
By: Ramez Ibrahim AL Fayez

Agenda ¡ Introduc9ons ¡ What is Solr? ¡ Main Solr Features and A@ributes ¡ Content, Query, Facet, API, Scalability ¡ Interface and useful commands ¡ Live Demo

Introduc9on � Search has become mission cri9cal for most enterprises
� Intranet � Web presence � E-‐commerce
� Exponen9al growth of data � Cost of not finding informa9on
� Knowledge (sharing) � Time � Money
� Informa9on blackhole

What is Solr? Official defini,on:
“Solr is an open source enterprise search pla7orm based on the Lucene Java search library, with an HTTP interface using XML, JSON or other formats. It provides hit highligh,ng, faceted search, caching, replica,on, a web administra,on interface and many more features. It runs in a Java servlet container such as Apache Tomcat.”
� h#p://lucene.apache.org/solr

What is Solr? � In 2004, Solr was created by Yonik Seeley at CNET Networks as an in-‐house project
to add search capability for the company website.
� Open-‐source, license-‐free search engine
� Built on top of Apache Lucene library, and adds enterprise search server features and capabili9es
� Web based applica9on that processes requests and returns responses via HTTP, and APIs

Why choosing Solr? � Customizable � High quality and easily modifiable relevancy � Very fast query and indexing performance � Open source so^ware is free � Highly flexible data processing/transforma9on � Easy scalability and great performance � Modern solu9on architecture based on XML and Java � Well integrated with the ecosystem around Big Data, such as Hadoop (also
Nutch, Tika)

Solr’s Main Features � Full text search
� Field search
� Number and date searching
� Facets
� Spelling assistance – “Did you mean…?”
� Related hits
� Query comple9on
� Admin GUI
� Data Import Handler � Index Databases, Mails, RSS, XMLs etc.
� Rich document support � PDF, MS Office, Images etc
� Replica9on for high query volume
� Distributed search for large indexes � Produc9on systems with 1B+ documents
� Very extensible and customizable � Embedded in commercial search products
from LucidWorks, DataStax, Cloudera, Hortonworks, Amazon CloudSearch and Riak

Main A@ribute � Index(ing) � Inverted index
� Document
� Field � Stored and/or indexed fields
� Analysis
� Tokeniza9on � Filters � Terms
� Query � Filter � Func9on � Facet

Content � Out of the box support for JSON
� Solr handles CSV, XML, Rich Content out of the box without having to install plugins

Indexing and Ranking � Solr use Inverted index
� For ranking, solr use TF-‐IDF and Similarity
� Similarity is a combina9on of Boolean model (BM) and Vector Space Model (VSM)
� Another feature, user can do re-‐rank to the query

Query � Common parameters
� Start, rows, fl, fq, sort
?q=*:*&start=0&rows=10&fl=9tle&fq=collec9on:popular&sort=9tle asc
� Slightly more advanced � &facets � &qf
&qf=keyword^4 content1^8 content2^3 content3^2 stem1^1.5 stem2^1.2 stem3^0.5

Facet “Faceted search is the dynamic clustering of items or search results into categories that let users drill into search results (or even skip searching en9rely) by any value in any field. “
� Naviga9on/discovery technique � Tally of docs for each dis9nct field value � Parameters
� &facet=true � &facet.field=category

API � REST API for adding field types, and dynamic fields
� Managing Request Handlers through API
� Improved APIs for managing collec9ons
� Implicit registra9on of replica9on, Real Time Get and Administra9on Handlers
� Out of the box support for JSON
� Solr handles CSV, XML, Rich Content out of the box without having to install plugins

Scalability � Architecture goals:
� More queries per second (qps) � Faster query execu9on � Bigger indexes � Faster indexing
� Scaling op9ons � Mul9core � Replica9on � Sharding

Useful commands � ./bin/solr {start|stop}
� ./bin/solr create -‐c <COLL_NAME>
� bin/post -‐c <COLL_NAME> <Files to index>
� /bin/solr delete
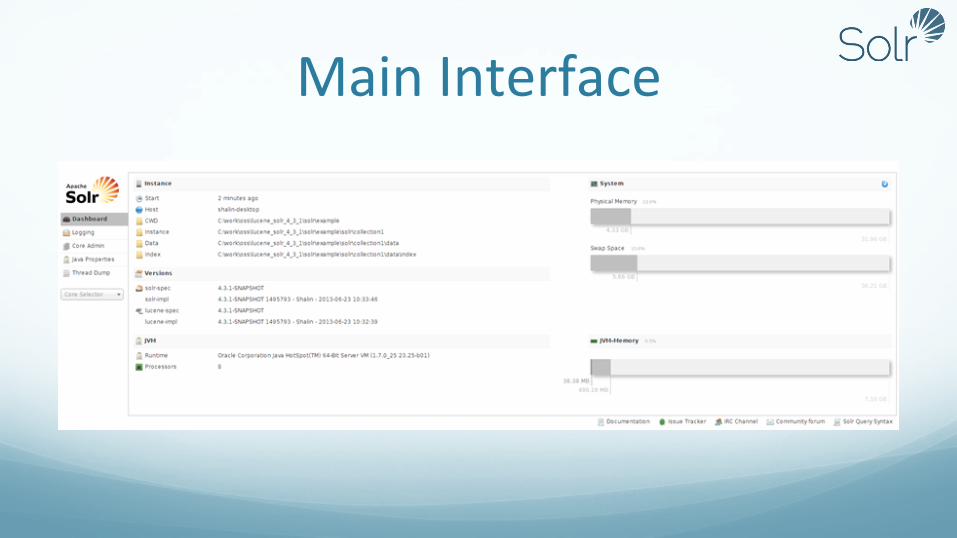
Main Interface


Finish !
Recommended

















