On the Dynamics of Interstate Migration:
Migration Costs and Self-Selection
Christian Bayer∗
Falko Juessen†‡
Universität Bonn and IGIERTechnische Universität Dortmund and IZA
First version: February 15, 2006This version: July 29, 2011
Abstract
This paper develops a dynamic structural model of migration decisions that is aggre-
gated to describe the behavior of interregional migration. Our structural approach
allows us to deal with dynamic self-selection problems that arise from the endogene-
ity of location choice and the persistence of migration incentives. The self-selection
problem is solved by keeping track of the distribution of migration incentives over
time. This econometric treatment has important consequences for the estimation
of structural parameters such as migration costs. For US interstate migration, we
obtain a cost estimate of roughly two-thirds of an average annual household income.
We also show that the treatment of income persistence has important consequences
for comparative statics of the model as well as microeconomic age patterns of mi-
gration.
KEYWORDS: Dynamic self-selection, dynamic discrete choice, aggregate migration,
indirect inference
JEL-codes: C24, C25, E24, J61
∗Universität Bonn, Department of Economics, Adenauerallee 24-42, 53113 Bonn, Germany, Tel.:+49-228-73 4073; email: [email protected].†Technische Universität Dortmund, Department of Economics, 44221 Dortmund, Germany; phone:
+49-231-755-3291; fax: +49-231-755-3069; email: [email protected]‡We would like to thank three anonymous referees for their valuable and helpful comments. All errors
are ours. We would further like to thank Francesc Ortega, Andreas Schabert and conference participantsat the NASM 2006, the SED Meeting 2006, the EEA Meeting 2006, the VfS Meeting 2006, the SMYE2007, the SCE Meeting 2007, the ERSA Meeting 2007, LAMES 2008, and at seminars held at IZA,Universität Bonn, the EUI, and Università Bocconi for their helpful comments and suggestions. Part ofthis paper was written while C. Bayer was visiting fellow at Yale University and Jean Monnet fellow at theEuropean University Institute. He is grateful for the support of these institutions. Financial support bythe Rudolf Chaudoire Foundation is gratefully acknowledged. The research has been supported by DFGunder Sonderforschungsbereich 475 and 823. We would like to thank Christian Wogatzke for excellentresearch assistance. A previous version of the paper has been circulated under the title "A generalizedoptions approach to aggregate migration with an application to US federal states".
1

1 Introduction
Migration choices are important economic decisions. Migration allows individual agents
to evade adverse shocks to their income and it is an important way of macroeconomic
adjustment (Blanchard and Katz, 1992, and Decressin and Fatas, 1995). Many fac-
tors influence the decision to migrate and a vast empirical literature has analyzed how
migration decisions are driven by economic incentives, in particular by income differ-
entials.1 Since migration is a dynamic discrete choice problem, advances in modelling
these problems2 have opened up new frontiers for empirical research on migration too.
This triggered a recent interest in structural models of migration.3 Common to these
papers is an i.i.d. assumption for the agents’incomes after controlling for observables.
In this paper, we highlight that a deviation from this i.i.d. assumption has stark
consequences for the estimation of structural parameters, the comparative statics ofmigration with respect to migration costs, and the age patterns of migrants. This is
because of dynamic self-selection. If (residual) incomes are autocorrelated (as shown
by e.g. Storesletten, Telmer and Yaron (2004) or Low, Meghir and Pistaferri (2010)),
repeated decision making implies that neither migrants nor the population taking mi-
gration decisions are a random sample with respect to income. The income of an agent
is typically highest in the place she currently lives in, because she will have—in her past—
selected herself into a region where she is best off.4
In non-repeated discrete-choice modelling ("now-or-never" type of decisions), various
solutions to self-selection problems have been discussed, see Heckmann and Robb (1985)
for an overview. In the context of migration, the role of such static self-selection for the
estimation of migration gains was discussed by Nakosteen and Zimmer (1980).5 Their
proposed solution builds on a selection model of the type popularized by Heckman (1974,
1976, 1978) and Lee (1978, 1979). However, it rests on the assumption of non-repeated
discrete choice and on residual income heterogeneity being i.i.d.
We first elaborate on the difference between dynamic and static self-selection in a
stylized two period setup that has the advantage of analytical tractability. Thereafter,
we develop a fully dynamic model of repeated migration choices. This model allows
1See Greenwood (1975, 1985, and 1997) and Cushing and Poot (2004) for survey articles.2See Keane and Wolpin (2009), Norets (2009), Aguirregabiria and Mira (2010).3See e.g. Armenter and Ortega (2010), Coen-Pirani (2010), Gemici (2011), or Kennan and Walker
(2011).4Norets (2008) shows that wrongly assuming i.i.d. unobservables can create significant estimation
biases in dynamic discrete choice models and therefore (Norets, 2009) develops a Bayesian estimationtechnique for this class of models with serially correlated unobservables.
5Examples of further studies adressing static self-selection in migration are: Borjas (1987), Borjas,Bronars, and Trejo (1992), Tunali (2000), and Hunt and Mueller (2004).
2

us to take a classical, simulation-based estimation approach of the structural parame-
ters while taking serial correlation in potential incomes and self-selection into account.
Our approach relies on explicitly modelling the dynamics of the distribution of poten-
tial incomes. Our modelling strategy follows Caballero and Engel’s (1999) paper on
investment, which highlights the interaction of lumpy investment and the evolution of
investment incentives. In the spirit of their model, we develop a microeconomic struc-
tural model of migration which can be used to describe the simultaneous evolution of
unobservable migration incentives and migration rates at an aggregate level. This allows
us to identify the model parameters from the business cycle frequency fluctuations in
migration rates. We use annual US state level migration flows from 1989-2008 from
the IRS. An advantage of our approach is that we can easily combine information from
different levels of aggregation. Specifically, we also exploit information on dispersions of
household incomes by state and year from the Current Population Survey (CPS).
In estimating our model, we obtain four important findings. First, we estimate
migration costs to be US$ 34,248 for a typical move between US states. This number
is substantially smaller than the ones reported in previous contributions, such as Davis,
Greenwood and Li (2001), but in line with Kennan and Walker’s (2011) estimate - at
least when they take expected payoff-shocks into account. Second, we show that it can
generate a substantial bias in estimated migration costs if one ignores the endogeneity
and the dynamics of the distribution of unobserved potential incomes. Third, we show
that the comparative statics of the model with respect to exogenous changes in migration
costs, for example due to more or less liquid housing markets, changes substantially with
assumptions regarding if and how to model persistence of potential income differences
across states. Fourth, we also document migration dynamics at the micro level that
differs from a model which does not keep track of the incentive distribution. One of
the best documented facts from microdata is that younger households are more likely
to migrate than older ones. The prominent explanation for this is the so-called human
capital channel where migration is an investment in human capital that pays off longer
for younger agents (Sjaastad, 1962). A problem with this explanation is that it cannot
capture the sharp decline in migration rates between ages 20 and 30.
We shut down this human capital channel and apply a perpetual-youth model instead
where the decision problem of the agent is stationary and independent of the agent’s
age. Nonetheless, age influences migration in our model because it is an argument of
the distribution of migration incentives. As in Jovanovic’s (1979) job search model,
the match between agent and region becomes more effi cient as agents get older, since
agents have selected themselves into their preferred region. This mechanism, while in
3

principle discussed in parallel work by Coen-Pirani (2010) and Kennan and Walker
(2011), provides in our setup a new quantitative explanation for the empirical age-
migration pattern. We show that autocorrelated incomes are key to the close quantitative
match of observed and model-implied age patterns if one does not want to rely on age-
dependent migration costs as in Kennan and Walker (2011). To make this point we
show that one obtains very different and counterfactual results if approximating the
persistence in incomes by a mixture of an i.i.d. and a fixed effect component.
Kennan and Walker (2011) have a framework where migration is an experience good
and choice is between 50 regions whereas we assume that the household knows alternative
opportunities at each point in time, modelled in a bi-regional setup. We use a bi-regional
setup because simulating the dynamic evolution of migration incentives is numerically
intense even if solving the microeconomic decision problem itself is quick. In Kennan
and Walker (2011), income dynamics is given by a combination of fixed location-specific
shocks and an i.i.d. component, whereas we model it as an autoregressive process. To
match age patterns of migration, Kennan and Walker consider age-specific migration
preferences. At the same time, they account for further household characteristics, ob-
taining identification from cross-individual variations in migration patterns, while our
identification relies on business cycle frequency movements in migration and hence im-
plicitly controls for factors that do not change over time.
Gemici (2011) also exploits differences in migration patterns across households and
provides a dynamic model of family migration decisions. Her model puts to the center
of attention the issues of intra-household bargaining and private externalities that job
offers (and moving choices) of one spouse cause for the other. Gemici (2011) models
persistence in income as a constant job-specific effect and households decide to change
jobs (and consequently place of residence) if they obtain a favorable job offer.
The remainder is organized as follows. Section 2 illustrates in a stylized two-period
model why dynamic self-selection implies that the evolution of migration incentives and
migration choices need to be estimated simultaneously. Section 3 extends the model
to a setup where an agent maximizes life-time well-being by repeated location choice
in a perpetual-youth model. Section 4 shows how to aggregate this model. Section 5
confronts the model with data and presents the estimates of the structural parameters.
Section 6 investigates the role of different assumptions on the persistence of incomes
for the comparative statics of the model and the age patterns of migration our model
implies. Section 7 concludes and an Appendix provides detailed proofs, details about
the numerical model, and some further robustness checks.
4

2 Why a dynamic model of migration and migration incentives?
Most micro studies and lately also more macro studies on migration link the individual
migration decision to a probabilistic model in which agent i migrates at time t if the
long-term gain in utility terms obtained by migration is large enough and exceeds some
threshold value c, see for example Davies, Greenwood, and Li (2001), Hunt and Mueller
(2004), or Kennan and Walker (2011).
2.1 Endogenous initial state
To illustrate the problems induced by dynamic self-selection in such setup, we first
consider a two-period, t = 0, 1, bi-regional example with regions A and B in this section.
In Section 3 we develop an infinite horizon, dynamic discrete choice model of migration
that can solve the problems highlighted here.
Let yiAt indicate whether agent i resides at time t in region A (yiAt = 1 if i in A and
yiAt = 0 if i in B). The decision problem in t = 1 can then be written as
yiA1 =
{1
0
if y∗iA1 > 0
if y∗iA1 ≤ 0(1)
where y∗iA1 is the latent utility agent i enjoys from living in region A relative to living
in region B (including eventual migration costs). Equation (2) below gives a parametric
form to this utility difference:
y∗iA1 =
{uiA1 − (uiB1 − c)(uiA1 − c)− uiB1
if agent i lives in A at time 0
if agent i lives in B at time 0
= γ (wiA1 − wiB1)− c (1− 2yiA0) + νi1. (2)
We assume that the flow utility uij1 from living in region j depends only on incomes
wij1. The parameter γ measures the marginal utility of income. The utility costs of
migration are described by c. The stochastic component νi1 reflects differences across
agents, omitted migration incentives, and/or some variability of migration costs.
Typically, we are interested in the structural parameters γ and c and hence would
estimate (1) respectively the parametric form (2) to infer these parameters with a dis-
crete choice estimator suitable for the distribution of shocks νi1, e.g. running a probit
estimation of migration choice on income differences as potential migration gains. Such
a direct approach is in general not feasible as potential migration gains are unobservable
to the econometrician, i.e. we observe wij1 only if the agent chooses to live in j.
A standard approach to solve this problem is to proxy the unobservable potential
5

income by the income a similar agent realizes in the other region using a Mincer-type
wage regression
wij1 = ζj1zi1 + w∗ij1,
where ζj1 measures the sensitivity of wages to observables zi1 and w∗ij1 is residual wage
heterogeneity.
Nakosteen and Zimmer (1980) highlighted that the self-selection of agents has to
be taken into account when estimating the average unobserved potential income gains,
ζj1zi1. We assume this problem to be solved, since we are here not interested in the effect
of classical self-selection. Therefore, we assume that the econometrician actually knows
ζj1 and thus also the average gain from migration.6 Nonetheless, if wage residuals w∗ij1are autocorrelated, the structural estimation of the decision problem defined in (1) and
(2) will be biased if the place of residence is a result of past decision making (dynamic
self-selection).
Replacing wij1 by the estimates ζj1zi1 in (1) , we obtain for the latent variable y∗i1
y∗iA1 = γ (ζA1 − ζB1) zi1 − c (1− 2yiA0) + γ (w∗iA1 − w∗iB1) + νi1︸ ︷︷ ︸:=ηi1
. (3)
The proxy-model (3) , which now is feasible to estimate (again with, say, a probit es-
timator), contains a composed error term that combines the original error νi1 from
the discrete choice problem (1) and a measurement error γ (w∗iA1 − w∗iB1) that captures
the residual income heterogeneity across agents after controlling for observables zi1. We
assume this term is orthogonal to (ζA1 − ζB1) zi1. Making use of the proxy income dif-
ference (ζA1 − ζB1) zi1 it is now feasible to estimate (1) and (3) with a discrete choice
estimator corresponding to the distribution of ηi1 (say probit for example), regressing
migration choices on imputed income differentials, (ζA1 − ζB1) zi1. However, for unbi-
ased estimates of c it is necessary that ηi1 and hence γ (w∗iA1 − w∗iB1) is also orthogonal
to the previous place of residence yiA0.
When studying regional migration this assumption is typically not satisfied. To see
how this leads to a bias in the estimate of migration costs c, consider the following two
scenarios, where in both scenarios the average migration rate is small, individual wages
are unobservable, and location B offers on average higher wages than location A.
6 In the terminology of the econometric literature on selection, this assumption means that the problemof estimating treatment effects can be readily solved. This selection problem lead Nakosteen and Zimmer(1980) to advocate a joint estimation of the latent income variable and the migration choice based ona model of the type popularized by Heckman (1974, 1976, 1978) and Lee (1978, 1979). See Heckmannand Robb (1985) for various consistent estimators of ζj1.
6

• In scenario 1, agents are initially randomly distributed across the two locations.
In this scenario, for migration rates to be low, it must be that migration costs are
large and hinder agents from moving from region A to B.
• In scenario 2, agents are initially self-selected in the two locations, such that they
are where they earn most. Suppose further extreme wage persistence: individual
wages remain constant over time. Now, we observe zero migration even in the
absence of migration costs, because households already are in the region where
they earn most. Any household that migrates would actually incur an income loss
and an aggregate income difference is not informative about the latent gain (or
loss) from moving for any given household.
If one mistakes scenario 2 for scenario 1, migration costs will be overestimated. A
setup in which time periods are relatively short, e.g. years, and where agents have repeat-
edly faced the decision to migrate is more like scenario 2 as there is high autocorrelation
in incomes. This holds true even after controlling for individual characteristics and fixed
individual heterogeneity, see for example Storesletten, Telmer and Yaron (2004) or Low,
Meghir and Pistaferri (2010).
To make the above argument formal, assume w∗ijt follows an AR(1) process
w∗ij1 = ρw∗ij0 + εij1
with i.i.d. innovations εij1. The initial conditions w∗ij0 are i.i.d., drawn from a normal
distribution N(0, σ2
0
). Replacing w∗ij1 in (3) , we obtain
y∗iA1 = γ (ζA1 − ζB1) zi1 − c (1− 2yiA0) + γ (ρ (w∗iA0 − w∗iB0) + εiA1 − εiB1) + νi1︸ ︷︷ ︸=ηi1
.
As long as ρ 6= 0, corr (yiA0, ηi1) 6= 0 if the location in the previous period yiA0 is a
function of the previous periods’ residual income difference (w∗iA0 − w∗iB0) . In general
this will be the case if the location yiA0 has been a result of migration choice and thus
is not random.
Scenario 2 refers to the case where each household initially is in the region where it
earns most income
yiA0 =
{1
0
ifwiA0 > wiB0
ifwiA0 ≤ wiB0
.
We can calculate the covariance of the composed error term ηi1 with yiA0 as (see
7

Appendix A)
cov (yiA0, ηi1) = 2γρσ0φ
((ζA1 − ζB1) zi1
2σ0
)> 0, (4)
where φ is the density of the standard normal distribution. Note that the covariance
is positive, implying an upwards bias in the estimate of migration costs c.7 In addition,
the bias is neither constant across individuals nor across time. It is largest when the
deterministic differences (ζA1−ζB1)zi12σ0
are small, i.e. when regions are much alike.
The bias vanishes if ρ = 0, which corresponds to the model considered by Nakosteen
and Zimmer (1980). It also vanishes if the location in period t = 0, yiA0, is not related
to the income difference in t = 0. That initial location is unrelated to initial income
differences is likely for example if one looks at location at the time of birth compared to
the location at another fixed age. Research on internal migration, however, has typically
not looked at this type of data. Migration data that comes at a yearly frequency typically
reflects the behavior of households who already faced migration decisions - even if most
of them decided not to move.
2.2 Dynamics of the distribution of potential incomes
The two-period model introduced above reflects this repeated decision process only up
to a limit, though it highlights the general problem arising from dynamic self-selection.
To fully address the dynamic character of the migration decision, we extend the model
to the infinite horizon in the next section. There, one important element will be the
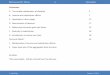
dynamics of the distribution of unobserved migration incentives sketched in Figure 1.
Suppose the composed error term ηit is initially normally distributed as in Figure
1 (a). The figure displays the distribution of potential incomes, γ (ζAt − ζBt) zit + ηit.
Low values imply that income in region B is favorable, high values imply better income
prospects in region A. In the absence of migration costs, all agents with γ (ζAt − ζBt) zit+ηit < 0 decide to live in region B and they decide to live in region A otherwise.
As a result of this self-selection, the distribution of income differences changes for
the next period. No agent who lives in region B prefers to live in region A, see Figure
1(b). Effectively, the right-hand part of the distribution in Figure 1(a) has been cut as
all agents with higher income in region A have chosen A as the region to live in.
Adding a normally distributed idiosyncratic income shock to the persistent income
difference leads to the distribution of income differences as displayed in Figure 1(c). The
colored-in region indicates the set of agents that will migrate from B to A after the
7The covariance is suffi cient to argue that a bias will be present. However, if the migration probabilityis given by a non-linear model such as logit or probit, it is not easily possible to derive an explicit biasformula as in a linear regression model.
8

Figure 1: Distribution of potential incomes in region A relative to B
(a) overall population (b) conditional on living in region B
3 2 1 0 1 2 30
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
Live in B Live in A
yiAt
: log income difference between state A and state B
popu
latio
n de
nsity
3 2 1 0 1 2 30
0.2
0.4
0.6
0.8
1
1.2
1.4
Live in B Live in A
yiAt
: log income difference between state A and state B
popu
latio
n de
nsity
(c) conditional on living in region B after (d) conditional on living in region B afterfirst move. After idiosyncratic first move. After idiosyncratic andshocks. aggregate shocks.
3 2 1 0 1 2 30
0.2
0.4
0.6
0.8
1
Live in B Live in A
yiAt
: log income difference between state A and state B
popu
latio
n de
nsity
3 2 1 0 1 2 30
0.2
0.4
0.6
0.8
1
Live in B Live in A
yiAt
: log income difference between state A and state B
popu
latio
n de
nsity
Shaded area: mass of agents who are better off living in region A instead of region B.
9

idiosyncratic shocks occurred.
Besides idiosyncratic shocks, aggregate shocks to the average income difference
γ (ζAt − ζBt) zit also influence the migration decisions of agents. Figure 1(d) shows thedistribution of migration incentives as in Figure 1(c), but after an adverse shock to
region B. Aggregate shocks shift the income differences for all agents and thus shift the
distribution of income differences before migration without directly altering its shape.
By comparing Figures 1(c) and 1(d), one can see that the shape of the distribution after
migration (the region not colored in) differs between both figures. As a consequence, one
needs to keep track of the evolution of the incentive distribution to determine aggregate
migration. Therefore, we develop a model based on dynamic optimal migration decisions
in the presence of persistent shocks to income. This model can then be aggregated and
used to simulate the evolution of migration and its incentives over time.
3 A simple stochastic model of migration decisions
We consider an economy with two regions, A and B. This economy is inhabited by a
continuum of agents of measure 1. Agents maximize future well-being over an infinite
horizon by location choice. In each period a constant fraction δ of randomly selected
agents dies and is replaced by newborn agents so that the overall population remains
constant ("perpetual youth model"). We model the economy in discrete time and at
each point in time an agent decides in which region to live and work. First, we consider
the decision problem of an individual agent i living in region j = A,B. Thereafter, we
discuss aggregation and the dynamics of the distribution of migration incentives.
Living in region j at time t gives the agent utility wijt that we interpret as utility
from income, which is stochastic in our model. We assume incomes to be composed
of a persistent (autocorrelated) component wijt and a transitory (i.i.d.) component
ϕijt.8 Both components vary over time and across individuals. We assume that only
the persistent component wijt is observed before migration. Consequently, in describing
migration behavior, we can focus exclusively on the effect of persistent variations in
potential incomes. Changes in the transitory component realize after migration and
hence do not affect migration choice. Therefore, we drop ϕijt for notational convenience
when describing migration as a function of incomes. However, when confronting our
model to data, including data on aggregate income, we need to take transitory income
fluctuations into account.
Moving from one region to the other comes at a cost. When an agent moves, she is
8See the evidence on transitory income fluctuations provided by Storesletten, Telmer, and Yaron(2004) for instance.
10

subject to a disutility c that enters additively in her utility function. We assume that
migration costs, c, are constant across agents and over time. The instantaneous utility
function uit(j, k) is given by
uit (j, k) = wijt − Ij 6=kc (5)
for an agent that has lived in region k in the preceding period and now lives in region j.
Here, I denotes an indicator function, which equals 1 if the agent has moved from region
k to j and 0 if the agent had lived in region j in the preceding period. Our assumption
of utility being linear in income can be understood as assuming complete markets and
perfect consumption insurance, where the allocation problem then simplifies to locating
the agent where she is most productive (taking migration costs into account).9
The agent discounts future utility by factor β < 1 and takes further into account the
probability of dying δ such that she effectively discounts future utility by β = β (1− δ) <1 and maximizes the so discounted sum of expected future utility by her location choice.
The agent knows the distribution of the persistent component of income wijt and forms
rational expectations. With wijt being stochastic, the potential migrant waits for good
income opportunities.10
The distribution of migration incentives, wijt, is assumed to be log-normal. In par-
ticular, we assume that log income in the two regions (free of transitory shocks), wijt,
follows an AR(1) process with normally distributed innovations ξijt and autoregressive
coeffi cient ρ :
ln (wijt) =: wijt = µj (1− ρ) + ρwijt−1 + ξijt, j = A,B. (6)
This process holds for the whole continuum of agents and each agent draws her own
series of innovations ξijt for both regions. The expected value of log income in region j
is µj . The innovations ξijt are composed of aggregate as well as idiosyncratic components.
They have mean zero, are serially uncorrelated, but may be correlated across regions A,B
(see Section 4.2.2). Note that transitory shocks to income, ϕijt, which are irrelevant for
migration choices will be added to aggregate income when matching our model to data.
The income distribution and migration costs, together with the utility function and
9Any deviation from this complete markets assumption makes wealth of the agent an important statevariable of the agent’s decision problem and we want to abstract from this complication.10Our model is based on the real-options approach to migration suggested by Burda (1993) and Burda
et al. (1998). Since the latter two papers only look at migration as a once and for all decision, theypreclude return migration and do not have to study the evolution of migration incentives, to which pastmigration decisions feed back.
11

the discount factor define the decision problem for the potential migrant. The optimiza-
tion problem is described by the following Bellman equation:
V (k,wiAt, wiBt) = maxj=A,B
{exp (wijt)− I{k 6=j}c+ βEtV (j, wiAt+1, wiBt+1)
}. (7)
Here, Et denotes the expectations operator with respect to information at time t and kdenotes the current region of the agent.11 The optimization problem is stationary and
in particular it is independent of age as agents die with a constant probability δ.
The optimal policy is relatively simple. The agent migrates from region k to region j
if and only if the costs of migration are lower than the sum of direct benefits of migration
expwijt − expwikt and the expected value gain
∆V (wiAt, wiBt) := βEt [V (B,wiAt+1, wiBt+1)− V (A,wiAt+1, wiBt+1)] . (8)
This means that the agent migrates from A to B if and only if
c ≤ exp (wiBt)− exp (wiBt) + ∆V (wiAt, wiBt) =: c (wiA, wiB) . (9)
This gives a critical level of costs ciA =: c (wiA, wiB) at which agent i living in region
A and facing potential incomes wiA, wiB is indifferent between moving and not moving
to region B. Note that due to individual differences in incomes the critical cost levels
for moving, ciA, differ across individuals, while migration costs c are common. This
introduces heterogeneity in migration decisions. A person moves from A to B if and
only if c ≤ ciA. Conversely, a person living in region B moves to region A if and only
if c ≤ ciB = −ciA. Note that ciA can be positive as well as negative. If ciA is positive,region B is more attractive. If it is negative, region A is more attractive and a person
living in region A would only have an incentive to move to region B if migration costs
were negative.
4 Aggregate migration and the dynamics of income distributions
4.1 Aggregate migration
Given this trigger rationale for migration, the hazard rate
Λj (wA, wB) :=
1if j = A and c ≤ c (wA, wB) or
if j = B and c ≤ −c (wA, wB)
0 otherwise
11Existence and uniqueness of the value function is proved in Appendix B.
12

determines whether a person living in region j moves to the other region if she faces the
potential incomes (wA, wB).
Now, consider the distribution Ft of (potential) incomes (wA, wB) and household
locations. Suppose this joint income and location distribution is the distribution after
the income shocks ξijt have been realized, but before migration decisions have been
taken. Let fjt denote the conditional density of this distribution, conditional on the
household living in region j at time t. Then, the actual fraction Λjt of households living
in j that migrate to the other region evaluates as
Λjt :=
∫Λj (wA, wB) · fjt (wA, wB) dwAdwB. (10)
This aggregate migration hazard can be thought of as a weighted mean of all microeco-
nomic migration hazards Λj (wA, wB), weighted by the density of income pairs (wA, wB)
from distribution Ft.
4.2 Dynamics of income distributions
The distribution Ft (and hence fjt) evolves over time and is a result of direct shocks to
income just as it is a result of past migration. In addition it is altered by the death and
birth of agents. We need to characterize the law of motion for Ft to close our model and
to obtain the sequence of aggregate migration rates.
4.2.1 The effect of migration on income distributions
In order to follow the evolution of Ft we need to characterize both the evolution of
the fraction Pjt of households living in each region and the conditional distribution of
incomes fjt (conditional on a household actually living in a specific region j).
The proportion of households living in region j at time t+ 1 is a result of migration
decisions at time t. The law of motion for Pjt is thus given by
Pjt+1 =(1− Λjt
)Pjt + Λ−jtP−jt. (11)
The first part of the sum reflects the fraction of households that remain in region j,
where(1− Λjt
)is the probability to stay in region j. The second part is the fraction
of households that migrate from region −j to region j. The probability δ of a householddying does not influence the proportion of households living in each region as a dying
household is by assumption replaced by a newborn one in the same region.
Since the microeconomic migration hazard depends on (wA, wB) , different potential
incomes result in different propensities to migrate. As a consequence, migration changes
13

not only the fraction Pjt of households living in region j at time t, but also the conditional
distribution of income, fjt. For example, households living in region A, earning a low
current income, wA, but facing a substantially higher potential income in B, wB, will
probably migrate. As a result, the number of those households will drop to zero in region
A after migration decisions have been taken, while the number of households facing a
smaller income differential might not change, recall Figure 1.
The distribution of migration incentives is thus a function of past migration decisions,
and we can express the new density of households with income (wA, wB) in region j after
migration, fjt, by
fjt (wA, wB) = [1− Λjt (wA, wB)]fjt(wA,wB)Pjt
Pjt+1+ Λ−jt (wA, wB)
f−jt(wA,wB)P−jtPjt+1
. (12)
The probability [1− Λjt (wA, wB)] is again the probability to stay in region j. The
term fjt (wA, wB)Pjt weights this probability and is the unconditional income density
for region j before migration has taken place. To obtain the conditional density after
migration, the unconditional income density, fjt (wA, wB)Pjt, is divided by Pjt+1, which
is the fraction (or probability) of households living in region j after migration (i.e. in
time t+ 1). Analogously, the second part of the sum is constructed.
4.2.2 The effect of income shocks on the income distribution
Besides migration, also shocks to income change the distribution of income pairs, Ft. The
shocks to income can be differentiated along two dimensions: One dimension is aggregate
vs. idiosyncratic, the other one is region-specific vs. economy-wide. For a single agent
we can decompose the total potential income wijt in region j (see equation 6) into
an aggregate regional-component zjt and an individual-specific regional-component w∗ijtbeing driven by shocks θjt and εijt, respectively:
wijt = zjt + w∗ijt (13)
zjt = µj (1− ρ) + ρzjt−1 + θjt
w∗ijt = ρw∗ijt−1 + εijt, j = A,B.
In case agent i is newborn in period t, we assume that she begins life without any past
idiosyncratic income advantage or disadvantage in region j, i.e. we set w∗ijt−1 = 0. Note
that t refers to natural time and not to the age of the agent. Further note that εijt and
θjt simply add additional structure to the income shock
ξijt = εijt + θjt
14

in equation (6) . We assume for convenience that the autocorrelation of aggregate and
idiosyncratic shocks is the same.
The regional-aggregate shock θjt for region j hits all agents equally and changes
their potential income for region j. Note that this shock does not depend on the actual
region the agent lives in. For example, a positive shock θAt > 0 increases the potential
income in region A for agents that currently live in this region as well as for agents
that are currently living in region B. They realize this potential income by deciding to
actually live in region A. The importance of economy-wide business cycles relative to the
size of region-specific aggregate fluctuations is reflected by the correlation ψθ between
aggregate shocks θAt and θBt. The higher is ψθ the more important are economy wide
shocks relative to region specific ones.
However, aggregate shocks are typically only a minor source of income variation
for an agent. Agents differ in various personal characteristics that result in different
income profiles over time. Individuals differ in their skills and while the demand may
grow for the skill of one person, demand may deteriorate for another person’s skills.
This heterogeneity is captured by the idiosyncratic shocks (εiAt, εiBt) . If εiAt is positive,
income prospects of the individual agent i increase in region A. The correlation ψε
between εiAt and εiBt reflects economy-wide demand shifts for a person’s individual skills.
Since we assume aggregate and idiosyncratic shocks to be independent, the variance of
the total shock to income, ξijt, is the sum of the variances of idiosyncratic and aggregate
shocks: σ2ξ = σ2
ε + σ2θ.
Persistence in incomes is captured by the autoregressive parameter ρ in equation
(13) . In our baseline setup, we abstain from the inclusion of permanently fixed individ-
ual differences (fixed effects) because this makes the model numerically more tractable.
However, we compare to a setup in which agents can be of 5 different types with fixed
preferences for or against region A but have i.i.d. income shocks otherwise.12
Aggregate and idiosyncratic shocks to income, birth and death of households, as
well as income persistence jointly determine the transition from fjt to fjt+1, details
are provided in Appendix C. The latter density now determines migration decisions in
time t + 1, starting the cycle over again. As a result it is both past income shocks and
12While the solution of the restricted dynamic programming problem of the agent can be obtainedquickly, the simulation of the distribution of migration incentives is numerically involved. The compu-tation time for the estimation amounts to roughly 12h on a 8-core Xeon (Clovertown) 3GHz machine.The alternative specification with fixed effects can be allowed for by modelling K types of agents thathave a fixed income advantage, κk ∈ R, from staying in region A instead of region B. The model thenis solved for each different type of agent as it is solved for the single type. An important aspect is thata κk-type agent upon dying in one region may be replaced by a different type in that region leading toan initial misallocation.
15

past migration decisions that drive the incentives to migrate. Making this explicit and
keeping track of the distributional dynamics of migration incentives is the key element
of our model, as it distinguishes our approach from other empirical models of migration.
4.3 Aggregate income
To link our model to aggregate data, we finally need to describe the evolution of aggregate
regional realized incomes. For region j, log aggregate income wjt is given by
wjt = ln
(∫exp (wj) fjt (wA, wB) dwAdwB
)+ ϕjt, (14)
where the first term is persistent, realized income. The second term, the transitory
income component ϕjt, measures fluctuations in income at a high frequency that are
irrelevant to the migration decision. More generally, it captures the idea that in reality
income measures migration incentives imperfectly. One reason is that any empirical
income concept is noisy as such. The inclusion of ϕjt reflects this agnostic view.
5 Estimation
5.1 Estimation technique and estimated parameters
We rely on an indirect inference procedure in order to find the parameters of our model
that allow us to match closest the observed patterns of migration that are in the data.
In particular, we apply a method of simulated moments (MSM) as has been proposed by
Gourieroux, Monfort, and Renault (1993) to obtain estimates of structural parameters
when the likelihood function of the structural model becomes intractable. This estimator
relies on numerical simulation of the model. Details are provided in Appendix E.
The idea behind a method of simulated moments is to: first, choose a set of moments
that captures the characteristics of the data, second, simulate the structural economic
model, and third, find parameters such that the simulated moments replicate the ob-
served moments closely.
A simulation of our model yields migration and income data for two regions. Of
course, the actual migrant faces a more complex decision problem than in our model.
Including D.C. as a destination region, an agent has to decide between 50 possible
alternative states where she can move to. To make this comparable to our model, the
50 alternatives in the data have to be aggregated to a single complementary region
for each of the 51 states.13 The average income of the alternative region is proxied
13Generating artificial bi-regional data means that we technically assume the best income opportunityover all alternative regions to follow a log-normal distribution as assumed in our model. An approxima-
16

by the population-weighted average income over all alternative 50 states. This data is
combined with migration data from the Internal Revenue Service (IRS). This database
contains annual state-to-state migration flow data for the US for the period 1989-2008.
We simulate our model for 51 pairs of regions and 70 years, but we drop the first 50 years
for each region to minimize the influence of our initial choice of the income distribution
F0. We choose F0 to equal the ergodic distribution in the absence of aggregate shocks, see
Appendix D for details. To reduce simulation uncertainty, we replicate each simulation
5 times and use the averages over these simulations.
We estimate all parameters of the model except for the discount factor β, the prob-
ability of dying δ, and average incomes. As we work with annual data, we choose the
discount factor to be β = 0.95. We fix the probability of dying to δ = 2.5% to reflect an
average working-life expectancy of 40 years and set the mean log household income to
µA = µB = 10.5 (roughly US$ 45,000).
All other parameters of our model are estimated. Our primary estimation target
are migration costs, c. Besides migration costs, we need to estimate the correlation of
persistent shocks to income across regions, ψε and ψθ, and the importance of common
shocks across individuals, i.e. the variance of aggregate shocks σ2θ.We assume ψε = ψθ =
ψ while we fix the correlation of transitory shocks ψϕ to the one of realized incomes in
the data (see Section 5.3.1. for a discussion of this choice). Finally, we need to estimate
the parameters of the idiosyncratic income process(ρ, σ2
ε
). We assume autocorrelation
is the same for aggregate and individual shocks. This latter assumption is for made for
convenience. Our complete set of estimated parameters is Θ =(c, ψ, ρ, σ2
θ, σ2ϕ, σ
2ε
).
5.2 Data
To estimate the model we exploit data on state-to-state migration rates and household
level and aggregate data on labor incomes.
5.2.1 IRS migration data
We use state-to-state migration data for the period 1989-2008 provided by the US Inter-
nal Revenue Service (IRS). The IRS calculates state-level (and county-level) migration
data for the entire United States based on year-to-year address changes reported on
individual income tax returns filed prior to late September of each calendar year. This
means the migration data is obtained by matching the Social Security number of the
primary taxpayer from one year to the next. The IRS data identifies households with
an address change since the previous year and then totals migration to and from each
tion of this sort cannot be avoided by assuming an extreme value distribution for incomes. This wouldonly work if migration incentives were serially uncorrelated.
17

state in the US to every other state. Given these bilateral migration flows, aggregate
gross immigration and outmigration for the 50 US states and the District of Columbia
can be computed, i.e. the number of households who moved to a state and the number
of households leaving a state, respectively. Migration rates are calculated by express-
ing gross immigration as proportions of the number of total population of households
(migrants and non-migrants) reported in the IRS data set.
The IRS migration data represents between 95 and 98 percent of total annual filings.
According to Gross (2005), the IRS migration data may be the largest data set that tracks
movement of both households and people from state to state. A particular advantage
of the data set is the relatively large time period covered (1989-2008) and the almost
universal coverage of households. This is important for our study as our identification
strategy exploits the time-series business-cycle volatility of state-level migration rates.
A shortcoming of the IRS data is that it does not represent the entire US popula-
tion. Households who are not required to file income tax returns are not covered. As a
result the IRS data under-represents the poor and the elderly (also excluded is a small
percentage of tax returns filed after late September of the filing year). However, com-
pared to other sources of migration data, such as the Current Population Survey (CPS)
for example, a decisive advantage of the IRS data is the size of the population that is
sampled. The CPS on average covers roughly 1000 households per state and year, with
much smaller numbers for smaller states. This introduces significant sampling variation
in migration rates that dominates the business cycle fluctuations at the state level that
we want to measure and exploit for identification, see Section 5.3.
5.2.2 Income data
State level income data is taken from the Regional Economic Accounts provided by the
BEA. We use as income data the average wage per job (Table CA34), which is the income
concept most closely related to our model. The data is deflated using the CPI.
To relate the dispersion of household incomes our model predicts to actual data we
use data from the March Supplement Files of the CPS of the US Census.14 We match
the dispersion of incomes across households in our model to the cross-sectional dispersion
of gross earnings in the CPS.
In the CPS, respondents are interviewed to obtain information about the employment
status and earnings of each member of the household 16 years of age and older. The
sample of the CPS is representative of the civilian non-institutional population. Gross
annual earnings are defined as income from wages and salaries including pay for overtime.
14We obtained the data through Unicon Research http://www.unicon.com/.
18

Table 1: Descriptive statistics
raw data state-wise linearlydetrended & demeaned
mean std min max mean std min maxINM 0.0373 0.0161 0.0130 0.1093 0.0373 0.0025 0.0261 0.0527
OUTM 0.0365 0.0143 0.0186 0.1146 0.0365 0.0023 0.0280 0.0758
Y 9.7994 0.1691 9.4341 10.4556 9.7994 0.0201 9.7456 9.8754
YC 9.8743 0.0677 9.7703 9.9823 9.8743 0.0168 9.8423 9.9046
YSTD 0.4656 0.0195 0.4008 0.5374 0.4656 0.0195 0.4008 0.5374
INM: In-migration rate from IRS data, OUTM: Out-migration rate from IRS data, Y: Averagewage per job (in logs) from BEA data, YC: Average wage per-job in the complementary region(in logs) from REIS data, YSTD: Cross-sectional standard deviation of log residual earningsfrom CPS.
Nominal earnings are deflated with the CPI and expressed in 2006 dollars. We use the
same period of time as for the IRS migration data (1989-2008).
Our selected sample comprises civilians aged 23 to 55. We drop individuals who work
less than 5 hours a week or less than 4 weeks a year and obtain earnings residuals by a
regression of log labor earnings on a set of age, year, state, and education dummies. To
control for outliers, we run the regression twice, dropping (for each age) the top-bottom
0.5 percentiles based on the residuals from the first-step regression. When relating the
dispersion of log income residuals from the CPS data to our model, we take into account
the demographic structure in our model and calculate, for each state and year, a weighted
standard deviation of log earnings residuals with the model-implied population weights
that depend on δ.
5.2.3 Descriptive statistics
As we focus on the business-cycle behavior of the data, we remove a state-specific linear
time trend and state fixed effects from both, migration and income data. Arguably
using an HP-filter with usual weights would remove too much fluctuations from slowly
evolving migration rates. Shimer (2005) makes a similar argument for filtering labor
market flows. Results do not qualitatively change if we use state-wise HP(100)-filtering
19

instead.15 Table 1 presents some descriptive statistics for the data used in the estimation.
After filtering out trends and taking out fixed state differences, in- and out-migration
rates are weakly negatively correlated (correlation coeffi cient: -0.31) and show mild
persistence (autocorrelation: 0.62). Overall migration activity (sums of in- and out-
migration) is roughly acyclical (correlation coeffi cient with income: 0.08). Further mo-
ments of the data are displayed in Table 3 where we compare these to the matched
moments from simulations of our model.
5.3 Identification
Our identification strategy is to match time-series volatilities in migration, i.e. the
business-cycle behavior. The idea behind this identification approach from business-
cycle-frequency fluctuations is that such approach controls for fixed state differences
like location, size, permanent or compensating income differentials by construction as
these differences do not change over the cycle. Similarly, this identification is arguably
not affected by non-economic migration incentives —again as they remain constant at
business cycle frequency.
5.3.1 Moments
Our identification strategy implies as an obvious first target to match the volatility of
migration rates σ (mjt) (over time and averaged across states). Given the volatility of
aggregate income shocks, this volatility measures how sensitive migration is to aggregate
conditions.
A more direct measure of this sensitivity is a regression of migration rates on the
incomes of the destination and the source region. To make such regression scale-invariant
with respect to incomes, we use log-deviations from average incomes as the income
variables, i.e. we estimate
mjt = α0 + α1 (wjt − wj.) + α2 (w−jt − w−j .) + ujt.
Higher migration costs make migration less sensitive to aggregate income shocks. Also
the intercept α0 reveals information about migration incentives. Higher migration costs
will typically lead to lower migration rates on average for example. Since this moment
does not strictly follow our identification strategy to identify from business cycle fluctu-
ations, we run one (exactly identified) estimation, where we exclude average migration
rates from the set of moment conditions.
To estimate the parameters of the income process(ψ, ρ, σ2
θ, σ2ϕ, σ
2ε
)we need further
15Results are available in Appendix F.
20

informative moments on income. Aggregate shocks θAt, θBt are common across indi-
viduals. Hence, both θAt and θBt are contained in realized aggregate incomes wAt, wBt(we observe from the REIS data). Note that as migration induces selection, aggregate
realized incomes will differ from the average potential income that all agents in the econ-
omy would obtain when living in a given state (where the realized incomes are those of
agents who actually choose to live in that given state). For this reason, also the corre-
lation of realized incomes σ (wAt, wBt) and their variance σ2 (wjt) are not identical to
the correlation, ψ, of potential incomes and their variance. Nonetheless, we can expect
the observable σ (wAt, wBt) and σ2 (wjt) to contain information on the correlation ψθbetween θAt and θBt and on their variance σ2
θ.
To estimate the parameters of the idiosyncratic income process, σ2ε and ρ, we exploit
information on the cross-sectional variance of realized incomes σ2 (wiAt) we observe from
the CPS data on household earnings. Again, migration affects the mapping from poten-
tial to realized incomes.
In summary, the mapping of parameters of the income process (ψε, ψθ, ρ, σ2θ, σ
2ϕ,
and σ2ε) to the discussed income moments depends on all model parameters including
migration costs. Nonetheless, these parameters can be identified if their variations lead
to changes in moments of observables, see Section 5.3.2.
However, for the idiosyncratic shocks the identification problem is more severe. While
the cross-sectional variance of incomes inherits the size of shocks σ2ε and their persistence
ρ, there is by construction no income data that allows to infer the regional correlation
of idiosyncratic income shocks ψε. A given agent is either in one or the other region so
that the shock εijt is observable only in one or the other region (and only for stayers).
And as the shock εijt refers to "residual" income after eliminating predictable income
components (such as regional averages) there is no agent in the other region that could
be matched in order to infer εiAt and εiBt simultaneously. There is no way to resolve this
problem, so that we need to assume that aggregate and individual correlation coeffi cients
are equal, i.e. ψε = ψθ = ψ. As argued, the correlation of aggregate shocks to potential
income, ψθ, translates to some extent into the correlation of realized incomes.
5.3.2 How variations in parameters affect moments
As discussed above, all model parameters affect more than one moment at the same
time. In fact, most parameters affect all moments simultaneously. Table 2 summarizes
these effects in a stylized way. Importantly, the parameters have quite different impacts
on the various moments, such that their combinations identify parameters. Technically
speaking, the Jacobian of moments with respect to parameters has full rank. This is
21

a necessary condition for identification of the model parameters. In the following, we
discuss how changes in model parameters affect the moments we aim to match.
The volatility of realized aggregate incomes increases in all "aggregate" pa-rameters
(c, ψ, σ2
θ, σ2ϕ
). Of course the reasons are different for the various parameters.
The variances of persistent and transitory aggregate shocks, σ2θ and σ
2ϕ, have a direct
and hence large effect. The impact of the persistent shock is somewhat muted by offset-
ting migration decisions. An increase in migration costs or in the regional correlation of
shocks limits the extent to which households can use migration to evade adverse income
shocks and hence indirectly increases income volatility.
The correlation of incomes is unaffected by the variance of transitory and per-sistent aggregate shocks. Only the covariance of shocks has a direct and positive impact
on the comovement of realized incomes, while higher migration costs decrease this co-
movement as they limit the extent of income synchronization through migration.
The volatility of migration rates is affected by all parameters except the varianceof transitory shocks. An increase in the aggregate income volatility σ2
θ directly increases
fluctuations in migration rates, because the distribution of potential incomes experiences
larger shifts. By contrast, higher migration costs or more correlated incomes decrease
the volatility of migration rates because migration rates respond less to income shocks
or because income shocks are less differential, respectively. Also the micro-parameters(ρ, σ2
ε
)have a large impact on the volatility of migration rates. If idiosyncratic incomes
become more volatile or more persistent, this increases the option value of migration
and hence (like a migration-cost increase) decreases migration volatility.
The sensitivity to income differences reacts to changes in model parameters asdoes the volatility of migration rates: Migration costs c, idiosyncratic income dispersion,
σε, and income persistence, ρ, all decrease the sensitivity of migration rates to aggregate
income differentials. They shift out the migration trigger Λi. Differently to their null-
effect on migration volatility, a larger variance of transitory shocks, σ2ϕ, decreases the
measured sensitivities of migration to aggregate income differentials as it decreases the
signal to noise ratio. Vice versa for a larger variance of persistent aggregate shocks, σ2θ.
A larger variance σ2θ increases the signal to noise ratio.
Average migration rates are affected by c, ψ, σ2ε, and ρ. The effect on average
migration rates is different between ρ and σε. In line with its effect on the volatility
of migration rates, an increase in ρ decreases average migration. Higher persistence in-
creases the extent of self-selection because a given region is preferable to an agent for
a longer period of time. The volatility of idiosyncratic incomes, σ2ε, has the opposite
effect. Although it increases option values of migration and hence shifts out Λi, it more
22

Table 2: Simulated moments estimation: Stylized Jacobian
Moments
Migration Rates Income SensitivityParameters σ(mjt) α0 σ (wjt) σAB (wjt) σ (wijt) α1 α2
MigrationCosts, c - - - - + - + - - - -Covariance ofShocks, ψ - - + + + - - - -AggregateShock, σ2
θ ++ 0 ++ 0* 0 ++ ++TransitoryShock, σ2
ϕ 0 0 ++ 0* 0 - - - -Autocorre-lation, ρ - - - - 0 + ++ - - - -IdiosyncraticShock, σ2
ε - - ++ 0 + ++ - - - -
σ(mjt) : time-series standard deviation of migration rates, α0 : average migration rate,σ (wjt) : time-series standard deviation of state-level average incomes, σAB (wjt) : correlationof state-level average incomes across states, σ (wijt) : cross-sectional standard deviation ofhousehold incomes, α1,2 : sensitivity of migration rates to home and destination log-incomes.The table contains the signs of the entries of the Jacobian of the moment condition withrespect to parameters. "+ +" stands for a strongly positive reaction, "+" for a positivereaction, "0" for roughly no reaction, "-" for a negative reaction, and "- -" for a stronglynegative reaction of the respective moment to a change in model parameters.*If the data moment is not perfectly matched the composition of persistent and transitoryshocks might matter, because income without transitory shocks in the simulation has acovariance different from the one of transitory shocks.
23

strongly increases the frequency at which this migration trigger is hit. Consequently,
average migration rates increase in σ2ε. The variance of aggregate income shocks, σ
2θ, has
almost no impact on aggregate migration rates. Aggregate shocks shift which region is
currently preferable to the average agent but do not contribute notably to the frequency
at which agents migrate. Income risk of agents is predominantly idiosyncratic. If poten-
tial incomes correlate more strongly (higher ψ) less is to be gained from relocation and
migration rates are lower on average; analogously for higher migration costs.
The dispersion of household incomes strongly depends on both the dispersionof idiosyncratic income shocks and their persistence, σε and ρ. Both parameters directly
increase the dispersion of realized incomes. To a far lesser extent, also higher migration
costs and more correlated income shocks increase this dispersion. In both cases, it be-comes more diffi cult for households to evade negative income shocks through migration.
5.3.3 Practical implementation
For the estimation, we match our set of estimated sample moments,
%S = {σ (mjt) , σ (wAt, wBt) , σ (wjt) , σ (wijt) , α0, α1, α2} to their corresponding esti-mates from simulated data from our model., i.e. we simulate our model for a given
vector of model parameters Θ and calculate the distance between the moments obtained
from this simulation % (Θ) and the sample moments %S . We use the covariance matrix of
%S obtained by 10,000 bootstrap replications as a weighting matrix so that our distance
and goodness-of-fit measure is
L = (%S − % (Θ))′ cov (%S)−1 (%S − % (Θ)) .
Under the null hypothesis of our model being the data generating process, cov(%S)−1
is the optimal weighting matrix. The actual estimation is carried out by minimizing the
distance measure L numerically by using a Nelder-Mead simplex algorithm.
5.4 Estimation results
Table 3 displays the point estimates of the matched moments calculated from the IRS,
REIS and CPS data and the corresponding moments obtained from the simulation of
our model under the estimated parameters. Parameter estimates are reported in Table
4. The column "(I) Baseline" refers to the estimation results from a specification setting
δ = 0.025, matching all discussed moments, and estimating the entire set of parameters.
Columns (II) to (IV) report robustness checks where we estimate an exactly identified
model excluding the average migration rate from the set of matched moments, set the
average working life to 50 years, or estimate without transitory shocks, respectively.
24

Table 3: Simulated moments estimation: moments estimates
Data Simulation(I) (II) (III) (IV) (V) uncon-
Moment Baseline exclude α0 δ = 0.02 σϕ = 0 ditionalStd. of migration
rates, σ (mijt) 0.002 0.002 0.002 0.002 0.004 0.002Corr. of agg. incomes,
σ (wAt, wBt) 0.620 0.589 0.591 0.587 0.416 0.540Std. of agg.
incomes, σ (wjt) 0.019 0.019 0.019 0.019 0.013 0.021Average migration
rate, α0 0.037 0.037 0.038 0.037 0.038 0.037Sensitivity to desti-
nation income, α1 0.045 0.049 0.048 0.050 0.229 0.070Sensitivity to source
income, α2 -0.053 -0.049 -0.049 -0.050 -0.212 -0.049Cross-sectional std.
of incomes, σ (wijt) 0.466 0.466 0.466 0.466 0.470 0.466
*: not matched. The column ‘Data’refers to the moments estimated from the combinedREIS/IRS/CPS data set, with data on 50 US states and D.C. over the period 1989-2008. Thecolumns ‘Simulation’refer to the moments estimated from the simulation of the model usingthe parameters given in Table 4. Both actual and simulated data are within-transformed andstate-wise linearly de-trended. The simulations generate a panel of 51 region-pairs and an70-year history of migration and income data. The first 50 years of simulated data are droppedin order to minimize the influence of initial values. Each simulation is repeated 5 times anddata moments are compared to the average over the 5 replications of the simulation.
The final column, (V), reports estimates where migration-induced income dynamics is
ignored. We discuss the results for this specification in the next section.
Overall our model is able to replicate the observed moments closely. In fact, the
χ2 (1)-distributed overidentification test reported at the bottom of the table does not
reject our model at the 5% level, see Table 4. The estimated migration costs are US$
34,248. This is substantially smaller than the estimates reported in previous contribu-
tions such as Davies, Greenwood, and Li (2001), but in line with Kennan and Walker
(2011) when they take into account expected pay-off shocks conditional on migration.
Parameter estimates from the robustness checks do not differ qualitatively from our
25

Table 4: Simulated moments estimation: structural parameter estimates
(I) (II) (III) (IV) (V) uncon-Baseline exclude α0 δ = 0.02 σϕ = 0 ditional
Autocorrelation 0.952 0.951 0.948 0.936 0.627of income, ρ (0.020) (0.168) (0.018) (0.005) (0.569)
Std. of idiosyncratic 0.172 0.173 0.175 0.195 0.366shocks, σε (0.022) (0.256) (0.019) (0.005) (0.206)
Std. of transitory 0.019 0.019 0.019 0 0.019shocks, σϕ (0.0001) (0.001) (0.001) — (0.001)
Std. of aggregate 0.751 0.747 0.765 1.261 1.196shocks, σθ (in %) (0.082) (0.131) (0.069) (0.030) (0.197)
Correlation of shocks 0.316 0.334 0.309 0.216 0.379across regions, ψ (0.343) (0.354) (0.325) (0.046) (0.102)
Migration cost, c, 10.441 10.421 10.425 10.707 11.349in logs (0.199) (0.292) (0.224) (0.038) (1.097)
Migration cost, c in $ 34,248 33,541 33,682 44,667 84,843Moment distance, χ2 (1) 3.053 2.913 3.514 1253 84.78p-value 0.081 — 0.061 0 0
Standard errors in parenthesis. Estimation is carried out using the simulated momentsestimator by Gourieroux, Monfort, and Renault (1993), which chooses structural modelparameters by matching the moments from a simulated panel of regions with data moments asdisplayed in Table 3. For details on the simulation, see notes to Table 3.
baseline specification.16
The estimated standard deviation of aggregate income shocks is 0.75% while the
standard deviation in idiosyncratic shocks is 17.2%. Hence aggregate shocks make up
0.18% of the total variance in income. There is a significant transitory income compo-
nent (measurement error) in the aggregate income fluctuations, which has an estimated
standard deviation of 1.9%. This means that transitory fluctuations in aggregate income
add a variance term that has about 40% of the long-run variance of the sum of potential
incomes and measurement error. However, migration smooths realized incomes so that
transitory shocks make up more of the aggregate variance in realized incomes.
The estimated standard deviation and persistence of idiosyncratic incomes is in line
with the numbers for example reported in Storesletten et al. (2004). The estimated
correlation of latent shocks to potential income across regions is 31.6%. This is roughly
16Further robustness checks are provided in Appendix F including alternative filtering of trends andalternative definitions of aggregate incomes.
26

half the observed correlation of realized incomes (62%, see Table 3). The key difference
between the two is that realized income comprises self-selection of the agents into the
region in which they are better off. Differential shocks to regional incomes are partly
offset by migration, while common income shocks do not trigger moves that offset the
shock. After an adverse income shock to a region, the low income agents of that region
move to the region that has become relatively richer. This dampens the income decrease
in the region hit by the shock and decreases average income in the other region. Hence,
migration ties together the average realized incomes in both regions more closely than
potential incomes are.
5.5 Ignoring dynamic self-selection
In the final column (V)of Table 4 we report the estimates for an approximate version
of our model. There, we purposely ignore the dynamic self-selection that shapes dis-
tributions of potential incomes and we replace the conditional density in (10) by its
unconditional counterpart. If self-selection played no role, this replacement was inno-
cent. The former place of residence was not informative for unobservable migration
incentives and conditional and unconditional distributions coincided. Hence, we should
obtain similar estimation results as in our baseline specification if self-selection was of
no concern. One may be tempted to think so as annual migration rates are small.
The column ‘unconditional’in Table 4 reports the estimation results from this ex-
ercise ignoring dynamic self-selection, i.e. using the unconditional income distributions
instead of the ones conditional on the place of residence. Neglecting self-selection seems
all but harmless. The point estimates of all model parameters change substantially.
Most importantly– and in line with our argument in Section 2– the estimated migra-
tion costs are with US$ 84,843 substantially larger than in the baseline estimation and
all other robustness checks. Hence, treating migration as a dynamic decision problem
at the micro level without taking care of dynamic self-selection in the aggregation may
lead to a severe bias.
6 (How) to model persistence matters
6.1 Two alternatives
Next, we show that modelling persistence in incomes and the way it is modelled have
stark consequences that are rooted in dynamic self-selection but go beyond a potential
bias in parameter estimates. For this purpose, we re-estimate the model for two spec-
ifications. In the first one, we fix the autocorrelation ρ at zero. In the second one,
we additionally introduce fixed household effects in incomes as an alternative way to
27

Table 5: Simulated moments estimation: Estimation results from models without dy-namic self-selection
fixedbaseline ρ = 0 effects
Autocorrelation 0.952 0 0of income, ρ (0.020) — —
Std. of fixed 0 0 0.347idiosyncratic effects, σκ — — (0.289)
Std. of idiosyncratic 0.172 0.442 0.420shocks, σε (0.022) (0.001) (0.063)
Std. of transitory 0.019 0.019 0.017shocks, σϕ (0.001) (0.001) (0.001)
Std. of aggregate 0.751 1.225 1.562shocks, σθ (in %) (0.082) (0.053) (0.095)
Correlation of shocks 0.316 0.457 0.451across regions, ψ (0.343) (0.124) (0.098)
Migration cost, c, 10.441 10.476 10.031in logs (0.199) (0.103) (0.358)
Migration cost, c in $ 34,248 35,471 22,715Moment distance, χ2 (1) 3.053 117.828 116.952p-value 0.081 0 0
See notes to Table 4. The fixed effects model assumes seven types of agents with equalpopulation size and different permanent attachment to either region A or B. As the migrationtriggers under ρ = 0 are further out in the ergodic unconditional income distribution, both theρ = 0 and fixed effects model are solved with a finer grid for the income process.
model persistence. In this second alternative, an agent permanently faces higher income
potential in one or the other region, but is randomly assigned to one of the regions at
birth. In this specification, we again need to take the self-selection of agents into regions
into account when estimating the model. The key difference to our baseline specification
is that under the fixed effects specification, persistent heterogeneity is revealed at labor
market entry while heterogeneity of agents is slowly building up over time in our baseline
specification. Estimation results for both experiments are reported in Table 5.
In interpreting the estimation results some care needs to be taken. Overall the
point estimates remain relatively similar (except for the variance of idiosyncratic income
shocks). Even though we obtain similar parameter estimates, the model under ρ = 0
exhibits very different elasticities with respect to migration costs as we will discuss later.
28

That migration cost estimates nonetheless remain similar is due to the fact that the lower
is ρ the smaller is the dispersion of the present values of income streams a household
obtains remaining in one region forever. In other words, the lower is ρ, the less extreme
are potential gains from migration.
Having this in mind, we set up an alternative specification that captures persistence
in incomes. The final column in Table 5 reports results from a specification, where we
set the autocorrelation ρ in (13) to zero, but introduce an additional fixed effect that
increases (or decreases) household i′s potential log-income in region A by κi permanently.
This implies that (13) is modified for region A to
wiAt = zAt + w∗iAt + κi.
To solve the model, we then specify that an agent can be one of 7 types, κi ∈ {κ1, . . . , κ7} ,each making up 1/7 of the entire population. We assume that upon birth, the type of the
household is randomly assigned. Note that this implies that households will dynamically
self-select based on the realization of κi but they may exhibit a strong mismatch with
their region when born. This specification is closest to the setup Kennan and Walker
(2011) consider. Still there are differences: in our setup agents know their potential
incomes before the migration decision (migration is no experience good) and migration
costs are fixed, besides our estimation strategy being different.
Again the estimated migration costs do not differ significantly from our baseline
result. They are in fact very close to what Kennan and Walker (2011) obtain when they
take into account the expected i.i.d. payoff shock of a migrant (their migration costs are
stochastic). Our estimation results indicate a substantial amount of perfectly persistent
heterogeneity σκ = 0.347, making up about 40% of the total income variance.
Although they have small effects regarding parameter estimates, model assumptions
on whether and how to model autocorrelations in income have strong consequences in
terms of model behavior. To illustrate this, we first look at exogenous changes in mi-
gration costs (compared to the estimated ones) and calculate the migration response.
Second, we analyze the age-patterns in migration predicted by our baseline model and
the alternative model specification with fixed effects. We show that only the baseline
specification is able to account for the empirically observed age patterns (without intro-
ducing age-dependent migration costs).
29

6.2 Counterfactual experiments
We consider three counterfactual experiments, where we vary migration costs in the
baseline, the no-autocorrelation, and the fixed-effects version of our model. In Table
6 we report migration rates and average incomes for these experiments together with
the numbers under the estimated migration costs. All parameters other than migration
costs we leave as estimated.
In the first experiment we set migration costs to zero. This allows us to determine a
steady state in which only the distribution of migration incentives and not costs of moves
determine the migration rate. In a situation in which unobservable migration incentives
are serially uncorrelated, i.e. drawn completely anew every period, migration rates are
50% on average in the absence of migration costs. In such a situation of zero costs
and i.i.d. incentives, every period half of the population in one region is better off by
moving to the other one. In fact this is what we find for the no-autocorrelation model. By
contrast, both our baseline model and the fixed effects model display migration rates well
below 50% in the absence of migration costs. In both setups, distributions of migration
incentives result from past migration decisions. Agents self-select into the region where
they are better off. Only those agents that have been on the margin —on the verge of
moving in the preceding period —are likely to migrate in the current period. Yet, the
difference between fixed effects and baseline AR-1 specification for income persistence is
tremendous. Migration rates increase to only 12.6% in the latter but increase to 37.7%
in the former specification, even though in both setups the migration rate is 3.7% under
the estimated costs. Under the AR-1 specification, dynamic self-selection plays a much
bigger role in determining migration rates than in the fixed effects setup.
A problem with the zero-cost counterfactual could be that the cost-decrease is dif-
ferent across models and this might be responsible for the different changes in migration
rates. Therefore, we consider a second experiment, where a migration subsidy of $10,000
is awarded. Yet, this does not change the picture, as one can see from Table 6. Migra-tion rates respond much stronger in the fixed effects and no autocorrelation specification
than they do in our baseline setup.
Finally, we consider an increase in migration costs by $30,000, which roughly doubles
costs in the baseline model. One may think of such experiment as a simulation of the
effect of a less liquid housing market such as after the financial crisis. Again, the different
empirical models make very different predictions. Our baseline model predicts a mild
decrease in migration activity by one percentage point, while the fixed effects model
predicts a decline by more than 2.5 percentage points. Also the impact on average
30

Table 6: Simulation results: variations in migration costs
Average Average AverageMigration costs migration rate log income income
Baseline (AR-1) zero costs 12.6% 10.84 50,869ρ = 0.952 10,000$ subsidy 4.3% 10.83 50,362
as estimated 3.7% 10.82 50,16130,000$ increase 2.7% 10.81 49,662
No autocorrelation, zero costs 50.0% 10.77 47,382ρ = 0 10,000$ subsidy 8.2% 10.67 43,217
as estimated 3.7% 10.64 41,89830,000$ increase 0.4% 10.61 40,376
Fixed effects, no further zero costs 37.7% 10.91 54,721autocorrelation, ρ = 0 10,000$ subsidy 10.4% 10.91 54,666
as estimated 3.7% 10.89 53,74530,000$ increase 1.2% 10.88 52,892
incomes is much larger in the latter model. Average incomes decline by 1.5% ($ 850) in
the fixed effects setup compared to 1% ($ 500) in our baseline model. In summary, if
one thinks about effects of changing migration costs, it very much matters for the results
how one models income persistence.
6.3 Age patterns of migration
There is a second point for which we want to highlight the differences implied by dif-
ferent strategies to model income persistence. So far, we focused on the estimation of
migration costs and aggregate measures in describing the role played by dynamic self-
selection. However, current contributions to the empirical study of migration go beyond
the representative agent assumption of our homogeneous migration-cost model (with
heterogeneous incentives). A well documented pattern in migration data is that younger
agents are significantly more likely to move than older agents.
The standard explanation of this pattern relies on the investment character of mi-
gration choices, the so-called human capital theory of migration. This theory rests on
the fact that younger agents face a longer period in which their migration choices can
pay off. As a consequence younger agents are more likely to migrate just as younger
agents are more likely to invest in human capital. While this human capital theory of
31

migration is able to explain well the difference in migration between job starters and
agents close to retirement, it has diffi culties in explaining the sharp decline in migration
rates between ages 20 and 35 (Kennan and Walker, 2011). Accordingly some authors
have suggested age-dependence of migration costs.17
Our model provides one possible explanation for the age-migration relation that
does not rely on age-dependent migration preferences. In our model, agents start their
working life randomly assigned to one of the two regions. Agents then repeatedly choose
whether to stay or to move to the alternative region observing their current potential
income differences, which result from their history of income shocks. This sequence of
income shocks and migration choices has two consequences. First, over the course of
their lives, agents accumulate income risk since income is highly autocorrelated. Thus
potential incomes become more dispersed between regions as agents get older. Second,
an agent stays in a given region if she earns more income in her current region than
in the alternative one. This means that ex-ante (i.e. before income shocks realize) the
match between agent and region becomes more effi cient as agents get older. They have
selected themselves into their preferred region. This increasing match effi ciency implies
that migration rates generally decline in age. This effect is similar to the role of age in
Jovanovic’s (1979) job search model and has in principle been discussed in work parallel
to ours (Kennan and Walker, 2011, Coen-Pirani, 2010). Here we show that the way
persistence in incomes is modelled is decisive for the extent this selection channel can
quantitatively account for the age patterns in migration as observed in the data.
To investigate this, we simulate 50,000 households over 50 periods of time for each
state, repeat the simulation 5 times, and store both household’s age and their migration
choices for the last 20 years of the simulation. This allows us to calculate migration rates
by age as displayed in Figure 2. We assume that a household enters the labor market at
the age of 21.18 One can see that the migration rate declines as the household becomes
older, but the drop in migration rates is smoothed over different ages. With our baseline
estimates, agents have a probability to migrate of 10% at the time they enter the labor
market, while agents who are 20 years older only migrate with a probability of 3%. This
age pattern is induced by agents choosing their optimal location over time.
We confront this implied age pattern of migration to observed migration rates by
age in the Current Population Survey (CPS). The available IRS data does not provide a
split-up of migration by age. However, here we can use the CPS data on migration rates
17Family formation and education choice (see for example Gemici, 2011) are examples for other po-tential explanations of the sharp decrease in migration rates between age 20 and age 35.18This corresponds to the midpoint estimate of first and last transition from school to work as reported
in Jacob and Weiss (2010) for the US.
32

Figure 2: Simulation results: migration rates by age
20 25 30 35 40 45 500
0.05
0.1
0.15
0.2
0.25
Age
Mig
ratio
n R
ate
Model (AR1)Model (Fixed effects)CPS
Model: Relative frequencies of migration conditional on age. The frequencies are obtained bysimulating the behavior (migration, income, death and birth) of a cross-section of 50,000households for 50 years. Reported frequencies are obtained by averaging over 5 repeatedsimulations using only the final 20 years of data in each simulation. "AR-1" refers to ourbaseline estimate, "Fixed effects" to the model which captures income persistence by fixedeffects instead.CPS: Average interstate migration rates of households by age from the Current PopulationSurvey (CPS), civilian population of age 21-50. Average over the years 1989-2004; there is nodata for 1995.
as we are not interested in fluctuations over time and states but just in the average age
pattern. CPS migration rates are overall slightly lower than the migration rates in the
IRS data.
As our model predicts, migration rates fall quickly in the first years after labor market
entry. However, our model underpredicts the decline in migration rates at later ages.
This is likely due to the eternal youth structure of our model that shuts down the human
capital channel of migration described before. Understanding the dynamic self-selection
channel as complementary to the human capital channel, we thus expect a richer model
encompassing both channels to fit the observed age patterns in migration rates closely
33

Figure 3: Simulation results: income dispersion by age
20 25 30 35 40 45 500
0.05
0.1
0.15
0.2
0.25
0.3
0.35
Age
Inco
me
vari
ance
AR1 realizedAR1 potentialFixedeffects realizedFixedeffects potential
"Realized": Variance of realized incomes in the economy. The variances are obtained bysimulating the behavior (migration, income, death and birth) of a cross-section of 50,000households for 50 years. Reported frequencies are obtained by averaging over 5 repeatedsimulations using only the final 20 years of data in each simulation. "Potential": Variance ofpotential incomes as given by the income process. "AR-1" refers to our baseline estimate,"Fixed effects" to the model which captures income persistence by fixed effects instead.
without making migration costs age-dependent.19
The figure also reveals that migration rates do not decline monotonically in age in
our model. At the time of entry into the labor market there is not much heterogeneity
across agents, but this heterogeneity quickly grows as agents accumulate shocks to their
potential incomes. This means that initially only few agents observe income differences
between both regions large enough to make them move. Therefore, under our estimated
migration costs, migration rates are highest one year after labor market entry. The same
holds true for the CPS data. After the first period there are many agents who would
earn more in the other region but not suffi ciently more to justify a move. In the second
19Of course, the close match of simulated and actual age patterns depends on our choice of age 21being the age of labor market entry. If labor market entry is around that age the match is roughly asgood as displayed in Figure 2. If labor market entry was substantially later the match would be worse.
34

period, many of these agents observe an income shock that is large enough to induce a
move, because income shocks are large relative to the observed heterogeneity at early
ages. In the following periods the effect of dynamic self-selection dominates the effect of
increasing heterogeneity, leading to the inverse hump-shaped pattern of migration rates.
The figure looks very different for the model with fixed effects, see again Figure 2.
Here we see a sharp spike of migration activity at labor market entry and a quick decline
thereafter. Since agents know where they are permanently better off at the time of
labor market entry, they seek to realize the income gain by immediate migration. In our
baseline model, by contrast, regional attachments slowly unfold in the course of time
and selection happens over a much longer time period.
For the same reason, we obtain fairly different results on the effect of migration on
the dispersion of incomes, see Figure 3. In the fixed effects model there is a substantial
difference between the realized income dispersion and the dispersion of potential incomes
already at labor market entry and it is almost independent of age. This is because agents
know the fixed effects part of potential income already at the time of labor-market entry
and hence if they are in a region that is permanently no good match at this time, they
move away quickly. By contrast, the effect of migration on income dispersion builds
up in age as the income dispersion fans out. Only for the fairly old workers there is
a large difference between realized and potential income dispersion. For the overall
population, however, the reduction in income dispersion by migration is relatively small
as the fraction of older workers is small in our model.20
7 Conclusion
We have provided a model of aggregate migration with microeconomic foundation. The
paper is a contribution to the recently evolving literature on structural models of mi-
gration. We explicitly deal with the problem that potential gains from migration are
unobservable and display a dynamic character. This dynamic character of migration
incentives has two aspects: First, the individual gains from migration evolve stochasti-
cally over time, but will typically be highly persistent. Second, at an aggregate level, the
distribution of migration incentives is a result of past migration decisions themselves.
Starting from the microeconomic decision problem allows us to keep track of the dy-
namics of the incentive distribution. This dynamics is driven by (dynamic) self-selection.
Neglecting this self-selection results in biased estimates of structural parameters, such
as migration costs. The estimated migration costs amount to about US$ 34,248, which
20Note that we take the population distribution in age into account when matching the wage dispersiondata, see Section 5.2.2.
35

corresponds to two-thirds of an average annual income.
Our analysis calls for a careful treatment of the self-selection problem when economic
incentives are not fully observable but persistent. This is particularly relevant for the
analysis of migration. Rather than being drawn every period anew, migration incentives
have a long memory. One example of this long memory of migration incentives is the
persistence that income displays. We integrated the persistence of unobserved migration
incentives in a structural dynamic microeconomic model of the migration decision. This
consequently allowed us to simulate the joint behavior of the observed migration rates,
of the unobserved migration incentives, and of their observable proxies, i.e. incomes.
Addressing the partial unobservability of migration incentives may not only be impor-
tant to macro-studies of migration. Also at a micro level, potential incomes are typically
unobservable and have to be proxied. However, such approximation regularly neglects
self-selection. If households live in their preferred place of residence as a result of their
location choice, and if all observable things are equal, then it must be the unobserved
component of their preferences that is in favor of the place in which they actually live.
Besides unobservable parts of income, this unobservable component of preferences can
also comprise different valuations of amenities and social networks. Even these factors
can be expected to exhibit persistence.
Future research calls for a more complex microeconomic model that integrates more
information into the macroeconomic analysis, for example labor market conditions and
amenities. Additionally, it would be desirable to extend our bi-regional approach to the
case of multiple regions, as in Davies, Greenwood and Li (2001) and Kennan and Walker
(2011). Further aspects, such as the interaction of migration and local labor markets,
could be analyzed in a general equilibrium framework as in Coen-Pirani (2010), but
our results call for an explicit treatment of the dynamic structure and persistence of
migration incentives.
Taking a more general perspective, our paper highlights the role of dynamic self-
selection in a model with imperfectly observed incentives. One can expect the econo-
metric issues that we raise to carry over to other examples of dynamic discrete choice
problems. Examples would be labor-market participation (see Keane and Wolpin, 2009)
or product switching (see e.g. Sweeting, 2007). Also in these frameworks our suggested
solution may well be applicable - explicit aggregation and taking the incentive dynamics
seriously.
36

References
[1] Adda, J. and R. Cooper (2003): "Dynamic Economics: Quantitative Methods and
Applications", MIT Press, Cambridge.
[2] Aguirregabiria, V. and P. Mira (2010): "Dynamic Discrete Choice Structural Mod-
els: A Survey", Journal of Econometrics, 156, 38-67.
[3] Armenter, R. and F. Ortega (2010): "Credible Redistribution Policies and Migration
across U.S. States", Review of Economic Dynamics 13, 403-423.
[4] Blanchard, O. and L. Katz (1992): "Regional evolutions", Brookings Papers on
Economic Activity, 1, 1-75.
[5] Breitung, J. and W. Meyer (1994): "Testing for unit roots in panel data: are wages
on different bargaining levels cointegrated?", Applied Economics, 26, 353-361.
[6] Burda, M. (1993): "The Determinants of East-West German Migration: Some First
Results", European Economic Review, 37, 452-462.
[7] Burda, M., M. Müller, W. Härdle, and A. Werwatz (1998): "Semiparametric Analy-
sis of German East-West Migration Intentions: Facts and Theory", Journal of Ap-
plied Econometrics, 13, 525-541.
[8] Borjas, G. J. (1987): "Self-selection and the earnings of immigrants", American
Economic Review, 77, 531-553.
[9] Borjas, G. J., S. Bronars, and S. Trejo (1992): "Self-selection and internal migration
in the United States", Journal of Urban Economics, 32, 159-185.
[10] Caballero, R. and E. M. R. A. Engel (1999): "Explaining Investment Dynamics in
U.S. Manufacturing: A Generalized (S,s) Approach", Econometrica, 67, 783-826.
[11] Chow, C. S. and J. N. Tsitsiklis (1991): "An optimal multigrid algorithm for con-
tinuous state discrete time stochastic control", IEEE Transactions on Automatic
Control, 36, 898—914.
[12] Cushing, B. and J. Poot (2004): "Crossing boundaries and borders: Regional science
advances in migration modelling", Papers in Regional Science, 83, 317-338.
[13] Coen-Pirani, D. (2010): "Understanding Gross Workers Flows Across U.S. States",
Journal of Monetary Economics, 57, 769-784.
[14] Davies, P. S., M. J. Greenwood, and H. Li (2001): "A Conditional Logit Approach
to U.S. State-to-State Migration", Journal of Regional Science, 41, 337-360.
[15] Decressin, J. and A. Fatas (1995): "Regional Labor Market Dynamics in Europe",
European Economic Review, 39, 1627-1655.
[16] Gemici, A. (2011): "Family Migration and Labour Market Outcomes", mimeo,
NYU.
37

[17] Gourieroux, C., A. Monfort, and E. Renault (1993): "Indirect inference", Journal
of Applied Econometrics, 8, 85-118.
[18] Greenwood, M. J. (1975): "Research on internal migration in the United States: A
survey", Journal of Economic Literature, 13, 397-433.
[19] Greenwood, M. J. (1985): "Human migration: Theory, models and empirical stud-
ies", Journal of Regional Science, 25, 521-544.
[20] Greenwood, M. J. (1997): "Internal migration in developed countries", in: Rosen-
zweig, M. R. and O. Stark (eds.), Handbook of population and family economics,
Volume 1B, Elsevier, Amsterdam.
[21] Gross, E. (2005): "Internal Revenue Service Area-To-Area Migration Data:
Strengths, Limitations, and Current Trends", American Statistical Association 2005
Conference Paper.
[22] Hassler, J., J. V. R. Mora, K. Storesletten, and F. Zilibotti (2005). "A Positive
Theory Of Geographic Mobility And Social Insurance", International Economic
Review, 46, 263-303.
[23] Heckman J. J. (1974): "Shadow Prices, Market Wages, and Labor Supply", Econo-
metrica, 42, 679-94.
[24] Heckman J. J. (1976): "The common structure of statistical models of truncation,
sample selection, and limited dependent variables and a simple estimator for such
models", Annals of Economic and Social Measurement, 5, 475-492.
[25] Heckman J. J. (1978): "Dummy Endogenous Variables in a Simultaneous Equations
System", Econometrica, 46, 931—59.
[26] Heckman J. J. and R. Robb (1985): "Alternative Methods for Evaluating the Impact
of Interventions", Journal of Econometrics, 30, 239-267.
[27] Hunt, G. L. and R. E. Mueller (2004): "North American Migration: Returns to
Skill, Border Effects and Mobility Costs", Review of Economics and Statistics, 86,
988-1007.
[28] Jacob, M. and F. Weiss (2010): "From Higher Education to Work", Higher Educa-
tion, 60, 529-542.
[29] Jovanovic, B. (1979): "Job Matching and the Theory of Turnover", Journal of
Political Economy, 87, 972-990.
[30] Keane M. P. and K. I. Wolpin (2009): "Empirical Applications of Discrete Choice
Dynamic Programming Models", Review of Economic Dynamics, 12, 1-22.
[31] Kennan, J. and J. R. Walker (2011): "The Effect of Expected Income on Individual
Migration Decisions", Econometrica, 79, 211-251.
[32] Lee L.F. (1978): "Unionism and Wage Rates: A Simultaneous Equation Model with
38

Qualitative and Limited Dependent Variables," International Economic Review 19,
415—33.
[33] Lee L.F. (1979): "Identification and Estimation in Binary Choice Models with
Limited (Censored) Dependent Variables," Econometrica, 47, 977—96.
[34] Levin, A., C. F. Lin, and C. S. J. Chu (2002): "Unit Root Tests in Panel Data:
Asymptotic and Finite Sample Properties", Journal of Econometrics, 108, 1-24.
[35] Low H., C. Meghir, and L. Pistaferri (2010): "Wage Risk and Employment Risk
over the Life Cycle", American Economic Review, 100, 1432—67.
[36] Nakosteen, R. A. and M. Zimmer (1980): "Migration and Income; The Question of
Self-Selection," Southern Economic Journal, 46, 840-851.
[37] Norets, A. (2008), "Implementation of Bayesian Inference in Dynamic Discrete
Choice Models", mimeo, Princeton University.
[38] Norets, A. (2009), "Inference in Dynamic Discrete Choice Models with Serially
Correlated Unobserved State Variables", Econometrica, 77, 1665-1682.
[39] Shimer, R. (2005), "The Cyclical Behavior of Equilibrium Unemployment and Va-
cancies", American Economic Review, 95, 25-49.
[40] Sjaastad, L. (1962): "The costs and returns of human migration", Journal of Polit-
ical Economy, 70, 80-93.
[41] Storesletten, K., C. I. Telmer, and A. Yaron (2004): "Cyclical Dynamics in Idio-
syncratic Labor-Market Risk", Journal of Political Economy, 112, 695-717.
[42] Sweeting, A. (2007): "Dynamic Product Repositioning in Differentiated Product
Industries: The Case of Format Switching in the Commercial Radio Industry",
NBER-WP 13522.
[43] Tauchen, G. (1986): "Finite state Markov-chain approximation to univariate and
vector autoregressions", Economics Letters, 20, 177-181.
[44] Tunali, I. (2000): "Rationality of Migration", International Economic Review, 41,
893-920.
39

Appendix
A Derivation of equation (4)
For the covariance between the error term ηi1 and location in period 0, yiA0, (as described
in Section 2, eq. (4)), we obtain:
cov (yiA0, ηi1) =E (yiA0ηi1)− E (ηi1)E (yiA0)
=E (ηi1|yiA0 = 1) Pr (yiA0 = 1)− E (ηi1) Pr (yiA0 = 1) .
Since E (ηi1) is by assumption zero, this simplifies to
cov (yiA0, ηi1) = E (ηi1|yiA0 = 1) Pr (yiA0 = 1) .
Using the definition of
ηi1 := γ (w∗iA1 − w∗iB1) + νi1
and
w∗ij1 = ρw∗ij0 + εij1
we can rewrite cov (yiA0, ηi1) as
cov (yiA0, ηi1) =E (γ (ρ (w∗iA0 − w∗iB0) + εiA1 − εiB1) + νi1|wiA0 > wiB0) Pr (wiA0 > wiB0)
= γρE ((w∗iA0 − w∗iB0) |wiA0 > wiB0) Pr (wiA0 > wiB0) ,
where the second equality follows from εijt and vit being orthogonal to all information
available at time t−1 and mean zero. Making use of the definition of wijt := ζjtzit+w∗ijtand the normality of w∗ijt we obtain
cov (yiA0, ηi1) = γρE ((w∗iA0 − w∗iB0) | (w∗iA0 − w∗iB0) > − (ζA1 − ζB1) zi1) Pr (wiA0 > wiB0)
= 2γρσ0
φ(−(ζA1−ζB1)zi1
2σ0
)(
1− Φ(−(ζA1−ζB1)zi1
2σ0
)) Pr ((w∗iA0 − w∗iB0) > − (ζA1 − ζB1) zi1)
= 2γρσ0φ
((ζA1 − ζB1) zi1
2σ0
),
where φ and Φ are the probability density function and cumulative distribution function
of a standard normal distribution respectively.
40

B Existence and uniqueness of the value function
We begin with proving existence and uniqueness of the value function. Notation is as in
the main text throughout this appendix, unless stated otherwise.
For the ease of exposition, we assume that the income process is only approximately
log-normal. In particular, we assume that income has a finite support.
Definition 1 Let W =[W,W
]be the support of w.
Definition 2 Define a mapping T according to the migration problem of a household,
that is
T (u) (k,wiAt, wiBt) = maxj=A,B
{exp (wijt)− I{k 6=j}c+ βEtu (j, wiAt+1, wiBt+1)
}. (15)
The mapping T is defined on the set of all real-valued, bounded functions B that arecontinuous with respect to wA,B and have domain D = {A,B} ×W2.
Lemma 3 The mapping T preserves boundedness.Proof. To show that T preserves boundedness one has to show that for any bounded
function u also Tu is bounded. Consider u to be bounded from above by u and bounded
from below by u. Then, Tu is bounded, because
Tu = maxj=A,B
{exp (wijt)− I{k 6=j}c+ βEtu (j, wiAt+1, wiBt+1)
}≤ exp
(W)
+ βu <∞,(16)
and
Tu= maxj=A,B
{exp (wijt)− I{k 6=j}c+ βEtu (j, wiAt+1, wiBt+1)
}(17)
≥ maxj=A,B
{exp (wijt)− I{k 6=j}c+ βu
}≥ exp (W ) + βu > −∞. (18)
Lemma 4 The mapping T preserves continuity.Proof. Since Tu is the maximum of two continuous functions, it is itself continuous.
Lemma 5 The mapping T satisfies Blackwell’s conditions.Proof. First, we need to show that for any u1 (·) < u2 (·) the mapping T preserves
the inequality. Since both the expectations operator and the max operator preserve the
41

inequality, T does also. Second, we need to show that T (u+ a) ≤ Tu + γa for any
constant a and some γ < 1. Straightforward algebra shows that
T (u+ a) = Tu+ βa. (19)
Since β < 1 by assumption, T satisfies Blackwell’s conditions.
Proposition 6 The mapping T has a unique fixed point on B, and hence the Bellman-equation has a unique solution.
Proof. Follows straightforwardly from the last three Lemmas.
C Effect of income shocks on the distribution of income
Idiosyncratic shocks, aggregate shocks, death and birth of agents, and the persistence
of the income process determine the transition of the distribution of income incentives
after migration to the distribution of migration incentives before migration in the next
period. For surviving households the income distribution at the beginning of period t+1
results from adding idiosyncratic and aggregate shocks to the distribution of income
after migration in period t, Ft, of which fjt (wA, wB) is the conditional density, see (12).
This means that for a surviving household an income of wijt+1 in period t+ 1 can result
from any possible combination of wijt and ξijt+1 = θjt+1 + εijt+1 for which
wijt+1 = µj (1− ρ) + ρwijt + θjt+1 + εijt+1 (20)
holds. Solving this equation for wijt, we obtain
w∗j (wijt+1, θjt+1, εijt+1) := wijt =wijt+1 − (θjt+1 + εjt+1)
ρ− µj
(1− ρ)
ρ. (21)
This w∗j (wijt+1, θjt+1, εijt+1) is the time-t potential income in region j that is consistent
with a future potential income of wijt+1 and realizations of shocks θjt+1 + εijt+1 at the
beginning of period t + 1. Now suppose that both kinds of shocks, θ and ε, have been
realized. Then, w∗A,B is a one-to-one mapping of future incomes (wiAt+1, wiBt+1) to
current income (wiAt, wiBt) .
The conditional density of observing the future income pair (wiAt+1, wiBt+1) can
thus be obtained from a retrospective. The income pair (w∗A, w∗B) of past incomes for
a surviving household corresponds uniquely to a future income pair (wiAt+1, wiBt+1) .
Consequently, we can express the density of the income distribution at time t + 1 (for
42

surviving households) using the income distribution after migration Ft, and its condi-
tional density fjt. The density of the income distribution Ft+1 conditional on surviving
and the region and the vector of shocks is given by
fjt+1 (wA, wB|θAt+1, θBt+1, εiAt+1, εiBt+1)
= fjt (w∗A (wA, θAt+1, εiAt+1) , w∗B (wB, θBt+1, εiBt+1)) . (22)
Weighting this density with the density of the idiosyncratic shocks h (εiAt+1, εiBt+1)
yields the density of observing the future income pair (w∗A, w∗B) together with the idio-
syncratic shocks (εiAt+1, εiBt+1) :
fjt (w∗A (wA, θAt+1, εiAt+1) , w∗B (wB, θBt+1, εiBt+1)) · h (εiAt+1, εiBt+1) .
Integrating over all possible idiosyncratic shocks (εiAt+1, εiBt+1) yields the density
fjt+1 of the income distribution before migration and conditional on surviving in period
t+ 1 for a certain combination of aggregate shocks (θAt+1, θBt+1):
fjt+1 (wA, wB|θAt+1, θBt+1) =∫fjt (w∗A (wA, θAt+1, εA) , w∗B (wB, θBt+1, εB)) · h (εA, εB) dεAdεB, j = A,B. (23)
Finally, the actual conditional distribution of potential incomes Fjt+1 and its density
fjt+1 is determined by a convex combination of fjt+1 (for surviving households) and the
distribution of income shocks (for newborn households)
fjt+1 (wA, wB|θAt+1, θBt+1, zAt+1, zBt+1)
= (1− δ) fjt+1 (wA, wB|θAt+1, θBt+1) + δh (εA − zAt+1, εB − zBt+1) .
For given aggregate states and shocks, this new distribution determines migration from
region j to region −j according to equation (10) for period t+ 1.
The evolution of income distributions can thus be summarized as follows. Between
two consecutive periods, the conditional distribution of potential incomes first evolves
as a result of migration decisions, moving the density from fjt to fjt. Thereafter, the
distribution is altered by aggregate and idiosyncratic shocks to income, moving the
density from fjt to fjt+1. Finally, a fraction of households dies and for this fraction the
distribution fjt+1 is replaced by the distribution of income shocks. This leads to the
new distribution fjt+1, which determines migration decisions in period t + 1, starting
43

the cycle over again.
D Invariant distribution
We prove that migration decisions and idiosyncratic shocks to income imply that poten-
tial income follows an ergodic Markov-process if there are no aggregate shocks. There-
fore, there is an invariant distribution the sequence of income distributions converges
to. For simplicity, we present the proof for an arbitrary discrete approximation of the
model with a continuous state-space for income.
Lemma 7 Assume an arbitrary discretization of the state space with n points for thepotential income in each of the regions. Then, we can capture the transition from ft to
ft+1, which are the unconditional densities of the distribution of households over both
regions and potential incomes, in a matrix Γ =
(Π (I −DA) ΠDB
ΠDA Π (I −DB)
)∈ R2n2×2n2.21
In this matrix, Π denotes the transition matrix that approximates the AR(1)-process for
income (including birth and death) by a Markov-chain, see Adda and Cooper (2003, pp.
56) for details. Matrix Dj , j = A,B is the n2 × n2 diagonal matrix with the migration
hazard rates for each of the n2 income pairs of the income grid.
Proof. First, we take a discrete state-space of n possible incomes for each region,
wA1...wAn and wB1...wBn. Second, we denote the vector of probabilities that describes
the distribution of potential incomes and household locations in the following form
f =(f (A,wA1, wB1) ... f (A,wAn, wB1) ... f (A,wAn, wBn) f (B,wA1, wB1) ... f (B,wAn, wBn)
)′.
(24)
Analogously, we define the distribution after migration but before idiosyncratic shocks,
f . Taking our law of motion from (23) , we obtain as a discretized analog
ft+1 =
(Π 0
0 Π
)ft. (25)
Now, define dh ∈ {0, 1} as the fraction of households that migrate and are in the h-thincome and location triple given our vectorization of the income grid. This means that
dh = Λj (wAk, wBl) , h = 1...2n2, where (j, wAk, wBl) is the h-th element in the vectorized
grid. Moreover, define D = diag (d) as the diagonal matrix with migration rates on the
diagonal and DA and DB as the diagonal matrices with only the first n2 and the last n2
21Since we work with a discretization, strictly speaking f is not a density, but a vector of probabilitiesfor drawing a location-income possibility vector from a given element of the grid.
44

elements of d, respectively. Then, we can describe the transition from ft to ft by
ft =
(I −DA DB
DA I −DB
)ft (26)
Combining the last two equations, we obtain
ft+1 =
(Π (I −DA) ΠDB
ΠDA Π (I −DB)
)ft. (27)
Lemma 8 For any distribution of idiosyncratic shocks with support equal to W2, matrix
Π has only strictly positive entries.
Proof. If the idiosyncratic shocks have support equal to W2, then every pair of potential
incomes can be reached from every other pair of incomes as a result of the shock, because
we assume the shocks to income to be approximately log-normal. Thus, all entries of Π
are strictly positive.
Lemma 9 Γ2 has only positive entries.
Proof. Due to cA = −cB, we can assume an ordering of states such that we can write
DA =
(Ina 0
0 0
)and DB =
(0 0
0 Inb
), without loss of generality, where Iz is a z×z unit
matrix. Accordingly, we define partitions of Π such that
Π =
(A1 A2
A3 A4
)=
(B1 B2
B3 B4
)
=
(C1 C2
C3 C4
)=
(D1 D2
D3 D4
),
where A1 ∈ R(n2−na)×(n2−na), B1 ∈ Rnb×nb , C1 ∈ Rna×na , D1 ∈ R(n2−nb)×(n2−nb).
This yields for Γ2 after some tedious algebra
Γ2 =
B2C3 A2A4 B2C4 A2B4
B4C3 A4A4 B4C4 A4B4
D1C1 C1A2 D1D1 C1B2
D3C1 C3A2 D3D1 C3B2
.
Each entry of this matrix is positive, since Π and hence its partitions are positive.
45

Proposition 10 Under the assumptions of the above Lemmas, migration and idiosyn-cratic shocks define an ergodic process with a stationary distribution F0 = limn→∞Bnei.
Proof. The above Lemma directly implies the ergodicity of the Markov chain.
E Numerical aspects
The first step in solving the model numerically is to obtain a solution to (7) . We do so
by value-function iteration.22 For this value-function iteration, we first approximate the
bivariate process of potential incomes for an individual agent in regions A and B
wijt = µj (1− ρ) + ρwijt−1 + ξijt (28)
by a Markov chain. Because wA and wB are correlated through the correlation structure
in ξ, it is easier to work with the orthogonal components(w+A , w
+B
)of (wA, wB) in the
value function iteration.
We evaluate the value function on an equi-spaced grid for the orthogonal components
with a width of ±3.5σ+A,B around their means, where σ
+A,B denote the long-run standard
deviations of the orthogonal components. The grid is chosen to capture almost all move-
ments of the income distribution F later on.23 Given this grid, we use Tauchen’s (1986)
algorithm to obtain the transition probabilities for the Markov-chain approximation of
the income process in (28) .
We apply a multigrid algorithm (see Chow and Tsitsiklis, 1991) to speed up the
calculation of the value function. This algorithm works iteratively. It first solves the
dynamic programming problem for a coarse grid and then doubles the number of grid
points in each iteration until the grid is fine enough. In between iterations the solution
for the coarser grid is used to generate the initial guess for the value-function iteration
on the new grid by spline interpolation. The initial grid has 16×16 points (income A ×income B) and the final grid has 128×128 points.
The solution of (7) yields the optimal migration policy and thus the microeconomic
migration hazard rates Λj . With these hazard rates, we can obtain a series of aggregate
22See for example Adda and Cooper (2003) for an overview of dynamic programming techniques.23The choice of ±3.5σ+A,B is motivated as follows. We obtain in the estimation that about 99%
of the income shocks is due to the idiosyncratic component. Therefore, we can expect 99.9% of themass of the income distribution to fall within ±3.29 ·
√0.99σ+A,B
∼= ±3.27σ+A,B around the mean of thedistribution for any given year. Additionally, the mean income for each year moves within the band±3.29 ·
√0.01σ+A,B
∼= ±0.33σ+A,B in again 99.9% of all years. Since the sum of both components is±3.6σ+A,B , a grid variation of ±3.5σ+A,B should not truncate the income distribution.
46

migration rates for a simulated economy as described in detail in Section 4.2 for any
realization of aggregate shocks (θjt)j=A,Bt=1...T and an initial distribution F0.
This means that we need an initial distribution of income F0 to solve the sequen-
tial problem. Following Caballero and Engel’s (1999) suggestion, we use the ergodic
distribution of income F that would be obtained in the absence of aggregate income
shocks.24
To simulate a series of migration rates that correspond to the aggregate migration
hazards(ΛAt,Bt
)t=1...T
, we draw a series of aggregate shocks (to the orthogonal basis)(θ+At, θ
+Bt
)t=1...T
from a normal distribution with variance φ ·(σ+A,B
)2, φ ∈ [0, 1] . The
weight φ measures the relative importance of aggregate shocks, relative to idiosyncratic
shocks, i.e. φ =σ2θ
σ2θ+σ2ε. Correspondingly, the orthogonal components of the idiosyncratic
shocks have variance (1− φ) ·(σ+A,B
)2.
As we did to approximate the microeconomic income process for value function iter-
ation, we also discretize the distribution of migration incentives over the chosen grid of
income to simulate its evolution. Accordingly, we replace the conditional density in (10)
by discrete probabilities. This means that for grid points (xAk, xBl) k, l = 1...64, (k, l
being the index of grid points) with a distance of 2h in between points, we calculate the
probabilities initially (for t = 0 and before the first aggregate shock) as
pk,l,0 =
∫ xA,k+h
xA,k−h
∫ xB,l+h
xB,l−hf0 (x1, x2) dx1dx2.
An aggregate shock θj in t = 0 now implies that the off-grid pair (xA,k + θA, xB,l + θB)
occurs with probability pk,l,0 after the aggregate shock. To re-obtain on-grid probabili-
ties, we use spline interpolation methods to find the on-grid probability after aggregate
but before idiosyncratic shocks, pk,l,1, restricting p to take values between 0 and 1. That
is, for each t we define a function τ with τ t (xA,k + θA,t+1, xB,l + θB,t+1) := pk,l,t and
obtain pk,l,t+1 as
pk,l,t+1 = τ t (xA,k, xB,l)
where τ t is the interpolation of τ t. Idiosyncratic shocks are accounted for by multiplying
after-aggregate-shock, on-grid income probabilities with the transition probability matrix
obtained from Tauchen’s algorithm and thus obtain pk,l,t+1, the probability to fall in the
k, l-cluster after idiosyncratic shocks. The effect of migration on the distribution of
migration incentives is captured by using a discretized version of (12) .
24This distribution is calculated by assuming that idiosyncratic shocks ω have the full variance of ξ.
47

We calculate aggregate migration rates this way, i.e. by directly simulating the
evolution of the incentive distribution instead of using a Monte Carlo method based on
drawing a sample of agents, for the reason that the latter is not adequate in our case.
We focus on aggregate behavior, but aggregate shocks turn out to be relatively small
(being responsible for less than 1% of the total variation in income, see the discussion
in Section 5.4). Hence sampling variation would exceed the true aggregate variation of
income most likely if we applied a Monte Carlo approximation.
F Further robustness checks
Tables 7 and 8 provide the simulated moments and parameter estimates for further ro-
bustness checks. These are: (I) HP-filtering of individual state series instead of linear
detrending, (II) using a common linear trend instead of a state-specific one, (III) re-
placing average wage per job by personal income, or (IV) by disposable income, or (V)
using the average wage per job of the 5 nearest neighbor states instead of all 50 alter-
natives, and finally (VI) replacing the average cross-sectional standard deviation by the
autocorrelation of aggregate incomes in the set of moments to be matched. Overall the
estimated parameters do not change by much, with the exception of the inclusion of au-
tocorrelation in aggregate incomes where transitory shocks almost vanish and migration
costs triple.
48

Table7:Robustnesschecks:momentestimates
(I)
(II)
(III)
(IV)
(V)Income
(VI)Including
HP-filtered
Common
PersonalDisposable
ofnearest
autocorrelation
Moment
Baseline
trend
lineartrend
income
income
neighbors
ofincomes
Std.ofmigration
0.002
0.002
0.004
0.002
0.002
0.002
0.003
rates,σ
(mijt)
(0.002)
(0.002)
(0.004)
(0.002)
(0.002)
(0.002)
(0.002)
Corr.ofagg.incomes,
0.589
0.69
0.454
0.527
0.483
0.553
0.475
σ(w
At,wBt)
(0.620)
(0.724)
(0.432)
(0.555)
(0.504)
(0.574)
(0.620)
Std.ofagg.
0.019
0.014
0.026
0.024
0.023
0.019
0.019
incomes,σ
(wjt
)(0.019)
(0.013)
(0.027)
(0.025)
(0.023)
(0.019)
(0.019)
Averagemigration
0.037
0.037
0.037
0.037
0.037
0.037
0.038
rate,α
0(0.037)
(0.037)
(0.037)
(0.037)
(0.037)
(0.037)
(0.037)
Sensitivitytodesti-
0.049
0.063
0.039
0.029
0.028
0.043
0.074
nationincome,α
1(0.045)
(0.041)
(0.052)
(0.044)
(0.036)
(0.040)
(0.045)
Sensitivitytosource
-0.049
-0.063
-0.041
-0.03
-0.029
-0.043
-0.111
income,α
2-(0.053)
-(0.042)
-(0.058)
-(0.045)
-(0.052)
-(0.043)
-(0.053)
Cross-sectionalstd.
0.466
0.466
0.465
0.465
0.465
0.466
—ofincomes,σ
(wijt)
(0.466)
(0.466)
(0.466)
(0.466)
(0.466)
(0.466)
—Autocorrelation
——
——
——
0.681
ofaggregateincomes
——
——
——
(0.744)
Actualdatamomentsinbrackets.
49

Table8:Robustnesschecks:structuralparameterestimates
(I)
(II)
(III)
(IV)
(V)Income
(VI)Including
HP-filtered
Common
PersonalDisposable
ofnearest
autocorrelation
Baseline
trend
lineartrend
income
income
neighbors
ofincomes
Autocorrelation
0.952
0.951
0.952
0.952
0.951
0.953
0.979
ofincome,ρ
(0.020)
(0.031)
(0.012)
(0.032)
(0.027)
(0.020)
(0.003)
Std.ofidiosyncratic
0.172
0.173
0.172
0.175
0.174
0.171
0.737
shocks,σε
(0.022)
(0.035)
(0.016)
(0.033)
(0.028)
(0.021)
(0.025)
Std.oftransitory
0.019
0.015
0.023
0.025
0.023
0.019
0.001
shocks,σϕ
(0.001)
(0.001)
(0.001)
(0.001)
(0.001)
(0.001)
(0.016)
Std.ofaggregate
0.751
0.619
0.987
0.768
0.751
0.742
3.805
shocks,σθ(in%)
(0.082)
(0.105)
(0.102)
(0.123)
(0.104)
(0.081)
(0.128)
Correlationofshocks
0.316
0.329
0.305
0.199
0.267
0.346
0.766
acrossregions,ψ
(0.343)
(0.364)
(0.195)
(0.501)
(0.462)
(0.377)
(0.062)
Migrationcost,c,
10.441
10.447
10.462
10.541
10.505
10.416
11.461
inlogs
(0.199)
(0.277)
(0.238)
(0.362)
(0.240)
(0.208)
(0.093)
Migrationcost,cin$
34248
34449
34961
37836
36489
33394
94939
Momentdistance,χ
2(1
)3.053
26.02
6.331
12.333
9.448
0.806
127.83
p-value
0.081
00.012
00.002
0.369
0
SeenotestoTable4.
50
Recommended