
Spark is going to replace Hadoop! Know Why?www.edureka.co/apache-spark-scala-training

Agenda
At the end of the session, you will be able to:
Understand Why Learn Spark?
Know Advantages of Spark & its Survey for 2015
Discover Spark Career Path
Understand how Companies are using Spark?
Slide 2 www.edureka.co/apache-spark-scala-training

Why Spark?
Slide 3 www.edureka.co/apache-spark-scala-training

Rise of Big Data
Unstructured Data
7000
6000
5000
4000
3000
2000
1000
0
2005 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015
Structured Data Un-structured Data
By 2020, IDC (International Data Corporation) predicts the number will have reached 40,000 EB, or 40 Zettabytes(ZB)
The world’s information is doubling every two years. By 2020, there will be 5,200 GB of data for every person onEarth.
Slide 4 www.edureka.co/apache-spark-scala-training

Application of Big Data
Source: Twitter
Slide 5 www.edureka.co/apache-spark-scala-training
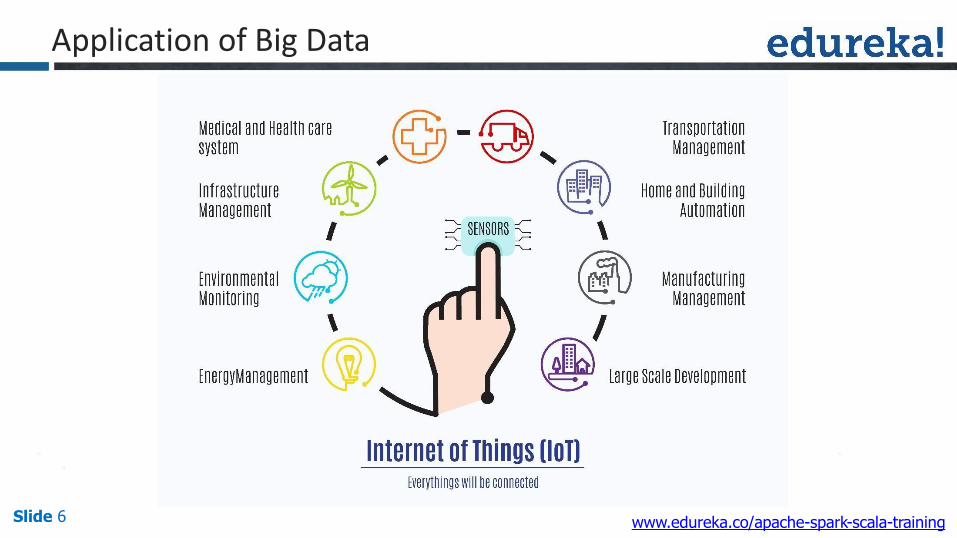
Application of Big Data
Slide 6 www.edureka.co/apache-spark-scala-training

Hadoop is not Enough!
Limitations:
Hadoop MapReduce is Limited to Batch Processing.Real-time processing was a big “No” in Hadoop
Real-time Processing
Hadoop MapReduce is fast but not fast enoughNot Fast Enough
Conclusion:
It is essential and can be achieved using Spark!
Slide 7 www.edureka.co/apache-spark-scala-training

Spark Survey and its Advantages
Slide 8 www.edureka.co/apache-spark-scala-training

Spark Survey 2015!
Slide 9 Source: Typesafe 2015 www.edureka.co/apache-spark-scala-training
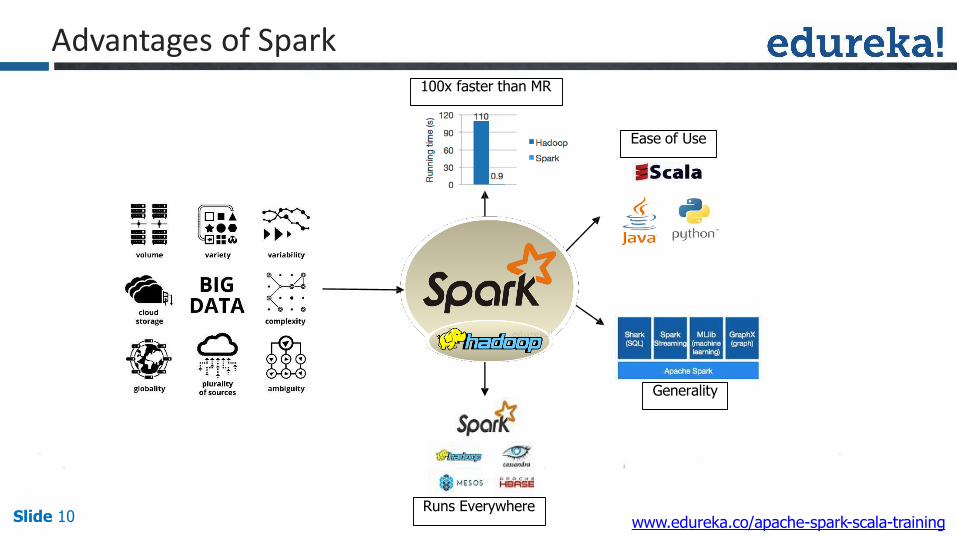
Advantages of Spark
Slide 10Runs Everywhere
Generality
Ease of Use
100x faster than MR
www.edureka.co/apache-spark-scala-training

Feature Comparision
Slide 11 Source: Databrix
Hadoop MapReduce HADOOP Spark
Fast 100x faster than MapReduce
Batch Processing Batch and Real-time Processing
Stores Data on Disk Stores Data in Memory
OpenSource OpenSource
Written in Java Written in Scala
www.edureka.co/apache-spark-scala-training
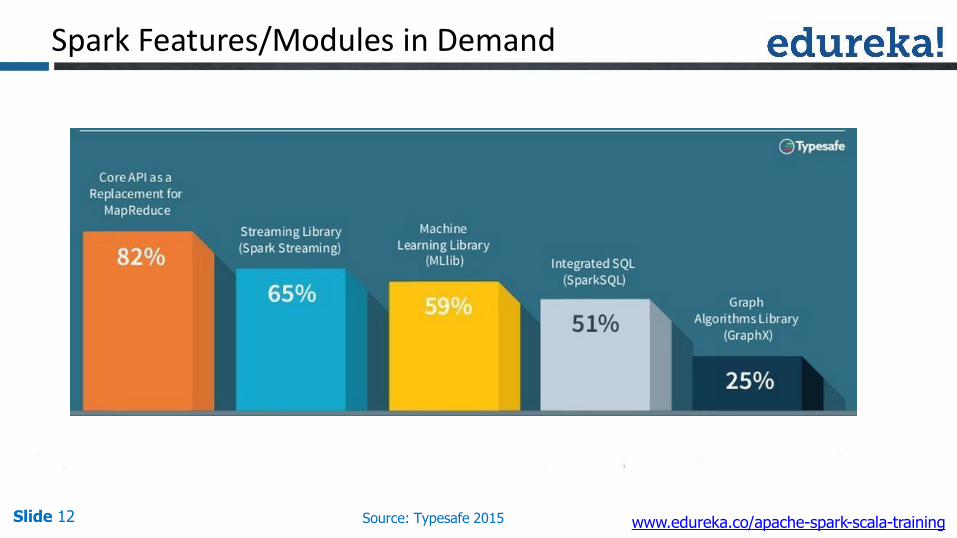
Spark Features/Modules in Demand
Slide 12 Source: Typesafe 2015 www.edureka.co/apache-spark-scala-training

New Features in 2015
Data Frames
• Similar API to data frames in R and Pandas• Automatically optimised via Spark SQL• Released in Spark 1.3
SparkR
• Released in Spark 1.4• Exposes DataFrames, RDD’s & ML library in R
Machine Learning Pipelines
• High Level API• Featurization• Evaluation• Model Tuning
External Data Sources
• Platform API to plug Data-Sources into Spark• Pushes logic into sources
Slide 13 Source: Databrix www.edureka.co/apache-spark-scala-training

Spark Career Path
Slide 14 www.edureka.co/apache-spark-scala-training

Job Roles & Industry Focus
Slide 15 Source: Typesafe 2015 www.edureka.co/apache-spark-scala-training
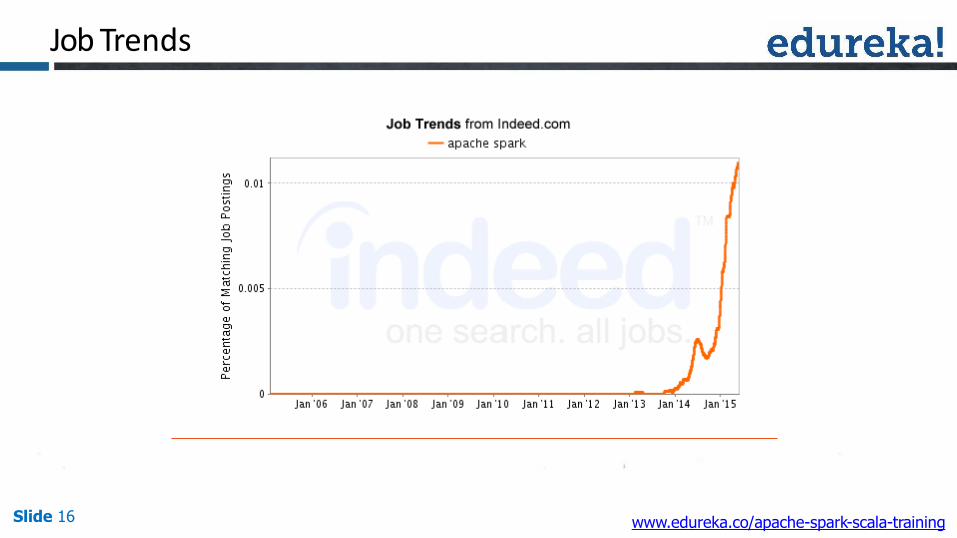
Job Trends
Slide 16 www.edureka.co/apache-spark-scala-training

Major Companies Using Hadoop
Slide 17 www.edureka.co/apache-spark-scala-training
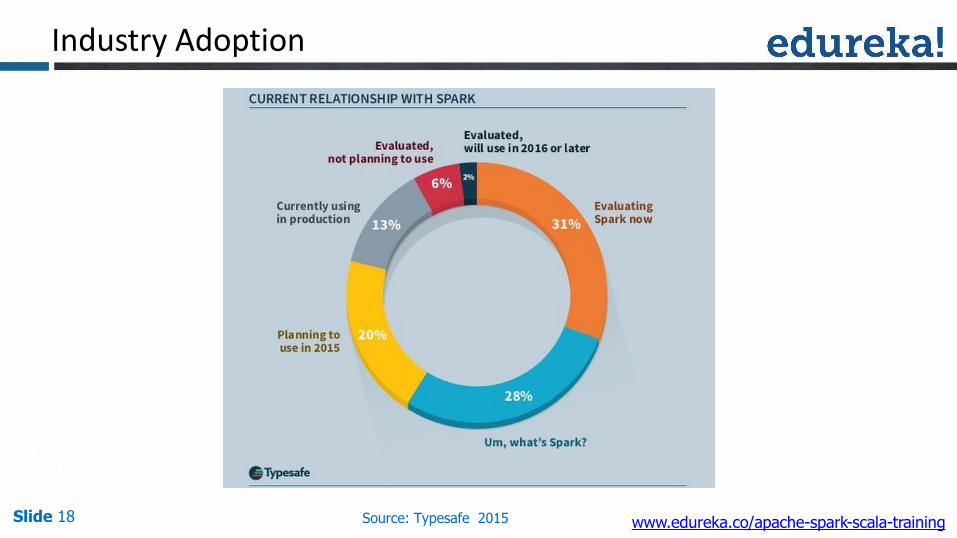
Industry Adoption
Slide 18 Source: Typesafe 2015 www.edureka.co/apache-spark-scala-training

How Companies are using Spark?
Slide 19 www.edureka.co/apache-spark-scala-training
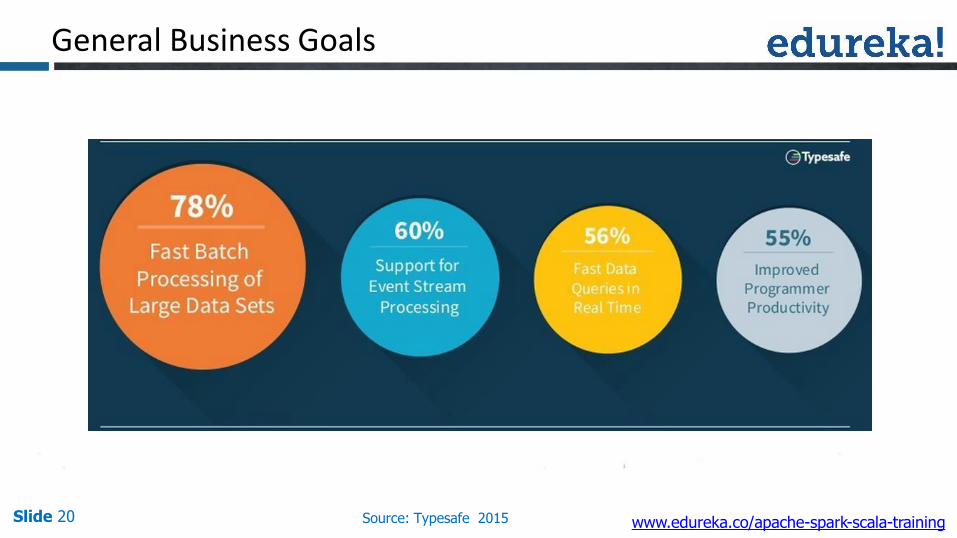
General Business Goals
Slide 20 Source: Typesafe 2015 www.edureka.co/apache-spark-scala-training
The Big Question!
Is Spark going to replace Hadoop?
Slide 22 www.edureka.co/apache-spark-scala-training

The Big Question!
Is Spark going to replace Hadoop?
Answer – Yes, Spark will be used on top of Hadoop and replace MapReduce
Reasons:
1.2.3.
Hadoop MapReduce cannot handle real-time processingHadoop MapReduce is slower than Hadoop SparkWith rise of IOT, Spark is a must
Slide 23 www.edureka.co/apache-spark-scala-training

Questions
Slide 24 www.edureka.co/apache-spark-scala-training

Survey
Your feedback is important to us, be it a compliment, a suggestion or a complaint. It helps us to make
the course better!
Please spare few minutes to take the survey after the webinar.
Slide 25 www.edureka.co/apache-spark-scala-training

Recommended


















