
+
Scientific Workflows
Programming Data-Oriented Applications in large-scale, distributed and heterogeneous resources
2MoRo, September 14th, 2010

+Outline
OMNI-DATA consortium
The workflow concept
Business workflows vs. scientific workflows
Scientific workflows Features
Achievements
Our research on scientific workflows Fault tolerance at workflow-level
Workflow performance prediction

+OMNI-DATA consortium
France
University of Pau, LIUPPA 6 persons
Company 2MoRo
Spain
University of Zaragoza I3A : 8 persons
BIFI : 6 persons
Company Cierzo
Siokia

+The workflow concept
The workflow concept has existed for decades
A workflow is a model to represent real work for further assessment
They have been also utilised in industry to manage business processes Workflows are designed to achieve processing intents of some
sort, such as physical transformation, service provision, or information processing.
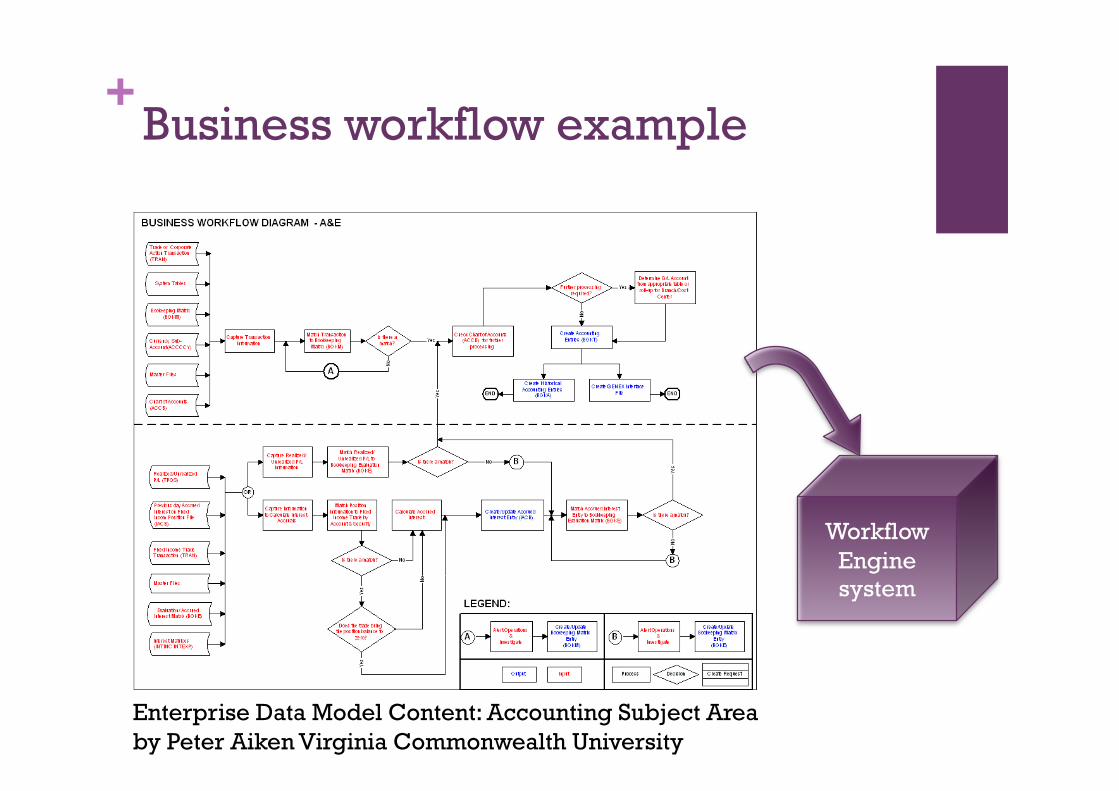
+Business workflow example
Enterprise Data Model Content: Accounting Subject Area by Peter Aiken Virginia Commonwealth University
Workflow Engine system
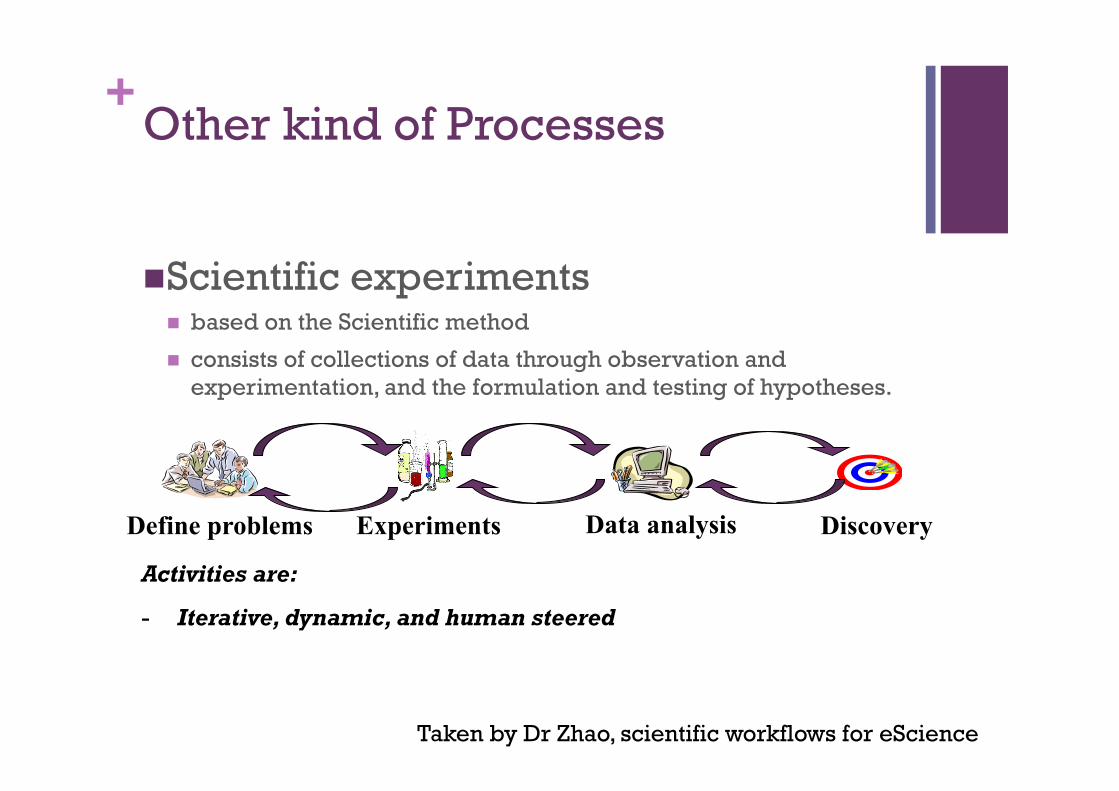
+Other kind of Processes
Scientific experiments based on the Scientific method
consists of collections of data through observation and experimentation, and the formulation and testing of hypotheses.
Define problems Experiments Data analysis Discovery
Activities are:
- Iterative, dynamic, and human steered
Taken by Dr Zhao, scientific workflows for eScience

+Business vs. Scientific workflows
Scientific and business workflows may not be distinguishable share common characteristics.
Scientific research requires flexible design and exploration capabilities that appear to depart
significantly from the more prescriptive use of workflows in business.
to ensure repeatable experiments.
to support a variety and heterogeneity of data.

+Scientific workflows
Data intensive analysis in the experiments heterogeneous databases are extensively accessed
Many large-scale scientific computations of interest are long-term lasting weeks if not months.
they can also involve much human intervention.

+Scientific workflows
The computing environments are heterogeneous including supercomputers, networks of workstations &
instruments.
users typically want some kind of a predictability of the time
Scientific activities requires the exploration of variants experimentation with alternative settings
configuration of experiments with different parameters
The computing environments are distributed & 3rd party fault tolerance is a must
flexibility in the interactions
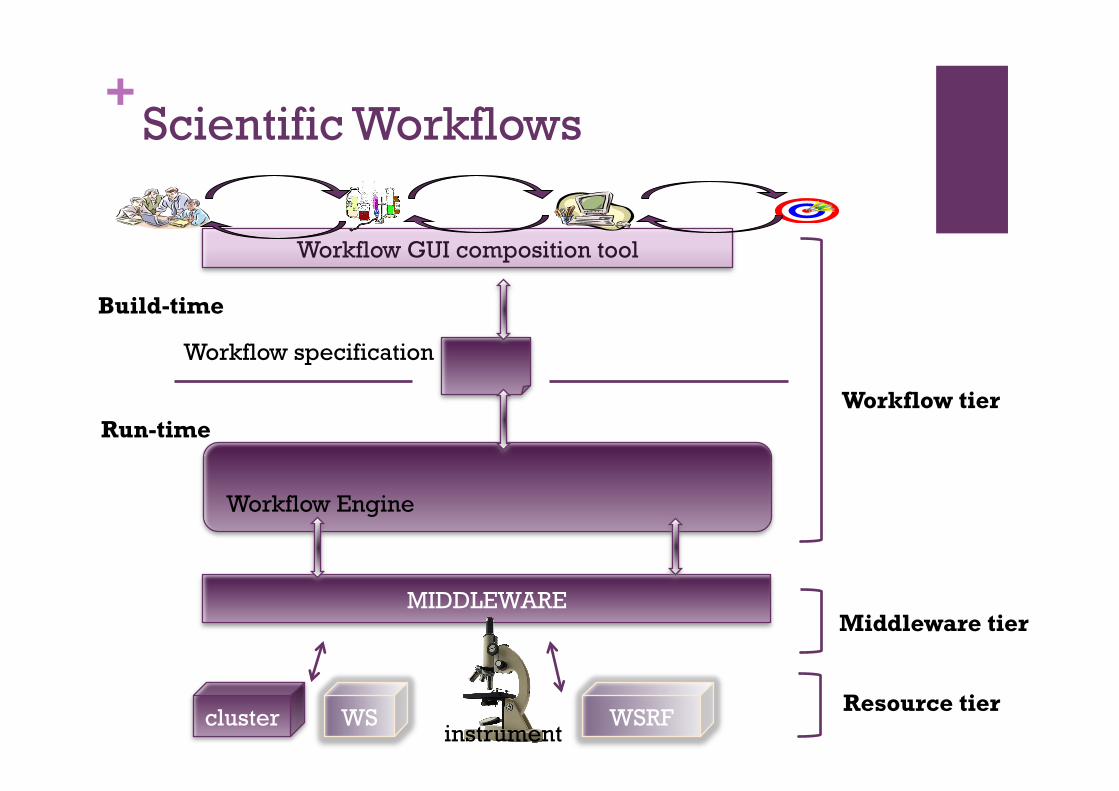
+Scientific Workflows
Workflow tier
Middleware tier
Resource tier
MIDDLEWARE
Workflow GUI composition tool
Workflow Engine
Workflow specification
Build-time
Run-time
cluster WS instrument
WSRF

+Scientific workflow achievements
Some examples Life sciences: bioinformatics
Astronomy: Montage
Data mining
Map / reduce based workflows

+Scientific workflow achievements
Life Sciences have terabytes of heterogeneous data and tools on the Web that need integrate in order to understand DNA, genes, genomes, proteins, biological pathways etc
858 public databases
150+ public web servers
Between 2,000 and 3,000 public services (e.g. sequence analysis programs like BLAST that use Web Service standards like WSDL and SOAP)
All these databases, servers and services allow us to perform many different sorts of computations on DNA, RNA and Proteins
Taken from slides by Dr Duncan Hull – myGrid project

+Scientific workflow achievements
Taken from slides by Dr Duncan Hull – myGrid project
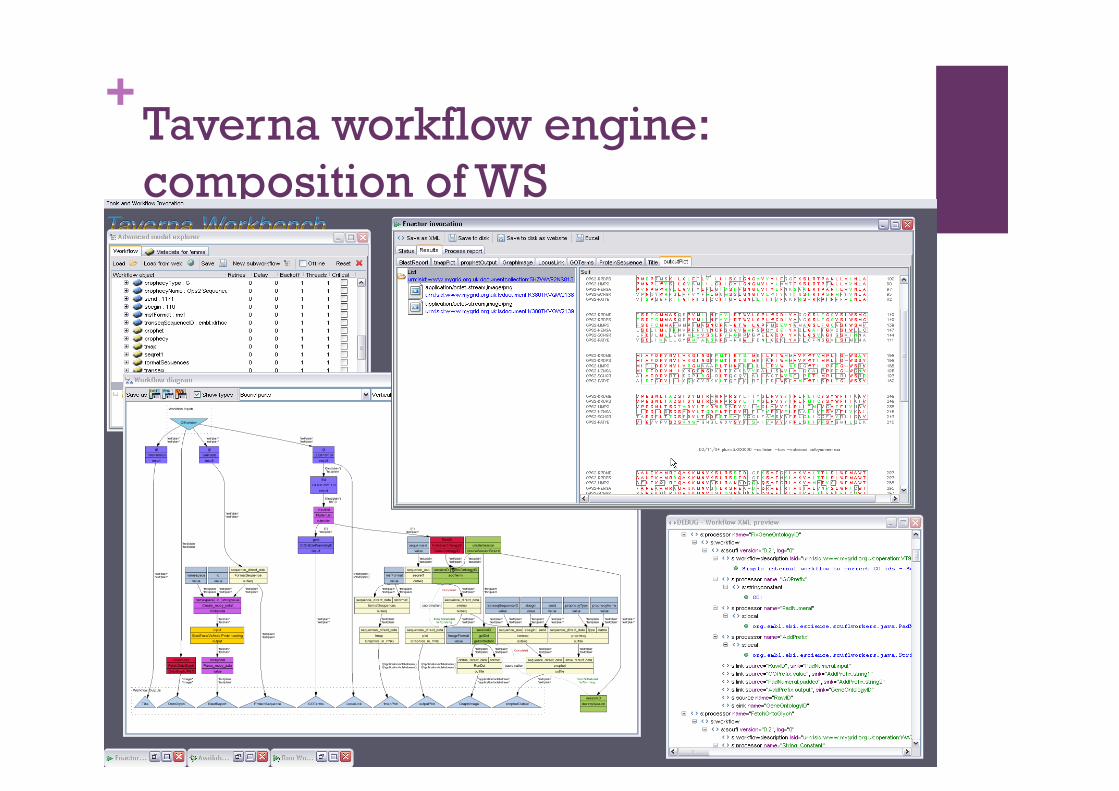
+Taverna workflow engine: composition of WS

+Astronomy: Montage
Montage is a centralized tool for assembling images of the universe.
The scientific workflow Pegasus can build enormous workflows expressing how an enormous number of images can be combined to for a bigger image. performance speed-up
experiments that could not be done otherwise.
A mosaic of M104 (also known as the Sombrero Galaxy) taken from http://montage.ipac.caltech.edu/

+Data mining
Data mining is the process of extracting patterns from data used in marketing, surveillance, fraud detection, and scientific
discovery.
Weka contains a collection of visualization tools and algorithms for data mining
Weka4WS supports distributed data mining on a Grid environment extends Weka
speeds up the execution of Weka workflows

+Map / reduce workflows
Paradigm for processing huge amounts of datasets
Map function m a dataset is automatically partitioned and function m is applied to
the slices (in parallel)
Reduce function r the outputs from the map are combined by function r
Some scientific workflows such as Kepler integrate such a new paradigm into pipelines of

+Our research on scientific workflows Workflow Fault tolerance Performance prediction Autonomic computing for workflows

+Background: Reference nets
Formal tool for representing processes
Rapid prototyping systems
Suitable for Scientific workflows characteristics ease the implementation of dynamic, flexible architectural
requirements
express dynamism & change in workflow specifications in a formal way
workflow specifications can be easily used for performance prediction models
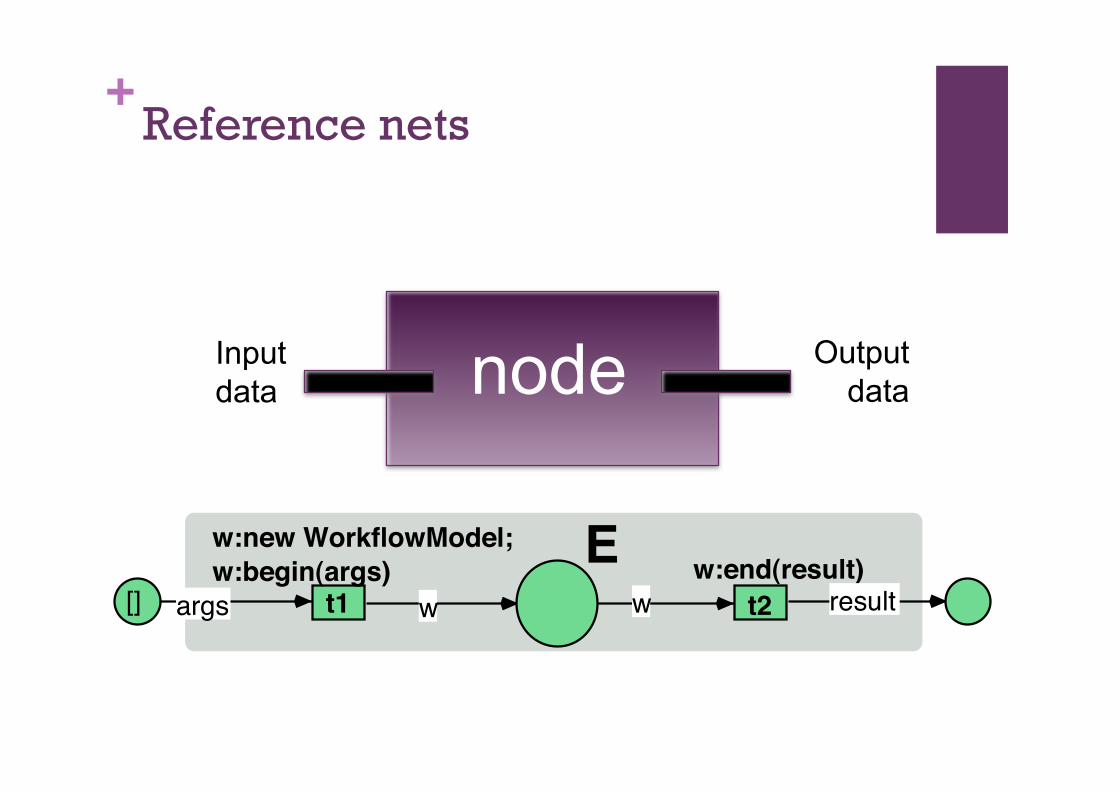
+Reference nets
t2[] wt1 w
w:end(result)w:new WorkflowModel;
w:begin(args)
args result
E
Input data
Output data node
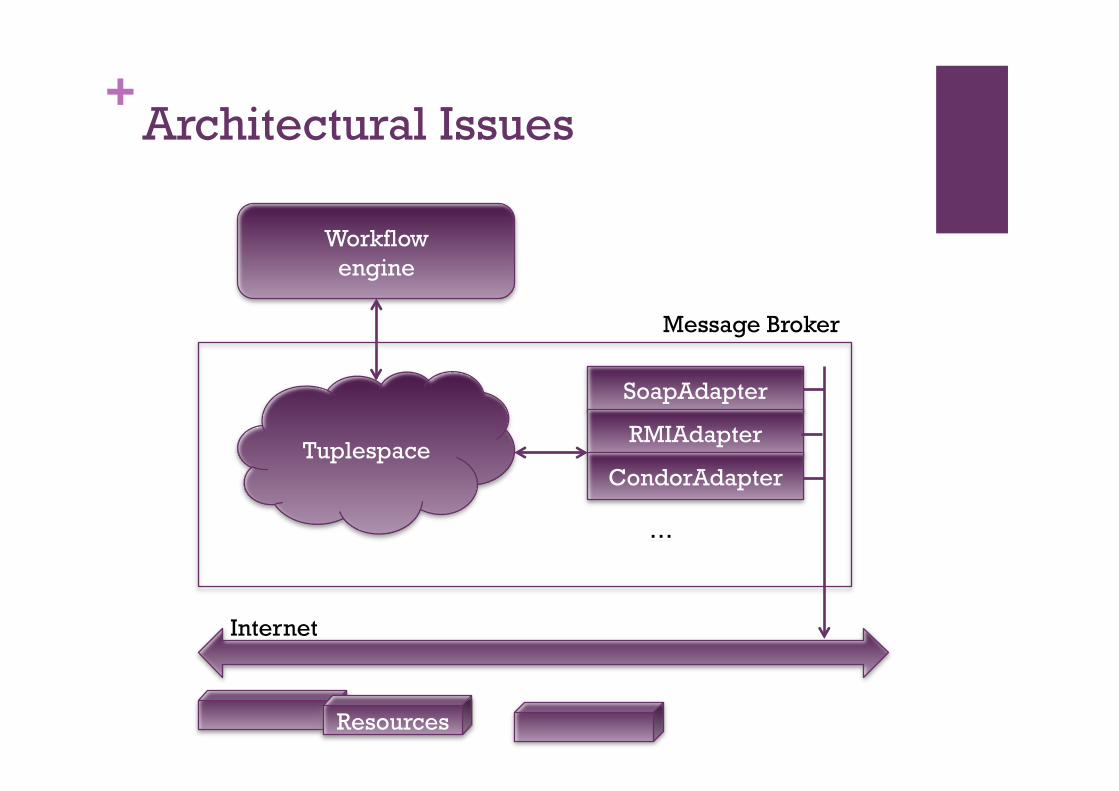
+Architectural Issues
Workflow engine
Tuplespace
SoapAdapter
RMIAdapter
CondorAdapter
…
Message Broker
Internet
Resources

+Expressing Scientific Workflows
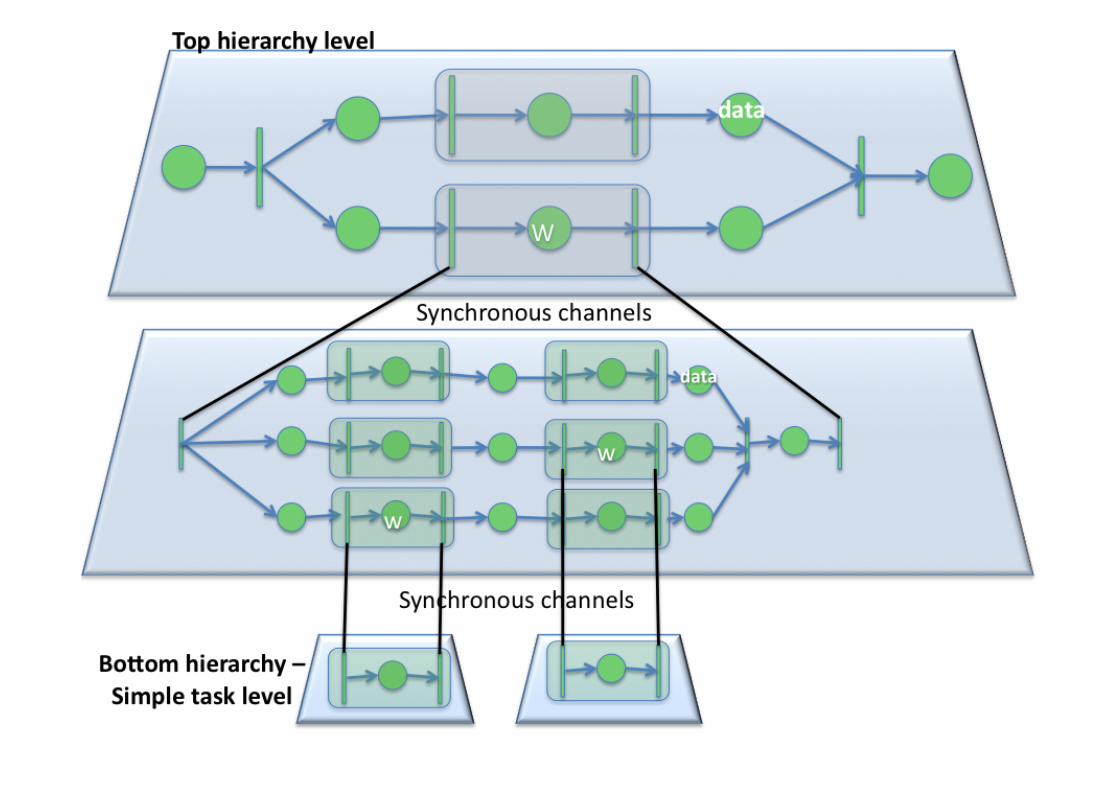
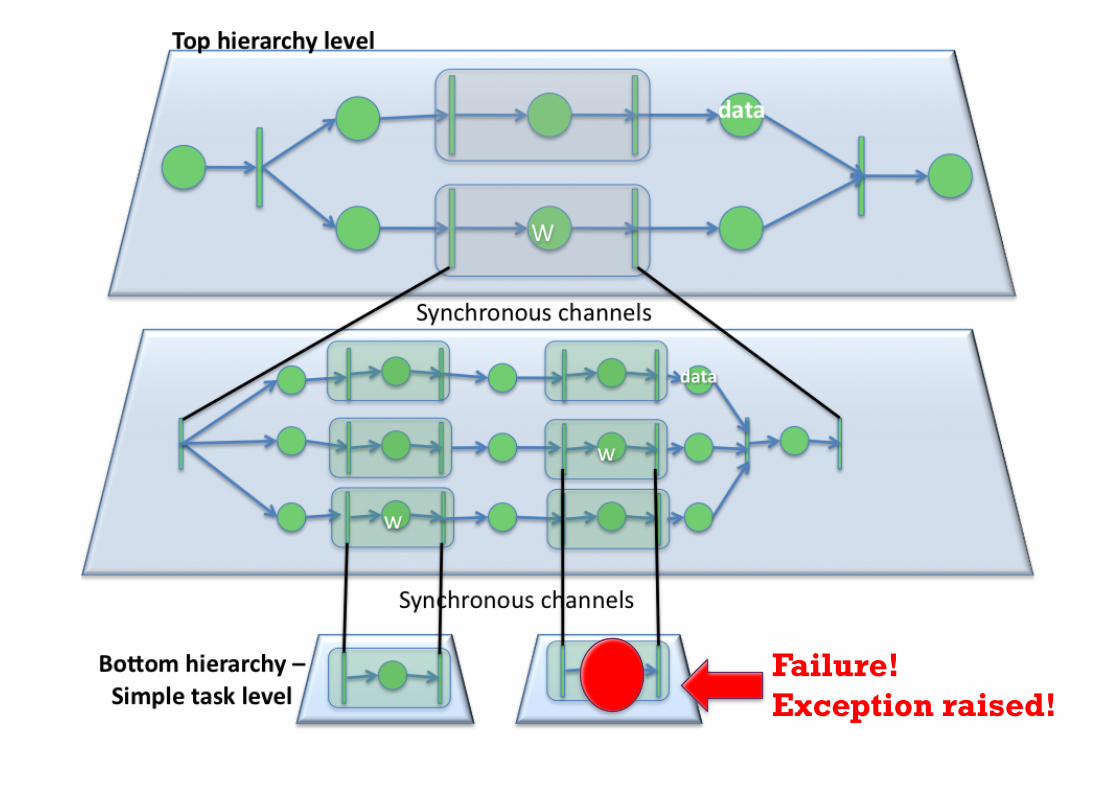
Failure! Exception raised!
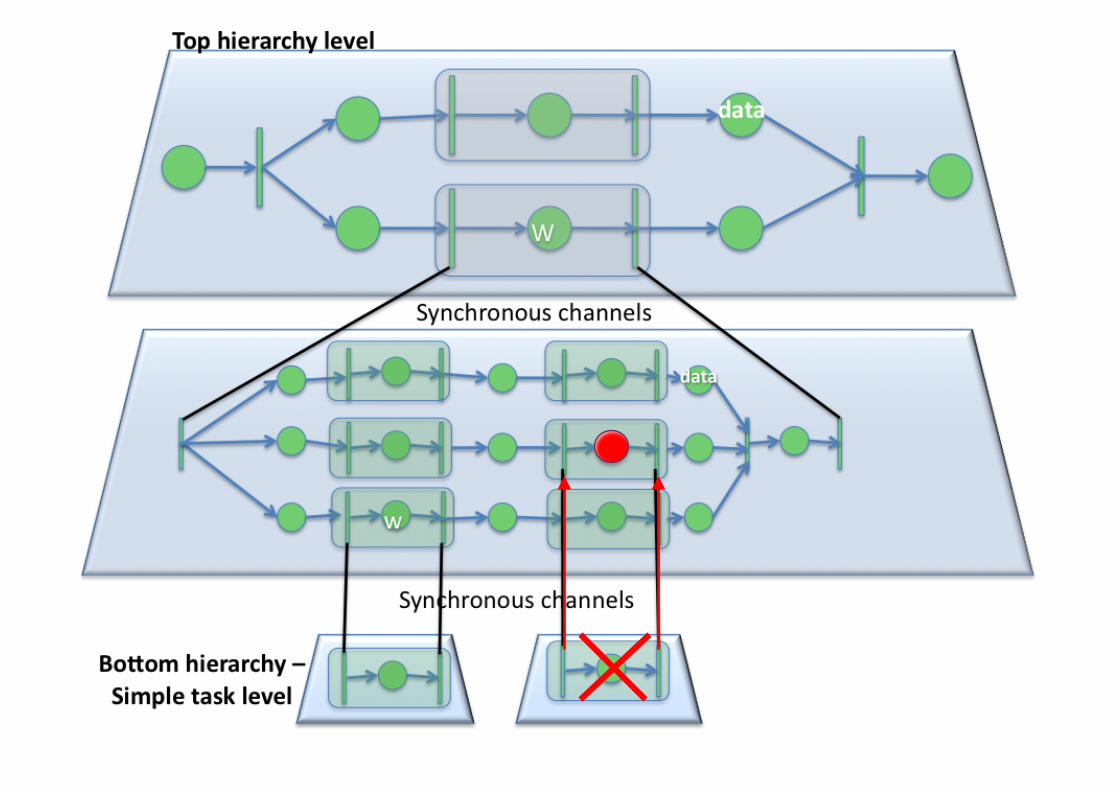
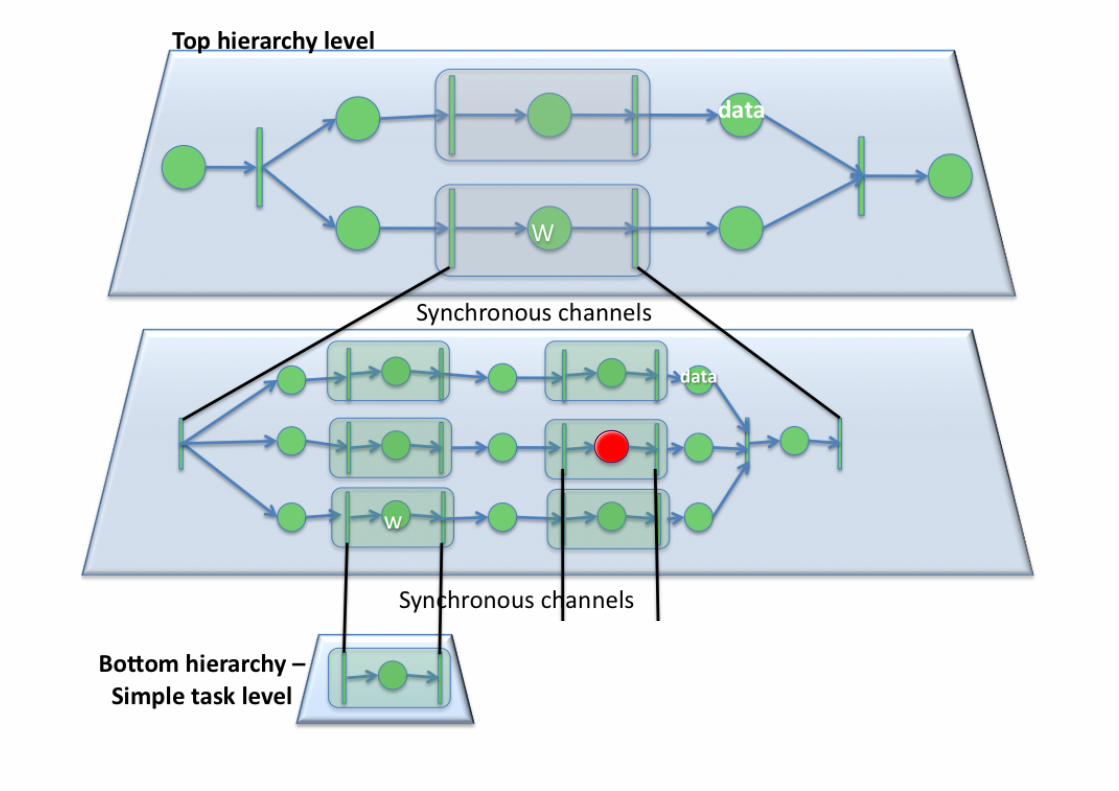
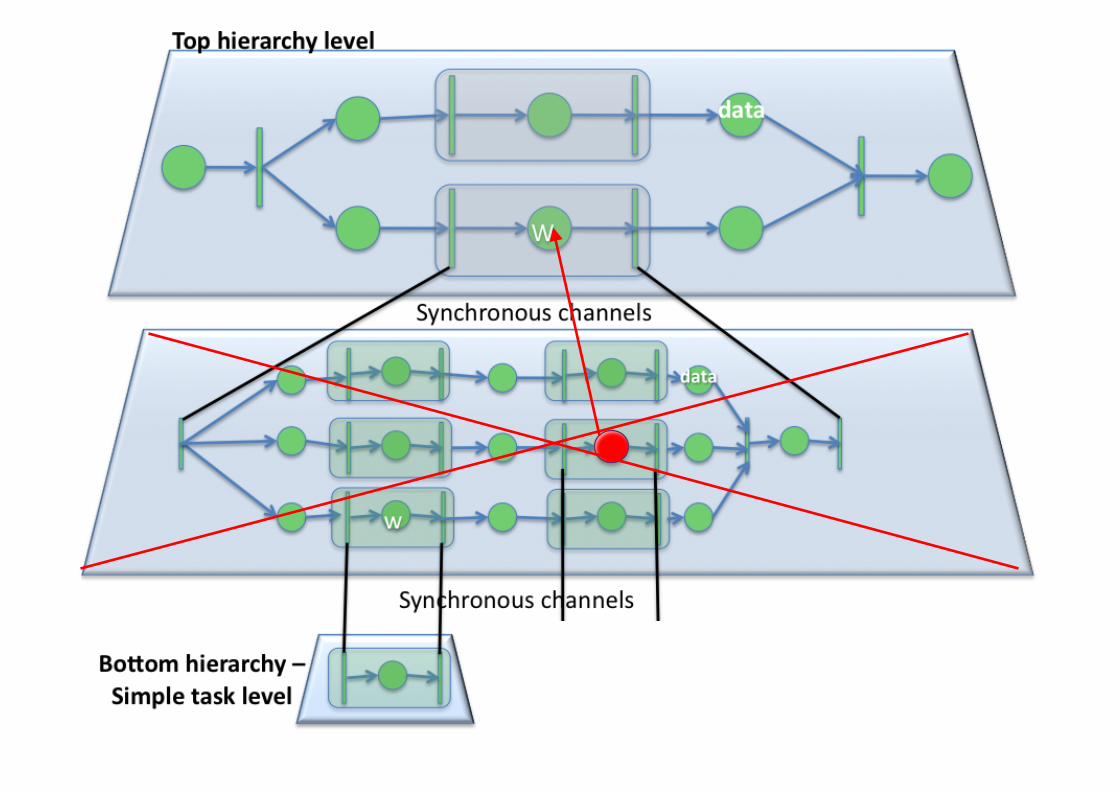
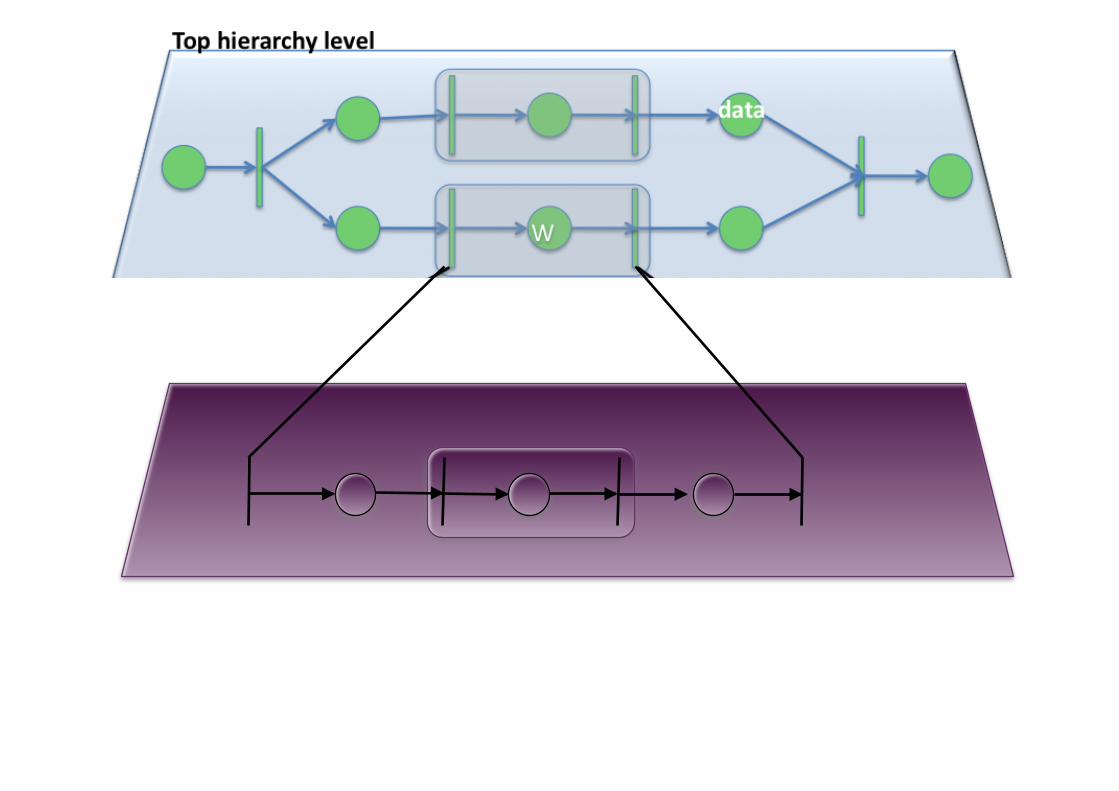

+Workflow Performance Prediction
The Reference net-based workflow representations are annotated / parameterised with time
We propose 3 different time profiles for feeding workflows: constant values
stochastic values
real values obtained from experimentation / instrumentation
By simulation, we obtain performance predictions
Recommended

















