

The Eyes of the BeholderDeveloping an Operational Gaze Controlled Narrative System
By Tore Vesterby (160875-xxxx)
& Jonas C. Voss (100975-xxxx)
Head Supervisor: John Paulin Hansen
Assisting Supervisor: Mark Rudolph
The IT University of Copenhagen
Sixteen-week Project
Autumn Semester 2003
Cover image courtesy of Tony Stone (GettyImages)<http://creative.gettyimages.com/stone/>


Acknowledgements
We would like to thank our supervisors John Paulin Hansen and Mark Rudolph for
their inspirational guidance through this field, which was almost completely new to us
when we began our journey. We have really been given the feeling that this is a new
field being explored and that we are pioneers on this road.
Thanks also to Susana Tosca for giving us a few minutes of her time, helping us get a
few extra cases for the screen shots of the computer games and lending us a bit of
literature.
A big thanks to Signe Storegaard who turned up for no pay to star in our little film,
and gratitude to Christian Elverdam, who did a masterful job of directing and
coordinating the shooting of the film.
Finally we would like to thank our testers who turned up in mid-December despite
busy work schedules before the yuletide.
Jonas C. Voss & Tore VesterbyDecember 19th, 2003.

Abstract
In this paper we present how a GANS (Gaze-Controlled Interactive Media) prototype
may be constructed using gaze tracking and multimedia technology. A GANS is a new
type of interactive media where the narrative is enhanced by the viewer’s participation
through gaze tracking. Our focus has been on designing a non-intrusive interface for
the system.
We have collected qualitative data from eleven testers, who have given us invaluable
feedback on what strengths and weaknesses there may be in using gaze tracking as
the only input device in this new medium.
Finally we explore how different cues can be used to secure the viewers participation,
by looking at what effects computer games and cinematography has used to obtain
viewer participation and to maintain the suspension of disbelief.

Table of Contents
Gaze Tracking: a Historical Overview .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .8
The First Connection between the Eyes and Cognition .................................................................. 8
Film Cutting and Gaze Tracking................................................................................................................... 9
Eye Tracking As a Means of HCI ................................................................................................................. 9
The Little Prince.............................................................................................................................................10
Seamless Interaction.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
Pioneers of the GANS ......................................................................................................................................15
Method .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
Gaze Tracking Today .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
Technical Issues with Gaze Trackers.......................................................................................................17
Audio in Gaze Tracking..................................................................................................................................18
Interest and Emotion Sensitive Media .....................................................................................................19
Guiding the Viewer’s Gaze ...........................................................................................................................21
Conscious and Unconscious Tracking ....................................................................................................22
Combining Gaze Tracking and Narrative ..............................................................................................22
Branching ..........................................................................................................................................................23
Exploratorium..................................................................................................................................................24
Parallel Streaming..........................................................................................................................................25
Summary .................................................................................................................................................................25
Defining the GANS framework .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
Metaphorical Framework ...............................................................................................................................27
Hotel Movie – The Story So Far .................................................................................................................28
Setting Up the GANS........................................................................................................................................29
Choice of Middleware: Macromedia Director ................................................................................30
The Gaze Tracker...............................................................................................................................................30
The Interpreter Module...................................................................................................................................31
Determining Viewer Interest ...................................................................................................................32
Determining Emotional Involvement..................................................................................................33
Producer Module................................................................................................................................................34
The Scene Script and Object Handler Team...................................................................................35
Summary .................................................................................................................................................................36
User Tests . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
Unanswered Questions ...................................................................................................................................37
Test Design............................................................................................................................................................37
Test Subjects ....................................................................................................................................................37

Groups and Calibration..............................................................................................................................38
Viewing the GANS Prototype .................................................................................................................39
Viewing the QTVR........................................................................................................................................39
Results from watching the GANS prototype ........................................................................................41
Results from the QTVR Exploratorium....................................................................................................43
Summary............................................................................................................................................................44
Interactive Cues in GANS.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
Visual Cues ............................................................................................................................................................47
Halo......................................................................................................................................................................47
Onscreen Eye and Head Movements .................................................................................................49
Blurring or fading..........................................................................................................................................50
Auditory Cues.......................................................................................................................................................51
Off Screen Sounds ........................................................................................................................................52
Object Sound or Dialogue........................................................................................................................52
Changing the Soundtrack..........................................................................................................................53
Summary .................................................................................................................................................................54
Conclusions and Future Perspectives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
Literature .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
Games .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
Storyboard..............................................................................................................................................................60
List of Shots ...........................................................................................................................................................62
Appendix II – Director Documentation .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
Overview ................................................................................................................................................................65
Lingo Scripts..........................................................................................................................................................66
Appendix III Emails to Testers. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
Initial Contact Email..........................................................................................................................................70
Follow Up Email .................................................................................................................................................71
Appendix IV Non-disclosure Agreement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
Non Disclosure Agreement ...........................................................................................................................72
Appendix V Interview Guides . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
Guide for the unconsciously tracked group ........................................................................................73
Guide for the consciously tracked group..............................................................................................74
Guide for the QTVR..........................................................................................................................................75
Appendix VI – The Learning Process . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77

Gaze Tracking: a Historical Overview
Many of us know the adage: The eyes are the mirrors of the soul. However, over the
last forty years or so research has shown that the eyes contain much more information
than purely our emotional disposition at a given time. The eyes can also be used to
track how we look at objects and how we use them to search for meaning. In short
our eyes contain an abundance of information that can be used to determine not only
what we are looking at, but also how we look at objects and what we are interested
in. In the following chapter we will present some of the early research in gaze
tracking1 done by the Russian psychologist, Alfred E. Yarbus. Followed by a
presentation of how gaze tracking has been tied together with motion pictures and
multimedia.
The First Connection between the Eyes and Cognition
One of the first researchers to begin measuring what the human eye sees when
examining objects was the aforementioned Yarbus. Published in English in 1967 his
book Eye Movement and Vision concludes, “…when examining complex objects, the
human eye fixates mainly on certain elements of objects.” (Yarbus, 1967: 171). This is
based on a series of experiments where he asked test subjects to examine different
works of art, either as a free examination or with instructions. He writes, “When
looking at a human face, an observer usually pays most attention to the eyes, lips and
the nose”. (Ibid: 191). This is shown below:
The fixation points on the left are from a subjectexamining the painting on the right (Yarbus 1968:180).
1 This discipline has also been called eye tracking. However we believe that the term eye trackingencapsulates gathering data about how a subject’s eyes move, whereas gaze tracking is the discipline oftracking where, and at what, a subject is looking at. Hence in this paper we will be using the term gazetracking.

Yarbus’ research also show that when looking at an image with a certain set of
instructions, the eye will focus on different aspects of different objects which leads him
to conclude that: “Records of eye movements [...] show clearly that the importance of the
elements giving information is determined by the problem faced by the observer, [...]”
(Ibid: 193). This shows that measuring the fixations of a person’s eyes when viewing
an image can give a good indication of what is important for him or her.
Film Cutting and Gaze Tracking
In 1978 Hochberg and Brooks attempted to find a connection between how a film is
cut and how user interest is affected by these cuts. In order to do so they set up a
number of experiments to track the viewer’s gaze when viewing different types of cuts
– either using abstract patterns or cut-outs from old magazines (Hochberg & Brooks,
1978: 297, 302). Their working hypothesis was that user interest in a given shot would
decay over time, but be renewed when a scene was cut.
They conclude that: “…the rate of active looking is maintained at a higher level when
there are more places at which to look, and when the cutting rate is higher”. (Ibid: 301).
This indicates that a cut in a film is a way of getting the viewer’s attention. Additionally
if a shot holds an abundance of objects or people to look at, that shot will be more
interesting to the viewer.
Eye Tracking As a Means of HCI
In 1984 Richard A. Bolt, presents the idea of using eye movements as a means of
Human Computer Interaction (HCI). He states that “Certainly the eye is a pointer par
excellence [...] We can look at some fine bit of detail in a scene, look away and then
return dead on target – all with exquisite repeatability” (Bolt, 1984: 54).
Bolt set up an experiment called The World of Windows to demonstrate how the eye
could be used as a pointing device. Many simultaneous TV-images with sound would
be presented to a viewer who was then able to select one of the sequences by looking
at a certain image for a given period of time. The system zoomed in on the visual and
also used what Bolt terms “auditory zooming” – i.e. the sound associated with the
visual became the only sound playing – in order to indicate that the clip had been
selected (Ibid: 62).
However, Bolt emphasised that the equipment needed at the time for gaze tracking
was either too cumbersome or too expensive for it to be used as a way of producing
common applications to be used by consumers. This meant that a gaze-controlled
application was not within consumer reach in the early 1980’s.

Furthermore Bolt envisioned a system that was to be operated by a multitude of
senses in order to allow the system anticipate what the user needs to get done; a multi
modal system by present day terms (Maglio 2003, Horvitz 2003). His idea for this was
centred around gaze tracking as the primary source of information on the user’s needs
(Bolt, 1984: 87). Bolt argued that “the user’s line of regard opens a subtle but powerful
aspect of machine-to-human awareness” as this is the same method a mother uses
when teaching a child the connection between words and objects (Ibid). Additionally
he states that the eyes may also be used to indicate where a persons “auditory
attention is directed” (Ibid: 88).
The Little Prince
In 1984 Bolt described a self-closing system where “the system has zoomed you in on
some item precisely because of the visual attention you paid it.” (1984: 95). By 1990
Starker and Bolt presented a working self-disclosing system, based on a children’s
book The Little Prince by Antoine de Saint Exupery.
The system used a small revolving 3-D planet with objects on its surface. A 2-D image
of the Little Prince would tell the viewer about the planet as seen below.
The Little Prince as seen by the viewer (Starker & Bolt 1990: 6)
However a gaze tracker would also measure where on the display the user was
looking and the narrator would then proceed to tell the user about the object they had
shown interest in. The system used an interest module to determine what objects the
user would look at and for how long. Additionally an object being looked at would

“blush…momentarily lightening its color on the display” in order to give feedback to
the user (Starker & Bolt 1990: 5).
The Little Prince as “seen” by the system (Starker & Bolt 1990: 6)
Starker and Bolt tested three different models (1990: 6ff), on the interest module, for
determining what object the user was interested in, and thus what the Little Price
should be talking about.
· Model One: Would increment the tally of an object by one, when the gaze
point coordinate would respond to the object or group of objects.
· Model Two: Would compare the elapsed time an object was looked at to the
number of times the object was looked at.
· Model Three: Would see if the object was looked at, and use a “fresh look
constant” to see if the object had the highest interest level over time. The
interest level would decay as time elapsed, if the user did not generate a “fresh
look” on the object.
Starker and Bolt determine that all three models could be used by the system, but
models two and three “more gracefully” inherently drop the interest level of objects if
they are not being looked at (1990: 7). By this we assume that they mean that the
models that allow drops in interest levels over time are more natural to the user,
which could be interpreted as them giving the user a better experience of the
suspense of disbelief.

After a set time of around 2.0 seconds, the system would compare all the interest
levels generated. The object, or group of objects, with the highest interest level would
be the focus of the narrative.
Starker and Bolt concluded that the system could be enhanced by using the duration
of the gaze compared to the duration of consecutive variables, and that a distinction
between causal and intense interest could be used to adjust the way the system reacts
to the user.
Additionally they propose that a better narrative model could utilise, “transitional text,
to “bridge” across interruptions and returns to any subject” (Starker & Bolt 1990: 8) and
also that “the current system does not “know” hat it has previously said. Sentences are
not repeated merely because the text file that keeps them is not rewound” (Ibid).

Seamless Interact ion
In this paper we attempt to carry the torch from Starker and Bolt into the present. We
have chosen to make the eye the sole control organ of how the plot of Gaze
Controlled Narrative Systems (GANS) evolves. We believe this is important, as tracking
the gaze of the viewer, and collecting data about the eye movements in certain scenes
of the medium, should not interrupt the way the viewer watches the movie. Unlike a
computer game there is no feedback from the system to the user during the playback
of the GANS.
Screenshot taken from the game Grand Theft Auto: Vice City byRockstar Games, 2002. Notice the pink arrow above the boat on theleft side of the screen. These arrows jump up and down above theboats indicating to the user that these objects are to be shot upon.Using such an effect in a motion picture could potentially ruin thesuspension of disbelief.
The same can be said of other types of interactive fiction. One of the first hypermedia
stories, A Story As You Like It by Raymond Queneau from 1969 (Samsel & Wimberley,
1998), asks the user direct questions in order to progress the story line, i.e. the user
has to make active decisions as they read the story. In her book Hamlet on the
Holodeck, Janet Murray envisions a Hyperserial where TV meets the internet, in a new
form of medium “in which we will be able to point and click through different branches
of a TV program as easily as we now use the remote to surf from one channel to
another.” (1997: 254). The latest interactive DVD published in Denmark, Switching
from April 2003, “is an attempt to think interactivity radically into storytelling and plot
technique.” (oncotype 2003). The premise of the movie is a love story between two
people, and in order to make the plot advance the viewer has to push the enter-button
on their remote in order to get alternate or story branches (dr.dk, 2003). All three types
of interaction above require that the user must make conscious decisions when

viewing the medium, which we believe may divert attention away from the main
storyline.
Thus, watching an interactive movie should not be a stop-and-go affair, as this
hampers the narrative aspect of a movie. Watching an interactive movie should still be
able to give you a feel of being on a bus that doesn’t stop, until you are at the last
stop. The interactivity however, based on where you look at the screen, should
implicitly let you decide which route to bus should take, giving the movie different
outcomes based on where the viewer has focused in different cuts of the movie. The
changes in the movie should not be noticeable to the viewer, they should just happen
as the story unfolds, making the interactive experience seamless to the viewer. This is
in stark contrast to the experience of agency “the satisfying power to take meaningful
action and see the results of our decisions and choices.” (Murray 1997: 126). Murray
also stresses that agency is not normally experienced within narratives, but may be
beneficial in virtual environments which need to be explored. We believe however,
that the notion of agency requires a more active viewer who constantly needs to make
decisions about what to do next within a given medium.
A GANS on the other hand should not prompt the user to make continuous conscious
decisions during the playback of the narrative, but rather invite the viewer to
experience a non-intrusive interface, which does not load the eyes with motor tasks.
We believe that in creating gaze-controlled narratives, the story will able to flow more
freely than when using a keyboard, mouse, game pad, or any other currently available
input device. Also these traditional input devices are dependent on GUI environments
that may interrupt the flow of the story as seen above.
We stress this because in some situations, the eye may be the only organ available for
a user to control a digital device, and although it takes some learning, it proves
successful for many with physical disabilities. Research has explored and discovered,
how using the eye as the sole primary control organ is not suitable, as eye movements
are not always voluntary, and also the hands and eyes tend to work in coordination
(Zhai 2003).
In other words, the movement of the eyes cannot always be interpreted as a conscious
decision, making them undesirable as a way to interact explicitly with a medium,
where the viewer has to answer explicitly asked questions by the movement of the
eyes. However, we believe, that it is possible to use the eye as the primary control
organ, especially if the level of interactivity is of a more implicit nature. Additionally
any misinterpretations of explicit decisions made by using the viewer’s gaze to control

the system are not as grave as those made at, say, a nuclear power plant control
centre.
Pioneers of the GANS
We do not believe that the issues with traditional interactive fiction are unique to the
past, but can be seen as challenges, for what we are attempting to achieve in this
paper: a multimedia system that dynamically reacts to the user’s gaze. This is not only
a question how the system should work on a technical level, but also a question of
how a user interacts with the medium, and how a director can create material for the
medium. We see rich possibilities in creating interactive narratives that are controlled
exclusively by where the viewer’s eyes look upon a display.
In this paper will explore the following research questions:
How can a prototype of a Gaze Controlled Narrative System be constructed using
currently available multimedia technology?
· What aspects of gaze tracking research need to be considered when
constructing such a prototype?
· How do viewers respond to a non-intrusive interface where the eye is the sole
means of controlling the narrative?
· What directorial options are available to the directors of these systems for
getting the viewers attention in this medium?

Method
Using the historical overview provided earlier we tie it to the present by a detailed
discussion of the research literature from the mid 1990’s till the present. This
discussion allows us to explore what is possible to achieve today not only on the
technological level, but also what can be measured in a viewer’s gaze, and how that
data can be utilised by a multimedia system. Furthermore we examine different
narrative structures for interactive media, and tie them specifically to the possibilities
presented by the research in the field of gaze tracking so far.
We created a GANS prototype, which encompasses a small branching sequence (see
p. 23) of an interactive film. The film sequences were shot on mini-DV tape and cut
using iMovie. These were then imported into Macromedia Director, where we wrote
scripts that could measure where the mouse was on the display at given intervals. The
scripts were written using a form of extreme programming technique, where we
would be two people at the computer at a time. This was done to make sure, that no
vital aspects of the scripts were left out, but it also made debugging much faster as
there were two pairs of eyes on the code at all times. Additionally we read posts on
the macromedia.director.lingo newsgroup when we hit impassable roadblocks in the
scripting.
The prototype was tested using the gaze tracker at the ITU on six male and five female
subjects who were contacted via email or phone. The test subjects watched the
prototype from three to four times, and were asked questions about their experience
after each viewing. Additionally they were asked to navigate a QuickTimeVR 360°
photograph of a room taken from the motion picture the Matrix.
We use the user feedback to further explore the narrative control functions of the
GANS, combined with the findings from the research literature. This is done with the
existing language and examples from motion pictures and computer games. This
combination provides us with a set of semantics that we can use to describe forms of
interaction with GANS, that we were unable to achieve with the prototype.

Gaze Tracking Today
Before diving head first into constructing a GANS, we shall explore the status of gaze
tracking research today, which will provide us with the theoretical framework for the
design of our prototype in the next chapter. Up until now, we have dealt solely with
how the research concerning gaze tracking has progressed from the 60’s to the early
90’s, but what is actually possible with gaze tracking technology today?
Technical Issues with Gaze Trackers
While Bolt (1984) talked about equipment in the area of $US 100.000 with at least one
operator, and the need of calibrating the equipment several times during a session,
hardware today is steadily becoming cheaper, and increasingly precise, which make
the possibilities for gaze tracking outside a lab situation much more plausible, and
affordable (Shell 2003). In this paper we will be working under the assumption that
low cost gaze trackers will be available to the public at large within the next five to
ten years.
But still in the present, Ohno et. al. present a gaze tracker dependent on only two
points for calibration to individuals. They propose a vector based calibration system
that use an eyeball model and pupil positions, which they show is easier to calibrate
than the point based systems being used today (Ohno et. al. 2002: pp. 128 ff).
Flickner et. al. have devised a method that uses two light sources in order to obtain
the gaze position of multiple viewers (see the image below). This system uses “the
“red eye” effect commonly seen in flash photography. The bright pupil image is
subtracted from the dark pupil image and adaptively thresholded to create a
computationally simple eye detector…” (Cited from: Zhai, 2003).
The top row of images shows calibration on a single subject where the bottomrow shows the calibration of multiple subjects. Both are achieved using the “redeye” effect (Zhai, 2003: 38).

The GazeTalk project being
developed by the IT University of
Copenhagen uses a standard web cam
and aims for a low budget solution
affordable to most consumers, but is
primarily targeted towards making
communication easier for severely
handicapped people. GazeTalk makes
use of a 4x3 on-screen grid to place a
fixation within. In effect this means
that the screen is separated into 12 squares each being around three fingers wide and
three fingers tall. This is a good pointer as to how big objects have to be on screen, to
be handled by gaze control with a tracking precision of 4 degrees. Future
development of the project might improve the tracking precision (Hansen et al, 2001).
To us these examples indicate that not only is the hardware on its way to becoming
affordable to consumers, but the software that actually detects the viewer’s gaze is
steadily becoming more sophisticated. Although we cannot say exactly how gaze
detection technology will progress within the next few years, we can assume that
there will be gaze trackers on the market for the technologically-inclined consumer.
For instance in a recent interview vice president of Sony Computer Entertainment
revealed that the PlayStation 3 will be shipped with a camera, which may be used to
track the users facial expressions (Viglid, 2003).
Audio in Gaze Tracking
The ideas put forward by Bolt in the mid 80’s have come a long way in being realised.
The ‘cocktail mélange’ of Bolts ‘virtual windows’ has been realized by Roel Vertegaal’s
GAZE and GAZE2 Groupware System (Vertegaal 1999, Vertegaal et al. 2003). In
GAZE2, a multiparty communication system, users communicate via video
conferencing, where on-screen windows represent each active participant in the
conference.
Via the data transmitted from
the eye tracker of each
participant, GAZE2 rotates 2D
images to show who the
participants are looking at,
thus providing the needed
face-to-face feel of an actual
Screen Dump of the first GazeTalk prototypedeveloped at the ITU (Hansen et al, 2001).
GAZE-2 session with 4 users. Everyone is currently lookingat the left person, who’s image is broadcast in a higherresolution. Frontal images are rotated to convey gazedirection (Vertegaal et al. 2003: 525).

physical meeting, and thereby avoiding the problem of turn taking in virtual meetings
(Vertegaal, 1999).
Another connection between audio and the viewer’s eyes can be found by measuring
the pupil dilations of the viewer. Partala et al. (2000) show how the viewer reacts
emotionally when affected by auditory stimuli. They operate with twelve sounds in
three categories:
Positive sounds were laughters (a baby, a man, a boy and a group laughing),neutral sounds were background noises (office noise, typewriter noise, trainnoise and traffic noise, and negative sounds included a couple fighting (x2), awoman screaming, and a man screaming and being shot. (Partala et al., 2000:126)
These noises were presented to test subjects who were given a set of headphones and
whose pupils were measured by an eye tracker before, during and after a sound was
played. Their experiments “…showed statistically significant pupil size variations as a
function of emotionally arousing stimuli.” (Ibid: 127). Additionally they find that pupil
sizes were larger during negative than positive stimuli.
Their experiments also point out that “[Pupil dilation]…peaks were reached at about
two or three seconds from the stimulus onset.” (Ibid: 125) This can be important when
setting up a system that dynamically tracks the viewer’s pupil dilations.
Interest and Emotion Sensitive Media
Hansen et. al (1995) they discuss the possibilities of making Interest and Emotion
Sensitive Media (IES), which incorporates gaze as one of several options for the user
interface They discuss tracking users’ interest in the objects on the screen by tracking
areas of attention and their affective reactions by using pupil dilations (Ibid: 5).
Glenstrup and Engell-Nielsen (1995) envision several uses of IES, including
recreational viewing, commercials, information browsing systems, television
programmes, and video games. They also explore some of the possibilities of tracking
several users at once. Even though it may be technically feasible to build a system that
incorporates gaze-track data from several viewers, we do not think that this is a must
for the first GANS prototypes. Consider that not all multimedia formats2 available today
need to be used by several subjects – single player computer games or hyper fiction
comes to mind. Starting with a production that is meant for a single user also
minimizes the technological requirements for the gaze tracking system.
2 Or even traditional media types; newspapers, magazines and books for instance.

In connection with IES it is also important to note how there can be different control
options available to the user, depending on the amount of control required by the
system (Velichkovsky & Hansen, 1996: 497).
The four illustrations below show different “hybrid solutions for a combination of
command and noncommand principles” (Ibid):
A. Traditional GUI buttons, which can be clicked on with the viewer’s gaze (gaze-
pointing).
B. The selection choices are highlighted by framing them with a black line.
C. The selection choices are displayed in a higher resolution than the non-
selectable areas.
D. The selection choices are implicit (non-visible) to the user.
Control options for the IES (Velichkovsky & Hansen, 1996)
.
Velichkovsky and Hansen state that where A should be used in a direct control
environment, and B and C are also explicitly marked. D on the other hand can be
used in a “quasi-passive mode of operation” (Ibid).
We believe that the formatting of attention areas is highly dependent on the type of
system one is trying to build. An information browsing system for a real estate agency
that could display the interior of houses gaze-control could benefit from visible
buttons in certain areas; i.e. an arrow pointing towards the dining room. However, for
a gaze-controlled medium, with a non-intrusive interface, the option of using an
invisible button (D) could be beneficiary in order to keep the viewer’s suspension of
disbelief at its highest.

Guiding the Viewer’s Gaze
If the interface is hidden from the viewer, how does the director then ensure, that the
viewer has paid attention to a vital object or character in a scene?
Velichkovsky et. al (1995) present a study of subjects viewing images with ambiguous
motifs. They use the image Earth by Giuseppe Arcimboldo to show how the subject’s
interpretation of the image can be manipulated using highlighting and blurring effects.
If the areas containing the face are highlighted and the animals blurred the subjects
would interpret the image as being a face or vice versa (Velichkovsky et al., 1995: 22).
A. Original image. B. Animal interpretation. C. Face interpretation.
The different image manipulations presented by Velichkovsky et. al (1995).
This is further exemplified by Baudisch et al. (2003: pp. 64-65) where an example
shows how, “By controlling luminance, color contrasts, and depth cues, the painter is
guiding the viewer’s gaze toward the depictions of Christ and the kneeling woman”
which they back up with gaze tracking data.
Using lightning to capture the viewer’s gaze (Baudisch et. al., 2003).

Another option for saving computer resources when dynamically altering content, in
accordance to where the viewer’s peripheral span3 is centred, is the Gaze-Contingent
Display (GCD). Baudisch et al. maintain that these maximises a systems resources by
using only a high resolution in one part of the screen where the rest can be displayed
at a much lower resolution, which dynamically changes as the viewer shifts his or her
gaze (Ibid: 62).
Last, but not least, they describe the possibilities of using real time 3D graphics to a
similar effect:
“One prominent example of an attentive 3D-rendering engine varies the Levelof Detail (LOD) at which an object is drawn based on the user’s gaze [6]. Thisway, unattended scene objects are modelled with fewer polygons, even whenthey are not distant in the scene.” (Ibid: 64).
This type of system dynamically adjusts the resolutions of the objects according to
where the user is looking. The advantage of using 3D graphics is not only a lower
demand on system requirements than real time images, but also that they can be
moved dynamically without having to make several takes of a scene, hereby reducing
production costs significantly.
Conscious and Unconscious Tracking
One thing is getting the viewer to pay attention to a certain object or character;
another is determining the intentionality of the viewer. The viewer could be actively
trying to make something happen by gazing intensely at a certain object, or she could
be watching the medium in a more passive manner, and the system itself determines
which action to take with the feedback it is receiving from the user.
Glenstrup and Engell-Nielsen use the notion of conscious and unconscious tracking of
viewers when watching an IES (1995: 66-67). Conscious tracking is when the user is
aware of the fact that her gaze is being tracked, and hence actively uses her eyes to
manipulate the IES. Unconscious tracking is when either the user forgets that she is
being tracked, or is unaware of the fact that gaze tracking is occurring. These two
types of tracking can be used on different levels depending on how the writer of the
interactive medium wants the interaction to take place, which we will elaborate on
below.
Combining Gaze Tracking and Narrative
Glenstrup and Engell-Nielsen also point out some of the difficulties in writing a script
for an interactive film where they address the issue of bottlenecks and the possibility
3 The central focus field of the human eye.

of backtracking (1995: 60). They conclude that it is up to the director of the film to
decide upon the narrative possibilities. This corresponds well to Samsel and
Wimberley’s ten different types of design structures that can be applied to interactive
media productions which are dependent on the nature of the interactive production
(1998: 21ff). Below we will take a closer look at the branching structure, the
Exploratorium and the parallel streaming structures4.
Branching
Samsel and Wimberley write, “in a typical branching structure, the user is presented
with several choices or options upon arriving at predesignated ‘forks in the road.’”
(1998: 26). Additionally they explain how a branching structure can be extended to
Branching with optional scenes (see below), where alternate scenes appear at certain
points in the story.
Traditional Branching Structure
The square represents the starting
point, and one circle represents one
branch on the “fork in the road”
(Samsel and Wimberley, 1998: 26).
Branching with Optional Scenes
Structure
The grey symbols represent the path
the viewer has chosen. The three
aligned circles in the middle are
scenes that “spin out from and
return to the main spine of the story”
(Ibid: 29).
We believe that the user’s gaze can determine where these forks in the road will lead.
However, we will stress that it is still up to the director to construct a storyline that
does not spin off in too many directions. This is known as bottlenecking, where the
4 However depending on the director of the production, any one of the models may be utilised
for creating an interactive production.

different branch options point back to the main spine of the story in order to keep the
narrative flow from spinning out of control (Ibid: 28).
Branching can be manipulated by either conscious or unconscious tracking. The
viewer could try to take the story in one direction by actively staring at an object; on
the other hand the system could just register the interest level of the user over a given
period of time as The Little Prince Storyteller demonstrated (see p. 11).
Exploratorium
Another structure of interest is what Samsel and Wimberley term the Exploratorium
where the user is free to explore objects on the screen in their own time. In other
words the main story line is on hold until the user has finished exploring the different
objects available. Samsel and Wimberley give an example from Mercer Mayer’s Just
Grandma and Me, where “there are numerous items that sing, dance, sputter and
animate within the scene. It’s up to the user to uncover them…, by interacting with the
environment.”
Exploratorium
The letters A-H are interactive
hot spots within the scene that
the user can choose to
manipulate (Samsel and
Wimberley, 1998: 32).
We think that the Exploratorium model is a good way to visualise the structure of a
scene where the user has to make conscious gaze decisions in a restricted
environment as in Starker and Bolt’s Little Prince Storyteller. Hereby the director gets
the option of presenting narrative elements that the viewer can explore, rather than
presenting them in the time flow of a traditional film scene with the inherent risk of
the viewer missing vital information.
The Exploratorium requires that conscious tracking takes place. Otherwise the viewer
will just be stuck in a Limbo where nothing occurs as she is not paying attention to the
objects or characters being presented.

Parallel Streaming
The final type of structure we will examine is the parallel streaming structure which
“…allows the writer to create a single linear story, while allowing the user to switch
between perspectives paths or states. The user can then experience the same series of
events from multiple points of view.” (Ibid: 32).
Parallel streaming structure
The letters A-H are interactive hot spots
within the scene that the user can
choose to manipulate (Samsel and
Wimberley, 1998: 33).
The switches between viewpoints can be achieved by measuring the viewer’s interest
level (Starker and Bolt 1990) as an indicator of where the camera should be placed.
This could also be extended to the dialogue, where the character receiving the highest
interest level is allowed to continue speaking. In a way this could be thought of as a
combination of the Exploratorium and the parallel streaming structure where objects
can be examined by the viewer not only from different angles, but also with different
levels of self-disclosing information depending on the time the viewer’s gaze is fixated
on the objects.
This structure can also combine both conscious and unconscious tracking. The viewer
can actively try to manipulate viewpoints, or just be unconsciously tracked. In both
cases the system could make the changes accordingly, depending on interest level.
Summary
In this chapter we have examined some of the technical issues with gaze trackers
today, and infer that in five to ten years a product could be available for purchase by
the average consumer. We have also looked at how audio has been in connection
with gaze tracking, as an indicator of what the viewer is listening to, and how pupil
dilations are affected by auditory stimuli. Additionally we explain the framework of
Interest and Emotion Sensitive Media, and the interactive control mechanism proposed
for these. This is supplemented by resent studies that show how the viewer’s gaze can
be directed to certain areas of images via highlighting, and how GCD’s and 3D
rendered objects can be useful in this field. Last but not least we have shown how
narrative structures of interactive movies can be used in combination with conscious
and unconscious gaze tracking.


Defining the GANS framework
In the following chapter we will set up a conceptual framework for GANS. We will be
using the previously describes theories and research results to specify what we
consider to be feasible narrative control functions in this new medium. Setting up a
conceptual framework that covers every nook and cranny of the interactive
possibilities in such environments is a huge task that cannot be solved on a theoretical
level only. Hence this chapter will describe a simple prototype we have built to test
some of these theories on actual users.
Just as the film medium used elements from theatre in its early years, this medium later
evolved its own set of visual and auditory semantics based in large upon both the
technical capabilities available to the directors5. We believe that GANS will at first
evolve using the semantics of traditional movies and computer games, but as time
passes proceed to evolve narrative principles unique to the medium itself.
Metaphorical Framework
Before we begin to describe how the GANS-system operates we will draw upon a
metaphor using a producer of modern day TV studio.
Imagine a live talk show, where the viewers are completely in charge of everything,
from the lighting on stage to the wardrobe of the host. The viewers decide by voting,
and the producer has to make the result of the votes shape the show. The voting
information from the viewers is channelled into the headset of the producer every
second of the show, and needs to be acted upon instantly. There is no time for
hesitation. However the show does have a prewritten script containing guests that
have to be introduced, certain bands that have to play, and performers that have to
perform during the show. If the viewers vote there is too much green light on the
stage, the producer calls to the gaffer and tells him to reduce the green. If the viewers
deem that the camera angle is wrong, he yells at the cameraman to move to another
angle. If the band gets the thumbs down by the crowd, he tells the host of the show to
cut them off, and makes the stage manager get the next band ready to play.
Instead of having a severely overstressed human being performing these production
tasks, we believe that a system, using simple scripts and some live action footage, can
create such an experience for a single viewer on a computer equipped with a gaze
tracker.
5 Sound, coloured film, computer graphics etc.

Hotel Movie – The Story So Far
We will illuminate the producer potential of GANS by using a small snippet we have
written for this purpose (see Appendix I) called Hotel Movie. This is closely based on a
scenario described in Hansen et al. 1995, however we have added a third character in
order to provide the scene with a little more mystery. It is set in a Film Noir setting, as
“The subject matter tends to be…contrasting black and white, - good and evil - with
little grey area.” (de Leeuw, 1997: 91). This setting gave us room to create a prototype
that could be open-ended, which turned out to be beneficial since we did not have
time to produce a complete film. In other words, we were able to create a simple plot
in this environment, which could be presented to the viewer with a simple “choice”
that would branch the main narrative in a bottleneck structure
For realizing the prototype, we needed
film material for a short movie, with a
storyline that provided for the parallel
streaming of the plot that we had
decided on. The story has three
characters, a shifty man, a man in a suit -
Tony, and a woman - Veronica. In short,
the film shows a shifty man with a
suitcase who peeks round a corner at
Tony and Veronica walking down the
street. They walk into a hotel, where the
shifty man is sitting in the lobby.
Veronica walks pass the front desk,
while the Tony walks up to the front
desk to get the keys for the hotel room.
The storyline then splits into two parallel
stories, one following Tony, and one
following Veronica (see illustration to the
right).
The Tony sequence sees him being handed the keys at the hotel reception, and then
he notices that the shifty man is following Veronica. He runs down the hallways of the
hotel, and misses the elevator just as the door slams shut in front of him. He then
proceeds up the stairs of the hotel, and enters a room, where the shifty man is lying
on the floor against the wall with the suitcase on the bed. Tony kneels and shakes the
shifty man, who slides over, dead.
The bottleneck structure of Hotel Movie. Tony’ssequence is the branch to the right, Veronica’sto the left.

Then Veronica enters the room, and she and Tony exchange blank stares at the end of
the sequence.
If you follow the woman, you watch the shifty man following her into the hallways of
the hotel to the elevator, and sliding into the elevator with the woman just before the
door slams shut. We watch them go up with the elevator, the woman clearly
uncomfortable with the shifty man standing behind her, clutching the briefcase in front
of him. The shifty man pushes her violently out of the elevator, and into a room. The
woman then enters the room, and the man in the suit and the woman exchanges
blank stares.
Basically, Hotel Movie has a sequence that is shared by both storylines, and then splits
into two separate stories to be connected in the end with a shared scene to tie the
narrative of the sequence together.
Of course, movies with parallel stories already exists, and we could have used parts of
one for the prototype, however we wanted to avoid showing the test persons elements
from a film where they might already know the plot, and where our manipulation of
the movie would potentially annoy, irritate or confuse them.
Essentially we got heaps of help from friends in completing the actual filming. We cast
ourselves as the shifty man and Tony, had a friend play Veronica, and one of our
fellow students acted as director for the shooting. This turned out to be a great
timesaver as he had done quite a bit of video work before we were able to get his
help in setting up shots that would not seem too amateurish or unbelievable.
Setting Up the GANS
The system for playing out the scene described above is shown below.
The Gaze Tracker
sends the viewer’s gaze
position and pupil
dilations to an
Interpreter Module,
which decodes the
coordinates the same
way a mouse position
would be detected.
This information is sent to the Producer Module, which can determine what to change
in the given scene according to the feedback received via the Interpreter. Using the
Diagram showing the overall structure of the GANS

television producer metaphor this is basically a diagram that shows how the viewer’s
votes are given to the director.
Choice of Middleware: Macromedia Director
For developing the prototype we faced the daunting task of having to code a set of
control functions, which could be used to realise the structure mentioned above. Since
none of us are programmers this could easily have pulled the plug on the technical
realisation of the project. However we are able to write simple scripts, and this is
where Macromedia Director came into the picture.
Among the strengths of Director is the ability to script the behaviour of the application
based on mouse movements6, which we found appealing since the eye tracker system
is built as an alternative to a mouse. Additionally Director is able to handle the
playback of video footage within this scripting environment. These two strengths
seemed to us, to be applicable in combining the movie clips into an actual bottleneck
branching structure (see p. 23) that could be controlled using the data collected by the
eye tracker equipment. For the prototype we use four mov-files (Quick Time Movie
Format) – one as an introduction, a second one for tracking and which of the last two
will be played is determined via the tracking mov-file.
Additionally Director has the ability to change the appearance of the mouse cursor,
which we could hide from the viewer when showing Hotel Movie. In other words, it
enabled us to present a system to the viewer that used unconscious tracking.
The Gaze Tracker
For the prototype we used the aforementioned gaze tracking equipment and software
developed by the GazeTalk7 project at the ITU (see p. 17). The gaze tracker can
determine where the user is looking by monitoring the position of the cursor on
screen - via X and Y coordinates.
The gaze tracker monitors the users eye movements, but since the mouse is hidden
the viewer is not necessarily conscious about being tracked. This is not on par with
how regular gaze trackers operate with fixations. Usually, fixations are counted as
confirming a selection on screen, e.g. selecting an option from a menu. The GANS is a
non-command interface just like the IES (Velichkovsky & Hansen 1996), it is there, and
6 The source codes for all scripts used in this chapter can be found in appendix II along with a
screen dump showing the actual structure of the application. Also we have included a cd-rom
with all mov-files and director files on it,7 http://www.itu.dk/research/EyeGazeInteraction/

yet again it is not there. It monitors the conscious and unconscious eye movements of
the viewer, which brings us to a problem concerning what movements to track. The
human eye has various ways of looking, as described by Bolt (1984), and the eye
tracker in the GANS should track them all.
The Interpreter Module
The function of the Interpreter Module is to
parse the data from the gaze tracker to the
Producer, which then determines what
consequences the data will have for the
GANS.
Before the Interpreter can send this data to
the Producer, however, we need to set up
specific guidelines for how the data is
collected. We wrote a script for Director
that would increment a variable each time
the eye dwelled on a certain area of the
screen (see Appendix II for the source
code of the scripts). These active areas
were made as non-visible rectangular
layers on top of the movie clip as shown to
the below.
Director determines the number of times
the mouse is within a rectangle for the 6.12
seconds that this film sequence – the
tracking_clip - plays. This number however
is dependent on the cpu-speed of the
computer the program is playing on.
Which means this number will vary
depending on what processor is used8.
We placed the tracking areas so they covered more than the actual film clip on the
screen9. This was because we had experienced that the tracker was slightly off
sometimes when we tried it out in May 2003.
8 We made sure that this number was more than one digit for our user tests.9 The prototype was played on a 1024x768 resolution monitor. The move took up an area of
720x324 pixels. The tracking areas took up 360x600 pixels each and were separated by an
Tracking areas used in Hotel Movie. Theseareas are not seen by the viewer when thesequence plays.

The tracking areas are purposely large because we were under the assumption that a
rough estimate would be enough to determine what the user was paying the most
attention to in the clip.
Determining Viewer Interest
In order to determine viewer interest the Interpreter Module needs to be able to
register a fixation. Our solution is slightly primitive as it only registers where the
mouse is at a given time during the tracking sequence. For instance the GAZE
Groupware system, a virtual meeting simulating a four-way round table, uses a fixation
time of 120 ms, which is equivalent to three camera frames (Vertegaal 1999). In case
of a GANS the Interpreter needs to determine which fixation can be considered the
most important fixation in order to avoid a situation where three or more objects get
selected at the same time.
We think that there may be two possible solutions to this problem in a GANS: a
counter dependent solution – which we have used for the prototype - and
accumulative counter set across scenes or sequences. Either solution should provide
what we shall term the dominant fixation - i.e. the fixation that is sent to the Producer
to be acted upon (see below) – but we believe that the accumulative counter set
across sequences will provide a richer interpretation of what the viewer is actually
interested in.
The counter based solution we have used, basically uses an algorithm which marks an
interactive element as spotted and sets a counter as proposed by Starker and Bolt
(1990). In our prototype we utilise counters by determining which interactive object
receives the highest number of fixations in a certain sequence. In Hotel Movie this is
determined during the tracking_clip above where Tony and Veronica walk side by
side. If the counter on the tracking area over Veronica gets the most increments after a
viewing the camera follows for the rest of the film – even though the viewer may be
watching Tony more during the introductory clip and the clip after the tracking_clip.
The total amount of each counter is displayed at the end of Hotel Movie in two alert
boxes10.
However we think that the Interpreter could compare the number of counts within
parts of the same sequence; what we call the accumulative counter measuring across
empty space of 4 pixels. Running it was not quite smooth as switching between the mov-files
would lag the playback of the films.10 Ideally these should be put into a log-file, which could also handle the exact time of each
fixation. Again our limited programming skills did not let us do this.
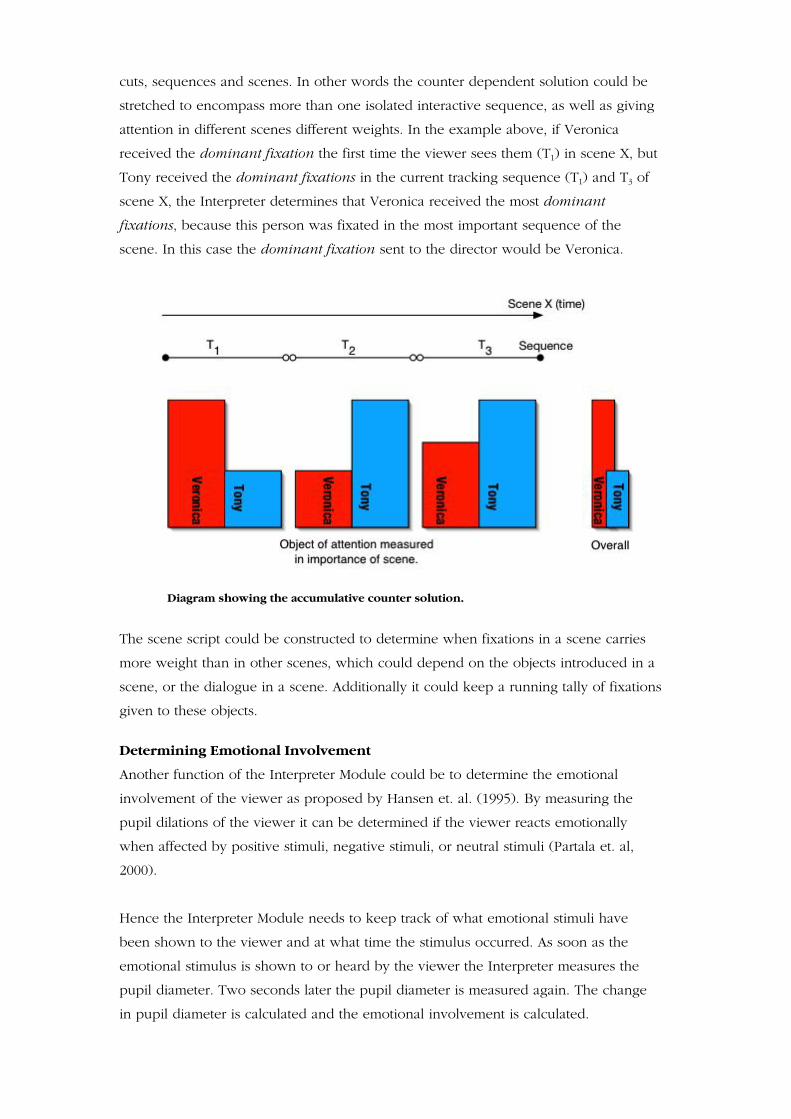
cuts, sequences and scenes. In other words the counter dependent solution could be
stretched to encompass more than one isolated interactive sequence, as well as giving
attention in different scenes different weights. In the example above, if Veronica
received the dominant fixation the first time the viewer sees them (T1) in scene X, but
Tony received the dominant fixations in the current tracking sequence (T1) and T3 of
scene X, the Interpreter determines that Veronica received the most dominant
fixations, because this person was fixated in the most important sequence of the
scene. In this case the dominant fixation sent to the director would be Veronica.
Diagram showing the accumulative counter solution.
The scene script could be constructed to determine when fixations in a scene carries
more weight than in other scenes, which could depend on the objects introduced in a
scene, or the dialogue in a scene. Additionally it could keep a running tally of fixations
given to these objects.
Determining Emotional Involvement
Another function of the Interpreter Module could be to determine the emotional
involvement of the viewer as proposed by Hansen et. al. (1995). By measuring the
pupil dilations of the viewer it can be determined if the viewer reacts emotionally
when affected by positive stimuli, negative stimuli, or neutral stimuli (Partala et. al,
2000).
Hence the Interpreter Module needs to keep track of what emotional stimuli have
been shown to the viewer and at what time the stimulus occurred. As soon as the
emotional stimulus is shown to or heard by the viewer the Interpreter measures the
pupil diameter. Two seconds later the pupil diameter is measured again. The change
in pupil diameter is calculated and the emotional involvement is calculated.

However the current version of the GazeTalk system does not incorporate a way of
measuring pupil dilations. Also since pupil dilations are affected by light changes, as
well as by emotional stimuli, the Interpreter would also have to take the light being
emitted by the display into consideration when determining the emotional
involvement of the viewer.
Producer Module
In the live television broadcast the producer shouts his decisions to the people
responsible for the different tasks as needed. The gaffer controls the lights, the camera
crew the visuals, and the sound crew the volume of the music being played.
In our GANS system the Producer Module could handle these tasks with the aid of sub
modules. This can be visualised like this:
Diagram showing the Producer Module and its sub modules.
When being passed information from the interpreter module, the Producer consults
the Scene Script sub-module to see if the viewer has been paying attention to the
objects needed to understand the scene, and the scene to follow. The Scene Script gets
this information from the Object Handler (see below). In our prototype there is only
one decision for these modules to make – the Tony clip or the Veronica clip – even if
for some reason the two areas should receive equal amounts of counts, the Producer
tells the Cue Handler to restart the film with a message that the tracking is off11.
However in a more finalised version of the system choices made by the Producer
about lighting, camera or sound changes could be sent to the Cue Handler who then
adjusts the respective aspects.
11 We consider this a clumsy solution that we were forced to make due to our limited
knowledge of algorithms. A more complete version of the system would need a better way of
handling such an event.

The Scene Script and Object Handler Team
The Scene Script is the narrative core of the GANS. This is where the Producer selects
what story elements should be played and in what order. It is similar to a stage
manager who makes sure the actors are ready to come on stage, or that the props for
the next sketch are ready. In our prototype there is only one scene, and all scripts are
tied to it via a Cast Library in Director. In developing a bigger system more
considerations will have to be taken, which we will show below.
Elements in of the Object Handler. Each object or actor is named here and has two Booleanelements N for Noticed and VO for object vital to the story. The stippled line indicates possibleactions for the Producer to take if the viewers has missed a VO.
The Scene Script could keep track of what interactive objects – which can be both
characters and physical objects - the viewer needs to have noticed in order for the
scene to progress. Some objects are vital for the narrative of the story and thus must
be detectable by the Scene Script. The Scene Script keeps track of what objects vital to
the story the viewer has noticed by checking if the object has had a dominant fixation
set on it. This check is made via the Object Handler. Basically this could be set up as
Boolean value on each interactive object; either the object has been noticed or it has
not. Additionally objects can be set with a Boolean value determining if they are vital
to the story or not.
On a final note the Scene Script could also handle which scene in the GANS is
playing, and have information about what objects vital to the story that must have been
noticed by the viewer in order for the scene to be played. Hence it is a form of safety
net that ensures that the narrative does not spin out of control, which we discussed in
the previous chapter. If certain objects vital to the story have not been noticed by the
viewer the Scene Script passes this information to the Producer who can then enforce
a Flashback scene or open an Exploratorium – which introduce the objects to the
viewer. For instance if Veronica received few counts in the tracking_clip the Object
Handler would send a message via the Scene Script to the Producer, who could then
tell the Cue Handler to play a clip with a close up of Veronica walking.

Summary
We have described our model for constructing a GANS using a live TV-show
metaphor, and have given examples of which elements we use in our prototype using
Macromedia Director. We have also discussed what elements and limitations we have
in the current prototype. Although the divisions of the prototype into modules and
sub-modules may seem a little overmuch for such a small work, we think that such a
model provides a better overview of how such a system could be thought of on a
larger scale.
Although the system looks operational on paper, there are quite a few uncertainties,
which we felt would be necessary to test on viewers. We will be looking at these
uncertainties in detail in the next chapter where we present our user tests.

User Tests
Before concluding whether or not our prototype was a successful execution of a
GANS using a non-intrusive interface, we found it prudent to test it on a group of
users, who could provide us with vital feedback for developing the system further.
Unanswered Questions
The purpose of testing the GANS framework was to shed some light on questions we
had pertaining to the consciousness of the viewer, the intrusive level of the interface
we had developed, and the possibility of using the eye as a control organ. We believe
the empirical data from such a test would give us a better idea of the actual system
requirements if the system were to be made by a development team.
We wanted to explore the following questions:
• If the test persons aren’t told that the film is interactive, do they notice it
anyway?
• If the test persons are told that they can control the movie, do they experience
this control?
• How do users experience using the eye as an input device in the GANS?
• How do users experience exploring a virtual environment with the eye as an
input device?
Test Design
Test Subjects
We tested the system on six male and five female subjects ages twenty-four to thirty
who were contacted either through friends or via email (see Appendix III). Our
selection criteria were:
- The subjects were not allowed to have prior knowledge of our project. I.e. no
close friends or relatives to whom we had inevitably spoken to about this.
- The subjects should not be completely dismissive of the Thriller genre, since there
would be no point in inviting subjects who would dismiss the content of the film
at once.
- The subjects should watch films alone sometimes, since we wanted to avoid using
subjects who would only consider using the film medium as a social medium, as
we think that multi-user trackers are quite far away from being developed.

- The subjects should not have a background in Film or Media Studies, or
production, since this could hamper their viewing of our “non-professional”
production12.
All the subjects were given two tasks: viewing our prototype and navigating a
QuickTimeVR photograph. Additionally we had them sign a Non-disclosure Agreement
(see Appendix IV), since some of the gaze tracking equipment being used was still in
development at the time we tested.
Groups and Calibration
We decided to split the test persons into two groups, one of three males and three
females, and one of three males and two females. The first group were told that we
were trying to track what people looked at, and paid attention to, when they were
watching thrillers. We did this with the intention of uncovering whether the interface
of the prototype was actually non-intrusive. Would the viewers find out, that they
unknowingly had decided to view another outcome of the movie, or would they even
notice a variation in the movie?
The second group was told that they could control the outcome of the movie
depending on where they looked during playback. We did this with the intention to
see, if the consciously tracked test persons would be overly conscious about what and
where they were looking at on screen, and if they would actively try to manipulate the
outcome of the movie.
Each subject was briefed separately – with the exception of FC1 and FC2 (see below).
Both subject groups were given a short introduction to the gaze tracking equipment,
and were either that we wanted to measure what they looked at, or that they could
control the movie13. Each user was then individually calibrated for the gaze tracker.
We wanted calibration scores of approximately five – preferably below – in order to
make sure that the calibration was precise enough to be measured by the tracking
areas in the prototype14.
12 It actually turned out that one of our subjects had a background in film, due to our troubles
finding testers. Fortunately she was very appreciative of the aesthetics and film technical
aspects of the production.13 The guides we used for the tests can be found in Appendix V.14 The GazeTalk system considers a score of 0-5 to be execellent. The final calibrations of nine
users were between 3.63 to 6.47, the average score being 4.65. Unfortunately we forgot to write
down the scores of two of the users, and the numbers are impossible to see on the tapes we
made of the sessions.

Viewing the GANS Prototype
We then asked the subjects to view the film, and told them they should feel free to
comment it, if they so desired. Most of the subjects, however, watched the prototype
quietly the first time. Presumably they were concentrating on the content.
Since the prototype is a fairly short affair – bordering on two minutes of footage in the
longest sequence – with only one branching point, showing it to each subject only
once wouldn’t be enough, as they wouldn’t be given the chance to see each of the
parallel stories. We decided to show the prototype three times to each test person, as
we believed this would tell us if there was any difference in the way people viewed
the same sequence several times in a row. Another reason for the three viewings was,
that we wanted to see if there were any difference between the way the consciously
tracked and the unconsciously tracked subjects watched the film several times.
At the end of the first viewing we wrote down the counter results from the tracking
areas. After the first viewing we asked the subjects about what they thought had
happened15. We would then ask the subject to view the clip again a second time, and
again ask them if they had noticed something different – even if they had seen the
same sequence. Then we would ask the subject to view it a third time, repeating the
questions above, but also asking if they felt that they could control the film if we had
told them so, or asking them why they thought they had seen different clips if they
were unaware that they could control the film. Due to the response of UM2, where he
said he thought we had made the program so that the first viewing was one movie
and the second another, we decided, on the spot, to make him view a final sequence.
This time we asked a question about the woman, just before the film cut to the
tracking_clip.
Our main stipulation about this setup is that it doesn’t provide a true impression of
how people might actually watch a GANS. It is probably not very natural to view a
two-minute sequence this many times in a row, unless we are talking about
advertisements that are seen many times over the course of a night, week or month.
Viewing the QTVR
The second and last part of the user test was the same for both groups. The test was
to navigate a QTVR we had chosen. The purpose of this test was to substantiate or
rebuke our hypothesis of the eye being an intuitive way of navigating and exploring a
15 We actually asked MU1, who he thought had comitted the murder, but realised that this was
too closed a question, since he seemed unsure that there had been a murder – i.e. the
suspicious man could have been knocked out, not neccessarily killed.

spatial setting. We also thought the QTVR could be a good low-cost way of setting up
an Exploratorium in a GANS.
We wanted a detailed QTVR so that the test persons would have plenty of things to
explore. We also wanted to get an idea of how much detail the test persons were able
to gather while controlling the field of vision with their eyes. We found a QTVR
showing The Oracle’s living room from The Matrix (Warner Brothers, 2003). This
QTVR is dense in details (among them a ‘ghost’ reflected on the TV screen in the
room), has lots of small items in the room and the resolution of the QTVR is very high,
which means that is possible to do extensive zooming without loosing too much
picture quality.
We decided to ask them to explore the room for as long as they liked, and they were
urged to comment on what they were looking at, or searching for, in the QTVR. First
they would use the gaze tracker where we would hold down the left mouse button for
them, and they could zoom in and out using the keyboard. After that they could try
the same procedure with the mouse. About half the subjects were allowed to explore
the room with the mouse first. We timed each exploration session with each input
device.
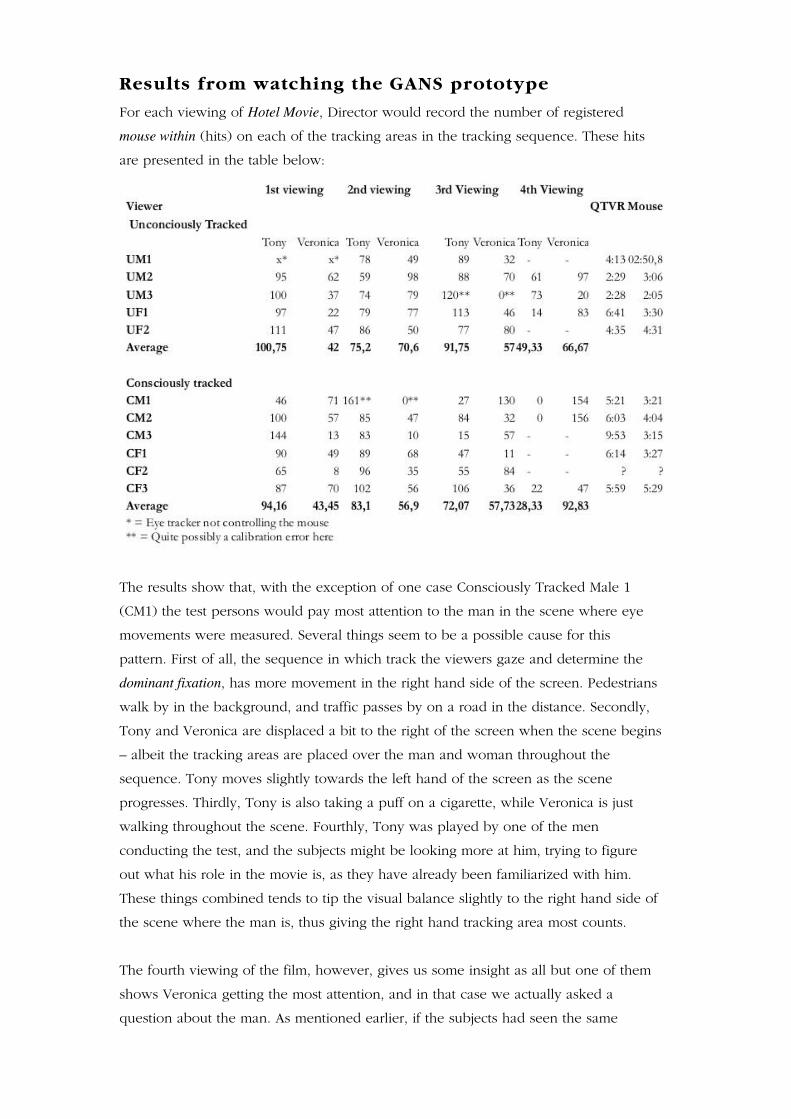
Results from watching the GANS prototype
For each viewing of Hotel Movie, Director would record the number of registered
mouse within (hits) on each of the tracking areas in the tracking sequence. These hits
are presented in the table below:
The results show that, with the exception of one case Consciously Tracked Male 1
(CM1) the test persons would pay most attention to the man in the scene where eye
movements were measured. Several things seem to be a possible cause for this
pattern. First of all, the sequence in which track the viewers gaze and determine the
dominant fixation, has more movement in the right hand side of the screen. Pedestrians
walk by in the background, and traffic passes by on a road in the distance. Secondly,
Tony and Veronica are displaced a bit to the right of the screen when the scene begins
– albeit the tracking areas are placed over the man and woman throughout the
sequence. Tony moves slightly towards the left hand of the screen as the scene
progresses. Thirdly, Tony is also taking a puff on a cigarette, while Veronica is just
walking throughout the scene. Fourthly, Tony was played by one of the men
conducting the test, and the subjects might be looking more at him, trying to figure
out what his role in the movie is, as they have already been familiarized with him.
These things combined tends to tip the visual balance slightly to the right hand side of
the scene where the man is, thus giving the right hand tracking area most counts.
The fourth viewing of the film, however, gives us some insight as all but one of them
shows Veronica getting the most attention, and in that case we actually asked a
question about the man. As mentioned earlier, if the subjects had seen the same

sequence all three times they viewed the film, we would ask them to watch the film a
fourth time. Immediately prior to the measuring scene, we would ask them if there
were anything in particular they had noticed about the woman. This effectively
resulted in the subjects giving the woman the most attention in the measuring scene,
causing Director to show the sequence they had not yet seen.
With the counts generated by Director being so varied, it is hard to use them as a
dependant variable precisely measuring the difference in the results between
consciously and unconsciously tracked subjects. However, if measured as relative
measurements, instead of absolute measurements, they tentatively hint at the focus on
the man weakening the more times the conscious subjects watch the sequence.
Through the qualitative interviews with the subjects we learned, that the consciously
tracked subjects claimed that they rarely noticed details of the story in the first
viewing, because they were all wrapped up in the ability to control the outcome of the
movie. However, when asked more in depth about details from the first viewing, they
were still able to recall details such as the shifty man, his bandaged hand, the lock on
the suitcase, and the facial expressions of the actors. The unconsciously tracked
subjects didn’t even consider that they were the ones controlling the movie. When
asked why he thought he was shown a different movie from the one he had just
viewed, one subject answered that he believed we, the test conductors, did this by
clicking the icon for the Director file twice instead of just once.
Of the consciously tracked subjects, only one suggested that we were measuring the
gaze in the actual measuring scene. The others thought we were measuring
throughout the movie, while two subjects thought we were measuring in the lobby
scene, where all three actors are in the same scene. In other words, none of them
could say for sure at which point they were being tracked, whether it was in a certain
scene, in several scenes, or throughout the movie. One of the consciously tracked
subjects expressed that he felt like being a passenger on a bus, i.e. he just got along
for the ride, but did not necessarily know where the bus was going. Another
consciously tracked user said she completely forgot that she could control the film,
and instead focused on what was happening.
Based on this, we can conclude, that the interface was indeed non-intrusive, and that
the interaction in the GANS prototype was in fact seamless, even though the prototype
was jumpy when switching between the different mov-files and the sound was
distorted in most of the viewings.

Results from the QTVR Exploratorium
Our reason for exploring a QTVR with the gaze tracker and the mouse was to
investigate how people experienced the difference of control with the two devices. We
expected the test subjects to be biased towards using the mouse, as this is an input
device they would probably all familiar with.
The task we gave the users was to explore the room for as long as they liked, and to
tell about what they saw, what they were looking for, and any details they cared to
mention. Our goal was to compare the time spent with the mouse and the time spent
with the gaze tracker. However during testing it became apparent that our test design
was not stringent enough for this type of comparison. First of all we had not given the
test subjects specific tasks. Secondly the fact that the gaze tracker lost calibration
during some of the tests made the time factor incomparable.
Initially most subjects found the combination of the gaze tracker and the QTVR to be
too hard to control, which is partly due to the control mechanism of the QTVR that –
for obvious reasons – has been optimised for using a mouse as the primary input
device. When moving the pointer in any direction, the movement accelerates as you
move further away from the point of departure. As the eye tends to move in saccades
(rapid and short movements), the QTVR interprets these as rapid movements with the
mouse, resulting in a see-saw effect making it virtually impossible to maintain a steady
view. This made for a very rough and jittery experience, bordering the uncontrollable.
The subjects described this experience as “being drunk” and “dizzy”, and one subject
had to stop the test because of feeling nauseous from the constant movements in
different directions16.
Another reason for the QTVR/gaze tracker combination being hard to control was, that
the subjects had a tendency to move their head when exploring the QTVR. This
caused the calibration to go awry quite fast, and quite often with some of the subjects.
As one subject noted, it is more natural to move the head to change the field of view,
and then use the eyes to explore the field for details and information. With the gaze
tracker and the QTVR the eyes were used for both, which made it quite difficult which
reflect Zhai’s findings about using the eye as the sole control organ (see p. 13). Thus
much of the time spent looking at the QTVR with the gaze tracker were due to
recalibrating and repositioning the subjects properly in front of the eye tracker
equipment.
16 She had, however, been using the gaze tracker for almost twelve minutes. We did not time
this though, because we were asking specific questions about the people whom the
appartment belonged to, which we did not ask any of the other subjects.

Although the majority of the test subjects found it hard to control, and demanding a lot
of concentration, they also found it “fun”, “natural”, and “exciting”. A few of them
found it to be more natural than using the mouse, and they would definitely choose
the gaze tracker over the mouse, if calibration weren’t lost so fast. Several found it to
be easier to control and navigate after 3-4 minutes with the gaze tracker.
One subject found that controlling the QTVR with the mouse was counter intuitive
compared to controlling it with the gaze tracker. He wanted the behaviour of the y-
axis to be reversed, so that pulling the mouse towards you resulted in the field of view
moving up instead of down.
Apart from the general experience of the gaze tracker being a bit too eager to spin out
of control, the subjects were all able to give very detailed descriptions of the room and
very vivid suggestions as to who might occupy such a space. They felt emerged in the
room, and wanted to go explore more, especially the darkened areas leading of to
other rooms, the titles of books and records, and the framed images residing on the
table in the room. To us this indicates that being able to explore a virtual space in a
GANS is a viable option, but the environment needs to be more finely tuned to the
way the gaze tracker operates.
Every subject found the mouse controlled test to be easy to navigate, calm and steady,
but maybe a little ordinary. One subject said she would choose according to the task
she had to accomplish, indicating that the goal of this test was probably too open or
too imprecise for some of the subjects.
Summary
The user tests were made to examine whether it was possible to tell a difference
between the way the conscious and the unconsciously tracked subjects watched the
film, whether the interface for the film was non-intrusive, and how test subjects
experienced navigating a spatial setting with the eye. Even though the quantitative
results are shaky, the qualitative data shows, that the conscious subjects viewed the
movie thinking about what might trigger the showing of a different sequence.
The test with the QTVR showed, that even though the subjects found navigating the
room with the gaze tracker fascinating, the problem of the system being too
responsive, an unstable calibration, and the loading of the eye with a motoring task in
addition to a viewing task made it difficult to for them to explore the QTVR with the
same ease and calmness as using the mouse.

Neither the conscious nor the unconscious subjects were forced to stop up at any
point in the narrative of the story because of interface issues. However the subjects
who were conscious of the ability to control the narrative expressed that they
constantly looked for some sort of recognition of what they were controlling. In other
words, they were looking for feedback from the system. The issue then becomes how
can non-intrusive feedback be applied to a GANS? We will explore some of the
possibilities in the following chapter.

Interact ive Cues in GANS
In the following chapter we will shift the focus back to the GANS framework. Our user
tests have provided valuable feedback, but due to the technical limitations of the
prototype we still feel that there are aspects of the system, which need to be
elaborated on, in order to show the full potential of the system. We have already
shown how by asking a question about the woman, we could make the user pay
attention to her. In this chapter we will look at potential uses of the Cue Handler in
getting the viewer’s attention.
As mentioned earlier the Cue Handler functions as gaffer, cameraman and sound crew
all wrapped up into one neat package. We will try to expand upon what types of cues
the Producer could call for depending on the narrative needs of the GANS according
to the viewer feedback received from the Interpreter.
Cue Handler is where the Producer Module chooses what the visual, auditory and
action based cues should be introduced in a scene. Additionally it should serve as a
helper in directing the viewer’s gaze towards the interactive elements in a scene. We
will present several visual and auditory cues of the cues we imagine would be
beneficial to a GANS director, either as direct feedback to the user, as one of our
testers requested, or on a more subliminal level. These correspond to Glenstrup and
Engell-Nielsen’s aforementioned conscious and unconscious tracking (see p. 22).
Although we have constructed our prototype using filmed footage, we believe that
future GANS could benefit from being constructed using 3D-modelling tools, since
these potentially require fewer man-hours than an entire film crew doing several shots
of one sequence17. Using 3D also opens up for using lighting in completely different
ways than live-action, since the same model of a room can have many different moods
created by lighting, which is much cheaper to program than to have a gaffer change
on a studio set. Last but not least, during our user tests we experienced that the
computer would need quite a few resources for both playing live action video and
doing calculations on the side. This of course, could be prescribed to our lack of
optimisation of the system, but as stated by Baudisch et al. (see p. 21) a 3D engine
will save system resources. Hence the cues we envision could be implemented in live
action sequences in post production, but we focus on their application in 3D-
environments.
17 We must add that Triple A games today rival the largest Holywood pictures in production
cost.

Visual Cues
The four visual cues we present are presented first by a brief description of the visual
effect, by what research in the field of gaze tracking justifies the use of the cue, the
use of similar cues in computer games or motion pictures, how the cue could be
implemented in the system and how the ties in with conscious or unconscious
tracking.
Halo
As the name suggests, the halo – or inner glow - is a faint aura of light either being
emitted by an object or character, or a faint glow above or below the object. It is a
similar effect to Velichkovsky and Hansen’s black line highlighting (see p. 19), but
could be less discreet than their example. The halo has been used in computer games
in various ways to indicate selections or objects that can be manipulated. The halo has
been used in computer games in various ways to indicate selections or objects that can
be manipulated for instance pressing the Alt key in Bioware’s Neverwinter Nights from
2002, shows a halo on objects in the vicinity of the central character, which can be
manipulated.
The halo can be used in a conscious tracking situation as a discreet means of telling
the viewer that their attempt at manipulating the GANS has succeeded. This could be
done by changing the emissive lighting of interactive object in 3D, or adding an
invisible object around the object with a transparency that glows when the dominant
fixation has been registered. However the intensity of the halo will probably have to
be very subtle if the interface is to remain non-intrusive.
With unconscious tracking it might be counterproductive to use halos in this way.
Unless the system is trying to “teach” the user that this is indeed an option in a GANS.
On the other hand the halo could also be used to get the viewer’s attention fixed on
an object vital to the story.
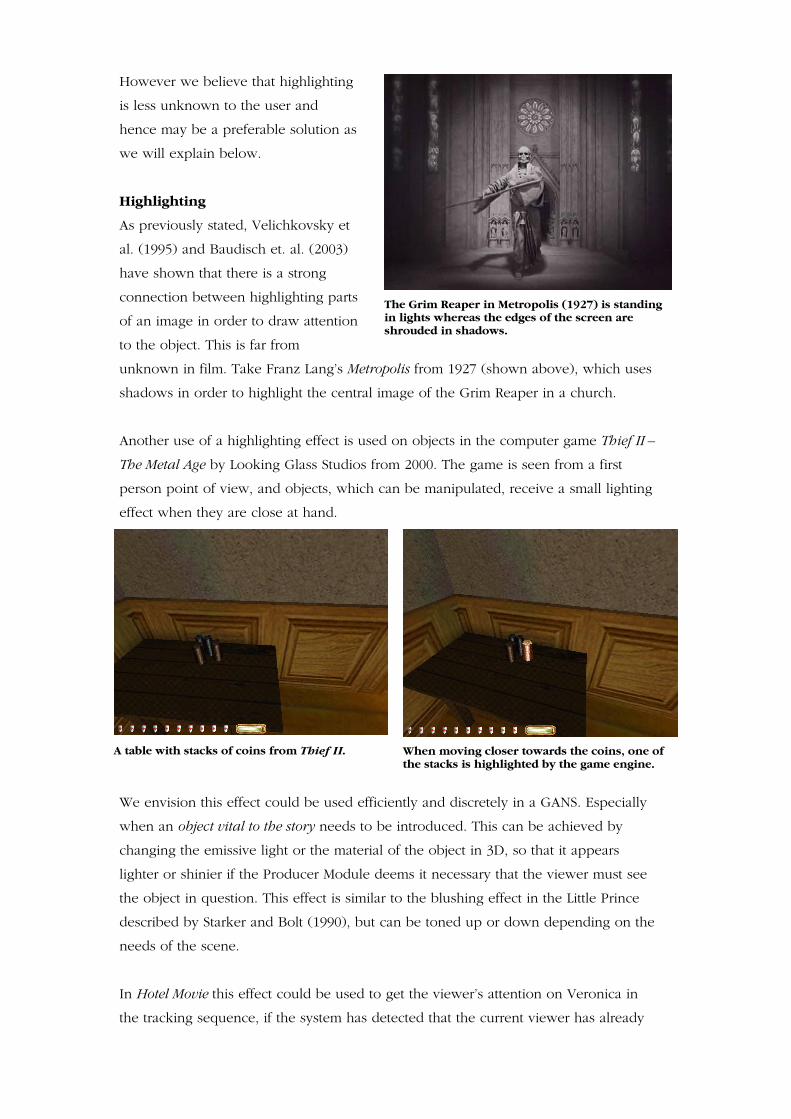
However we believe that highlighting
is less unknown to the user and
hence may be a preferable solution as
we will explain below.
Highlighting
As previously stated, Velichkovsky et
al. (1995) and Baudisch et. al. (2003)
have shown that there is a strong
connection between highlighting parts
of an image in order to draw attention
to the object. This is far from
unknown in film. Take Franz Lang’s Metropolis from 1927 (shown above), which uses
shadows in order to highlight the central image of the Grim Reaper in a church.
Another use of a highlighting effect is used on objects in the computer game Thief II –
The Metal Age by Looking Glass Studios from 2000. The game is seen from a first
person point of view, and objects, which can be manipulated, receive a small lighting
effect when they are close at hand.
A table with stacks of coins from Thief II. When moving closer towards the coins, one ofthe stacks is highlighted by the game engine.
We envision this effect could be used efficiently and discretely in a GANS. Especially
when an object vital to the story needs to be introduced. This can be achieved by
changing the emissive light or the material of the object in 3D, so that it appears
lighter or shinier if the Producer Module deems it necessary that the viewer must see
the object in question. This effect is similar to the blushing effect in the Little Prince
described by Starker and Bolt (1990), but can be toned up or down depending on the
needs of the scene.
In Hotel Movie this effect could be used to get the viewer’s attention on Veronica in
the tracking sequence, if the system has detected that the current viewer has already
The Grim Reaper in Metropolis (1927) is standingin lights whereas the edges of the screen areshrouded in shadows.

seen the movie once. This time the Producer wants attention on Veronica, so placing a
spotlight on her could be used to generate attention rather than us indirectly telling
the viewer to pay attention to her. Also using a spot would still be within the genre
conventions of the Film Noir. The spotlight could also be used as a means of showing
a conscious viewer that their attempts at controlling the GANS have succeeded.
Highlighting could also be effective in a scene utilising the Exploratorium structure, to
show which object or character being selected. If more tracking options had been
enabled, we could have detected if the user had noticed the briefcase in the
introductory sequence. The system could later set up an Exploratorium on a police
desktop where photographs of the briefcase and the suspects are in plain view.
Onscreen Eye and Head Movements
We have been focusing on the eyes of the viewer throughout this paper. However it
would be prudent also to focus on the eyes of the actors in the GANS. If we consider
that the eye is an excellent pointing device, as pointed out by Bolt (1984), then why
not use this pointing device to show the viewer that an object or another character can
be fixated on.
This concept is used extensively in the game Grim Fandango by LucasArts from 1998.
The player controls the main character – Manuel Calavera - via a third person view,
however there is no visible GUI in the game which helps you see what objects can be
picked up, or whom you can talk to (see below). Instead the head of Manuel moves
to face the object of interest, and the player must push a key on the keyboard to
activate the interaction.
A. Manuel is seen walkingin the left side of thescreen. Notice that his headis facing the direction he’swalking.
B. As he passes by thewall decoration on theleft, his head begins toturn towards it.

C. He continues to look atthe object as he walks by it.
D. His head returns to thedefault position when theobject is out of his field ofinterest.
The GANS could make good use of this effect, by registering the viewer’s fixations
when one or more of the characters look at an object. It would be quite simple to tilt
the heads of a 3D actor in order to focus on the brief case on the bed in the final
scene. If the system registers a dominant fixation the camera could be moved towards
the object creating a zooming effect, and then be placed at a new viewpoint facing
whoever is talking at that given moment18.
Again this can be done on either a conscious or unconscious tracking level. On the
conscious level, the viewer can benefit from this effect as it indicates a type of
feedback from the system. On the unconscious level the Producer could force the
camera zoom if the user is not focusing on the briefcase and hence bring the briefcase
into a position where it is difficult to ignore by the viewer.
Blurring or fading
The last visual cue we will be describing is the blurring or fading effect. This is a
similar effect to what Velichkovsky and Hansen’s (1996) resolution effect (see p. 21).
This also goes hand in hand with the GCD described by Baudisch et. al. (2003). In
addition to the possibility of saving system resources this can be used as an attention
grabbing effect.
A demonstration of how this effect can be constructed is exemplified below in a
presentation by Brian Taylor (2003), an animator currently working on his
independent 3D computer animated film, Rustboy.
18 Hereby we are not claiming that camera control should be given to the viewer, as the QTVR
data showed us earlier.

A. The foreground image in the shot whichwill be in focus.
B. The background image before it isblurred.
C. The background image is blurred. D. The image from frame A is in focus, and thebackground is in faded by the blurring.
Both our tests and the findings of Yarbus (1968) show that the viewer will look at the
image searching for what reveals vital information. In the shot above the “vital
information” is put in the front of the image – the gauge – and the detail level is also
higher, since it is in focus.
A similar effect could be achieved by the Producer Module in a GANS by
programming a switch in that contains different textures for a 3D object, one where
the object is blurred and one where it is in focus19. The Cue Handler could then set a
blur texture on an object or character that did not received the dominant fixation in a
sequence, thus putting the object(s) which did in a more central viewing position.
This effect could also be used to phase out objects that are not vital to the story if a
conscious viewer is attempting to activate them, indicating that the objects are not vital
to the story and should be ignored. However this seems to be drastic, and in the end
may be too intrusive, countering our vision of the non-intrusive interface.
Auditory Cues
Instead of using visual cues the Producer Module could opt to use auditory cues in
order to attract the viewer’s attention or to give system feedback. This corresponds 19 A series of transitional texture states would also be needed if the change from focus to blur is
to be smooth.

well to the findings of Bolt (1984) and Vertegaal (1999) (see p. 18) and again with us
asking the test subjects a direct question about a character.
Off Screen Sounds
Off screen sounds are normally used to establish a connection with something
happening off screen, or to emphasize the mood of a scene. Carol Reed has used it in
the film-noir classic “The Third Man” from 1949, where Harry Lime (Orson Welles)
escapes from his pursuer in the sewers of Vienna. The camera focuses on the pursuer
throughout the scene, while the footsteps of Harry Lime can be heard off screen
running away to underline his successful getaway.
Robert Bresson uses off screen sounds of leaves being raked and keys scraping against
metal railings to “[...] heighten the sense that a time of crisis has arrived for the central
characters” (Pavelin, 2003).
In the GANS, off screen sounds could be used in the classic way, to set the mood of a
scene. To emphasize the gloomy situation and the dilapidated neighbourhood the
warehouse is situated in, faint sounds of police sirens could be played in the
background, and maybe the sound of dogs barking outside the warehouse every now
and then.
In our scene we could implement a sound node containing a police siren at the end of
the scene. This sound node could be pulled towards the room – with a tracking area
to the right of the screen – and the volume increased accordingly creating a Doppler
effect. If the users gaze attempts to ‘follow’ the sirens the system could register a
dominant fixation on the sound. This could be a hint to the Scene Script that Tony is
about to break, as he also glances nervously towards the sirens, grabs the briefcase
and runs. If the Sirens are ignored the story could branch in a way where Tony and
Veronica coolly and calmly take the briefcase and leave the building.
When and if, these sounds should be invoked could be possibly controlled by the
Producer based on the emotional involvement of the viewer because, as stated by
Partala et al. (2000), auditory stimuli have a noticeable effect on the emotional
involvement of viewers. Yet we think this type of tracking is commercially further off,
than position tracking.
Object Sound or Dialogue
By object sound we mean the way an object can have an auditory ‘aura’; a theme or
sound that is connected to the objects presence, form or history, and is played, either
explicit or as a variant over the current theme, to accentuate its presence in the scene.

In Thief II the when picking up the stack of coins from the example above the game
will play a small light pitched ringing sound, indicating that an object of monetary
value has been picked up.
In the GANS, the object sound could be used as a way to discreetly verify that a user
has seen an object vital to the story, tell what kind of object it is, or by implying
interactive possibilities with an object. The briefcase in our script could have a small
rustling sound placed on it, in case of a dominant fixation.
Focusing on an actor can be achieved in a much more subtle way. In the tracking
sequence of Hotel Movie Veronica could start talking if the Producer knew that this
was the second time the viewer was watching the movie, and had been paying more
attention to Tony the first time. In this way the GANS can become a self-revealing
system similar to The Little Price Storyteller, but still remain non-intrusive to the
narrative.
Changing the Soundtrack
Changing the sound level of the soundtrack is a classical means of intensifying a scene
in a film, to intensify the emotional effect of the scene, best illustrated by the shower
scene in Hitchcock's ‘Psycho’ from 1960.
Bolt (1984: pp. 62ff) changes the level of the soundtrack to complete the cocktail
mélange imagery of the ‘World of Windows’. All windows have a soundtrack that is
played at equal level, until the user fixates on a window for several seconds. The
systems then zooms the window being fixated, and plays only the soundtrack related
to that window. Vertegaal (1999) uses a similar approach to communicate user
attention in GAZE2.
In ‘Star Wars - Episode I’ where the characteristic theme of Darth Vader is played
discreetly on top of the current theme, when Yoda speaks of Anakin towards the end
of the film. The intertextuality combined with the theme playing in the background,
means that the clue about Darth Vader’s origin can’t possibly be eluded.
In the GANS we believe changes in the soundtrack tune and level can help create the
proper mood or communicate the interactivity, as in the examples listed, in case the
viewer (measured by pupil dilation with the limitations listed above) doesn’t respond
emotionally as intended to a scene. This could be done by programming a switch that
uses a script to pick out which background music should be played depending on the
data received the viewer.

Summary
Although we have presented several options of how GANS can make use of visual and
auditory cues, we by no means hold that this is an extensive list. We have explained
how visual cues such as halos, highlighting, head movements and blurring can be
used on a visual level both to give system non-intrusive feedback and to focus the
viewer’s attention to a certain object or character. The same goes for auditory cues –
off screen sound, object sound, dialogue and soundtrack changes.
Combinations of the different types of cues are also a possibility, which we have not
explored above. Imagine two couples having a conversation at two separate tables in
a restaurant. The couple that get the least attention are blurred out and their
conversation fades out of the soundscape. The camera zooms in on the other couple
and increases the volume of their conversation at the same time. The viewer is not
emotionally interested though, so the Producer calls for a change to a more tragic
piece of music hoping for a response in him.

Conclusions and Future Perspectives
We have found that a GANS prototype can be constructed in a fairly short time period,
using a gaze tracker, two infrared lights, and Macromedia Director as middleware. The
tracking does not have to be very precise in order for the system to be able to discern
where the viewer’s attention is on the screen, as we have demonstrated in our user
tests.
Users respond positively to a non-intrusive interface where the actual interaction with
the system is hidden from them. Viewers can be tracked consciously or unconsciously
about the gaze by GANS. This will have an impact on the system measuring a
dominant fixation in a given sequence or scene. Basically this may allow for two
types of interactivity – an active interactivity and a laid-back interactivity. The viewer
can try to actively manipulate the different elements of the GANS or she can slouch in
her armchair and be surprised at what the system decides to throw at her. It appears
to us that the laid-back interactivity may put less stress on the viewer since when users
are conscious of the system they may expect a little feedback in order for them to
relax when first viewing a GANS..
In getting the viewer’s attention we have provided a set of cues, which may be used in
further development of such systems. However these cues are dependent on the use
of metaphors and elements of existing media types, and will probably have to evolve
as the medium evolves. Additionally being able to measure the position and pupil
dilations of the viewer are vital in order to fully realise all the cues we propose. These
are prerequisites that might not be completely obtainable in the resolution of the
display or in the preciseness of the gaze tracking hardware and software available
today, or in the case of pupil dilations – the near future.
The question that still needs answering here is how many constraints do these cues
put on the creator of this new type of interactive media? We have given examples of
how the GANS system can attempt to attract user attention or to give feedback on user
actions, in ways that probably do not interfere in subtle ways with the cornerstone of
the narrative. Yet it is also possible that even more precision of the gaze trackers and a
constant improvement in rendering power the temptation to add even more bells and
whistles to the GANS productions may interfere with the narrative flow in the long
run.
This paper raises a plethora of issues related to the ideas and suggestions we present
concerning the future of interactive media combined with gaze tracking. Most of the

ideas we put forth stems from elaborating on what means conventional media use
today to heighten user interaction or attention, and how these can be used together
with gaze tracking to create a new type of media with possibilities of more enhanced
viewer interaction and submersion in the suspension of disbelief.
To be able to say more about this, we need to implement feedback possibilities and
more branching options in a new prototype, and test these ideas on actual users,
because only by doing so will put us in a position to tell whether conventional
methods apply to this media. We also have a need to explore the options of writing
what Starker and Bolt call the “transitional text, to “bridge” across interruptions and
returns to any subject” (1990:8). Even though it may be possible to write a manuscript
that can handle a branching structure in mid-conversation how does one overcome
interruptions by other characters, since when talking naturally the speaker will pause
briefly when someone attempts to interrupt them. Is it possible to maintain the
suspension of disbelief then?
Also since the eye may not be ideal as a singular input device we need to look into
how natural speaking or even mouse or remote control actions may be paired with
gaze tracking in the creation of multi-modal narrative systems.

Li terature
Baudisch, P., DeCarlo, D., Duchowski, A. T. & Geisler, W. S. 2003. ‘Focusing on the
Essential: Considering Attention in Display Design’. Communications of the ACM
[Electronic], vol. 46, no. 3, pp. 60-66. ACM Press. Available:
http://doi.acm.org/10.1145/636772.636799
Bolt, R. A. 1984. The Human Interface – Where People and Computers Meet. Lifetime
Learning Publications, Belmont, California.
Hansen, J. P., Hansen, D. W. & Johansen, A. S. 2001. ’Bringing Gaze-based Interaction
Back to Basics’, in Universal Access In HCI, Stephanidis, C: (Editor). Lawrence
Erlbaum Associates. Pp. 325-328.
Hansen, J. P., Andersen, A. W. & Roed, P. (1995). ‘Eye-Gaze Control of Multimedia
Systems’, in Advances in Human Factors/Ergonomics: Symbiosis of Human and
Artifact, Y. Anzai, K. Ogawa and H. Mori (Editors), Elsevier Science B.V., 1995,
pp. 37-42.
Hochberg, J. & Brooks, Virginia. 1978. ‘Film Cutting and Visual Momentum’, in Eye
movements and the higher psychological functions, Senders, J. W, Fisher, D. F. &
Monty, R. A. (Editors). Lawrence Erlbaum Associates, Hillsdale, New Jersey.
1978, pp. 293-313.
Horvitz, E., Kadie, C., Paek, T. & Hovel, D. 2003. ‘Models of Attention in Computing
and Communication: From Principles to Applications’. Communications of the
ACM [Electronic], vol. 46, no.4, pp. 52-59. ACM Press. Available:
http://doi.acm.org/10.1145/636772.636798
Glenstrup, J. A. & Engell-Nielsen, Theo. 1995. Eye Controlled Media: Present and
Future State. Thesis for partial fulfilment of the requirements for a Bachelor’s
Degree in Information Psychology at the Laboratory of Psychology, University of
Copenhagen.
Jacob, R. J. K. 1991. ’The Use of Eye Movements in Human-Computer Interaction
Techniques: What You Look At is What You Get’. ACM Transactions on
Information Systems, vol. 9, No 3, pp. 152-169.
Leeuw, B. D. 1997. ‘Digital Cinematography’. AP Professional.
Maglio, P. P. & Campbell, C. S. 2003. ‘Attentive Agents’. Communications of the ACM
[Electronic], vol. 46, no. 3, pp. 47-51. ACM Press. Available:
http://doi.acm.org/10.1145/636772.636797
Murray, J. 1997. ‘Hamlet on the Holodeck’. The MIT Press, Cambridge, Massachusetts,
USA.
oncotype – noodlefilm [Online]. Available: http://www.oncotype.dk/noodlefilm.phtml
[2003, May 11]

Ohno, T., Mukava, N. & Yoshikava, A. 2002. FreeGaze: A Gaze Tracking System for
Everyday Gaze Interaction. Proceedings of the symposium on ETRA 2002
[Electronic]. Pp. 125- 132. ACM Press, New Orleans, Louisiana. Available:
http://doi.acm.org/10.1145/507072.507098 [2003, May 26].
Partala, T., Jokiniemi, M. & Surakka, V. 2000. ’Pupillary Responses To Emotionally
Provocative Stimuli’. Proceedings of the symposium on Eye tracking research &
applications 2000 [Electronic], pp. 123-129. ACM Press, Palm Beach Gardens,
Florida, United States. Available: http://doi.acm.org/10.1145/355017.355042
Pavelin, Alan. Robert Bresson [Online]. Available:
http://www.sensesofcinema.com/contents/directors/02/bresson.html [2003, May
29]
Samsel, J. & Wimberley D. 1998. Writing for Interactive Media – The Complete Guide.
Allwoth Press, New York.
Shell, J.S., Selker, T. & Vertegaal, R. 2003. ’Interacting with Groups of Computers’.
Communications of the ACM [Electronic], vol. 46, pp. 40-46. ACM Press,
Available: http://doi.acm.org/10.1145/636772.636796 [2003, May. 1].
Starker, I., & Bolt, R. A. 1990. ‘A gaze-responsive self-disclosing display’. Proceedings
of the SIGCHI conference on Human factors in computing systems [Electronic],
pp. 3-10. ACM Press, Seattle, Washington, United States. Available:
http://doi.acm.org/10.1145/97243.97245
Taylor, B. Rustboy [Online]. Available http://www.rustboy.com/rustweb.htm [2003, May
27]
trackIR: products [Online]. Available:
http://games.naturalpoint.com/products/overview.html [2003, May 29].
Velichkovsky, B. M. & Hansen, J. P. 1996. ‘New technological windows into mind:
there is more in eyes and brains for human-computer interaction’. Proceedings of
the SIGCHI conference on Human factors in computing systems [Electronic], pp.
496—503. ACM Press, Vancouver, British Columbia, Canada.
Available: http://doi.acm.org/10.1145/238386.238619
Vertegaal, R. 1999. ’The GAZE Groupware System: Mediating Joint Attention in
Multiparty Comunication and Collaboration’. Proceedings of ACM CHI’99
Conference on Human Factors in Computing Systems. ACM, Pittsburgh, PA USA.
Vertegaal, R., Weevers, I., Sohn, C., Cheung C. 2003. ‘New directions in video
conferencing: GAZE-2: conveying eye contact in group video conferencing using
eye-controlled camera direction’. Proceedings of the conference on Human
factors in computing systems [Electronic], pp. 521 – 528.�ACM, Ft. Lauderdale,
Florida, USA.
Available:
http://portal.acm.org/ft_gateway.cfm?id=642702&type=pdf&coll=portal&dl=ACM&
CFID=15100947&CFTOKEN=35207257

Vraast-Thomsen, N. 2003. ‘dr.dk/kultur-Switching - den interaktive film.’ [Online],
Available:
http://dr.dk/kultur/indexfilm.asp?ArticleID=18122&ArticleTypeID=4&SubjectID=9
7&action=artikel [2003, May 11.]
Viglid, Thomas. ‘Styr computeren med et smil’ – in Danish. [Online], Available:
http://politiken.dk/VisArtikel.iasp?PageID=298349&TemplateID=5567 [2003,
December 12.]
Warner Brothers, 2003. [Online]. Available:
http://pdl.warnerbros.com/thematrix/us/med/vr_oracle_04.mov
Yarbus, A. L. (Haigh, B.) 1967. Eye Movements and Vision. Plenum Press, New York.
Zhai, S. 2003. ‘What’s in the Eyes for Attentative Input’. Communications of the ACM
[Electronic], vol. 46, no. 3, pp. 34-39. ACM Press. Available:
http://doi.acm.org/10.1145/636772.636795
Games
Bioware, 2002. Neverwinter Nights. Atari.
Looking Glass Stuidos, 2000. Thief II – the Metal Age. Eidos.
LucasArts, 1998. Grim Fandango. LucasArts.
Rockstar Games. Grand Theft Auto – Vice City. 2002

Appendix I Hotel Movie Extra
Storyboard
Before the actual shooting we drew up the ”storyboard” below and made a text
description of what was to be in each shot.


List of Shots
Shot 1: The street
A man and a woman walks down the street. The man is carrying a briefcase. What
they will be wearing hasn’t been decided just yet, but a suggestion is that they are
both well dressed, the man in a suit, and the woman in a dress.
The man and woman are a couple, but not close.
The shot should be made so that the man is taking one side of the shot, and the
woman the other side of the shot.
The purpose of the shot is to give the viewer the opportunity of visually getting an
impression of who the persons are from their facial expressions, the way they walk,
and the way they dress.

Shot 2+3: The Man and The Woman
The purpose of these shots is to show the face of the man and the woman one by one
in close-up. Again we want the viewer to get the possibility of creating their own
impression of the two people, solely by the way they look and their characteristics.
Shot 4: The street, again
Once again, a picture of the man and the woman walking down the street, and still to
give the viewer the possibility of getting an impression of the two persons.
Shot 5: The hotel entrance from the outside
Still-shot of the hotel entrance, we want to tell the viewer they are heading towards a
hotel.
Shot 6: Man and Woman walks into the hotel (branching)
Sequence where the man and the woman walk into the hotel. This is a branching
point in the story. Depending on who the viewer has looked at the most in the
previous part of the film, the man or the woman will be followed.
If the viewer has looked mostly on the man, the following will happen:
Shot 7: The Man, The Lobby, The Shifty Man
The Hotel lobby, the man walks in heading towards the reception. A Shifty Man is
sitting on a couch. He is shifty because he has his hand wrapped with band aid, and
has an unhealthy cough. In the background the woman can be seen walking towards
the elevator, she enters it, and just as the door closes the Shifty Man rushes towards
the elevator and enters it just as the doors are closing.
Shot 8: Leaving the reception
The man leaves the reception
Shot 9: Man up the stairs
Shot where the man climbs stairs in the hotel.
If you followed the woman, the following will be shown:
Shot 7: The Woman, the elevator, lobby, Shifty Man
You follow the lady into the hotel lobby, maybe getting a glimpse of the man
collecting the key at the reception.

She walks over to the elevator and pushes the button for it. As the elevator arrives she
enters it, and just as the doors close, the Shifty Man from the lobby enters the elevator.
Shot 8: Shifty Man, The Woman, elevator
Shot from inside the elevator, where the woman is standing in front of the Shifty Man,
they are both facing the camera. You can see a red blotch on the Shifty Man’s
stomach, he has blood on his fingers.
Shot 9: Leaving the elevator
The elevator stops, and they leave it going in opposite directions. down the corridor.
The two branches meets up again.
Shot 10: Man and Woman meet in corridor
The Man and the woman meet each other in a corridor on the hotel.
Shot 11: Hotel room with corpse
Shot from of hotel room where the Shifty Man is lying on the floor with a suitcase by
his side. The room bears witness of a fight, the Shifty man has blood on his clothes.
Appendix II – Direc tor Documentation
Overview
All the scripts presented below are commented at the beginning in order to show what
the purpose of the script is and how it operates. They are written in Lingo, the native
scripting language of Director, which shares a syntax similar to that of Java or C++.
The scripts are presented in alphabetical order, however the screen dump below
shows where each script is actually located in the Time Line of Director. The Time
Line is based on classic animation techniques using key frames and tweens. The
structure of the scripts in relation to the time line can be seen in the screen dump
above20.
20 ButtonTony and ButtonVeronica are the tracking areas used in the tracking_clip. The
GoToWoman script is residue from an earlier test version. It is not used in the prototype.

Lingo Scripts
EndSequenceHandler
-- This script is placed at the end of both at
-- the end of the Tony clip and the end of the
-- Veronica Clip. It makes sure that Director
-- waits until the clip has finished playing
-- before going to the "End" section.
on exitFrame
go to the Frame
if (sprite(1).movierate = 0) then
go to "End"
end if
end
FixationResults
-- The script takes the values from the tracking sequence
-- and outputs them as alerts in the "End" section.
-- The $id_Alpha and {charset9981: are just bogus texts
-- so that we acutally hide exactly what the numbers mean
-- from the user, but we can write them down ourselves.
global TonyCounter
global VeroniCounter
on exitFrame me
alert "$id_Alpha:"&&TonyCounter&&""
alert "{charset9981:"&&VeroniCounter&&"}"
end
HideCursor
-- Hides the mouse cursor before the film is played, so the
-- viewer is not distracted by it. I.e. it is non-intrusive.
on exitFrame me
cursor 200
end
ShowCursor
-- Unhides the cursor in the "End" section, so that we can click the
-- alert boxes away. And click on the "Play it again, Sam" button
-- to replay the film for the viewer.
on exitFrame me

cursor -1
end
Hold frame
-- Standard Director handler which makes sure
-- that the program stops moving forward in the score
-- until another event is triggered
on exitFrame me
go to the frame
end
PretrackHandler
-- Similar to the EndSequenceHandler, but makes sure
-- director doesn't play the Tracking clip until the
-- intro_clip quick time has finished playing
on exitFrame
go to the Frame
if (sprite(1).movierate = 0) then
go to "Tracking"
end if
end
TonyCounter
-- TONY TRACKING
-- This script is placed on the "TonyButton" and is what
-- checks if the mouse is over Tony i.e. the viewer is
-- looking in this region of the film.
--
-- It defines "TonyCounter" as a variable, which can be
-- displayed in the "End" section. It is set to 0 to begin with
-- so that it resets if the film is seen more than once.
--
-- It also sets a property, "Position" which is then set to
-- "in" if the cursor goes from outside the "TonyButton" and
-- "out" if it moves outside the button.
global TonyCounter
property Position
on beginSprite me
TonyCounter = 0
end
on mouseEnter
Position = #in
end
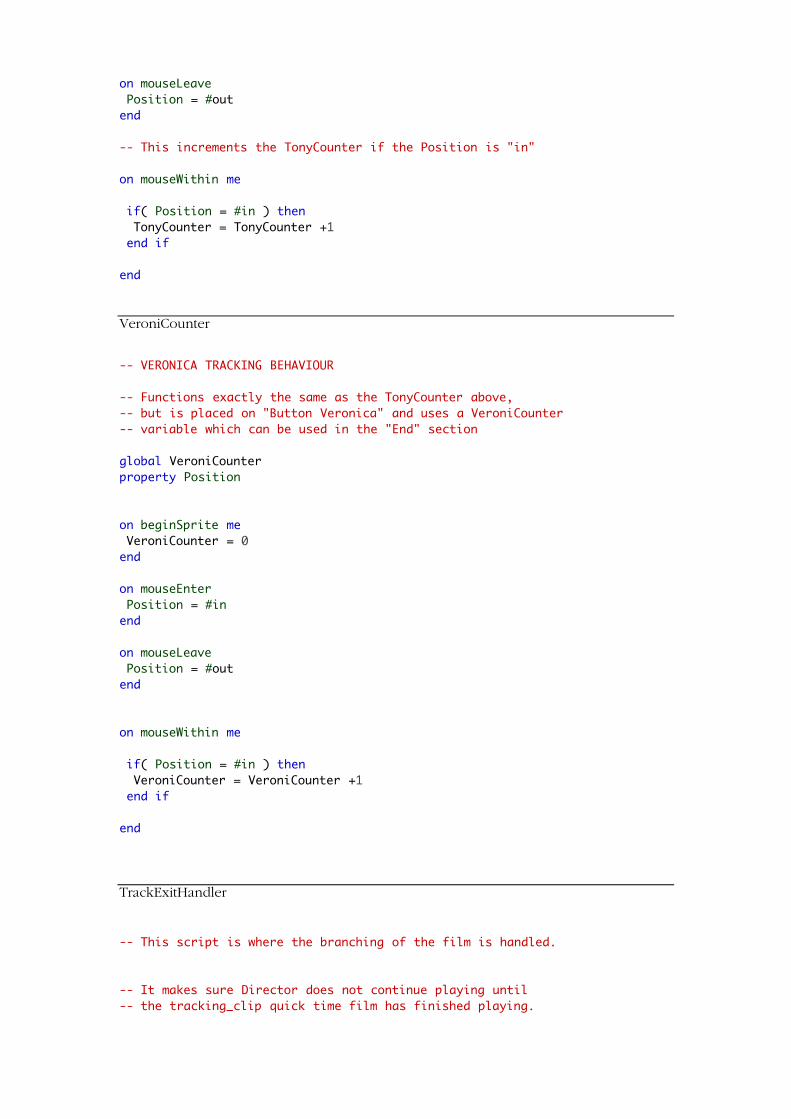
on mouseLeave
Position = #out
end
-- This increments the TonyCounter if the Position is "in"
on mouseWithin me
if( Position = #in ) then
TonyCounter = TonyCounter +1
end if
end
VeroniCounter
-- VERONICA TRACKING BEHAVIOUR
-- Functions exactly the same as the TonyCounter above,
-- but is placed on "Button Veronica" and uses a VeroniCounter
-- variable which can be used in the "End" section
global VeroniCounter
property Position
on beginSprite me
VeroniCounter = 0
end
on mouseEnter
Position = #in
end
on mouseLeave
Position = #out
end
on mouseWithin me
if( Position = #in ) then
VeroniCounter = VeroniCounter +1
end if
end
TrackExitHandler
-- This script is where the branching of the film is handled.
-- It makes sure Director does not continue playing until
-- the tracking_clip quick time film has finished playing.

-- Then it checks to see which Counter has the biggest value
-- and goes to the appropriate branch of the film.
-- If the values are equal we echo an error message, and
-- restart the entire film. This however should really be
-- handled more elegantly, by picking a random branch to
-- go to. But our programming skills failed us here.
global TonyCounter
global VeroniCounter
on exitFrame
go to the Frame
if (sprite(1).movierate = 0) then
if (VeroniCounter > TonyCounter) then
go to "Woman"
else if (VeroniCounter < TonyCounter) then
go to "Man"
else
alert "Miscalibration, please watch the sequence again."
go to "Intro"
end if
end if
end

Appendix II I Emai ls to Testers
Initial Contact Email
From:[email protected]
Date: 09. december 2003 15:42:58 MET
Subject: Testpersoner ønskes / Test persons wanted
Hej alle (English version below)
Vi er to DKM'ere der er i gang med et projekt hvor vi vil måle hvad folk kigger på når de ser en krimifilm.
Derfor har vi brug for seks mænd og seks kvinder på torsdag og fredag i denne uge til nogle tests. Vi regner med det
vil tage ca. tredive minutter - som sandsynligvis bliver videofilmet.
Hvis du har tid, så send en mail hurtigst muligt til: [email protected]
Mvh,
Tore Vesterby og Jonas C. Voss
----------------------------------------------------------------------
Hi all,
We are two DKM-students who are doing a project trying to determine what people look at when watching a thriller.
Hence we need six men and six women this coming Thursday and Friday for conducting a series of tests on our
prototype. We assume that a session will take roughly thirty minutes of your time - which will probably be taped on
video.
If you have time to spare, please send a mail as quickly as possible to: [email protected]
Best regards,
Tore Vesterby and Jonas C. Voss

Follow Up Email
Date: 09. december 2003 18:19:44 MET
From: [email protected]
Subject: Re: Testpersoner ønskes / Test persons wanted
Hi Xxxxxx
We have a few questions to ask you, before we ask you to participate in the tests.
* What is your gender, male or female?
* Do you watch movies alone at home, from time to time?
* What do you think of thrillers movies? Do you like them?
* Have you heard anything about this specific project, prior to what we have
told you in this and the previous mail sent out where we asked for test
persons?
We are looking forward to hearing from you.
Kind Regards,
Tore & Jonas

Appendix IV Non-disc losure Agreement
Non Disclosure Agreement

Appendix V Interview Guides
Guide for the unconsciously tracked group
1. Introduction
a. We are testing what people notice when they watch thrillers.
b. How?
i. Two Infared lights, and a camera. The lights are not harmful
to you in any way.
c. First we calibrate the camera
d. Then you watch the film clip. You’re welcome to comment the film
as you watch it.
2. Calibration
a. Help with the calibration
b. Create a new user profile.
i. Calibrate the system
ii. Must be 5 or lower
c. “Please try to sit as still as possible from now on.”
d. “Try not to turn your head.”
3. First viewing
a. The film may flicker at certain times – technology issue.
a. Start the player.
b. Wait...
ii. “What do you think happened?”21
iii. “Why do you think he/she did it?”
! Check the calibration by making them look at the text on screen.
4. Second viewing
a. Interesting, however we’d like to measure where you look again.
b. The user watches the prototype again.
c. If they’ve seen the same sequence again, we ask them:
i. “Do you still think the same thing happened?”
ii. “Why?”
d. If they saw a different sequence, we ask them:
21 With the first test person, we asked “Who do you think committed the murder?”, but we
found the question to be too closed and guiding. We changed the question to the above for the
remaining tests.

i. “Did you experience any changes in the film?”
ii. “What had changed?”
! Check the calibration by making them look at the text on screen.
5. Third and final viewing
a. “Ok. One last time.”
b. The user watches the prototype for the last time.
c. If they’ve seen the same sequence as the first and second viewing, we
ask them:
i. “Do you still think the same thing happened?”
ii. “Why?”
d. If they saw a different sequence from first and second viewing, we ask
them:
i. “Did you experience any changes in the film?”
ii. “What had changed?”
! Turn off the eye tracker
Guide for the consciously tracked group
1. Introduction
a. We are testing what people notice when they watch thrillers.
b. The interesting thing here is, that the viewer can decide how the
movie can evolve. In other words, what you look at in the movie
influences how it develops.
c. How?
i. Two Infrared lights, and a camera. The lights are not harmful
to you in any way.
d. First we calibrate the camera
e. Then you watch the film clip. You’re welcome to comment the film
as you watch it.
2. Calibration
e. Help with the calibration
f. Create a new user profile.
i. Calibrate the system
ii. Must be 5 or lower
g. “Please try to sit as still as possible from now on.”
i. “Try not to turn your head.”
3. First viewing
a. “The film may flicker at certain times – technological issue.”

b. Start the player.
c. Wait...
i. “What do you think happened?”
ii. “Why do you think so?”
! Check the calibration by making them look at the text on screen.
4. Second viewing
a. Interesting, however we’d like to measure where you look again.
b. The user watches the prototype again.
c. We ask them:
i. Do you still believe the same person did it?
ii. Why?
! Check the calibration by making them look at the text on screen.
5. Third and final viewing
a. “Ok. One last time.”
b. The user watches the prototype for the last time.
c. “Did you experience having control of the film?”
i. “How did you experience having control of the film”
d. “What did you think of the clip?”
! Turn off the eye tracker
Guide for the QTVR
1. QTVR
a. We’d like for you to do one more thing for us, ok?
b. Open the QTVR
c. Have you tried using a 360º photograph before?
i. No? Let me explain.
1. It’s like standing in the middle of a room.
2. Move the cursor to look around
3. Shift zooms in. Ctrl zoom out.
ii. Yes? Ok.
! Get a stopwatch ready.
2. Navigation
a. Explore the room for as long as you like using the mouse.
i. Feel free to comment on what you’re thinking.
ii. Start stopwatch – stop when they are through
b. Now let me turn this on (turn on the eye tracker)
! Check the calibration

i. Look around again, while holding down the mouse button, but
don’t move the mouse.
Start stopwatch – stop when they’re done
c. What did you find interesting?
i. How did you find looking around the room?
1. With the eye tracker?
2. With the mouse?
ii. Which did you prefer?
1. Why?

Appendix VI – The Learning Process
After a short and bitter discussion last semester with the examination office about the
time of day, we are pleased to have been able to fulfil the goals we had set ourselves
for this sixteen week project.
We have set out what we said we would accomplish in the project agreement. We
have constructed a working prototype based on prior research in the field, and added
a couple of new ideas to it. We have also successfully tested the prototype on real
people, however the actual testing was done quite late in December. This is a pity,
since we are under the impression that more quotes from the users and a proper
transcription of the interviews could probably have made our empirical chapter come
more alive. As it stands now it appears only a brief summary of seven hours of tests.
We could also have used more man power in the programming and coding
department, especially since we were forced to drop our initial idea of building a
prototype in a 3D environment, which could exemplify changes of camera angles and
lights.
Additionally we would have liked to construct several examples of dialogue and
dialogue trees, which could have give us the opportunity to visualise what potential
problems and challenges we are facing in that department. Although we fear how the
filming would have evolved had we all had to remember our lines.
Nevertheless it has been an immensely enjoyable challenge getting all the bits and
pieces to fit together in a field that is not only new to us, but apparently to a great part
of the research community.
Recommended
















