The Plant Journal (1997) 11(5), 1127-1140
TECHNICAL ADVANCE
Identification of members of gene families in Arabidopsis thaliana by contig construction from partial cDNA sequences: 106 genes encoding 50 cytoplasmic ribosomal proteins
Richard Cooke, Monique Raynal, Michele Laudi6 and Michel Delseny Laboratoire de Physiologie et Biologie Mol~culaires V~g~tales, UMR5545 du CNRS, Universite de Perpignan, Avenue de Villeneuve, 66860 Perpignan-Cedex, France
Summary
Partial cDNA sequencing to obtain expressed sequence tags (ESTs) has led to the identification of tags to about 8000 of the estimated 20 000 genes in Arabidopsis thaliana. This figure represents four to five times the number of complete coding sequences from this organism available in international databases. In contrast to mammals, many proteins are encoded by multigene families in A. thaliana. Using ribosomal protein gene families as an example, it is possible to construct relatively long sequences from overlapping ESTs which are of sufficiently high quality to be able to unambiguously identify tags to individual members of multigene families, even when the sequences are highly conserved. A total of 106 genes encoding 50 different cytoplasmic ribosomal protein types have been identified, most proteins being encoded by at least two and up to four genes. Coding sequences of members of individual gene families are almost always very highly conserved and derived amino acid sequences are almost, if not completely, identical in the vast majority of cases. Sequence divergence is observed in untranslated regions which allows the definition of gene-specific probes. The method can be used to construct high-quality tags to any protein.
Introduction
Partial cDNA sequencing to provide expressed sequence tags (ESTs) has led to the accumulation of a considerable amount of information on the transcribed genome of Arabidopsis thaliana (Cooke et aL, 1996; H6fte et aL, 1993; Newman et aL, 1994). One of the most surprising observa-
Received 15 July 1996; revised 20 December 1996; accepted 29 January 1997. *For correspondence (fax +33 68668499; e-mail: [email protected]).
tions made after analysis of A. thaliana ESTs is that many proteins for which only one gene is known in mammals are encoded by multigene families in this plant (HOfte et al., 1993). This was already established in plants for proteins such as tubulins (Snustad et al., 1992), but has also been demonstrated for housekeeping proteins, heat shock proteins, histones, late embryogenesis abundant proteins or components of the translation machinery (see, for example, Delseny and Cooke, in press; Genschik et al., 1994; Santos et al., 1996) and putative regulatory proteins (Urao et al., 1994). Sequence conservation between differ- ent members of a multigene family is often such that the encoded proteins have identical amino acid sequences and the non-coding regions are highly conserved. The number of gene families in A. thaliana makes it difficult to estimate how many unique genes have been tagged by ESTs. However, taking into account redundancy and multiple non- overlapping tags to the same gene, the 28 000 sequences in the EST databank, dbEST (Boguski et al., 1993) probably represent tags to at least 8000 of the estimated 20 000 genes from this organism. This figure is four or five times greater than the number of complete A. thaliana coding sequences in the international databanks. Thus, for many genes, the only available sequence data is provided by ESTs and it was of interest to determine whether this considerable reservoir of sequences could be used to define unique tags to a large number of genes.
Partial sequence data is useful in gene identification, but the limit of 300-350 bases of useful information for each EST can make definitive identification of the tagged gene hazardous. As ESTs are being used not only as tags to isolate complete gene sequences but also in physical and genetic mapping, it is important to be able to distinguish between closely related members of the same gene family. Contigs can be assembled from the whole EST database, but the very presence of multigene families makes this difficult: if criteria of overlaps are too stringent, overlapping sequences will not be detected, whereas, if they are less stringent, tags to different members of the same family will be assembled into the same contig. As most mapping is at present carried out using tags to genes for which the protein product is known in at least one other organism, it is possible to identify all tags to genes encoding these
1127

1128 Richard Cooke et al.
proteins before assembling contigs. The assembled sequences can then be compared to identify tags to differ- ent genes.
We tested the method of contig construction using ribosomal protein genes as an example. There are only 14 A. thaliana cytoplasmic ribosomal protein coding sequences in international databanks, and studies show that the proteins encoded by multiple copies apparently have identical or near-identical amino acid sequences (van Lijsebettens et aL, 1994; Williams and Sussex, 1994). We demonstrate that ESTs can be used to obtain relatively long, high-quality sequences by construction of contigs that are tags to individual members of gene families, even when gene sequences are highly conserved. This analysis shows that the majority of cytoplasmic ribosomal proteins in A. thaliana are encoded by at least two genes.
Results
Previous analyses of EST sequences showed that tags to many ribosomal protein genes had been obtained (Cooke et aL, 1996; H6fte et al., 1993, Newman et aL, 1994). In order to identify tags to cytoplasmic ribosomal protein genes among the A. thaliana ESTs, we chose to use the sequences of all known cytoplasmic ribosomal proteins from Saccharomyces cerevisiae. Yeast was chosen as sequences of the majority of cytoplasmic ribosomal proteins are available and the use of sequences from one organism avoids the problem of different nomenclatures for homologous proteins which is common for ribosomal proteins. Interrogation of the Swiss-Prot database identi- fied sequences for 42 yeast large-subunit and 22 small-subunit proteins. We used the TFASTA program of Pearson and Lipman (1988), which allows sensitive align- ment between an amino acid sequence and the translation in all six frames of a nucleotide databank, to align these sequences against all A. thaliana sequences from dbEST. EST sequences for which putative translation products gave highly significant alignment scores with the yeast proteins were extracted from GenBank. In all, 453 EST sequences were identified and retrieved. These were imported into a Sequencher (Gene Codes, Ann Arbor, MI) project and cleaned as described in Experimental procedures.
Quality of assembled sequences
Despite uncertainties or erroneous base calls, the quality of EST data obtained from automatic sequencers is such that the uncorrected sequences obtained are usually at least 97-98% identical to known sequences over more than 300 bases. Furthermore, uncertainties are very rarely found at the same position in different tags to the same gene, and given the large number of ESTs currently available,
overlapping tags can easily be found. In fact, over the first 300 bases, most of the errors of the automatic analysis programme are in the attribution of the base after a G residue. Thus, variations in EST sequences after a G should be treated with caution. Spuriously inserted bases are generally only found beyond 300-350 bases and were thus mostly eliminated by the trimming of all ESTs (see Experimental procedures). Sequence from the first bases of overlapping tags almost always allows the elimination of remaining insertions.
We constructed contigs in two steps: a first passage with assembly parameters of 80% identity in 30 bases to maximize the detection of overlaps, followed by a lower- stringency run at 70% identity in 40 bases. Surprisingly, and despite the relatively non-stringent criteria, a comparison of the ESTs identified by the TFASTA alignment and contigs showed that only three sequences were incorporated into contigs which tag genes encoding a different ribosomal protein than the one which was used to identify them. These sequences were removed manually. The ESTs which were not incorporated into contigs were found to corre- spond to tags to genes encoding organellar proteins, to the less highly conserved C-terminal extremity and 3' non- coding region of a gene, or, in one case, to members of a multigene family in which the coding region is very short and the untranslated regions highly divergent (see below). Figure 1 shows an example of the final alignments for tags to two different small-subunit $6 protein genes. The highlighted differences show that there are four identical tags to each of two genes. Sequence differences increase with increasing length of the ESTs, as can be seen for the first sequence, T22239, in which there are a number of ambiguous bases and false base calls towards the end. However, these differences are seen in only one sequence at any given position and can be attributed to sequencing errors in that particular EST. Spurious inserted bases have been removed during correction of the sequence ATTS1319 and appear as colons in this sequence compared with the other ESTs. In this case, only partial tags were constructed, but these are sufficiently long to identify tags to the two different genes unambiguously. The 3' sequence corres- ponding to ATTS1319 is available, but no truncated cDNAs have been sequenced which would have allowed recon- stitution of the complete coding sequence.
In order to be able to use the reconstructed sequences, it is necessary to know whether they are of sufficiently good quality to be able to distinguish between tags to closely related genes. To test the accuracy, all contigs were saved, eliminating systematically all gaps that had been inserted during construction. The resulting sequences were then aligned against the non-redundant protein databank using the BLASTX programme (Altschul et al., 1990). The majority of contigs, particularly for tags to relatively small proteins, gave long, non-gapped alignments with the cor-

Ribosomal multigene families in Arabidopsis thaliana 1129
T 2 2 2 3 9 . . . . . . . . . . . . . . . . . . A . . . . . . N . . . . . . . . . . . . . . . . . . . . . . . I T 2 2 2 3 9
T 4 5 5 1 5 . . . . . . . . . . . . . . . T . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . T T 4 5 5 1 5
T 4 6 7 2 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . ~ T 4 6 7 2 3
T 0 4 2 9 0
T 2 2 2 3 9 ~ . . . . . . . . . . . . . . . . . . . . ~ . . . . . . . . . . C - - C . . . . . G - - C H ~ 7 2 8 3
T4~SlS ~ ................... ~ .......... C-- C ..... G--C T41955
T46723 &G- . . . . . . . . . . . . . . . . . . . . ~ . . . . . . . . . . C - - C . . . . - - G - - C T14075
T04290 ............... ~ .......... C-- C .... -G--C ATTBI319
H $ 7 2 8 3 - ~ . . . . . . . . . . T - - G . . . . . A - - T
T41955 ~ ....... T-- g ..... A--T T22239
T14075 . . . . . . . T-- G . . . . . A--T T45515
ATTS1319 ...... T-- G ..... A--T T46723
T04290
T22239 --C--G--TN -A ..... A ........... T --C--T--A ..... C--C-- H37283
T45515 --C--G--T- -A ..... A ........... T --C--T--A ..... C--C-- T41955
T46723 --C--G--T- -A ..... A ........... T --C--T--A ..... C--C-- ATTSI319
T 0 4 2 9 0 - - C - - G - - T - - A . . . . - A . . . . . . . . . . . T - - C - - T - - A . . . . . C - - C - -
S 3 7 2 8 3 - - T - - A - - C - - G . . . . . G . . . . . . . . . . . C - - T - - C - - G . . . . . A - - T - - T 4 5 5 1 5
T 4 1 9 5 5 - - T - - A - - C - - G . . . . - G . . . . . . . . . . - C - - T - ~ C - - G . . . . . A - - T - - T 4 6 7 2 3
T14075 --T--A--C- -G ..... G ........... C --T--C--G ..... A--T-- T04290
ATTSI319 --T--A--C- -G ..... G ........... C --T--C--G ..... A--T-- H37283
T41955
T22239 C .... T ......... GC ..... H-G ..... T--C ......... C-A .... ATT81319
T45515 C .... T ......... GC ...... -G ..... T--C ......... C-A ....
T46723 C .... T ......... GC ....... G ..... T--C ......... C-A ....
T04290 C .... T ......... GC ....... G ..... T--C ........ -C-A ....
a37283 G .... A ......... AA ....... A ..... C--T ......... T-G ....
T41955 G .... A ......... AA ....... A ..... C--T ......... T-G ....
T14075 G----A ......... AA ....... A ..... C--T ......... T-B ....
ATTSI319 G .... A ......... AA ....... A ..... C--T ......... T-G ....
. . . . A . . . . . G - ---G . . . . g A . . . . . . . . . . T . . . . . . N - T - - T . . . . . . .
. . . . A . . . . . G . . . . . . . . A . . . . . . . . . . T . . . . . . A . . . . . . . . . . . .
. . . . A . . . . . 6t . . . . . . . . A . . . . . . . . . . T . . . . . . A . . . . . . . . . . . .
. . . . A . . . . . g . . . . . . . . A . . . . . . . . . . T . . . . . . A . . . . . . . . . . . .
. . . . G . . . . . A . . . . . . . . T . . . . . . . . . . A - - - T - - T - - C l i - T . . . . . .
. . . . G . . . . . A . . . . . . . . T . . . . . . . . . . A - - - T - - T - - C - - T . . . . . .
- - - - ( ; . . . . . A . . . . . . . l i T . . . . . . . . . . A
. . . . G . . . . . A . . . . . . . . T . . . . . . . . . . A - - - T - - T - - C - - T - - : - - =
. . . . . . . . C - - l i b . . . . . . . G . . . . . . . . . . . C l i - - N . . . . . . B : - -
. . . . . . . . . . . . . . . . . . . . . . . . C . . . . . . . . . . . . . . . . . . . T . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . C . . . . . . . . . . . . . . . . . . . T . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . C . . . . . . . . . . . . . . . . . . . T . . . . .
. . . . . . . . . . . . . . G - - G . . . . . . . . G . . . . . . . . C . . . . . T - - C . . . . .
. . . . . . . . . . . . . - G - - G . . . . . . . . G . . . . . . . . C - - - S - T - - C . . . . .
. . . . . . . . . . . . . : G - - G . . . . . . . : G . . . . . . . . C . . . . . T - - C . . . . .
T . . . . . . . . . . . . T . . . . . . . T-T--TT ......... C - - G-
............. T ......... T--T ..... -GN--C ........ GU--
............. T ......... T--T .......... C ........ G---
. . . . . . . . . . . . . A . . . . . . . . . C - - C - - I I . . . . . . . T . . . . . . . . . . . .
T . . . . N . . . . l i - - A B . . . . . . . . C - - C . . . . . . . . . . T . . . . . . . . . . . .
. . . . . . . . . . . . . A . . . . . . . . : C - - C . . . . . . . . . . T . . . . . . . . . . . .
Rgure 1. Multiple sequence alignment of ESTs to two different ribosomal protein $6 genes. Sequences were aligned as described in Experimental procedures. Only the first 300 bases of each contig are shown. Identical residues are shown by hyphens to emphasize base differences between the two groups of sequences. The ATG start codons and an upstream in-frame stop codon in the first contig are shown in bold type. ESTs are identified by their EMBL or GenBank ID.
responding protein, indicating that even frame-shift errors are largely eliminated in this procedure (results not shown). This indicates that inserted gaps in contigs represent spuri- ous bases inserted towards the end of the ESTs. The quality of contigs is lower for longer sequences or contigs constructed using only uncorrected ESTs. In addition to testing the accuracy of the sequences, BLASTX alignment allowed us to identify contigs which correspond to non- overlapping regions of the same protein and which could otherwise have been considered to be tags to different genes. In contrast, it allowed the identification of tags to genes of the same family which show nucleotide similarity that is too low for contigs to have been constructed using our parameters. This is the case for the tags to genes encoding the L41 protein, a very small protein, in which the non-coding regions are highly divergent (see below).
Comparison of contigs with known sequences
For tags to genes for which several members of a gene family have been completely and independently sequenced, it is possible to make a direct comparison of the accuracy of the assembled sequences. Figure 2 shows the alignment of the four different contigs assembled from tags to small-subunit S18 genes with the published coding sequences of the three genes (van Lijsebettens et aL, 1994). These code for perfectly identical proteins and their nucleotide sequences are extremely similar, particularly in the coding regions. Despite this high sequence conserva- tion, it is obvious that each contig can be unambiguously attributed to the corresponding complete cDNA sequence.
Contig RS18-4.nuc, which has been assembled only from uncorrected EST sequences, is of much lower quality than the other three for which at least one manually corrected tag has been used. Even so, it is possible to assign this contig as the tag to gene ATS18RP3. This alignment also provides confirmation that the two contigs RS18-3.nuc and RS18-4.nuc are tags to the same gene, ATS18RP2, and only overlap by 11 bases. The only differences between this almost full-length contig of 569 bases and the correct sequence retrieved from EMBL are two unattributed bases in the former sequence.
Quality of tags to new genes
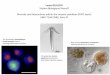
A second test of the quality of the reconstructed sequences is to compare the predicted amino acid sequence of the contig with known sequences of homologous proteins. We chose as an example the A. thaliana homologues of the yeast RL1 protein. There are no complete sequences for the A. thaliana protein in the databanks. We identified tags to two different genes encoding RLl-type proteins, one of 952 bases and the other of 354 bases. The positions of the 12 ESTs used to construct the former contig are shown in Figure 3(a). At least three EaTs overlap at all positions except the 3' end. The majority of the tags are at the 5' end and correspond to partial sequences of complete or almost complete cDNAs. However, several incomplete cDNAs have been sequenced, containing the sequence in the central coding region, while tags ATTS0270 and ATTS0271 are 5' and 3' sequences of one clone, confirming that the contig corresponds to a single gene. Translation

1130 Richard Cooke et al.
ATS18P-PZ RS1S-2.nuc
ATSISRP3 R518-I .nu~
ATSlaRP1 RS18-2.nuc
ATS18RP3 RS18-1.nu~
ATSIaRPI R~lS-2.nuo
ATSI 8RP2
RSlS-3 onUC
ATSISRP3 RSlS-l.nu~
ATS~SRPI RS18-2. nuc
ATSI 8P.P2
RS~8-3. nuc
ATSI 8RP3 RSI8-1. nuc
ATSISRPI RSIS-2.nuc
ATSI8RP2 RSlS-3.nuc
ATSISRP3 RSlS-l.nuc
~GCCTCC~GA~AAAAGAGCTTAATCCTC
GC~'T, CCTCCAGAGTL~AA~AGAGCTTAATCCTC
~GACe~'~/~"TTCIT
~-A-,TAGTNTTCTTC~CTNCTCCAGC GATCGTTT~AAGAC~3TTCTTCTT
CTCTCGCGATCTTECTCGGCATCCaAAA~TGTCTCTA~CGAGGaGTTTCA CTCTCGCGAT~TC~TGTCTCTAGTTGCT, AACGAGGAGTTTCA
AATCAAA~TGTC TG~aGTTI~A CTCACAAAt CTCA~AATCAAAA TnAGG~GTTTC~
+ + +
GC~TATTCTGCGT~TGCTCA&TACTA~TGGGAA~AT~-~-~C
C~ACATTTTGCGTGT~AACACTAAC~TGGTAAGCAAAAGATTATGTTTC:C CTCA~CACTAAC GTT~AT~GTAAGC~t2~AAGATTATGTTTGC
ACA~'/~TACTAATGTTC, A~TAAGCAGAAGATTATGTTTGC ACACATTCTTC~TACTAATGTTGATGG TAAGCAG~AGATTATGTTTGC
~CCTCAATCAAGGGTATTGGAAGGCGATTC-GCTAACATTGTGTGCAAGAAGGC TTTGACCTCAATCAAGGGTATTGGAAGGCGATTGGCTAACATTGTGTGCAAGAAGGC
C C ~ A C ~ A T C ~ T A T T ~ C ~ T ~ C A T T ~ G ~ G C CCTTACCTCTATCAAAGGTATTGGAAGGAGATTGGCCAACATT~TCTC~GAAAGC
C CTTAC CTCTAT~GGTATTGGTAG~CGATTGGCTAACATTGTC~GAAGGC CCTTACCTCTAT~GGTATTGGTAGC~CGATTC~AACATTC~GAAGGC
TGATGTTG~CAT~AA~GGGCTGG~GAACTAA~GATTGATAAC CT
TC:AT~CATC~GC=GCTG~AGAACTAAGTGCTGCTGAGATTGATA~C CT
CGATGTCGACATGAACAAGAGG~ATCTGCAGCTGAGATTGACAACCT CGATGTCGACATGAACA&GAGGGCTGGTGAGTTA~GCTGAGATTGACAACCT
TGATGTCGACATGAACAR/%AGGGC TGG TGAGTTA ~GATAACCT
TGATGTCGACATGAACAAAAGGGCTGGTGAGTTATCTGC~GCT~AGATTGATAACCT . * ** ** . *
ATS18RP1
RSlS-2.nuc
ATSISRP2
RSlS-3.nuc
ATS18RP3 RSlS-l.nuo
ATSISRP1
RSlS-2.nuc
ATS18RP2 RS18-3. nuo RS18-4.nuc
ATS 18~P3
RS18-I .nuo
ATS18RPI RS18-2.nuc
ATSISRP2 RS18-4.nuc
ATS18RP3 RSIS-I.nuc
ATSISRPI RSl8-2.nu~
ATSISRP2
RSIS-4.nuc
ATSISRP2 ]%518-4 .nuc
ACAAAAGGATTACAAGGATC~w~%AT TGCTCTTGACAT ACAAAAG~ATTACAAGGATGGGA&ATACTC~TTTCCAATC~CAT
ACA~TTACA~G~ATGGGAAGTA~GTT~TC~-~2 C~CAT
ACAGAttAGATTACAAGGATGGGAAGTnCTCTCAAG~TnCCCTTGACAT + +
GCAGAAGGATTACAAAGATGGCAAGTA~GTT~T~CAT GCA~GGATTA C 3 ~ % A G A T C ~ G T A ~ G T T ~ T ~ C A T
\a
Ga~GTTG~GAGATC, A~GaA~TCAGA~ACCATC~TC~TCTGAG GAAGTTGAGAGATGATCTTGAGCGTCTCAAGAAGATCAGAAACCATC GTGGTCTGAG
GAAC~TCAGGG~TG~TCTTGAGCGTCTCAAGAAR~TCAGAAACCATCGTGG~CT~AG GAAGCTCAGGG~TGATCTT
GGATGATC TTGAC~GTCTCAA~I~%AATCAGAAACC ATCGT~ TG~G
GAAGCTGA~ TGA~ TCTTGA~CGTCTCAAGAAGATCAGAA~CCACCGTGGTITGaG GAAGCTGAGAGATGATCTTnAACGGnTCAAGA~GATCAGAP~CCACCGTGG~G
GCACTACTGGGGTCTCCGTGTACGTGGACAGCAC~CCA~AACCACCeG~CGCCGTGG
GCACTACTGGGGTCTCCGTGTACGTGGACAGCACAC~CCACCGGACGgCGTGG
ACATTACTGGGGTCTCCGTGTTCGTGGACAACACACCAAC~%CA~CTGGTCGCAGA~
ACATTACTG TCTCC GTGTTC GTGGACAACACAC CA~GACAACTGGTC~J%GAGG
GCATTACTGGGGTCTCCGTGTCAGAGGACAACACACCAAGACTACTGG GCATTACTGGGGTCTCCGTGTCAZL%GGt CAACACAnCAAGgCTnCTt G
AP~GACTG~,G TG ~ ' ~ C C,~AGAAGCG'IWL~ A
AAAGA~TGTGTCTAAGAAGC G TTAAGC C~ATGTTGC TAGTTGCAGCTGGAT
A A ~ G A ~ TGTGTCTAAGAAGC~FEAAGCCAATG TT~C TAGTTGC~GCTGGAT STP
TGGATCTTTGATAAGG&CTGAATTTTAAATTTTGTTGTTCGTACAA~-~-~-~CAC GAC TOGATCTTTGATAAGGACTGAATTTTAAATTTTGTTG TTC GTACAATI~F2GCAC GAC
ATSISRP1
RS18-2 .hUe
ATSI8RP2 RS18-3 .nua
ATSISRP3 RSI8-1 .nuc
CATGACAATCGTTGCTAACCCTCGC~TCCCAGACTGGTTTCTTAACAG ATSISRP2
CATGACAATCGTTGCTAACCCTCGCCAGTTCAAGATCCCAGACTGGTTTCTTAACAG RSl8-4.nuc
CATGACTATTGTTGCAAACC CAAC:ACAGTTCAAGATTCCAGACTGG z-z~-I-£~AACAG
CATGACTATTG ~CCCA~GACAGTTCAAGATTCC~CTG~rI-~-I-I~ACAG ATS18RP2
CATGACAATCG TTGCAAAC CCAC GTCAGTTCAAGATCCCAGAC TGGTTCTTGAACAG RSlS-4.nuc
CATC',ACAATCG TTGCAAACCCACGTCAG~GATCCCAGACTC, GTTCTTGAACAG \ m
* * * * * * * *
TC GATTTTGGGTCTTTTGTGAGAGATCTTC TCTACTGTCATATTG~'F~'AAGATAA
TC'GATTTTGGG~..,'I-~.-~,=.v.~TGAGAGR.TCTTCTCT.~CTG TCATATTGC-L'~-.I.-~'~T~
TGTTGCTTACTGGAT
TGTTGCTTACTGGAT
Figure 2. Sequence alignment of constructed contigs tagging the three genes encoding ribosomal proteins S18. Contigs were constructed as described in Experimental procedures and are identified as RS18-1.nuc to RS18-4.nuc. The complete mRNA sequences are derived from those presented in van Lijsebettens et a/. (1994) and have been truncated to the length of the corresponding contigs. Each contig is aligned independently with the corresponding complete sequence and all sequences further aligned with respect to the coding region. Asterisks show positions at which base differences are found in at least one sequence, and plus signs (+) show residues where the contig and corresponding sequences differ. Additional bases are indicated below the sequence after the insertion point. MET and STP indicate the limits of the coding regions.
of the longest assembled tag to this gene gives a 293 amino acid protein. Figure 3(b) shows a multiple sequence alignment of this conceptual translation with complete sequences for other organisms (rice, the yeast sequence, chick, human and Xenopus laevis). The alignment is excel- lent with all homologous sequences in the highly conserved N-terminal region, diverging only where the rice, yeast and animal sequences also diverge. In fact, divergence from the rice sequence may well be due to a sequence error in the latter, as the RLI_ATH sequence shows full-length alignments with no frame shift with all other sequences except that of rice and a single base change in the rice coding sequence leads to an amino acid sequence highly similar to that of A. thaliana and of the same length (results not shown). These two reconstruction experiments emphasise that high-quality, relatively long sequences can be obtained from assembled ESTs.
Global analysis of contigs
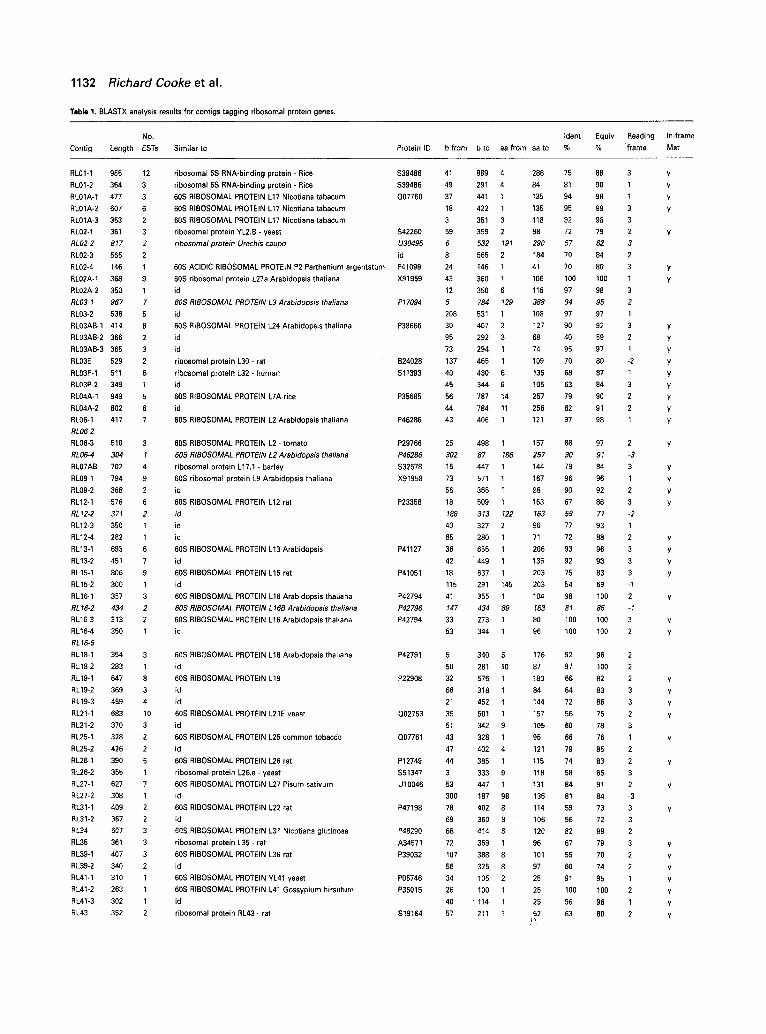
Table 1 summarizes the results of 8LASTX alignments of all contigs against the non-redundant protein databank, presenting for each contig its length, the number of ESTs used to construct it, the name of the protein with which the most highly significant alignment was found, the co- ordinates on the nucleotide and amino acid sequences, and the percentages of identical and equivalent amino acid residues given by the BLAST alignment. As the N-terminal sequences are often very different between proteins from widely divergent origins, often leading to insertions or deletions, we also indicate whether an upstream in-frame methionine codon is found, an indication that the coding sequence is probably complete at the N-terminal end. Obviously, it is necessary for all tags to genes from the same family to overlap sufficiently to be able to assign
Ribosomal mult igene families in Arabidops is thal iana 1131
Figure 3. Construction of a complete tag to a ribosomal protein L1 gene and comparison of the derived amino acid sequence with known sequences of the homologous protein in other organisms. (a) Relative positions of the 12 ESTs used to construct the 952 base sequence. ESTs ape identified by their EMBL or GenBank IDs and their positions on the contig are shown. (b) Multiple sequence alignment of the derived amino acid sequence with sequences of homologous proteins from rice, yeast, chick, man and Xenopus laevis. Sequences are identified by their Swiss-Prot ID. Alignment was carried out using ClustalW (Thompson et aL, 1994) and shaded using Kay Hofmann's BOXSHADE programme (ISREC, Lausanne). Identical residues are shown'in white on a black background, similar residues are black on a grey background.
individual tags to individual genes. Contigs for which this is not the case are italic in Table 1 and were not taken into account for further analysis.
Given the number of genes identified for certain proteins, it is important to eliminate the possibil ity that some of them could be organellar ribosomal protein genes. For almost all proteins considered, the sequence of the gene for at least one of the corresponding organellar proteins is known and appears in the list of similarities detected by' the SLASTX alignment at a lower level of significance than the cytoplasmic .protein. BLASTN and BLASTX alignments identified contigs RL06-2, RL16-5, RS15-2 and. R$15-3 as tags to genes encoding organellar proteins. The sequence of the RL16-5 contig shows significant similarity to the cyanellar genome of Cyanophora paradoxa and the chloro-
plast genome of Euglena gracilis but not to those of higher plants, strongly suggesting that it tags the corresponding gene which has-migrated to the nucleus in A. tha/iana. The tag to the mitochondrial RS15 gene, RS15-2, shows similarity at the nucleotide level to nuclear genes for the same protein in other organisms and is thus probably also a tag to a nuclear gene. BLASTN analysis (Altschul eta/., 1990) of the RL06-2 and RS15-3 contigs shows that the corresponding proteins are almost certainly encoded by the chloroplast genome in A. thaliana, probably reflecting slight contamination by chloroplast DNA of the mRNA used to prepare the cDNA libraries. These sequences were not included in further analysis. In only one case, the large- subunit L15 protein, there is no sequence for either a cytoplasmic or organellar gene and the two derived amino
1132 Richard Cooke et al.
Tab le 1. BLASTX analysis results for contigs tagging ribosomal protein genes.
No. Ident Equiv Reading In-frame
Contig Length E S T s Similar to Protein tD b from b to aa from aa to % % frame Met
RL01-1 955 12
RLOl-2 354 3
RLO1A-'r 477 3
RLO1A-2 607 6
RL01A-3 353 2
RL02-1 361 3
RL02-2 817 2
RL02-3 565 2
RL02-4 146 1
RL02A-1 368 9
RL02A-2 350 1
RL03- I 967 7
RL03-2 536 5
RL03AB-1 414 8
RL03AB-2 366 2
RL03AB-3 365 3
RL03E 529 2
RLO3P-1 511 6
RLO3P-2 349 1
RLO4A-1 949 5
RLO4A-2 802 6
RL06-1 417 7
RLO6-2 RL06-3 510 3
RL06-4 304 1
RL07AB 702 4
RL09-1 794 9
RLO9-2 368 2
RL12-1 576 6
RL12-2 371 2
RL12-3 350 1
RL12-4 282 1
RL13-1 693 6
RL13-2 451 7
RL15-1 806 9
RL15-2 300 1
RL16-1 357 3
RL 16-2 434 2
RL16-3 313 2
RL16-4 350 1
RL 16-5
RL18-1 354 3
RL18-2 283 1
RL19-1 647 8
RL19-2 369 3
RL19-3 459 4
RL21-1 683 10
RL21-2 370 3
RL25-1 328 2
RL25-2 426 2
RL26-1 390 5
RL26-2 355 1
RL27-1 627 7
RL27-2 308 1
RL31-1 409 2
RL31-2 367 2
RL34 607 3
RL35 361 3
RL39-1 407 3
RL39-2 340 2
RL41-1 310 1
RL41-2 263 1
RL41-3 302 1
RL43 352 2
ribosomal 5S RNA-binding protein - Rice S39486 41 889 4 286 75 88 3 y
ribosomal 5S RNA-binding protein - Rice $39486 49 291 4 84 81 90 1 y
60S RIBOSOMAL PROTEIN L17 Nicotiana tabacum Q07760 37 441 1 135 94 98 1 y
60S RIBOSOMAL PROTEIN L17 Nicotiana tabacum 18 422 1 135 95 99 3 y
60S RIBOSOMAL PROTEIN L17 Nicotisna tabacum 3 351 3 118 92 98 3
ribosomal protein YL2.B - yeast $42260 59 359 2 98 72 79 2 y
ribosomal protein Urachis caupo U30495 6 532 191 290 57 82 3 id 8 565 2 184 70 84 2
60S ACIDIC RIBOSOMAL PROTEIN P2 Parthenium argentatum P41099 24 146 1 41 70 80 3 y
60S ribosomal protein L27a Arabidopsis thaliana X91959 43 360 1 106 100 100 1 y
id 12 350 6 118 97 98 3
60S RIBOSOMAL PROTEIN L3 Arabidopsis thaliana P17094 5 784 129 388 94 95 2 id 208 531 1 108 97 97 1
60S RIBOSOMAL PROTEIN L24 Arabidopsis thaliana P38666 30 407 2 127 90 92 3 y
id 95 292 3 68 40 59 2 y
id 73 294 1 74 95 97 1 y
ribosomal protein L30 - rat B24028 137 465 1 109 70 80 -2 y
ribosomal protein L32 - human $1t393 40 430 6 135 68 87 1 y
id 45 344 6 105 63 84 3 y
6OS RIBOSOMAL PROTEIN L7A rice P35685 56 787 14 257 79 90 2 y
id 44 784 11 256 82 91 2 y
60S RIBOSOMAL PROTEIN L2 Arabidopsis thaliana P46286 43 406 1 121 97 98 1 y
60S RIBOSOMAL PROTEIN L2 - tomato P29766 25 498 1 157 88 97 2 y
60S RIBOSOMAL PROTEIN L2 Arabidopsis thaliana P46286 302 87 186 257 90 91 -3
ribosomal protein L17.1 - barley S32578 15 447 1 144 79 84 3 y
60S ribosomal protein L9 Arabidopsis thaliana X91958 73 571 1 167 96 96 1 y
id 56 368 I 98 90 92 2 y
60S RIBOSOMAL PROTEIN L12 rat P23358 18 509 1 163 67 86 3 y
id 188 313 122 163 59 71 -2
id 40 327 2 96 77 93 1
id 65 280 1 71 72 88 2 y
60S RIBOSOMAL PROTEIN L13 Arabidopsis P41127 36 655 1 206 93 96 3 y
id 42 449 1 135 92 93 3 y
60S RIBOSOMAL PROTEIN L15 rat P41051 18 637 1 203 75 83 3 y
id 115 291 145 203 54 69 -1
60S RIBOSOMAL PROTEIN L16 Arabidopsis thaliana P42794 41 355 1 104 98 100 2 y
60S R/BOSOMAL PROTEIN L 16B Arabidopsis thaliana P42796 147 434 89 183 81 85 -1
60S RIBOSOMAL PROTEIN L16 Arabidopsis thaliana P42794 33 273 1 80 100 100 3 y
id 53 344 1 96 100 100 2 y
60S RIBOSOMAL PROTEIN L18 Arabidopsis thaliana P42791 5 340 5 176 92 96 2
id 50 281 10 87 97 100 2
60S RIBOSOMAL PROTEIN L19 P22908 32 576 1 180 66 82 2 y
id 66 318 1 84 64 83 3 y
id 21 452 1 144 72 86 3 y
60S RIBOSOMAL PROTEIN L21E yeast Q02753 35 501 1 157 56 75 2 y
id 51 342 9 105 60 78 3
60S RIBOSOMAL PROTEIN L25 common tobacco Q07761 43 328 1 95 66 76 1 y
id 47 402 4 121 79 85 2
60S RIBOSOMAL PROTEIN L26 rat P12749 44 385 1 115 74 83 2 y
ribosomal protein L26.e - yeast S51347 3 333 9 118 58 85 3
6OS RIBOSOMAL PROTEIN L27 Pisum sativum U10046 53 447 1 131 84 91 2 y
id 300 187 98 135 81 84 -3
60S RIBOSOMAL PROTEIN L22 rat P47198 78 402 8 114 59 73 3 y
id 69 360 8 106 56 72 3
60S RIBOSOMAL PROTEIN L31 Nicotiana glutinosa P46290 68 414 6 120 82 88 2
ribosomal protein L35 - rat A34571 72 359 1 96 67 79 3 y
60S RIBOSOMAL PROTEIN L36 rat P39032 107 388 8 101 55 70 2 y
id 56 325 8 97 60 74 2 y
60S RIBOSOMAL PROTEIN YL41 yeast P05746 34 105 2 25 91 95 1 y
60S RIBOSOMAL PROTEIN L41 Gossypium hirsutum P35015 26 100 1 25 100 100 2 y
id 40 " 114 1 25 96 96 1 y
ribosomal protein RL43 - rat S19164 57 . 211 1 j52 63 80 2 y
Ribosomal multigene families in Arabidopsis thaliana 1133
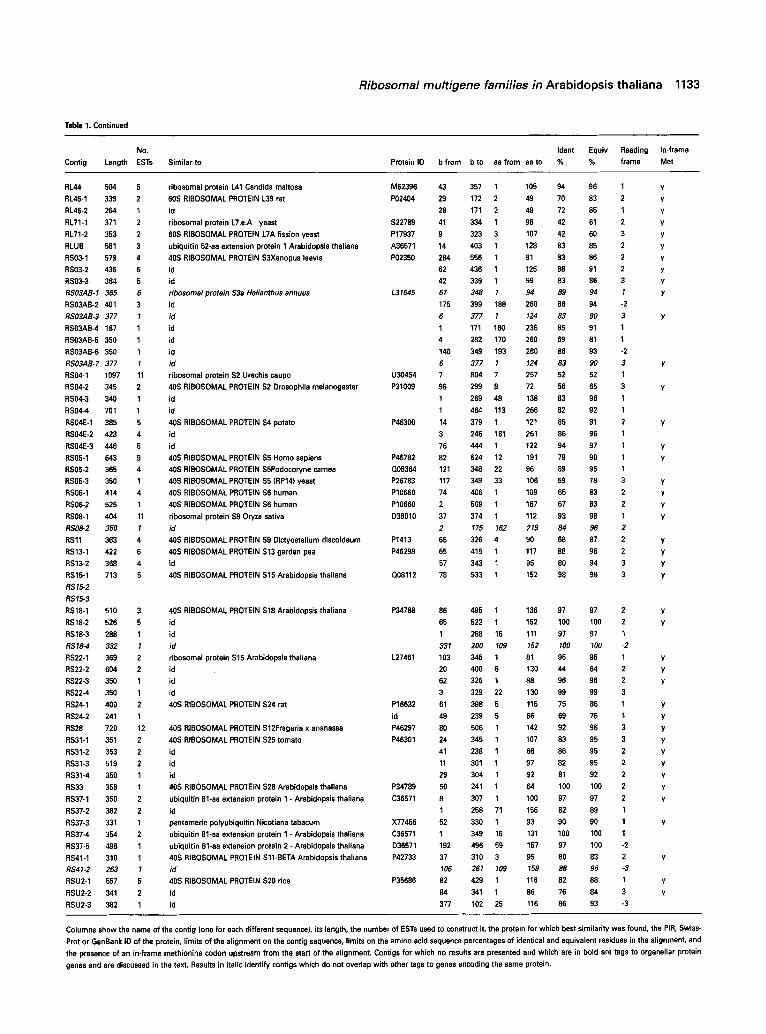
Table 1, Continued
No, Ident Equiv Reading In-frame
Contig Length ESTs Similar to Protein ID b from b to aa from aa to % % frame Met
RL44 504 5 ribosomal protein L41 Csndida maltosa M62396 43
RL46-1 339 2 60S RIBOSOMAL PROTEIN L39 rat P02404 29
RL46-2 264 1 id 28
RL71-1 371 2 ribosomal protein LT.e.A - yeast $22789 41
RL71-2 353 2 60S RIBOSOMAL PROTEIN L7A fission yeast P17937 9
RLUB 581 3 ubiquitin 52-aa extension protein 1 Arabidopsis thaliana A36571 14
RS03-1 579 4 40S RIBOSOMAL PROTEIN S3Xsnopus laevis P02350 284 RS03-2 436 6 id 62
RSO3-3 364 5 id 42 RSO3AB-1 365 6 ribosomal protein S3a Helianthus annuus L31645 67
RS03AB-2 401 3 id 175
RSO3AB-3 377 I id 6
RS03AB-4 187 1 id 1
RSO3AB-5 350 1 id 4
RS03AB-6 350 1 id t40
RSO3AB-7 377 I id 6 RS04-1 1097 11 ribosomal protein $2 Urechis caupo U30454 7
RS04-2 345 2 40S RIBOSOMAL PROTEIN $2 Drosophila melanogaster P31009 96
RS04-3 340 1 id 1
RSO4-4 701 1 id 1 RS04E-1 385 5 40S RIBOSOMAL PROTEIN $4 potato P46300 14
RS04E-2 423 4 id 3 RS04E-3 446 5 id 76
RS05-1 643 9 40S RIBOSOMAL PROTEIN $5 Homo sapiens P46782 82 RS05-2 365 4 40S RIBOSOMAL PROTEIN S5Podocoryne carnea Q08364 121
RS05-3 350 1 40S RIBOSOMAL PROTEIN $5 (RP14) yeast P26783 117 RS06-1 414 4 40S RIBOSOMAL PROTEIN $6 human P10660 74
RS06-2 525 1 40S RIBOSOMAL PROTEIN $6 human P10660 2
RS08-1 404 11 ribosomal protein $80ryza sativa D38010 37
RS08-2 350 I id 2 RS11 363 4 40S RIBOSOMAL PROTEIN $9 Dictyostelium discoideum P1413 65
RS13-1 422 6 40S RIBOSOMAL PROTEIN $13 garden pea P46298 65
RS13-2 368 4 id 57 RS15-1 713 5 4OS RIBOSOMAL PROTEIN $15 Arabidopsis thaliena Q08112 78
RS15-2
RS15-3
RS18-1 510 3 40S RIBOSOMAL PROTEIN $18 Arabidopsis thaliana P34788 86
RS18-2 526 5 id 65
RS18-3 288 1 id 1
RS18-4 332 I id 331 RS22-1 369 2 ribosomal protein $15 Arabidopsis thaliana L27461 103
RS22-2 604 2 id 20 RS22-3 350 1 id 62
RS22-4 350 I id 3
RS24-1 400 2 40S RIBOSOMAL PROTEIN $24 rat P16632 61
RS24-2 241 1 id 49
RS28 720 12 40S RIBOSOMAL PROTEIN S12Fragaria x ananassa P46297 80
RS31-1 351 2 4OS RIBOSOMAL PROTEIN $25 tomato P46301 24
RS31-2 353 2 id 41
RS31-3 519 2 id 11
RS31-4 350 1 id 29 RS33 358 1 40S RIBOSOMAL PROTEIN $28 Arabidopsis thaliana P34789 50
RS37-1 350 2 ubiquitin 81-aa extension protein 1 - Arabidopsis thaliana C36571 8
RS37-2 382 2 id 1
RS37-3 331 1 pentameric polyubiquitin Nicotiana tabacum X77456 52 RS37-4 354 2 ubiquitin 81-aa extension protein 1 - Arabidopsis thaliana C36571 1
RS37-5 498 1 ubiquitin 81-aa extension protein 2 - Arsbidopsis thaliana D36571 192
RS41-1 310 1 405 RIBOSOMAL PROTEIN S11-BETA Arabidopsis thaliana P42733 37 RS41-2 263 I id 106 RSU2-1 557 5 40S RIBOSOMAL PROTEIN $20 rice P35686 82
RSU2-2 341 2 id 84
RSU2-3 382 1 id 377
357 1 105 94 96 1 y
172 2 49 70 83 2 y
171 2 49 72 85 1 y
334 1 98 42 61 2 y 323 3 107 42 60 3 y
403 1 128 83 85 2 y 556 1 91 83 86 2 y
436 1 125 88 91 2 y 339 1 99 83 86 3 y 348 I 94 89 94 1 y
399 188 260 86 94 -2 377 I 124 83 90 3 y
171 180 236 85 91 1 282 170 260 69 81 1
349 193 260 86 93 -2 377 1 124 83 90 3 y 804 7 257 52 52 1
299 8 72 56 65 3 y
269 48 138 83 96 1
464 113 266 82 92 1
379 1 121 85 91 2 y
246 181 261 86 96 1 444 1 122 94 97 1 y
624 12 191 79 90 1 y 348 22 96 89 95 1 349 33 106 59 78 3 y
406 1 109 65 83 2 y
509 1 167 67 83 2 y
374 1 112 93 98 1 y 175 162 219 84 96 2
326 4 90 68 87 2 y
415 1 117 88 96 2 y
343 1 95 80 94 3 y 533 1 152 98 98 3 y
495 1 136 97 97 2 y
522 1 152 100 100 2 y
288 16 111 97 97 1
2O0 109 152 100 100 -2
345 1 81 95 95 1 y 4OO 6 130 44 64 2 y 326 1 88 96 96 2 y
329 22 130 99 99 3
398 5 115 75 86 1 y 239 5 66 69 76 1 y
506 1 142 92 96 3 y
345 1 107 83 95 3 y
238 1 66 86 95 2 y
301 1 97 82 95 2 y
304 1 92 81 92 2 y 241 1 64 100 100 2 y
307 1 100 97 97 2 y
258 71 156 82 89 1
330 1 93 90 90 1 y 349 16 131 100 100 1 496 59 157 97 100 -2
310 3 95 80 83 2 y 261 109 159 88 95 -3 429 1 116 82 88 1 y
341 1 86 76 84 3 y
102 25 116 86 93 -3
Columns show the name of the contig (one for each different sequence), its length, the number of ESTs used to construct it, the protein for which best similarity was found, the PIR, Swiss-
Prot or GenBank ID of the protein, limits of the alignment on the contig sequence, limits on the amino acid sequence percentages of identical and equivalent residues in the alignment, and
the presence of an in-frame methionine codon upstream from the start of the alignment. Contigs for which no results are presented and which are in bold are tags to organellar protein
genes and are discussed in the text. Results in italic identify contigs which do not overlap with other tags to genes encoding the same protein.

1134 Richard Cooke et al.
acid sequences are considerably different. It is thus possible that the second L15 gene corresponds to a nuclear gene encoding an organellar protein.
A second possible origin of nearly identical sequences could have been the use of different ecotypes of Arabidopsis thaliana for the construction of cDNA libraries. In fact, all but two of the cDNA libraries used were prepared using the Columbia ecotype and there are no contigs which contain only ESTs from either of these libraries. The differences observed can therefore be attributed to multiple genes from one ecotype rather than allelic variation of the same gene.
Ribosomal protein gene families in Arabidopsis
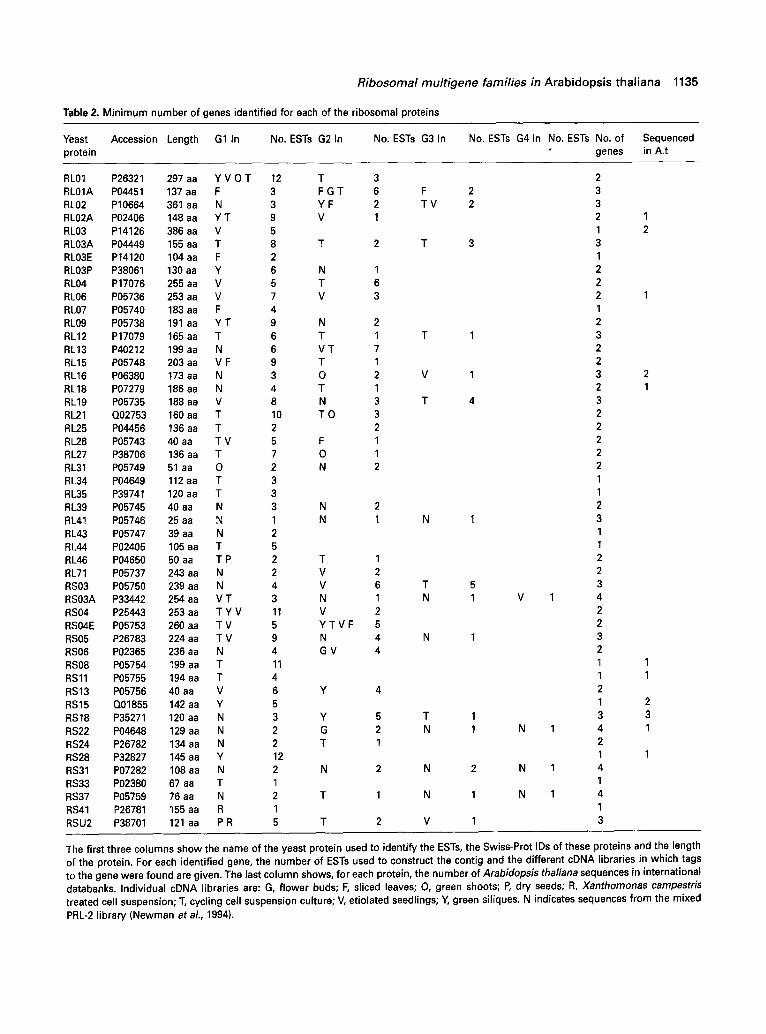
Table 2 shows the number of different genes encoding each protein unambiguously identified by this method, the individual cDNA libraries in which they were sequenced where this is known, and the number of completely sequenced A. thatiana cDNAs or genes for each protein. After elimination of non-overlapping sequences, we identi- fied tags to genes encoding 50 different ribosomal protein types, 31 for large-subunit components and 19 for those from the 40S subunit. We have eliminated gene families for which the results were unclear or difficult to interpret. This was the case for the large-subunit acidic ribosomal proteins, in which glycine-rich stretches make comparisons difficult, and for the large-subunit ubiquitin conjugates, for which it is impossible to distinguish between tags to ubiquitin genes and ribosomal ubiquitin conjugate genes. The most striking observation is that, of these 50 proteins, only 13 are apparently encoded by only one gene. For 22 proteins we have identified two genes, while there are at least three genes for 11 proteins and four for the remaining four, giving a total of 106 genes. Even these figures are minimal estimates as genes expressed only at a low level or under particular conditions may not yet have been tagged. This is the case for the RS15 protein for which we have tags to one gene, whereas there are two sequences in GenBank and Southern analysis shows from seven to ten fragments hybridizing to a cDNA probe (Sangwan etal., 1993), suggesting there could be several more genes, or possibly pseudogenes, encoding members of this protein family. On the other hand, in the case of the RL2A, RL06 and RS22 proteins, we have identified tags to one or several genes in addition to those already known.
Table 2 also shows individual cDNA libraries in which tags to ribosomal protein genes have been sequenced. The greatest number are found in the cell suspension culture cDNA library and the proportion is even greater if the number of ESTs sequenced in each library is taken into account. In fact, almost 12% of sequences from the cDNA library prepared from exponentially growing cultures are tags to ribosomal protein genes (R. Cooke, unpublished
data). This drops to about 1.5% for the immature silique, etiolated seedling, green shoot and sliced leaf libraries and is even lower for flower bud and dry seed cDNAs. Previous work on ribosomal protein gene expression has shown a strong correlation between cell division or growth and gene expression (Williams and Sussex, 1994, and references therein). Our observations are in agreement with this, as, in a cell suspension culture, all, or almost all, cells grow and divide, whereas in individual plant tissues, growth and division are limited to particular regions of the tissues.
Sequence conservation in multigene families
It is obviously impossible to present nucleotide and amino acid sequence alignments for all contigs. This information will be made available on the World Wide Web, linked to existing Arabidopsis servers. Figure 4 shows, as an example, the reconstruction of three coding regions, two partial and one complete, for the large-subunit protein L1A using respectively three, six and two ESTs. The first two sequences contain the complete coding region for the protein, while the third is truncated at both the 5' and 3' ends. In addition, one tag, ATTS3894, used to construct the sequence RL01A-2.nuc, contains the complete 3' non- coding region of the cDNA, meaning that this sequence is almost, if not entirely, complete. Apart from one amino acid insertion at the fifth residue in the derived sequence for the second gene and a difference in residue 6/7 (arginine in sequences one and two being replaced by vatine in sequence three), the derived amino acid sequences of the three proteins are identical. This may appear surprising as the nucleotide sequences of the three tags show respect- ively 4.5%, 5.7% and 9.5% differences from the consensus sequence. However, it can be seen from the sequence differences highlighted on the figure that these are almost exclusively located in the third position of the codons. The underlined sequences in the figure indicate two regions in which all or almost all amino acids are encoded by a different codon in at least one of the genes. Surprisingly, this variation in codons is much less marked towards the C-terminal end of the protein. Codon usage has been demonstrated to be an important mechanism in transla- tional control in bacteria (Sorenson et aL, 1989) and has been proposed to play a role in translational efficiency in eukaryotes (Hoekema et aL, 1987). However, analysis of the codon usage in the three sequences presented here shows no clear differences.
Sequence divergence in non-coding regions
In contrast to the extremely high sequence conservation within protein-coding regions, the 5' and 3' non-coding regions are almost always highly divergent. Obviously, more information can be obtained on the former as not all
Ribosomal mult igene famil ies in A r a b i d o p s i s t ha l i ana 1135
Table 2. Minimum number of genes identified for each of the ribosomal proteins
Yeast Accession Length G1 In No. ESTs G2 In No. ESTs G3 In No. ESTs G4 In No. ESTs No. of Sequenced protein genes in A.t
RL01 P26321 297 aa Y V 0 T 12 T 3 2 RLO1A P04451 137 aa F 3 F G T 6 F 2 3 RL02 P10664 361 aa N 3 Y F 2 T V 2 3 RLO2A P02406 148aa Y T 9 V 1 2 1 RL03 P14126 386 aa V 5 1 2 RLO3A P04449 155 aa T 8 T 2 T 3 3 RLO3E P14120 104 aa F 2 1 RLO3P P38061 130 aa Y 6 N 1 2 RL04 P17076 255 aa V 5 T 6 2 RL06 P05736 253 aa V 7 V 3 2 1 RL07 P05740 183 aa F 4 1 RL09 P05738 191 aa Y T 9 N 2 2 RL12 P17079 165 aa T 6 T 1 T 1 3 RL13 P40212 199 aa N 6 V T 7 2 RL15 P05748 203 aa V F 9 T 1 2 RL16 P06380 173 aa N 3 0 2 V 1 3 2 ~L18 P07279 186 aa N 4 T 1 2 1 ~L19 P05735 188 aa V 8 N 3 T 4 3 ~L21 Q02753 160 aa T 10 T 0 3 2 ~L25 P04456 136 aa T 2 2 2 ~L26 P05743 40 aa T V 5 F 1 2 ~L27 P38706 136 aa T 7 0 1 2 ~L31 P05749 51 aa 0 2 N 2 2 ~L34 P04649 112 aa T 3 1 ~L35 P39741 120 aa T 3 1 RL39 P05745 40 aa N 3 N 2 2 RL41 P05746 25 aa N 1 N 1 N 1 3 RL43 P05747 39 aa N 2 1 RL44 P02405 105 aa T 5 1 RL46 P04650 50 aa T P 2 T 1 2 RL71 P05737 243 aa N 2 V 2 2 RS03 P05750 239 aa N 4 V 6 T 5 3 RSO3A P33442 254 aa V T 3 N 1 N 1 V 1 4 RS04 P25443 253 aa T Y V 11 V 2 2 RSO4E P05753 260 aa T V 5 Y T V F 5 2 RS05 P26783 224 aa T V 9 N 4 N 1 3 RS06 P02365 236 aa N 4 G V 4 2 RS08 P05754 199 aa T 11 1 1 RS11 P05755 194 aa T 4 1 1 RS13 P05756 40 aa V 6 Y 4 2 RS15 Q01855 142 aa Y 5 1 2 RS18 P35271 120 aa N 3 Y 5 T 1 3 3 RS22 P04648 129 aa N 2 G 2 N 1 N 1 4 1 RS24 P26782 134 aa N 2 T 1 2 RS28 P32827 145 aa Y 12 1 1 RS31 P07282 108 aa N 2 N 2 N 2 N 1 4 RS33 P02380 67 aa T 1 1 RS37 P05759 76 aa N 2 T 1 N 1 N 1 4 RS41 P26781 155 aa R 1 1 RSU2 P38701 121 aa P R 5 T 2 V 1 3
The first three columns show the name of the yeast protein used to identify the ESTs, the Swiss-Prot IDs of these proteins and the length of the protein. For each identified gene, the number of ESTs used to construct the contig and the different cDNA libraries in which tags to the gene were found are given. The last column shows, for each protein, the number of Arabidopsis tha/iana sequences in international databanks. Individual cDNA libraries are: G, flower buds; F, sliced leaves; O, green shoots; P, dry seeds; R, Xanthomonas campestris treated cell suspension; T, cycling cell suspension culture; V, etiolated seedlings; Y, green siliques. N indicates sequences from the mixed PRL-2 library (Newman et al., 1994).

1136 Richard Cooke et al.
RL01A- 1 .nu~= I~CATCAG~GCCCTAGA - - - T ~ - CG--CG - -A: .................. C--
. . . . . . R R L 0 1 A - 2 . n u o - - - ( ~ C T A - T C - G C - - C . . . . . . . . . . . . . . . . . . . A - A
. . . . . . R RL01A-3. nuc ..... AGG- -CUT-
• - R - V
AAACJLTCAGAAGCCCTAG~ 5~RCYSTB 5AAMCATGTCGAA~GA: = : GGAVGT
M 5 K R G ?
RL0 IA- 1. nu~ ........ G- ......................... T ..... G--C--T ........ A
RL0 IA-2. nuc .................... G- ...................... A ........... T
R L 0 1 A - 3 . n u c . . . . . T . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . G . . . . . G - - G - - G
GGAGC~CTCTGGTAACAAATTCAGGATGTCACTGG~TC TTC CVGTC~AC~ACD
G G T 8 G N K F R M S L G L P V A A T
RL01A-I. nuu ........... A ........ T ....................... C--T .........
RL01A~2 .nuc ........... T ........... A ....................... G .........
RL01A-3. nuc ........... C--T ................. T--C ........... C--G ..... T
GTGAACTGTGCHGACA~ACCGGT~TAJ~R~CCTTTACATCATTTCB GTTA~AGGA
V ~ C A D N T G A K N L Y I I ~ V K G
RL01A-I. nu¢ .............. C ..... G ....................................
RL01A-2. nuc .... -G ........... C --T--G--A- -A- -G ........... T ........... T
RL01A-3. nu¢ .................... A .............. C--C--A ........ G ......
ATC~GTCGTCTTAATC GDTTACCTTCTG C TTGTGTTGGTGACATGGTTAT~GCC
I ~ U R L S R L P 8 A C V g D M V H A t * * * * * * . * . * * * *
R L O 1 A - 1 . n u c ................. A - - A - - C .......................... G . . . . . .
R L 0 1 A - 2 . n u c . . . . . T . . . . . . . . . . . . . . . . . . . . . C - T - - G . . . . . B . . . . . . . . . . . . . . . . . .
R L 0 1 A - 3 . n u c - C . . . . . A - - G . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . C . . . . . C - - -
A C T G ' I ~ A A G A A A G G T A A G C C T C , A T C T C A G ~ A ~ ; ~ A G G T T C T T C C T G C T G T C A T T G T T
T V K K G K P D L R K K V L P A V I V
~ O 1 A - 1 . n u c . . . . . . . . T . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . R . . . .
. . . . . . . . . . . . . . . . . ? -
~ 0 1 A - 2 . n u c . . . . - G & - G . . . . . W . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
R L 0 1 A - 3 . n u c . . . . . . . . C - - A . . . . . . . . . . . . . . . . . T . . . . . . . . . . . . . . . . . C . . . . . . . . .
A~CRACGBAA~CC AT~G CCGRAAG~ GG T~TTTTCATGTA~G~TAAT
R q R K P W R R ~ D G V F M ¥ F E D R *~ * * + ÷
RL01A-I .nuc .........................................................
RL01A-2. nuc .........................................................
RL01A-3. nuc ........ C ..... C ..... C ............................. NT-
GC TGGAGTG~%TT~ C CT~AGG~AGAAAT~GGTTCTGC~TTACTGGAC CT
A G V I Y W P K G E M X G 8 A I T G P
RL0 IA- 1. nuc .........................................................
~01A-Z .nuc .........................................................
ATTGGGA~AGTGT~ GGATCTC~GGCCAAGGATTGC TAGTGCT~TAACGCC ATT
I G K E C A D L W P R I A S A A N A I
RL0 IA-I .nuc .......................
RL01A-2. nu~ ............ : .......... TT~C TGGTTATGTATC TQTC TTC AACGAAAC GC ~
GTC TGAAGATCAATTTATCAC TT
V .
RLO IA- 2. nuc A~TAGTTGGTGTTTTGAGTGTTTTAAGTAGAGAC GRCAATCTT~T~AGCTTCA~
R L 0 I A - 2 .nuc ACAT
Figure 4. Contig and derived amino acid sequences for three ribosomal protein RL1A genes. Identical residues are shown by hyphens, gaps by colons. Underlined contig residues are differences which me not codon third-base changes. The last two lines of each block show consensus nucleotide and amino acid sequences (amino acid residues are below the first base of each codon). Asterisks indicate base differences in at least one sequence. Thick lines highlight regions in which conservative codon third-base changes are found in at least one sequence for all or almost all amino acid residues.
EST clones are sequenced from the 3' extremity. A typical example of this divergence is presented in Figure 5, which shows the alignments of the three tags to genes encoding the L41 protein. This is a particularly small protein (25 res- idues) and even short tags contain high-quality sequence for both coding and non-coding regions. It can be seen that, whereas the coding regions of the three tags are once again highly conserved, the three sequences diverge considerably both upstream and downstream. For all three, the 5' non-coding region is very different. In fact, the sequence RL41-1.nuc shows no similarity whatever to the two other sequences in either of the non-coding regions. For the two other tags, the sequences also diverge immedi- ately after the stop codon, but two very similar regions can be seen around 100 bases downstream. The high conservation of these motifs within such highly divergent sequences suggests that they may be important in the control of translation of the messengers. It is interesting to note that a sequence identical to the first of these two regions is also found in the 3' non-translated region of the mRNA of the homologous gene in cotton (EMBL accession X75423).
Identification of less highly conserved sequences
As shown above, the vast majority of ribosomal protein genes identified during this study are members of gene families with a small number of highly conserved products. There are, however, a certain number of intriguing excep- tions, as illustrated in Figure 6 for the three contigs constructed from tags identified by TFASTA alignment (Pearson and Lipman, 1988) with the almost identical yeast proteins RL03A and RL03B. BLASTX analysis of these contigs shows 90 and 95% identity at the amino acid level with the previously submitted A, thaliana protein sequence RL24 (Swiss-Prot RL24 ARATH) for contigs RL03AB-1 and RL03AB-3, respectively. In addition, the nucleotide sequences show considerable similarity to the A. thaliana sequence and that of barley (EMBL accession X94296). The sequences are in fact probably almost, if not completely, identical, as most of the differences correspond to uncer- tainties in the contig or RL24 sequences (Xs in the figure). On the other hand, the contig RL03AB-2 shows relatively low amino acid sequence similarity to the other plant sequences (40% amino acid identity with A. thaliana RL24)

R L 4 1 - 3 . n U O
RL41-2.nuo
RL41-l.nuo
#i
RL41-3.nuo
RL41-2.nuo
RL41-l.nue
RL41-3.nuc
RL41-2.nuo
RL41-1.nuo
# z o l
RL41-3.nuo
RL41-2.nuo
RL41 - I. nuo
#15z
RL41 - 3 • nuo
RL41-2. nuo
RL41-1 .nuo
#201
RL41-3.nuo
RL41-2. nuo
RL41-l.nuo
#251
R L 4 1 - 3 . n u o R L 4 1 - 2 . n u o
R L 4 1 - 1 . n u o
# 3 0 1
RL41-1 .nuo
#35z
Ribosomal multigene families in Arabidopsis thaliana 1137
CGGCC=&C&'~L%~I'GA~I~CTt~. = C=C~'L~J~.CA~'J~M=GAGCGA
A ~ . G C C & M R A K
AGTGARAGAAGAAGCGCATGAGGAGATTAAAGAGGAAGCGTCGAAAGATG
AGTGCO, AGAA~GTATGAGGAGACTA~AGA~GCCGAAAGATG
AGTGGAGA~AGAAGCGAG~CGGCGTCTGAAGCGTAAGAGGAGAAAGATG
- R - - - V . . . . . . . . . .
AGTGGAAGAA~L~TGAGGAGACTAAAGAGGAAGCGB~GATG
W K K K R M R R L K R K R R K M
AGACAGCGATCCAAGTAGAC : ." : TCCA: AGTTCCTCCCCCAAA: TAACTA
AGACAG~GTAGTCCATTCCATAGGACGTGTCTCA~TTNCTA
AGGGCTAGATCCAAGTAAACAACTCGCCTCAACTCGGCCTACTGGNTCTN - A . . . .
AGACAGCGATCCAAGTAG
T C ' I ' T A T G T A A T A ~ A G T T T C T T G ~ 4 ~ - j . T j . - j . - ~ % : G C k ~ ~ CC~CCCACC, A . T G A C . I ~ . ~ C C A C A C ~ - Z , ~ . A ~ T C A c r CG
C ' G T C A ~ ~ C A C C T C C ~ T C I ~ C O Z ' G G C G ¢ ~ ~ T
G"I~,A = T : = GTATGT~%AA ATCTATCTAATCACA
CTCAGTCTGTATTTTGAATTTGGTTCACTCCTAT: ATCCA = CTAGATGCA
GGCATTTGGAGGATC, GAA~C~CTTTAGCTTGTRANGAC
GATCCTTTATCTAAA~A
AGTCCaGTG'I~GTCAAGGGNATGTTT~CAAGGHA GCTTT
Figure 5. Contig and derived amino acid sequences for three ribosomal protein RL41 genes. Identical amino acid residues are shown by hyphens, gaps by colons. The last two lines of each block show consensus nucleotide and amino acid sequences (amino acid residues are below the first base of each codon). Base differences in the coding regions are in lower case. A short, imperfect repeat in RL41-3 is underlined. Conserved regions in the 3' untranslated sequences of RL41-3 and RL41-2 are boxed.
and the nucleotide sequence is very different. Surprisingly, it is more similar to the mammalian sequences (human and rat) and shows 76% sequence identity to the putative product of an open reading frame of Saccharomyces cerevi- siae identified by genomic sequencing. The yeast gene product also shows greatest similarity to other ribosomal L24/L3AB proteins, but so far it has not been shown that the gene is in fact transcribed. However, TBLASTN alignment (Altschul et al., 1990) of the putative RL03AB-2 translation product against the EST database identifies one rice EST and a considerable number of human ESTs, indicating that the homologous gene is also present and transcribed in these organisms. BLASTN alignment of the nucleotide sequence against dbEST confirms that the A. thaliana sequence shows significant similarity to these ESTs rather than to the other A. thaliana ESTs.
Discussion
We have shown that it is possible to assemble relatively long, high-quality contiguous sequences from tags to ribo- somal protein genes, and that these contigs are of sufficient quality to distinguish between tags to very closely related genes. For 30 of the 50 ribosomal proteins for which we have constructed contigs, at least one has an in-frame methionine codon and is long enough to contain the entire coding region. It should be emphasized that this approach identifies only functional genes as the analysis is carried out on expressed sequence tags. The method described is applicable to the identification and construction of contigs tagging genes encoding any known protein if the amino acid sequence is relatively well conserved between species. The demonstration that very few ESTs are assembled into contigs to which they do not belong suggests that the method could also be used on larger sequence sets to assemble contigs from ESTs which tag no known gene.
The high sequence conservation in individual families, particularly in coding regions, indicates that the use of complete ESTs as tags to map corresponding genes by hybridization may lead to erroneous or, more probably, uninterpretable results due to hybridization to multiple loci. However, in most cases, the non-coding regions of different members of multigene families are sufficiently divergent to allow the identification of short regions which could be used to define gene-specific primers for mapping by PCR. We have begun mapping of members of multigene families using this method and have unambiguously mapped, for example, the three RSU2 genes (see Table 1) to three different loci (unpublished data). The three different genes encoding ribosomal protein S18 are also dispersed on the genetic map (van Lijsebettens et aL, 1994). Mapping of a larger number of members of ribosomal gene families will show whether this dispersion is found for the majority of such genes. It will be of particular interest to identify markers flanking the different members of these families as this should answer questions on the organization and evolution of the genome. Is Arabidopsis thaliana a diploid or polyploid species? Are different genes from multigene families found within blocks of conserved sequence, and, if so, what is the size of the duplicated blocks? Recently, Wu et aL (1995) carried out an analysis of the genomic organization of 67 rice ribosomal protein genes using Southern hybridization. Their results are in agreement with those presented here, showing that almost 90% are apparently encoded by small multigene families in rice and no clustering of genes can be detected. Tags to at least one member of each ribosomal protein family described here have already been sequenced in rice. Clones corresponding to homologous genes in A. thaliana and rice will be useful in comparative studies on the mechanisms involved in genome evolution.


Ribosomal mul t igene fami l ies in Arabidops is tha l iana 1139
sequent analysis, which is essential in order to obtain a minimal estimate of the number of members of different gene families. Non-overlapping tags are similarly present in the data set of Rounsley etaL (1996) and this should be borne in mind when considering the number of different tags found for a given gene family as separate sequences may tag the same gene. Further, contig construction from the entire EST database can lead to the creation of artefactual assemblies. A tentative consensus sequence similar to one of our RL03P gene tags is identified on the web server as a homeobox protein gene tag and in fact contains two divergent coding sequences. While it is neces- sary to take these limitations into consideration, EST data nevertheless remains a rich source of sequence information in the study of plant gene structure and expression.
Experimental procedures
calls in automatic sequence output), tags to individual genes were identified and the corresponding contigs exported as individual sequences, removing all gaps. These were analysed by BLASTX alignment (Altschul et aL, 1990) against all protein sequences,
Multiple sequence alignments
Multiple sequence alignments were carried out using ClustalW (Thompson et aL, 1994) and prepared for publication with Kay Hofmann's Boxshade programme (ISREC, Lausanne).
Acknowledgements
The authors gratefully acknowledge support from the Centre National de la Recherche Scientifique (Groupe de Recherche 1003), the Groupe de Recherche et d'Etude des Genomes, and the European Community (European Scientists Sequencing Arabidopsis project), We thank all our colleagues from the Groupe de Recherche and Tom Newman and Takuji Sasaki for fruitful discussions.
Identification of tags to ribosomal genes
Amino acid sequences of cytoplasmic ribosomal proteins from yeast were obtained by interrogation of the Swiss-Prot database using EMBL-Search (EMBL, Heidelberg) and were aligned against all Arebidopsis thaliana ESTs in GenBank using TFASTA (Pearson and Lipman, 1988). Sequences whose putative translation products showed significant similarity to the yeast proteins were retrieved from GenBank using the RETRIEVE e-mail server at the NCBI, Bethesda, MD.
Assembly of contigs
EST sequences were imported into a project in Sequencher (Gene Codes, Ann Arbor, MI), Using the trim command, 3' ends were automatically trimmed when five or more ambiguities were found in a contiguous stretch of 25 bases. Remaining sequences were inspected and those which contained ambiguous base calls were further trimmed to a maximum length of 330 bases. This length was chosen as it is the average length of sequences submitted to EMBL by the European sequencing consortium (Cooke et aL, 1996; H6fte et aL, 1993) and thus corresponds to the average length of high-quality sequence data which can be obtained from a single- pass sequencing run. These trimming criteria were applied to all sequences from the American project (Newman et aL, 1994). Longer, manually corrected sequences from the European consor- tium were left unedited if they contained no ambiguities.
Contigs were constructed in two stages. A first assembly using parameters of 80% sequence identity for a minimum 30 base overlap allows the detection of even relatively short overlaps without the incorporation of ESTs into contigs to which they do not belong. A second pass, using lower identity (70%) but a greater overlap (40 bases) creates contigs from closely related sequences.
Identification and confirmation of individual tags
All contigs were inspected to compare sequence differences. At almost all positions of a contig, at least two and up to 12 different ESTs had contributed to the assembled sequence. Discounting base differences after G residues (the site of most erroneous base
References
Altschul, S.F., Gish, W., Miller, W., Myers, E.W. and Lipman, D, (1990) Basic local alignment search tool. J. Mol. Biol. 215, 403-410.
Andersson, S., Saeboe-Larssen, S., Lambertsson, A., Merriam, J. and Jacobs-Lorena, M. (1994) A Drosophila third chromosome Minute locus encodes a ribosomal protein. Genetics, 137, 513-520.
Boguski, M.S., Lowe, T.M.J. and Tolstoshev, S.H. (1993) dbEST- database for 'expressed sequence tags'. Nature Genetics, 4, 332-333.
Cooke, R., Raynal, M., Laudie, M. et al., (1996) Further progress towards a catalogue of all Arabidopsis genes: analysis of a set of 5000 non-redundant ESTs. Plant J., 9, 101-124.
Delseny, M. and Cooke, R. The Arabidopsis nuclear genome. In ICRF Handbook of Genome Analysis (Spurt, N. eta/., eds). London: Blackwell Scientific Publications (in press).
Etter, A., Bernard, V., Kenzelmann, M., Tobler, H. and Muller, E (1994) Ribosomal heterogeneity from chromatin diminution in Ascaris lumbricoides. Science, 265, 954-956.
Genschik, P., Durr, A. and Fleck, J. (1994) Differential expression of several E2-type ubiquitin carrier protein genes at different developmental stages in Arabidopsis tha/iana and Nicotiana sy/vestris. Mo/. Gen. Genet. 244, 548-556.
Hoekema, A., Kastelein, R.A., Vasser, M. and de Boer, H.A. (1987) Codon replacement in the PGK1 gene of Saccharomyces cerevisiae: experimental approach to study the role of biased codon usage in gene expression. Mol. Cell Biol. 7, 2914-2924.
H6fte, H., Desprez, T., Amselem, J. et al., (1993) An inventory of 1152 expressed sequence tags obtained by partial sequencing of cDNA from Arabidopsis tha/iana. Plant J., 4, 1051-1061.
Kim, Y., Zhang, H. and Scholl, R.L. (1990) Two evolutionarily divergent genes encode a cytoplasmic ribosomal protein of Arabidopsis thaliana. Gene, 93, 177-182.
van Lijsebettens, M., Vanderhaeghen, R., De Block, M., Bauw, G., Villarroel, R. and van Montagu, M. (1994) An S18 ribosomal protein gene copy at the Arebidopsis PFL locus affects plant development by its specific expression in meristems. EMBO J. 13, 3378-3388.
Newman, T., De Bruijn, E, Green, P. et eL (1994) Genes galore: a summary of the methods for accessing the results of large scale

1140 Richard Cooke et al.
partial sequencing of anonymous Arabidopsis thaliana cDNA clones. Plant PhysioL 106, 1241-1255.
Pearson, W.R. and Lipman, D.J. (1988) Improved tools for biological sequence comparison. Proc. Natl Acad. ScL USA, 86, 2444-2448.
Rotenber9, M.O., Moritz, M. and Woolford, J.L. Jr (1988) Depletion of Saccharomyces cerevisiae ribosomal protein L16 causes a decrease in 60S ribosomal subunits and formation of half-mer polyribosomes. Genes Dev. 2, 160-172.
Rounsley, S., Glodek, A., Sutton, G., Shirley, B., Adams, M., Venter, J.C. and Kerlavage, A.R. (1996) Arabidopsis EST analysis at TIGR. Weeds World, 3(i), 26-33.
Sangwan, V., Lenvik, T.R. and Gantt, S. (1993) The Arabidopsis the~lena ribosomal protein $15 (rig) gene. Biochim. Biophys, Acta 1216, 221-226.
Santos, M., Gousseau, H., Lister, C., Foyer, C., Creissen, G. and Mullineaux, P. (1996) Cytosolic ascorbate peroxidase from Arabidopsis thaliana L. is encoded by a small multigene family. Planta, 198, 64-69.
Snustad D.P., Haas N.A., Kopczak S.D. and Silflow C.D. (1992) The small genome of Arabidopsis contains at least nine expressed beta-tubulin genes. P/ant Ce//, 4, 549-556
Sorenson, M.A., Kurland, C.G. and Pedersen, S. (1989) Codon usage determines translation rate in Escherichia co/i. J. Mo/. Biol. 207, 365-377.
Standart, N. and Jackson, R.J. (1994) Regulation of translation by specific protein/RNA interactions. Biochimie, 76, 887-879.
Thompson, J.D., Higgins, D.G. and Gibson, T.J. (1994) CLUSTAL W: improving the sensitivity of progressive multiple sequence alignment through sequence weighting, positions-specific gap penalties and weight matrix choice. Nucl. Acids Res. 22, 4673- 4680.
Urao, T., Katagiri, T., Mizoguchi, 1"., Yamaguchi-Shinozaki, K., Hayashida, N. and Shinozaki, K. (1994) Two genes that encode Ca2+-dependent protein kinases are induced by drought and high-salt stresses in Arabidopsis thaliana. Mol. Gen. Genet. 244, 331-340.
Williams, M,E. and Sussex, I.M. (1994) Developmental regulation of ribosomal protein L16 genes in Arabidopsis tha/iana. Plant J. 8, 65-76.
Wu, J., Matsui, E., Yamamoto, K., Nagamura, Y., Kurata, N., Sasaki, 1". and Minobe, Y. (1995) Genomic organization of 57 ribosomal protein genes in rice (Oryza satire L.) through RFLP mapping. Genome, 38, 1189-1200.
For Data Library accession numbers of the sequences described in this paper, see Tables 1 and 2.
Recommended