
Design of High Performance Pattern Matching Engine Through
Compact Deterministic Finite Automata
Department of Computer Science and Information Engineering National Cheng Kung University, Taiwan R.O.C.
Authors: Piyachon, P. Yan Luo
Publisher: DAC 2008 45th ACM, June 8-13, 2008, Anaheim, California, USA.
Present: Chia-Ming ,Chuang Date: 11, 26, 2008
1

Outline
1. Introduction 2. Proposed schemes 3. Architecture 4. Experiments 5. Conclusion
2
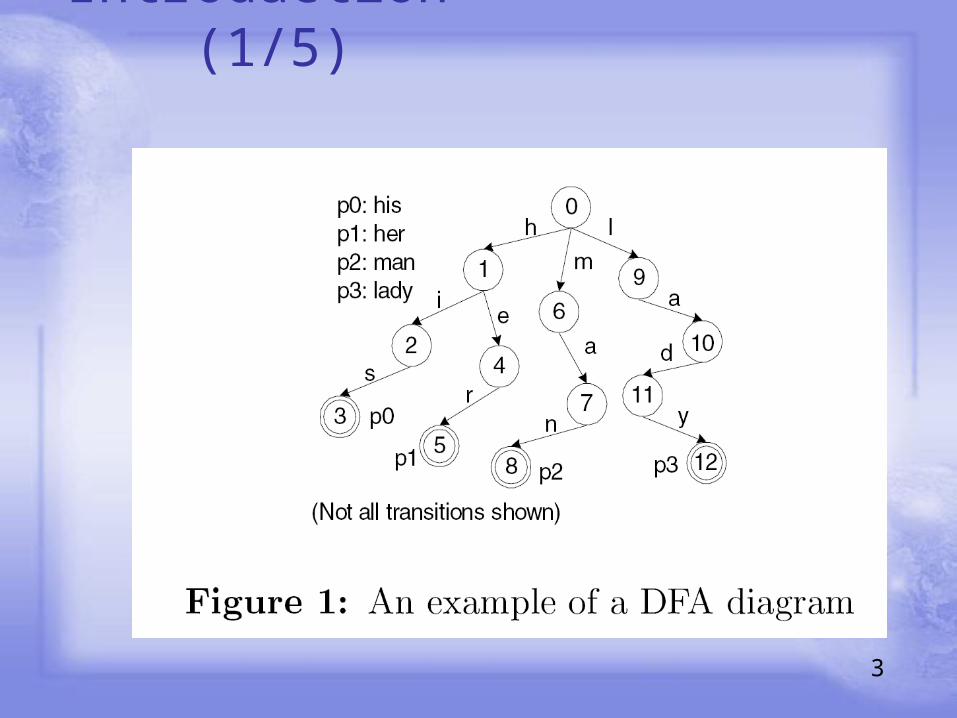
Introduction (1/5)
3
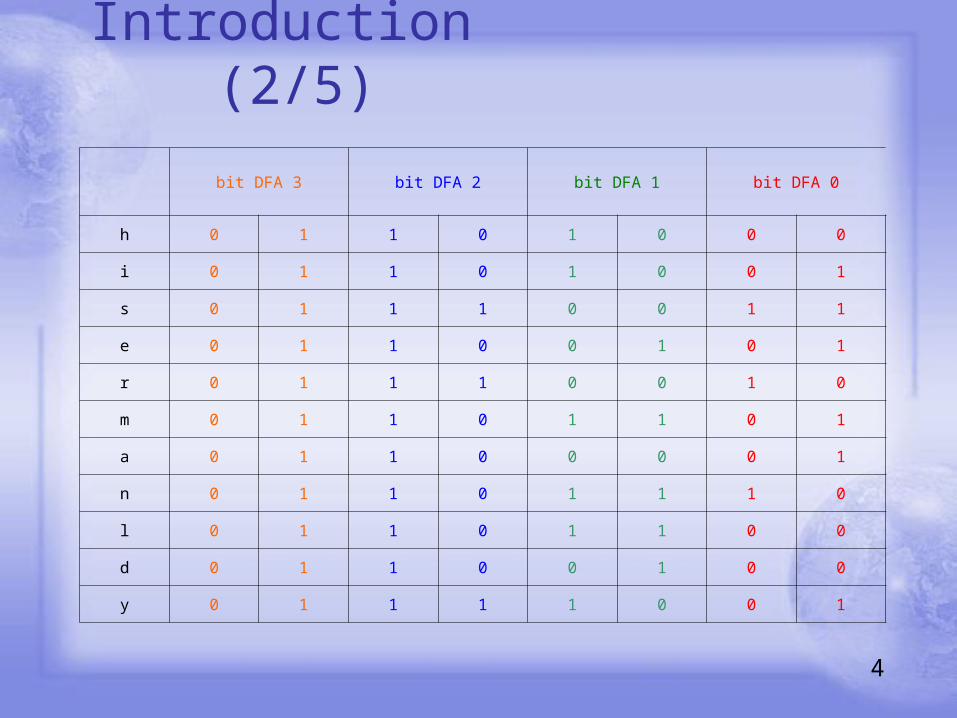
Introduction (2/5)
4
bit DFA 3 bit DFA 2 bit DFA 1 bit DFA 0
h 0 1 1 0 1 0 0 0
i 0 1 1 0 1 0 0 1
s 0 1 1 1 0 0 1 1
e 0 1 1 0 0 1 0 1
r 0 1 1 1 0 0 1 0
m 0 1 1 0 1 1 0 1
a 0 1 1 0 0 0 0 1
n 0 1 1 0 1 1 1 0
l 0 1 1 0 1 1 0 0
d 0 1 1 0 0 1 0 0
y 0 1 1 1 1 0 0 1

5
Introduction (3/5)

Introduction (4/5)
6
Implementation Issues: The bit-DFA method requires thousands of processing elements to implement thousands of bit-DFA, which is not practical under today’s silicontechnology.
Memory Wastage:Since introduced in 2005 , the bit-DFA method has not been put into its limitation to give optimal memory efficiency.

Introduction (5/5)
7

Outline
1. Introduction 2. Proposed schemes 3. Architecture 4. Experiments 5. Conclusion
7

Proposed schemes (1/7)
8

Proposed schemes (2/7)
9
(一 ) We design two schemes to determine the matched patterns: LTT for common output states, and CLT for unique ones.
(一 ) the state ξ3,0 is a common output state and,π0,0∩π1,0∩π2,0∩π3,0 = {p0}.

Proposed schemes (3/7)
10

Proposed schemes (4/7)
11
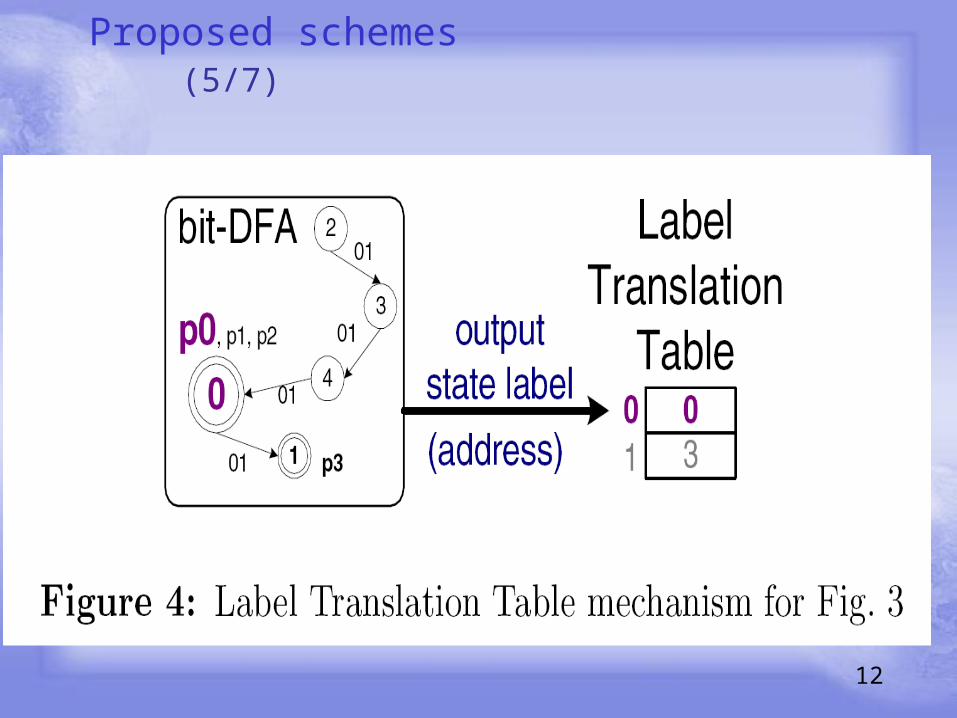
Proposed schemes (5/7)
12
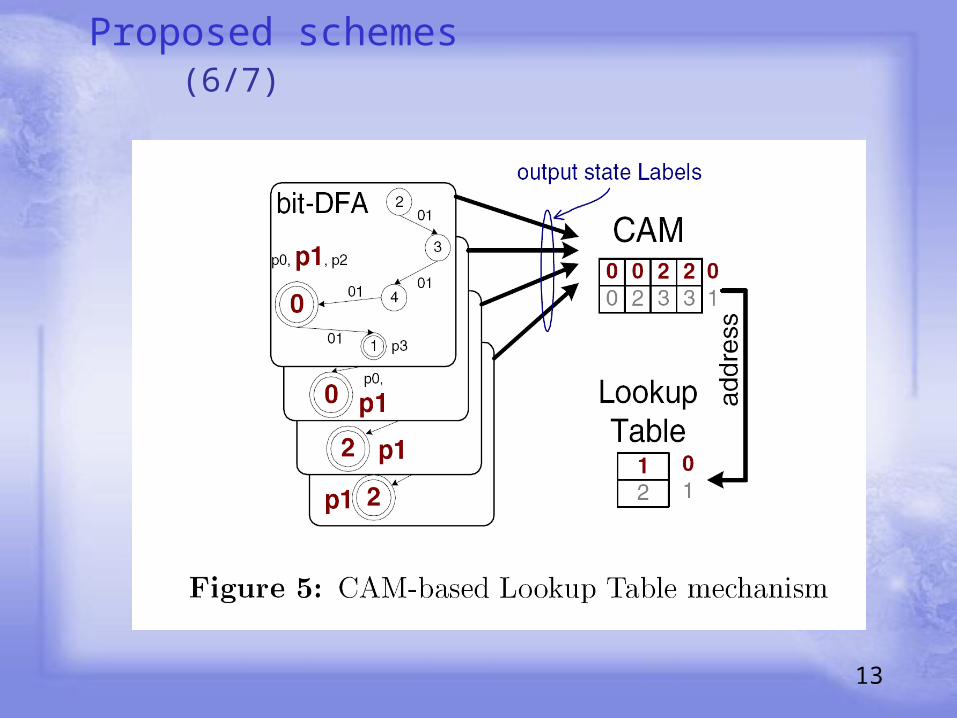
Proposed schemes (6/7)
13
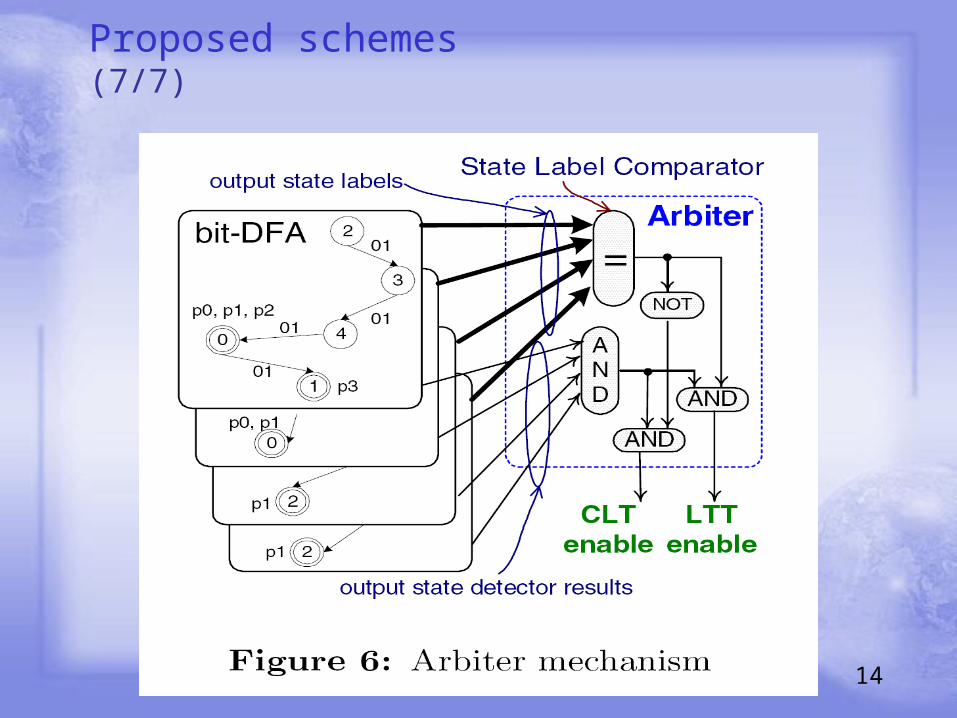
Proposed schemes (7/7)
14

Outline
1. Introduction 2. Proposed schemes 3. Architecture 4. Experiments 5. Conclusion
15
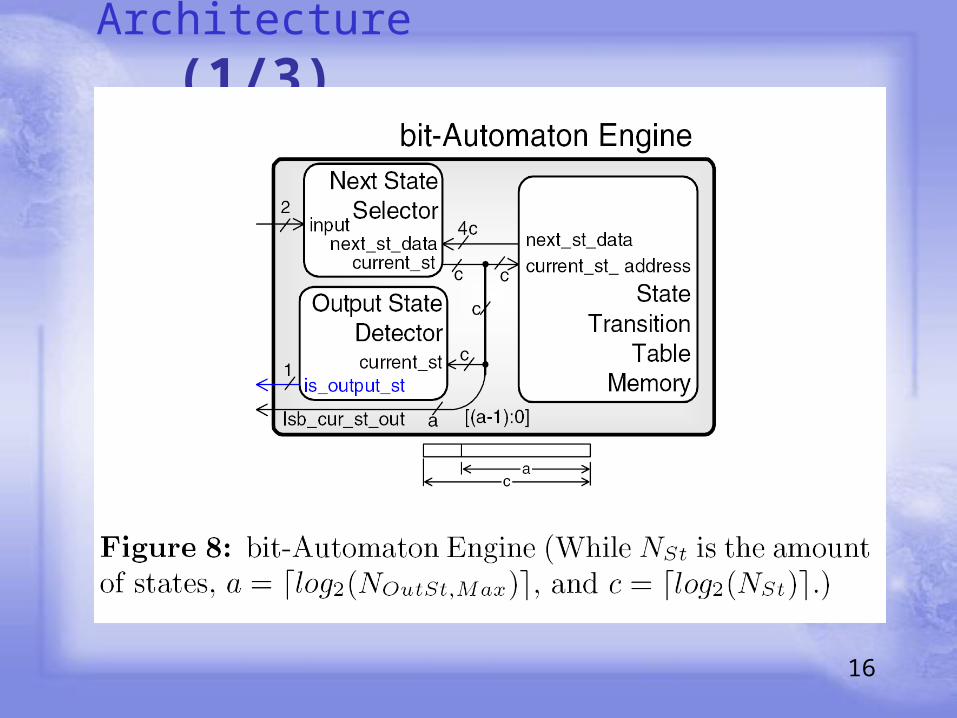
Architecture (1/3)
16
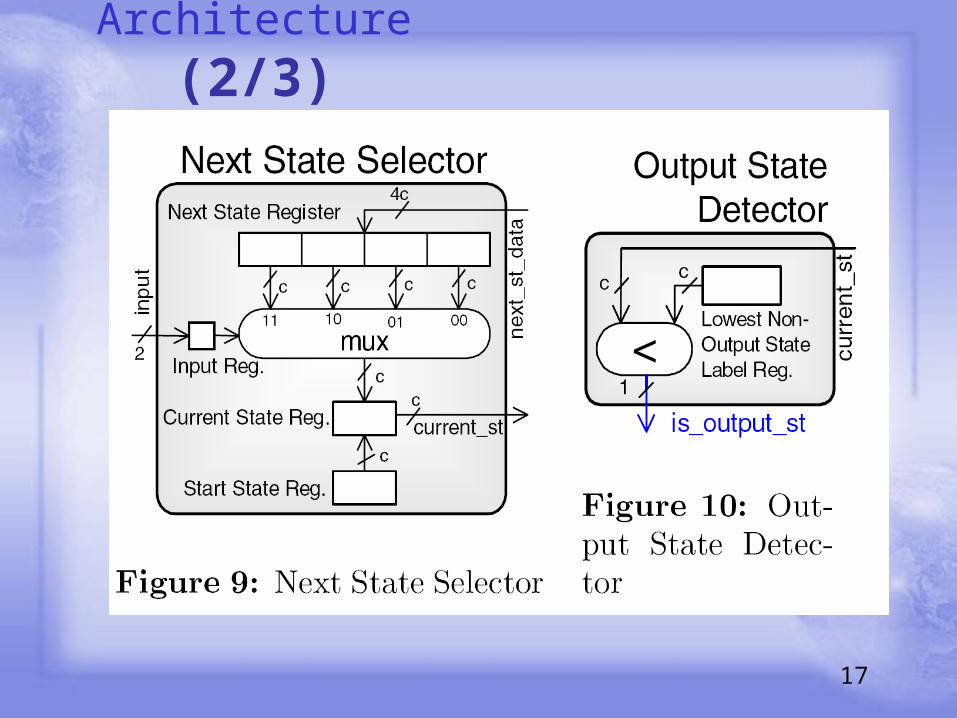
Architecture (2/3)
17
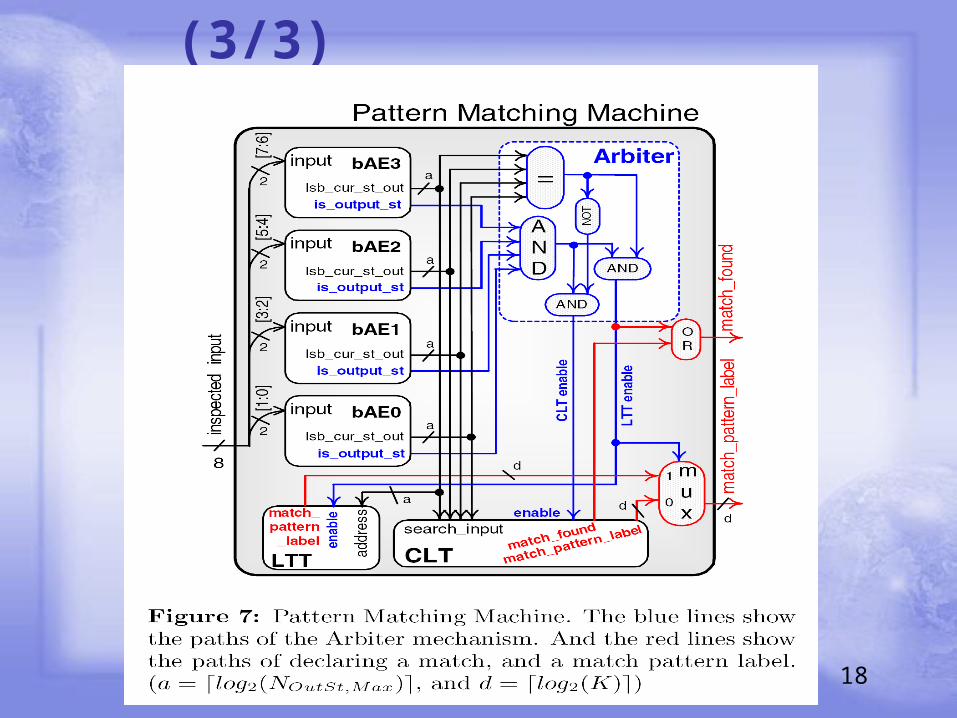
Architecture (3/3)
18

Outline
1. Introduction 2. Proposed schemes 3. Architecture 4. Experiments 5. Conclusion
19
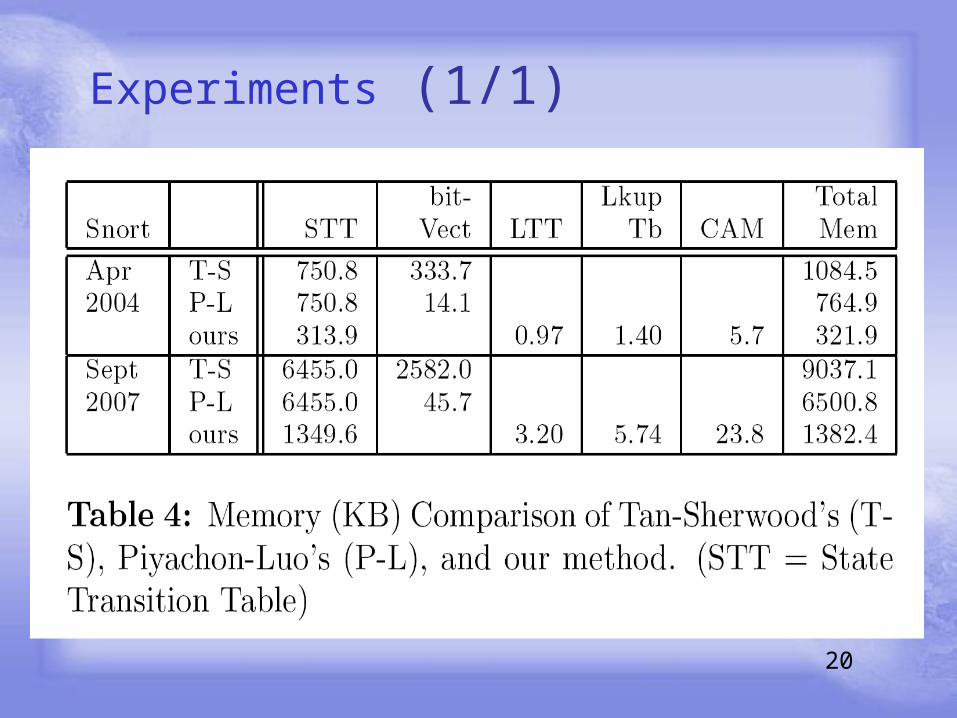
Experiments (1/1)
20

Outline
1. Introduction 2. Proposed schemes 3. Architecture 4. Experiments 5. Conclusion
21

Conclusion (1/1)
(ㄧ ) We proposed using Label Translation Table and CAM-basedLookup Table methods to tackle the problems. The proposedschemes reduces the usage by up to 85%
(二 ) We present the architecture that realizes our proposedmethods. The architecture suits for both ASIC and FPGAimplementation as well as multi-core system
22
Recommended

















