
Deep Generative ModelsMijung Kim

Discriminative vs. Generative Learning
Discriminative Learning Generative Learning
Learn 𝑝(𝑦|𝑥) directly Model 𝑝 𝑦 , 𝑝 𝑥 𝑦 first,
Then derive the posterior distribution:
𝑝 𝑦 𝑥 =𝑝 𝑥 𝑦 𝑝(𝑦)
𝑝(𝑥)
2
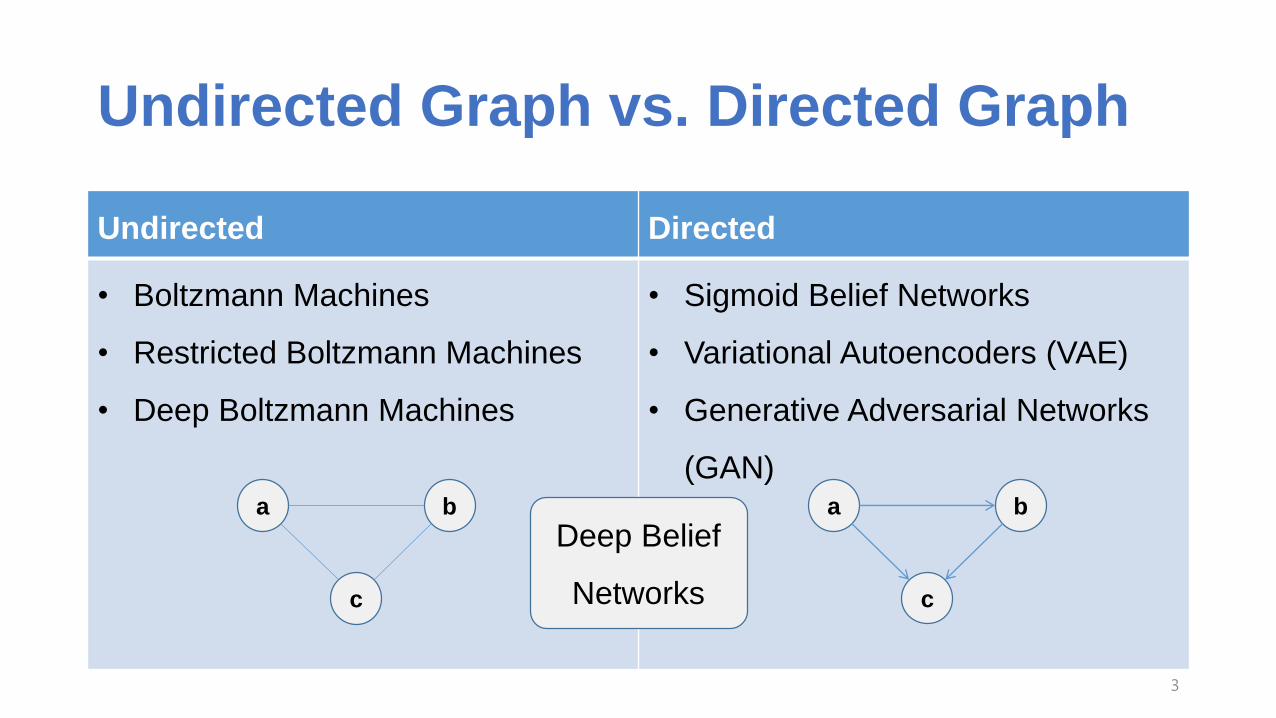
Undirected Graph vs. Directed Graph
Undirected Directed
• Boltzmann Machines
• Restricted Boltzmann Machines
• Deep Boltzmann Machines
• Sigmoid Belief Networks
• Variational Autoencoders (VAE)
• Generative Adversarial Networks
(GAN)
3
a b
c
a b
c
Deep Belief
Networks

Boltzmann Machines
• Stochastic Recurrent Neural Network and Markov Random
Field invented by Hinton and Sejnowski in 1985
• 𝑷 𝒙 =𝐞𝐱𝐩(−𝑬 𝒙 )
𝒁> E(x): Energy function
> Z: partition function where σ𝑥 𝑃 𝑥 = 1
• Energy-based model: positive values all the time
• Single visible layer and single hidden layer
• Fully connected: not practical to implement
4

Restricted Boltzmann Machines
• Dimensionality reduction, classification, regression,
collaborative filtering, feature learning and topic modeling
• 𝑷 𝐯 = 𝒗, 𝐡 = 𝒉 =𝟏
𝒁𝐞𝐱𝐩(−𝑬 𝒗, 𝒉 )
• Two layers like BMs
• Building blocks of deep probabilistic models
• Gibbs sampling with Contrastive Divergence (CD) or Persistent
CD
5
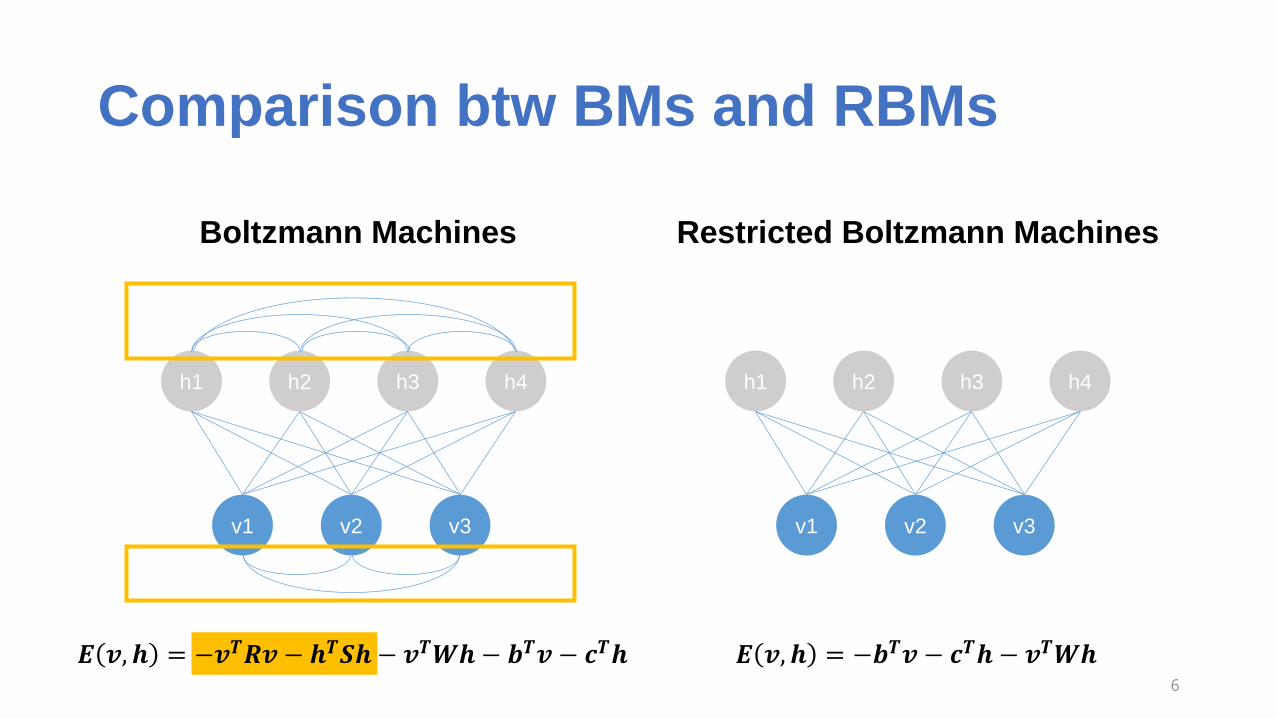
Comparison btw BMs and RBMs
Boltzmann Machines Restricted Boltzmann Machines
v1 v2 v3
h1 h2 h3 h4
v1 v2 v3
h1 h2 h3 h4
6
𝑬 𝒗, 𝒉 = −𝒗𝑻𝑹𝒗 − 𝒉𝑻𝑺𝒉 − 𝒗𝑻𝑾𝒉− 𝒃𝑻𝒗 − 𝒄𝑻𝒉 𝑬 𝒗, 𝒉 = −𝒃𝑻𝒗 − 𝒄𝑻𝒉 − 𝒗𝑻𝑾𝒉
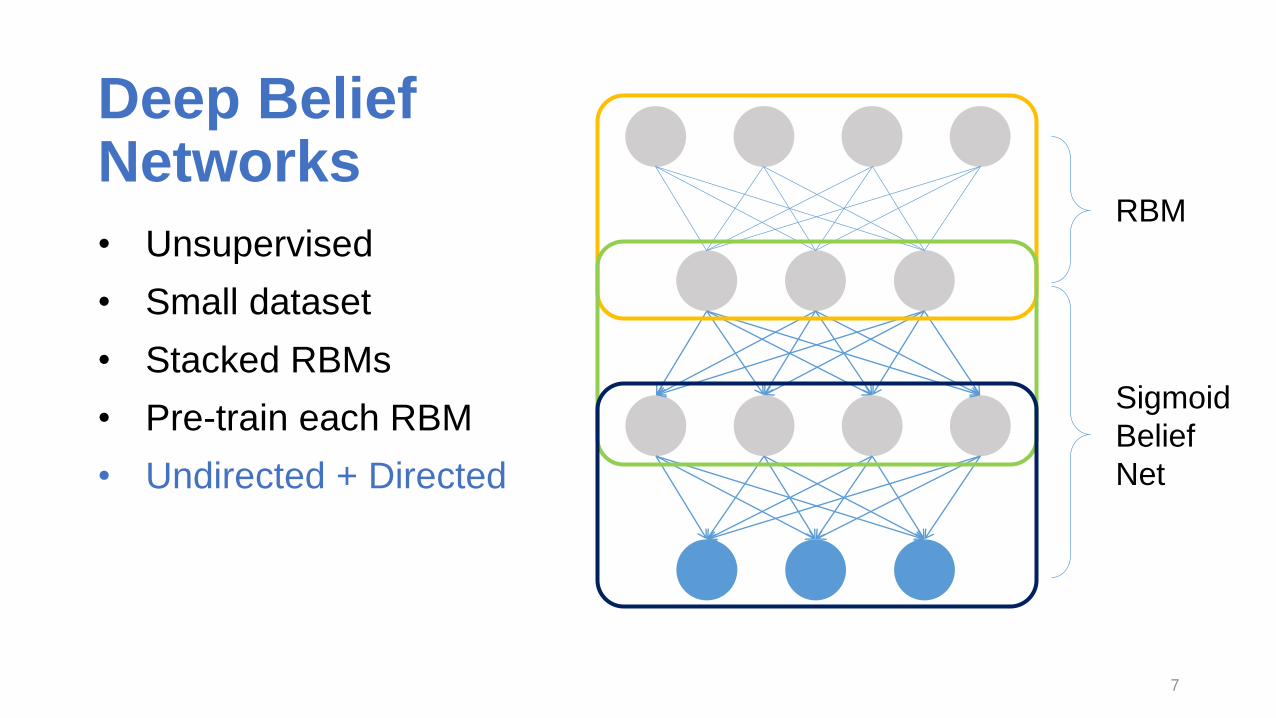
Deep Belief Networks
• Unsupervised
• Small dataset
• Stacked RBMs
• Pre-train each RBM
• Undirected + Directed
7
RBM
Sigmoid
Belief
Net
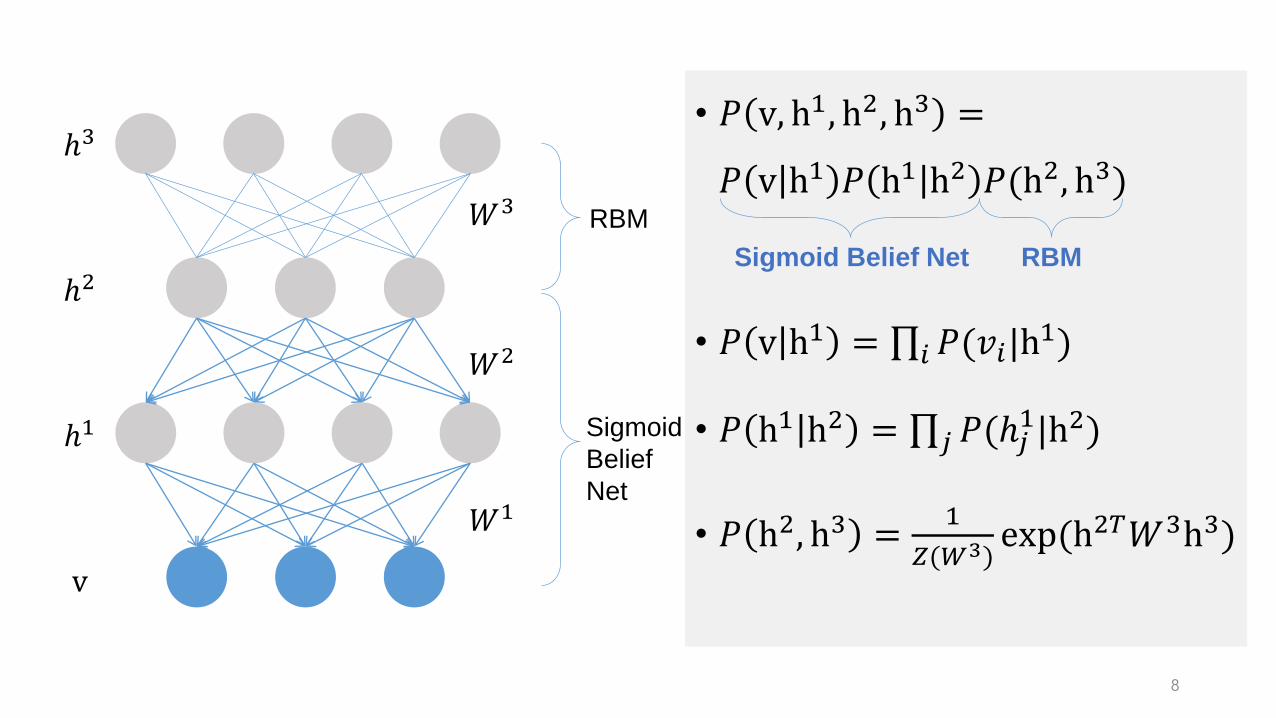
• 𝑃 v, h1, h2, h3 =
𝑃 v h1 𝑃 h1 h2 𝑃(h2, h3)
• 𝑃 v h1 = ς𝑖 𝑃(𝑣𝑖|h1)
• 𝑃 h1 h2 = ς𝑗 𝑃(ℎ𝑗1|h2)
• 𝑃 h2, h3 =1
𝑍(𝑊3)exp(h2𝑇𝑊3h3)
8
RBM
Sigmoid
Belief
Net
ℎ1
ℎ2
ℎ3
v
𝑊3
𝑊2
𝑊1
Sigmoid Belief Net RBM

Limitations of DBN (By Ruslan Salakhutdinov)
• Explaining away
• Greedy layer-wise pre-training
> no optimization over all layers
• Approximation inference is feed-forward
> no bottom-up and top-down
9
http://www.slideshare.net/zukun/p05-deep-boltzmann-machines-cvpr2012-deep-learning-methods-for-vision
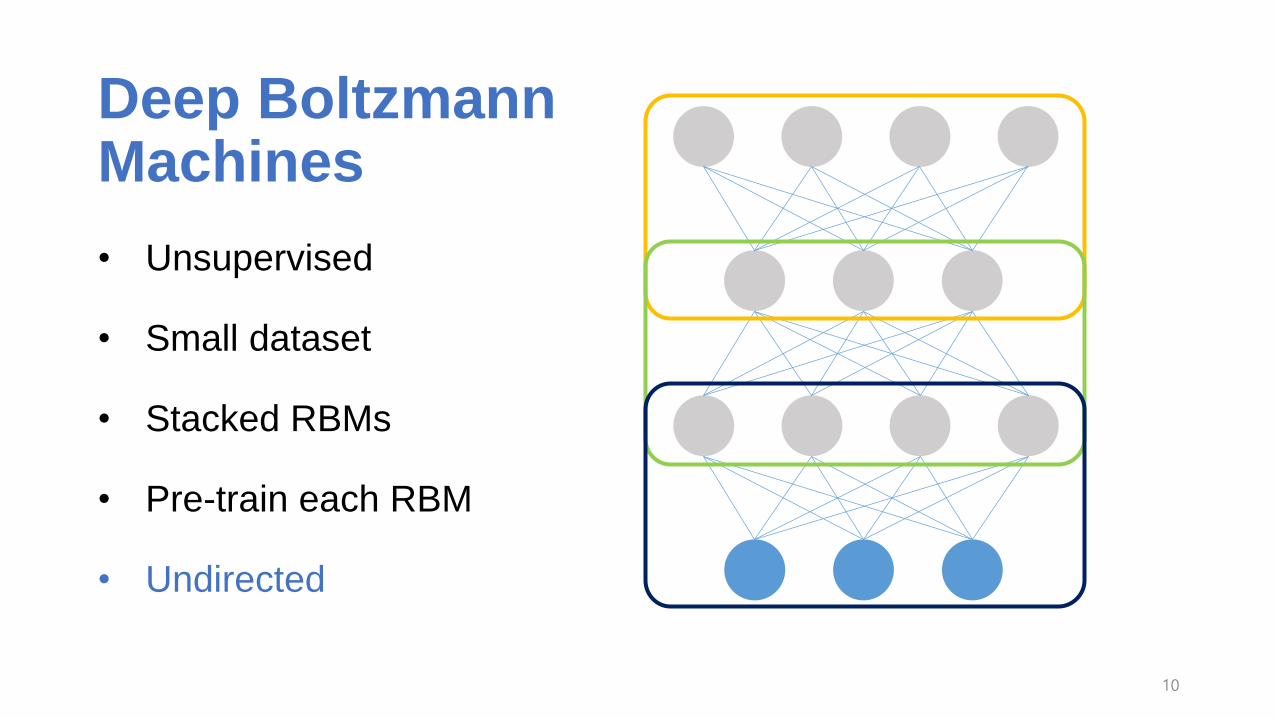
Deep Boltzmann Machines
• Unsupervised
• Small dataset
• Stacked RBMs
• Pre-train each RBM
• Undirected
10
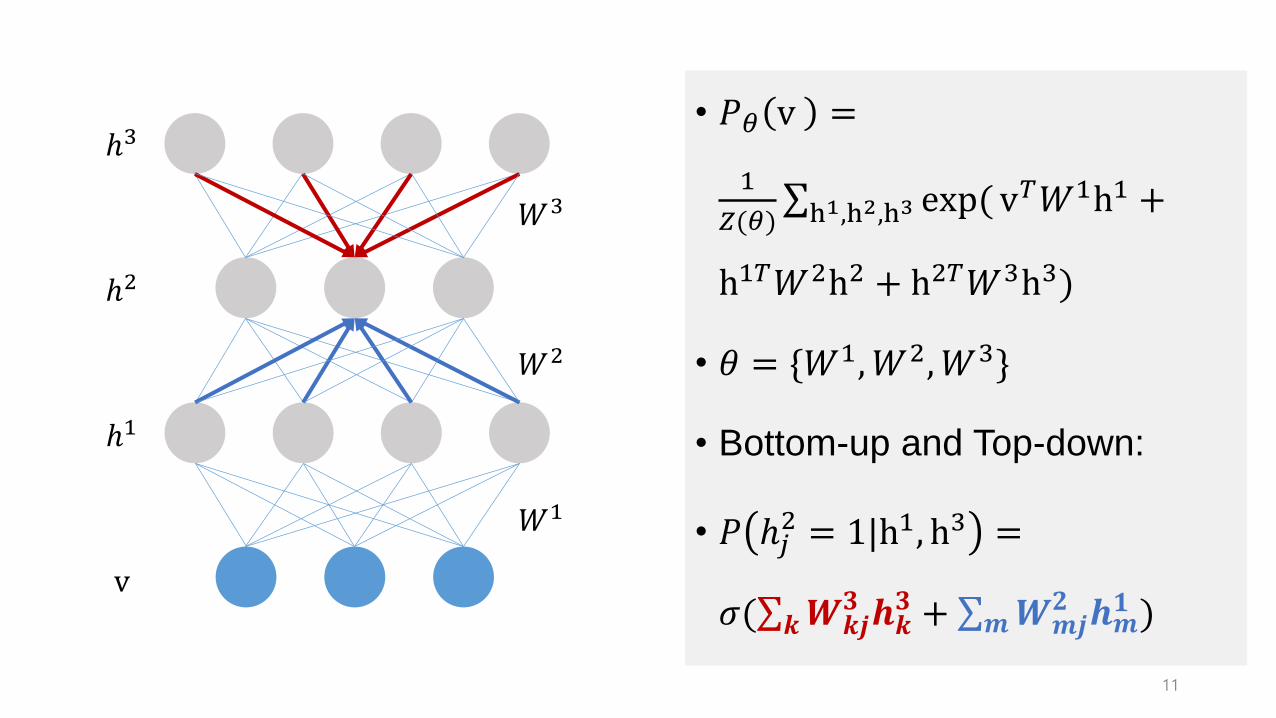
• 𝑃𝜃 v =
1
𝑍(𝜃)σh1,h2,h3 exp( v
𝑇𝑊1h1 +
h1𝑇𝑊2h2 + h2𝑇𝑊3h3)
• 𝜃 = {𝑊1,𝑊2,𝑊3}
• Bottom-up and Top-down:
• 𝑃 ℎ𝑗2 = 1|h1, h3 =
𝜎(σ𝒌𝑾𝒌𝒋𝟑 𝒉𝒌
𝟑 + σ𝒎𝑾𝒎𝒋𝟐 𝒉𝒎
𝟏 )
11
ℎ1
ℎ2
ℎ3
v
𝑊3
𝑊2
𝑊1
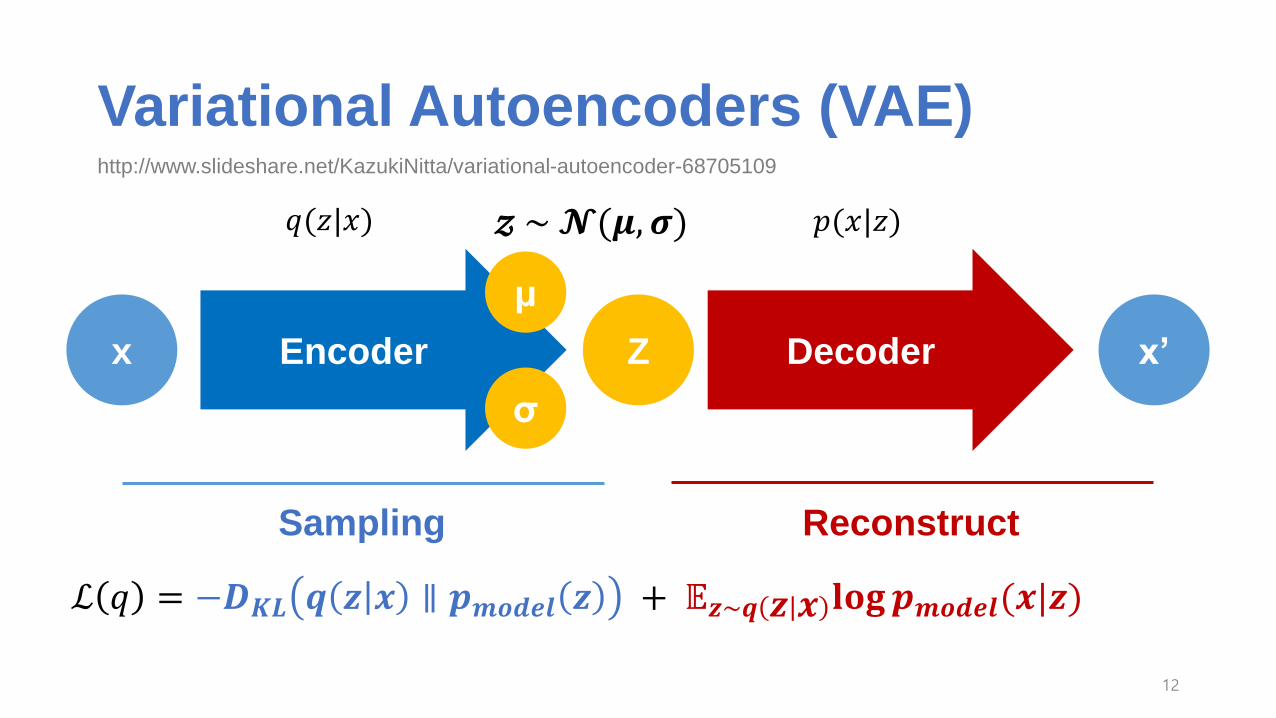
Variational Autoencoders (VAE)
12
Encoder Decoderx x’
μ
σ
Z
𝑞(𝑧|𝑥) 𝑝(𝑥|𝑧)
Sampling Reconstruct
ℒ 𝑞 = −𝑫𝑲𝑳 𝒒 𝒛 𝒙 ∥ 𝒑𝒎𝒐𝒅𝒆𝒍 𝒛 + 𝔼𝒛~𝒒 𝒛 𝒙 𝐥𝐨𝐠𝒑𝒎𝒐𝒅𝒆𝒍(𝒙|𝒛)
𝔃 ~𝓝(𝝁, 𝝈)
http://www.slideshare.net/KazukiNitta/variational-autoencoder-68705109
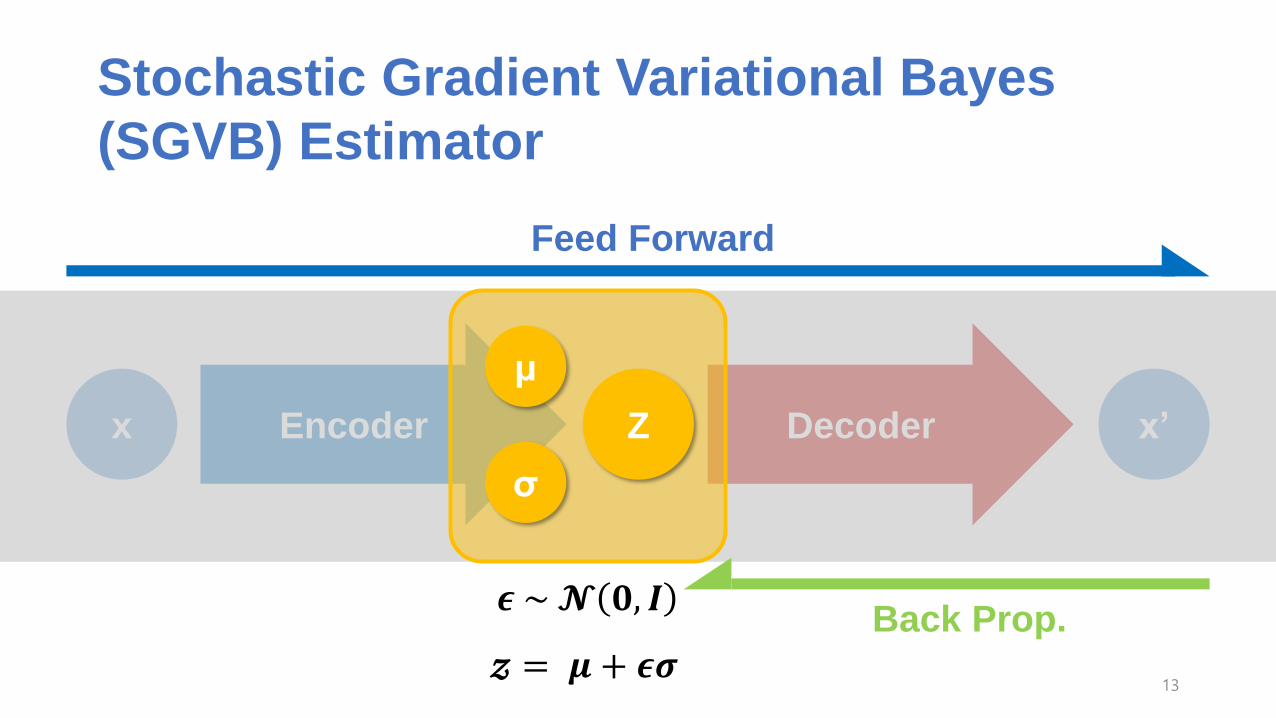
Stochastic Gradient Variational Bayes
(SGVB) Estimator
13
Encoder Decoderx x’
μ
σ
Z
Back Prop.
Feed Forward
𝝐 ~𝓝 𝟎, 𝑰
𝔃 = 𝝁 + 𝝐𝝈
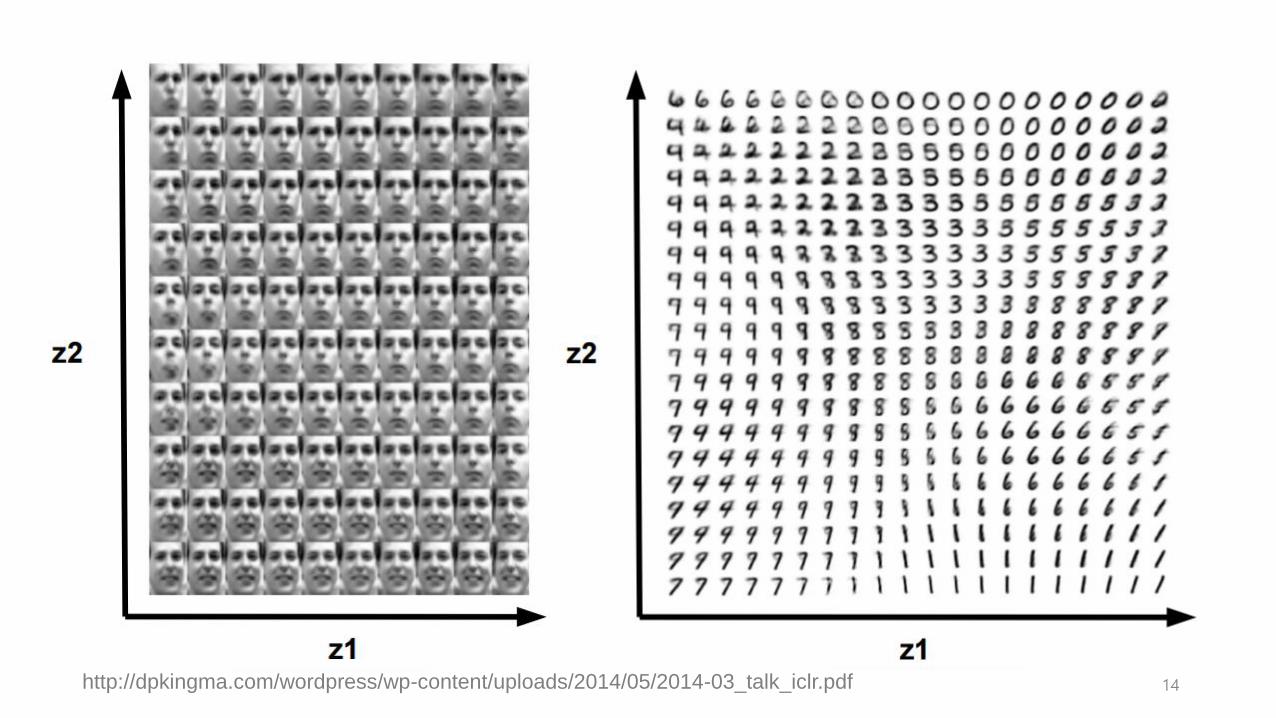
14http://dpkingma.com/wordpress/wp-content/uploads/2014/05/2014-03_talk_iclr.pdf

Generative Adversarial Networks(GAN)
15
Data Sample DiscriminatorGenerator
Sample
Noise
Yes or No
Generator
https://ishmaelbelghazi.github.io/ALI
Convolutional Neural Networks
16
Image Classification
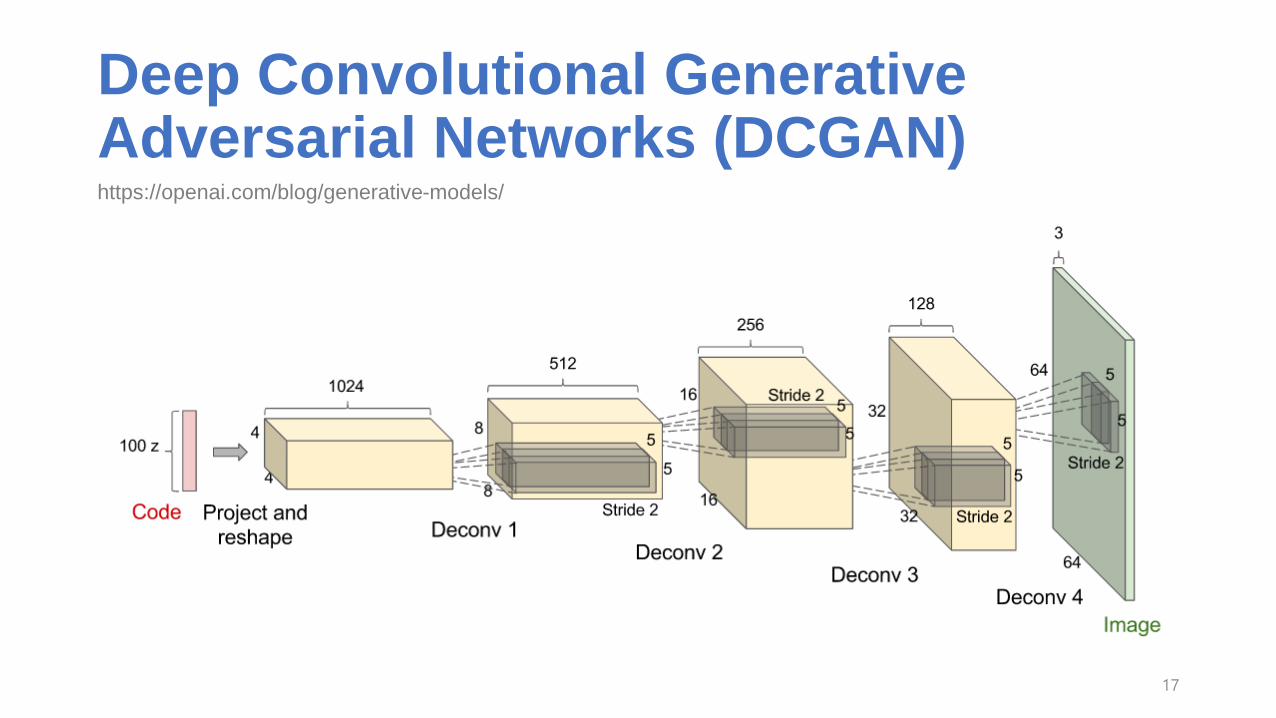
Deep Convolutional Generative Adversarial Networks (DCGAN)
17
https://openai.com/blog/generative-models/

Real Images vs. Generated images
18
http://kenkihara.com/projects/GAN.html
Recommended

















