
Optimizing MapReduce for GPUs with Effective
Shared Memory Usage
Department of Computer Science and Engineering
The Ohio State University
Linchuan Chen and Gagan Agrawal

Outline
Introduction Background System Design Experiment Results Related Work Conclusions and Future Work

Introduction
Motivations GPUs
Suitable for extreme-scale computing Cost-effective and Power-efficient
MapReduce Programming Model Emerged with the development of Data-Intensive Computing
GPUs have been proved to be suitable for implementing MapReduce
Utilizing the fast but small shared memory for MapReduce is chanllenging Storing (Key, Value) pairs leads to high memory overhead, pr
ohibiting the use of shared memory

Introduction
Our approach Reduction-based method
Reduce the (key, value) pair to the reduction object immediately after it is generated by the map function
Very suitable for reduction-intensive applications
A general and efficient MapReduce framework Dynamic memory allocation within a reduction object Maintaining a memory hierarchy Multi-group mechanism Overflow handling

Outline
Introduction Background System Design Experiment Results Related Work Conclusions and Future Work
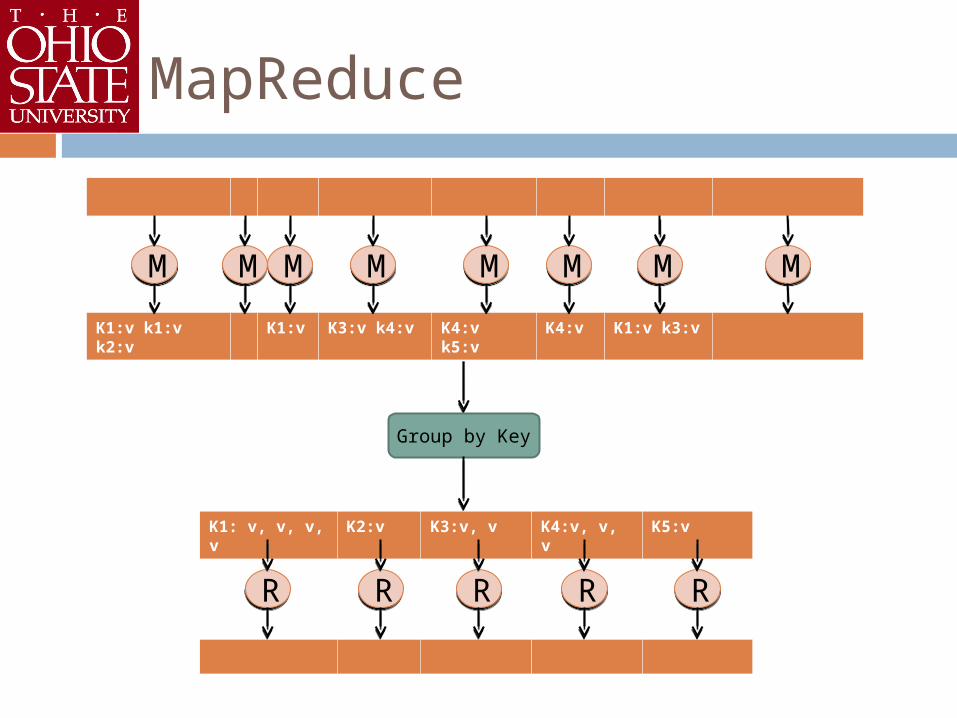
MapReduce
K1: v, v, v, v K2:v K3:v, v K4:v, v, v K5:v
MM
Group by Key
K1:v k1:v k2:v K1:v K3:v k4:v K4:v k5:v K4:v K1:v k3:v
MM MM MM MM MM MM MM
RR RR RR RR RR

MapReduce
Programming Model Map()
Generates a large number of (key, value) pairs Reduce()
Merges the values associated with the same key
Efficient Runtime System Parallelization Concurrency Control Resource Management Fault Tolerance … …

GPUs
Host
Kernel 1
Kernel 2
Device
Grid 1
Block(0, 0)
Block(1, 0)
Block(2, 0)
Block(0, 1)
Block(1, 1)
Block(2, 1)
Grid 2
Block (1, 1)
Thread(0, 1)
Thread(1, 1)
Thread(2, 1)
Thread(3, 1)
Thread(4, 1)
Thread(0, 2)
Thread(1, 2)
Thread(2, 2)
Thread(3, 2)
Thread(4, 2)
Thread(0, 0)
Thread(1, 0)
Thread(2, 0)
Thread(3, 0)
Thread(4, 0)
(Device) Grid
ConstantMemory
TextureMemory
DeviceMemory
Block (0, 0)
Shared Memory
LocalMemor
y
Thread (0, 0)
Registers
LocalMemor
y
Thread (1, 0)
Registers
Block (1, 0)
Shared Memory
LocalMemor
y
Thread (0, 0)
Registers
LocalMemor
y
Thread (1, 0)
Registers
Host
Processing Component Memory Component

Outline
Introduction Background System Design Experiment Results Related Work Conclusions and Future Work

Traditional MapReduce
map(input){ (key, value) = process(input); emit(key, value);}
grouping the key-value pairs (by runtime system)
reduce(key, iterator){ for each value in iterator result = operation(result, value); emit(key, result);}
System Design

Reduction-based approach
map(input, reduction_object){ (key, value) = process(input); reduction_object->insert(key, value);}
reduce(value1, value2){ value1 = operation(value1, value2);}
Reduces the memory overhead of storing key-value pairsMakes it possible to effectively utilize shared memory on a GPUEliminates the need of groupingEspecially suitable for reduction-intensive applications
System Design

Chanllenges
Result collection and overflow handling Maintain a memory hierarchy
Trade off space requirement and locking overhead A multi-group scheme
To keep the framework general and efficient A well defined data structure for the reduction object
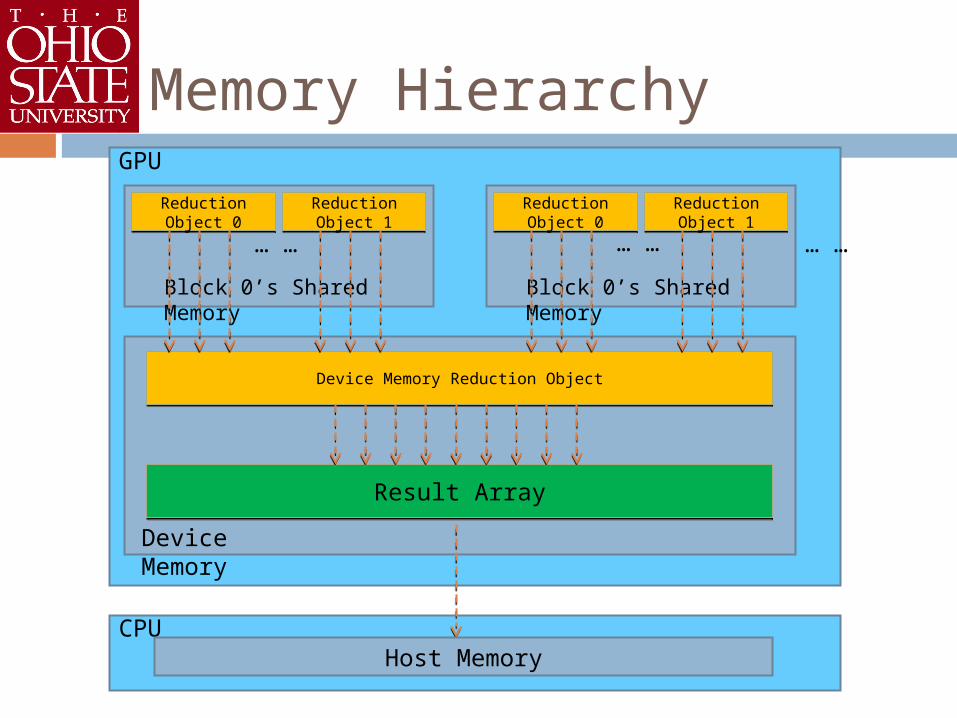
Memory Hierarchy
CPU
GPU
Reduction Object 0
Reduction Object 0
Reduction Object 1
Reduction Object 1
Block 0’s Shared Memory
Reduction Object 0
Reduction Object 0
Reduction Object 1
Reduction Object 1
Block 0’s Shared Memory
… … … … … …
Device Memory Reduction ObjectDevice Memory Reduction Object
Result ArrayResult Array
Host Memory
Device Memory

Reduction Object
Updating the reduction object Use locks to synchronize
Memory allocation in reduction object Dynamic memory allocation Multiple offsets in device memory reduction object
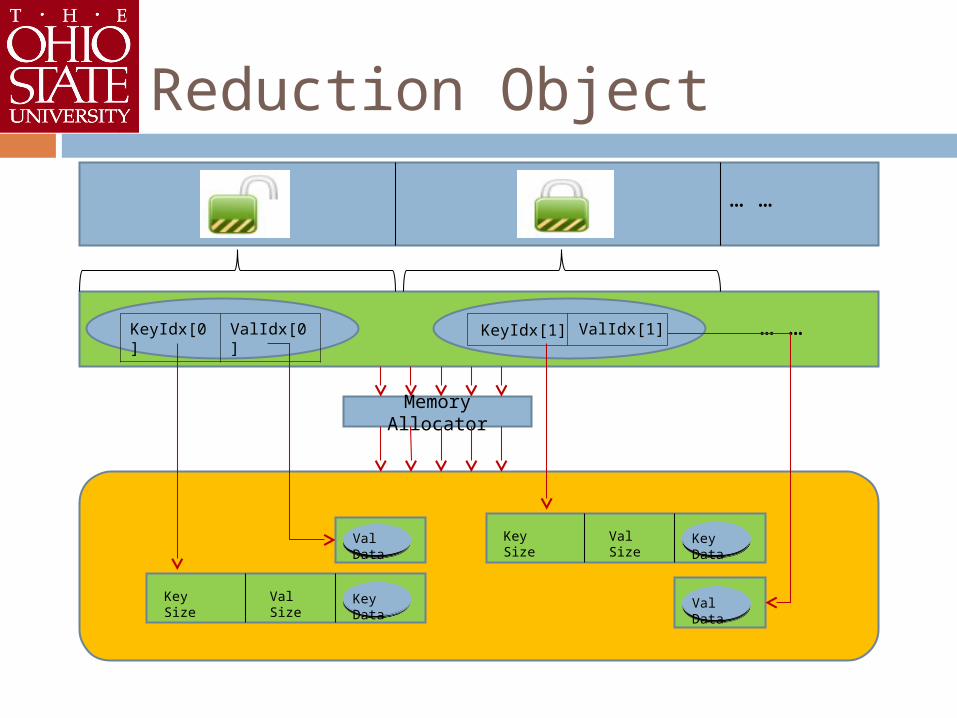
Reduction Object
KeyIdx[0] ValIdx[0] … …
… …
Key Size Val Size Key Data
Val Data
Val Data
Memory Allocator
Key Size Val Size Key Data
KeyIdx[1] ValIdx[1]

Multi-group Scheme Locks are used for synchronization
Large number of threads in each thread block Lead to severe contention on the shared memory RO
One solution: full replication every thread owns a shared memory RO
leads to memory overhead and combination overhead
Trade-off multi-group scheme
divide threads in each thread block into multiple sub-groups
each sub-group owns a shared memory RO
Choice of groups numbers Contention overhead
Combination overhead

Overflow Handling
Swapping Merge the full shared memory ROs to the device
memory RO Empty the full shared memory ROs
In-object sorting Sort the buckets in the reduction object and delet
e the unuseful data Users define the way of comparing two buckets

Discussion
Reduction-intensive applications Our framework has a big advantage
Applications with few or no reduction No need to use shared memory
Users need to setup system parameters Develop auto-tuning techniques in future work

Extension for Multi-GPU
Shared memory usage can speed up single node execution Potentially benefits the overall performance
Reduction objects can avoid global shuffling overhead Can also reduce communication overhead

Outline
Introduction Background System Design Experiment Results Related Work Conclusions and Future Work

Experiment Results Applications used
5 reduction-intensive 2 map computation-intensive Tested with small, medium and large datasets
Evaluation of the multi-group scheme 1, 2, 4 groups
Comparison with other implementations Sequential implementations MapCG Ji et al.'s work
Evaluating the swapping mechanism Test with large number of distinct keys
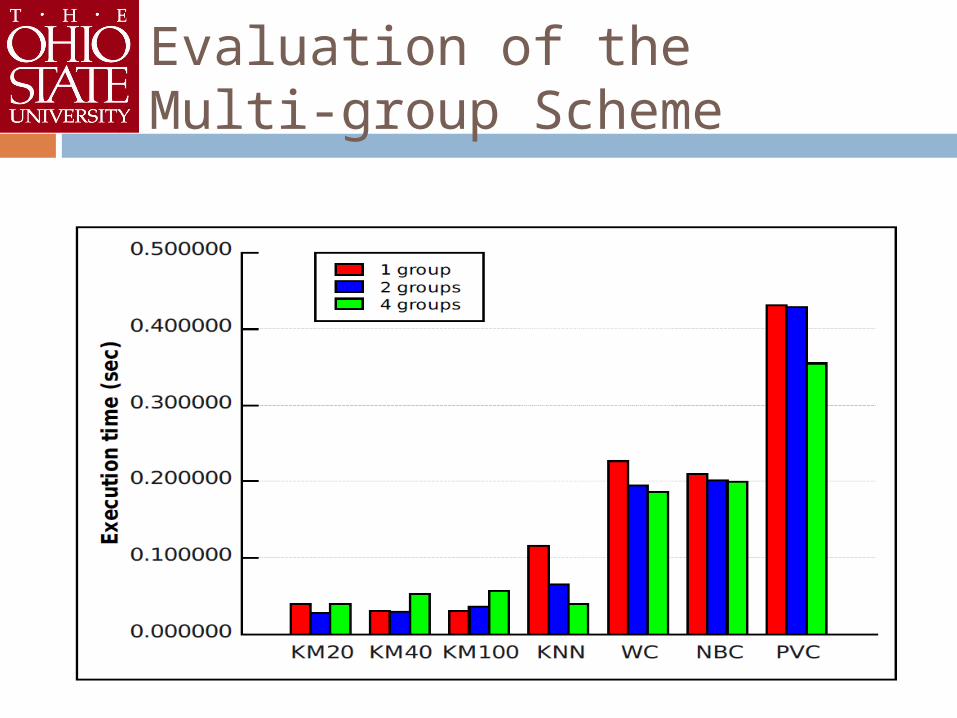
Evaluation of the Multi-group Scheme
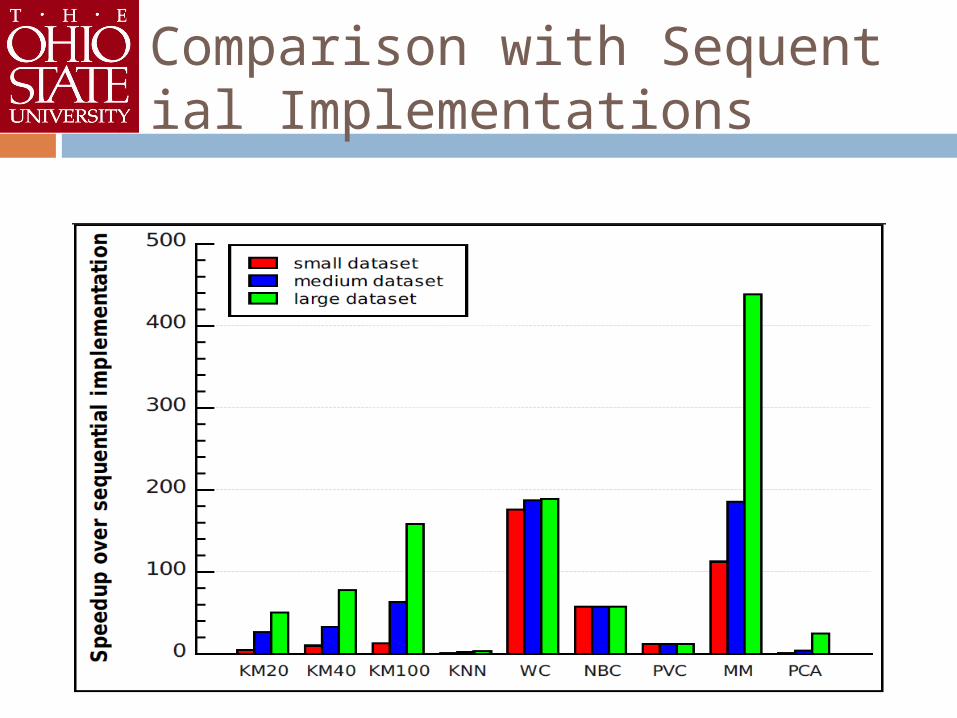
Comparison with Sequential Implementations
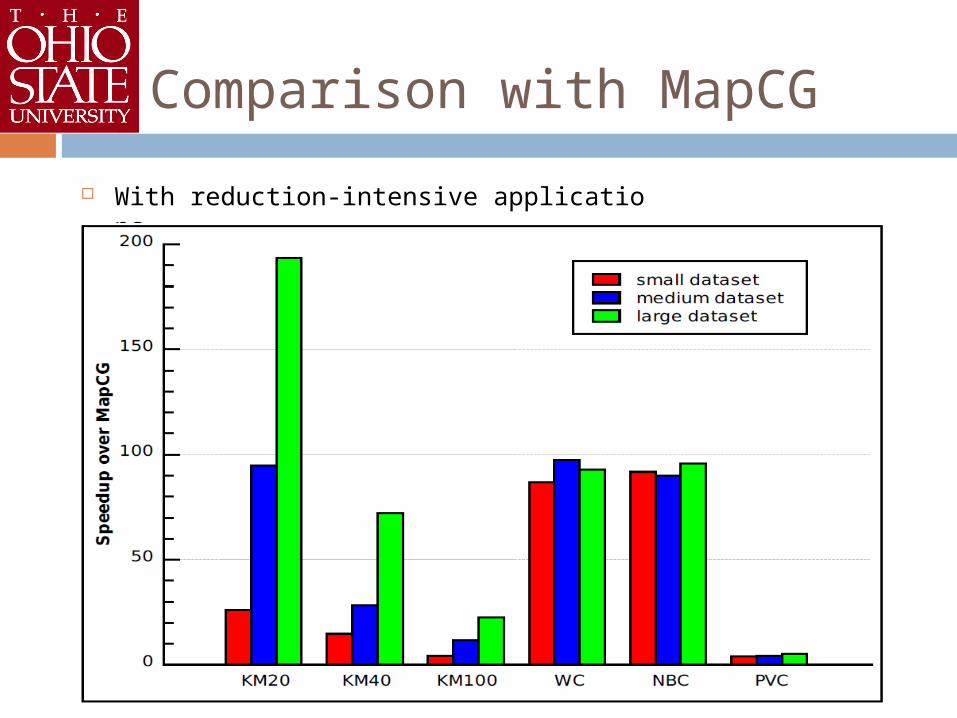
Comparison with MapCG
With reduction-intensive applications
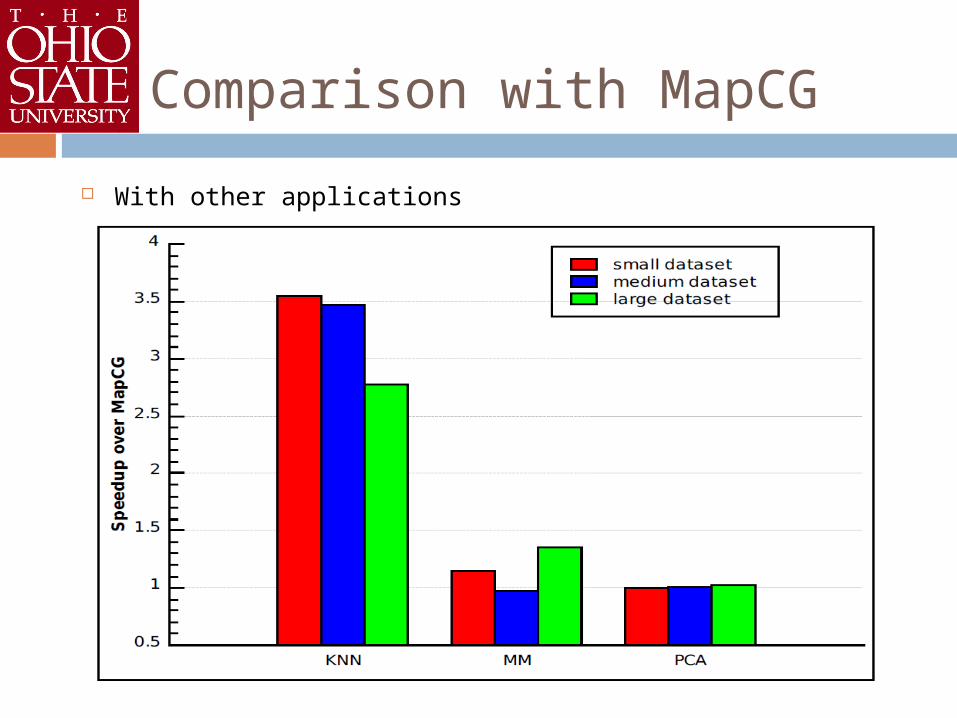
Comparison with MapCG
With other applications
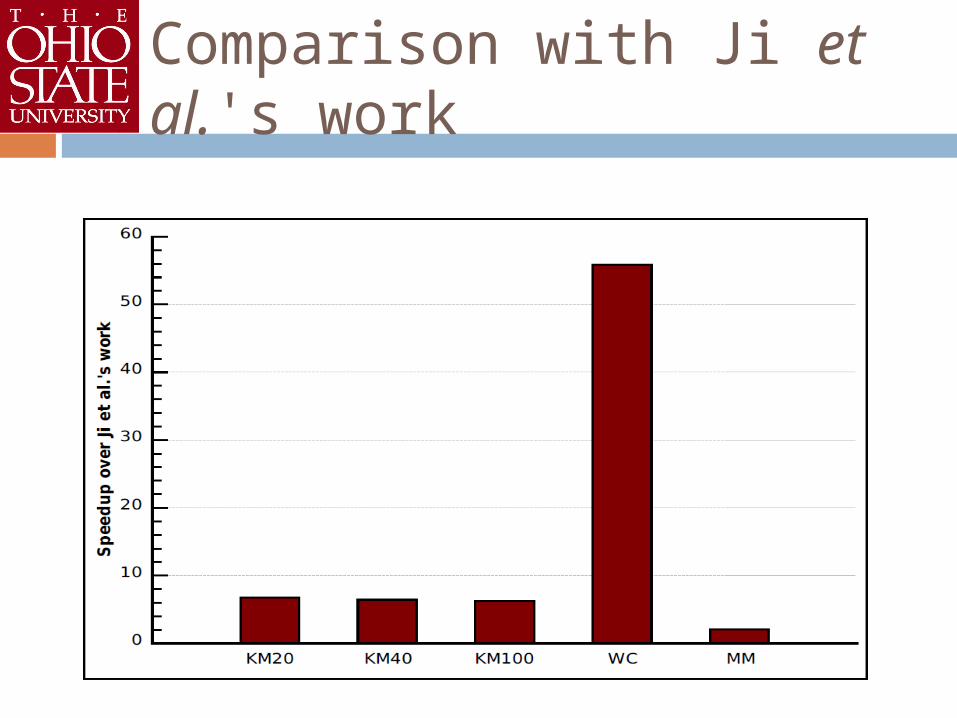
Comparison with Ji et al.'s work
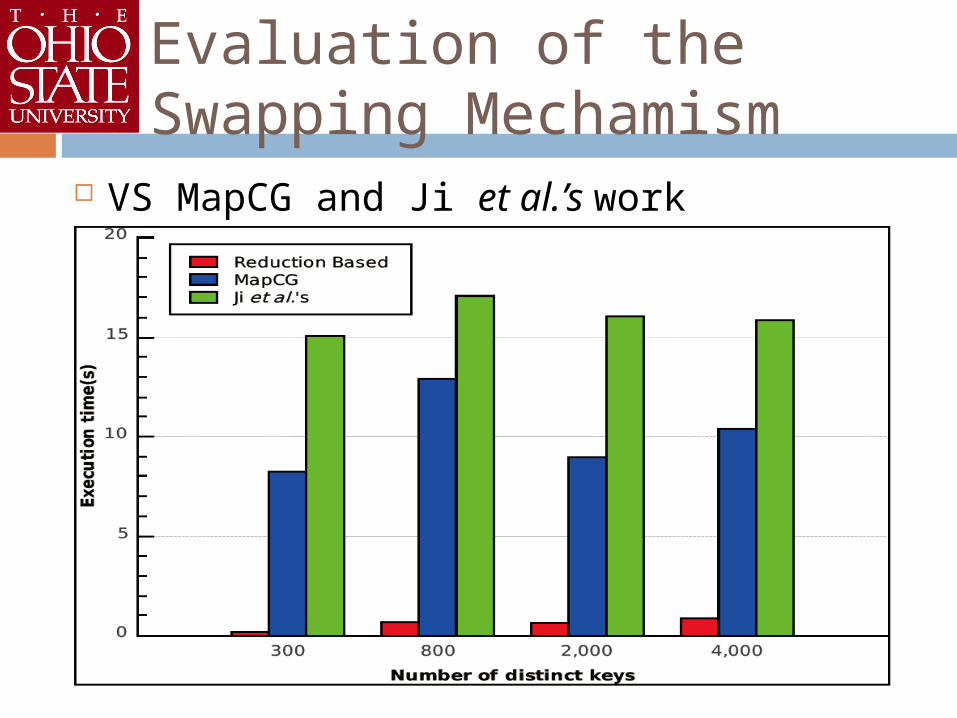
Evaluation of the Swapping Mechamism
VS MapCG and Ji et al.’s work

Evaluation of the Swapping Mechamism
VS MapCG
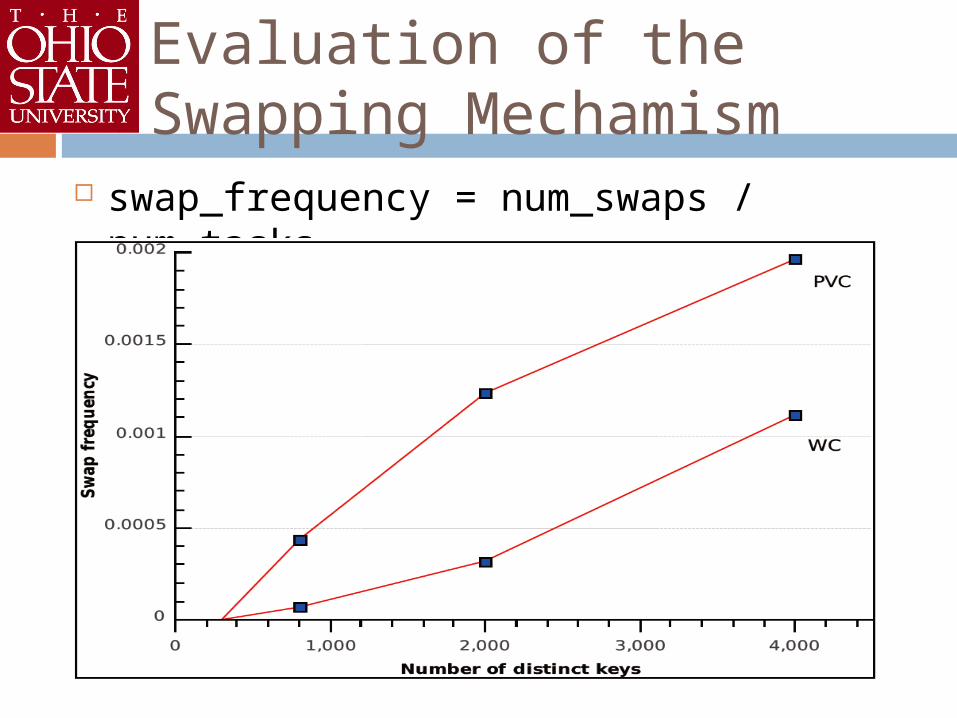
Evaluation of the Swapping Mechamism
swap_frequency = num_swaps / num_tasks

Outline
Introduction Background System Design Experiment Results Related Work Conclusions and Future Work

Related Work
MapReduce for multi-core systems Phoenix, Phoenix Rebirth
MapReduce on GPUs Mars, MapCG
MapReduce-like framework on GPUs for SVM Catanzaro et al.
MapReduce in heterogeneous environments MITHRA, IDAV
Utilizing shared memory of GPUs for specific applications Nyland et al., Gutierrez et al.
Compiler optimizations for utilizing shared memory Baskaran et al. (PPoPP '08), Moazeni et al. (SASP '09)

Conclusions and Future Work
Reduction-based MapReduce Storing the reduction object on the memory hi
erarchy of the GPU A multi-group scheme Improved performance compared with previou
s implementations Future work: extend our framework to support
new architectures

Thank you!
Recommended

















