
1
Supplementary Information Appendix
Identification of the VERNALIZATION 4 gene reveals the origin of
spring growth habit in ancient wheats from South Asia
Nestor Kippes, Juan M. Debernardi, Hans Vasquez-Gross, Bala A. Akpinar, Budak Hikmet,
Kenji Kato, Shiaoman Chao, Eduard Akhunov and Jorge Dubcovsky*
* correspondence to: [email protected]
This file includes:
SI Appendix, Methods S1 to S6
SI Appendix, Figures S1 to S14
SI Appendix, Tables S1 to S8
SI Appendix, References

2
SI Appendix, Methods
SI Appendix, Method S1. TILLING Mutants Screening
A mutagenized population of 1,153 lines of TDF treated with 0.9% EMS was screened with
three different set of primers using a CelI assay described before (1). The first set of PCR
primers (TILL-5DS-F1 and TILL-A-DS-R10, Table S8) included the VRN-D4 specific SNP
A367C, and amplified a region from exon 4 to 8 only from VRN-D4. Two additional sets of
primers, developed in a previous study (2), were used to amplify different regions of the VRN-D4
gene. Primers V1A-5PRIME-F1 and V1-INT1R amplified a region including exon 1, whereas
primers VA1-3PRIME-F2 and VA1-3PRIME-R3 amplified a region from exon 3 to 6. Even
though these primers amplified both VRN-D4 and VRN-A1, mutations were still detectable with
the CelI assay. To determine which of the two genes carry the detected mutations, we extracted
RNA from the first leaf of selected mutants and sequenced the resulting cDNAs. Since only
VRN-D4 is expressed in unvernalized plants during the early stages of development (Fig. S3), the
mutations detected in the cDNAs from the first leaf were assigned to VRN-D4. The potential
effect of these mutations on protein structure and function was predicted using programs
PROVEAN (3), SIFT (4), and PolyPhen-2 (5).
VRN-D4 specific primers: Using primers TILL-5DS-F1 and TILL-A-DS-R10 (Table S8) we
detected 21 mutations. Ten of these mutations were located in the VRN-D4 coding region, and
four of them were predicted to produce amino acid changes. Prediction programs consistently
identified mutation E158K in the K-box as having the strongest effect among the mutations
detected (Table S1). The same prediction programs suggested limited effects for the other three
mutations (A180T, D184N and A219T, Table S1). Based on these results the last three mutations
were discarded and only the E158K mutation was selected for further phenotypic
characterization. RNAs were extracted from the first leaf of the E158K mutant line and the
presence of the causing mutation in the transcripts was validated by sequencing the
corresponding cDNAs.
VRN-D4 and VRN-A1 specific primers: The screening of the TDF TILLING population with
primers V1A-5PRIME-F1 and V1-INT1R yielded 19 mutants, but only 3 of them were mapped

3
within the exon 1 region. Two of these mutations were predicted to generate amino acid changes
(E12K and E42K) but, unfortunately, both were located in the VRN-A1 gene.
Primers VA1-3PRIME-F2 and VA1-3PRIME-R3 detected 7 mutants in the exons 3-6 region.
One of these mutations was predicted to produce an amino acid change (E129K) but it was
located in the VRN-A1 gene. A second mutation resulted in the loss of the donor splicing site of
the fourth exon of VRN-D4. The un-spliced intron sequence is predicted to encode two premature
stop codons 8 bp and 17 bp downstream of the induced mutation. The first stop codon is
predicted to truncate the protein after position 143. This premature stop codon eliminates 30% of
the K-box and more than 40% of the protein and, therefore, will almost certainly result in a non-
functional protein. To confirm the presence of these premature stop codons in the VRN-D4
transcripts we extracted RNA from the first leaf of unvernalized mutant and wildtype TDF
plants. Amplified VRN-D4 cDNAs were cloned using NEB® PCR Cloning Kit (New England
Biolabs, USA) and sequenced by Sanger sequencing. The presence of the un-spliced intron and
the two predicted stop codons was detected in the sequences of 16 independent clones from the
TDF mutant plant. The sequenced transcripts included the diagnostic A367C SNP, confirming
that they were encoded by VRN-D4. By contrast, all the sequences from the 22 clones from
wildtype TDF used as control showed the correctly spliced transcripts with the A367C natural
SNP corresponding to VRN-D4.
Visualization of the effect of VRN-D4 mutations: We selected 268 protein sequences from
PROVEAN (provean.jcvi.org) using a BLAST search with the VRN-D4 protein as query. These
protein sequences were aligned using MEGA 6 (6) (http://www.megasoftware.net/) and the
multiple alignment file was used to generate Figure S8 using the program WebLogo
(weblogo.berkeley.edu), in which the size of the letters for the different amino acids are
proportional to their frequency in the multiple alignment.
SI Appendix, Method S2. BAC Sequencing and Physical Map
We screened the Minimum Tiling Path (MTP) clones of the 5DS physical map constructed from
ditelosomic 5DS stock in Chinese Spring (CS-dt5DS) using three sets of primers for VRN-D4
(Table S8). The 5DS BAC library was developed by the Institute of Experimental Botany AS CR
and the physical map was generated by the International Wheat Genome Sequencing Consortium

4
(IWGSC, www.wheatgenome.org). We identified one BAC (TaeCsp5DShA_0038_M14) that is
part of overlapping contigs CTG87 and CTG61 (Table S2). A total of 12 MTP clones from these
two contigs were selected for sequencing. Sequencing libraries were prepared using the KAPA
LTP Library Preparation Kit according to manufacturer instructions (KAPA Biosystems, USA)
with an average insert size of 250 bp. Four additional libraries were prepared for BACs 9-12
(Table S2) with an average insert size of 400 bp to increase the quality of the assembly in this
region. Libraries were barcoded, pooled, and sequenced at the Beijing Genomic Institute
(Sacramento, CA, USA) using 100-bp paired-end reads (Illumina Hi Seq2500).
Each BAC was assembled using Abyss v1.5.2 (k=63) and combined libraries with 250 and 400-
bp insert sizes to assess library coverage (individual BACs coverage was higher than 100X).
Since extensive overlap existed between adjacent BACs, a better assembly was obtained by
analyzing together the Illumina reads from groups of four BACs and performing the assembly
with Abyss (k=63). Additional contigs generated from 454 sequencing of the same BACs were
used to fill some of the gaps between the Illumina contigs. 454 sequencing was carried out on GS
FLX Titanium platform (Roche 454 Life Sciences, Branford, CT, USA) using kits and
instructions provided by the manufacturer. The assembled 680-kb sequence was deposited in
GenBank (AC270085).
Genes were annotated using the TriAnnot pipeline (7). The resulting assembly was compared
using BLAT with the IWGSC sequence of the 5AL chromosome arm
(https://urgi.versailles.inra.fr/blast/), with the A genome of T. urartu (8) and with three different
Ae. tauschii databases (http://plants.ensembl.org/Aegilops_tauschii/, GCA_000347335.1 (9),
http://aegilops.wheat.ucdavis.edu/ATGSP/, (10), and
https://urgi.versailles.inra.fr/download/iwgsc/TGAC_WGS_assemblies_of_other_wheat_species,
TGAC_WGS_tauschii_v1). Hits were filtered to be larger than 500 bp and more than 99%
identical (Fig. 3A). Results were converted to gff format and visualized using IGV
(www.broadinstitute.org/igv/).
SI Appendix, Method S3. Marker for the 5DS/5AL Insertion Site
Based on the comparisons described in the previous section, one of the 5DS/5AL insertion
borders was identified 88,344 bp upstream of the start codon of VRN-D4 (henceforth “upstream

5
insertion site”, Fig. 3B). Upstream of this point, the CS-dt5DS sequence was 99.3% identical to
Ae. tauschii contig 5265.1, and downstream of this point it was 99.6 % identical to contig
IWGSC_5AL_2795346 (chromosome arm 5AL). We designed primers VRND4-ins.F4
(CGTCTACAGAACCAGCTGAC) and VRND4-ins.R3 (GAAAATCAGGGTGTGACAAA) at both sides of
this 5DS/5AL insertion point. These primers amplify a 1,440-bp product only in the lines
carrying the 5DS/5AL insertion. As a PCR amplification control, we included a second pair of
primers that amplifies a gene located in the centromeric region of chromosome arm 5DL
(BJ315664) (11). Primers BJ315664-F (ACTTGCGTTCCATGTTCACACTTGTAGG) and BJ315664-R
(GCGCTCCTGGCAGCAGTCTC) amplify a 687-bp product in all lines.
The other border of the 5DS/5AL insertion was identified within a 1.7-kb region located 201,341
to 203,027 bp downstream of VRN-D4 (henceforth “downstream insertion site”, Fig 3B). The
CS-dt5DS sequences flanking this region are 98.7% identical to 5AL contig 2801682 and 99.8%
identical to Ae. tauschii contig 280242 (TGAC_WGS_tauschii_v1). We used primers VRND4-
ins2.F1 (TATCTACACCCAGCGAGAGA) and VRND4-ins2.R1 (GGCCTACCAAAAACAAAAGT) to
amplify a PCR product of 1,283bp. As a positive control we use primers for BE606654, a gene
located in chromosome arm 5DS (11). Primers BE606654-F (ACCGACAAGAACTCCTAGAT) and
BE606654-R (CAAAAGCATCGCAGAGAAACAC), amplify a 534-bp product in all lines.
PCR reactions were conducted in a total volume of 20 μl containing 10 mM Tris–HCl, PH 8.3,
50 mM KCl, 2 mM MgCl2, 0.2 mM dNTP, 0.5 μM of each primer for the insertion and 0.05 μM
of each control primer, 50–100 ng of genomic DNA, and 0.5 U Taq DNA polymerase. PCR
amplification was performed as follows. 94°C for 5 m, 8 cycles of initial touch down starting at
65°C (-0.5°C per cycle), followed by 32 cycles of 94 °C for 30 s, 61 °C for 30 s, and 72 °C for
90 s, with a final extension at 72 °C for 7 min.
SI Appendix, Method S4. RNA-EMSA
RNA probes (27 nt and 34 nt) biotinylated at the 3’ were acquired from SIGMA-ALDRICH (St.
Louis, MO USA). Purified RNase-free proteins GST-TaGRP2 and GST (as control) were used in
the binding assays. GST-TaGRP2 was cloned in the pGEX-6P-1 vector, expressed in E. coli, and
purified using GST SpinTrap Purification Module (GE Healthcare) (Fig. S9A). RNA-
Electrophoretic Mobility Shift Assays (EMSA) were performed according to the LightShift®

6
Chemiluminescent RNA EMSA Kit instructions (Pierce, USA), including 5% DMSO in the
binding reaction. To avoid variation in protein quantity between binding reactions, a master mix
with GST-TaGRP2 and all the binding components, except RNA probes, was prepared and
aliquoted. We also included a pre-incubation step of the free RNA probes for 3 minutes at 80 °C
to favor complete denaturation of the RNA structure. Samples were then allowed to re-nature
slowly at room temperature before adding to the binding reaction. A separate experiment was
performed by transferring the samples from room temperature to 4°C and performing the binding
reaction at this temperature to simulate vernalization conditions. Probe sequences are listed in
Table S8. RNA structure for the 27-nt and 34-nt probes and for the larger flanking region
(including 200 nt from each side of the T. monococcum RIP-3) were generated with the program
RNAfold (12) using default parameters.
SI Appendix, Method S5. Population Structure analysis
To determine if the absence of VRN-D4 in two lines classified as T. aestivum ssp.
sphaerococcum from China (CItr 8610 and CItr 10911, Supplemental Table S6) was the result of
introgression from other T. aestivum subspecies, we performed a population structure analysis.
The analysis included 100 T. aestivum lines from six different subspecies: T. aestivum ssp.
aestivum (10 spring and 10 winter accessions), T. aestivum ssp. compactum (17 accession), T.
aestivum ssp. macha (15 accession), T. aestivum ssp. spelta (15 accession), and T. aestivum ssp.
sphaerococcum (33 accessions, including the two conflictive accessions from China) (Table S6).
A total of 16,371 polymorphic SNP were used to determine the population structure (13), using a
model-based method (Bayesian clustering) implemented in STRUCTURE v.2.3.4 (13). The SNP
data for the 100 accessions listed in Table S6 was deposited in the Triticeae Toolbox website
(https://triticeaetoolbox.org/wheat/). The number of subpopulations (K) tested varied from 2 to 8.
For each K value 10 runs were repeated separately, starting with a burn-in period of 5,000
iterations, and followed by a sampling phase of 10,000 replicates. To detect the numbers of
groups that better fit with the population structure, a plot of the mean likelihood values per K
was produce using STRUCTURE HARVESTER v 0.6.93 (14). The kinship matrix was
calculated using 16,371 SNPs with the program TASSEL 4.3.10 (www.maizegenetics.net). The
heat map graph representing the kinship values was constructed in R (www.r-project.org).

7
SI Appendix, Method S6. Genetic Diversity
Variability at each locus was determined using the Polymorphism Index Content (PIC) (15). PIC
values were calculated separately for each of the five subspecies.
n
iipPIC 21 (where pi
is the frequency of the ith allele)
Genetic diversity was estimated using Weir’s formula (16) that is equivalent to an average PIC
value,
l i
ipL
D 211
where p is the frequency of the i allele at the l locus and L is the number of loci. PIC
values for each subspecies were averaged across genomes (Table S7), chromosomes (Fig. S12),
and chromosome regions (Fig. 5E). To reduce the effect of ascertainment bias in the last two
parameters, the average diversity per chromosome or chromosome region (for each of the
subspecies) was divided by the corresponding genome average in Table S7. This ratio is referred
to as “standardized genetic diversity”. The values from Table S7 cannot be used to compare
diversity levels among subspecies because many of the SNPs used in this study were specifically
selected for higher minor allele frequencies in T. aestivum ssp. aestivum (17). These values were
calculated only to standardize the average genetic diversity values per chromosome and
chromosome region. These studies were performed using a subset of 14,236 SNP for which
chromosome locations were available.
8
SI Appendix, Figures
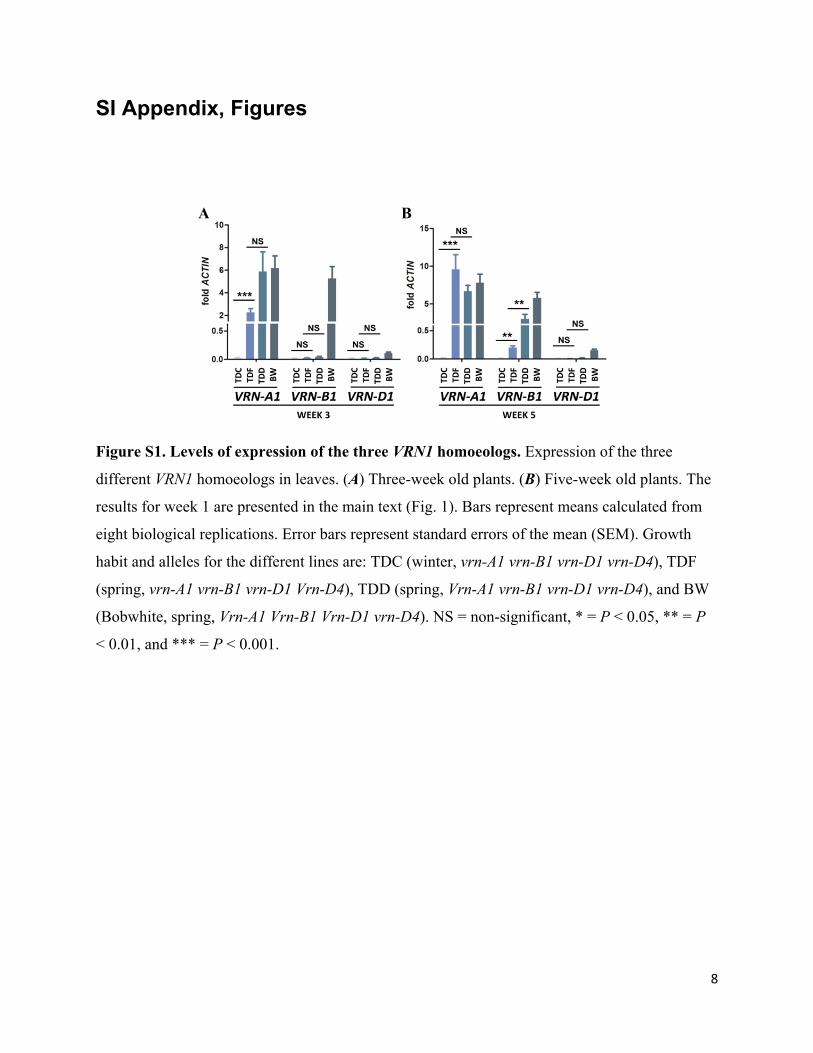
Figure S1. Levels of expression of the three VRN1 homoeologs. Expression of the three
different VRN1 homoeologs in leaves. (A) Three-week old plants. (B) Five-week old plants. The
results for week 1 are presented in the main text (Fig. 1). Bars represent means calculated from
eight biological replications. Error bars represent standard errors of the mean (SEM). Growth
habit and alleles for the different lines are: TDC (winter, vrn-A1 vrn-B1 vrn-D1 vrn-D4), TDF
(spring, vrn-A1 vrn-B1 vrn-D1 Vrn-D4), TDD (spring, Vrn-A1 vrn-B1 vrn-D1 vrn-D4), and BW
(Bobwhite, spring, Vrn-A1 Vrn-B1 Vrn-D1 vrn-D4). NS = non-significant, * = P < 0.05, ** = P
< 0.01, and *** = P < 0.001.
A B
9
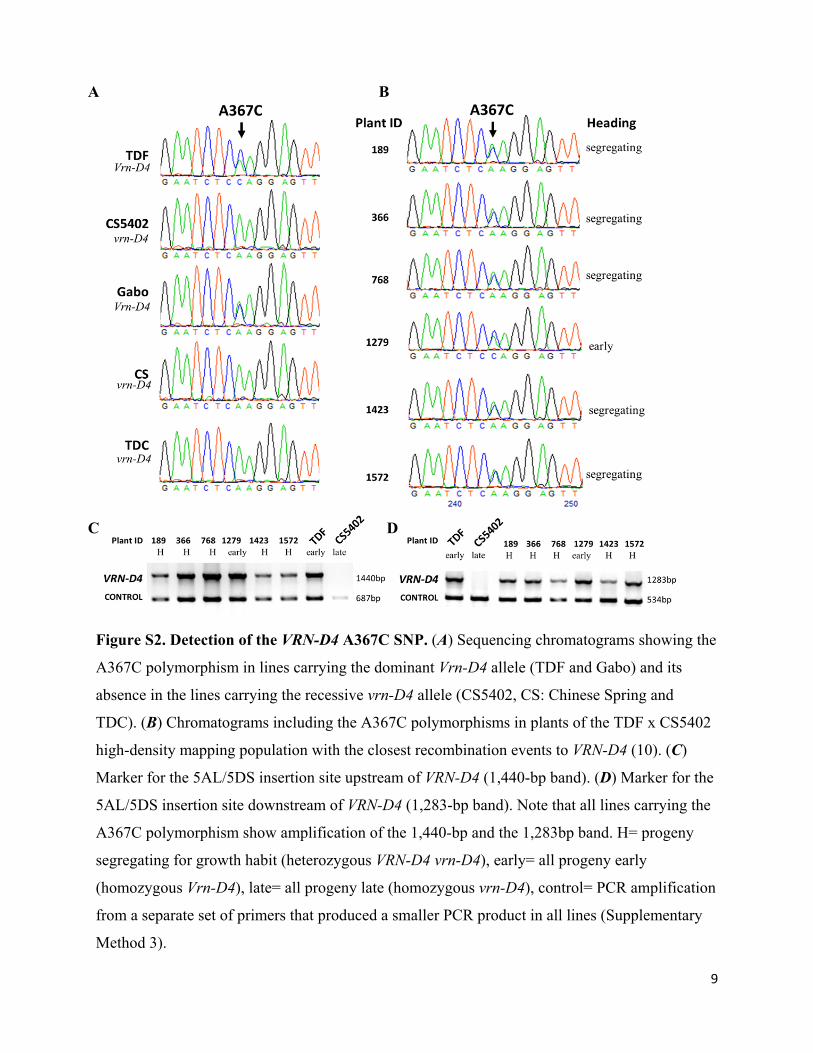
Figure S2. Detection of the VRN-D4 A367C SNP. (A) Sequencing chromatograms showing the
A367C polymorphism in lines carrying the dominant Vrn-D4 allele (TDF and Gabo) and its
absence in the lines carrying the recessive vrn-D4 allele (CS5402, CS: Chinese Spring and
TDC). (B) Chromatograms including the A367C polymorphisms in plants of the TDF x CS5402
high-density mapping population with the closest recombination events to VRN-D4 (10). (C)
Marker for the 5AL/5DS insertion site upstream of VRN-D4 (1,440-bp band). (D) Marker for the
5AL/5DS insertion site downstream of VRN-D4 (1,283-bp band). Note that all lines carrying the
A367C polymorphism show amplification of the 1,440-bp and the 1,283bp band. H= progeny
segregating for growth habit (heterozygous VRN-D4 vrn-D4), early= all progeny early
(homozygous Vrn-D4), late= all progeny late (homozygous vrn-D4), control= PCR amplification
from a separate set of primers that produced a smaller PCR product in all lines (Supplementary
Method 3).
A B
C D

10
Figure S3. Expression of VRN1 paralogs from chromosome arms 5AL (VRN-A1) and 5DS
(temporary name VRN-5DS). RNA was extracted one, two, and three weeks after germination
from leaves of TDC (winter, vrn-A1 vrn-B1 vrn-D1 vrn-5DS), TDF (spring, vrn-A1 vrn-B1 vrn-
D1 Vrn-5DS), TDD (Vrn-A1 vrn-B1 vrn-D1 vrn-5DS) and BW (Bobwhite, Vrn-A1 Vrn-B1 Vrn-
D1 vrn-5DS). RT-PCR with primers cDNA-VRN1-A-5DS forward and reverse (Table S8)
amplified both VRN-A1 and VRN-5DS. The two transcripts can be differentiated by the A367C
polymorphism, which generates an additional BstNI restriction site in VRN-5DS. After BstNI
digestion, the 251-bp fragment detected in VRN-A1 (arrowhead) is cut into two fragments of 195
bp and 56 bp in VRN-5DS (arrows). In TDF, where VRN-5DS and vrn-A1 are together, only
VRN-5DS transcripts (“C” variant at position 367) are detected during the first three weeks. At
five weeks, a faint band for VRN-A1 is also detected in TDF (“A” variant at position 367). TDC
has a winter growth habit so no VRN1 gene is expressed. Three biological repetitions per
genotype were tested. ACTIN (18) was used as control for PCR amplification and to confirm
similar cDNA levels in all the reactions. These results support the hypothesis that VRN-5DS is
VRN-D4.

11
VRN-D4 1 MGRGKVQLKRIENKINRQVTFSKRRSGLLKKAHEISVLCDAEVGLIIFSTKGKLYEFSTESCMDKILERYERYSYAEKVLVS 82 Chinese_Spring 1 MGRGKVQLKRIENKINRQVTFSKRRSGLLKKAHEISVLCDAEVGLIIFSTKGKLYEFSTESCMDKILERYERYSYAEKVLVS 82 Jagger-JQ915055.1 1 MGRGKVQLKRIENKINRQVTFSKRRSGLLKKAHEISVLCDAEVGLIIFSTKGKLYEFSTESCMDKILERYERYSYAEKVLVS 82 Claire-JF965395.1 1 MGRGKVQLKRIENKINRQVTFSKRRSGLLKKAHEISVLCDAEVGLIIFSTKGKLYEFSTESCMDKILERYERYSYAEKVLVS 82 2174-JQ915056.1 1 MGRGKVQLKRIENKINRQVTFSKRRSGLLKKAHEISVLCDAEVGLIIFSTKGKLYEFSTESCMDKILERYERYSYAEKVLVS 82 TDC-AY747600.1 1 MGRGKVQLKRIENKINRQVTFSKRRSGLLKKAHEISVLCDAEVGLIIFSTKGKLYEFSTESCMDKILERYERYSYAEKVVSL 82 Hereward-JF965397.1 1 MGRGKVQLKRIENKINRQVTFSKRRSGLLKKAHEISVLCDAEVGLIIFSTKGKLYEFSTESCMDKILERYERYSYAEKVLVS 82 Malacca-JF965396.1 1 MGRGKVQLKRIENKINRQVTFSKRRSGLLKKAHEISVLCDAEVGLIIFSTKGKLYEFSTESCMDKILERYERYSYAEKVLVS 82 Tm_G2528-AY244509.2 1 MGRGKVQLKRIENKINRQVTFSKRRSGLLKKAHEISVLCDAEVGLIIFSTKGKLYEFSTESCMDKILERYERYSYAEKVLVS 82 T.urartu 1 MGRGKVQLKRIENKINRQVTFSKRRSGLLKKAHEISVLCDAEVGLIIFSTKGKLYEFSTESCMDKILERYERYSYAEKVLVS 82 T.turgidum-AAW73219 1 MGRGKVQLKRIENKINRQVTFSKRRSGLLKKAHEISVLCDAEVGLIIFSTKGKLYEFSTESCMDKILERYERYSYAEKVLVS 82 Tm_DV92-AY188331.1 1 MGRGKVQLKRIENKINRQVTFSKRRSGLLKKAHEISVLCDAEVGLIIFSTKGKLYEFSTESCMDKILERYERYSYAEKVLVS 82 VRN-D4 81 SESEIQGNWCHEYRKLKAKVETIQKCQKHLMGEDLESLNLQELQQLEQQLESSLKHIRSRKNQLMHESISELQKKERSLQEE 164 Chinese_Spring 81 SESEIQGNWCHEYRKLKAKVETIQKCQKHLMGEDLESLNLKELQQLEQQLESSLKHIRSRKNQLMHESISELQKKERSLQEE 164 Jagger-JQ915055.1 81 SESEIQGNWCHEYRKLKAKVETIQKCQKHLMGEDLESLNLKELQQLEQQLESSLKHIRSRKNQLMHESISELQKKERSLQEE 164 Claire-JF965395.1 81 SESEIQGNWCHEYRKLKAKVETIQKCQKHLMGEDLESLNLKELQQLEQQLESSLKHIRSRKNQLMHESISELQKKERSLQEE 164 2174-JQ915056.1 81 SESEIQGNWCHEYRKLKAKVETIQKCQKHLMGEDFESLNLKELQQLEQQLESSLKHIRSRKNQLMHESISELQKKERSLQEE 164 TDC-AY747600.1 81 SESEIQGNWCHEYRKLKAKVETIQKCQKHLMGEDLESLNLKELQQLEQQLESSLKHIRSRKNQLMHESISELQKKERSLQEE 164 Hereward-JF965397.1 81 SESEIQGNWCHEYRKLKAKVETIQKCQKHLMGEDLESLNLKELQQLEQQLESSLKHIRSRKNQLMHESISELQKKERSLQEE 164 Malacca-JF965396.1 81 SESEIQGNWCHEYRKLKAKVETIQKCQKHLMGEDLESLNLKELQQLEQQLESSLKHIRSRKNQLMHESISELQKKERSLQEE 164 Tm_G2528-AY244509.2 81 SESEIQGNWCHEYRKLKAKVETIQKCQKHLMGEDLESLNLKELQQLEQQLESSLKHIRSRKNQLMHESISELQKKERSLQEE 164 T.urartu 81 SESEIQGNWCHEYRKLKAKVETIQKCQKHLMGEDLESLNLKELQQLEQQLESSLKHIRSRKNQLMHESISELQKKERSLQEE 164 T.turgidum-AAW73219 81 SESEIQGNWCHEYRKLKAKVETIQKCQKHLMGEDLESLNLKELQQLEQQLESSLKHIRSRKNQLMHESISELQKKERSLQEE 164 Tm_DV92-AY188331.1 81 SESEIQGNWCHEYRKLKAKVETIQKCQKHLMGEDLESLNLKELQQLEQQLESSLKHIRSRKNQLMHESISELQKKERSLQEE 164 VRN-D4 161 NKVLQKELVEKQKAHAAQQDQTQPQTSSSSSSFMLRDAPPAANTSIHPAATGERAEDAAVQPQAPPRTGLPPWMVSHING* 245 Chinese_Spring 161 NKVLQKELVEKQKAHAAQQDQTQPQTSSSSSSFMLRDAPPAANTSIHPAATGERAEDAAVQPQAPPRTGLPPWMVSHING* 245 Jagger-JQ915055.1 161 NKVLQKELVEKQKAHAAQQDQTQPQTSSSSSSFMLRDAPPAANTSIHPAATGERAEDAAVQPQAPPRTGLPPWMVSHING* 245 Claire-JF965395.1 161 NKVLQKELVEKQKAHAAQQDQTQPQTSSSSSSFMLRDAPPAANTSIHPAATGERAEDAAVQPQAPPRTGLPPWMVSHING* 245 2174-JQ915056.1 161 NKVLQKELVEKQKAHVAQQDQTQPQTSSSSSSFMLRDAPPAANTSIHPAATGERAEDAAVQPQAPPRTGLPPWMVSHING* 245 TDC-AY747600.1 161 NKVLQKELVEKQKAHAAQQDQTQPQTSSSSSSFMLRDAPPAANTSIHPAATGERAEDAAVQPQAPPRTGLPPWMVSHING* 24 Hereward-JF965397.1 161 NKVLQKELVEKQKAHVAQQDQTQPQTSSSSSSFMLRDAPPAANTSIHPAATGERAEDAAVQPQAPPRTGLPPWMVSHING* 245 Malacca-JF965396.1 161 NKVLQKELVEKQKAHVAQQDQTQPQTSSSSSSFMLRDAPPAANTSIHPAATGERAEDAAVQPQAPPRTGLPPWMVSHING* 245 AY244509.2-Tm_G2528 161 NKVLQKELVEKQKAHAAQQDQTQPQTSSSSSSFMLRDAPPAANTSIHPAAAGERAEDAAVQPQAPPRTGLPPWMVSHING* 245 T.urartu 161 NKVLQKELVEKQKAHAAQQDQTQPQTSSSSSSFMLRDAPPAANTSIHPAAAGERAEDAAVQPQAPPRTGPPPWMVSHING* 245 T.turgidum-AAW73219 161 NKVLQKELVEKQKAHAAQQDQTQPQTSSSSSSFMLRDAPPAANTSIHPAATGERAEDAAVQPQAPPRTGLPPWMVSHING* 245 Tm_DV92-AY188331.1 161 NKVLQKELVEKQKAHAAQQDQTQPQTSSSSSSFMLRDAPPAANTSIHPAAAGERAEDAAVQPQAPPRTGLPPWMVSHING* 245
Figure S4. VRN-D4 protein sequence analysis. Multiple sequence alignment between the
predicted protein sequence of VRN-D4 and the publicly available VRN1 protein sequences.
Highlighted in red is the K123Q amino acid change characteristic of VRN-D4. The K-Box
domain is highlighted in light gray. T. urartu sequence was obtained from plants.ensembl.org
(scaffold60538). The complete Chinese Spring VRN-A1 (GenBank KR422423) and VRN-D4
(GenBank KR422424) sequences were obtained in this study.

12
Figure S5. Conservation of amino acids affected by natural and induced mutations in VRN-D4. A multiple alignment of 268 sequences including AP1, AG, FUL, CAULIFLOWER, VRN1 and other related MAD-BOX proteins was used to generate a graphical representation of the conservation at each amino acid position. We used the WebLogo tool (weblogo.berkeley.edu) that generates a graph where the size of each amino acid letter is proportional to its frequency at that position. The region shown covers amino acids 115 to 175 (VRN-D4 coordinates) in the K-Box domain. Arrows indicate the natural amino acid change K123Q and the EMS induced amino acid change E158K. Note that the amino acids resulting from these mutations are not detected among the 268 closest available sequences for this protein domain.

13
Figure S6. PCR amplification of VRN-A1 flanking genes from chromosome arm 5DS. DNA
extracted from flow-sorted 5DS chromosome arms arm (Institute of Experimental Botany,
Olomouc, Czech Republic) was used to test if genes flanking VRN-A1 on chromosome arm 5AL
(18) were also present in the 5AL segment inserted in chromosome arm 5DS. CS: Chinese
Spring, 5DS: 5DS arm DNA, TDC: Triple Dirk C. Using the same 5DS DNA sample for all
primers, only the VRN-A1 marker was amplified, indicating that PHYC, CYS and AGLG1 are not
present in 5DS. Multiple bands in CYS PCR amplification corresponds to multiple copies of
CYS genes, none of them present in the 5DS arm DNA. A BLAST search of the CS-dt5DS
database showed no genes with significant similarity to PHYC, CYS and AGLG1, confirming the
PCR results.
900 bp 750 bp
CS 5DS TDC CS 5DS TDC CS 5DS TDC CS 5DS TDC VRN1 PHYC CYS AGLG1
14
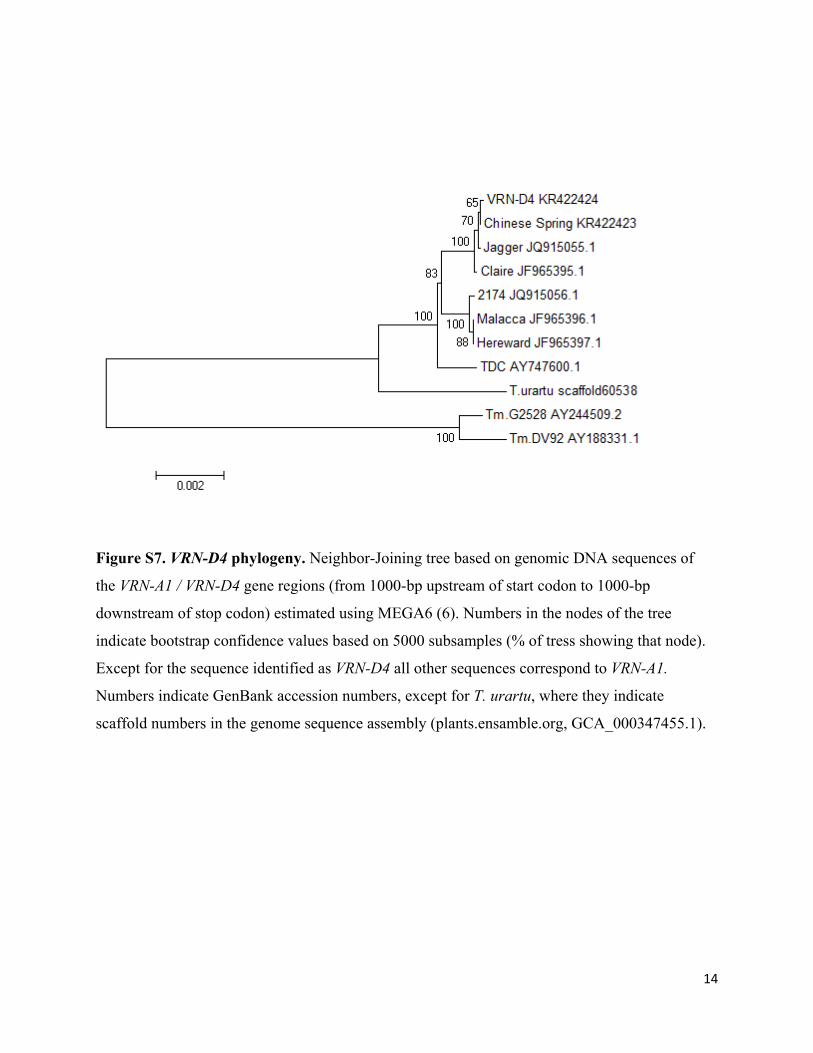
Figure S7. VRN-D4 phylogeny. Neighbor-Joining tree based on genomic DNA sequences of
the VRN-A1 / VRN-D4 gene regions (from 1000-bp upstream of start codon to 1000-bp
downstream of stop codon) estimated using MEGA6 (6). Numbers in the nodes of the tree
indicate bootstrap confidence values based on 5000 subsamples (% of tress showing that node).
Except for the sequence identified as VRN-D4 all other sequences correspond to VRN-A1.
Numbers indicate GenBank accession numbers, except for T. urartu, where they indicate
scaffold numbers in the genome sequence assembly (plants.ensamble.org, GCA_000347455.1).
15
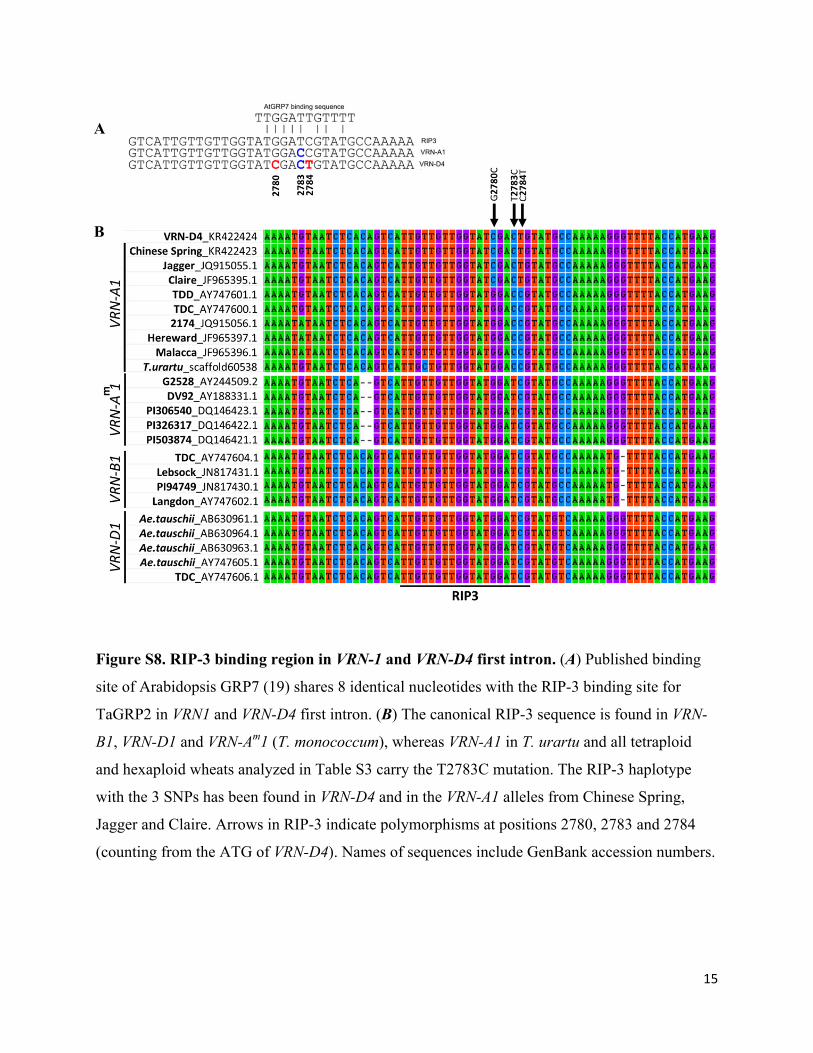
Figure S8. RIP-3 binding region in VRN-1 and VRN-D4 first intron. (A) Published binding
site of Arabidopsis GRP7 (19) shares 8 identical nucleotides with the RIP-3 binding site for
TaGRP2 in VRN1 and VRN-D4 first intron. (B) The canonical RIP-3 sequence is found in VRN-
B1, VRN-D1 and VRN-Am1 (T. monococcum), whereas VRN-A1 in T. urartu and all tetraploid
and hexaploid wheats analyzed in Table S3 carry the T2783C mutation. The RIP-3 haplotype
with the 3 SNPs has been found in VRN-D4 and in the VRN-A1 alleles from Chinese Spring,
Jagger and Claire. Arrows in RIP-3 indicate polymorphisms at positions 2780, 2783 and 2784
(counting from the ATG of VRN-D4). Names of sequences include GenBank accession numbers.
A
B
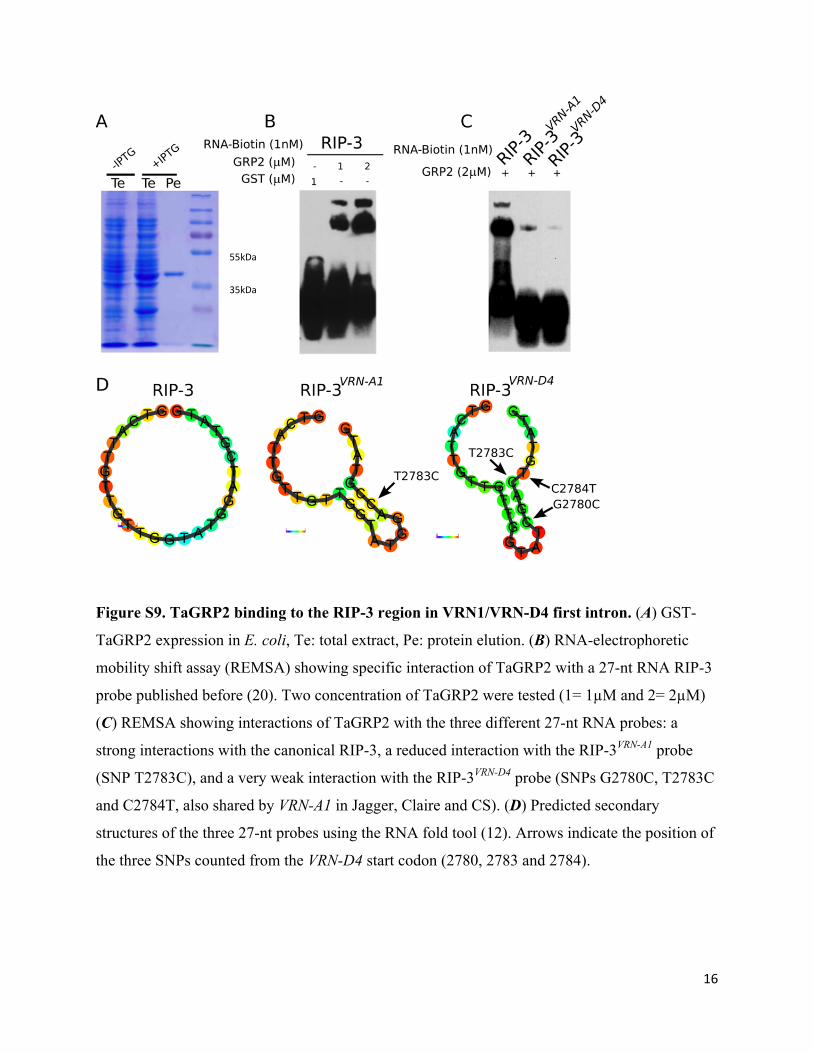
16
Figure S9. TaGRP2 binding to the RIP-3 region in VRN1/VRN-D4 first intron. (A) GST-
TaGRP2 expression in E. coli, Te: total extract, Pe: protein elution. (B) RNA-electrophoretic
mobility shift assay (REMSA) showing specific interaction of TaGRP2 with a 27-nt RNA RIP-3
probe published before (20). Two concentration of TaGRP2 were tested (1= 1µM and 2= 2µM)
(C) REMSA showing interactions of TaGRP2 with the three different 27-nt RNA probes: a
strong interactions with the canonical RIP-3, a reduced interaction with the RIP-3VRN-A1 probe
(SNP T2783C), and a very weak interaction with the RIP-3VRN-D4 probe (SNPs G2780C, T2783C
and C2784T, also shared by VRN-A1 in Jagger, Claire and CS). (D) Predicted secondary
structures of the three 27-nt probes using the RNA fold tool (12). Arrows indicate the position of
the three SNPs counted from the VRN-D4 start codon (2780, 2783 and 2784).
55kDa
35kDa

17
Figure S10. Collection site of the T. aestivum ssp. sphaerococcum entries from the NSGC.
Colors represent each geographical location according to the collection site coordinates available
at GRIN (www.ars-grin.gov/npgs/searchgrin.html). Points were positioned according to the
collection site coordinates using Google Maps (maps.google.com). All entries carry VRN-D4
with the exception of CItr 8610 and CItr 10911, both collected in east-China (light gray).
18
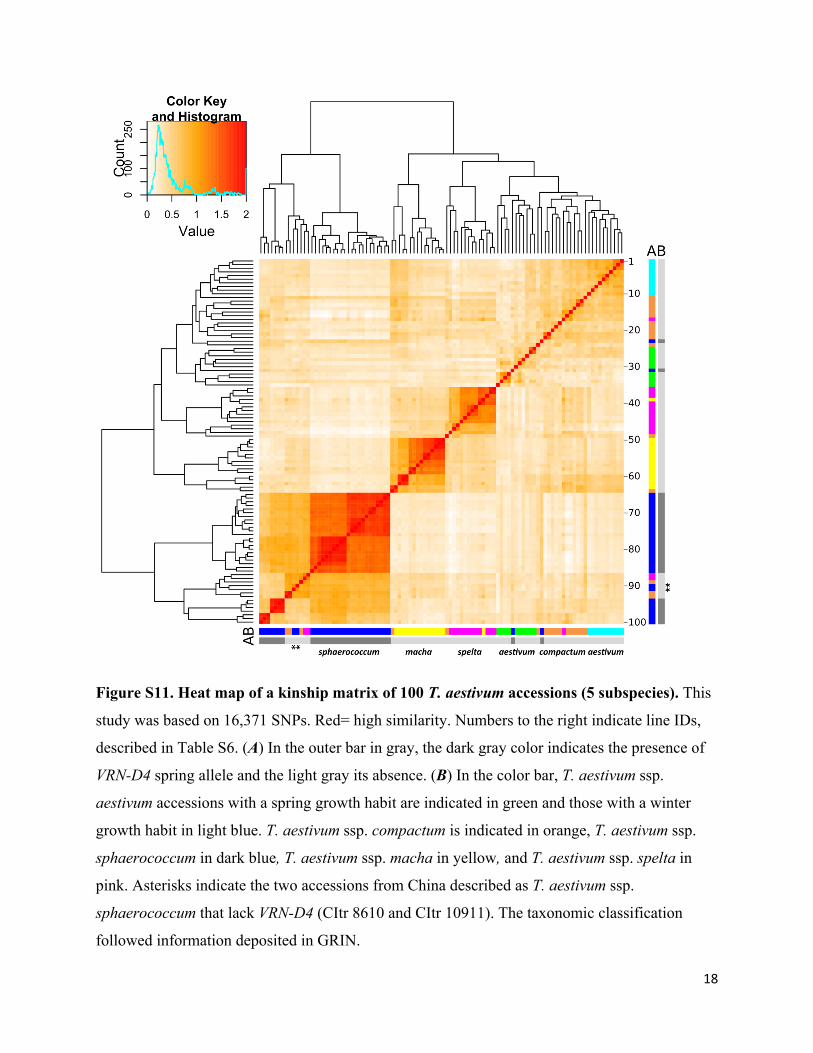
Figure S11. Heat map of a kinship matrix of 100 T. aestivum accessions (5 subspecies). This
study was based on 16,371 SNPs. Red= high similarity. Numbers to the right indicate line IDs,
described in Table S6. (A) In the outer bar in gray, the dark gray color indicates the presence of
VRN-D4 spring allele and the light gray its absence. (B) In the color bar, T. aestivum ssp.
aestivum accessions with a spring growth habit are indicated in green and those with a winter
growth habit in light blue. T. aestivum ssp. compactum is indicated in orange, T. aestivum ssp.
sphaerococcum in dark blue, T. aestivum ssp. macha in yellow, and T. aestivum ssp. spelta in
pink. Asterisks indicate the two accessions from China described as T. aestivum ssp.
sphaerococcum that lack VRN-D4 (CItr 8610 and CItr 10911). The taxonomic classification
followed information deposited in GRIN.

19
Figure S12. Genetic diversity by subspecies and chromosomes. (A) Standardized genetic
diversity* across complete chromosomes. Note that in T. aestivum ssp. sphaerococcum (sphaero.)
chromosome 5D is the one with the lowest average diversity, and also that in the other four
subspecies the same chromosome shows higher diversity. (B) Standardized genetic diversity
values for the distal and proximal regions of chromosomes from the D genome. Note that none
of the other D genome chromosomes of T. aestivum ssp. sphaerococcum shows a reduction in
standardized genetic diversity as severe as the one observed in the proximal region of
chromosome 5D.
* Genetic diversity was first calculated for each locus (14,236 SNP) and each subspecies using the Polymorphism
Information Content (PIC) formula. PIC values were then averaged for each chromosome. To reduce the effect of
ascertainment bias, the average diversity of each chromosome was divided by the average genetic diversity of the
corresponding genome/subspecies (“standardized diversity”, Table S7, Supplementary Method S6).
20
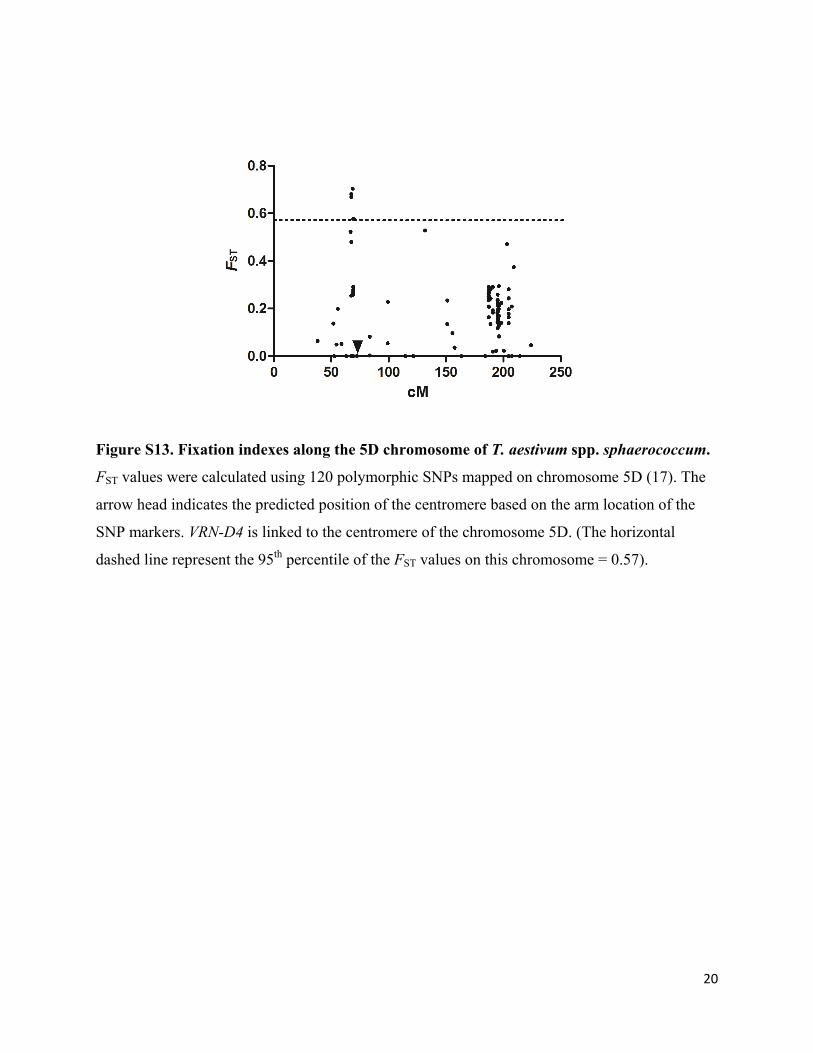
Figure S13. Fixation indexes along the 5D chromosome of T. aestivum spp. sphaerococcum.
FST values were calculated using 120 polymorphic SNPs mapped on chromosome 5D (17). The
arrow head indicates the predicted position of the centromere based on the arm location of the
SNP markers. VRN-D4 is linked to the centromere of the chromosome 5D. (The horizontal
dashed line represent the 95th percentile of the FST values on this chromosome = 0.57).
21
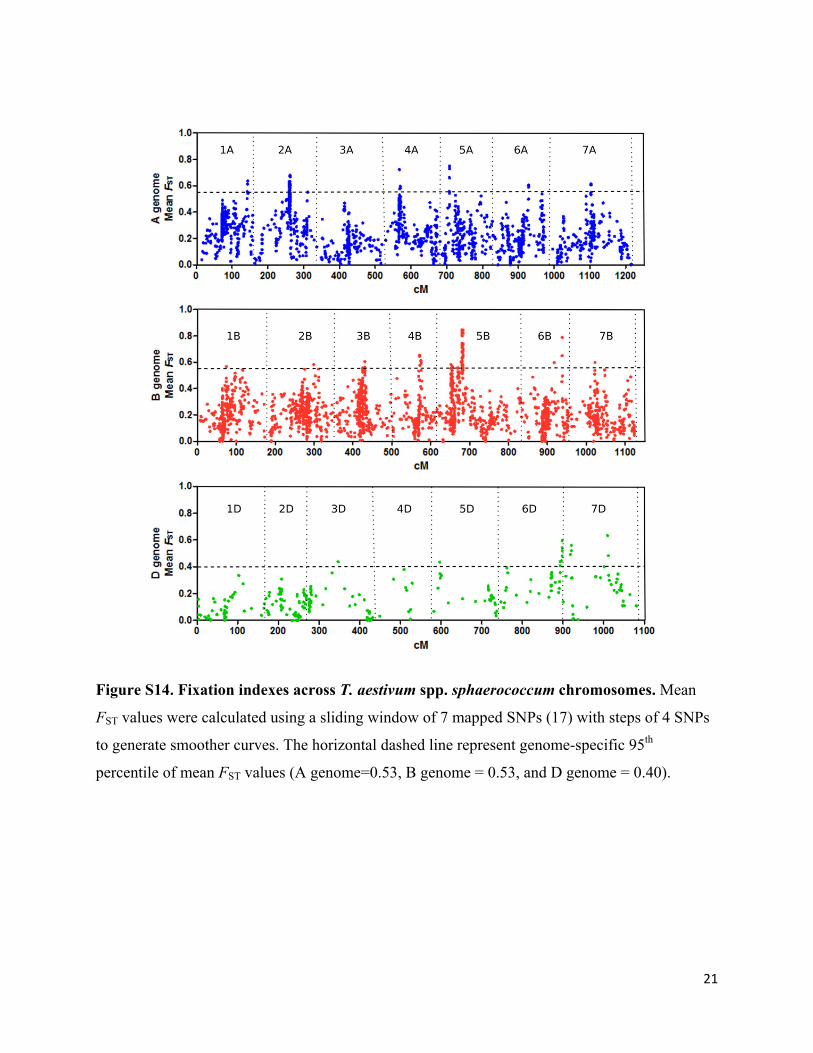
Figure S14. Fixation indexes across T. aestivum spp. sphaerococcum chromosomes. Mean
FST values were calculated using a sliding window of 7 mapped SNPs (17) with steps of 4 SNPs
to generate smoother curves. The horizontal dashed line represent genome-specific 95th
percentile of mean FST values (A genome=0.53, B genome = 0.53, and D genome = 0.40).
22
SI Appendix, Tables
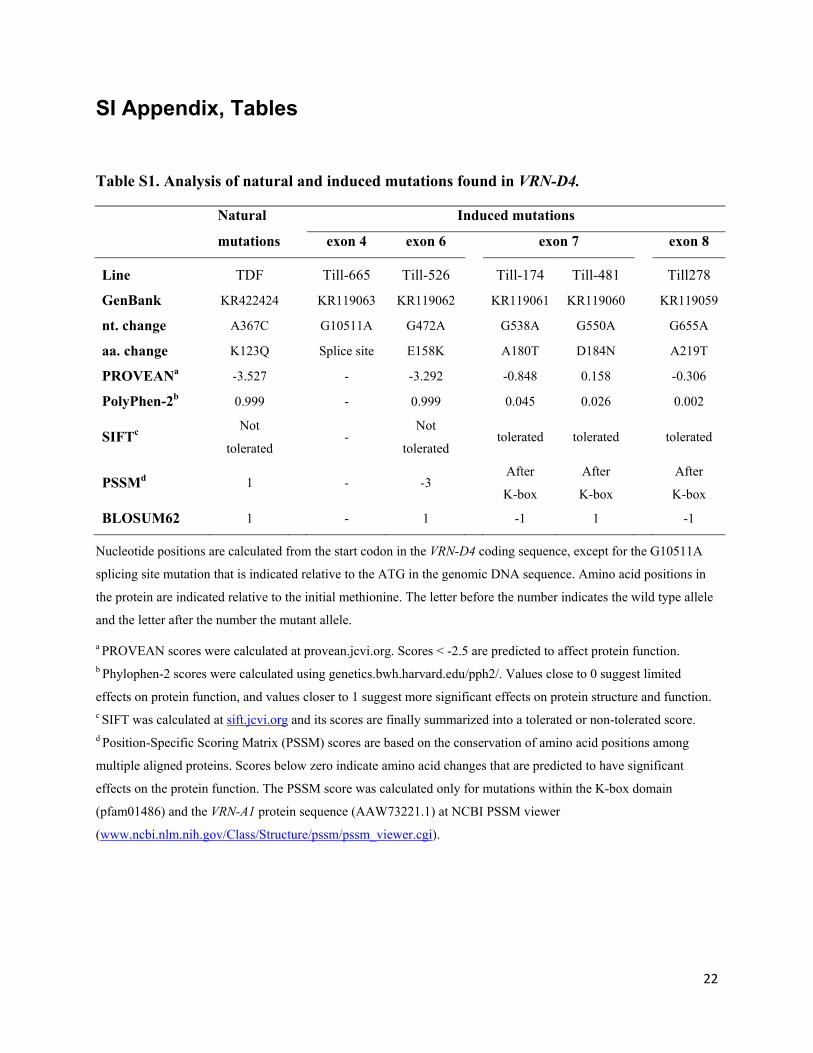
Table S1. Analysis of natural and induced mutations found in VRN-D4.
Natural Induced mutations
mutations exon 4 exon 6 exon 7 exon 8
Line TDF Till-665 Till-526 Till-174 Till-481 Till278
GenBank KR422424
KR119063 KR119062 KR119061 KR119060
KR119059
nt. change A367C
G10511A G472A G538A G550A
G655A
aa. change K123Q
Splice site E158K A180T D184N
A219T
PROVEANa -3.527
- -3.292 -0.848 0.158
-0.306
PolyPhen-2b 0.999
- 0.999 0.045 0.026
0.002
SIFTc Not
tolerated -
Not
tolerated tolerated tolerated
tolerated
PSSMd 1
- -3
After
K-box
After
K-box
After
K-box
BLOSUM62 1
- 1 -1 1
-1
Nucleotide positions are calculated from the start codon in the VRN-D4 coding sequence, except for the G10511A
splicing site mutation that is indicated relative to the ATG in the genomic DNA sequence. Amino acid positions in
the protein are indicated relative to the initial methionine. The letter before the number indicates the wild type allele
and the letter after the number the mutant allele.
a PROVEAN scores were calculated at provean.jcvi.org. Scores < -2.5 are predicted to affect protein function. b Phylophen-2 scores were calculated using genetics.bwh.harvard.edu/pph2/. Values close to 0 suggest limited
effects on protein function, and values closer to 1 suggest more significant effects on protein structure and function. c SIFT was calculated at sift.jcvi.org and its scores are finally summarized into a tolerated or non-tolerated score. d Position-Specific Scoring Matrix (PSSM) scores are based on the conservation of amino acid positions among
multiple aligned proteins. Scores below zero indicate amino acid changes that are predicted to have significant
effects on the protein function. The PSSM score was calculated only for mutations within the K-box domain
(pfam01486) and the VRN-A1 protein sequence (AAW73221.1) at NCBI PSSM viewer
(www.ncbi.nlm.nih.gov/Class/Structure/pssm/pssm_viewer.cgi).
23
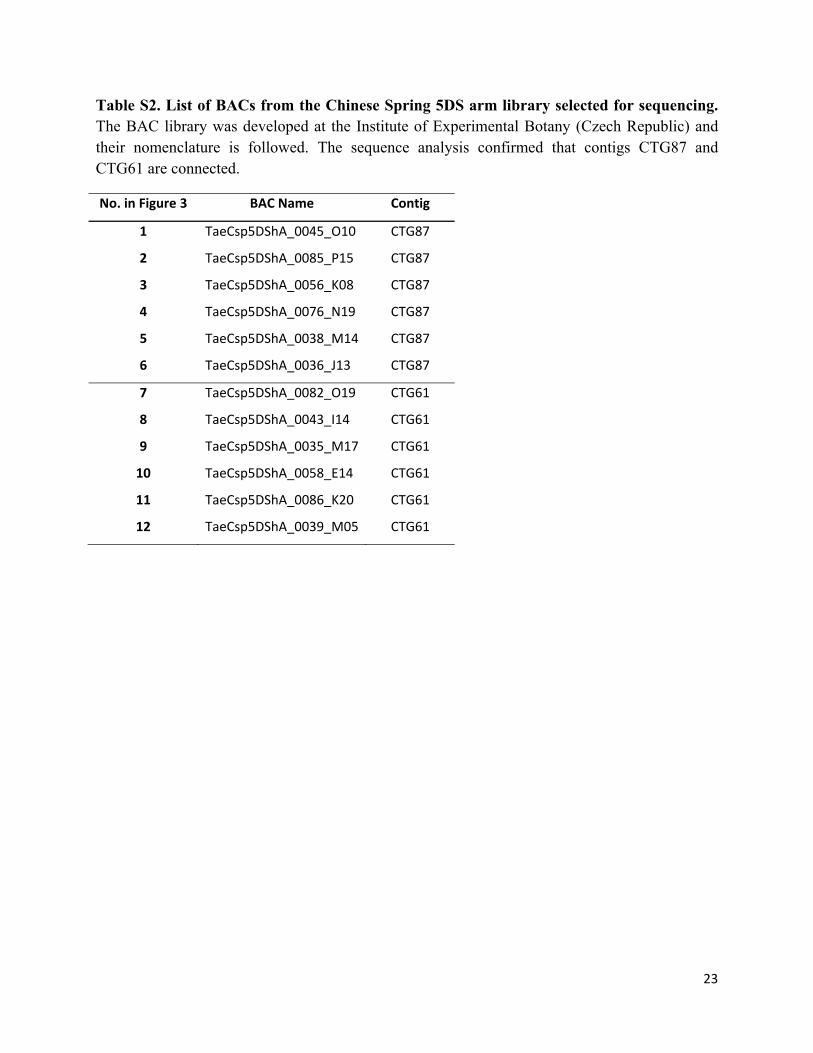
Table S2. List of BACs from the Chinese Spring 5DS arm library selected for sequencing. The BAC library was developed at the Institute of Experimental Botany (Czech Republic) and their nomenclature is followed. The sequence analysis confirmed that contigs CTG87 and CTG61 are connected.
No. in Figure 3 BAC Name Contig
1 TaeCsp5DShA_0045_O10 CTG87
2 TaeCsp5DShA_0085_P15 CTG87
3 TaeCsp5DShA_0056_K08 CTG87
4 TaeCsp5DShA_0076_N19 CTG87
5 TaeCsp5DShA_0038_M14 CTG87
6 TaeCsp5DShA_0036_J13 CTG87
7 TaeCsp5DShA_0082_O19 CTG61
8 TaeCsp5DShA_0043_I14 CTG61
9 TaeCsp5DShA_0035_M17 CTG61
10 TaeCsp5DShA_0058_E14 CTG61
11 TaeCsp5DShA_0086_K20 CTG61
12 TaeCsp5DShA_0039_M05 CTG61

24
Table S3. Accessions sequenced for the VRN1 RIP-3 region. ‘PI’ and ‘CItr’ numbers are from GRIN identifiers, ‘UH’ numbers are from the University of Haifa wheat germplasm collection (21, 22), and ‘MG’ and ‘ IDG’ are from the University of Bologna T. dicoccum collection.
Wheat Location Identifiers
T. urartu El Beqaa, Lebanon PI 428275, PI 428280, PI 428282, PI 428283, PI 428285, PI 428286, PI 428287, PI 428288PI 428291, PI 428292, PI 428294, PI 428295, PI 428296, PI 428304, PI 428321, PI 428327, PI 538741, PI 428279, PI 538740, PI 428293, PI 428276
Urfa, Turkey PI 428222, PI 428223, PI 428240, PI 428244, PI 428251, PI 428239, PI 538733
Mardin, Turkey PI 428201, PI 428202, PI 428228
T. dicoccoides Beir‐Oren, Israel UH 28
Daliyya, Israel (south Haifa) UH 29
Diyarbakir, Turkey PI 428028, PI 428041
Gamla, Golan Heights UH 08
Iraq UH 41, UH 42
J'aba, Mid‐north Israel UH 23
Kokhav‐Hashahar UH 19
Mt. Gerizim, Israel UH 17
Rosh‐Pinna UH 09
Seryia UH 40
Golan Heights UH 11
Yabad, West Bank UH 32
Yehudiyya UH 07
T. dicoccum Armenia MG 5274
Ethiopia MG 5306
Georgia MG 5314, MG 5315
Germany MG 5398
Iran MG 5273, MG 5275, MG 5276
Italy IDG 8634
Kenia MG 3428, MG 3430
Palestine PI 355496
Russia MG 5269, MG 5270
Turkey PI 94626
T. aestivum Canada Norstar (CItr 17735), Fife (PI 283820)
Argentina Barleta (CItr 8398)
Australia Falcon (PI 292578), Golden drop (PI 92399)
Sweden Kronen (PI 278526)
United States Little club (CItr 4066), Sterling (CItr 17859), Finch (PI 628640), Alpowa (PI 566596), Louise (PI 634865), Eltan (PI 536994)
25
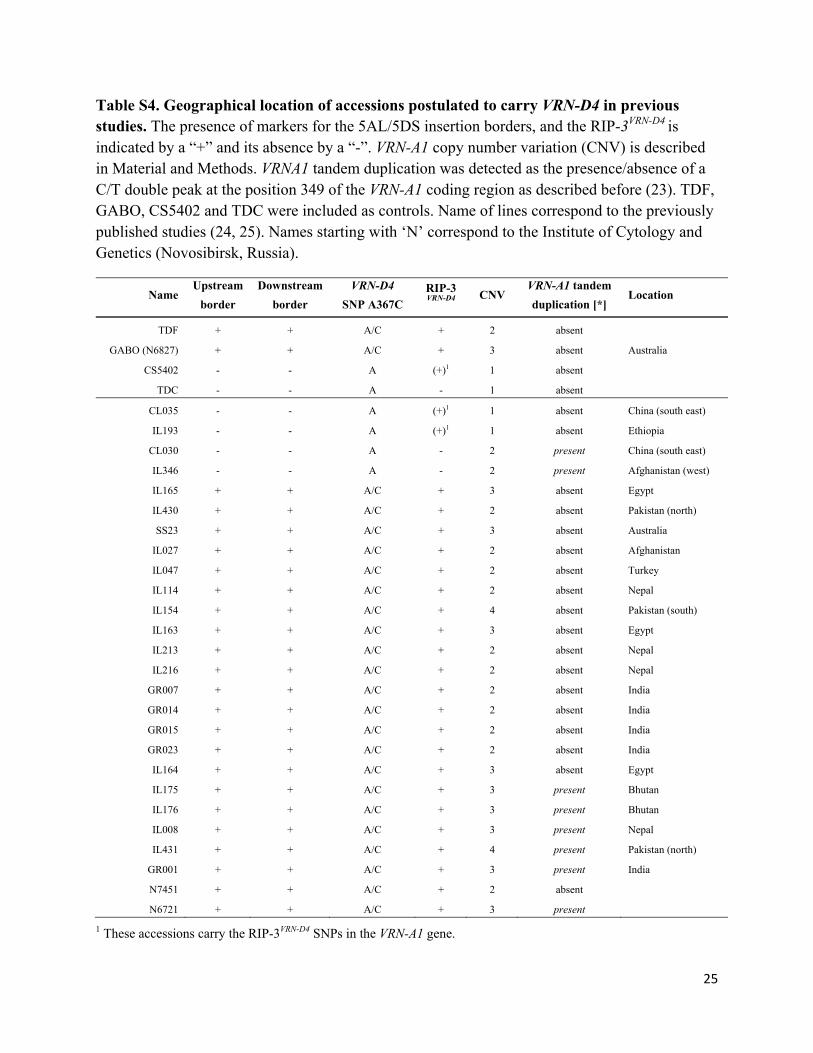
Table S4. Geographical location of accessions postulated to carry VRN-D4 in previous studies. The presence of markers for the 5AL/5DS insertion borders, and the RIP-3VRN-D4 is indicated by a “+” and its absence by a “-”. VRN-A1 copy number variation (CNV) is described in Material and Methods. VRNA1 tandem duplication was detected as the presence/absence of a C/T double peak at the position 349 of the VRN-A1 coding region as described before (23). TDF, GABO, CS5402 and TDC were included as controls. Name of lines correspond to the previously published studies (24, 25). Names starting with ‘N’ correspond to the Institute of Cytology and Genetics (Novosibirsk, Russia).
Name Upstream
border
Downstream
border
VRN-D4
SNP A367C RIP-3 VRN-D4
CNV VRN-A1 tandem
duplication [*] Location
TDF + + A/C + 2 absent
GABO (N6827) + + A/C + 3 absent Australia
CS5402 - - A (+)1 1 absent
TDC - - A - 1 absent
CL035 - - A (+)1 1 absent China (south east)
IL193 - - A (+)1 1 absent Ethiopia
CL030 - - A - 2 present China (south east)
IL346 - - A - 2 present Afghanistan (west)
IL165 + + A/C + 3 absent Egypt
IL430 + + A/C + 2 absent Pakistan (north)
SS23 + + A/C + 3 absent Australia
IL027 + + A/C + 2 absent Afghanistan
IL047 + + A/C + 2 absent Turkey
IL114 + + A/C + 2 absent Nepal
IL154 + + A/C + 4 absent Pakistan (south)
IL163 + + A/C + 3 absent Egypt
IL213 + + A/C + 2 absent Nepal
IL216 + + A/C + 2 absent Nepal
GR007 + + A/C + 2 absent India
GR014 + + A/C + 2 absent India
GR015 + + A/C + 2 absent India
GR023 + + A/C + 2 absent India
IL164 + + A/C + 3 absent Egypt
IL175 + + A/C + 3 present Bhutan
IL176 + + A/C + 3 present Bhutan
IL008 + + A/C + 3 present Nepal
IL431 + + A/C + 4 present Pakistan (north)
GR001 + + A/C + 3 present India
N7451 + + A/C + 2 absent
N6721 + + A/C + 3 present
1 These accessions carry the RIP-3VRN-D4 SNPs in the VRN-A1 gene.
26
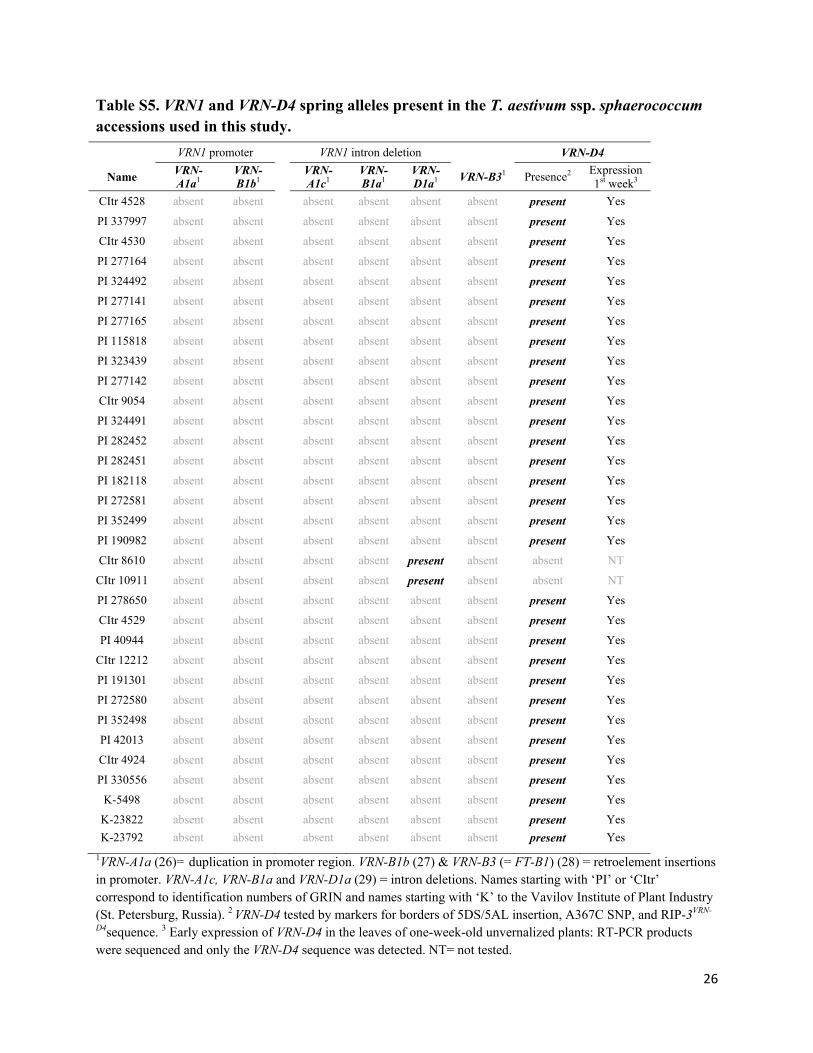
Table S5. VRN1 and VRN-D4 spring alleles present in the T. aestivum ssp. sphaerococcum accessions used in this study.
VRN1 promoter VRN1 intron deletion VRN-D4
Name VRN-A1a1
VRN-B1b1
VRN-A1c1
VRN-B1a1
VRN-D1a1
VRN-B31 Presence2 Expression 1st week3
CItr 4528 absent absent absent absent absent absent present Yes
PI 337997 absent absent absent absent absent absent present Yes
CItr 4530 absent absent absent absent absent absent present Yes
PI 277164 absent absent absent absent absent absent present Yes
PI 324492 absent absent absent absent absent absent present Yes
PI 277141 absent absent absent absent absent absent present Yes
PI 277165 absent absent absent absent absent absent present Yes
PI 115818 absent absent absent absent absent absent present Yes
PI 323439 absent absent absent absent absent absent present Yes
PI 277142 absent absent absent absent absent absent present Yes
CItr 9054 absent absent absent absent absent absent present Yes
PI 324491 absent absent absent absent absent absent present Yes
PI 282452 absent absent absent absent absent absent present Yes
PI 282451 absent absent absent absent absent absent present Yes
PI 182118 absent absent absent absent absent absent present Yes
PI 272581 absent absent absent absent absent absent present Yes
PI 352499 absent absent absent absent absent absent present Yes
PI 190982 absent absent absent absent absent absent present Yes
CItr 8610 absent absent absent absent present absent absent NT
CItr 10911 absent absent absent absent present absent absent NT
PI 278650 absent absent absent absent absent absent present Yes
CItr 4529 absent absent absent absent absent absent present Yes
PI 40944 absent absent absent absent absent absent present Yes
CItr 12212 absent absent absent absent absent absent present Yes
PI 191301 absent absent absent absent absent absent present Yes
PI 272580 absent absent absent absent absent absent present Yes
PI 352498 absent absent absent absent absent absent present Yes
PI 42013 absent absent absent absent absent absent present Yes
CItr 4924 absent absent absent absent absent absent present Yes
PI 330556 absent absent absent absent absent absent present Yes
K-5498 absent absent absent absent absent absent present Yes
K-23822 absent absent absent absent absent absent present Yes
K-23792 absent absent absent absent absent absent present Yes
1VRN-A1a (26)= duplication in promoter region. VRN-B1b (27) & VRN-B3 (= FT-B1) (28) = retroelement insertions in promoter. VRN-A1c, VRN-B1a and VRN-D1a (29) = intron deletions. Names starting with ‘PI’ or ‘CItr’ correspond to identification numbers of GRIN and names starting with ‘K’ to the Vavilov Institute of Plant Industry (St. Petersburg, Russia). 2 VRN-D4 tested by markers for borders of 5DS/5AL insertion, A367C SNP, and RIP-3VRN-
D4sequence. 3 Early expression of VRN-D4 in the leaves of one-week-old unvernalized plants: RT-PCR products were sequenced and only the VRN-D4 sequence was detected. NT= not tested.
27
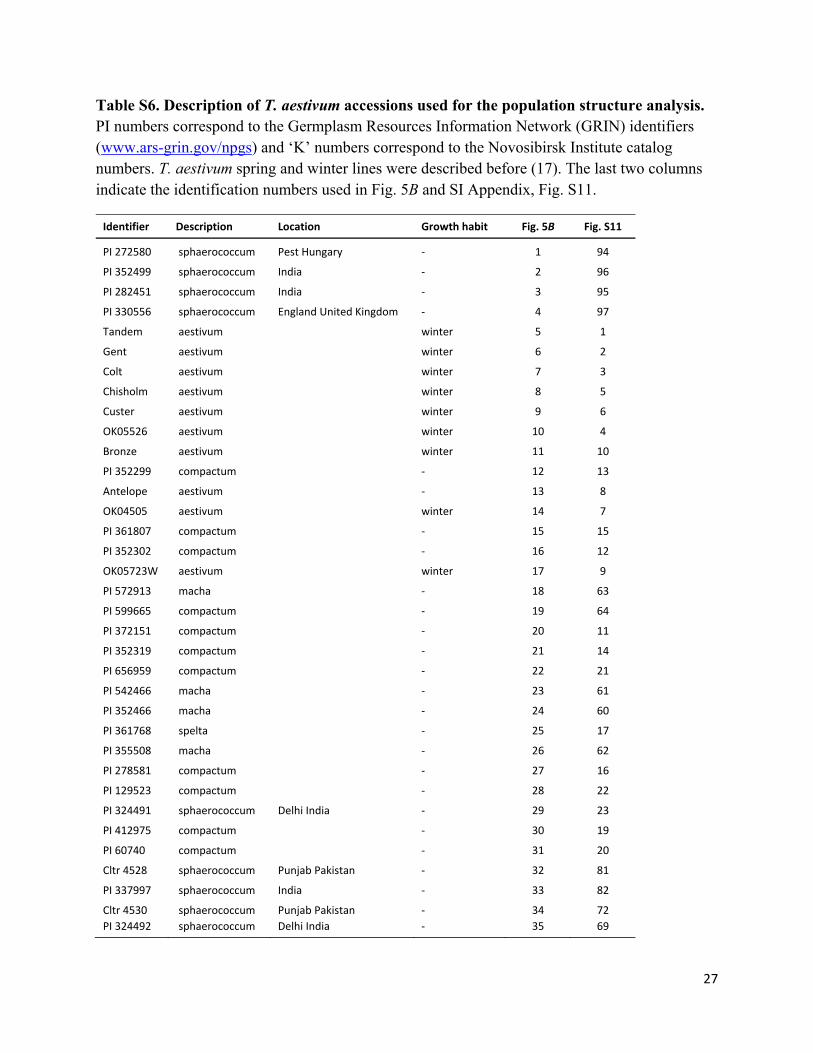
Table S6. Description of T. aestivum accessions used for the population structure analysis. PI numbers correspond to the Germplasm Resources Information Network (GRIN) identifiers (www.ars-grin.gov/npgs) and ‘K’ numbers correspond to the Novosibirsk Institute catalog numbers. T. aestivum spring and winter lines were described before (17). The last two columns indicate the identification numbers used in Fig. 5B and SI Appendix, Fig. S11.
Identifier Description Location Growth habit Fig. 5B Fig. S11
PI 272580 sphaerococcum Pest Hungary ‐ 1 94
PI 352499 sphaerococcum India ‐ 2 96
PI 282451 sphaerococcum India ‐ 3 95
PI 330556 sphaerococcum England United Kingdom ‐ 4 97
Tandem aestivum winter 5 1
Gent aestivum winter 6 2
Colt aestivum winter 7 3
Chisholm aestivum winter 8 5
Custer aestivum winter 9 6
OK05526 aestivum winter 10 4
Bronze aestivum winter 11 10
PI 352299 compactum ‐ 12 13
Antelope aestivum ‐ 13 8
OK04505 aestivum winter 14 7
PI 361807 compactum ‐ 15 15
PI 352302 compactum ‐ 16 12
OK05723W aestivum winter 17 9
PI 572913 macha ‐ 18 63
PI 599665 compactum ‐ 19 64
PI 372151 compactum ‐ 20 11
PI 352319 compactum ‐ 21 14
PI 656959 compactum ‐ 22 21
PI 542466 macha ‐ 23 61
PI 352466 macha ‐ 24 60
PI 361768 spelta ‐ 25 17
PI 355508 macha ‐ 26 62
PI 278581 compactum ‐ 27 16
PI 129523 compactum ‐ 28 22
PI 324491 sphaerococcum Delhi India ‐ 29 23
PI 412975 compactum ‐ 30 19
PI 60740 compactum ‐ 31 20
Cltr 4528 sphaerococcum Punjab Pakistan ‐ 32 81
PI 337997 sphaerococcum India ‐ 33 82
Cltr 4530 sphaerococcum Punjab Pakistan ‐ 34 72
PI 324492 sphaerococcum Delhi India ‐ 35 69
28
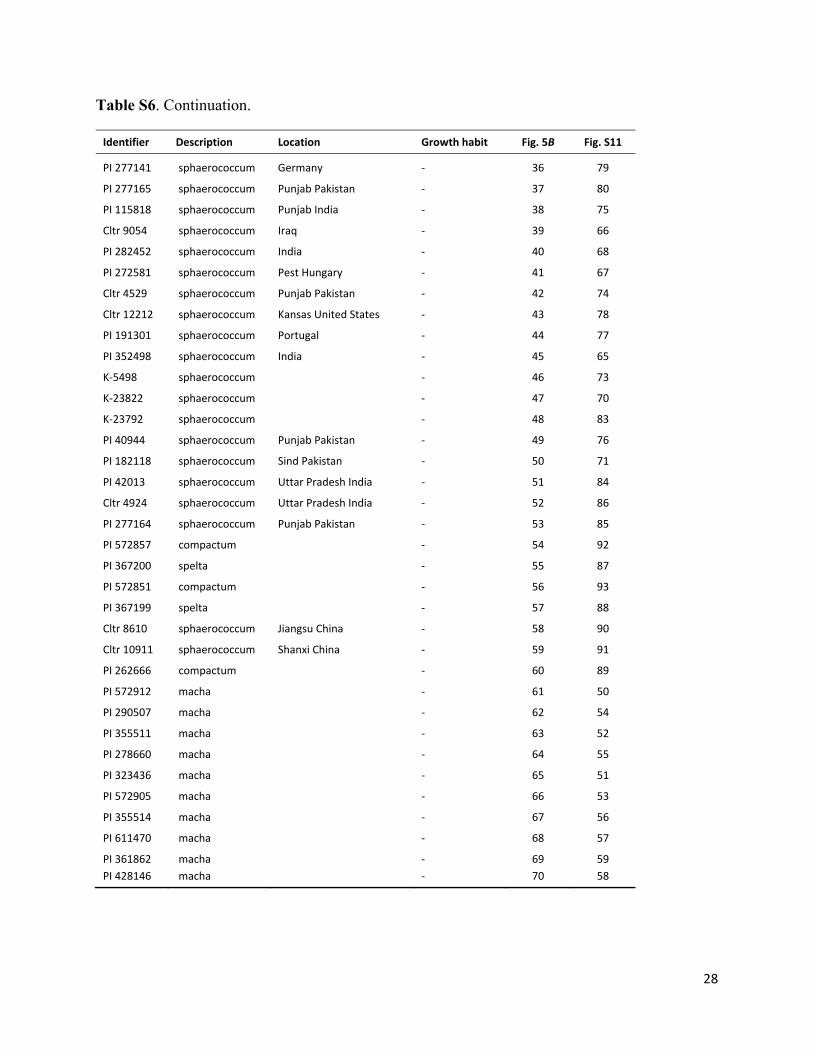
Table S6. Continuation.
Identifier Description Location Growth habit Fig. 5B Fig. S11
PI 277141 sphaerococcum Germany ‐ 36 79
PI 277165 sphaerococcum Punjab Pakistan ‐ 37 80
PI 115818 sphaerococcum Punjab India ‐ 38 75
Cltr 9054 sphaerococcum Iraq ‐ 39 66
PI 282452 sphaerococcum India ‐ 40 68
PI 272581 sphaerococcum Pest Hungary ‐ 41 67
Cltr 4529 sphaerococcum Punjab Pakistan ‐ 42 74
Cltr 12212 sphaerococcum Kansas United States ‐ 43 78
PI 191301 sphaerococcum Portugal ‐ 44 77
PI 352498 sphaerococcum India ‐ 45 65
K‐5498 sphaerococcum ‐ 46 73
K‐23822 sphaerococcum ‐ 47 70
K‐23792 sphaerococcum ‐ 48 83
PI 40944 sphaerococcum Punjab Pakistan ‐ 49 76
PI 182118 sphaerococcum Sind Pakistan ‐ 50 71
PI 42013 sphaerococcum Uttar Pradesh India ‐ 51 84
Cltr 4924 sphaerococcum Uttar Pradesh India ‐ 52 86
PI 277164 sphaerococcum Punjab Pakistan ‐ 53 85
PI 572857 compactum ‐ 54 92
PI 367200 spelta ‐ 55 87
PI 572851 compactum ‐ 56 93
PI 367199 spelta ‐ 57 88
Cltr 8610 sphaerococcum Jiangsu China ‐ 58 90
Cltr 10911 sphaerococcum Shanxi China ‐ 59 91
PI 262666 compactum ‐ 60 89
PI 572912 macha ‐ 61 50
PI 290507 macha ‐ 62 54
PI 355511 macha ‐ 63 52
PI 278660 macha ‐ 64 55
PI 323436 macha ‐ 65 51
PI 572905 macha ‐ 66 53
PI 355514 macha ‐ 67 56
PI 611470 macha ‐ 68 57
PI 361862 macha ‐ 69 59
PI 428146 macha ‐ 70 58

29
Table S6. Continuation.
Identifier Description Location Growth habit Fig. 5B Fig. S11
WA8100 aestivum Spring 71 29
Tara2002 aestivum Spring 72 32
Macon aestivum Spring 73 34
H0900009 aestivum Spring 74 33
Alturas aestivum Spring 75 30
IDO377s aestivum Spring 76 28
PI 277142 sphaerococcum India ‐ 77 31
H0800080 aestivum Spring 78 35
9245 aestivum Spring 79 25
9248 aestivum Spring 80 26
PI 190982 sphaerococcum Belgium ‐ 81 99
PI 323439 sphaerococcum Vienna Austria ‐ 82 98
PI 278650 sphaerococcum United Kingdom ‐ 83 100
PI 572850 compactum ‐ 84 24
Treasure aestivum Spring 85 27
PI 25970 compactum ‐ 86 18
PI 56213 compactum ‐ 87 49
PI 323438 spelta ‐ 88 40
PI 295059 spelta ‐ 89 37
PI 306550 spelta ‐ 90 36
PI 428178 macha ‐ 91 39
PI 355642 spelta ‐ 92 42
PI 631161 spelta ‐ 93 43
PI 348303 spelta ‐ 94 41
PI 221419 spelta ‐ 95 38
PI 192717 spelta ‐ 96 44
PI 348033 spelta ‐ 97 45
PI 348273 spelta ‐ 98 48
PI 378469 spelta ‐ 99 46
PI 469032 spelta ‐ 100 47
30
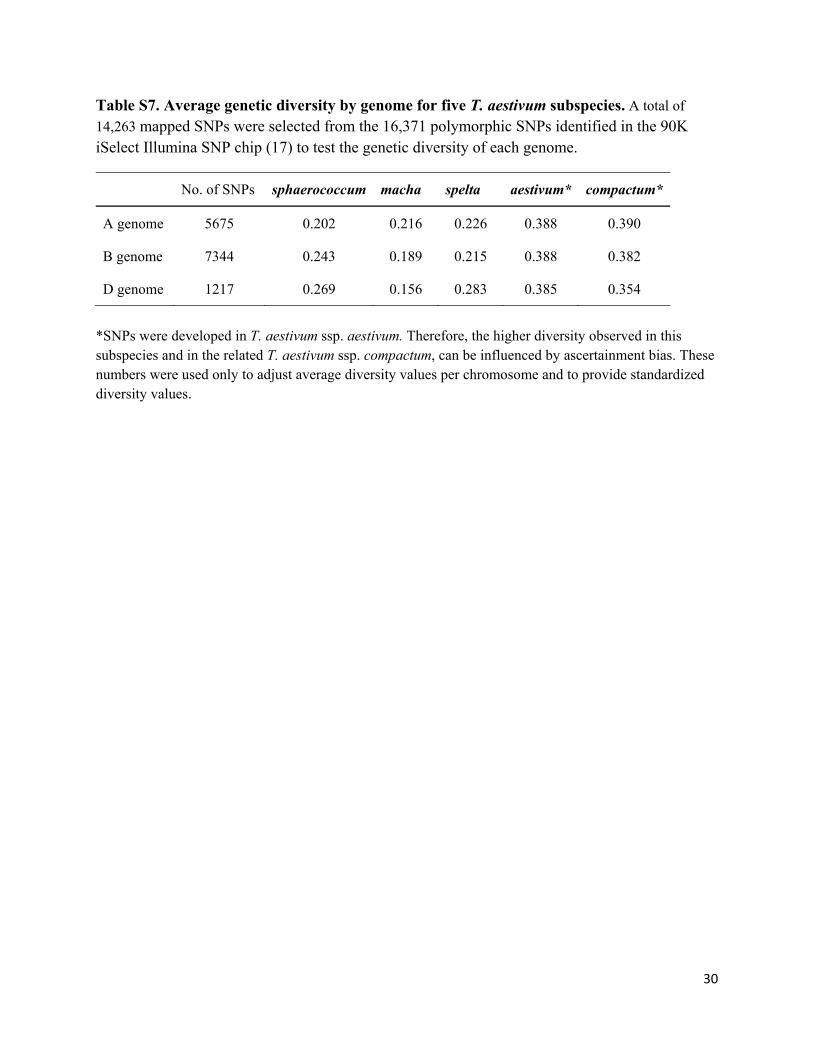
Table S7. Average genetic diversity by genome for five T. aestivum subspecies. A total of
14,263 mapped SNPs were selected from the 16,371 polymorphic SNPs identified in the 90K iSelect Illumina SNP chip (17) to test the genetic diversity of each genome.
No. of SNPs sphaerococcum macha spelta aestivum* compactum*
A genome 5675 0.202 0.216 0.226 0.388 0.390
B genome 7344 0.243 0.189 0.215 0.388 0.382
D genome 1217 0.269 0.156 0.283 0.385 0.354
*SNPs were developed in T. aestivum ssp. aestivum. Therefore, the higher diversity observed in this subspecies and in the related T. aestivum ssp. compactum, can be influenced by ascertainment bias. These numbers were used only to adjust average diversity values per chromosome and to provide standardized diversity values.
31
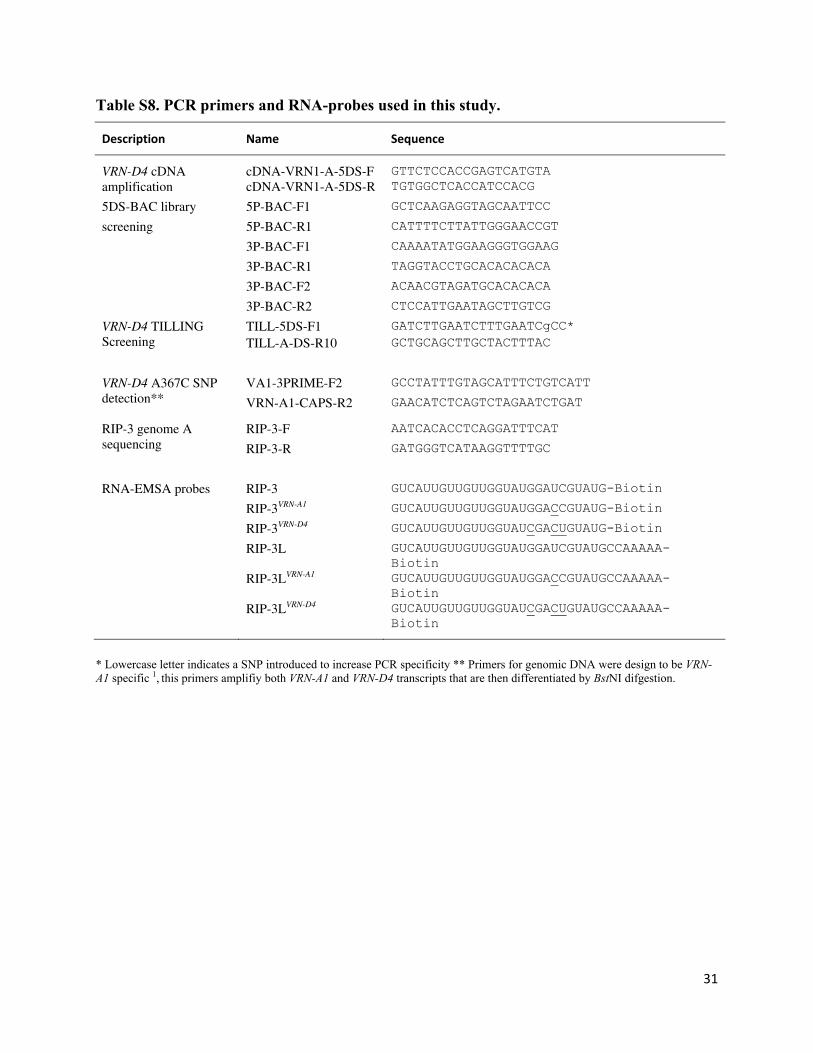
Table S8. PCR primers and RNA-probes used in this study.
Description Name Sequence
VRN-D4 cDNA amplification
cDNA-VRN1-A-5DS-F GTTCTCCACCGAGTCATGTA cDNA-VRN1-A-5DS-R TGTGGCTCACCATCCACG
5DS-BAC library 5P-BAC-F1 GCTCAAGAGGTAGCAATTCC
screening 5P-BAC-R1 CATTTTCTTATTGGGAACCGT
3P-BAC-F1 CAAAATATGGAAGGGTGGAAG
3P-BAC-R1 TAGGTACCTGCACACACACA
3P-BAC-F2 ACAACGTAGATGCACACACA
3P-BAC-R2 CTCCATTGAATAGCTTGTCG
VRN-D4 TILLING Screening
TILL-5DS-F1 GATCTTGAATCTTTGAATCgCC* TILL-A-DS-R10 GCTGCAGCTTGCTACTTTAC
VRN-D4 A367C SNP detection**
VA1-3PRIME-F2 GCCTATTTGTAGCATTTCTGTCATT
VRN-A1-CAPS-R2 GAACATCTCAGTCTAGAATCTGAT
RIP-3 genome A sequencing
RIP-3-F AATCACACCTCAGGATTTCAT
RIP-3-R GATGGGTCATAAGGTTTTGC
RNA-EMSA probes RIP-3 GUCAUUGUUGUUGGUAUGGAUCGUAUG-Biotin
RIP-3VRN-A1 GUCAUUGUUGUUGGUAUGGACCGUAUG-Biotin
RIP-3VRN-D4 GUCAUUGUUGUUGGUAUCGACUGUAUG-Biotin
RIP-3L GUCAUUGUUGUUGGUAUGGAUCGUAUGCCAAAAA-Biotin
RIP-3LVRN-A1 GUCAUUGUUGUUGGUAUGGACCGUAUGCCAAAAA-Biotin
RIP-3LVRN-D4 GUCAUUGUUGUUGGUAUCGACUGUAUGCCAAAAA-Biotin
* Lowercase letter indicates a SNP introduced to increase PCR specificity ** Primers for genomic DNA were design to be VRN-A1 specific 1, this primers amplifiy both VRN-A1 and VRN-D4 transcripts that are then differentiated by BstNI difgestion.

32
References
1. Uauy C, et al. (2009) A modified TILLING approach to detect induced mutations in
tetraploid and hexaploid wheat. BMC Plant Biol 9:115-128.
2. Chen A, Dubcovsky J (2012) Wheat TILLING mutants show that the vernalization gene
VRN1 down-regulates the flowering repressor VRN2 in leaves but is not essential for
flowering. PLoS Genet 8:e1003134.
3. Choi Y, Sims GE, Murphy S, Miller JR, Chan AP (2012) Predicting the functional effect
of amino acid substitutions and indels. PLoS One 7:e46688.
4. Ng PC, Henikoff S (2001) Predicting deleterious amino acid substitutions. Genome Res
11:863-874.
5. Adzhubei IA, et al. (2010) A method and server for predicting damaging missense
mutations. Nat Methods 7:248-249.
6. Tamura K, Stecher G, Peterson D, Filipski A, Kumar S (2013) MEGA6: Molecular
evolutionary genetics analysis version 6.0. Mol Biol Evol 30:2725-2729.
7. Leroy P, et al. (2012) TriAnnot: a versatile and high performance pipeline for the
automated annotation of plant genomes. Front Plant Sci 3:1-14.
8. Ling HQ, et al. (2013) Draft genome of the wheat A-genome progenitor Triticum urartu.
Nature 496:87-90.
9. Jia JZ, et al. (2013) Aegilops tauschii draft genome sequence reveals a gene repertoire for
wheat adaptation. Nature 496:91-95.
10. Luo MC, et al. (2013) A 4-gigabase physical map unlocks the structure and evolution of
the complex genome of Aegilops tauschii, the wheat D-genome progenitor. Proc Natl
Acad Sci USA 110:7940-7945.
11. Kippes N, et al. (2014) Fine mapping and epistatic interactions of the vernalization gene
VRN-D4 in hexaploid wheat. Theor Appl Genet 289:47–62.
12. Gruber AR, Lorenz R, Bernhart SH, Neuboock R, Hofacker IL (2008) The Vienna RNA
websuite. Nucleic Acids Res 36:W70-W74.
13. Pritchard JK, Stephens M, Donnelly P (2000) Inference of population structure using
multilocus genotype data. Genetics 155:945-959.

33
14. Earl DA, Vonholdt BM (2012) STRUCTURE HARVESTER: a website and program for
visualizing STRUCTURE output and implementing the Evanno method. Conserv Genet
Resour 4:359-361.
15. Anderson JA, Churchill GA, Autrique JE, Tanksley SD, Sorrells ME (1993) Optimizing
parental selection for genetic-linkage maps. Genome 36:181-186.
16. Weir BS (1996) Genetic data analyisis II (Sinauer Publishers Sunder-land, MA).
17. Wang S, et al. (2014) Characterization of polyploid wheat genomic diversity using a
high-density 90,000 SNP array. Plant Biotechnol J 12:787-796.
18. Yan L, et al. (2003) Positional cloning of wheat vernalization gene VRN1. Proc Natl
Acad Sci USA 100:6263-6268.
19. Leder V, et al. (2014) Mutational definition of binding requirements of an hnRNP-like
protein in Arabidopsis using fluorescence correlation spectroscopy. Biochem Bioph Res
Co 453:69-74.
20. Xiao J, et al. (2014) O-GlcNAc-mediated interaction between VER2 and TaGRP2 elicits
TaVRN1 mRNA accumulation during vernalization in winter wheat. Nat Commun 5:4572.
21. Nevo E, Beiles A (1989) Genetic diversity of wild emmer wheat in Israel and Turkey -
structure, evolution, and application in breeding. Theor Appl Genet 77:421-455.
22. Peleg Z, et al. (2005) Genetic diversity for drought resistance in wild emmer wheat and
its ecogeographical associations. Plant Cell Environ 28:176-191.
23. Diaz A, Zikhali M, Turner AS, Isaac P, Laurie DA (2012) Copy number variation
affecting the Photoperiod-B1 and Vernalization-A1 genes is associated with altered
flowering time in wheat (Triticum aestivum). PLoS One 7:e33234.
24. Iwaki K, Haruna S, Niwa T, Kato K (2001) Adaptation and ecological differentiation in
wheat with special reference to geographical variation of growth habit and Vrn genotype.
Plant Breeding 120:107-114.
25. Iwaki K, Nakagawa K, Kuno H, Kato K (2000) Ecogeographical differentiation in east
Asian wheat, revealed from the geographical variation of growth habit and Vrn genotype.
Euphytica 111:137-143.
26. Yan L, et al. (2004) Allelic variation at the VRN-1 promoter region in polyploid wheat.
Theor Appl Genet 109:1677-1686.

34
27. Chu CG, et al. (2011) A novel retrotransposon inserted in the dominant Vrn-B1 allele
confers spring growth habit in tetraploid wheat (Triticum turgidum L.). G3-Genes Genom
Genet 1:637-645.
28. Yan L, et al. (2006) The wheat and barley vernalization gene VRN3 is an orthologue of
FT. Proc Natl Acad Sci USA 103:19581-19586.
29. Fu D, et al. (2005) Large deletions within the first intron in VRN-1 are associated with
spring growth habit in barley and wheat. Mol Genet Genomics 273:54-65.
Recommended











![Gene Regulatory Variation Mediates Flowering Responses to … · Gene Regulatory Variation Mediates Flowering Responses to Vernalization along an Altitudinal Gradient in Arabidopsis1[W][OPEN]](https://img.pdfslide.us/doc/110x75/5f98e88dad46a25c2151eba2/gene-regulatory-variation-mediates-flowering-responses-to-gene-regulatory-variation.jpg)





