
EMC Proven Professional Knowledge Sharing 2010
Documentum Disaster Recovery Implementation
Narsingarao Miriyala
Narsingarao MiriyalaEMC [email protected]

2010 EMC Proven Professional Knowledge Sharing 2
Table of Contents
Introduction .............................................................................................. 3
Audience ................................................................................................... 3
Benefits and Costs ..................................................................................... 3
Documentum Repository Overview .......................................................... 4
Disaster Recovery Fundamentals .............................................................. 7
Data Replication ....................................................................................... 9
Symmetrix Remote Data Facility (SRDF) ...................................................................................... 9
MirrorView Replication ............................................................................................................... 9
IP Replicator .............................................................................................................................. 10
Documentum DR Models ........................................................................ 10
Metadata and Content on EMC Symmetrix .............................................................................. 11
Metadata on Symmetrix and Content on CLARiiON ................................................................. 12
Metadata and Content on CLARiiON ......................................................................................... 14
Restore From Snaps ................................................................................ 17
Table of Figures Figure 1 (Documentum Repository) ................................................................................................ 4 Figure 2 (Content Object Relation Model) ...................................................................................... 5 Figure 3 (Documentum Transaction) ............................................................................................... 6 Figure 4 (Documentum Orphan Objects) ........................................................................................ 6 Figure 5 (Orphan Content) .............................................................................................................. 7 Figure 6 (Orphan Repository Objects) ............................................................................................. 8 Figure 7 (Metadata & Content on Symmetrix) .............................................................................. 12 Figure 8 (Metadata on Symmetrix & Content on CLARiiON) ........................................................ 14 Figure 9 (Content and Metadata on CLARiiON) ............................................................................ 16 Figure 10 (Content and Data Snaps) .............................................................................................. 17
Disclaimer: The views, processes or methodologies published in this compilation are those of the authors. They do not necessarily reflect EMC Corporation’s views, processes, or methodologies

2010 EMC Proven Professional Knowledge Sharing 3
Introduction This article presents a Disaster Recovery (DR) strategy to successfully recover the
repository at a DR site when content and metadata is replicated synchronously or
asynchronously to DR site. It also explains various models to deploy DR solutions using
EMC storage and replication software. This article will not address the following topics:
Documentum software configurations on primary and DR sites, recovering your system
from backups, nor FAST Index data.
Audience This article is for customers, partners and consultants who are considering deployment
of a DR solution. I assume that you are familiar with Documentum repository, EMC
storage products, and replication software.
Benefits and Costs When architecting a DR solution, one needs to consider the costs and benefits of each
available model. Some have higher monetary costs, but bring flexible and tasty benefits.
Others are cheaper upfront, but contain significant technical limitations and restrictions.
Typically, for every project there exists a Service Level Agreement (SLA). It defines
Recovery Time Objective (RTO) and Recovery Point Objective (RPO). RPO and RTO
are inversely proportional to the cost of the DR solution. In other words, the smaller the
gap between the data at source and target sites, the higher the costs of the DR solution

2010 EMC Proven Professional Knowledge Sharing 4
Documentum Repository Overview Before we talk about the recovery process, let’s discuss few basics of the Documentum
Repository. The Repository consists of two main components: a Relational Database
and a File System as shown in Figure 1 (Documentum Repository). All the metadata is
stored in the database and the associated content files are stored in a file system. We
need to synchronize both these components to successfully recover the system. Many
customers use the Network File System for storing the Content File; the Network File
system provides HA.
Figure 1 (Documentum Repository)

2010 EMC Proven Professional Knowledge Sharing 5
Every content file on storage has an associated persistent content object in the
database. This persistent object is associated with one or more sysobjects as shown in
Figure 2 (Content Object Relation Model). The Content object has metadata about a
document such as format, size, location of the file in the storage, etc. The associated
sysobject has system related metadata such as object name, owner, creation and
modified date etc. Please refer to the Documentum Object reference PDF document for
a complete list of the metadata attributes for content and sysobject.
Figure 2 (Content Object Relation Model)
Let’s understand how Documentum processes a content transaction as illustrated in
Figure 3 (Documentum Transaction). When a user imports a document into the
repository, the content server starts a database transaction, enters a new row in
database tables, saves the document into the file system, and commits the transaction in
the database. If you look more closely, database transactions are committed only after
saving the content into the file system. The transaction is rolled back and an error
message appears if, for any reason, the file system is full or unavailable.

2010 EMC Proven Professional Knowledge Sharing 6
Figure 3 (Documentum Transaction)
When you delete a Document using Webtop or any interface in a regular system, the
system will delete the sysobject but will not delete the content object and actual file in
the file system. The Content object and Content File are marked as orphans as shown in
Figure 4 (Documentum Orphan Objects). If you are using Trusted Content Services
(TCS) and enable the digital shredding option on the file store, the system will delete
sysobject, content object, and the actual file in a single transaction. This option is
usually used in compliance environments.
Figure 4 (Documentum Orphan Objects)

2010 EMC Proven Professional Knowledge Sharing 7
Documentum provides two utilities to delete orphan files on the file system and in the
database:
• dmfilescan: This utility scans for orphan content files on storage and generated
scripts to delete the content in the file system.
• dmclean: This utility scans the repository and finds all orphan Content objects,
ACL, annotations etc.
The Administrator can run the scripts to clean up the orphan files and objects.
Disaster Recovery Fundamentals Content files on DR storage should be always ahead of the metadata in the DR
database. This is a guiding principle for successful repository recovery at a DR site.
This method ensures that every sysobject in the repository has an associated content
file in the file system (Storage). As content is ahead of metadata, you will notice Content
files on file systems with no reference to any sysobjects in the database as shown in
Figure 5 (Orphan Content). Remove this orphan content using the “dmfilescan” utility.
Figure 5 (Orphan Content)

2010 EMC Proven Professional Knowledge Sharing 8
On the other hand, a sysobject in a database may reference a content file on a file
system that doesn’t exist as shown in Figure 6 (Orphan Repository Objects). This is
considered a corrupt repository. A repository is corrupt when objects in the database
are ahead of the content in the file system. You have only one option. You have to
recover the repository from this corruption by rolling-forward the database transactions
to the time that the last content file was saved to the file system.
Figure 6 (Orphan Repository Objects)
The question is how to make sure that the content is always ahead of the Database at
the DR site. You can achieve this by using various replication mechanisms, storage
consistency groups, and data and content snaps.

2010 EMC Proven Professional Knowledge Sharing 9
Data Replication EMC supports various replication mechanisms between EMC storage devices. In this
article, we will talk about few of them including SRDF, MirrorView, and IP Replicator.
Symmetrix Remote Data Facility (SRDF) SRDF replication software is used for data replication between EMC Symmetrix® storage
devices. There are multiple SRDF supported modes. With Documentum replication we
talk primarily about two modes: SRDF Synchronous and SRDF Asynchronous.
• Synchronous Mode (SRDF/S) – Provides real-time mirroring of data between
primary and DR Symmetrix systems. Data is simultaneously written to both
systems’ cache in real-time before the application I/O is completed, thus ensuring
the highest possible data availability. Data must be successfully stored in both
the primary and DR Symmetrix systems before a positive acknowledgement is
sent to the primary host. This mode is used primarily for metropolitan area
networks where there are distances between two data centers.
• Asynchronous mode (SRDF/A) – Provides a consistent point-in-time image on
the DR site only slightly behind the source system. This mode allows replication
over unlimited distance, with minimum to no effect on the performance of the
local production repository. SRDF/A delivers high-performance and extended
distance replication.
MirrorView Replication MirrorView replication software is used to replicate data between EMC CLARiiON®
storage systems. This software supports the storage managed propagation of changes
made to data stored in a LUN on one CLARiiON system to a corresponding LUN on the
DR CLARiiON system. The propagation of changes from a LUN on one storage system
(primary LUN), to a corresponding LUN (DR LUN) on another system can be done in
either synchronous or asynchronous mode.
In synchronous mode, a write that changes the content of the primary LUN is not
acknowledged to the server host as successfully complete until the change is

2010 EMC Proven Professional Knowledge Sharing 10
successfully propagated to the DR storage system. In the asynchronous mode, changes
to the primary LUN(s) are not immediately propagated. Instead they are traced and
periodically propagated from primary LUN (s) to the DR LUN (s) as a batch.
IP Replicator This replication software is used for data replication on EMC Celerra® systems. IP
replicator is an extremely useful and easy-to-use feature that protects the physical NAS
and iSCSI environments. It uses a snapshot-based approach to provide an efficient data
replication solution over Internet Protocol (IP) networks. This is an Asynchronous
replication where customers can set granular recovery point objectives (RPOs) for each
of the objects being replicated. This allows you to meet business compliance service
levels especially when scaling a large NAS infrastructure.
Documentum DR Models In this section, I will discuss different DR models where metadata and content will be
replicated synchronously or asynchronously to a DR site. Data recovery point snaps will
be created for metadata and content for a successful recovery.
All the models have advantages and disadvantages. Implementation costs vary from
DMX/SRDF solutions to Celerra/IP replication solutions. Each model has to be reviewed
and validated to your business needs before making a final decision. The data volume
size and distance between the two sites are only two of the factors you must consider
before selecting a particular solution.
We will make the following assumptions to design these models:
• Oracle Database for storing metadata
• Distance between Primary and DR Site is within the metropolitan WAN area
(100 miles are less)
• File Systems are NFS mounted to content servers
• RPO of 0 to 20 minutes

2010 EMC Proven Professional Knowledge Sharing 11
The following models will be discussed in depth below:
1. Content and metadata on an EMC Symmetrix storage system on primary and DR site and replication using SRDF/S
2. Content and metadata on EMC CLARiiON storage systems on primary and DR
site and replication using EMC Recovery Point
3. Content on EMC CLARiiON and metadata on Symmetrix storage system and replication using IP Replicator for CLARiiON and SRDF/S for Symmetrix
Metadata and Content on EMC Symmetrix Oracle Data and Content are stored on a Symmetrix system at the primary and DR sites.
Oracle is connected to storage by SAN, and content file systems are mounted onto
Content Servers using a NAS gateway as shown in Figure 7 (Metadata & Content on
Symmetrix). Both the Content and Oracle data are replicated to the DR site using SRDF
synchronous mode. You should create a Single Consistency group for Oracle and
content data volumes.
The RPO should be zero and RTO should be minimal (< 30 minutes) to recover the
system during DR Failover since both data and content are always in synch. For
additional protection against data corruption, you can create checkpoint snaps on the
DR site at selected intervals, for example every 10 minutes you can create a snap of
data and content. You can have 3 to 5 rolling snaps on the target side.
The data on the DR side is dark; you cannot mount the data for Read/write while the
primary device is up and running with replication turned ON. In a disaster, follow these
steps to recover the system at the DR site:
• Stop replicating the data
• Make the metadata and content volumes on the DR side primary
• Mount the data and content
• Start the Oracle Database
• Start the Content Server
• Run Documentum dmfilescan and dmclean jobs
• Execute the scripts generated from the above jobs
• Run Documentum consistency check job, validate the results

2010 EMC Proven Professional Knowledge Sharing 12
Figure 7 (Metadata & Content on Symmetrix)
Metadata on Symmetrix and Content on CLARiiON Oracle data is stored on Symmetrix DMX® and Content is stored on CLARiiON storage
at the primary and DR sites. Oracle is connected to storage by SAN and content file
systems are mounted onto Content Servers using the NAS gateway as shown in Figure
8 (Metadata on Symmetrix & Content on CLARiiON).
Metadata is replicated to the DR site using SRDF/S replication mode. You should create
a Single Consistency group for metadata volumes on the DMX array. On the target side,
the system should be configured to take snaps of replicated Oracle data every 10
minutes. You should have 3 to 5 rolling snap checkpoints created on target site.

2010 EMC Proven Professional Knowledge Sharing 13
Content is replicated from the NFS server (EMC Celerra) to DR NFS server using
Asynchronous IP Replicator. Create a consistency group for all the Content File Systems
to be replicated to the DR site. The replication time interval is based on factors such as
RPO and the amount of content generated in 10 minutes. If you have an RPO of 20
minutes and you have set 10 minute intervals to replicate the content, you should have
enough bandwidth between the two sites to replicate the content in 10 minutes. My
recommendation is to work with an EMC NAS SME to design and configure the IP
Replicator for content replication.
In a real disaster, follow these steps to recover the repository at the DR site:
• Stop replicating the data and content from the primary to the DR site • Check the last content replicated time to the DR site • Select the database replicated snap which is older than the last content
replicated time • Mount the data on DMX, and content on CLARiiON • Mount content file systems from NAS to content servers • Start the Oracle Database • Check for any inconsistencies on the database • Start the Content Server • Run Documentum dmfilescan and dmclean jobs to clean orphan content and
objects in repository • Execute the scripts generated from the above jobs • Run Documentum consistency check job, validate the results

2010 EMC Proven Professional Knowledge Sharing 14
Figure 8 (Metadata on Symmetrix & Content on CLARiiON)
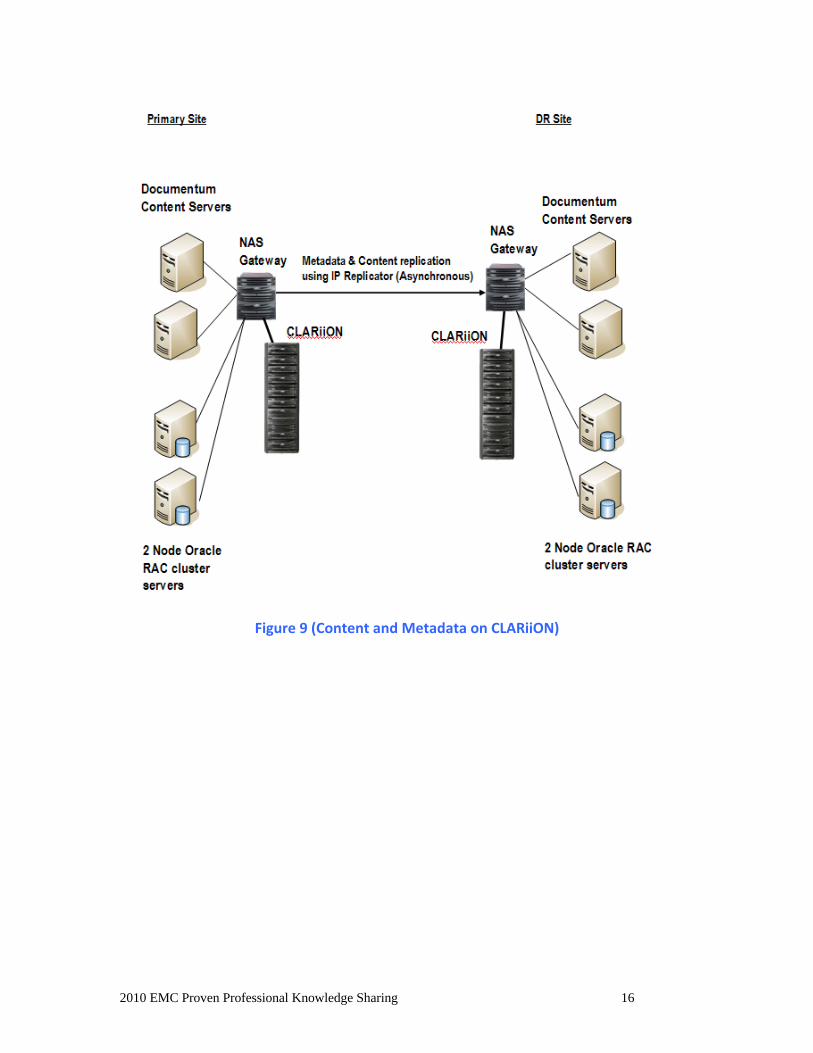
Metadata and Content on CLARiiON Oracle Data and content are stored in CLARiiON storage at primary and DR sites.
Metadata and Content file systems are NFS mounted (EMC Celerra) to Oracle and
Content servers respectively as shown in Figure 9 (Content and Metadata on
CLARiiON).
Both Metadata and Content are replicated from the NFS server (EMC Celerra) to the DR
NFS server using Asynchronous IP Replicator. Replication time intervals are based on
factors such as RPO and the amount of content generated in 10 minutes. With an RPO
of 20 minutes, and 10 minute intervals to replicate content, you should have enough
bandwidth between the two sites to replicate the content in 10 minutes.

2010 EMC Proven Professional Knowledge Sharing 15
Create rolling data snaps on the target side every 10 minutes for Oracle data. Work with
an EMC NAS SME to design and configure the IP Replicator for content replication.
Follow these steps in a real disaster to recover the repository at the DR site:
• Stop replicating the data and content from the primary to the DR site
• Check the last content replicated time to the DR site
• Select the database replicated snap that is older than content replication time
• Mount the data and content on the CLARiiON
• Mount metadata & content file systems from NAS to Oracle and content servers
respectively at the DR site
• Start the Oracle Database
• Check for any inconsistencies on the database
• Start the Content Server
• Run Documentum dmfilescan and dmclean jobs to clean orphan content and
objects in repository
• Execute the scripts generated from the above jobs
• Run Documentum consistency check job, validate the results
2010 EMC Proven Professional Knowledge Sharing 16
Figure 9 (Content and Metadata on CLARiiON)

2010 EMC Proven Professional Knowledge Sharing 17
Restore From Snaps As discuss in earlier sections, we need to restore the repository with content ahead of
the database. Your content snap should be more recent than the data snap. As shown in
Figure 10 (Content and Data Snaps) below, the database and content snaps are taken
5 minutes apart with 10 minute intervals between each snap. The Snap restore
compatibility table gives the database snap and associated content snaps that can be
used to restore the content. The last column gives the maximum amount of data lost.
This time may vary if the content is replicated asynchronously or the replication
mechanism is broken.
Figure 10 (Content and Data Snaps)
Snap Restore Compatibility
Database Snap
Compatible Content Snaps
Max Estimated Data Loss
D5 C5 5 MinutesD4 C4,C5 15 MinutesD3 C3,C4,C5 25 Minutes
D2 C2,C3,C4,C5 35 Minutes
D1 C1,C2,C3,C4,C5 45 Minutes
Recommended
















![Disaster Recovery Center (Disaster Assistance … Library/Disaster Recovery Center...Disaster Recovery Center (Disaster Assistance Center) Standard Operating Guide [Appendix to: ]](https://img.pdfslide.us/doc/110x75/5b0334ba7f8b9a2d518bd9d9/disaster-recovery-center-disaster-assistance-librarydisaster-recovery-centerdisaster.jpg)