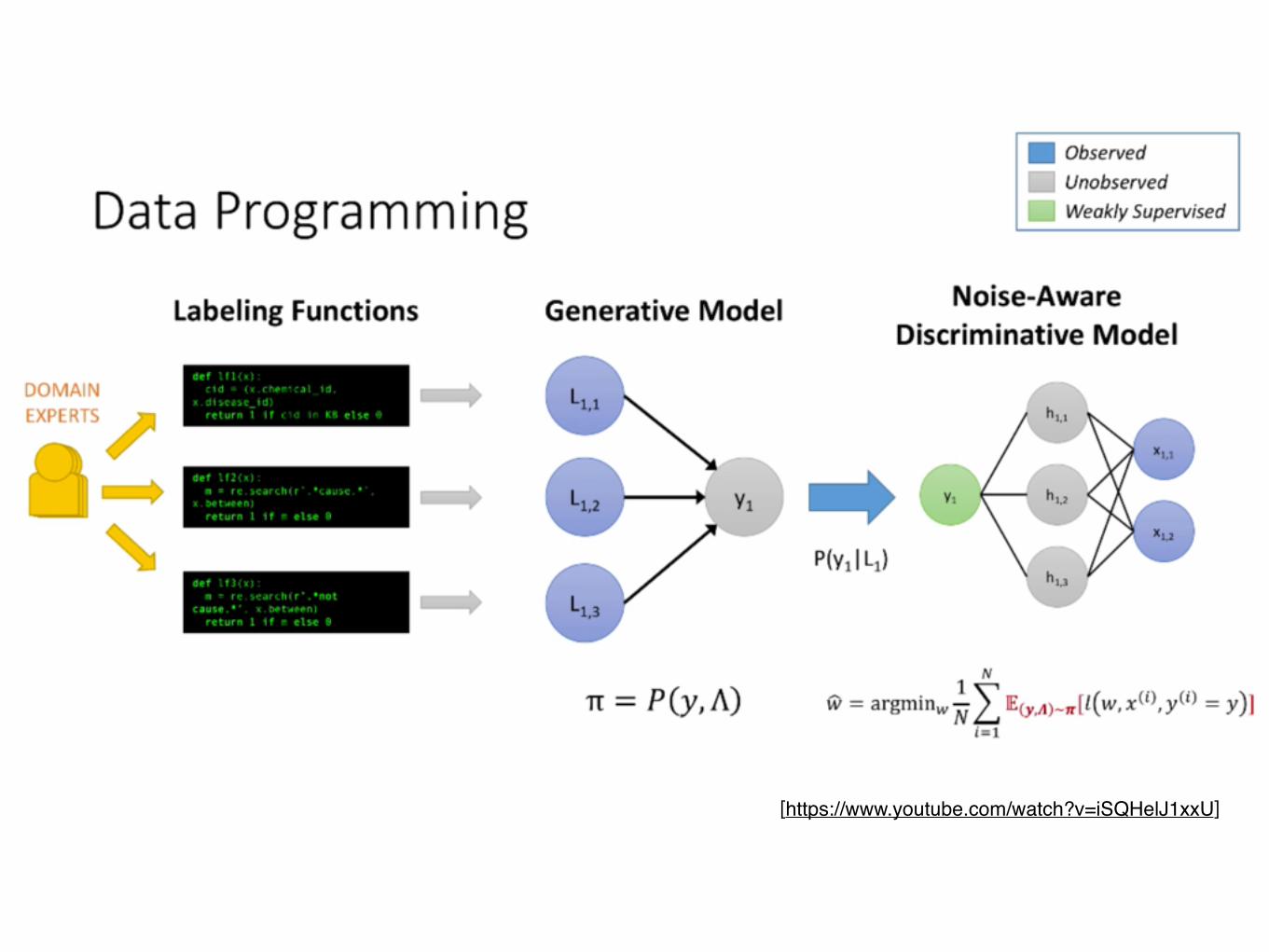
Data Programming: Creating Large Training Sets, Quickly
Recruit Communications, EngineerKotaro Tanahashi
Alexander Ratner, Christopher De Sa, Sen Wu, Daniel Selsam, Christopher Ré Stanford University
NIPS 2016, reading meet up
[https://www.youtube.com/watch?v=iSQHelJ1xxU]
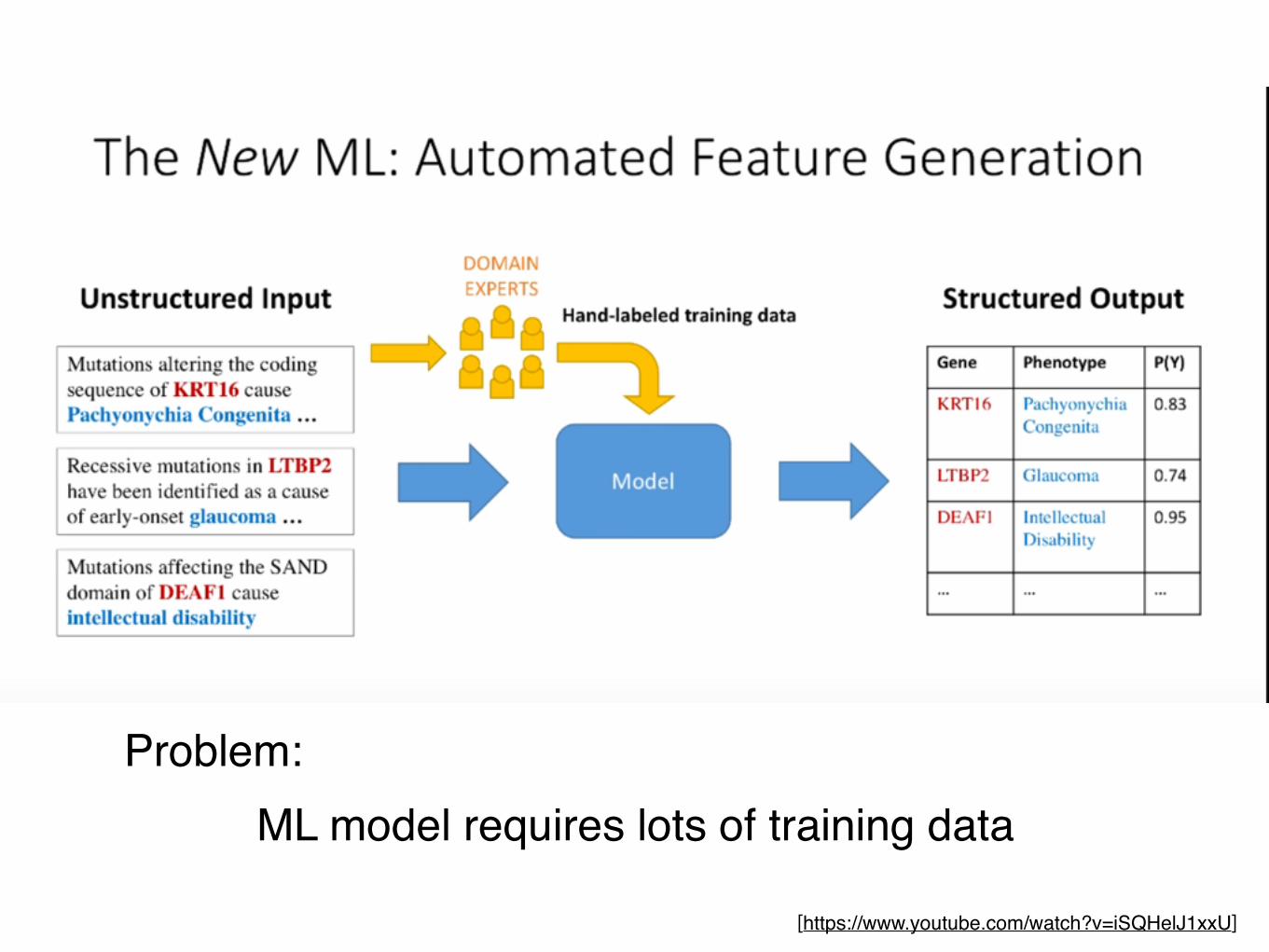
ML model requires lots of training dataProblem:
[https://www.youtube.com/watch?v=iSQHelJ1xxU]
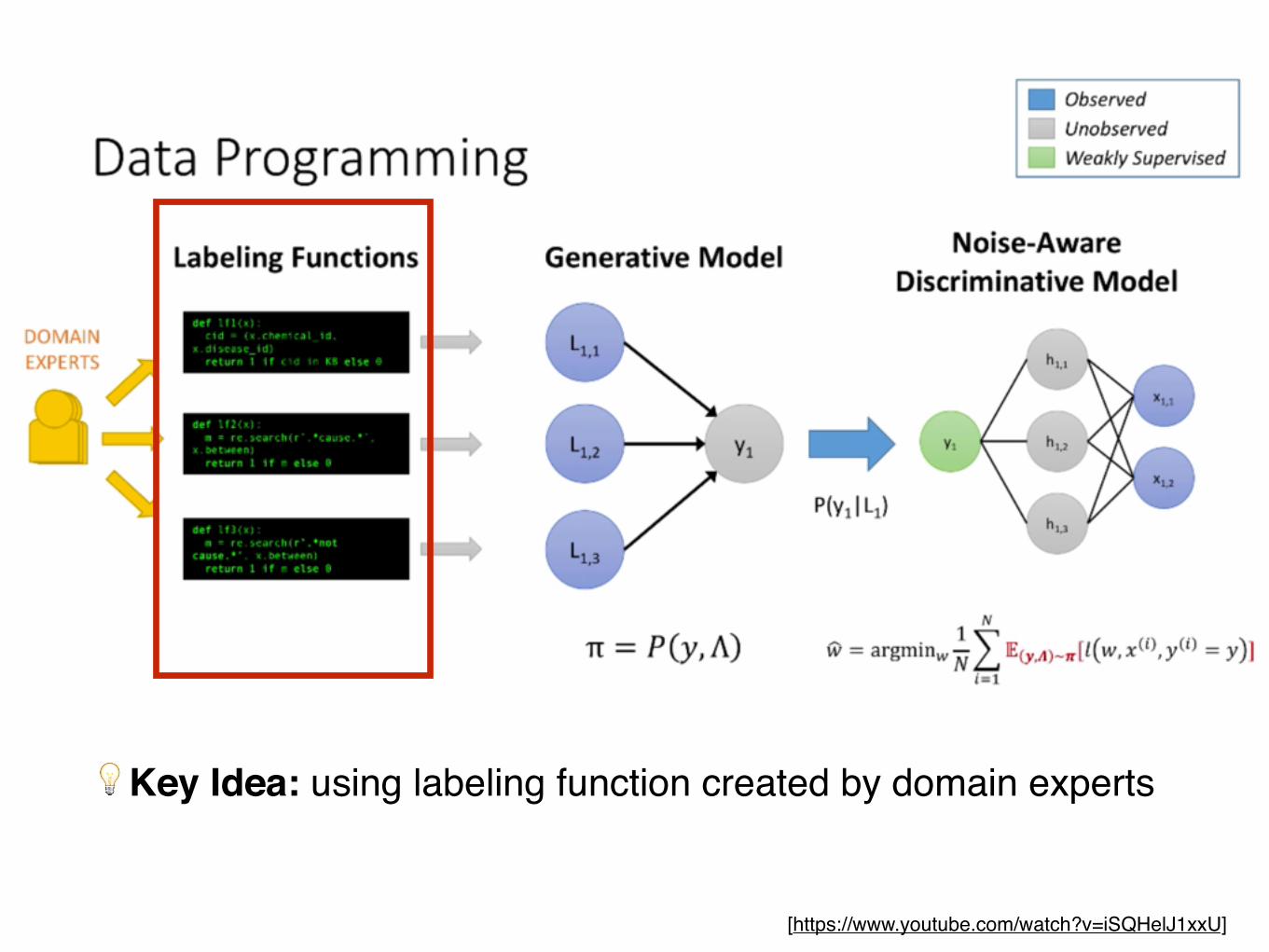
💡Key Idea: using labeling function created by domain experts

Examples of Labeling Function
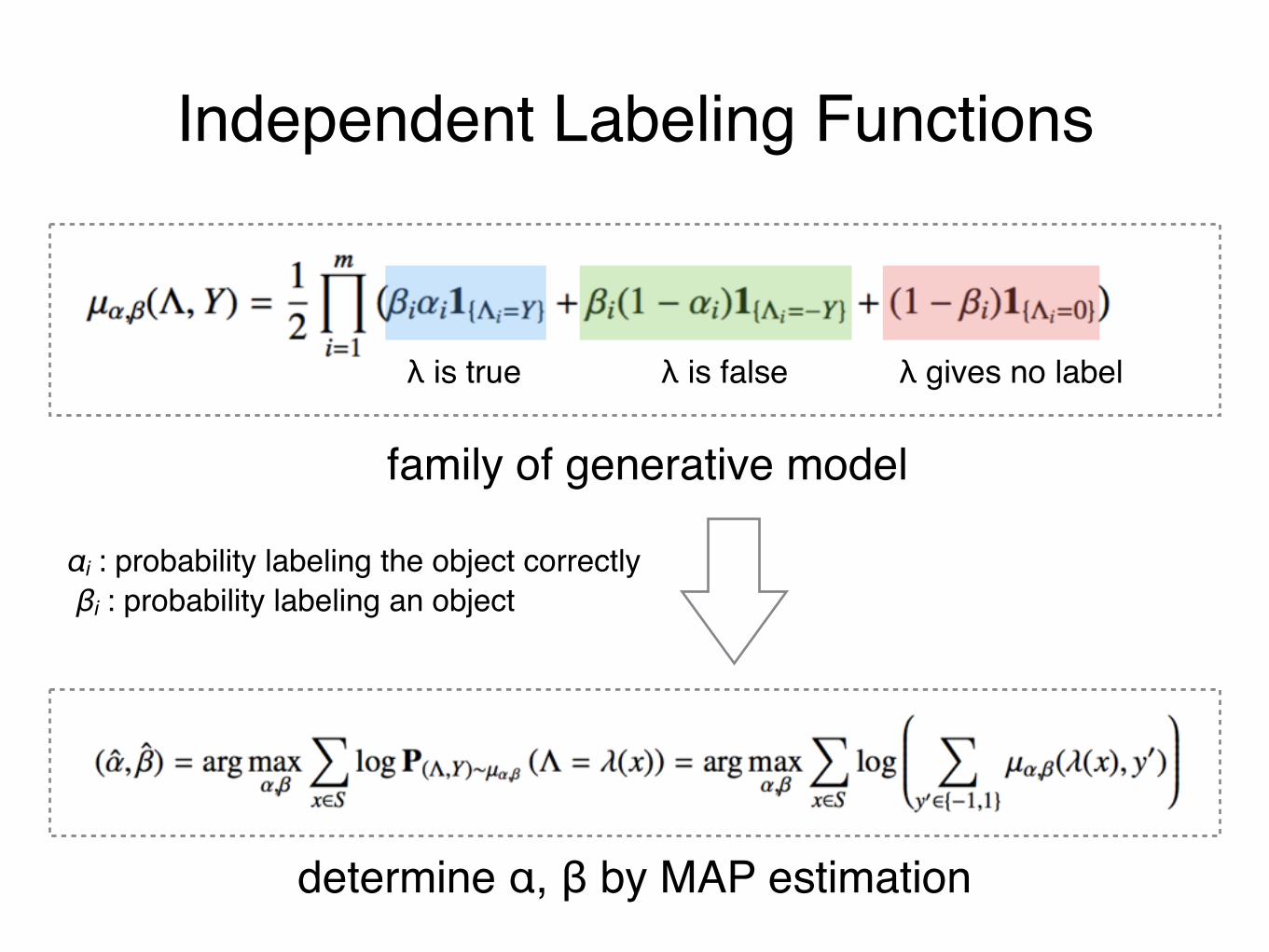
Independent Labeling Functions
λ is true λ is false λ gives no label
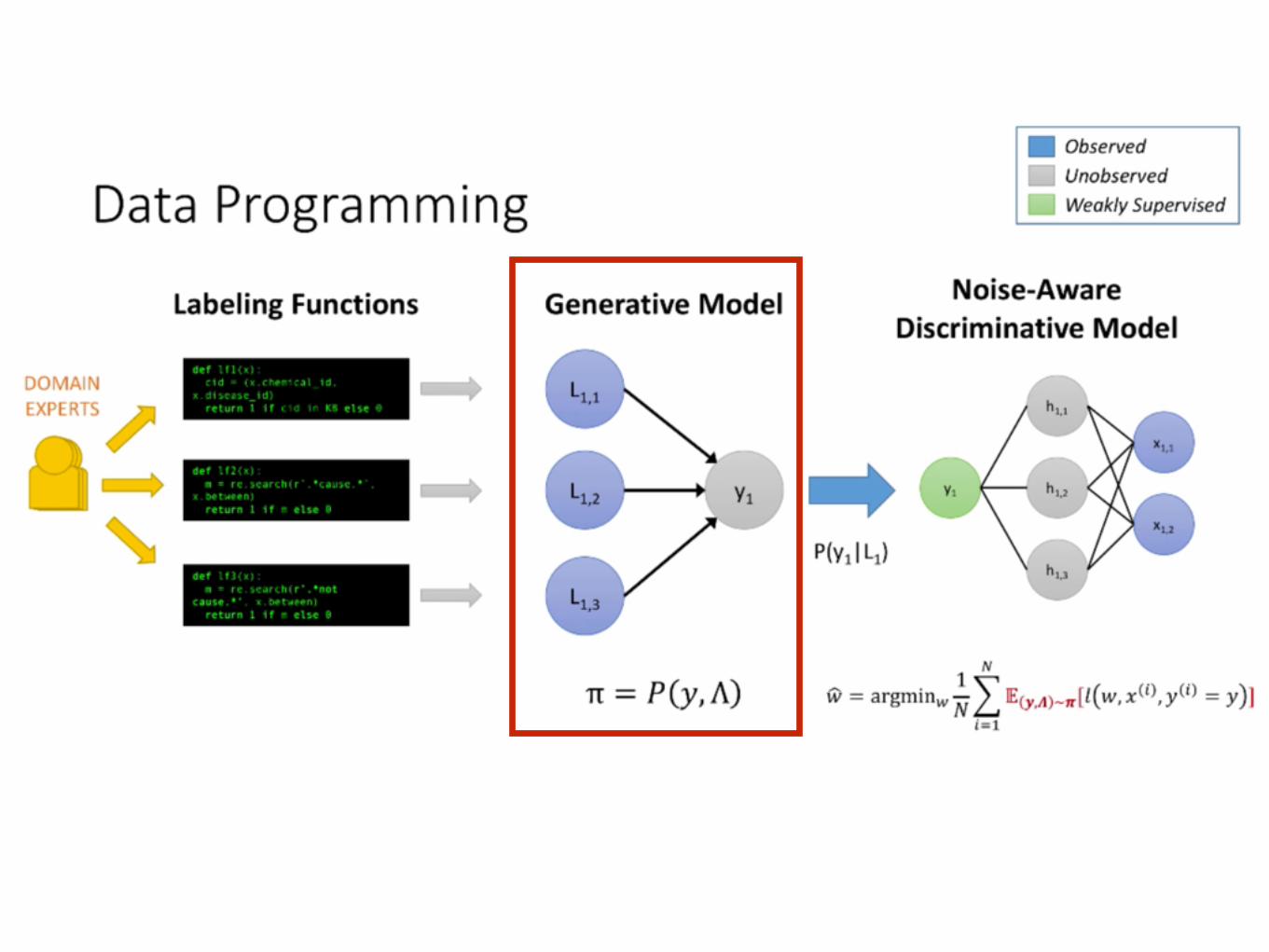
family of generative model
αi : probability labeling the object correctly βi : probability labeling an object
determine α, β by MAP estimation

Training of wfinal goal is training w in
optimal w is obtained by
f(x) : arbitrary feature mapping
noise-aware empirical risk
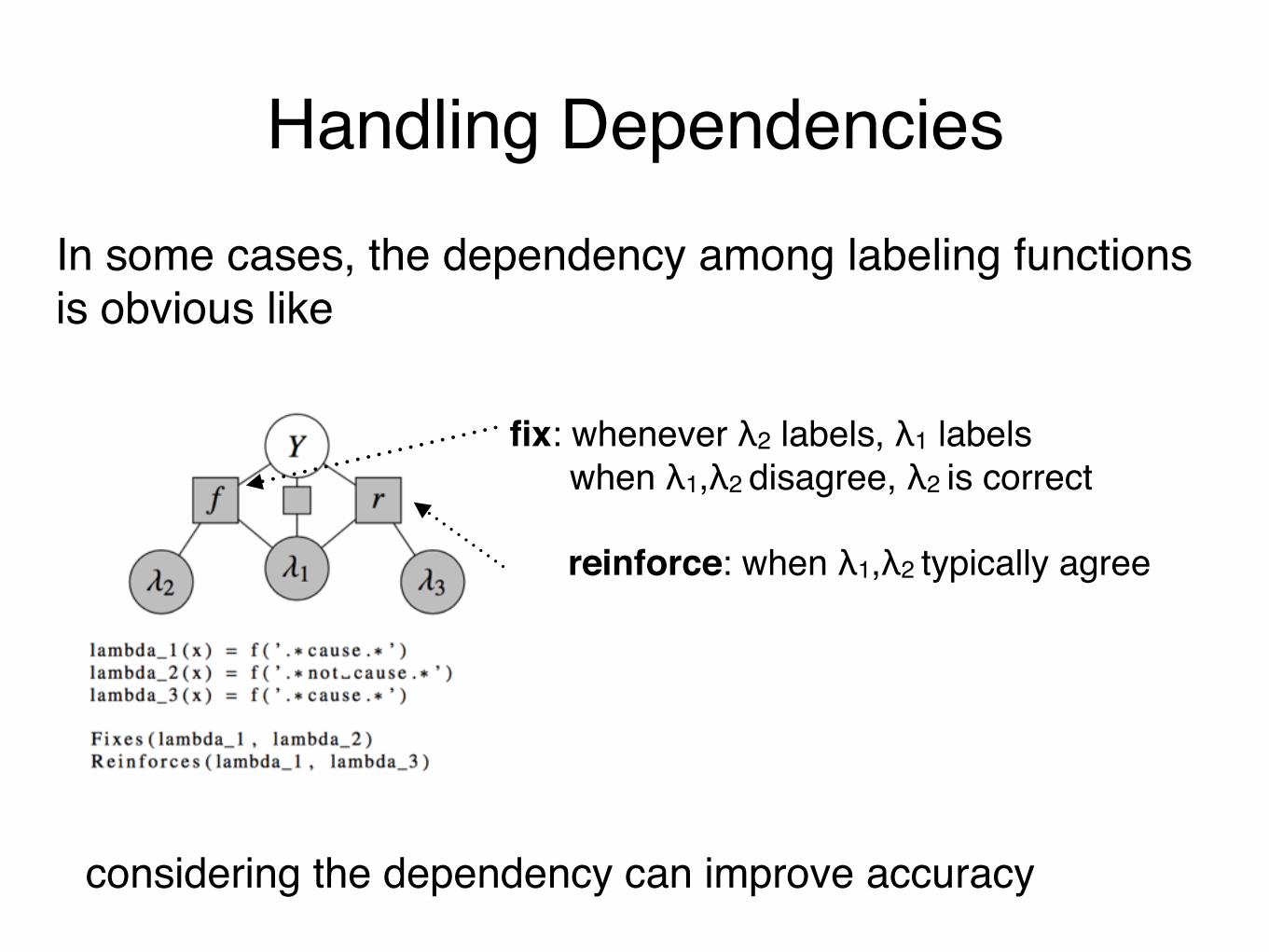
Handling DependenciesIn some cases, the dependency among labeling functions is obvious like
considering the dependency can improve accuracy
fix: whenever λ2 labels, λ1 labels when λ1,λ2 disagree, λ2 is correct
reinforce: when λ1,λ2 typically agree

Generalization of Generative Model
λ is true λ is false λ gives no label
generalize
h is a factor function
α, β → θ

Represent Dependency by h
For a fixing dependency
whenever λj labels, λi labels
λj is true and λi is false
θ
Training procedure is same as before
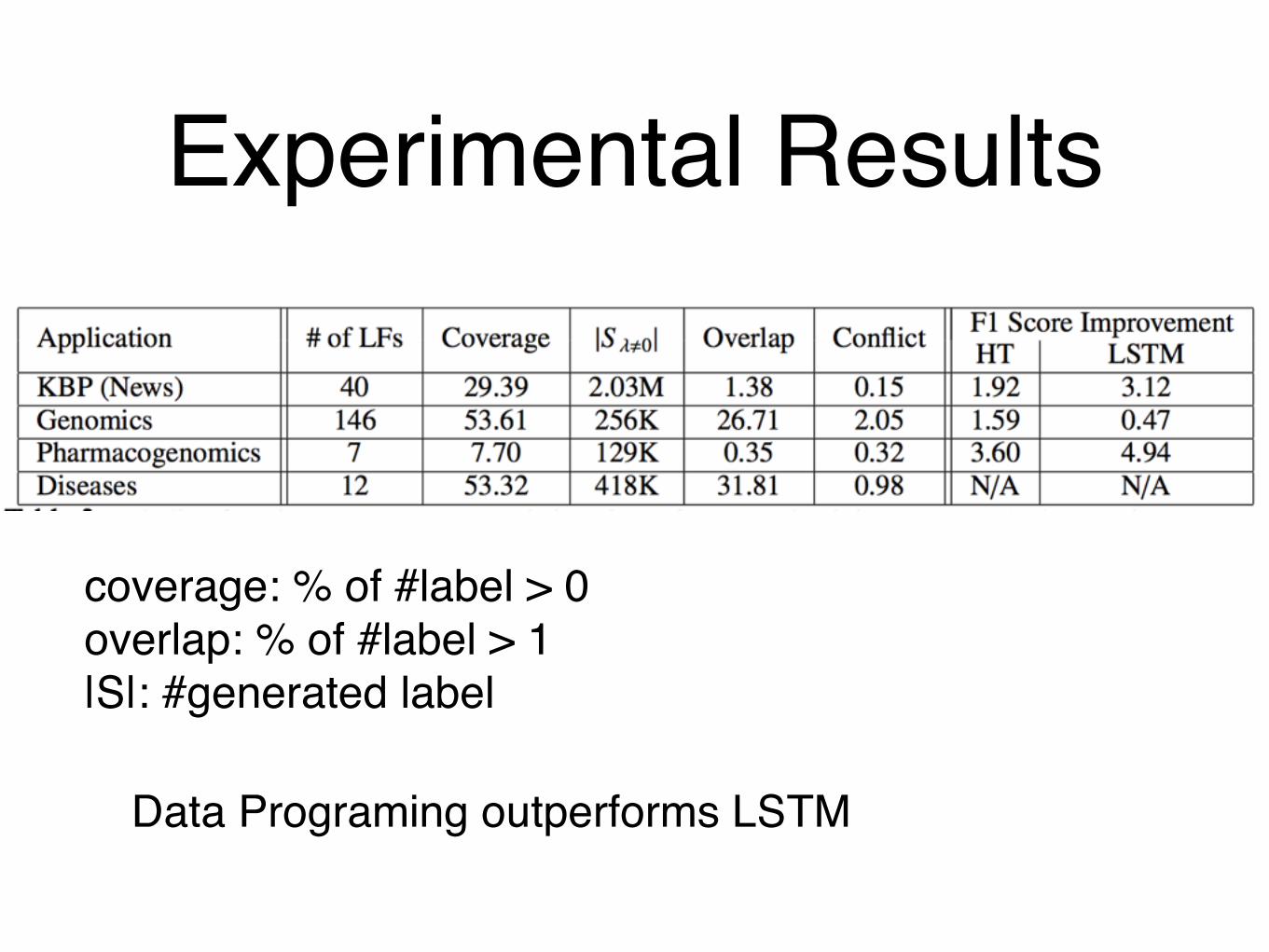
Experimental Results
coverage: % of #label > 0overlap: % of #label > 1|S|: #generated label
Data Programing outperforms LSTM

RCO tech-blog
絶賛毎日更新中!
Recommended