
Development of a Naïve Bayesian Classifier for “Big Five” Item
Domains
Alan D. MeadCassia K. Carter
Illinois Institute of Technology

Agenda
• The problem: items and domain• Bayesian classification• Research Questions• Method• Results• Future Directions

Items and Domains
• In most tests, items are assigned to domains– To meet content specifications– To provide feedback by domain
• Items are usually assigned by the item writers and double-checked during item review
• For many tests, manual classification is reliable and easy

Personality Domains
• This research stemmed from two projects aimed at automating the development of personality items– Project 1: Personality items generated from templates– Project 2: LSA was used to assemble items from a large
pool according to semantic similarity between items and a construct definition
• Manual classification is not perfectly reliable• It would be good to have a methodological way to
classify items into domains

Big Five Dimensions
• The Big Five is a common, high-level taxonomy for personality constructs:– Conscientiousness (“I like order” C+)– Agreeableness (“I insult people” A-)– Neuroticism (“I often feel blue” N+)– Openness (“I do not have a good imagination” O-)– Extraversion (“I am the life of the party” E+)
• “I am a warm, nurturing person” E+ or A+?• “I am very traditional” O- or C+?

Choice of Methodology
• In this classification problem, there will be no response data– If we had response data, we could use EFA/CFA
• Predictors are the presence of specific words– These data are probably of a nominal level of
measurement• Sample size is the number of items to classify– We might easily have many more predictors than
rows of data (even ignoring interaction terms)

Choice of Methods
• When X/predictors and Y/domains are metric, many techniques exist (LDF/Regression, LCA, factor analytic approaches, etc.)
• When X is metric but Y is categorical, logistic regression is suitable
• What to use when X and Y are not metric?– Naïve Bayesian Classifiers are one solution

Bayesian Classification
• Predict nominal classes (domain) from nominal predictors (presence of specific words)
• Handle problems with many predictors• Have a history of successful application• Are computationally simple• Have been shown to be robust to technical
issues like high degrees of multidimensionality and noise

Bayesian Classification (cont.)
• Compute P(domain|item) for each domain• Classify as domain of maximum probability:
Predicted domain = argmax P(domain|item)= argmax P(item|domain)P(domain)/P(item)= argmax P(item|domain)P(domain)= argmax P(w1,w2,…,wn|domain)P(domain)
≈ argmax P(w1|d.)P(w2|d.) … P(wn|d.)P(d.)
• “Naïve” refers to this assumption of independence of the predictors
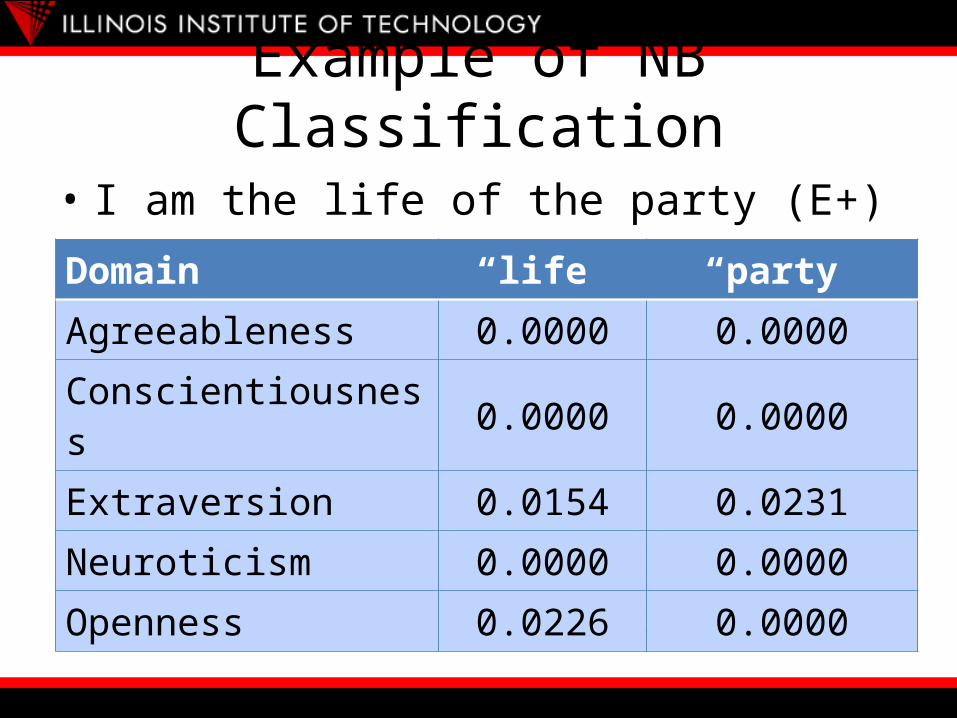
Example of NB Classification
• I am the life of the party (E+)
• Classified as extraversion
Domain “life” “party”Agreeableness 0.0000 0.0000Conscientiousness 0.0000 0.0000Extraversion 0.0154 0.0231Neuroticism 0.0000 0.0000Openness 0.0226 0.0000

Research Questions
• RQ1: How well does this method work?• Can it be improved?– RQ2: Does adding additional items help improve
classification accuracy?– RQ3: Does type of item added in matter?– RQ4: How to handle unknown words?

Method
• Compiled a database of five forms of various Big Five personality tests; N=655
• Leave one out cross-validation (LOOCV) was used:– Hold out item 1; Train classifier on remaining items;
Classify item 1– Hold out item 2; Train classifier on remaining items;
Classify item 2– Repeat for items 3, 4, …, N– Compare predicted domain to actual domain

Pre-processing & Processing
• Force all terms to lowercase• Discard any punctuation• Discard common words (I, am, a, the, etc.)• Use Porter stemming to produce rough
lemmas (annoyed, annoy, annoys, annoying -> “anno”)
• Ignore unknown words (i.e., discard them)

RQ1: Classification ResultsPredicted
Actual 1 2 3 4 51. Agreeableness 87 6 8 11 92. Conscientiousness 6 83 6 8 143. Extraversion 10 9 64 22 134. Neuroticism 6 6 4 95 65. Openness 8 10 6 8 92
• 70.5% accuracy (see diagonal)• Too few Extraversion

RQ2: Adding In Items
• Added in items written as a part of three grad-level classes– All Big Five items, classified by students who wrote
them– Blind manual classification– Final item set included items where agreement
occurred for original classification and two independent raters
• New N=1116

Additional Items ResultsPredicted
Actual 1 2 3 4 51. Agreeableness 156 17 21 10 92. Conscientiousness 10 178 9 8 133. Extraversion 23 14 153 18 104. Neuroticism 10 16 12 170 55. Openness 13 14 20 10 141
•Accuracy 75.3%•Increase only about 3% above set of 655 items•Now Openness lowest, Extraversion still low

RQ3: Type of Item
• Does type of item added into database matter?– Template Group 1: Template items where frequency words varied (“I
{always/sometimes/never/rarely/often} enjoy spending time with other people”)• N = 940
– Template Group 2: Manually generated templates based on IPIP items (“I have difficulty {dreaming up| conceiving of| brainstorming| devising| inventing| making up| planning| scheming| visualizing} things.”)• N = 194
– Template Group 3: I am a BLANK person (“I am an energetic person”)• N = 1,239
– Student Item Set: Another group of student-written Big Five items only reviewed by one rater

Type of Item ResultsAnalysis Items % Correct ClassificationOriginal 655 70.5
Augmented 1116 75.3
Template Group 1 940 86.3
Template Group 2 194 70.6
Template Group 3 1239 24.9
Augmented + Group 1 2057 80.8
Augmented + Group 2 1311 76.1
Augmented + Group 3 2356 53.7
Student Item Set 394 60.2
Augmented + Student Set 1510 75.0
Augmented + Student + Group 2 1704 75.6

Type of Item Results
• Adjective-based items had lowest accuracy– Items come down to a single word, often unique
• Template items with high redundancy were best on their own– However, accuracy for this group dropped when added
to overall set• Template items with less redundancy improved
overall accuracy somewhat• Adding more items doesn’t help dramatically– But adding in items with more information does help

RQ4: Unknown Terms
• Unknown terms are a real problem– “I am filled with doubts about things” was seen as
“things” because “doubts” and “filled” were used only in this item
– Many items hinge upon a single word (e.g., “workaholic”)
• Solution: Replace unknown term with sense 1 from wiktionary.org; e.g.:– http://en.wiktionary.org/wiki/advance

Unknown Term Example
• “I sometimes feel bashful.”– “bashful” is not known
• Lookup up bashful: “inclined to avoid notice”• “I sometimes feel inclined to avoid notice.”• Simplistic approach:– Ignored grammatical implications– In this case, it wasn’t possible to match senses, so
sometimes the wrong definition was used.– Did not check that definition used known terms

Results: Unknown Terms
OriginallyAFTER: MISS HITMISS 12 1HIT 4 14
• 84% unchanged• Originally 48% correct; After defining
unknown terms, 58% correct• 4 items (13%) improved; 1 item (3%) became
a miss

Unknown Terms
• Small improvements using this method• Would work better if the correct sense could
be chosen– Often sense 1 was not the correct part of speech– Some words did not have correct senses on
Wiktionary• Could try using synonyms

Future Directions
• Find more personality items• Explore better ontologies (e.g., WordNet)• Analyze words more carefully– Part-of-speech (POS) tagging– Try using word-sense disambiguation– Search definitions for “personality-ish” definitions
• Use Laplace smoothing and POS tag to handle unknown terms algorithmically
Recommended


















