
EU LeadMark Wilkinson
Isaac Peral Distinguished Researcher, CBGP-UPM, Madrid
USA LeadMichel Dumontier
Associate Professor, Biomedical Informatics, Stanford, USA
FAIRport Project LeadBarend Mons
Professor, Leiden University Medical Centre, Netherlands
Data FAIRport Skunkworks
Common repository access via meta-meta-descriptors

What is a FAIRport?
● Findable - (meta)data should be uniquely and persistently identifiable
● Accessible - identifiers should provide a mechanism for (meta)data access, including authentication, access protocol, license, etc.
● Interoperable - (meta)data should be machine-accessible, using a machine-parseable syntax and, where possible, shared common vocabularies.
● Reusable - there should be sufficient machine-readable metadata that it is possible to “integrate like-with-like”, and that component data objects can be precisely and comprehensively cited post-integration.

The Problem

End-user view of “The Problem”
Tissue rejection experimental context. Today, I’m looking for microarray data of human liver cells on a time-course following liver transplant.
What repositories could contain such data?
● GEO? EUDat? FigShare? Dryad? Atlas?
● What fields in those repositories would I need to search, using what vocabularies, to find the microarray studies that are relevant?

Dissecting the problem
There are a lot of repositories!
General Purpose: DataVerse, Dryad, EUDat, Figshare, etc.
Special Purpose: PDB, UniProt, NCBI, GEO, Atlas, EnsEMBL

Dissecting the problem
Lack of harmonized metadata structures, or even rich descriptions of the contents of these repositories, hinders us from (for example):
● knowing where we can look for certain types of data
● knowing if two repositories contain records about the same thing
● Cross-referencing or “joining” across repositories to integrate disparate data about the same thing
● Knowing which repository I could/should deposit my data to (and how)

“Skunkworks” Challenge
If we wanted to enable this kind of FAIR discovery and integration over myriad repositories, what infrastructure
(existing/new) would we need?

If we wanted to enable this kind of FAIR discovery and integration over myriad repositories, what infrastructure
(existing/new) would we need?
Discussions with Tim Clark revealed that the core objectives of Skunkworks were very similar to those of
Force 11 Data Citation Implementation Working Group Team 4 - “Common repository interfaces”
...so we joined forces :-)
“Skunkworks” Challenge

The Solution?

Shared Metadata Descriptors?
They already exist! (e.g. DCAT)
Are not (yet) widely implemented
But are not sufficiently rich......only describe “core” metadata
We need to query, e.g. experimental context and domain-specific metadata

So... extend DCAT?

So... extend DCAT?
...extend it where?...too many specialist domains & data
resistance to harmonization
resistance to implementation(time, money, expertise, ‘just don’t care’)
attempting to impose standards is a Mug’s game!

Common provider-implemented API?

Common provider-implemented API?
a la TDWG/TAPIR and caBIO...too many specialist domains & data
resistance to harmonization
resistance to implementation(time, money, expertise, ‘just don’t care’)
attempting to impose standards is a Mug’s game!

Where else could the solution be?
What exactly *is* our problem?

What exactly *is* our problem?
Data Record (e.g. XML, RDF)
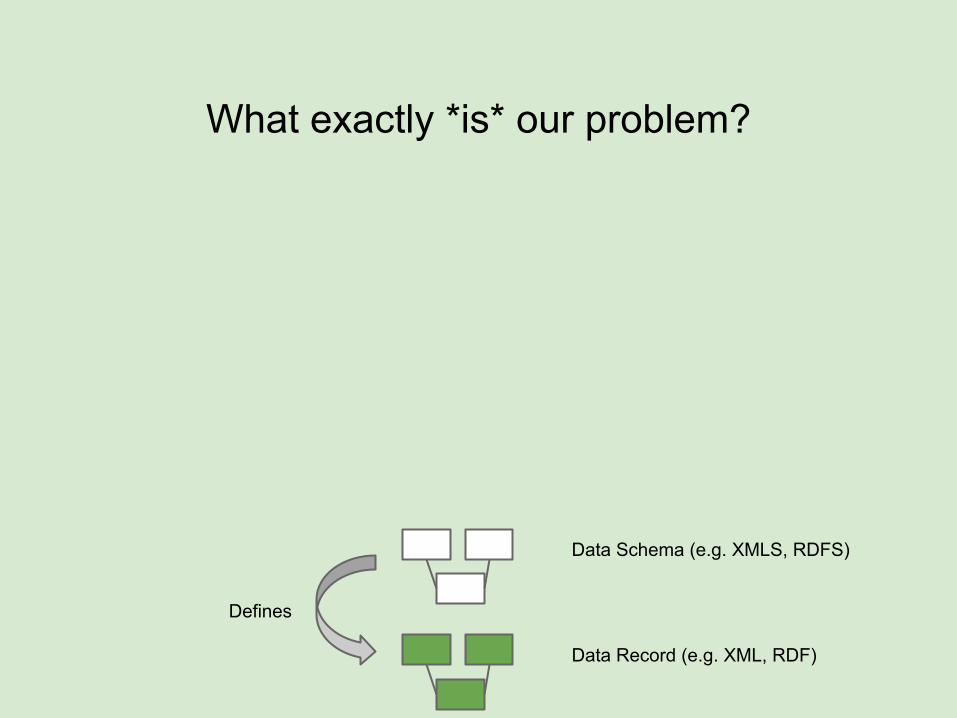
What exactly *is* our problem?
Data Record (e.g. XML, RDF)
Data Schema (e.g. XMLS, RDFS)
Defines
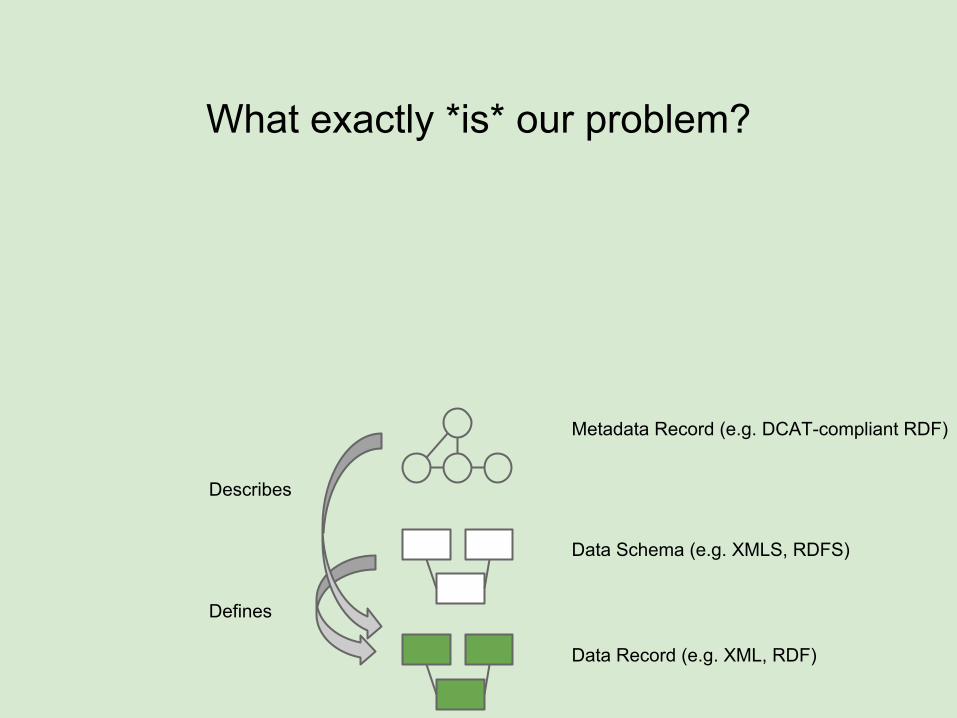
What exactly *is* our problem?
Data Record (e.g. XML, RDF)
Data Schema (e.g. XMLS, RDFS)
Metadata Record (e.g. DCAT-compliant RDF)
Defines
Describes
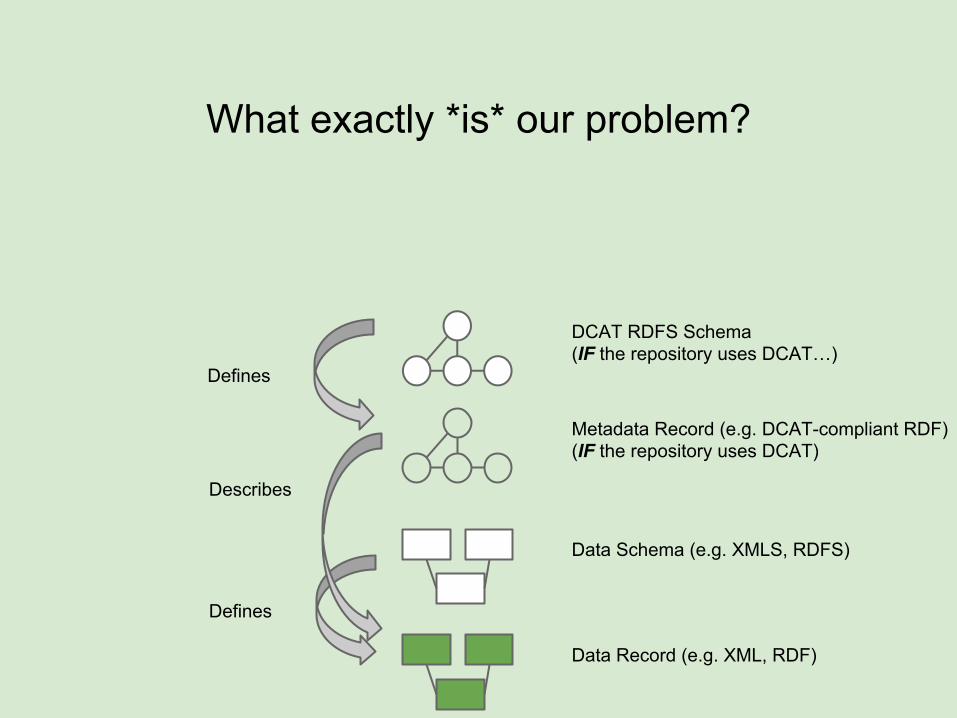
What exactly *is* our problem?
Data Record (e.g. XML, RDF)
Data Schema (e.g. XMLS, RDFS)
Metadata Record (e.g. DCAT-compliant RDF)(IF the repository uses DCAT)
DCAT RDFS Schema(IF the repository uses DCAT…)
Defines
Describes
Defines
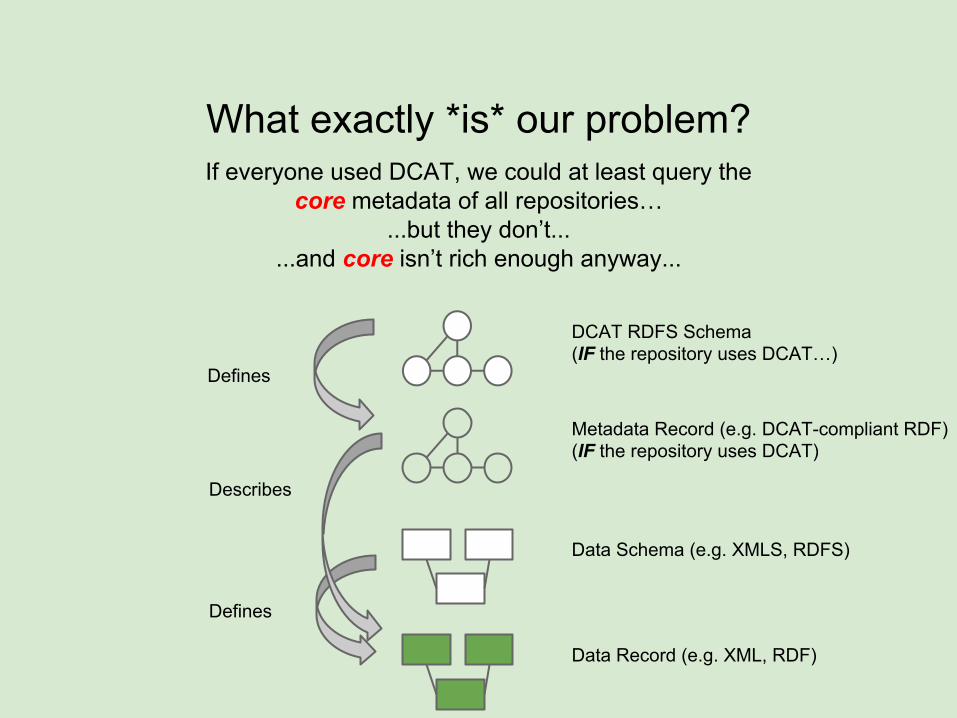
What exactly *is* our problem?
Data Record (e.g. XML, RDF)
Data Schema (e.g. XMLS, RDFS)
Metadata Record (e.g. DCAT-compliant RDF)(IF the repository uses DCAT)
DCAT RDFS Schema(IF the repository uses DCAT…)
Defines
Describes
Defines
If everyone used DCAT, we could at least query the core metadata of all repositories…
...but they don’t......and core isn’t rich enough anyway...
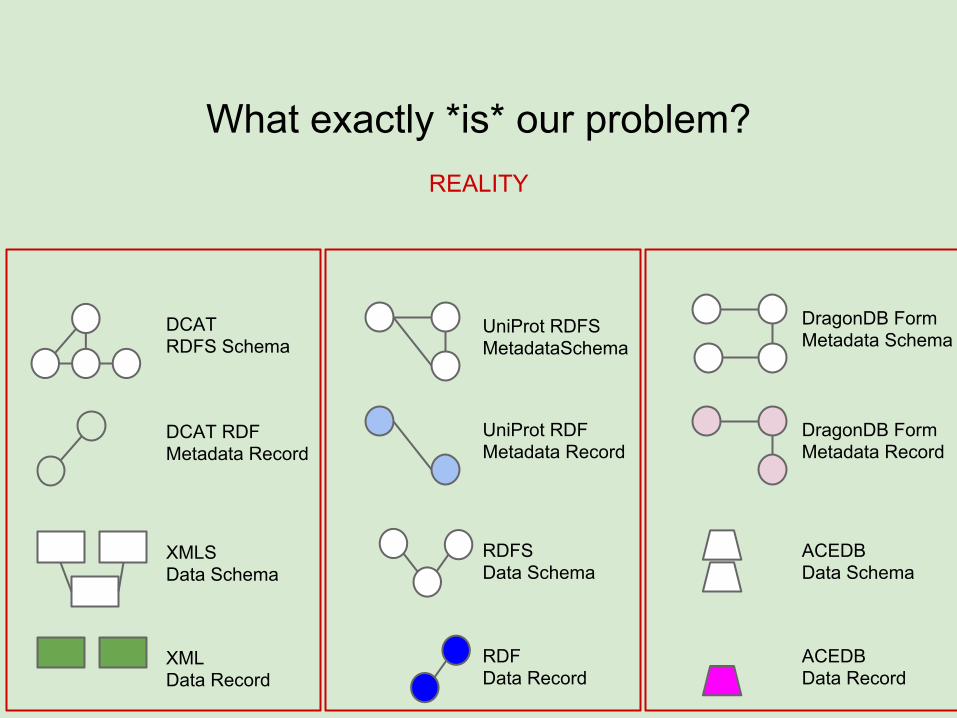
What exactly *is* our problem?
XML Data Record
XMLS Data Schema
DCAT RDF Metadata Record
RDF Data Record
RDFS Data Schema
UniProt RDFMetadata Record
ACEDBData Record
ACEDB Data Schema
DragonDB FormMetadata Record
DCAT RDFS Schema
UniProt RDFSMetadataSchema
DragonDB FormMetadata Schema
REALITY
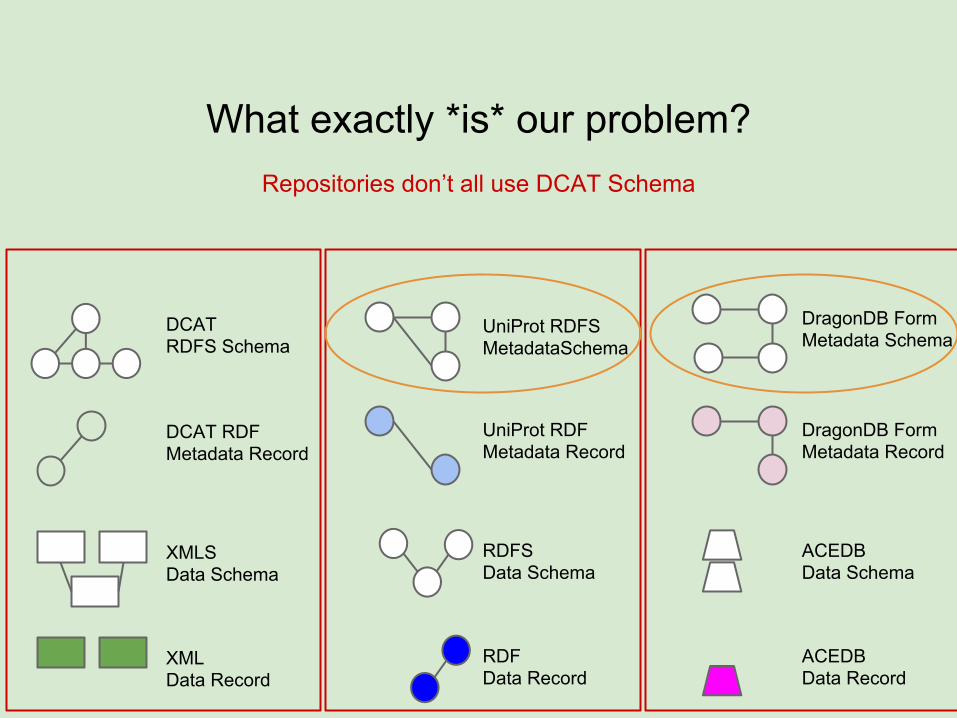
What exactly *is* our problem?
XML Data Record
XMLS Data Schema
DCAT RDF Metadata Record
RDF Data Record
RDFS Data Schema
UniProt RDFMetadata Record
ACEDBData Record
ACEDB Data Schema
DragonDB FormMetadata Record
DCAT RDFS Schema
UniProt RDFSMetadataSchema
DragonDB FormMetadata Schema
Repositories don’t all use DCAT Schema
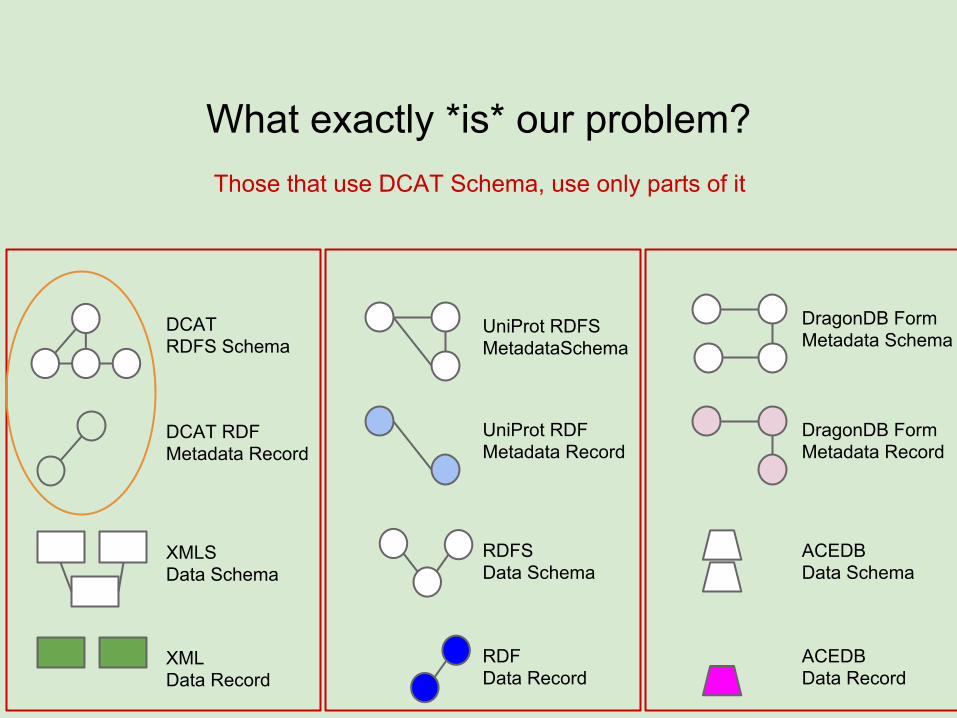
What exactly *is* our problem?
XML Data Record
XMLS Data Schema
DCAT RDF Metadata Record
RDF Data Record
RDFS Data Schema
UniProt RDFMetadata Record
ACEDBData Record
ACEDB Data Schema
DragonDB FormMetadata Record
DCAT RDFS Schema
UniProt RDFSMetadataSchema
DragonDB FormMetadata Schema
Those that use DCAT Schema, use only parts of it
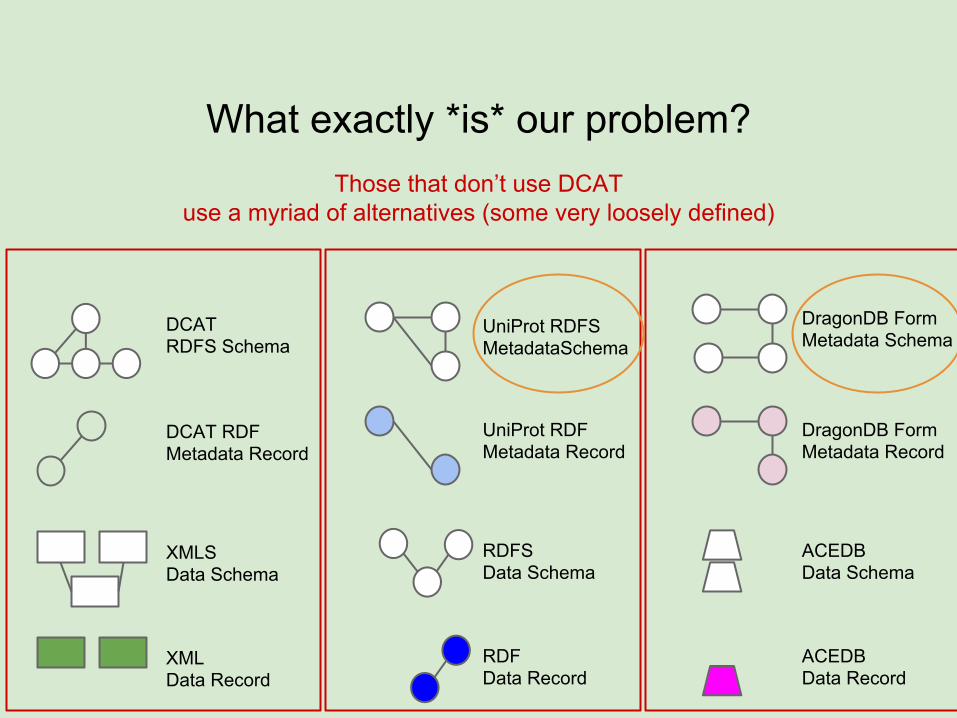
What exactly *is* our problem?
XML Data Record
XMLS Data Schema
DCAT RDF Metadata Record
RDF Data Record
RDFS Data Schema
UniProt RDFMetadata Record
ACEDBData Record
ACEDB Data Schema
DragonDB FormMetadata Record
DCAT RDFS Schema
UniProt RDFSMetadataSchema
DragonDB FormMetadata Schema
Those that don’t use DCATuse a myriad of alternatives (some very loosely defined)
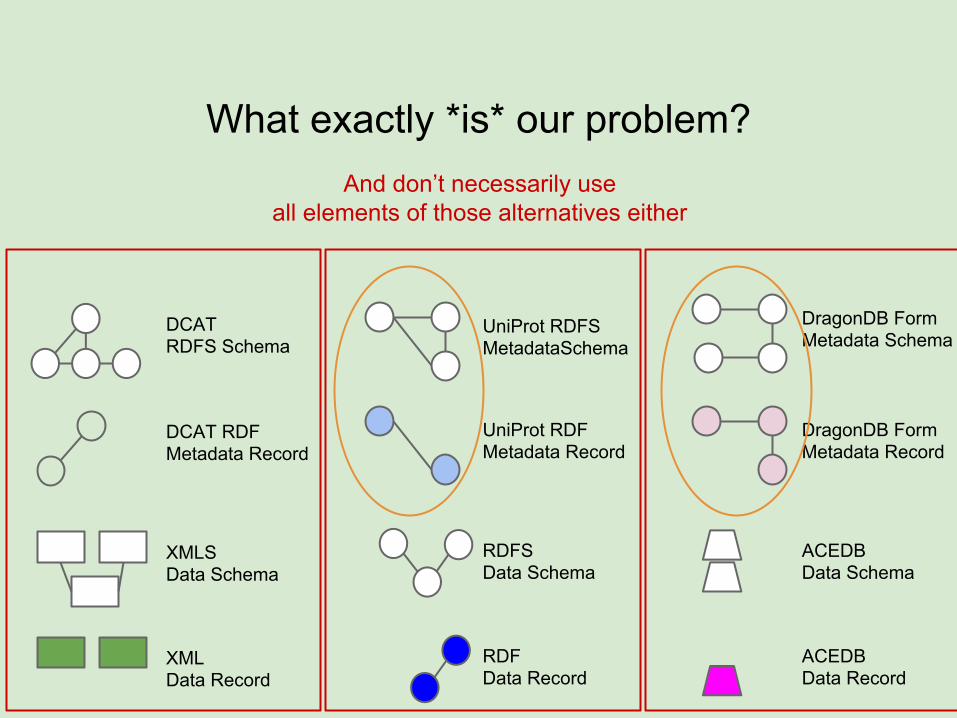
What exactly *is* our problem?
XML Data Record
XMLS Data Schema
DCAT RDF Metadata Record
RDF Data Record
RDFS Data Schema
UniProt RDFMetadata Record
ACEDBData Record
ACEDB Data Schema
DragonDB FormMetadata Record
DCAT RDFS Schema
UniProt RDFSMetadataSchema
DragonDB FormMetadata Schema
And don’t necessarily useall elements of those alternatives either
What exactly *is* our problem?
XML Data Record
XMLS Data Schema
DCAT RDF Metadata Record
RDF Data Record
RDFS Data Schema
UniProt RDFMetadata Record
ACEDBData Record
ACEDB Data Schema
DragonDB FormMetadata Record
DCAT RDFS Schema
UniProt RDFSMetadataSchema
DragonDB FormMetadata Schema
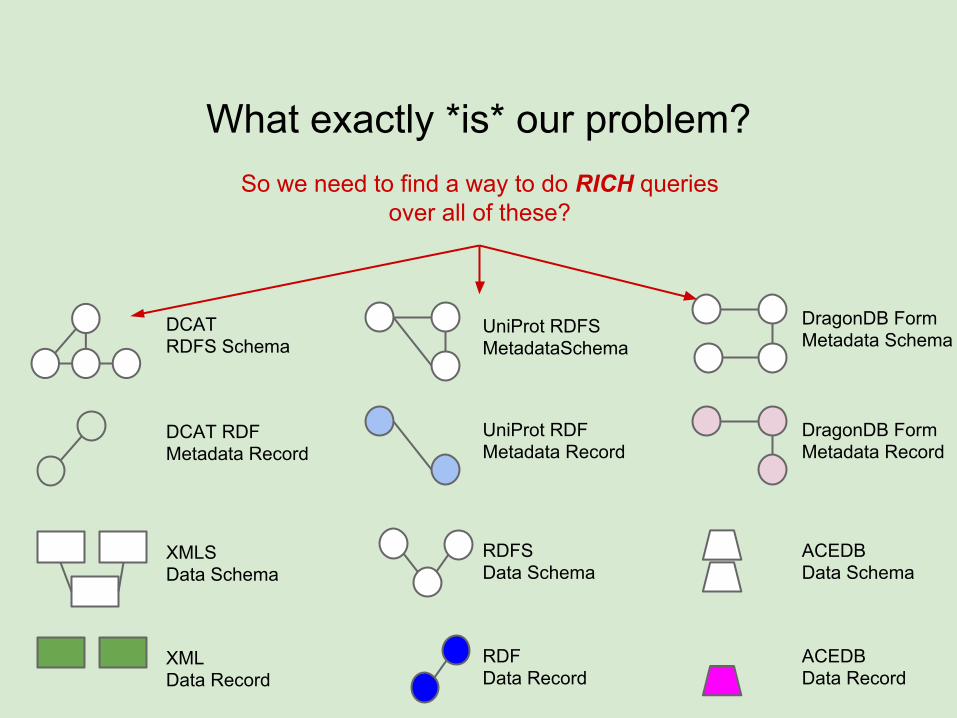
So we need to find a way to do RICH queries over all of these?
What exactly *is* our problem?
XML Data Record
XMLS Data Schema
DCAT RDF Metadata Record
RDF Data Record
RDFS Data Schema
UniProt RDFMetadata Record
ACEDBData Record
ACEDB Data Schema
DragonDB FormMetadata Record
DCAT RDFS Schema
UniProt RDFSMetadataSchema
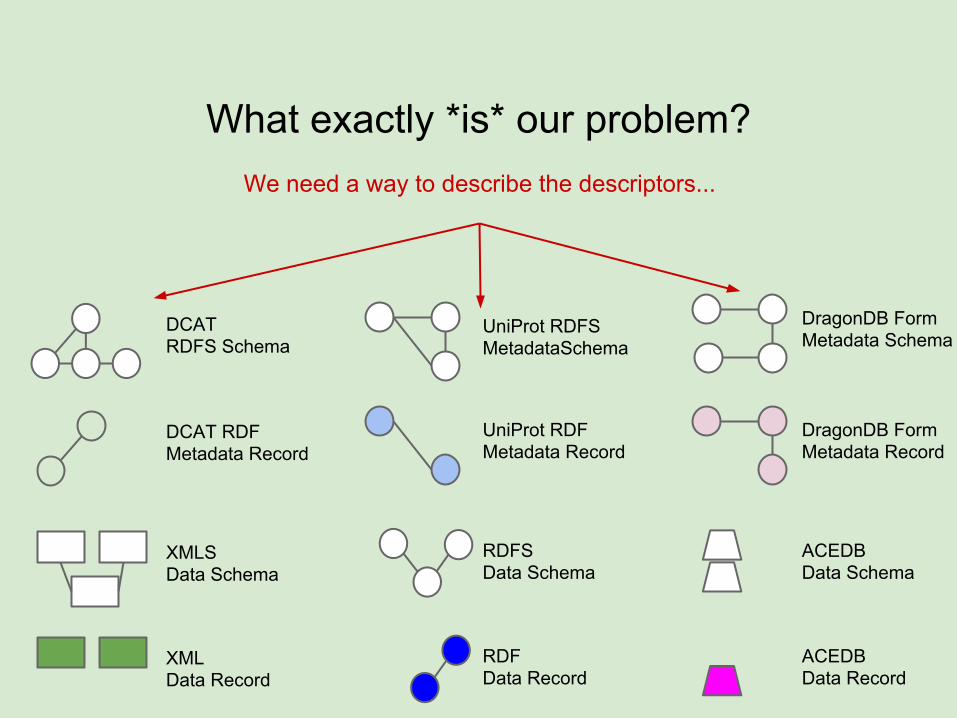
DragonDB FormMetadata Schema
We need a way to describe the descriptors...

Desiderata of meta-meta descriptors
● Must describe legacy data (i.e. not just DCAT or other “modern” data)
● Must describe a multitude of data formats (XML, RDF, Key/Value, etc.)
● Must be capable of describing any kind of value constraint, e.g. plain text,
numerical, arbitrary CV, rdf:range, or equivalent OWL construct
● Must be modular, identifiable, shareable, and reusable (to stem the
proliferation of new formats)
● Must be hierarchical to allow composite re-use of shared descriptors
● Must use standard technologies, and re-use existing vocabularies if poss.
● Must be extremely lightweight and “trivial” to create
● Must NOT require the participation of the repository host (no buy-in required)

The Solution?(or at least, our best attempt to date!)

Exemplar use-cases:
● A piece of software that can generate a “sensible” data submission form for any repository
(at the Force 2015 meeting a few months ago I gave a presentation of a working example of this… so I won’t repeat that today…)
● A piece of software that can generate a “sensible” query form/interface for any repository
(demonstration of this today!)
Skunkworks Task #1 - [F]indable
Invent harmonized cross-repository meta-descriptors

“FAIR Profiles”
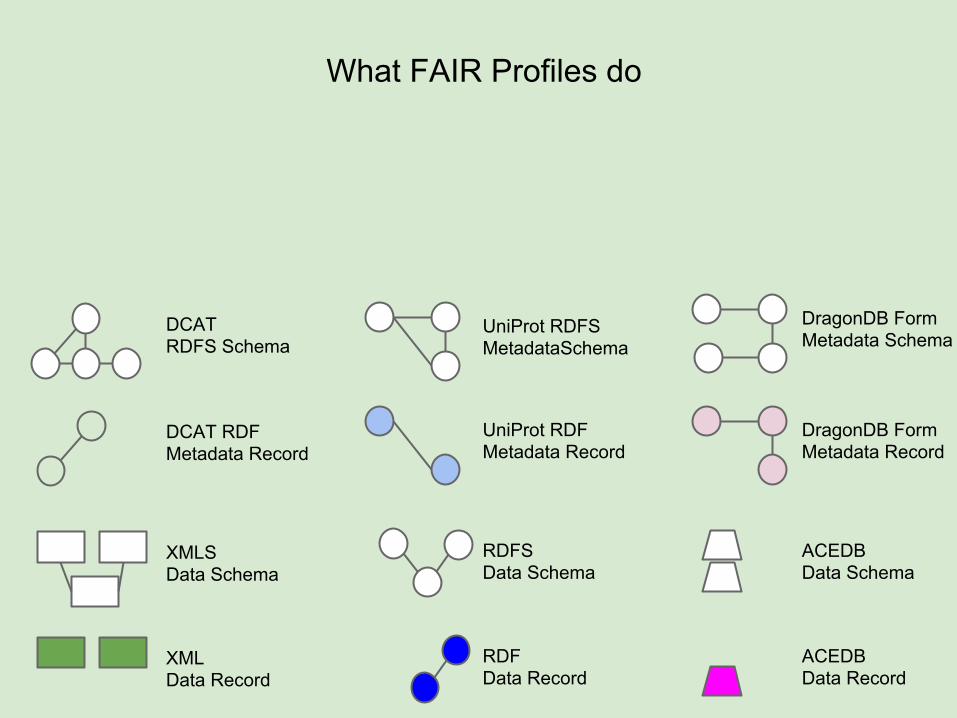
FAIR Profiles provide a common way to describe a repository’s metadata
(and data, for that matter!)
XML Data Record
XMLS Data Schema
DCAT RDF Metadata Record
RDF Data Record
RDFS Data Schema
UniProt RDFMetadata Record
ACEDBData Record
ACEDB Data Schema
DragonDB FormMetadata Record
DCAT RDFS Schema
UniProt RDFSMetadataSchema
DragonDB FormMetadata Schema
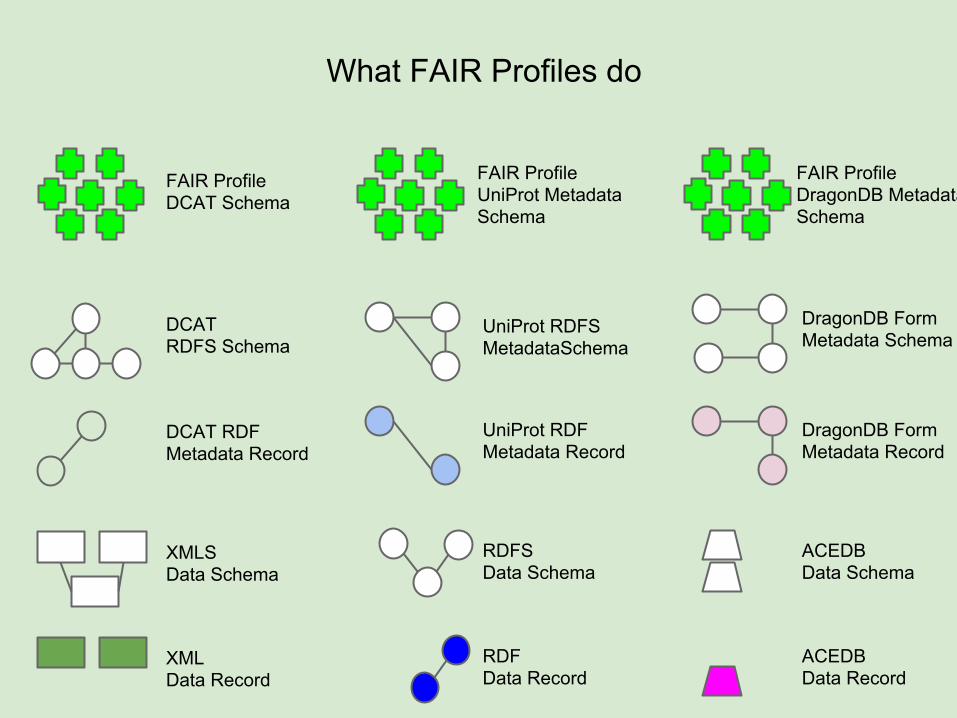
What FAIR Profiles do
XML Data Record
XMLS Data Schema
DCAT RDF Metadata Record
RDF Data Record
RDFS Data Schema
UniProt RDFMetadata Record
ACEDBData Record
ACEDB Data Schema
DragonDB FormMetadata Record
DCAT RDFS Schema
UniProt RDFSMetadataSchema
DragonDB FormMetadata Schema
FAIR ProfileDCAT Schema
FAIR ProfileUniProt Metadata Schema
FAIR ProfileDragonDB Metadata Schema
What FAIR Profiles do
XML Data Record
XMLS Data Schema
DCAT RDF Metadata Record
RDF Data Record
RDFS Data Schema
UniProt RDFMetadata Record
ACEDBData Record
ACEDB Data Schema
DragonDB FormMetadata Record
DCAT RDFS Schema
UniProt RDFSMetadataSchema
DragonDB FormMetadata Schema
FAIR ProfileDCAT Schema
FAIR ProfileUniProt Metadata Schema
FAIR ProfileDragonDB Metadata Schema
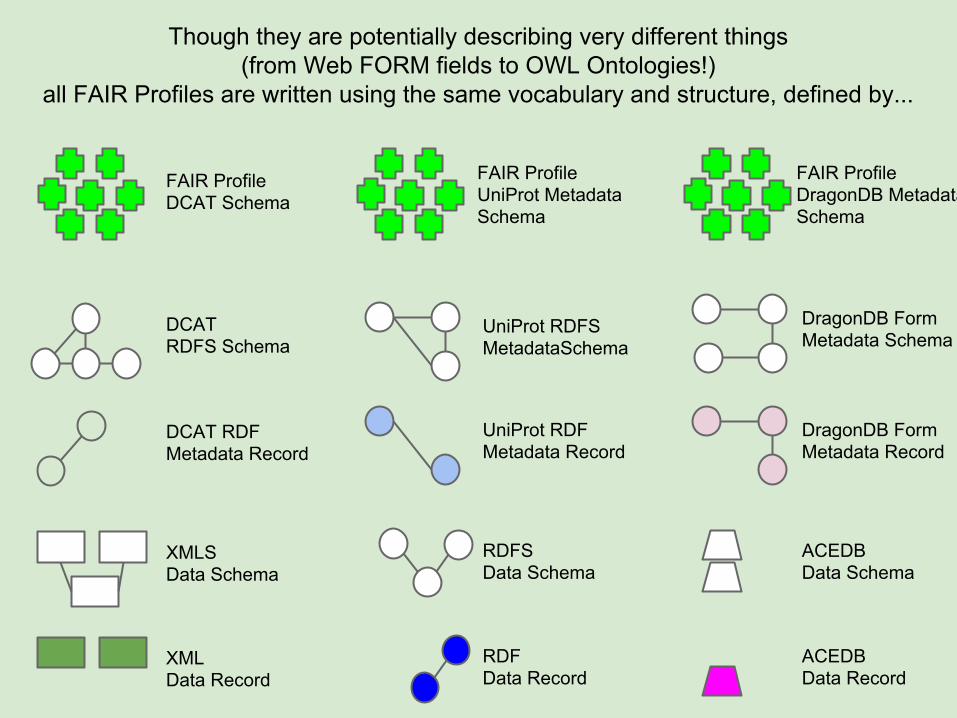
Though they are potentially describing very different things(from Web FORM fields to OWL Ontologies!)
all FAIR Profiles are written using the same vocabulary and structure, defined by...
XML Data Record
XMLS Data Schema
DCAT RDF Metadata Record
RDF Data Record
RDFS Data Schema
UniProt RDFMetadata Record
ACEDBData Record
ACEDB Data Schema
DragonDB FormMetadata Record
DCAT RDFS Schema
UniProt RDFSMetadataSchema
DragonDB FormMetadata Schema
FAIR ProfileDCAT Schema
FAIR ProfileUniProt Metadata Schema
FAIR ProfileDragonDB Metadata Schema

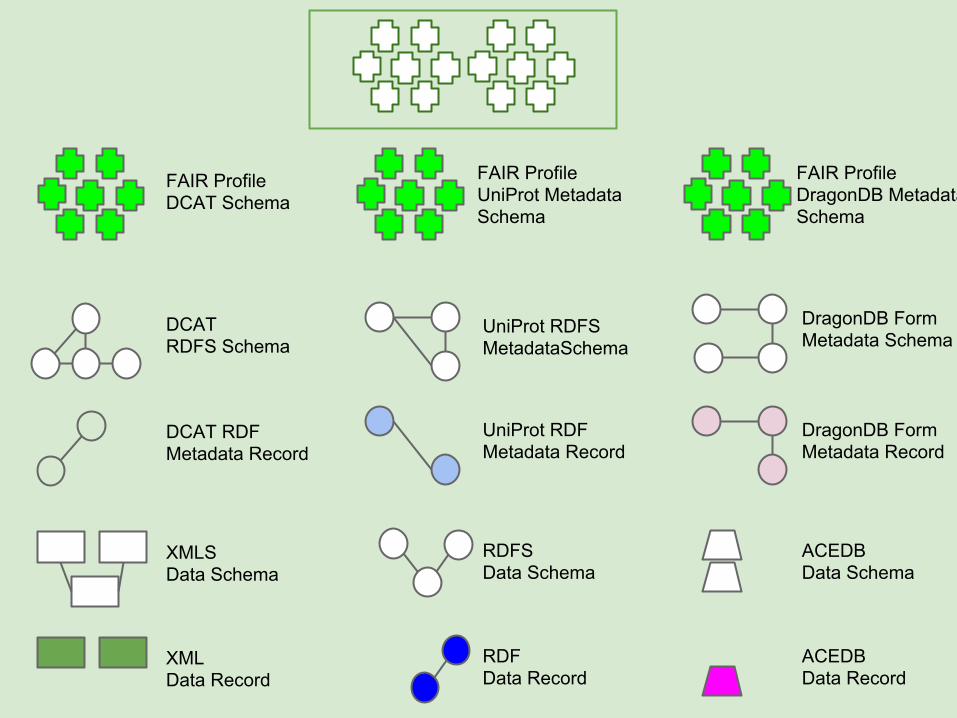
The FAIR Profile Schema
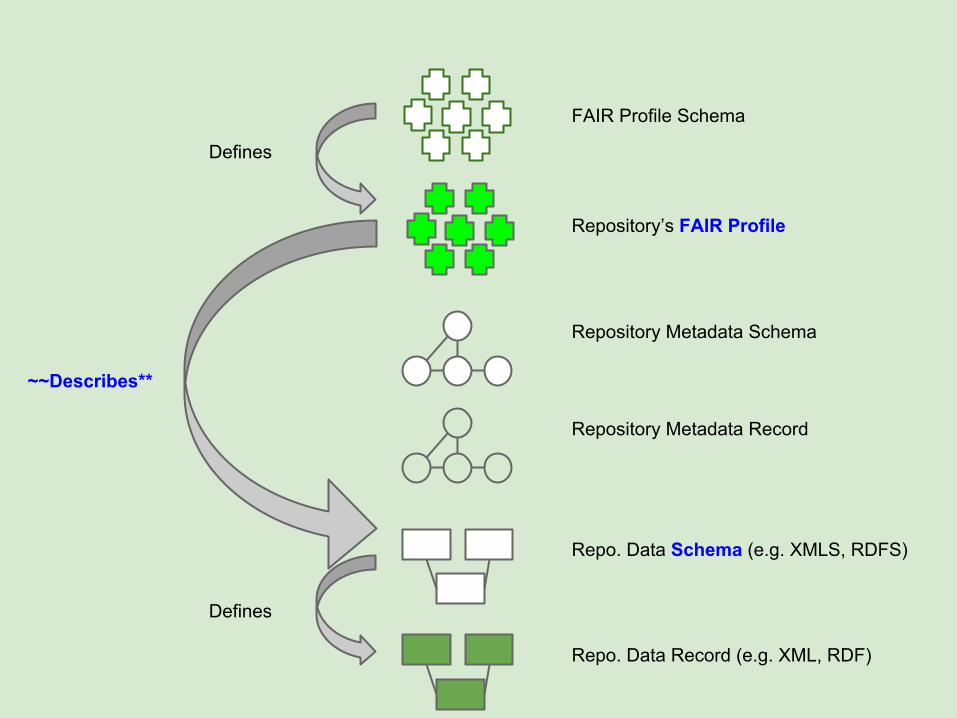
Repo. Data Record (e.g. XML, RDF)
Repo. Data Schema (e.g. XMLS, RDFS)
Repository Metadata Record
Repository Metadata Schema
Defines
Describes
Defines
Defines
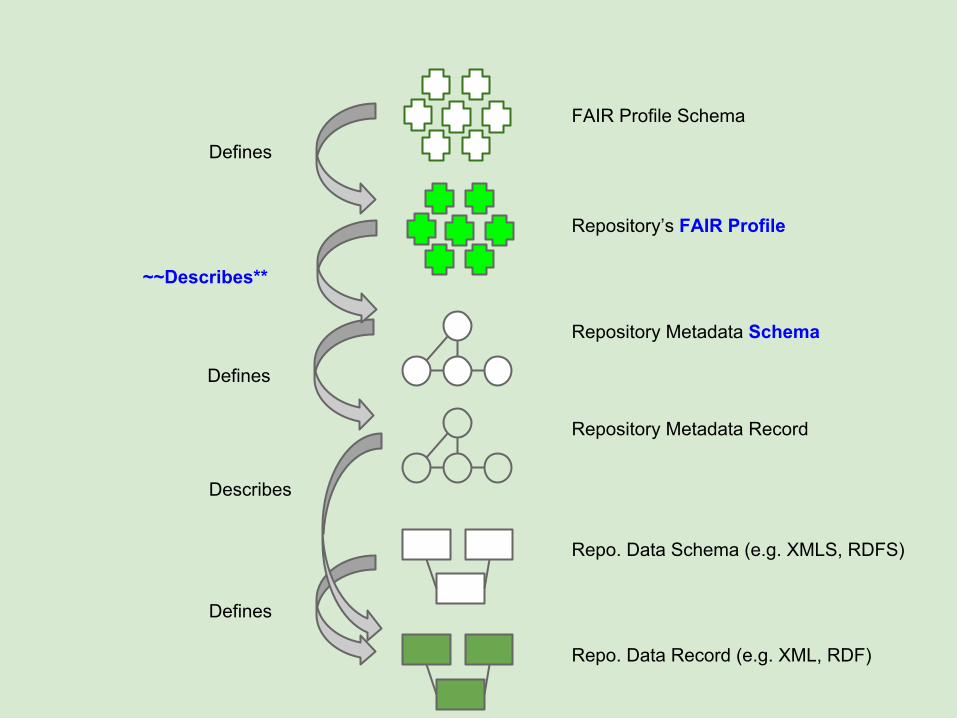
~~Describes**
Repository’s FAIR Profile
FAIR Profile Schema
Repo. Data Record (e.g. XML, RDF)
Repo. Data Schema (e.g. XMLS, RDFS)
Repository Metadata Record
Repository Metadata Schema
Defines
Defines
~~Describes**
Repository’s FAIR Profile
FAIR Profile Schema
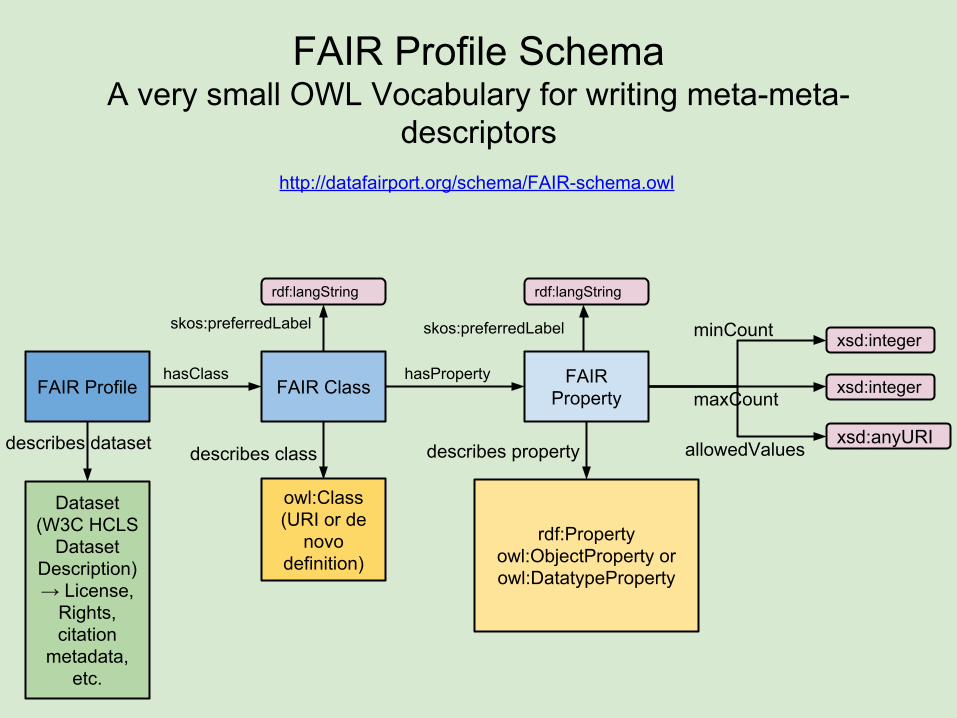
FAIR Profile SchemaA very small OWL Vocabulary for writing meta-meta-
descriptors
FAIR Profile FAIR Class
Dataset (W3C HCLS
Dataset Description)→ License,
Rights, citation
metadata, etc.
hasClass hasProperty
describes dataset
owl:Class(URI or de
novo definition)
rdf:Propertyowl:ObjectProperty or owl:DatatypeProperty
describes property
minCount
xsd:anyURI
xsd:integer
xsd:integermaxCount
allowedValues
FAIR Property
describes class
rdf:langString
skos:preferredLabel skos:preferredLabel
rdf:langString
http://datafairport.org/schema/FAIR-schema.owl
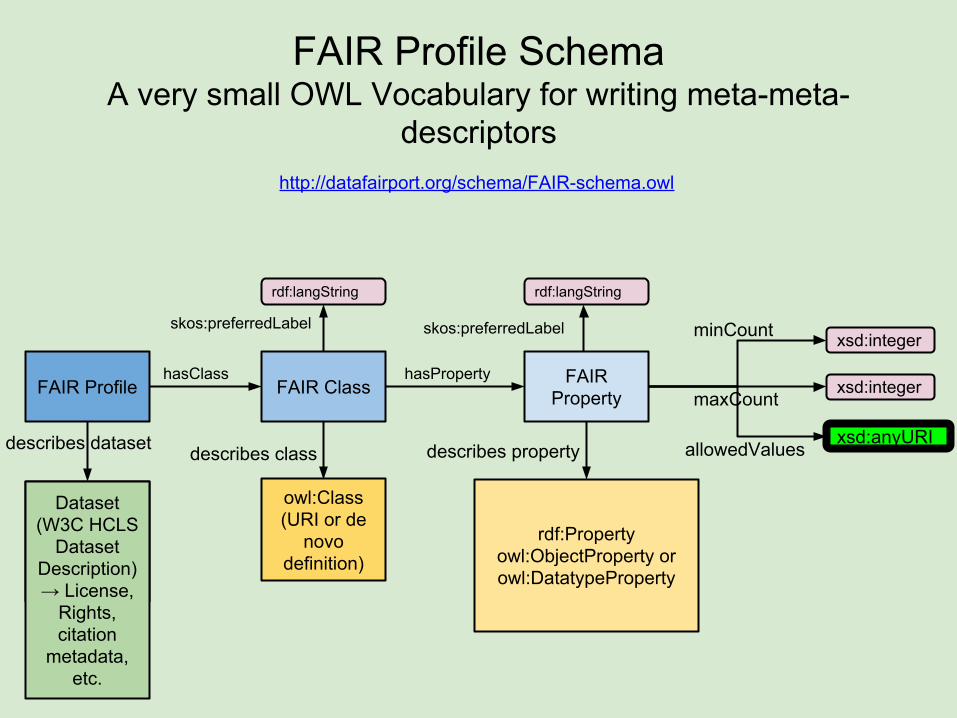
FAIR Profile SchemaA very small OWL Vocabulary for writing meta-meta-
descriptors
FAIR Profile FAIR Class
Dataset (W3C HCLS
Dataset Description)
hasClass hasProperty
describes dataset
owl:Class(URI or de
novo definition)
rdf:Propertyowl:ObjectProperty or owl:DatatypeProperty
describes property
minCount
xsd:anyURI
xsd:integer
xsd:integermaxCount
allowedValues
FAIR Property
describes class
rdf:langString
skos:preferredLabel skos:preferredLabel
rdf:langString
http://datafairport.org/schema/FAIR-schema.owl
Dataset (W3C HCLS
Dataset Description)→ License,
Rights, citation
metadata, etc.

xsd:anyURI
allowedValues
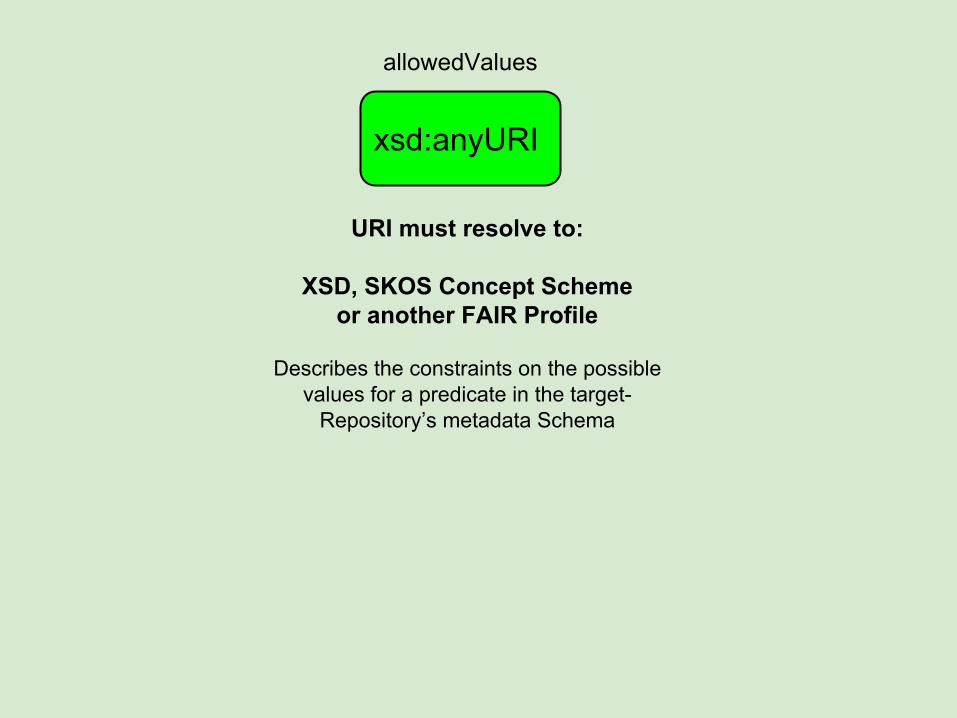
URI must resolve to:
XSD, SKOS Concept Schemeor another FAIR Profile
Describes the constraints on the possible values for a predicate in the target-
Repository’s metadata Schema
xsd:anyURI
allowedValues

URI must resolve to:
XSD, SKOS Concept Schemeor another FAIR Profile
Describes the constraints on the possible values for a predicate in the target-
Repository’s metadata Schema
NOTE: we cannot use rdfs:range because we are meta-modelling a schema! The
predicate is a CLASS at the meta-model level, so use of rdfs:range is not appropriate.
xsd:anyURI
allowedValues
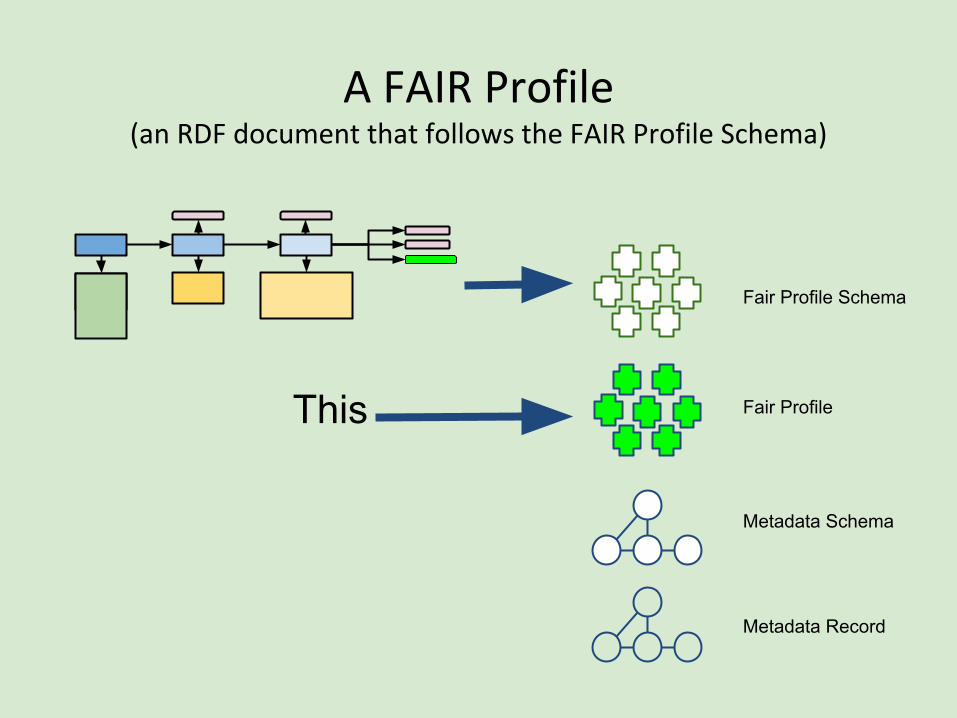
A FAIR Profile (an RDF document that follows the FAIR Profile Schema)
This
Metadata Record
Metadata Schema
Fair Profile
Fair Profile Schema

What a FAIR Profile is:
A meta-description of the (meta)data in a repository

What a FAIR Profile is:
A meta-description of the (meta)data in a repository
What a FAIR Profile is NOT:
THE meta-description of the (meta)data in a repository

What a FAIR Profile is:
A meta-description of the (meta)data in a repository
if you were to view it from a particular “perspective”
(also known as a “lens*” over the data)
* Scientific Lenses to Support Multiple Views over Linked Chemistry Data; DOI:10.1007/978-3-319-11964-9_7

What a FAIR Profile is:
A meta-description of the (meta)data in a repository
if you were to view it from a particular “perspective”
(also known as a “lens*” over the data)
this is where the FAIRport approach becomes distinctly powerful!

What a FAIR Profile is:
A meta-description of the (meta)data in a repository
if you were to view it from a particular “perspective”
(also known as a “lens*” over the data)
but first, look at the other FAIRport components

Skunkworks Task #2 - [A]cessible
Are there already access layer definitions?

A set of behaviors for providing a unified (albeit simplistic!) access layer for “records” contained in any Web resource
Skunkworks Task #2 - [A]cessible
Are there already access layer definitions?

LDP sits at a URL waiting
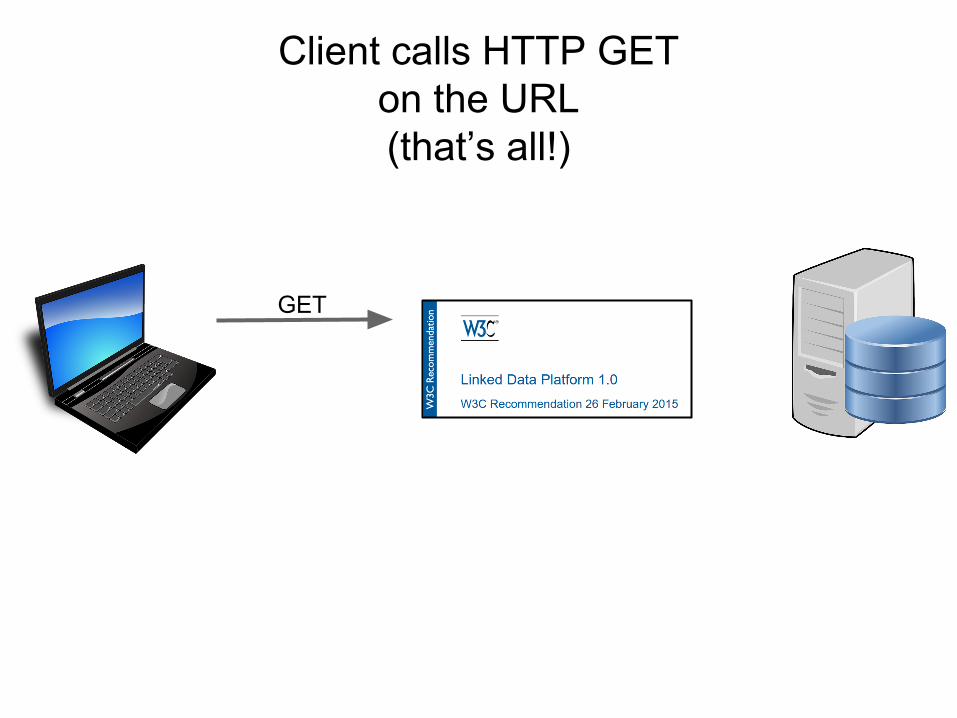
GET
Client calls HTTP GETon the URL(that’s all!)

??
LDP communicates with the repository
(how? entirely up to you!)

Repository returns data“about available records”(how? entirely up to you!)
??

LDP returns you anRDF representation of the
list of records’ URLs
<RDF>URL1URL2URL3URL4URL5URL6……...</RDF>
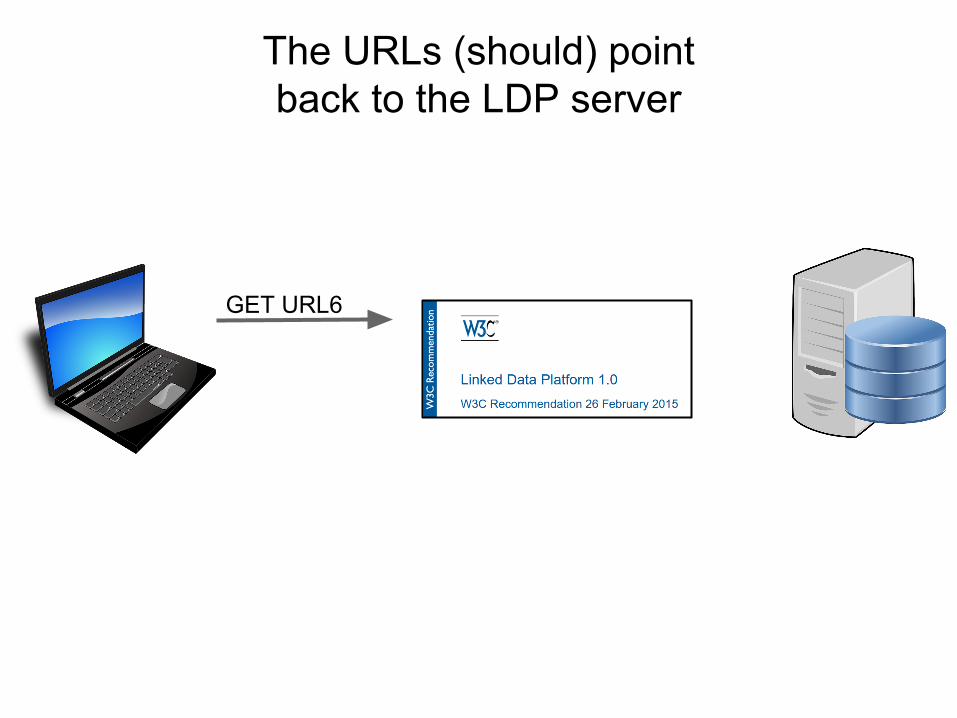
GET URL6
The URLs (should) point back to the LDP server

??
LDP communicates with the repository about that record
??

LDP returns you DCAT Distributions for all
available formats of that record that the repo provides
<RDF>
<dcat:Dist.><format xml> URL6a
<dcat:Dist.><format html>URL6b
</RDF>
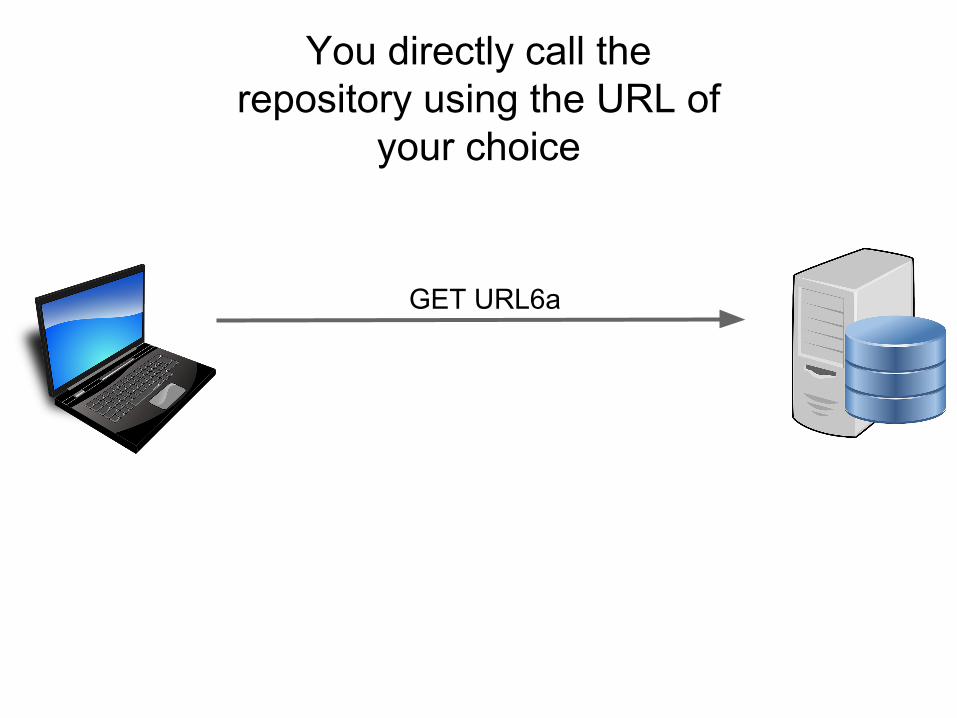
You directly call the repository using the URL of
your choice
GET URL6a
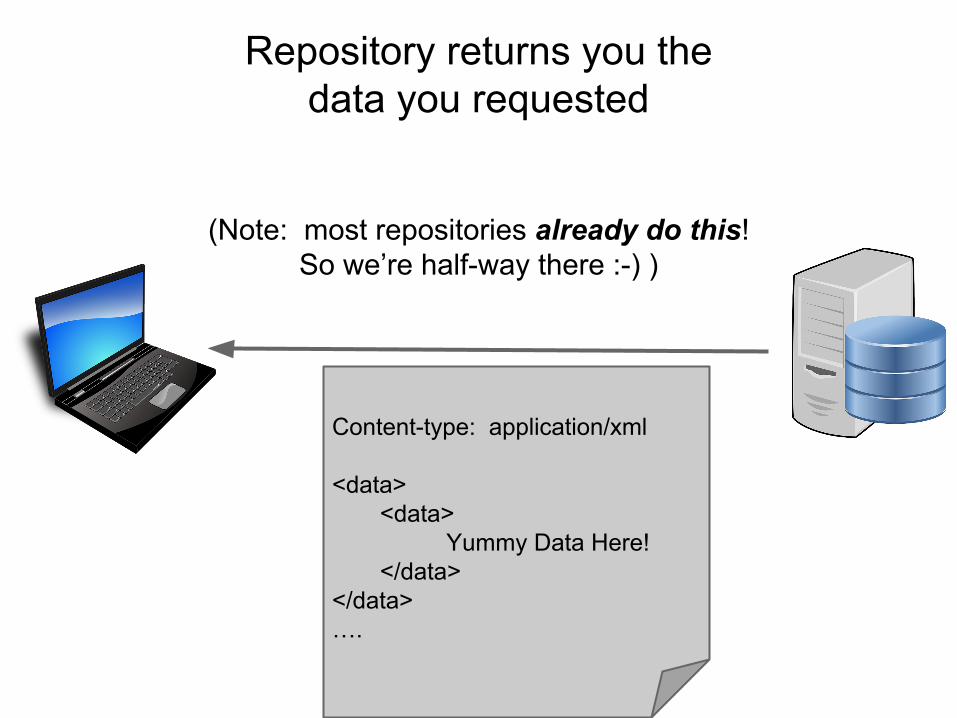
Repository returns you the data you requested
Content-type: application/xml
<data><data> Yummy Data Here!</data>
</data>….
(Note: most repositories already do this! So we’re half-way there :-) )

The first time I wrote one of these from scratch, it was about 170 lines of code, and took less than 4 hours
(including reading the W3C documentation!)

The first time I wrote one of these from scratch, it was about 170 lines of code, and took less than 4 hours
(including reading the W3C documentation!)
When one of these is associated with a FAIR Profile we call it a “FAIR Accessor”

Skunkworks Task #3 - [I]nteroperable
This is “the holy grail”!!

Skunkworks Task #3 - [I]nteroperable
This is “the holy grail”!!
This is where the FAIR Profile reveals its utility
“what it IS” vs. “what it IS NOT”

What a FAIR Profile is:
A meta-description of the (meta)data in a repository
if you were to view it from a particular “perspective”
(also known as a “lens” over the data)

Skunkworks Task #3 - [I]nteroperable
“FAIR Projectors”
A FAIR Projector is a (potentially) small, modular, reusable Web based service that “projects” data
from a repository into the format described by a FAIR Profile

Skunkworks Task #3 - [I]nteroperable
“FAIR Projectors”
A FAIR Projector is a (potentially) small, modular, reusable Web based service that “projects” data
from a repository into the format described by a FAIR Profile
http://linkeddatafragments.org/

RESTful access to RDF data resources
RESTful hypermedia controls (e.g. pagination) defined by Hydra W3C Community Group
http://www.hydra-cg.com/
implementedBy
implementedBy
GET
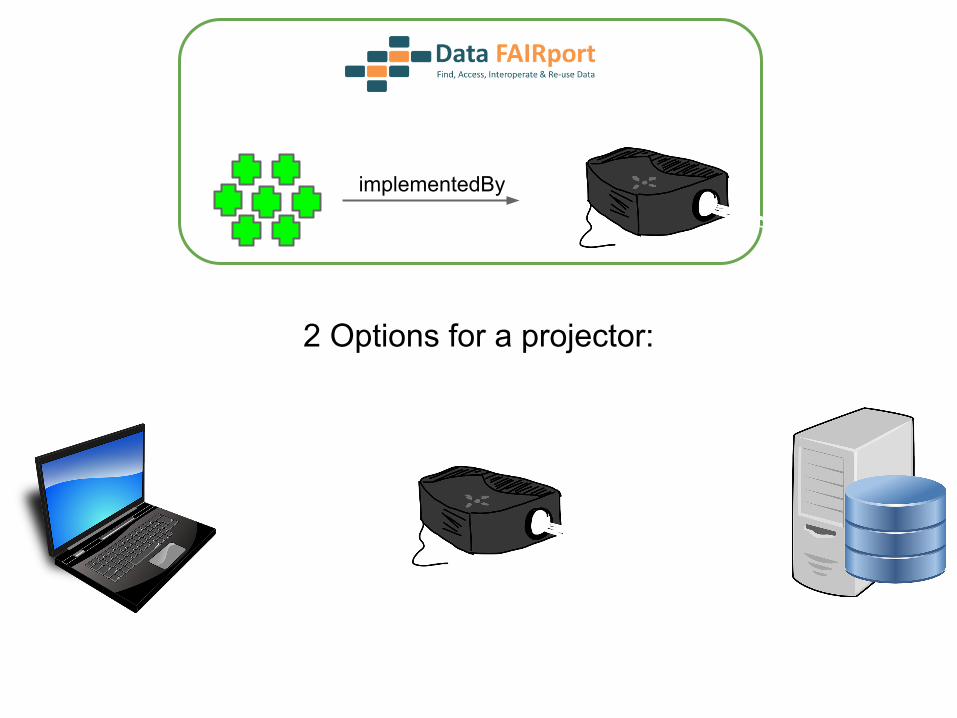
implementedBy
2 Options for a projector:
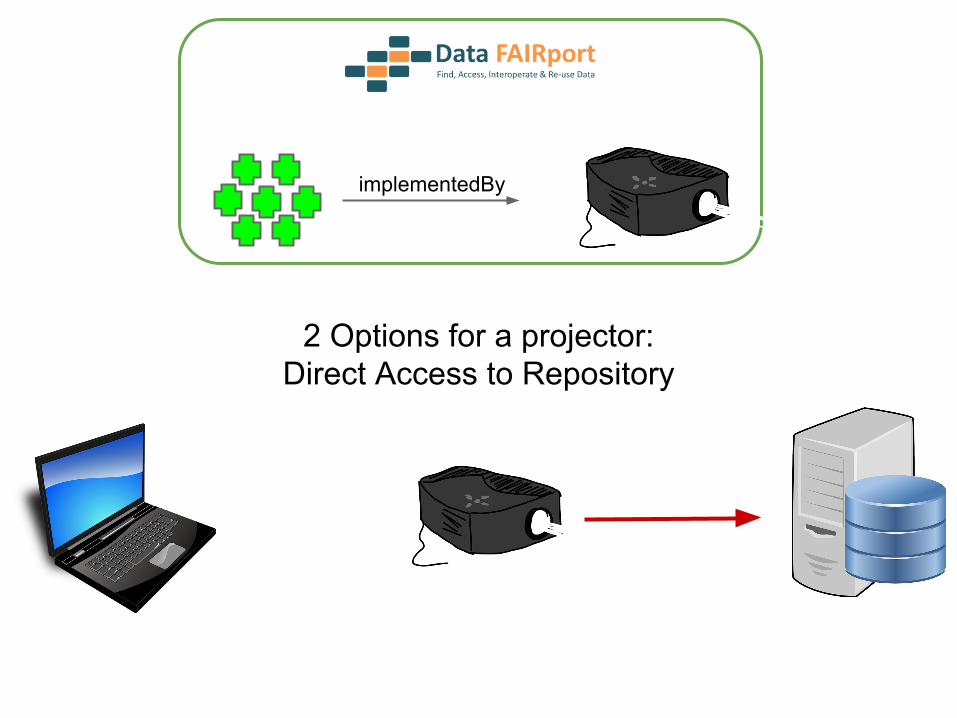
implementedBy
2 Options for a projector:Direct Access to Repository
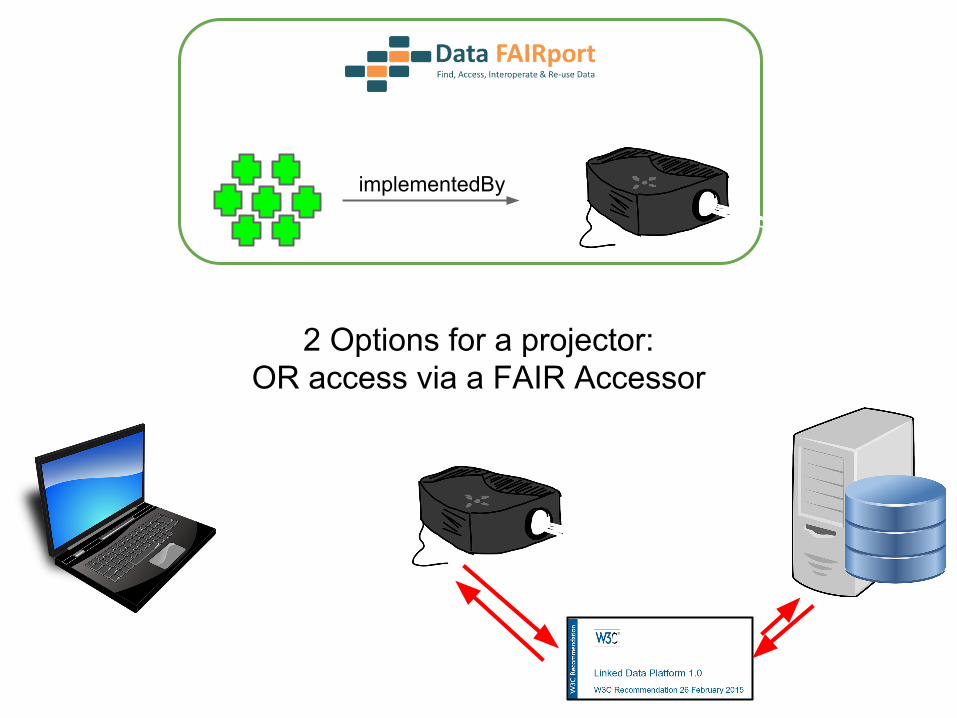
implementedBy
2 Options for a projector:OR access via a FAIR Accessor
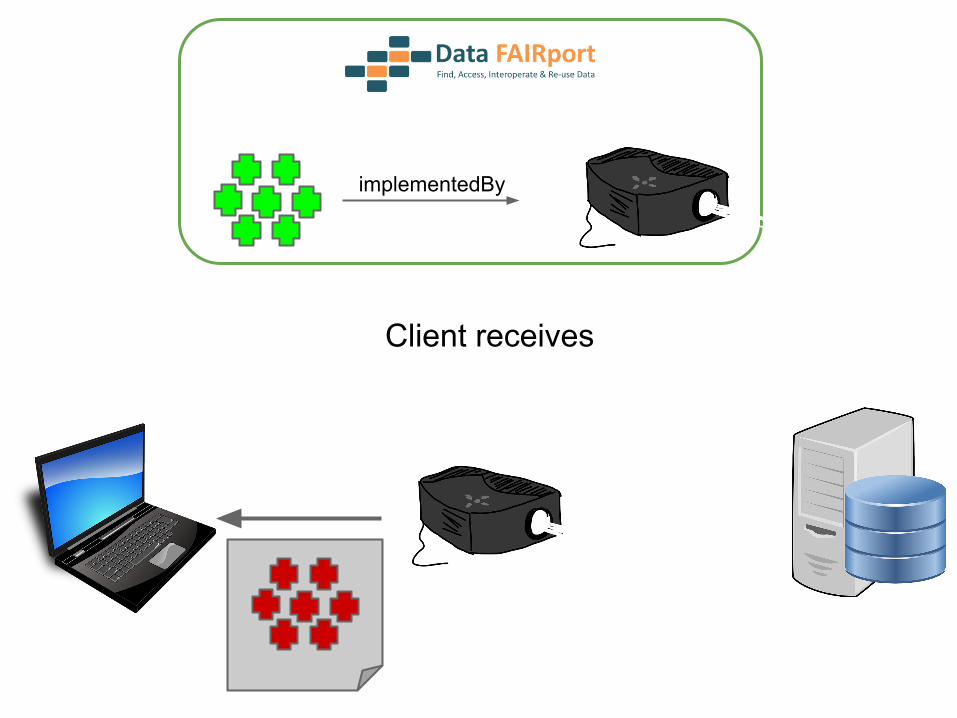
implementedBy
Client receives
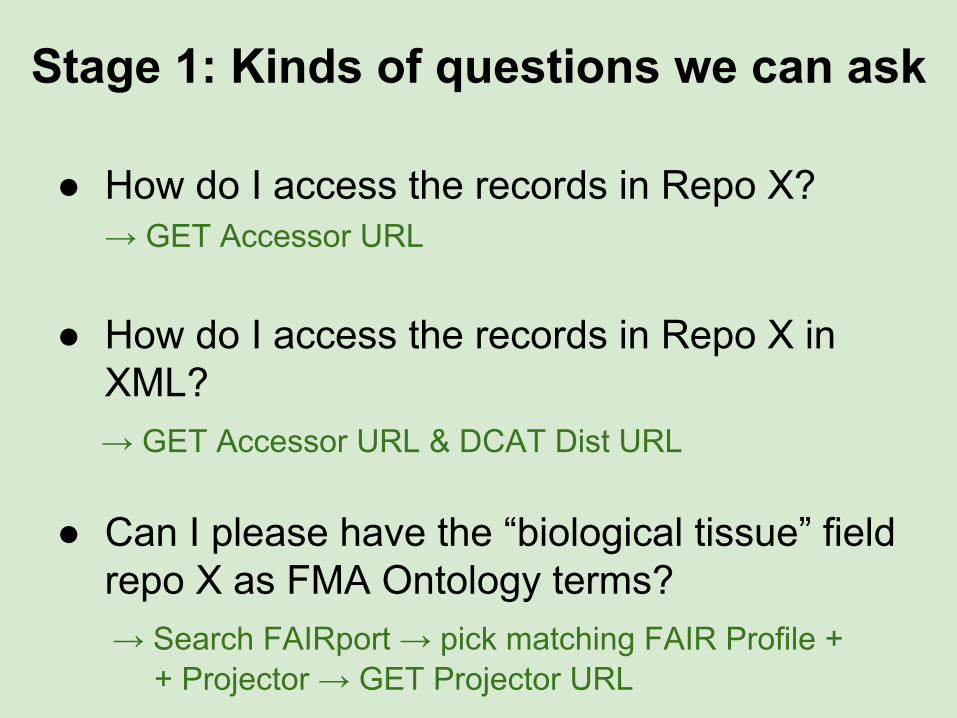
Stage 1: Kinds of questions we can ask
● How do I access the records in Repo X?→ GET Accessor URL
● How do I access the records in Repo X in XML?
→ GET Accessor URL & DCAT Dist URL
● Can I please have the “biological tissue” field repo X as FMA Ontology terms?
→ Search FAIRport → pick matching FAIR Profile + + Projector → GET Projector URL

The first time I wrote one of these from scratch, it was about 300 lines of Perl code,
and took about 6 hours (including reading the LDF documentation!)
and it projected three different FAIR Profiles

Stage 2: Leverage the Modularity
implementedBy
Stage 2: Leverage the Modularity
implementedByimplementedBy
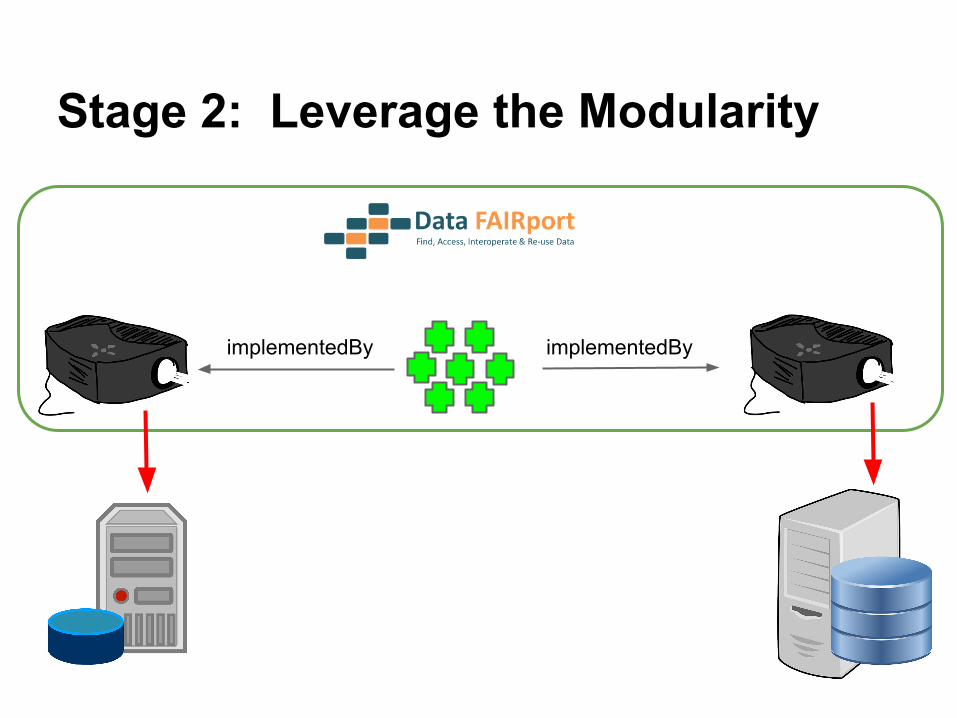
Stage 2: Leverage the Modularity
implementedByimplementedBy
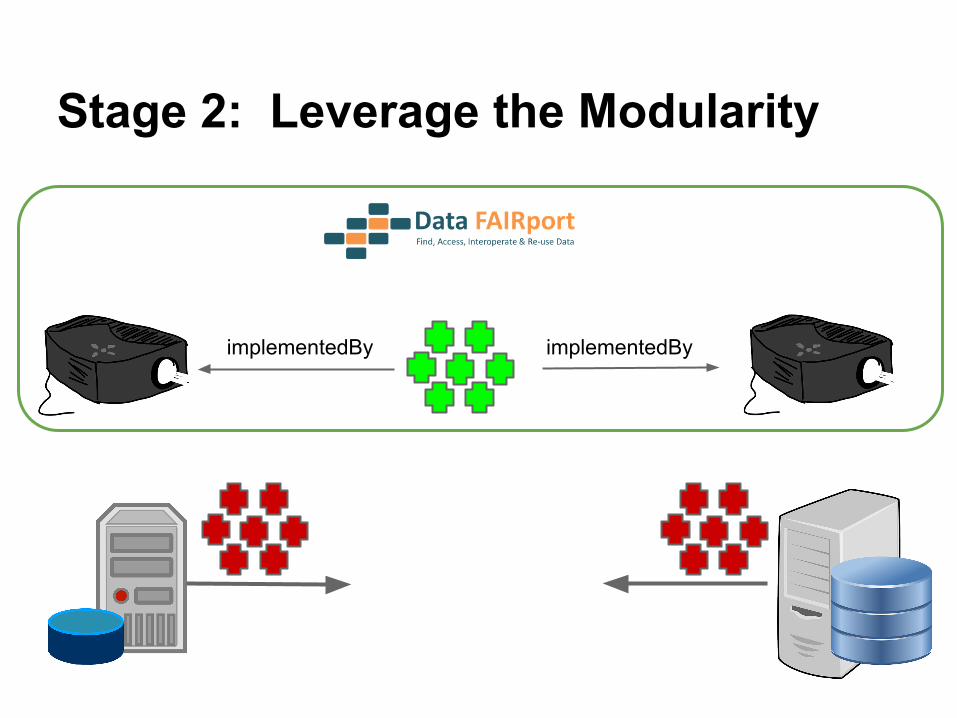
Stage 2: Leverage the Modularity
implementedByimplementedBy
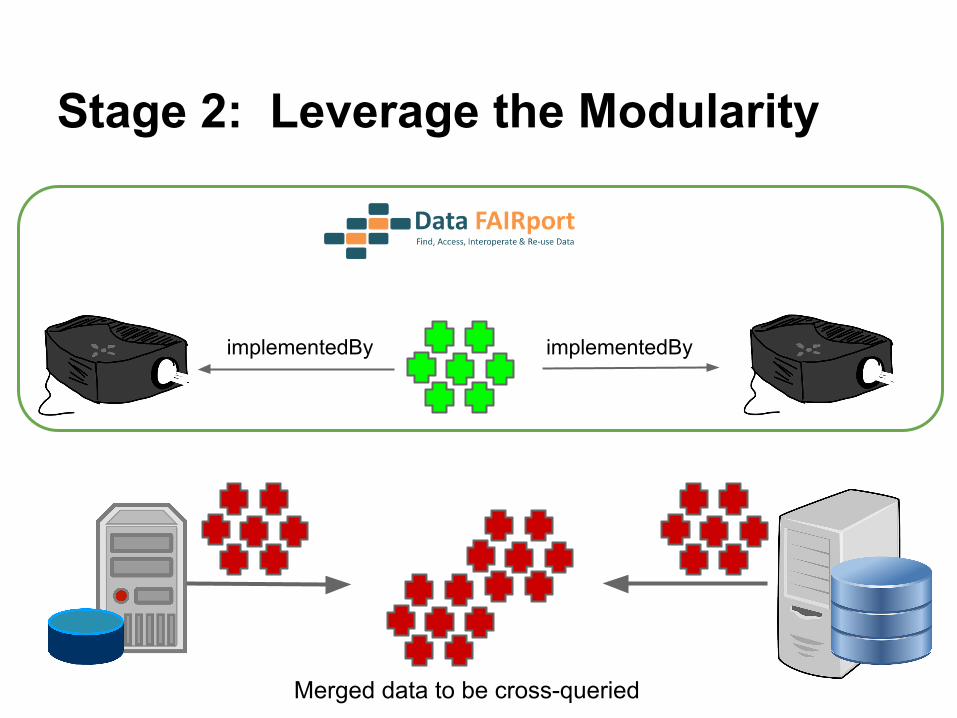
Stage 2: Leverage the Modularity
implementedByimplementedBy
Merged data to be cross-queried


Main features of FAIR Profiles● Do not require repository participation - anyone can write a Profile
● Provides a purpose-driven, potentially non-comprehensive “view” on a repository
● FAIR Profiles of any given repository facet may be different! May use different vocabularies or may interpret fields differently, depending on the needs of the Profile author
● FAIR profiles can/should be indexed and shared (e.g. in a FAIRport Registry), to facilitate cross-repository interoperability and integration
● There is no (obvious) reason why a FAIR profile could not be used to describe the DATA in the repository, not just the metadata… ○ my examples on the final page of this slideshow do exactly that!
● FAIR Profiles can be used both at the “read” and at the “write” end of data publishing… (Force 11 Oxford meeting demo was for “write” interfaces)

Main features of FAIRPort Platform
● GET GET GET!! We didn’t invent any new technology or API :-) :-)
● All components modular, re-usable, and often will be written by 3rd parties○ → encourages the creation of an ecosystem of these lightweight,
discoverable little data transformers
● All components identified by URL, and can be “cobbled together” in whatever way a client needs on a particular day (and this can happen automatically!)
● Because everything is identified by a URL, and we only use HTTP GET, components can be “chained” (e.g. the Projector calls GET on the URL of another Projector)○ → i.e. I simply don’t care how the Projector or Accessor work “under the
hood”. I only look at the FAIR Profile and then call GET.

Skunkworks Participants● Mark Wilkinson● Michel Dumontier● Barend Mons● Tim Clark● Jun Zhao● Paolo Ciccarese● Paul Groth● Erik van Mulligen● Luiz Olavo Bonino da
Silva Santos● Matthew Gamble● Carole Goble● Joël Kuiper● Morris Swertz● Erik Schultes
● Erik Schultes● Mercè Crosas● Adrian Garcia● Philip Durbin● Jeffrey Grethe● Katy Wolstencroft● Sudeshna Das● M. Emily Merrill

Working Examples - One (small) dataset (the Allele slice of my own DragonDB): http://antirrhinum.net An example record in the repository's native format is here: http://antirrhinum.net/cgi-bin/ace/generic/xml/DragonDB?name=cho;class=Allele
- Three different FAIR Profiles - one with textual descriptions and gene cross-references, the other two with phenotypic images described using the SIO ontology, or the EDAM ontology (respectively). This is the "F" in FAIR, since these can (in principle) be searched and queried in order to find repositories that potentially have your data of interest, in your desired format. * http://biordf.org/DataFairPort/ProfileSchemas/DragonDB_Allele_ProfileAlleleDescriptions.rdf * http://biordf.org/DataFairPort/ProfileSchemas/DragonDB_Allele_ProfileImagesEDAM.rdf * http://biordf.org/DataFairPort/ProfileSchemas/DragonDB_Allele_ProfileImagesSIO.rdf
- a "FAIR Accessor" that provides a Linked Data Platform-compliant way to retrieve all of the URIs for the Allele records, as well as their various representations (described as DCAT Distributions). This is the "A" in FAIR. http://antirrhinum.net/cgi-bin/LDP/Alleles
- a "FAIR Projector" that takes the data from the Allele records and "projects" it as RDF that is compliant with whichever Profile you chose. This is the 'I" in FAIR. http://biordf.org/cgi-bin/DataFairPort/DragonDB_LDF_Profiler (you wont see anything if you just surf to that endpoint. It's a RESTful web service that requires additional URL components, as described below)
- Profiles and Accessors and Projectors are linked by small fragments of RDF, but in principle they are all independent from one another. This describes the accessor for a given Profile: http://biordf.org/DataFairPort/DragonDB_Allele_Accessor.rdf This describes the projector for a given profile: http://biordf.org/DataFairPort/DragonDB_FAIRDataProjector.rdf (in this case, the same file is describing all three FAIR projections, but these could be published independently just as easily)
Three “Projections” of the DragonDB Allele Data (note that most of the process above is achieved simply by called GET on the URLs below!!)
http://biordf.org/cgi-bin/DataFairPort/DragonDB_LDF_Profiler/DragonDB_Allele_ProfileAlleleDescriptions/http://biordf.org/cgi-bin/DataFairPort/DragonDB_LDF_Profiler/DragonDB_Allele_ProfileImagesSIO/http://biordf.org/cgi-bin/DataFairPort/DragonDB_LDF_Profiler/DragonDB_Allele_ProfileImagesEDAM/
Recommended



















