
Open Forum: Open Science
Debbie BardUsing containers and
supercomputers to solve the
mysteries of the Universe

Shifter:
containers for
HPC
What’s a
supercomputer?
Containers for
supercomputing
Agenda
Awesome
science
The nature of the
Universe
Developing new
technologies
Containerizing
open science
Reproducible
science

Shifter
Containerizing
Supercomputers

Supercomputing for Open Science
• Most widely used computing center in DoE Office of
Science
• 6000+ users, 750+ codes, 2000+ papers/year
• Biology, Energy, Environment
• Computing
• Materials, Chemistry, Geophysics
• Particle Physics, Cosmology
• Nuclear Physics
• Fusion Energy, Plasma Physics

NERSC Cori cabinetNERSC Mendel Cluster cabinet
It’s all about the connections
What’s a supercomputer?

• Edison Cray XC30
• 2.5PF
• 357TB RAM
• ~5000 nodes, ~130k cores
• Cori Cray XC40
• Data-intensive (32-core
Haswells, 128GB) partition
• Compute-intensive (68-core
KNLs, 90GB) partition
• ~10k nodes, ~700k cores

• Edison Cray XC30
• 2.5PF
• 357TB RAM
• ~5000 nodes, ~130k cores
• Cori Cray XC40
• Data-intensive (32-core
Haswells, 128GB) partition
• Compute-intensive (68-core
KNLs, 90GB) partition
• ~10k nodes, ~700k cores
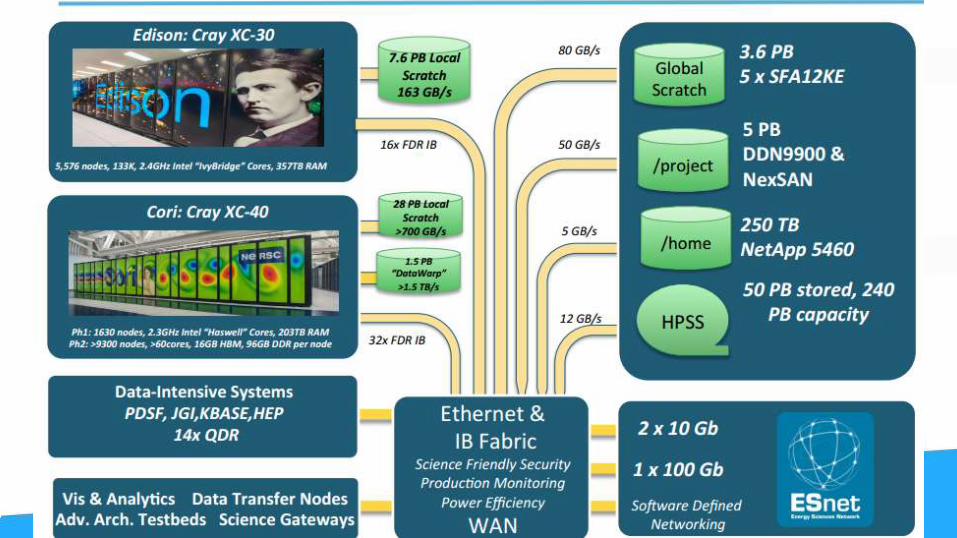
>10PB project file system (GPFS)>38PB scratch file system (Lustre)
>1.5PB Burst Buffer (flash)
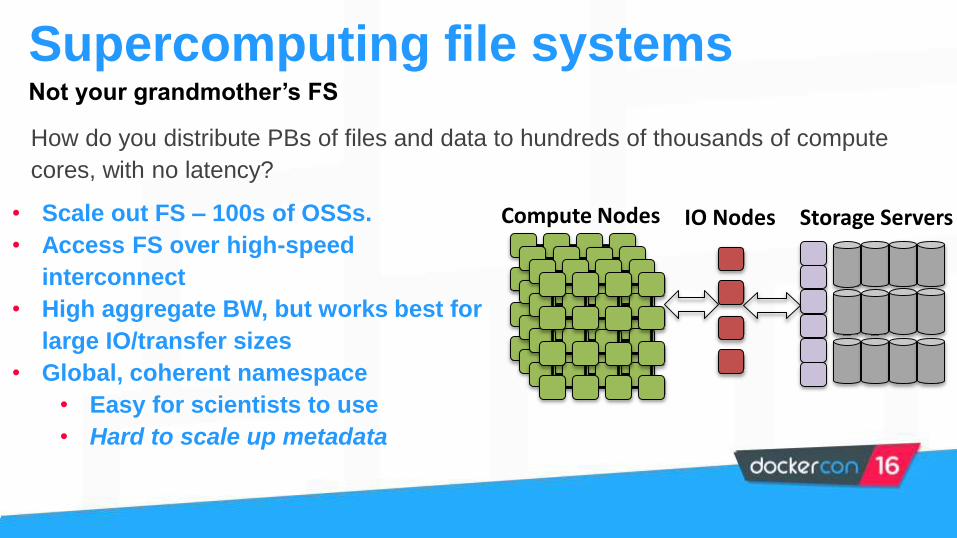
Supercomputing file systems
• Scale out FS – 100s of OSSs.
• Access FS over high-speed
interconnect
• High aggregate BW, but works best for
large IO/transfer sizes
• Global, coherent namespace
• Easy for scientists to use
• Hard to scale up metadata
Not your grandmother’s FS
Compute Nodes IO Nodes Storage Servers
How do you distribute PBs of files and data to hundreds of thousands of compute
cores, with no latency?
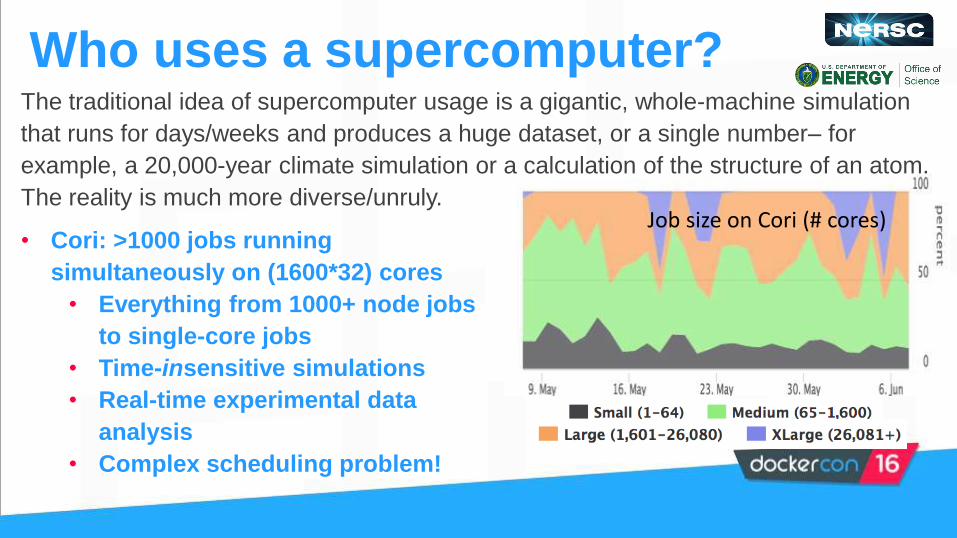
• Cori: >1000 jobs running
simultaneously on (1600*32) cores
• Everything from 1000+ node jobs
to single-core jobs
• Time-insensitive simulations
• Real-time experimental data
analysis
• Complex scheduling problem!
Who uses a supercomputer?
Job size on Cori (# cores)
The traditional idea of supercomputer usage is a gigantic, whole-machine simulation
that runs for days/weeks and produces a huge dataset, or a single number– for
example, a 20,000-year climate simulation or a calculation of the structure of an atom.
The reality is much more diverse/unruly.

Supercomputing issues
Screamingly fast interconnect, no local disk,
and custom compute environment designed
to accelerate parallel apps – but not
everything can adapt easily to this
environment.
• Portability
• Custom Cray SUSE Linux-based
environment – hard to use standard
Linux-based code/libs
• Scientists often run at multiple sites –
wherever they can get the cycles
LHC Grid Computing
Our users want to run complex software stacks on multiple platforms
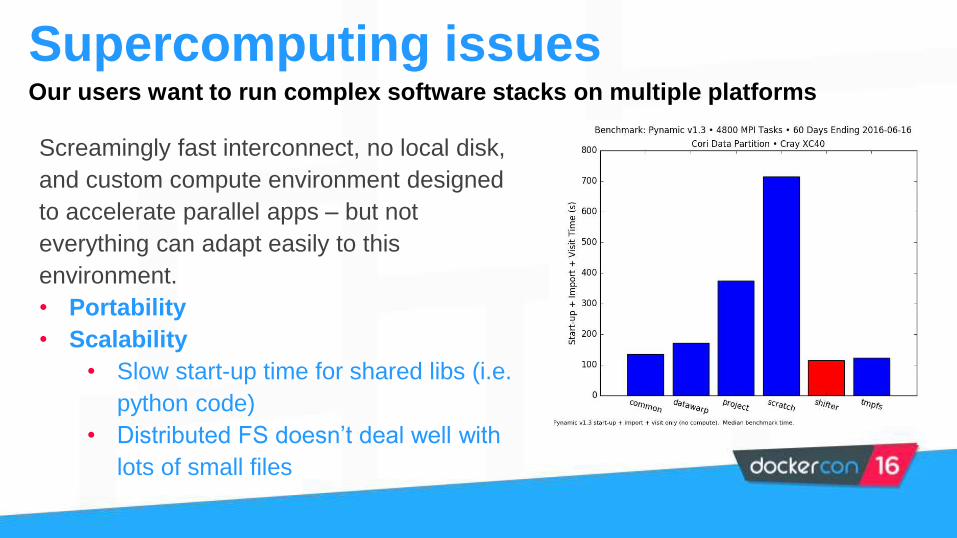
Supercomputing issues
Screamingly fast interconnect, no local disk,
and custom compute environment designed
to accelerate parallel apps – but not
everything can adapt easily to this
environment.
• Portability
• Scalability
• Slow start-up time for shared libs (i.e.
python code)
• Distributed FS doesn’t deal well with
lots of small files
Our users want to run complex software stacks on multiple platforms

Supercomputing issues
Screamingly fast interconnect and custom
compute environment designed to accelerate
parallel apps – but not everything can adapt
easily to this environment.
• Portability
• Scalability
• Slow start-up time for shared libs (i.e.
python code)
• Distributed FS doesn’t deal well with
lots of small files
Our users want to run complex software stacks on multiple platforms
Containers for HPC!

Why not simply use Docker?
• Underlying custom OS
• Highly-optimized interconnect
• Security issues: if you can start a Docker container,
you can start it as root – map in other volumes with
root access!
Shifter enables the collaborative nature of Docker for
science and large-scale systems
Enable Docker functionality and direct compatibility, but
customizing for the needs of HPC systems
Shifter directly imports Docker images
Containers on supercomputers

Why not simply use Docker?
• Underlying custom OS
• Highly-optimized interconnect
• Security issues: if you can start a Docker container,
you can start it as root – map in other volumes with
root access!
Shifter uses loop mount of image file – moves metadata
operations (like file lookup) to the compute node, rather than
relying on central metadata servers of parallel file system.
Gives much faster shared library performance…
High performance at huge scale
Containers on supercomputers
Why not simply use Docker?
• Underlying custom OS
• Highly-optimized interconnect
• Security issues: if you can start a Docker container,
you can start it as root – map in other volumes with
root access!
Shifter uses loop mount of image file – moves metadata
operations (like file lookup) to the compute node, rather than
relying on central metadata servers of parallel file system.
Gives much faster shared library performance…
High performance at huge scale

Awesome Science
Containerizing the Unvierse

Dark Energy Survey
What is the Universe made of?
How and why is it expanding?
Astronomy Data Analysis

Dark Energy Survey
What is the Universe made of?
How and why is it expanding?
Astronomy Data ProcessingLight from some of these galaxies was emitted 13 billion years ago

Dark Energy Survey
Astronomy Data Analysis
Measuring the expansion history of the
universe to understand the nature of Dark
Energy.
Data analysis code: identify objects
(stars, galaxies, quasars, asteroids etc) in
images, calibrate, measure their
properties.
• Why Containers?
• Complicated software stack – runs
on laptops to supercomputers
• Python-based code; lots of imports
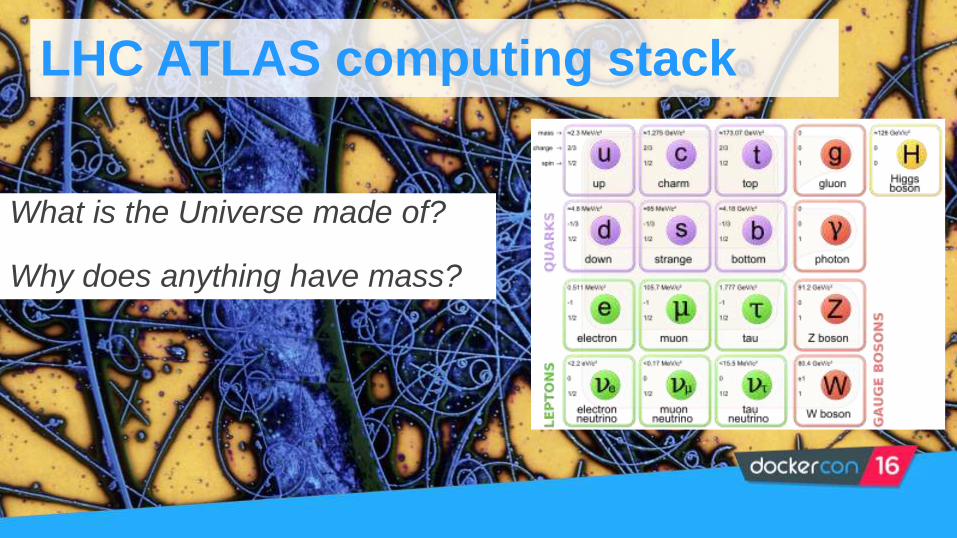
LHC ATLAS computing stack
What is the Universe made of?
Why does anything have mass?

A billion proton-proton collisions per second and multi-GB of data per second.
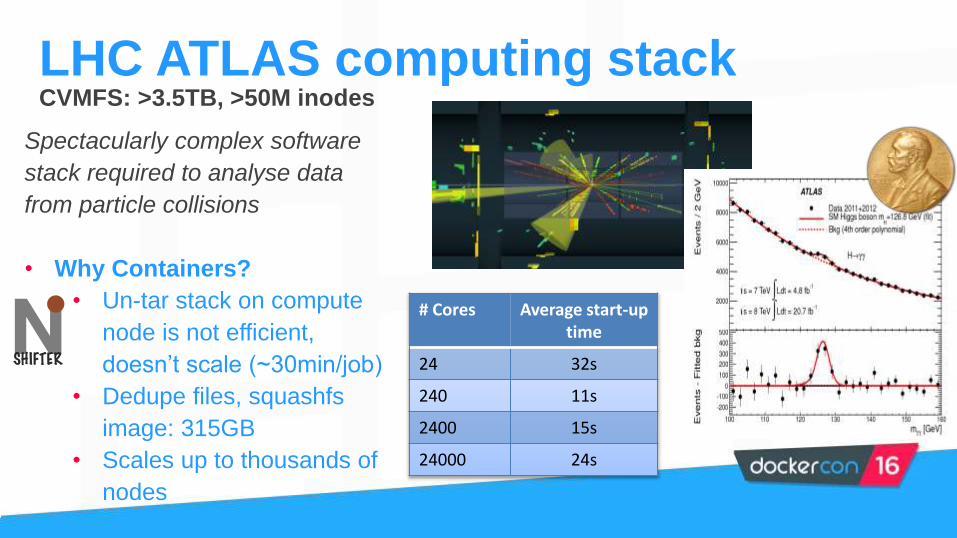
CVMFS: >3.5TB, >50M inodes
Spectacularly complex software
stack required to analyse data
from particle collisions
• Why Containers?
• Un-tar stack on compute
node is not efficient,
doesn’t scale (~30min/job)
• Dedupe files, squashfs
image: 315GB
• Scales up to thousands of
nodes
LHC ATLAS computing stack
# Cores Average start-up time
24 32s
240 11s
2400 15s
24000 24s

How does photosynthesis happen?
How do drugs dock with proteins in our cells?
Why do jet engines fail?
LCLSLinac Coherent Light Source

Suepr-intense femtosecond x-ray pulses
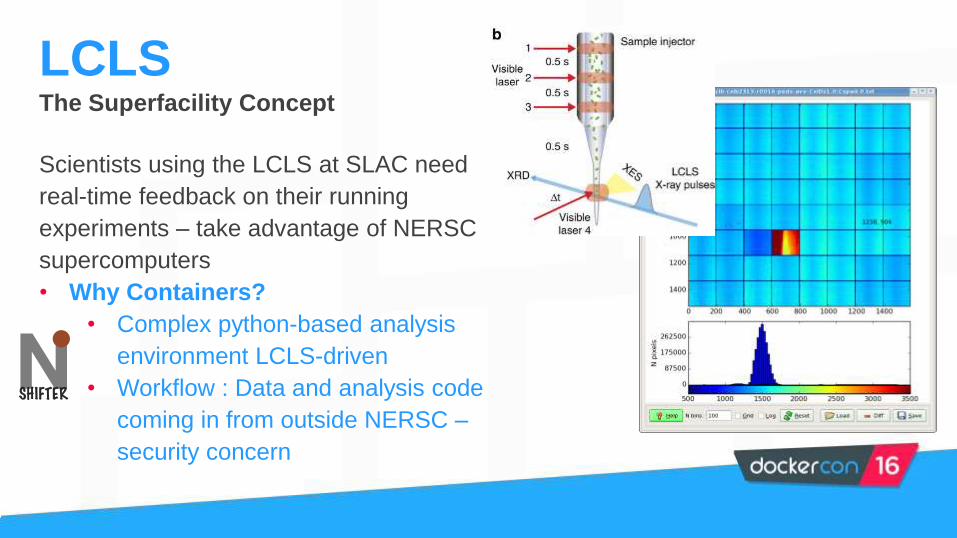
The Superfacility Concept
Scientists using the LCLS at SLAC need
real-time feedback on their running
experiments – take advantage of NERSC
supercomputers
• Why Containers?
• Complex python-based analysis
environment LCLS-driven
• Workflow : Data and analysis code
coming in from outside NERSC –
security concern
LCLS

Containerizing Open Science

Post-experiment data analysis
Everyone agrees this is essential (federally mandated!), but
noone knows how to do it properly/coherently
• Algorithms: need to run scripts that produced the
results
• Environment: need to replicate the OS, software
libraries, compiler version
• Data: large volumes, databases, calibration data,
metadata…
Scientific Reproducibility
https://www.whitehouse.gov/sites/default/files/microsites/ostp/ostp_public_access_memo_2013.pdf

Containers foreverInce, Hatton & Graham-Cumming, Nature 482, 485 (2012)
Scientific communication relies on evidence that cannot be entirely included in publications, but the rise of computational science has added a new layer of inaccessibility. Although it is now accepted that data should be made available on request, the current regulations regarding the availability of software are inconsistent. We argue that, with some exceptions, anything less than the release of source programs is intolerable for results that depend on computation. The vagaries of hardware, software and natural language will always ensure that exact reproducibility remains uncertain, but withholding code increases the chances that efforts to reproduce results will fail.

Containers offer the possibility of
encapsulating analysis code and
compute environment to ensure
reproducibility of algorithms and
environment.
• Enable reproduction of results on
any compute system
Containers forever?

In case you can’t think of anything to talk about
• Make this publishable: DOI for DockerHub images, as for github repos.
• Link github/Docker repos?
• How to link data to containers?
• How to maintain containers over the long term?
• Long-term data access efforts in many areas of science – thinking 20
years ahead. Are containers viable in this timeframe?
Discussion Points

Backup Slides

Shifter!=Docker• User runs as the user in the container – not root• Image modified at container construction time:
• Modifies /etc, /var, /opt• replaces /etc/passwd, /etc/group other files for site/security
needs• adds /var/hostsfile to identify other nodes in the calculation
(like $PBS_NODEFILE)• Injects some support software in /opt/udiImage
• Adds mount points for parallel filesystems• Your homedir can stay the same inside and outside of the
container• Site configurable
• Image readonly on the Computational Platform• to modify your image, push an update using Docker
• Shifter only uses mount namespaces, not network or process namespaces• Allows your application to leverage the HSN and more easily integrate
with the system• Shifter does not use cgroups directly
• Allows the site workload manager (e.g., SLURM, Torque) to manage resources
• Shifter uses individual compressed filesystem files to store images, not the Docker graph
• Uses more diskspace, but delivers high performance at scale
• Shifter integrates with your Workload Manager• Can instantiate container on thousands of
nodes• Run parallel MPI jobs
• Specialized sshd run within container for exclusive-node for non-native-MPI parallel jobs
• PBS_NODESFILE equivalent provided within container (/var/hostsfile)
• Similar to Cray CCM functionality• Acts in place of CCM if shifter “image” is
pointed to /dsl VFS tree

Shifter~=Docker
• Sets up user-defined image under user control
• Allows volume remapping
• mount /a/b/c on /b/a/c in container
• Containers can be “run”
• Environment variables, working directory, entrypoint scripts can be defined and run
• Can instantiate multiple containers on same node
Recommended

















