
Universität Mannheim – Name of Presenter: Titel of Talk/Slideset (Version: 27.6.2014) – Slide 1
Unsupervised Does Not Mean Uninterpretable: The Case for Word Sense Induction and
Disambiguation
Chris [email protected]
Alexander [email protected]
Stefano [email protected]
Simone Paolo [email protected]
Eugen [email protected]

Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 2
Word Sense Disambiguation and Word Sense Induction
- Word Sense Disambiguation (WSD) is the ability to computationally determine which sense of a word is activated by its use in a particular context (Navigli, 2009).
- Word Sense Induction (WSI) concerns the automatic identification of the senses of a word (Agirre and Soroa, 2007).

Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 3
Motivation
- Knowledge-based sense representations:
- Definitions, synonyms, taxonomic relations and images make this representation easily interpretable.
BabelNet.org

Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 4
Motivation
- Unsupervised knowledge-free sense representations:
- Absence of definitions, hypernyms, images, and the dense feature representation make this representation uninterpretable.
- RQ: Can we make unsupervised knowledge-free sense representations interpretable?
...
AdaGram sense embeddings (Bartunov et al., 2016)

Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 5
SOTA
Supervised approaches (Ng, 1997; Lee and Ng, 2002; Klein et al., 2002; Wee, 2010; Zhong and Ng, 2010):
- require large amounts of sense-labeled examples per target word

Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 6
SOTA
Supervised approaches (Ng, 1997; Lee and Ng, 2002; Klein et al., 2002; Wee, 2010; Zhong and Ng, 2010):
- require large amounts of sense-labeled examples per target word
Knowledge-based approaches:
- “Classic” approaches (Lesk,1986; Banerjee and Pedersen, 2002; Pedersen et al., 2005; Miller et al., 2012; Moro et al., 2014):
- Approaches based on sense embeddings (Chen et al., 2014; Rothe and Schütze, 2015; Camacho-Collados et al., 2015; Iacobacci et al., 2015; Nieto Pina and Johansson, 2016)
- require manually created lexical semantic resources

Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 7
SOTA
Unsupervised knowledge-free approaches:
- Context clustering (Pedersen and Bruce, 1997; Schütze, 1998) including knowledge-free sense embeddings (Huang et al., 2012; Tian et al., 2014; Neelakantan et al., 2014; Li and Jurafsky, 2015; Bartunov et al., 2016)
- Dense vector sense representations are not interpretable.

Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 8
SOTA
Unsupervised knowledge-free approaches:
- Context clustering (Pedersen and Bruce, 1997; Schütze, 1998) including knowledge-free sense embeddings (Huang et al., 2012; Tian et al., 2014; Neelakantan et al., 2014; Li and Jurafsky, 2015; Bartunov et al., 2016)
- Dense vector sense representations are not interpretable.
- Word ego-network clustering methods (Lin, 1998; Pantel and Lin, 2002; Widdows and Dorow, 2002; Biemann, 2006; Hope and Keller, 2013):
- Sparse interpretable graph representations: used in our work.

Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 9
Unsupervised & Knowledge-Free & Interpretable WSD
A novel approach to WSD/WSI:✓ Unsupervised &✓ Knowledge-free &✓ Interpretable
Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 10
Unsupervised & Knowledge-Free & Interpretable WSD
A novel approach to WSD/WSI:✓ Unsupervised &✓ Knowledge-free &✓ Interpretable
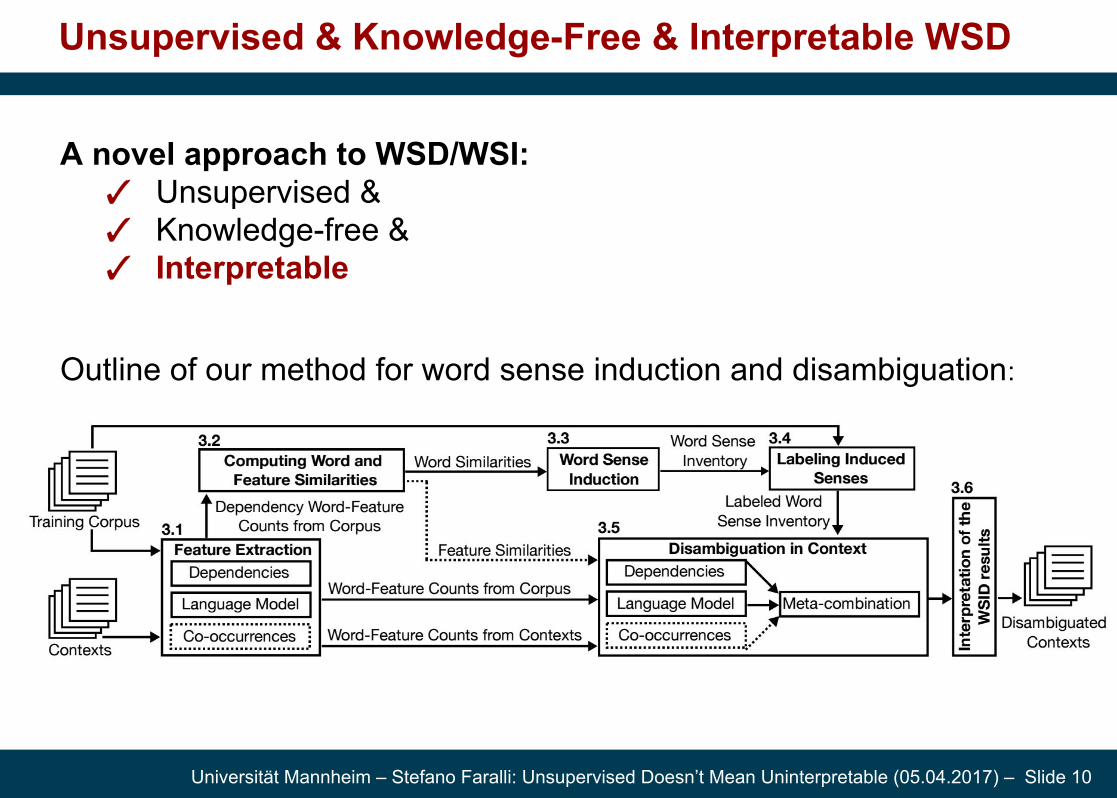
Outline of our method for word sense induction and disambiguation:
Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 11
Unsupervised & Knowledge-Free & Interpretable WSD
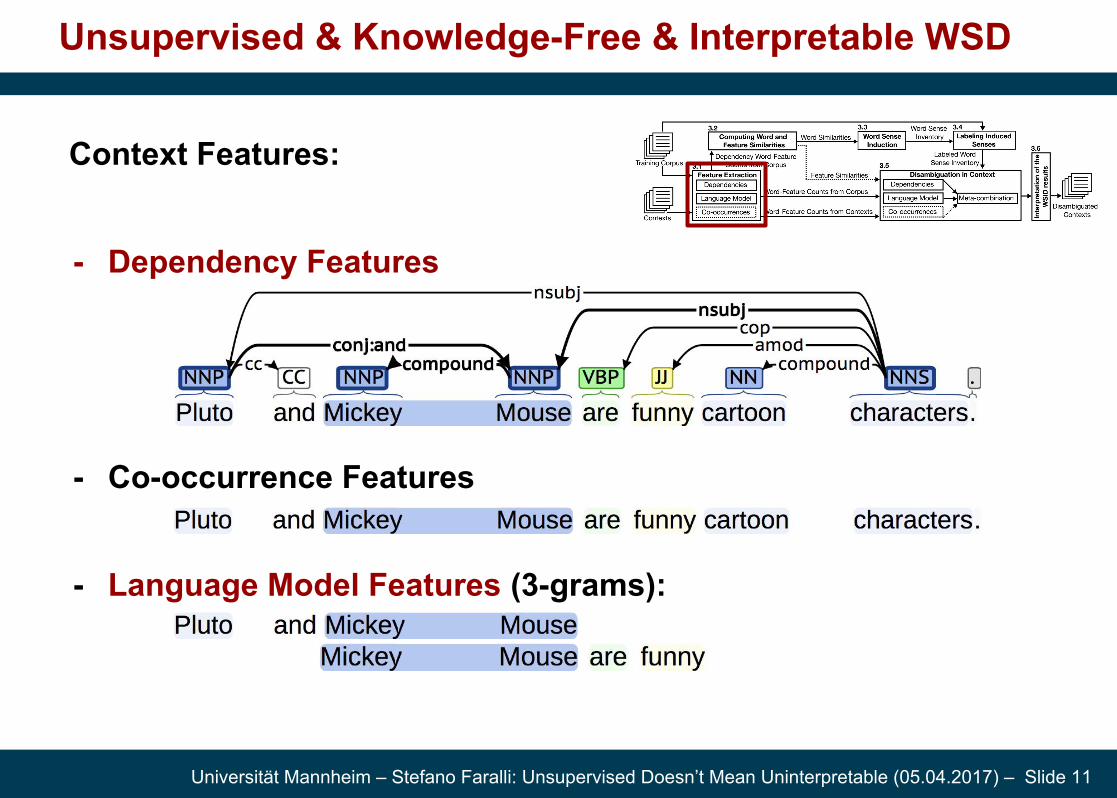
Context Features:
- Dependency Features
- Co-occurrence Features
- Language Model Features (3-grams):

Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 12
Unsupervised & Knowledge-Free & Interpretable WSD
Word and Feature Similarity Graphs:
- Count-based approach, JoBimText (Biemann and Riedl, 2013)- Dependency-based features- LMI normalization (Evert, 2005)- 1000 most salient features- 200 most similar words per term
+ Sparse interpretable features + Performance is comparable to word2vec/f (Riedl, 2016)
Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 13
Unsupervised & Knowledge-Free & Interpretable WSD
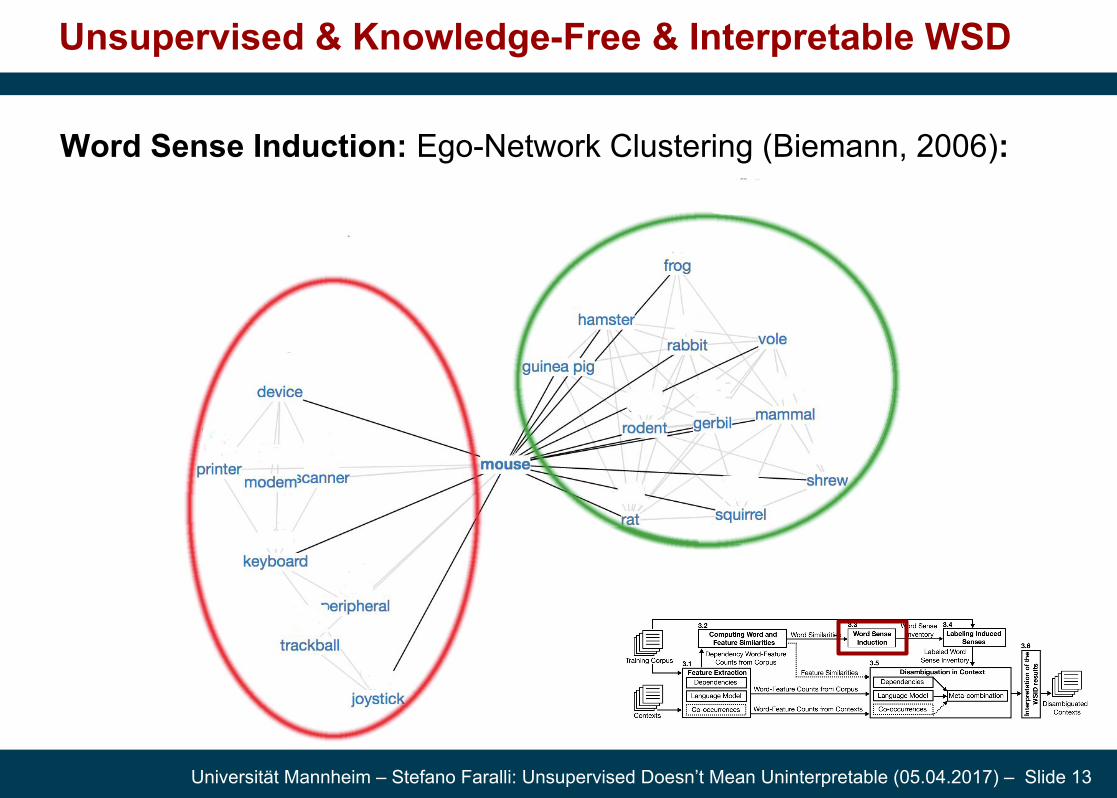
Word Sense Induction: Ego-Network Clustering (Biemann, 2006):
Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 14
Unsupervised & Knowledge-Free & Interpretable WSD
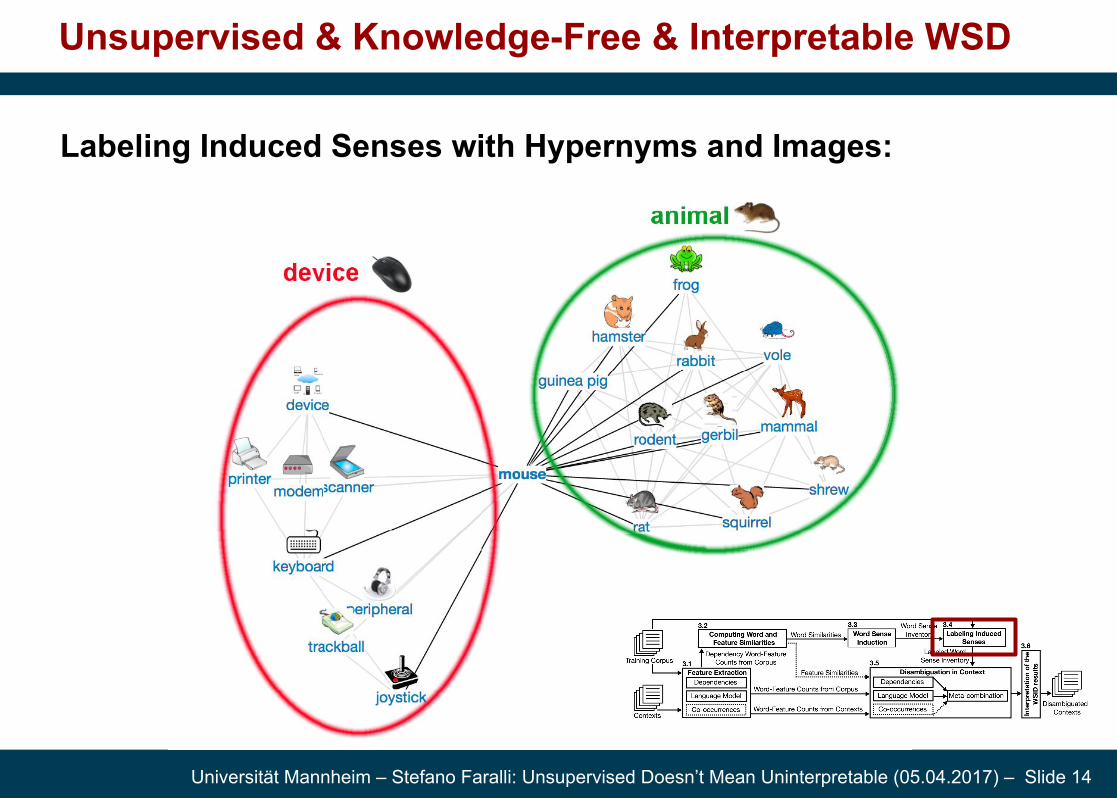
Labeling Induced Senses with Hypernyms and Images:

Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 15
Unsupervised & Knowledge-Free & Interpretable WSD
Word Sense Disambiguation with Induced Word Sense Inventory:
- Max. similarity of context and sense representations.

Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 16
Unsupervised & Knowledge-Free & Interpretable WSD
Word Sense Disambiguation with Induced Word Sense Inventory:
- Max. similarity of context and sense representations.
Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 17
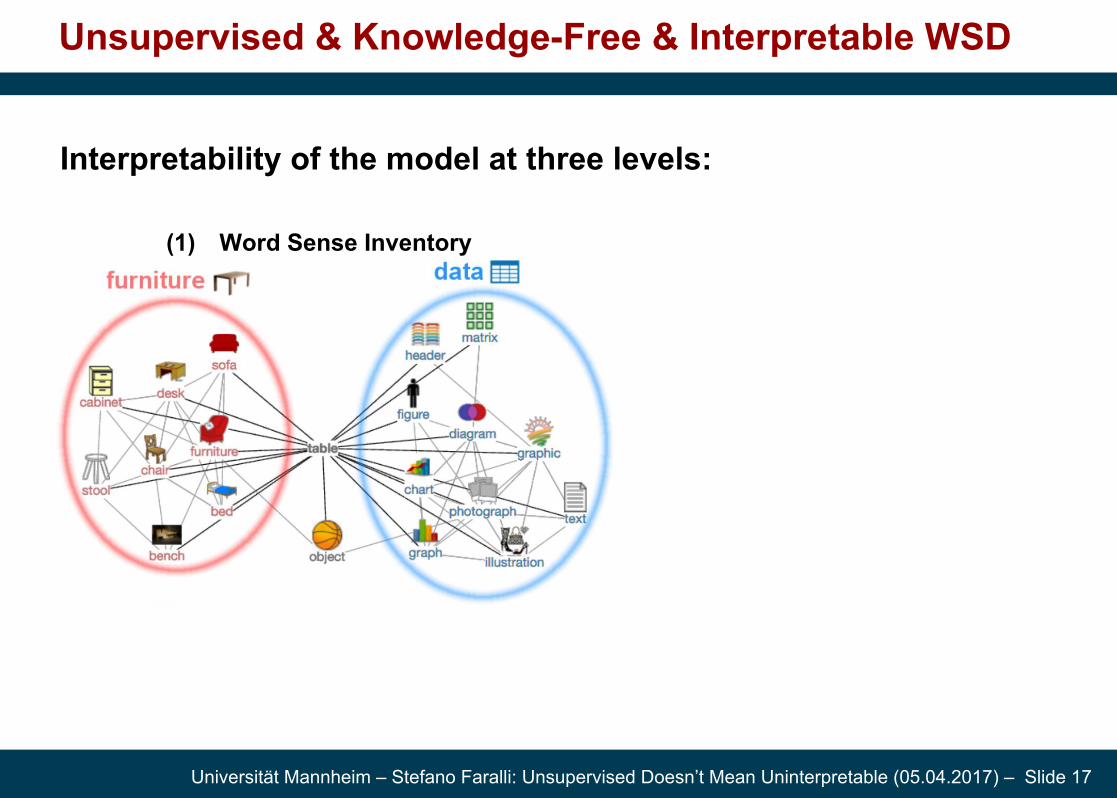
Unsupervised & Knowledge-Free & Interpretable WSD
Interpretability of the model at three levels:
(1) Word Sense Inventory (2) Sense Feature Representations
(3) Disambiguation in Context
Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 18
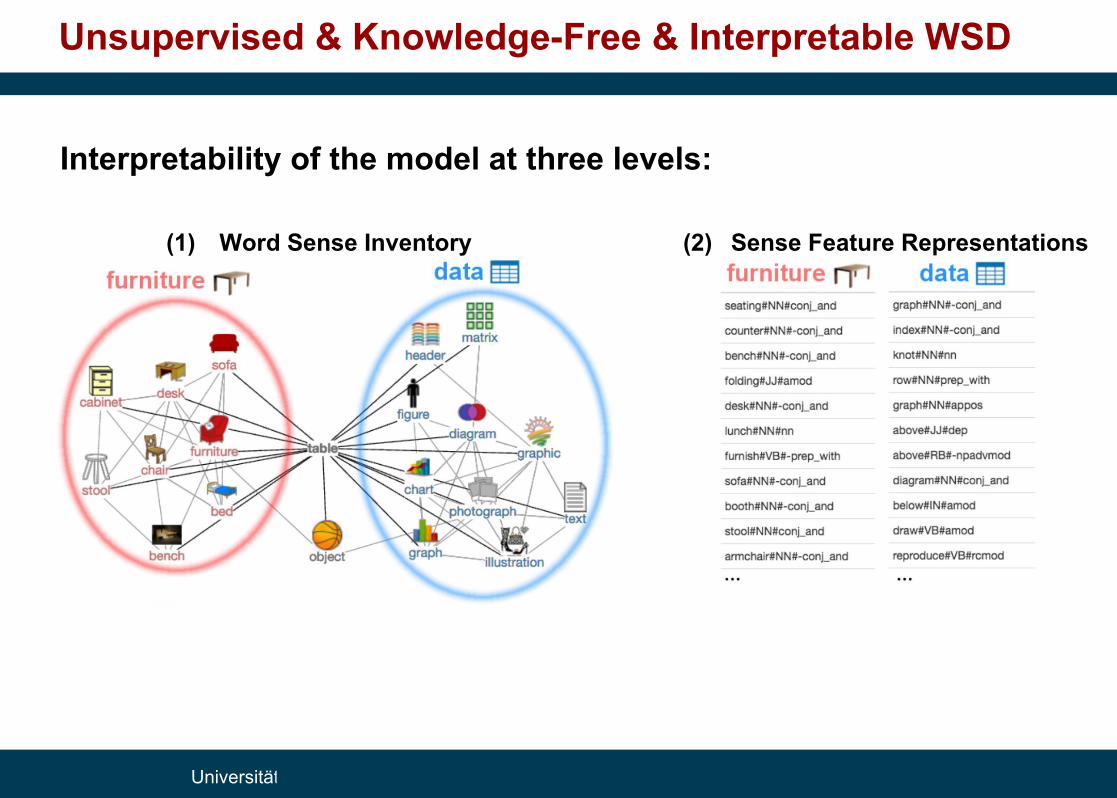
Unsupervised & Knowledge-Free & Interpretable WSD
Interpretability of the model at three levels:
(1) Word Sense Inventory (2) Sense Feature Representations
(3) Disambiguation in Context
Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 19
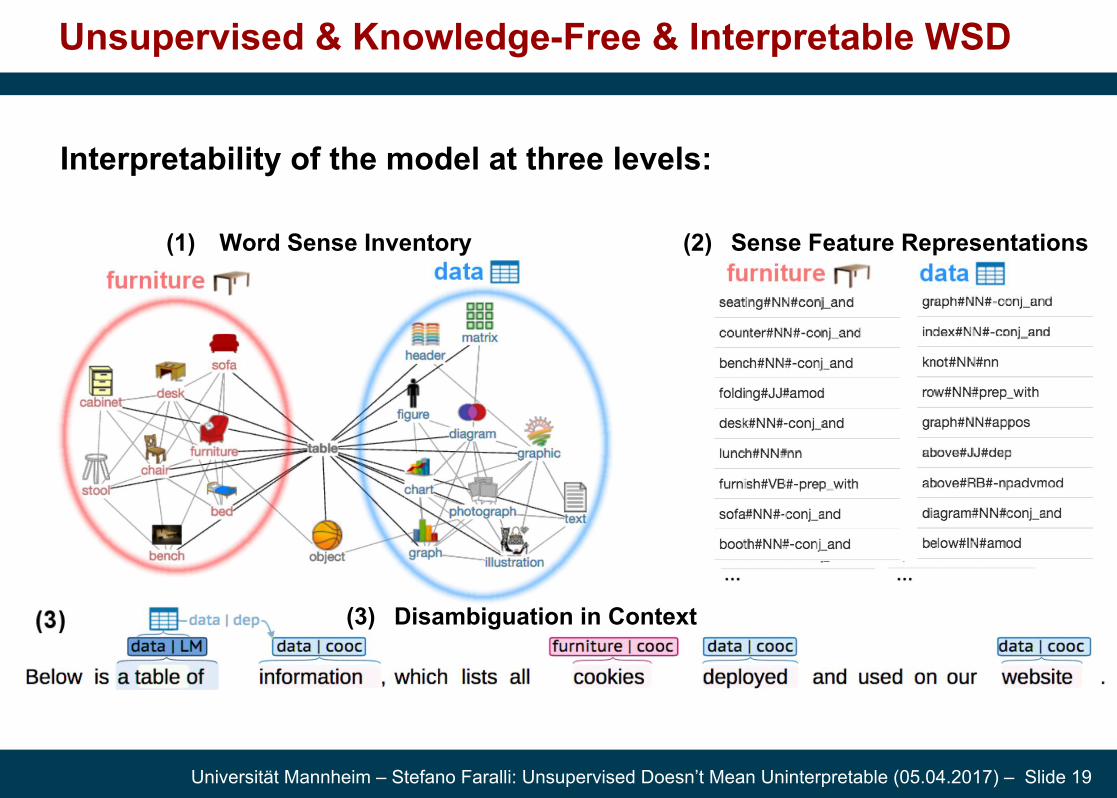
Unsupervised & Knowledge-Free & Interpretable WSD
Interpretability of the model at three levels:
(1) Word Sense Inventory (2) Sense Feature Representations
(3) Disambiguation in Context

Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 20
Unsupervised & Knowledge-Free & Interpretable WSD
- Hypernymy labels help to interpret the automatically induced senses.
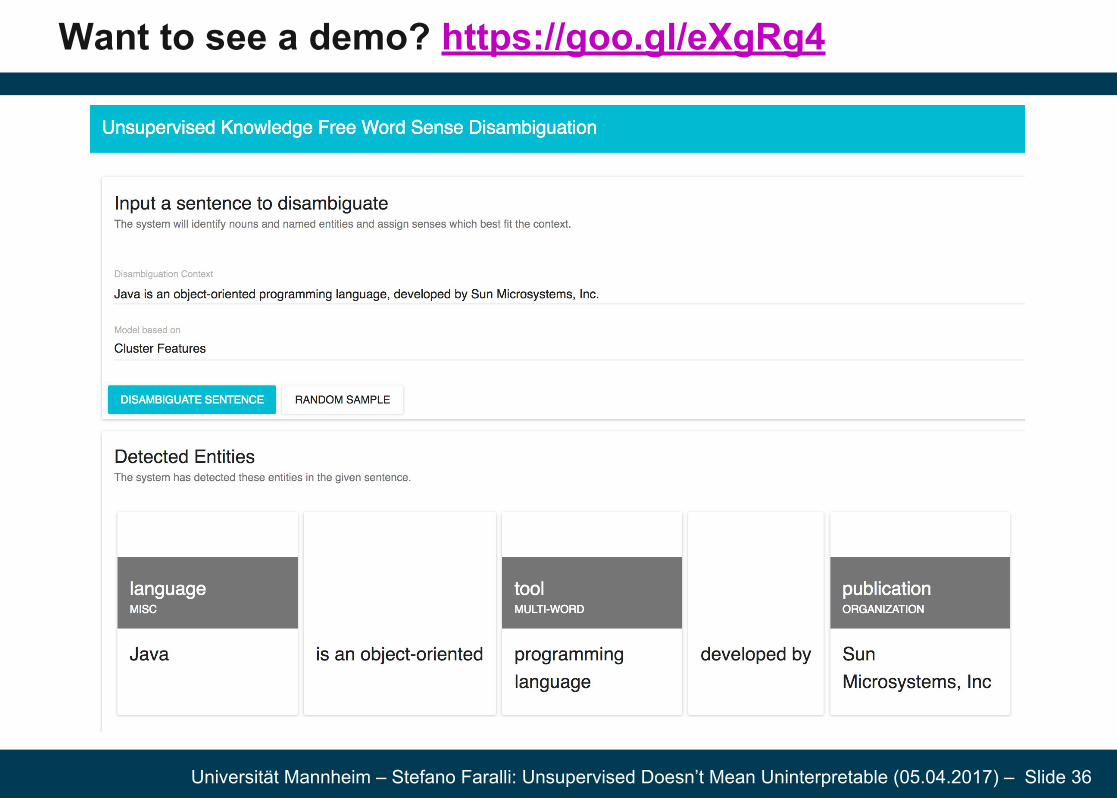
- A live demo: https://goo.gl/eXgRg4
The best match
The context
The worst match

Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 21
Unsupervised & Knowledge-Free & Interpretable WSD
Similarity of the context and the sense representation based on the sparse features can be traced back:
Features that explain the sense choice

Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 22
Evaluation
RQ 1:
Which combination of unsupervised features yields the best results?

Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 23
Evaluation
RQ 1:
Which combination of unsupervised features yields the best results?
RQ 2:
How does the granularity of an induced inventory impact performance?

Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 24
Evaluation
RQ 1:
Which combination of unsupervised features yields the best results?
RQ 2:
How does the granularity of an induced inventory impact performance?
RQ 3:
What is the quality of our approach compares to SOTA unsupervised WSD systems, including those based on the uninterpretable models?

Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 25
RQ1: Dataset and Evaluation Metrics
Which combination of unsupervised features yields the best results?
- Dataset:- TWSI 2.0: Turk Bootstrap Word Sense Inventory (Biemann, 2012) - 2,333 senses (avg. polysemy of 2.31)- 145,140 annotated sentences: the full version- 6,166 annotated sentences: the sense-balanced version
- No monosemous words

Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 26
RQ1: Dataset and Evaluation Metrics
Which combination of unsupervised features yields the best results?
- Dataset:- TWSI 2.0: Turk Bootstrap Word Sense Inventory (Biemann, 2012) - 2,333 senses (avg. polysemy of 2.31)- 145,140 annotated sentences: the full version- 6,166 annotated sentences: the sense-balanced version
- No monosemous words
- Evaluation Metrics:- Mapping the induced inventory to the gold sense inventory - Precision, Recall, F1
Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 27
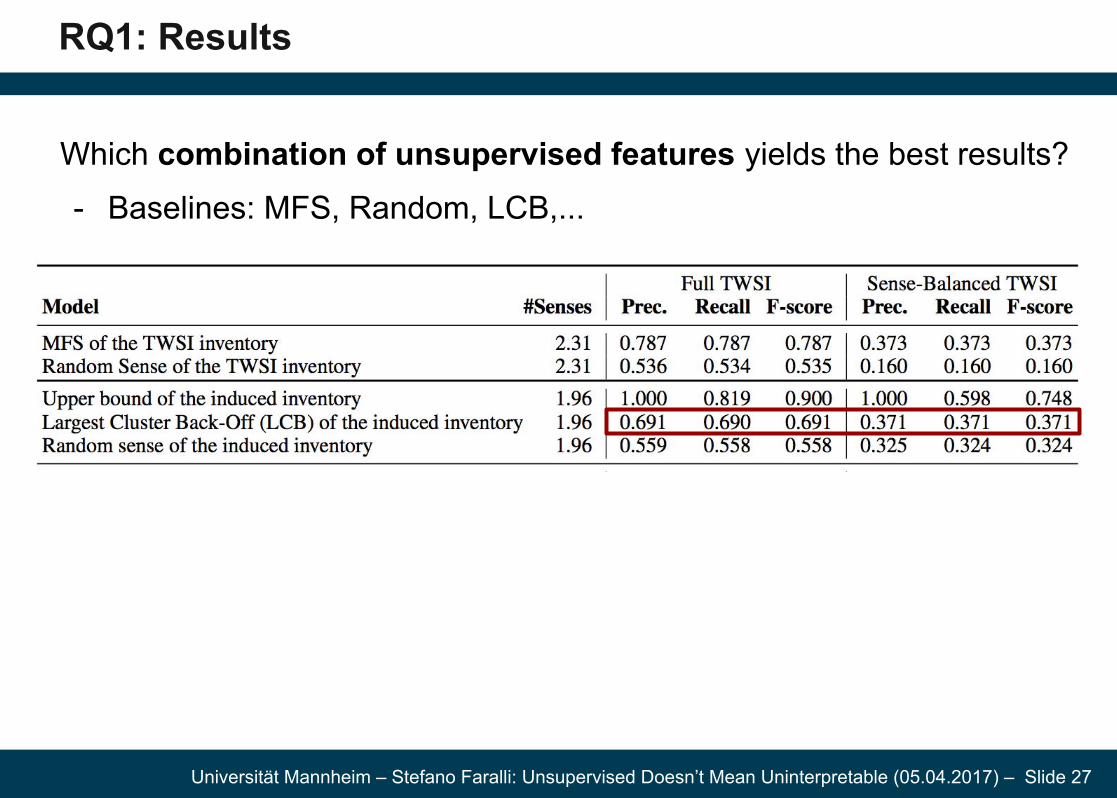
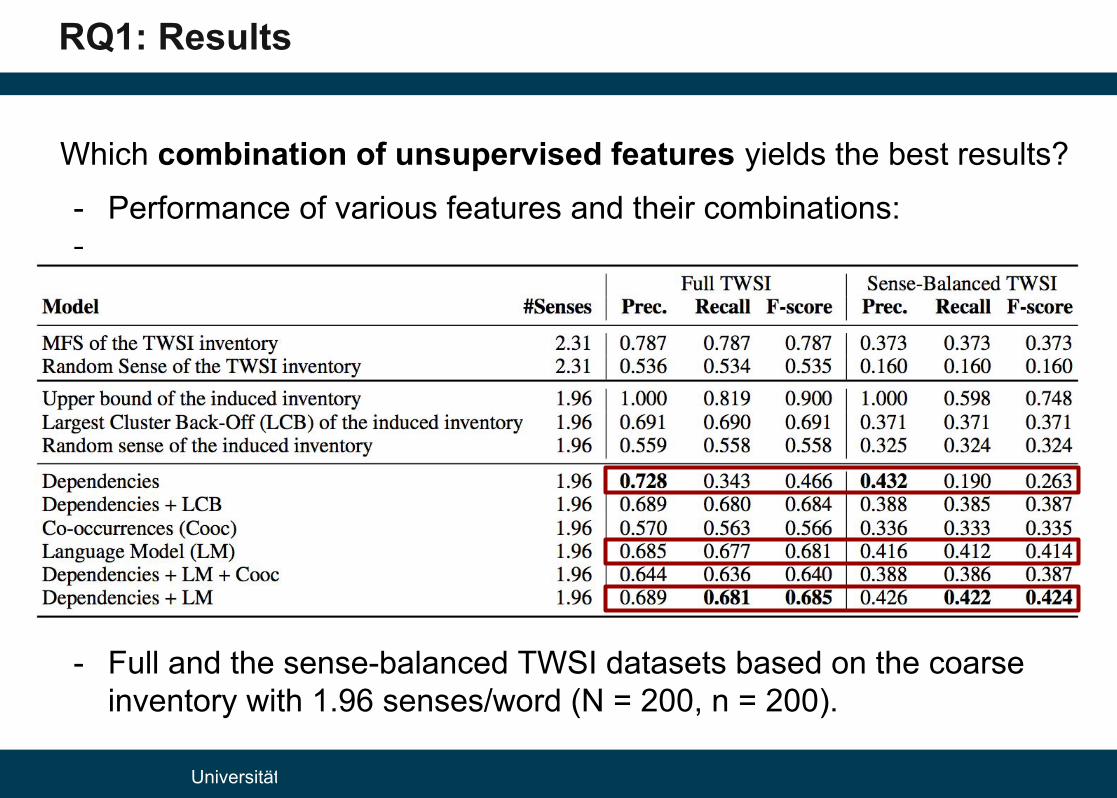
RQ1: Results
Which combination of unsupervised features yields the best results?
- Baselines: MFS, Random, LCB,...
Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 28
RQ1: Results
Which combination of unsupervised features yields the best results?
- Performance of various features and their combinations:------------ Full and the sense-balanced TWSI datasets based on the coarse
inventory with 1.96 senses/word (N = 200, n = 200).

Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 29
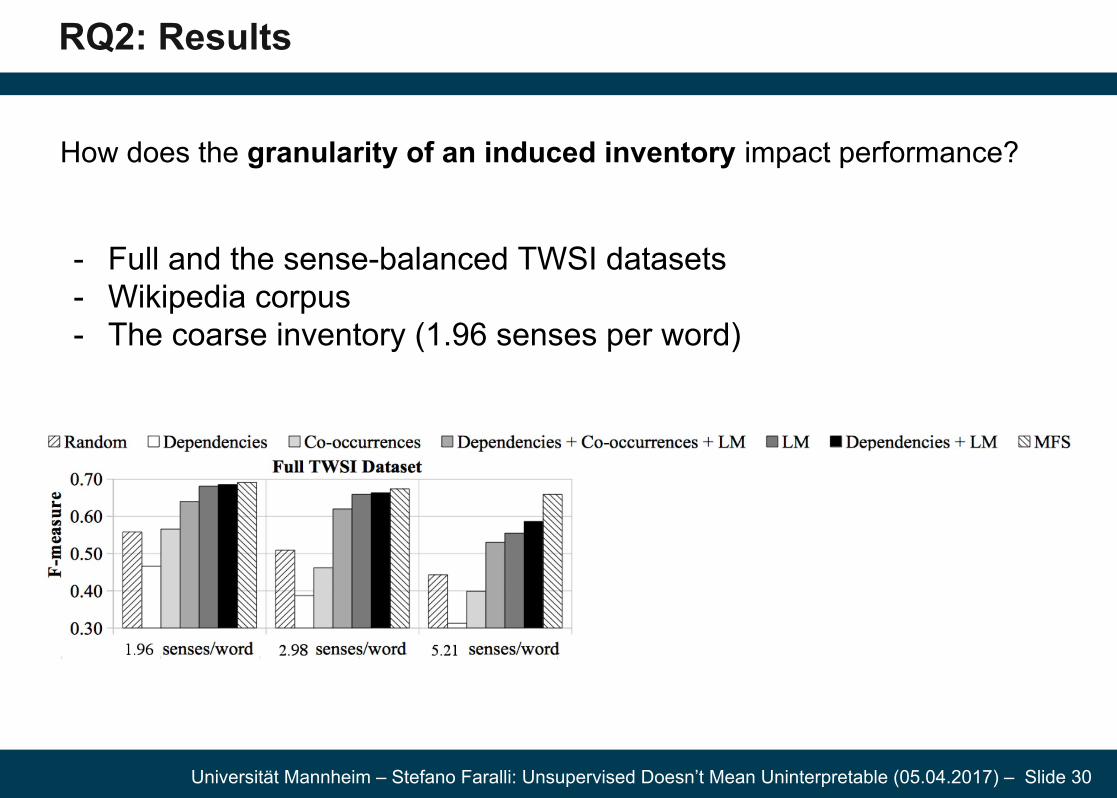
RQ2: Results
How does the granularity of an induced inventory impact performance?
- Full and the sense-balanced TWSI datasets- Wikipedia corpus - The coarse inventory (1.96 senses per word)
Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 30
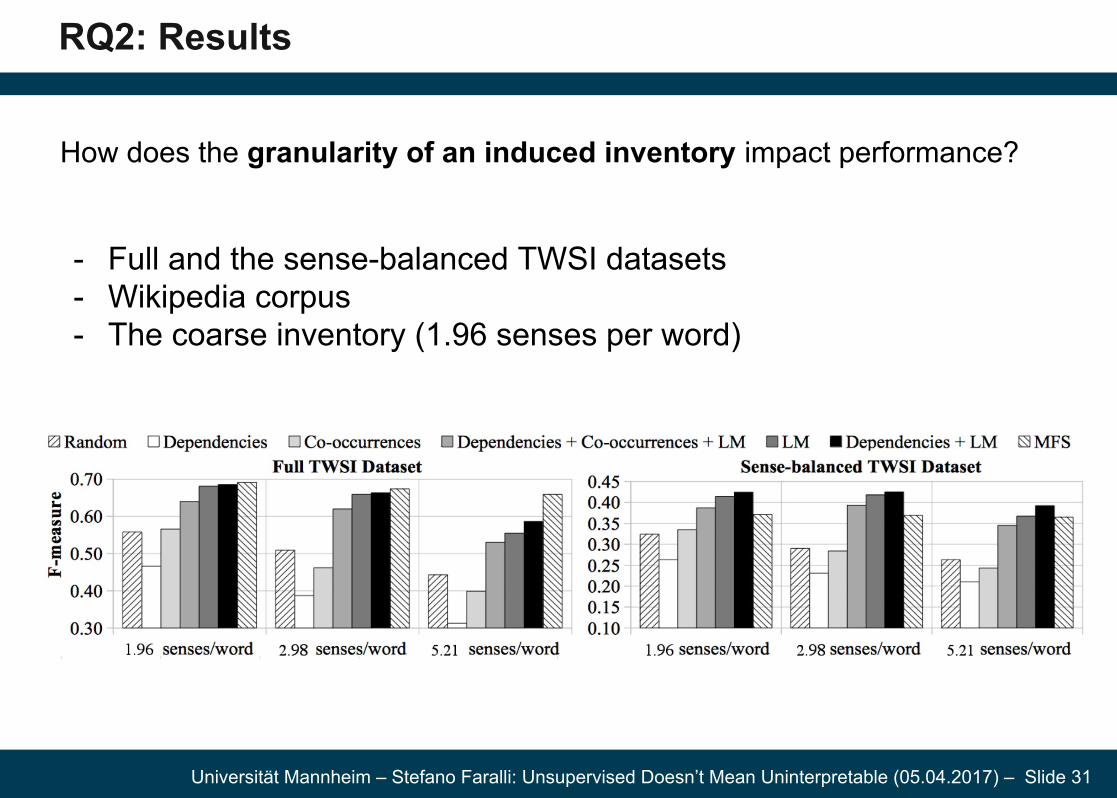
RQ2: Results
How does the granularity of an induced inventory impact performance?
- Full and the sense-balanced TWSI datasets- Wikipedia corpus - The coarse inventory (1.96 senses per word)
Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 31
RQ2: Results
How does the granularity of an induced inventory impact performance?
- Full and the sense-balanced TWSI datasets- Wikipedia corpus - The coarse inventory (1.96 senses per word)

Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 32
RQ3: Dataset and Evaluation Metrics
What is the quality of our approach compares to SOTA unsupervised WSD systems, including those based on the uninterpretable models?
Dataset: - SemEval 2013 Task 13: WSI for Graded and Non-Graded Senses- 4,664 contexts- 6,73 senses per word

Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 33
RQ3: Dataset and Evaluation Metrics
What is the quality of our approach compares to SOTA unsupervised WSD systems, including those based on the uninterpretable models?
Dataset: - SemEval 2013 Task 13: WSI for Graded and Non-Graded Senses- 4,664 contexts- 6,73 senses per word
Evaluation Metrics:
- Supervised metrics (Jacc. Ind., Tau, WNDCG)- Requite mapping of the induced sense inventory to the gold inventory
- Unsupervised metrics (Fuzzy NMI, Fuzzy B-Cubed)- No mapping is required
Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 34
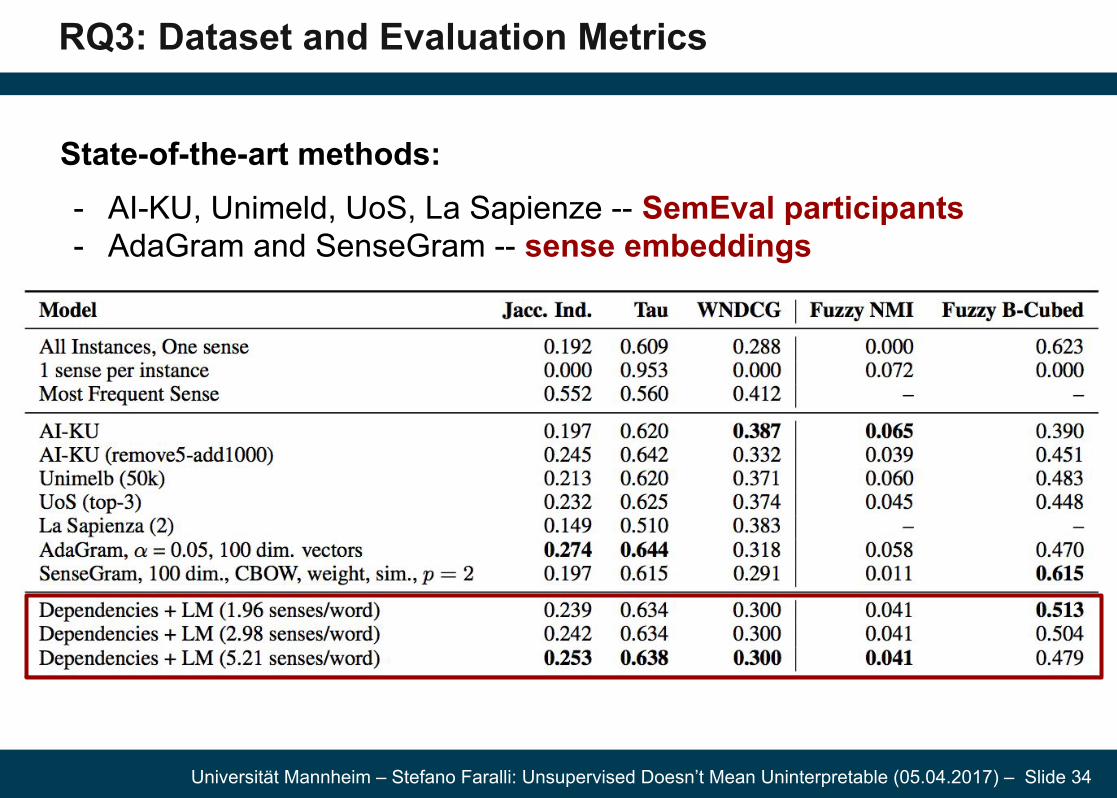
RQ3: Dataset and Evaluation Metrics
State-of-the-art methods:- AI-KU, Unimeld, UoS, La Sapienze -- SemEval participants- AdaGram and SenseGram -- sense embeddings-

Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 35
Conclusions
− We presented a novel approach to WSD:• Unsupervised +• Knowledge-free +• Based on ego-network clustering +• Interpretable at the levels of
i. Word sense inventoryii. Sense representationsiii. Disambiguation results
− The method yields SOTA results, comparable to uninterpretable models, e.g. sense embeddings, while being human-readable.
− Interpretability of the knowledge-based sense representations, can be achieved using unsupervised knowledge-free framework.
goo.gl/eXgRg4
Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 36
Want to see a demo? https://goo.gl/eXgRg4

Universität Mannheim – Name of Presenter: Titel of Talk/Slideset (Version: 27.6.2014) – Slide 37
We acknowledge the support of:
Development of the demo: Fide Marten
Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 38
References
- Eneko Agirre and Philip G. Edmonds. 2007. Word sense disambiguation: Algorithms and applications, volume 33. Springer Science & Business Media.- Satanjeev Banerjee and Ted Pedersen. 2002. An adapted Lesk algorithm for word sense disambiguation using WordNet. In Proceedings of the Third International
Conference on Intelligent Text Processing and Computational Linguistics, pages 136–145, Mexico City, Mexico. Springer.- Sergey Bartunov, Dmitry Kondrashkin, Anton Osokin, and Dmitry Vetrov. 2016. Breaking sticks and ambiguities with adaptive skip-gram. In Proceedings of the 19th
International Conference on Artificial Intelligence and Statistics (AISTATS’2016), Cadiz, Spain.- Osman Baskaya, Enis Sert, Volkan Cirik, and Deniz Yuret. 2013. AI-KU: Using Substitute Vectors and Co-Occurrence Modeling for Word Sense Induction and
Disambiguation. In Second Joint Conference on Lexical and Computational Semantics (*SEM), Volume 2: Proceedings of the Seventh International Workshop on Semantic Evaluation (SemEval 2013), volume 2, pages 300–306, Atlanta, GA, USA. Association for Computational Linguistics.
- Chris Biemann and Martin Riedl. 2013. Text: Now in 2D! a framework for lexical expansion with contextual similarity. Journal of Language Modelling, 1(1):55–95.- Chris Biemann. 2006. Chinese Whispers: an effi- cient graph clustering algorithm and its application to natural language processing problems. In Proceedings of the
first workshop on graph based methods for natural language processing, pages 73–80, New York City, NY, USA. Association for Computational Linguistics.- Chris Biemann. 2012. Turk Bootstrap Word Sense Inventory 2.0: A Large-Scale Resource for Lexical Substitution. In Proceedings of the 8th International Conference
on Language Resources and Evaluation, pages 4038–4042, Istanbul, Turkey. European Language Resources Association.- Ignacio Iacobacci, Mohammad Taher Pilehvar, and Roberto Navigli. 2015. SensEmbed: learning sense embeddings for word and relational similarity. In Proceedings of
the 53rd Annual Meeting of the Association for Computational Linguistics (ACL’2015), pages 95–105, Beijing, China. Association for Computational Linguistics.- Nancy Ide and Jean Veronis. 1998. Introduction to ´ the special issue on word sense disambiguation: the state of the art. Computational linguistics, 24(1):2– 40.- David Jurgens and Ioannis Klapaftis. 2013. Semeval- 2013 Task 13: Word Sense Induction for Graded and Non-graded Senses. In Proceedings of the 2nd Joint
Conference on Lexical and Computational Semantics (*SEM), Volume 2: Proceedings of the Seventh International Workshop on Semantic Evaluation (SemEval’2013), pages 290–299, Montreal, Canada. Association for Computational Linguistics.
- Jey Han Lau, Paul Cook, and Timothy Baldwin. 2013. unimelb: Topic Modelling-based Word Sense Induction. In Second Joint Conference on Lexical and Computational Semantics (*SEM), Volume 2: Proceedings of the Seventh International Workshop on Semantic Evaluation (SemEval 2013), volume 2, pages 307–311, Atlanta, GA, USA. Association for Computational Linguistics.
- Michael Lesk. 1986. Automatic Sense Disambiguation Using Machine Readable Dictionaries: How to Tell a Pine Cone from an Ice Cream Cone. In Proceedings of the 5th annual international conference on Systems documentation, pages 24–26, Toronto, ON, Canada. ACM.
- Andrea Moro, Alessandro Raganato, and Roberto Navigli. 2014. Entity linking meets word sense disambiguation: a unified approach. Transactions of the Association for Computational Linguistics, 2:231– 244.
- Roberto Navigli and Simone Paolo Ponzetto. 2010. Babelnet: Building a very large multilingual semantic network. In Proceedings of the 48th Annual Meeting of the Association of Computational Linguistics, pages 216–225, Uppsala, Sweden.
- Arvind Neelakantan, Jeevan Shankar, Alexandre Passos, and Andrew McCallum. 2014. Efficient non-parametric estimation of multiple embeddings per word in vector space. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1059–1069, Doha, Qatar. Association for Computational Linguistics.
- Luis Nieto Pina and Richard Johansson. 2016. Em- ˜ bedding senses for efficient graph-based word sense disambiguation. In Proceedings of TextGraphs-10: the Workshop on Graph-based Methods for Natural Language Processing, pages 1–5, San Diego, CA, USA. Association for Computational Linguistics
- Martin Riedl. 2016. Unsupervised Methods for Learning and Using Semantics of Natural Language. Ph.D. thesis, Technische Universitat Darm- ¨ stadt, Darmstadt.- Sascha Rothe and Hinrich Schutze. 2015. Autoex- ¨ tend: Extending word embeddings to embeddings for synsets and lexemes. In Proceedings of the 53rd Annual
Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 1793–1803, Beijing, China. Association for Computational Linguistics
- Jean Veronis. 2004. HyperLex: Lexical cartogra- ´ phy for information retrieval. Computer Speech and Language, 18:223–252.

Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 39
RQ4: Results
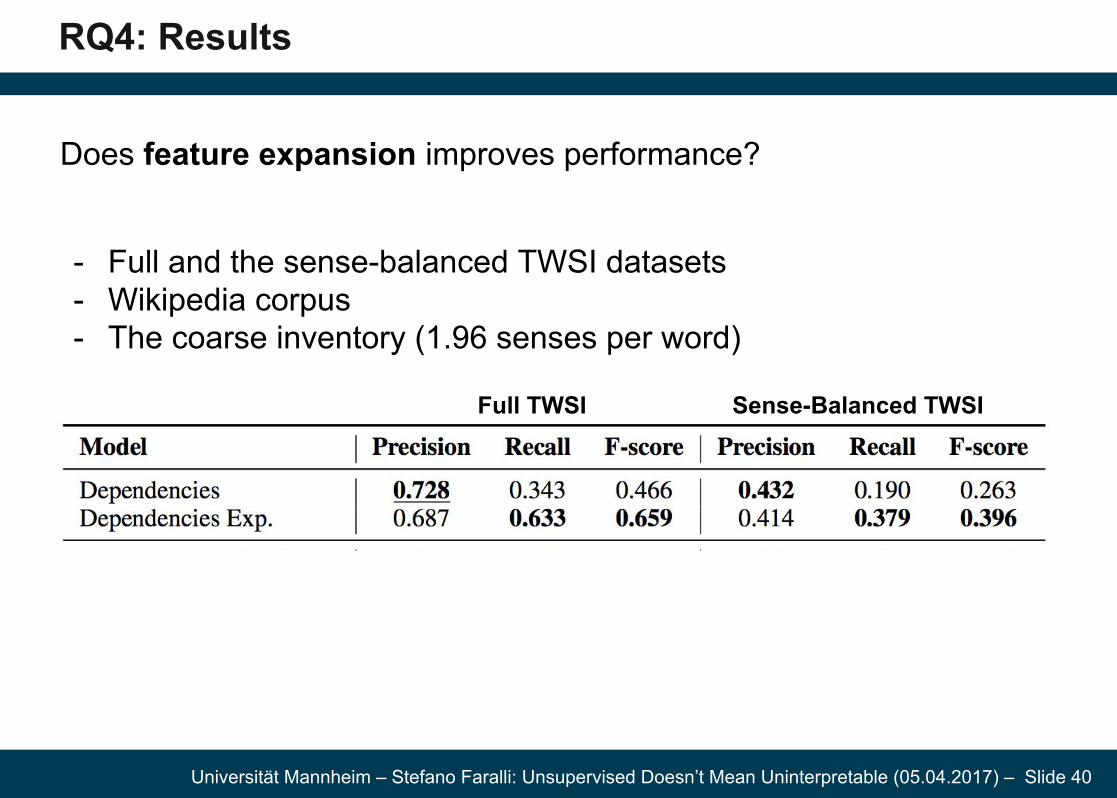
Does feature expansion improves performance?
- Full and the sense-balanced TWSI datasets- Wikipedia corpus - The coarse inventory (1.96 senses per word)
Full TWSI Sense-Balanced TWSI
Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 40
RQ4: Results
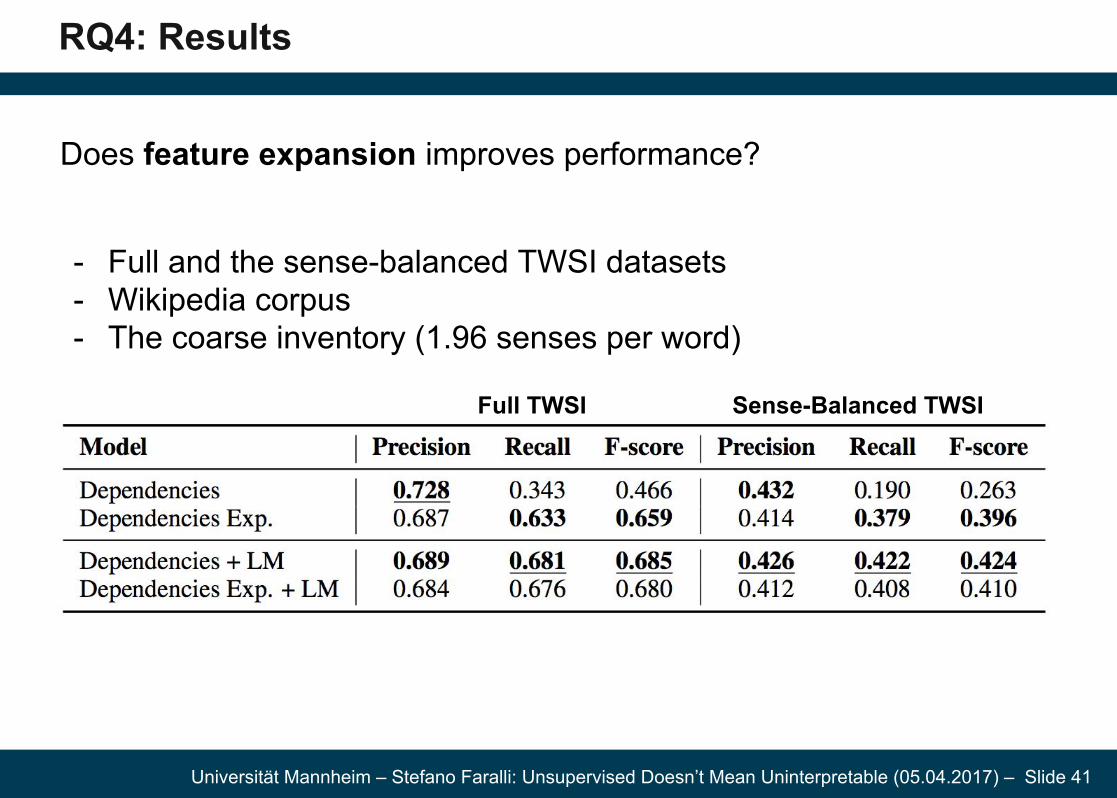
Does feature expansion improves performance?
- Full and the sense-balanced TWSI datasets- Wikipedia corpus - The coarse inventory (1.96 senses per word)
Full TWSI Sense-Balanced TWSI
Universität Mannheim – Stefano Faralli: Unsupervised Doesn’t Mean Uninterpretable (05.04.2017) – Slide 41
RQ4: Results
Does feature expansion improves performance?
- Full and the sense-balanced TWSI datasets- Wikipedia corpus - The coarse inventory (1.96 senses per word)
Full TWSI Sense-Balanced TWSI
Recommended

















