Application Performance Management for
CFML and ColdBox
Darren Pywell / Joel Watson

About Darren
● CTO at Intergral (The FusionReactor people…) ● 18 yrs CF experience (CF released 20 years ago!) ● Over 33 years in Software ● Worked in HP’s OpenView Network + System
Management Software Division before Intergral ● Background in Network and System Management
for banks ● Responsible for all Fusion(X) products ● Based in Stuttgart, Germany for last 25 years :-)

Overview
• The need for monitoring • Gartner Application Performance Model • Core APM • Stability • When things go wrong • World Premier! • Monitoring ProfileBox and FusionReactor

The Need for APM
Modern IT solutions need to be monitored and managed in a complete, end-to-end manner
Detail remains important and has to be set into a well-understood overall picture of system behavior
Five distinct dimensions of application performance exist, each one complementary to the others

Gartner's APM Model
Five Dimensions:
End-user experience monitoring Transaction profiling
Runtime application architecture Component deep-dive monitoring
Analytics
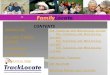
UEM in Action
Application Server
APM Solution
<html>
body...
<script> uem tracker... </script> </html>
UEM tracker
ServerNetworkBrowser
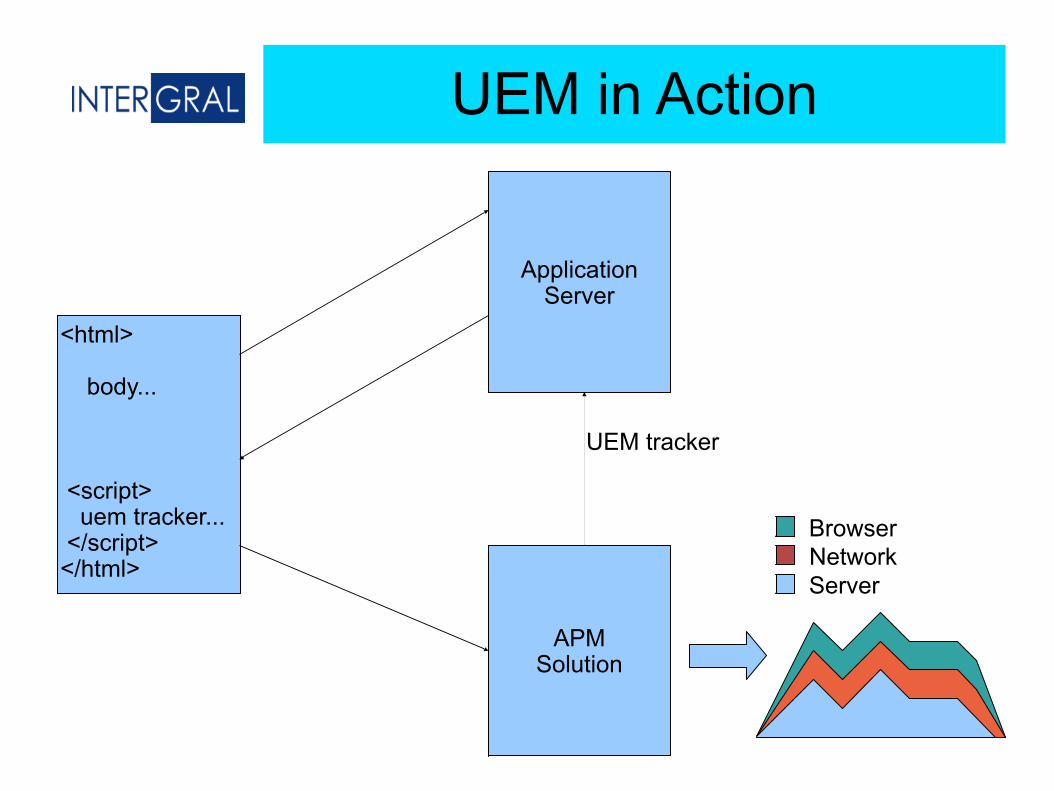
UEM in Action
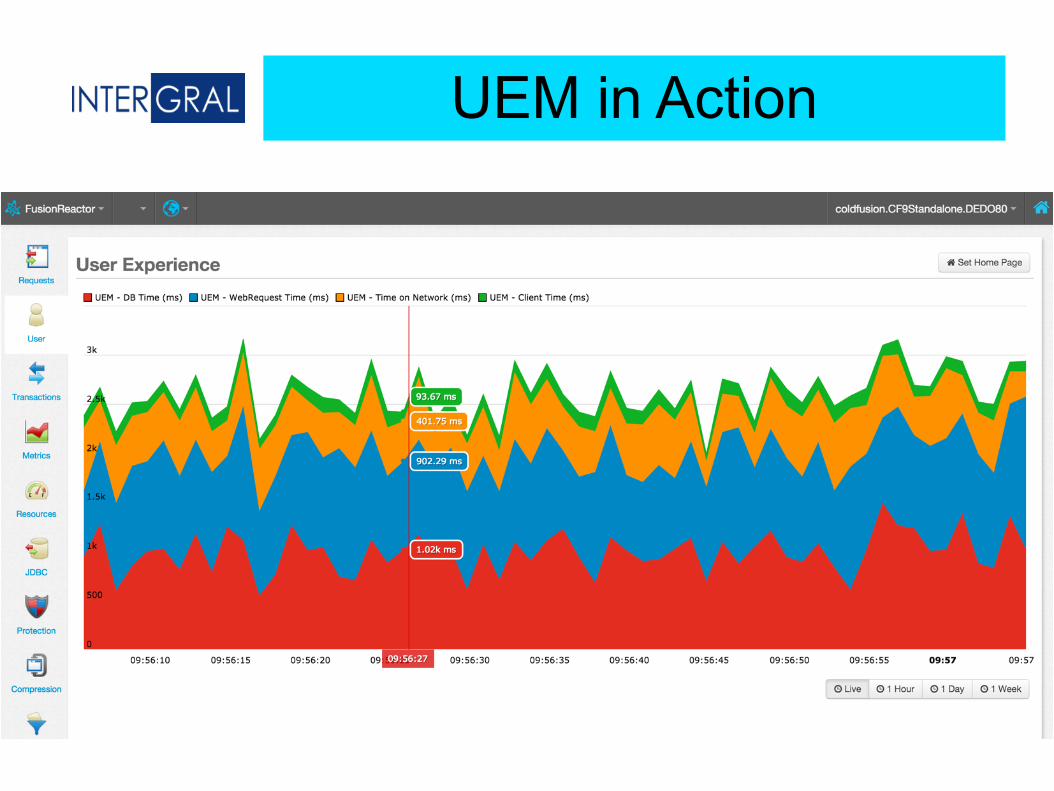
Transaction Call Stack
CFHTTP
Total Transaction
Exits Platform
Component 1
Component 2
Component 3
JDBC
Depth of Call Stack
Coverage (60% or more)
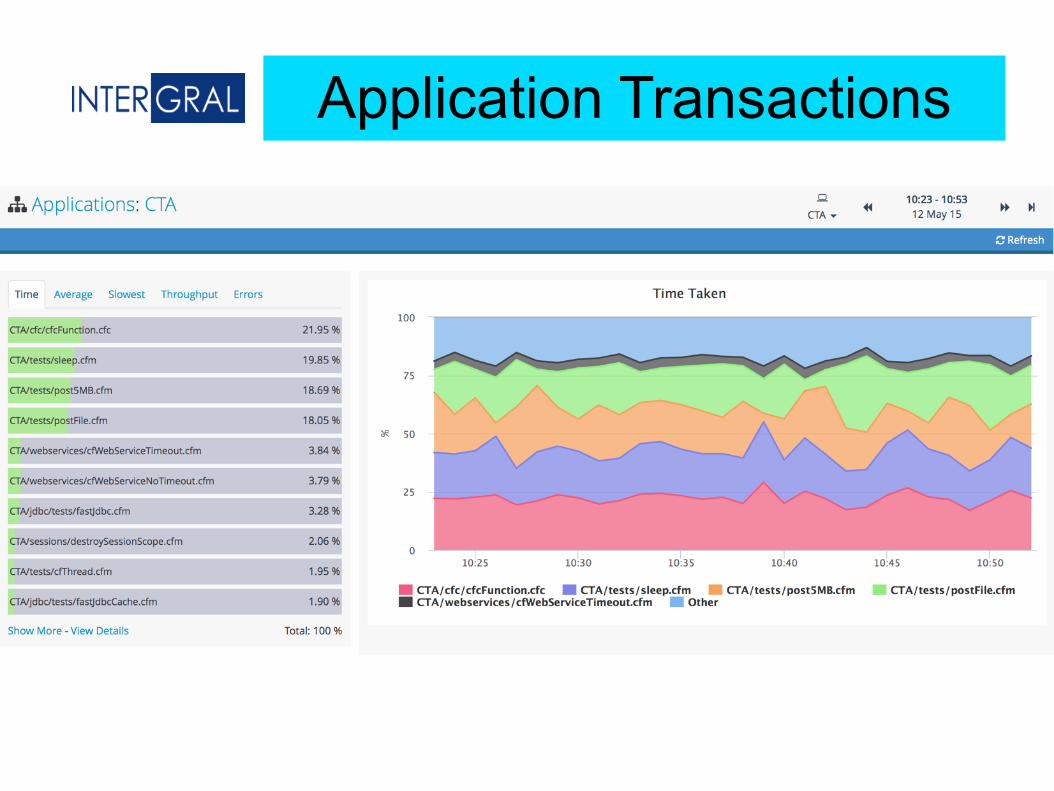
Application Transactions

Applications
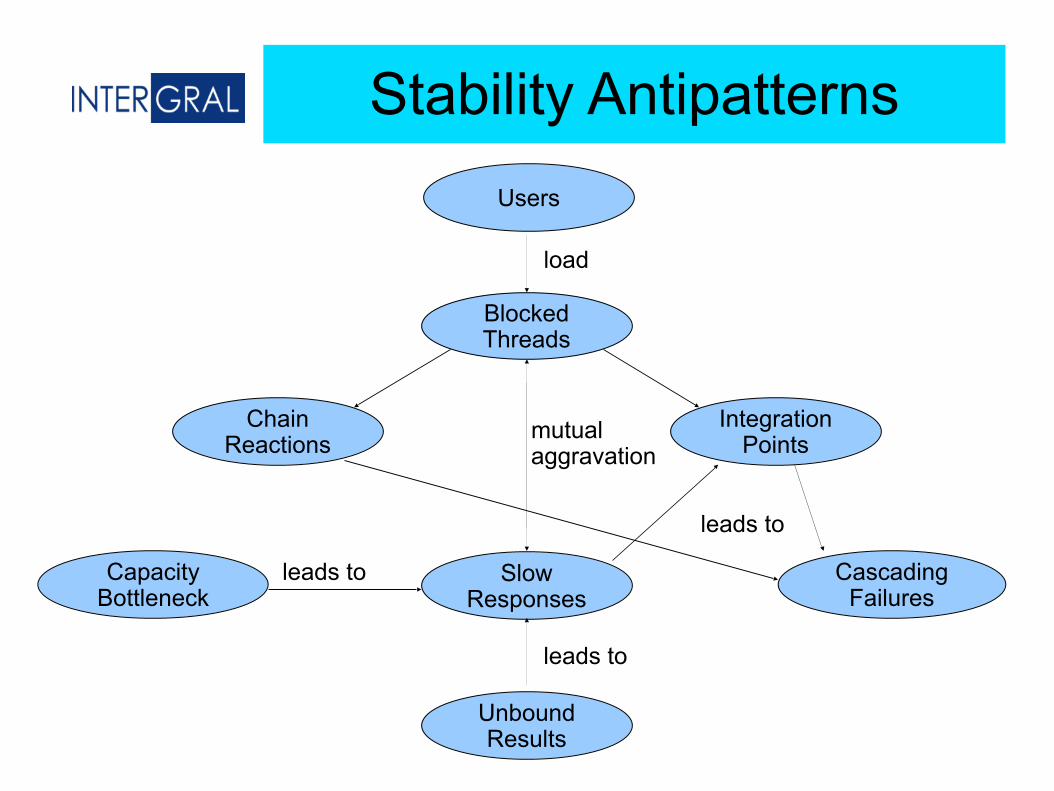
Stability Antipatterns
Integration Points
Chain Reactions
Slow Responses
Unbound Results
Capacity Bottleneck
Cascading Failures
load
leads to
leads to
leads to
mutual aggravation
Blocked Threads
Users

Stability Antipatterns
● Blocked ThreadsAlmost all stability issues relate to Block Threads eventually. Caused by locks,synchronizers,resources waits,exhaustion
● Chain ReactionBlocked threads on one server increase load on others. This slows the them down, causing more blocked threads...
● Integration PointExit points from the platform. Typical systems today may touch 8 or more on average. You're at the mercy of someone else...
● Cascade FailureOccurs when problems in one layer causes problems in the previous. Cracks jump from system to system. Be paranoid about integration and stay up even if they do down.
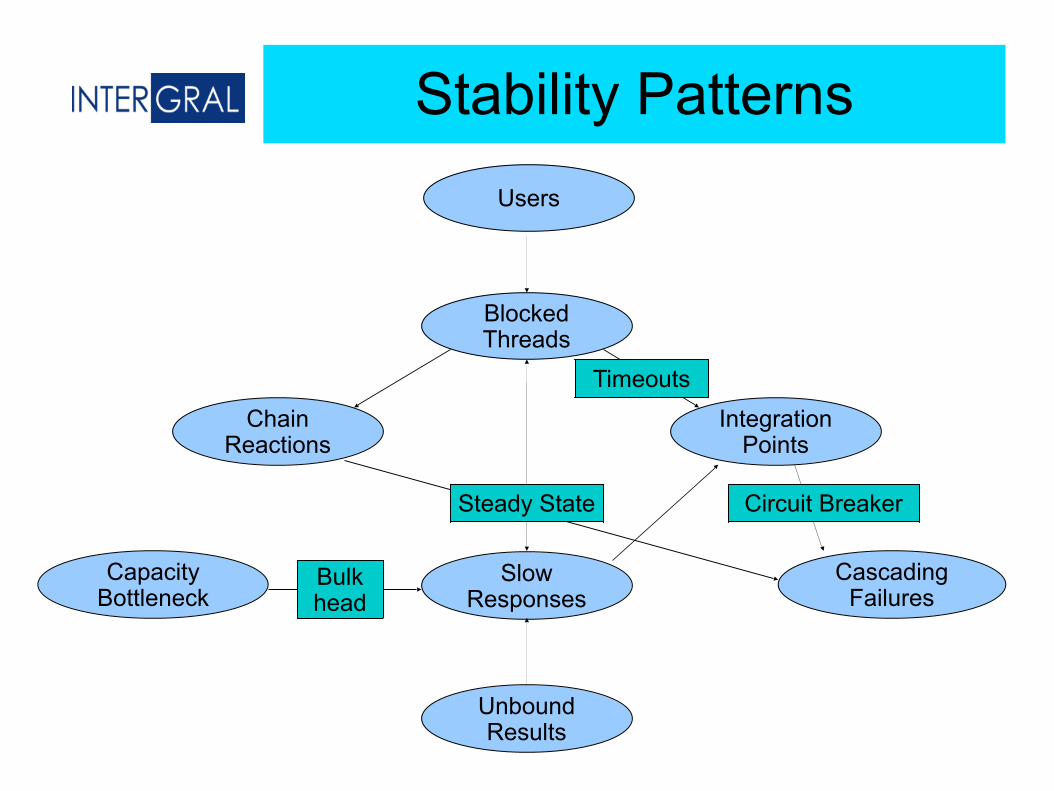
Stability Patterns
Blocked Threads
Users
Integration Points
Chain Reactions
Slow Responses
Unbound Results
Capacity Bottleneck
Cascading Failures
Circuit BreakerSteady State
Bulkhead
Timeouts
Stability Patterns
● Circuit BreakerProtects callers by not calling if Integration Point has failed. Fast-fail when the breaker is open.
● Steady-State System must run without you touching it. Anything that grows resource (DB,files) must have a something that cleans it up. Use caching to maintain performance.
● BulkheadPartitions capacity to preserve functionality. Use pools to protect critical actions
● TimeoutsUse timeouts to prevent integration points becoming blocked threads. Consider (delayed) retries.

When things go wrong
• Avoid Blame!!! • Reduce Service instead of Outage • Monitor and Gather Data • Mean Time to Restore Service (MTRS) • Always generate a test for every bug you find • Tools are critical (ProfileBox) • How can you debug a production problem?

UPD Unattended Production Debugging
World Premier!!!

UPD
What if you could…
debug when you’re not there? safely debug a production system?
fix a problem without changing code?
Now you can!!!

Thanks for listening...
More information on:
http://www.fusion-reactor.com
Email: [email protected] Web: www.intergral.com
Recommended