gather now
Define harvesting parameters Seed URLs, filters, gather settings
View gathering titles Pause, view, modify, stop Statistics

Worktrays - Preserve Manage quality checking process Not yet archived – working area Analyse harvested instance:
Completeness No unwanted content Functionality
Fix problems (or ‘refer to IT’) WebDAV, FTP and Samba access to files
Decision on instance: Archive or Delete


Worktrays - Publish
Manages the public access to archived instances
Set up Title Entry Pages Add notes Issues Copyright statements Browse listings


Worktrays - Catalogue
Add ANBD number Automatically creates AGLS
metadata for Title Entry Page

Administration
Manage Agency information Add users Manage user access Run reports
Agency statistics and totals Titles and instances selected, process and
archived for specified period New title instances archived Scheduled gathers
Recommended



![Wellcome Library & JISC Web Archiving Project Presented by Michael Day, UKOLN, University of Bath [Author of the Web Archiving feasibility study] Digital](https://img.pdfslide.us/doc/110x75/56649e715503460f94b6f902/wellcome-library-jisc-web-archiving-project-presented-by-michael-day-ukoln.jpg)














