
Top-k Interesting Phrase Mining in Ad-hoc Collectionsusing Sequence Pattern Indexing
Chuancong Gao, Sebastian Michel
Max-Planck Institute for Informatics & Saarland UniversitySaarbrucken, Germany
EDBT, March 28, 2012
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 1 / 31

Motivation
Lost overview on current presidential campaign topics?Get an update on key phrases of Mitt Romney!
• Want concise summary.
• Solution: Mining top-k phrases w.r.t. subset of all documents.
• Sub-set of documents is determined in ad-hoc fashion.
• E.g., using keyword queries, restriction to categorical attributes.
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 2 / 31

Motivation (Example)
1988 George Bush Kinder, Gentler Nation1992 Bill Clinton Dont stop thinking about tomorrow1992 Bill Clinton Putting People First1992 Ross Perot Ross for Boss1996 Bill Clinton Building a bridge to the 21st century1996 Bob Dole The Better Man for a Better America2000 Al Gore Prosperity and progress2000 George W. Bush Compassionate conservatism2000 George W. Bush Leave no child behind2000 Ralph Nader Government of, by, and for the people...2004 John Kerry Let America be America Again2004 George W. Bush Yes, America Can!2008 John McCain Country First2008 Barack Obama Change We Can Believe In2008 Barack Obama Yes We Can!
http://www.presidentsusa.net/campaignslogans.html
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 3 / 31

Problem Statement
Given: a document corpus
Task: Create an Index
• that organizes documents and phrases
• in a compact way
• to query for top-k phrases of arbitrary ad-hoc collections.
• Devise appropriate algorithms to use the index efficiently.
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 4 / 31

Problem Definition
Given a document corpus D and a subset D ′.
Find the top-k frequent phrases with the highest interestingness in D ′.
Ad-hoc Document SubsetD ′ is not known upfront
PhraseA phrase p is contained in document d iff p is a continuous sub-sequenceof d (notation p v d).
• p’s length is restricted by min-len and max-len.
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 5 / 31

Problem Definition (Cont.)
Frequency
The frequency of a phrase p in D ′ is called the support value of p w.r.t.D ′, denoted by supD′
p .
• supD′p = |{d |d ∈ D ′ ∧ p v d}|
• A phrase is called frequent in a document collection D ′ iff p’s supportis larger than the user-specified threshold min-supD′
.
Interestingness
The interestingness measure we adopted is the confidence value (orrelevance value), defined as
conf D′p =
supD′p
supDp
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 6 / 31

Example
Find the top-k (k = 3) interesting phrases for 4 documents.
DD ′
ID Document
d1 〈eabefcad〉d2 〈dcbeafe〉d3 〈fceacd〉d4 〈acfdbeacd〉
(a) Documents
k
ID Phrase Conf.p1 〈ac〉 2/2
p2 〈bea〉 2/2
p3 〈ea〉 3/4
p4 〈be〉 2/3
· · · · · ·(b) Top-k Phrases
(min-supD′
= 2, k = 3, min-len = 2, max-len = 4)
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 7 / 31

Outline
Existing Approaches
Sequence Patter Indexing
Experiments
Conclusion
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 8 / 31

Existing Approaches - Phrase Inverted Indexing
(A. Simitsis et al. - Multidimensional content eXploration. VLDB’08)
Indexing Steps
For each phrase p, store an inverted list that contains the IDs of alldocuments containing p.
Example index:
ID Document IDs
p1 {d1, d2}p2 {d1, d3}p3 {d1, d3, d4}p4 {d1, d2, d3, d4}
Given an ad-hoc collection D ′: Alg. requires a full scan of all the invertedlists.
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 9 / 31

Existing Approaches - Forward Indexing
(S. Bedathur et al. - Interesting-Phrase Mining for Ad-Hoc Text Analytics.VLDB’10)
Indexing Steps
Builds a forward list for each document d ∈ D, containing all the IDs ofphrases contained in d .
Example index structure:
ID Forward List
d1 {p1:2, p2:2, p3:3, p4:4}d2 {p1:2, p4:4}d3 {p2:2, p3:3, p4:4}d4 {p3:3, p4:4}
Numbers after “:” denote global support values.
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 10 / 31

Existing Approaches - Forward Indexing (Cont.)
Query Processing
Compute top-k phrases with |D ′|-way merge join.
• Global support value of p stored explicitly in list.
• Local support value + confidence is computed during the join process.
• Nice: only the forward lists of documents in D ′ need be to scanned.
• Even better: can apply early termination:
• phrase IDs in each forward list stored in ascending order of globalsupport values
• then, conf D′
p has an upper bound min
{1,|D′|supD
p
}.
• Can stop if the top-k results we found can not be topped anymore.
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 11 / 31

Prefix-Maximal Indexing
(S. Bedathur et al. - Interesting-Phrase Mining for Ad-Hoc Text Analytics.VLDB’10)
Key Idea
Store only prefix-maximal phrases (small subset of all phrases) w.r.t. eachdocument in the corpus.
• A phrase p is called maximal w.r.t. a document d ∈ D iff 6 ∃p′ that p′
is frequent and p @ p′.
• A phrase p is called prefix-maximal w.r.t. a document d ∈ D iff p ismaximal and @p′ that p′ is maximal and p is a prefix of p′.
Significantly reduces the index size comparing to Forward Indexing.
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 12 / 31

Phrase-Maximal Index. Comparison
Comparison: all phrases, maximal phrases, and prefix-maximal phrases:
ID Phrases
d1 {ad, be, bef, befc, ca, cad, ea, ef, efc, efca, fc, fca, fcad}d2 {be, bea, cb, cbe, cbea, dc, dcb, dcbe, ea, fe}d3 {ac, acd, cd, ce, cea, ceac, ea, eac, eacd, fc, fce, fcea}d4 {ac, acd, acf, acfd, be, bea, cd, cf, cfd, ea, eac, fd}
· · · · · ·ID Prefix-Maximal Phrases
d1 {ad, befc, cad, ea, efca, fcad}d2 {bea, cbea, dcbe, ea, fe}d3 {acd, cd, ceac, eacd, fcea}d4 {acd, acfd, bea, cfd, eac, fd}
· · · · · ·
ID Maximal Phrases
d1 {befc, ea, efca, fcad}d2 {cbea, dcbe, fe}d3 {ceac, eacd, fcea}d4 {acd, acfd, bea, eac}
· · · · · ·
Max. phrases keep index small, but top-k phrases computation is difficult.
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 13 / 31

Existing Approaches - Phrase-Maximal Indexing (Cont.)
The top-k phrases are computed by |D ′|-way merge join.
• Support values computed when merging all the forward lists in D ′.
• The confidence values are calculated by using a separate globalsupport value dictionary.
• Issues:• A full scan of the forward lists of D ′ is required, since no early
termination can be applied.
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 14 / 31

Objectives
Devise an approach that
1. is as fast as Forward Indexing (i.e., we must deviseearly stopping)
2. and has an index as small (or smaller than)Phrase-Maximal Indexing
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 15 / 31

Outline
Existing Approaches
Sequence Patter Indexing
Experiments
Conclusion
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 16 / 31

Our Approach - Key Ideas
We also store prefix-maximal phrases for each document d ∈ D, but ...
Lexicographical order vs. matching position order:
ID Prefix-Maximal Phrases
d1 {ad, befc, cad, ea, efca, fcad}d2 {bea, cbea, dcbe, ea, fe}d3 {acd, cd, ceac, eacd, fcea}d4 {acd, acfd, bea, cfd, eac, fd}
· · · · · ·ID Prefix-Maximal Phrases (Ordered by Position)
d1 {ea@1, befc@3, efca@4, fcad@5, cad@6, ad@7}d2 {dcbe@1, cbea@2, bea@3, ea@4, fe@6}d3 {fcea@1, ceac@2, eacd@3, acd@4, cd@5}d4 {acfd@1, cfd@2, fd@3, bea@5, eacd@6, acd@7}
· · · · · ·
– Duplicate Prefix Sub-Phrase Comparing to Previous Phrase – Duplicate Prefixes among Phrases
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 17 / 31
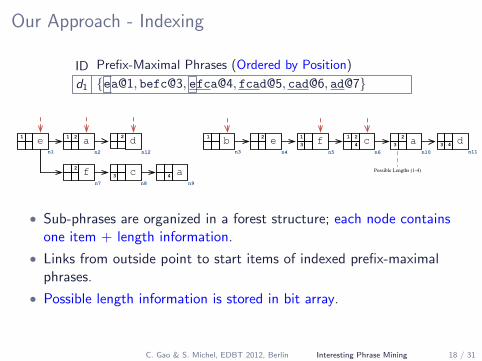
Our Approach - Indexing
ID Prefix-Maximal Phrases (Ordered by Position)
d1 {ea@1, befc@3, efca@4, fcad@5, cad@6, ad@7}
a1 2e1 b1 e2 f1
3 c2
4
f2 c3 a4
a3d d41 2
3
2
n1 n2 n3 n4 n5 n6
n7 n8 n9
n10 n11n12
Possible Lengths (1-4)
• Sub-phrases are organized in a forest structure; each node containsone item + length information.
• Links from outside point to start items of indexed prefix-maximalphrases.
• Possible length information is stored in bit array.
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 18 / 31

Memory Layout
a1 2e1 b1 e2 f1
3 c2
4
f2 c3 a4
a3d d41 2
3
2
n1 n2 n3 n4 n5 n6
n7 n8 n9
n10 n11n12
Possible Lengths (1-4)
ae d f c a e f cb
00
00100000
00110000
0001000014 0101
000000101000
00110100
00010000
00001000
01000100
00100000
00 04 06 10 14 18 22 26 30 34 38
00
06 10 26 34
8 bits24 bits1+15 bits16 bits
a d00011000
01001100
42 46
38
50
01001100
Word / Link
End of Branch
Possible Lengths (1-6)
(Number below cells indicate a relative memory address)
Each node is assigned with 4 bytes (32 bits); the first byte storing flags, the last 3 bytes storethe item.
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 19 / 31

Our Approach - Indexing (Cont.) - Improving
a1 2e1 b1 e2 f1
3 c2
4
f2 c3 a4
a3d d41 2
3
2
n1 n2 n3 n4 n5 n6
n7 n8 n9
n10 n11n12
Possible Lengths (1-4)
• Still some duplications like e → f → c → a and a→ d .
• Further improvement: utilize specific matching positions (instead ofjust matching orders).
• Idea: Use graph structure to eliminate more duplicates.
a1 2e1 b1 e2 f1
3 c2
4 a3 d4
1 23
n1 n2 n3 n4 n5 n6 n7 n8
23 4
2
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 20 / 31

Our Approach - Top-k Phrase Computing
Computation is done in two steps (interleaved): |D ′|-way merge join andgrowing patterns:
Merge join approach is used on phrase prefixes with length 1
• Index contains an address list for different items in document d .
• Apply |D ′|-way merge join on these address lists to retrieve alllength-1 phrases.
Extend each length-1 phrase
In each step: the prefix is extended with one of the local frequent items.
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 21 / 31

Optimizations
Early Stopping
• Can tell when it is “OK” to stop retrieving more length 1 patterns
Search Space Pruning
• During expansion of a length-1 pattern to larger patterns, stop whenunpromising.
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 22 / 31

Our Approach - Summary
Our Method’s Advantages:
• Index with little redundancy
• Algorithms fully utilize this new index structure.
• Visiting only frequent phrases:
• With early termination in |D ′|-merge join process.• And search space pruning in pattern-growth process.
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 23 / 31

Outline
Existing Approaches
Sequence Patter Indexing
Experiments
Conclusion
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 24 / 31
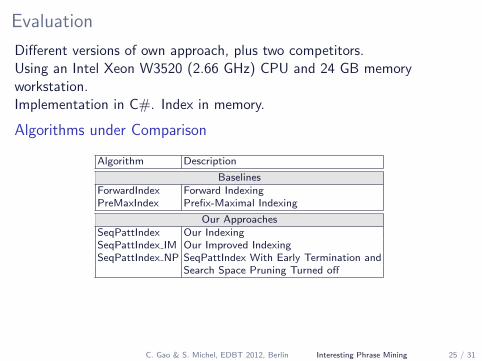
Evaluation
Different versions of own approach, plus two competitors.Using an Intel Xeon W3520 (2.66 GHz) CPU and 24 GB memoryworkstation.Implementation in C#. Index in memory.
Algorithms under Comparison
Algorithm Description
BaselinesForwardIndex Forward IndexingPreMaxIndex Prefix-Maximal Indexing
Our ApproachesSeqPattIndex Our IndexingSeqPattIndex IM Our Improved IndexingSeqPattIndex NP SeqPattIndex With Early Termination and
Search Space Pruning Turned off
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 25 / 31

Datasets
Global Per DocumentDataset #Doc. #Word Max. Len. Avg. Len. Avg. #WordPubMed Titles 17,826,927 2,028,673 167 11.59 10.99PubMed Abstracts 2,500,000 2,075,526 1599 149.72 92.1
Extracted from PubMed – the largest free publication database on lifesciences and biomedical topics.
• Titles are rather short, little redundancy per title.
• Abstracts contain much more information, more redundancydocument.
Great to study pros and cons of the discussed approaches.
Queries: Generated
• to simulate different kind of queries (by size of D ′)
• grouped phrases by global support according to several ranges
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 26 / 31

Evaluation - In-Memory Index Size (in MB)
SeqPattIndexSeqPattIndex_IM
PreMaxIndexForwardIndex
1000
2000
3000
4000
5000
5 10 15 20 25
Index
Siz
e (i
n M
B)
Minimum Support
(a) PubMed Titles
1000
2000
3000
4000
5000
6000
7000
5 10 15 20 25
Index
Siz
e (i
n M
B)
Minimum Support
(b) PubMed Abstracts
• PubMed Titles: improved approach close to original one, as phrases in titles have littleredundancy
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 27 / 31
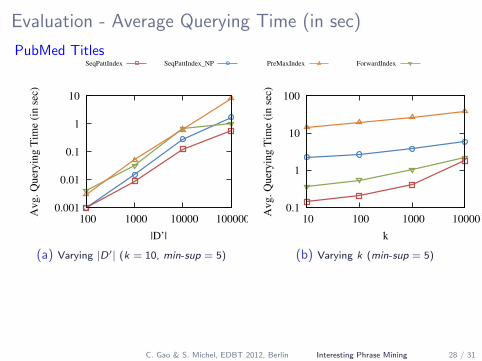
Evaluation - Average Querying Time (in sec)
PubMed TitlesSeqPattIndex SeqPattIndex_NP PreMaxIndex ForwardIndex
0.001
0.01
0.1
1
10
100 1000 10000 100000
Avg
. Q
uer
yin
g T
ime
(in
sec
)
|D’|
(a) Varying |D′| (k = 10, min-sup = 5)
0.1
1
10
100
10 100 1000 10000
Avg
. Q
uer
yin
g T
ime
(in
sec
)
k
(b) Varying k (min-sup = 5)
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 28 / 31

Evaluation - Average Querying Time (in sec)
PubMed Abstract
SeqPattIndex SeqPattIndex_NP PreMaxIndex ForwardIndex
0.01
0.1
1
10
100
100 1000 10000 100000
Avg
. Q
uer
yin
g T
ime
(in s
ec)
|D’|
(a) Varying |D′| (k = 10, min-sup = 5)
0.1
1
10
100
10000
10 100 1000 10000
Avg
. Q
uer
yin
g T
ime
(in s
ec)
k
(b) Varying k (min-sup = 5)
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 29 / 31

Outline
Existing Approaches
Sequence Patter Indexing
Experiments
Conclusion
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 30 / 31

Conclusion
• Presented approach to ad-hoc frequent phrases mining
• Making use of redundancy of sequentially alignedphrases
• Index is very compact.
• High performance in query processing based on earlystopping and search space pruning.
C. Gao & S. Michel, EDBT 2012, Berlin Interesting Phrase Mining 31 / 31
Recommended

















