
1
USENETDHT: A LOW-OVERHEAD DESIGN FOR USENET
EMIL SIT, ROBERT MORRIS AND FRANS KAASHOEK (MIT)NSDI 08
Presentation prepared by: Nikos Chondros
May 21, 2010
For MDE519. Distributed Systems
Prof. Mema Roussopoulos

2
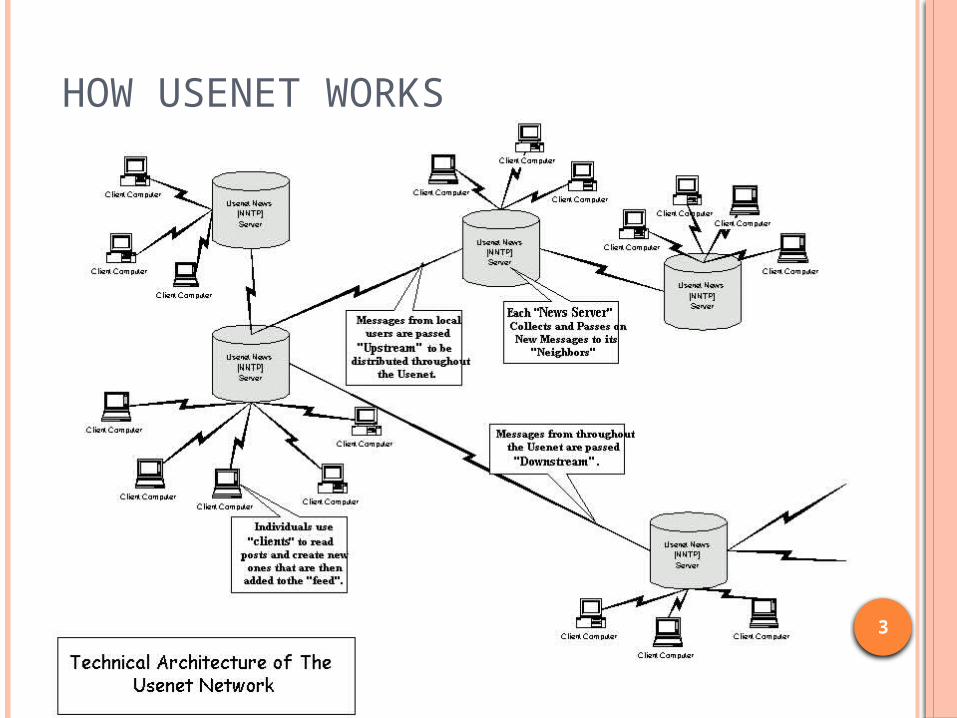
WHAT IS USENET
Usenet is a worldwide distributed Internet discussion system
Operating since 1981 Content creators post messages to
newsgroups Content consumers “subscribe” to
newsgroups, download all “new” message headers and finally download specific messages to read
3
HOW USENET WORKS

4
USENET MESSAGE
Header Subject Author Date Newsgroups to be posted to
Body Actual text of message UUencoded binary attachments

5
THE PROBLEM
Usenet places large overhead to participating servers Each server hosts a (large) subset of the groups However, it has a complete copy of the headers
and message bodies in these groups Binary objects (multimedia mostly) contained in
the bodies are large and have to be replicated everywhere
As a result, content is saved for a very short period of time. Giganews.com claims approx 2 years currently and that’s not a free service. Free servers from ISPs are limited to a (very) few months.

6
THE CENTRAL IDEA OF THE PAPER
Let’s make Usenet distributed Each server to host part of the data-set All servers to cooperate in a DHT to provide the
service to clients Let each server host the complete database of
headers Size is small (a few hundred bytes per message) Quick response to clients building their list
Each server to “cache” popular content locally to avoid accessing the DHT repeatedly

7
WHAT’S THE POTENTIAL GAIN?
Each message (body) stored in two places (and the second is for replication)
Scalability (simply add more nodes) Traffic of incoming updates severely reduced
to headers only Storage requirements on each server
reduced to 2/n of the full load

8
APPROACH
Use a DHT to distribute the content to servers DHash (details coming)
Based on Chord
Replicate the messages to more than one server for safety DHash already touched that but authors
contribute to it with a finer-grain solution

9
USENETDHT CLIENT OPERATION
Figure 1: Messages exchanged during during UsenetDHT reads and writes. 1. Client A posts an article to his local NNTP front-end. 2. The front-end stores the article in DHash (via a DHash gateway, not shown). 3. After successful writes, the front-end propagates the article's metadata to other front-ends. 4. Client B checks for new news and asks for the article. 5. Client B's front-end retrieves the article from the DHT and returns it to her.

10
SO WHAT’S DHASH
Published at SOSP 01 Wide-area cooperative storage with CFS (MIT)
DHash uses Chord to organize nodes and resolve “keys”
DHash itself stores unstructured objects reliably (more to come)
FYI, CFS uses the SFS file system toolkit to provide a filesystem that splits file contents to blocks and stores each one seperately on DHash.

11
DHASH REPLICATION (FOR SAFETY)
With a parameter k, store the content to the k consecutive Chord nodes starting from the “owner”.
Why? After a block’s successor fails, the block is immediately available at its new successor.
Key
Key’s owner
Key owner’s
successorExample for k=2

12
WHAT’S WRONG WITH THAT?
Efficiency! How do you manage these copies when new
nodes arrive and old ones leave? How do you maintain k copies only (optimal)
DHash targeted small blocks, parts of the files. These guys want to store a complete Usenet message with it, which can be quite large

13
HERE COMES “PASSING TONE”
Ideally: Generate repairs only for those objects with fewer than
k remaining replicas But that’s a tough nut to crack as no global “directory” exists!
Actually, on each node: Keep a synchronization data structure for objects that
“belong” to me, using Merkle trees (more soon) Make sure I have a copy of all objects I am responsible
for Any objects stored here, for which I am not responsible
for anymore, make them available to whoever of my immediate neighbors now is.
Ask Chord to maintain O(logn) predecessors Now the node knows the range of objects it is required
to replicate (the ones owned by its k predecessors)
14
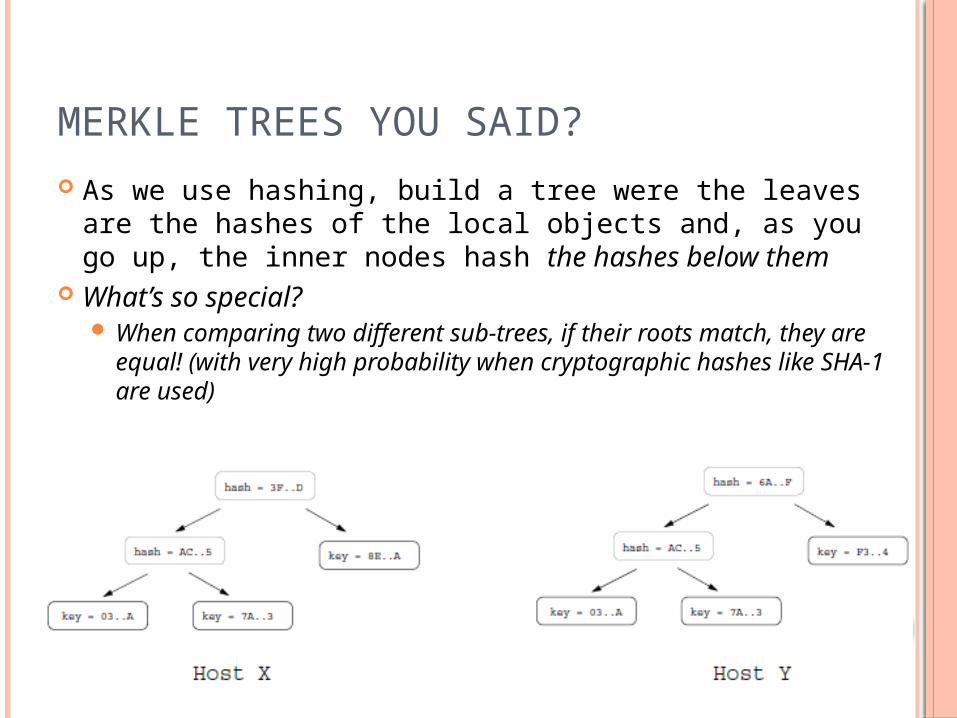
MERKLE TREES YOU SAID?
As we use hashing, build a tree were the leaves are the hashes of the local objects and, as you go up, the inner nodes hash the hashes below them
What’s so special? When comparing two different sub-trees, if their roots
match, they are equal! (with very high probability when cryptographic hashes like SHA-1 are used)

15
PASSING TONE “LOCAL MAINTENANCE” (OBJECTS THAT A NODE IS RESPONSIBLE FOR BUT DOES NOT CURRENTLY “HAVE”)
Each server synchronizes only with its direct predecessor and successor
Walk down the relevant branches of the Merkle tree and efficiently identify objects the current node is missing that are available at its neighbors.
n.local_maintenance(): a, b = n.pred_k, n # k-th predecessor to n for partner in n.succ, n.pred:
diffs = partner.synchronize(a, b) for o in diffs:
data = partner.fetch(o) n.db.insert(o, data)

16
PASSING TONE “GLOBAL MAINTENANCE” (OBJECTS THAT A NODE “HAS” BUT IS NOT CURRENTLY RESPONSIBLE FOR)
Iterate over the database and identify objects no longer responsible for (not in its replica set)
Contact the current successor and synchronize for the set that he is responsible for
Still, does not delete objects (it lets them expire)

17
DEALING WITH EXPIRATION
Eventually, even in UsenetDHT, articles will expire
Handle this by not including expired object in the Merkle trees Requires clocks to be synchronized among peers
so that they expire articles together
18
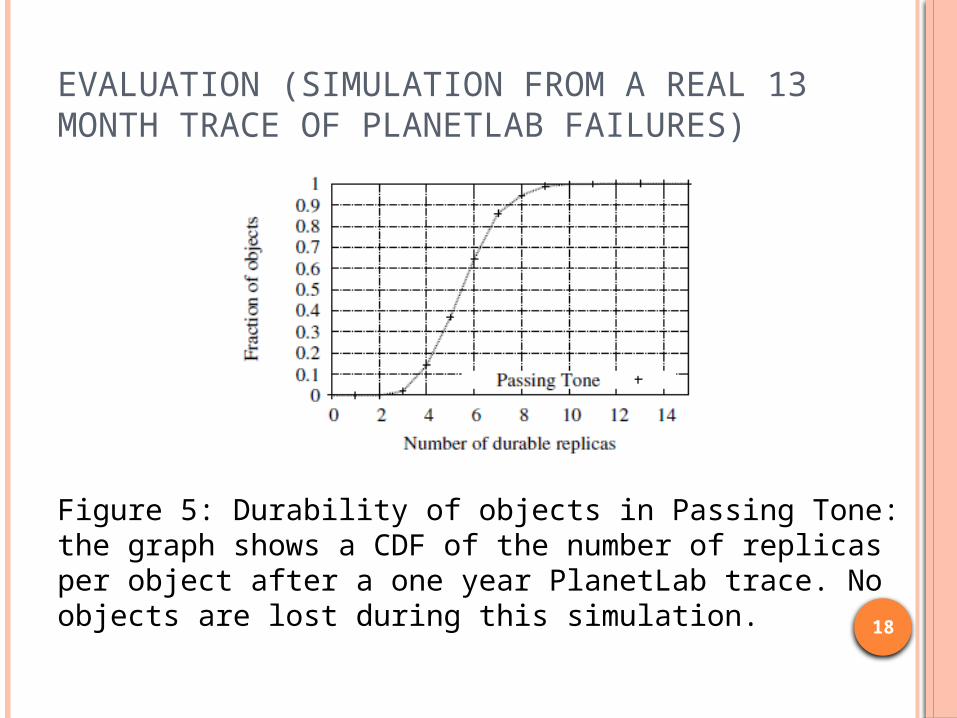
EVALUATION (SIMULATION FROM A REAL 13 MONTH TRACE OF PLANETLAB FAILURES)
Figure 5: Durability of objects in Passing Tone: the graph shows a CDF of the number of replicas per object after a one year PlanetLab trace. No objects are lost during this simulation.
19
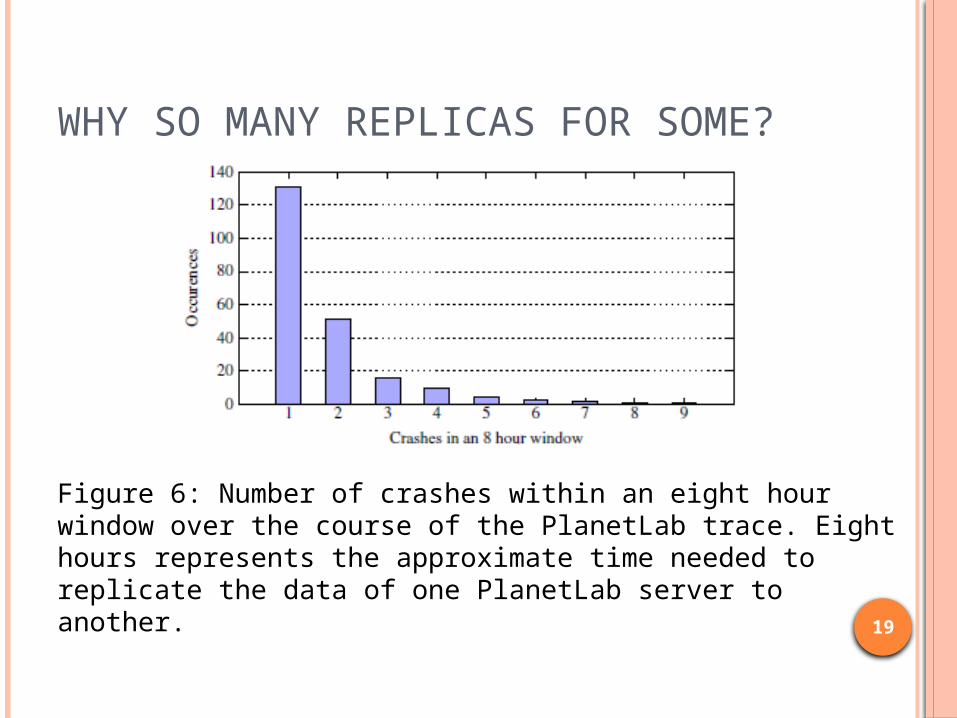
WHY SO MANY REPLICAS FOR SOME?
Figure 6: Number of crashes within an eight hour window over the course of the PlanetLab trace. Eight hours represents the approximate time needed to replicate the data of one PlanetLab server to another.
20
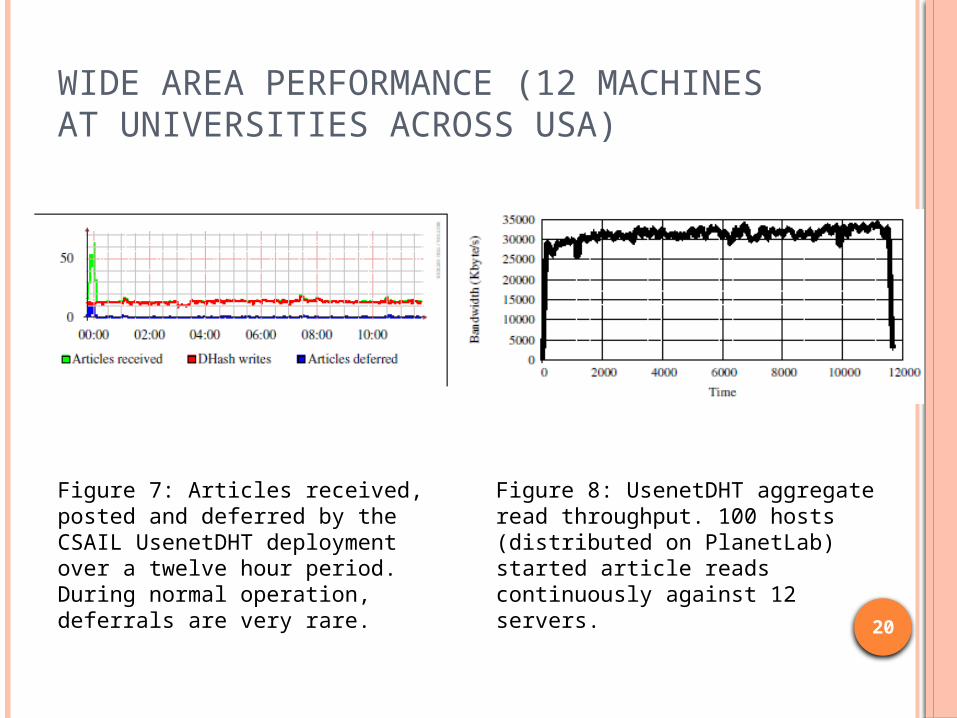
WIDE AREA PERFORMANCE (12 MACHINES AT UNIVERSITIES ACROSS USA)
Figure 7: Articles received, posted and deferred by the CSAIL UsenetDHT deployment over a twelve hour period. During normal operation, deferrals are very rare.
Figure 8: UsenetDHT aggregate read throughput. 100 hosts (distributed on PlanetLab) started article reads continuously against 12 servers.

21
PASSING TONE EFFICIENCY
Figure 9: Number of repairs and number of writes over time, where we introduce a simple transient failure, a server addition, and a second transient failure. The second failure demonstrates behavior under recovery and also what would have happened in a permanent failure.
22
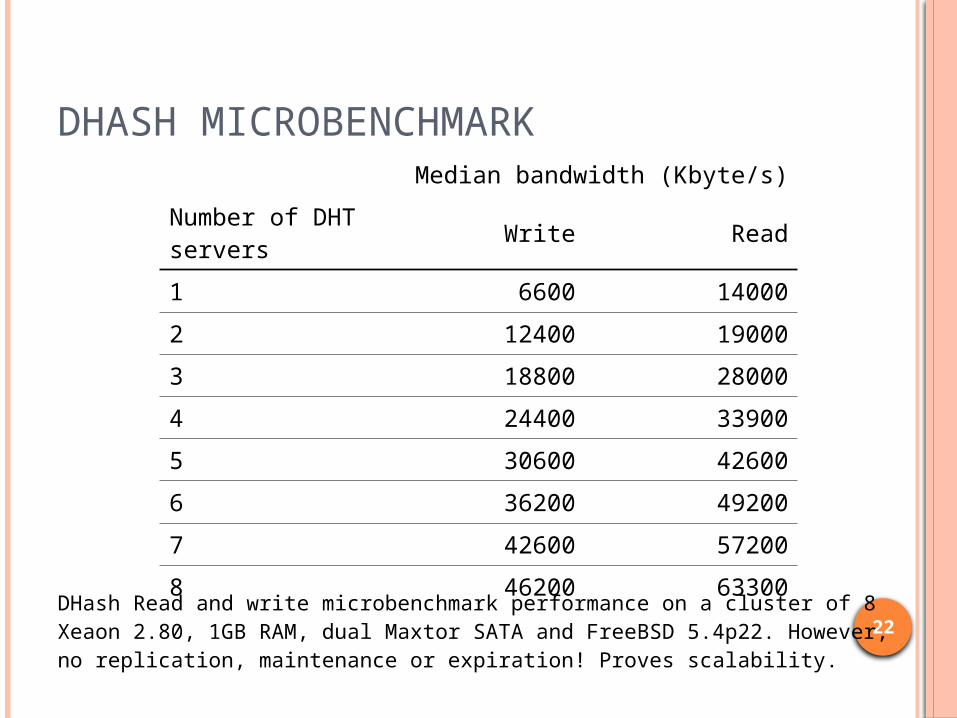
DHASH MICROBENCHMARKMedian bandwidth (Kbyte/s)
Number of DHT servers Write Read
1 6600 14000
2 12400 19000
3 18800 28000
4 24400 33900
5 30600 42600
6 36200 49200
7 42600 57200
8 46200 63300
DHash Read and write microbenchmark performance on a cluster of 8 Xeaon 2.80, 1GB RAM, dual Maxtor SATA and FreeBSD 5.4p22. However, no replication, maintenance or expiration! Proves scalability.

23
UsenetDHT: potential savings
• Suppose 300 site network• Each site reads 1% of all articles
Net bandwidth Storage
Usenet
UsenetDHT
12 Megabyte/s 10 Terabyte/week
120 Kbyte/s 60 Gbyte/week

24
SOURCES
Emil Sit, Robert Morris, and M. Frans Kaashoek, “UsenetDHT: A low-overhead design for Usenet”, NSDI08
http://www.sscnet.ucla.edu/soc/csoc/papers/sunbelt97/Usenet%20Technical%20Architecture.jpg
Wikipedia article on Usenet Dabek, F., Kaashoek, M. F., Karger, D., Morris, R.,
and Stoica, I. “Wide-area cooperative storage with CFS”. In Proc. of the 18th ACM Symposium on Operating System Principles (Oct. 2001)
Josh Cates , Robust and Efficient Data Management for a Distributed Hash Table, Master’s thesis MIT 2003
Ross Anderson, “Future Peer-to-Peer Systems” presentation
Recommended
















