
Text Mining 101 Manohar Swamynathan August 2012
agenda o Text Mining Process Steps
o Calculate Term Weight
o Similarity Distance Measure
o Common Text Mining Techniques
o Appendix
- Required R packages for Text Mining
- Implemented Examples
o R code for obtaining and analyzing tweets o RTextTools ndash Ensemble Classification
o References
Manohar Swamynathan Aug 2012
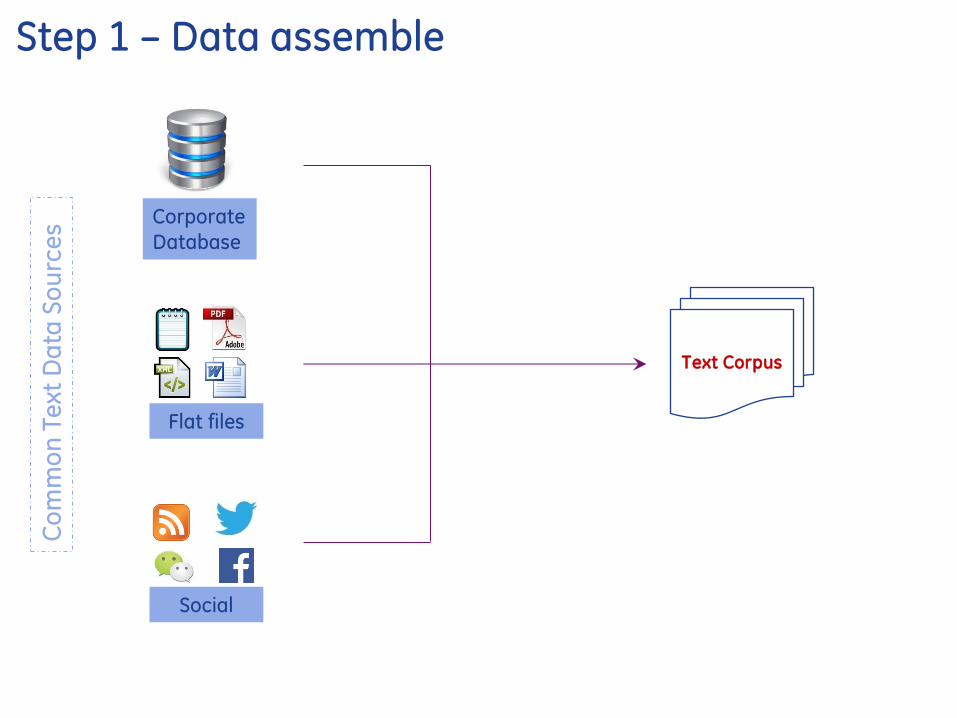
Step 1 ndash Data assemble
Text Corpus
Flat files
Social
Corporate
Database
Co
mm
on
Te
xt D
ata
So
urc
es
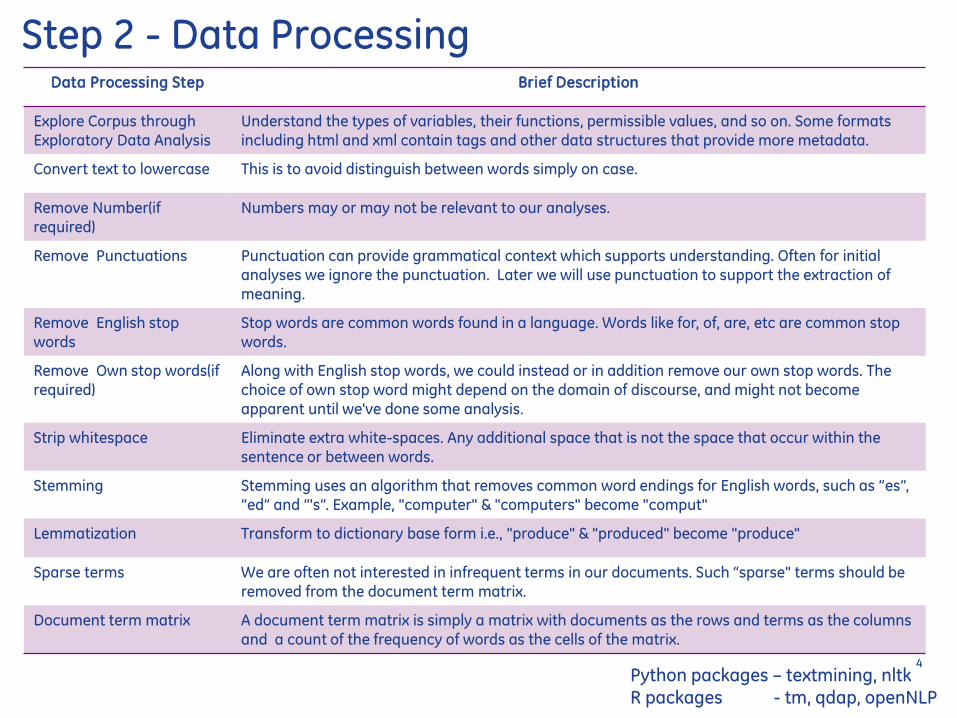
Data Processing Step Brief Description
Explore Corpus through Exploratory Data Analysis
Understand the types of variables their functions permissible values and so on Some formats including html and xml contain tags and other data structures that provide more metadata
Convert text to lowercase This is to avoid distinguish between words simply on case
Remove Number(if required)
Numbers may or may not be relevant to our analyses
Remove Punctuations Punctuation can provide grammatical context which supports understanding Often for initial analyses we ignore the punctuation Later we will use punctuation to support the extraction of meaning
Remove English stop words
Stop words are common words found in a language Words like for of are etc are common stop words
Remove Own stop words(if required)
Along with English stop words we could instead or in addition remove our own stop words The choice of own stop word might depend on the domain of discourse and might not become
apparent until weve done some analysis
Strip whitespace
Eliminate extra white-spaces Any additional space that is not the space that occur within the sentence or between words
Stemming
Stemming uses an algorithm that removes common word endings for English words such as ldquoesrdquo ldquoedrdquo and ldquosrdquo Example computer amp computers become comput
Lemmatization Transform to dictionary base form ie produce amp produced become produce
Sparse terms
We are often not interested in infrequent terms in our documents Such ldquosparse terms should be removed from the document term matrix
Document term matrix A document term matrix is simply a matrix with documents as the rows and terms as the columns and a count of the frequency of words as the cells of the matrix
Step 2 - Data Processing
4 Python packages ndash textmining nltk R packages - tm qdap openNLP
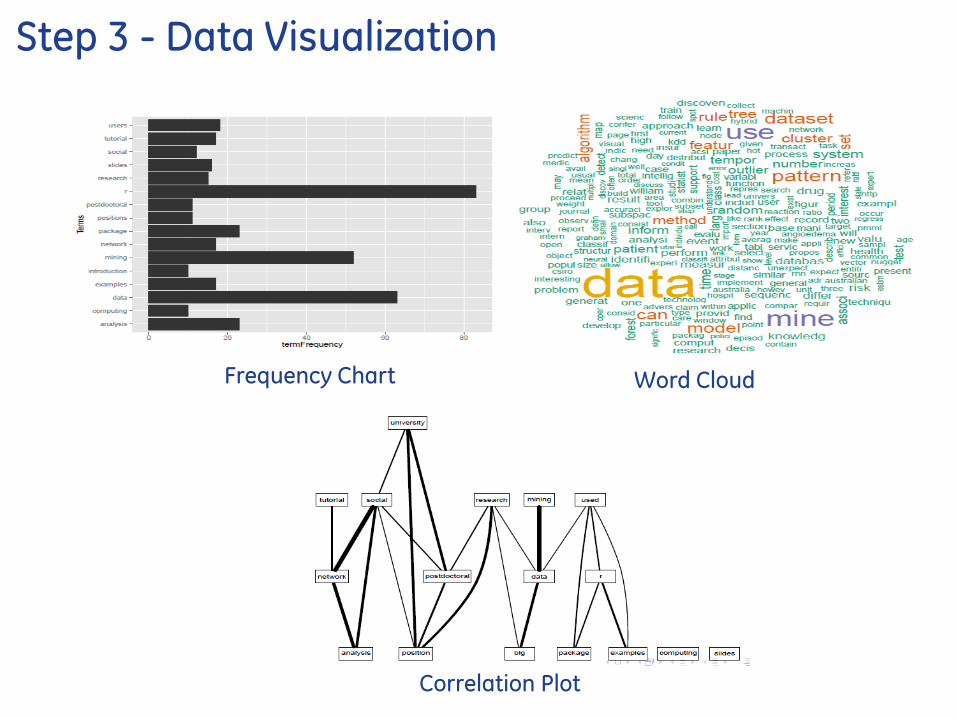
Step 3 - Data Visualization
Frequency Chart Word Cloud
Correlation Plot
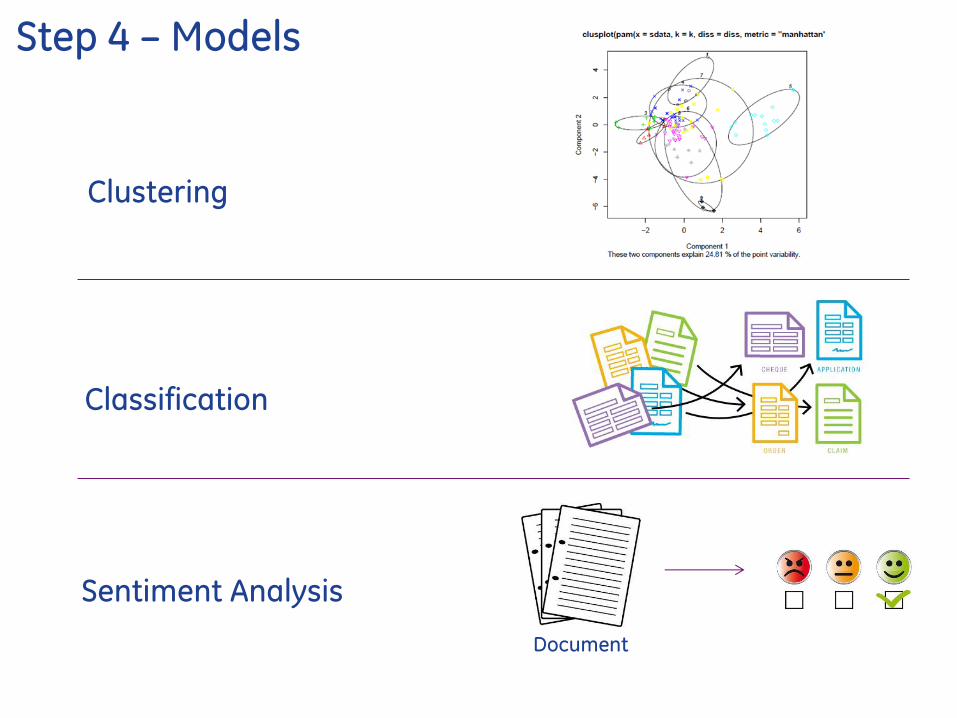
Step 4 ndash Models
Clustering
Classification
Sentiment Analysis
Document
Term Frequency - How frequently term appears Term Frequency TF(t) = (Number of times term t appears in a document) (Total number of terms in the document)
Example
Calculate Term Weight (TF IDF)
Inverse Document Frequency - How important a term is
Document Frequency DF = d (number of documents containing a given term) D (the size of the collection of documents)
To normalize take log(dD) but often D gt d and log(dD) will give negative value So invert the ratio inside log expression Essentially we are compressing the scale of values so that very large or very small quantities are smoothly compared
Inverse Document Frequency IDF(t) = log(Total number of documents Number of documents with term t in it)
7
- Assume we have overall 10 million documents and the word spindle appears in one thousand of these - Consider 2 documents containing 100 total words each and contains term spindle x number of times
Document spindle ndash Frequency Total Words TF IDF TF IDF
1 3 100 3100 = 003 log(100000001000) = 4 003 4 = 012
2 30 100 30100 = 3 log(100000001000) = 4 03 4 = 12
Similarity Distance Measure
Example Text 1 statistics skills and programming skills are equally important for analytics
Text 2 statistics skills and domain knowledge are important for analytics
Text 3 I like reading books and travelling
The three vectors are
T1 = (1211011111000000)
T2 = (1110110111100000)
T3 = (0010000000011111)
Degree of Similarity (T1 amp T2) = (T1 T2) (sqrt(sum(T1^2)) sqrt(sum(T2^2))) = 77
Degree of Similarity (T1 amp T3) = (T1 T3) (sqrt(sum(T1^2)) sqrt(sum(T3^2))) = 12
Additional Reading Here is a detailed paper on comparing the efficiency of different distance measures for text documents
URL ndash 1) httphomeiitkacin~spranjalcs671projectreportpdf
2) httpusersdsicupves~prossoresourcesBarronEtAl_ICON09pdf
statistics skills and programming knowledge are equally important for analytics domain I like reading books travelling
Text 1 1 2 1 1 0 1 1 1 1 1 0 0 0 0 0 0
Text 2 1 1 1 0 1 1 0 1 1 1 1 0 0 0 0 0
Text 3 0 0 1 0 0 0 0 0 0 0 0 1 1 1 1 1
X
Y
Euclidean
Cosine
- cosine value will be a number between 0 and 1 - Smaller the angel bigger the cosine valuesimilarity
8
Common Text Mining Techniques
bull N-grams
bull Shallow Natural Language Processing
bull Deep Natural Language Processing
Example defense attorney for liberty and
montecitordquo 1-gram defense attorney for liberty and montecito 2-gram defense attorney for liberty and montecito attorney for liberty and attorney for 3-gram defense attorney for liberty and montecito attorney for liberty for liberty and liberty and montecito 4-gram defense attorney for liberty attorney for liberty and for liberty and montecito 5-gram defense attorney for liberty and montecito attorney for liberty and montecito
Application
Probabilistic language model for predicting the
next item in a sequence in the form of a (n minus 1)
Widely used in probability communication
theory computational linguistics biological
sequence analysis
Advantage
Relatively simple
Simply increasing n model can be used to store
more context
Disadvantage
Semantic value of the item is not considered
n-gram Definition
bull n-gram is a contiguous sequence of n items from a given sequence of text
bull The items can be letters words syllables or base pairs according to the application
10
Application
- Taxonomy extraction (predefined terms and entities)
- Entities People organizations locations times dates prices genes proteins diseases
medicines
- Concept extraction (main idea or a theme)
Advantage
- Less noisy than n-grams
Disadvantage
- Does not specify role of items in the main sentence
Shallow NLP Technique Definition
- Assign a syntactic label (noun verb etc) to a chunk
- Knowledge extraction from text through semanticsyntactic analysis approach
11
Sentence - ldquoThe driver from Europe crashed the car with the white bumperrdquo
1-gram
the
driver
from
europe
crashed
the
car
with
the
white
bumper
Part of Speech
DT ndash Determiner
NN - Noun singular or mass
IN - Preposition or subordinating conjunction
NNP - Proper Noun singular
VBD - Verb past tense
DT ndash Determiner
NN - Noun singular or mass
IN - Preposition or subordinating conjunction
DT ndash Determiner
JJ ndash Adjective
NN - Noun singular or mass
- Convert to lowercase amp PoS tag
Concept Extraction
- Remove Stop words
- Retain only Nounrsquos amp Verbrsquos
- Bi-gram with Nounrsquos amp Verbrsquos retained
Bi-gram PoS
car white NN JJ
crashed car VBD NN
driver europe NN NNP
europe crashed NNP VBD
white bumper JJ NN
3-gram PoS
car white bumper NN JJ NN
crashed car white VBD NN JJ
driver europe crashed NN NNP VBD
europe crashed car NNP VBD NN
- 3-gram with Nounrsquos amp Verbrsquos retained
Conclusion
1-gram Reduced noise however no clear context Bi-gram amp 3-gram Increased context however there
is a information loss
Shallow NLP Technique
12
Stop words NounVerb
Definition
- Extension to the shallow NLP
- Detected relationships are expressed as complex construction to retain the context
- Example relationships Located in employed by part of married to
Applications
- Develop features and representations appropriate for complex interpretation tasks
- Fraud detection - Life science prediction activities based on complex RNA-Sequence
Deep NLP technique
Example
The above sentence can be represented using triples (Subject Predicate [Modifier] Object) without loosing the context
Triples
driver crash car
driver crash with bumper
driver be from Europe 13
Technique General Steps Pros Cons
N-Gram
- Convert to lowercase
- Remove punctuations - Remove special characters Simple technique Extremely noisy
Shallow NLP
technique
- POS tagging
- Lemmatization ie transform to
dictionary base form ie produce amp produced become produce
- Stemming ie transform to root word
ie 1) computer amp computers become
comput
2) product produce amp produced
become produc
- Chunking ie identify the phrasal
constituents in a sentence including
nounverb phrase etc and splits the
sentence into chunks of semantically
related words
Less noisy than N-
Grams
Computationally
expensive
solution for
analyzing the
structure of texts
Does not specify
the internal
structure or the
role of words in
the sentence
Deep NLP
technique
- Generate syntactic relationship
between each pair of words
- Extract subject predicate nagation
objecct and named entity to form triples
Context of the
sentence is
retained
Sentence level
analysis is too
structured
Techniques - Summary
14
Appendix
15
2A - Explore Corpus through EDA 2B - Convert text to lowercase 2C - Remove
a) Numbers(if required) b) Punctuations c) English stop words d) Own stop words(if
required)
e) Strip whitespace f) LemmatizationStemming g) Sparse terms
2D - Create document term matrix
Step 3 - Visualization
Corpus
Web
Documents
Step 1 ndash Data Assemble
Step 2 ndash Data Processing
Step 4 ndash Build Model(s)
Clustering
Classification
Sentiment Analysis
Fre
qu
en
cy
Ch
art
W
ord
Clo
ud
C
orr
ela
tio
n P
lot
R - Text Mining Process Overview
16
DB
Package Name
Category Description
tm Text Mining A framework for text mining applications
topicmodels Topic Modelling Fit topic models with Latent Dirichlet Allocation (LDA) and Comparative Text Mining (CTM)
wordcloud Visualization Plot a cloud comparing the frequencies of words across documents
lda Topic Modelling Fit topic models with Latent Dirichlet Allocation
wordnet Text Mining Database of English which is commonly used in linguistics and text mining
RTextTools Text Mining Automatic text classification via supervised learning
qdap Sentiment analysis
Transcript analysis text mining and natural language processing
tmplugindc Text Mining A plug-in for package tm to support distributed text mining
tmpluginmail Text Mining A plug-in for package tm to handle mail
textir Text Mining A suite of tools for inference about text documents and associated sentiment
tau Text Mining Utilities for text analysis
textcat Text Mining N-gram based text categorization
SnowballC Text Mining Word stemmer
twitteR Text Mining Provides an interface to the Twitter web API
ROAuth Text Mining Allows users to authenticate to the server of their choice (like Twitter)
RColorBrewer Visualization The packages provides palettes for drawing nice maps shaded according to a variable
ggplot2 Visualization
Graphing package implemented on top of the R statistical package Inspired by the Grammar of Graphics seminal work of Leland Wilkinson
R ndash Required packages for Text Mining
17
Example 1 - Obtaining and analyzing tweets
Objective R code for analyzing tweets relating to AAA2011 (text mining topic modelling network analysis clustering and sentiment analysis)
What does the code do
The code details ten steps in the analysis and visualization of the tweets
Acquiring the raw Twitter data
Calculating some basic statistics with the raw Twitter data
Calculating some basic retweet statistics
Calculating the ratio of retweets to tweets
Calculating some basic statistics about URLs in tweets
Basic text mining for token frequency and token association analysis (word cloud)
Calculating sentiment scores of tweets including on subsets containing tokens of interest
Hierarchical clustering of tokens based on multi scale bootstrap resampling
Topic modelling the tweet corpus using latent Dirichlet allocation
Network analysis of tweeters based on retweets
Code Source Code was taken from following link and tweakedadded additional bits where required to ensure code runs fine httpsgithubcombenmarwickAAA2011-Tweets
How to Run or Test the code - From the word doc copy the R code in the given sequence highlighted in yellow color and paste on your R console
18
RTextTools ndash Example for supervised Learning for Text Classification using Ensemble
RTextTools is a free open source R machine learning package for automatic text classification
The package includes nine algorithms for ensemble classification (svm slda boosting bagging random forests glmnet decision trees neural networks and maximum entropy) comprehensive analytics and thorough documentation
Users may use n-fold cross validation to calculate the accuracy of each algorithm on their dataset and determine which algorithms to use in their ensemble
(Using a four-ensemble agreement approach Collingwood and Wilkerson (2012) found that when four of their algorithms agree on the label of a textual document the machine label matches the human label over 90 of the time The rate is just 45 when only two algorithms agree on the text label)
Code Source The codes is readily available for download and usage from the following link httpsgithubcomtimjurkaRTextTools The code can be implemented without modification for testing however itrsquos set up such that changes can be incorporated easily based on our requirement
Additional Reading httpwwwrtexttoolscomabout-the-projecthtml
19
Example 2 - RTextTools
Penn Treebank - httpswwwlingupenneducoursesFall_2003ling001penn_treebank_poshtml
Stanford info lab - Finding Similar Items httpinfolabstanfordedu~ullmanmmdsch3pdf
TRIPLET EXTRACTION FROM SENTENCES URL - httpailabijssidelia_rusuPapersis_2007pdf
Shallow and Deep NLP Processing for ontology learning a Quick Overview httpazouaqathabascaucapublicationsConferences20Workshops20Books5BBC25D_KDW_2010pdf
References
20

agenda o Text Mining Process Steps
o Calculate Term Weight
o Similarity Distance Measure
o Common Text Mining Techniques
o Appendix
- Required R packages for Text Mining
- Implemented Examples
o R code for obtaining and analyzing tweets o RTextTools ndash Ensemble Classification
o References
Manohar Swamynathan Aug 2012
Step 1 ndash Data assemble
Text Corpus
Flat files
Social
Corporate
Database
Co
mm
on
Te
xt D
ata
So
urc
es
Data Processing Step Brief Description
Explore Corpus through Exploratory Data Analysis
Understand the types of variables their functions permissible values and so on Some formats including html and xml contain tags and other data structures that provide more metadata
Convert text to lowercase This is to avoid distinguish between words simply on case
Remove Number(if required)
Numbers may or may not be relevant to our analyses
Remove Punctuations Punctuation can provide grammatical context which supports understanding Often for initial analyses we ignore the punctuation Later we will use punctuation to support the extraction of meaning
Remove English stop words
Stop words are common words found in a language Words like for of are etc are common stop words
Remove Own stop words(if required)
Along with English stop words we could instead or in addition remove our own stop words The choice of own stop word might depend on the domain of discourse and might not become
apparent until weve done some analysis
Strip whitespace
Eliminate extra white-spaces Any additional space that is not the space that occur within the sentence or between words
Stemming
Stemming uses an algorithm that removes common word endings for English words such as ldquoesrdquo ldquoedrdquo and ldquosrdquo Example computer amp computers become comput
Lemmatization Transform to dictionary base form ie produce amp produced become produce
Sparse terms
We are often not interested in infrequent terms in our documents Such ldquosparse terms should be removed from the document term matrix
Document term matrix A document term matrix is simply a matrix with documents as the rows and terms as the columns and a count of the frequency of words as the cells of the matrix
Step 2 - Data Processing
4 Python packages ndash textmining nltk R packages - tm qdap openNLP
Step 3 - Data Visualization
Frequency Chart Word Cloud
Correlation Plot
Step 4 ndash Models
Clustering
Classification
Sentiment Analysis
Document
Term Frequency - How frequently term appears Term Frequency TF(t) = (Number of times term t appears in a document) (Total number of terms in the document)
Example
Calculate Term Weight (TF IDF)
Inverse Document Frequency - How important a term is
Document Frequency DF = d (number of documents containing a given term) D (the size of the collection of documents)
To normalize take log(dD) but often D gt d and log(dD) will give negative value So invert the ratio inside log expression Essentially we are compressing the scale of values so that very large or very small quantities are smoothly compared
Inverse Document Frequency IDF(t) = log(Total number of documents Number of documents with term t in it)
7
- Assume we have overall 10 million documents and the word spindle appears in one thousand of these - Consider 2 documents containing 100 total words each and contains term spindle x number of times
Document spindle ndash Frequency Total Words TF IDF TF IDF
1 3 100 3100 = 003 log(100000001000) = 4 003 4 = 012
2 30 100 30100 = 3 log(100000001000) = 4 03 4 = 12
Similarity Distance Measure
Example Text 1 statistics skills and programming skills are equally important for analytics
Text 2 statistics skills and domain knowledge are important for analytics
Text 3 I like reading books and travelling
The three vectors are
T1 = (1211011111000000)
T2 = (1110110111100000)
T3 = (0010000000011111)
Degree of Similarity (T1 amp T2) = (T1 T2) (sqrt(sum(T1^2)) sqrt(sum(T2^2))) = 77
Degree of Similarity (T1 amp T3) = (T1 T3) (sqrt(sum(T1^2)) sqrt(sum(T3^2))) = 12
Additional Reading Here is a detailed paper on comparing the efficiency of different distance measures for text documents
URL ndash 1) httphomeiitkacin~spranjalcs671projectreportpdf
2) httpusersdsicupves~prossoresourcesBarronEtAl_ICON09pdf
statistics skills and programming knowledge are equally important for analytics domain I like reading books travelling
Text 1 1 2 1 1 0 1 1 1 1 1 0 0 0 0 0 0
Text 2 1 1 1 0 1 1 0 1 1 1 1 0 0 0 0 0
Text 3 0 0 1 0 0 0 0 0 0 0 0 1 1 1 1 1
X
Y
Euclidean
Cosine
- cosine value will be a number between 0 and 1 - Smaller the angel bigger the cosine valuesimilarity
8
Common Text Mining Techniques
bull N-grams
bull Shallow Natural Language Processing
bull Deep Natural Language Processing
Example defense attorney for liberty and
montecitordquo 1-gram defense attorney for liberty and montecito 2-gram defense attorney for liberty and montecito attorney for liberty and attorney for 3-gram defense attorney for liberty and montecito attorney for liberty for liberty and liberty and montecito 4-gram defense attorney for liberty attorney for liberty and for liberty and montecito 5-gram defense attorney for liberty and montecito attorney for liberty and montecito
Application
Probabilistic language model for predicting the
next item in a sequence in the form of a (n minus 1)
Widely used in probability communication
theory computational linguistics biological
sequence analysis
Advantage
Relatively simple
Simply increasing n model can be used to store
more context
Disadvantage
Semantic value of the item is not considered
n-gram Definition
bull n-gram is a contiguous sequence of n items from a given sequence of text
bull The items can be letters words syllables or base pairs according to the application
10
Application
- Taxonomy extraction (predefined terms and entities)
- Entities People organizations locations times dates prices genes proteins diseases
medicines
- Concept extraction (main idea or a theme)
Advantage
- Less noisy than n-grams
Disadvantage
- Does not specify role of items in the main sentence
Shallow NLP Technique Definition
- Assign a syntactic label (noun verb etc) to a chunk
- Knowledge extraction from text through semanticsyntactic analysis approach
11
Sentence - ldquoThe driver from Europe crashed the car with the white bumperrdquo
1-gram
the
driver
from
europe
crashed
the
car
with
the
white
bumper
Part of Speech
DT ndash Determiner
NN - Noun singular or mass
IN - Preposition or subordinating conjunction
NNP - Proper Noun singular
VBD - Verb past tense
DT ndash Determiner
NN - Noun singular or mass
IN - Preposition or subordinating conjunction
DT ndash Determiner
JJ ndash Adjective
NN - Noun singular or mass
- Convert to lowercase amp PoS tag
Concept Extraction
- Remove Stop words
- Retain only Nounrsquos amp Verbrsquos
- Bi-gram with Nounrsquos amp Verbrsquos retained
Bi-gram PoS
car white NN JJ
crashed car VBD NN
driver europe NN NNP
europe crashed NNP VBD
white bumper JJ NN
3-gram PoS
car white bumper NN JJ NN
crashed car white VBD NN JJ
driver europe crashed NN NNP VBD
europe crashed car NNP VBD NN
- 3-gram with Nounrsquos amp Verbrsquos retained
Conclusion
1-gram Reduced noise however no clear context Bi-gram amp 3-gram Increased context however there
is a information loss
Shallow NLP Technique
12
Stop words NounVerb
Definition
- Extension to the shallow NLP
- Detected relationships are expressed as complex construction to retain the context
- Example relationships Located in employed by part of married to
Applications
- Develop features and representations appropriate for complex interpretation tasks
- Fraud detection - Life science prediction activities based on complex RNA-Sequence
Deep NLP technique
Example
The above sentence can be represented using triples (Subject Predicate [Modifier] Object) without loosing the context
Triples
driver crash car
driver crash with bumper
driver be from Europe 13
Technique General Steps Pros Cons
N-Gram
- Convert to lowercase
- Remove punctuations - Remove special characters Simple technique Extremely noisy
Shallow NLP
technique
- POS tagging
- Lemmatization ie transform to
dictionary base form ie produce amp produced become produce
- Stemming ie transform to root word
ie 1) computer amp computers become
comput
2) product produce amp produced
become produc
- Chunking ie identify the phrasal
constituents in a sentence including
nounverb phrase etc and splits the
sentence into chunks of semantically
related words
Less noisy than N-
Grams
Computationally
expensive
solution for
analyzing the
structure of texts
Does not specify
the internal
structure or the
role of words in
the sentence
Deep NLP
technique
- Generate syntactic relationship
between each pair of words
- Extract subject predicate nagation
objecct and named entity to form triples
Context of the
sentence is
retained
Sentence level
analysis is too
structured
Techniques - Summary
14
Appendix
15
2A - Explore Corpus through EDA 2B - Convert text to lowercase 2C - Remove
a) Numbers(if required) b) Punctuations c) English stop words d) Own stop words(if
required)
e) Strip whitespace f) LemmatizationStemming g) Sparse terms
2D - Create document term matrix
Step 3 - Visualization
Corpus
Web
Documents
Step 1 ndash Data Assemble
Step 2 ndash Data Processing
Step 4 ndash Build Model(s)
Clustering
Classification
Sentiment Analysis
Fre
qu
en
cy
Ch
art
W
ord
Clo
ud
C
orr
ela
tio
n P
lot
R - Text Mining Process Overview
16
DB
Package Name
Category Description
tm Text Mining A framework for text mining applications
topicmodels Topic Modelling Fit topic models with Latent Dirichlet Allocation (LDA) and Comparative Text Mining (CTM)
wordcloud Visualization Plot a cloud comparing the frequencies of words across documents
lda Topic Modelling Fit topic models with Latent Dirichlet Allocation
wordnet Text Mining Database of English which is commonly used in linguistics and text mining
RTextTools Text Mining Automatic text classification via supervised learning
qdap Sentiment analysis
Transcript analysis text mining and natural language processing
tmplugindc Text Mining A plug-in for package tm to support distributed text mining
tmpluginmail Text Mining A plug-in for package tm to handle mail
textir Text Mining A suite of tools for inference about text documents and associated sentiment
tau Text Mining Utilities for text analysis
textcat Text Mining N-gram based text categorization
SnowballC Text Mining Word stemmer
twitteR Text Mining Provides an interface to the Twitter web API
ROAuth Text Mining Allows users to authenticate to the server of their choice (like Twitter)
RColorBrewer Visualization The packages provides palettes for drawing nice maps shaded according to a variable
ggplot2 Visualization
Graphing package implemented on top of the R statistical package Inspired by the Grammar of Graphics seminal work of Leland Wilkinson
R ndash Required packages for Text Mining
17
Example 1 - Obtaining and analyzing tweets
Objective R code for analyzing tweets relating to AAA2011 (text mining topic modelling network analysis clustering and sentiment analysis)
What does the code do
The code details ten steps in the analysis and visualization of the tweets
Acquiring the raw Twitter data
Calculating some basic statistics with the raw Twitter data
Calculating some basic retweet statistics
Calculating the ratio of retweets to tweets
Calculating some basic statistics about URLs in tweets
Basic text mining for token frequency and token association analysis (word cloud)
Calculating sentiment scores of tweets including on subsets containing tokens of interest
Hierarchical clustering of tokens based on multi scale bootstrap resampling
Topic modelling the tweet corpus using latent Dirichlet allocation
Network analysis of tweeters based on retweets
Code Source Code was taken from following link and tweakedadded additional bits where required to ensure code runs fine httpsgithubcombenmarwickAAA2011-Tweets
How to Run or Test the code - From the word doc copy the R code in the given sequence highlighted in yellow color and paste on your R console
18
RTextTools ndash Example for supervised Learning for Text Classification using Ensemble
RTextTools is a free open source R machine learning package for automatic text classification
The package includes nine algorithms for ensemble classification (svm slda boosting bagging random forests glmnet decision trees neural networks and maximum entropy) comprehensive analytics and thorough documentation
Users may use n-fold cross validation to calculate the accuracy of each algorithm on their dataset and determine which algorithms to use in their ensemble
(Using a four-ensemble agreement approach Collingwood and Wilkerson (2012) found that when four of their algorithms agree on the label of a textual document the machine label matches the human label over 90 of the time The rate is just 45 when only two algorithms agree on the text label)
Code Source The codes is readily available for download and usage from the following link httpsgithubcomtimjurkaRTextTools The code can be implemented without modification for testing however itrsquos set up such that changes can be incorporated easily based on our requirement
Additional Reading httpwwwrtexttoolscomabout-the-projecthtml
19
Example 2 - RTextTools
Penn Treebank - httpswwwlingupenneducoursesFall_2003ling001penn_treebank_poshtml
Stanford info lab - Finding Similar Items httpinfolabstanfordedu~ullmanmmdsch3pdf
TRIPLET EXTRACTION FROM SENTENCES URL - httpailabijssidelia_rusuPapersis_2007pdf
Shallow and Deep NLP Processing for ontology learning a Quick Overview httpazouaqathabascaucapublicationsConferences20Workshops20Books5BBC25D_KDW_2010pdf
References
20
Step 1 ndash Data assemble
Text Corpus
Flat files
Social
Corporate
Database
Co
mm
on
Te
xt D
ata
So
urc
es
Data Processing Step Brief Description
Explore Corpus through Exploratory Data Analysis
Understand the types of variables their functions permissible values and so on Some formats including html and xml contain tags and other data structures that provide more metadata
Convert text to lowercase This is to avoid distinguish between words simply on case
Remove Number(if required)
Numbers may or may not be relevant to our analyses
Remove Punctuations Punctuation can provide grammatical context which supports understanding Often for initial analyses we ignore the punctuation Later we will use punctuation to support the extraction of meaning
Remove English stop words
Stop words are common words found in a language Words like for of are etc are common stop words
Remove Own stop words(if required)
Along with English stop words we could instead or in addition remove our own stop words The choice of own stop word might depend on the domain of discourse and might not become
apparent until weve done some analysis
Strip whitespace
Eliminate extra white-spaces Any additional space that is not the space that occur within the sentence or between words
Stemming
Stemming uses an algorithm that removes common word endings for English words such as ldquoesrdquo ldquoedrdquo and ldquosrdquo Example computer amp computers become comput
Lemmatization Transform to dictionary base form ie produce amp produced become produce
Sparse terms
We are often not interested in infrequent terms in our documents Such ldquosparse terms should be removed from the document term matrix
Document term matrix A document term matrix is simply a matrix with documents as the rows and terms as the columns and a count of the frequency of words as the cells of the matrix
Step 2 - Data Processing
4 Python packages ndash textmining nltk R packages - tm qdap openNLP
Step 3 - Data Visualization
Frequency Chart Word Cloud
Correlation Plot
Step 4 ndash Models
Clustering
Classification
Sentiment Analysis
Document
Term Frequency - How frequently term appears Term Frequency TF(t) = (Number of times term t appears in a document) (Total number of terms in the document)
Example
Calculate Term Weight (TF IDF)
Inverse Document Frequency - How important a term is
Document Frequency DF = d (number of documents containing a given term) D (the size of the collection of documents)
To normalize take log(dD) but often D gt d and log(dD) will give negative value So invert the ratio inside log expression Essentially we are compressing the scale of values so that very large or very small quantities are smoothly compared
Inverse Document Frequency IDF(t) = log(Total number of documents Number of documents with term t in it)
7
- Assume we have overall 10 million documents and the word spindle appears in one thousand of these - Consider 2 documents containing 100 total words each and contains term spindle x number of times
Document spindle ndash Frequency Total Words TF IDF TF IDF
1 3 100 3100 = 003 log(100000001000) = 4 003 4 = 012
2 30 100 30100 = 3 log(100000001000) = 4 03 4 = 12
Similarity Distance Measure
Example Text 1 statistics skills and programming skills are equally important for analytics
Text 2 statistics skills and domain knowledge are important for analytics
Text 3 I like reading books and travelling
The three vectors are
T1 = (1211011111000000)
T2 = (1110110111100000)
T3 = (0010000000011111)
Degree of Similarity (T1 amp T2) = (T1 T2) (sqrt(sum(T1^2)) sqrt(sum(T2^2))) = 77
Degree of Similarity (T1 amp T3) = (T1 T3) (sqrt(sum(T1^2)) sqrt(sum(T3^2))) = 12
Additional Reading Here is a detailed paper on comparing the efficiency of different distance measures for text documents
URL ndash 1) httphomeiitkacin~spranjalcs671projectreportpdf
2) httpusersdsicupves~prossoresourcesBarronEtAl_ICON09pdf
statistics skills and programming knowledge are equally important for analytics domain I like reading books travelling
Text 1 1 2 1 1 0 1 1 1 1 1 0 0 0 0 0 0
Text 2 1 1 1 0 1 1 0 1 1 1 1 0 0 0 0 0
Text 3 0 0 1 0 0 0 0 0 0 0 0 1 1 1 1 1
X
Y
Euclidean
Cosine
- cosine value will be a number between 0 and 1 - Smaller the angel bigger the cosine valuesimilarity
8
Common Text Mining Techniques
bull N-grams
bull Shallow Natural Language Processing
bull Deep Natural Language Processing
Example defense attorney for liberty and
montecitordquo 1-gram defense attorney for liberty and montecito 2-gram defense attorney for liberty and montecito attorney for liberty and attorney for 3-gram defense attorney for liberty and montecito attorney for liberty for liberty and liberty and montecito 4-gram defense attorney for liberty attorney for liberty and for liberty and montecito 5-gram defense attorney for liberty and montecito attorney for liberty and montecito
Application
Probabilistic language model for predicting the
next item in a sequence in the form of a (n minus 1)
Widely used in probability communication
theory computational linguistics biological
sequence analysis
Advantage
Relatively simple
Simply increasing n model can be used to store
more context
Disadvantage
Semantic value of the item is not considered
n-gram Definition
bull n-gram is a contiguous sequence of n items from a given sequence of text
bull The items can be letters words syllables or base pairs according to the application
10
Application
- Taxonomy extraction (predefined terms and entities)
- Entities People organizations locations times dates prices genes proteins diseases
medicines
- Concept extraction (main idea or a theme)
Advantage
- Less noisy than n-grams
Disadvantage
- Does not specify role of items in the main sentence
Shallow NLP Technique Definition
- Assign a syntactic label (noun verb etc) to a chunk
- Knowledge extraction from text through semanticsyntactic analysis approach
11
Sentence - ldquoThe driver from Europe crashed the car with the white bumperrdquo
1-gram
the
driver
from
europe
crashed
the
car
with
the
white
bumper
Part of Speech
DT ndash Determiner
NN - Noun singular or mass
IN - Preposition or subordinating conjunction
NNP - Proper Noun singular
VBD - Verb past tense
DT ndash Determiner
NN - Noun singular or mass
IN - Preposition or subordinating conjunction
DT ndash Determiner
JJ ndash Adjective
NN - Noun singular or mass
- Convert to lowercase amp PoS tag
Concept Extraction
- Remove Stop words
- Retain only Nounrsquos amp Verbrsquos
- Bi-gram with Nounrsquos amp Verbrsquos retained
Bi-gram PoS
car white NN JJ
crashed car VBD NN
driver europe NN NNP
europe crashed NNP VBD
white bumper JJ NN
3-gram PoS
car white bumper NN JJ NN
crashed car white VBD NN JJ
driver europe crashed NN NNP VBD
europe crashed car NNP VBD NN
- 3-gram with Nounrsquos amp Verbrsquos retained
Conclusion
1-gram Reduced noise however no clear context Bi-gram amp 3-gram Increased context however there
is a information loss
Shallow NLP Technique
12
Stop words NounVerb
Definition
- Extension to the shallow NLP
- Detected relationships are expressed as complex construction to retain the context
- Example relationships Located in employed by part of married to
Applications
- Develop features and representations appropriate for complex interpretation tasks
- Fraud detection - Life science prediction activities based on complex RNA-Sequence
Deep NLP technique
Example
The above sentence can be represented using triples (Subject Predicate [Modifier] Object) without loosing the context
Triples
driver crash car
driver crash with bumper
driver be from Europe 13
Technique General Steps Pros Cons
N-Gram
- Convert to lowercase
- Remove punctuations - Remove special characters Simple technique Extremely noisy
Shallow NLP
technique
- POS tagging
- Lemmatization ie transform to
dictionary base form ie produce amp produced become produce
- Stemming ie transform to root word
ie 1) computer amp computers become
comput
2) product produce amp produced
become produc
- Chunking ie identify the phrasal
constituents in a sentence including
nounverb phrase etc and splits the
sentence into chunks of semantically
related words
Less noisy than N-
Grams
Computationally
expensive
solution for
analyzing the
structure of texts
Does not specify
the internal
structure or the
role of words in
the sentence
Deep NLP
technique
- Generate syntactic relationship
between each pair of words
- Extract subject predicate nagation
objecct and named entity to form triples
Context of the
sentence is
retained
Sentence level
analysis is too
structured
Techniques - Summary
14
Appendix
15
2A - Explore Corpus through EDA 2B - Convert text to lowercase 2C - Remove
a) Numbers(if required) b) Punctuations c) English stop words d) Own stop words(if
required)
e) Strip whitespace f) LemmatizationStemming g) Sparse terms
2D - Create document term matrix
Step 3 - Visualization
Corpus
Web
Documents
Step 1 ndash Data Assemble
Step 2 ndash Data Processing
Step 4 ndash Build Model(s)
Clustering
Classification
Sentiment Analysis
Fre
qu
en
cy
Ch
art
W
ord
Clo
ud
C
orr
ela
tio
n P
lot
R - Text Mining Process Overview
16
DB
Package Name
Category Description
tm Text Mining A framework for text mining applications
topicmodels Topic Modelling Fit topic models with Latent Dirichlet Allocation (LDA) and Comparative Text Mining (CTM)
wordcloud Visualization Plot a cloud comparing the frequencies of words across documents
lda Topic Modelling Fit topic models with Latent Dirichlet Allocation
wordnet Text Mining Database of English which is commonly used in linguistics and text mining
RTextTools Text Mining Automatic text classification via supervised learning
qdap Sentiment analysis
Transcript analysis text mining and natural language processing
tmplugindc Text Mining A plug-in for package tm to support distributed text mining
tmpluginmail Text Mining A plug-in for package tm to handle mail
textir Text Mining A suite of tools for inference about text documents and associated sentiment
tau Text Mining Utilities for text analysis
textcat Text Mining N-gram based text categorization
SnowballC Text Mining Word stemmer
twitteR Text Mining Provides an interface to the Twitter web API
ROAuth Text Mining Allows users to authenticate to the server of their choice (like Twitter)
RColorBrewer Visualization The packages provides palettes for drawing nice maps shaded according to a variable
ggplot2 Visualization
Graphing package implemented on top of the R statistical package Inspired by the Grammar of Graphics seminal work of Leland Wilkinson
R ndash Required packages for Text Mining
17
Example 1 - Obtaining and analyzing tweets
Objective R code for analyzing tweets relating to AAA2011 (text mining topic modelling network analysis clustering and sentiment analysis)
What does the code do
The code details ten steps in the analysis and visualization of the tweets
Acquiring the raw Twitter data
Calculating some basic statistics with the raw Twitter data
Calculating some basic retweet statistics
Calculating the ratio of retweets to tweets
Calculating some basic statistics about URLs in tweets
Basic text mining for token frequency and token association analysis (word cloud)
Calculating sentiment scores of tweets including on subsets containing tokens of interest
Hierarchical clustering of tokens based on multi scale bootstrap resampling
Topic modelling the tweet corpus using latent Dirichlet allocation
Network analysis of tweeters based on retweets
Code Source Code was taken from following link and tweakedadded additional bits where required to ensure code runs fine httpsgithubcombenmarwickAAA2011-Tweets
How to Run or Test the code - From the word doc copy the R code in the given sequence highlighted in yellow color and paste on your R console
18
RTextTools ndash Example for supervised Learning for Text Classification using Ensemble
RTextTools is a free open source R machine learning package for automatic text classification
The package includes nine algorithms for ensemble classification (svm slda boosting bagging random forests glmnet decision trees neural networks and maximum entropy) comprehensive analytics and thorough documentation
Users may use n-fold cross validation to calculate the accuracy of each algorithm on their dataset and determine which algorithms to use in their ensemble
(Using a four-ensemble agreement approach Collingwood and Wilkerson (2012) found that when four of their algorithms agree on the label of a textual document the machine label matches the human label over 90 of the time The rate is just 45 when only two algorithms agree on the text label)
Code Source The codes is readily available for download and usage from the following link httpsgithubcomtimjurkaRTextTools The code can be implemented without modification for testing however itrsquos set up such that changes can be incorporated easily based on our requirement
Additional Reading httpwwwrtexttoolscomabout-the-projecthtml
19
Example 2 - RTextTools
Penn Treebank - httpswwwlingupenneducoursesFall_2003ling001penn_treebank_poshtml
Stanford info lab - Finding Similar Items httpinfolabstanfordedu~ullmanmmdsch3pdf
TRIPLET EXTRACTION FROM SENTENCES URL - httpailabijssidelia_rusuPapersis_2007pdf
Shallow and Deep NLP Processing for ontology learning a Quick Overview httpazouaqathabascaucapublicationsConferences20Workshops20Books5BBC25D_KDW_2010pdf
References
20
Data Processing Step Brief Description
Explore Corpus through Exploratory Data Analysis
Understand the types of variables their functions permissible values and so on Some formats including html and xml contain tags and other data structures that provide more metadata
Convert text to lowercase This is to avoid distinguish between words simply on case
Remove Number(if required)
Numbers may or may not be relevant to our analyses
Remove Punctuations Punctuation can provide grammatical context which supports understanding Often for initial analyses we ignore the punctuation Later we will use punctuation to support the extraction of meaning
Remove English stop words
Stop words are common words found in a language Words like for of are etc are common stop words
Remove Own stop words(if required)
Along with English stop words we could instead or in addition remove our own stop words The choice of own stop word might depend on the domain of discourse and might not become
apparent until weve done some analysis
Strip whitespace
Eliminate extra white-spaces Any additional space that is not the space that occur within the sentence or between words
Stemming
Stemming uses an algorithm that removes common word endings for English words such as ldquoesrdquo ldquoedrdquo and ldquosrdquo Example computer amp computers become comput
Lemmatization Transform to dictionary base form ie produce amp produced become produce
Sparse terms
We are often not interested in infrequent terms in our documents Such ldquosparse terms should be removed from the document term matrix
Document term matrix A document term matrix is simply a matrix with documents as the rows and terms as the columns and a count of the frequency of words as the cells of the matrix
Step 2 - Data Processing
4 Python packages ndash textmining nltk R packages - tm qdap openNLP
Step 3 - Data Visualization
Frequency Chart Word Cloud
Correlation Plot
Step 4 ndash Models
Clustering
Classification
Sentiment Analysis
Document
Term Frequency - How frequently term appears Term Frequency TF(t) = (Number of times term t appears in a document) (Total number of terms in the document)
Example
Calculate Term Weight (TF IDF)
Inverse Document Frequency - How important a term is
Document Frequency DF = d (number of documents containing a given term) D (the size of the collection of documents)
To normalize take log(dD) but often D gt d and log(dD) will give negative value So invert the ratio inside log expression Essentially we are compressing the scale of values so that very large or very small quantities are smoothly compared
Inverse Document Frequency IDF(t) = log(Total number of documents Number of documents with term t in it)
7
- Assume we have overall 10 million documents and the word spindle appears in one thousand of these - Consider 2 documents containing 100 total words each and contains term spindle x number of times
Document spindle ndash Frequency Total Words TF IDF TF IDF
1 3 100 3100 = 003 log(100000001000) = 4 003 4 = 012
2 30 100 30100 = 3 log(100000001000) = 4 03 4 = 12
Similarity Distance Measure
Example Text 1 statistics skills and programming skills are equally important for analytics
Text 2 statistics skills and domain knowledge are important for analytics
Text 3 I like reading books and travelling
The three vectors are
T1 = (1211011111000000)
T2 = (1110110111100000)
T3 = (0010000000011111)
Degree of Similarity (T1 amp T2) = (T1 T2) (sqrt(sum(T1^2)) sqrt(sum(T2^2))) = 77
Degree of Similarity (T1 amp T3) = (T1 T3) (sqrt(sum(T1^2)) sqrt(sum(T3^2))) = 12
Additional Reading Here is a detailed paper on comparing the efficiency of different distance measures for text documents
URL ndash 1) httphomeiitkacin~spranjalcs671projectreportpdf
2) httpusersdsicupves~prossoresourcesBarronEtAl_ICON09pdf
statistics skills and programming knowledge are equally important for analytics domain I like reading books travelling
Text 1 1 2 1 1 0 1 1 1 1 1 0 0 0 0 0 0
Text 2 1 1 1 0 1 1 0 1 1 1 1 0 0 0 0 0
Text 3 0 0 1 0 0 0 0 0 0 0 0 1 1 1 1 1
X
Y
Euclidean
Cosine
- cosine value will be a number between 0 and 1 - Smaller the angel bigger the cosine valuesimilarity
8
Common Text Mining Techniques
bull N-grams
bull Shallow Natural Language Processing
bull Deep Natural Language Processing
Example defense attorney for liberty and
montecitordquo 1-gram defense attorney for liberty and montecito 2-gram defense attorney for liberty and montecito attorney for liberty and attorney for 3-gram defense attorney for liberty and montecito attorney for liberty for liberty and liberty and montecito 4-gram defense attorney for liberty attorney for liberty and for liberty and montecito 5-gram defense attorney for liberty and montecito attorney for liberty and montecito
Application
Probabilistic language model for predicting the
next item in a sequence in the form of a (n minus 1)
Widely used in probability communication
theory computational linguistics biological
sequence analysis
Advantage
Relatively simple
Simply increasing n model can be used to store
more context
Disadvantage
Semantic value of the item is not considered
n-gram Definition
bull n-gram is a contiguous sequence of n items from a given sequence of text
bull The items can be letters words syllables or base pairs according to the application
10
Application
- Taxonomy extraction (predefined terms and entities)
- Entities People organizations locations times dates prices genes proteins diseases
medicines
- Concept extraction (main idea or a theme)
Advantage
- Less noisy than n-grams
Disadvantage
- Does not specify role of items in the main sentence
Shallow NLP Technique Definition
- Assign a syntactic label (noun verb etc) to a chunk
- Knowledge extraction from text through semanticsyntactic analysis approach
11
Sentence - ldquoThe driver from Europe crashed the car with the white bumperrdquo
1-gram
the
driver
from
europe
crashed
the
car
with
the
white
bumper
Part of Speech
DT ndash Determiner
NN - Noun singular or mass
IN - Preposition or subordinating conjunction
NNP - Proper Noun singular
VBD - Verb past tense
DT ndash Determiner
NN - Noun singular or mass
IN - Preposition or subordinating conjunction
DT ndash Determiner
JJ ndash Adjective
NN - Noun singular or mass
- Convert to lowercase amp PoS tag
Concept Extraction
- Remove Stop words
- Retain only Nounrsquos amp Verbrsquos
- Bi-gram with Nounrsquos amp Verbrsquos retained
Bi-gram PoS
car white NN JJ
crashed car VBD NN
driver europe NN NNP
europe crashed NNP VBD
white bumper JJ NN
3-gram PoS
car white bumper NN JJ NN
crashed car white VBD NN JJ
driver europe crashed NN NNP VBD
europe crashed car NNP VBD NN
- 3-gram with Nounrsquos amp Verbrsquos retained
Conclusion
1-gram Reduced noise however no clear context Bi-gram amp 3-gram Increased context however there
is a information loss
Shallow NLP Technique
12
Stop words NounVerb
Definition
- Extension to the shallow NLP
- Detected relationships are expressed as complex construction to retain the context
- Example relationships Located in employed by part of married to
Applications
- Develop features and representations appropriate for complex interpretation tasks
- Fraud detection - Life science prediction activities based on complex RNA-Sequence
Deep NLP technique
Example
The above sentence can be represented using triples (Subject Predicate [Modifier] Object) without loosing the context
Triples
driver crash car
driver crash with bumper
driver be from Europe 13
Technique General Steps Pros Cons
N-Gram
- Convert to lowercase
- Remove punctuations - Remove special characters Simple technique Extremely noisy
Shallow NLP
technique
- POS tagging
- Lemmatization ie transform to
dictionary base form ie produce amp produced become produce
- Stemming ie transform to root word
ie 1) computer amp computers become
comput
2) product produce amp produced
become produc
- Chunking ie identify the phrasal
constituents in a sentence including
nounverb phrase etc and splits the
sentence into chunks of semantically
related words
Less noisy than N-
Grams
Computationally
expensive
solution for
analyzing the
structure of texts
Does not specify
the internal
structure or the
role of words in
the sentence
Deep NLP
technique
- Generate syntactic relationship
between each pair of words
- Extract subject predicate nagation
objecct and named entity to form triples
Context of the
sentence is
retained
Sentence level
analysis is too
structured
Techniques - Summary
14
Appendix
15
2A - Explore Corpus through EDA 2B - Convert text to lowercase 2C - Remove
a) Numbers(if required) b) Punctuations c) English stop words d) Own stop words(if
required)
e) Strip whitespace f) LemmatizationStemming g) Sparse terms
2D - Create document term matrix
Step 3 - Visualization
Corpus
Web
Documents
Step 1 ndash Data Assemble
Step 2 ndash Data Processing
Step 4 ndash Build Model(s)
Clustering
Classification
Sentiment Analysis
Fre
qu
en
cy
Ch
art
W
ord
Clo
ud
C
orr
ela
tio
n P
lot
R - Text Mining Process Overview
16
DB
Package Name
Category Description
tm Text Mining A framework for text mining applications
topicmodels Topic Modelling Fit topic models with Latent Dirichlet Allocation (LDA) and Comparative Text Mining (CTM)
wordcloud Visualization Plot a cloud comparing the frequencies of words across documents
lda Topic Modelling Fit topic models with Latent Dirichlet Allocation
wordnet Text Mining Database of English which is commonly used in linguistics and text mining
RTextTools Text Mining Automatic text classification via supervised learning
qdap Sentiment analysis
Transcript analysis text mining and natural language processing
tmplugindc Text Mining A plug-in for package tm to support distributed text mining
tmpluginmail Text Mining A plug-in for package tm to handle mail
textir Text Mining A suite of tools for inference about text documents and associated sentiment
tau Text Mining Utilities for text analysis
textcat Text Mining N-gram based text categorization
SnowballC Text Mining Word stemmer
twitteR Text Mining Provides an interface to the Twitter web API
ROAuth Text Mining Allows users to authenticate to the server of their choice (like Twitter)
RColorBrewer Visualization The packages provides palettes for drawing nice maps shaded according to a variable
ggplot2 Visualization
Graphing package implemented on top of the R statistical package Inspired by the Grammar of Graphics seminal work of Leland Wilkinson
R ndash Required packages for Text Mining
17
Example 1 - Obtaining and analyzing tweets
Objective R code for analyzing tweets relating to AAA2011 (text mining topic modelling network analysis clustering and sentiment analysis)
What does the code do
The code details ten steps in the analysis and visualization of the tweets
Acquiring the raw Twitter data
Calculating some basic statistics with the raw Twitter data
Calculating some basic retweet statistics
Calculating the ratio of retweets to tweets
Calculating some basic statistics about URLs in tweets
Basic text mining for token frequency and token association analysis (word cloud)
Calculating sentiment scores of tweets including on subsets containing tokens of interest
Hierarchical clustering of tokens based on multi scale bootstrap resampling
Topic modelling the tweet corpus using latent Dirichlet allocation
Network analysis of tweeters based on retweets
Code Source Code was taken from following link and tweakedadded additional bits where required to ensure code runs fine httpsgithubcombenmarwickAAA2011-Tweets
How to Run or Test the code - From the word doc copy the R code in the given sequence highlighted in yellow color and paste on your R console
18
RTextTools ndash Example for supervised Learning for Text Classification using Ensemble
RTextTools is a free open source R machine learning package for automatic text classification
The package includes nine algorithms for ensemble classification (svm slda boosting bagging random forests glmnet decision trees neural networks and maximum entropy) comprehensive analytics and thorough documentation
Users may use n-fold cross validation to calculate the accuracy of each algorithm on their dataset and determine which algorithms to use in their ensemble
(Using a four-ensemble agreement approach Collingwood and Wilkerson (2012) found that when four of their algorithms agree on the label of a textual document the machine label matches the human label over 90 of the time The rate is just 45 when only two algorithms agree on the text label)
Code Source The codes is readily available for download and usage from the following link httpsgithubcomtimjurkaRTextTools The code can be implemented without modification for testing however itrsquos set up such that changes can be incorporated easily based on our requirement
Additional Reading httpwwwrtexttoolscomabout-the-projecthtml
19
Example 2 - RTextTools
Penn Treebank - httpswwwlingupenneducoursesFall_2003ling001penn_treebank_poshtml
Stanford info lab - Finding Similar Items httpinfolabstanfordedu~ullmanmmdsch3pdf
TRIPLET EXTRACTION FROM SENTENCES URL - httpailabijssidelia_rusuPapersis_2007pdf
Shallow and Deep NLP Processing for ontology learning a Quick Overview httpazouaqathabascaucapublicationsConferences20Workshops20Books5BBC25D_KDW_2010pdf
References
20
Step 3 - Data Visualization
Frequency Chart Word Cloud
Correlation Plot
Step 4 ndash Models
Clustering
Classification
Sentiment Analysis
Document
Term Frequency - How frequently term appears Term Frequency TF(t) = (Number of times term t appears in a document) (Total number of terms in the document)
Example
Calculate Term Weight (TF IDF)
Inverse Document Frequency - How important a term is
Document Frequency DF = d (number of documents containing a given term) D (the size of the collection of documents)
To normalize take log(dD) but often D gt d and log(dD) will give negative value So invert the ratio inside log expression Essentially we are compressing the scale of values so that very large or very small quantities are smoothly compared
Inverse Document Frequency IDF(t) = log(Total number of documents Number of documents with term t in it)
7
- Assume we have overall 10 million documents and the word spindle appears in one thousand of these - Consider 2 documents containing 100 total words each and contains term spindle x number of times
Document spindle ndash Frequency Total Words TF IDF TF IDF
1 3 100 3100 = 003 log(100000001000) = 4 003 4 = 012
2 30 100 30100 = 3 log(100000001000) = 4 03 4 = 12
Similarity Distance Measure
Example Text 1 statistics skills and programming skills are equally important for analytics
Text 2 statistics skills and domain knowledge are important for analytics
Text 3 I like reading books and travelling
The three vectors are
T1 = (1211011111000000)
T2 = (1110110111100000)
T3 = (0010000000011111)
Degree of Similarity (T1 amp T2) = (T1 T2) (sqrt(sum(T1^2)) sqrt(sum(T2^2))) = 77
Degree of Similarity (T1 amp T3) = (T1 T3) (sqrt(sum(T1^2)) sqrt(sum(T3^2))) = 12
Additional Reading Here is a detailed paper on comparing the efficiency of different distance measures for text documents
URL ndash 1) httphomeiitkacin~spranjalcs671projectreportpdf
2) httpusersdsicupves~prossoresourcesBarronEtAl_ICON09pdf
statistics skills and programming knowledge are equally important for analytics domain I like reading books travelling
Text 1 1 2 1 1 0 1 1 1 1 1 0 0 0 0 0 0
Text 2 1 1 1 0 1 1 0 1 1 1 1 0 0 0 0 0
Text 3 0 0 1 0 0 0 0 0 0 0 0 1 1 1 1 1
X
Y
Euclidean
Cosine
- cosine value will be a number between 0 and 1 - Smaller the angel bigger the cosine valuesimilarity
8
Common Text Mining Techniques
bull N-grams
bull Shallow Natural Language Processing
bull Deep Natural Language Processing
Example defense attorney for liberty and
montecitordquo 1-gram defense attorney for liberty and montecito 2-gram defense attorney for liberty and montecito attorney for liberty and attorney for 3-gram defense attorney for liberty and montecito attorney for liberty for liberty and liberty and montecito 4-gram defense attorney for liberty attorney for liberty and for liberty and montecito 5-gram defense attorney for liberty and montecito attorney for liberty and montecito
Application
Probabilistic language model for predicting the
next item in a sequence in the form of a (n minus 1)
Widely used in probability communication
theory computational linguistics biological
sequence analysis
Advantage
Relatively simple
Simply increasing n model can be used to store
more context
Disadvantage
Semantic value of the item is not considered
n-gram Definition
bull n-gram is a contiguous sequence of n items from a given sequence of text
bull The items can be letters words syllables or base pairs according to the application
10
Application
- Taxonomy extraction (predefined terms and entities)
- Entities People organizations locations times dates prices genes proteins diseases
medicines
- Concept extraction (main idea or a theme)
Advantage
- Less noisy than n-grams
Disadvantage
- Does not specify role of items in the main sentence
Shallow NLP Technique Definition
- Assign a syntactic label (noun verb etc) to a chunk
- Knowledge extraction from text through semanticsyntactic analysis approach
11
Sentence - ldquoThe driver from Europe crashed the car with the white bumperrdquo
1-gram
the
driver
from
europe
crashed
the
car
with
the
white
bumper
Part of Speech
DT ndash Determiner
NN - Noun singular or mass
IN - Preposition or subordinating conjunction
NNP - Proper Noun singular
VBD - Verb past tense
DT ndash Determiner
NN - Noun singular or mass
IN - Preposition or subordinating conjunction
DT ndash Determiner
JJ ndash Adjective
NN - Noun singular or mass
- Convert to lowercase amp PoS tag
Concept Extraction
- Remove Stop words
- Retain only Nounrsquos amp Verbrsquos
- Bi-gram with Nounrsquos amp Verbrsquos retained
Bi-gram PoS
car white NN JJ
crashed car VBD NN
driver europe NN NNP
europe crashed NNP VBD
white bumper JJ NN
3-gram PoS
car white bumper NN JJ NN
crashed car white VBD NN JJ
driver europe crashed NN NNP VBD
europe crashed car NNP VBD NN
- 3-gram with Nounrsquos amp Verbrsquos retained
Conclusion
1-gram Reduced noise however no clear context Bi-gram amp 3-gram Increased context however there
is a information loss
Shallow NLP Technique
12
Stop words NounVerb
Definition
- Extension to the shallow NLP
- Detected relationships are expressed as complex construction to retain the context
- Example relationships Located in employed by part of married to
Applications
- Develop features and representations appropriate for complex interpretation tasks
- Fraud detection - Life science prediction activities based on complex RNA-Sequence
Deep NLP technique
Example
The above sentence can be represented using triples (Subject Predicate [Modifier] Object) without loosing the context
Triples
driver crash car
driver crash with bumper
driver be from Europe 13
Technique General Steps Pros Cons
N-Gram
- Convert to lowercase
- Remove punctuations - Remove special characters Simple technique Extremely noisy
Shallow NLP
technique
- POS tagging
- Lemmatization ie transform to
dictionary base form ie produce amp produced become produce
- Stemming ie transform to root word
ie 1) computer amp computers become
comput
2) product produce amp produced
become produc
- Chunking ie identify the phrasal
constituents in a sentence including
nounverb phrase etc and splits the
sentence into chunks of semantically
related words
Less noisy than N-
Grams
Computationally
expensive
solution for
analyzing the
structure of texts
Does not specify
the internal
structure or the
role of words in
the sentence
Deep NLP
technique
- Generate syntactic relationship
between each pair of words
- Extract subject predicate nagation
objecct and named entity to form triples
Context of the
sentence is
retained
Sentence level
analysis is too
structured
Techniques - Summary
14
Appendix
15
2A - Explore Corpus through EDA 2B - Convert text to lowercase 2C - Remove
a) Numbers(if required) b) Punctuations c) English stop words d) Own stop words(if
required)
e) Strip whitespace f) LemmatizationStemming g) Sparse terms
2D - Create document term matrix
Step 3 - Visualization
Corpus
Web
Documents
Step 1 ndash Data Assemble
Step 2 ndash Data Processing
Step 4 ndash Build Model(s)
Clustering
Classification
Sentiment Analysis
Fre
qu
en
cy
Ch
art
W
ord
Clo
ud
C
orr
ela
tio
n P
lot
R - Text Mining Process Overview
16
DB
Package Name
Category Description
tm Text Mining A framework for text mining applications
topicmodels Topic Modelling Fit topic models with Latent Dirichlet Allocation (LDA) and Comparative Text Mining (CTM)
wordcloud Visualization Plot a cloud comparing the frequencies of words across documents
lda Topic Modelling Fit topic models with Latent Dirichlet Allocation
wordnet Text Mining Database of English which is commonly used in linguistics and text mining
RTextTools Text Mining Automatic text classification via supervised learning
qdap Sentiment analysis
Transcript analysis text mining and natural language processing
tmplugindc Text Mining A plug-in for package tm to support distributed text mining
tmpluginmail Text Mining A plug-in for package tm to handle mail
textir Text Mining A suite of tools for inference about text documents and associated sentiment
tau Text Mining Utilities for text analysis
textcat Text Mining N-gram based text categorization
SnowballC Text Mining Word stemmer
twitteR Text Mining Provides an interface to the Twitter web API
ROAuth Text Mining Allows users to authenticate to the server of their choice (like Twitter)
RColorBrewer Visualization The packages provides palettes for drawing nice maps shaded according to a variable
ggplot2 Visualization
Graphing package implemented on top of the R statistical package Inspired by the Grammar of Graphics seminal work of Leland Wilkinson
R ndash Required packages for Text Mining
17
Example 1 - Obtaining and analyzing tweets
Objective R code for analyzing tweets relating to AAA2011 (text mining topic modelling network analysis clustering and sentiment analysis)
What does the code do
The code details ten steps in the analysis and visualization of the tweets
Acquiring the raw Twitter data
Calculating some basic statistics with the raw Twitter data
Calculating some basic retweet statistics
Calculating the ratio of retweets to tweets
Calculating some basic statistics about URLs in tweets
Basic text mining for token frequency and token association analysis (word cloud)
Calculating sentiment scores of tweets including on subsets containing tokens of interest
Hierarchical clustering of tokens based on multi scale bootstrap resampling
Topic modelling the tweet corpus using latent Dirichlet allocation
Network analysis of tweeters based on retweets
Code Source Code was taken from following link and tweakedadded additional bits where required to ensure code runs fine httpsgithubcombenmarwickAAA2011-Tweets
How to Run or Test the code - From the word doc copy the R code in the given sequence highlighted in yellow color and paste on your R console
18
RTextTools ndash Example for supervised Learning for Text Classification using Ensemble
RTextTools is a free open source R machine learning package for automatic text classification
The package includes nine algorithms for ensemble classification (svm slda boosting bagging random forests glmnet decision trees neural networks and maximum entropy) comprehensive analytics and thorough documentation
Users may use n-fold cross validation to calculate the accuracy of each algorithm on their dataset and determine which algorithms to use in their ensemble
(Using a four-ensemble agreement approach Collingwood and Wilkerson (2012) found that when four of their algorithms agree on the label of a textual document the machine label matches the human label over 90 of the time The rate is just 45 when only two algorithms agree on the text label)
Code Source The codes is readily available for download and usage from the following link httpsgithubcomtimjurkaRTextTools The code can be implemented without modification for testing however itrsquos set up such that changes can be incorporated easily based on our requirement
Additional Reading httpwwwrtexttoolscomabout-the-projecthtml
19
Example 2 - RTextTools
Penn Treebank - httpswwwlingupenneducoursesFall_2003ling001penn_treebank_poshtml
Stanford info lab - Finding Similar Items httpinfolabstanfordedu~ullmanmmdsch3pdf
TRIPLET EXTRACTION FROM SENTENCES URL - httpailabijssidelia_rusuPapersis_2007pdf
Shallow and Deep NLP Processing for ontology learning a Quick Overview httpazouaqathabascaucapublicationsConferences20Workshops20Books5BBC25D_KDW_2010pdf
References
20
Step 4 ndash Models
Clustering
Classification
Sentiment Analysis
Document
Term Frequency - How frequently term appears Term Frequency TF(t) = (Number of times term t appears in a document) (Total number of terms in the document)
Example
Calculate Term Weight (TF IDF)
Inverse Document Frequency - How important a term is
Document Frequency DF = d (number of documents containing a given term) D (the size of the collection of documents)
To normalize take log(dD) but often D gt d and log(dD) will give negative value So invert the ratio inside log expression Essentially we are compressing the scale of values so that very large or very small quantities are smoothly compared
Inverse Document Frequency IDF(t) = log(Total number of documents Number of documents with term t in it)
7
- Assume we have overall 10 million documents and the word spindle appears in one thousand of these - Consider 2 documents containing 100 total words each and contains term spindle x number of times
Document spindle ndash Frequency Total Words TF IDF TF IDF
1 3 100 3100 = 003 log(100000001000) = 4 003 4 = 012
2 30 100 30100 = 3 log(100000001000) = 4 03 4 = 12
Similarity Distance Measure
Example Text 1 statistics skills and programming skills are equally important for analytics
Text 2 statistics skills and domain knowledge are important for analytics
Text 3 I like reading books and travelling
The three vectors are
T1 = (1211011111000000)
T2 = (1110110111100000)
T3 = (0010000000011111)
Degree of Similarity (T1 amp T2) = (T1 T2) (sqrt(sum(T1^2)) sqrt(sum(T2^2))) = 77
Degree of Similarity (T1 amp T3) = (T1 T3) (sqrt(sum(T1^2)) sqrt(sum(T3^2))) = 12
Additional Reading Here is a detailed paper on comparing the efficiency of different distance measures for text documents
URL ndash 1) httphomeiitkacin~spranjalcs671projectreportpdf
2) httpusersdsicupves~prossoresourcesBarronEtAl_ICON09pdf
statistics skills and programming knowledge are equally important for analytics domain I like reading books travelling
Text 1 1 2 1 1 0 1 1 1 1 1 0 0 0 0 0 0
Text 2 1 1 1 0 1 1 0 1 1 1 1 0 0 0 0 0
Text 3 0 0 1 0 0 0 0 0 0 0 0 1 1 1 1 1
X
Y
Euclidean
Cosine
- cosine value will be a number between 0 and 1 - Smaller the angel bigger the cosine valuesimilarity
8
Common Text Mining Techniques
bull N-grams
bull Shallow Natural Language Processing
bull Deep Natural Language Processing
Example defense attorney for liberty and
montecitordquo 1-gram defense attorney for liberty and montecito 2-gram defense attorney for liberty and montecito attorney for liberty and attorney for 3-gram defense attorney for liberty and montecito attorney for liberty for liberty and liberty and montecito 4-gram defense attorney for liberty attorney for liberty and for liberty and montecito 5-gram defense attorney for liberty and montecito attorney for liberty and montecito
Application
Probabilistic language model for predicting the
next item in a sequence in the form of a (n minus 1)
Widely used in probability communication
theory computational linguistics biological
sequence analysis
Advantage
Relatively simple
Simply increasing n model can be used to store
more context
Disadvantage
Semantic value of the item is not considered
n-gram Definition
bull n-gram is a contiguous sequence of n items from a given sequence of text
bull The items can be letters words syllables or base pairs according to the application
10
Application
- Taxonomy extraction (predefined terms and entities)
- Entities People organizations locations times dates prices genes proteins diseases
medicines
- Concept extraction (main idea or a theme)
Advantage
- Less noisy than n-grams
Disadvantage
- Does not specify role of items in the main sentence
Shallow NLP Technique Definition
- Assign a syntactic label (noun verb etc) to a chunk
- Knowledge extraction from text through semanticsyntactic analysis approach
11
Sentence - ldquoThe driver from Europe crashed the car with the white bumperrdquo
1-gram
the
driver
from
europe
crashed
the
car
with
the
white
bumper
Part of Speech
DT ndash Determiner
NN - Noun singular or mass
IN - Preposition or subordinating conjunction
NNP - Proper Noun singular
VBD - Verb past tense
DT ndash Determiner
NN - Noun singular or mass
IN - Preposition or subordinating conjunction
DT ndash Determiner
JJ ndash Adjective
NN - Noun singular or mass
- Convert to lowercase amp PoS tag
Concept Extraction
- Remove Stop words
- Retain only Nounrsquos amp Verbrsquos
- Bi-gram with Nounrsquos amp Verbrsquos retained
Bi-gram PoS
car white NN JJ
crashed car VBD NN
driver europe NN NNP
europe crashed NNP VBD
white bumper JJ NN
3-gram PoS
car white bumper NN JJ NN
crashed car white VBD NN JJ
driver europe crashed NN NNP VBD
europe crashed car NNP VBD NN
- 3-gram with Nounrsquos amp Verbrsquos retained
Conclusion
1-gram Reduced noise however no clear context Bi-gram amp 3-gram Increased context however there
is a information loss
Shallow NLP Technique
12
Stop words NounVerb
Definition
- Extension to the shallow NLP
- Detected relationships are expressed as complex construction to retain the context
- Example relationships Located in employed by part of married to
Applications
- Develop features and representations appropriate for complex interpretation tasks
- Fraud detection - Life science prediction activities based on complex RNA-Sequence
Deep NLP technique
Example
The above sentence can be represented using triples (Subject Predicate [Modifier] Object) without loosing the context
Triples
driver crash car
driver crash with bumper
driver be from Europe 13
Technique General Steps Pros Cons
N-Gram
- Convert to lowercase
- Remove punctuations - Remove special characters Simple technique Extremely noisy
Shallow NLP
technique
- POS tagging
- Lemmatization ie transform to
dictionary base form ie produce amp produced become produce
- Stemming ie transform to root word
ie 1) computer amp computers become
comput
2) product produce amp produced
become produc
- Chunking ie identify the phrasal
constituents in a sentence including
nounverb phrase etc and splits the
sentence into chunks of semantically
related words
Less noisy than N-
Grams
Computationally
expensive
solution for
analyzing the
structure of texts
Does not specify
the internal
structure or the
role of words in
the sentence
Deep NLP
technique
- Generate syntactic relationship
between each pair of words
- Extract subject predicate nagation
objecct and named entity to form triples
Context of the
sentence is
retained
Sentence level
analysis is too
structured
Techniques - Summary
14
Appendix
15
2A - Explore Corpus through EDA 2B - Convert text to lowercase 2C - Remove
a) Numbers(if required) b) Punctuations c) English stop words d) Own stop words(if
required)
e) Strip whitespace f) LemmatizationStemming g) Sparse terms
2D - Create document term matrix
Step 3 - Visualization
Corpus
Web
Documents
Step 1 ndash Data Assemble
Step 2 ndash Data Processing
Step 4 ndash Build Model(s)
Clustering
Classification
Sentiment Analysis
Fre
qu
en
cy
Ch
art
W
ord
Clo
ud
C
orr
ela
tio
n P
lot
R - Text Mining Process Overview
16
DB
Package Name
Category Description
tm Text Mining A framework for text mining applications
topicmodels Topic Modelling Fit topic models with Latent Dirichlet Allocation (LDA) and Comparative Text Mining (CTM)
wordcloud Visualization Plot a cloud comparing the frequencies of words across documents
lda Topic Modelling Fit topic models with Latent Dirichlet Allocation
wordnet Text Mining Database of English which is commonly used in linguistics and text mining
RTextTools Text Mining Automatic text classification via supervised learning
qdap Sentiment analysis
Transcript analysis text mining and natural language processing
tmplugindc Text Mining A plug-in for package tm to support distributed text mining
tmpluginmail Text Mining A plug-in for package tm to handle mail
textir Text Mining A suite of tools for inference about text documents and associated sentiment
tau Text Mining Utilities for text analysis
textcat Text Mining N-gram based text categorization
SnowballC Text Mining Word stemmer
twitteR Text Mining Provides an interface to the Twitter web API
ROAuth Text Mining Allows users to authenticate to the server of their choice (like Twitter)
RColorBrewer Visualization The packages provides palettes for drawing nice maps shaded according to a variable
ggplot2 Visualization
Graphing package implemented on top of the R statistical package Inspired by the Grammar of Graphics seminal work of Leland Wilkinson
R ndash Required packages for Text Mining
17
Example 1 - Obtaining and analyzing tweets
Objective R code for analyzing tweets relating to AAA2011 (text mining topic modelling network analysis clustering and sentiment analysis)
What does the code do
The code details ten steps in the analysis and visualization of the tweets
Acquiring the raw Twitter data
Calculating some basic statistics with the raw Twitter data
Calculating some basic retweet statistics
Calculating the ratio of retweets to tweets
Calculating some basic statistics about URLs in tweets
Basic text mining for token frequency and token association analysis (word cloud)
Calculating sentiment scores of tweets including on subsets containing tokens of interest
Hierarchical clustering of tokens based on multi scale bootstrap resampling
Topic modelling the tweet corpus using latent Dirichlet allocation
Network analysis of tweeters based on retweets
Code Source Code was taken from following link and tweakedadded additional bits where required to ensure code runs fine httpsgithubcombenmarwickAAA2011-Tweets
How to Run or Test the code - From the word doc copy the R code in the given sequence highlighted in yellow color and paste on your R console
18
RTextTools ndash Example for supervised Learning for Text Classification using Ensemble
RTextTools is a free open source R machine learning package for automatic text classification
The package includes nine algorithms for ensemble classification (svm slda boosting bagging random forests glmnet decision trees neural networks and maximum entropy) comprehensive analytics and thorough documentation
Users may use n-fold cross validation to calculate the accuracy of each algorithm on their dataset and determine which algorithms to use in their ensemble
(Using a four-ensemble agreement approach Collingwood and Wilkerson (2012) found that when four of their algorithms agree on the label of a textual document the machine label matches the human label over 90 of the time The rate is just 45 when only two algorithms agree on the text label)
Code Source The codes is readily available for download and usage from the following link httpsgithubcomtimjurkaRTextTools The code can be implemented without modification for testing however itrsquos set up such that changes can be incorporated easily based on our requirement
Additional Reading httpwwwrtexttoolscomabout-the-projecthtml
19
Example 2 - RTextTools
Penn Treebank - httpswwwlingupenneducoursesFall_2003ling001penn_treebank_poshtml
Stanford info lab - Finding Similar Items httpinfolabstanfordedu~ullmanmmdsch3pdf
TRIPLET EXTRACTION FROM SENTENCES URL - httpailabijssidelia_rusuPapersis_2007pdf
Shallow and Deep NLP Processing for ontology learning a Quick Overview httpazouaqathabascaucapublicationsConferences20Workshops20Books5BBC25D_KDW_2010pdf
References
20

Term Frequency - How frequently term appears Term Frequency TF(t) = (Number of times term t appears in a document) (Total number of terms in the document)
Example
Calculate Term Weight (TF IDF)
Inverse Document Frequency - How important a term is
Document Frequency DF = d (number of documents containing a given term) D (the size of the collection of documents)
To normalize take log(dD) but often D gt d and log(dD) will give negative value So invert the ratio inside log expression Essentially we are compressing the scale of values so that very large or very small quantities are smoothly compared
Inverse Document Frequency IDF(t) = log(Total number of documents Number of documents with term t in it)
7
- Assume we have overall 10 million documents and the word spindle appears in one thousand of these - Consider 2 documents containing 100 total words each and contains term spindle x number of times
Document spindle ndash Frequency Total Words TF IDF TF IDF
1 3 100 3100 = 003 log(100000001000) = 4 003 4 = 012
2 30 100 30100 = 3 log(100000001000) = 4 03 4 = 12
Similarity Distance Measure
Example Text 1 statistics skills and programming skills are equally important for analytics
Text 2 statistics skills and domain knowledge are important for analytics
Text 3 I like reading books and travelling
The three vectors are
T1 = (1211011111000000)
T2 = (1110110111100000)
T3 = (0010000000011111)
Degree of Similarity (T1 amp T2) = (T1 T2) (sqrt(sum(T1^2)) sqrt(sum(T2^2))) = 77
Degree of Similarity (T1 amp T3) = (T1 T3) (sqrt(sum(T1^2)) sqrt(sum(T3^2))) = 12
Additional Reading Here is a detailed paper on comparing the efficiency of different distance measures for text documents
URL ndash 1) httphomeiitkacin~spranjalcs671projectreportpdf
2) httpusersdsicupves~prossoresourcesBarronEtAl_ICON09pdf
statistics skills and programming knowledge are equally important for analytics domain I like reading books travelling
Text 1 1 2 1 1 0 1 1 1 1 1 0 0 0 0 0 0
Text 2 1 1 1 0 1 1 0 1 1 1 1 0 0 0 0 0
Text 3 0 0 1 0 0 0 0 0 0 0 0 1 1 1 1 1
X
Y
Euclidean
Cosine
- cosine value will be a number between 0 and 1 - Smaller the angel bigger the cosine valuesimilarity
8
Common Text Mining Techniques
bull N-grams
bull Shallow Natural Language Processing
bull Deep Natural Language Processing
Example defense attorney for liberty and
montecitordquo 1-gram defense attorney for liberty and montecito 2-gram defense attorney for liberty and montecito attorney for liberty and attorney for 3-gram defense attorney for liberty and montecito attorney for liberty for liberty and liberty and montecito 4-gram defense attorney for liberty attorney for liberty and for liberty and montecito 5-gram defense attorney for liberty and montecito attorney for liberty and montecito
Application
Probabilistic language model for predicting the
next item in a sequence in the form of a (n minus 1)
Widely used in probability communication
theory computational linguistics biological
sequence analysis
Advantage
Relatively simple
Simply increasing n model can be used to store
more context
Disadvantage
Semantic value of the item is not considered
n-gram Definition
bull n-gram is a contiguous sequence of n items from a given sequence of text
bull The items can be letters words syllables or base pairs according to the application
10
Application
- Taxonomy extraction (predefined terms and entities)
- Entities People organizations locations times dates prices genes proteins diseases
medicines
- Concept extraction (main idea or a theme)
Advantage
- Less noisy than n-grams
Disadvantage
- Does not specify role of items in the main sentence
Shallow NLP Technique Definition
- Assign a syntactic label (noun verb etc) to a chunk
- Knowledge extraction from text through semanticsyntactic analysis approach
11
Sentence - ldquoThe driver from Europe crashed the car with the white bumperrdquo
1-gram
the
driver
from
europe
crashed
the
car
with
the
white
bumper
Part of Speech
DT ndash Determiner
NN - Noun singular or mass
IN - Preposition or subordinating conjunction
NNP - Proper Noun singular
VBD - Verb past tense
DT ndash Determiner
NN - Noun singular or mass
IN - Preposition or subordinating conjunction
DT ndash Determiner
JJ ndash Adjective
NN - Noun singular or mass
- Convert to lowercase amp PoS tag
Concept Extraction
- Remove Stop words
- Retain only Nounrsquos amp Verbrsquos
- Bi-gram with Nounrsquos amp Verbrsquos retained
Bi-gram PoS
car white NN JJ
crashed car VBD NN
driver europe NN NNP
europe crashed NNP VBD
white bumper JJ NN
3-gram PoS
car white bumper NN JJ NN
crashed car white VBD NN JJ
driver europe crashed NN NNP VBD
europe crashed car NNP VBD NN
- 3-gram with Nounrsquos amp Verbrsquos retained
Conclusion
1-gram Reduced noise however no clear context Bi-gram amp 3-gram Increased context however there
is a information loss
Shallow NLP Technique
12
Stop words NounVerb
Definition
- Extension to the shallow NLP
- Detected relationships are expressed as complex construction to retain the context
- Example relationships Located in employed by part of married to
Applications
- Develop features and representations appropriate for complex interpretation tasks
- Fraud detection - Life science prediction activities based on complex RNA-Sequence
Deep NLP technique
Example
The above sentence can be represented using triples (Subject Predicate [Modifier] Object) without loosing the context
Triples
driver crash car
driver crash with bumper
driver be from Europe 13
Technique General Steps Pros Cons
N-Gram
- Convert to lowercase
- Remove punctuations - Remove special characters Simple technique Extremely noisy
Shallow NLP
technique
- POS tagging
- Lemmatization ie transform to
dictionary base form ie produce amp produced become produce
- Stemming ie transform to root word
ie 1) computer amp computers become
comput
2) product produce amp produced
become produc
- Chunking ie identify the phrasal
constituents in a sentence including
nounverb phrase etc and splits the
sentence into chunks of semantically
related words
Less noisy than N-
Grams
Computationally
expensive
solution for
analyzing the
structure of texts
Does not specify
the internal
structure or the
role of words in
the sentence
Deep NLP
technique
- Generate syntactic relationship
between each pair of words
- Extract subject predicate nagation
objecct and named entity to form triples
Context of the
sentence is
retained
Sentence level
analysis is too
structured
Techniques - Summary
14
Appendix
15
2A - Explore Corpus through EDA 2B - Convert text to lowercase 2C - Remove
a) Numbers(if required) b) Punctuations c) English stop words d) Own stop words(if
required)
e) Strip whitespace f) LemmatizationStemming g) Sparse terms
2D - Create document term matrix
Step 3 - Visualization
Corpus
Web
Documents
Step 1 ndash Data Assemble
Step 2 ndash Data Processing
Step 4 ndash Build Model(s)
Clustering
Classification
Sentiment Analysis
Fre
qu
en
cy
Ch
art
W
ord
Clo
ud
C
orr
ela
tio
n P
lot
R - Text Mining Process Overview
16
DB
Package Name
Category Description
tm Text Mining A framework for text mining applications
topicmodels Topic Modelling Fit topic models with Latent Dirichlet Allocation (LDA) and Comparative Text Mining (CTM)
wordcloud Visualization Plot a cloud comparing the frequencies of words across documents
lda Topic Modelling Fit topic models with Latent Dirichlet Allocation
wordnet Text Mining Database of English which is commonly used in linguistics and text mining
RTextTools Text Mining Automatic text classification via supervised learning
qdap Sentiment analysis
Transcript analysis text mining and natural language processing
tmplugindc Text Mining A plug-in for package tm to support distributed text mining
tmpluginmail Text Mining A plug-in for package tm to handle mail
textir Text Mining A suite of tools for inference about text documents and associated sentiment
tau Text Mining Utilities for text analysis
textcat Text Mining N-gram based text categorization
SnowballC Text Mining Word stemmer
twitteR Text Mining Provides an interface to the Twitter web API
ROAuth Text Mining Allows users to authenticate to the server of their choice (like Twitter)
RColorBrewer Visualization The packages provides palettes for drawing nice maps shaded according to a variable
ggplot2 Visualization
Graphing package implemented on top of the R statistical package Inspired by the Grammar of Graphics seminal work of Leland Wilkinson
R ndash Required packages for Text Mining
17
Example 1 - Obtaining and analyzing tweets
Objective R code for analyzing tweets relating to AAA2011 (text mining topic modelling network analysis clustering and sentiment analysis)
What does the code do
The code details ten steps in the analysis and visualization of the tweets
Acquiring the raw Twitter data
Calculating some basic statistics with the raw Twitter data
Calculating some basic retweet statistics
Calculating the ratio of retweets to tweets
Calculating some basic statistics about URLs in tweets
Basic text mining for token frequency and token association analysis (word cloud)
Calculating sentiment scores of tweets including on subsets containing tokens of interest
Hierarchical clustering of tokens based on multi scale bootstrap resampling
Topic modelling the tweet corpus using latent Dirichlet allocation
Network analysis of tweeters based on retweets
Code Source Code was taken from following link and tweakedadded additional bits where required to ensure code runs fine httpsgithubcombenmarwickAAA2011-Tweets
How to Run or Test the code - From the word doc copy the R code in the given sequence highlighted in yellow color and paste on your R console
18
RTextTools ndash Example for supervised Learning for Text Classification using Ensemble
RTextTools is a free open source R machine learning package for automatic text classification
The package includes nine algorithms for ensemble classification (svm slda boosting bagging random forests glmnet decision trees neural networks and maximum entropy) comprehensive analytics and thorough documentation
Users may use n-fold cross validation to calculate the accuracy of each algorithm on their dataset and determine which algorithms to use in their ensemble
(Using a four-ensemble agreement approach Collingwood and Wilkerson (2012) found that when four of their algorithms agree on the label of a textual document the machine label matches the human label over 90 of the time The rate is just 45 when only two algorithms agree on the text label)
Code Source The codes is readily available for download and usage from the following link httpsgithubcomtimjurkaRTextTools The code can be implemented without modification for testing however itrsquos set up such that changes can be incorporated easily based on our requirement
Additional Reading httpwwwrtexttoolscomabout-the-projecthtml
19
Example 2 - RTextTools
Penn Treebank - httpswwwlingupenneducoursesFall_2003ling001penn_treebank_poshtml
Stanford info lab - Finding Similar Items httpinfolabstanfordedu~ullmanmmdsch3pdf
TRIPLET EXTRACTION FROM SENTENCES URL - httpailabijssidelia_rusuPapersis_2007pdf
Shallow and Deep NLP Processing for ontology learning a Quick Overview httpazouaqathabascaucapublicationsConferences20Workshops20Books5BBC25D_KDW_2010pdf
References
20

Similarity Distance Measure
Example Text 1 statistics skills and programming skills are equally important for analytics
Text 2 statistics skills and domain knowledge are important for analytics
Text 3 I like reading books and travelling
The three vectors are
T1 = (1211011111000000)
T2 = (1110110111100000)
T3 = (0010000000011111)
Degree of Similarity (T1 amp T2) = (T1 T2) (sqrt(sum(T1^2)) sqrt(sum(T2^2))) = 77
Degree of Similarity (T1 amp T3) = (T1 T3) (sqrt(sum(T1^2)) sqrt(sum(T3^2))) = 12
Additional Reading Here is a detailed paper on comparing the efficiency of different distance measures for text documents
URL ndash 1) httphomeiitkacin~spranjalcs671projectreportpdf
2) httpusersdsicupves~prossoresourcesBarronEtAl_ICON09pdf
statistics skills and programming knowledge are equally important for analytics domain I like reading books travelling
Text 1 1 2 1 1 0 1 1 1 1 1 0 0 0 0 0 0
Text 2 1 1 1 0 1 1 0 1 1 1 1 0 0 0 0 0
Text 3 0 0 1 0 0 0 0 0 0 0 0 1 1 1 1 1
X
Y
Euclidean
Cosine
- cosine value will be a number between 0 and 1 - Smaller the angel bigger the cosine valuesimilarity
8
Common Text Mining Techniques
bull N-grams
bull Shallow Natural Language Processing
bull Deep Natural Language Processing
Example defense attorney for liberty and
montecitordquo 1-gram defense attorney for liberty and montecito 2-gram defense attorney for liberty and montecito attorney for liberty and attorney for 3-gram defense attorney for liberty and montecito attorney for liberty for liberty and liberty and montecito 4-gram defense attorney for liberty attorney for liberty and for liberty and montecito 5-gram defense attorney for liberty and montecito attorney for liberty and montecito
Application
Probabilistic language model for predicting the
next item in a sequence in the form of a (n minus 1)
Widely used in probability communication
theory computational linguistics biological
sequence analysis
Advantage
Relatively simple
Simply increasing n model can be used to store
more context
Disadvantage
Semantic value of the item is not considered
n-gram Definition
bull n-gram is a contiguous sequence of n items from a given sequence of text
bull The items can be letters words syllables or base pairs according to the application
10
Application
- Taxonomy extraction (predefined terms and entities)
- Entities People organizations locations times dates prices genes proteins diseases
medicines
- Concept extraction (main idea or a theme)
Advantage
- Less noisy than n-grams
Disadvantage
- Does not specify role of items in the main sentence
Shallow NLP Technique Definition
- Assign a syntactic label (noun verb etc) to a chunk
- Knowledge extraction from text through semanticsyntactic analysis approach
11
Sentence - ldquoThe driver from Europe crashed the car with the white bumperrdquo
1-gram
the
driver
from
europe
crashed
the
car
with
the
white
bumper
Part of Speech
DT ndash Determiner
NN - Noun singular or mass
IN - Preposition or subordinating conjunction
NNP - Proper Noun singular
VBD - Verb past tense
DT ndash Determiner
NN - Noun singular or mass
IN - Preposition or subordinating conjunction
DT ndash Determiner
JJ ndash Adjective
NN - Noun singular or mass
- Convert to lowercase amp PoS tag
Concept Extraction
- Remove Stop words
- Retain only Nounrsquos amp Verbrsquos
- Bi-gram with Nounrsquos amp Verbrsquos retained
Bi-gram PoS
car white NN JJ
crashed car VBD NN
driver europe NN NNP
europe crashed NNP VBD
white bumper JJ NN
3-gram PoS
car white bumper NN JJ NN
crashed car white VBD NN JJ
driver europe crashed NN NNP VBD
europe crashed car NNP VBD NN
- 3-gram with Nounrsquos amp Verbrsquos retained
Conclusion
1-gram Reduced noise however no clear context Bi-gram amp 3-gram Increased context however there
is a information loss
Shallow NLP Technique
12
Stop words NounVerb
Definition
- Extension to the shallow NLP
- Detected relationships are expressed as complex construction to retain the context
- Example relationships Located in employed by part of married to
Applications
- Develop features and representations appropriate for complex interpretation tasks
- Fraud detection - Life science prediction activities based on complex RNA-Sequence
Deep NLP technique
Example
The above sentence can be represented using triples (Subject Predicate [Modifier] Object) without loosing the context
Triples
driver crash car
driver crash with bumper
driver be from Europe 13
Technique General Steps Pros Cons
N-Gram
- Convert to lowercase
- Remove punctuations - Remove special characters Simple technique Extremely noisy
Shallow NLP
technique
- POS tagging
- Lemmatization ie transform to
dictionary base form ie produce amp produced become produce
- Stemming ie transform to root word
ie 1) computer amp computers become
comput
2) product produce amp produced
become produc
- Chunking ie identify the phrasal
constituents in a sentence including
nounverb phrase etc and splits the
sentence into chunks of semantically
related words
Less noisy than N-
Grams
Computationally
expensive
solution for
analyzing the
structure of texts
Does not specify
the internal
structure or the
role of words in
the sentence
Deep NLP
technique
- Generate syntactic relationship
between each pair of words
- Extract subject predicate nagation
objecct and named entity to form triples
Context of the
sentence is
retained
Sentence level
analysis is too
structured
Techniques - Summary
14
Appendix
15
2A - Explore Corpus through EDA 2B - Convert text to lowercase 2C - Remove
a) Numbers(if required) b) Punctuations c) English stop words d) Own stop words(if
required)
e) Strip whitespace f) LemmatizationStemming g) Sparse terms
2D - Create document term matrix
Step 3 - Visualization
Corpus
Web
Documents
Step 1 ndash Data Assemble
Step 2 ndash Data Processing
Step 4 ndash Build Model(s)
Clustering
Classification
Sentiment Analysis
Fre
qu
en
cy
Ch
art
W
ord
Clo
ud
C
orr
ela
tio
n P
lot
R - Text Mining Process Overview
16
DB
Package Name
Category Description
tm Text Mining A framework for text mining applications
topicmodels Topic Modelling Fit topic models with Latent Dirichlet Allocation (LDA) and Comparative Text Mining (CTM)
wordcloud Visualization Plot a cloud comparing the frequencies of words across documents
lda Topic Modelling Fit topic models with Latent Dirichlet Allocation
wordnet Text Mining Database of English which is commonly used in linguistics and text mining
RTextTools Text Mining Automatic text classification via supervised learning
qdap Sentiment analysis
Transcript analysis text mining and natural language processing
tmplugindc Text Mining A plug-in for package tm to support distributed text mining
tmpluginmail Text Mining A plug-in for package tm to handle mail
textir Text Mining A suite of tools for inference about text documents and associated sentiment
tau Text Mining Utilities for text analysis
textcat Text Mining N-gram based text categorization
SnowballC Text Mining Word stemmer
twitteR Text Mining Provides an interface to the Twitter web API
ROAuth Text Mining Allows users to authenticate to the server of their choice (like Twitter)
RColorBrewer Visualization The packages provides palettes for drawing nice maps shaded according to a variable
ggplot2 Visualization
Graphing package implemented on top of the R statistical package Inspired by the Grammar of Graphics seminal work of Leland Wilkinson
R ndash Required packages for Text Mining
17
Example 1 - Obtaining and analyzing tweets
Objective R code for analyzing tweets relating to AAA2011 (text mining topic modelling network analysis clustering and sentiment analysis)
What does the code do
The code details ten steps in the analysis and visualization of the tweets
Acquiring the raw Twitter data
Calculating some basic statistics with the raw Twitter data
Calculating some basic retweet statistics
Calculating the ratio of retweets to tweets
Calculating some basic statistics about URLs in tweets
Basic text mining for token frequency and token association analysis (word cloud)
Calculating sentiment scores of tweets including on subsets containing tokens of interest
Hierarchical clustering of tokens based on multi scale bootstrap resampling
Topic modelling the tweet corpus using latent Dirichlet allocation
Network analysis of tweeters based on retweets
Code Source Code was taken from following link and tweakedadded additional bits where required to ensure code runs fine httpsgithubcombenmarwickAAA2011-Tweets
How to Run or Test the code - From the word doc copy the R code in the given sequence highlighted in yellow color and paste on your R console
18
RTextTools ndash Example for supervised Learning for Text Classification using Ensemble
RTextTools is a free open source R machine learning package for automatic text classification
The package includes nine algorithms for ensemble classification (svm slda boosting bagging random forests glmnet decision trees neural networks and maximum entropy) comprehensive analytics and thorough documentation
Users may use n-fold cross validation to calculate the accuracy of each algorithm on their dataset and determine which algorithms to use in their ensemble
(Using a four-ensemble agreement approach Collingwood and Wilkerson (2012) found that when four of their algorithms agree on the label of a textual document the machine label matches the human label over 90 of the time The rate is just 45 when only two algorithms agree on the text label)
Code Source The codes is readily available for download and usage from the following link httpsgithubcomtimjurkaRTextTools The code can be implemented without modification for testing however itrsquos set up such that changes can be incorporated easily based on our requirement
Additional Reading httpwwwrtexttoolscomabout-the-projecthtml
19
Example 2 - RTextTools
Penn Treebank - httpswwwlingupenneducoursesFall_2003ling001penn_treebank_poshtml
Stanford info lab - Finding Similar Items httpinfolabstanfordedu~ullmanmmdsch3pdf
TRIPLET EXTRACTION FROM SENTENCES URL - httpailabijssidelia_rusuPapersis_2007pdf
Shallow and Deep NLP Processing for ontology learning a Quick Overview httpazouaqathabascaucapublicationsConferences20Workshops20Books5BBC25D_KDW_2010pdf
References
20

Common Text Mining Techniques
bull N-grams
bull Shallow Natural Language Processing
bull Deep Natural Language Processing
Example defense attorney for liberty and
montecitordquo 1-gram defense attorney for liberty and montecito 2-gram defense attorney for liberty and montecito attorney for liberty and attorney for 3-gram defense attorney for liberty and montecito attorney for liberty for liberty and liberty and montecito 4-gram defense attorney for liberty attorney for liberty and for liberty and montecito 5-gram defense attorney for liberty and montecito attorney for liberty and montecito
Application
Probabilistic language model for predicting the
next item in a sequence in the form of a (n minus 1)
Widely used in probability communication
theory computational linguistics biological
sequence analysis
Advantage
Relatively simple
Simply increasing n model can be used to store
more context
Disadvantage
Semantic value of the item is not considered
n-gram Definition
bull n-gram is a contiguous sequence of n items from a given sequence of text
bull The items can be letters words syllables or base pairs according to the application
10
Application
- Taxonomy extraction (predefined terms and entities)
- Entities People organizations locations times dates prices genes proteins diseases
medicines
- Concept extraction (main idea or a theme)
Advantage
- Less noisy than n-grams
Disadvantage
- Does not specify role of items in the main sentence
Shallow NLP Technique Definition
- Assign a syntactic label (noun verb etc) to a chunk
- Knowledge extraction from text through semanticsyntactic analysis approach
11
Sentence - ldquoThe driver from Europe crashed the car with the white bumperrdquo
1-gram
the
driver
from
europe
crashed
the
car
with
the
white
bumper
Part of Speech
DT ndash Determiner
NN - Noun singular or mass
IN - Preposition or subordinating conjunction
NNP - Proper Noun singular
VBD - Verb past tense
DT ndash Determiner
NN - Noun singular or mass
IN - Preposition or subordinating conjunction
DT ndash Determiner
JJ ndash Adjective
NN - Noun singular or mass
- Convert to lowercase amp PoS tag
Concept Extraction
- Remove Stop words
- Retain only Nounrsquos amp Verbrsquos
- Bi-gram with Nounrsquos amp Verbrsquos retained
Bi-gram PoS
car white NN JJ
crashed car VBD NN
driver europe NN NNP
europe crashed NNP VBD
white bumper JJ NN
3-gram PoS
car white bumper NN JJ NN
crashed car white VBD NN JJ
driver europe crashed NN NNP VBD
europe crashed car NNP VBD NN
- 3-gram with Nounrsquos amp Verbrsquos retained
Conclusion
1-gram Reduced noise however no clear context Bi-gram amp 3-gram Increased context however there
is a information loss
Shallow NLP Technique
12
Stop words NounVerb
Definition
- Extension to the shallow NLP
- Detected relationships are expressed as complex construction to retain the context
- Example relationships Located in employed by part of married to
Applications
- Develop features and representations appropriate for complex interpretation tasks
- Fraud detection - Life science prediction activities based on complex RNA-Sequence
Deep NLP technique
Example
The above sentence can be represented using triples (Subject Predicate [Modifier] Object) without loosing the context
Triples
driver crash car
driver crash with bumper
driver be from Europe 13
Technique General Steps Pros Cons
N-Gram
- Convert to lowercase
- Remove punctuations - Remove special characters Simple technique Extremely noisy
Shallow NLP
technique
- POS tagging
- Lemmatization ie transform to
dictionary base form ie produce amp produced become produce
- Stemming ie transform to root word
ie 1) computer amp computers become
comput
2) product produce amp produced
become produc
- Chunking ie identify the phrasal
constituents in a sentence including
nounverb phrase etc and splits the
sentence into chunks of semantically
related words
Less noisy than N-
Grams
Computationally
expensive
solution for
analyzing the
structure of texts
Does not specify
the internal
structure or the
role of words in
the sentence
Deep NLP
technique
- Generate syntactic relationship
between each pair of words
- Extract subject predicate nagation
objecct and named entity to form triples
Context of the
sentence is
retained
Sentence level
analysis is too
structured
Techniques - Summary
14
Appendix
15
2A - Explore Corpus through EDA 2B - Convert text to lowercase 2C - Remove
a) Numbers(if required) b) Punctuations c) English stop words d) Own stop words(if
required)
e) Strip whitespace f) LemmatizationStemming g) Sparse terms
2D - Create document term matrix
Step 3 - Visualization
Corpus
Web
Documents
Step 1 ndash Data Assemble
Step 2 ndash Data Processing
Step 4 ndash Build Model(s)
Clustering
Classification
Sentiment Analysis
Fre
qu
en
cy
Ch
art
W
ord
Clo
ud
C
orr
ela
tio
n P
lot
R - Text Mining Process Overview
16
DB
Package Name
Category Description
tm Text Mining A framework for text mining applications
topicmodels Topic Modelling Fit topic models with Latent Dirichlet Allocation (LDA) and Comparative Text Mining (CTM)
wordcloud Visualization Plot a cloud comparing the frequencies of words across documents
lda Topic Modelling Fit topic models with Latent Dirichlet Allocation
wordnet Text Mining Database of English which is commonly used in linguistics and text mining
RTextTools Text Mining Automatic text classification via supervised learning
qdap Sentiment analysis
Transcript analysis text mining and natural language processing
tmplugindc Text Mining A plug-in for package tm to support distributed text mining
tmpluginmail Text Mining A plug-in for package tm to handle mail
textir Text Mining A suite of tools for inference about text documents and associated sentiment
tau Text Mining Utilities for text analysis
textcat Text Mining N-gram based text categorization
SnowballC Text Mining Word stemmer
twitteR Text Mining Provides an interface to the Twitter web API
ROAuth Text Mining Allows users to authenticate to the server of their choice (like Twitter)
RColorBrewer Visualization The packages provides palettes for drawing nice maps shaded according to a variable
ggplot2 Visualization
Graphing package implemented on top of the R statistical package Inspired by the Grammar of Graphics seminal work of Leland Wilkinson
R ndash Required packages for Text Mining
17
Example 1 - Obtaining and analyzing tweets
Objective R code for analyzing tweets relating to AAA2011 (text mining topic modelling network analysis clustering and sentiment analysis)
What does the code do
The code details ten steps in the analysis and visualization of the tweets
Acquiring the raw Twitter data
Calculating some basic statistics with the raw Twitter data
Calculating some basic retweet statistics
Calculating the ratio of retweets to tweets
Calculating some basic statistics about URLs in tweets
Basic text mining for token frequency and token association analysis (word cloud)
Calculating sentiment scores of tweets including on subsets containing tokens of interest
Hierarchical clustering of tokens based on multi scale bootstrap resampling
Topic modelling the tweet corpus using latent Dirichlet allocation
Network analysis of tweeters based on retweets
Code Source Code was taken from following link and tweakedadded additional bits where required to ensure code runs fine httpsgithubcombenmarwickAAA2011-Tweets
How to Run or Test the code - From the word doc copy the R code in the given sequence highlighted in yellow color and paste on your R console
18
RTextTools ndash Example for supervised Learning for Text Classification using Ensemble
RTextTools is a free open source R machine learning package for automatic text classification
The package includes nine algorithms for ensemble classification (svm slda boosting bagging random forests glmnet decision trees neural networks and maximum entropy) comprehensive analytics and thorough documentation
Users may use n-fold cross validation to calculate the accuracy of each algorithm on their dataset and determine which algorithms to use in their ensemble
(Using a four-ensemble agreement approach Collingwood and Wilkerson (2012) found that when four of their algorithms agree on the label of a textual document the machine label matches the human label over 90 of the time The rate is just 45 when only two algorithms agree on the text label)
Code Source The codes is readily available for download and usage from the following link httpsgithubcomtimjurkaRTextTools The code can be implemented without modification for testing however itrsquos set up such that changes can be incorporated easily based on our requirement
Additional Reading httpwwwrtexttoolscomabout-the-projecthtml
19
Example 2 - RTextTools
Penn Treebank - httpswwwlingupenneducoursesFall_2003ling001penn_treebank_poshtml
Stanford info lab - Finding Similar Items httpinfolabstanfordedu~ullmanmmdsch3pdf
TRIPLET EXTRACTION FROM SENTENCES URL - httpailabijssidelia_rusuPapersis_2007pdf
Shallow and Deep NLP Processing for ontology learning a Quick Overview httpazouaqathabascaucapublicationsConferences20Workshops20Books5BBC25D_KDW_2010pdf
References
20

Example defense attorney for liberty and
montecitordquo 1-gram defense attorney for liberty and montecito 2-gram defense attorney for liberty and montecito attorney for liberty and attorney for 3-gram defense attorney for liberty and montecito attorney for liberty for liberty and liberty and montecito 4-gram defense attorney for liberty attorney for liberty and for liberty and montecito 5-gram defense attorney for liberty and montecito attorney for liberty and montecito
Application
Probabilistic language model for predicting the
next item in a sequence in the form of a (n minus 1)
Widely used in probability communication
theory computational linguistics biological
sequence analysis
Advantage
Relatively simple
Simply increasing n model can be used to store
more context
Disadvantage
Semantic value of the item is not considered
n-gram Definition
bull n-gram is a contiguous sequence of n items from a given sequence of text
bull The items can be letters words syllables or base pairs according to the application
10
Application
- Taxonomy extraction (predefined terms and entities)
- Entities People organizations locations times dates prices genes proteins diseases
medicines
- Concept extraction (main idea or a theme)
Advantage
- Less noisy than n-grams
Disadvantage
- Does not specify role of items in the main sentence
Shallow NLP Technique Definition
- Assign a syntactic label (noun verb etc) to a chunk
- Knowledge extraction from text through semanticsyntactic analysis approach
11
Sentence - ldquoThe driver from Europe crashed the car with the white bumperrdquo
1-gram
the
driver
from
europe
crashed
the
car
with
the
white
bumper
Part of Speech
DT ndash Determiner
NN - Noun singular or mass
IN - Preposition or subordinating conjunction
NNP - Proper Noun singular
VBD - Verb past tense
DT ndash Determiner
NN - Noun singular or mass
IN - Preposition or subordinating conjunction
DT ndash Determiner
JJ ndash Adjective
NN - Noun singular or mass
- Convert to lowercase amp PoS tag
Concept Extraction
- Remove Stop words
- Retain only Nounrsquos amp Verbrsquos
- Bi-gram with Nounrsquos amp Verbrsquos retained
Bi-gram PoS
car white NN JJ
crashed car VBD NN
driver europe NN NNP
europe crashed NNP VBD
white bumper JJ NN
3-gram PoS
car white bumper NN JJ NN
crashed car white VBD NN JJ
driver europe crashed NN NNP VBD
europe crashed car NNP VBD NN
- 3-gram with Nounrsquos amp Verbrsquos retained
Conclusion
1-gram Reduced noise however no clear context Bi-gram amp 3-gram Increased context however there
is a information loss
Shallow NLP Technique
12
Stop words NounVerb
Definition
- Extension to the shallow NLP
- Detected relationships are expressed as complex construction to retain the context
- Example relationships Located in employed by part of married to
Applications
- Develop features and representations appropriate for complex interpretation tasks
- Fraud detection - Life science prediction activities based on complex RNA-Sequence
Deep NLP technique
Example
The above sentence can be represented using triples (Subject Predicate [Modifier] Object) without loosing the context
Triples
driver crash car
driver crash with bumper
driver be from Europe 13
Technique General Steps Pros Cons
N-Gram
- Convert to lowercase
- Remove punctuations - Remove special characters Simple technique Extremely noisy
Shallow NLP
technique
- POS tagging
- Lemmatization ie transform to
dictionary base form ie produce amp produced become produce
- Stemming ie transform to root word
ie 1) computer amp computers become
comput
2) product produce amp produced
become produc
- Chunking ie identify the phrasal
constituents in a sentence including
nounverb phrase etc and splits the
sentence into chunks of semantically
related words
Less noisy than N-
Grams
Computationally
expensive
solution for
analyzing the
structure of texts
Does not specify
the internal
structure or the
role of words in
the sentence
Deep NLP
technique
- Generate syntactic relationship
between each pair of words
- Extract subject predicate nagation
objecct and named entity to form triples
Context of the
sentence is
retained
Sentence level
analysis is too
structured
Techniques - Summary
14
Appendix
15
2A - Explore Corpus through EDA 2B - Convert text to lowercase 2C - Remove
a) Numbers(if required) b) Punctuations c) English stop words d) Own stop words(if
required)
e) Strip whitespace f) LemmatizationStemming g) Sparse terms
2D - Create document term matrix
Step 3 - Visualization
Corpus
Web
Documents
Step 1 ndash Data Assemble
Step 2 ndash Data Processing
Step 4 ndash Build Model(s)
Clustering
Classification
Sentiment Analysis
Fre
qu
en
cy
Ch
art
W
ord
Clo
ud
C
orr
ela
tio
n P
lot
R - Text Mining Process Overview
16
DB
Package Name
Category Description
tm Text Mining A framework for text mining applications
topicmodels Topic Modelling Fit topic models with Latent Dirichlet Allocation (LDA) and Comparative Text Mining (CTM)
wordcloud Visualization Plot a cloud comparing the frequencies of words across documents
lda Topic Modelling Fit topic models with Latent Dirichlet Allocation
wordnet Text Mining Database of English which is commonly used in linguistics and text mining
RTextTools Text Mining Automatic text classification via supervised learning
qdap Sentiment analysis
Transcript analysis text mining and natural language processing
tmplugindc Text Mining A plug-in for package tm to support distributed text mining
tmpluginmail Text Mining A plug-in for package tm to handle mail
textir Text Mining A suite of tools for inference about text documents and associated sentiment
tau Text Mining Utilities for text analysis
textcat Text Mining N-gram based text categorization
SnowballC Text Mining Word stemmer
twitteR Text Mining Provides an interface to the Twitter web API
ROAuth Text Mining Allows users to authenticate to the server of their choice (like Twitter)
RColorBrewer Visualization The packages provides palettes for drawing nice maps shaded according to a variable
ggplot2 Visualization
Graphing package implemented on top of the R statistical package Inspired by the Grammar of Graphics seminal work of Leland Wilkinson
R ndash Required packages for Text Mining
17
Example 1 - Obtaining and analyzing tweets
Objective R code for analyzing tweets relating to AAA2011 (text mining topic modelling network analysis clustering and sentiment analysis)
What does the code do
The code details ten steps in the analysis and visualization of the tweets
Acquiring the raw Twitter data
Calculating some basic statistics with the raw Twitter data
Calculating some basic retweet statistics
Calculating the ratio of retweets to tweets
Calculating some basic statistics about URLs in tweets
Basic text mining for token frequency and token association analysis (word cloud)
Calculating sentiment scores of tweets including on subsets containing tokens of interest
Hierarchical clustering of tokens based on multi scale bootstrap resampling
Topic modelling the tweet corpus using latent Dirichlet allocation
Network analysis of tweeters based on retweets
Code Source Code was taken from following link and tweakedadded additional bits where required to ensure code runs fine httpsgithubcombenmarwickAAA2011-Tweets
How to Run or Test the code - From the word doc copy the R code in the given sequence highlighted in yellow color and paste on your R console
18
RTextTools ndash Example for supervised Learning for Text Classification using Ensemble
RTextTools is a free open source R machine learning package for automatic text classification
The package includes nine algorithms for ensemble classification (svm slda boosting bagging random forests glmnet decision trees neural networks and maximum entropy) comprehensive analytics and thorough documentation
Users may use n-fold cross validation to calculate the accuracy of each algorithm on their dataset and determine which algorithms to use in their ensemble
(Using a four-ensemble agreement approach Collingwood and Wilkerson (2012) found that when four of their algorithms agree on the label of a textual document the machine label matches the human label over 90 of the time The rate is just 45 when only two algorithms agree on the text label)
Code Source The codes is readily available for download and usage from the following link httpsgithubcomtimjurkaRTextTools The code can be implemented without modification for testing however itrsquos set up such that changes can be incorporated easily based on our requirement
Additional Reading httpwwwrtexttoolscomabout-the-projecthtml
19
Example 2 - RTextTools
Penn Treebank - httpswwwlingupenneducoursesFall_2003ling001penn_treebank_poshtml
Stanford info lab - Finding Similar Items httpinfolabstanfordedu~ullmanmmdsch3pdf
TRIPLET EXTRACTION FROM SENTENCES URL - httpailabijssidelia_rusuPapersis_2007pdf
Shallow and Deep NLP Processing for ontology learning a Quick Overview httpazouaqathabascaucapublicationsConferences20Workshops20Books5BBC25D_KDW_2010pdf
References
20
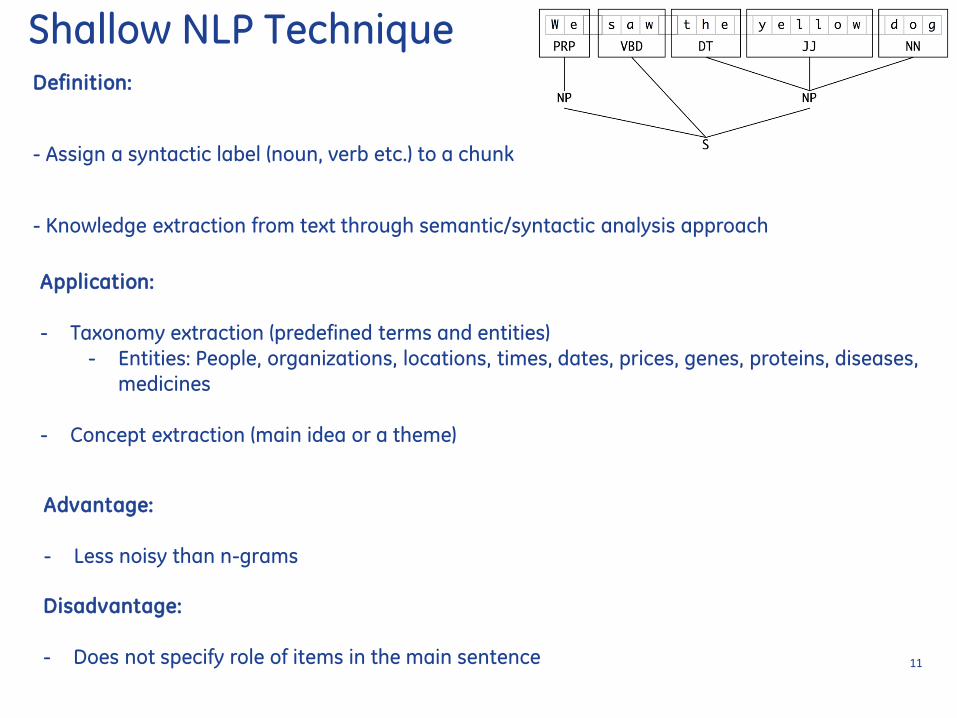
Application
- Taxonomy extraction (predefined terms and entities)
- Entities People organizations locations times dates prices genes proteins diseases
medicines
- Concept extraction (main idea or a theme)
Advantage
- Less noisy than n-grams
Disadvantage
- Does not specify role of items in the main sentence
Shallow NLP Technique Definition
- Assign a syntactic label (noun verb etc) to a chunk
- Knowledge extraction from text through semanticsyntactic analysis approach
11
Sentence - ldquoThe driver from Europe crashed the car with the white bumperrdquo
1-gram
the
driver
from
europe
crashed
the
car
with
the
white
bumper
Part of Speech
DT ndash Determiner
NN - Noun singular or mass
IN - Preposition or subordinating conjunction
NNP - Proper Noun singular
VBD - Verb past tense
DT ndash Determiner
NN - Noun singular or mass
IN - Preposition or subordinating conjunction
DT ndash Determiner
JJ ndash Adjective
NN - Noun singular or mass
- Convert to lowercase amp PoS tag
Concept Extraction
- Remove Stop words
- Retain only Nounrsquos amp Verbrsquos
- Bi-gram with Nounrsquos amp Verbrsquos retained
Bi-gram PoS
car white NN JJ
crashed car VBD NN
driver europe NN NNP
europe crashed NNP VBD
white bumper JJ NN
3-gram PoS
car white bumper NN JJ NN
crashed car white VBD NN JJ
driver europe crashed NN NNP VBD
europe crashed car NNP VBD NN
- 3-gram with Nounrsquos amp Verbrsquos retained
Conclusion
1-gram Reduced noise however no clear context Bi-gram amp 3-gram Increased context however there
is a information loss
Shallow NLP Technique
12
Stop words NounVerb
Definition
- Extension to the shallow NLP
- Detected relationships are expressed as complex construction to retain the context
- Example relationships Located in employed by part of married to
Applications
- Develop features and representations appropriate for complex interpretation tasks
- Fraud detection - Life science prediction activities based on complex RNA-Sequence
Deep NLP technique
Example
The above sentence can be represented using triples (Subject Predicate [Modifier] Object) without loosing the context
Triples
driver crash car
driver crash with bumper
driver be from Europe 13
Technique General Steps Pros Cons
N-Gram
- Convert to lowercase
- Remove punctuations - Remove special characters Simple technique Extremely noisy
Shallow NLP
technique
- POS tagging
- Lemmatization ie transform to
dictionary base form ie produce amp produced become produce
- Stemming ie transform to root word
ie 1) computer amp computers become
comput
2) product produce amp produced
become produc
- Chunking ie identify the phrasal
constituents in a sentence including
nounverb phrase etc and splits the
sentence into chunks of semantically
related words
Less noisy than N-
Grams
Computationally
expensive
solution for
analyzing the
structure of texts
Does not specify
the internal
structure or the
role of words in
the sentence
Deep NLP
technique
- Generate syntactic relationship
between each pair of words
- Extract subject predicate nagation
objecct and named entity to form triples
Context of the
sentence is
retained
Sentence level
analysis is too
structured
Techniques - Summary
14
Appendix
15
2A - Explore Corpus through EDA 2B - Convert text to lowercase 2C - Remove
a) Numbers(if required) b) Punctuations c) English stop words d) Own stop words(if
required)
e) Strip whitespace f) LemmatizationStemming g) Sparse terms
2D - Create document term matrix
Step 3 - Visualization
Corpus
Web
Documents
Step 1 ndash Data Assemble
Step 2 ndash Data Processing
Step 4 ndash Build Model(s)
Clustering
Classification
Sentiment Analysis
Fre
qu
en
cy
Ch
art
W
ord
Clo
ud
C
orr
ela
tio
n P
lot
R - Text Mining Process Overview
16
DB
Package Name
Category Description
tm Text Mining A framework for text mining applications
topicmodels Topic Modelling Fit topic models with Latent Dirichlet Allocation (LDA) and Comparative Text Mining (CTM)
wordcloud Visualization Plot a cloud comparing the frequencies of words across documents
lda Topic Modelling Fit topic models with Latent Dirichlet Allocation
wordnet Text Mining Database of English which is commonly used in linguistics and text mining
RTextTools Text Mining Automatic text classification via supervised learning
qdap Sentiment analysis
Transcript analysis text mining and natural language processing
tmplugindc Text Mining A plug-in for package tm to support distributed text mining
tmpluginmail Text Mining A plug-in for package tm to handle mail
textir Text Mining A suite of tools for inference about text documents and associated sentiment
tau Text Mining Utilities for text analysis
textcat Text Mining N-gram based text categorization
SnowballC Text Mining Word stemmer
twitteR Text Mining Provides an interface to the Twitter web API
ROAuth Text Mining Allows users to authenticate to the server of their choice (like Twitter)
RColorBrewer Visualization The packages provides palettes for drawing nice maps shaded according to a variable
ggplot2 Visualization
Graphing package implemented on top of the R statistical package Inspired by the Grammar of Graphics seminal work of Leland Wilkinson
R ndash Required packages for Text Mining
17
Example 1 - Obtaining and analyzing tweets
Objective R code for analyzing tweets relating to AAA2011 (text mining topic modelling network analysis clustering and sentiment analysis)
What does the code do
The code details ten steps in the analysis and visualization of the tweets
Acquiring the raw Twitter data
Calculating some basic statistics with the raw Twitter data
Calculating some basic retweet statistics
Calculating the ratio of retweets to tweets
Calculating some basic statistics about URLs in tweets
Basic text mining for token frequency and token association analysis (word cloud)
Calculating sentiment scores of tweets including on subsets containing tokens of interest
Hierarchical clustering of tokens based on multi scale bootstrap resampling
Topic modelling the tweet corpus using latent Dirichlet allocation
Network analysis of tweeters based on retweets
Code Source Code was taken from following link and tweakedadded additional bits where required to ensure code runs fine httpsgithubcombenmarwickAAA2011-Tweets
How to Run or Test the code - From the word doc copy the R code in the given sequence highlighted in yellow color and paste on your R console
18
RTextTools ndash Example for supervised Learning for Text Classification using Ensemble
RTextTools is a free open source R machine learning package for automatic text classification
The package includes nine algorithms for ensemble classification (svm slda boosting bagging random forests glmnet decision trees neural networks and maximum entropy) comprehensive analytics and thorough documentation
Users may use n-fold cross validation to calculate the accuracy of each algorithm on their dataset and determine which algorithms to use in their ensemble
(Using a four-ensemble agreement approach Collingwood and Wilkerson (2012) found that when four of their algorithms agree on the label of a textual document the machine label matches the human label over 90 of the time The rate is just 45 when only two algorithms agree on the text label)
Code Source The codes is readily available for download and usage from the following link httpsgithubcomtimjurkaRTextTools The code can be implemented without modification for testing however itrsquos set up such that changes can be incorporated easily based on our requirement
Additional Reading httpwwwrtexttoolscomabout-the-projecthtml
19
Example 2 - RTextTools
Penn Treebank - httpswwwlingupenneducoursesFall_2003ling001penn_treebank_poshtml
Stanford info lab - Finding Similar Items httpinfolabstanfordedu~ullmanmmdsch3pdf
TRIPLET EXTRACTION FROM SENTENCES URL - httpailabijssidelia_rusuPapersis_2007pdf
Shallow and Deep NLP Processing for ontology learning a Quick Overview httpazouaqathabascaucapublicationsConferences20Workshops20Books5BBC25D_KDW_2010pdf
References
20
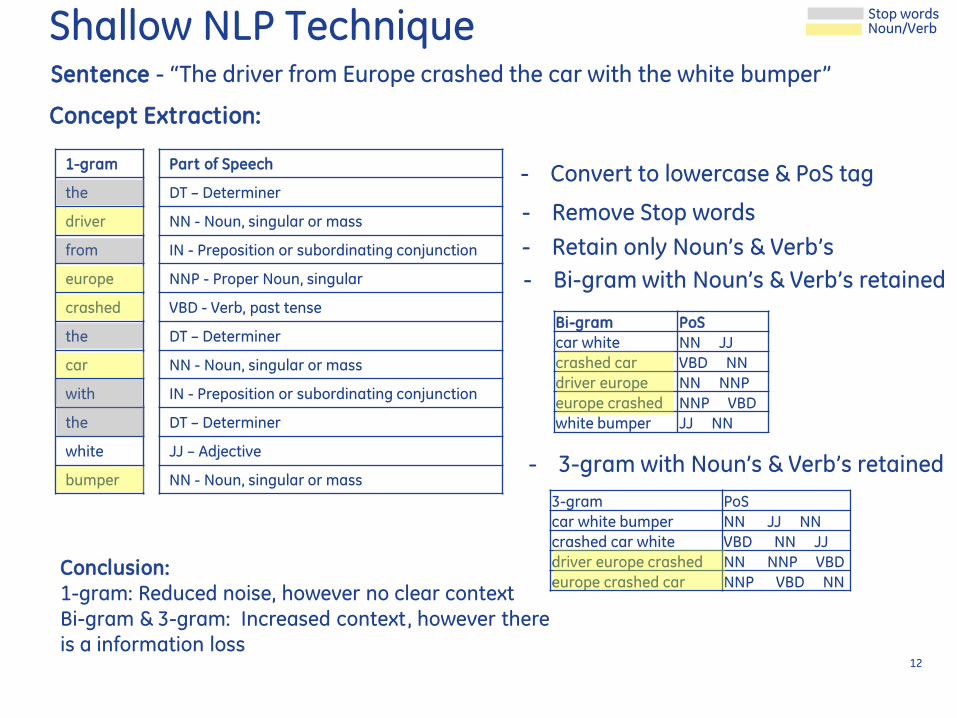
Sentence - ldquoThe driver from Europe crashed the car with the white bumperrdquo
1-gram
the
driver
from
europe
crashed
the
car
with
the
white
bumper
Part of Speech
DT ndash Determiner
NN - Noun singular or mass
IN - Preposition or subordinating conjunction
NNP - Proper Noun singular
VBD - Verb past tense
DT ndash Determiner
NN - Noun singular or mass
IN - Preposition or subordinating conjunction
DT ndash Determiner
JJ ndash Adjective
NN - Noun singular or mass
- Convert to lowercase amp PoS tag
Concept Extraction
- Remove Stop words
- Retain only Nounrsquos amp Verbrsquos
- Bi-gram with Nounrsquos amp Verbrsquos retained
Bi-gram PoS
car white NN JJ
crashed car VBD NN
driver europe NN NNP
europe crashed NNP VBD
white bumper JJ NN
3-gram PoS
car white bumper NN JJ NN
crashed car white VBD NN JJ
driver europe crashed NN NNP VBD
europe crashed car NNP VBD NN
- 3-gram with Nounrsquos amp Verbrsquos retained
Conclusion
1-gram Reduced noise however no clear context Bi-gram amp 3-gram Increased context however there
is a information loss
Shallow NLP Technique
12
Stop words NounVerb
Definition
- Extension to the shallow NLP
- Detected relationships are expressed as complex construction to retain the context
- Example relationships Located in employed by part of married to
Applications
- Develop features and representations appropriate for complex interpretation tasks
- Fraud detection - Life science prediction activities based on complex RNA-Sequence
Deep NLP technique
Example
The above sentence can be represented using triples (Subject Predicate [Modifier] Object) without loosing the context
Triples
driver crash car
driver crash with bumper
driver be from Europe 13
Technique General Steps Pros Cons
N-Gram
- Convert to lowercase
- Remove punctuations - Remove special characters Simple technique Extremely noisy
Shallow NLP
technique
- POS tagging
- Lemmatization ie transform to
dictionary base form ie produce amp produced become produce
- Stemming ie transform to root word
ie 1) computer amp computers become
comput
2) product produce amp produced
become produc
- Chunking ie identify the phrasal
constituents in a sentence including
nounverb phrase etc and splits the
sentence into chunks of semantically
related words
Less noisy than N-
Grams
Computationally
expensive
solution for
analyzing the
structure of texts
Does not specify
the internal
structure or the
role of words in
the sentence
Deep NLP
technique
- Generate syntactic relationship
between each pair of words
- Extract subject predicate nagation
objecct and named entity to form triples
Context of the
sentence is
retained
Sentence level
analysis is too
structured
Techniques - Summary
14
Appendix
15
2A - Explore Corpus through EDA 2B - Convert text to lowercase 2C - Remove
a) Numbers(if required) b) Punctuations c) English stop words d) Own stop words(if
required)
e) Strip whitespace f) LemmatizationStemming g) Sparse terms
2D - Create document term matrix
Step 3 - Visualization
Corpus
Web
Documents
Step 1 ndash Data Assemble
Step 2 ndash Data Processing
Step 4 ndash Build Model(s)
Clustering
Classification
Sentiment Analysis
Fre
qu
en
cy
Ch
art
W
ord
Clo
ud
C
orr
ela
tio
n P
lot
R - Text Mining Process Overview
16
DB
Package Name
Category Description
tm Text Mining A framework for text mining applications
topicmodels Topic Modelling Fit topic models with Latent Dirichlet Allocation (LDA) and Comparative Text Mining (CTM)
wordcloud Visualization Plot a cloud comparing the frequencies of words across documents
lda Topic Modelling Fit topic models with Latent Dirichlet Allocation
wordnet Text Mining Database of English which is commonly used in linguistics and text mining
RTextTools Text Mining Automatic text classification via supervised learning
qdap Sentiment analysis
Transcript analysis text mining and natural language processing
tmplugindc Text Mining A plug-in for package tm to support distributed text mining
tmpluginmail Text Mining A plug-in for package tm to handle mail
textir Text Mining A suite of tools for inference about text documents and associated sentiment
tau Text Mining Utilities for text analysis
textcat Text Mining N-gram based text categorization
SnowballC Text Mining Word stemmer
twitteR Text Mining Provides an interface to the Twitter web API
ROAuth Text Mining Allows users to authenticate to the server of their choice (like Twitter)
RColorBrewer Visualization The packages provides palettes for drawing nice maps shaded according to a variable
ggplot2 Visualization
Graphing package implemented on top of the R statistical package Inspired by the Grammar of Graphics seminal work of Leland Wilkinson
R ndash Required packages for Text Mining
17
Example 1 - Obtaining and analyzing tweets
Objective R code for analyzing tweets relating to AAA2011 (text mining topic modelling network analysis clustering and sentiment analysis)
What does the code do
The code details ten steps in the analysis and visualization of the tweets
Acquiring the raw Twitter data
Calculating some basic statistics with the raw Twitter data
Calculating some basic retweet statistics
Calculating the ratio of retweets to tweets
Calculating some basic statistics about URLs in tweets
Basic text mining for token frequency and token association analysis (word cloud)
Calculating sentiment scores of tweets including on subsets containing tokens of interest
Hierarchical clustering of tokens based on multi scale bootstrap resampling
Topic modelling the tweet corpus using latent Dirichlet allocation
Network analysis of tweeters based on retweets
Code Source Code was taken from following link and tweakedadded additional bits where required to ensure code runs fine httpsgithubcombenmarwickAAA2011-Tweets
How to Run or Test the code - From the word doc copy the R code in the given sequence highlighted in yellow color and paste on your R console
18
RTextTools ndash Example for supervised Learning for Text Classification using Ensemble
RTextTools is a free open source R machine learning package for automatic text classification
The package includes nine algorithms for ensemble classification (svm slda boosting bagging random forests glmnet decision trees neural networks and maximum entropy) comprehensive analytics and thorough documentation
Users may use n-fold cross validation to calculate the accuracy of each algorithm on their dataset and determine which algorithms to use in their ensemble
(Using a four-ensemble agreement approach Collingwood and Wilkerson (2012) found that when four of their algorithms agree on the label of a textual document the machine label matches the human label over 90 of the time The rate is just 45 when only two algorithms agree on the text label)
Code Source The codes is readily available for download and usage from the following link httpsgithubcomtimjurkaRTextTools The code can be implemented without modification for testing however itrsquos set up such that changes can be incorporated easily based on our requirement
Additional Reading httpwwwrtexttoolscomabout-the-projecthtml
19
Example 2 - RTextTools
Penn Treebank - httpswwwlingupenneducoursesFall_2003ling001penn_treebank_poshtml
Stanford info lab - Finding Similar Items httpinfolabstanfordedu~ullmanmmdsch3pdf
TRIPLET EXTRACTION FROM SENTENCES URL - httpailabijssidelia_rusuPapersis_2007pdf
Shallow and Deep NLP Processing for ontology learning a Quick Overview httpazouaqathabascaucapublicationsConferences20Workshops20Books5BBC25D_KDW_2010pdf
References
20
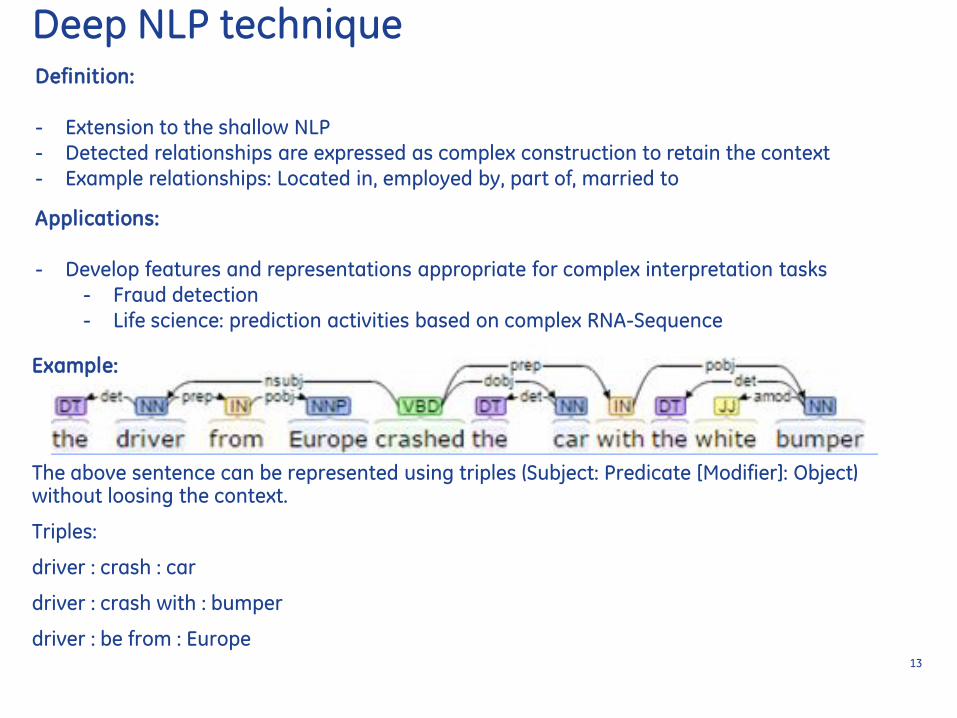
Definition
- Extension to the shallow NLP
- Detected relationships are expressed as complex construction to retain the context
- Example relationships Located in employed by part of married to
Applications
- Develop features and representations appropriate for complex interpretation tasks
- Fraud detection - Life science prediction activities based on complex RNA-Sequence
Deep NLP technique
Example
The above sentence can be represented using triples (Subject Predicate [Modifier] Object) without loosing the context
Triples
driver crash car
driver crash with bumper
driver be from Europe 13
Technique General Steps Pros Cons
N-Gram
- Convert to lowercase
- Remove punctuations - Remove special characters Simple technique Extremely noisy
Shallow NLP
technique
- POS tagging
- Lemmatization ie transform to
dictionary base form ie produce amp produced become produce
- Stemming ie transform to root word
ie 1) computer amp computers become
comput
2) product produce amp produced
become produc
- Chunking ie identify the phrasal
constituents in a sentence including
nounverb phrase etc and splits the
sentence into chunks of semantically
related words
Less noisy than N-
Grams
Computationally
expensive
solution for
analyzing the
structure of texts
Does not specify
the internal
structure or the
role of words in
the sentence
Deep NLP
technique
- Generate syntactic relationship
between each pair of words
- Extract subject predicate nagation
objecct and named entity to form triples
Context of the
sentence is
retained
Sentence level
analysis is too
structured
Techniques - Summary
14
Appendix
15
2A - Explore Corpus through EDA 2B - Convert text to lowercase 2C - Remove
a) Numbers(if required) b) Punctuations c) English stop words d) Own stop words(if
required)
e) Strip whitespace f) LemmatizationStemming g) Sparse terms
2D - Create document term matrix
Step 3 - Visualization
Corpus
Web
Documents
Step 1 ndash Data Assemble
Step 2 ndash Data Processing
Step 4 ndash Build Model(s)
Clustering
Classification
Sentiment Analysis
Fre
qu
en
cy
Ch
art
W
ord
Clo
ud
C
orr
ela
tio
n P
lot
R - Text Mining Process Overview
16
DB
Package Name
Category Description
tm Text Mining A framework for text mining applications
topicmodels Topic Modelling Fit topic models with Latent Dirichlet Allocation (LDA) and Comparative Text Mining (CTM)
wordcloud Visualization Plot a cloud comparing the frequencies of words across documents
lda Topic Modelling Fit topic models with Latent Dirichlet Allocation
wordnet Text Mining Database of English which is commonly used in linguistics and text mining
RTextTools Text Mining Automatic text classification via supervised learning
qdap Sentiment analysis
Transcript analysis text mining and natural language processing
tmplugindc Text Mining A plug-in for package tm to support distributed text mining
tmpluginmail Text Mining A plug-in for package tm to handle mail
textir Text Mining A suite of tools for inference about text documents and associated sentiment
tau Text Mining Utilities for text analysis
textcat Text Mining N-gram based text categorization
SnowballC Text Mining Word stemmer
twitteR Text Mining Provides an interface to the Twitter web API
ROAuth Text Mining Allows users to authenticate to the server of their choice (like Twitter)
RColorBrewer Visualization The packages provides palettes for drawing nice maps shaded according to a variable
ggplot2 Visualization
Graphing package implemented on top of the R statistical package Inspired by the Grammar of Graphics seminal work of Leland Wilkinson
R ndash Required packages for Text Mining
17
Example 1 - Obtaining and analyzing tweets
Objective R code for analyzing tweets relating to AAA2011 (text mining topic modelling network analysis clustering and sentiment analysis)
What does the code do
The code details ten steps in the analysis and visualization of the tweets
Acquiring the raw Twitter data
Calculating some basic statistics with the raw Twitter data
Calculating some basic retweet statistics
Calculating the ratio of retweets to tweets
Calculating some basic statistics about URLs in tweets
Basic text mining for token frequency and token association analysis (word cloud)
Calculating sentiment scores of tweets including on subsets containing tokens of interest
Hierarchical clustering of tokens based on multi scale bootstrap resampling
Topic modelling the tweet corpus using latent Dirichlet allocation
Network analysis of tweeters based on retweets
Code Source Code was taken from following link and tweakedadded additional bits where required to ensure code runs fine httpsgithubcombenmarwickAAA2011-Tweets
How to Run or Test the code - From the word doc copy the R code in the given sequence highlighted in yellow color and paste on your R console
18
RTextTools ndash Example for supervised Learning for Text Classification using Ensemble
RTextTools is a free open source R machine learning package for automatic text classification
The package includes nine algorithms for ensemble classification (svm slda boosting bagging random forests glmnet decision trees neural networks and maximum entropy) comprehensive analytics and thorough documentation
Users may use n-fold cross validation to calculate the accuracy of each algorithm on their dataset and determine which algorithms to use in their ensemble
(Using a four-ensemble agreement approach Collingwood and Wilkerson (2012) found that when four of their algorithms agree on the label of a textual document the machine label matches the human label over 90 of the time The rate is just 45 when only two algorithms agree on the text label)
Code Source The codes is readily available for download and usage from the following link httpsgithubcomtimjurkaRTextTools The code can be implemented without modification for testing however itrsquos set up such that changes can be incorporated easily based on our requirement
Additional Reading httpwwwrtexttoolscomabout-the-projecthtml
19
Example 2 - RTextTools
Penn Treebank - httpswwwlingupenneducoursesFall_2003ling001penn_treebank_poshtml
Stanford info lab - Finding Similar Items httpinfolabstanfordedu~ullmanmmdsch3pdf
TRIPLET EXTRACTION FROM SENTENCES URL - httpailabijssidelia_rusuPapersis_2007pdf
Shallow and Deep NLP Processing for ontology learning a Quick Overview httpazouaqathabascaucapublicationsConferences20Workshops20Books5BBC25D_KDW_2010pdf
References
20
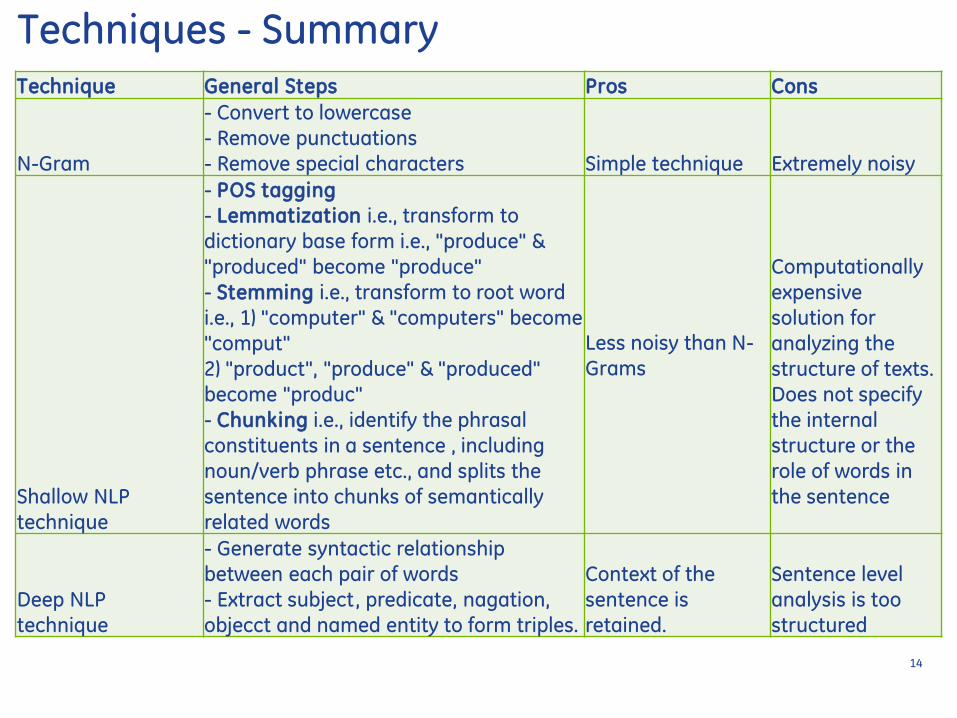
Technique General Steps Pros Cons
N-Gram
- Convert to lowercase
- Remove punctuations - Remove special characters Simple technique Extremely noisy
Shallow NLP
technique
- POS tagging
- Lemmatization ie transform to
dictionary base form ie produce amp produced become produce
- Stemming ie transform to root word
ie 1) computer amp computers become
comput
2) product produce amp produced
become produc
- Chunking ie identify the phrasal
constituents in a sentence including
nounverb phrase etc and splits the
sentence into chunks of semantically
related words
Less noisy than N-
Grams
Computationally
expensive
solution for
analyzing the
structure of texts
Does not specify
the internal
structure or the
role of words in
the sentence
Deep NLP
technique
- Generate syntactic relationship
between each pair of words
- Extract subject predicate nagation
objecct and named entity to form triples
Context of the
sentence is
retained
Sentence level
analysis is too
structured
Techniques - Summary
14
Appendix
15
2A - Explore Corpus through EDA 2B - Convert text to lowercase 2C - Remove
a) Numbers(if required) b) Punctuations c) English stop words d) Own stop words(if
required)
e) Strip whitespace f) LemmatizationStemming g) Sparse terms
2D - Create document term matrix
Step 3 - Visualization
Corpus
Web
Documents
Step 1 ndash Data Assemble
Step 2 ndash Data Processing
Step 4 ndash Build Model(s)
Clustering
Classification
Sentiment Analysis
Fre
qu
en
cy
Ch
art
W
ord
Clo
ud
C
orr
ela
tio
n P
lot
R - Text Mining Process Overview
16
DB
Package Name
Category Description
tm Text Mining A framework for text mining applications
topicmodels Topic Modelling Fit topic models with Latent Dirichlet Allocation (LDA) and Comparative Text Mining (CTM)
wordcloud Visualization Plot a cloud comparing the frequencies of words across documents
lda Topic Modelling Fit topic models with Latent Dirichlet Allocation
wordnet Text Mining Database of English which is commonly used in linguistics and text mining
RTextTools Text Mining Automatic text classification via supervised learning
qdap Sentiment analysis
Transcript analysis text mining and natural language processing
tmplugindc Text Mining A plug-in for package tm to support distributed text mining
tmpluginmail Text Mining A plug-in for package tm to handle mail
textir Text Mining A suite of tools for inference about text documents and associated sentiment
tau Text Mining Utilities for text analysis
textcat Text Mining N-gram based text categorization
SnowballC Text Mining Word stemmer
twitteR Text Mining Provides an interface to the Twitter web API
ROAuth Text Mining Allows users to authenticate to the server of their choice (like Twitter)
RColorBrewer Visualization The packages provides palettes for drawing nice maps shaded according to a variable
ggplot2 Visualization
Graphing package implemented on top of the R statistical package Inspired by the Grammar of Graphics seminal work of Leland Wilkinson
R ndash Required packages for Text Mining
17
Example 1 - Obtaining and analyzing tweets
Objective R code for analyzing tweets relating to AAA2011 (text mining topic modelling network analysis clustering and sentiment analysis)
What does the code do
The code details ten steps in the analysis and visualization of the tweets
Acquiring the raw Twitter data
Calculating some basic statistics with the raw Twitter data
Calculating some basic retweet statistics
Calculating the ratio of retweets to tweets
Calculating some basic statistics about URLs in tweets
Basic text mining for token frequency and token association analysis (word cloud)
Calculating sentiment scores of tweets including on subsets containing tokens of interest
Hierarchical clustering of tokens based on multi scale bootstrap resampling
Topic modelling the tweet corpus using latent Dirichlet allocation
Network analysis of tweeters based on retweets
Code Source Code was taken from following link and tweakedadded additional bits where required to ensure code runs fine httpsgithubcombenmarwickAAA2011-Tweets
How to Run or Test the code - From the word doc copy the R code in the given sequence highlighted in yellow color and paste on your R console
18
RTextTools ndash Example for supervised Learning for Text Classification using Ensemble
RTextTools is a free open source R machine learning package for automatic text classification
The package includes nine algorithms for ensemble classification (svm slda boosting bagging random forests glmnet decision trees neural networks and maximum entropy) comprehensive analytics and thorough documentation
Users may use n-fold cross validation to calculate the accuracy of each algorithm on their dataset and determine which algorithms to use in their ensemble
(Using a four-ensemble agreement approach Collingwood and Wilkerson (2012) found that when four of their algorithms agree on the label of a textual document the machine label matches the human label over 90 of the time The rate is just 45 when only two algorithms agree on the text label)
Code Source The codes is readily available for download and usage from the following link httpsgithubcomtimjurkaRTextTools The code can be implemented without modification for testing however itrsquos set up such that changes can be incorporated easily based on our requirement
Additional Reading httpwwwrtexttoolscomabout-the-projecthtml
19
Example 2 - RTextTools
Penn Treebank - httpswwwlingupenneducoursesFall_2003ling001penn_treebank_poshtml
Stanford info lab - Finding Similar Items httpinfolabstanfordedu~ullmanmmdsch3pdf
TRIPLET EXTRACTION FROM SENTENCES URL - httpailabijssidelia_rusuPapersis_2007pdf
Shallow and Deep NLP Processing for ontology learning a Quick Overview httpazouaqathabascaucapublicationsConferences20Workshops20Books5BBC25D_KDW_2010pdf
References
20

Appendix
15
2A - Explore Corpus through EDA 2B - Convert text to lowercase 2C - Remove
a) Numbers(if required) b) Punctuations c) English stop words d) Own stop words(if
required)
e) Strip whitespace f) LemmatizationStemming g) Sparse terms
2D - Create document term matrix
Step 3 - Visualization
Corpus
Web
Documents
Step 1 ndash Data Assemble
Step 2 ndash Data Processing
Step 4 ndash Build Model(s)
Clustering
Classification
Sentiment Analysis
Fre
qu
en
cy
Ch
art
W
ord
Clo
ud
C
orr
ela
tio
n P
lot
R - Text Mining Process Overview
16
DB
Package Name
Category Description
tm Text Mining A framework for text mining applications
topicmodels Topic Modelling Fit topic models with Latent Dirichlet Allocation (LDA) and Comparative Text Mining (CTM)
wordcloud Visualization Plot a cloud comparing the frequencies of words across documents
lda Topic Modelling Fit topic models with Latent Dirichlet Allocation
wordnet Text Mining Database of English which is commonly used in linguistics and text mining
RTextTools Text Mining Automatic text classification via supervised learning
qdap Sentiment analysis
Transcript analysis text mining and natural language processing
tmplugindc Text Mining A plug-in for package tm to support distributed text mining
tmpluginmail Text Mining A plug-in for package tm to handle mail
textir Text Mining A suite of tools for inference about text documents and associated sentiment
tau Text Mining Utilities for text analysis
textcat Text Mining N-gram based text categorization
SnowballC Text Mining Word stemmer
twitteR Text Mining Provides an interface to the Twitter web API
ROAuth Text Mining Allows users to authenticate to the server of their choice (like Twitter)
RColorBrewer Visualization The packages provides palettes for drawing nice maps shaded according to a variable
ggplot2 Visualization
Graphing package implemented on top of the R statistical package Inspired by the Grammar of Graphics seminal work of Leland Wilkinson
R ndash Required packages for Text Mining
17
Example 1 - Obtaining and analyzing tweets
Objective R code for analyzing tweets relating to AAA2011 (text mining topic modelling network analysis clustering and sentiment analysis)
What does the code do
The code details ten steps in the analysis and visualization of the tweets
Acquiring the raw Twitter data
Calculating some basic statistics with the raw Twitter data
Calculating some basic retweet statistics
Calculating the ratio of retweets to tweets
Calculating some basic statistics about URLs in tweets
Basic text mining for token frequency and token association analysis (word cloud)
Calculating sentiment scores of tweets including on subsets containing tokens of interest
Hierarchical clustering of tokens based on multi scale bootstrap resampling
Topic modelling the tweet corpus using latent Dirichlet allocation
Network analysis of tweeters based on retweets
Code Source Code was taken from following link and tweakedadded additional bits where required to ensure code runs fine httpsgithubcombenmarwickAAA2011-Tweets
How to Run or Test the code - From the word doc copy the R code in the given sequence highlighted in yellow color and paste on your R console
18
RTextTools ndash Example for supervised Learning for Text Classification using Ensemble
RTextTools is a free open source R machine learning package for automatic text classification
The package includes nine algorithms for ensemble classification (svm slda boosting bagging random forests glmnet decision trees neural networks and maximum entropy) comprehensive analytics and thorough documentation
Users may use n-fold cross validation to calculate the accuracy of each algorithm on their dataset and determine which algorithms to use in their ensemble
(Using a four-ensemble agreement approach Collingwood and Wilkerson (2012) found that when four of their algorithms agree on the label of a textual document the machine label matches the human label over 90 of the time The rate is just 45 when only two algorithms agree on the text label)
Code Source The codes is readily available for download and usage from the following link httpsgithubcomtimjurkaRTextTools The code can be implemented without modification for testing however itrsquos set up such that changes can be incorporated easily based on our requirement
Additional Reading httpwwwrtexttoolscomabout-the-projecthtml
19
Example 2 - RTextTools
Penn Treebank - httpswwwlingupenneducoursesFall_2003ling001penn_treebank_poshtml
Stanford info lab - Finding Similar Items httpinfolabstanfordedu~ullmanmmdsch3pdf
TRIPLET EXTRACTION FROM SENTENCES URL - httpailabijssidelia_rusuPapersis_2007pdf
Shallow and Deep NLP Processing for ontology learning a Quick Overview httpazouaqathabascaucapublicationsConferences20Workshops20Books5BBC25D_KDW_2010pdf
References
20
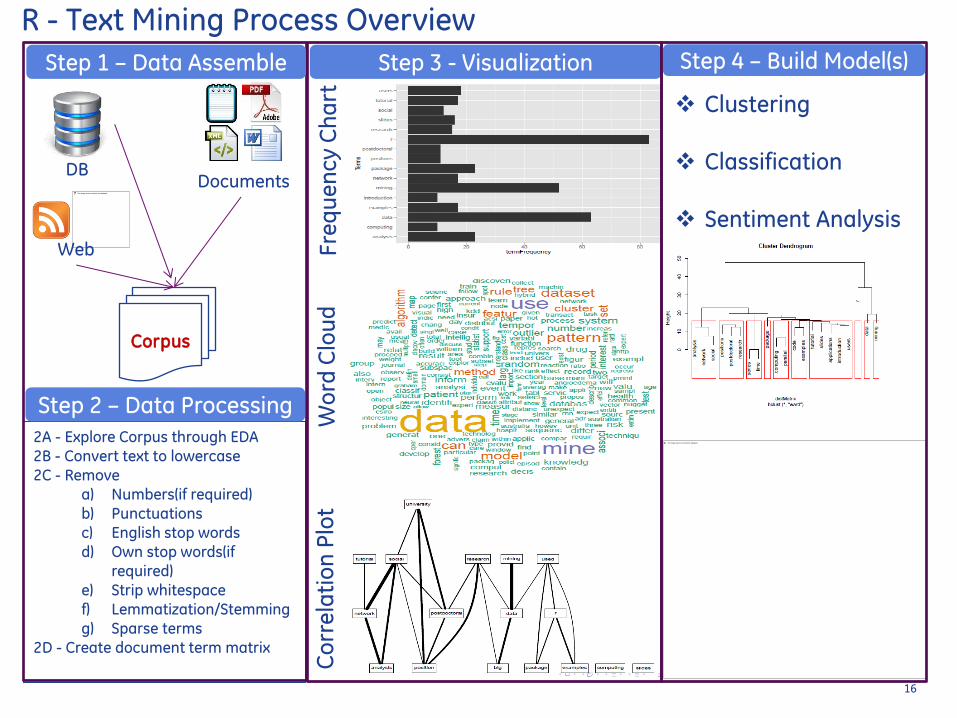
2A - Explore Corpus through EDA 2B - Convert text to lowercase 2C - Remove
a) Numbers(if required) b) Punctuations c) English stop words d) Own stop words(if
required)
e) Strip whitespace f) LemmatizationStemming g) Sparse terms
2D - Create document term matrix
Step 3 - Visualization
Corpus
Web
Documents
Step 1 ndash Data Assemble
Step 2 ndash Data Processing
Step 4 ndash Build Model(s)
Clustering
Classification
Sentiment Analysis
Fre
qu
en
cy
Ch
art
W
ord
Clo
ud
C
orr
ela
tio
n P
lot
R - Text Mining Process Overview
16
DB
Package Name
Category Description
tm Text Mining A framework for text mining applications
topicmodels Topic Modelling Fit topic models with Latent Dirichlet Allocation (LDA) and Comparative Text Mining (CTM)
wordcloud Visualization Plot a cloud comparing the frequencies of words across documents
lda Topic Modelling Fit topic models with Latent Dirichlet Allocation
wordnet Text Mining Database of English which is commonly used in linguistics and text mining
RTextTools Text Mining Automatic text classification via supervised learning
qdap Sentiment analysis
Transcript analysis text mining and natural language processing
tmplugindc Text Mining A plug-in for package tm to support distributed text mining
tmpluginmail Text Mining A plug-in for package tm to handle mail
textir Text Mining A suite of tools for inference about text documents and associated sentiment
tau Text Mining Utilities for text analysis
textcat Text Mining N-gram based text categorization
SnowballC Text Mining Word stemmer
twitteR Text Mining Provides an interface to the Twitter web API
ROAuth Text Mining Allows users to authenticate to the server of their choice (like Twitter)
RColorBrewer Visualization The packages provides palettes for drawing nice maps shaded according to a variable
ggplot2 Visualization
Graphing package implemented on top of the R statistical package Inspired by the Grammar of Graphics seminal work of Leland Wilkinson
R ndash Required packages for Text Mining
17
Example 1 - Obtaining and analyzing tweets
Objective R code for analyzing tweets relating to AAA2011 (text mining topic modelling network analysis clustering and sentiment analysis)
What does the code do
The code details ten steps in the analysis and visualization of the tweets
Acquiring the raw Twitter data
Calculating some basic statistics with the raw Twitter data
Calculating some basic retweet statistics
Calculating the ratio of retweets to tweets
Calculating some basic statistics about URLs in tweets
Basic text mining for token frequency and token association analysis (word cloud)
Calculating sentiment scores of tweets including on subsets containing tokens of interest
Hierarchical clustering of tokens based on multi scale bootstrap resampling
Topic modelling the tweet corpus using latent Dirichlet allocation
Network analysis of tweeters based on retweets
Code Source Code was taken from following link and tweakedadded additional bits where required to ensure code runs fine httpsgithubcombenmarwickAAA2011-Tweets
How to Run or Test the code - From the word doc copy the R code in the given sequence highlighted in yellow color and paste on your R console
18
RTextTools ndash Example for supervised Learning for Text Classification using Ensemble
RTextTools is a free open source R machine learning package for automatic text classification
The package includes nine algorithms for ensemble classification (svm slda boosting bagging random forests glmnet decision trees neural networks and maximum entropy) comprehensive analytics and thorough documentation
Users may use n-fold cross validation to calculate the accuracy of each algorithm on their dataset and determine which algorithms to use in their ensemble
(Using a four-ensemble agreement approach Collingwood and Wilkerson (2012) found that when four of their algorithms agree on the label of a textual document the machine label matches the human label over 90 of the time The rate is just 45 when only two algorithms agree on the text label)
Code Source The codes is readily available for download and usage from the following link httpsgithubcomtimjurkaRTextTools The code can be implemented without modification for testing however itrsquos set up such that changes can be incorporated easily based on our requirement
Additional Reading httpwwwrtexttoolscomabout-the-projecthtml
19
Example 2 - RTextTools
Penn Treebank - httpswwwlingupenneducoursesFall_2003ling001penn_treebank_poshtml
Stanford info lab - Finding Similar Items httpinfolabstanfordedu~ullmanmmdsch3pdf
TRIPLET EXTRACTION FROM SENTENCES URL - httpailabijssidelia_rusuPapersis_2007pdf
Shallow and Deep NLP Processing for ontology learning a Quick Overview httpazouaqathabascaucapublicationsConferences20Workshops20Books5BBC25D_KDW_2010pdf
References
20
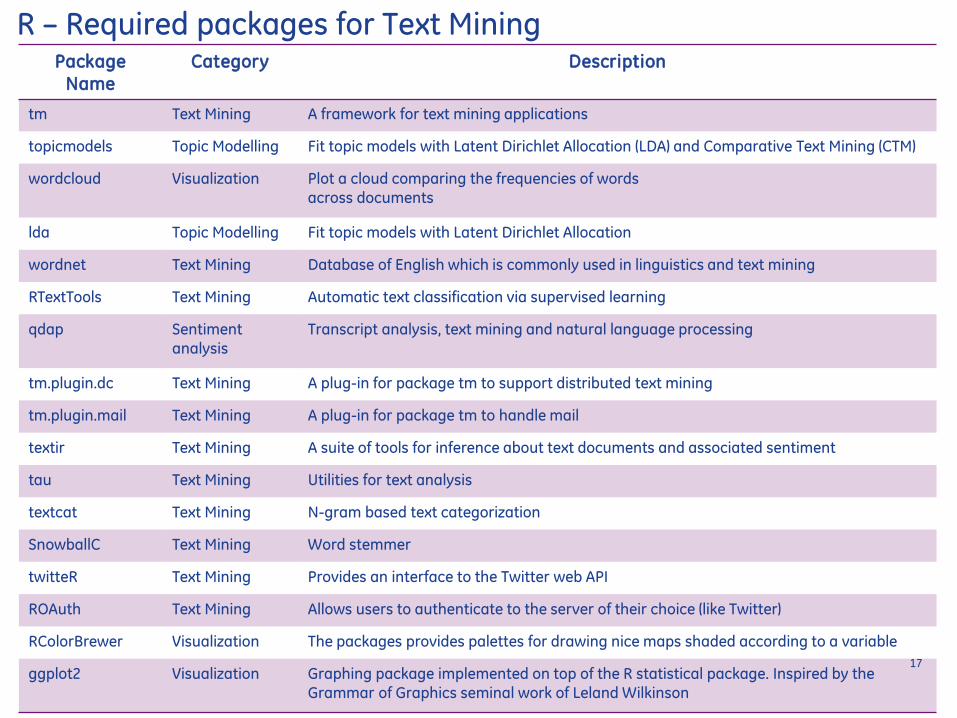
Package Name
Category Description
tm Text Mining A framework for text mining applications
topicmodels Topic Modelling Fit topic models with Latent Dirichlet Allocation (LDA) and Comparative Text Mining (CTM)
wordcloud Visualization Plot a cloud comparing the frequencies of words across documents
lda Topic Modelling Fit topic models with Latent Dirichlet Allocation
wordnet Text Mining Database of English which is commonly used in linguistics and text mining
RTextTools Text Mining Automatic text classification via supervised learning
qdap Sentiment analysis
Transcript analysis text mining and natural language processing
tmplugindc Text Mining A plug-in for package tm to support distributed text mining
tmpluginmail Text Mining A plug-in for package tm to handle mail
textir Text Mining A suite of tools for inference about text documents and associated sentiment
tau Text Mining Utilities for text analysis
textcat Text Mining N-gram based text categorization
SnowballC Text Mining Word stemmer
twitteR Text Mining Provides an interface to the Twitter web API
ROAuth Text Mining Allows users to authenticate to the server of their choice (like Twitter)
RColorBrewer Visualization The packages provides palettes for drawing nice maps shaded according to a variable
ggplot2 Visualization
Graphing package implemented on top of the R statistical package Inspired by the Grammar of Graphics seminal work of Leland Wilkinson
R ndash Required packages for Text Mining
17
Example 1 - Obtaining and analyzing tweets
Objective R code for analyzing tweets relating to AAA2011 (text mining topic modelling network analysis clustering and sentiment analysis)
What does the code do
The code details ten steps in the analysis and visualization of the tweets
Acquiring the raw Twitter data
Calculating some basic statistics with the raw Twitter data
Calculating some basic retweet statistics
Calculating the ratio of retweets to tweets
Calculating some basic statistics about URLs in tweets
Basic text mining for token frequency and token association analysis (word cloud)
Calculating sentiment scores of tweets including on subsets containing tokens of interest
Hierarchical clustering of tokens based on multi scale bootstrap resampling
Topic modelling the tweet corpus using latent Dirichlet allocation
Network analysis of tweeters based on retweets
Code Source Code was taken from following link and tweakedadded additional bits where required to ensure code runs fine httpsgithubcombenmarwickAAA2011-Tweets
How to Run or Test the code - From the word doc copy the R code in the given sequence highlighted in yellow color and paste on your R console
18
RTextTools ndash Example for supervised Learning for Text Classification using Ensemble
RTextTools is a free open source R machine learning package for automatic text classification
The package includes nine algorithms for ensemble classification (svm slda boosting bagging random forests glmnet decision trees neural networks and maximum entropy) comprehensive analytics and thorough documentation
Users may use n-fold cross validation to calculate the accuracy of each algorithm on their dataset and determine which algorithms to use in their ensemble
(Using a four-ensemble agreement approach Collingwood and Wilkerson (2012) found that when four of their algorithms agree on the label of a textual document the machine label matches the human label over 90 of the time The rate is just 45 when only two algorithms agree on the text label)
Code Source The codes is readily available for download and usage from the following link httpsgithubcomtimjurkaRTextTools The code can be implemented without modification for testing however itrsquos set up such that changes can be incorporated easily based on our requirement
Additional Reading httpwwwrtexttoolscomabout-the-projecthtml
19
Example 2 - RTextTools
Penn Treebank - httpswwwlingupenneducoursesFall_2003ling001penn_treebank_poshtml
Stanford info lab - Finding Similar Items httpinfolabstanfordedu~ullmanmmdsch3pdf
TRIPLET EXTRACTION FROM SENTENCES URL - httpailabijssidelia_rusuPapersis_2007pdf
Shallow and Deep NLP Processing for ontology learning a Quick Overview httpazouaqathabascaucapublicationsConferences20Workshops20Books5BBC25D_KDW_2010pdf
References
20

Example 1 - Obtaining and analyzing tweets
Objective R code for analyzing tweets relating to AAA2011 (text mining topic modelling network analysis clustering and sentiment analysis)
What does the code do
The code details ten steps in the analysis and visualization of the tweets
Acquiring the raw Twitter data
Calculating some basic statistics with the raw Twitter data
Calculating some basic retweet statistics
Calculating the ratio of retweets to tweets
Calculating some basic statistics about URLs in tweets
Basic text mining for token frequency and token association analysis (word cloud)
Calculating sentiment scores of tweets including on subsets containing tokens of interest
Hierarchical clustering of tokens based on multi scale bootstrap resampling
Topic modelling the tweet corpus using latent Dirichlet allocation
Network analysis of tweeters based on retweets
Code Source Code was taken from following link and tweakedadded additional bits where required to ensure code runs fine httpsgithubcombenmarwickAAA2011-Tweets
How to Run or Test the code - From the word doc copy the R code in the given sequence highlighted in yellow color and paste on your R console
18
RTextTools ndash Example for supervised Learning for Text Classification using Ensemble
RTextTools is a free open source R machine learning package for automatic text classification
The package includes nine algorithms for ensemble classification (svm slda boosting bagging random forests glmnet decision trees neural networks and maximum entropy) comprehensive analytics and thorough documentation
Users may use n-fold cross validation to calculate the accuracy of each algorithm on their dataset and determine which algorithms to use in their ensemble
(Using a four-ensemble agreement approach Collingwood and Wilkerson (2012) found that when four of their algorithms agree on the label of a textual document the machine label matches the human label over 90 of the time The rate is just 45 when only two algorithms agree on the text label)
Code Source The codes is readily available for download and usage from the following link httpsgithubcomtimjurkaRTextTools The code can be implemented without modification for testing however itrsquos set up such that changes can be incorporated easily based on our requirement
Additional Reading httpwwwrtexttoolscomabout-the-projecthtml
19
Example 2 - RTextTools
Penn Treebank - httpswwwlingupenneducoursesFall_2003ling001penn_treebank_poshtml
Stanford info lab - Finding Similar Items httpinfolabstanfordedu~ullmanmmdsch3pdf
TRIPLET EXTRACTION FROM SENTENCES URL - httpailabijssidelia_rusuPapersis_2007pdf
Shallow and Deep NLP Processing for ontology learning a Quick Overview httpazouaqathabascaucapublicationsConferences20Workshops20Books5BBC25D_KDW_2010pdf
References
20

RTextTools ndash Example for supervised Learning for Text Classification using Ensemble
RTextTools is a free open source R machine learning package for automatic text classification
The package includes nine algorithms for ensemble classification (svm slda boosting bagging random forests glmnet decision trees neural networks and maximum entropy) comprehensive analytics and thorough documentation
Users may use n-fold cross validation to calculate the accuracy of each algorithm on their dataset and determine which algorithms to use in their ensemble
(Using a four-ensemble agreement approach Collingwood and Wilkerson (2012) found that when four of their algorithms agree on the label of a textual document the machine label matches the human label over 90 of the time The rate is just 45 when only two algorithms agree on the text label)
Code Source The codes is readily available for download and usage from the following link httpsgithubcomtimjurkaRTextTools The code can be implemented without modification for testing however itrsquos set up such that changes can be incorporated easily based on our requirement
Additional Reading httpwwwrtexttoolscomabout-the-projecthtml
19
Example 2 - RTextTools
Penn Treebank - httpswwwlingupenneducoursesFall_2003ling001penn_treebank_poshtml
Stanford info lab - Finding Similar Items httpinfolabstanfordedu~ullmanmmdsch3pdf
TRIPLET EXTRACTION FROM SENTENCES URL - httpailabijssidelia_rusuPapersis_2007pdf
Shallow and Deep NLP Processing for ontology learning a Quick Overview httpazouaqathabascaucapublicationsConferences20Workshops20Books5BBC25D_KDW_2010pdf
References
20

Penn Treebank - httpswwwlingupenneducoursesFall_2003ling001penn_treebank_poshtml
Stanford info lab - Finding Similar Items httpinfolabstanfordedu~ullmanmmdsch3pdf
TRIPLET EXTRACTION FROM SENTENCES URL - httpailabijssidelia_rusuPapersis_2007pdf
Shallow and Deep NLP Processing for ontology learning a Quick Overview httpazouaqathabascaucapublicationsConferences20Workshops20Books5BBC25D_KDW_2010pdf
References
20
Recommended

















