
Utterance Verification for Spontaneous Mandarin Speech Keyword Spotting
Liu Xin, BinXi Wang
Presenter: Kai-Wun Shih
No.306, P.O. Box 1001 ,ZhengZhou,450002, Henan, P.R. China

2
Outline
Introduction
Feature Extraction and Acoustic Modeling
Keyword Recognition
Keyword Verification And Confidence
Measures
Experiments and Results
Conclusions

Introduction (1/2)
3
Utterance verification represents an important technology in the design of user-friendly speech recognition systems.
Recognizers equipped with a keyword spotting capability allow users the flexibility to speak naturally without the need to follow a rigid speaking format.
Introduction (2/2)
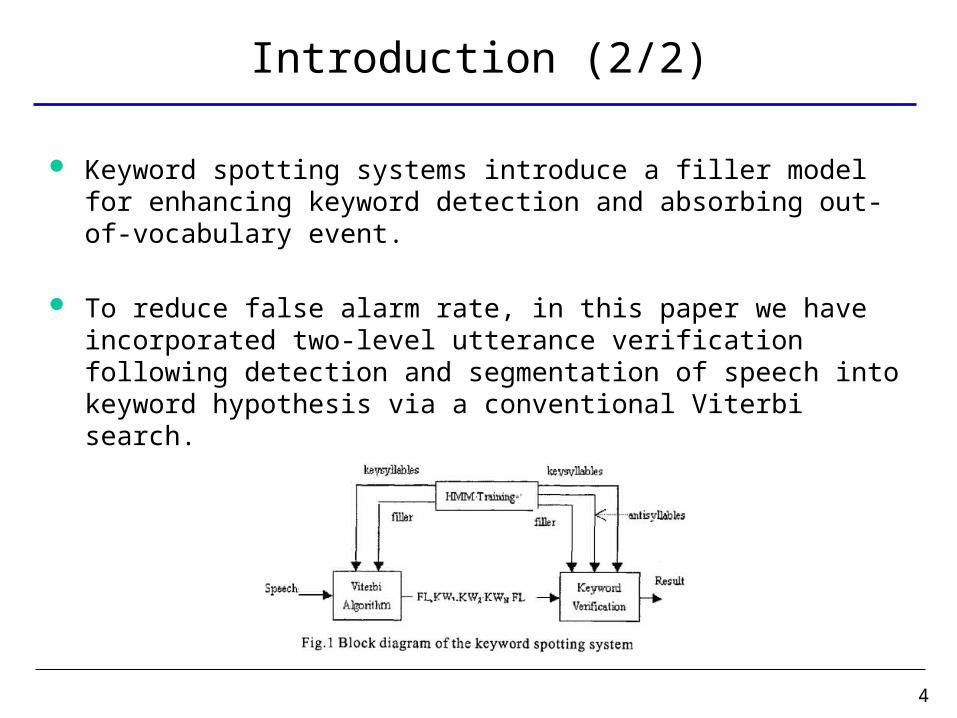
Keyword spotting systems introduce a filler model for enhancing keyword detection and absorbing out-of-vocabulary event.
To reduce false alarm rate, in this paper we have incorporated two-level utterance verification following detection and segmentation of speech into keyword hypothesis via a conventional Viterbi search.
4

Feature Extraction and Acoustic
Modeling (1/3)•
5

Considering that Chinese is a monosyllable language, we choose syllable as the base recognition units.
Except for the background silence unit, each syllable is modeled by six-state left-to-right hidden markov models (HMM).
Each state is characterized by a mixture Gaussian state observation density.
Training of each syllable model consisted of estimating the mean, covariance, and mixture weights for each state using maximum likelihood(ML) estimation.
6
Feature Extraction and Acoustic
Modeling (2/3)

For each syllable model, an anti-syllable model was also trained.
In general, for every syllable model, the corresponding anti-syllable model should be trained on the data of all syllables but that of syllable.
Aside from syllable and anti-syllable models, we also introduced a general acoustic filler model trained on non-keyword speech data, and a silence model trained on the non-speech segments of the signal.
7
Feature Extraction and Acoustic
Modeling (3/3)

•
8
Keyword Recognition (1/2)

9
Keyword Recognition (2/2)•

10
Keyword Verification And Confidence Measures
(1/9)•

11
Keyword Verification And Confidence Measures
(2/9)•

12
Keyword Verification And Confidence Measures
(3/9)•

13
Keyword Verification And Confidence Measures
(4/9)•

14
Keyword Verification And Confidence Measures
(5/9)•

15
Keyword Verification And Confidence Measures
(6/9)•

The third one focuses on less confident syllables rather than averaging all the subwords.
In order to find less confident syllables, we normalize the log likelihood ratio assuming a Gaussian distribution for every syllable. We denote this normalization log likelihood as .
where and are the mean and the variance for syllable class of n.
16
Keyword Verification And Confidence Measures
(7/9)

17
Keyword Verification And Confidence Measures
(8/9)•

The fourth confidence measure uses the sigmoid function. This form is used as a loss function for training with the minimum error rate criteria.
, are used to control the slope and the range of the sigmoid function. For every confidence measure, a specific threshold is set up. If its value is below the threshold, the candidate is discarded from the word lattice.
18
Keyword Verification And Confidence Measures
(9/9)
(7)

In this system, 20 city names were selected as the keywords. A continuous telephone-speech database was employed to train the system which is composed of short spontaneous speech, syllables, words and sentences. This database was pronounced by 70 speakers (50 males,20 females). We also recorded 205 utterances for testing spoken by a different group of 20 speakers (15 males, 5 females) responding to 20 city names.
19
Experiments and Results
Average Detection
Rate
Average False Alarm
Rate
No verification
87.5% 12.0%
86.5% 8.4%
86.8% 7.4%
87.5% 7.0%
86.7% 8.2%Table1 Performance with several confidence measures

The spotting system adopts a Wastage strategy, with recognition followed by verification and the basic unit of the system is syllable. In the second stage, a keyword verification function with four different confidence measures is evaluated.
Experiment results show that utterance verification with the third confidence measure outperforms the baseline system.
20
Conclusions

END
21
Recommended

















