
This article was downloaded by: [North Dakota State University]On: 21 October 2014, At: 16:35Publisher: RoutledgeInforma Ltd Registered in England and Wales Registered Number: 1072954 Registeredoffice: Mortimer House, 37-41 Mortimer Street, London W1T 3JH, UK
The Interpreter and Translator TrainerPublication details, including instructions for authors andsubscription information:http://www.tandfonline.com/loi/ritt20
The design and evaluation of aStatistical Machine Translation syllabusfor translation studentsStephen Dohertya & Dorothy Kennya
a Centre for Next Generation Localisation & Centre for Translationand Textual Studies, School of Applied Language and InterculturalStudies, Dublin City University, Dublin, IrelandPublished online: 27 Aug 2014.
To cite this article: Stephen Doherty & Dorothy Kenny (2014) The design and evaluation of aStatistical Machine Translation syllabus for translation students, The Interpreter and TranslatorTrainer, 8:2, 295-315, DOI: 10.1080/1750399X.2014.937571
To link to this article: http://dx.doi.org/10.1080/1750399X.2014.937571
PLEASE SCROLL DOWN FOR ARTICLE
Taylor & Francis makes every effort to ensure the accuracy of all the information (the“Content”) contained in the publications on our platform. However, Taylor & Francis,our agents, and our licensors make no representations or warranties whatsoever as tothe accuracy, completeness, or suitability for any purpose of the Content. Any opinionsand views expressed in this publication are the opinions and views of the authors,and are not the views of or endorsed by Taylor & Francis. The accuracy of the Contentshould not be relied upon and should be independently verified with primary sourcesof information. Taylor and Francis shall not be liable for any losses, actions, claims,proceedings, demands, costs, expenses, damages, and other liabilities whatsoever orhowsoever caused arising directly or indirectly in connection with, in relation to or arisingout of the use of the Content.
This article may be used for research, teaching, and private study purposes. Anysubstantial or systematic reproduction, redistribution, reselling, loan, sub-licensing,systematic supply, or distribution in any form to anyone is expressly forbidden. Terms &Conditions of access and use can be found at http://www.tandfonline.com/page/terms-and-conditions

The design and evaluation of a Statistical Machine Translationsyllabus for translation students
Stephen Doherty* and Dorothy Kenny
Centre for Next Generation Localisation & Centre for Translation and Textual Studies, School ofApplied Language and Intercultural Studies, Dublin City University, Dublin, Ireland
(Received 11 September 2013; accepted 10 April 2014)
Despite the acknowledged importance of translation technology in translation studiesprogrammes and the current ascendancy of Statistical Machine Translation (SMT),there has been little reflection to date on how SMT can or should be integrated into thetranslation studies curriculum. In a companion paper we set out a rationale forincluding a holistic SMT syllabus in the translation curriculum. In this paper, weshow how the priorities and aspirations articulated in that source can be operationalisedin the translation technology classroom and lab. We draw on our experience ofdesigning and evaluating an SMT syllabus for a cohort of postgraduate studenttranslators at Dublin City University in 2012. In particular, we report on data derivedfrom a mixed-methods approach that aims to capture the students’ view of the syllabusand their self-assessment of their own learning. Using the construct of self-efficacy, weshow significant increases in students’ knowledge of and confidence in using machinetranslation in general and SMT in particular, after completion of teaching units in SMT.We report on additional insights gleaned from student assignments, and conclude withideas for future refinements of the syllabus.
Keywords: Statistical Machine Translation; syllabus design; Cloud-based SMT; machinetranslation evaluation; self-efficacy
1. Introduction
Different commentators have vastly different views on the role of translators in StatisticalMachine Translation (SMT). These range from the irenic (see Way and Hearne 2011;Karamanis, Luz, and Doherty 2011) to the antagonistic (see Wiggins 2011), althoughO’Hagan (2012, 525) has also identified a fair measure of ‘mutual indifference’ betweentranslation studies in general and more technologically oriented fields. But where transla-tion scholars and teachers do engage with SMT they can disagree on how much transla-tors need to know about the technology: enough to use Google Translate? Enough to fixthe output of SMT systems? Or enough to build their own SMT systems? What’s more,depending on the future one predicts for the translation profession, different types ofcontent would seem appropriate in the translation curriculum; in the somewhat determi-nistic picture presented by Anthony Pym (2012) and Ignacio Garcia (2011), translators aredue to morph into post-editors, whose job it will be to fix the output of machinetranslation (MT) systems. In this scenario, it seems clear that what translators need toknow is how to intervene after run-time in SMT workflows. Other commentators avoidacts of prophecy; Michael Cronin claims that ‘it would be foolish in the extreme to try to
*Corresponding author. Email: [email protected]
The Interpreter and Translator Trainer, 2014Vol. 8, No. 2, 295–315, http://dx.doi.org/10.1080/1750399X.2014.937571
© 2014 Taylor & Francis
Dow
nloa
ded
by [
Nor
th D
akot
a St
ate
Uni
vers
ity]
at 1
6:35
21
Oct
ober
201
4

predict what might or might not be the ultimate success of automated systems in dealingwith problems or questions of translatability’ (Cronin 2013, 2), a view that suggests thereare no long-term certainties that can underwrite translation studies curricula in general ortranslation technology syllabi in particular. This lack of certainty is all too familiar toproponents of ‘expansive learning’; writing about studies of learning conducted in work-place settings, Engeström and Sannino (2010, 3) argue that
traditional modes of learning deal with tasks in which the contents to be learned are wellknown ahead of time by those who design, manage and implement various programs oflearning. When whole collective activity systems, such as work processes and organizations,need to redefine themselves, traditional modes of learning are not enough. Nobody knowsexactly what needs to be learned. The design of the new activity and the acquisition of theknowledge and skills it requires are increasingly intertwined. (Our emphasis)
Despite the undoubted wisdom of Cronin’s and Engeström and Sannino’s positions, thoseof us who teach translation technology are faced now with questions about what, and howmuch, we should include in teaching modules dealing with SMT. While the activities inwhich we are interested may fall into the category of work processes that are currentlyredefining themselves (and so ‘nobody knows exactly what needs to be learned’), giventhe ‘traditional’ academic context in which we work, we still need to prepare syllabi as ifthe contents were well known in advance. In other words, we are faced with issues ofselection that are not unlike those faced by syllabus designers in other fields.
David Nunan, in his classic on the subject, sums up the problem of syllabus design inapplied linguistics as follows:
If we had consensus on just what it was that we were supposed to teach in order for learnersto develop proficiency in a second or foreign language; if we knew a great deal more than wedo about language learning; if it were possible to teach the totality of a given language, and ifwe had complete descriptions of the target language, problems associated with selecting andsequencing content and learning experiences would be relatively straight-forward. As ithappens, there is not a great deal of agreement within the teaching profession on the natureof language and language learning. As a consequence, we must make judgements in selectingsyllabus components from all the options which are available to us . . . these judgements arenot value-free, but reflect our beliefs about the nature of language and learning. (1988, 10)
Among other things, syllabus design involves selection of content (we leave aside hereissues of methodology) based on necessarily partial knowledge of – in some cases –rapidly changing fields, practicalities such as the availability of resources, and our ownvalues and beliefs about the fields in which we work. This is why it is important to scopethe field (as best one can) prior to syllabus design, to ascertain what will be practicable ina given situation (for example, from a technical point of view) and to identify, in a self-reflexive move, one’s own values and beliefs as they pertain to the field in question. Wehave attempted to do all three in a companion paper to this one (Kenny and Doherty, thisvolume). In that source, we explain the rudiments of Statistical Machine Translation; howSMT systems are created and evaluated and the extent to which they are used inprofessional practice; where humans (and especially translators) fit into SMT workflows;how translator trainers can overcome conceptual, ethical and technical challenges indesigning SMT syllabi; and, most importantly, what we believe about the role of transla-tors in SMT. In a nutshell, we believe that an SMT syllabus should be devised in such away as to be holistic and empowering for translators. This means that translators shouldnot be excluded a priori from any step in SMT workflows to which they could
296 S. Doherty and D. Kenny
Dow
nloa
ded
by [
Nor
th D
akot
a St
ate
Uni
vers
ity]
at 1
6:35
21
Oct
ober
201
4

conceivably contribute and add value. It means that translators should be able to claim ifnot ‘ownership’ then at least ‘co-ownership’ of the translation process (cf. Wiggins 2011,quoted in Kenny and Doherty, this issue). Rather than being instrumentalised, we want tosee translators recognised for ‘playing their part from within, in translation’s transforma-tion of itself’, to paraphrase Tim Ingold (2011, 6, quoted in Cronin 2013, 51).
In the current paper we show how the priorities and aspirations articulated in Kennyand Doherty (this issue) can be operationalised in the translation technology classroomand lab. We set out an outline syllabus in SMT for translators and describe how thissyllabus was implemented and evaluated among a cohort of postgraduate students intranslation studies and translation technology at Dublin City University (DCU), Ireland, in2012. In evaluating the syllabus, we draw on the psychological construct of self-efficacy,as measured using a quantitative psychometric questionnaire, as well as qualitativecomments made by students. We conclude by reflecting on what we as syllabus designersand lecturers learned from the process and how we anticipate the teaching of SMT, andclosely related technologies, developing.
In the following, we assume that the reader is familiar with the basic principles onwhich SMT is based, how SMT systems are normally implemented and evaluated, andwhat is involved in Cloud-based SMT. Readers who need guidance on these points arereferred, in the first instance, to Kenny and Doherty (this issue). In keeping with commonpractice, we distinguish in the following between a more narrowly defined SMT syllabusand a more broadly defined translation studies curriculum (see, for example, Kelly2005, 158).
2. A Statistical Machine Translation syllabus for students of translation
2.1 Needs analysis
A needs analysis is generally regarded as a necessary first step in syllabus design (Nunan1988; Kelly 2005, 43). Robinson (1991) identifies two broad types of needs analysis: thefirst is learner-based in that learners are asked directly about their needs, using ques-tionnaires, interviews or other instruments. The second gleans information not fromlearners but from an analysis of the target situation, the syllabus designers selectingcontent on the basis of their own observations of the field of interest, or from existingcase studies, published data, and so on. In cases where learners have little prior under-standing of a given area, or of their own potential for action in that area, a learner-basedneeds analysis can be of limited value. For this reason we conducted an informal target-situation analysis based on both published and unpublished accounts of trends in thetranslation market (see Kenny and Doherty [this issue] for a review of such sources); ourknowledge of the technology at hand and the technical possibilities that were beginning toopen up in early 2012 (due to the advent of customisable, Cloud-based SMT services);and our appraisal of students’ profiles and especially their existing technical skills. Wewere also guided, of course, by the value judgements that we inevitably made about ourarea (see above), in particular those regarding the role of human translators in SMTworkflows.
Our needs analysis indicated that we should create a syllabus that would be tailored tomeet the needs of postgraduate translation students – who are not majoring in computerscience and who may not have a high standard of IT and/or programming skills. It wouldcontain both theoretical and practical components, on the basis that if students did notgrasp the concepts behind the probabilistic processing that underpins SMT, they would
The Interpreter and Translator Trainer 297
Dow
nloa
ded
by [
Nor
th D
akot
a St
ate
Uni
vers
ity]
at 1
6:35
21
Oct
ober
201
4

not be able to intervene appropriately at different points in the SMT workflow or tointerpret automatic evaluations of SMT output in particular (see Kenny and Doherty, thisissue). The theoretical content would underpin the practical components in which studentswould learn, inter alia, how to gather appropriate data; how to train an SMT system; howto improve system performance; and how to evaluate MT output, and in particular SMToutput.
Given known shortcomings of SMT systems, contemporary research in the area ofteninvolves integrating the strengths of SMT with those of the other main paradigm inmachine translation research: Rule-Based Machine Translation, or RBMT. There arealso obvious synergies between SMT and translation memory technology: not only doesthe widespread use of translation memory tools result in the production of parallel corporathat are used to train SMT systems, but such translation memory tools provide convenientenvironments in which SMT output can be edited (or ‘post-edited’) by translators. Thedependencies between SMT and RBMT on the one hand, and between SMT and transla-tion memory on the other, mean that SMT cannot be considered in isolation from thesetwo technologies, and a course on SMT must also refer to RBMT and translation memory.In our particular case we set about integrating an enhanced SMT syllabus into a broadertranslation technology module in which translation memory and RBMT were alreadycovered. In what follows we outline the syllabus for the entire translation technologymodule but place particular emphasis and provide greater detail on the SMT components;from the above discussion it should be clear that, in a stand-alone SMT module, syllabusdesigners would still have to integrate content related to translation memory and RBMT.We focus here also on syllabus content rather than individual teaching and learningactivities (in particular lab activities), a detailed discussion of which goes beyond thescope of the current paper.1 As is always the case in curricular/syllabus design, however,context is key, and in the following we start by outlining the broad context within whichwe designed our SMT syllabus.
2.2 Context
The SMT syllabus outlined in this paper is delivered as one-half of the module ‘translationtechnology’, which is a compulsory module on the MA in Translation Studies and theMSc in Translation Technology at DCU. In 2012, the year in which the study reported onbelow was conducted, 38 students were enrolled on the module, 32 from the MA and 6from the MSc programme.2 The students typically range in age from around 23 to 60,with an average age of around 26. Around two-thirds of the students on these programmesare typically Irish (with mother tongue English or, to a far lesser extent, Irish); the otherthird mostly stem from other, non-English speaking countries in the European Union, orfrom further afield, including North America and Asia. The vast majority of students havean undergraduate degree in languages, or in languages in combination with anothersubject (business, law, etc.). Very few students have an undergraduate qualificationspecifically in translation studies. Technical competence at intake is mostly restricted toan ability to use typical office applications. Almost none of our students have priorcomputer programming experience, and only two or three each year (the translationgraduates) have been exposed to translation technologies (other than technologies thatfeature extremely simple interfaces, such as Google Translate).
As its name suggests, the translation technology module is designed to introducestudents to specialist technologies used in the translation industry, giving students hands-
298 S. Doherty and D. Kenny
Dow
nloa
ded
by [
Nor
th D
akot
a St
ate
Uni
vers
ity]
at 1
6:35
21
Oct
ober
201
4

on experience of these technologies, and encouraging critical reflection on their value.The specific learning outcomes for the module are expressed as follows:
On completion of this module students will be able to
● Demonstrate an understanding of the principles of translation memory technology.● Use at least one commercial translation memory tool.● Demonstrate an understanding of the principles of contemporary machine transla-
tion, including rule-based MT and statistical MT.● Manage full translation workflows involving translation memory and machine
translation tools.● Critically evaluate contemporary translation technologies and texts produced using
these technologies.
The module is delivered over 18 hours of lectures and 18 hours of labs per student.Resources available are good: practical classes take place in dedicated computer labs3
with specialised software (including translation memory, terminology management,localisation, and corpus processing software) and students can access all relevant toolsin a second, self-access lab. As some tools are Cloud-based, students are free to workfrom any location of their choice on many occasions. The translation technology moduleis worth 10 ECTS (European Credit Transfer System) credits, as implemented in theIrish higher education sector. This equates to one-sixth of the taught mastersprogramme.4
2.3 Outline syllabus
The indicative content covered in the translation technology module (lectures and labs) isas follows:
(1) Translation memory and translation memory tools● Basic concepts: repetition, similarity, similarity metrics, segmentation, matching● Implementation: interfaces, editing, tool integration, web-based TM tools● Ancillary programs: alignment, concordancing, etc.● Evaluation: retrieval performance, usability, etc.● Export and interchange formats and compatibility issues● Professional issues: ethics, payment, collaboration
(2) Machine translation● Brief history● Rule-Based Machine Translation: basic architectures, linguistic issues, etc.● Statistical Machine Translation
– Basic architecture: training, tuning, decoding– Word and phrase alignment– N-gram processing– Noisy channel model– Log linear model
● MT evaluation– Human evaluation: accuracy, fluency, usability, etc.– Automatic evaluation metrics: precision and recall, f-measure, word error
rate, translation error rate, BLEU, Meteor, etc.● Pre- and post-processing
The Interpreter and Translator Trainer 299
Dow
nloa
ded
by [
Nor
th D
akot
a St
ate
Uni
vers
ity]
at 1
6:35
21
Oct
ober
201
4

– Controlled language, style guides, glossary creation– Post-editing: differences between RBMT and SMT, computer-assisted post-
editing, post-editing interfaces● Human and professional issues in machine translation: ethics, payment, colla-
boration, the role of the human translator, translation workflows, etc.
In selecting aspects of the SMT workflow on which to concentrate in our syllabus, weprioritised those phases during which the human translator’s ability to intervene is great-est. For this reason we place more emphasis on training than we do on decoding, forexample, and thus spend more time discussing how the target language and translationitself are modelled statistically than we do on how decoding algorithms are optimised. Wealso emphasise the role of human translators in evaluating MT output and in interpretingautomatic evaluation metrics (AEMs).
The details of how SMT works and especially how SMT engines are trained – whichinvolves much discussion of n-gram based probabilistic processing and is thereforeextremely relevant to an understanding of automatic evaluation metrics as well – areaddressed primarily in one two-hour lecture. In two two-hour instructor-guided practicallabs, students then have the opportunity to source their own training data and to use thesedata to build their own Cloud-based SMT engines.
Human and automatic evaluation of MT are also addressed in both lectures andpractical labs. In the case of human evaluation, we introduce standard approaches inone two-hour lecture. These typically involve judges scoring MT outputs on the basis oftheir accuracy (how well do they reflect the source text?) and fluency (how good are theyas instances of the target language?). We stress the fact that, to be reliable and valid,human evaluations should be carefully constructed so that each output is seen by multiplescorers, no single scorer judges both fluency and adequacy for the same output, outputsare presented in randomised order to judges (so as to avoid ‘halo’ effects), and so on. (Thereader is referred to White, O’Connell, and O’Mara (1994) for an example of such acarefully constructed evaluation.) We also conduct human evaluation exercises in thelecture, under conditions of varying desirability (e.g. with students evaluating eitherfluency or accuracy, or both fluency and accuracy; and with outputs being evaluated byone or multiple scorers, etc.). In other words, students learn about best practice in humanevaluation not just by hearing about it, but by experiencing it.
AEMs are generally dealt with in both a two-hour lecture and a two-hour lab. Whilebasic concepts (e.g. precision and recall, edit distance, etc.) and specific metrics (f-measure,TER, Bleu, etc.) can be fruitfully addressed in an interactive lecture, students also gain frombeing able to compute AEM scores themselves in the practical lab using the tools describedin section 2.5 below. Again students learn by doing: by comparing AEM scores with humanjudgements of the quality of MT output, they develop an ability to discriminate betweendifferent AEMs, and to identify the strengths and weaknesses of different approaches.
Pre-processing and post-processing of MT output are also covered in a single two-hour lecture and a two-hour lab. Lab-based SMT post-editing exercises can be carried outusing standard office applications, translation memory tools, or the interface provided bythe SMT platform in use.
2.4 Assessment
The translation technology module is assessed using two ‘take-home’ assignments. Thefirst, worth 40%, is based on translation memory technology and is completed in pairs; the
300 S. Doherty and D. Kenny
Dow
nloa
ded
by [
Nor
th D
akot
a St
ate
Uni
vers
ity]
at 1
6:35
21
Oct
ober
201
4

second, completed individually, involves the creation and evaluation of a statisticalmachine translation engine. In it, students are required to:
● acquire training data● train an engine using an SMT platform in the Cloud● test the engine, by using it to translate one text from the same domain as their
training data (an ‘in-domain’ text) and one text from a different domain (an ‘out-of-domain’ text)
● evaluate the engine’s output, to establish its baseline performance● consider ways of improving the output through a variety of possible interventions;
for example, by:
– changing the input, e.g. by ‘controlling’ the language used– changing the process, e.g. by uploading more training data or uploading a
glossary to force lexical selection in the target language– changing the output, e.g. through the use of systematic post-editing
● implement selected interventions● retest the engine using in-domain and out-of-domain source texts● evaluate the improved engine’s output
Students are required to report on and critically evaluate the whole cycle – from trainingto testing, evaluation, intervention, retesting and re-evaluation – in a written papersubmitted at the end of the module.
The technical details of how students carried out this project in 2012 are presented insection 2.5 below. To a large extent the solutions adopted reflected the tools andtechniques to which students were exposed in theoretical lectures and practical labs. Onoccasion, students showed great independence by seeking out solutions that had not beencovered in the taught course.
2.5 Technical implementation
Data acquisition
The first challenge faced by students in the completion of their assignments was theacquisition of enough high-quality aligned bilingual data to train an SMT system. Thiswas done under the guidance of the lab instructor. In most cases, students used the DGT-TM, the multilingual translation memory made available by the European Commission’sDirectorate General for Translation through the Commission’s Joint Research Centre (fordetails see Steinberger et al. 2012).5 The 2011 release of the DGT-TM, used by ourstudents in 2012, contained translation units in 22 different EU languages, allowing a totalof 231 different language pairs.6 Users can extract language-pair specific translationmemories (in most cases totalling up to just under two million translation units) fromthe DGT-TM using a program provided by the Joint Research Centre and known asTMXtract. Students with language pairs other than those contained in the DGT-TM had tolook elsewhere for training data, however, and even students who used DGT-TM dataoften supplemented these data with bilingual data or monolingual target-language trainingdata from other sources. Given that students had different language pairs (at least 15different language pairs were attested in the cohort in question), and that – even within thesame language pair – students selected different sets of training data (from the same
The Interpreter and Translator Trainer 301
Dow
nloa
ded
by [
Nor
th D
akot
a St
ate
Uni
vers
ity]
at 1
6:35
21
Oct
ober
201
4

source or a variety of different sources), no two students ended up with the same trainingdata. This means that each student built and tested a unique SMT engine.
Students were instructed to make judgements about the quality of training data basedon their own linguistic and translation expertise and on criteria such as authorship andhomogeneity of data, file mark-up (condition of internal tags), etc. Size of training data isa thorny issue; there is no generally agreed-upon optimal size for corpora used in SMT,7
and issues of scarcity (where the probabilities central to the SMT approach cannot becalculated with any confidence) and practicality (to do with limited quantities of verifiedhigh-quality aligned data, windows for run-time and associated computing power) con-stantly impinge on efforts to build SMT engines. We discussed these issues with studentsat several points. Automatic evaluation metrics (discussed below) can be used to ascertainwhether more training data would be beneficial in individual cases, and we encouragestudents to identify a point of diminishing returns, one at which improvements in SMTquality (as identified using AEMs) are outweighed by the burden of having to upload andprocess more training data.8
A further challenge lies in the identification of in-domain versus out-of-domain text.Despite the importance of ‘domain’ in machine translation research, the concept isgenerally left vague. Typical ‘domains’ mentioned in the literature are linked to specia-lised fields of professional/scientific activity (e.g. ‘medical’ texts), particular modes ofcommunication (‘newswire’, ‘movie subtitles’) or particular communicative contexts(‘parliamentary debates’). We maintained this flexibility in our treatment of ‘domain’,so that students had maximum flexibility in sourcing suitable training data for theirengines. Students had to be able to argue convincingly, however, that the texts in theirtraining corpus displayed a certain homogeneity, in terms of characteristics such as theirsubject matter, text type, authors, and so on, and that ‘in-domain’ test data shared most of– if not all – these characteristics, while ‘out-of-domain’ test data did not. Thus, if studentstrained their engines on texts from the DGT-TM (and thus on European Union legisla-tion), then a previously unseen European directive would constitute ‘in-domain’ test data,while technical specifications for a computer would constitute out-of-domain test data.Domain choices and boundaries were discussed in labs and re-emerged as a theme inassignments as students attempted to account for changes in SMT output following theaddition of extra training data from the same domain, or mixed domains.
SMT platform
As described in Kenny and Doherty (this issue), a number of Cloud-based SMT solutionsare now available to translators. In 2012 all students used one such solution known asSmartMATE.9 SmartMATE is described in Doherty, Kenny, and Way (2012). Like otherCloud-based SMT systems, it allows users to upload bilingual training data in the form of.tmx files (a generic data exchange format used by translation memory tools).10 Once thetraining data have been uploaded, and the SMT engine built, the user can input newdocuments for translation in a variety of formats, including .doc, .rtf and .html, althoughthe system actually uses XLIFF (XML Localisation Interchange File Format) as itsinternal processing format. Users can also upload customised glossaries to exert greatercontrol over the translation of individual words or terms. The system offers both transla-tion memory and SMT functions. It also provides an editing environment that facilitatescollaborative post-editing and quality assessment (Penkale and Way 2012). Once the useris satisfied with the translation job, the XLIFF file is reformatted back to its original inputfile type, and the translated file is output.
302 S. Doherty and D. Kenny
Dow
nloa
ded
by [
Nor
th D
akot
a St
ate
Uni
vers
ity]
at 1
6:35
21
Oct
ober
201
4

One of features offered by Cloud-based SMT platforms is direct access to automaticevaluation metrics; in other words, the system displays to the user a series of automati-cally computed scores that are intended to indicate the general quality of translationsoutput by a particular engine. To gauge the quality of an individual sentence output by aparticular engine a different tool is required, however, and in 2012 the vast majority of ourstudents relied on Asiya-Online, discussed below, to compute automatic evaluation scores.
Machine translation evaluation methods and tools
As already indicated, our students had been instructed in best practice in human evalua-tion of MT output, and they had available to them a pool of fellow students who couldhave acted as evaluators for outputs from their engines. In practice, students tended to relyon a single scorer (themselves) to judge fluency and adequacy of all outputs, thuscompromising the reliability and validity of their human evaluations. We return to thispoint below. In summary, 21 of the students (or 55%) opted for adequacy/fluency scoringto evaluate the MT output. Twenty-nine students (76%) sought to provide a typology oferrors in translations produced by their engine, with a view to ascertaining whether therewere any specific interventions they could make to eliminate some of these errors. Thetypology most commonly adopted by such students was that proposed by Vilar et al.(2006). Fourteen students used both adequacy/fluency scores and an error typology toevaluate outputs.
Automatic evaluation metrics can be used in a variety of ways. Typically, MTdevelopers use scripts written in popular programming languages such as Perl. Thesescripts are freely available online, but require knowledge of the programming languageand appropriate software to be utilised. For example, Perl cannot be used on a standardWindows set-up or without specific training. With this in mind, and due to time con-straints and the fact that most of our students have no knowledge of programminglanguages (other than the small number who had learned Java), we sought a means tofacilitate the calculation of popular AEMs. There are several online interfaces where userscan input two strings – a machine translation output and a human ‘reference’ translation –in order to calculate the ‘edit distance’ between them, where increasing distance isassumed to mean decreasing quality of the machine translation output (see Koehn 2010,222–232).11 One online service, Asiya-Online, has the signal merit of calculating scoresfor several different AEMs simultaneously.12 This is of particular significance given ourdesire to encourage critical reflection on the strengths and weaknesses of a variety ofquality metrics (human and automatic). The Asiya-Online service was used both in ourteaching and by the vast majority of students in completion of their assignments. It takesas input source-language segments, their human translations and their machine transla-tions (for full details, see Giménez and González 2013). As indicated in Kenny andDoherty (this issue), most AEMs are then calculated by considering n-gram level differ-ences between the human reference translation and the machine translation.
Interventions
As outlined in section 2.4 above, students could choose from a number of possibleinterventions in an attempt to improve the performance of their SMT engines. The mostpopular intervention proved to be editing the source text, often using controlled languagerules such as those outlined in O’Brien (2003). Students who intervened in this way hadusually already conducted an error analysis of the output from their SMT engine, in order
The Interpreter and Translator Trainer 303
Dow
nloa
ded
by [
Nor
th D
akot
a St
ate
Uni
vers
ity]
at 1
6:35
21
Oct
ober
201
4

to isolate particular problems in the target text. These students typically concluded thatmost of their edits made little difference to the quality of SMT output when theyretranslated their source text. The exception was shortening sentence length, an edit thatusually had a positive impact.13 The second most popular intervention was the uploadingof a document-specific glossary, an intervention that had an almost universally positiveimpact. Other possible, and arguably more promising, interventions – for example,uploading more training data – were, disappointingly, poorly represented in our sample.In total, 27 students implemented 2 main interventions (e.g. editing the source text anduploading a glossary), while 11 students were content with just a single intervention. Onaverage, students carried out 1.6 interventions each.14
3. Evaluation
Like all modules taught at DCU, the translation technologymodule is evaluated by students ina standardised ‘survey of student opinion of teaching’ (SSOT). In the present case, however,we wished to elicit more detailed data on student learning about SMT, to assist in furtherrefinement of the syllabus, among other things. The main instrument we used for this purposeis a quantitative measure known as self-efficacy. In the first part of this section we start byexplaining the construct of self-efficacy and how it is typically employed in technologicalcontexts. We then describe howwe used self-efficacy in evaluating student learning of SMTatDCU in 2012. We also elicited rich qualitative data from students in the self-reflexivecomponents of their SMT assignments. In the second half of this section we explain howthese data were coded and analysed, and we present the main findings of this analysis.
It should be noted that the evaluation reported on below was conducted with theapproval of the university’s research ethics committee. In adherence to a transparent andethical code of conduct, the researchers, who were also the students’ lecturers, explained,prior to the commencement of the first lecture on SMT, the aims of the project.Participants were asked to read a Plain Language Statement, which described the project,its aims, stakeholders and the nature and consequences of participation or non-participa-tion. Intending participants were also asked to sign an informed consent form. Throughoutthe project, the voluntary and anonymous nature of student participation was stressed.
3.1 Self-efficacy
Self-efficacy is the main component of social cognitive learning theory, a paradigm thatposits models as the principal source for learning new behaviours and instigating beha-vioural change (Bandura 1977; Sims and Manz 1982). The construct of self-efficacypertains to an individual’s – in this case the student translator’s – confidence in his or herability to control his or her own thoughts, feelings and actions to produce a desired outcomein a given set of contexts (Bandura 1986). That is to say, the focus is not wholly on theactual skills students may have, but on their judgement of what they can do with theseskills. The construct is purposely non-specific so that in application it can be modified topertain to specific situations and technologies; for example, computer self-efficacy(Compeau and Higgins 1995) and Internet self-efficacy (Joo, Bong, and Choi 2000).
Self-efficacy has a long history in psychology and continues to be used in contem-porary research. Of particular significance to the present paper, self-efficacy has beenshown to greatly influence academic performance (e.g. Filippello et al. 2013; Parker et al.2014; Wright et al. 2014), performance with technologies (e.g. Hong et al. 2014; Shankand Cotten 2014) and learning outcomes and satisfaction with courses in technologies
304 S. Doherty and D. Kenny
Dow
nloa
ded
by [
Nor
th D
akot
a St
ate
Uni
vers
ity]
at 1
6:35
21
Oct
ober
201
4

(e.g. Ertmer et al. 1994; Kuo et al. 2014). In the context of our evaluation, we canconclude that if we observe an increase in self-efficacy after students have completed ourSMT course, then this can be reliably interpreted as an indication that their technical andacademic performance using MT has indeed improved.
Both direct experiences (e.g. using the software oneself) and indirect experiences (e.g.observing others using the software) allow an individual to gain insight into his or herown ability to carry out a given set of tasks. Such insight is typically captured by means ofself-report measurements. Compeau and Higgins (1995) provide a validated instrumentfor assessing computer self-efficacy in the form of a 10-item questionnaire. Their instru-ment is adapted for use in our evaluation.
3.2 Using self-efficacy to evaluate learning of SMT at DCU
Methodology
As already indicated, Compeau and Higgins (1995) 10-item questionnaire was adapted foruse in our study. Participants were given 10 examples of contextually relevant situationswhere they were asked to rate their ability to complete a task using an SMT system.Example situations included the following: ‘I could use an SMT system, if someoneshowed me how to do it first’ or ‘I could use an SMT system, if I had only the softwaremanuals for reference.’ In each case, participants had to answer either ‘Yes’ or ‘No’ andthen indicate their level of confidence in their answer. Confidence was rated across 3bands, spanning a range from 1 to 10: not at all confident (1–3), moderately confident (4–6) and totally confident (7–10). To reuse the above examples, a participant might indicatethat she or he would feel moderately confident in using SMT effectively if someoneguided the way first (a positive answer), but moderately confident that she or he could notuse the SMT package using only the software manuals as a reference (a negative answer).Self-efficacy items were preceded by a short series of questions that elicited demographicinformation (e.g. on the sex and age of participants) and information on participants’technical and professional profiles (e.g. amount of time spent using computers, knowledgeof translation memory, knowledge of machine translation). The full questionnaire isreproduced in Appendix 1. Questionnaires were distributed as hard copies at the begin-ning of the SMT course (the first time point, t1) and upon its completion, six weeks later(the second time point, t2); the two versions were identical in their content and appear-ance. Data analysis was carried out in Microsoft Excel and SPSS.
Results and discussion
Twenty-nine (out of 38) students took part in the survey at both the beginning and end ofthe SMT course (females = 21, males = 8, average age = 26 years). Two participantsindicated that they had professional experience with machine translation. This experiencerelated to very short-term and recent university projects and was therefore deemed not toaffect the responses given by these participants.
Several language pairs were represented in the cohort, and some participants had twoor three language pairs (see Table 1).
Participants reported spending on average between 20 and 39 hours a week usingtheir computers, and no significant change was observed between the two time points.15
Most participants reported an ‘average’ level of knowledge of translation memories att1. This had increased, but not significantly so, to ‘above average’ at t2.16 A significant
The Interpreter and Translator Trainer 305
Dow
nloa
ded
by [
Nor
th D
akot
a St
ate
Uni
vers
ity]
at 1
6:35
21
Oct
ober
201
4
increase in participants’ understanding of machine translation was, however, reportedbetween t1 and t2.17
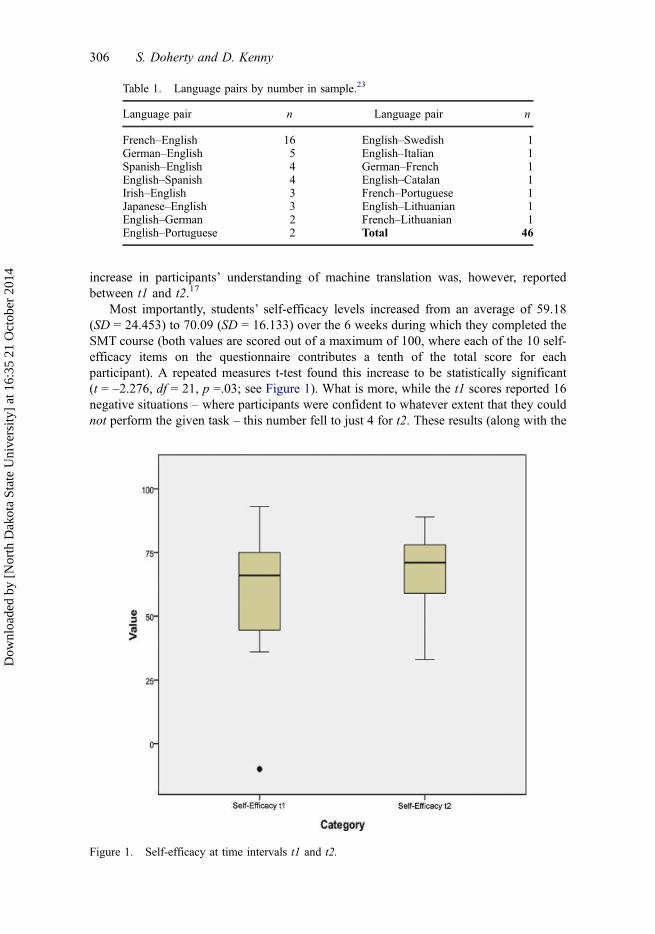
Most importantly, students’ self-efficacy levels increased from an average of 59.18(SD = 24.453) to 70.09 (SD = 16.133) over the 6 weeks during which they completed theSMT course (both values are scored out of a maximum of 100, where each of the 10 self-efficacy items on the questionnaire contributes a tenth of the total score for eachparticipant). A repeated measures t-test found this increase to be statistically significant(t = –2.276, df = 21, p =.03; see Figure 1). What is more, while the t1 scores reported 16negative situations – where participants were confident to whatever extent that they couldnot perform the given task – this number fell to just 4 for t2. These results (along with the
Table 1. Language pairs by number in sample.23
Language pair n Language pair n
French–English 16 English–Swedish 1German–English 5 English–Italian 1Spanish–English 4 German–French 1English–Spanish 4 English–Catalan 1Irish–English 3 French–Portuguese 1Japanese–English 3 English–Lithuanian 1English–German 2 French–Lithuanian 1English–Portuguese 2 Total 46
Figure 1. Self-efficacy at time intervals t1 and t2.
306 S. Doherty and D. Kenny
Dow
nloa
ded
by [
Nor
th D
akot
a St
ate
Uni
vers
ity]
at 1
6:35
21
Oct
ober
201
4

significant increase in participants’ reported understanding of machine translation referredto above) can be interpreted as positive teaching and learning outcomes.
Eight participants reported reductions in self-efficacy, although the average decrease inscores was found to be insignificant for this subgroup (t =.979, df = 7, p = .36), where themean of t1, 78.88 (SD = 18.635), dropped to 68.00 at t2 (SD = 23.458). Qualitative datafrom the participants in question indicated that this subgroup’s initial appraisal of theirability to use SMT systems was based solely on their exposure to Google Translate, whichhas an extremely simple interface and affords the user little means of intervention,18 withno option to train the system, for example. Having run through a full training, testing andevaluation cycle with a customisable Cloud-based SMT system, this subgroup stated thatthey had initially underestimated the complexity of SMT systems and hence overestimatedtheir ability to use them. Slight decreases in self-efficacy for this subgroup thus para-doxically indicate a greater understanding of SMT at t2 than at t1.
The quantitative data elicited through the participant questionnaire allow for furtherdetailed analyses of correlations between variables such as gender and self-efficacy, age andcomputer use, and so on. Space constraints prevent us from elaborating further on suchcorrelations here. One result that may be of particular interest to current readers, however, isthe fact that no statistically significant correlation was found between self-efficacy andgrades awarded in the end-of-module assignment (r =.052, p = .79 at t1; r = -.137, p =.543at t2). This result highlights the fact that our self-efficacy questionnaire and summativeassessments measure different things, from different perspectives. As already indicated, self-efficacy is a self-reported measure of an individual’s confidence in his or her ability toproduce a particular outcome (in our case all such outcomes related to the use of SMT). Ourstandardised criteria for the assessment of technology assignments, on the other hand, takein factors such as students’ technical engagement with and critical evaluation of a technol-ogy, their knowledge of relevant literature, their creativity in addressing problems, theirwriting standard, whether they met the deadline, and so on. Self-efficacy measures and end-of-module assignments are thus complementary instruments for measuring learning.
3.3 Qualitative evaluation
In their end-of-module assignments, students were required to reflect critically on theirwork, in particular the methodology they adopted. Most students took the opportunity toreflect not just on their own methodology, but also on the module itself and especially thetechnical resources available. Students also engaged in much self-reflection, commenting,for example, on their own subjectivity. Such critical reflection proved to be rich source ofqualitative data about the student experience of the module, and we collated relevantextracts from all student work with a view to identifying recurring themes. In thefollowing, we comment on the themes most commonly addressed by the students.These relate to technical issues, issues in SMT evaluation, quality thresholds and overallunderstanding of SMT. Where appropriate, we illustrate points using quotes taken directlyfrom student assignments. In each case an indication is given of which participant is beingquoted (e.g. P20 = Participant 20).
Technical and evaluation issues
Throughout the course of the module, the students experienced a series of technical issues.Some technical problems were fairly trivial, and while they slowed some students down,they were easy to diagnose (and ultimately resolve). Such problems included difficulties
The Interpreter and Translator Trainer 307
Dow
nloa
ded
by [
Nor
th D
akot
a St
ate
Uni
vers
ity]
at 1
6:35
21
Oct
ober
201
4

downloading large files and inadequate storage space on networked drives; the filescontaining training data acquired by students from the DGT-TM (see above; andSteinberger et al. 2012) often ran to nearly 100 megabytes even in compressed format;few students had worked with such large files before but they all eventually managed tofind solutions to the downloading and storage problems. Some students commented atlength on problems using the file compression software installed in the university’scomputer labs. While it is not self-evident that all students actually needed to use thissoftware,19 the comments they made are telling as they sometimes point to confusionabout the file formats with which students were dealing. We return to this point below.
While handling large files caused problems for some students, these problems wereultimately resolved and all students managed to secure a set of training data in .tmxformat. The problems raised by tools used to generate AEM scores, on the other hand,were not always resolved. Many students struggled with the Asiya-Online toolkit, andover half of the students (20 out of 38) eventually abandoned their attempt to use thisresource despite the fact that they had had previous hands-on training with the tool, thatrelevant materials had been provided in labs and that support materials were also availableonline. The following quote from one student who succeeded in using Asiya-Online (P22)illustrates the kinds of problems students faced, as well as their – often collaborative –attempts to diagnose those problems, and the solutions they ultimately opted for:
On the first try no results were returned so the second attempt was carried out using the firstthree sentences of each text. This attempt was also fruitless so we decided to resave the threedocuments again and switched to coding from ANSI to UTF-8. This produced some results. . . It once again proved difficult to get Asiya Toolkit to process the text and after severalfailed attempts where, after pressing the ‘Run Asiya’ button, the screen just stayed blank, wetried to input small chunks of text at a time. This worked for a time and we managed toprocess segments 1–14 of the document in groups of 4–5 sentences. (P22)
The readiness of students to experiment and share ideas indicates a positive learningenvironment, and there is no doubt that students learned much in their endeavours. Itshould also be noted that when the SMT syllabus was redelivered in 2013, 28 out of 29students had little difficulty using this toolkit. This was due to a number of factors,including greater lecturer awareness of the problems students were likely to face and, mostimportantly, an enhanced interface to the toolkit itself.
On occasion, students ran up against problems that were due to the fact that theirhuman reference translations and their machine translations simply did not align:
The software would not process the files unless they contained the exact same number ofsentences; sentences must also be numbered and match. This does not take into account thatin human translation, one source segment is often translated as two target segments, or viceversa. As a result I was forced to number and manually align the source, reference and outputfiles in order to force them to match. This could compromise their reliability. Only throughperseverance and extensive trial and error did the metrics work. These were certainly not idealconditions in which to carry out the evaluations. (P16)
If this was a problem after the students’ first round of testing of the SMT system, itbecame more acute after the second round, as while student interventions in the sourcetext may have improved the SMT output from a human’s point of view, the sameinterventions made the SMT output less similar to the human reference translations thanit had been previously, and so even more difficult for the Asiya toolkit to deal with:
308 S. Doherty and D. Kenny
Dow
nloa
ded
by [
Nor
th D
akot
a St
ate
Uni
vers
ity]
at 1
6:35
21
Oct
ober
201
4

It was hoped that the edits carried out on the ST and the other interventions would enableAsiya to compute the automatic metrics for the second evaluation. Disappointingly, Asiyaonline . . . failed to provide any results for the post-intervention texts. This was attributed tothe fact that post-intervention the ST and thus the TT had a far greater number of segmentsthan the reference translation. (P32)
And even if Asiya-Online could deal with such segments, it might give lower scores forbetter SMT outputs (as judged by a human), as post-intervention SMT outputs would beless like the reference translation than poorer pre-intervention SMT outputs:
The researcher would argue that the [automatic] metrics are not as reliable as the humanevaluation techniques in this instance, for the following reason: the source text has been soaltered by the implementation of the [controlled language] rules that it no longer correspondsto the reference translation . . . although it may be an adequate representation of the sourcetext, [the new target text] will therefore receive lower AEM scores. (P16)
Students thus came face to face with the technical and the theoretical limitations of AEMs;but while human evaluation might have seemed a technically simpler solution for manystudents, they soon found discovered that judging accuracy and fluency of machineoutputs, and categorising errors in the same outputs, were not without their own difficul-ties. Evaluator fatigue and subjectivity loomed large among these problems.
Most students proposed ways of mitigating the problem of subjectivity (although, ofcourse, subjectivity can never be eliminated from human evaluation), e.g. by using‘objective’ error classifications or by reverting to the multiple-evaluator design promotedin lectures:
The selection of evaluation metrics is also slightly flawed as all human evaluation is quitesubjective, and even though it was attempted to remove this by implementing a strict errorclassification system, this still left the researcher alone to subjectively decide which errorsbelonged to which classification, and what they actually considered to be errors. (P1)
More than one evaluator should be used to ensure greater reliability of results (P16)
Reassuringly, students also recognised quality thresholds below which it was not wortheither trying to catalogue all the errors in the SMT output or to make changes to the sourcetext to facilitate SMT:
[A]ttempting to quantify the number or type of errors in a translated text that didn’t even offerrecognizable sentences seemed like a questionable use of time. (P3)20
The same error typology used to evaluate the in-domain text was initially employed for [theout-of-domain] text but had to be abandoned as the framework could not cope with the highvolume and variety of error that appeared in the output. (P22)
These comments suggest that students do not try slavishly to redeem or even accommo-date poor-quality machine outputs; student translators have no difficulty in using theirjudgement to allocate resources to tasks that will ultimately bear most fruit.
Students also commented, usually in their conclusions, on how their understanding ofSMT had grown during the project. Some students remarked in particular on how theyhad moved from a superficial understanding of SMT, encouraged by exposure to simple-to-use interfaces, to an appreciation of the complexity involved:
The Interpreter and Translator Trainer 309
Dow
nloa
ded
by [
Nor
th D
akot
a St
ate
Uni
vers
ity]
at 1
6:35
21
Oct
ober
201
4

The general relative simplicity of a MT-user interface (basically select the languages, copyand paste the source text into the application, then press the ‘translate’ button and wait for theoutput) masks the complexity of processes involved in the background. (P28)
Enhanced understanding of the technology was accompanied by a nuanced approach tothe overall evaluation of SMT. Students experienced for themselves how the same SMTengine could produce both good and bad output:
It is clear that the [engine] still has a long way to go when dealing with out-of-domain texts.However, when provided with a suitable [in-domain] text, it is truly impressive how good thetranslation can be. (P4)
4. Conclusions
In this paper we have described the design, delivery and evaluation of a new StatisticalMachine Translation syllabus at DCU. Both quantitative and qualitative evaluations (theformer based on the construct of self efficacy; the latter on student comments in theirwritten assignments) indicate positive learning outcomes, with significant increasesobserved in SMT self-efficacy and ample evidence of enhanced critical appreciationamong students of the technologies involved. Our experience indicates that it is bothpossible and worthwhile to involve translation students in the whole SMT workflow. Inthis rest of this section we reflect on what we, as syllabus designers and lecturers, learnedfrom the process described in this paper, and how we see the teaching of SMT totranslators developing.
We noted earlier that some students faced basic technical difficulties, especially whenhandling large quantities of data at the beginning of this project. These difficulties are notunexpected – given the nature of the module, as well as previous experience at DCU (e.g.Doherty and Moorkens 2013) and feedback from colleagues teaching translation technol-ogy to similar cohorts across Europe,21 but addressing such issues is critical to improvingthe student experience of the module. It is tempting to claim that translation technologymodules should address only specialised translation tools, and that students should alreadyhave mastered basic office applications, but such a position appears to be based on anunderstanding of technical competence as progressing in a linear fashion, with more basicor general technologies ‘picked up’ before more advanced or specialised technologies.This is not necessarily what happens organically in our experience, and it is not uncom-mon for basic interventions to have to be made by lecturers in more advanced technolo-gical modules. Ideally, lecturers would have at their disposal ready-made guides to avariety of tools, that can be drawn upon as and when they are needed. This is the approachtaken by the CERTT (The Collection of Electronic Resources in TranslationTechnologies) team in Ottawa (Bowker and Marshman 2010; Marshman and Bowker2012). It is an approach that can also be supported by short training videos available formany common software programs on media such as YouTube.
A second point worth noting is that while students reported at length on technicaldifficulties with tools like Asiya, they did not dwell on technical issues that had arisen inthe very early stages of the project with the SMT platform in use. This is probablybecause the students had direct access to developers of the platform, and if problems arosethe developers could keep students informed of why there was a problem (e.g. in the caseof a server malfunction) and how and when the problem would be resolved. In general,this kind of interaction helps to minimise learner anxiety, saves time and allows students
310 S. Doherty and D. Kenny
Dow
nloa
ded
by [
Nor
th D
akot
a St
ate
Uni
vers
ity]
at 1
6:35
21
Oct
ober
201
4

to use their newly acquired knowledge in dialogue with professionals actually working inthe field. Meanwhile, developers benefit from intensive feedback on their technologyfrom plausible end-users and from having multiple users load test their infrastructure.They also stand ultimately to grow the market for their technologies. There is thus muchto be gained on both sides from collaborations between industry and academia in this area.
A further lesson learned from the experience reported on in this paper is that an intensefocus on automatic evaluation, an area that was new and in some cases challenging to ourstudents, may have come at the expense of a rigorous approach to human evaluation. Itappears that in their eagerness to implement AEMs correctly, many students treated thetechnically less demanding area of human evaluation with less respect than it deserved. Thisis a risk that we have attempted to counter in subsequent iterations, by encouraging studentsto collaborate in the evaluation of the output of each other’s SMT engines.
Finally, we must acknowledge the truism that technology is constantly evolving; overthe two iterations of delivery of the syllabus we describe in this paper, we have used twodifferent Cloud-based SMT systems (first SmartMATE, then KantanMT.com) and haveseen the Asiya-Online toolkit overhauled. We note now the availability of an onlinetoolkit to support human evaluation of machine translation output22 and look forward totesting it for use in future teaching. We have no doubt that while the SMT syllabusoutlined above will remain relatively stable in the short to medium term, its technicalimplementation will continue to morph as the commercial market for Cloud-based SMTevolves and more open-access tools become available.
AcknowledgementsThe authors would like to thank all the students who participated, as well as Prof. Andy Way and DrJie Jiang, who supported us in our use of Cloud-based SMT throughout this project, and the twoanonymous reviewers who provided valuable feedback on this paper.
FundingThis research was supported by the Science Foundation Ireland [grant number 07/CE/I1142] as partof the Centre for Next Generation Localisation (www.cngl.ie) at DCU.
Notes1. Interested readers may contact the authors for more information on course content.2. The MA and the MSc overlap to a large extent but differ in that MSc students are required to
study a programming language (Java), whereas MA students are not, and while MA studentsmust complete specialised language-pair specific translation practice modules, MSc studentsare not obliged to do so.
3. See Doherty and Moorkens (2013) for a photograph of this lab set-up.4. The programmes in question are each worth 90 ECTS credits, with 60 credits allocated to the
taught course and a further 30 to a research dissertation. For details of the ECTS system, seehttp://ec.europa.eu/education/tools/ects_en.htm. (All web links in this paper were last accessedin March 2014.)
5. The DGT-TM is accessible from http://ipsc.jrc.ec.europa.eu/index.php?id=197. It contains theentire body of European legislation, comprising all the treaties, regulations and directivesadopted by the European Union.
6. Since 2012 a small amount of material for a twenty-third language, Irish or Gaeilge, has beenadded to the DGT-TM.
The Interpreter and Translator Trainer 311
Dow
nloa
ded
by [
Nor
th D
akot
a St
ate
Uni
vers
ity]
at 1
6:35
21
Oct
ober
201
4

7. In practice, many SMT engines are trained on corpora of 200,000 high-quality alignedtranslation units in specialised domains while others, e.g. Google Translate, may employmillions of translation units and have wider coverage.
8. This ‘burden’ should not be exaggerated, however; while increasing the quantity of data usedto train an engine inevitably slows down the training process, many students dealt effectivelywith such restrictions by leaving engines to train overnight; and, as the service is based in theCloud, students can access it off-campus and even via smartphones.
9. When the syllabus was re-delivered in 2013 (a process not reported on in detail here), theplatform used by the vast majority of students was KantanMT.com.
10. TMX files contain source-language units aligned with their target-language translations, alongwith any relevant metadata (e.g. the date the ‘translation unit’ was created, the name of theclient, etc.).
11. Given the dynamic nature of such websites, readers are advised to type ‘edit distancecalculator’, ‘General Text Matcher’ or ‘Levenshtein distance calculator’ into their searchengines to find instances of such services.
12. Asiya-Online is available from http://asiya.lsi.upc.edu/demo/asiya_online.php.13. This outcome underlines how difficult it is to move from linguistic diagnoses of problems in
SMT output to linguistic interventions in source texts that can help solve those problems (seeKenny and Doherty, this issue).
14. When we re-implemented our SMT syllabus in 2013, the interventions were distributed asfollows: bilingual training data added: 27; glossary uploaded: 18; target-language training dataadded: 12; source text edited: 11; post-edits made: 5. The average number of interventionsmade per student rose to 2.5, with 29 students making 73 interventions between them.
15. The questionnaire item here was: ‘How much time, on average, do you spend using acomputer per week?’ The scale presented to respondents was: 1 = 0 hrs, 2 = 1 to 10 hrs,3 = 11 to 19 hrs, 4 = 20 to 39 hrs, 5 = 30+ hrs. Results at t1 were as follows: t1 median = 4,mean = 4.20, SD =.71. At t2 the mean had decreased very slightly: t2 median = 4, mean =4.15, SD =.88). Unsurprisingly, a repeated measures t-test found no significant changebetween the two time points, where t = 4.38, df = 19, p =.666.
16. Item: ‘How would you rate your knowledge of translation memories (TMs)?’ Scale: 1 = poor,2 = below average, 3 = average, 4 = above average, 5 = excellent. Results at t1: median = 3,mean = 3.20, SD =.81. Results at t2: median = 4, mean = 3.50, SD =.69. A repeated measurest-test found no significant change between the two time points (t = -1.831, df = 19, p =.0828).
17. Item: How would you rate your knowledge of machine translation (MT)?’ Scale: 1 = poor,2 = below average, 3 = average, 4 = above average, 5 = excellent. Results at t1: median = 3,mean = 2.80, SD =.616. Results at t2: median = 4, mean = 3.45, SD =.686). A repeatedmeasures t-test found a significant increase for this item (t = -3.322, df = 19, p =.004).
18. This is one reason why Google Translate could not be used to deliver the syllabus describedhere.
19. For example, DGT-TM files are ‘zipped’ (that is, individual .tmx files are compressed and thengrouped into archives), but students do not need to ‘unzip’ them as the bilingual translationmemory extraction tool provided by the Joint Research Centre (see above; and Steinbergeret al. 2012) can extract bilingual .tmx files directly from zipped files.
20. This comment relates to output from a Japanese—English SMT engine that was trained oninadequate data.
21. We are grateful, in particular, to colleagues on the OPTIMALE project (http://www.translator-training.eu/) who have shared similar experiences with us.
22. See the COSTA MT Evaluation Tool: An Open Toolkit for Human Machine TranslationEvaluation, https://code.google.com/p/costa-mt-evaluation-tool/.
23. In order to protect the anonymity of questionnaires, we elicited information on studentslanguage pairs independently.
ReferencesBandura, A. 1977. Social Learning Theory. Englewood Cliffs, NJ: Prentice-Hall.Bandura, A. 1986. Social Foundations of Thought and Action: A Social Cognitive Theory.
Englewood Cliffs, NJ: Prentice-Hall.
312 S. Doherty and D. Kenny
Dow
nloa
ded
by [
Nor
th D
akot
a St
ate
Uni
vers
ity]
at 1
6:35
21
Oct
ober
201
4

Bowker, L., and E. Marshman. 2010. “Toward a Model of Active and Situated Learning in theTeaching of Computer-Aided Translation: Introducing the CERTT Project.” In Journal ofTranslation Studies, Special Issue on The Teaching of Computer-Aided Translation 13(1&2),edited by Sin-Wai Chan, 199–226.
Compeau, D. R., and C. A. Higgins. 1995. “Computer Self-Efficacy: Development of a Measure andInitial Test.” MIS Quarterly 19 (2): 189–211. doi:10.2307/249688.
Cronin, M. 2013. Translation in the Digital Age. London: Routledge.Doherty, S., and J. Moorkens 2013. “Investigating the Experience of Translation Technology Labs:
Pedagogical Implications.” Journal of Specialised Translation 19: 122–136. http://www.jostrans.org/issue19/art_doherty.php.
Doherty, S., D. Kenny, and A. Way. 2012. “Taking Statistical Machine Translation to the StudentTranslator.” In Proceedings of the Conference of the Association for Machine Translation in theAmericas (AMTA), San Diego, CA, 28 October – 1 November 2012. http://www.mt-archive.info/AMTA-2012-Doherty-1.pdf (accessed 14 August 2014).
Engeström, Y., and A. Sannino. 2010. “Studies of Expansive Learning: Foundations, Findings andFuture Challenges.” Educational Research Review 5: 1–24. doi:10.1016/j.edurev.2009.12.002.
Ertmer, P., E. Evenbeck, K. Cennamo, and J. Lehman. 1994. “Enhancing Self-Efficacy forComputer Technologies Through the Use of Positive Classroom Experiences.” EducationalTechnology Research and Development 42 (3): 45–62. doi:10.1007/BF02298094.
European Commission Joint Research Council. 2014. “Directorate-General for TranslationTranslation Memory – DGT-TM.” http://ipsc.jrc.ec.europa.eu/index.php?id=197 (accessed 14August 2014).
Filippello, P., L. Sorrenti, R. Larcan, and A. Rizzo. 2013. “Academic Underachievement, Self-Esteem and Self-Efficacy in Decision Making.” Mediterranean Journal of Clinical Psychology1 (3): 1–11.
Garcia, I. 2011. “Translating by Post-Editing: Is it the Way Forward?” Machine Translation 25 (3):217–237. doi:10.1007/s10590-011-9115-8.
Giménez, J., and M. González. 2013. Asiya - An Open Toolkit for Automatic Machine Translation(Meta-)Evaluation. Technical Manual Version 2.0. Barcelona: Universitat Politècnica deCatalunya. http://asiya.lsi.upc.edu/Asiya_technical_manual_v2.0.pdf (accessed 14 August 2014).
Hong, J.-C., M.-Y. Hwang, K.-H. Tai, and Y.-L. Chen. 2014. “Using Calibration to EnhanceStudents’ Self-Confidence in English Vocabulary Learning Relevant to their Judgment ofOver-Confidence and Predicted by Smartphone Self-Efficacy and English Learning Anxiety.”Computers and Education 72: 313–322. doi:10.1016/j.compedu.2013.11.011.
Ingold, T. 2011. Being Alive: Essays on Movement and Perception. London: Routledge.Joo, Y. J., M. Bong, and H-J. Choi. 2000. “Self-Efficacy for Self-Regulated Learning, Academic
Self-Efficacy, and Internet Self-Efficacy in Web-Based Instruction.” Educational TechnologyResearch and Development 48: 5–17. doi:10.1007/BF02313398.
Karamanis, N., S. Luz, and G. Doherty. 2011. “Translation Practice in the Workplace: ContextualAnalysis and Implications for Machine Translation.” Machine Translation 25 (1): 35–52.doi:10.1007/s10590-011-9093-x.
Kelly, D. 2005. A Handbook for Translator Trainers. Manchester: St. Jerome.Kenny, D., and S. Doherty. 2014. “Statistical Machine Translation in the Translation Curriculum:
Overcoming Obstacles and Empowering Translators.” The Interpreter and Translator Traine8 (2). doi:10.1080/1750399X.2014.936112.
Koehn, P. 2010. Statistical Machine Translation. Cambridge: Cambridge University Press.Kuo, Y.-C., A. Walker, K. Schroder, and B. Belland. 2014. “Interaction, Internet Self-Efficacy, and
Self-Regulated Learning as Predictors of Student Satisfaction in Online Education Courses.”The Internet and Higher Education 20: 35–50. doi:10.1016/j.iheduc.2013.10.001.
Marshman, E., and L. Bowker. 2012. “Translation Technologies as Seen Through the Eyes ofEducators and Students: Harmonizing Views with the Help of a Centralized Teaching andLearning Resource.” In Global Trends in Translator and Interpreter Training, edited by S.Hubscher-Davison and M. Borodo, 69–95. London: Continuum.
Nunan, D. 1988. Syllabus Design. Oxford: Oxford University Press.O’Brien, S. 2003. “Controlling Controlled English An Analysis of Several Controlled Language
Rule Sets.” EAMT-CLAW Proceedings. http://www.mt-archive.info/CLT-2003-Obrien.pdf(accessed 14 August 2014).
The Interpreter and Translator Trainer 313
Dow
nloa
ded
by [
Nor
th D
akot
a St
ate
Uni
vers
ity]
at 1
6:35
21
Oct
ober
201
4

O’Hagan, M. 2012. “The Impact of New Technologies on Translation Studies: A TechnologicalTurn?” In The Routledge Handbook of Translation Studies, edited by C. Millán-Varela and F.Bartrina, 503–518. London: Routledge.
Parker, P., H. Marsh, J. Ciarrochi, S. Marshall, and A. S. Abduljabbar. 2014. “Juxtaposing MathSelf-Efficacy and Self-Concept as Predictors of Long-Term Achievement Outcomes.”Educational Psychology: An International Journal of Experimental Educational Psychology34 (1): 29–48. doi:10.1080/01443410.2013.797339.
Penkale, S., and A. Way. 2012. “An Online End-To-End MT Postediting Framework.” InProceedings of AMTA Workshop on Post-editing, 28 October 2012, San Diego, CA. http://www.mt-archive.info/AMTA-2012-Penkale.pdf (accessed 14 August 2014).
Pym, A. 2012. “Translation skill-sets in a machine-translation age.” http://usuaris.tinet.cat/apym/on-line/training/2012_competence_pym.pdf (accessed 14 August 2014).
Reed, K., H. Doty, and D. May. 2005. “The Impact of Aging on Self-Efficacy and Computer SkillAcquisition.” Journal of Managerial Issues 17: 212–228.
Robinson, P. 1991. ESP Today: A Practitioner’s Guide. Hemel Hempstead: Prentice Hall.Shank, D., and S. Cotten. 2014. “Does Technology Empower Urban Youth? The Relationship of
Technology Use to Self-Efficacy.” Computers and Education 70: 184–193. doi:10.1016/j.compedu.2013.08.018.
Sims, H. P., and C. C. Manz. 1982. “Social Learning Theory.” Journal of Organizational BehaviorManagement 3 (4): 55–63. doi:10.1300/J075v03n04_06.
Steinberger, R., A. Eisele, S. Klocek, S. Pilos, and P. Schlüter. 2012. “DGT-TM: A freely AvailableTranslation Memory in 22 Languages.” In Proceedings of the 8th international conference onLanguage Resources and Evaluation (LREC’2012), Istanbul, 21–27 May 2012. http://www.lrec-conf.org/proceedings/lrec2012/index.html.
Vilar, D., J. Xu, L. F. D’Haro, and H. Ney. 2006. “Error analysis of statistical machine translationoutput.” In Proceedings of the Fifth International Conference on Language Resources andEvaluation, Genoa, Italy, 697–702.
Way, A., and M. Hearne. 2011. “On the Role of Translations in State-of-the-Art Statistical MachineTranslation.” Language and Linguistics Compass 5: 227–248. doi:10.1111/j.1749-818X.2011.00275.x.
White, J. S., T. A. O’Connell, and F. E. O’Mara. 1994. “The ARPA MT evaluation methodologies:Evolution, lessons, and future approaches.” In Proceedings of the Conference of the Associationfor Machine Translation in the Americas (AMTA 1994). Proceedings of the First Conference ofthe Association for Machine Translation in the Americas, 5–8 October 1994, Columbia, MD,193–205.
Wiggins, D. 2011. Blogpost to Automated Language Translation Group. Accessed October 13.http://www.linkedin.com/groups/Looks-like-licencebased-model-MT-148593.S.74453505?qid=579815d2-fdfd-46bb-ac04-3530d8808772andtrk=group_search_item_list-0-b-ttl.
Wright, S., K. Perrone-McGovern, J. Boo, and A. V. White. 2014. “Influential Factors in Academicand Career Self-Efficacy: Attachment, Supports, and Career Barriers.” Journal of Counselingand Development 92 (1): 36–46. doi:10.1002/j.1556-6676.2014.00128.x.
314 S. Doherty and D. Kenny
Dow
nloa
ded
by [
Nor
th D
akot
a St
ate
Uni
vers
ity]
at 1
6:35
21
Oct
ober
201
4
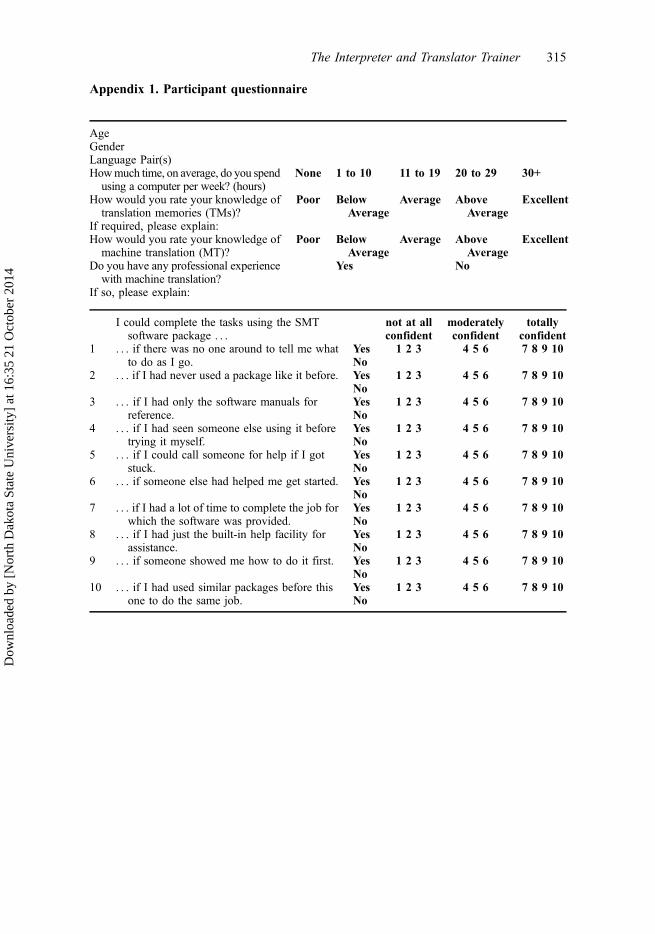
Appendix 1. Participant questionnaire
AgeGenderLanguage Pair(s)Howmuch time, on average, do you spendusing a computer per week? (hours)
None 1 to 10 11 to 19 20 to 29 30+
How would you rate your knowledge oftranslation memories (TMs)?
Poor BelowAverage
Average AboveAverage
Excellent
If required, please explain:How would you rate your knowledge ofmachine translation (MT)?
Poor BelowAverage
Average AboveAverage
Excellent
Do you have any professional experiencewith machine translation?
Yes No
If so, please explain:
I could complete the tasks using the SMTsoftware package . . .
not at allconfident
moderatelyconfident
totallyconfident
1 . . . if there was no one around to tell me whatto do as I go.
Yes 1 2 3 4 5 6 7 8 9 10No
2 . . . if I had never used a package like it before. Yes 1 2 3 4 5 6 7 8 9 10No
3 . . . if I had only the software manuals forreference.
Yes 1 2 3 4 5 6 7 8 9 10No
4 . . . if I had seen someone else using it beforetrying it myself.
Yes 1 2 3 4 5 6 7 8 9 10No
5 . . . if I could call someone for help if I gotstuck.
Yes 1 2 3 4 5 6 7 8 9 10No
6 . . . if someone else had helped me get started. Yes 1 2 3 4 5 6 7 8 9 10No
7 . . . if I had a lot of time to complete the job forwhich the software was provided.
Yes 1 2 3 4 5 6 7 8 9 10No
8 . . . if I had just the built-in help facility forassistance.
Yes 1 2 3 4 5 6 7 8 9 10No
9 . . . if someone showed me how to do it first. Yes 1 2 3 4 5 6 7 8 9 10No
10 . . . if I had used similar packages before thisone to do the same job.
Yes 1 2 3 4 5 6 7 8 9 10No
The Interpreter and Translator Trainer 315
Dow
nloa
ded
by [
Nor
th D
akot
a St
ate
Uni
vers
ity]
at 1
6:35
21
Oct
ober
201
4
Recommended





![Lecture 22: Statistical Machine Translation€¦ · Statistical Machine Translation We want the best (most likely) [English] translation for the [Chinese] input: argmax English P(](https://img.pdfslide.us/doc/110x75/5f8300468b40600d3c195d38/lecture-22-statistical-machine-translation-statistical-machine-translation-we-want.jpg)











