
Extreme DXT Compression Peter Uličiansky
Cauldron, Ltd.
Overview
• Simple highly optimized algorithm
• Uses SSE2 and SSSE3 for maximum performance
• Quality comparable to “Real-Time DXT Compression” algorithm
• Performance roughly 300%
• What’s identical to “Real-Time DXT Compression”
o Only non-transparent compression scheme for DXT1
o Only six intermediate alpha values compression scheme for DXT5
o Uses bounding box method for representative color and alpha values
• Computes color and alpha indices by division (fixed point multiplication)
o Uses lookup tables for color/alpha dividers
)()()(
)()()(4
minmaxminmaxminmax
minminmin
BBGGRR
BBGGRRColorIndex
−+−+−
−+−+−∗=
)(
)(8
minmax
min
AA
AAAlphaIndex
−
−∗=
• Converts natural index ordering to DXT index ordering by lookup tables
o Tightly packs natural indices first
o Then converts four color indices at once/two alpha indices at once
• Just two functions (CompressImageDXT1, CompressImageDXT5)
o Saves function call overhead
• No comparisons, jumps, loops (except height/width loops)
• Processes two 4x4 blocks at once
o Better utilization of registers
o Hides instruction latency in some places
o No need to “extract block” first
• Constant/temporary data just 24 * 16 = 384 bytes
• Lookup tables just 3072 + 1024 + 256 + 1280 = 5632 bytes
• Although some parts of DXT1/DXT5 compression algorithms are identical
different instruction ordering is crucial for maximum performance
• Code is optimized for Core 2 Duo so Pentium 4 performance is not optimal
(Don’t see much point in optimizing for Pentium 4 these days)

Color Compression Comparison
Original image Extreme DXT Comp. Real-Time DXT Comp.
Alpha Compression Comparison
Original image Extreme DXT Comp. Real-Time DXT Comp.
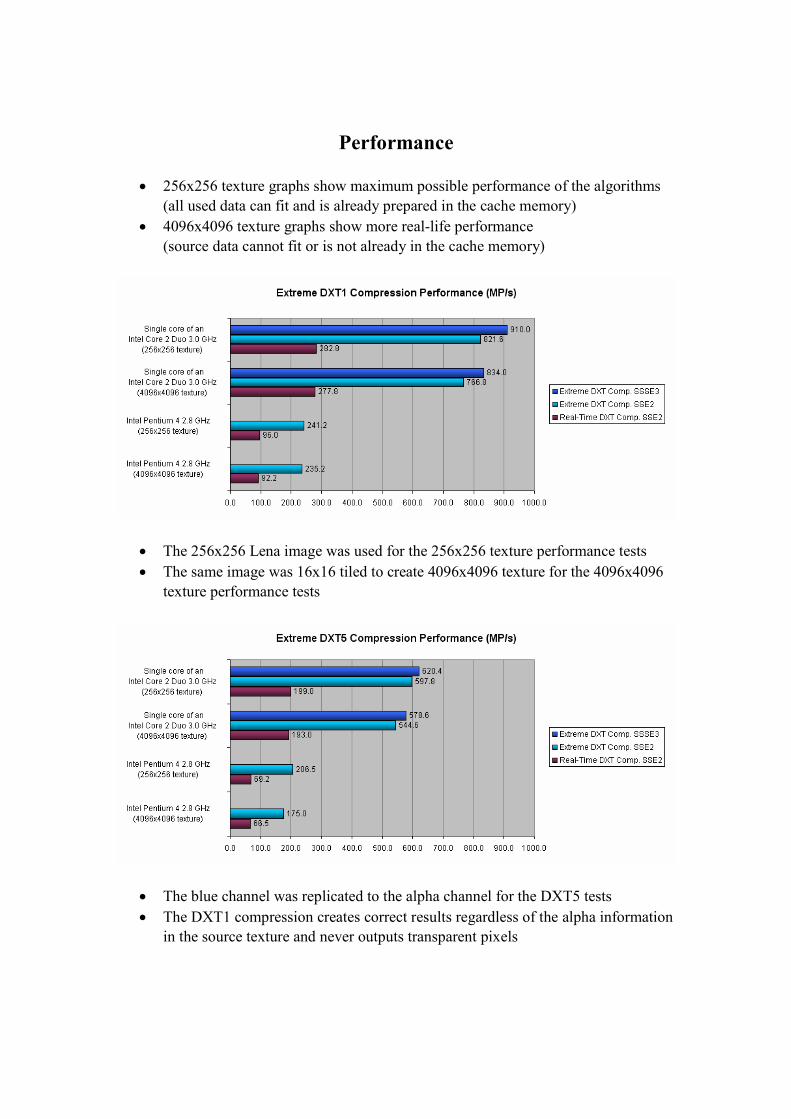
Performance
• 256x256 texture graphs show maximum possible performance of the algorithms
(all used data can fit and is already prepared in the cache memory)
• 4096x4096 texture graphs show more real-life performance
(source data cannot fit or is not already in the cache memory)
• The 256x256 Lena image was used for the 256x256 texture performance tests
• The same image was 16x16 tiled to create 4096x4096 texture for the 4096x4096
texture performance tests
• The blue channel was replicated to the alpha channel for the DXT5 tests
• The DXT1 compression creates correct results regardless of the alpha information
in the source texture and never outputs transparent pixels
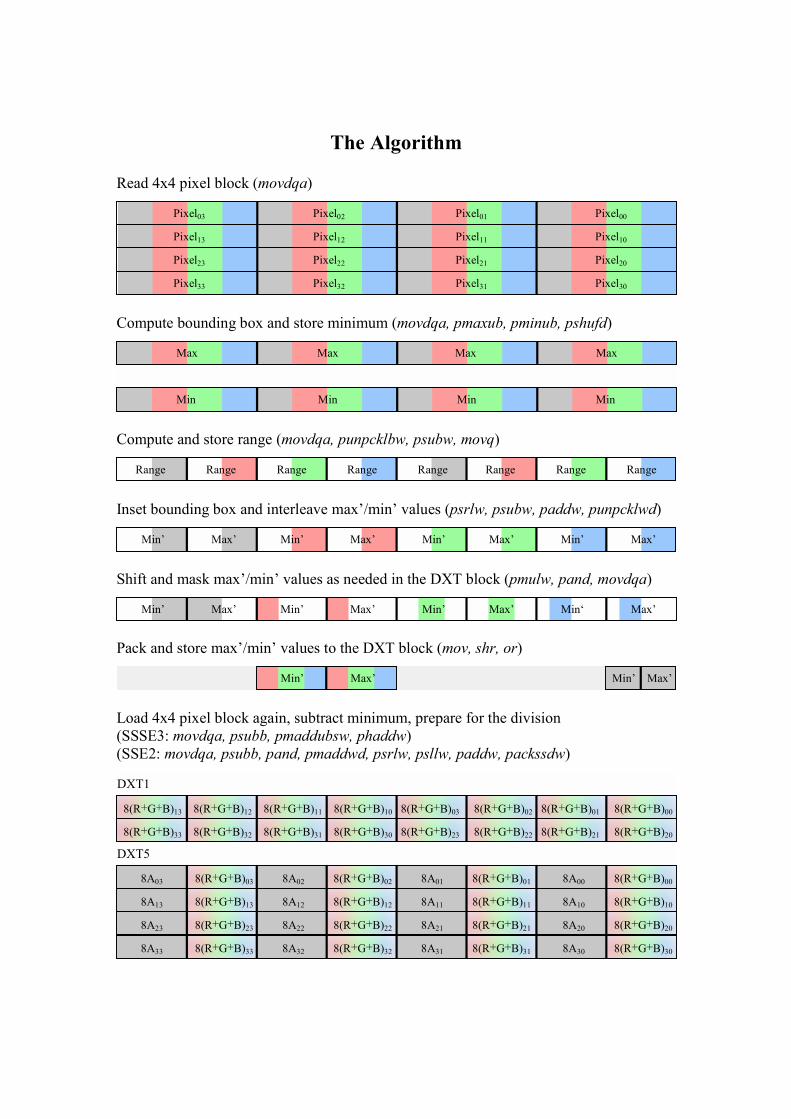
The Algorithm
Read 4x4 pixel block (movdqa)
Compute bounding box and store minimum (movdqa, pmaxub, pminub, pshufd)
Compute and store range (movdqa, punpcklbw, psubw, movq)
Inset bounding box and interleave max’/min’ values (psrlw, psubw, paddw, punpcklwd)
Shift and mask max’/min’ values as needed in the DXT block (pmulw, pand, movdqa)
Pack and store max’/min’ values to the DXT block (mov, shr, or)
Load 4x4 pixel block again, subtract minimum, prepare for the division
(SSSE3: movdqa, psubb, pmaddubsw, phaddw)
(SSE2: movdqa, psubb, pand, pmaddwd, psrlw, psllw, paddw, packssdw)
Min’ Max’ Min’ Max’
Pixel03 Pixel02 Pixel01 Pixel00
Pixel13 Pixel12 Pixel11 Pixel10
Pixel23 Pixel22 Pixel21 Pixel20
Pixel33 Pixel32 Pixel31 Pixel30
Max Max Max Max
Min Min Min Min
Range Range Range Range Range Range Range Range
Min’ Max’ Min’ Max’ Min’ Max’ Min’ Max’
Min’ Max’ Min’ Max’ Min’ Max’ Min‘ Max’
8(R+G+B)13 8(R+G+B)12 8(R+G+B)11 8(R+G+B)10 8(R+G+B)03 8(R+G+B)02 8(R+G+B)01 8(R+G+B)00
8(R+G+B)33 8(R+G+B)32 8(R+G+B)31 8(R+G+B)30 8(R+G+B)23 8(R+G+B)22 8(R+G+B)21 8(R+G+B)20
8A03 8(R+G+B)03 8A02 8(R+G+B)02 8A01 8(R+G+B)01 8A00 8(R+G+B)00
8A13 8(R+G+B)13 8A12 8(R+G+B)12 8A11 8(R+G+B)11 8A10 8(R+G+B)10
8A23 8(R+G+B)23 8A22 8(R+G+B)22 8A21 8(R+G+B)21 8A20 8(R+G+B)20
8A33 8(R+G+B)33 8A32 8(R+G+B)32 8A31 8(R+G+B)31 8A30 8(R+G+B)30
DXT5
DXT1
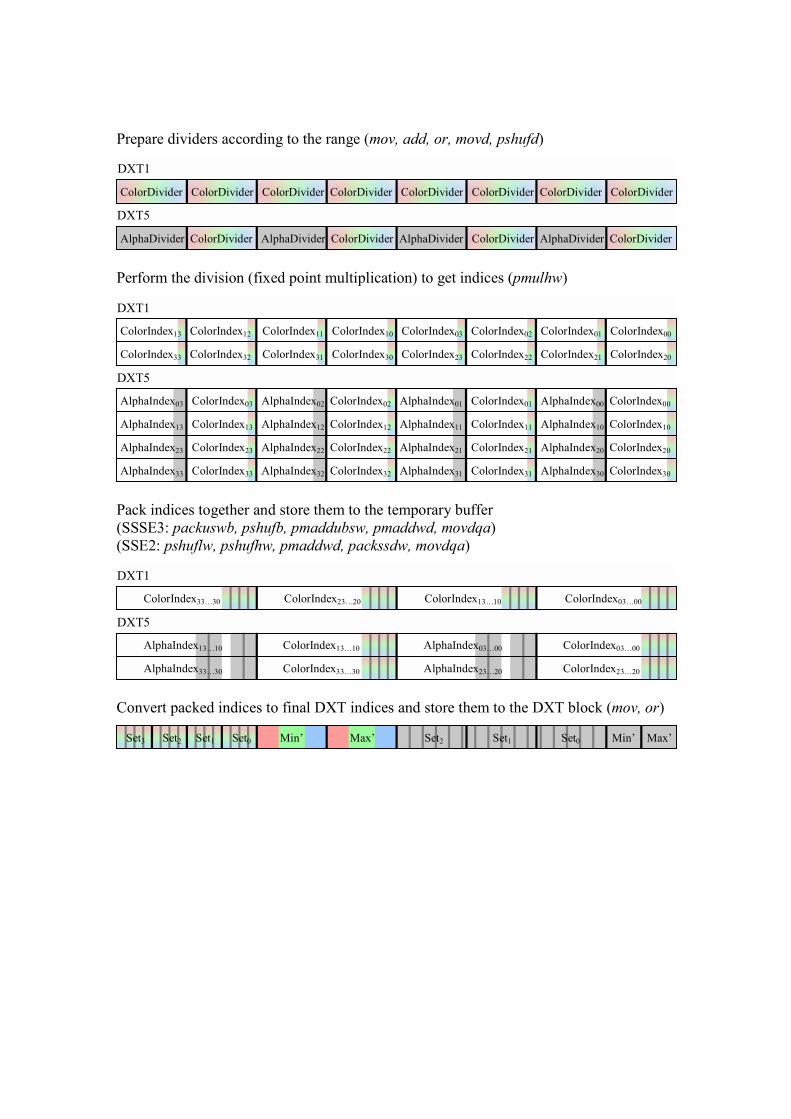
Prepare dividers according to the range (mov, add, or, movd, pshufd)
Perform the division (fixed point multiplication) to get indices (pmulhw)
Pack indices together and store them to the temporary buffer
(SSSE3: packuswb, pshufb, pmaddubsw, pmaddwd, movdqa)
(SSE2: pshuflw, pshufhw, pmaddwd, packssdw, movdqa)
Convert packed indices to final DXT indices and store them to the DXT block (mov, or)
ColorDivider ColorDivider ColorDivider ColorDivider ColorDivider ColorDivider ColorDivider ColorDivider
AlphaDivider ColorDivider AlphaDivider ColorDivider AlphaDivider ColorDivider AlphaDivider ColorDivider
DXT5
DXT1
DXT5
ColorIndex13 ColorIndex12 ColorIndex11 ColorIndex10 ColorIndex03 ColorIndex02 ColorIndex01 ColorIndex00
ColorIndex33 ColorIndex32 ColorIndex31 ColorIndex30 ColorIndex23 ColorIndex22 ColorIndex21 ColorIndex20
AlphaIndex03 ColorIndex03 AlphaIndex02 ColorIndex02 AlphaIndex01 ColorIndex01 AlphaIndex00 ColorIndex00
AlphaIndex13 ColorIndex13 AlphaIndex12 ColorIndex12 AlphaIndex11 ColorIndex11 AlphaIndex10 ColorIndex10
AlphaIndex23 ColorIndex23 AlphaIndex22 ColorIndex22 AlphaIndex21 ColorIndex21 AlphaIndex20 ColorIndex20
AlphaIndex33 ColorIndex33 AlphaIndex32 ColorIndex32 AlphaIndex31 ColorIndex31 AlphaIndex30 ColorIndex30
DXT1
DXT5
ColorIndex33…30 ColorIndex23…20 ColorIndex13…10 ColorIndex03…00
AlphaIndex13…10 ColorIndex13…10 AlphaIndex03…00 ColorIndex03…00
AlphaIndex33…30 ColorIndex33…30 AlphaIndex23…20 ColorIndex23…20
Set3 Set2 Set1 Set0 Min’ Max’ Set2 Set1 Set0 Min’ Max’
DXT1

/************************************************************************************************************* Extreme DXT Compression Copyright (C) 2008 Cauldron, Ltd. Written by Peter Uličiansky Microsoft Public License (Ms-PL) This license governs use of the accompanying software. If you use the software, you accept this license. If you do not accept the license, do not use the software. 1. Definitions The terms "reproduce," "reproduction," "derivative works," and "distribution" have the same meaning here as under U.S. copyright law. A "contribution" is the original software, or any additions or changes to the software. A "contributor" is any person that distributes its contribution under this license. "Licensed patents" are a contributor's patent claims that read directly on its contribution. 2. Grant of Rights (A) Copyright Grant- Subject to the terms of this license, including the license conditions and limitations in section 3, each contributor grants you a non-exclusive, worldwide, royalty-free copyright license to reproduce its contribution, prepare derivative works of its contribution, and distribute its contribution or any derivative works that you create. (B) Patent Grant- Subject to the terms of this license, including the license conditions and limitations in section 3, each contributor grants you a non-exclusive, worldwide, royalty-free license under its licensed patents to make, have made, use, sell, offer for sale, import, and/or otherwise dispose of its contribution in the software or derivative works of the contribution in the software. 3. Conditions and Limitations (A) No Trademark License- This license does not grant you rights to use any contributors' name, logo, or trademarks. (B) If you bring a patent claim against any contributor over patents that you claim are infringed by the software, your patent license from such contributor to the software ends automatically. (C) If you distribute any portion of the software, you must retain all copyright, patent, trademark, and attribution notices that are present in the software. (D) If you distribute any portion of the software in source code form, you may do so only under this license by including a complete copy of this license with your distribution. If you distribute any portion of the software in compiled or object code form, you may only do so under a license that complies with this license. (E) The software is licensed "as-is." You bear the risk of using it. The contributors give no express warranties, guarantees, or conditions. You may have additional consumer rights under your local laws which this license cannot change. To the extent permitted under your local laws, the contributors exclude the implied warranties of merchantability, fitness for a particular purpose and non-infringement. *************************************************************************************************************/
DWORD COLOR_DIVIDER_TABLE[768]; DWORD ALPHA_DIVIDER_TABLE[256]; BYTE COLOR_INDICES_TABLE[256]; WORD ALPHA_INDICES_TABLE[640]; __declspec(align(16)) const BYTE SSE2_BYTE_0 [1 * 16] = {0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00}; __declspec(align(16)) const BYTE SSE2_WORD_1 [1 * 16] = {0x01,0x00,0x01,0x00,0x01,0x00,0x01,0x00,0x01,0x00,0x01,0x00,0x01,0x00,0x01,0x00}; __declspec(align(16)) const BYTE SSE2_WORD_8 [1 * 16] = {0x08,0x00,0x08,0x00,0x08,0x00,0x08,0x00,0x08,0x00,0x08,0x00,0x08,0x00,0x08,0x00}; __declspec(align(16)) const BYTE SSE2_BOUNDS_MASK [1 * 16] = {0x00,0x1F,0x00,0x1F,0xE0,0x07,0xE0,0x07,0x00,0xF8,0x00,0xF8,0x00,0xFF,0xFF,0x00}; __declspec(align(16)) const BYTE SSE2_BOUNDS_SCALE [1 * 16] = {0x20,0x00,0x20,0x00,0x08,0x00,0x08,0x00,0x00,0x01,0x00,0x01,0x00,0x01,0x01,0x00}; __declspec(align(16)) const BYTE SSE2_INDICES_MASK_0 [1 * 16] = {0xFF,0x00,0xFF,0x00,0xFF,0x00,0xFF,0x00,0xFF,0x00,0xFF,0x00,0xFF,0x00,0xFF,0x00}; __declspec(align(16)) const BYTE SSE2_INDICES_MASK_1 [1 * 16] = {0x00,0xFF,0x00,0x00,0x00,0xFF,0x00,0x00,0x00,0xFF,0x00,0x00,0x00,0xFF,0x00,0x00}; __declspec(align(16)) const BYTE SSE2_INDICES_MASK_2 [1 * 16] = {0x08,0x08,0x08,0x00,0x08,0x08,0x08,0x00,0x08,0x08,0x08,0x00,0x08,0x08,0x08,0x00}; __declspec(align(16)) const BYTE SSE2_INDICES_SCALE_0[1 * 16] = {0x01,0x00,0x04,0x00,0x10,0x00,0x40,0x00,0x01,0x00,0x04,0x00,0x10,0x00,0x40,0x00}; __declspec(align(16)) const BYTE SSE2_INDICES_SCALE_1[1 * 16] = {0x01,0x00,0x04,0x00,0x01,0x00,0x08,0x00,0x10,0x00,0x40,0x00,0x00,0x01,0x00,0x08}; __declspec(align(16)) const BYTE SSE2_INDICES_SCALE_2[1 * 16] = {0x01,0x04,0x10,0x40,0x01,0x04,0x10,0x40,0x01,0x04,0x10,0x40,0x01,0x04,0x10,0x40}; __declspec(align(16)) const BYTE SSE2_INDICES_SCALE_3[1 * 16] = {0x01,0x04,0x01,0x04,0x01,0x08,0x01,0x08,0x01,0x04,0x01,0x04,0x01,0x08,0x01,0x08}; __declspec(align(16)) const BYTE SSE2_INDICES_SCALE_4[1 * 16] = {0x01,0x00,0x10,0x00,0x01,0x00,0x00,0x01,0x01,0x00,0x10,0x00,0x01,0x00,0x00,0x01}; __declspec(align(16)) const BYTE SSE2_INDICES_SHUFFLE[1 * 16] = {0x00,0x02,0x04,0x06,0x01,0x03,0x05,0x07,0x08,0x0A,0x0C,0x0E,0x09,0x0B,0x0D,0x0F}; __declspec(align(16)) BYTE sse2_minimum[2 * 16]; __declspec(align(16)) BYTE sse2_range [2 * 16]; __declspec(align(16)) BYTE sse2_bounds [2 * 16]; __declspec(align(16)) BYTE sse2_indices[4 * 16];

void CompressImageDXT1(const BYTE* argb, BYTE* dxt1, int width, int height) { int x_count; int y_count; __asm { mov esi, DWORD PTR argb // src mov edi, DWORD PTR dxt1 // dst mov eax, DWORD PTR height mov DWORD PTR y_count, eax y_loop: mov eax, DWORD PTR width mov DWORD PTR x_count, eax x_loop: mov eax, DWORD PTR width // width * 1 lea ebx, DWORD PTR [eax + eax*2] // width * 3 movdqa xmm0, XMMWORD PTR [esi + 0] // src + width * 0 + 0 movdqa xmm3, XMMWORD PTR [esi + eax*4 + 0] // src + width * 4 + 0 movdqa xmm1, xmm0 pmaxub xmm0, xmm3 pmaxub xmm0, XMMWORD PTR [esi + eax*8 + 0] // src + width * 8 + 0 pmaxub xmm0, XMMWORD PTR [esi + ebx*4 + 0] // src + width * 12 + 0 pminub xmm1, xmm3 pminub xmm1, XMMWORD PTR [esi + eax*8 + 0] // src + width * 8 + 0 pminub xmm1, XMMWORD PTR [esi + ebx*4 + 0] // src + width * 12 + 0 pshufd xmm2, xmm0, 0x4E pshufd xmm3, xmm1, 0x4E pmaxub xmm0, xmm2 pminub xmm1, xmm3 pshufd xmm2, xmm0, 0xB1 pshufd xmm3, xmm1, 0xB1 pmaxub xmm0, xmm2 pminub xmm1, xmm3 movdqa xmm4, XMMWORD PTR [esi + 16] // src + width * 0 + 16 movdqa xmm7, XMMWORD PTR [esi + eax*4 + 16] // src + width * 4 + 16 movdqa xmm5, xmm4 pmaxub xmm4, xmm7 pmaxub xmm4, XMMWORD PTR [esi + eax*8 + 16] // src + width * 8 + 16 pmaxub xmm4, XMMWORD PTR [esi + ebx*4 + 16] // src + width * 12 + 16 pminub xmm5, xmm7 pminub xmm5, XMMWORD PTR [esi + eax*8 + 16] // src + width * 8 + 16 pminub xmm5, XMMWORD PTR [esi + ebx*4 + 16] // src + width * 12 + 16 pshufd xmm6, xmm4, 0x4E pshufd xmm7, xmm5, 0x4E pmaxub xmm4, xmm6 pminub xmm5, xmm7 pshufd xmm6, xmm4, 0xB1 pshufd xmm7, xmm5, 0xB1 pmaxub xmm4, xmm6 pminub xmm5, xmm7 movdqa XMMWORD PTR sse2_minimum[ 0], xmm1 movdqa XMMWORD PTR sse2_minimum[16], xmm5 movdqa xmm7, XMMWORD PTR SSE2_BYTE_0 punpcklbw xmm0, xmm7 punpcklbw xmm4, xmm7 punpcklbw xmm1, xmm7 punpcklbw xmm5, xmm7 movdqa xmm2, xmm0 movdqa xmm6, xmm4 psubw xmm2, xmm1 psubw xmm6, xmm5 movq MMWORD PTR sse2_range[ 0], xmm2 movq MMWORD PTR sse2_range[16], xmm6 psrlw xmm2, 4 psrlw xmm6, 4 psubw xmm0, xmm2 psubw xmm4, xmm6 paddw xmm1, xmm2 paddw xmm5, xmm6 punpcklwd xmm0, xmm1 pmullw xmm0, XMMWORD PTR SSE2_BOUNDS_SCALE pand xmm0, XMMWORD PTR SSE2_BOUNDS_MASK movdqa XMMWORD PTR sse2_bounds[ 0], xmm0

punpcklwd xmm4, xmm5 pmullw xmm4, XMMWORD PTR SSE2_BOUNDS_SCALE pand xmm4, XMMWORD PTR SSE2_BOUNDS_MASK movdqa XMMWORD PTR sse2_bounds[16], xmm4 movzx ecx, WORD PTR sse2_range [ 0] movzx edx, WORD PTR sse2_range [16] mov eax, DWORD PTR sse2_bounds[ 0] mov ebx, DWORD PTR sse2_bounds[16] shr eax, 8 shr ebx, 8 or eax, DWORD PTR sse2_bounds[ 4] or ebx, DWORD PTR sse2_bounds[20] or eax, DWORD PTR sse2_bounds[ 8] or ebx, DWORD PTR sse2_bounds[24] mov DWORD PTR [edi + 0], eax mov DWORD PTR [edi + 8], ebx add cx, WORD PTR sse2_range [ 2] add dx, WORD PTR sse2_range [18] add cx, WORD PTR sse2_range [ 4] add dx, WORD PTR sse2_range [20] mov ecx, DWORD PTR COLOR_DIVIDER_TABLE[ecx*4] mov edx, DWORD PTR COLOR_DIVIDER_TABLE[edx*4] #ifdef FIX_DXT1_BUG movzx eax, WORD PTR [edi + 0] xor ax, WORD PTR [edi + 2] cmovz ecx, eax movzx ebx, WORD PTR [edi + 8] xor bx, WORD PTR [edi + 10] cmovz edx, ebx #endif // FIX_DXT1_BUG mov eax, DWORD PTR width // width * 1 lea ebx, DWORD PTR [eax + eax*2] // width * 3 movdqa xmm0, XMMWORD PTR [esi + 0] // src + width * 0 + 0 movdqa xmm1, XMMWORD PTR [esi + eax*4 + 0] // src + width * 4 + 0 movdqa xmm7, XMMWORD PTR sse2_minimum[ 0] psubb xmm0, xmm7 psubb xmm1, xmm7 movdqa xmm2, XMMWORD PTR [esi + eax*8 + 0] // src + width * 8 + 0 movdqa xmm3, XMMWORD PTR [esi + ebx*4 + 0] // src + width * 12 + 0 psubb xmm2, xmm7 psubb xmm3, xmm7 #ifdef USE_SSSE3 movd xmm7, ecx pshufd xmm7, xmm7, 0x00 movdqa xmm6, XMMWORD PTR SSE2_INDICES_MASK_2 pmaddubsw xmm0, xmm6 pmaddubsw xmm1, xmm6 phaddw xmm0, xmm1 pmaddubsw xmm2, xmm6 pmaddubsw xmm3, xmm6 phaddw xmm2, xmm3 pmulhw xmm0, xmm7 pmulhw xmm2, xmm7 packuswb xmm0, xmm2 pmaddubsw xmm0, XMMWORD PTR SSE2_INDICES_SCALE_2 pmaddwd xmm0, XMMWORD PTR SSE2_WORD_1 movdqa XMMWORD PTR sse2_indices[ 0], xmm0 #else // USE_SSSE3 movdqa xmm4, xmm0 movdqa xmm5, xmm1 movdqa xmm6, XMMWORD PTR SSE2_INDICES_MASK_0 movdqa xmm7, XMMWORD PTR SSE2_INDICES_MASK_1 pand xmm0, xmm6 pand xmm1, xmm6 pmaddwd xmm0, XMMWORD PTR SSE2_WORD_8 pmaddwd xmm1, XMMWORD PTR SSE2_WORD_8 pand xmm4, xmm7 pand xmm5, xmm7

psrlw xmm4, 5 psrlw xmm5, 5 paddw xmm0, xmm4 paddw xmm1, xmm5 movdqa xmm4, xmm2 movdqa xmm5, xmm3 pand xmm2, xmm6 pand xmm3, xmm6 pmaddwd xmm2, XMMWORD PTR SSE2_WORD_8 pmaddwd xmm3, XMMWORD PTR SSE2_WORD_8 pand xmm4, xmm7 pand xmm5, xmm7 psrlw xmm4, 5 psrlw xmm5, 5 paddw xmm2, xmm4 paddw xmm3, xmm5 movd xmm7, ecx pshufd xmm7, xmm7, 0x00 packssdw xmm0, xmm1 pmulhw xmm0, xmm7 pmaddwd xmm0, XMMWORD PTR SSE2_INDICES_SCALE_0 packssdw xmm2, xmm3 pmulhw xmm2, xmm7 pmaddwd xmm2, XMMWORD PTR SSE2_INDICES_SCALE_0 packssdw xmm0, xmm2 pmaddwd xmm0, XMMWORD PTR SSE2_WORD_1 movdqa XMMWORD PTR sse2_indices[ 0], xmm0 #endif // USE_SSSE3 movdqa xmm0, XMMWORD PTR [esi + 16] // src + width * 0 + 16 movdqa xmm1, XMMWORD PTR [esi + eax*4 + 16] // src + width * 4 + 16 movdqa xmm7, XMMWORD PTR sse2_minimum[16] psubb xmm0, xmm7 psubb xmm1, xmm7 movdqa xmm2, XMMWORD PTR [esi + eax*8 + 16] // src + width * 8 + 16 movdqa xmm3, XMMWORD PTR [esi + ebx*4 + 16] // src + width * 12 + 16 psubb xmm2, xmm7 psubb xmm3, xmm7 #ifdef USE_SSSE3 movd xmm7, edx pshufd xmm7, xmm7, 0x00 movdqa xmm6, XMMWORD PTR SSE2_INDICES_MASK_2 pmaddubsw xmm0, xmm6 pmaddubsw xmm2, xmm6 pmaddubsw xmm1, xmm6 pmaddubsw xmm3, xmm6 phaddw xmm0, xmm1 phaddw xmm2, xmm3 pmulhw xmm0, xmm7 pmulhw xmm2, xmm7 packuswb xmm0, xmm2 pmaddubsw xmm0, XMMWORD PTR SSE2_INDICES_SCALE_2 pmaddwd xmm0, XMMWORD PTR SSE2_WORD_1 movdqa XMMWORD PTR sse2_indices[32], xmm0 #else // USE_SSSE3 movdqa xmm4, xmm0 movdqa xmm5, xmm1 movdqa xmm6, XMMWORD PTR SSE2_INDICES_MASK_0 movdqa xmm7, XMMWORD PTR SSE2_INDICES_MASK_1 pand xmm4, xmm7 pand xmm5, xmm7 psrlw xmm4, 5 psrlw xmm5, 5 pand xmm0, xmm6 pand xmm1, xmm6 pmaddwd xmm0, XMMWORD PTR SSE2_WORD_8 pmaddwd xmm1, XMMWORD PTR SSE2_WORD_8 paddw xmm0, xmm4 paddw xmm1, xmm5 movdqa xmm4, xmm2 movdqa xmm5, xmm3 pand xmm4, xmm7 pand xmm5, xmm7

psrlw xmm4, 5 psrlw xmm5, 5 pand xmm2, xmm6 pand xmm3, xmm6 pmaddwd xmm2, XMMWORD PTR SSE2_WORD_8 pmaddwd xmm3, XMMWORD PTR SSE2_WORD_8 paddw xmm2, xmm4 paddw xmm3, xmm5 movd xmm7, edx pshufd xmm7, xmm7, 0x00 packssdw xmm0, xmm1 pmulhw xmm0, xmm7 pmaddwd xmm0, XMMWORD PTR SSE2_INDICES_SCALE_0 packssdw xmm2, xmm3 pmulhw xmm2, xmm7 pmaddwd xmm2, XMMWORD PTR SSE2_INDICES_SCALE_0 packssdw xmm0, xmm2 pmaddwd xmm0, XMMWORD PTR SSE2_WORD_1 movdqa XMMWORD PTR sse2_indices[32], xmm0 #endif // USE_SSSE3 movzx eax, BYTE PTR sse2_indices[ 0] movzx ebx, BYTE PTR sse2_indices[ 4] mov cl, BYTE PTR COLOR_INDICES_TABLE[eax*1 + 0] mov ch, BYTE PTR COLOR_INDICES_TABLE[ebx*1 + 0] mov BYTE PTR [edi + 4], cl mov BYTE PTR [edi + 5], ch movzx eax, BYTE PTR sse2_indices[ 8] movzx ebx, BYTE PTR sse2_indices[12] mov dl, BYTE PTR COLOR_INDICES_TABLE[eax*1 + 0] mov dh, BYTE PTR COLOR_INDICES_TABLE[ebx*1 + 0] mov BYTE PTR [edi + 6], dl mov BYTE PTR [edi + 7], dh movzx eax, BYTE PTR sse2_indices[32] movzx ebx, BYTE PTR sse2_indices[36] mov cl, BYTE PTR COLOR_INDICES_TABLE[eax*1 + 0] mov ch, BYTE PTR COLOR_INDICES_TABLE[ebx*1 + 0] mov BYTE PTR [edi + 12], cl mov BYTE PTR [edi + 13], ch movzx eax, BYTE PTR sse2_indices[40] movzx ebx, BYTE PTR sse2_indices[44] mov dl, BYTE PTR COLOR_INDICES_TABLE[eax*1 + 0] mov dh, BYTE PTR COLOR_INDICES_TABLE[ebx*1 + 0] mov BYTE PTR [edi + 14], dl mov BYTE PTR [edi + 15], dh add esi, 32 // src += 32 add edi, 16 // dst += 16 sub DWORD PTR x_count, 8 jnz x_loop mov eax, DWORD PTR width // width * 1 lea ebx, DWORD PTR [eax + eax*2] // width * 3 lea esi, DWORD PTR [esi + ebx*4] // src += width * 12 sub DWORD PTR y_count, 4 jnz y_loop } } void CompressImageDXT5(const BYTE* argb, BYTE* dxt5, int width, int height) { int x_count; int y_count; __asm { mov esi, DWORD PTR argb // src mov edi, DWORD PTR dxt5 // dst mov eax, DWORD PTR height mov DWORD PTR y_count, eax y_loop: mov eax, DWORD PTR width mov DWORD PTR x_count, eax

x_loop: mov eax, DWORD PTR width // width * 1 lea ebx, DWORD PTR [eax + eax*2] // width * 3 movdqa xmm0, XMMWORD PTR [esi + 0] // src + width * 0 + 0 movdqa xmm3, XMMWORD PTR [esi + eax*4 + 0] // src + width * 4 + 0 movdqa xmm1, xmm0 pmaxub xmm0, xmm3 pminub xmm1, xmm3 pmaxub xmm0, XMMWORD PTR [esi + eax*8 + 0] // src + width * 8 + 0 pminub xmm1, XMMWORD PTR [esi + eax*8 + 0] // src + width * 8 + 0 pmaxub xmm0, XMMWORD PTR [esi + ebx*4 + 0] // src + width * 12 + 0 pminub xmm1, XMMWORD PTR [esi + ebx*4 + 0] // src + width * 12 + 0 pshufd xmm2, xmm0, 0x4E pmaxub xmm0, xmm2 pshufd xmm3, xmm1, 0x4E pminub xmm1, xmm3 pshufd xmm2, xmm0, 0xB1 pmaxub xmm0, xmm2 pshufd xmm3, xmm1, 0xB1 pminub xmm1, xmm3 movdqa xmm4, XMMWORD PTR [esi + 16] // src + width * 0 + 16 movdqa xmm7, XMMWORD PTR [esi + eax*4 + 16] // src + width * 4 + 16 movdqa xmm5, xmm4 pmaxub xmm4, xmm7 pminub xmm5, xmm7 pmaxub xmm4, XMMWORD PTR [esi + eax*8 + 16] // src + width * 8 + 16 pminub xmm5, XMMWORD PTR [esi + eax*8 + 16] // src + width * 8 + 16 pmaxub xmm4, XMMWORD PTR [esi + ebx*4 + 16] // src + width * 12 + 16 pminub xmm5, XMMWORD PTR [esi + ebx*4 + 16] // src + width * 12 + 16 pshufd xmm6, xmm4, 0x4E pmaxub xmm4, xmm6 pshufd xmm7, xmm5, 0x4E pminub xmm5, xmm7 pshufd xmm6, xmm4, 0xB1 pmaxub xmm4, xmm6 pshufd xmm7, xmm5, 0xB1 pminub xmm5, xmm7 movdqa XMMWORD PTR sse2_minimum[ 0], xmm1 movdqa XMMWORD PTR sse2_minimum[16], xmm5 movdqa xmm7, XMMWORD PTR SSE2_BYTE_0 punpcklbw xmm0, xmm7 punpcklbw xmm4, xmm7 punpcklbw xmm1, xmm7 punpcklbw xmm5, xmm7 movdqa xmm2, xmm0 movdqa xmm6, xmm4 psubw xmm2, xmm1 psubw xmm6, xmm5 movq MMWORD PTR sse2_range[ 0], xmm2 movq MMWORD PTR sse2_range[16], xmm6 psrlw xmm2, 4 psrlw xmm6, 4 psubw xmm0, xmm2 psubw xmm4, xmm6 paddw xmm1, xmm2 paddw xmm5, xmm6 punpcklwd xmm0, xmm1 pmullw xmm0, XMMWORD PTR SSE2_BOUNDS_SCALE pand xmm0, XMMWORD PTR SSE2_BOUNDS_MASK movdqa XMMWORD PTR sse2_bounds[ 0], xmm0 punpcklwd xmm4, xmm5 pmullw xmm4, XMMWORD PTR SSE2_BOUNDS_SCALE pand xmm4, XMMWORD PTR SSE2_BOUNDS_MASK movdqa XMMWORD PTR sse2_bounds[16], xmm4 mov eax, DWORD PTR sse2_bounds[ 0] mov ebx, DWORD PTR sse2_bounds[16] shr eax, 8 shr ebx, 8 movzx ecx, WORD PTR sse2_bounds[13] movzx edx, WORD PTR sse2_bounds[29] mov DWORD PTR [edi + 0], ecx mov DWORD PTR [edi + 16], edx

or eax, DWORD PTR sse2_bounds[ 4] or ebx, DWORD PTR sse2_bounds[20] or eax, DWORD PTR sse2_bounds[ 8] or ebx, DWORD PTR sse2_bounds[24] mov DWORD PTR [edi + 8], eax mov DWORD PTR [edi + 24], ebx movzx ecx, WORD PTR sse2_range [ 0] movzx edx, WORD PTR sse2_range [16] add cx, WORD PTR sse2_range [ 2] add dx, WORD PTR sse2_range [18] add cx, WORD PTR sse2_range [ 4] add dx, WORD PTR sse2_range [20] movzx ecx, WORD PTR COLOR_DIVIDER_TABLE[ecx*4] movzx edx, WORD PTR COLOR_DIVIDER_TABLE[edx*4] #ifdef FIX_DXT5_BUG movzx eax, WORD PTR [edi + 8] xor ax, WORD PTR [edi + 10] cmovz ecx, eax movzx ebx, WORD PTR [edi + 24] xor bx, WORD PTR [edi + 26] cmovz edx, ebx #endif // FIX_DXT5_BUG movzx eax, WORD PTR sse2_range [ 6] movzx ebx, WORD PTR sse2_range [22] mov eax, DWORD PTR ALPHA_DIVIDER_TABLE[eax*4] mov ebx, DWORD PTR ALPHA_DIVIDER_TABLE[ebx*4] or ecx, eax or edx, ebx mov eax, DWORD PTR width // width * 1 lea ebx, DWORD PTR [eax + eax*2] // width * 3 movdqa xmm0, XMMWORD PTR [esi + 0] // src + width * 0 + 0 movdqa xmm1, XMMWORD PTR [esi + eax*4 + 0] // src + width * 4 + 0 movdqa xmm7, XMMWORD PTR sse2_minimum[ 0] psubb xmm0, xmm7 psubb xmm1, xmm7 movdqa xmm2, XMMWORD PTR [esi + eax*8 + 0] // src + width * 8 + 0 psubb xmm2, xmm7 movdqa xmm3, XMMWORD PTR [esi + ebx*4 + 0] // src + width * 12 + 0 psubb xmm3, xmm7 movdqa xmm6, XMMWORD PTR SSE2_INDICES_MASK_0 movdqa xmm7, XMMWORD PTR SSE2_WORD_8 movdqa xmm4, xmm0 movdqa xmm5, xmm1 pand xmm0, xmm6 pand xmm1, xmm6 psrlw xmm4, 8 psrlw xmm5, 8 pmaddwd xmm0, xmm7 pmaddwd xmm1, xmm7 psllw xmm4, 3 psllw xmm5, 3 paddw xmm0, xmm4 paddw xmm1, xmm5 movdqa xmm4, xmm2 movdqa xmm5, xmm3 pand xmm2, xmm6 pand xmm3, xmm6 psrlw xmm4, 8 psrlw xmm5, 8 pmaddwd xmm2, xmm7 pmaddwd xmm3, xmm7 psllw xmm4, 3 psllw xmm5, 3 paddw xmm2, xmm4 paddw xmm3, xmm5 #ifdef USE_SSSE3 movd xmm7, ecx pshufd xmm7, xmm7, 0x00 movdqa xmm5, XMMWORD PTR SSE2_INDICES_SCALE_3 movdqa xmm6, XMMWORD PTR SSE2_INDICES_SCALE_4

pmulhw xmm0, xmm7 pmulhw xmm1, xmm7 pmulhw xmm2, xmm7 pmulhw xmm3, xmm7 packuswb xmm0, xmm1 pshufb xmm0, XMMWORD PTR SSE2_INDICES_SHUFFLE pmaddubsw xmm0, xmm5 pmaddwd xmm0, xmm6 movdqa XMMWORD PTR sse2_indices[ 0], xmm0 packuswb xmm2, xmm3 pshufb xmm2, XMMWORD PTR SSE2_INDICES_SHUFFLE pmaddubsw xmm2, xmm5 pmaddwd xmm2, xmm6 movdqa XMMWORD PTR sse2_indices[16], xmm2 #else // USE_SSSE3 movd xmm7, ecx pshufd xmm7, xmm7, 0x00 pmulhw xmm0, xmm7 pmulhw xmm1, xmm7 pshuflw xmm0, xmm0, 0xD8 pshufhw xmm0, xmm0, 0xD8 pshuflw xmm1, xmm1, 0xD8 pshufhw xmm1, xmm1, 0xD8 movdqa xmm6, XMMWORD PTR SSE2_INDICES_SCALE_1 pmaddwd xmm0, xmm6 pmaddwd xmm1, xmm6 packssdw xmm0, xmm1 pshuflw xmm0, xmm0, 0xD8 pshufhw xmm0, xmm0, 0xD8 pmaddwd xmm0, XMMWORD PTR SSE2_WORD_1 movdqa XMMWORD PTR sse2_indices[ 0], xmm0 pmulhw xmm2, xmm7 pmulhw xmm3, xmm7 pshuflw xmm2, xmm2, 0xD8 pshufhw xmm2, xmm2, 0xD8 pshuflw xmm3, xmm3, 0xD8 pshufhw xmm3, xmm3, 0xD8 pmaddwd xmm2, xmm6 pmaddwd xmm3, xmm6 packssdw xmm2, xmm3 pshuflw xmm2, xmm2, 0xD8 pshufhw xmm2, xmm2, 0xD8 pmaddwd xmm2, XMMWORD PTR SSE2_WORD_1 movdqa XMMWORD PTR sse2_indices[16], xmm2 #endif // USE_SSSE3 movdqa xmm0, XMMWORD PTR [esi + 16] // src + width * 0 + 16 movdqa xmm1, XMMWORD PTR [esi + eax*4 + 16] // src + width * 4 + 16 movdqa xmm7, XMMWORD PTR sse2_minimum[16] psubb xmm0, xmm7 psubb xmm1, xmm7 movdqa xmm2, XMMWORD PTR [esi + eax*8 + 16] // src + width * 8 + 16 psubb xmm2, xmm7 movdqa xmm3, XMMWORD PTR [esi + ebx*4 + 16] // src + width * 12 + 16 psubb xmm3, xmm7 movdqa xmm6, XMMWORD PTR SSE2_INDICES_MASK_0 movdqa xmm7, XMMWORD PTR SSE2_WORD_8 movdqa xmm4, xmm0 movdqa xmm5, xmm1 pand xmm0, xmm6 pand xmm1, xmm6 pmaddwd xmm0, xmm7 pmaddwd xmm1, xmm7 psrlw xmm4, 8 psrlw xmm5, 8 psllw xmm4, 3 psllw xmm5, 3 paddw xmm0, xmm4 paddw xmm1, xmm5 movdqa xmm4, xmm2 movdqa xmm5, xmm3 pand xmm2, xmm6 pand xmm3, xmm6 pmaddwd xmm2, xmm7 pmaddwd xmm3, xmm7

psrlw xmm4, 8 psrlw xmm5, 8 psllw xmm4, 3 psllw xmm5, 3 paddw xmm2, xmm4 paddw xmm3, xmm5 #ifdef USE_SSSE3 movd xmm7, edx pshufd xmm7, xmm7, 0x00 movdqa xmm5, XMMWORD PTR SSE2_INDICES_SCALE_3 movdqa xmm6, XMMWORD PTR SSE2_INDICES_SCALE_4 pmulhw xmm0, xmm7 pmulhw xmm1, xmm7 pmulhw xmm2, xmm7 pmulhw xmm3, xmm7 packuswb xmm0, xmm1 pshufb xmm0, XMMWORD PTR SSE2_INDICES_SHUFFLE pmaddubsw xmm0, xmm5 pmaddwd xmm0, xmm6 movdqa XMMWORD PTR sse2_indices[32], xmm0 packuswb xmm2, xmm3 pshufb xmm2, XMMWORD PTR SSE2_INDICES_SHUFFLE pmaddubsw xmm2, xmm5 pmaddwd xmm2, xmm6 movdqa XMMWORD PTR sse2_indices[48], xmm2 #else // USE_SSSE3 movd xmm7, edx pshufd xmm7, xmm7, 0x00 pmulhw xmm0, xmm7 pmulhw xmm1, xmm7 pshuflw xmm0, xmm0, 0xD8 pshufhw xmm0, xmm0, 0xD8 pshuflw xmm1, xmm1, 0xD8 pshufhw xmm1, xmm1, 0xD8 movdqa xmm6, XMMWORD PTR SSE2_INDICES_SCALE_1 pmaddwd xmm0, xmm6 pmaddwd xmm1, xmm6 packssdw xmm0, xmm1 pshuflw xmm0, xmm0, 0xD8 pshufhw xmm0, xmm0, 0xD8 pmaddwd xmm0, XMMWORD PTR SSE2_WORD_1 movdqa XMMWORD PTR sse2_indices[32], xmm0 pmulhw xmm2, xmm7 pmulhw xmm3, xmm7 pshuflw xmm2, xmm2, 0xD8 pshufhw xmm2, xmm2, 0xD8 pshuflw xmm3, xmm3, 0xD8 pshufhw xmm3, xmm3, 0xD8 pmaddwd xmm2, xmm6 pmaddwd xmm3, xmm6 packssdw xmm2, xmm3 pshuflw xmm2, xmm2, 0xD8 pshufhw xmm2, xmm2, 0xD8 pmaddwd xmm2, XMMWORD PTR SSE2_WORD_1 movdqa XMMWORD PTR sse2_indices[48], xmm2 #endif // USE_SSSE3 movzx eax, BYTE PTR sse2_indices[ 0] movzx ebx, BYTE PTR sse2_indices[ 8] mov cl, BYTE PTR COLOR_INDICES_TABLE[eax*1 + 0] mov ch, BYTE PTR COLOR_INDICES_TABLE[ebx*1 + 0] mov BYTE PTR [edi + 12], cl mov BYTE PTR [edi + 13], ch movzx eax, BYTE PTR sse2_indices[16] movzx ebx, BYTE PTR sse2_indices[24] mov dl, BYTE PTR COLOR_INDICES_TABLE[eax*1 + 0] mov dh, BYTE PTR COLOR_INDICES_TABLE[ebx*1 + 0] mov BYTE PTR [edi + 14], dl mov BYTE PTR [edi + 15], dh movzx eax, BYTE PTR sse2_indices[32] movzx ebx, BYTE PTR sse2_indices[40] mov cl, BYTE PTR COLOR_INDICES_TABLE[eax*1 + 0] mov ch, BYTE PTR COLOR_INDICES_TABLE[ebx*1 + 0] mov BYTE PTR [edi + 28], cl mov BYTE PTR [edi + 29], ch

movzx eax, BYTE PTR sse2_indices[48] movzx ebx, BYTE PTR sse2_indices[56] mov dl, BYTE PTR COLOR_INDICES_TABLE[eax*1 + 0] mov dh, BYTE PTR COLOR_INDICES_TABLE[ebx*1 + 0] mov BYTE PTR [edi + 30], dl mov BYTE PTR [edi + 31], dh movzx eax, BYTE PTR sse2_indices[ 4] movzx ebx, BYTE PTR sse2_indices[36] mov cx, WORD PTR ALPHA_INDICES_TABLE[eax*2 + 0] mov dx, WORD PTR ALPHA_INDICES_TABLE[ebx*2 + 0] movzx eax, BYTE PTR sse2_indices[ 5] movzx ebx, BYTE PTR sse2_indices[37] or cx, WORD PTR ALPHA_INDICES_TABLE[eax*2 + 128] or dx, WORD PTR ALPHA_INDICES_TABLE[ebx*2 + 128] movzx eax, BYTE PTR sse2_indices[12] movzx ebx, BYTE PTR sse2_indices[44] or cx, WORD PTR ALPHA_INDICES_TABLE[eax*2 + 256] or dx, WORD PTR ALPHA_INDICES_TABLE[ebx*2 + 256] mov WORD PTR [edi + 2], cx mov WORD PTR [edi + 18], dx mov cx, WORD PTR ALPHA_INDICES_TABLE[eax*2 + 384] mov dx, WORD PTR ALPHA_INDICES_TABLE[ebx*2 + 384] movzx eax, BYTE PTR sse2_indices[13] movzx ebx, BYTE PTR sse2_indices[45] or cx, WORD PTR ALPHA_INDICES_TABLE[eax*2 + 512] or dx, WORD PTR ALPHA_INDICES_TABLE[ebx*2 + 512] movzx eax, BYTE PTR sse2_indices[20] movzx ebx, BYTE PTR sse2_indices[52] or cx, WORD PTR ALPHA_INDICES_TABLE[eax*2 + 640] or dx, WORD PTR ALPHA_INDICES_TABLE[ebx*2 + 640] movzx eax, BYTE PTR sse2_indices[21] movzx ebx, BYTE PTR sse2_indices[53] or cx, WORD PTR ALPHA_INDICES_TABLE[eax*2 + 768] or dx, WORD PTR ALPHA_INDICES_TABLE[ebx*2 + 768] mov WORD PTR [edi + 4], cx mov WORD PTR [edi + 20], dx mov cx, WORD PTR ALPHA_INDICES_TABLE[eax*2 + 896] mov dx, WORD PTR ALPHA_INDICES_TABLE[ebx*2 + 896] movzx eax, BYTE PTR sse2_indices[28] movzx ebx, BYTE PTR sse2_indices[60] or cx, WORD PTR ALPHA_INDICES_TABLE[eax*2 + 1024] or dx, WORD PTR ALPHA_INDICES_TABLE[ebx*2 + 1024] movzx eax, BYTE PTR sse2_indices[29] movzx ebx, BYTE PTR sse2_indices[61] or cx, WORD PTR ALPHA_INDICES_TABLE[eax*2 + 1152] or dx, WORD PTR ALPHA_INDICES_TABLE[ebx*2 + 1152] mov WORD PTR [edi + 6], cx mov WORD PTR [edi + 22], dx add esi, 32 // src += 32 add edi, 32 // dst += 32 sub DWORD PTR x_count, 8 jnz x_loop mov eax, DWORD PTR width // width * 1 lea ebx, DWORD PTR [eax + eax*2] // width * 3 lea esi, DWORD PTR [esi + ebx*4] // src += width * 12 sub DWORD PTR y_count, 4 jnz y_loop } }

void PrepareColorDividerTable() { for (int i = 0; i < 768; i++) { COLOR_DIVIDER_TABLE[i] = (((1 << 15) / (i + 1)) << 16) | ((1 << 15) / (i + 1)); } } void PrepareAlphaDividerTable() { for (int i = 0; i < 256; i++) { ALPHA_DIVIDER_TABLE[i] = (((1 << 16) / (i + 1)) << 16); } } void PrepareColorIndicesTable() { const BYTE COLOR_INDEX[] = {1, 3, 2, 0}; for (int i = 0; i < 256; i++) { BYTE ci3 = COLOR_INDEX[(i & 0xC0) >> 6] << 6; BYTE ci2 = COLOR_INDEX[(i & 0x30) >> 4] << 4; BYTE ci1 = COLOR_INDEX[(i & 0x0C) >> 2] << 2; BYTE ci0 = COLOR_INDEX[(i & 0x03) >> 0] << 0; COLOR_INDICES_TABLE[i] = ci3 | ci2 | ci1 | ci0; } } void PrepareAlphaIndicesTable() { const int SHIFT_LEFT [] = {0, 1, 2, 0, 1, 2, 3, 0, 1, 2}; const int SHIFT_RIGHT[] = {0, 0, 0, 2, 2, 2, 2, 1, 1, 1}; const WORD ALPHA_INDEX[] = {1, 7, 6, 5, 4, 3, 2, 0}; for (int j = 0; j < 10; j++) { int sl = SHIFT_LEFT [j] * 6; int sr = SHIFT_RIGHT[j] * 2; for (int i = 0; i < 64; i++) { WORD ai1 = ALPHA_INDEX[(i & 0x38) >> 3] << 3; WORD ai0 = ALPHA_INDEX[(i & 0x07) >> 0] << 0; ALPHA_INDICES_TABLE[(j * 64) + i] = ((ai1 | ai0) << sl) >> sr; } } }
Recommended

















