
The safe way to make Ceph storage enterprise ready
Build your own [disaster]
Copyright 2015 FUJITSU
Paul von Stamwitz
Sr Storage Architect
Storage Planning RampD Center
2015-07-16
1
The safe and convenient way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
2
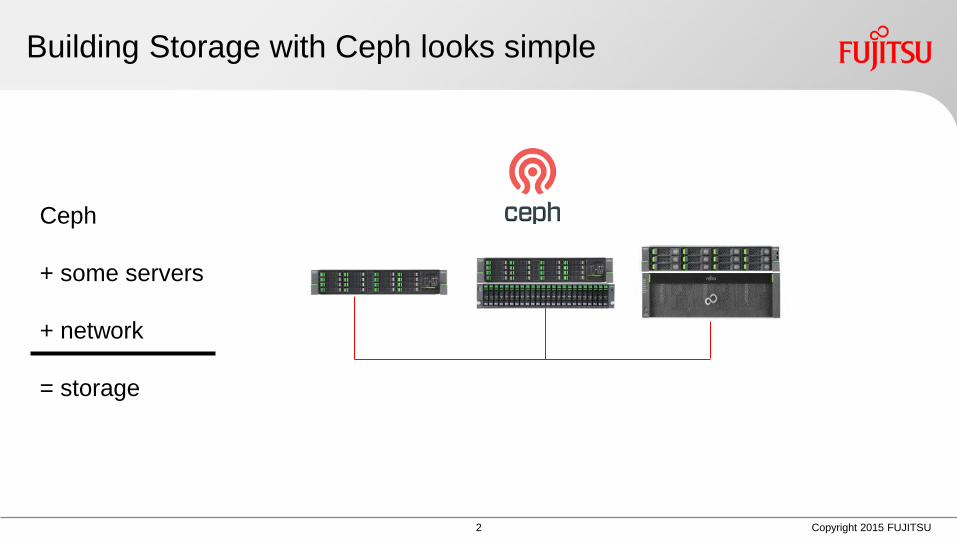
Building Storage with Ceph looks simple
Copyright 2015 FUJITSU
Ceph
+ some servers
+ network
= storage
3
Building Storage with Ceph looks simple ndash buthelliphellip
Many new Complexities
Rightsizing server disk types network
bandwidth
Silos of management tools (HW SW)
Keeping Ceph versions with versions of
server HW OS connectivity drivers in sync
Management of maintenance and support
contracts of components
Troubleshooting
Copyright 2015 FUJITSU
Build Ceph source storage yourself
4
The challenges of software defined storage
What users want
Open standards
High scalability
High reliability
Lower costs
No-lock in from a vendor
What users may get
An own developed storage system based on open
industry standard HW amp SW components
High scalability and reliability If the stack works
Lower investments but higher operational efforts
Lock-in into the own stack
Copyright 2015 FUJITSU
5
ETERNUS CD10000 ndash Making Ceph enterprise ready
Build Ceph source storage yourself Out of the box ETERNUS CD10000
incl support
incl maintenance
ETERNUS CD10000 combines open source storage with enterprisendashclass quality of service
E2E Solution Contract by Fujitsu based on Red Hat Ceph Enterprise
Easy Deployment Management by Fujitsu
+
+
+ Lifecycle Management for Hardware amp Software by Fujitsu
+
6
Fujitsu Maintenance Support and Professional Services
ETERNUS CD10000 A complete offer
Copyright 2015 FUJITSU
7
Unlimited Scalability
Cluster of storage nodes
Capacity and performance scales by
adding storage nodes
Three different node types enable
differentiated service levels
Density capacity optimized
Performance optimized
Optimized for small scale dev amp test
1st version of CD10000 (Q32014) is
released for a range of 4 to 224 nodes
Scales up to gt50 Petabyte
Copyright 2015 FUJITSU
Basic node 12 TB Performance node 35 TB Capacity node 252 TB
8
Immortal System
Copyright 2015 FUJITSU
Node1 Node2 Node(n)
+
Adding nodes
with new generation
of hardware
helliphelliphellip +
Adding nodes
New Node1
Non-disruptive add remove exchange of hardware (disks and nodes)
Mix of nodesdisks of different generations online technology refresh
Very long lifecycle reduces migration efforts and costs
9
TCO optimized
Based on x86 industry standard architectures
Based on open source software (Ceph)
High-availability and self-optimizing functions are part
of the design at no extra costs
Highly automated and fully integrated management
reduces operational efforts
Online maintenance and technology refresh reduce
costs of downtime dramatically
Extreme long lifecycle delivers investment protection
End-to-end design an maintenance from Fujitsu
reduces evaluation integration maintenance costs
Copyright 2015 FUJITSU
Better service levels at reduced costs ndash business centric storage
10
One storage ndash seamless management
ETERNUS CD10000 delivers one seamless
management for the complete stack
Central Ceph software deployment
Central storage node management
Central network management
Central log file management
Central cluster management
Central configuration administration and
maintenance
SNMP integration of all nodes and
network components
Copyright 2015 FUJITSU
11
Seamless management (2)
Dashboard ndash Overview of cluster status
Server Management ndash Management of cluster hardware ndash addremove server
(storage node) replace storage devices
Cluster Management ndash Management of cluster resources ndash cluster and pool creation
Monitoring the cluster ndash Monitoring overall capacity pool utilization status of OSD
Monitor and MDS processes Placement Group status and RBD status
Managing OpenStack Interoperation Connection to OpenStack Server and
placement of pools in Cinder multi-backend
12
Optional use of Calamari Management GUI
12
13
Example Replacing an HDD
Plain Ceph
taking the failed disk offline in Ceph
taking the failed disk offline on OS
Controller Level
identify (right) hard drive in server
exchanging hard drive
partitioning hard drive on OS level
Make and mount file system
bring the disk up in Ceph again
On ETERNUS CD10000
vsm_cli ltclustergt replace-disk-out
ltnodegt ltdevgt
exchange hard drive
vsm_cli ltclustergt replace-disk-in
ltnodegt ltdevgt
14
Example Adding a Node
Plain Ceph
Install hardware
Install OS
Configure OS
Partition disks (OSDs Journals)
Make filesystems
Configure network
Configure ssh
Configure Ceph
Add node to cluster
On ETERNUS CD10000
Install hardware
bull hardware will automatically PXE boot
and install the current cluster
environment including current
configuration
Node automatically available to GUI
Add node to cluster with mouse click
on GUI
bull Automatic PG adjustment if needed
15
Adding and Integrating Apps
The ETERNUS CD10000 architecture
enables the integration of apps
Fujitsu is working with customers and
software vendors to integrate selected
storage apps
Eg archiving sync amp share data
discovery cloud appshellip
Copyright 2015 FUJITSU
Cloud
Services
Sync
amp Share Archive
iRODS data
discovery
ET
ER
NU
S C
D1
00
00
Object Level
Access
Block Level
Access
File Level
Access
Central Management
Ceph Storage System SW and Fujitsu
Extensions
10GbE Frontend Network
Fast Interconnect Network
Perf
orm
ance N
odes
Capacity N
odes
16
ETERNUS CD10000 at University Mainz
Large university in Germany
Uses iRODS Application for library services
iRODS is an open-source data management software in use at research
organizations and government agencies worldwide
Organizes and manages large depots of distributed digital data
Customer has built an interface from iRODS to Ceph
Stores raw data of measurement instruments (eg research in chemistry and
physics) for 10+ years meeting compliance rules of the EU
Need to provide extensive and rapidly growing data volumes online at
reasonable costs
Will implement a sync amp share service on top of ETERNUS CD10000
17
Summary ETERNUS CD10k ndash Key Values
Copyright 2015 FUJITSU
ETERNUS CD10000
ETERNUS
CD10000
Unlimited
Scalability
TCO
optimized
The new
unified
Immortal
System
Zero
Downtime
ETERNUS CD10000 combines open source storage with enterprisendashclass quality of service
18
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
19
What is OpenStack
Free open source (Apache license) software governed by a non-profit foundation
(corporation) with a mission to produce the ubiquitous Open Source Cloud
Computing platform that will meet the needs of public and private clouds
regardless of size by being simple to implement and massively scalable
Platin
Gold
Corporate
hellip
hellip
Massively scalable cloud operating system that
controls large pools of compute storage and
networking resources
Community OSS with contributions from 1000+
developers and 180+ participating organizations
Open web-based API Programmatic IaaS
Plug-in architecture allows different hypervisors
block storage systems network implementations
hardware agnostic etc
httpwwwopenstackorgfoundationcompanies
20
Attained fast growing customer interest
VMware clouds dominate
OpenStack clouds already 2
Worldwide adoption
Source OpenStack User Survey and Feedback Nov 3rd 2014
Source OpenStack User Survey and Feedback May 13th 2014
21
Why are Customers so interested
Source OpenStack User Survey and Feedback Nov 3rd 2014
Greatest industry amp community support
compared to alternative open platforms
Eucalyptus CloudStack OpenNebula
ldquoAbility to Innovaterdquo jumped from 6 to 1
22
OpenStackorg User Survey Paris Nov 2014
23
OpenStack Cloud Layers
OpenStack and ETERNUS CD10000
Physical Server (CPU Memory SSD HDD) and Network
Base Operating System (CentOS)
OAM
-dhcp
-Deploy
-LCM
Hypervisor
KVM ESXi
Hyper-V
Compute (Nova)
Network
(Neutron) +
plugins
Dashboard (Horizon)
Billing Portal
OpenStack
Cloud APIs
RADOS
Block
(RBD)
S3
(Rados-GW)
Object (Swift) Volume (Cinder)
Authentication (Keystone)
Images (Glance)
EC2 API
Metering (Ceilometer)
Manila (File)
File
(CephFS)
Fujitsu
Open Cloud
Storage
24
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
25
Backgrounds (1)
Erasure codes for content data
Content data for ICT services is ever-growing
Demand for higher space efficiency and durability
Reed Solomon code (de facto erasure code) improves both
Reed Solomon Code (Old style)Triple Replication
However Reed Solomon code is not so recovery-efficient
content data
copy copy
3x space
parity parity
15x space
content data
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom

1
The safe and convenient way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
2
Building Storage with Ceph looks simple
Copyright 2015 FUJITSU
Ceph
+ some servers
+ network
= storage
3
Building Storage with Ceph looks simple ndash buthelliphellip
Many new Complexities
Rightsizing server disk types network
bandwidth
Silos of management tools (HW SW)
Keeping Ceph versions with versions of
server HW OS connectivity drivers in sync
Management of maintenance and support
contracts of components
Troubleshooting
Copyright 2015 FUJITSU
Build Ceph source storage yourself
4
The challenges of software defined storage
What users want
Open standards
High scalability
High reliability
Lower costs
No-lock in from a vendor
What users may get
An own developed storage system based on open
industry standard HW amp SW components
High scalability and reliability If the stack works
Lower investments but higher operational efforts
Lock-in into the own stack
Copyright 2015 FUJITSU
5
ETERNUS CD10000 ndash Making Ceph enterprise ready
Build Ceph source storage yourself Out of the box ETERNUS CD10000
incl support
incl maintenance
ETERNUS CD10000 combines open source storage with enterprisendashclass quality of service
E2E Solution Contract by Fujitsu based on Red Hat Ceph Enterprise
Easy Deployment Management by Fujitsu
+
+
+ Lifecycle Management for Hardware amp Software by Fujitsu
+
6
Fujitsu Maintenance Support and Professional Services
ETERNUS CD10000 A complete offer
Copyright 2015 FUJITSU
7
Unlimited Scalability
Cluster of storage nodes
Capacity and performance scales by
adding storage nodes
Three different node types enable
differentiated service levels
Density capacity optimized
Performance optimized
Optimized for small scale dev amp test
1st version of CD10000 (Q32014) is
released for a range of 4 to 224 nodes
Scales up to gt50 Petabyte
Copyright 2015 FUJITSU
Basic node 12 TB Performance node 35 TB Capacity node 252 TB
8
Immortal System
Copyright 2015 FUJITSU
Node1 Node2 Node(n)
+
Adding nodes
with new generation
of hardware
helliphelliphellip +
Adding nodes
New Node1
Non-disruptive add remove exchange of hardware (disks and nodes)
Mix of nodesdisks of different generations online technology refresh
Very long lifecycle reduces migration efforts and costs
9
TCO optimized
Based on x86 industry standard architectures
Based on open source software (Ceph)
High-availability and self-optimizing functions are part
of the design at no extra costs
Highly automated and fully integrated management
reduces operational efforts
Online maintenance and technology refresh reduce
costs of downtime dramatically
Extreme long lifecycle delivers investment protection
End-to-end design an maintenance from Fujitsu
reduces evaluation integration maintenance costs
Copyright 2015 FUJITSU
Better service levels at reduced costs ndash business centric storage
10
One storage ndash seamless management
ETERNUS CD10000 delivers one seamless
management for the complete stack
Central Ceph software deployment
Central storage node management
Central network management
Central log file management
Central cluster management
Central configuration administration and
maintenance
SNMP integration of all nodes and
network components
Copyright 2015 FUJITSU
11
Seamless management (2)
Dashboard ndash Overview of cluster status
Server Management ndash Management of cluster hardware ndash addremove server
(storage node) replace storage devices
Cluster Management ndash Management of cluster resources ndash cluster and pool creation
Monitoring the cluster ndash Monitoring overall capacity pool utilization status of OSD
Monitor and MDS processes Placement Group status and RBD status
Managing OpenStack Interoperation Connection to OpenStack Server and
placement of pools in Cinder multi-backend
12
Optional use of Calamari Management GUI
12
13
Example Replacing an HDD
Plain Ceph
taking the failed disk offline in Ceph
taking the failed disk offline on OS
Controller Level
identify (right) hard drive in server
exchanging hard drive
partitioning hard drive on OS level
Make and mount file system
bring the disk up in Ceph again
On ETERNUS CD10000
vsm_cli ltclustergt replace-disk-out
ltnodegt ltdevgt
exchange hard drive
vsm_cli ltclustergt replace-disk-in
ltnodegt ltdevgt
14
Example Adding a Node
Plain Ceph
Install hardware
Install OS
Configure OS
Partition disks (OSDs Journals)
Make filesystems
Configure network
Configure ssh
Configure Ceph
Add node to cluster
On ETERNUS CD10000
Install hardware
bull hardware will automatically PXE boot
and install the current cluster
environment including current
configuration
Node automatically available to GUI
Add node to cluster with mouse click
on GUI
bull Automatic PG adjustment if needed
15
Adding and Integrating Apps
The ETERNUS CD10000 architecture
enables the integration of apps
Fujitsu is working with customers and
software vendors to integrate selected
storage apps
Eg archiving sync amp share data
discovery cloud appshellip
Copyright 2015 FUJITSU
Cloud
Services
Sync
amp Share Archive
iRODS data
discovery
ET
ER
NU
S C
D1
00
00
Object Level
Access
Block Level
Access
File Level
Access
Central Management
Ceph Storage System SW and Fujitsu
Extensions
10GbE Frontend Network
Fast Interconnect Network
Perf
orm
ance N
odes
Capacity N
odes
16
ETERNUS CD10000 at University Mainz
Large university in Germany
Uses iRODS Application for library services
iRODS is an open-source data management software in use at research
organizations and government agencies worldwide
Organizes and manages large depots of distributed digital data
Customer has built an interface from iRODS to Ceph
Stores raw data of measurement instruments (eg research in chemistry and
physics) for 10+ years meeting compliance rules of the EU
Need to provide extensive and rapidly growing data volumes online at
reasonable costs
Will implement a sync amp share service on top of ETERNUS CD10000
17
Summary ETERNUS CD10k ndash Key Values
Copyright 2015 FUJITSU
ETERNUS CD10000
ETERNUS
CD10000
Unlimited
Scalability
TCO
optimized
The new
unified
Immortal
System
Zero
Downtime
ETERNUS CD10000 combines open source storage with enterprisendashclass quality of service
18
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
19
What is OpenStack
Free open source (Apache license) software governed by a non-profit foundation
(corporation) with a mission to produce the ubiquitous Open Source Cloud
Computing platform that will meet the needs of public and private clouds
regardless of size by being simple to implement and massively scalable
Platin
Gold
Corporate
hellip
hellip
Massively scalable cloud operating system that
controls large pools of compute storage and
networking resources
Community OSS with contributions from 1000+
developers and 180+ participating organizations
Open web-based API Programmatic IaaS
Plug-in architecture allows different hypervisors
block storage systems network implementations
hardware agnostic etc
httpwwwopenstackorgfoundationcompanies
20
Attained fast growing customer interest
VMware clouds dominate
OpenStack clouds already 2
Worldwide adoption
Source OpenStack User Survey and Feedback Nov 3rd 2014
Source OpenStack User Survey and Feedback May 13th 2014
21
Why are Customers so interested
Source OpenStack User Survey and Feedback Nov 3rd 2014
Greatest industry amp community support
compared to alternative open platforms
Eucalyptus CloudStack OpenNebula
ldquoAbility to Innovaterdquo jumped from 6 to 1
22
OpenStackorg User Survey Paris Nov 2014
23
OpenStack Cloud Layers
OpenStack and ETERNUS CD10000
Physical Server (CPU Memory SSD HDD) and Network
Base Operating System (CentOS)
OAM
-dhcp
-Deploy
-LCM
Hypervisor
KVM ESXi
Hyper-V
Compute (Nova)
Network
(Neutron) +
plugins
Dashboard (Horizon)
Billing Portal
OpenStack
Cloud APIs
RADOS
Block
(RBD)
S3
(Rados-GW)
Object (Swift) Volume (Cinder)
Authentication (Keystone)
Images (Glance)
EC2 API
Metering (Ceilometer)
Manila (File)
File
(CephFS)
Fujitsu
Open Cloud
Storage
24
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
25
Backgrounds (1)
Erasure codes for content data
Content data for ICT services is ever-growing
Demand for higher space efficiency and durability
Reed Solomon code (de facto erasure code) improves both
Reed Solomon Code (Old style)Triple Replication
However Reed Solomon code is not so recovery-efficient
content data
copy copy
3x space
parity parity
15x space
content data
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom
2
Building Storage with Ceph looks simple
Copyright 2015 FUJITSU
Ceph
+ some servers
+ network
= storage
3
Building Storage with Ceph looks simple ndash buthelliphellip
Many new Complexities
Rightsizing server disk types network
bandwidth
Silos of management tools (HW SW)
Keeping Ceph versions with versions of
server HW OS connectivity drivers in sync
Management of maintenance and support
contracts of components
Troubleshooting
Copyright 2015 FUJITSU
Build Ceph source storage yourself
4
The challenges of software defined storage
What users want
Open standards
High scalability
High reliability
Lower costs
No-lock in from a vendor
What users may get
An own developed storage system based on open
industry standard HW amp SW components
High scalability and reliability If the stack works
Lower investments but higher operational efforts
Lock-in into the own stack
Copyright 2015 FUJITSU
5
ETERNUS CD10000 ndash Making Ceph enterprise ready
Build Ceph source storage yourself Out of the box ETERNUS CD10000
incl support
incl maintenance
ETERNUS CD10000 combines open source storage with enterprisendashclass quality of service
E2E Solution Contract by Fujitsu based on Red Hat Ceph Enterprise
Easy Deployment Management by Fujitsu
+
+
+ Lifecycle Management for Hardware amp Software by Fujitsu
+
6
Fujitsu Maintenance Support and Professional Services
ETERNUS CD10000 A complete offer
Copyright 2015 FUJITSU
7
Unlimited Scalability
Cluster of storage nodes
Capacity and performance scales by
adding storage nodes
Three different node types enable
differentiated service levels
Density capacity optimized
Performance optimized
Optimized for small scale dev amp test
1st version of CD10000 (Q32014) is
released for a range of 4 to 224 nodes
Scales up to gt50 Petabyte
Copyright 2015 FUJITSU
Basic node 12 TB Performance node 35 TB Capacity node 252 TB
8
Immortal System
Copyright 2015 FUJITSU
Node1 Node2 Node(n)
+
Adding nodes
with new generation
of hardware
helliphelliphellip +
Adding nodes
New Node1
Non-disruptive add remove exchange of hardware (disks and nodes)
Mix of nodesdisks of different generations online technology refresh
Very long lifecycle reduces migration efforts and costs
9
TCO optimized
Based on x86 industry standard architectures
Based on open source software (Ceph)
High-availability and self-optimizing functions are part
of the design at no extra costs
Highly automated and fully integrated management
reduces operational efforts
Online maintenance and technology refresh reduce
costs of downtime dramatically
Extreme long lifecycle delivers investment protection
End-to-end design an maintenance from Fujitsu
reduces evaluation integration maintenance costs
Copyright 2015 FUJITSU
Better service levels at reduced costs ndash business centric storage
10
One storage ndash seamless management
ETERNUS CD10000 delivers one seamless
management for the complete stack
Central Ceph software deployment
Central storage node management
Central network management
Central log file management
Central cluster management
Central configuration administration and
maintenance
SNMP integration of all nodes and
network components
Copyright 2015 FUJITSU
11
Seamless management (2)
Dashboard ndash Overview of cluster status
Server Management ndash Management of cluster hardware ndash addremove server
(storage node) replace storage devices
Cluster Management ndash Management of cluster resources ndash cluster and pool creation
Monitoring the cluster ndash Monitoring overall capacity pool utilization status of OSD
Monitor and MDS processes Placement Group status and RBD status
Managing OpenStack Interoperation Connection to OpenStack Server and
placement of pools in Cinder multi-backend
12
Optional use of Calamari Management GUI
12
13
Example Replacing an HDD
Plain Ceph
taking the failed disk offline in Ceph
taking the failed disk offline on OS
Controller Level
identify (right) hard drive in server
exchanging hard drive
partitioning hard drive on OS level
Make and mount file system
bring the disk up in Ceph again
On ETERNUS CD10000
vsm_cli ltclustergt replace-disk-out
ltnodegt ltdevgt
exchange hard drive
vsm_cli ltclustergt replace-disk-in
ltnodegt ltdevgt
14
Example Adding a Node
Plain Ceph
Install hardware
Install OS
Configure OS
Partition disks (OSDs Journals)
Make filesystems
Configure network
Configure ssh
Configure Ceph
Add node to cluster
On ETERNUS CD10000
Install hardware
bull hardware will automatically PXE boot
and install the current cluster
environment including current
configuration
Node automatically available to GUI
Add node to cluster with mouse click
on GUI
bull Automatic PG adjustment if needed
15
Adding and Integrating Apps
The ETERNUS CD10000 architecture
enables the integration of apps
Fujitsu is working with customers and
software vendors to integrate selected
storage apps
Eg archiving sync amp share data
discovery cloud appshellip
Copyright 2015 FUJITSU
Cloud
Services
Sync
amp Share Archive
iRODS data
discovery
ET
ER
NU
S C
D1
00
00
Object Level
Access
Block Level
Access
File Level
Access
Central Management
Ceph Storage System SW and Fujitsu
Extensions
10GbE Frontend Network
Fast Interconnect Network
Perf
orm
ance N
odes
Capacity N
odes
16
ETERNUS CD10000 at University Mainz
Large university in Germany
Uses iRODS Application for library services
iRODS is an open-source data management software in use at research
organizations and government agencies worldwide
Organizes and manages large depots of distributed digital data
Customer has built an interface from iRODS to Ceph
Stores raw data of measurement instruments (eg research in chemistry and
physics) for 10+ years meeting compliance rules of the EU
Need to provide extensive and rapidly growing data volumes online at
reasonable costs
Will implement a sync amp share service on top of ETERNUS CD10000
17
Summary ETERNUS CD10k ndash Key Values
Copyright 2015 FUJITSU
ETERNUS CD10000
ETERNUS
CD10000
Unlimited
Scalability
TCO
optimized
The new
unified
Immortal
System
Zero
Downtime
ETERNUS CD10000 combines open source storage with enterprisendashclass quality of service
18
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
19
What is OpenStack
Free open source (Apache license) software governed by a non-profit foundation
(corporation) with a mission to produce the ubiquitous Open Source Cloud
Computing platform that will meet the needs of public and private clouds
regardless of size by being simple to implement and massively scalable
Platin
Gold
Corporate
hellip
hellip
Massively scalable cloud operating system that
controls large pools of compute storage and
networking resources
Community OSS with contributions from 1000+
developers and 180+ participating organizations
Open web-based API Programmatic IaaS
Plug-in architecture allows different hypervisors
block storage systems network implementations
hardware agnostic etc
httpwwwopenstackorgfoundationcompanies
20
Attained fast growing customer interest
VMware clouds dominate
OpenStack clouds already 2
Worldwide adoption
Source OpenStack User Survey and Feedback Nov 3rd 2014
Source OpenStack User Survey and Feedback May 13th 2014
21
Why are Customers so interested
Source OpenStack User Survey and Feedback Nov 3rd 2014
Greatest industry amp community support
compared to alternative open platforms
Eucalyptus CloudStack OpenNebula
ldquoAbility to Innovaterdquo jumped from 6 to 1
22
OpenStackorg User Survey Paris Nov 2014
23
OpenStack Cloud Layers
OpenStack and ETERNUS CD10000
Physical Server (CPU Memory SSD HDD) and Network
Base Operating System (CentOS)
OAM
-dhcp
-Deploy
-LCM
Hypervisor
KVM ESXi
Hyper-V
Compute (Nova)
Network
(Neutron) +
plugins
Dashboard (Horizon)
Billing Portal
OpenStack
Cloud APIs
RADOS
Block
(RBD)
S3
(Rados-GW)
Object (Swift) Volume (Cinder)
Authentication (Keystone)
Images (Glance)
EC2 API
Metering (Ceilometer)
Manila (File)
File
(CephFS)
Fujitsu
Open Cloud
Storage
24
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
25
Backgrounds (1)
Erasure codes for content data
Content data for ICT services is ever-growing
Demand for higher space efficiency and durability
Reed Solomon code (de facto erasure code) improves both
Reed Solomon Code (Old style)Triple Replication
However Reed Solomon code is not so recovery-efficient
content data
copy copy
3x space
parity parity
15x space
content data
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom

3
Building Storage with Ceph looks simple ndash buthelliphellip
Many new Complexities
Rightsizing server disk types network
bandwidth
Silos of management tools (HW SW)
Keeping Ceph versions with versions of
server HW OS connectivity drivers in sync
Management of maintenance and support
contracts of components
Troubleshooting
Copyright 2015 FUJITSU
Build Ceph source storage yourself
4
The challenges of software defined storage
What users want
Open standards
High scalability
High reliability
Lower costs
No-lock in from a vendor
What users may get
An own developed storage system based on open
industry standard HW amp SW components
High scalability and reliability If the stack works
Lower investments but higher operational efforts
Lock-in into the own stack
Copyright 2015 FUJITSU
5
ETERNUS CD10000 ndash Making Ceph enterprise ready
Build Ceph source storage yourself Out of the box ETERNUS CD10000
incl support
incl maintenance
ETERNUS CD10000 combines open source storage with enterprisendashclass quality of service
E2E Solution Contract by Fujitsu based on Red Hat Ceph Enterprise
Easy Deployment Management by Fujitsu
+
+
+ Lifecycle Management for Hardware amp Software by Fujitsu
+
6
Fujitsu Maintenance Support and Professional Services
ETERNUS CD10000 A complete offer
Copyright 2015 FUJITSU
7
Unlimited Scalability
Cluster of storage nodes
Capacity and performance scales by
adding storage nodes
Three different node types enable
differentiated service levels
Density capacity optimized
Performance optimized
Optimized for small scale dev amp test
1st version of CD10000 (Q32014) is
released for a range of 4 to 224 nodes
Scales up to gt50 Petabyte
Copyright 2015 FUJITSU
Basic node 12 TB Performance node 35 TB Capacity node 252 TB
8
Immortal System
Copyright 2015 FUJITSU
Node1 Node2 Node(n)
+
Adding nodes
with new generation
of hardware
helliphelliphellip +
Adding nodes
New Node1
Non-disruptive add remove exchange of hardware (disks and nodes)
Mix of nodesdisks of different generations online technology refresh
Very long lifecycle reduces migration efforts and costs
9
TCO optimized
Based on x86 industry standard architectures
Based on open source software (Ceph)
High-availability and self-optimizing functions are part
of the design at no extra costs
Highly automated and fully integrated management
reduces operational efforts
Online maintenance and technology refresh reduce
costs of downtime dramatically
Extreme long lifecycle delivers investment protection
End-to-end design an maintenance from Fujitsu
reduces evaluation integration maintenance costs
Copyright 2015 FUJITSU
Better service levels at reduced costs ndash business centric storage
10
One storage ndash seamless management
ETERNUS CD10000 delivers one seamless
management for the complete stack
Central Ceph software deployment
Central storage node management
Central network management
Central log file management
Central cluster management
Central configuration administration and
maintenance
SNMP integration of all nodes and
network components
Copyright 2015 FUJITSU
11
Seamless management (2)
Dashboard ndash Overview of cluster status
Server Management ndash Management of cluster hardware ndash addremove server
(storage node) replace storage devices
Cluster Management ndash Management of cluster resources ndash cluster and pool creation
Monitoring the cluster ndash Monitoring overall capacity pool utilization status of OSD
Monitor and MDS processes Placement Group status and RBD status
Managing OpenStack Interoperation Connection to OpenStack Server and
placement of pools in Cinder multi-backend
12
Optional use of Calamari Management GUI
12
13
Example Replacing an HDD
Plain Ceph
taking the failed disk offline in Ceph
taking the failed disk offline on OS
Controller Level
identify (right) hard drive in server
exchanging hard drive
partitioning hard drive on OS level
Make and mount file system
bring the disk up in Ceph again
On ETERNUS CD10000
vsm_cli ltclustergt replace-disk-out
ltnodegt ltdevgt
exchange hard drive
vsm_cli ltclustergt replace-disk-in
ltnodegt ltdevgt
14
Example Adding a Node
Plain Ceph
Install hardware
Install OS
Configure OS
Partition disks (OSDs Journals)
Make filesystems
Configure network
Configure ssh
Configure Ceph
Add node to cluster
On ETERNUS CD10000
Install hardware
bull hardware will automatically PXE boot
and install the current cluster
environment including current
configuration
Node automatically available to GUI
Add node to cluster with mouse click
on GUI
bull Automatic PG adjustment if needed
15
Adding and Integrating Apps
The ETERNUS CD10000 architecture
enables the integration of apps
Fujitsu is working with customers and
software vendors to integrate selected
storage apps
Eg archiving sync amp share data
discovery cloud appshellip
Copyright 2015 FUJITSU
Cloud
Services
Sync
amp Share Archive
iRODS data
discovery
ET
ER
NU
S C
D1
00
00
Object Level
Access
Block Level
Access
File Level
Access
Central Management
Ceph Storage System SW and Fujitsu
Extensions
10GbE Frontend Network
Fast Interconnect Network
Perf
orm
ance N
odes
Capacity N
odes
16
ETERNUS CD10000 at University Mainz
Large university in Germany
Uses iRODS Application for library services
iRODS is an open-source data management software in use at research
organizations and government agencies worldwide
Organizes and manages large depots of distributed digital data
Customer has built an interface from iRODS to Ceph
Stores raw data of measurement instruments (eg research in chemistry and
physics) for 10+ years meeting compliance rules of the EU
Need to provide extensive and rapidly growing data volumes online at
reasonable costs
Will implement a sync amp share service on top of ETERNUS CD10000
17
Summary ETERNUS CD10k ndash Key Values
Copyright 2015 FUJITSU
ETERNUS CD10000
ETERNUS
CD10000
Unlimited
Scalability
TCO
optimized
The new
unified
Immortal
System
Zero
Downtime
ETERNUS CD10000 combines open source storage with enterprisendashclass quality of service
18
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
19
What is OpenStack
Free open source (Apache license) software governed by a non-profit foundation
(corporation) with a mission to produce the ubiquitous Open Source Cloud
Computing platform that will meet the needs of public and private clouds
regardless of size by being simple to implement and massively scalable
Platin
Gold
Corporate
hellip
hellip
Massively scalable cloud operating system that
controls large pools of compute storage and
networking resources
Community OSS with contributions from 1000+
developers and 180+ participating organizations
Open web-based API Programmatic IaaS
Plug-in architecture allows different hypervisors
block storage systems network implementations
hardware agnostic etc
httpwwwopenstackorgfoundationcompanies
20
Attained fast growing customer interest
VMware clouds dominate
OpenStack clouds already 2
Worldwide adoption
Source OpenStack User Survey and Feedback Nov 3rd 2014
Source OpenStack User Survey and Feedback May 13th 2014
21
Why are Customers so interested
Source OpenStack User Survey and Feedback Nov 3rd 2014
Greatest industry amp community support
compared to alternative open platforms
Eucalyptus CloudStack OpenNebula
ldquoAbility to Innovaterdquo jumped from 6 to 1
22
OpenStackorg User Survey Paris Nov 2014
23
OpenStack Cloud Layers
OpenStack and ETERNUS CD10000
Physical Server (CPU Memory SSD HDD) and Network
Base Operating System (CentOS)
OAM
-dhcp
-Deploy
-LCM
Hypervisor
KVM ESXi
Hyper-V
Compute (Nova)
Network
(Neutron) +
plugins
Dashboard (Horizon)
Billing Portal
OpenStack
Cloud APIs
RADOS
Block
(RBD)
S3
(Rados-GW)
Object (Swift) Volume (Cinder)
Authentication (Keystone)
Images (Glance)
EC2 API
Metering (Ceilometer)
Manila (File)
File
(CephFS)
Fujitsu
Open Cloud
Storage
24
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
25
Backgrounds (1)
Erasure codes for content data
Content data for ICT services is ever-growing
Demand for higher space efficiency and durability
Reed Solomon code (de facto erasure code) improves both
Reed Solomon Code (Old style)Triple Replication
However Reed Solomon code is not so recovery-efficient
content data
copy copy
3x space
parity parity
15x space
content data
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom

4
The challenges of software defined storage
What users want
Open standards
High scalability
High reliability
Lower costs
No-lock in from a vendor
What users may get
An own developed storage system based on open
industry standard HW amp SW components
High scalability and reliability If the stack works
Lower investments but higher operational efforts
Lock-in into the own stack
Copyright 2015 FUJITSU
5
ETERNUS CD10000 ndash Making Ceph enterprise ready
Build Ceph source storage yourself Out of the box ETERNUS CD10000
incl support
incl maintenance
ETERNUS CD10000 combines open source storage with enterprisendashclass quality of service
E2E Solution Contract by Fujitsu based on Red Hat Ceph Enterprise
Easy Deployment Management by Fujitsu
+
+
+ Lifecycle Management for Hardware amp Software by Fujitsu
+
6
Fujitsu Maintenance Support and Professional Services
ETERNUS CD10000 A complete offer
Copyright 2015 FUJITSU
7
Unlimited Scalability
Cluster of storage nodes
Capacity and performance scales by
adding storage nodes
Three different node types enable
differentiated service levels
Density capacity optimized
Performance optimized
Optimized for small scale dev amp test
1st version of CD10000 (Q32014) is
released for a range of 4 to 224 nodes
Scales up to gt50 Petabyte
Copyright 2015 FUJITSU
Basic node 12 TB Performance node 35 TB Capacity node 252 TB
8
Immortal System
Copyright 2015 FUJITSU
Node1 Node2 Node(n)
+
Adding nodes
with new generation
of hardware
helliphelliphellip +
Adding nodes
New Node1
Non-disruptive add remove exchange of hardware (disks and nodes)
Mix of nodesdisks of different generations online technology refresh
Very long lifecycle reduces migration efforts and costs
9
TCO optimized
Based on x86 industry standard architectures
Based on open source software (Ceph)
High-availability and self-optimizing functions are part
of the design at no extra costs
Highly automated and fully integrated management
reduces operational efforts
Online maintenance and technology refresh reduce
costs of downtime dramatically
Extreme long lifecycle delivers investment protection
End-to-end design an maintenance from Fujitsu
reduces evaluation integration maintenance costs
Copyright 2015 FUJITSU
Better service levels at reduced costs ndash business centric storage
10
One storage ndash seamless management
ETERNUS CD10000 delivers one seamless
management for the complete stack
Central Ceph software deployment
Central storage node management
Central network management
Central log file management
Central cluster management
Central configuration administration and
maintenance
SNMP integration of all nodes and
network components
Copyright 2015 FUJITSU
11
Seamless management (2)
Dashboard ndash Overview of cluster status
Server Management ndash Management of cluster hardware ndash addremove server
(storage node) replace storage devices
Cluster Management ndash Management of cluster resources ndash cluster and pool creation
Monitoring the cluster ndash Monitoring overall capacity pool utilization status of OSD
Monitor and MDS processes Placement Group status and RBD status
Managing OpenStack Interoperation Connection to OpenStack Server and
placement of pools in Cinder multi-backend
12
Optional use of Calamari Management GUI
12
13
Example Replacing an HDD
Plain Ceph
taking the failed disk offline in Ceph
taking the failed disk offline on OS
Controller Level
identify (right) hard drive in server
exchanging hard drive
partitioning hard drive on OS level
Make and mount file system
bring the disk up in Ceph again
On ETERNUS CD10000
vsm_cli ltclustergt replace-disk-out
ltnodegt ltdevgt
exchange hard drive
vsm_cli ltclustergt replace-disk-in
ltnodegt ltdevgt
14
Example Adding a Node
Plain Ceph
Install hardware
Install OS
Configure OS
Partition disks (OSDs Journals)
Make filesystems
Configure network
Configure ssh
Configure Ceph
Add node to cluster
On ETERNUS CD10000
Install hardware
bull hardware will automatically PXE boot
and install the current cluster
environment including current
configuration
Node automatically available to GUI
Add node to cluster with mouse click
on GUI
bull Automatic PG adjustment if needed
15
Adding and Integrating Apps
The ETERNUS CD10000 architecture
enables the integration of apps
Fujitsu is working with customers and
software vendors to integrate selected
storage apps
Eg archiving sync amp share data
discovery cloud appshellip
Copyright 2015 FUJITSU
Cloud
Services
Sync
amp Share Archive
iRODS data
discovery
ET
ER
NU
S C
D1
00
00
Object Level
Access
Block Level
Access
File Level
Access
Central Management
Ceph Storage System SW and Fujitsu
Extensions
10GbE Frontend Network
Fast Interconnect Network
Perf
orm
ance N
odes
Capacity N
odes
16
ETERNUS CD10000 at University Mainz
Large university in Germany
Uses iRODS Application for library services
iRODS is an open-source data management software in use at research
organizations and government agencies worldwide
Organizes and manages large depots of distributed digital data
Customer has built an interface from iRODS to Ceph
Stores raw data of measurement instruments (eg research in chemistry and
physics) for 10+ years meeting compliance rules of the EU
Need to provide extensive and rapidly growing data volumes online at
reasonable costs
Will implement a sync amp share service on top of ETERNUS CD10000
17
Summary ETERNUS CD10k ndash Key Values
Copyright 2015 FUJITSU
ETERNUS CD10000
ETERNUS
CD10000
Unlimited
Scalability
TCO
optimized
The new
unified
Immortal
System
Zero
Downtime
ETERNUS CD10000 combines open source storage with enterprisendashclass quality of service
18
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
19
What is OpenStack
Free open source (Apache license) software governed by a non-profit foundation
(corporation) with a mission to produce the ubiquitous Open Source Cloud
Computing platform that will meet the needs of public and private clouds
regardless of size by being simple to implement and massively scalable
Platin
Gold
Corporate
hellip
hellip
Massively scalable cloud operating system that
controls large pools of compute storage and
networking resources
Community OSS with contributions from 1000+
developers and 180+ participating organizations
Open web-based API Programmatic IaaS
Plug-in architecture allows different hypervisors
block storage systems network implementations
hardware agnostic etc
httpwwwopenstackorgfoundationcompanies
20
Attained fast growing customer interest
VMware clouds dominate
OpenStack clouds already 2
Worldwide adoption
Source OpenStack User Survey and Feedback Nov 3rd 2014
Source OpenStack User Survey and Feedback May 13th 2014
21
Why are Customers so interested
Source OpenStack User Survey and Feedback Nov 3rd 2014
Greatest industry amp community support
compared to alternative open platforms
Eucalyptus CloudStack OpenNebula
ldquoAbility to Innovaterdquo jumped from 6 to 1
22
OpenStackorg User Survey Paris Nov 2014
23
OpenStack Cloud Layers
OpenStack and ETERNUS CD10000
Physical Server (CPU Memory SSD HDD) and Network
Base Operating System (CentOS)
OAM
-dhcp
-Deploy
-LCM
Hypervisor
KVM ESXi
Hyper-V
Compute (Nova)
Network
(Neutron) +
plugins
Dashboard (Horizon)
Billing Portal
OpenStack
Cloud APIs
RADOS
Block
(RBD)
S3
(Rados-GW)
Object (Swift) Volume (Cinder)
Authentication (Keystone)
Images (Glance)
EC2 API
Metering (Ceilometer)
Manila (File)
File
(CephFS)
Fujitsu
Open Cloud
Storage
24
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
25
Backgrounds (1)
Erasure codes for content data
Content data for ICT services is ever-growing
Demand for higher space efficiency and durability
Reed Solomon code (de facto erasure code) improves both
Reed Solomon Code (Old style)Triple Replication
However Reed Solomon code is not so recovery-efficient
content data
copy copy
3x space
parity parity
15x space
content data
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom
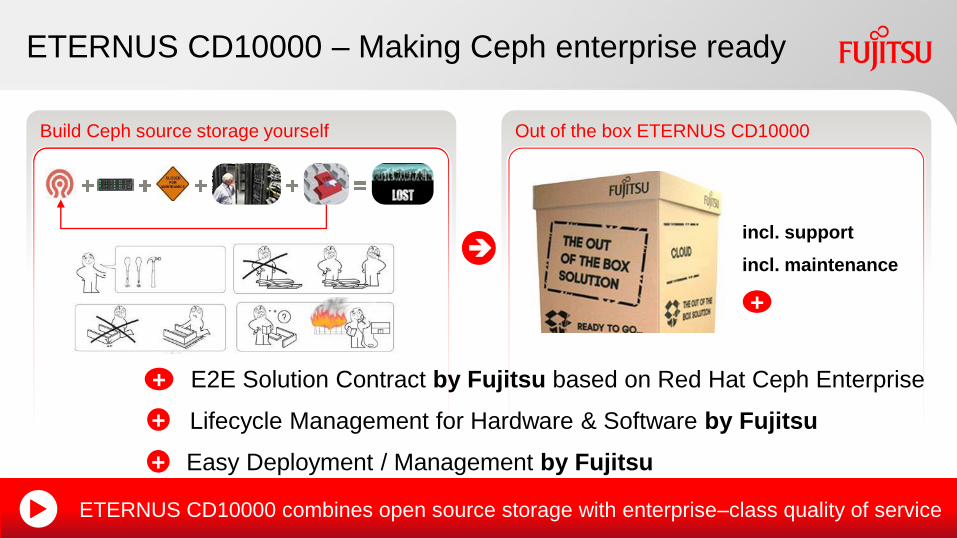
5
ETERNUS CD10000 ndash Making Ceph enterprise ready
Build Ceph source storage yourself Out of the box ETERNUS CD10000
incl support
incl maintenance
ETERNUS CD10000 combines open source storage with enterprisendashclass quality of service
E2E Solution Contract by Fujitsu based on Red Hat Ceph Enterprise
Easy Deployment Management by Fujitsu
+
+
+ Lifecycle Management for Hardware amp Software by Fujitsu
+
6
Fujitsu Maintenance Support and Professional Services
ETERNUS CD10000 A complete offer
Copyright 2015 FUJITSU
7
Unlimited Scalability
Cluster of storage nodes
Capacity and performance scales by
adding storage nodes
Three different node types enable
differentiated service levels
Density capacity optimized
Performance optimized
Optimized for small scale dev amp test
1st version of CD10000 (Q32014) is
released for a range of 4 to 224 nodes
Scales up to gt50 Petabyte
Copyright 2015 FUJITSU
Basic node 12 TB Performance node 35 TB Capacity node 252 TB
8
Immortal System
Copyright 2015 FUJITSU
Node1 Node2 Node(n)
+
Adding nodes
with new generation
of hardware
helliphelliphellip +
Adding nodes
New Node1
Non-disruptive add remove exchange of hardware (disks and nodes)
Mix of nodesdisks of different generations online technology refresh
Very long lifecycle reduces migration efforts and costs
9
TCO optimized
Based on x86 industry standard architectures
Based on open source software (Ceph)
High-availability and self-optimizing functions are part
of the design at no extra costs
Highly automated and fully integrated management
reduces operational efforts
Online maintenance and technology refresh reduce
costs of downtime dramatically
Extreme long lifecycle delivers investment protection
End-to-end design an maintenance from Fujitsu
reduces evaluation integration maintenance costs
Copyright 2015 FUJITSU
Better service levels at reduced costs ndash business centric storage
10
One storage ndash seamless management
ETERNUS CD10000 delivers one seamless
management for the complete stack
Central Ceph software deployment
Central storage node management
Central network management
Central log file management
Central cluster management
Central configuration administration and
maintenance
SNMP integration of all nodes and
network components
Copyright 2015 FUJITSU
11
Seamless management (2)
Dashboard ndash Overview of cluster status
Server Management ndash Management of cluster hardware ndash addremove server
(storage node) replace storage devices
Cluster Management ndash Management of cluster resources ndash cluster and pool creation
Monitoring the cluster ndash Monitoring overall capacity pool utilization status of OSD
Monitor and MDS processes Placement Group status and RBD status
Managing OpenStack Interoperation Connection to OpenStack Server and
placement of pools in Cinder multi-backend
12
Optional use of Calamari Management GUI
12
13
Example Replacing an HDD
Plain Ceph
taking the failed disk offline in Ceph
taking the failed disk offline on OS
Controller Level
identify (right) hard drive in server
exchanging hard drive
partitioning hard drive on OS level
Make and mount file system
bring the disk up in Ceph again
On ETERNUS CD10000
vsm_cli ltclustergt replace-disk-out
ltnodegt ltdevgt
exchange hard drive
vsm_cli ltclustergt replace-disk-in
ltnodegt ltdevgt
14
Example Adding a Node
Plain Ceph
Install hardware
Install OS
Configure OS
Partition disks (OSDs Journals)
Make filesystems
Configure network
Configure ssh
Configure Ceph
Add node to cluster
On ETERNUS CD10000
Install hardware
bull hardware will automatically PXE boot
and install the current cluster
environment including current
configuration
Node automatically available to GUI
Add node to cluster with mouse click
on GUI
bull Automatic PG adjustment if needed
15
Adding and Integrating Apps
The ETERNUS CD10000 architecture
enables the integration of apps
Fujitsu is working with customers and
software vendors to integrate selected
storage apps
Eg archiving sync amp share data
discovery cloud appshellip
Copyright 2015 FUJITSU
Cloud
Services
Sync
amp Share Archive
iRODS data
discovery
ET
ER
NU
S C
D1
00
00
Object Level
Access
Block Level
Access
File Level
Access
Central Management
Ceph Storage System SW and Fujitsu
Extensions
10GbE Frontend Network
Fast Interconnect Network
Perf
orm
ance N
odes
Capacity N
odes
16
ETERNUS CD10000 at University Mainz
Large university in Germany
Uses iRODS Application for library services
iRODS is an open-source data management software in use at research
organizations and government agencies worldwide
Organizes and manages large depots of distributed digital data
Customer has built an interface from iRODS to Ceph
Stores raw data of measurement instruments (eg research in chemistry and
physics) for 10+ years meeting compliance rules of the EU
Need to provide extensive and rapidly growing data volumes online at
reasonable costs
Will implement a sync amp share service on top of ETERNUS CD10000
17
Summary ETERNUS CD10k ndash Key Values
Copyright 2015 FUJITSU
ETERNUS CD10000
ETERNUS
CD10000
Unlimited
Scalability
TCO
optimized
The new
unified
Immortal
System
Zero
Downtime
ETERNUS CD10000 combines open source storage with enterprisendashclass quality of service
18
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
19
What is OpenStack
Free open source (Apache license) software governed by a non-profit foundation
(corporation) with a mission to produce the ubiquitous Open Source Cloud
Computing platform that will meet the needs of public and private clouds
regardless of size by being simple to implement and massively scalable
Platin
Gold
Corporate
hellip
hellip
Massively scalable cloud operating system that
controls large pools of compute storage and
networking resources
Community OSS with contributions from 1000+
developers and 180+ participating organizations
Open web-based API Programmatic IaaS
Plug-in architecture allows different hypervisors
block storage systems network implementations
hardware agnostic etc
httpwwwopenstackorgfoundationcompanies
20
Attained fast growing customer interest
VMware clouds dominate
OpenStack clouds already 2
Worldwide adoption
Source OpenStack User Survey and Feedback Nov 3rd 2014
Source OpenStack User Survey and Feedback May 13th 2014
21
Why are Customers so interested
Source OpenStack User Survey and Feedback Nov 3rd 2014
Greatest industry amp community support
compared to alternative open platforms
Eucalyptus CloudStack OpenNebula
ldquoAbility to Innovaterdquo jumped from 6 to 1
22
OpenStackorg User Survey Paris Nov 2014
23
OpenStack Cloud Layers
OpenStack and ETERNUS CD10000
Physical Server (CPU Memory SSD HDD) and Network
Base Operating System (CentOS)
OAM
-dhcp
-Deploy
-LCM
Hypervisor
KVM ESXi
Hyper-V
Compute (Nova)
Network
(Neutron) +
plugins
Dashboard (Horizon)
Billing Portal
OpenStack
Cloud APIs
RADOS
Block
(RBD)
S3
(Rados-GW)
Object (Swift) Volume (Cinder)
Authentication (Keystone)
Images (Glance)
EC2 API
Metering (Ceilometer)
Manila (File)
File
(CephFS)
Fujitsu
Open Cloud
Storage
24
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
25
Backgrounds (1)
Erasure codes for content data
Content data for ICT services is ever-growing
Demand for higher space efficiency and durability
Reed Solomon code (de facto erasure code) improves both
Reed Solomon Code (Old style)Triple Replication
However Reed Solomon code is not so recovery-efficient
content data
copy copy
3x space
parity parity
15x space
content data
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom
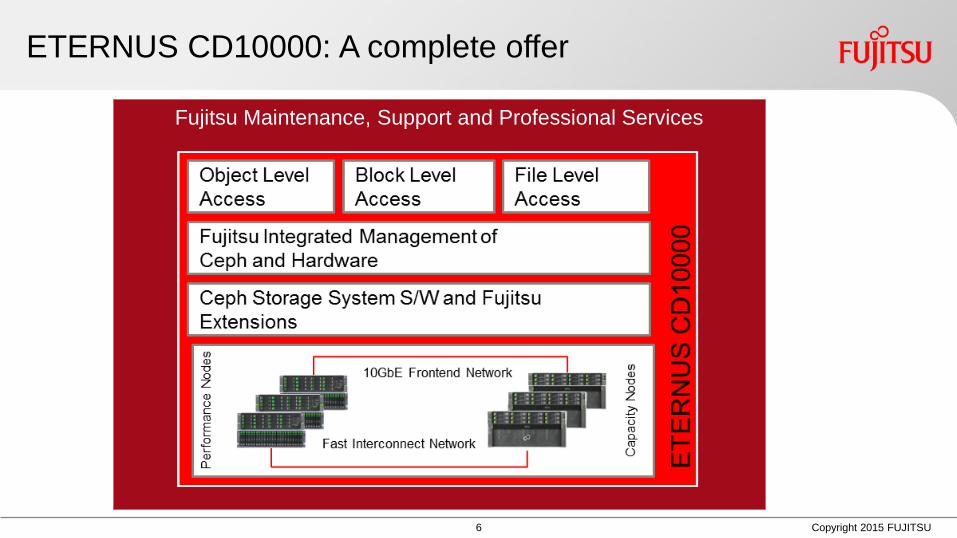
6
Fujitsu Maintenance Support and Professional Services
ETERNUS CD10000 A complete offer
Copyright 2015 FUJITSU
7
Unlimited Scalability
Cluster of storage nodes
Capacity and performance scales by
adding storage nodes
Three different node types enable
differentiated service levels
Density capacity optimized
Performance optimized
Optimized for small scale dev amp test
1st version of CD10000 (Q32014) is
released for a range of 4 to 224 nodes
Scales up to gt50 Petabyte
Copyright 2015 FUJITSU
Basic node 12 TB Performance node 35 TB Capacity node 252 TB
8
Immortal System
Copyright 2015 FUJITSU
Node1 Node2 Node(n)
+
Adding nodes
with new generation
of hardware
helliphelliphellip +
Adding nodes
New Node1
Non-disruptive add remove exchange of hardware (disks and nodes)
Mix of nodesdisks of different generations online technology refresh
Very long lifecycle reduces migration efforts and costs
9
TCO optimized
Based on x86 industry standard architectures
Based on open source software (Ceph)
High-availability and self-optimizing functions are part
of the design at no extra costs
Highly automated and fully integrated management
reduces operational efforts
Online maintenance and technology refresh reduce
costs of downtime dramatically
Extreme long lifecycle delivers investment protection
End-to-end design an maintenance from Fujitsu
reduces evaluation integration maintenance costs
Copyright 2015 FUJITSU
Better service levels at reduced costs ndash business centric storage
10
One storage ndash seamless management
ETERNUS CD10000 delivers one seamless
management for the complete stack
Central Ceph software deployment
Central storage node management
Central network management
Central log file management
Central cluster management
Central configuration administration and
maintenance
SNMP integration of all nodes and
network components
Copyright 2015 FUJITSU
11
Seamless management (2)
Dashboard ndash Overview of cluster status
Server Management ndash Management of cluster hardware ndash addremove server
(storage node) replace storage devices
Cluster Management ndash Management of cluster resources ndash cluster and pool creation
Monitoring the cluster ndash Monitoring overall capacity pool utilization status of OSD
Monitor and MDS processes Placement Group status and RBD status
Managing OpenStack Interoperation Connection to OpenStack Server and
placement of pools in Cinder multi-backend
12
Optional use of Calamari Management GUI
12
13
Example Replacing an HDD
Plain Ceph
taking the failed disk offline in Ceph
taking the failed disk offline on OS
Controller Level
identify (right) hard drive in server
exchanging hard drive
partitioning hard drive on OS level
Make and mount file system
bring the disk up in Ceph again
On ETERNUS CD10000
vsm_cli ltclustergt replace-disk-out
ltnodegt ltdevgt
exchange hard drive
vsm_cli ltclustergt replace-disk-in
ltnodegt ltdevgt
14
Example Adding a Node
Plain Ceph
Install hardware
Install OS
Configure OS
Partition disks (OSDs Journals)
Make filesystems
Configure network
Configure ssh
Configure Ceph
Add node to cluster
On ETERNUS CD10000
Install hardware
bull hardware will automatically PXE boot
and install the current cluster
environment including current
configuration
Node automatically available to GUI
Add node to cluster with mouse click
on GUI
bull Automatic PG adjustment if needed
15
Adding and Integrating Apps
The ETERNUS CD10000 architecture
enables the integration of apps
Fujitsu is working with customers and
software vendors to integrate selected
storage apps
Eg archiving sync amp share data
discovery cloud appshellip
Copyright 2015 FUJITSU
Cloud
Services
Sync
amp Share Archive
iRODS data
discovery
ET
ER
NU
S C
D1
00
00
Object Level
Access
Block Level
Access
File Level
Access
Central Management
Ceph Storage System SW and Fujitsu
Extensions
10GbE Frontend Network
Fast Interconnect Network
Perf
orm
ance N
odes
Capacity N
odes
16
ETERNUS CD10000 at University Mainz
Large university in Germany
Uses iRODS Application for library services
iRODS is an open-source data management software in use at research
organizations and government agencies worldwide
Organizes and manages large depots of distributed digital data
Customer has built an interface from iRODS to Ceph
Stores raw data of measurement instruments (eg research in chemistry and
physics) for 10+ years meeting compliance rules of the EU
Need to provide extensive and rapidly growing data volumes online at
reasonable costs
Will implement a sync amp share service on top of ETERNUS CD10000
17
Summary ETERNUS CD10k ndash Key Values
Copyright 2015 FUJITSU
ETERNUS CD10000
ETERNUS
CD10000
Unlimited
Scalability
TCO
optimized
The new
unified
Immortal
System
Zero
Downtime
ETERNUS CD10000 combines open source storage with enterprisendashclass quality of service
18
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
19
What is OpenStack
Free open source (Apache license) software governed by a non-profit foundation
(corporation) with a mission to produce the ubiquitous Open Source Cloud
Computing platform that will meet the needs of public and private clouds
regardless of size by being simple to implement and massively scalable
Platin
Gold
Corporate
hellip
hellip
Massively scalable cloud operating system that
controls large pools of compute storage and
networking resources
Community OSS with contributions from 1000+
developers and 180+ participating organizations
Open web-based API Programmatic IaaS
Plug-in architecture allows different hypervisors
block storage systems network implementations
hardware agnostic etc
httpwwwopenstackorgfoundationcompanies
20
Attained fast growing customer interest
VMware clouds dominate
OpenStack clouds already 2
Worldwide adoption
Source OpenStack User Survey and Feedback Nov 3rd 2014
Source OpenStack User Survey and Feedback May 13th 2014
21
Why are Customers so interested
Source OpenStack User Survey and Feedback Nov 3rd 2014
Greatest industry amp community support
compared to alternative open platforms
Eucalyptus CloudStack OpenNebula
ldquoAbility to Innovaterdquo jumped from 6 to 1
22
OpenStackorg User Survey Paris Nov 2014
23
OpenStack Cloud Layers
OpenStack and ETERNUS CD10000
Physical Server (CPU Memory SSD HDD) and Network
Base Operating System (CentOS)
OAM
-dhcp
-Deploy
-LCM
Hypervisor
KVM ESXi
Hyper-V
Compute (Nova)
Network
(Neutron) +
plugins
Dashboard (Horizon)
Billing Portal
OpenStack
Cloud APIs
RADOS
Block
(RBD)
S3
(Rados-GW)
Object (Swift) Volume (Cinder)
Authentication (Keystone)
Images (Glance)
EC2 API
Metering (Ceilometer)
Manila (File)
File
(CephFS)
Fujitsu
Open Cloud
Storage
24
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
25
Backgrounds (1)
Erasure codes for content data
Content data for ICT services is ever-growing
Demand for higher space efficiency and durability
Reed Solomon code (de facto erasure code) improves both
Reed Solomon Code (Old style)Triple Replication
However Reed Solomon code is not so recovery-efficient
content data
copy copy
3x space
parity parity
15x space
content data
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom

7
Unlimited Scalability
Cluster of storage nodes
Capacity and performance scales by
adding storage nodes
Three different node types enable
differentiated service levels
Density capacity optimized
Performance optimized
Optimized for small scale dev amp test
1st version of CD10000 (Q32014) is
released for a range of 4 to 224 nodes
Scales up to gt50 Petabyte
Copyright 2015 FUJITSU
Basic node 12 TB Performance node 35 TB Capacity node 252 TB
8
Immortal System
Copyright 2015 FUJITSU
Node1 Node2 Node(n)
+
Adding nodes
with new generation
of hardware
helliphelliphellip +
Adding nodes
New Node1
Non-disruptive add remove exchange of hardware (disks and nodes)
Mix of nodesdisks of different generations online technology refresh
Very long lifecycle reduces migration efforts and costs
9
TCO optimized
Based on x86 industry standard architectures
Based on open source software (Ceph)
High-availability and self-optimizing functions are part
of the design at no extra costs
Highly automated and fully integrated management
reduces operational efforts
Online maintenance and technology refresh reduce
costs of downtime dramatically
Extreme long lifecycle delivers investment protection
End-to-end design an maintenance from Fujitsu
reduces evaluation integration maintenance costs
Copyright 2015 FUJITSU
Better service levels at reduced costs ndash business centric storage
10
One storage ndash seamless management
ETERNUS CD10000 delivers one seamless
management for the complete stack
Central Ceph software deployment
Central storage node management
Central network management
Central log file management
Central cluster management
Central configuration administration and
maintenance
SNMP integration of all nodes and
network components
Copyright 2015 FUJITSU
11
Seamless management (2)
Dashboard ndash Overview of cluster status
Server Management ndash Management of cluster hardware ndash addremove server
(storage node) replace storage devices
Cluster Management ndash Management of cluster resources ndash cluster and pool creation
Monitoring the cluster ndash Monitoring overall capacity pool utilization status of OSD
Monitor and MDS processes Placement Group status and RBD status
Managing OpenStack Interoperation Connection to OpenStack Server and
placement of pools in Cinder multi-backend
12
Optional use of Calamari Management GUI
12
13
Example Replacing an HDD
Plain Ceph
taking the failed disk offline in Ceph
taking the failed disk offline on OS
Controller Level
identify (right) hard drive in server
exchanging hard drive
partitioning hard drive on OS level
Make and mount file system
bring the disk up in Ceph again
On ETERNUS CD10000
vsm_cli ltclustergt replace-disk-out
ltnodegt ltdevgt
exchange hard drive
vsm_cli ltclustergt replace-disk-in
ltnodegt ltdevgt
14
Example Adding a Node
Plain Ceph
Install hardware
Install OS
Configure OS
Partition disks (OSDs Journals)
Make filesystems
Configure network
Configure ssh
Configure Ceph
Add node to cluster
On ETERNUS CD10000
Install hardware
bull hardware will automatically PXE boot
and install the current cluster
environment including current
configuration
Node automatically available to GUI
Add node to cluster with mouse click
on GUI
bull Automatic PG adjustment if needed
15
Adding and Integrating Apps
The ETERNUS CD10000 architecture
enables the integration of apps
Fujitsu is working with customers and
software vendors to integrate selected
storage apps
Eg archiving sync amp share data
discovery cloud appshellip
Copyright 2015 FUJITSU
Cloud
Services
Sync
amp Share Archive
iRODS data
discovery
ET
ER
NU
S C
D1
00
00
Object Level
Access
Block Level
Access
File Level
Access
Central Management
Ceph Storage System SW and Fujitsu
Extensions
10GbE Frontend Network
Fast Interconnect Network
Perf
orm
ance N
odes
Capacity N
odes
16
ETERNUS CD10000 at University Mainz
Large university in Germany
Uses iRODS Application for library services
iRODS is an open-source data management software in use at research
organizations and government agencies worldwide
Organizes and manages large depots of distributed digital data
Customer has built an interface from iRODS to Ceph
Stores raw data of measurement instruments (eg research in chemistry and
physics) for 10+ years meeting compliance rules of the EU
Need to provide extensive and rapidly growing data volumes online at
reasonable costs
Will implement a sync amp share service on top of ETERNUS CD10000
17
Summary ETERNUS CD10k ndash Key Values
Copyright 2015 FUJITSU
ETERNUS CD10000
ETERNUS
CD10000
Unlimited
Scalability
TCO
optimized
The new
unified
Immortal
System
Zero
Downtime
ETERNUS CD10000 combines open source storage with enterprisendashclass quality of service
18
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
19
What is OpenStack
Free open source (Apache license) software governed by a non-profit foundation
(corporation) with a mission to produce the ubiquitous Open Source Cloud
Computing platform that will meet the needs of public and private clouds
regardless of size by being simple to implement and massively scalable
Platin
Gold
Corporate
hellip
hellip
Massively scalable cloud operating system that
controls large pools of compute storage and
networking resources
Community OSS with contributions from 1000+
developers and 180+ participating organizations
Open web-based API Programmatic IaaS
Plug-in architecture allows different hypervisors
block storage systems network implementations
hardware agnostic etc
httpwwwopenstackorgfoundationcompanies
20
Attained fast growing customer interest
VMware clouds dominate
OpenStack clouds already 2
Worldwide adoption
Source OpenStack User Survey and Feedback Nov 3rd 2014
Source OpenStack User Survey and Feedback May 13th 2014
21
Why are Customers so interested
Source OpenStack User Survey and Feedback Nov 3rd 2014
Greatest industry amp community support
compared to alternative open platforms
Eucalyptus CloudStack OpenNebula
ldquoAbility to Innovaterdquo jumped from 6 to 1
22
OpenStackorg User Survey Paris Nov 2014
23
OpenStack Cloud Layers
OpenStack and ETERNUS CD10000
Physical Server (CPU Memory SSD HDD) and Network
Base Operating System (CentOS)
OAM
-dhcp
-Deploy
-LCM
Hypervisor
KVM ESXi
Hyper-V
Compute (Nova)
Network
(Neutron) +
plugins
Dashboard (Horizon)
Billing Portal
OpenStack
Cloud APIs
RADOS
Block
(RBD)
S3
(Rados-GW)
Object (Swift) Volume (Cinder)
Authentication (Keystone)
Images (Glance)
EC2 API
Metering (Ceilometer)
Manila (File)
File
(CephFS)
Fujitsu
Open Cloud
Storage
24
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
25
Backgrounds (1)
Erasure codes for content data
Content data for ICT services is ever-growing
Demand for higher space efficiency and durability
Reed Solomon code (de facto erasure code) improves both
Reed Solomon Code (Old style)Triple Replication
However Reed Solomon code is not so recovery-efficient
content data
copy copy
3x space
parity parity
15x space
content data
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom
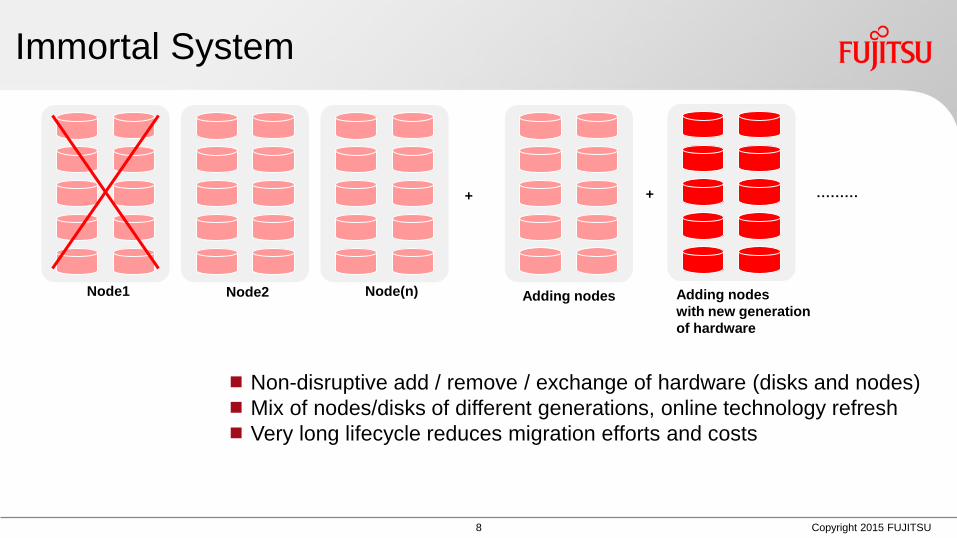
8
Immortal System
Copyright 2015 FUJITSU
Node1 Node2 Node(n)
+
Adding nodes
with new generation
of hardware
helliphelliphellip +
Adding nodes
New Node1
Non-disruptive add remove exchange of hardware (disks and nodes)
Mix of nodesdisks of different generations online technology refresh
Very long lifecycle reduces migration efforts and costs
9
TCO optimized
Based on x86 industry standard architectures
Based on open source software (Ceph)
High-availability and self-optimizing functions are part
of the design at no extra costs
Highly automated and fully integrated management
reduces operational efforts
Online maintenance and technology refresh reduce
costs of downtime dramatically
Extreme long lifecycle delivers investment protection
End-to-end design an maintenance from Fujitsu
reduces evaluation integration maintenance costs
Copyright 2015 FUJITSU
Better service levels at reduced costs ndash business centric storage
10
One storage ndash seamless management
ETERNUS CD10000 delivers one seamless
management for the complete stack
Central Ceph software deployment
Central storage node management
Central network management
Central log file management
Central cluster management
Central configuration administration and
maintenance
SNMP integration of all nodes and
network components
Copyright 2015 FUJITSU
11
Seamless management (2)
Dashboard ndash Overview of cluster status
Server Management ndash Management of cluster hardware ndash addremove server
(storage node) replace storage devices
Cluster Management ndash Management of cluster resources ndash cluster and pool creation
Monitoring the cluster ndash Monitoring overall capacity pool utilization status of OSD
Monitor and MDS processes Placement Group status and RBD status
Managing OpenStack Interoperation Connection to OpenStack Server and
placement of pools in Cinder multi-backend
12
Optional use of Calamari Management GUI
12
13
Example Replacing an HDD
Plain Ceph
taking the failed disk offline in Ceph
taking the failed disk offline on OS
Controller Level
identify (right) hard drive in server
exchanging hard drive
partitioning hard drive on OS level
Make and mount file system
bring the disk up in Ceph again
On ETERNUS CD10000
vsm_cli ltclustergt replace-disk-out
ltnodegt ltdevgt
exchange hard drive
vsm_cli ltclustergt replace-disk-in
ltnodegt ltdevgt
14
Example Adding a Node
Plain Ceph
Install hardware
Install OS
Configure OS
Partition disks (OSDs Journals)
Make filesystems
Configure network
Configure ssh
Configure Ceph
Add node to cluster
On ETERNUS CD10000
Install hardware
bull hardware will automatically PXE boot
and install the current cluster
environment including current
configuration
Node automatically available to GUI
Add node to cluster with mouse click
on GUI
bull Automatic PG adjustment if needed
15
Adding and Integrating Apps
The ETERNUS CD10000 architecture
enables the integration of apps
Fujitsu is working with customers and
software vendors to integrate selected
storage apps
Eg archiving sync amp share data
discovery cloud appshellip
Copyright 2015 FUJITSU
Cloud
Services
Sync
amp Share Archive
iRODS data
discovery
ET
ER
NU
S C
D1
00
00
Object Level
Access
Block Level
Access
File Level
Access
Central Management
Ceph Storage System SW and Fujitsu
Extensions
10GbE Frontend Network
Fast Interconnect Network
Perf
orm
ance N
odes
Capacity N
odes
16
ETERNUS CD10000 at University Mainz
Large university in Germany
Uses iRODS Application for library services
iRODS is an open-source data management software in use at research
organizations and government agencies worldwide
Organizes and manages large depots of distributed digital data
Customer has built an interface from iRODS to Ceph
Stores raw data of measurement instruments (eg research in chemistry and
physics) for 10+ years meeting compliance rules of the EU
Need to provide extensive and rapidly growing data volumes online at
reasonable costs
Will implement a sync amp share service on top of ETERNUS CD10000
17
Summary ETERNUS CD10k ndash Key Values
Copyright 2015 FUJITSU
ETERNUS CD10000
ETERNUS
CD10000
Unlimited
Scalability
TCO
optimized
The new
unified
Immortal
System
Zero
Downtime
ETERNUS CD10000 combines open source storage with enterprisendashclass quality of service
18
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
19
What is OpenStack
Free open source (Apache license) software governed by a non-profit foundation
(corporation) with a mission to produce the ubiquitous Open Source Cloud
Computing platform that will meet the needs of public and private clouds
regardless of size by being simple to implement and massively scalable
Platin
Gold
Corporate
hellip
hellip
Massively scalable cloud operating system that
controls large pools of compute storage and
networking resources
Community OSS with contributions from 1000+
developers and 180+ participating organizations
Open web-based API Programmatic IaaS
Plug-in architecture allows different hypervisors
block storage systems network implementations
hardware agnostic etc
httpwwwopenstackorgfoundationcompanies
20
Attained fast growing customer interest
VMware clouds dominate
OpenStack clouds already 2
Worldwide adoption
Source OpenStack User Survey and Feedback Nov 3rd 2014
Source OpenStack User Survey and Feedback May 13th 2014
21
Why are Customers so interested
Source OpenStack User Survey and Feedback Nov 3rd 2014
Greatest industry amp community support
compared to alternative open platforms
Eucalyptus CloudStack OpenNebula
ldquoAbility to Innovaterdquo jumped from 6 to 1
22
OpenStackorg User Survey Paris Nov 2014
23
OpenStack Cloud Layers
OpenStack and ETERNUS CD10000
Physical Server (CPU Memory SSD HDD) and Network
Base Operating System (CentOS)
OAM
-dhcp
-Deploy
-LCM
Hypervisor
KVM ESXi
Hyper-V
Compute (Nova)
Network
(Neutron) +
plugins
Dashboard (Horizon)
Billing Portal
OpenStack
Cloud APIs
RADOS
Block
(RBD)
S3
(Rados-GW)
Object (Swift) Volume (Cinder)
Authentication (Keystone)
Images (Glance)
EC2 API
Metering (Ceilometer)
Manila (File)
File
(CephFS)
Fujitsu
Open Cloud
Storage
24
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
25
Backgrounds (1)
Erasure codes for content data
Content data for ICT services is ever-growing
Demand for higher space efficiency and durability
Reed Solomon code (de facto erasure code) improves both
Reed Solomon Code (Old style)Triple Replication
However Reed Solomon code is not so recovery-efficient
content data
copy copy
3x space
parity parity
15x space
content data
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom

9
TCO optimized
Based on x86 industry standard architectures
Based on open source software (Ceph)
High-availability and self-optimizing functions are part
of the design at no extra costs
Highly automated and fully integrated management
reduces operational efforts
Online maintenance and technology refresh reduce
costs of downtime dramatically
Extreme long lifecycle delivers investment protection
End-to-end design an maintenance from Fujitsu
reduces evaluation integration maintenance costs
Copyright 2015 FUJITSU
Better service levels at reduced costs ndash business centric storage
10
One storage ndash seamless management
ETERNUS CD10000 delivers one seamless
management for the complete stack
Central Ceph software deployment
Central storage node management
Central network management
Central log file management
Central cluster management
Central configuration administration and
maintenance
SNMP integration of all nodes and
network components
Copyright 2015 FUJITSU
11
Seamless management (2)
Dashboard ndash Overview of cluster status
Server Management ndash Management of cluster hardware ndash addremove server
(storage node) replace storage devices
Cluster Management ndash Management of cluster resources ndash cluster and pool creation
Monitoring the cluster ndash Monitoring overall capacity pool utilization status of OSD
Monitor and MDS processes Placement Group status and RBD status
Managing OpenStack Interoperation Connection to OpenStack Server and
placement of pools in Cinder multi-backend
12
Optional use of Calamari Management GUI
12
13
Example Replacing an HDD
Plain Ceph
taking the failed disk offline in Ceph
taking the failed disk offline on OS
Controller Level
identify (right) hard drive in server
exchanging hard drive
partitioning hard drive on OS level
Make and mount file system
bring the disk up in Ceph again
On ETERNUS CD10000
vsm_cli ltclustergt replace-disk-out
ltnodegt ltdevgt
exchange hard drive
vsm_cli ltclustergt replace-disk-in
ltnodegt ltdevgt
14
Example Adding a Node
Plain Ceph
Install hardware
Install OS
Configure OS
Partition disks (OSDs Journals)
Make filesystems
Configure network
Configure ssh
Configure Ceph
Add node to cluster
On ETERNUS CD10000
Install hardware
bull hardware will automatically PXE boot
and install the current cluster
environment including current
configuration
Node automatically available to GUI
Add node to cluster with mouse click
on GUI
bull Automatic PG adjustment if needed
15
Adding and Integrating Apps
The ETERNUS CD10000 architecture
enables the integration of apps
Fujitsu is working with customers and
software vendors to integrate selected
storage apps
Eg archiving sync amp share data
discovery cloud appshellip
Copyright 2015 FUJITSU
Cloud
Services
Sync
amp Share Archive
iRODS data
discovery
ET
ER
NU
S C
D1
00
00
Object Level
Access
Block Level
Access
File Level
Access
Central Management
Ceph Storage System SW and Fujitsu
Extensions
10GbE Frontend Network
Fast Interconnect Network
Perf
orm
ance N
odes
Capacity N
odes
16
ETERNUS CD10000 at University Mainz
Large university in Germany
Uses iRODS Application for library services
iRODS is an open-source data management software in use at research
organizations and government agencies worldwide
Organizes and manages large depots of distributed digital data
Customer has built an interface from iRODS to Ceph
Stores raw data of measurement instruments (eg research in chemistry and
physics) for 10+ years meeting compliance rules of the EU
Need to provide extensive and rapidly growing data volumes online at
reasonable costs
Will implement a sync amp share service on top of ETERNUS CD10000
17
Summary ETERNUS CD10k ndash Key Values
Copyright 2015 FUJITSU
ETERNUS CD10000
ETERNUS
CD10000
Unlimited
Scalability
TCO
optimized
The new
unified
Immortal
System
Zero
Downtime
ETERNUS CD10000 combines open source storage with enterprisendashclass quality of service
18
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
19
What is OpenStack
Free open source (Apache license) software governed by a non-profit foundation
(corporation) with a mission to produce the ubiquitous Open Source Cloud
Computing platform that will meet the needs of public and private clouds
regardless of size by being simple to implement and massively scalable
Platin
Gold
Corporate
hellip
hellip
Massively scalable cloud operating system that
controls large pools of compute storage and
networking resources
Community OSS with contributions from 1000+
developers and 180+ participating organizations
Open web-based API Programmatic IaaS
Plug-in architecture allows different hypervisors
block storage systems network implementations
hardware agnostic etc
httpwwwopenstackorgfoundationcompanies
20
Attained fast growing customer interest
VMware clouds dominate
OpenStack clouds already 2
Worldwide adoption
Source OpenStack User Survey and Feedback Nov 3rd 2014
Source OpenStack User Survey and Feedback May 13th 2014
21
Why are Customers so interested
Source OpenStack User Survey and Feedback Nov 3rd 2014
Greatest industry amp community support
compared to alternative open platforms
Eucalyptus CloudStack OpenNebula
ldquoAbility to Innovaterdquo jumped from 6 to 1
22
OpenStackorg User Survey Paris Nov 2014
23
OpenStack Cloud Layers
OpenStack and ETERNUS CD10000
Physical Server (CPU Memory SSD HDD) and Network
Base Operating System (CentOS)
OAM
-dhcp
-Deploy
-LCM
Hypervisor
KVM ESXi
Hyper-V
Compute (Nova)
Network
(Neutron) +
plugins
Dashboard (Horizon)
Billing Portal
OpenStack
Cloud APIs
RADOS
Block
(RBD)
S3
(Rados-GW)
Object (Swift) Volume (Cinder)
Authentication (Keystone)
Images (Glance)
EC2 API
Metering (Ceilometer)
Manila (File)
File
(CephFS)
Fujitsu
Open Cloud
Storage
24
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
25
Backgrounds (1)
Erasure codes for content data
Content data for ICT services is ever-growing
Demand for higher space efficiency and durability
Reed Solomon code (de facto erasure code) improves both
Reed Solomon Code (Old style)Triple Replication
However Reed Solomon code is not so recovery-efficient
content data
copy copy
3x space
parity parity
15x space
content data
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom

10
One storage ndash seamless management
ETERNUS CD10000 delivers one seamless
management for the complete stack
Central Ceph software deployment
Central storage node management
Central network management
Central log file management
Central cluster management
Central configuration administration and
maintenance
SNMP integration of all nodes and
network components
Copyright 2015 FUJITSU
11
Seamless management (2)
Dashboard ndash Overview of cluster status
Server Management ndash Management of cluster hardware ndash addremove server
(storage node) replace storage devices
Cluster Management ndash Management of cluster resources ndash cluster and pool creation
Monitoring the cluster ndash Monitoring overall capacity pool utilization status of OSD
Monitor and MDS processes Placement Group status and RBD status
Managing OpenStack Interoperation Connection to OpenStack Server and
placement of pools in Cinder multi-backend
12
Optional use of Calamari Management GUI
12
13
Example Replacing an HDD
Plain Ceph
taking the failed disk offline in Ceph
taking the failed disk offline on OS
Controller Level
identify (right) hard drive in server
exchanging hard drive
partitioning hard drive on OS level
Make and mount file system
bring the disk up in Ceph again
On ETERNUS CD10000
vsm_cli ltclustergt replace-disk-out
ltnodegt ltdevgt
exchange hard drive
vsm_cli ltclustergt replace-disk-in
ltnodegt ltdevgt
14
Example Adding a Node
Plain Ceph
Install hardware
Install OS
Configure OS
Partition disks (OSDs Journals)
Make filesystems
Configure network
Configure ssh
Configure Ceph
Add node to cluster
On ETERNUS CD10000
Install hardware
bull hardware will automatically PXE boot
and install the current cluster
environment including current
configuration
Node automatically available to GUI
Add node to cluster with mouse click
on GUI
bull Automatic PG adjustment if needed
15
Adding and Integrating Apps
The ETERNUS CD10000 architecture
enables the integration of apps
Fujitsu is working with customers and
software vendors to integrate selected
storage apps
Eg archiving sync amp share data
discovery cloud appshellip
Copyright 2015 FUJITSU
Cloud
Services
Sync
amp Share Archive
iRODS data
discovery
ET
ER
NU
S C
D1
00
00
Object Level
Access
Block Level
Access
File Level
Access
Central Management
Ceph Storage System SW and Fujitsu
Extensions
10GbE Frontend Network
Fast Interconnect Network
Perf
orm
ance N
odes
Capacity N
odes
16
ETERNUS CD10000 at University Mainz
Large university in Germany
Uses iRODS Application for library services
iRODS is an open-source data management software in use at research
organizations and government agencies worldwide
Organizes and manages large depots of distributed digital data
Customer has built an interface from iRODS to Ceph
Stores raw data of measurement instruments (eg research in chemistry and
physics) for 10+ years meeting compliance rules of the EU
Need to provide extensive and rapidly growing data volumes online at
reasonable costs
Will implement a sync amp share service on top of ETERNUS CD10000
17
Summary ETERNUS CD10k ndash Key Values
Copyright 2015 FUJITSU
ETERNUS CD10000
ETERNUS
CD10000
Unlimited
Scalability
TCO
optimized
The new
unified
Immortal
System
Zero
Downtime
ETERNUS CD10000 combines open source storage with enterprisendashclass quality of service
18
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
19
What is OpenStack
Free open source (Apache license) software governed by a non-profit foundation
(corporation) with a mission to produce the ubiquitous Open Source Cloud
Computing platform that will meet the needs of public and private clouds
regardless of size by being simple to implement and massively scalable
Platin
Gold
Corporate
hellip
hellip
Massively scalable cloud operating system that
controls large pools of compute storage and
networking resources
Community OSS with contributions from 1000+
developers and 180+ participating organizations
Open web-based API Programmatic IaaS
Plug-in architecture allows different hypervisors
block storage systems network implementations
hardware agnostic etc
httpwwwopenstackorgfoundationcompanies
20
Attained fast growing customer interest
VMware clouds dominate
OpenStack clouds already 2
Worldwide adoption
Source OpenStack User Survey and Feedback Nov 3rd 2014
Source OpenStack User Survey and Feedback May 13th 2014
21
Why are Customers so interested
Source OpenStack User Survey and Feedback Nov 3rd 2014
Greatest industry amp community support
compared to alternative open platforms
Eucalyptus CloudStack OpenNebula
ldquoAbility to Innovaterdquo jumped from 6 to 1
22
OpenStackorg User Survey Paris Nov 2014
23
OpenStack Cloud Layers
OpenStack and ETERNUS CD10000
Physical Server (CPU Memory SSD HDD) and Network
Base Operating System (CentOS)
OAM
-dhcp
-Deploy
-LCM
Hypervisor
KVM ESXi
Hyper-V
Compute (Nova)
Network
(Neutron) +
plugins
Dashboard (Horizon)
Billing Portal
OpenStack
Cloud APIs
RADOS
Block
(RBD)
S3
(Rados-GW)
Object (Swift) Volume (Cinder)
Authentication (Keystone)
Images (Glance)
EC2 API
Metering (Ceilometer)
Manila (File)
File
(CephFS)
Fujitsu
Open Cloud
Storage
24
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
25
Backgrounds (1)
Erasure codes for content data
Content data for ICT services is ever-growing
Demand for higher space efficiency and durability
Reed Solomon code (de facto erasure code) improves both
Reed Solomon Code (Old style)Triple Replication
However Reed Solomon code is not so recovery-efficient
content data
copy copy
3x space
parity parity
15x space
content data
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom

11
Seamless management (2)
Dashboard ndash Overview of cluster status
Server Management ndash Management of cluster hardware ndash addremove server
(storage node) replace storage devices
Cluster Management ndash Management of cluster resources ndash cluster and pool creation
Monitoring the cluster ndash Monitoring overall capacity pool utilization status of OSD
Monitor and MDS processes Placement Group status and RBD status
Managing OpenStack Interoperation Connection to OpenStack Server and
placement of pools in Cinder multi-backend
12
Optional use of Calamari Management GUI
12
13
Example Replacing an HDD
Plain Ceph
taking the failed disk offline in Ceph
taking the failed disk offline on OS
Controller Level
identify (right) hard drive in server
exchanging hard drive
partitioning hard drive on OS level
Make and mount file system
bring the disk up in Ceph again
On ETERNUS CD10000
vsm_cli ltclustergt replace-disk-out
ltnodegt ltdevgt
exchange hard drive
vsm_cli ltclustergt replace-disk-in
ltnodegt ltdevgt
14
Example Adding a Node
Plain Ceph
Install hardware
Install OS
Configure OS
Partition disks (OSDs Journals)
Make filesystems
Configure network
Configure ssh
Configure Ceph
Add node to cluster
On ETERNUS CD10000
Install hardware
bull hardware will automatically PXE boot
and install the current cluster
environment including current
configuration
Node automatically available to GUI
Add node to cluster with mouse click
on GUI
bull Automatic PG adjustment if needed
15
Adding and Integrating Apps
The ETERNUS CD10000 architecture
enables the integration of apps
Fujitsu is working with customers and
software vendors to integrate selected
storage apps
Eg archiving sync amp share data
discovery cloud appshellip
Copyright 2015 FUJITSU
Cloud
Services
Sync
amp Share Archive
iRODS data
discovery
ET
ER
NU
S C
D1
00
00
Object Level
Access
Block Level
Access
File Level
Access
Central Management
Ceph Storage System SW and Fujitsu
Extensions
10GbE Frontend Network
Fast Interconnect Network
Perf
orm
ance N
odes
Capacity N
odes
16
ETERNUS CD10000 at University Mainz
Large university in Germany
Uses iRODS Application for library services
iRODS is an open-source data management software in use at research
organizations and government agencies worldwide
Organizes and manages large depots of distributed digital data
Customer has built an interface from iRODS to Ceph
Stores raw data of measurement instruments (eg research in chemistry and
physics) for 10+ years meeting compliance rules of the EU
Need to provide extensive and rapidly growing data volumes online at
reasonable costs
Will implement a sync amp share service on top of ETERNUS CD10000
17
Summary ETERNUS CD10k ndash Key Values
Copyright 2015 FUJITSU
ETERNUS CD10000
ETERNUS
CD10000
Unlimited
Scalability
TCO
optimized
The new
unified
Immortal
System
Zero
Downtime
ETERNUS CD10000 combines open source storage with enterprisendashclass quality of service
18
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
19
What is OpenStack
Free open source (Apache license) software governed by a non-profit foundation
(corporation) with a mission to produce the ubiquitous Open Source Cloud
Computing platform that will meet the needs of public and private clouds
regardless of size by being simple to implement and massively scalable
Platin
Gold
Corporate
hellip
hellip
Massively scalable cloud operating system that
controls large pools of compute storage and
networking resources
Community OSS with contributions from 1000+
developers and 180+ participating organizations
Open web-based API Programmatic IaaS
Plug-in architecture allows different hypervisors
block storage systems network implementations
hardware agnostic etc
httpwwwopenstackorgfoundationcompanies
20
Attained fast growing customer interest
VMware clouds dominate
OpenStack clouds already 2
Worldwide adoption
Source OpenStack User Survey and Feedback Nov 3rd 2014
Source OpenStack User Survey and Feedback May 13th 2014
21
Why are Customers so interested
Source OpenStack User Survey and Feedback Nov 3rd 2014
Greatest industry amp community support
compared to alternative open platforms
Eucalyptus CloudStack OpenNebula
ldquoAbility to Innovaterdquo jumped from 6 to 1
22
OpenStackorg User Survey Paris Nov 2014
23
OpenStack Cloud Layers
OpenStack and ETERNUS CD10000
Physical Server (CPU Memory SSD HDD) and Network
Base Operating System (CentOS)
OAM
-dhcp
-Deploy
-LCM
Hypervisor
KVM ESXi
Hyper-V
Compute (Nova)
Network
(Neutron) +
plugins
Dashboard (Horizon)
Billing Portal
OpenStack
Cloud APIs
RADOS
Block
(RBD)
S3
(Rados-GW)
Object (Swift) Volume (Cinder)
Authentication (Keystone)
Images (Glance)
EC2 API
Metering (Ceilometer)
Manila (File)
File
(CephFS)
Fujitsu
Open Cloud
Storage
24
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
25
Backgrounds (1)
Erasure codes for content data
Content data for ICT services is ever-growing
Demand for higher space efficiency and durability
Reed Solomon code (de facto erasure code) improves both
Reed Solomon Code (Old style)Triple Replication
However Reed Solomon code is not so recovery-efficient
content data
copy copy
3x space
parity parity
15x space
content data
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom
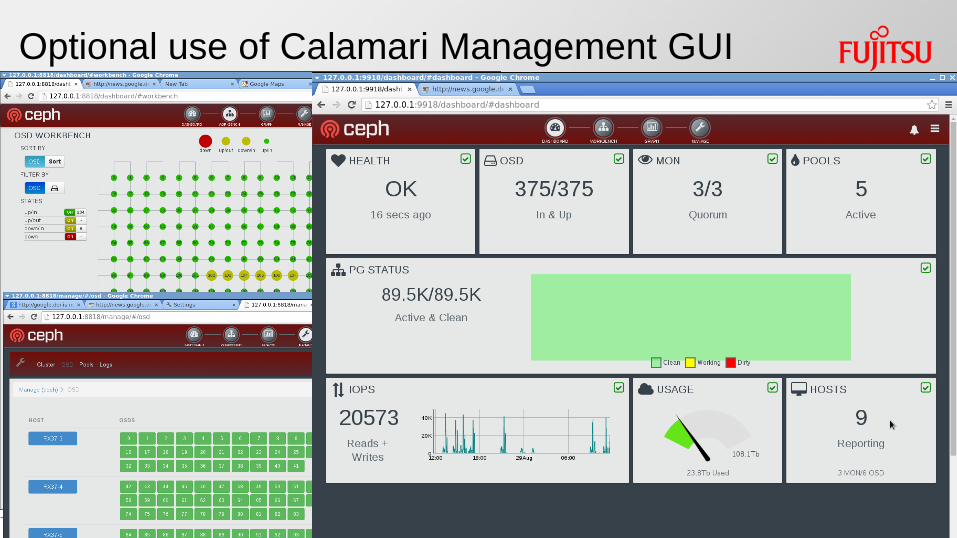
12
Optional use of Calamari Management GUI
12
13
Example Replacing an HDD
Plain Ceph
taking the failed disk offline in Ceph
taking the failed disk offline on OS
Controller Level
identify (right) hard drive in server
exchanging hard drive
partitioning hard drive on OS level
Make and mount file system
bring the disk up in Ceph again
On ETERNUS CD10000
vsm_cli ltclustergt replace-disk-out
ltnodegt ltdevgt
exchange hard drive
vsm_cli ltclustergt replace-disk-in
ltnodegt ltdevgt
14
Example Adding a Node
Plain Ceph
Install hardware
Install OS
Configure OS
Partition disks (OSDs Journals)
Make filesystems
Configure network
Configure ssh
Configure Ceph
Add node to cluster
On ETERNUS CD10000
Install hardware
bull hardware will automatically PXE boot
and install the current cluster
environment including current
configuration
Node automatically available to GUI
Add node to cluster with mouse click
on GUI
bull Automatic PG adjustment if needed
15
Adding and Integrating Apps
The ETERNUS CD10000 architecture
enables the integration of apps
Fujitsu is working with customers and
software vendors to integrate selected
storage apps
Eg archiving sync amp share data
discovery cloud appshellip
Copyright 2015 FUJITSU
Cloud
Services
Sync
amp Share Archive
iRODS data
discovery
ET
ER
NU
S C
D1
00
00
Object Level
Access
Block Level
Access
File Level
Access
Central Management
Ceph Storage System SW and Fujitsu
Extensions
10GbE Frontend Network
Fast Interconnect Network
Perf
orm
ance N
odes
Capacity N
odes
16
ETERNUS CD10000 at University Mainz
Large university in Germany
Uses iRODS Application for library services
iRODS is an open-source data management software in use at research
organizations and government agencies worldwide
Organizes and manages large depots of distributed digital data
Customer has built an interface from iRODS to Ceph
Stores raw data of measurement instruments (eg research in chemistry and
physics) for 10+ years meeting compliance rules of the EU
Need to provide extensive and rapidly growing data volumes online at
reasonable costs
Will implement a sync amp share service on top of ETERNUS CD10000
17
Summary ETERNUS CD10k ndash Key Values
Copyright 2015 FUJITSU
ETERNUS CD10000
ETERNUS
CD10000
Unlimited
Scalability
TCO
optimized
The new
unified
Immortal
System
Zero
Downtime
ETERNUS CD10000 combines open source storage with enterprisendashclass quality of service
18
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
19
What is OpenStack
Free open source (Apache license) software governed by a non-profit foundation
(corporation) with a mission to produce the ubiquitous Open Source Cloud
Computing platform that will meet the needs of public and private clouds
regardless of size by being simple to implement and massively scalable
Platin
Gold
Corporate
hellip
hellip
Massively scalable cloud operating system that
controls large pools of compute storage and
networking resources
Community OSS with contributions from 1000+
developers and 180+ participating organizations
Open web-based API Programmatic IaaS
Plug-in architecture allows different hypervisors
block storage systems network implementations
hardware agnostic etc
httpwwwopenstackorgfoundationcompanies
20
Attained fast growing customer interest
VMware clouds dominate
OpenStack clouds already 2
Worldwide adoption
Source OpenStack User Survey and Feedback Nov 3rd 2014
Source OpenStack User Survey and Feedback May 13th 2014
21
Why are Customers so interested
Source OpenStack User Survey and Feedback Nov 3rd 2014
Greatest industry amp community support
compared to alternative open platforms
Eucalyptus CloudStack OpenNebula
ldquoAbility to Innovaterdquo jumped from 6 to 1
22
OpenStackorg User Survey Paris Nov 2014
23
OpenStack Cloud Layers
OpenStack and ETERNUS CD10000
Physical Server (CPU Memory SSD HDD) and Network
Base Operating System (CentOS)
OAM
-dhcp
-Deploy
-LCM
Hypervisor
KVM ESXi
Hyper-V
Compute (Nova)
Network
(Neutron) +
plugins
Dashboard (Horizon)
Billing Portal
OpenStack
Cloud APIs
RADOS
Block
(RBD)
S3
(Rados-GW)
Object (Swift) Volume (Cinder)
Authentication (Keystone)
Images (Glance)
EC2 API
Metering (Ceilometer)
Manila (File)
File
(CephFS)
Fujitsu
Open Cloud
Storage
24
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
25
Backgrounds (1)
Erasure codes for content data
Content data for ICT services is ever-growing
Demand for higher space efficiency and durability
Reed Solomon code (de facto erasure code) improves both
Reed Solomon Code (Old style)Triple Replication
However Reed Solomon code is not so recovery-efficient
content data
copy copy
3x space
parity parity
15x space
content data
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom

13
Example Replacing an HDD
Plain Ceph
taking the failed disk offline in Ceph
taking the failed disk offline on OS
Controller Level
identify (right) hard drive in server
exchanging hard drive
partitioning hard drive on OS level
Make and mount file system
bring the disk up in Ceph again
On ETERNUS CD10000
vsm_cli ltclustergt replace-disk-out
ltnodegt ltdevgt
exchange hard drive
vsm_cli ltclustergt replace-disk-in
ltnodegt ltdevgt
14
Example Adding a Node
Plain Ceph
Install hardware
Install OS
Configure OS
Partition disks (OSDs Journals)
Make filesystems
Configure network
Configure ssh
Configure Ceph
Add node to cluster
On ETERNUS CD10000
Install hardware
bull hardware will automatically PXE boot
and install the current cluster
environment including current
configuration
Node automatically available to GUI
Add node to cluster with mouse click
on GUI
bull Automatic PG adjustment if needed
15
Adding and Integrating Apps
The ETERNUS CD10000 architecture
enables the integration of apps
Fujitsu is working with customers and
software vendors to integrate selected
storage apps
Eg archiving sync amp share data
discovery cloud appshellip
Copyright 2015 FUJITSU
Cloud
Services
Sync
amp Share Archive
iRODS data
discovery
ET
ER
NU
S C
D1
00
00
Object Level
Access
Block Level
Access
File Level
Access
Central Management
Ceph Storage System SW and Fujitsu
Extensions
10GbE Frontend Network
Fast Interconnect Network
Perf
orm
ance N
odes
Capacity N
odes
16
ETERNUS CD10000 at University Mainz
Large university in Germany
Uses iRODS Application for library services
iRODS is an open-source data management software in use at research
organizations and government agencies worldwide
Organizes and manages large depots of distributed digital data
Customer has built an interface from iRODS to Ceph
Stores raw data of measurement instruments (eg research in chemistry and
physics) for 10+ years meeting compliance rules of the EU
Need to provide extensive and rapidly growing data volumes online at
reasonable costs
Will implement a sync amp share service on top of ETERNUS CD10000
17
Summary ETERNUS CD10k ndash Key Values
Copyright 2015 FUJITSU
ETERNUS CD10000
ETERNUS
CD10000
Unlimited
Scalability
TCO
optimized
The new
unified
Immortal
System
Zero
Downtime
ETERNUS CD10000 combines open source storage with enterprisendashclass quality of service
18
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
19
What is OpenStack
Free open source (Apache license) software governed by a non-profit foundation
(corporation) with a mission to produce the ubiquitous Open Source Cloud
Computing platform that will meet the needs of public and private clouds
regardless of size by being simple to implement and massively scalable
Platin
Gold
Corporate
hellip
hellip
Massively scalable cloud operating system that
controls large pools of compute storage and
networking resources
Community OSS with contributions from 1000+
developers and 180+ participating organizations
Open web-based API Programmatic IaaS
Plug-in architecture allows different hypervisors
block storage systems network implementations
hardware agnostic etc
httpwwwopenstackorgfoundationcompanies
20
Attained fast growing customer interest
VMware clouds dominate
OpenStack clouds already 2
Worldwide adoption
Source OpenStack User Survey and Feedback Nov 3rd 2014
Source OpenStack User Survey and Feedback May 13th 2014
21
Why are Customers so interested
Source OpenStack User Survey and Feedback Nov 3rd 2014
Greatest industry amp community support
compared to alternative open platforms
Eucalyptus CloudStack OpenNebula
ldquoAbility to Innovaterdquo jumped from 6 to 1
22
OpenStackorg User Survey Paris Nov 2014
23
OpenStack Cloud Layers
OpenStack and ETERNUS CD10000
Physical Server (CPU Memory SSD HDD) and Network
Base Operating System (CentOS)
OAM
-dhcp
-Deploy
-LCM
Hypervisor
KVM ESXi
Hyper-V
Compute (Nova)
Network
(Neutron) +
plugins
Dashboard (Horizon)
Billing Portal
OpenStack
Cloud APIs
RADOS
Block
(RBD)
S3
(Rados-GW)
Object (Swift) Volume (Cinder)
Authentication (Keystone)
Images (Glance)
EC2 API
Metering (Ceilometer)
Manila (File)
File
(CephFS)
Fujitsu
Open Cloud
Storage
24
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
25
Backgrounds (1)
Erasure codes for content data
Content data for ICT services is ever-growing
Demand for higher space efficiency and durability
Reed Solomon code (de facto erasure code) improves both
Reed Solomon Code (Old style)Triple Replication
However Reed Solomon code is not so recovery-efficient
content data
copy copy
3x space
parity parity
15x space
content data
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom

14
Example Adding a Node
Plain Ceph
Install hardware
Install OS
Configure OS
Partition disks (OSDs Journals)
Make filesystems
Configure network
Configure ssh
Configure Ceph
Add node to cluster
On ETERNUS CD10000
Install hardware
bull hardware will automatically PXE boot
and install the current cluster
environment including current
configuration
Node automatically available to GUI
Add node to cluster with mouse click
on GUI
bull Automatic PG adjustment if needed
15
Adding and Integrating Apps
The ETERNUS CD10000 architecture
enables the integration of apps
Fujitsu is working with customers and
software vendors to integrate selected
storage apps
Eg archiving sync amp share data
discovery cloud appshellip
Copyright 2015 FUJITSU
Cloud
Services
Sync
amp Share Archive
iRODS data
discovery
ET
ER
NU
S C
D1
00
00
Object Level
Access
Block Level
Access
File Level
Access
Central Management
Ceph Storage System SW and Fujitsu
Extensions
10GbE Frontend Network
Fast Interconnect Network
Perf
orm
ance N
odes
Capacity N
odes
16
ETERNUS CD10000 at University Mainz
Large university in Germany
Uses iRODS Application for library services
iRODS is an open-source data management software in use at research
organizations and government agencies worldwide
Organizes and manages large depots of distributed digital data
Customer has built an interface from iRODS to Ceph
Stores raw data of measurement instruments (eg research in chemistry and
physics) for 10+ years meeting compliance rules of the EU
Need to provide extensive and rapidly growing data volumes online at
reasonable costs
Will implement a sync amp share service on top of ETERNUS CD10000
17
Summary ETERNUS CD10k ndash Key Values
Copyright 2015 FUJITSU
ETERNUS CD10000
ETERNUS
CD10000
Unlimited
Scalability
TCO
optimized
The new
unified
Immortal
System
Zero
Downtime
ETERNUS CD10000 combines open source storage with enterprisendashclass quality of service
18
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
19
What is OpenStack
Free open source (Apache license) software governed by a non-profit foundation
(corporation) with a mission to produce the ubiquitous Open Source Cloud
Computing platform that will meet the needs of public and private clouds
regardless of size by being simple to implement and massively scalable
Platin
Gold
Corporate
hellip
hellip
Massively scalable cloud operating system that
controls large pools of compute storage and
networking resources
Community OSS with contributions from 1000+
developers and 180+ participating organizations
Open web-based API Programmatic IaaS
Plug-in architecture allows different hypervisors
block storage systems network implementations
hardware agnostic etc
httpwwwopenstackorgfoundationcompanies
20
Attained fast growing customer interest
VMware clouds dominate
OpenStack clouds already 2
Worldwide adoption
Source OpenStack User Survey and Feedback Nov 3rd 2014
Source OpenStack User Survey and Feedback May 13th 2014
21
Why are Customers so interested
Source OpenStack User Survey and Feedback Nov 3rd 2014
Greatest industry amp community support
compared to alternative open platforms
Eucalyptus CloudStack OpenNebula
ldquoAbility to Innovaterdquo jumped from 6 to 1
22
OpenStackorg User Survey Paris Nov 2014
23
OpenStack Cloud Layers
OpenStack and ETERNUS CD10000
Physical Server (CPU Memory SSD HDD) and Network
Base Operating System (CentOS)
OAM
-dhcp
-Deploy
-LCM
Hypervisor
KVM ESXi
Hyper-V
Compute (Nova)
Network
(Neutron) +
plugins
Dashboard (Horizon)
Billing Portal
OpenStack
Cloud APIs
RADOS
Block
(RBD)
S3
(Rados-GW)
Object (Swift) Volume (Cinder)
Authentication (Keystone)
Images (Glance)
EC2 API
Metering (Ceilometer)
Manila (File)
File
(CephFS)
Fujitsu
Open Cloud
Storage
24
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
25
Backgrounds (1)
Erasure codes for content data
Content data for ICT services is ever-growing
Demand for higher space efficiency and durability
Reed Solomon code (de facto erasure code) improves both
Reed Solomon Code (Old style)Triple Replication
However Reed Solomon code is not so recovery-efficient
content data
copy copy
3x space
parity parity
15x space
content data
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom
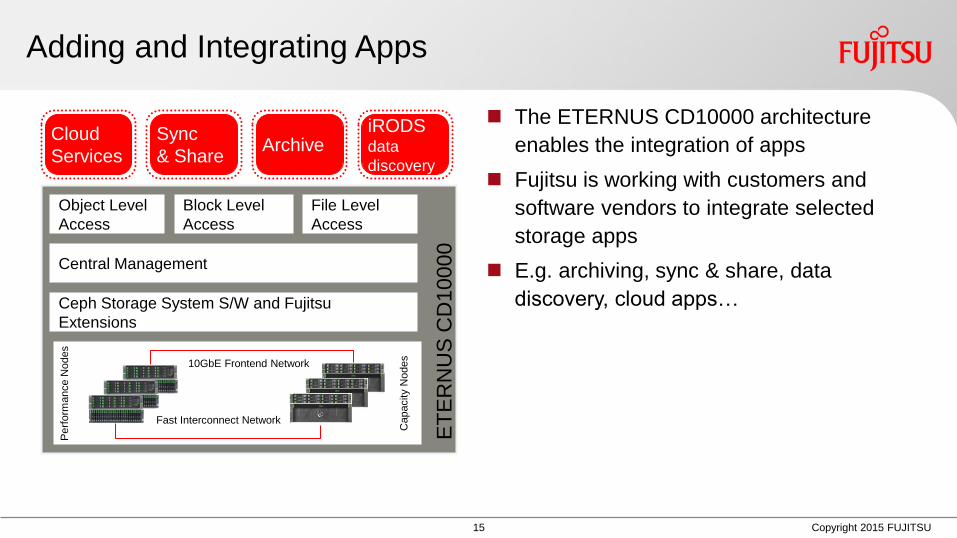
15
Adding and Integrating Apps
The ETERNUS CD10000 architecture
enables the integration of apps
Fujitsu is working with customers and
software vendors to integrate selected
storage apps
Eg archiving sync amp share data
discovery cloud appshellip
Copyright 2015 FUJITSU
Cloud
Services
Sync
amp Share Archive
iRODS data
discovery
ET
ER
NU
S C
D1
00
00
Object Level
Access
Block Level
Access
File Level
Access
Central Management
Ceph Storage System SW and Fujitsu
Extensions
10GbE Frontend Network
Fast Interconnect Network
Perf
orm
ance N
odes
Capacity N
odes
16
ETERNUS CD10000 at University Mainz
Large university in Germany
Uses iRODS Application for library services
iRODS is an open-source data management software in use at research
organizations and government agencies worldwide
Organizes and manages large depots of distributed digital data
Customer has built an interface from iRODS to Ceph
Stores raw data of measurement instruments (eg research in chemistry and
physics) for 10+ years meeting compliance rules of the EU
Need to provide extensive and rapidly growing data volumes online at
reasonable costs
Will implement a sync amp share service on top of ETERNUS CD10000
17
Summary ETERNUS CD10k ndash Key Values
Copyright 2015 FUJITSU
ETERNUS CD10000
ETERNUS
CD10000
Unlimited
Scalability
TCO
optimized
The new
unified
Immortal
System
Zero
Downtime
ETERNUS CD10000 combines open source storage with enterprisendashclass quality of service
18
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
19
What is OpenStack
Free open source (Apache license) software governed by a non-profit foundation
(corporation) with a mission to produce the ubiquitous Open Source Cloud
Computing platform that will meet the needs of public and private clouds
regardless of size by being simple to implement and massively scalable
Platin
Gold
Corporate
hellip
hellip
Massively scalable cloud operating system that
controls large pools of compute storage and
networking resources
Community OSS with contributions from 1000+
developers and 180+ participating organizations
Open web-based API Programmatic IaaS
Plug-in architecture allows different hypervisors
block storage systems network implementations
hardware agnostic etc
httpwwwopenstackorgfoundationcompanies
20
Attained fast growing customer interest
VMware clouds dominate
OpenStack clouds already 2
Worldwide adoption
Source OpenStack User Survey and Feedback Nov 3rd 2014
Source OpenStack User Survey and Feedback May 13th 2014
21
Why are Customers so interested
Source OpenStack User Survey and Feedback Nov 3rd 2014
Greatest industry amp community support
compared to alternative open platforms
Eucalyptus CloudStack OpenNebula
ldquoAbility to Innovaterdquo jumped from 6 to 1
22
OpenStackorg User Survey Paris Nov 2014
23
OpenStack Cloud Layers
OpenStack and ETERNUS CD10000
Physical Server (CPU Memory SSD HDD) and Network
Base Operating System (CentOS)
OAM
-dhcp
-Deploy
-LCM
Hypervisor
KVM ESXi
Hyper-V
Compute (Nova)
Network
(Neutron) +
plugins
Dashboard (Horizon)
Billing Portal
OpenStack
Cloud APIs
RADOS
Block
(RBD)
S3
(Rados-GW)
Object (Swift) Volume (Cinder)
Authentication (Keystone)
Images (Glance)
EC2 API
Metering (Ceilometer)
Manila (File)
File
(CephFS)
Fujitsu
Open Cloud
Storage
24
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
25
Backgrounds (1)
Erasure codes for content data
Content data for ICT services is ever-growing
Demand for higher space efficiency and durability
Reed Solomon code (de facto erasure code) improves both
Reed Solomon Code (Old style)Triple Replication
However Reed Solomon code is not so recovery-efficient
content data
copy copy
3x space
parity parity
15x space
content data
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom

16
ETERNUS CD10000 at University Mainz
Large university in Germany
Uses iRODS Application for library services
iRODS is an open-source data management software in use at research
organizations and government agencies worldwide
Organizes and manages large depots of distributed digital data
Customer has built an interface from iRODS to Ceph
Stores raw data of measurement instruments (eg research in chemistry and
physics) for 10+ years meeting compliance rules of the EU
Need to provide extensive and rapidly growing data volumes online at
reasonable costs
Will implement a sync amp share service on top of ETERNUS CD10000
17
Summary ETERNUS CD10k ndash Key Values
Copyright 2015 FUJITSU
ETERNUS CD10000
ETERNUS
CD10000
Unlimited
Scalability
TCO
optimized
The new
unified
Immortal
System
Zero
Downtime
ETERNUS CD10000 combines open source storage with enterprisendashclass quality of service
18
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
19
What is OpenStack
Free open source (Apache license) software governed by a non-profit foundation
(corporation) with a mission to produce the ubiquitous Open Source Cloud
Computing platform that will meet the needs of public and private clouds
regardless of size by being simple to implement and massively scalable
Platin
Gold
Corporate
hellip
hellip
Massively scalable cloud operating system that
controls large pools of compute storage and
networking resources
Community OSS with contributions from 1000+
developers and 180+ participating organizations
Open web-based API Programmatic IaaS
Plug-in architecture allows different hypervisors
block storage systems network implementations
hardware agnostic etc
httpwwwopenstackorgfoundationcompanies
20
Attained fast growing customer interest
VMware clouds dominate
OpenStack clouds already 2
Worldwide adoption
Source OpenStack User Survey and Feedback Nov 3rd 2014
Source OpenStack User Survey and Feedback May 13th 2014
21
Why are Customers so interested
Source OpenStack User Survey and Feedback Nov 3rd 2014
Greatest industry amp community support
compared to alternative open platforms
Eucalyptus CloudStack OpenNebula
ldquoAbility to Innovaterdquo jumped from 6 to 1
22
OpenStackorg User Survey Paris Nov 2014
23
OpenStack Cloud Layers
OpenStack and ETERNUS CD10000
Physical Server (CPU Memory SSD HDD) and Network
Base Operating System (CentOS)
OAM
-dhcp
-Deploy
-LCM
Hypervisor
KVM ESXi
Hyper-V
Compute (Nova)
Network
(Neutron) +
plugins
Dashboard (Horizon)
Billing Portal
OpenStack
Cloud APIs
RADOS
Block
(RBD)
S3
(Rados-GW)
Object (Swift) Volume (Cinder)
Authentication (Keystone)
Images (Glance)
EC2 API
Metering (Ceilometer)
Manila (File)
File
(CephFS)
Fujitsu
Open Cloud
Storage
24
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
25
Backgrounds (1)
Erasure codes for content data
Content data for ICT services is ever-growing
Demand for higher space efficiency and durability
Reed Solomon code (de facto erasure code) improves both
Reed Solomon Code (Old style)Triple Replication
However Reed Solomon code is not so recovery-efficient
content data
copy copy
3x space
parity parity
15x space
content data
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom
17
Summary ETERNUS CD10k ndash Key Values
Copyright 2015 FUJITSU
ETERNUS CD10000
ETERNUS
CD10000
Unlimited
Scalability
TCO
optimized
The new
unified
Immortal
System
Zero
Downtime
ETERNUS CD10000 combines open source storage with enterprisendashclass quality of service
18
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
19
What is OpenStack
Free open source (Apache license) software governed by a non-profit foundation
(corporation) with a mission to produce the ubiquitous Open Source Cloud
Computing platform that will meet the needs of public and private clouds
regardless of size by being simple to implement and massively scalable
Platin
Gold
Corporate
hellip
hellip
Massively scalable cloud operating system that
controls large pools of compute storage and
networking resources
Community OSS with contributions from 1000+
developers and 180+ participating organizations
Open web-based API Programmatic IaaS
Plug-in architecture allows different hypervisors
block storage systems network implementations
hardware agnostic etc
httpwwwopenstackorgfoundationcompanies
20
Attained fast growing customer interest
VMware clouds dominate
OpenStack clouds already 2
Worldwide adoption
Source OpenStack User Survey and Feedback Nov 3rd 2014
Source OpenStack User Survey and Feedback May 13th 2014
21
Why are Customers so interested
Source OpenStack User Survey and Feedback Nov 3rd 2014
Greatest industry amp community support
compared to alternative open platforms
Eucalyptus CloudStack OpenNebula
ldquoAbility to Innovaterdquo jumped from 6 to 1
22
OpenStackorg User Survey Paris Nov 2014
23
OpenStack Cloud Layers
OpenStack and ETERNUS CD10000
Physical Server (CPU Memory SSD HDD) and Network
Base Operating System (CentOS)
OAM
-dhcp
-Deploy
-LCM
Hypervisor
KVM ESXi
Hyper-V
Compute (Nova)
Network
(Neutron) +
plugins
Dashboard (Horizon)
Billing Portal
OpenStack
Cloud APIs
RADOS
Block
(RBD)
S3
(Rados-GW)
Object (Swift) Volume (Cinder)
Authentication (Keystone)
Images (Glance)
EC2 API
Metering (Ceilometer)
Manila (File)
File
(CephFS)
Fujitsu
Open Cloud
Storage
24
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
25
Backgrounds (1)
Erasure codes for content data
Content data for ICT services is ever-growing
Demand for higher space efficiency and durability
Reed Solomon code (de facto erasure code) improves both
Reed Solomon Code (Old style)Triple Replication
However Reed Solomon code is not so recovery-efficient
content data
copy copy
3x space
parity parity
15x space
content data
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom

18
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
19
What is OpenStack
Free open source (Apache license) software governed by a non-profit foundation
(corporation) with a mission to produce the ubiquitous Open Source Cloud
Computing platform that will meet the needs of public and private clouds
regardless of size by being simple to implement and massively scalable
Platin
Gold
Corporate
hellip
hellip
Massively scalable cloud operating system that
controls large pools of compute storage and
networking resources
Community OSS with contributions from 1000+
developers and 180+ participating organizations
Open web-based API Programmatic IaaS
Plug-in architecture allows different hypervisors
block storage systems network implementations
hardware agnostic etc
httpwwwopenstackorgfoundationcompanies
20
Attained fast growing customer interest
VMware clouds dominate
OpenStack clouds already 2
Worldwide adoption
Source OpenStack User Survey and Feedback Nov 3rd 2014
Source OpenStack User Survey and Feedback May 13th 2014
21
Why are Customers so interested
Source OpenStack User Survey and Feedback Nov 3rd 2014
Greatest industry amp community support
compared to alternative open platforms
Eucalyptus CloudStack OpenNebula
ldquoAbility to Innovaterdquo jumped from 6 to 1
22
OpenStackorg User Survey Paris Nov 2014
23
OpenStack Cloud Layers
OpenStack and ETERNUS CD10000
Physical Server (CPU Memory SSD HDD) and Network
Base Operating System (CentOS)
OAM
-dhcp
-Deploy
-LCM
Hypervisor
KVM ESXi
Hyper-V
Compute (Nova)
Network
(Neutron) +
plugins
Dashboard (Horizon)
Billing Portal
OpenStack
Cloud APIs
RADOS
Block
(RBD)
S3
(Rados-GW)
Object (Swift) Volume (Cinder)
Authentication (Keystone)
Images (Glance)
EC2 API
Metering (Ceilometer)
Manila (File)
File
(CephFS)
Fujitsu
Open Cloud
Storage
24
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
25
Backgrounds (1)
Erasure codes for content data
Content data for ICT services is ever-growing
Demand for higher space efficiency and durability
Reed Solomon code (de facto erasure code) improves both
Reed Solomon Code (Old style)Triple Replication
However Reed Solomon code is not so recovery-efficient
content data
copy copy
3x space
parity parity
15x space
content data
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom

19
What is OpenStack
Free open source (Apache license) software governed by a non-profit foundation
(corporation) with a mission to produce the ubiquitous Open Source Cloud
Computing platform that will meet the needs of public and private clouds
regardless of size by being simple to implement and massively scalable
Platin
Gold
Corporate
hellip
hellip
Massively scalable cloud operating system that
controls large pools of compute storage and
networking resources
Community OSS with contributions from 1000+
developers and 180+ participating organizations
Open web-based API Programmatic IaaS
Plug-in architecture allows different hypervisors
block storage systems network implementations
hardware agnostic etc
httpwwwopenstackorgfoundationcompanies
20
Attained fast growing customer interest
VMware clouds dominate
OpenStack clouds already 2
Worldwide adoption
Source OpenStack User Survey and Feedback Nov 3rd 2014
Source OpenStack User Survey and Feedback May 13th 2014
21
Why are Customers so interested
Source OpenStack User Survey and Feedback Nov 3rd 2014
Greatest industry amp community support
compared to alternative open platforms
Eucalyptus CloudStack OpenNebula
ldquoAbility to Innovaterdquo jumped from 6 to 1
22
OpenStackorg User Survey Paris Nov 2014
23
OpenStack Cloud Layers
OpenStack and ETERNUS CD10000
Physical Server (CPU Memory SSD HDD) and Network
Base Operating System (CentOS)
OAM
-dhcp
-Deploy
-LCM
Hypervisor
KVM ESXi
Hyper-V
Compute (Nova)
Network
(Neutron) +
plugins
Dashboard (Horizon)
Billing Portal
OpenStack
Cloud APIs
RADOS
Block
(RBD)
S3
(Rados-GW)
Object (Swift) Volume (Cinder)
Authentication (Keystone)
Images (Glance)
EC2 API
Metering (Ceilometer)
Manila (File)
File
(CephFS)
Fujitsu
Open Cloud
Storage
24
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
25
Backgrounds (1)
Erasure codes for content data
Content data for ICT services is ever-growing
Demand for higher space efficiency and durability
Reed Solomon code (de facto erasure code) improves both
Reed Solomon Code (Old style)Triple Replication
However Reed Solomon code is not so recovery-efficient
content data
copy copy
3x space
parity parity
15x space
content data
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom
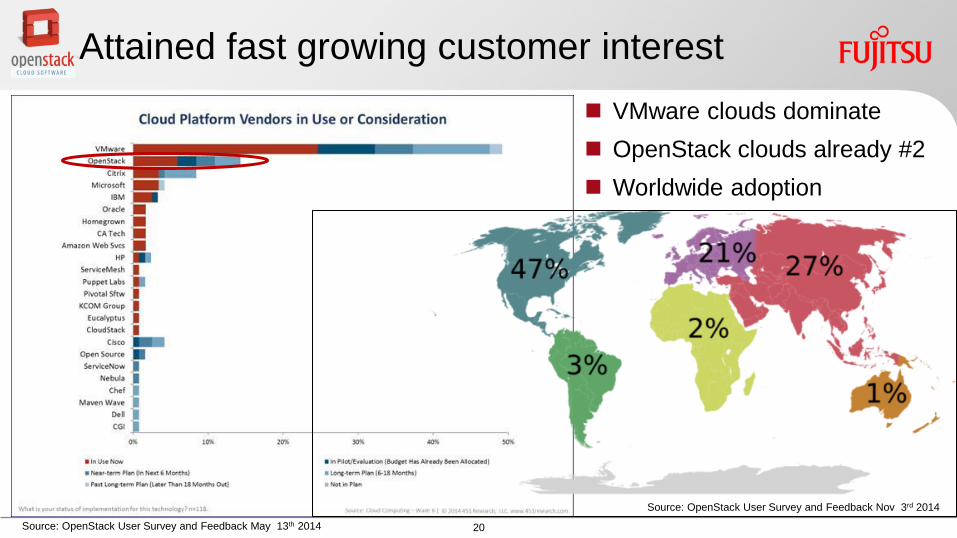
20
Attained fast growing customer interest
VMware clouds dominate
OpenStack clouds already 2
Worldwide adoption
Source OpenStack User Survey and Feedback Nov 3rd 2014
Source OpenStack User Survey and Feedback May 13th 2014
21
Why are Customers so interested
Source OpenStack User Survey and Feedback Nov 3rd 2014
Greatest industry amp community support
compared to alternative open platforms
Eucalyptus CloudStack OpenNebula
ldquoAbility to Innovaterdquo jumped from 6 to 1
22
OpenStackorg User Survey Paris Nov 2014
23
OpenStack Cloud Layers
OpenStack and ETERNUS CD10000
Physical Server (CPU Memory SSD HDD) and Network
Base Operating System (CentOS)
OAM
-dhcp
-Deploy
-LCM
Hypervisor
KVM ESXi
Hyper-V
Compute (Nova)
Network
(Neutron) +
plugins
Dashboard (Horizon)
Billing Portal
OpenStack
Cloud APIs
RADOS
Block
(RBD)
S3
(Rados-GW)
Object (Swift) Volume (Cinder)
Authentication (Keystone)
Images (Glance)
EC2 API
Metering (Ceilometer)
Manila (File)
File
(CephFS)
Fujitsu
Open Cloud
Storage
24
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
25
Backgrounds (1)
Erasure codes for content data
Content data for ICT services is ever-growing
Demand for higher space efficiency and durability
Reed Solomon code (de facto erasure code) improves both
Reed Solomon Code (Old style)Triple Replication
However Reed Solomon code is not so recovery-efficient
content data
copy copy
3x space
parity parity
15x space
content data
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom
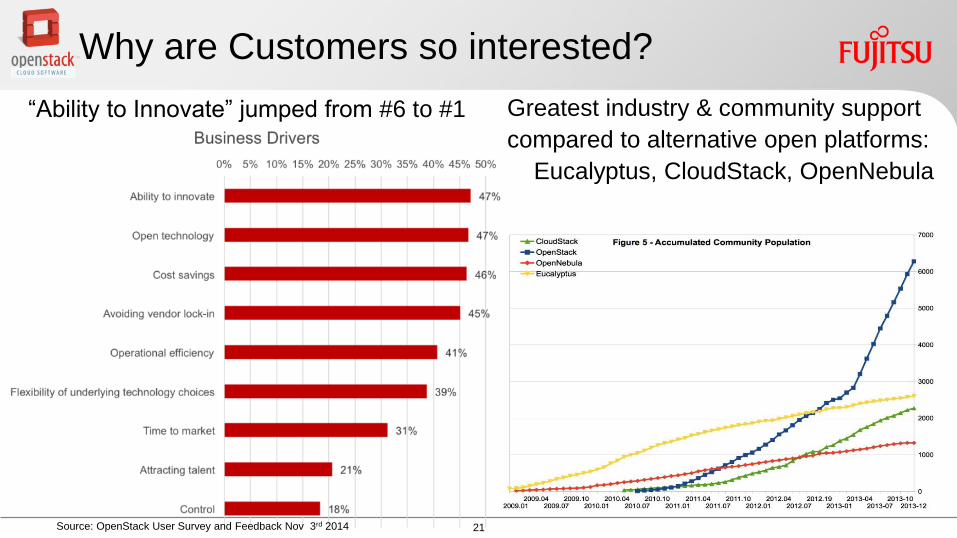
21
Why are Customers so interested
Source OpenStack User Survey and Feedback Nov 3rd 2014
Greatest industry amp community support
compared to alternative open platforms
Eucalyptus CloudStack OpenNebula
ldquoAbility to Innovaterdquo jumped from 6 to 1
22
OpenStackorg User Survey Paris Nov 2014
23
OpenStack Cloud Layers
OpenStack and ETERNUS CD10000
Physical Server (CPU Memory SSD HDD) and Network
Base Operating System (CentOS)
OAM
-dhcp
-Deploy
-LCM
Hypervisor
KVM ESXi
Hyper-V
Compute (Nova)
Network
(Neutron) +
plugins
Dashboard (Horizon)
Billing Portal
OpenStack
Cloud APIs
RADOS
Block
(RBD)
S3
(Rados-GW)
Object (Swift) Volume (Cinder)
Authentication (Keystone)
Images (Glance)
EC2 API
Metering (Ceilometer)
Manila (File)
File
(CephFS)
Fujitsu
Open Cloud
Storage
24
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
25
Backgrounds (1)
Erasure codes for content data
Content data for ICT services is ever-growing
Demand for higher space efficiency and durability
Reed Solomon code (de facto erasure code) improves both
Reed Solomon Code (Old style)Triple Replication
However Reed Solomon code is not so recovery-efficient
content data
copy copy
3x space
parity parity
15x space
content data
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom
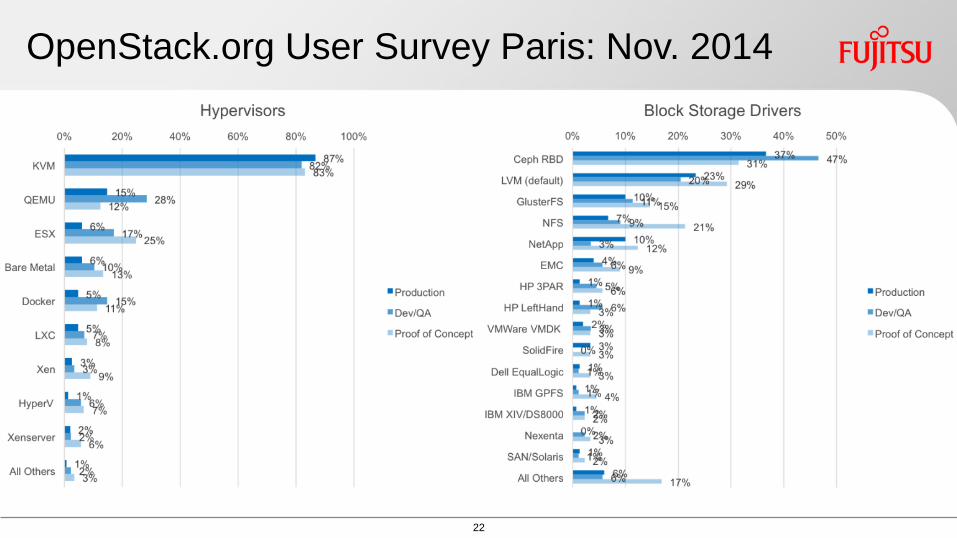
22
OpenStackorg User Survey Paris Nov 2014
23
OpenStack Cloud Layers
OpenStack and ETERNUS CD10000
Physical Server (CPU Memory SSD HDD) and Network
Base Operating System (CentOS)
OAM
-dhcp
-Deploy
-LCM
Hypervisor
KVM ESXi
Hyper-V
Compute (Nova)
Network
(Neutron) +
plugins
Dashboard (Horizon)
Billing Portal
OpenStack
Cloud APIs
RADOS
Block
(RBD)
S3
(Rados-GW)
Object (Swift) Volume (Cinder)
Authentication (Keystone)
Images (Glance)
EC2 API
Metering (Ceilometer)
Manila (File)
File
(CephFS)
Fujitsu
Open Cloud
Storage
24
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
25
Backgrounds (1)
Erasure codes for content data
Content data for ICT services is ever-growing
Demand for higher space efficiency and durability
Reed Solomon code (de facto erasure code) improves both
Reed Solomon Code (Old style)Triple Replication
However Reed Solomon code is not so recovery-efficient
content data
copy copy
3x space
parity parity
15x space
content data
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom

23
OpenStack Cloud Layers
OpenStack and ETERNUS CD10000
Physical Server (CPU Memory SSD HDD) and Network
Base Operating System (CentOS)
OAM
-dhcp
-Deploy
-LCM
Hypervisor
KVM ESXi
Hyper-V
Compute (Nova)
Network
(Neutron) +
plugins
Dashboard (Horizon)
Billing Portal
OpenStack
Cloud APIs
RADOS
Block
(RBD)
S3
(Rados-GW)
Object (Swift) Volume (Cinder)
Authentication (Keystone)
Images (Glance)
EC2 API
Metering (Ceilometer)
Manila (File)
File
(CephFS)
Fujitsu
Open Cloud
Storage
24
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
25
Backgrounds (1)
Erasure codes for content data
Content data for ICT services is ever-growing
Demand for higher space efficiency and durability
Reed Solomon code (de facto erasure code) improves both
Reed Solomon Code (Old style)Triple Replication
However Reed Solomon code is not so recovery-efficient
content data
copy copy
3x space
parity parity
15x space
content data
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom

24
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
25
Backgrounds (1)
Erasure codes for content data
Content data for ICT services is ever-growing
Demand for higher space efficiency and durability
Reed Solomon code (de facto erasure code) improves both
Reed Solomon Code (Old style)Triple Replication
However Reed Solomon code is not so recovery-efficient
content data
copy copy
3x space
parity parity
15x space
content data
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom
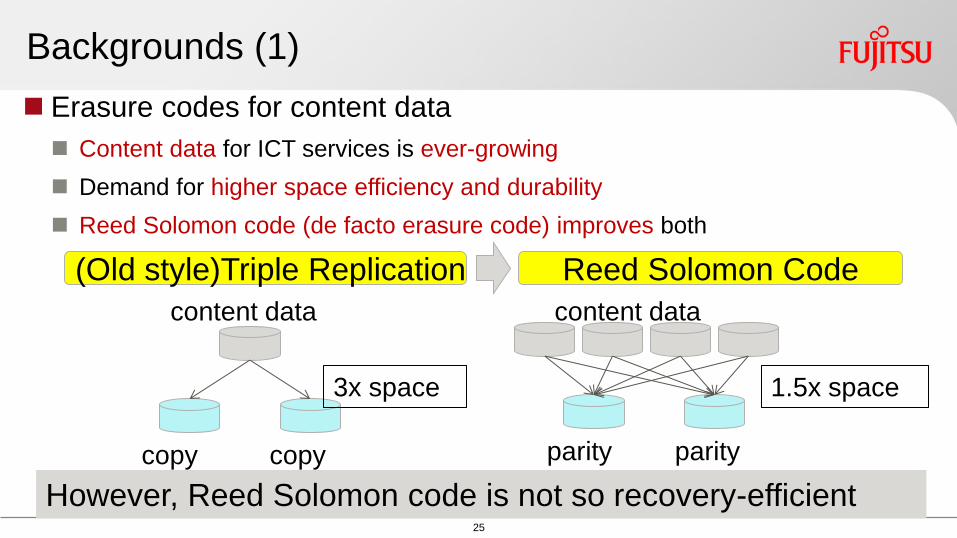
25
Backgrounds (1)
Erasure codes for content data
Content data for ICT services is ever-growing
Demand for higher space efficiency and durability
Reed Solomon code (de facto erasure code) improves both
Reed Solomon Code (Old style)Triple Replication
However Reed Solomon code is not so recovery-efficient
content data
copy copy
3x space
parity parity
15x space
content data
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom
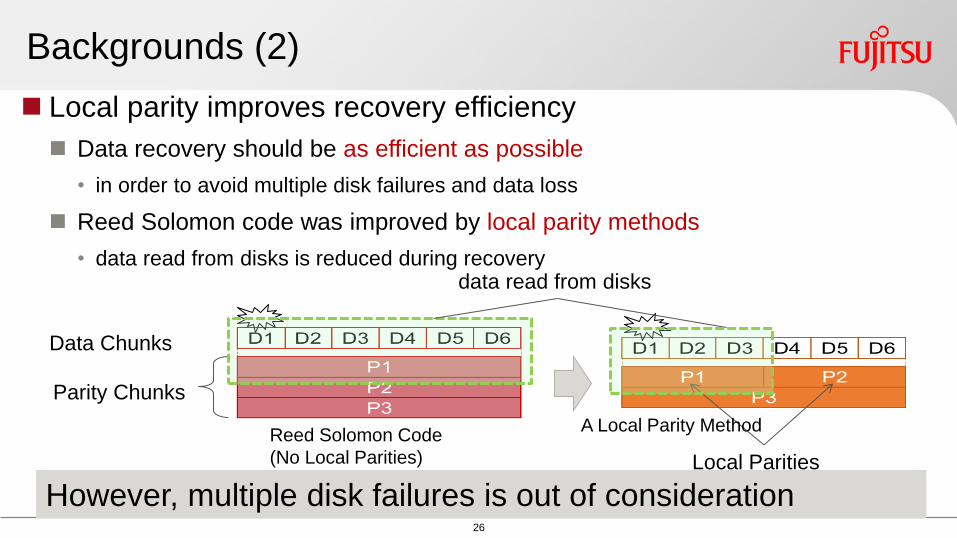
26
Backgrounds (2)
Local parity improves recovery efficiency
Data recovery should be as efficient as possible
bull in order to avoid multiple disk failures and data loss
Reed Solomon code was improved by local parity methods
bull data read from disks is reduced during recovery
Data Chunks
Parity Chunks
Reed Solomon Code
(No Local Parities) Local Parities
data read from disks
However multiple disk failures is out of consideration
A Local Parity Method
27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom

27
Local parity method for multiple disk failures
Existing methods is optimized for single disk failure
bull eg Microsoft MS-LRC Facebook Xorbas
However Its recovery overhead is large in case of multiple disk failures
bull because they have a chance to use global parities for recovery
Our Goal
A Local Parity Method
Our goal is a method efficiently handling multiple disk failures
Multiple Disk Failures
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom
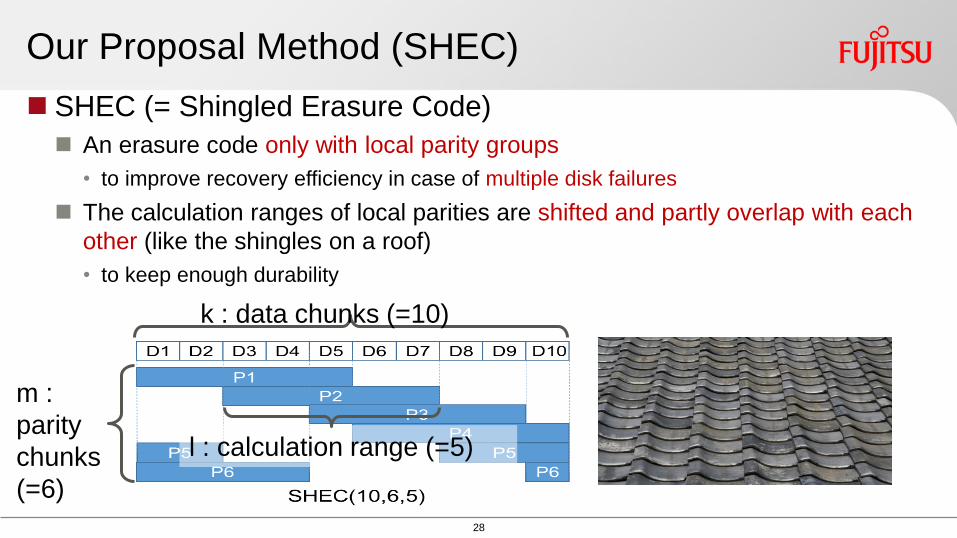
28
SHEC (= Shingled Erasure Code)
An erasure code only with local parity groups
bull to improve recovery efficiency in case of multiple disk failures
The calculation ranges of local parities are shifted and partly overlap with each
other (like the shingles on a roof)
bull to keep enough durability
Our Proposal Method (SHEC)
k data chunks (=10)
m
parity
chunks
(=6)
l calculation range (=5)
29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom

29
1 mSHEC is more adjustable than Reed Solomon code
because SHEC provides many recovery-efficient layouts
including Reed Solomon codes
2 mSHECrsquos recovery time was ~20 faster than Reed
Solomon code in case of double disk failures
3 mSHEC erasure-code included in Hammer release
4 For more information see httpswikicephcomPlanningBlueprintsHammerShingled_Erasure_Code_(SHEC)
or ask Fujitsu
Summary mSHEC
30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom

30
The safe way to make Ceph storage enterprise ready
ETERNUS CD10k integrated in OpenStack
mSHEC Erasure Code from Fujitsu
Contribution to performance enhancements
31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom

31
Areas to improve Ceph performance
Ceph has an adequate performance today
But there are performance issues which prevent us from taking full
advantage of our hardware resources
Two main goals for improvement
(1) Decrease latency in the Ceph code path
(2) Enhance large cluster scalability with many nodes ODS
32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom

32
LTTng general httplttngorg
General
open source tracing framework for Linux
trace Linux kernel and user space applications
low overhead and therefore usable on
production systems
activate tracing at runtime
Ceph code contains LTTng trace points already
Our LTTng based profiling
activate within a function collect timestamp information at the interesting places
save collected information in a single trace point at the end of the function
transaction profiling instead of function profiling use Ceph transaction ids to
correlate trace points
focused on primary and secondary write operations
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom
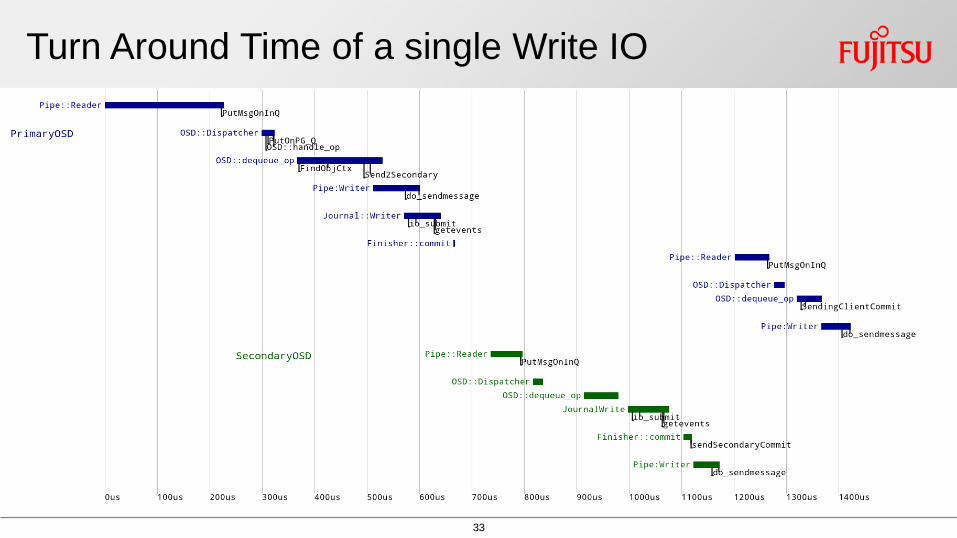
33
Turn Around Time of a single Write IO
34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom

34
LTTng data evaluation Replication Write
Observation
replication write latency suffers from the large variance problem
minimum and average differ by a factor of 2
This is a common problem visible for many ceph-osd components
Why is variance so large
Observation No single hotspot visible
Observation Active processing steps do not differ between minimum and average
sample as much as the total latency does
Additional latency penalty mostly at the switch from
sub_op_modify_commit to Pipewriter
no indication that queue length is the cause
Question Can the overall thread load on the system and Linux scheduling be the
reason for the delayed start of the Pipewriter thread
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom
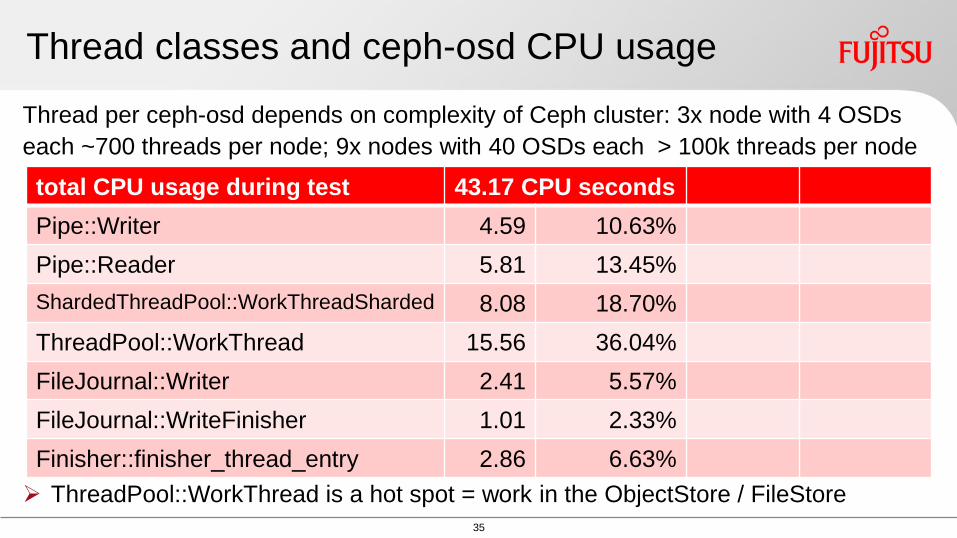
35
Thread classes and ceph-osd CPU usage
Thread per ceph-osd depends on complexity of Ceph cluster 3x node with 4 OSDs
each ~700 threads per node 9x nodes with 40 OSDs each gt 100k threads per node
ThreadPoolWorkThread is a hot spot = work in the ObjectStore FileStore
total CPU usage during test 4317 CPU seconds
PipeWriter 459 1063
PipeReader 581 1345
ShardedThreadPoolWorkThreadSharded 808 1870
ThreadPoolWorkThread 1556 3604
FileJournalWriter 241 557
FileJournalWriteFinisher 101 233
Finisherfinisher_thread_entry 286 663
36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom

36
FileStore benchmarking
most of the work is done in FileStoredo_transactions
each write transaction consists of
3 calls to omap_setkeys
the actual call to write to the file system
2 calls to setattr
Proposal coalesce calls to omap_setkeys
1 function call instead of 3 calls set 5 key value pairs instead of 6 (duplicate key)
Official change was to coalesce at the higher PG layer
37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom

37
Other areas of investigation and improvement
Lock analysis
RWLock instead of mutex
Start with CRC locks
Bufferlist tuning
Optimize for jumbo packets
malloc issues
Copyright 2015 FUJITSU
38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom

38
Summary and Conclusion
ETERNUS CD10k is the safe way to make Ceph enterprise ready
Unlimited Scalability 4 to 224 nodes scales up to gt50 Petabyte
Immortal System with Zero downtime Non-disruptive add remove exchange of hardware (disks and nodes) or Software update
TCO optimized Highly automated and fully integrated management reduces operational efforts
Tight integration in OpenStack with own GUI
Fujitsu will continue to enhance ease-of-use and performance
This is important
As Cephrsquos popularity increases competitors will attack Ceph in these areas
39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom

39 39 Copyright 2015 FUJITSU
pvonstamwitzusfujitsucom
Recommended

















