
Data Mining: Clustering (K-means)
— Chapter 8 —
1

2
Chapter 8. Cluster Analysis: Basic Concepts and Methods
Cluster Analysis: Basic Concepts
Partitioning Methods
Hierarchical Methods
Density-Based Methods
Grid-Based Methods
Evaluation of Clustering
Summary
2

3
What is Cluster Analysis?
Cluster: A collection of data objects
similar (or related) to one another within the same group
dissimilar (or unrelated) to the objects in other groups
Cluster analysis (or clustering, data segmentation, …)
Finding similarities between data according to the
characteristics found in the data and grouping similar
data objects into clusters
Unsupervised learning: no predefined classes (i.e., learning
by observations vs. learning by examples: supervised)
Typical applications
As a stand-alone tool to get insight into data distribution
As a preprocessing step for other algorithms

การจดกลมในการท าเหมองขอมลคออะไร
Cluster : เปนกลมหรอแหลงเกบสะสม (collection) ของวตถตางๆ สามารถน ามาจดกลมกนตามความเหมอน (Similarity)
สามารถน ามาจดกลมกนตามความแตกตาง (Dissimilarity or Distance)
Cluster Analysis เปนกระบวนการจดวตถตางๆ ใหอยกลมทเหมาะสม ซงมคณสมบตทวตถทอยในกลมเดยวกนจะ
คลายกน แตมความแตกตางจากวตถในกลมอน
Clustering การจดกลมจะแตกตางจากการแบงประเภทขอมล (Classification) โดยจะแบงกลมขอมล
จากความคลาย โดยไมมการก าหนดคลาสประเภทขอมลไวกอนหรอไมทราบจ านวนกลมลวงหนา เปนการเรยนรแบบไมมผสอน (unsupervised classification)
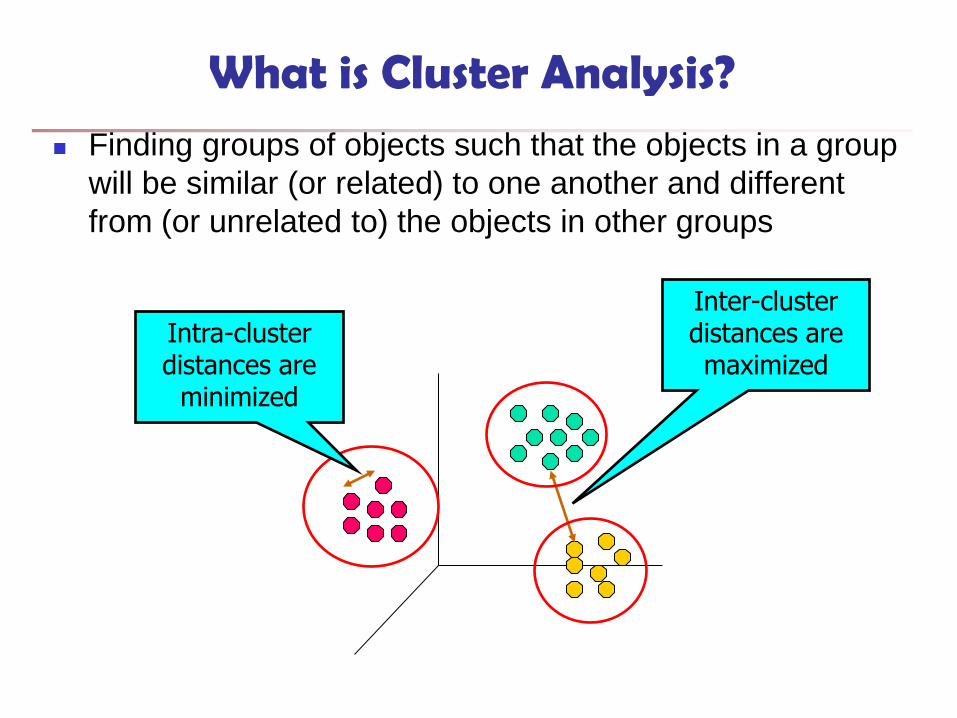
What is Cluster Analysis? Finding groups of objects such that the objects in a group
will be similar (or related) to one another and different
from (or unrelated to) the objects in other groups
Inter-cluster distances are maximized
Intra-cluster distances are
minimized
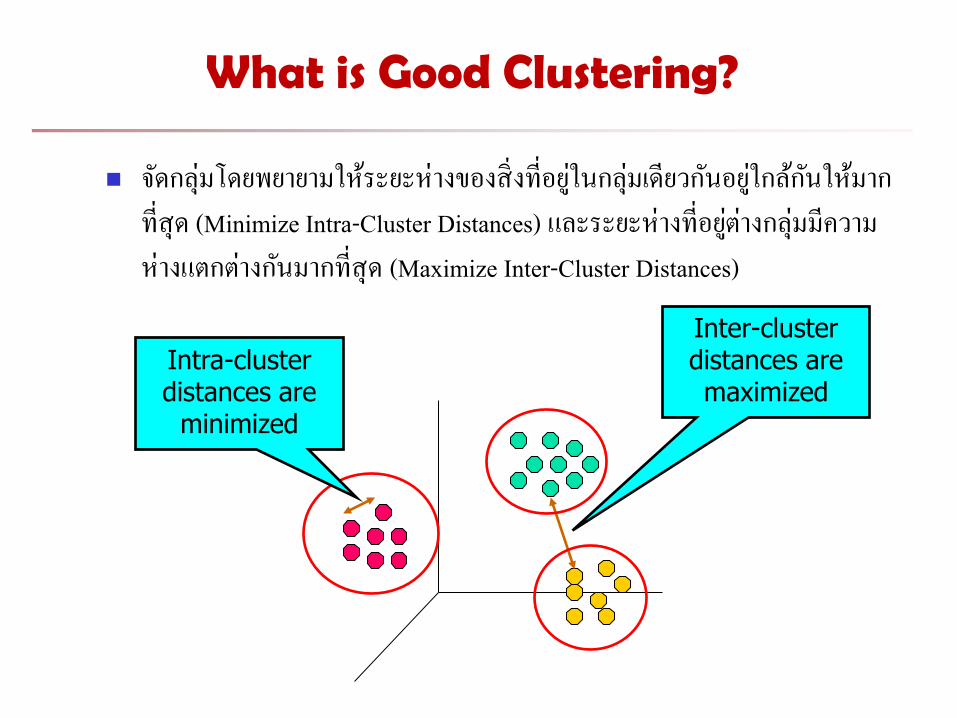
What is Good Clustering?
จดกลมโดยพยายามใหระยะหางของสงทอยในกลมเดยวกนอยใกลกนใหมากทสด (Minimize Intra-Cluster Distances) และระยะหางทอยตางกลมมความหางแตกตางกนมากทสด (Maximize Inter-Cluster Distances)
Inter-cluster distances are maximized
Intra-cluster distances are
minimized
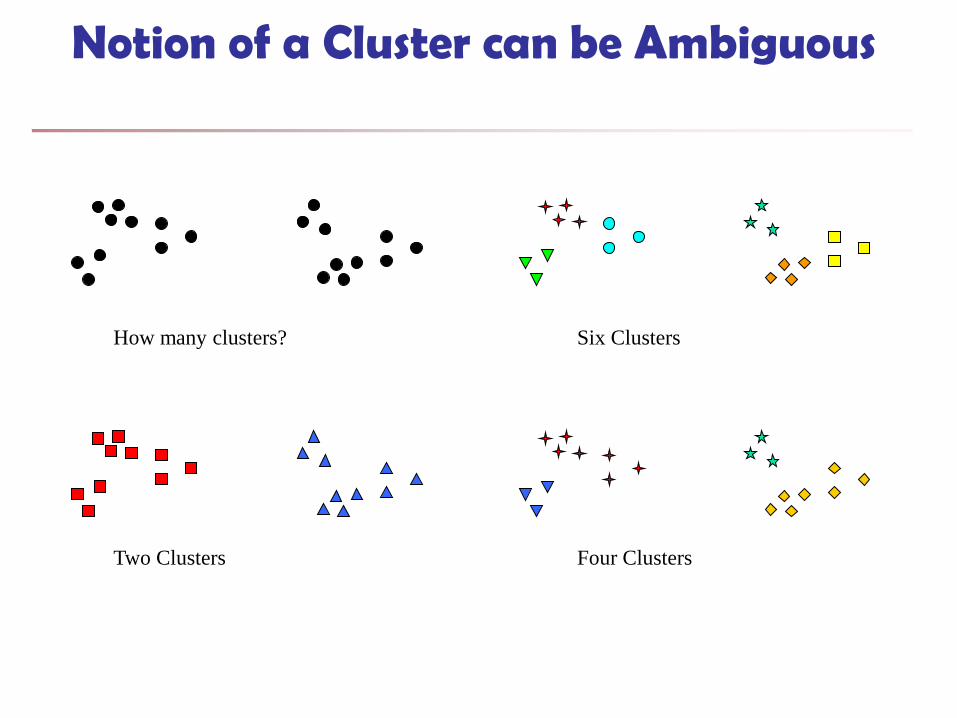
Notion of a Cluster can be Ambiguous
How many clusters?
Four Clusters Two Clusters
Six Clusters

Clustering Algorithms
K-means clustering **
Hierarchical clustering

K-means Clustering
ใชหลกการการตดแบง (Partition) แบงวตถ n ตวในฐานขอมล D
ออกเปนจ านวน k กลม (สมมตวาเราทราบคา k)
อลกอรทม k-Means จะตดแบงวตถออกเปน k กลม โดยการแทนแตละกลมดวยคาเฉลยของกลม ซงใชเปนจดศนยกลางของกลมในการวดระยะหางของตวอยางในกลมเดยวกน
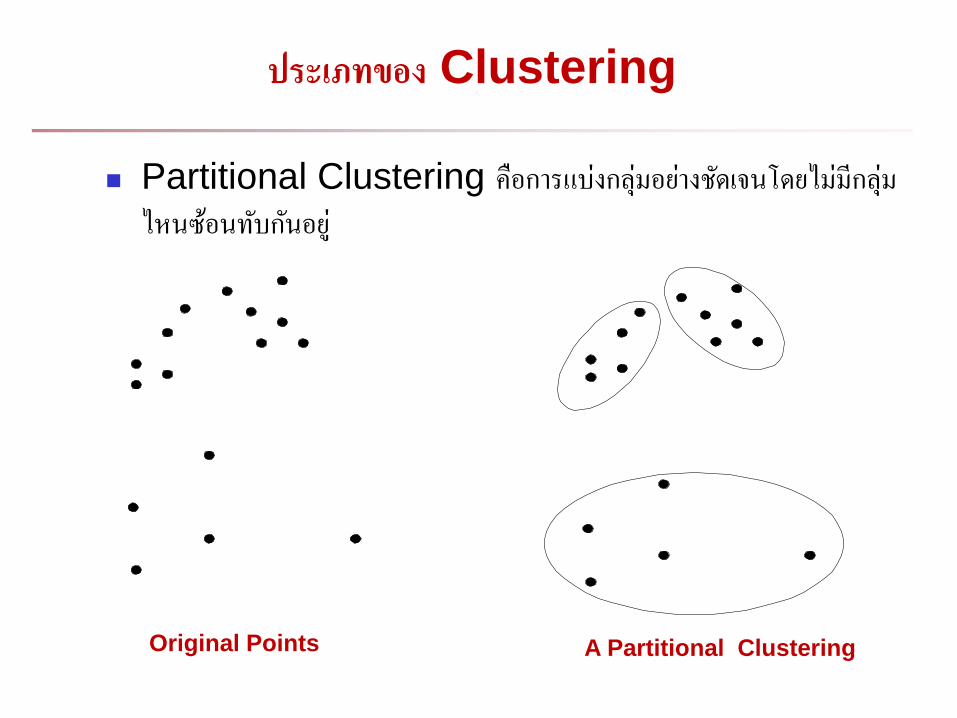
ประเภทของ Clustering
Partitional Clustering คอการแบงกลมอยางชดเจนโดยไมมกลมไหนซอนทบกนอย
Original Points A Partitional Clustering
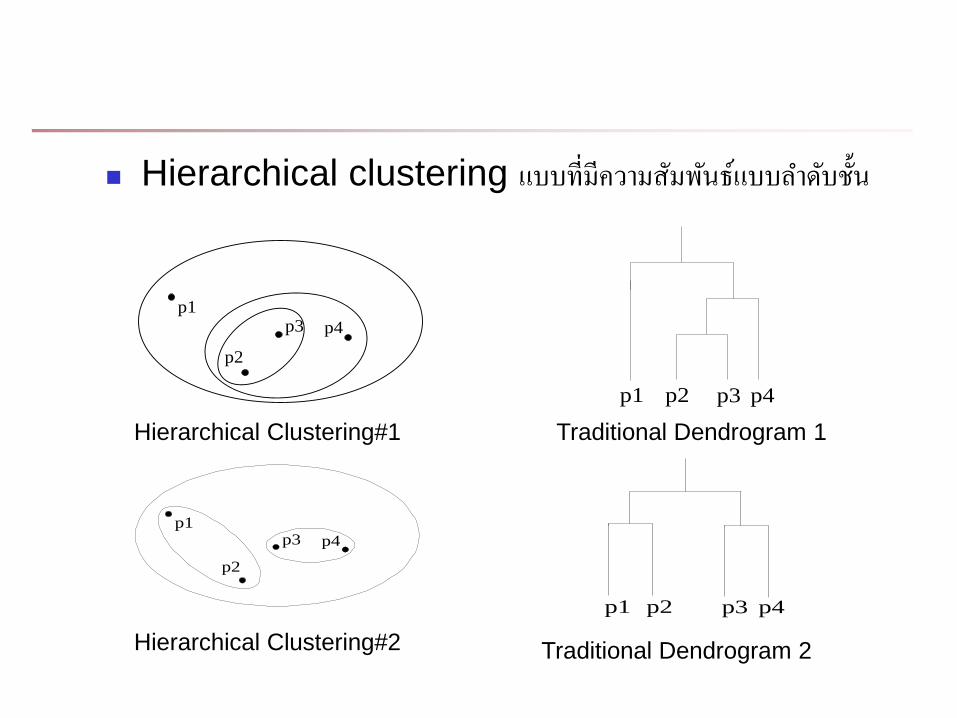
Hierarchical clustering แบบทมความสมพนธแบบล าดบชน
p4
p1p3
p2
p4
p1 p3
p2
p4p1 p2 p3
p4p1 p2 p3
Hierarchical Clustering#1
Hierarchical Clustering#2
Traditional Dendrogram 1
Traditional Dendrogram 2

Partitioning Algorithms: Basic Concept
Partitioning method: Partitioning a database D of n objects into a set of
k clusters, such that the sum of squared distances is minimized (where
ci is the centroid or medoid of cluster Ci)
Given k, find a partition of k clusters that optimizes the chosen
partitioning criterion
Global optimal: exhaustively enumerate all partitions
Heuristic methods: k-means and k-medoids algorithms
k-means (MacQueen’67, Lloyd’57/’82): Each cluster is represented
by the center of the cluster
k-medoids or PAM (Partition around medoids) (Kaufman &
Rousseeuw’87): Each cluster is represented by one of the objects
in the cluster
2
1 )),(( iCp
k
i cpdEi
12

The K-Means Clustering Method
Given k, the k-means algorithm is implemented in four
steps:
Partition objects into k nonempty subsets
Compute seed points as the centroids of the
clusters of the current partitioning (the centroid is
the center, i.e., mean point, of the cluster)
Assign each object to the cluster with the nearest
seed point
Go back to Step 2, stop when the assignment does
not change
13

K-means Clustering Algorithm
Method
1) ก าหนดหรอสมคาเรมตน จ านวน k คา(กลม) และก าหนดจดศนยกลางเรมตน k จด เรยกวา cluster centers หรอ(centroid)
2) น าวตถทงหมดจดเขากลม โดยท าการหาคาระยะหางระหวางขอมลกบจดศนยกลาง หากขอมลไหนใกลคาจดศนยกลางตวไหนทสดอยกลมนน
3) หาคาเฉลย (Mean) แตละกลม ใหเปนคาจดศนยกลางใหม 4) ท าซ าขอ 2) จนกระทงคาเฉลยหรอจดศนยกลางในแตละกลมจะไม
เปลยนแปลง
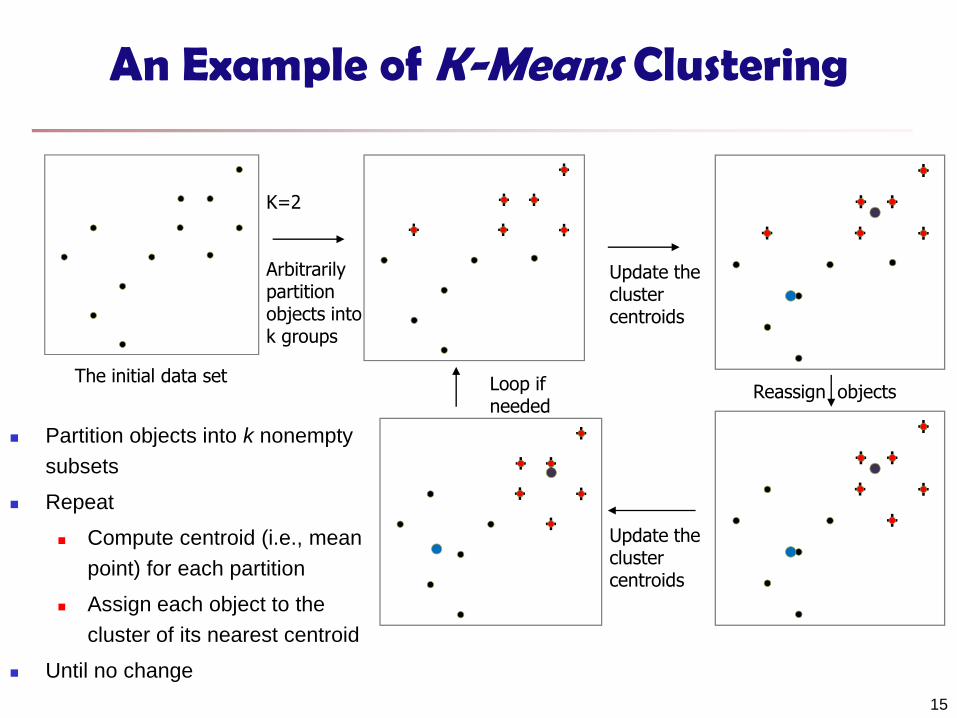
An Example of K-Means Clustering
K=2
Arbitrarily partition objects into k groups
Update the cluster centroids
Update the cluster centroids
Reassign objects Loop if needed
15
The initial data set
Partition objects into k nonempty
subsets
Repeat
Compute centroid (i.e., mean
point) for each partition
Assign each object to the
cluster of its nearest centroid
Until no change
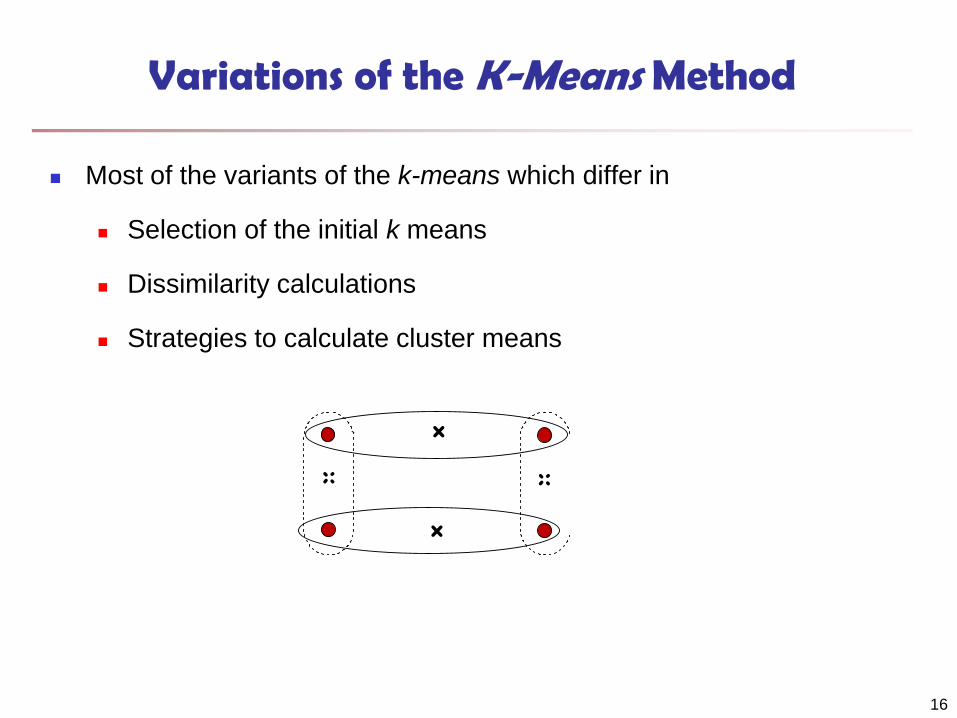
Variations of the K-Means Method
Most of the variants of the k-means which differ in
Selection of the initial k means
Dissimilarity calculations
Strategies to calculate cluster means
16

17
มาตรวดความเหมอน

18
การจดกลมโดยใชหลกเกณฑตางๆ
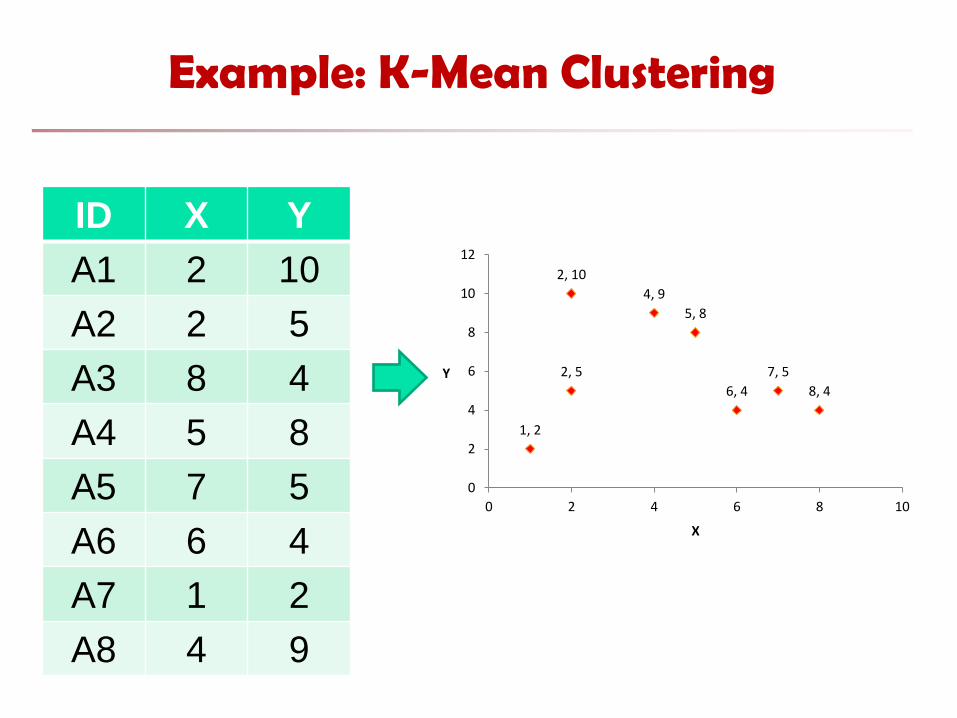
Example: K-Mean Clustering
ID X Y
A1 2 10
A2 2 5
A3 8 4
A4 5 8
A5 7 5
A6 6 4
A7 1 2
A8 4 9
2, 10
2, 5
8, 4
5, 8
7, 5
6, 4
1, 2
4, 9
0
2
4
6
8
10
12
0 2 4 6 8 10
Y
X
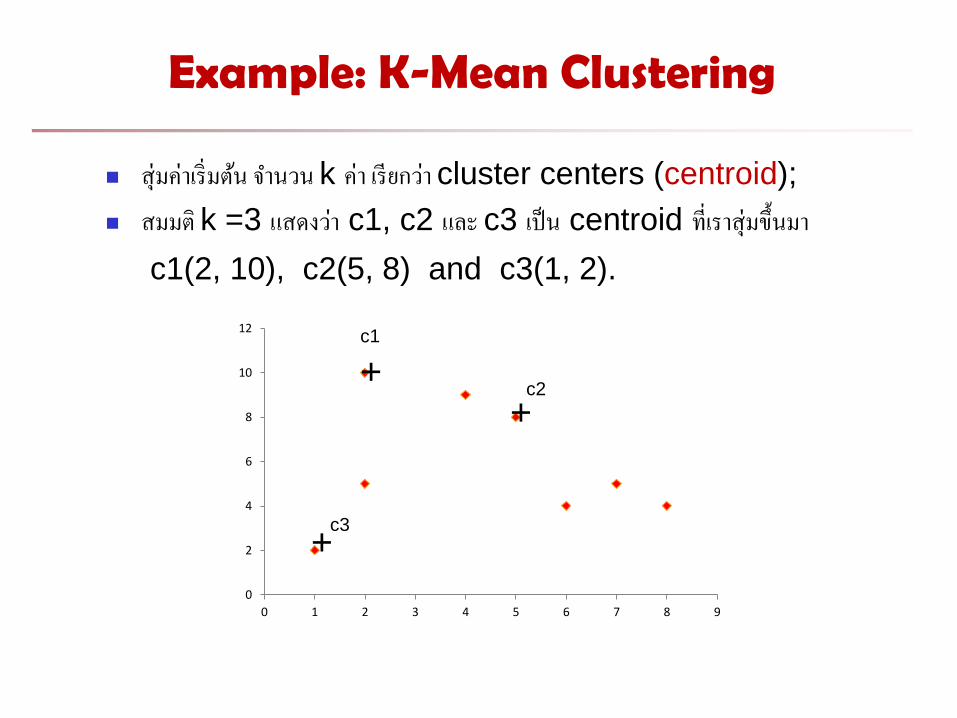
Example: K-Mean Clustering
สมคาเรมตน จ านวน k คา เรยกวา cluster centers (centroid);
สมมต k =3 แสดงวา c1, c2 และ c3 เปน centroid ทเราสมขนมา
c1(2, 10), c2(5, 8) and c3(1, 2).
0
2
4
6
8
10
12
0 1 2 3 4 5 6 7 8 9
+ +
+
c1
c2
c3

Example: K-Mean Clustering
หาความหางกนระหวางขอมล 2 ขอมล คอ หาความหางจากขอมล A =(x1, y1)
และ centroid =(x2, y2)
𝑥1 − 𝑥22 + 𝑦1 − 𝑦2
2
c1(2, 10) c2 (5, 8) c3(1, 2)
Point Dist Mean 1 Dist Mean 2 Dist Mean 3 Cluster
A1 (2, 10)
A2 (2, 5)
A3 (8, 4)
A4 (5, 8)
A5 (7, 5)
A6 (6, 4)
A7 (1, 2)
A8 (4, 9)
Solution:
Iteration 1

Example: K-Mean Clustering
ขนตอนท 2 หาระยะหางระหวางขอมล กบจดศนยกลาง (ตวอยางบางชดขอมล)
point mean1
x1, y1 x2, y2
(2, 10) (2, 10)
distance(point, mean1) = 𝑥1 − 𝑥22 + 𝑦1 − 𝑦2
2
= 2 − 2 2 + 10 − 10 2
= 0
point mean2
x1, y1 x2, y2
(2, 10) (5, 8)
distance(point, mean2) = 𝑥1 − 𝑥22 + 𝑦1 − 𝑦2
2
= 2 − 5 2 + 10 − 8 2
= 3.61
point mean3
x1, y1 x2, y2
(2, 10) (1, 2)
distance(point, mean3) = 𝑥1 − 𝑥22 + 𝑦1 − 𝑦2
2
= 2 − 1 2 + 10 − 2 2
= 8.06
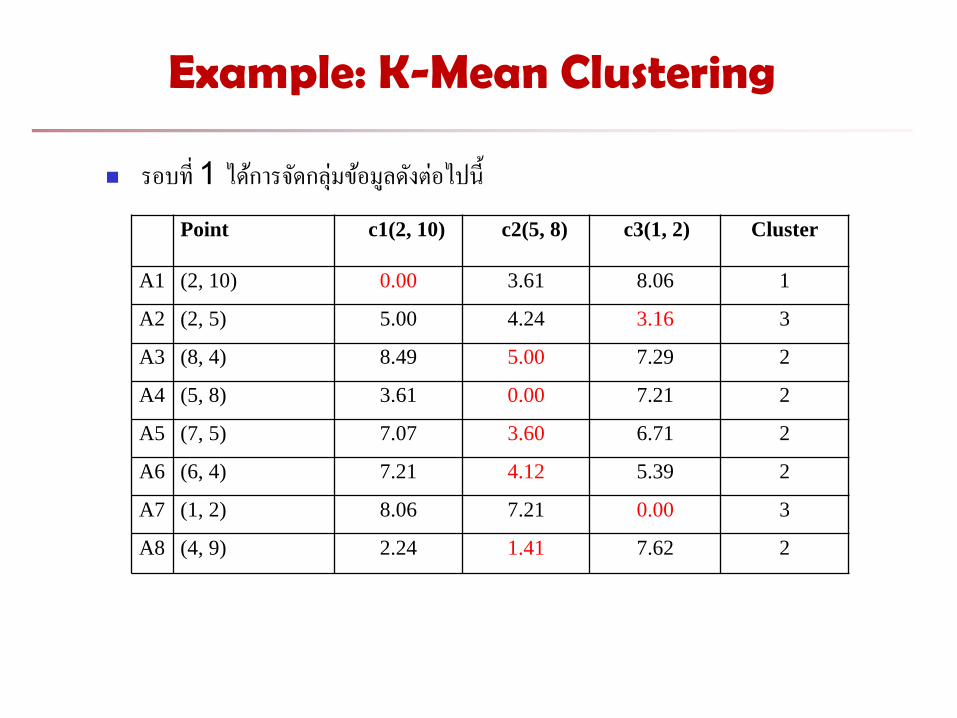
Example: K-Mean Clustering
รอบท 1 ไดการจดกลมขอมลดงตอไปน
Point
c1(2, 10) c2(5, 8) c3(1, 2) Cluster
A1 (2, 10) 0.00 3.61 8.06 1
A2 (2, 5) 5.00 4.24 3.16 3
A3 (8, 4) 8.49 5.00 7.29 2
A4 (5, 8) 3.61 0.00 7.21 2
A5 (7, 5) 7.07 3.60 6.71 2
A6 (6, 4) 7.21 4.12 5.39 2
A7 (1, 2) 8.06 7.21 0.00 3
A8 (4, 9) 2.24 1.41 7.62 2
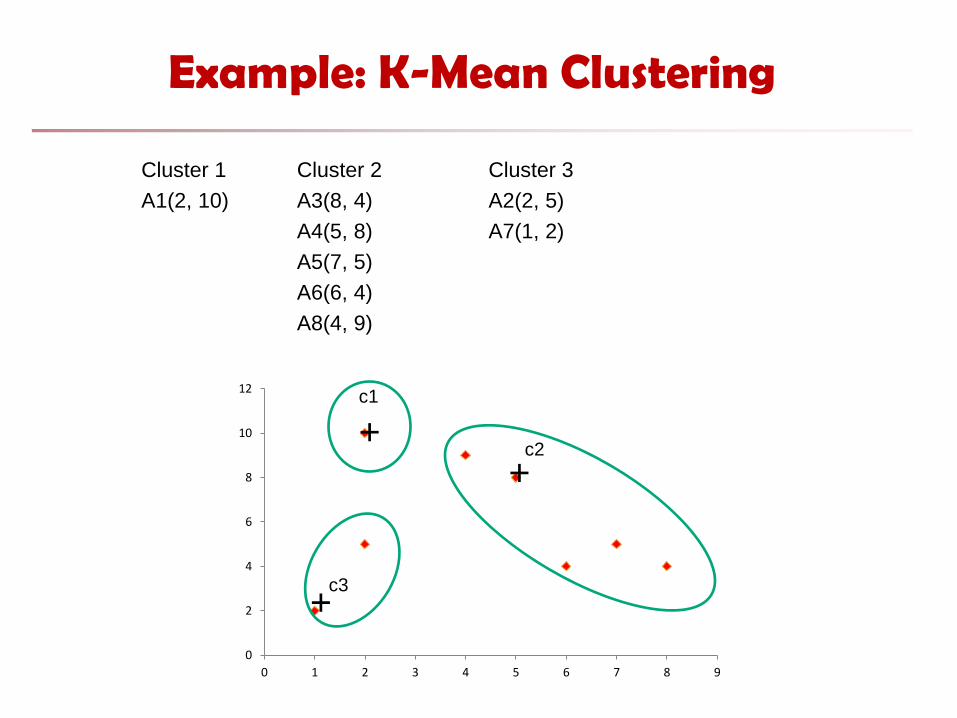
Example: K-Mean Clustering
Cluster 1 Cluster 2 Cluster 3
A1(2, 10) A3(8, 4) A2(2, 5)
A4(5, 8) A7(1, 2)
A5(7, 5)
A6(6, 4)
A8(4, 9)
0
2
4
6
8
10
12
0 1 2 3 4 5 6 7 8 9
+ +
c1
c2
c3 +

Example: K-Mean Clustering
ขนตอนท 3 หาคาเฉลยแตละกลม ใหเปน คาจดศนยกลางใหม
ส าหรบ Cluster 1 มจดเดยวคอ A1(2, 10) แสดงวา C1(2,10) ยงคงเดม ส าหรบ Cluster 2 ม 5 จดอยกลมเดยวกน เพราะฉะนนหา C2 ใหม
( (8+5+7+6+4)/5, (4+8+5+4+9)/5 ) = C2(6, 6)
ส าหรบ Cluster 3 ม 2 จดอยกลมเดยวกน
( (2+1)/2, (5+2)/2 ) = C3(1.5, 3.5)
Cluster 1 Cluster 2 Cluster 3
A1(2, 10) A3(8, 4) A2(2, 5)
A4(5, 8) A7(1, 2)
A5(7, 5)
A6(6, 4)
A8(4, 9)
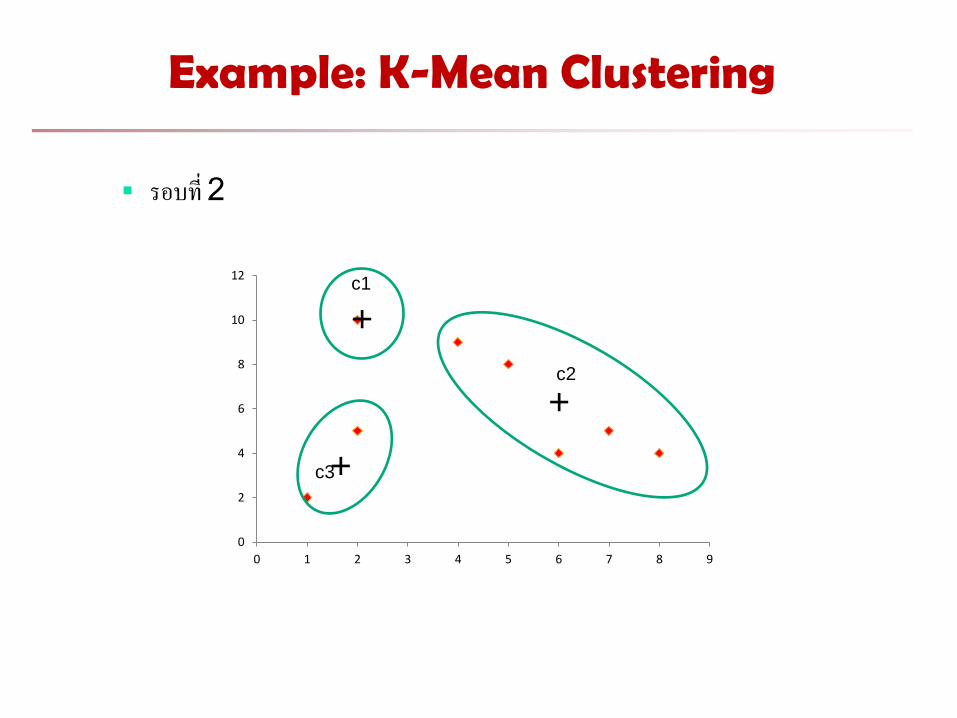
Example: K-Mean Clustering
0
2
4
6
8
10
12
0 1 2 3 4 5 6 7 8 9
+
+
c1
c2
c3 +
รอบท 2
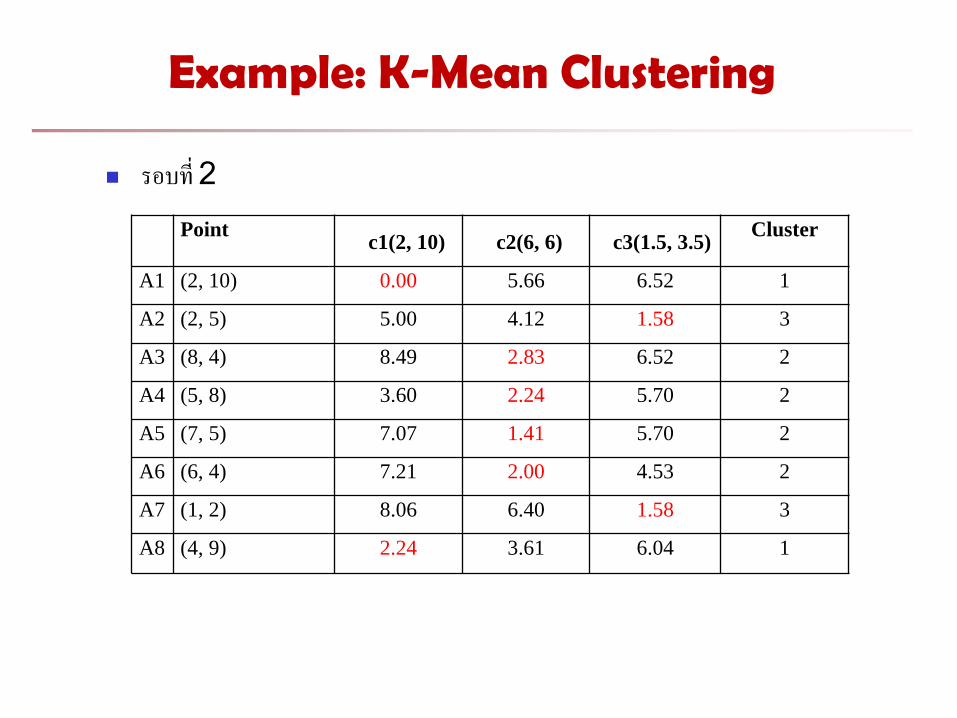
Example: K-Mean Clustering
รอบท 2
Point
c1(2, 10) c2(6, 6) c3(1.5, 3.5)
Cluster
A1 (2, 10) 0.00 5.66 6.52 1
A2 (2, 5) 5.00 4.12 1.58 3
A3 (8, 4) 8.49 2.83 6.52 2
A4 (5, 8) 3.60 2.24 5.70 2
A5 (7, 5) 7.07 1.41 5.70 2
A6 (6, 4) 7.21 2.00 4.53 2
A7 (1, 2) 8.06 6.40 1.58 3
A8 (4, 9) 2.24 3.61 6.04 1
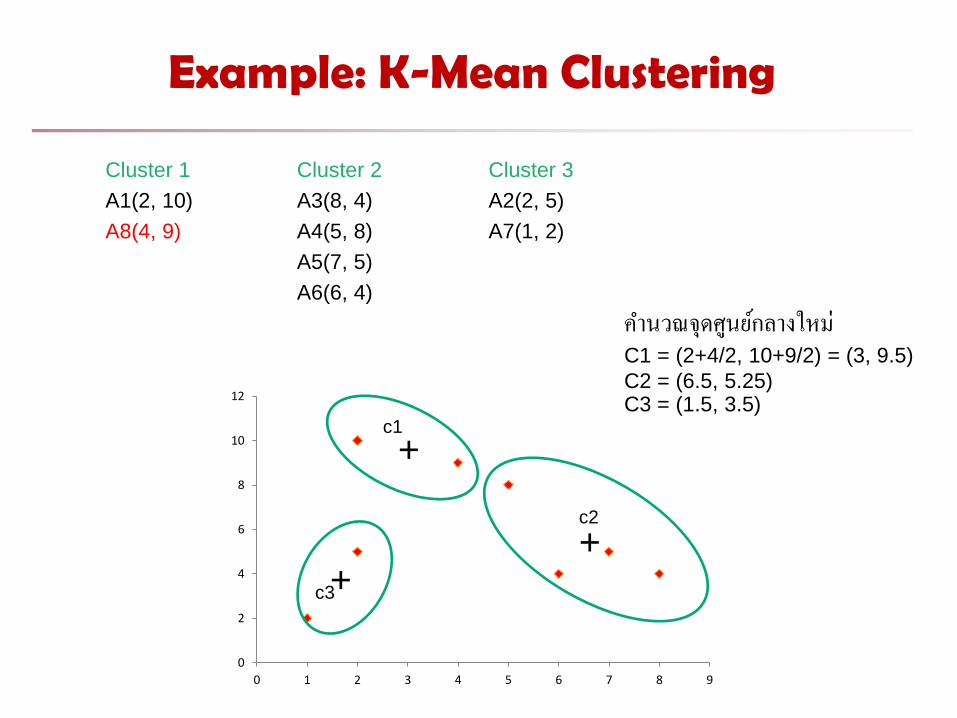
Example: K-Mean Clustering
Cluster 1 Cluster 2 Cluster 3
A1(2, 10) A3(8, 4) A2(2, 5)
A8(4, 9) A4(5, 8) A7(1, 2)
A5(7, 5)
A6(6, 4)
0
2
4
6
8
10
12
0 1 2 3 4 5 6 7 8 9
+
+
c1
c2
c3 +
ค านวณจดศนยกลางใหม C1 = (2+4/2, 10+9/2) = (3, 9.5)
C2 = (6.5, 5.25) C3 = (1.5, 3.5)
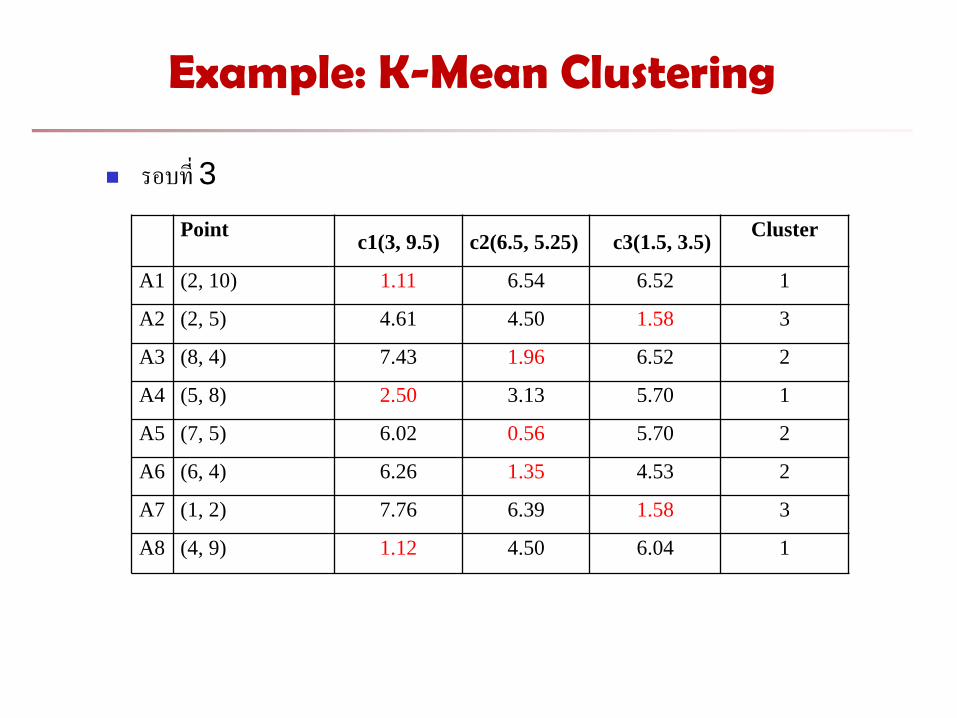
Example: K-Mean Clustering
รอบท 3
Point
c1(3, 9.5) c2(6.5, 5.25) c3(1.5, 3.5)
Cluster
A1 (2, 10) 1.11 6.54 6.52 1
A2 (2, 5) 4.61 4.50 1.58 3
A3 (8, 4) 7.43 1.96 6.52 2
A4 (5, 8) 2.50 3.13 5.70 1
A5 (7, 5) 6.02 0.56 5.70 2
A6 (6, 4) 6.26 1.35 4.53 2
A7 (1, 2) 7.76 6.39 1.58 3
A8 (4, 9) 1.12 4.50 6.04 1
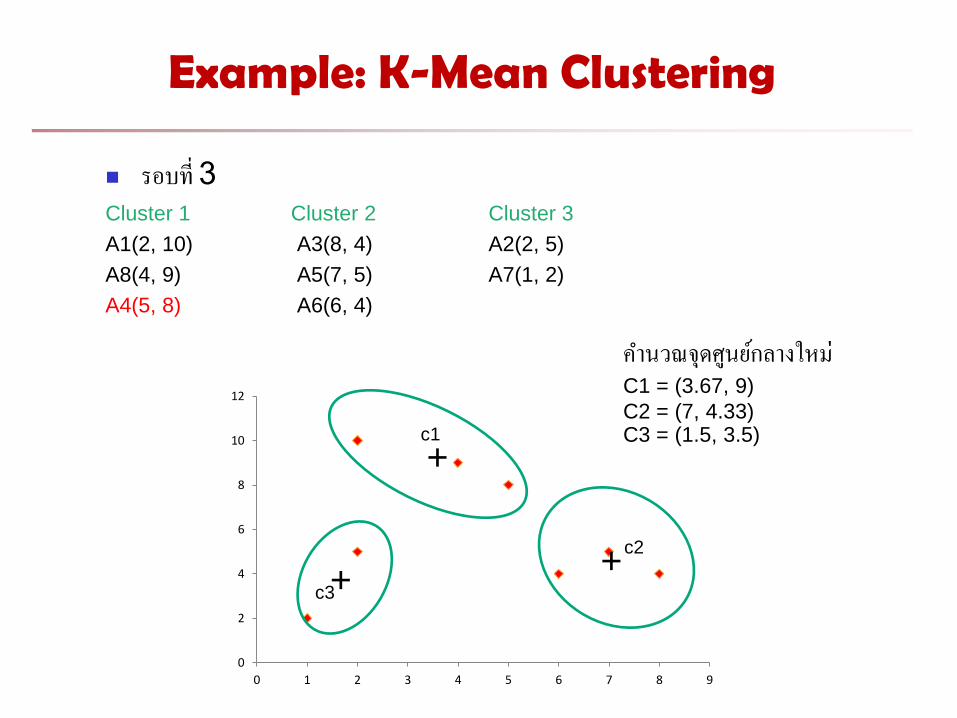
Example: K-Mean Clustering
รอบท 3 Cluster 1 Cluster 2 Cluster 3
A1(2, 10) A3(8, 4) A2(2, 5)
A8(4, 9) A5(7, 5) A7(1, 2)
A4(5, 8) A6(6, 4)
0
2
4
6
8
10
12
0 1 2 3 4 5 6 7 8 9
+
+
c1
c2
c3 +
ค านวณจดศนยกลางใหม C1 = (3.67, 9)
C2 = (7, 4.33) C3 = (1.5, 3.5)
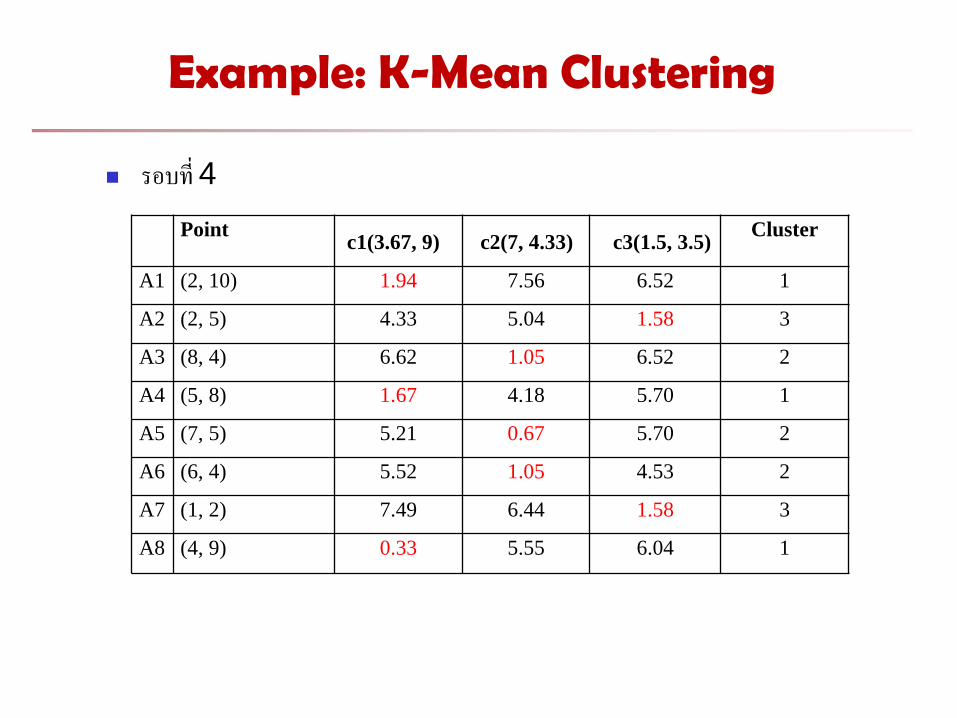
Example: K-Mean Clustering
รอบท 4
Point
c1(3.67, 9) c2(7, 4.33) c3(1.5, 3.5)
Cluster
A1 (2, 10) 1.94 7.56 6.52 1
A2 (2, 5) 4.33 5.04 1.58 3
A3 (8, 4) 6.62 1.05 6.52 2
A4 (5, 8) 1.67 4.18 5.70 1
A5 (7, 5) 5.21 0.67 5.70 2
A6 (6, 4) 5.52 1.05 4.53 2
A7 (1, 2) 7.49 6.44 1.58 3
A8 (4, 9) 0.33 5.55 6.04 1
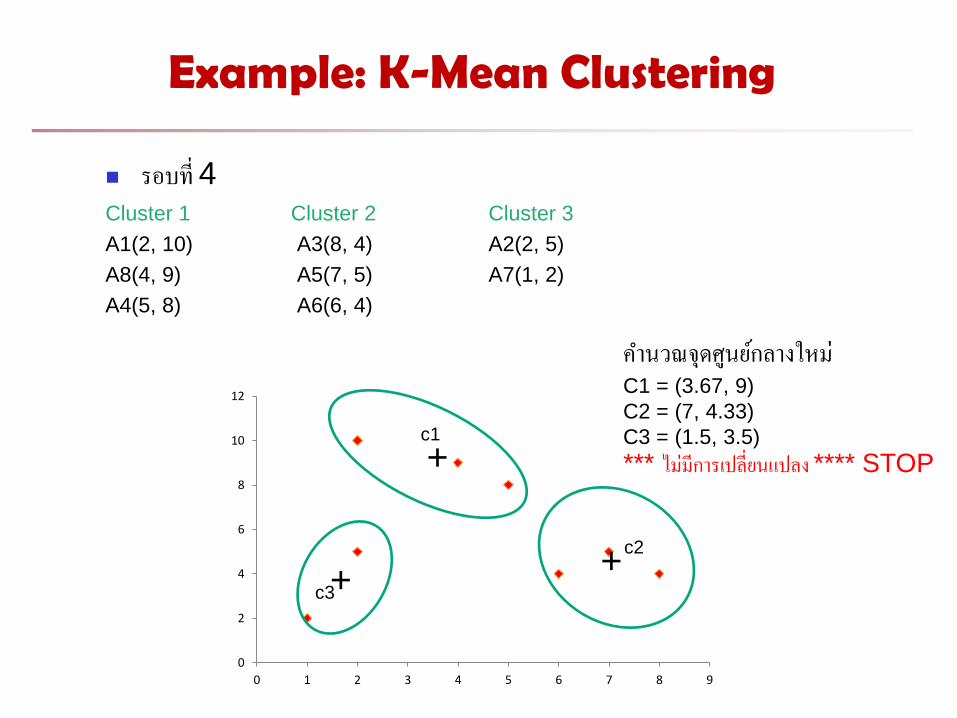
Example: K-Mean Clustering
รอบท 4 Cluster 1 Cluster 2 Cluster 3
A1(2, 10) A3(8, 4) A2(2, 5)
A8(4, 9) A5(7, 5) A7(1, 2)
A4(5, 8) A6(6, 4)
0
2
4
6
8
10
12
0 1 2 3 4 5 6 7 8 9
+
+
c1
c2
c3 +
ค านวณจดศนยกลางใหม C1 = (3.67, 9)
C2 = (7, 4.33)
C3 = (1.5, 3.5)
*** ไมมการเปลยนแปลง **** STOP

33
ขอดและขอดอยของเทคนค K-means
ขอด 1. เมอจ านวนขอมลมจ านวนมาก และมจ านวนกลมนอย การหาคาเฉลยแบบ K-means อาจจะค านวณไดเรวกวา การจดกลมแบบอน ๆ (Hierarchical)
2. ขนตอนการหาคาเฉลยแบบ K-means อาจจะไดสมาชก ภายในกลมหนาแนนกวาการจดกลมแบบ Hierarchical
โดยเฉพาะถากลมเปนวงกลม

34
ขอดและขอดอยของเทคนค K-means (cont)
ขอดอย 1. การหาคา K ทเหมาะสมคาดเดาไดยาก 2. ท างานไดไมดถากลมขอมลไมเปนรปวงกลม 3. มขอจ ากดในเรองของขนาด ความหนาแนน และรปราง

Limitations of K-means
K-means has problems when clusters are of
differing
Sizes (ขนาด) Densities (ความหนาแนน)
Non-globular shapes (รปรางของขอมลทไมเปนวงกลม)
K-means has problems when the data contains
outliers.
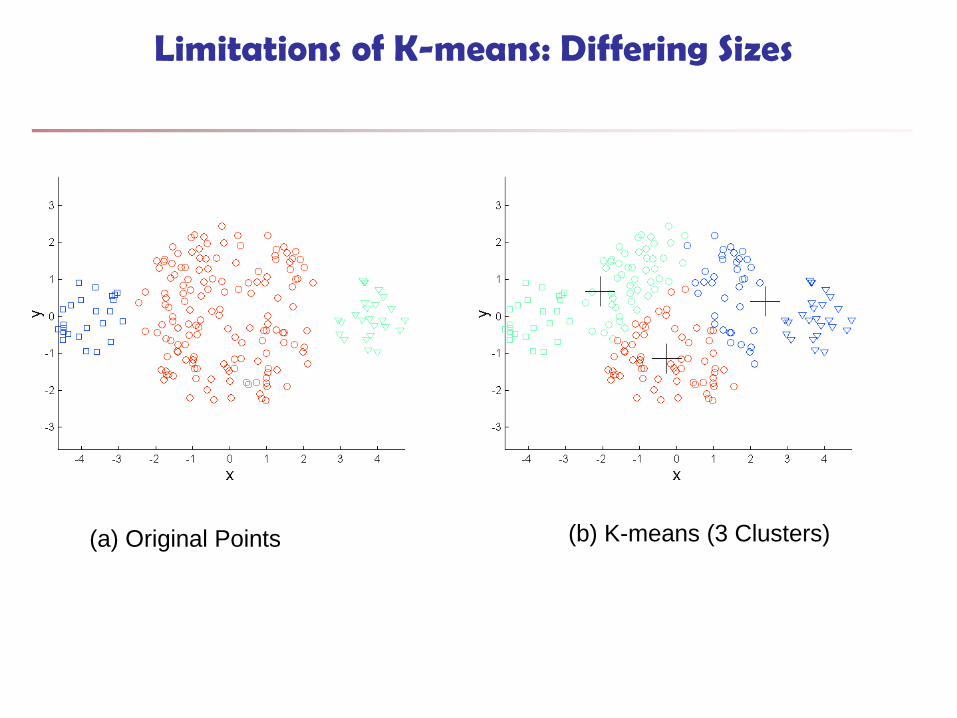
Limitations of K-means: Differing Sizes
(a) Original Points (b) K-means (3 Clusters)
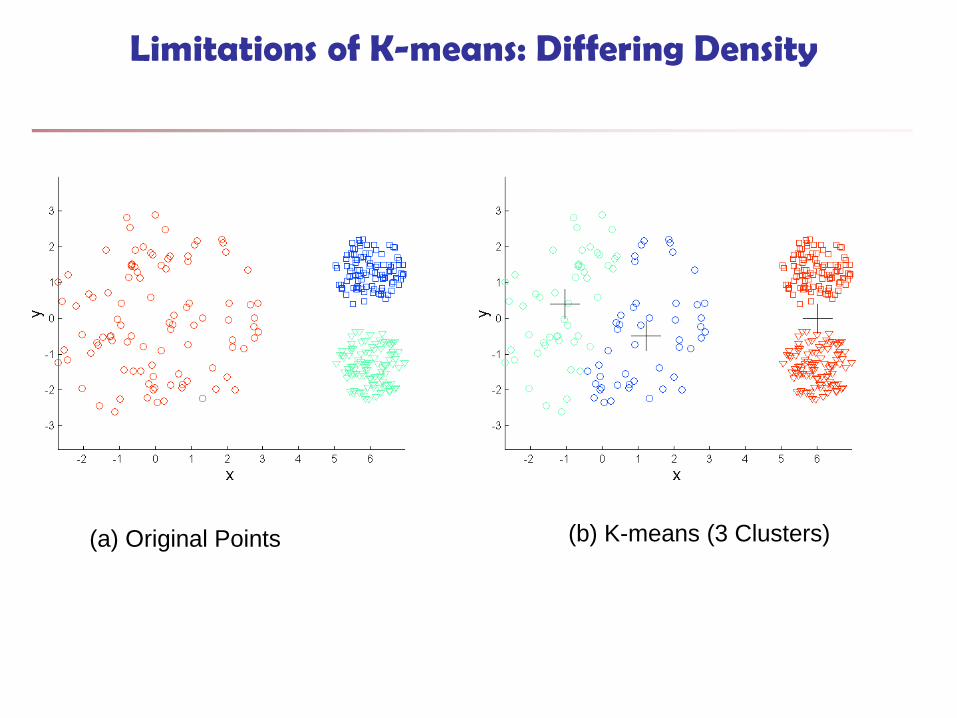
Limitations of K-means: Differing Density
(a) Original Points (b) K-means (3 Clusters)
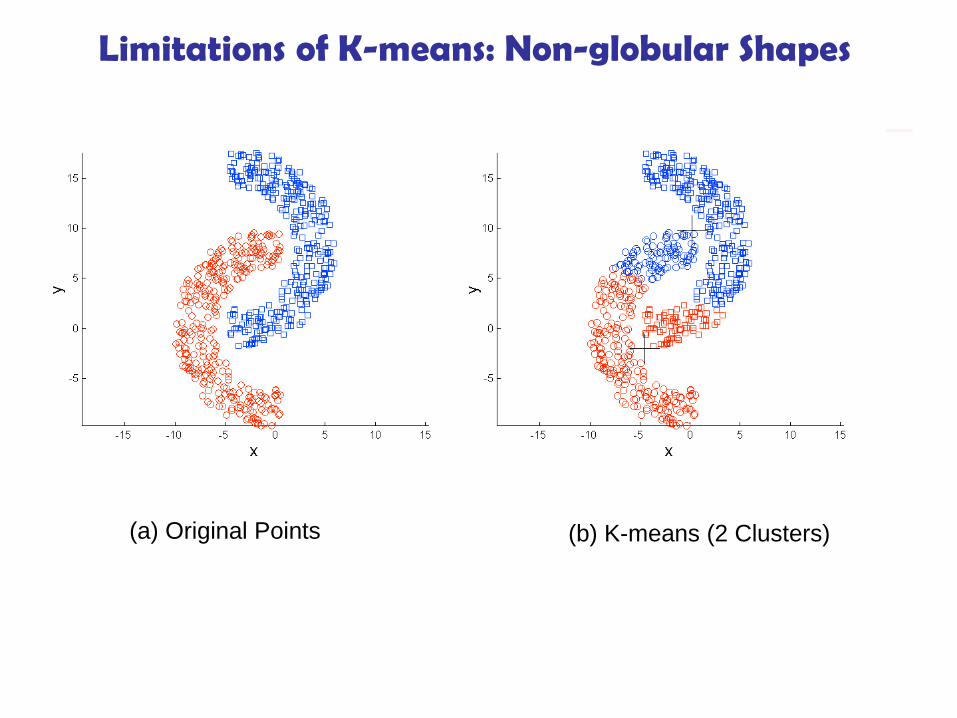
Limitations of K-means: Non-globular Shapes
(a) Original Points (b) K-means (2 Clusters)
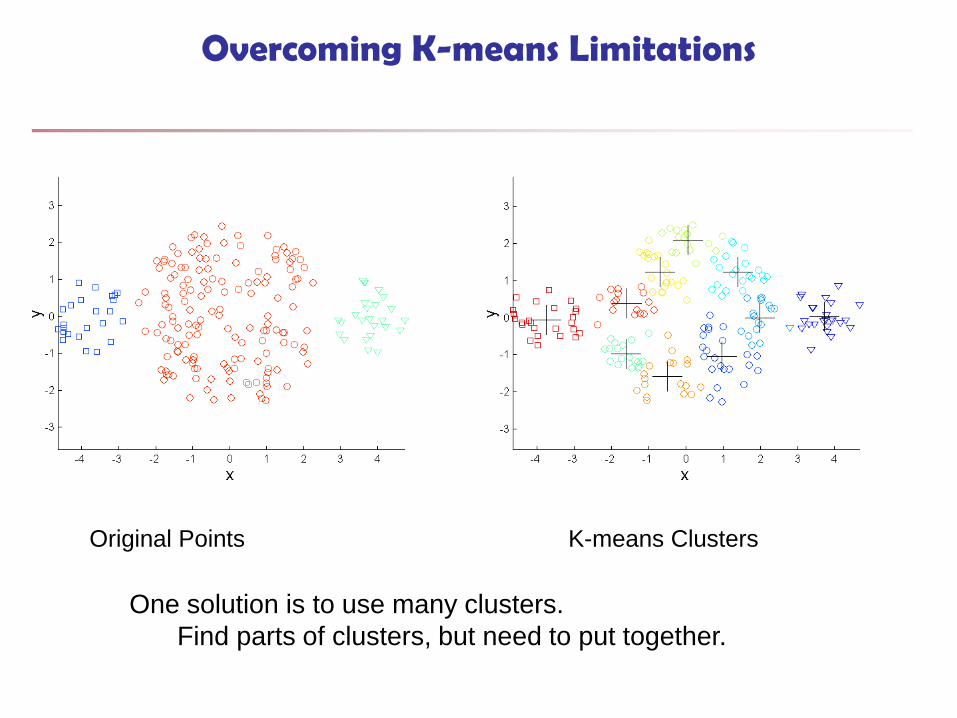
Overcoming K-means Limitations
Original Points K-means Clusters
One solution is to use many clusters.
Find parts of clusters, but need to put together.
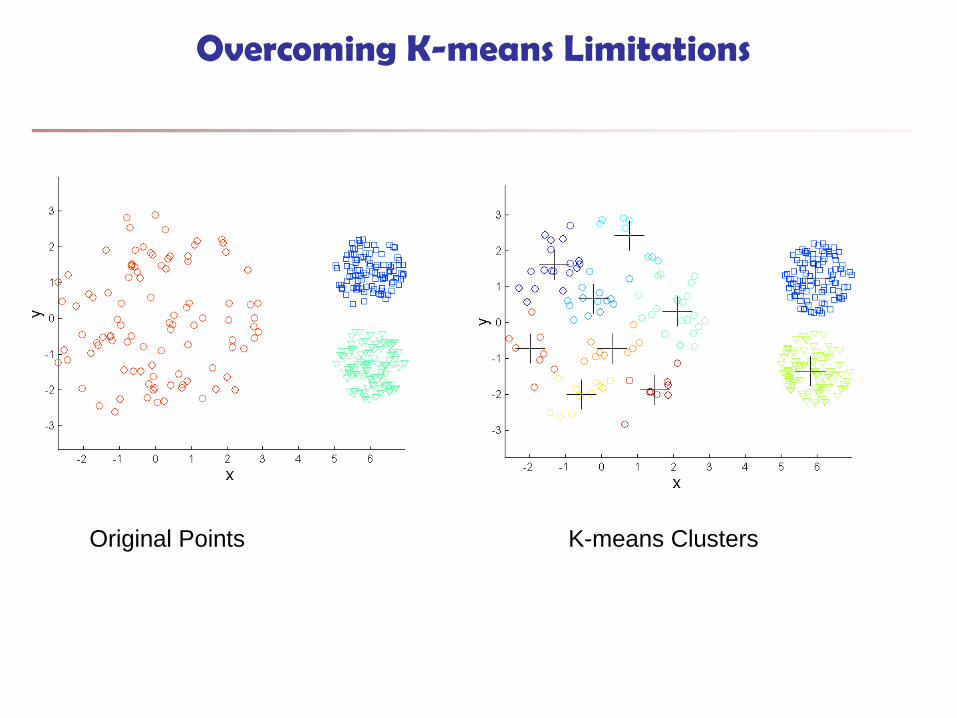
Overcoming K-means Limitations
Original Points K-means Clusters
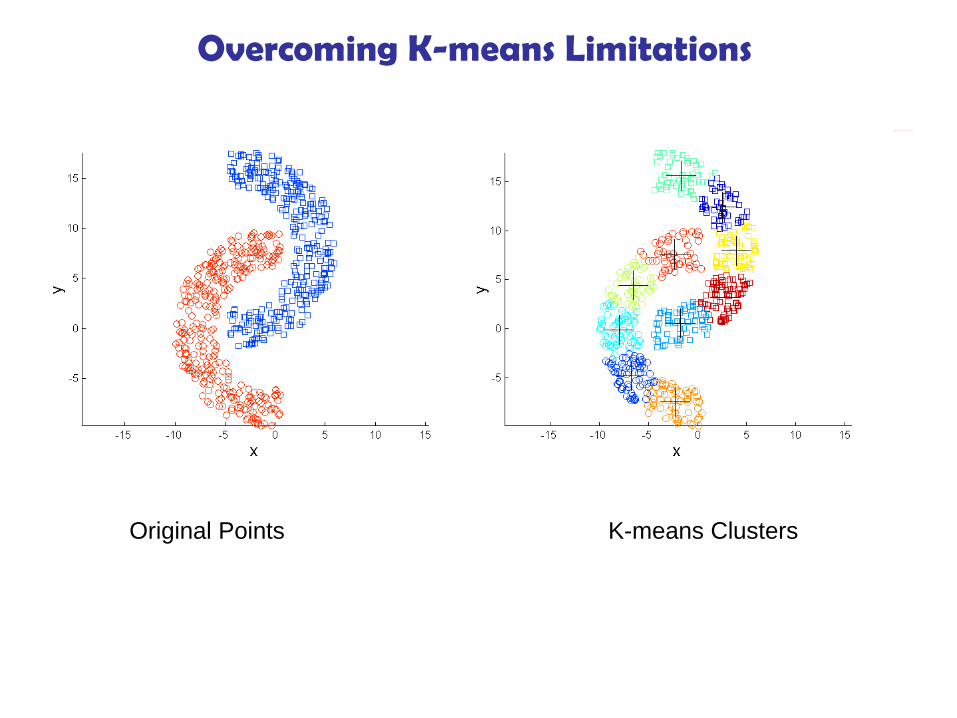
Overcoming K-means Limitations
Original Points K-means Clusters

What Is the Problem of the K-Means Method?
The k-means algorithm is sensitive to outliers !
Since an object with an extremely large value may substantially
distort the distribution of the data
K-Medoids: Instead of taking the mean value of the object in a cluster
as a reference point, medoids can be used, which is the most
centrally located object in a cluster
0
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 10
0
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 10
42
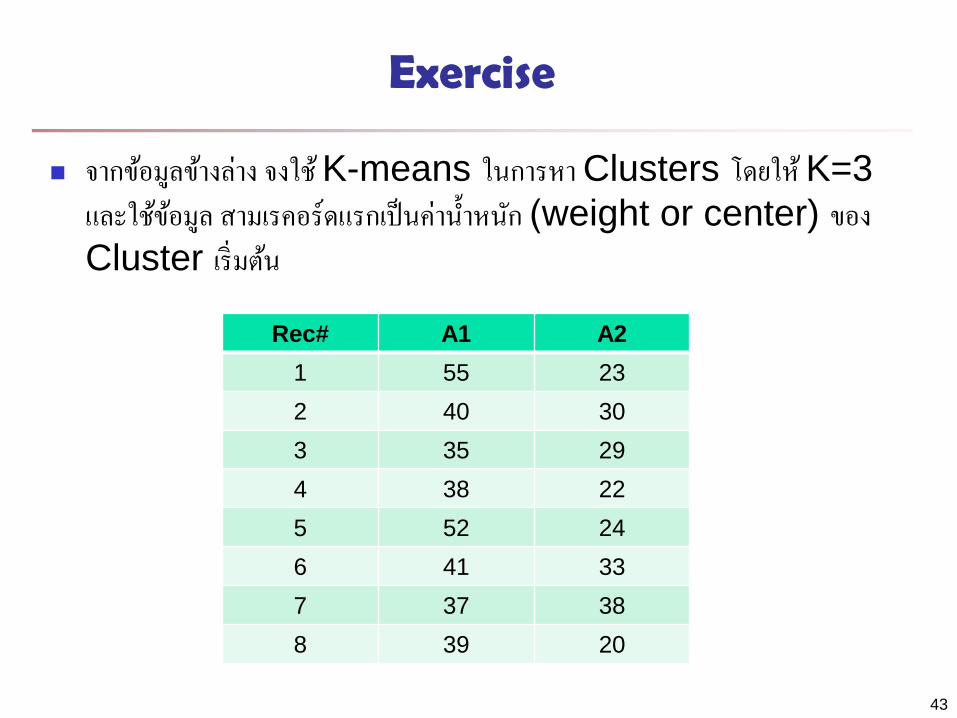
Exercise
จากขอมลขางลาง จงใช K-means ในการหา Clusters โดยให K=3
และใชขอมล สามเรคอรดแรกเปนคาน าหนก (weight or center) ของ Cluster เรมตน
43
Rec# A1 A2
1 55 23
2 40 30
3 35 29
4 38 22
5 52 24
6 41 33
7 37 38
8 39 20
Recommended


: a (m1=4)-approximation algorithm for squared matrices. [KMS97]:](https://img.pdfslide.us/doc/110x75/5f473f8f45406e46c569abc3/partitioning-spatially-located-load-with-rectangles-esaulepublic-website.jpg)

![Parallel OLAP query processing in database clusters with ... · Parallel OLAP query processing in database clusters with data replication ... tual partitioning technique [8],](https://img.pdfslide.us/doc/110x75/5af41d357f8b9a154c8de05e/parallel-olap-query-processing-in-database-clusters-with-olap-query-processing.jpg)












