
November 2005 CSA3180: Statistics I 1
CSA3180: Natural Language Processing
Statistics 1 – Empirical Approach• Historical Background• Fundamental Issues• Tokenisation and Preprocessing

November 2005 CSA3180: Statistics I 2
Introduction
• Slides based on Lectures by Mike Rosner (2003) and BNC2 POS Tagging Manual (Leech and Smith, 2000)
• “Foundations of Statistical Language Processing”, Manning and Schütze, MIT, 1999
• Resources for statistical/empirical NLP• http://nlp.stanford.edu/links/statnlp.html• McEnery & Wilson notes on Corpus Linguistics• http://
www.ling.lancs.ac.uk/monkey/ihe/linguistics/contents.htm

November 2005 CSA3180: Statistics I 3
Historical Perspective
• Pre-Chomsky linguistics (e.g. Boas 1940) was largely empirical
• 1970s: Rationalist approach to AI systems in restricted domains (e.g. Winograd 1972, Woods 1977, Waltz 1978)
• 1980s: hand-coded grammars and knowledge bases (e.g. Allen 1987)
• Hand-coded systems need great deal of domain-specific/expert knowledge engineering
• Systems brittle, unscaleable and inflexible• Second half of 1980s: focus shifted from rationalist
methods to empirical/corpus-based methods• Development largely data driven

November 2005 CSA3180: Statistics I 4
Historical Perspective
• Linguistics Research: Automatic Induction of lexical and syntactic information from corpora
• Speech Recognition: resulted in Hidden Markov Models (HMM) based methods (IBM Yorktown Heights) that outperformed previous knowledge-based approaches
• Use of probabilistic finite state machines to model word pronunciations
• Make use of hill-climbing training algorithms to fit model parameters to actual speech data

November 2005 CSA3180: Statistics I 5
Application Areas
• Success of statistical methods in speech spread to other areas like POS tagging, spelling correction, and parsing
• POS Tagging: assigning appropriate syntactic class tags to words
• Machine Translation: training on bilingual corpora to extract word and contextual mappings
• Parsing: based on tree banks (large databases of sentences annotated with syntactic parse trees), such as probabilistic CFGs (PCFGs)
• Word-sense disambiguation: attachment, anaphora resolution, discourse segmentation
• Content-based document processing:– Information Extraction: text filled templates– Information Retrieval: query text set of relevant documents

November 2005 CSA3180: Statistics I 6
Empirical Approach: Issues
• Potential for solutions to old problems:– Knowledge Acquisition– Coverage– Robustness– Domain Independence
• Feasibility depends on data and computing resources• Pros
– Emphasis on applications and evaluation– Scalability and applicability to real-life domains
• Cons– Results always corpus dependent

November 2005 CSA3180: Statistics I 7
Corpus: Starting Point
• Corpus (corpora) is an organised body of materials from language that is used as the basis for empirical studies.
• Important corpus characteristics:– Statistical: Representativeness/balance– Medium: printed, electronic text, speech, video, images– Language: monolingual/multilingual– Information Content: plain text vs. tagged text– Structure: trees vs. sentences– Size– Standards– Quality

November 2005 CSA3180: Statistics I 8
Corpora Examples
• Project Gutenberg – collection of public domain texts• http://www.gutenberg.org• Brown Corpus – tagged corpus of around 1 million words
put together at Brown University in 1960s and 70s. Balanced corpus of American English.
• British National Corpus – a balanced corpus of British English containing over 100 million words with morphosyntactic annotation.
• http://www.natcorp.ox.ac.uk• Penn Treebank• WordNet• Canadian Hansards• LDC GigaWord

November 2005 CSA3180: Statistics I 9
Tagset Example• Here are some example POS tags from the BNC
(CLAWS4 – BNC Basic Tagset/C5 Tagset)AJ0
Adjective (general or positive) (e.g. good, old, beautiful)
AJC
Comparative adjective (e.g. better, older)
AJS
Superlative adjective (e.g. best, oldest)
AT0
Article (e.g. the, a, an, no)
AV0
General adverb: an adverb not subclassified as AVP or AVQ (see below) (e.g. often, well, longer (adv.), furthest.
AVP
Adverb particle (e.g. up, off, out)

November 2005 CSA3180: Statistics I 10
Tagset Examples• Here are some example POS tags from the BNC
(CLAWS4 – BNC Basic Tagset/C5 Tagset)AVQ
Wh-adverb (e.g. when, where, how, why, wherever)
CJC
Coordinating conjunction (e.g. and, or, but)
CJS
Subordinating conjunction (e.g. although, when)
CJT
The subordinating conjunction that
CRD
Cardinal number (e.g. one, 3, fifty-five, 3609)
DPS
Possessive determiner-pronoun (e.g. your, their, his)

November 2005 CSA3180: Statistics I 11
Tagset Examples• Here are some example POS tags from the BNC
(CLAWS4 – BNC Basic Tagset/C5 Tagset)DT0
General determiner-pronoun: i.e. a determiner-pronoun which is not a DTQ or an AT0.
DTQ
Wh-determiner-pronoun (e.g. which, what, whose, whichever)
EX0
Existential there, i.e. there occurring in the there is ... or there are ... construction
ITJ
Interjection or other isolate (e.g. oh, yes, mhm, wow)
NN0
Common noun, neutral for number (e.g. aircraft, data, committee)

November 2005 CSA3180: Statistics I 12
Tagset Examples• Here are some example POS tags from the BNC
(CLAWS4 – BNC Basic Tagset/C5 Tagset)NN1
Singular common noun (e.g. pencil, goose, time, revelation)
NN2
Plural common noun (e.g. pencils, geese, times, revelations)
NP0
Proper noun (e.g. London, Michael, Mars, IBM)
ORD
Ordinal numeral (e.g. first, sixth, 77th, last) .
PNI
Indefinite pronoun (e.g. none, everything, one [as pronoun], nobody)
PNP
Personal pronoun (e.g. I, you, them, ours)

November 2005 CSA3180: Statistics I 13
Tagset Examples• Here are some example POS tags from the BNC
(CLAWS4 – BNC Basic Tagset/C5 Tagset)PNQ
Wh-pronoun (e.g. who, whoever, whom)
PNX
Reflexive pronoun (e.g. myself, yourself, itself, ourselves)
POS
The possessive or genitive marker 's or '
PRF
The preposition of
PRP
Preposition (except for of) (e.g. about, at, in, on, on behalf of, with)
PUL
Punctuation: left bracket - i.e. ( or [

November 2005 CSA3180: Statistics I 14
Tagset Examples• Here are some example POS tags from the BNC
(CLAWS4 – BNC Basic Tagset/C5 Tagset)PUN
Punctuation: general separating mark - i.e. . , ! , : ; - or ?
PUQ
Punctuation: quotation mark - i.e. ' or "
PUR
Punctuation: right bracket - i.e. ) or ]
TO0
Infinitive marker to
UNC
Unclassified items which are not appropriately considered as items of the English lexicon.

November 2005 CSA3180: Statistics I 15
Tagset Examples• Here are some example POS tags from the BNC
(CLAWS4 – BNC Basic Tagset/C5 Tagset)VBB
The present tense forms of the verb BE, except for is, 's: i.e. am, are, 'm, 're and be [subjunctive or imperative]
VBD
The past tense forms of the verb BE: was and were
VBG
The -ing form of the verb BE: being
VBI
The infinitive form of the verb BE: be
VBN
The past participle form of the verb BE: been
VBZ
The -s form of the verb BE: is, 's

November 2005 CSA3180: Statistics I 16
Tagset Examples• Here are some example POS tags from the BNC
(CLAWS4 – BNC Basic Tagset/C5 Tagset)VDB
The finite base form of the verb BE: do
VDD
The past tense form of the verb DO: did
VDG
The -ing form of the verb DO: doing
VDI
The infinitive form of the verb DO: do
VDN
The past participle form of the verb DO: done
VDZ
The -s form of the verb DO: does, 's

November 2005 CSA3180: Statistics I 17
Tagset Examples• Here are some example POS tags from the BNC
(CLAWS4 – BNC Basic Tagset/C5 Tagset)VHB
The finite base form of the verb HAVE: have, 've
VHD
The past tense form of the verb HAVE: had, 'd
VHG
The -ing form of the verb HAVE: having
VHI
The infinitive form of the verb HAVE: have
VHN
The past participle form of the verb HAVE: had
VHZ
The -s form of the verb HAVE: has, 's

November 2005 CSA3180: Statistics I 18
Tagset Examples• Here are some example POS tags from the BNC
(CLAWS4 – BNC Basic Tagset/C5 Tagset)VM0
Modal auxiliary verb (e.g. will, would, can, could, 'll, 'd)
VVB
The finite base form of lexical verbs (e.g. forget, send, live, return) [Including the imperative and present subjunctive]
VVD
The past tense form of lexical verbs (e.g. forgot, sent, lived, returned)
VVG
The -ing form of lexical verbs (e.g. forgetting, sending, living, returning)
VVI
The infinitive form of lexical verbs (e.g. forget, send, live, return)
VVN
The past participle form of lexical verbs (e.g. forgotten, sent, lived, returned)

November 2005 CSA3180: Statistics I 19
Tagset Examples• Here are some example POS tags from the BNC
(CLAWS4 – BNC Basic Tagset/C5 Tagset)
VVZ
The -s form of lexical verbs (e.g. forgets, sends, lives, returns)
XX0
The negative particle not or n't
ZZ0
Alphabetical symbols (e.g. A, a, B, b, c, d)

November 2005 CSA3180: Statistics I 20
Tagging Algorithms• Manual Tagging• Automatic Tagging
– Stochastic: Most probable sequence of categories– Rule Based: E.g. if preceding word is a DT0
(determiner) then the next tag is probably NN0 or NN1 or NN2 (nouns)
– Transformation Based: trainable, machine-learning taggers

November 2005 CSA3180: Statistics I 21
Low Level Processing• Pre-processing
– Filtering headers, whitespace, etc.– Reformatting and creation of appropriate “wrappers”
• Data Gathering/Formatting/Transformation/Input• Tokenisation• Normalisation• Initial Tag Assignment• Tag Selection/Disambiguation• Post-processing

November 2005 CSA3180: Statistics I 22
Tokenisation• Divide input text into units called tokens – can be
either individual word tokens or orthographic sentences
• Tokens usually of different types: words, numbers, punctuation
• What is a word?
“a string of contiguous alphanumeric characters with space on either side; may include hyphens and apostrophes but no other punctuation marks”.
(Kucera and Francis,1967)

November 2005 CSA3180: Statistics I 23
Tokenisation• Token segments usually demarcated by white
space or sentence boundaries (i.e. final sentence punctuation followed by initial capital letter of next sentence)
• Not straightforward due to ambiguity of punctuation marks and of capital letters!

November 2005 CSA3180: Statistics I 24
Tokenisation Problems• Words may contain non-alphanumeric
characters:£27.40B.Sc.IT(Hons.)cya l8r :-)www.maltalinks.com• Presence of spaces around words do not
necessarily indicate a unit break, e.g. Coca Cola• Items of particular semantic types that use
spaces, e.g. phone numbers:+1 202-456-1414

November 2005 CSA3180: Statistics I 25
Tokenisation Problems• Some languages use spaces very sparingly (like
agglomerative languages such as German or Turkish)
• Geschwendigkeitsbegrenzung (speed limit)
• Rindfleischetikettierungsüberwachungsaufgabenübertragungsgesetz (beef labelling law)
• [[[Rind]fleisch] beef meat• [[etikettier[ungs]] label ing• [[[über]wachungs] over watch• [[[auf]gaben] task over• [[[über]trag[ungs]] give ing• [gesetz]]]]]]] law

November 2005 CSA3180: Statistics I 26
Tokenisation Problems
• Some languages do not use spaces at all! (like Chinese, Japanese, Thai)
• Word segmentation for these languages can approach that of sentence segmentation in other languages
• Probabilistic word segmentation gives quite good results

November 2005 CSA3180: Statistics I 27
Tokenisation Problems
• Specialised formats (like phone numbers, URLs) takes us from tokenisation towards Information Extraction
• Hand crafted rules and regular expressions can be used to handle some common cases
• Brittle and inflexible – automated learning methods are preferable

November 2005 CSA3180: Statistics I 28
Punctuation
• Detaching spaces, semi-colons, commas, etc. from words is quite easy
• Periods and apostrophes present special problems
• Periods:– End of sentence (.)– Abbreviations (e.g., etc., B.Sc.)– Numbers and date formats

November 2005 CSA3180: Statistics I 29
Apostrophe
• Contractions
• (won’t, they’re, can’t, it’s)
• Merged forms
• (dunno, aintcha)
• Trailing enclitics
• Solution is often to have lookup tables for common (and not so common) forms
November 2005 CSA3180: Statistics I 30
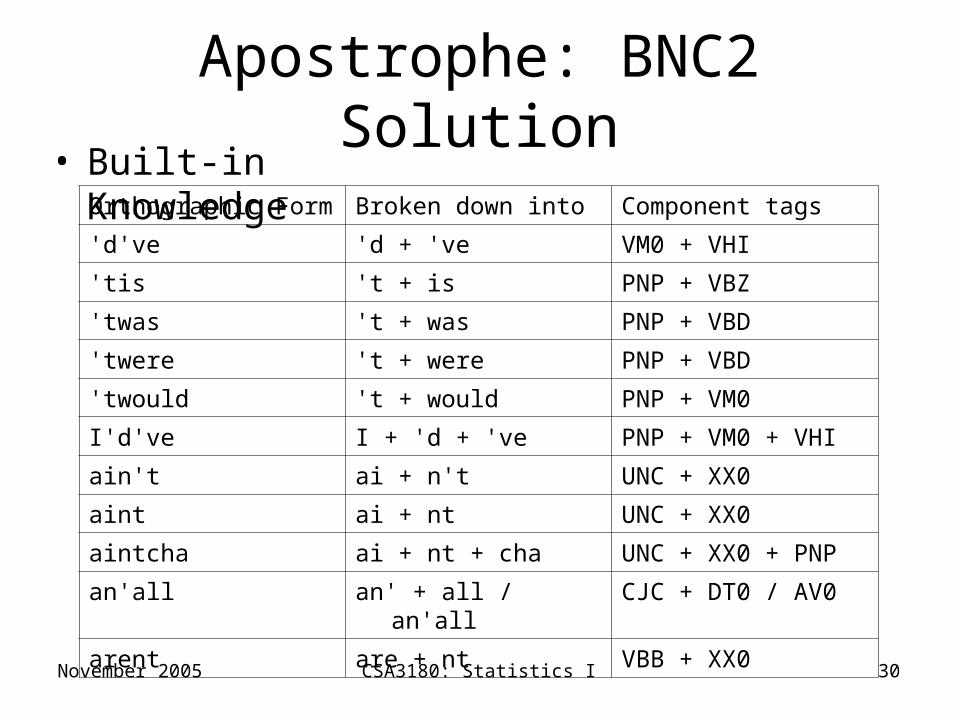
Apostrophe: BNC2 Solution• Built-in Knowledge
Orthographic Form Broken down into Component tags
'd've 'd + 've VM0 + VHI
'tis 't + is PNP + VBZ
'twas 't + was PNP + VBD
'twere 't + were PNP + VBD
'twould 't + would PNP + VM0
I'd've I + 'd + 've PNP + VM0 + VHI
ain't ai + n't UNC + XX0
aint ai + nt UNC + XX0
aintcha ai + nt + cha UNC + XX0 + PNP
an'all an' + all / an'all CJC + DT0 / AV0
arent are + nt VBB + XX0
November 2005 CSA3180: Statistics I 31
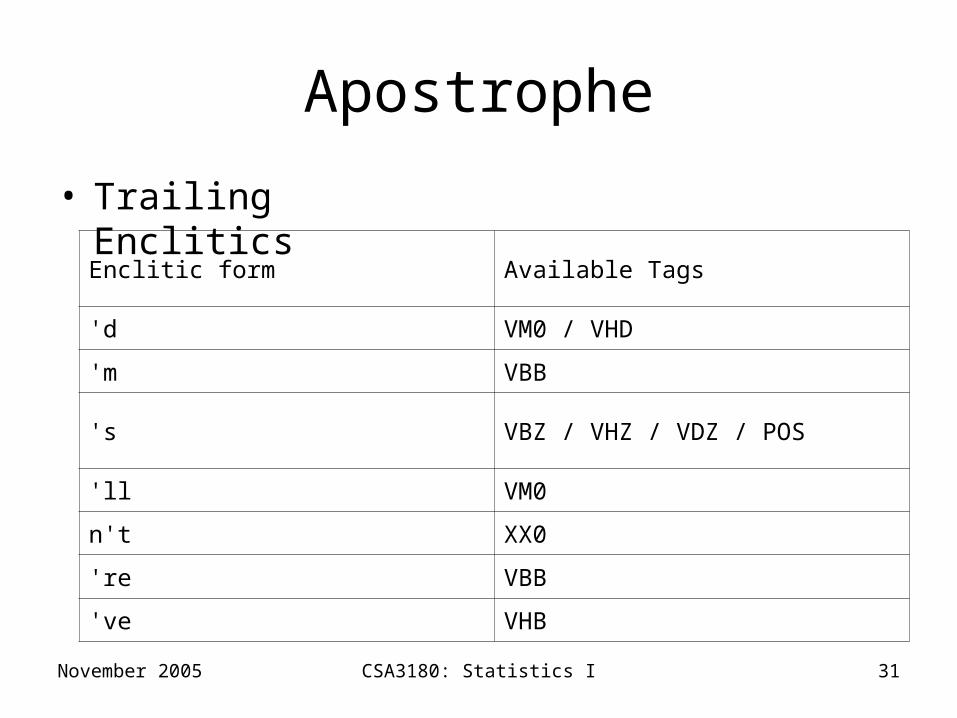
Apostrophe
• Trailing Enclitics
Enclitic form Available Tags
'd VM0 / VHD
'm VBB
's VBZ / VHZ / VDZ / POS
'll VM0
n't XX0
're VBB
've VHB

November 2005 CSA3180: Statistics I 32
Hyphens
• Hyphens are usually treated as word internal
• Not always the case (e.g. il-ktieb in Maltese)
• Hyphens can also be used as quotation marks

November 2005 CSA3180: Statistics I 33
Uppercase/Lowercase• Two tokens containing same characters are
often instances of the same type• The, THE, the• Mapping to same case can work in reducing
amount of data to be stored (e.g. map all instances of the to “the”)
• Heuristics:– Map first character of a sentence to lowercase– Map all words in titles to lowercase
• Problems:– Identification of sentence boundaries– Identification of proper names

November 2005 CSA3180: Statistics I 34
Types vs. Tokens
• How many words are there in this sentence?
The quick brown fox jumps over the lazy dog
• 9 tokens• 8 types: the, quick, brown, fox, jumps,
over, lazy, dog• Wordform types: every different/unique
form• Lemmas: every root word/unique entry

November 2005 CSA3180: Statistics I 35
How many words in English?• Switchboard Corpus of spoken English: 2.4
million tokens, 20,000 wordform types• Shakespeare: 884,647 tokens, 29,066 wordform
types• Gutenberg project and GigaWord sample from
Morpho Challenge 2005: 24,447,034 tokens, 167,377 types
• http://www.cis.hut.fi/morphochallenge2005/datasets.shtml
• Type/token ratio

November 2005 CSA3180: Statistics I 36
Normalisation
• Are “eat” and “eats” different words?
• Two different wordforms
• Same lemma (same stem)
• Stemming vs. morphological analysis (depends on application)
• Porter stemmer
Recommended

















