Data Integration
Rachel Pottinger and Liang Sun
CSE 590ES
January 24, 2000

What is Data Integration?Providing
uniform (sources transparent to user)
access to (query, and eventually updates to)
multiple
autonomous (can’t affect behavior of sources)
heterogeneous (different models and schemas)
data sources
Sounds like the devices in Portolano!

Outline
• Architecture of data integration system
• Source description & query reformulation
• Query optimization

Motivation
• Enterprise data integration; web-site construction.
• World-wide web:
– comparison shopping (Netbot, Junglee)
– portals integrating data from multiple sources
– XML integration
• Science & culture
– Medical genetics: integrating genomic data
– Astrophysics: monitoring events in the sky
– Environment: Puget Sound Regional Synthesis Model
– Culture: uniform access to all the cultural databases produced by countries in Europe.

(some) Research Prototypes• DISCO (INRIA)
• Garlic (IBM)
• HERMES (U. of Maryland)
• InfoMaster (Stanford)
• Information Manifold (AT&T)
• IRO-DB (Versailles)
• SIMS, ARIADNE (USC/ISI)
• The Internet Softbot/Occam/Razor/Tukwila (us)
• TSIMMIS (Stanford)
• XMAS (UCSD)
• WHIRL (AT&T)

Principle Dimensions of Data Integration
• Virtual vs. materialized architecture
• Mediated schema?Pros:– Can ask questions over different schemas
Cons:– Requires query reformulation

Mediated schema exampleReal database schemas: imdb(title, actor, director, genre,country) seattlesidewalk(title, theatre, time, price) showtimes(city, title, theatre, time) mrshowbiz(title, year, review) siskelebert(title, review)Mediated schemas:
movieInfo(ID, title, genre, country, year, director)movieShowtime(ID, city, theatre, time)
movieActor(ID, actor)movieReview(ID, review)
Query: query(M,theatre, time):- movieActor(M, “tom hanks”),
movieShowtime(M, “seattle”, theatre,time).
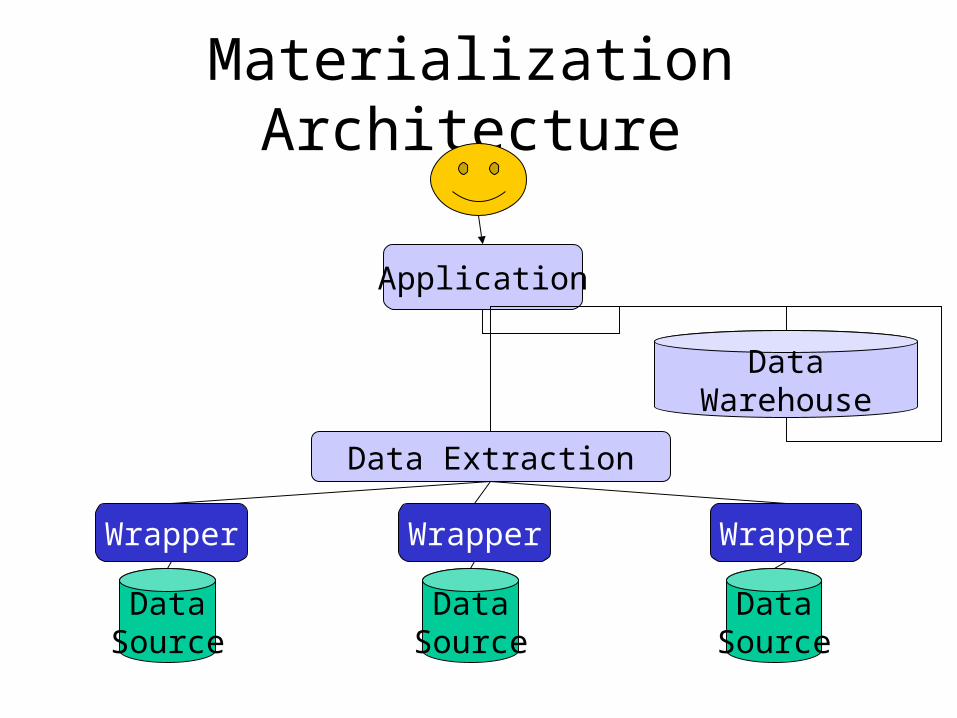
Materialization Architecture
DataSource
DataSource
DataSource
WrapperWrapperWrapper
Data Extraction
DataWarehouse
Application
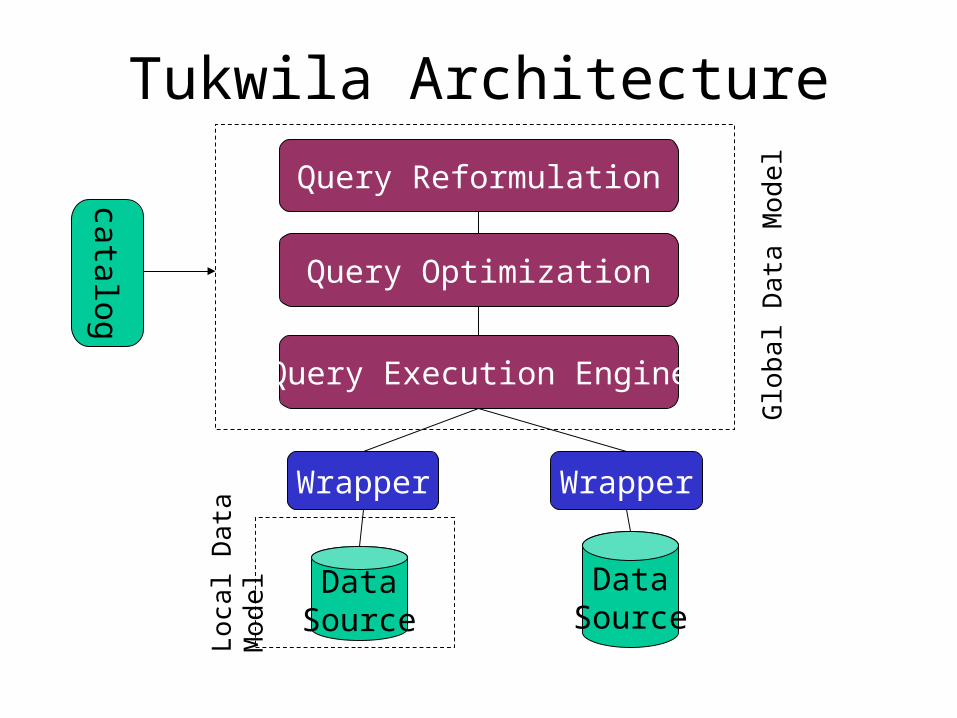
Tukwila Architecture
DataSource
Wrapper Wrapper
Query Execution Engine
Query Optimization
Query Reformulation
Glo
bal D
ata
Mod
el
DataSource
Loc
al D
ata
Mod
el
catalog

Translating between data models
• Where is the wrapper?
• How intelligent is the wrapper?
Exported schemaQuery in exported schema
Data in global data model
Native schema Query in native schema Data in local data model
Glo
bal D
ML
ocal
DM

Describing Information Sources
• User queries refer to the mediated schema
• Sources store data in the local schemas
• Content descriptions provide the mappings between the mediated and local schemas
Content DescriptionsMediatedSchemaRelations
InformationSourceRelations

Data Source Catalogs
Catalogs contain descriptions of:
• Logical source contents
• Source capabilities
• Source completeness
• Mirror sources
• Physical properties of the source and network
• Source reliability

Desiderata from source descriptions
• Distinguish between sources with closely related data: so we can prune access to irrelevant sources
• Enable easy addition of new information sources: because sources are dynamically being added and removed
• Be able to find sources relevant to a query: reformulate queries such that we obtain guarantees on which sources we access

Query Reformulation ProblemProblem: reformulate user query referring to mediated schema
onto local schemas
Given
• a query Q in terms of the mediated-schema
• descriptions of the data sources
Find a query Q’ that uses only the data source relation such that
• Q’ Q (i.e., answers are correct) and
• Q’ provides all possible answers to Q using the sources

Approaches to Specification of Source Descriptions
• Mediated schema relations defined as views over the source relations
• Source relations defined as views over mediated-schema relations
• Sources described as concepts in a description logic

The Global As View ApproachMediated-schema relations described in terms of
source relations
Movies and their years can be obtained from either DB1 or DB2:
MovieYear(title,year):-DB1(title,director,year)
MovieYear(title,year):-DB2(title, director, year)
Movie reviews can be obtained by joining DB1 and DB3
MovieRev(title,director,review):- DB1(title, director, year) & DB3(title,review)

Query Reformulation in GAVQuery reformulation is done by rule unfolding
Query: find reviews for 1997 movies:
q(title,review):- MovieYear(title,1997)& MovieRev(title,director,review)
Reformulated query on the sources:
q(title, review):- DB1(title,director,year) & DB3(title,review)
q(title,review):-DB1(title,director,year) & DB2(title,director,year)&DB3(title,review)
Containment check shows second rule is redundant

The Local As View Approach
Every data source is described as a query expression (view!) over mediated-schema relations
S1: V1(title,year,director) year 1960 & genre = ‘Comedy’ & Movie(title,year,director,genre)
S2: V2(title,review) Review(title,review)

Query ReformulationFind reviews for comedies produced after 1950:
q(title,review):-Movie(title,year,director,‘Comedy’) & year 1950 & Review(title,review)
V1(title,year,director) year 1960 & genre = ‘Comedy’ & Movie(title,year,director,genre)
V2(title,review) Review(title,review)
The reformulated query on the sources:
q’(title,review):-V1(title,year,director) & V2(title,review)

Comparison of the approaches
Local as view approach:
• Easier to add sources: specify the query expression
• Easier to specify constraints on source contents
Global as view:
• Query reformulation is straightforward

The Query Optimization Problem
(currently divorced from reformulation problem)
The goal of a query optimizer:
Translate a declarative query into an equivalent imperative program of minimal cost
The imperative program is a query execution plan: an operator tree in some algebra
Basic notions in optimization:
• search space, search strategy, cost model

Similarities of Data Integration with Optimization in DDBMS
A distributed database:• Query execution distributed over multiple sites• Communication costs significant
Consequences for Query Optimization• Optimizer needs to decide operation locality• Plans should exploit independent parallelism• Plans should reduce communication overhead• Caching can become a significant factor

Differences from DDBMS
Capabilities of data sources:• May provide only limited access patterns to data• May have additional query processing capabilities
Information about sources and network are missing:• cost of answering queries unknown• statistics harder to estimate• transfer rates unpredictable
In DDBMS data is distributed by precise rules

Modeling Source Capabilities
Negative capabilities:
• A web-site may require certain inputs
• Need to consider only valid query execution plans
Positive capabilities:
• A source may be an ODBC compliant database
• Need to decide the placement of operations according to capabilities
Problem: how to describe and use source capabilities

Negative Capabilities
We model access limitations by binding patterns:
Sources: CitationDBbf(X,Y) Cites(X,Y)
CitingPapersf(X) Cites(X,Y)
Query: Q(X):- Cites(X,a)
Need to consider only valid plans:
q(X) :-CitingPapers(Y) &CitationDB(Y,a)
Requires recursive rewritings to find all solutions

Optimization with positive capabilities
• Schema dependent vs. schema independent: Source able to perform joins, selections, or specifically R S
Describing and using positive capabilities:
• Positive-capabilities testing module (PCTM): is a plan valid?
• Level of specification: declarative query vs. logical query execution plan.
• Interaction between optimizer and PCTM

Dealing with unexpected data transfer delays
Problem: even the best plan can be bad with data transfer delays
Query scrambling [Urhan et al, SIGMOD-98]: a set of runtime techniques to adapt to initial delays by:
• Rescheduling the query execution plan: leave plan unchanged, but evaluate different operators
• Operator synthesis: modify tree by removing or rearranging operators

Adaptive Query Processing (teaser for next week)
Tukwila: a more general framework for query processing in data integration
Due to lack of stats and network delays, interleaves query optimization and execution:
• Execute plan fragments; re-optimize
• Can decide to re-optimize even if next fragment is planned
• Adaptive operators for data integration
• Rule based mechanism for coordinating execution and optimization

Conclusions
Data integration handles many problems needed for embedded systems applications
• Many data sources
• Easy addition and deletion of sources
• Different source capabilities
• Dealing with network delays
• Easy for user
Recommended



![[XLS] · Web viewK J Purdon PULANE MARTHA TAUOE RACHEL STANDERS GEORGE LOUIS KHUTHALONG MATLOPORO WILLIAM TENNER N T KALASHE BRENDA MAY POTTINGER A M NUNN JOHN BRUCE YENDALL N P J](https://img.pdfslide.us/doc/110x75/5b05e9c37f8b9abf568c4591/xls-viewk-j-purdon-pulane-martha-tauoe-rachel-standers-george-louis-khuthalong.jpg)