
Sentiment Classification
N-grams as Linguistic Features

Why high order n-gram ?
• Negative views • “highly recommend staying away …“
• Positive views • “recommend …“
• “highly recommend …“
• Fuzzy n-gram• In addition, while it is difficult to model positive and
negative expressions by lexico-syntactic patterns due to extreme variety.

Make helpful high order n-gram
• n-gram violates the independence ?
• Composite model combining unigrams and bigrams gives much higher performance than using only bigrams.
• Classifier DefinitionThe classifiers we employ do not require independent features.

Make helpful high order n-gram
• Reduce n-gram data
• reduce computational complexity
• offline operation

Method – pick features (1)
• term t
• class c
• A be the number of times t and c co-occur.
• B be the number of times t occurs without c.
• C be the number of times c occurs without t.
• D be the number of times neither t nor c occurs,
• N be the number of documents.

Method – pick features (2)
Features Meaning
A + C ↑ ↓ Class c is large, dilute features
B +D ↑ ↓ Without c is large, class c may not important
A +B ↑ ↓ Item t in more class
C + D ↑ ↓ Item t not in more class
AD ↑ ↑ More features in class c (frequently appear)
CB ↑ ↑ More features in class c (rare)

Method – pick features (3)• Take top M ranked n-grams as features in the
classification experiments.
• Example. (in positive comments)• Score 0.517334 (of the best)• Score 0.325458 (as well as)• Score 0.200934 (lot of fun)• Score 0.197970 (nice to see)• … ignore
• w(0, …, 0) = w(`of the best`, `as well as`, …)w(1, …, 0) mean which comment appears `of the best`
• erase n-gram record which not in top M ranked n-grams in Language Model.
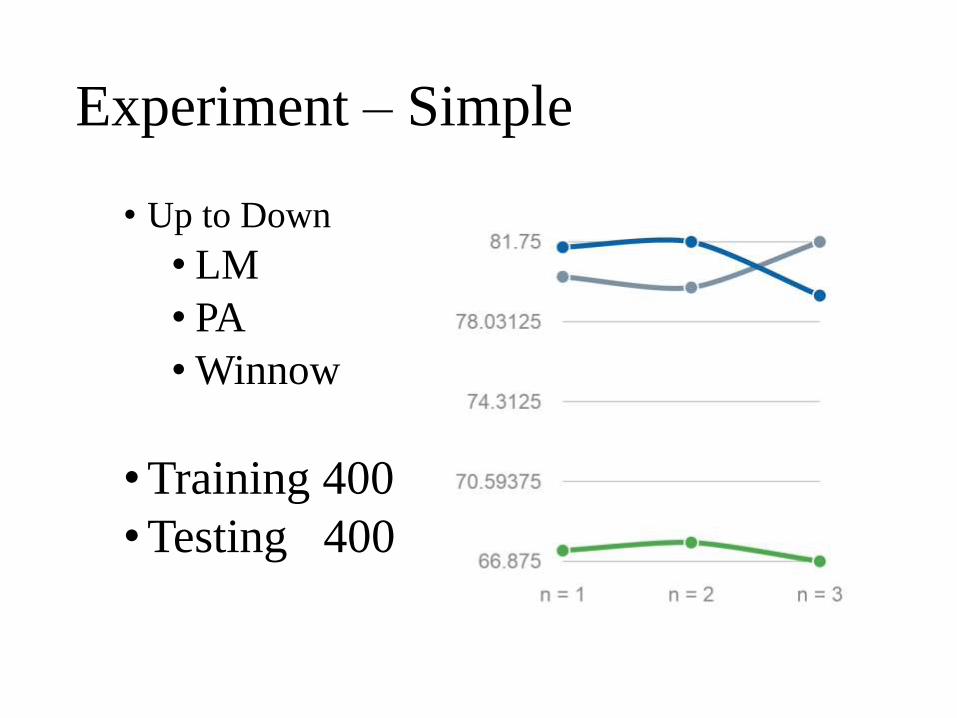
Experiment – Simple
• Up to Down
• LM
• PA
• Winnow
•Training 400
•Testing 400

Experiment – Observe
• Class `Negative`
• LM performance depend strongly `training data` P = 10%~90%
Table `Language Model Class Negative`|Truth\Classifier| Classifier no| Classifier yes|| ------| ------| ------|| Truth no| 400| 0|| Truth yes| 360| 40|
Table `Passive-Aggressive Class Negative`|Truth\Classifier| Classifier no| Classifier yes|| ------| ------| ------|| Truth no| 289| 111|| Truth yes| 54| 346|

Experiment – Three-Ways
•三個不同的模型進行投票
•根據其信任度PA≒ LM > Winnow
•三者持相同意見
• PA持不同意見於 LM和Winnow
LM: POS Winnow: POS
PA: POS
LM: NEG Winnow: NEG
PA: NEG
LM: NEG Winnow: NEG
PA: POS
Occur 55 % ↑ , Precision 92% ↑
If LM-option = Winnow-option
final-option = LM-option
Else
final-option = PA-option
Precision 72% ↑
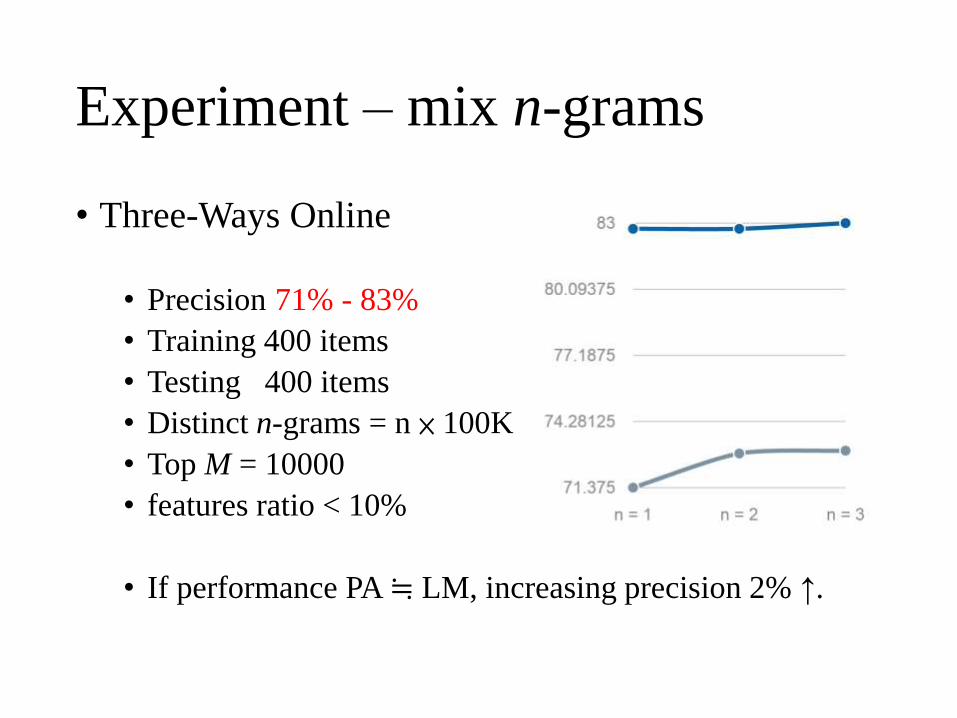
Experiment – mix n-grams
• Three-Ways Online
• Precision 71% - 83%
• Training 400 items
• Testing 400 items
• Distinct n-grams = n × 100K
• Top M = 10000
• features ratio < 10%
• If performance PA ≒ LM, increasing precision 2% ↑.

Experiment – LM filter
• When Language Model testing
• Remove objective sentence by Language Model predict function.
• “it's a comedy , and teenagers have little clout , but for my money, …”
• If Predict(sentence) < threshold, then remove it.
• Not helpful, Precision ↓

Experiment – Weight Vector
• When using Passive-Aggressive and Winnow Algorithm
• AFINN-111.txt
• Score(n-grams) = \sum weight(w_{i})
• Robustness ↑
AFINN-111.txt
abhors -3abilities 2ability 2aboard 1absentee -1absentees -1absolve 2absolved 2…
Recommended

















