
Machine Learning course
Part 4b: Learning from Heterogeneous Data
28 January 2021
Nada LavračJožef Stefan Institute, University of Ljubljana
Ljubljana, Slovenia

2
Learning from heterogeneous data
• Motivation for heterogeneous data analysis• Semantic relational learning
– Propositionalization approach (repeated from Lesson 3)– Top-down search for rules with Hedwig– Reducing the search with NetSDM
• Propositionalization of heterogeneous information networks– TEHmMINE – HINMINE
• Practical exercises with HINMINE

3
Learning from heterogeneous data● Learning from complex multi-
relational data and complexstructured data○ propositionalization, e.g., RSD
● Learning by using domain knowledgein the form of ontologies = semanticdata mining
○ propositionalization, e.g., SEGS, SDM-SEGS, SDM-Aleph,
○ Direct search, e.g., Hedwig, NetSDM
○ Learning from heterogeneousinformation networks○ Propositionalization, e.g.,
TEHmINE, HINMINE

4
Learning from heterogeneous data
• Propositionalization of heterogeneous information networks– Introduction to heterogeneous information networks– Network decomposition– TEHmMINE - propositionalization of text enriched
heterogeneous networks– HINMINE – propositionalization of heterogeneous
information networks

From homogeneous to heterogeneous information networks
• Given the hype of (social) network analysis …. …. there are numerous approaches to mining homogeneous
networks, e.g., Label propagation, PageRank, but…. mining heterogeneous information networks is still a
challenge for data scientists ….… especially those interested in exploratory data
analysis, interested in finding patterns in the data
• Let us first explain what are homogeneous and heterogeneous information networks …
5

Examples of information networks
• Citation networks• Online social
networks• Biological
networks– Ontologies – Bio2RDF – …
• Knowledge graphs
Example of a citation network and network schema fromSun, Y. and Han, J. (2012). Mining Heterogeneous Information Networks: Principles and Methodologies. Morgan & Claypool Publishers
6

Homogeneous Networks (homogeneous graphs)
cites
cites
cites
cites
cites
7

Heterogeneous Networks (multilayer networks, heterogeneous graphs)
ECML 2010
ECML
ECML 2009
authorOf
authorOf
inProceedings
inProceedings
is-a is-a
authorOf
authorOf inProceedings
cites
authorOf
authorOf
Jawei Han, 2009
8

Heterogeneous (multilayer) networks9
•

Heterogeneous Information Networks (enriched heterogeneous networks)
text
text
ECML 2010
ECML
ECML 2009
authorOf
authorOf
inProceedings
inProceedings
is-a is-a
text
authorOf
authorOf inProceedings
cites
authorOf
authorOf
10
Jawei Han, 2009

11
Learning from heterogeneous data
• Propositionalization of heterogeneous information networks– Introduction to heterogeneous information networks– Network decomposition– TEHmMINE - propositionalization of text enriched
heterogeneous networks– HINMINE – propositionalization of heterogeneous
information networks

Heterogeneous network decomposition: Variant 1 (basic): Build separate homogeneous
networks for every relation type
12
coauthor
cites
same event
A-P-A
A-P-P-A
A-P-E-P-A
ECML 2010
ECML
ECML 2009
authorOf
authorOf
inProceedings
inProceedings
is-a is-a
authorOf
authorOf inProceedings
cites
authorOf
authorOf

Structural context 3
Structural context 2
Structural context 1
Heterogeneous network decomposition:Separate networks for each context
13
coauthor
cites
same event
A-P-A
A-P-P-A
A-P-E-P-A
• Build 3 contexts for 3 types of relations

Heterogeneous network decomposition:Feature vector construction
Feature vector
Feature vector
Feature vector
14
• Build 3 contexts for 3 types of relations• Build 1 feature vector for each context
• Simplest feature vectors with binary values– 1 if two nodes are connected– 0 if two nodes are not connected
coauthor
cites
same event
A-P-A
A-P-P-A
A-P-E-P-A

Heterogeneous network decomposition:Feature vector construction
Feature vector
Feature vector
Feature vector
15
• Build 3 contexts for 3 types of relations• Build 1 feature vector for each context
• More elaborate feature vectors: node weights in [0,1]– e.g., 0.80 if two nodes are strongly connected– e.g., 0.06 if two nodes are weakly connected
• E.g., use PageRank or Label propagation for node weighting
coauthor
cites
same event
A-P-A
A-P-P-A
A-P-E-P-A
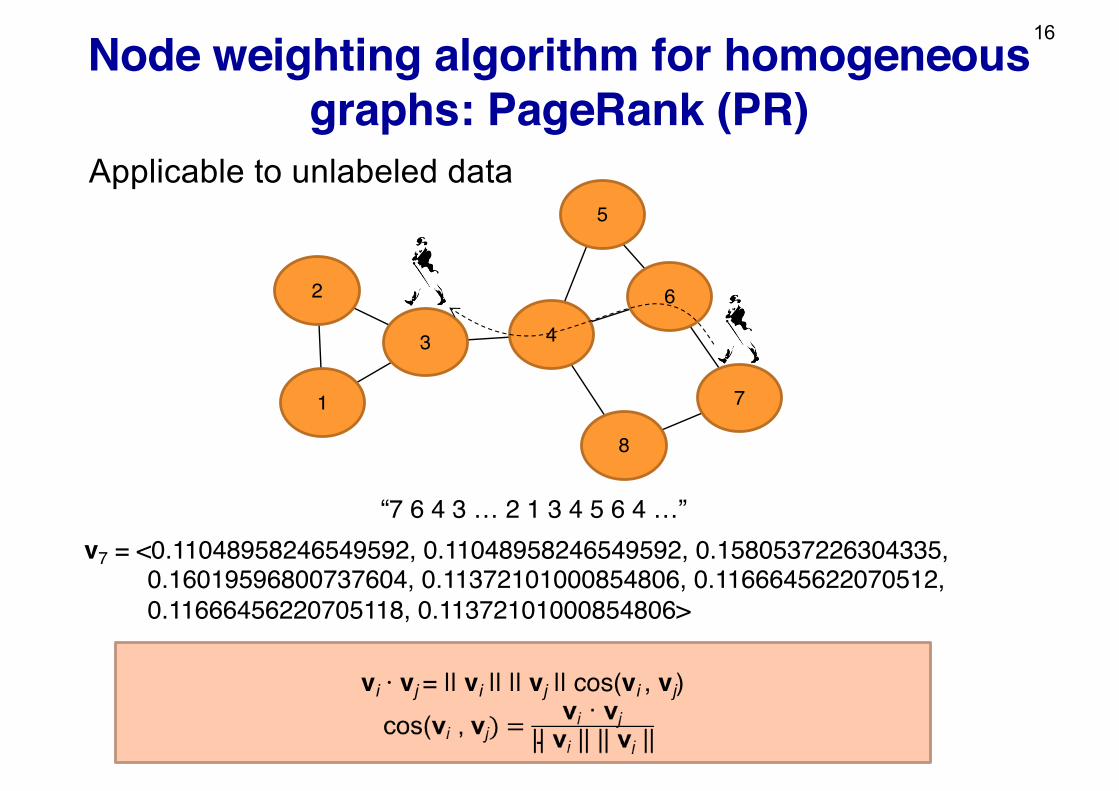
Node weighting algorithm for homogeneous graphs: PageRank (PR)
16
“7 6 4 3 … 2 1 3 4 5 6 4 …”
7
8
43
62
1
v7 = <0.11048958246549592, 0.11048958246549592, 0.1580537226304335, 0.16019596800737604, 0.11372101000854806, 0.1166645622070512, 0.11666456220705118, 0.11372101000854806>
vi · vj = || vi || || vj || cos(vi , vj)
5
Applicable to unlabeled data

Node weighting algorithm for homogeneous graphs: P-PR
17
“7 6 4 3 … 2 1 3 4 5 6 4 …”
7
8
43
62
1
v7 = <0.03231790708792279, 0.03231790708792279, 0.06558329330534093, 0.1345132775193426, 0.11077477809360317, 0.17097261700323155, 0.2915146558654654, 0.16200556403717076>
5
Applicable to unlabeled data
vi · vj = || vi || || vj || cos(vi , vj)

Node weighting algorithm for homogeneous graphs: Label propagation
• Introduced by Zhou et al. (2004)• Works by “propagating” class labels along links in a network• Nodes with known labels have weight 1
18
Applicable to labeled data

Node weighting algorithm for homogeneous graphs: Label propagation
• Introduced by Zhou et al. (2004)• Works by “propagating” class labels along links in a network• Nodes with known labels have weight 1
19
Advanced approach:• Unbalanced datasets can cause the algorithm to over-estimate the majority class• Improvement: Nodes with known labels have weight set to
Applicable to unlabeled data

Fusion of decomposed networks: Joining feature vectors
Feature vector
Feature vector
Feature vector
20
• Build 3 contexts for 3 types of relations• Build 1 feature vector for each context• Join contexts through feature vector concatenation
Preserving unit length
Combining feature vectors

Heterogeneous network decomposition: Variant 2 (multipath): join all relation types
21
coauthor
cites
same event
A-P-A
A-P-P-A
A-P-E-P-A
ECML 2010
ECML
ECML 2009
authorOf
authorOf
inProceedings
inProceedings
is-a is-a
authorOf
authorOf inProceedings
cites
authorOf
authorOf

Single structural context
Heterogeneous network decomposition:Variant 2 (multipath): Network homogenization
22
coauthor
cites
same event
A-P-A
A-P-P-A
A-P-E-P-A
• Join 3 contexts into a single relation type:– Network homogenization into 1 context– New relation A-Rel-A, composed of paths
involving A-P-A, A-P-P-A and/or A-P-E-P-A

Heterogeneous network decomposition:Variant 2 (multipath): Network homogenization
23
coauthor
cites
same event
A-P-A
A-P-P-A
A-P-E-P-A
• Join 3 contexts into a single relation type:– Network homogenization into 1 context– New relation A-Rel-A, composed of paths
involving A-P-A, A-P-P-A and/or A-P-E-P-A

24
Learning from heterogeneous data
• Propositionalization of heterogeneous information networks– Introduction to heterogeneous information networks– Network decomposition– TEHmMINE - propositionalization of text enriched
heterogeneous networks– HINMINE – propositionalization of heterogeneous
information networks

Text-Enriched Heterogeneous Information Networks
text
text
ECML 2010
ECML
ECML 2009
authorOf
authorOf
inProceedings
inProceedings
is-a is-a
text
authorOf
authorOf inProceedings
cites
authorOf
authorOf
25

Structural context 3
Structural context 2
Structural context 1
Textual context
TEHmINe Methodology (Grčar et al. 2015)Decomposition variant 1
26
coauthor
cites
same event
A-P-A
A-P-P-A
A-P-E-P-A

TEHmINe Methodology (Grčar et al. 2015)27
Feature vector
Feature vector
Feature vector
Bag-of-words feature vector
TF-IDF(Salton, 1989)
coauthor
cites
same event
A-P-A
A-P-P-A
A-P-E-P-A

TEHmINe Methodology
Feature vector
Feature vector
Feature vector
Bag-of-words feature vector
TF-IDF(Salton, 1989)
28
coauthor
cites
same event
A-P-A
A-P-P-A
A-P-E-P-A
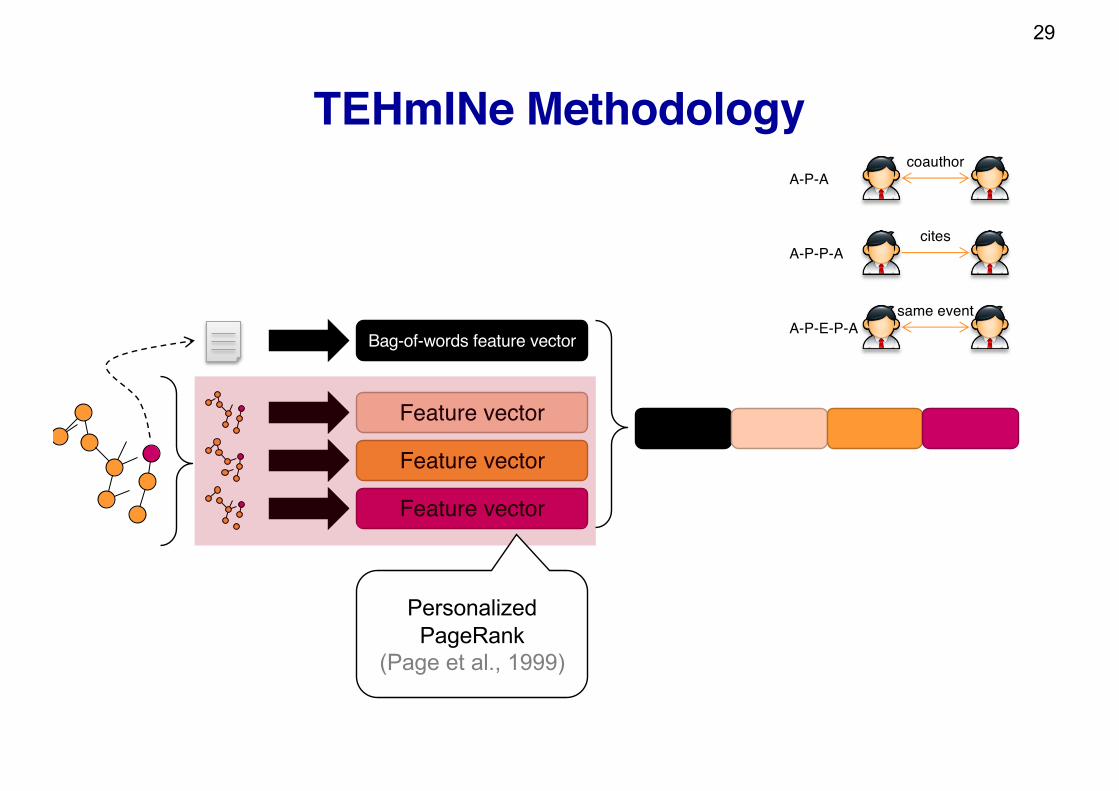
TEHmINe Methodology
Feature vector
Feature vector
Feature vector
Bag-of-words feature vector
29
Personalized PageRank
(Page et al., 1999)
coauthor
cites
same event
A-P-A
A-P-P-A
A-P-E-P-A

TEHmINe Methodology
Feature vector
Feature vector
Feature vector
Bag-of-words feature vector
Preserving unit length
Combining feature vectors
30
coauthor
cites
same event
A-P-A
A-P-P-A
A-P-E-P-A

TEHmINe Methodology
Feature vector
Feature vector
Feature vector
Bag-of-words feature vector
• Build a matrix with as many rows as there are nodes in the network
• Use text mining or a ML algorithm to build a classifier
31

Building models in TEHmINE
• Sparse feature vectors– Supervised: k-NN, SVM, Naive Bayes…– Unsupervised: k-Medoids, agglomerative
clustering…– With some care: centroid classifier, k-Means– Other things: LSI, MDS…
• Centroid classifier– Highly efficient, quite accurate in text mining
scenarios
(Mitchell, 1997; Feldman & Sanger, 2006; Joachims et al., 2006; Witten et al., 2011)

VideoLectures.net Use Case Dataset
• Videolectures.net portal– About 23,500 lectures (Jan. 2021)
• Less lectures used in the experiments– Structure (heterogeneous network)
• 3,520 English lectures; 1,156 manually categorized into 129 categories
• 2,706 authors, 219 events, 3,274 users’ click streams
– Text • Lecture titles, 2,537 lectures have short
descriptions and/or slide titles
• Categorization of video lectures into the VideoLectures.net taxonomy
33
http//:videolectures.net

VideoLectures.net Use Case Problem Statement
Where?
Interest

VideoLectures.net Use CaseDataset (Decomposed Network)
• Same-event graph– Two interlinked lectures were recorded at the same
event
• Same-author graph– Two interlinked lectures were given by the same
author
• Viewed-together graph– Two interlinked lectures were viewed together by the
same portal user
35

1. Computer science / Semantic Web / Ontologies2. Computer Science / Semantic Web3. Computer Science / Software Tools4. Computer Science / Information Extraction5. Computer Science / Natural Language Processing …
Classifier
Classification Training
VideoLectures.net Use CaseCategorization
36

37
Learning from heterogeneous data
• Motivation for heterogeneous data analysis• Semantic relational learning
– Propositionalization approach (repeated from Lesson 3)– Top-down search for rules with Hedwig– Reducing the search with NetSDM
• Propositionalization of heterogeneous information networks– TEHmMINE– HINMINE
• Practical exercises

Advances over TEHmINE - Motivation
• In a citation network, some researchers author many papers or papers in many different fields of research
• A coauthorship link induced by such authors is less informative – its weight should be smaller
• This is similar to how TF-IDF weighing penalizes very common words
38
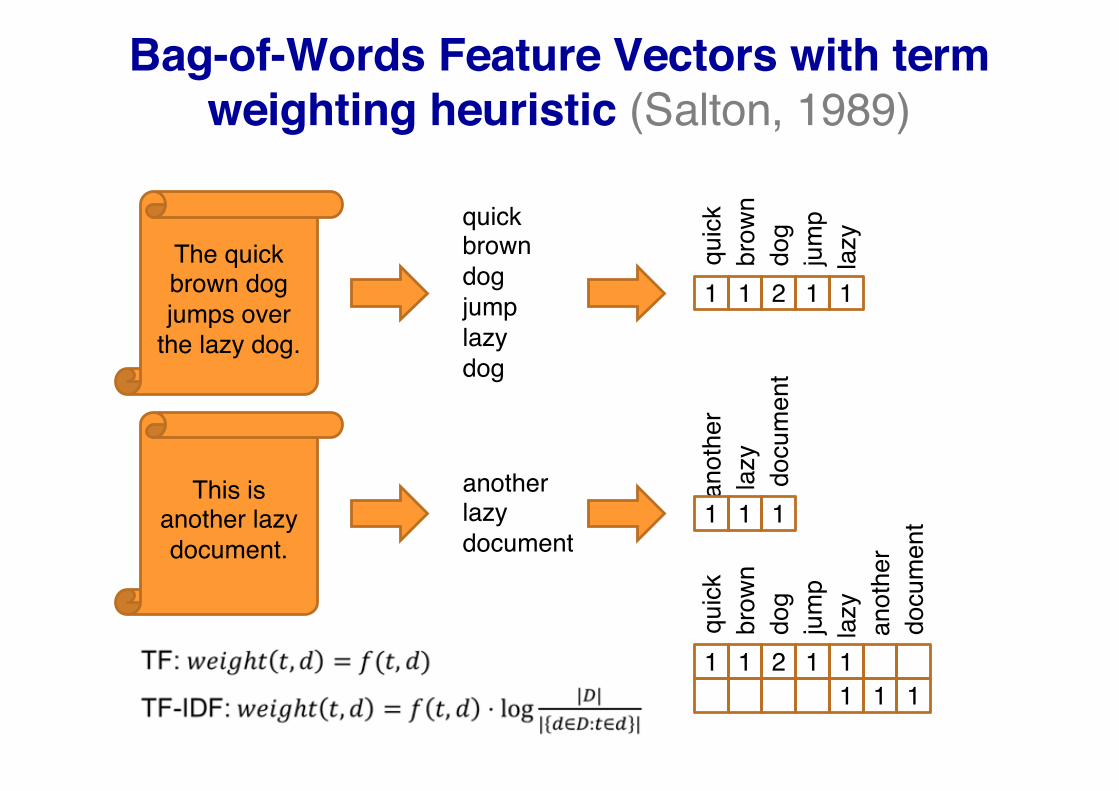
Bag-of-Words Feature Vectors with term weighting heuristic (Salton, 1989)
The quick brown dog jumps over
the lazy dog.
This is another lazy document.
quickbrowndogjumplazydog
1 1 2 1 1
quic
kbr
own
dog
jum
pla
zy
anotherlazydocument
anot
her
lazy docu
men
t
1 1 1
1 1 2 1 1
quic
k
dog
jum
pla
zybrow
n
anot
her
docu
men
t
1 1 1

From term weighting to node weighting heuristics
40
B = set of the base node typeE = set of edges in entire networkm = current/observed nodeM = set of all nodesc = class labelC = set of all class labelsP = probability

Term weighting heuristics
41

Tf Counts each appearance of each word in a document equally
Tfidf Gives a greater weight to a word if it appears only in a small number of documents
Chi Given a term, measures how dependent the class label of a document is to the appearance of the given word in the document
Ig Measures how much information about the class label of a document is gained by the appearance of a given word in the document
Gr A modification of the ig scheme, normalized by the total entropy of each classDelta Measures the difference between the tf-idf value of a term when looking only at
documents of one class compared to the tf-idf value when looking at the other classes
Rf Measures the ratio between the tf-idf value of a term when looking only at documents of one class compared to the tf-idf value when looking at the other classes
bm25 Gives greater weights to words that appear in short documents and words that appear in a small number of documents
Heuristics properties (text mining)42

Graph node weighting heuristics
43
B = set of the base node typeE = set of edges in entire networkm = current/observed nodeM = set of all nodesc = class labelC = set of all class labelsP = probability

Tf Counts each midpoint connecting two base nodes equally
Tfidf Gives a greater weight to a midpoint node if it is connected to only a small number of base nodes
Chi Given a midpoint node, measures how dependent the class label of a base node is to the existence of a link between the base node and the given midpoint node
Ig Measures how much information about the class of a base node is gained by the existence of a link between a given midpoint node and the base node
Gr A modification of the IG scheme, normalized by the total entropy of each classDelta Measures the difference between the tf-idf value of a midpoint when only observing
the base nodes of one class compared to looking at the other classesRf Measures the ratio between the tf-idf value of a midpoint when only observing the
base nodes of one class compared to looking at the other classesbm25 Gives greater weights to midpoints that are connected to a small number of base
nodes and to nodes of low degree
Heuristics properties (network analysis)44

HINMINE methodology and goals
• Test different node weighting heuristics in the network decomposition step to test whether penalizing non-informative connecting nodes will increase performance.
• Compare Label propagation and P-PR• Test 2 implementation variants:
– Variant 1 (basic) as in TEHmINE, and – Variant 2 (multipath) considering all relation types/paths jointly as a single
relation type
45
(a)

HINMINE methodology: Two decomposition variants 1 and 2
46
Variant 1 (basic)
Variant 2 (multipath)

Experimental evaluationWe tested the effects of the heuristics on three data sets:1. E-commerce data set
– Nodes of 5 types– Deconstructed into 4 networks (A, B, C and D)
2. ACM papers data set– Papers and their atuthors– Deconstructed via a paper-author-paper link– 320,339 nodes (test of scalability)
3. IMDB data set– Movies and actors, deconstructed into 1 homogeneous network– 10,198 nodes in one or more of 20 genres (test of stability in the
case of many labels)
47

HINMINE Conclusions
• Network decomposition algorithm can be improved using text-mining inspired node weighting
• Label propagation algorithm can be improved when data is highly unbalanced
• Two implementation variants were considered, and (a slight modification of) variant 2 was implemented in Jupyter Python notebooks
• Results were published in JIIS 2017
Kralj, Jan, Marko Robnik-Šikonja, and Nada Lavrač. “Heterogeneous NetworkDecomposition and Weighting with Text Mining Heuristics.”
48

49Learning from heterogeneous data: Current research and conclusions
● Unifying propositionalization and embeddings → Unifying symbolic and neural representation learning (NeSy) ○ MLJ 2020 paper: Propositionalization and Embeddings: Two
sides of the same coin, by Lavrač et al., ○ Springer 2021 book: Representation learning:
Propositionalization and embeddings, by Lavrač et al.
● Data representation /representation learning is a key factor to successful machine learning○ Transferable across problems○ Common to most input types (texts, graphs, images, time
series, tables)○ Achievable by exploiting the available high-end (cheap)
computers
Recommended

















