
It’s all in the Content: State of the art Best
Answer Prediction based on Discretisation
of Shallow Linguistic Features
George Gkotsis, Karen Stepanyan, Carlos
Pedrinaci, John Domingue, Maria Liakata*
Knowledge Media Institute, The Open University
*Department of Computer Science, University of Warwick

Outline
• Motivation
• Problem description
• Proposed solution
• Evaluation
• Discussion & Conclusion
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)

Motivation
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)

Questions on social networking sites
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
Recommendations
&
opinions
Authoritative
responses
Expert &
Empirical
knowledge

Queries on CQA
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)

Why best answer prediction?
• Information overload
• Increase awareness in the community
• Answer questions more efficiently
• One way to study social media reception
• Plus:
• Finding experts in communities
• Study of language use
• Trend analysis
• …
• Visit
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)

Problem description
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
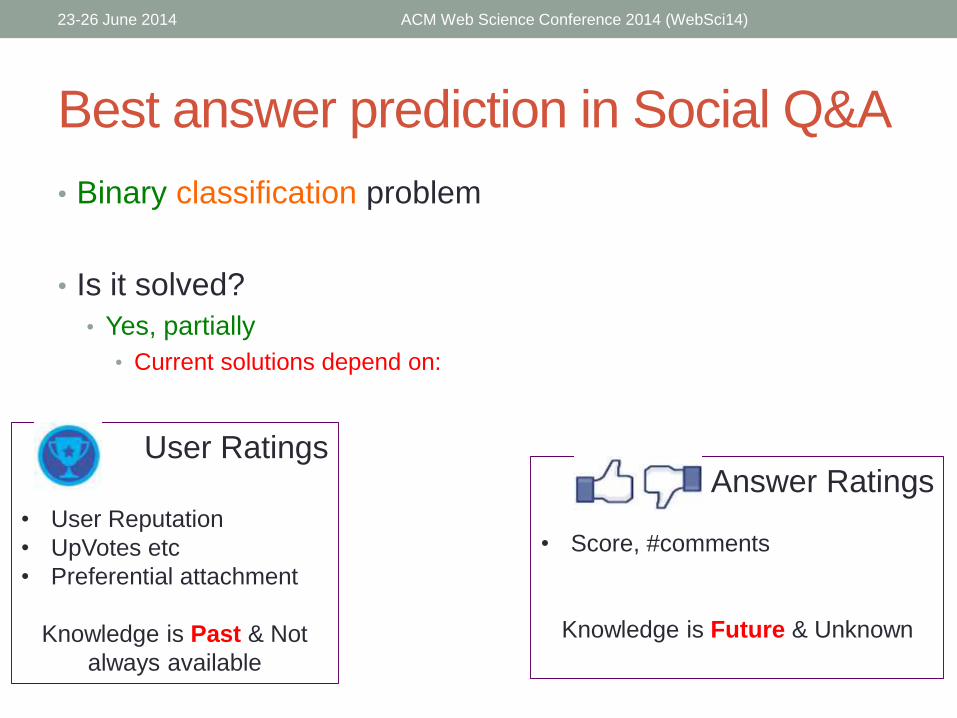
Best answer prediction in Social Q&A
• Binary classification problem
• Is it solved?
• Yes, partially
• Current solutions depend on:
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
Answer Ratings
• Score, #comments
Knowledge is Future & Unknown
User Ratings
• User Reputation
• UpVotes etc
• Preferential attachment
Knowledge is Past & Not
always available

State of the art solutions
“…we observe significant assortativity in the reputations of
co-answerers, relationships between reputation and
answer speed, and that the probability of an answer
being chosen as the best one strongly depends on
temporal characteristics of answer arrivals.”
Ashton Anderson, Daniel Huttenlocher, Jon Kleinberg, Jure Leskovec
Discovering Value from Community Activity on Focused Question
Answering Sites: A Case Study of Stack Overflow.
KDD 2012
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)

State of the art solutions (cont.)
“When available, scoring (or rating) features improve
prediction results significantly, which demonstrates the
value of community feedback and reputation for identifying
valuable answers.”
Grégoire Burel, Yulan He, Harith Alani.
Automatic Identification of Best Answers in Online Enquiry
Communities
ESWC 2012
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
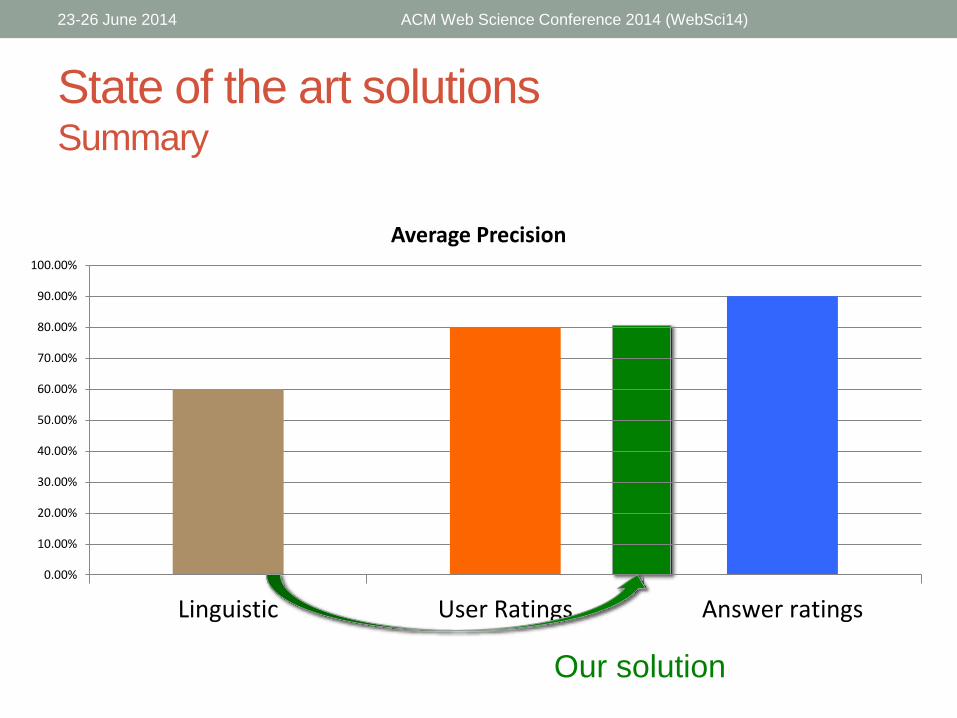
State of the art solutionsSummary
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
Our solution
0.00%
10.00%
20.00%
30.00%
40.00%
50.00%
60.00%
70.00%
80.00%
90.00%
100.00%
Linguistic User Ratings Answer ratings
Average Precision

StackExchange network
SE “is all about getting answers, it’s not a
discussion forum, there’s no chit-chat”
• 123 Q&A sites
• 5,622,330 users
• 9.5 million questions
• 16.3 million answers
• 9.3 million visits per day
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
20 June 2014:

Training Dataset
September 2013 dump
StackOverflow & 20 of the most active SE websites
Questions with Accepted Answers
• 4,366,662 Non Accepted Answers
• 3,939,224 Accepted Answers
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
Accepted Answers
47%
Non Accepted Answers …
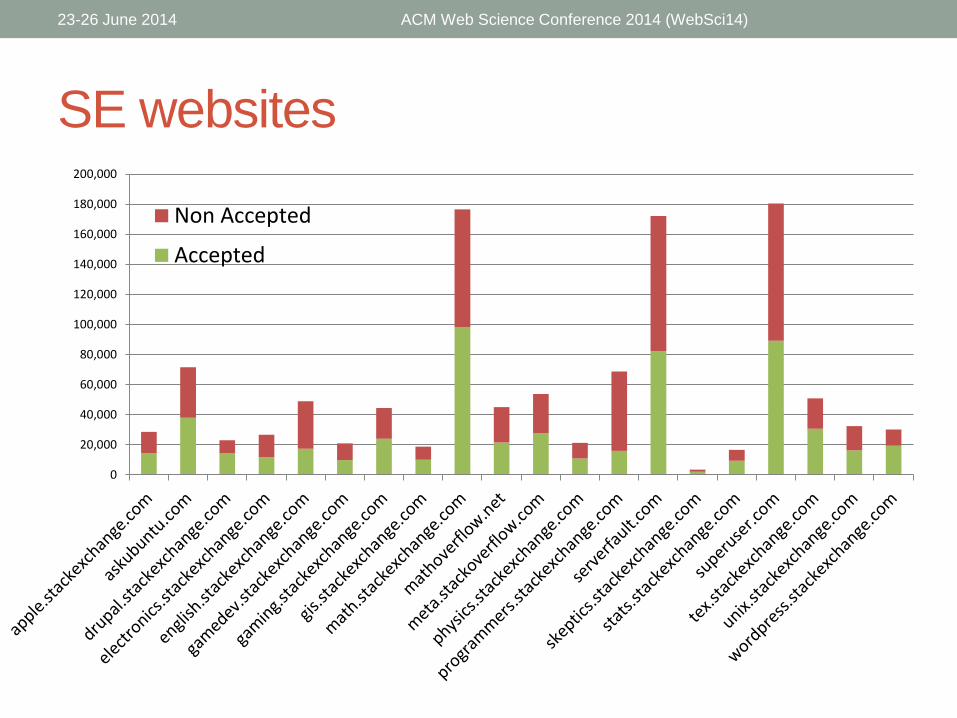
SE websites
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
0
20,000
40,000
60,000
80,000
100,000
120,000
140,000
160,000
180,000
200,000
Non Accepted
Accepted
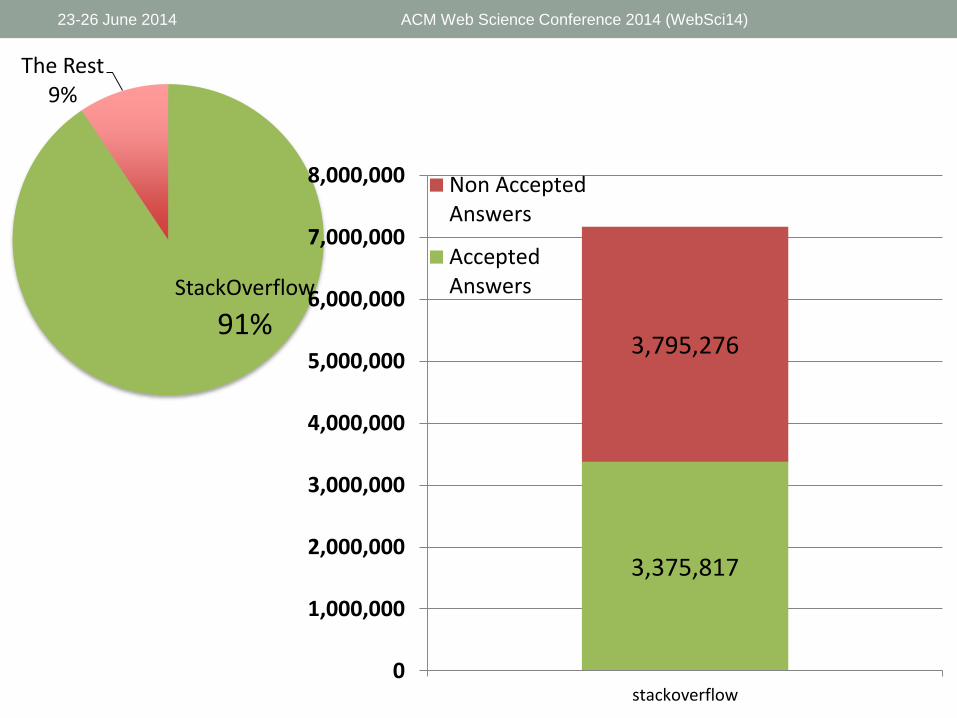
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
StackOverflow
91%
The Rest9%
3,375,817
3,795,276
0
1,000,000
2,000,000
3,000,000
4,000,000
5,000,000
6,000,000
7,000,000
8,000,000
stackoverflow
Non AcceptedAnswers
AcceptedAnswers

Shallow Linguistic features
• Long history, coming from studies on readability
1. Average number of characters per word
2. Average number of words per sentence
3. Number of words in the longest sentence
4. Answer length
5. Log Likehood:
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
Pitler and Nenkova, 2008
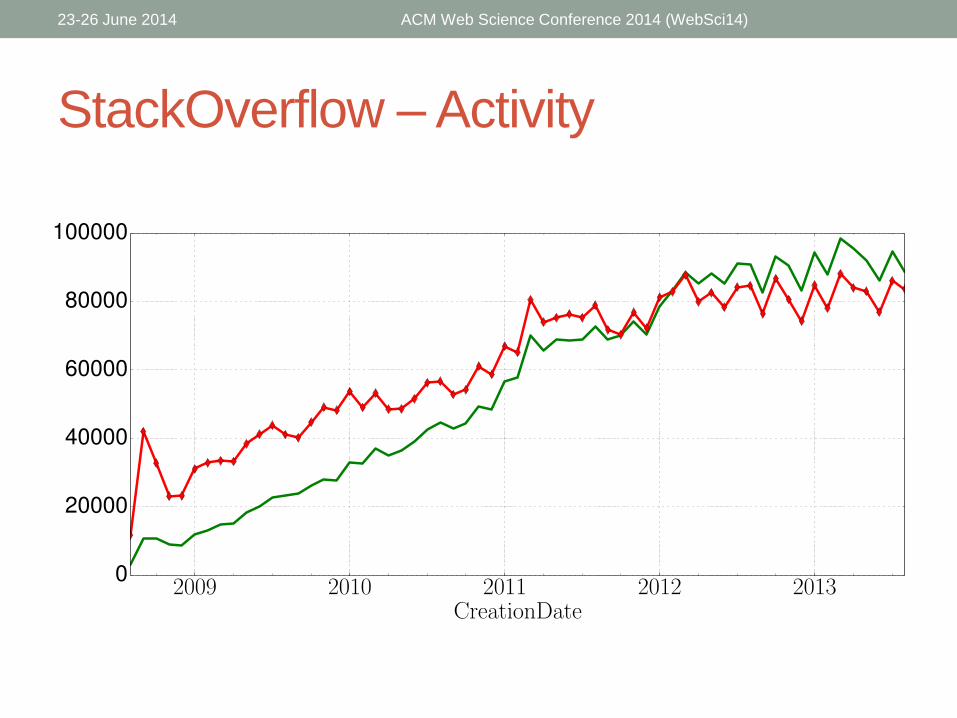
StackOverflow – Activity
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
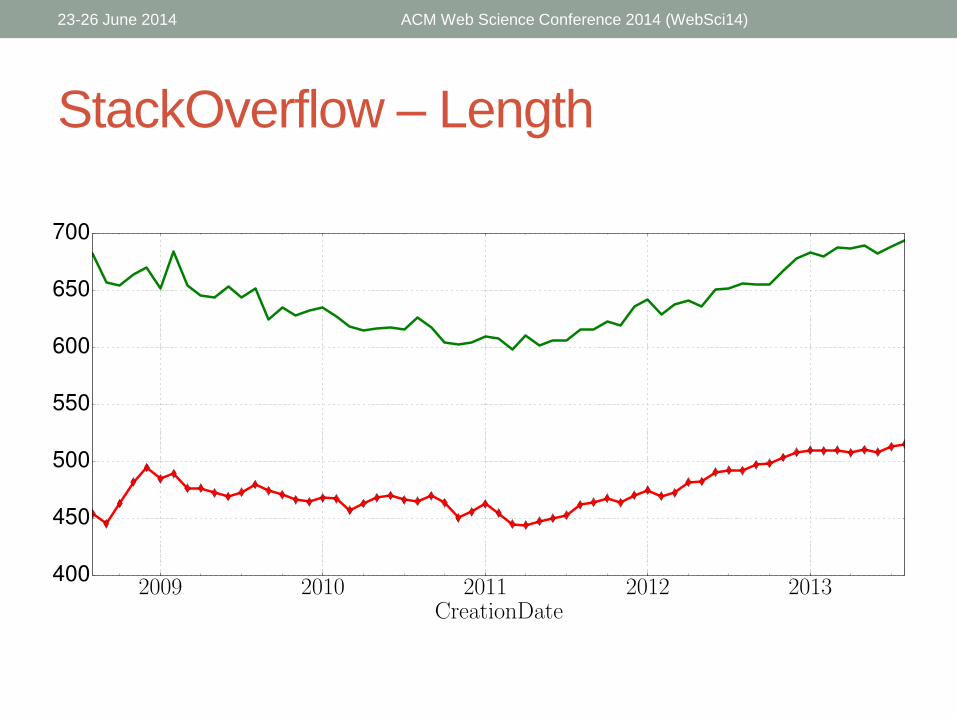
StackOverflow – Length
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
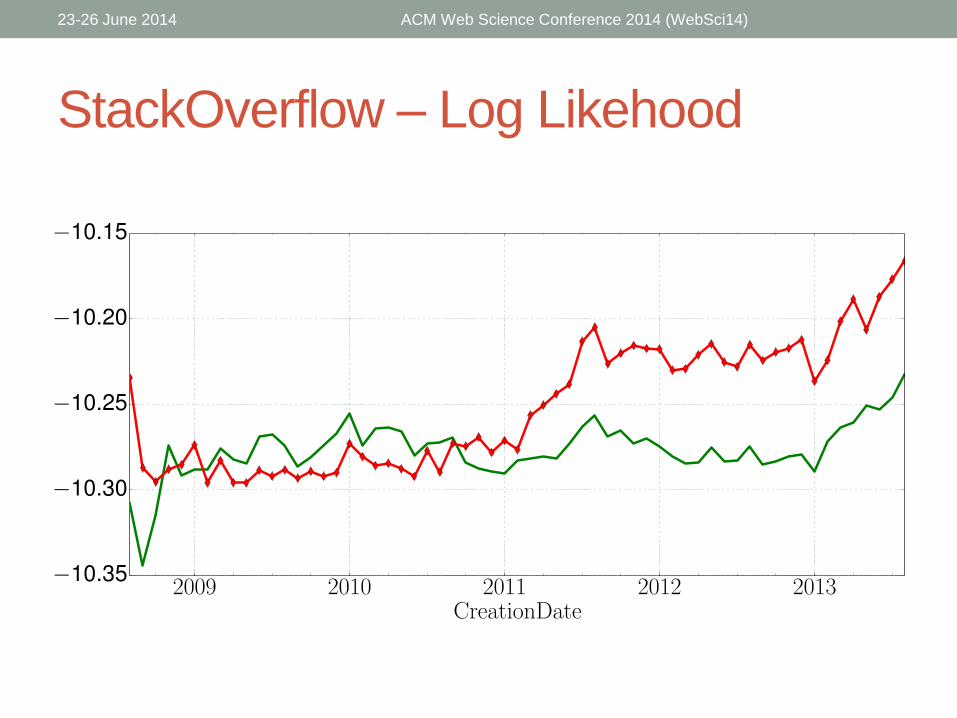
StackOverflow – Log Likehood
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
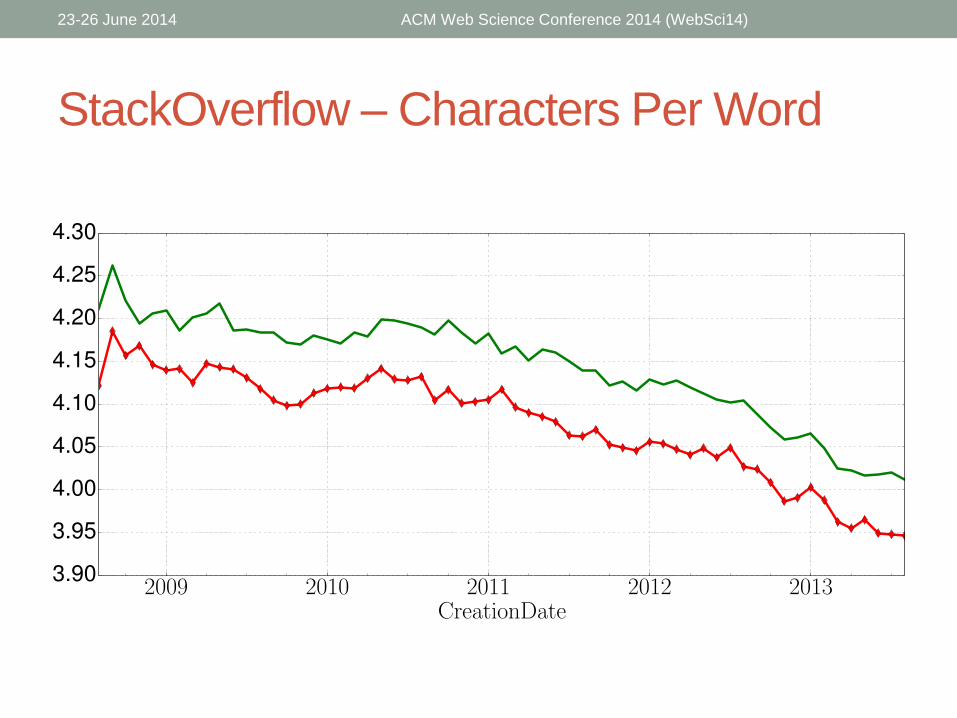
StackOverflow – Characters Per Word
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
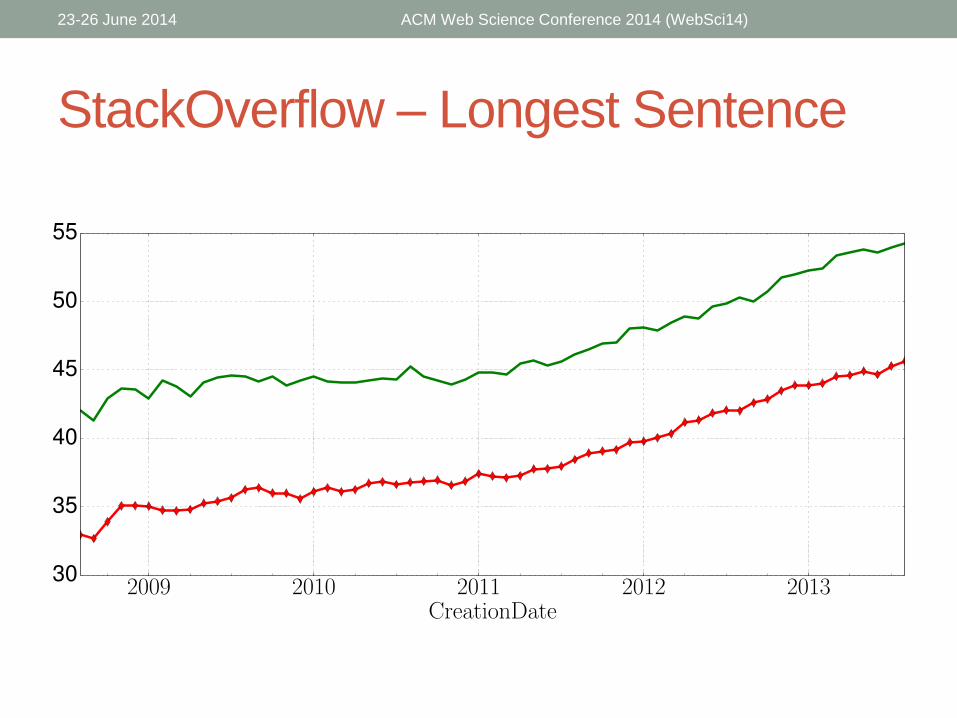
StackOverflow – Longest Sentence
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
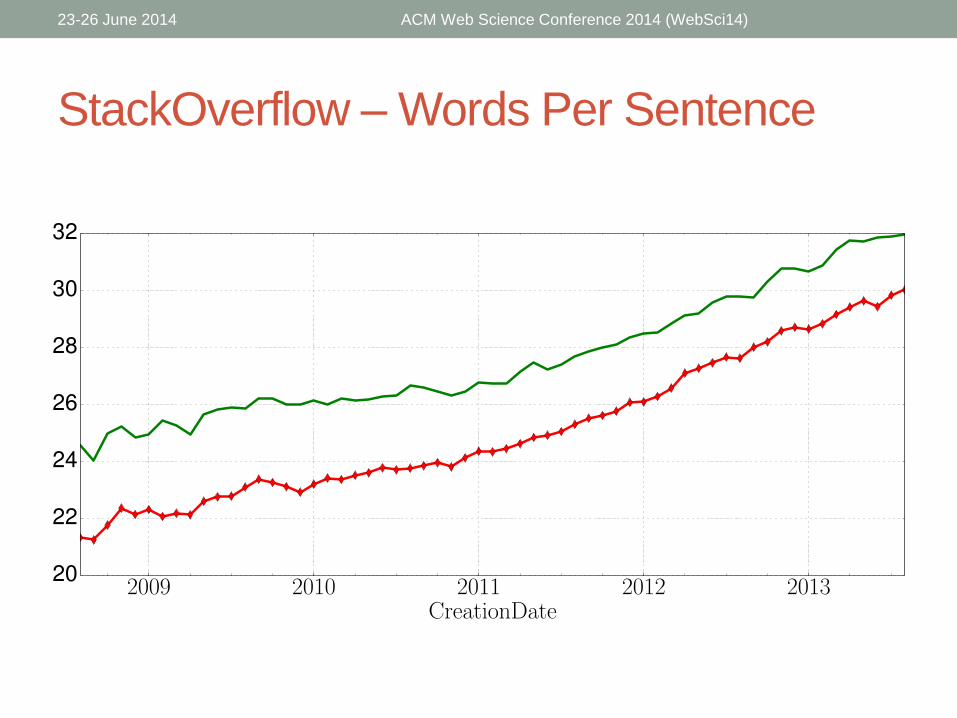
StackOverflow – Words Per Sentence
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
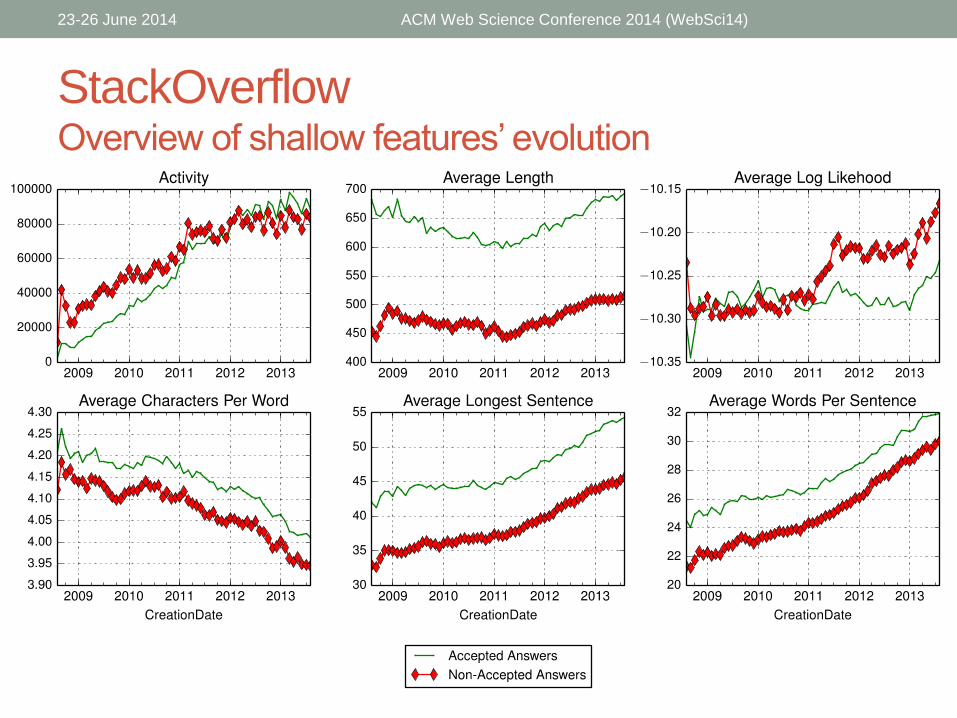
StackOverflowOverview of shallow features’ evolution
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)

Shallow features: Observations
• Accepted answers tend to be:
• Longer
• Differ more from the community vocabulary
• Contain shorter words
• Have longer longest sentences
• Have more words per sentence
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
But how good are shallow features?

But how good are shallow features?
• 58% macro precision (our baseline)
• Possible reasons
1. Evolution of language characteristics
• Language becomes more eloquent
2. Variance is huge
3. Universal classifier looks unreachable, e.g.:
• SuperUser average length is 577
• Skeptics average length is 2,154
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)

Proposed solution
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)

Objectives
• Build a classifier which is:
1. Based on linguistic features solely
2. Robust
• Performs equally well to other classifiers that use user ratings (past
knowledge) or answer ratings (future knowledge)
3. Universal
• Same classifier applicable to as many SE websites possible
(domain agnostic)
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)

Feature discretisationExample for Length
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
Group by question
Question Id
1
5
Answer Id
6
7
Length
2 200
3 150
4 250
150
100
Sort by Length in descending order
Rank
LengthD
1
2
3
1
2

Information Gain from Discretisation
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
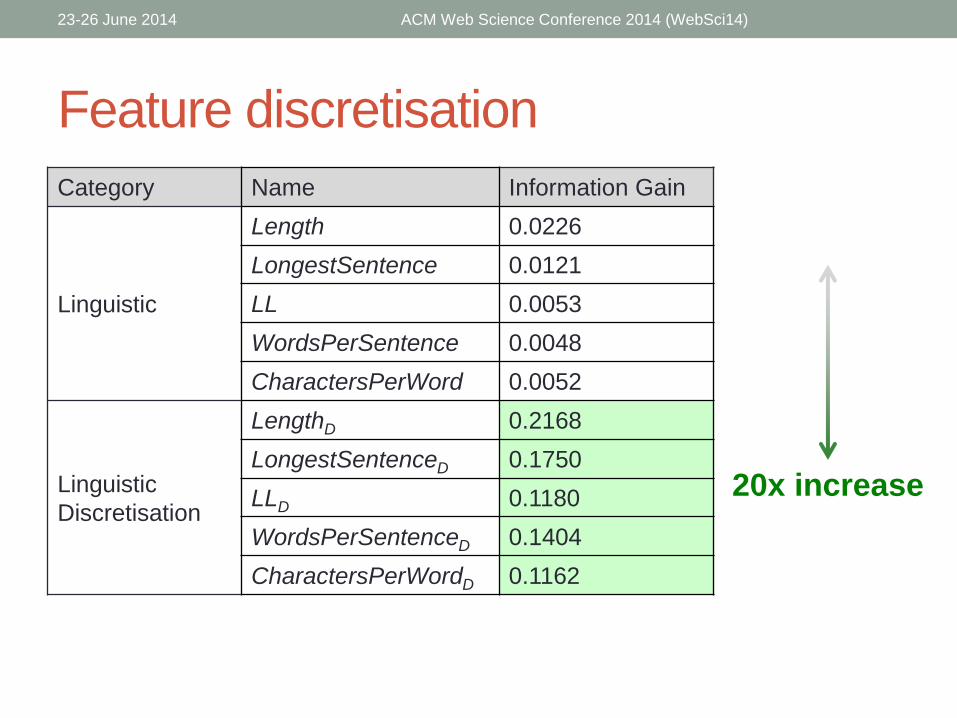
Feature discretisation
Category Name Information Gain
Linguistic
Length 0.0226
LongestSentence 0.0121
LL 0.0053
WordsPerSentence 0.0048
CharactersPerWord 0.0052
Linguistic
Discretisation
LengthD 0.2168
LongestSentenceD 0.1750
LLD 0.1180
WordsPerSentenceD 0.1404
CharactersPerWordD 0.1162
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
20x increase
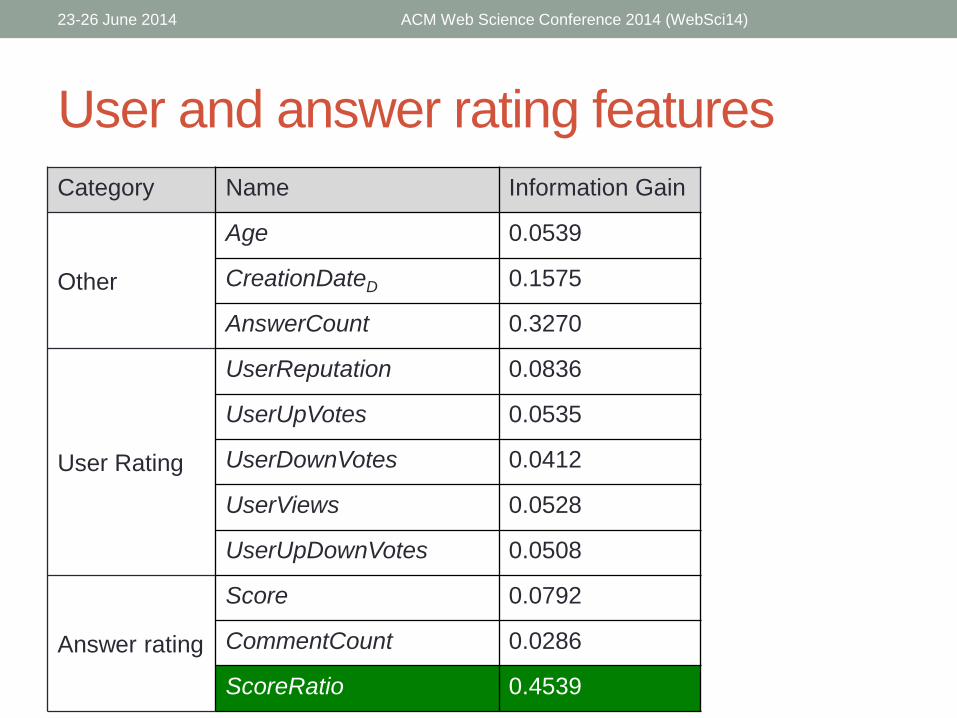
User and answer rating features
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
Category Name Information Gain
Other
Age 0.0539
CreationDateD 0.1575
AnswerCount 0.3270
User Rating
UserReputation 0.0836
UserUpVotes 0.0535
UserDownVotes 0.0412
UserViews 0.0528
UserUpDownVotes 0.0508
Answer rating
Score 0.0792
CommentCount 0.0286
ScoreRatio 0.4539

Evaluation
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)

What are we evaluating?
1. Prediction
2. How good is it compared with the SOTA?
3. Generality
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)

1. Prediction – Features used
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
Linguistic
Linguistic
Discretisation
Other
User
Rating
Answer
Rating
Past Knowledge Future Knowledge

1. Prediction
• Classifier was Alternate Decision Trees (ADT)
• Binary, boosting, numerical data
• Weka
• 10-fold validation
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
Linguistic
Linguistic
Discretisation
Other
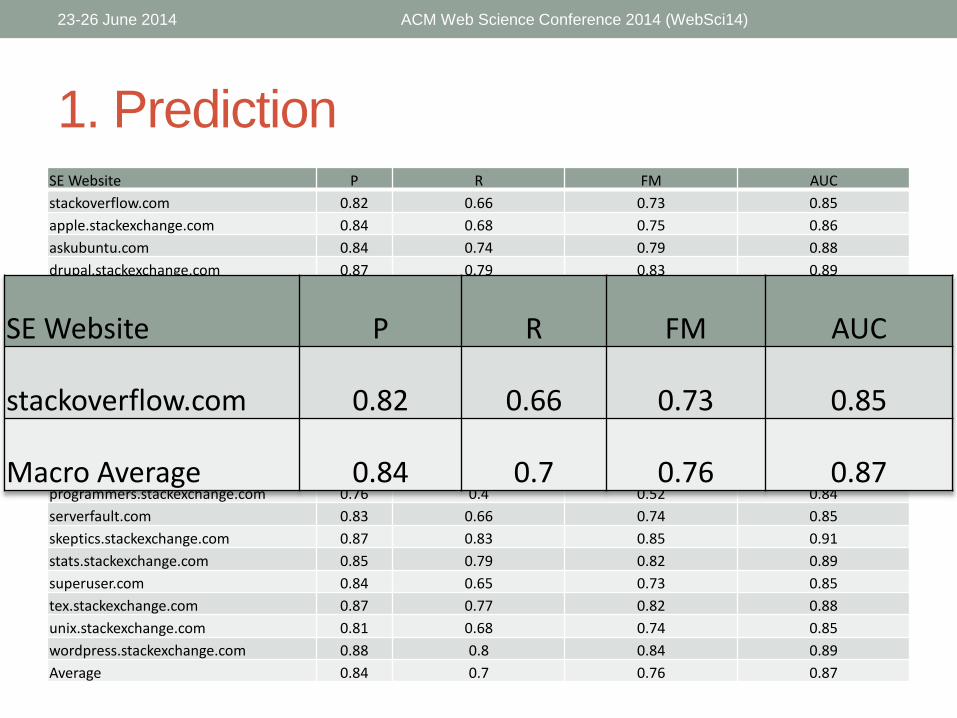
1. PredictionSE Website P R FM AUC
stackoverflow.com 0.82 0.66 0.73 0.85
apple.stackexchange.com 0.84 0.68 0.75 0.86
askubuntu.com 0.84 0.74 0.79 0.88
drupal.stackexchange.com 0.87 0.79 0.83 0.89
electronics.stackexchange.com 0.79 0.65 0.71 0.84
english.stackexchange.com 0.77 0.52 0.62 0.83
gamedev.stackexchange.com 0.82 0.71 0.76 0.87
gaming.stackexchange.com 0.87 0.79 0.83 0.91
gis.stackexchange.com 0.85 0.73 0.78 0.87
math.stackexchange.com 0.85 0.74 0.79 0.87
mathoverflow.net 0.83 0.7 0.76 0.87
meta.stackoverflow.com 0.87 0.69 0.77 0.87
physics.stackexchange.com 0.86 0.71 0.78 0.88
programmers.stackexchange.com 0.76 0.4 0.52 0.84
serverfault.com 0.83 0.66 0.74 0.85
skeptics.stackexchange.com 0.87 0.83 0.85 0.91
stats.stackexchange.com 0.85 0.79 0.82 0.89
superuser.com 0.84 0.65 0.73 0.85
tex.stackexchange.com 0.87 0.77 0.82 0.88
unix.stackexchange.com 0.81 0.68 0.74 0.85
wordpress.stackexchange.com 0.88 0.8 0.84 0.89
Average 0.84 0.7 0.76 0.87
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
SE Website P R FM AUC
stackoverflow.com 0.82 0.66 0.73 0.85
Macro Average 0.84 0.7 0.76 0.87

2. Comparison with other solutions
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
Linguistic
Linguistic
Discretisation
Other
User
Rating
Answer
Rating
Case Features Used
1 Linguistic
2 Linguistic & Discretisation
3 Linguistic & Discretisation &
Other
4 Linguistic & Other & User
Rating
(no discretisation)
5 Linguistic & Other & User
Rating
(with discretisation)
6 All features
(Answer and User Rating
with discretisation)
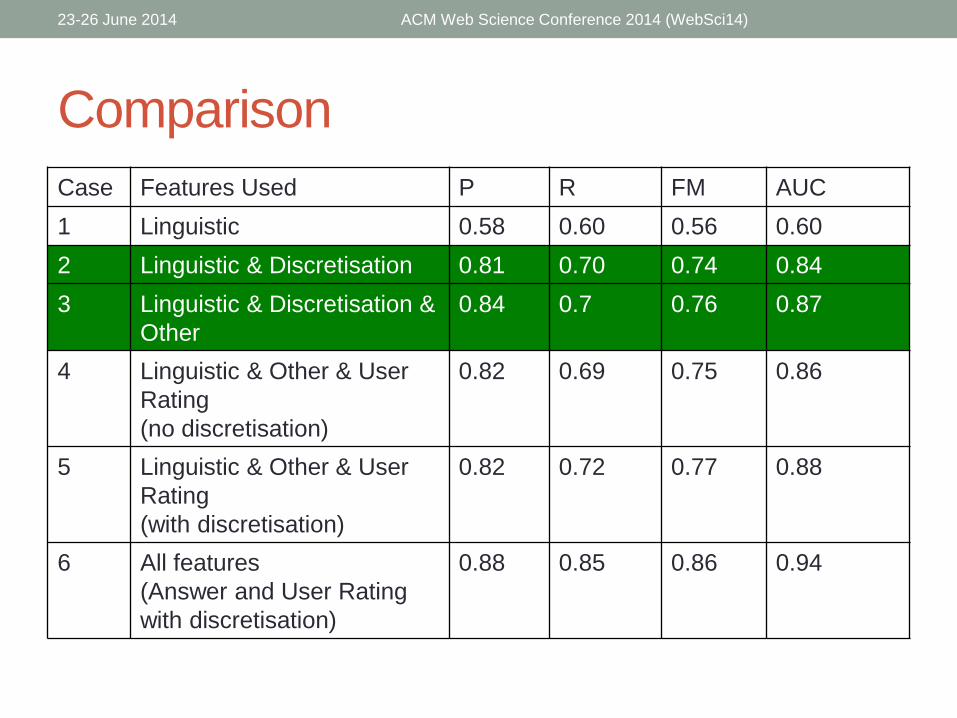
Comparison
Case Features Used P R FM AUC
1 Linguistic 0.58 0.60 0.56 0.60
2 Linguistic & Discretisation 0.81 0.70 0.74 0.84
3 Linguistic & Discretisation &
Other
0.84 0.7 0.76 0.87
4 Linguistic & Other & User
Rating
(no discretisation)
0.82 0.69 0.75 0.86
5 Linguistic & Other & User
Rating
(with discretisation)
0.82 0.72 0.77 0.88
6 All features
(Answer and User Rating
with discretisation)
0.88 0.85 0.86 0.94
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
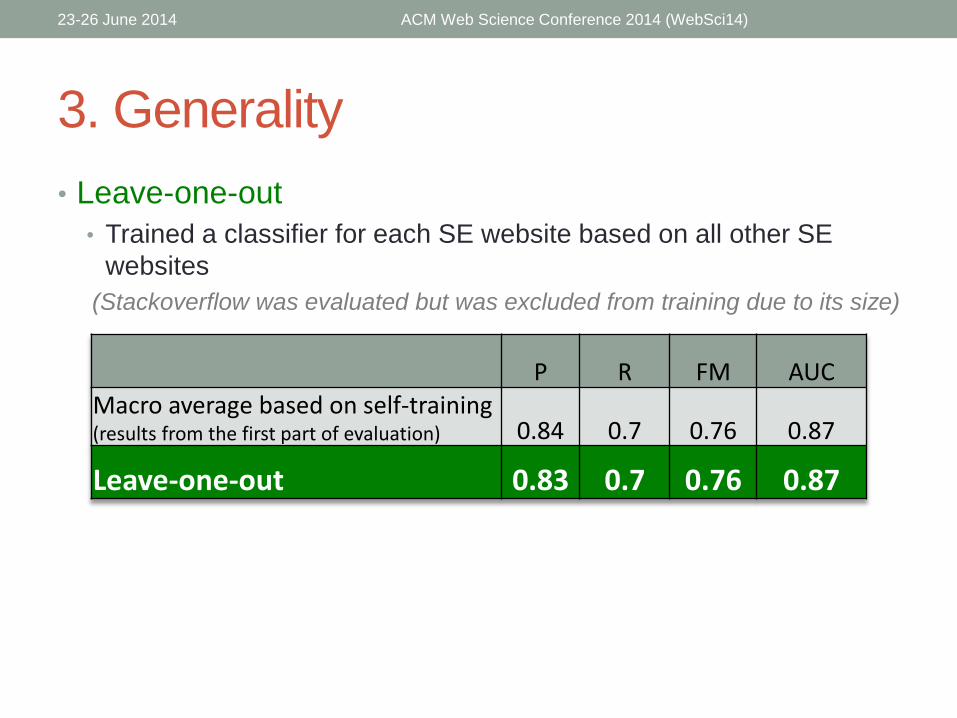
3. Generality
• Leave-one-out
• Trained a classifier for each SE website based on all other SE
websites
(Stackoverflow was evaluated but was excluded from training due to its size)
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
P R FM AUCMacro average based on self-training(results from the first part of evaluation) 0.84 0.7 0.76 0.87
Leave-one-out 0.83 0.7 0.76 0.87

Discussion & Conclusion
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)

Best Answer prediction
• Community feedback on the answers remains the best
way for determining the best answer, but
• Discretisation reveals a lot more information
• Content features, even shallow ones CAN be very informative
• Independent from past (not always available) knowledge
• Independent from future knowledge
• Web application/service is under development
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
Best Answer Prediction
User & answer rating
Linguistic features
?
Proposed
solution

Thank you
23-26 June 2014 ACM Web Science Conference 2014 (WebSci14)
http://xkcd.com/386/
Recommended

















